Линейная регрессия
Содержание
Введение
1. Теоретическая часть
.1 Линейная регрессия
.1.1 Парная линейная регрессия
.1.2 Множественная линейная
регрессия
.2 Теорема Гаусса-Маркова
. Практическая часть
.1. Характеристика экзогенных и
эндогенных переменных
.2 Построение двухфакторного
уравнения регрессии
2.3 Построение однофакторных
уравнений регрессии
.4 Прогнозирование значения
результативного признака
Заключение
Список используемых источников
Введение
При решении практических задач исследователи
сталкиваются с тем, что корреляционные связи не ограничиваются связями между
двумя признаками: результативным у и факторным х.
В действительности результативный признак
зависит от нескольких факторных.
Задачи многофакторного анализа:
. Обосновать взаимосвязи факторов,
влияющих на исследуемый показатель.
2. Определить степень влияния каждого
фактора на результативный признак путем построения модели-уравнения
множественной регрессии, которая позволяет установить, в каком направлении и на
какую величину изменится результативный показатель при изменении каждого
фактора, входящего в модель.
. Количественно оценить тесноту связи
между результативным признаком и факторами.
1. Теоретическая часть
.1 Линейная регрессия
.1.1 Парная линейная регрессия
Регрессионное уравнение, разрешённое относительно
исследуемой переменной у при наличии одной факторной переменной x, в общем виде
записывается как:
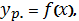 (1.1)
(1.1)
уравнение регрессия
экзогенный гаусс
и показывает, каково будет в среднем
значение переменной y, если переменная х примет конкретное значение. Индекс р
указывает на то, что мы получаем расчётное значение переменной y. Термин в
среднем употреблен потому, что при влиянии неучтённых в модели факторов и в
следствие погрешностей измерения фактическое значение переменной y может быть
разным для одного значения x.
Если f(x) является линейной
функцией, то получим общий вид модели парной линейной регрессии:
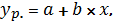 (1.2)
(1.2)
где a Ї постоянная величина (или
свободный член уравнения), Ї коэффициент регрессии, определяющий наклон линии,
вдоль которой рассеяны наблюдения.
Коэффициент регрессии характеризует
изменение переменной y при изменении значения x на единицу. Если 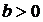 , то
переменные положительно коррелированны, если
, то
переменные положительно коррелированны, если  Ї отрицательно коррелированны.
Фактическое значение исследуемой переменной y тогда может быть представлено в
виде:
Ї отрицательно коррелированны.
Фактическое значение исследуемой переменной y тогда может быть представлено в
виде:
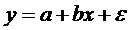 , (1.3)
, (1.3)
где е Ї разность между фактическим
значением (результатом наблюдения) и значением, рассчитанным по уравнению
модели.
Если модель адекватно описывает
исследуемый процесс, то е Ї независимая нормально распределённая случайная
величина с нулевым математическим ожиданием (Ме = 0) и постоянной дисперсией
(Dе = у2). Наличие случайной компоненты е отражает тот факт, что
присутствуют другие факторы, влияющие на исследуемую переменную и не учтённые в
модели.
Построение уравнения регрессии сводится
к оценке ее параметров. Для оценки используется метод наименьших квадратов
(МНК). МНК позволяет получить такие оценки параметров, при которых сумма
квадратов отклонений фактических значений результативного признака у от оценок 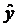 минимальна,
т.е.
минимальна,
т.е.
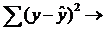 min.
min.
В результате операции МНК получаются
оценки коэффициентов регрессии:
b = Cov
(X,Y): , (1.4)=
, (1.4)=  (1.5)
(1.5)
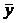 =
= 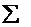 уi:
n;
уi:
n; 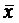 = хi:
n; Cov (X,Y) =
= хi:
n; Cov (X,Y) = 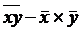 ; =
; =  .
.
Надежность оценок a и b
характеризуется их дисперсиями:
Проверка качества уравнения регрессии
осуществляется по ряду позиций.
Оценка статистической значимости коэффициентов
регрессии.
 (1.6)
(1.6)
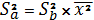 , (1.7)
, (1.7)
S2 = еi2:(n - 2), 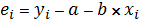 .
.
Используется критерий Стьюдента.
Вычисляются 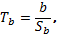
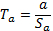 и сравниваются с tкрит. Результатом
сравнения является вывод о значимости коэффициентов a и b.
и сравниваются с tкрит. Результатом
сравнения является вывод о значимости коэффициентов a и b.
Интервальные оценки коэффициентов уравнения
регрессии.
Так как объем выборки ограничен, то a и b Ї случайные
величины, поэтому желательно найти доверительные интервалы для истинных
значений  0,1. Для этого
также используется t Ї критерий Стьюдента.
0,1. Для этого
также используется t Ї критерий Стьюдента.
Проверка значимости уравнения
регрессии в целом.
Позволяет установить, соответствует ли
математическая модель экспериментальным данным и достаточно ли включенных в уравнение
объясняющих переменных для описания зависимой переменной. Мерой общего качества
уравнения регрессии является коэффициент детерминации R2:
 . (1.8)
. (1.8)
Выражение (1.8) вытекает из соотношения:
 , (1.9)
, (1.9)
где  Ї объясненная сумма квадратов, она
характеризует разброс, обусловленный регрессией;
Ї объясненная сумма квадратов, она
характеризует разброс, обусловленный регрессией;
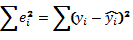 Ї остаточная (необъясненная) сумма
квадратов, характеризует случайную составляющую разброса yi
относительно линии регрессии
Ї остаточная (необъясненная) сумма
квадратов, характеризует случайную составляющую разброса yi
относительно линии регрессии  .
.
Из соотношений (1.8) и (1.9) следует, что
коэффициент детерминации R2
есть ни что иное, как:
R2 = 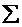 ki2:
ki2:  ( yi - )2.
(1.10)
( yi - )2.
(1.10)
В итоге, коэффициент детерминации
можно вычислить по (1.8) или по (1.10).
Прогноз значений зависимой
переменной.
Под прогнозными понимаем значениях Yр при
определенных значениях объясняющей переменной Хр. Так как задача
решается в условиях неопределенности то прогноз удобнее всего давать на основе
интервальных оценок, построенных с заданной надежностью 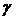 .
.
Причем здесь возможно два подхода:
) предсказание среднего значения,
т.е. M (Y: Х=xр);
) предсказание индивидуальных
значений Y: Х=xр.
Интервальный прогноз для среднего
значения вычисляется следующим образом:
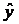 р =
р = 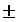 tкр
S
tкр
S  , (1.11)
, (1.11)
где 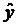 р = a+ bxр ;
р = a+ bxр ;
tкр Ї
критическое значение, полученное по распределению Стьюдента при количестве
степеней свободы 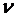 = n - 2 и
заданной вероятности
= n - 2 и
заданной вероятности 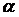 /2.
/2.
Интервальный прогноз для
индивидуального значения вычисляется по формуле:
р = tкр S  . (1.12)
. (1.12)
.1.2 Множественная линейная регрессия
Линейная модель множественной регрессии имеет
вид:
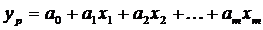 ,(1.13)
,(1.13)
где 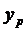 Ї расчётные значения исследуемой
переменной,
Ї расчётные значения исследуемой
переменной,
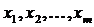 - факторные переменные.
- факторные переменные.
Каждый из коэффициентов уравнения  имеет такую
экономическую интерпретацию: он показывает, насколько изменится значение
исследуемого признака при изменении соответствующего фактора на 1 при
неизменных значениях других факторных переменных.
имеет такую
экономическую интерпретацию: он показывает, насколько изменится значение
исследуемого признака при изменении соответствующего фактора на 1 при
неизменных значениях других факторных переменных.
Фактическое значение исследуемой
переменной тогда представимо в виде:
 (1.14)
(1.14)
Для адекватности модели необходимо,
чтобы случайная величина е, являющаяся разностью между
фактическими и расчётными значениями, имела нормальный закон распределения с
математическим ожиданием равным нулю и постоянной дисперсией у2.
Имея n наборов
данных наблюдений, с использованием представления (1.14), мы можем записать n уравнений
вида:
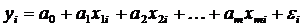 ,(1.15)
,(1.15)
где 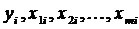 ¾ значения исследуемой и факторных переменных в
i-м наблюдении,
¾ значения исследуемой и факторных переменных в
i-м наблюдении,
еi Ї
отклонение фактического значения yi от
расчётного значения yрi.
Систему уравнений (1.15) удобно
исследовать в матричном виде:
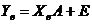 ,(1.16)
,(1.16)
где Yв Ї вектор
выборочных данных наблюдений исследуемой переменной (n элементов),
Xв Ї матрица
выборочных данных наблюдений факторных переменных (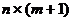 элементов),
элементов),
А Ї вектор параметров уравнения (m+1
элементов),
E Ї вектор случайных
отклонений (n элементов):
 (1.17)
(1.17)
При построении модели множественной регрессии
возникает необходимость оценки (вычисления) коэффициентов линейной функции,
которые в матричной форме записи обозначены вектором A.
Формула для вычисления параметров регрессионного уравнения методом наименьших
квадратов (МНК) по данным наблюдений следующая:
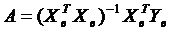 . (1.18)
. (1.18)
Нахождение параметров с помощью
соотношения (1.18) возможно лишь в том случае, когда между различными столбцами
и различными строками матрицы исходных данных X отсутствует
строгая линейная зависимость (иначе не существует обратная матрица). Это
условие не выполняется, если существует линейная или близкая к ней связь между
результатами двух различных наблюдений, или же если такая связь существует
между двумя различными факторными переменными. Линейная или близкая к ней связь
между факторами называется мультиколлинеарностью. Чтобы избавиться от
мультиколлинеарности, в модель включают один из линейно связанных между собой факторов,
причём тот, который в большей степени связан с исследуемой переменной.
На практике чтобы избавиться от
мультиколлениарности проверяют для каждой пары факторных переменных выполнение
следующих условий:
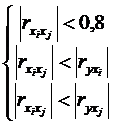 .(1.19)
.(1.19)
То есть коэффициент корреляции между
двумя факторными переменными должен быть меньше 0,8 и, одновременно, меньше
коэффициентов корреляции между исследуемой переменной и каждой из этих двух
факторных переменных. Если хотя бы одно из условий (1.19) не выполняется, то в
модель включают только один из этих двух факторов, а именно, тот, у которого
модуль коэффициента корреляции с Y больше.
Значимость параметров модели
множественной регрессии aj проверяется
с помощью t-критерия
Стьюдента аналогично тому, как мы проверяли значимость коэффициентов модели
парной регрессии. Для каждого параметра уравнения вычисляется t-статистика:
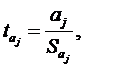 (1.20)
(1.20)
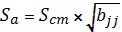 ,
,
где Sст Ї стандартная
ошибка оценки,
bjj Ї
диагональный элемент матрицы 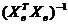 .
.
Далее по таблицам определяется
значение tкр в
зависимости от уровня значимости б и параметра n-m-1. Наконец,
каждая из t-статистик
(1.20) сравнивается с табличным значением. Если РtajР > tкр, то
коэффициент aj считается
значимым. В противном случае коэффициент не является значимым и его можно
положить равным нулю, тем самым исключить из модели фактор xj (качество
модели при этом не ухудшится).
Качество модели оценивается стандартным способом
для уравнений регрессии: по адекватности и точности на основе анализа остатков
регрессии е.
Как и в случае парной линейной
регрессии, коэффициент детерминации 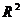 можно вычислить по формуле (1.8), индекс
корреляции R (в случае
линейной множественной регрессии он называется коэффициентом множественной
регрессии)
можно вычислить по формуле (1.8), индекс
корреляции R (в случае
линейной множественной регрессии он называется коэффициентом множественной
регрессии) 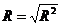 , среднюю
относительную ошибку
, среднюю
относительную ошибку 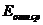 по формуле:
по формуле:
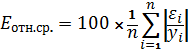 (1.21).
(1.21).
Процедура проверки значимости
уравнения регрессии в целом также производится аналогично случаю парной
регрессии. Вычисляется F-критерий Фишера по формуле:
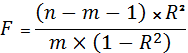
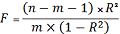 (1.22)
(1.22)
затем определяется критическое
значение и сравнивается с расчётным значением.
Важную роль при оценке влияния
отдельных факторов играют коэффициенты регрессионной модели aj. Однако
непосредственно с их помощью нельзя сопоставить факторы по степени их влияния
на зависимую переменную из-за различия единиц измерения и разного масштаба
колебаний (степени колеблемости) при использовании разных наборов результатов
наблюдений.
Для устранения таких различий
применяются частные коэффициенты эластичности:
 , (1.24)
, (1.24)
где 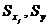 Ї среднеквадратические отклонения
переменных:
Ї среднеквадратические отклонения
переменных:
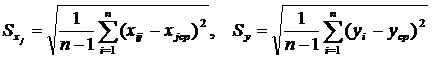 . (1.25)
. (1.25)
Коэффициент эластичности показывает,
на сколько процентов изменяется исследуемая переменная при изменении факторной
переменной на 1 процент. Если коэффициент эластичности меньше 0, то при
увеличении значения фактора исследуемая переменная уменьшается. Таким образом,
коэффициенты эластичности можно сравнивать между собой по модулю для выяснения
того, изменения какого фактора больше влияют на изменение исследуемой
переменной. Однако коэффициент эластичности не учитывает степень колеблемости
факторов.
Бета-коэффициент показывает, на
какую часть величины среднеквадратического отклонения  изменится
переменная y с
изменением соответствующей независимой переменной xj на величину
своего среднеквадратического отклонения при фиксированном уровне значений
остальных факторных переменных.
изменится
переменная y с
изменением соответствующей независимой переменной xj на величину
своего среднеквадратического отклонения при фиксированном уровне значений
остальных факторных переменных.
Указанные коэффициенты позволяют
упорядочить факторы по степени их влияния на исследуемую переменную.
Долю влияния фактора в суммарном
влиянии всех факторов можно оценить по величине дельта - коэффициентов:
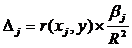 ,(1.26)
,(1.26)
где  Ї коэффициент парной корреляции
между фактором xj и исследуемой переменной y.
Ї коэффициент парной корреляции
между фактором xj и исследуемой переменной y.
Одной из важнейших целей построения
эконометрической модели является прогнозирование поведения исследуемого
процесса или объекта.
Как и в случае парной регрессии
вычисляются точечное и интервальное прогнозные значения исследуемой переменной.
Точечный прогноз осуществляется
подстановкой прогнозного набора факторных переменных в уравнение регрессии:
 .(1.27)
.(1.27)
Если прогноз осуществляется не для
одного набора факторных переменных, а для некоторого ряда наборов, то ряд
точечных прогнозов исследуемой переменной можно представить в виде вектора, и
вычислять его удобнее с использованием операций с матрицами:
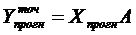 ,(1.28)
,(1.28)
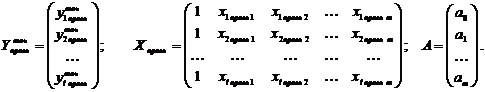 (1.29)
(1.29)
Интервальный прогноз в рамках модели
множественной регрессии строится с использованием соотношений, являющихся
обобщением формул парной регрессионной модели. Для нахождения размаха
доверительного интервала необходимо вычислить матрицу V:
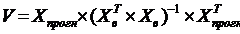 . (1.30)
. (1.30)
В выражении (1.30) участвуют матрица
Xв,
составленная из значений факторных переменных, имевших место в рядах наблюдений
и матрица Xпрогн,
составленная из прогнозируемых значений факторных переменных. Размерность
матрицы V равна 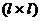 , то есть
зависит от числа прогнозируемых наборов факторных переменных. Размах
прогнозного интервала для i-го набора факторных переменных
равен:
, то есть
зависит от числа прогнозируемых наборов факторных переменных. Размах
прогнозного интервала для i-го набора факторных переменных
равен:
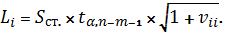 (1.31)
(1.31)
где  Ї диагональный элемент матрицы
(1.30). Тогда фактические значения исследуемой величины y для i-го набора
значений факторных переменных с вероятностью (1-б) попадают в интервал:
Ї диагональный элемент матрицы
(1.30). Тогда фактические значения исследуемой величины y для i-го набора
значений факторных переменных с вероятностью (1-б) попадают в интервал:
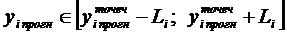 . (1.32)
. (1.32)
.2 Теорема Гаусса-Маркова
Рассмотрим основные гипотезы модели
множественной линейной регрессии:
1) 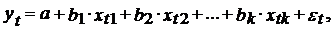 (t = 1, 2,…, n) Ї
спецификация модели.
(t = 1, 2,…, n) Ї
спецификация модели.
) 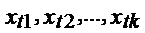 Ї детерминированные (независимые)
переменные.
Ї детерминированные (независимые)
переменные.
)  Ї не зависит от t.
Ї не зависит от t.
) 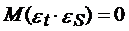 (при t ≠ s) Ї
некоррелированность ошибок для разных наблюдений.
(при t ≠ s) Ї
некоррелированность ошибок для разных наблюдений.
)  ~
~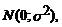 т.е.
т.е. 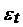 Ї нормально распределенная
случайная величина с математическим ожиданием, равным 0, и дисперсией
Ї нормально распределенная
случайная величина с математическим ожиданием, равным 0, и дисперсией  .
.
В этом случае модель 1-3 называется нормальной
линейной множественной регрессионной моделью.
Гипотезы, лежащие в основе множественной
регрессии, удобно записать в матричной форме.
Обозначим
 Ї матрица-столбец;
Ї матрица-столбец;
 Ї вектор коэффициентов размерности
Ї вектор коэффициентов размерности 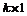 ;
;
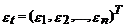 Ї вектор ошибок;
Ї вектор ошибок;
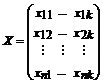 Ї матрица объясняющих переменных
Ї матрица объясняющих переменных 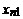 …
… 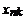 размерности
размерности
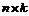 .
.
Столбцами матрицы X являются
векторы регрессоров размерности 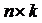 , т.е.
, т.е. 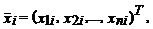 i = 1, 2,…, n.
i = 1, 2,…, n.
Тогда условия гипотез 1-3 в
матричной форме будут иметь вид:
) 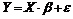 Ї спецификация модели.
Ї спецификация модели.
) X Ї
детерминированная матрица, имеющая максимальный ранг, равный k.
) 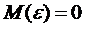 ,
, 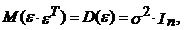
где 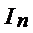 Ї единичная матрица.
Ї единичная матрица.
)  ~
~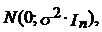 т.е.
т.е. 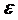 Ї нормально распределенный
случайный вектор со средним 0 и матрицей ковариаций
Ї нормально распределенный
случайный вектор со средним 0 и матрицей ковариаций 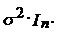
Как и в случае регрессионного
уравнения с одной переменной, целью метода является выбор вектора оценок 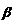 ,
минимизирующего сумму квадратов остатков
,
минимизирующего сумму квадратов остатков 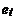 (т.е. квадрат длины вектора
остатков e):
(т.е. квадрат длины вектора
остатков e):
 Ї min.
Ї min.

Применяя необходимые условия
минимума с использованием дифференцирования по вектору  получим:
получим:
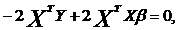
откуда, учитывая невырожденность
матрицы 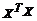 находим
оценку метода наименьших квадратов (МНК):
находим
оценку метода наименьших квадратов (МНК):
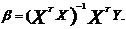 (1.33)
(1.33)
Теорема Гаусса-Маркова утверждает,
что модель с гипотезами 1-3 имеет оценку МНК 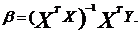 наиболее эффективную (в смысле
наименьшей дисперсии) оценку в классе линейных (по Y)
несмещенных оценок.
наиболее эффективную (в смысле
наименьшей дисперсии) оценку в классе линейных (по Y)
несмещенных оценок.
2. Практическая часть
.1 Характеристика экзогенных и эндогенных
переменных
В практической части работы будут проведены
исследования зависимости между объясняемой (экзогенной) переменной у Ї индекс
человеческого развития в ряде государств мира и объясняющими (эндогенными)
переменными: х1 Ї ВВП 1997г., % к 1990г. и х6 Ї ожидаемая
продолжительность жизни при рождении 1997г., число лет. Значения переменных
приведены в Таблице 2.1
Таблица 2.1 - Исходные данные
|
Страна
|
у
|
х1
|
х6
|
|
Австрия
|
0,904
|
115,0
|
77,0
|
|
Австралия
|
0,922
|
123,0
|
78,2
|
|
Белоруссия
|
0,763
|
74,0
|
68,0
|
|
Бельгия
|
0,923
|
111,0
|
77,2
|
|
Великобритания
|
0,918
|
113,0
|
77,2
|
|
Германия
|
0,906
|
110,0
|
77,2
|
|
Дания
|
0,905
|
119,0
|
75,7
|
|
Индия
|
0,545
|
146,0
|
62,6
|
|
Испания
|
0,894
|
113,0
|
78,0
|
|
Италия
|
0,900
|
108,0
|
78,2
|
|
Канада
|
0,932
|
113,0
|
79,0
|
|
Казахстан
|
0,740
|
71,0
|
67,6
|
|
Китай
|
0,701
|
210,0
|
69,8
|
|
Латвия
|
0,744
|
94,0
|
68,4
|
|
Нидерланды
|
0,921
|
118,0
|
77,9
|
|
Норвегия
|
0,927
|
130,0
|
78,1
|
|
Польша
|
0,802
|
127,0
|
72,5
|
|
Россия
|
0,747
|
61,0
|
66,6
|
|
США
|
0,927
|
117,0
|
76,7
|
|
Украина
|
0,721
|
46,0
|
68,8
|
|
Финляндия
|
0,913
|
107,0
|
76,8
|
|
Франция
|
0,918
|
110,0
|
78,1
|
Построим графики зависимости результативного
признака от каждого фактора в отдельности, используя MS
Excel for
Windows:
Рисунок 2.1 Ї График зависимости у от х1
Рисунок 2.2 Ї График зависимости у от х6
На обоих графиках прослеживается преимущественно
линейная форма зависимости между переменными, поэтому можно высказать
предположение о линейной форме зависимости у от обоих факторов.
Рассчитаем парные коэффициенты корреляции,
применяя формулы:
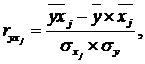 (2.1)
(2.1)
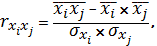
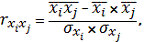 (2.2)
(2.2)
где средние значения находятся так:
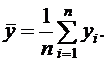 (2.3)
(2.3)
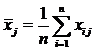 (2.4)
(2.4)
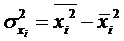 (2.5)
(2.5)
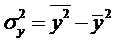 (2.6)
(2.6)
Таблица 2.2 Ї Расчетная таблица для определения парных коэффициентов
корреляции
|
Страна
|
у
|
х1
|
х6
|
(х1)2
|
х1 х6
|
у х1
|
у х6
|
у2
|
|
Австрия
|
0,904
|
115
|
77
|
13225
|
8855
|
103,96
|
69,608
|
0,817216
|
|
Австралия
|
0,922
|
123
|
78,2
|
15129
|
9618,6
|
113,406
|
72,1004
|
0,850084
|
|
Белоруссия
|
0,763
|
74
|
68
|
5476
|
5032
|
56,462
|
51,884
|
0,582169
|
|
Бельгия
|
0,923
|
111
|
77,2
|
12321
|
8569,2
|
102,453
|
71,2556
|
0,851929
|
|
Великобритания
|
0,918
|
113
|
77,2
|
12769
|
8723,6
|
103,734
|
70,8696
|
0,842724
|
|
Германия
|
0,906
|
110
|
77,2
|
12100
|
8492
|
99,66
|
69,9432
|
0,820836
|
|
Дания
|
0,905
|
119
|
75,7
|
14161
|
9008,3
|
107,695
|
68,5085
|
0,819025
|
|
Индия
|
0,545
|
146
|
62,6
|
21316
|
9139,6
|
|
|
|
Испания
|
0,894
|
113
|
78
|
12769
|
8814
|
101,022
|
69,732
|
0,799236
|
|
Италия
|
0,9
|
108
|
78,2
|
11664
|
8445,6
|
97,2
|
70,38
|
0,81
|
|
Канада
|
0,932
|
113
|
79
|
12769
|
8927
|
105,316
|
73,628
|
0,868624
|
|
Казахстан
|
0,74
|
71
|
67,6
|
5041
|
4799,6
|
52,54
|
50,024
|
0,5476
|
|
Китай
|
0,701
|
210
|
69,8
|
44100
|
14658
|
147,21
|
48,9298
|
0,491401
|
|
Латвия
|
0,744
|
94
|
68,4
|
8836
|
6429,6
|
69,936
|
50,8896
|
0,553536
|
|
Нидерланды
|
0,921
|
118
|
77,9
|
13924
|
9192,2
|
108,678
|
71,7459
|
0,848241
|
|
Норвегия
|
0,927
|
130
|
78,1
|
16900
|
10153
|
120,51
|
72,3987
|
0,859329
|
|
Польша
|
0,802
|
127
|
72,5
|
16129
|
9207,5
|
101,854
|
58,145
|
0,643204
|
|
Россия
|
0,747
|
61
|
66,6
|
3721
|
4062,6
|
45,567
|
49,7502
|
0,558009
|
|
США
|
0,927
|
117
|
76,7
|
13689
|
8973,9
|
108,459
|
71,1009
|
0,859329
|
|
Украина
|
0,721
|
46
|
68,8
|
2116
|
3164,8
|
33,166
|
49,6048
|
0,519841
|
|
Финляндия
|
0,913
|
107
|
76,8
|
11449
|
8217,6
|
97,691
|
70,1184
|
0,833569
|
|
Франция
|
0,918
|
110
|
78,1
|
12100
|
8591
|
100,98
|
71,6958
|
0,842724
|
|
Чехия
|
0,833
|
99,2
|
73,9
|
9840,64
|
7330,88
|
82,6336
|
61,5587
|
0,693889
|
|
Швейцария
|
0,914
|
101
|
78,6
|
10201
|
7938,6
|
92,314
|
71,8404
|
0,835396
|
|
Швеция
|
0,923
|
105
|
78,5
|
11025
|
8242,5
|
96,915
|
72,4555
|
0,851929
|
|
У
|
21,24
|
2741
|
1860,6
|
322770,6
|
204586,6
|
2328,93
|
1592,28
|
18,29687
|
|
Ср.знач.
|
0,849
|
109,6
|
74,424
|
12910,82
|
8183,467
|
93,1573
|
63,6914
|
0,7319
|
Получим расчетные
значения:

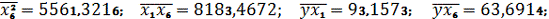
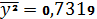
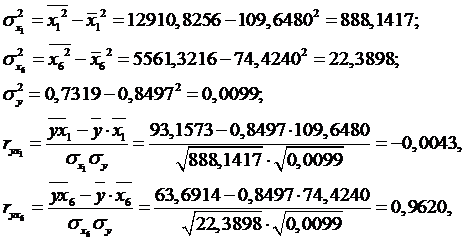
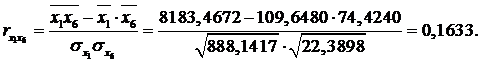
Анализ показывает, что зависимая переменная у
имеет тесную связь с х6 (ryx6 = 0,9620) и менее тесную,
очень слабую связь с х1 (ryx1 = -0,0043).
Факторы x1 и x6 не тесно
связаны между собой ( = 0,1633), что свидетельствует об
отсутствии между ними коллинеарности.
= 0,1633), что свидетельствует об
отсутствии между ними коллинеарности.
.2 Построение двухфакторного
уравнения регрессии
Построим уравнение множественной
регрессии в линейной форме с двумя факторами.
Линейное уравнение множественной
регрессии имеет вид:

где 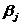 (j = 1, k ) - стандартизированные
коэффициенты регрессии.
(j = 1, k ) - стандартизированные
коэффициенты регрессии.
В двухфакторном
регрессионном анализе найти уравнение регрессии в стандартизированном масштабе 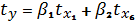 можно через формулы:
можно через формулы:
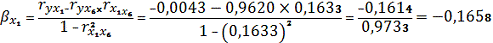
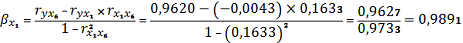
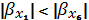 , следовательно делаем
вывод, что фактор x6 влияет
на результативный признак сильнее чем фактор x1.
, следовательно делаем
вывод, что фактор x6 влияет
на результативный признак сильнее чем фактор x1.
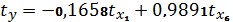
Возвращаемся к натуральному масштабу
используя следующие формулы:
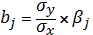 и
и 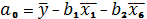
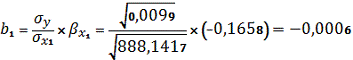
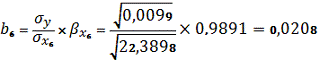
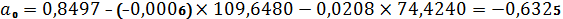
Определяем коэффициент
множественной корреляции, используя следующую формулу:

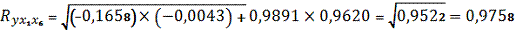
Коэффициент корреляции показывает,
что связь между y и факторами прямая и сильная.
Далее определяем коэффициент
детерминации по формуле:
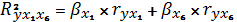
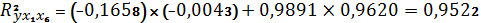
Коэффициент детерминации 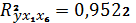 означает, что наша модель объясняет
95,2% общего разброса значений результативного признака, т.е. долю факторной
дисперсии в общей дисперсии.
означает, что наша модель объясняет
95,2% общего разброса значений результативного признака, т.е. долю факторной
дисперсии в общей дисперсии.
Сравнительную оценку силы связи
факторов проведем с помощью общих (средних) коэффициентов эластичности,
используя следующую формулу:
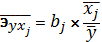
Средние значения следующие:

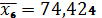
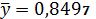
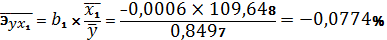
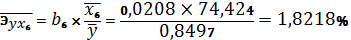
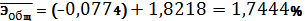
При изменении фактора х1
на 1% Y изменится
от своей величины на 0,0774% при неизменном х6. При изменении
фактора х6 на 1% Y изменится от своей величины на
1,8218% при неизменном х1. Наименьшее влияние на Y оказывает
фактор х1 Ї ВВП 1997г., % к 1990г.
Определим общий F-критерий
Фишера по формуле:
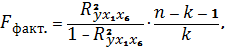
где n
Ї объем выборки,
k Ї число факторов
модели.
Получим:
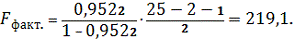
Так как 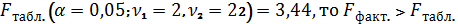

и поэтому уравнение регрессии, и
показатель тесноты связи на 95% уровне статистически значимы.
Для оценки статистической значимости
модели по параметрам рассчитывают t-критерии
Стьюдента.
Поскольку, то t-статистики
Стьюдента:
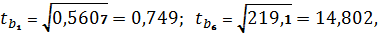
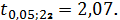
 следовательно, коэффициент
регрессии b1 статистически значимый.
следовательно, коэффициент
регрессии b1 статистически значимый.
 следовательно, коэффициент
регрессии b6 статистически не значим.
следовательно, коэффициент
регрессии b6 статистически не значим.
.3 Построение однофакторных
уравнений регрессии
Строим однофакторные уравнения линейной
регрессии, которое имеет вид:
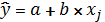



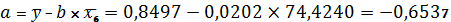
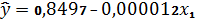
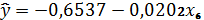
На основе коэффициентов корреляции рассчитываем
коэффициенты детерминации:

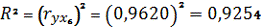
Доля факторной дисперсии в общей для первого
однофакторного уравнения регрессии составляет 0,002%, тогда как для второго
уравнения Ї 92,5%. Второе уравнение значительно качественнее первого.
2.4 Прогнозирование значения результативного
признака
На основе полученных трех уравнений регрессии
определим прогнозное значения результативного признака, используя средние
величины факторных признаков:
Для множественной регрессии:
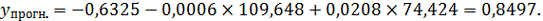
Для однофакторной регрессии у и Х1:
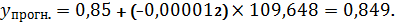
Для однофакторной регрессии у и Х6:

Учитывая, что у линейной множественной регрессии
коэффициент детерминации - 0,9522 самый высокий, то из 3-х моделей выбор делаем
в ее пользу, т.е. в пользу модели:
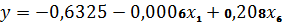
Заключение
Данная работа выполнена в соответствии с
изученными теоретическими материалами по построению линейных моделей регрессии,
краткий обзор которых приведен в теоретической части работы.
В практической части работы рассматривались
зависимости между объясняемой (экзогенной) переменной у Ї индекс человеческого
развития в ряде государств мира и объясняющими (эндогенными) переменными: х1
Ї ВВП 1997 г., % к 1990 г. и х6 Ї ожидаемая продолжительность жизни
при рождении 1997 г., число лет. С использованием возможностей MS
Excel for
Windows были получены
графические изображения парных зависимостей, на основании которых, был сделан
вывод о необходимости построения линейных моделей регрессии, которые и были
построены:
Модель
множественной линейной регрессии
и две
модели парных линейных регрессий:
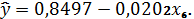
Первая и третья модели оказались статистически
(95%) значимы и значимы их коэффициенты (на основании критерия Фишера и
Стьюдента), их прогнозные значения достаточно близки: 0,849 и 0,851
соответственно. На основании сравнения коэффициентов детерминации: 0,9522 и
0,9254 выбор сделан в пользу первой модели, так как она объясняет 95,2%
факторной дисперсии в общей и ее следует использовать для прогнозных расчетов.
список
используемых источников
1. Бабешко, Л.О. Основы эконометрического
моделирования: учеб. пособие. Изд. 2-е. испр. / Л.О. Бабешко. - М.: КомКнига,
2006, -432 с.
. Бывшев, В.А. Эконометрика: учеб.
пособие / В.А. Бывшев. - М.: Финансы и статистика, 2008. -480 с.
. Доугерти, К. Введение в
эконометрику: учебник: пер. с англ./ К. Доугерти. - М.: Инфра-М, 2009.
. Елисеева, И.И. Практикум по
эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордиенко и
др., под ред. И.И. Елисеевой. - М.: Финансы и статистика. 2001.
. Кремер, Н.Ш. Эконометрика: Учебник
/ Н.Ш. Кремер, Б.А. Путко, Под ред. Н.Ш. Кремера. - М.: ЮНИТИ-ДАНА, 2002.
. Эконометрика: Учебник, - 2-е изд., перераб. и доп. - 2-е изд., / И.И. Елисеева, С.В. Курышева, Т.В. Костеева и др. /
под ред. И.И. Елисеевой. - М.: Финансы и статистика. 2007.
. Айвазян, С.А. Прикладная
статистика и основы эконометрики / С.А. Айвазян, В.С. Мхитарян. - М.: ЮНИТИ,
1998.