Основы статистики
Лабораторная
работа №1
Первичная
обработка данных
При проведении экспериментов фиксировались значения случайной
величины X, Время простоя состава под скрещением, (в мин.).
Задание: произвести первичную обработку полученных опытных
данных с целью изучения свойств случайной величины Х.
) Составим расчетную таблицу, в которой запишем вариационный
ряд (элементы выборки в порядке возрастания признака) и произведем расчеты,
необходимые для вычисления числовых характеристик.
Таблица 1 - Расчетная таблица
|
Номер п/п
|
Выборка, мин.
|
Вариационный
ряд, 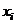 , мин. , мин.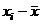 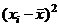  
|
|
|
|
|
|
1
|
23,3
|
0,24
|
-10,2363
|
104,7825
|
-1072,5888
|
10979,3765
|
|
2
|
7,04
|
0,42
|
-10,0563
|
101,1298
|
-1016,9954
|
10227,2446
|
|
3
|
2,47
|
0,55
|
-9,9263
|
98,5321
|
-978,0624
|
9708,5734
|
|
4
|
39,8
|
0,68
|
-9,7963
|
95,9681
|
-940,1360
|
9209,8852
|
|
5
|
0,42
|
1,46
|
-9,0163
|
81,2943
|
-732,9762
|
6608,7578
|
|
6
|
15
|
1,48
|
-8,9963
|
80,9340
|
-728,1094
|
6550,3145
|
|
7
|
18,1
|
2,16
|
-8,3163
|
69,1614
|
-575,1693
|
4783,2993
|
|
8
|
5,5
|
2,47
|
-8,0063
|
64,1014
|
-513,2170
|
4108,9861
|
|
9
|
1,48
|
3,21
|
-7,2663
|
52,7996
|
-383,6595
|
2787,7978
|
|
10
|
10,8
|
5,01
|
-5,4663
|
29,8808
|
-163,3384
|
892,8622
|
|
11
|
16,9
|
5,3
|
-5,1763
|
26,7944
|
-138,6969
|
717,9413
|
|
12
|
9,77
|
5,5
|
-4,9763
|
24,7639
|
-123,2334
|
613,2504
|
|
13
|
0,55
|
7,04
|
-3,4363
|
11,8084
|
-40,5776
|
139,4380
|
|
14
|
26,2
|
8,96
|
-1,5163
|
2,2993
|
-3,4865
|
5,2866
|
|
15
|
1,46
|
9,09
|
-1,3863
|
1,9219
|
-2,6644
|
3,6938
|
|
16
|
5,3
|
9,45
|
-1,0263
|
1,0534
|
-1,0811
|
1,1096
|
|
17
|
9,09
|
9,77
|
-0,7063
|
0,4989
|
-0,3524
|
0,2489
|
|
18
|
8,96
|
10,4
|
-0,0763
|
0,0058
|
-0,0004
|
0,0000
|
|
19
|
11,7
|
10,8
|
0,3237
|
0,1048
|
0,0339
|
0,0110
|
|
20
|
12
|
11,5
|
1,0237
|
1,0479
|
1,0727
|
1,0981
|
|
21
|
0,68
|
11,7
|
1,2237
|
1,4974
|
1,8323
|
2,2421
|
|
22
|
2,16
|
12
|
1,5237
|
2,3216
|
3,5373
|
5,3896
|
|
23
|
0,24
|
15
|
4,5237
|
20,4636
|
92,5703
|
418,7573
|
|
24
|
11,5
|
16,9
|
6,4237
|
41,2635
|
265,0629
|
1702,6759
|
|
25
|
5,01
|
18,1
|
7,6237
|
58,1203
|
443,0897
|
3377,9685
|
|
26
|
19,3
|
19,3
|
8,8237
|
77,8571
|
686,9850
|
6061,7270
|
|
27
|
3,21
|
23,3
|
12,8237
|
164,4464
|
2108,8062
|
27042,6273
|
|
28
|
26,5
|
26,2
|
15,7237
|
247,2337
|
3887,4202
|
61124,4992
|
|
29
|
10,4
|
26,5
|
16,0237
|
256,7579
|
4114,2029
|
65924,6158
|
|
30
|
9,45
|
39,8
|
29,3237
|
859,8774
|
25214,7590
|
739389,1891
|
|
Итого
|
314,290
|
314,290
|
0,0000
|
2578,7215
|
29405,0276
|
972388,8669
|
) Найдем размах выборки
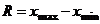 = 39,56.
= 39,56.
) Длина интервала
 = 6,697.
= 6,697.
) границы интервалов:  = 0,24,
= 0,24, 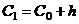 = 6,937,
= 6,937, 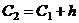 = = 13,634,
= = 13,634,  = 20,331,
= 20,331, 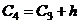 = 27,029,
= 27,029, 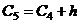 = 33,726,
= 33,726,
 = 40,423
= 40,423 .
.
) Построим интервальный статистический ряд:
Таблица 2 - Интервальный статистический ряд
|
Границы
интервалов  , мин.Частоты , мин.Частоты  Частости Частости 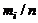 Накопленные частости Накопленные частости
|
|
|
|
|
(0,24; 6,937)
|
12
|
12/30
|
12/30
|
|
(6,937; 13,634)
|
10
|
10/30
|
22/30
|
|
(13,634;
20,331)
|
4
|
4/30
|
26/30
|
|
(20,331;
27,029)
|
3
|
3/30
|
29/30
|
|
(27,029;
33,726)
|
0
|
0/30
|
29/30
|
|
(33,726;
40,423)
|
1
|
1/30
|
1
|
|
Итого
|
30
|
1
|
|
) Вычислим числовые характеристики.
В качестве оценки математического ожидания используется
среднее арифметическое 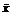 наблюденных значений. Эта статистика
называется выборочным средним.
наблюденных значений. Эта статистика
называется выборочным средним.
 .
.
Для оценивания по выборочным данным моды распределения,
используется то значение сгруппированного статистического ряда 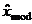 , которому соответствует наибольшее
значение частоты. По интервальному статистическому ряду определяется модальный
интервал, в который попало наибольшее число элементов выборки, и в
качестве точечной оценки моды может использоваться среднее значение этого
интервала.
, которому соответствует наибольшее
значение частоты. По интервальному статистическому ряду определяется модальный
интервал, в который попало наибольшее число элементов выборки, и в
качестве точечной оценки моды может использоваться среднее значение этого
интервала.
 .
.
Для определения выборочного значения медианы используется
вариационный ряд. В качестве оценки медианы 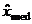 принимают средний (т.е.
принимают средний (т.е. 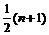 -й) член этого ряда, если значение n - нечётно и среднее
арифметическое между двумя средними (т.е. между
-й) член этого ряда, если значение n - нечётно и среднее
арифметическое между двумя средними (т.е. между  -м и
-м и  -м) членами этого ряда, если n - чётно. В
нашем случае объем выборки
-м) членами этого ряда, если n - чётно. В
нашем случае объем выборки 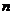 = 40 - четное, т.е. в качестве оценки медианы примем
= 40 - четное, т.е. в качестве оценки медианы примем
= 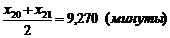 .
.
В качестве оценки дисперсии используется статистика
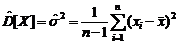 =
= 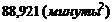 .
.
Оценка среднего квадратического отклонения 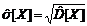 =
=  .
.
Оценка коэффициента вариации  .
.
Оценка коэффициента асимметрии
 .
.
Оценка коэффициента эксцесса
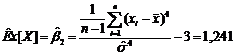 .
.
) Для приближённого построения эмпирической функции
распределения воспользуемся соотношением:
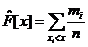

) Построим гистограмму частот и эмпирическую функцию
распределения.
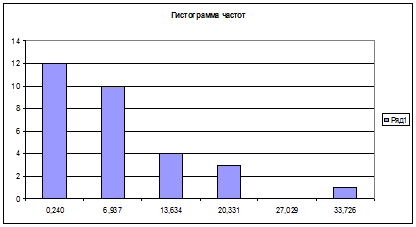
Рисунок 1 - Гистограмма частот

Рисунок 2 - Функция распределения
Вывод. В результате исследования выборки значений непрерывной
случайной величины, характеризующей время простоя состава под скрещением,
получили следующие результаты, мин.: минимальное время простоя - 0,24,
максимальное - 39,8, среднее значение времени простоя состава под скрещением -
10,476, наиболее вероятное время простоя состава под скрещением - 3,589,
средневероятное - 9,270, среднеквадратическое отклонение времени простоя
состава под скрещением от среднего значения составило 9,430. Оценка
коэффициента вариации составила 159,638%, что указывает на большую колеблемость
признака относительно среднего значения, оценка коэффициента асимметрии
составила 1,209, оценка коэффициента эксцесса составила 1,241.
Лабораторная
работа №2
Подбор
закона распределения одномерной случайной величины
Цель работы: изучить
методику применения критерия 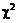 Пирсона для проверки гипотезы о виде закона распределения
случайной величины.
Пирсона для проверки гипотезы о виде закона распределения
случайной величины.
Задание: с
помощью критерия проверить согласование выдвинутой
гипотезы о виде закона распределения исследуемой случайной величины с
имеющимися выборочными данными.
Алгоритм применения критерия c2 для проверки гипотезы о
виде закона распределения исследуемой случайной величины.
Выборочные данные представляются в виде интервального или
сгруппированного статистического ряда.
Выбирается уровень значимости a.
Формулируется гипотеза о виде закона распределения
исследуемой случайной величины.
4 Вычисляются вероятности pi попадания значений
случайной величины Х в рассматриваемые разряды разбиения: 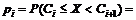
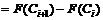 , (
, (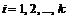 ), где F(x) - гипотетическая функция
распределения случайной величины X.
), где F(x) - гипотетическая функция
распределения случайной величины X.
Замечание.
Если изучается непрерывная случайная величина, то при вычислении значений 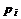 необходимо изменить границы
первого и последнего частичных интервалов разбиения таким образом, чтобы учесть
все возможные значения, которые может принять случайная величина
предполагаемого класса. В зависимости от конкретного вида проверяемой гипотезы
границы частичных интервалов необходимо изменить следующим образом:
необходимо изменить границы
первого и последнего частичных интервалов разбиения таким образом, чтобы учесть
все возможные значения, которые может принять случайная величина
предполагаемого класса. В зависимости от конкретного вида проверяемой гипотезы
границы частичных интервалов необходимо изменить следующим образом:
|
Вид закона
распределения
|
Первый интервал
разбиения
|
Последний
интервал разбиения
|
|
Равномерный
|
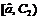 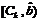
|
|
|
Экспоненциальный
|
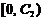 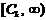
|
|
|
Нормальный
|
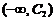
|
|
5 Определяются значения теоретических частот npi (i
= 1, 2,…, k). При необходимости для обеспечения условия npi
³ 3 (если объем выборки 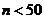 ), npi ³
5 (если объем выборки
), npi ³
5 (если объем выборки 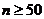 ), объединяются несколько соседних
разрядов разбиения.
), объединяются несколько соседних
разрядов разбиения.
Вычисляется наблюдаемое значение критерия
c2: 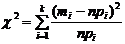 .
.
По таблицам квантилей распределения c2
определяется критическое значение  , соответствующее заданному уровню значимости a и числу степеней свободы
, соответствующее заданному уровню значимости a и числу степеней свободы
n = k
- r - 1.
Если расчётное значение критерия попадает в критическую область,
т.е. 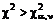 , то проверяемая гипотеза отвергается (при
этом вероятность отклонения верной гипотезы равна a).
, то проверяемая гипотеза отвергается (при
этом вероятность отклонения верной гипотезы равна a).
В случаях, когда наблюденное значение c2 не превышает критического  , считают, что выдвинутая гипотеза не противоречит опытным данным.
Подчеркнем, что полученный результат свидетельствует лишь о приемлемом
согласовании проверяемой гипотезы с имеющимися выборочными данными и, в общем
случае, не является доказательством истинности этой гипотезы.
, считают, что выдвинутая гипотеза не противоречит опытным данным.
Подчеркнем, что полученный результат свидетельствует лишь о приемлемом
согласовании проверяемой гипотезы с имеющимися выборочными данными и, в общем
случае, не является доказательством истинности этой гипотезы.
По таблице, полученной в лабораторной работе №1 и по гистограмме
частот выдвигаем нулевую гипотезу о виде закона распределения случайной
величины 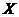 (времени простоя состава под скрещением).
(времени простоя состава под скрещением).
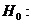 Случайная величина (время простоя состава под скрещением) распределена по
показательному (экспоненциальному) закону.
Случайная величина (время простоя состава под скрещением) распределена по
показательному (экспоненциальному) закону.
Выбираем уровень значимости  .
.
Вычислим вероятности pi попадания значений случайной
величины Х в рассматриваемые разряды разбиения по формуле:
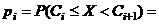

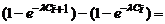 =
=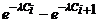 .
.
Проверим гипотезу 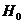 с помощью критерия согласия Хи-квадрат Пирсона.
с помощью критерия согласия Хи-квадрат Пирсона.
Вычислим параметр 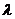 =
= 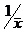 =
=  = 0,095453244 = 0,095.
= 0,095453244 = 0,095.
Так как изучается непрерывная случайная величина, то при
вычислении значений необходимо изменить границы
первого и последнего частичных интервалов разбиения. В нашем случае проверяется
гипотеза о показательном законе распределения.
|
Вид закона
распределения
|
Первый интервал
разбиения
|
Последний
интервал разбиения
|
|
Экспоненциальный
|
|
|
Вычислим вероятности по формуле
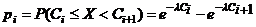
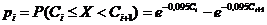 .
.
Пример расчета:
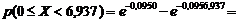 1 - 0,516= 0,484.
1 - 0,516= 0,484.
Для того чтобы облегчить расчеты, можно с помощью пакета программ  выполнить промежуточные расчеты, которые
необходимо оформить в виде таблицы:
выполнить промежуточные расчеты, которые
необходимо оформить в виде таблицы:
Таблица 1 - Расчетная таблица вероятностей
|
Граница
интервала  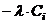 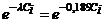 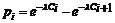 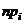
|
|
|
|
|
|
0
|
0
|
1
|
0,484
|
0,484
|
|
6,937
|
-0,662
|
0,516
|
0,244
|
0,244
|
|
13,634
|
-1,301
|
0,272
|
0,129
|
0,129
|
|
20,331
|
-1,941
|
0,144
|
0,068
|
0,068
|
|
27,029
|
-2,580
|
0,076
|
0,036
|
|
33,726
|
-3,219
|
0,040
|
0,040
|
0,040
|
|
 -0-- -0--
|
|
|
|
|
|
Итого
|
-
|
-
|
1
|
30
|
Таблица 2 - Расчет c2
Границы интервалов Частоты эмпирические Вероятности
|
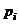 Частоты теоретические Частоты теоретические 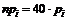 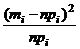
|
|
|
|
|
|
(0; 6,937)
|
12
|
0,484
|
14,528
|
0,440
|
|
(6,937; 13,634)
|
10
|
0,244
|
7,308
|
0,992
|
|
(13,634;
20,331)
|
4
|
0,129
|
3,856
|
0,003
|
|
(20,331;
27,029)
|
3
|
0,068
|
2,035
|
|
|
(27,029;
33,726)
|
0
|
0,036
|
1,074
|
|
|
(33,726; ∞)
|
1
|
0,040
|
1,200
|
|
|
Итого
|
30
|
1
|
30
|
1,435= c2
|
Вычислим число степеней свободы n =
k - r - 1 = 3-1-1= 1, где k = 3 -
число интервалов в таблице 2 после объединения, r =1 - число параметров
выбранного закона распределения - в нашем случае показательный закон (один
параметр ).
По таблицам квантилей распределения c2
определяется критическое значение, соответствующее заданному уровню значимости a=0,05 и числу степеней свободы n = 1.
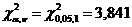
Вывод. Сравниваем полученное значение в таблице 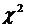 = 1,435 с табличным
= 1,435 с табличным 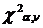 = 3,841. Так как расчетное = 1,435 меньше, чем табличное = 3,841, то гипотеза о показательном законе
распределения подтвердилась.
= 3,841. Так как расчетное = 1,435 меньше, чем табличное = 3,841, то гипотеза о показательном законе
распределения подтвердилась.
Лабораторная
работа №3
Построение
регрессионной модели системы двух случайных величин
Цель работы: изучить основные методы регрессионного и
корреляционного анализа; исследовать зависимость между двумя случайными величинами,
заданными выборками.
Задание: по виду корреляционного поля сделать
предположение о форме регрессионной зависимости между двумя случайными
величинами; используя метод наименьших квадратов, найти параметры уравнения
регрессии; оценить качество описания зависимости полученным уравнением
регрессии.
По результатам пятнадцати совместных измерений веса грузового
поезда, т, и соответствующего времени нахождения поезда на участке Y, ч, представленных в
таблице 1, следует исследовать зависимость между данными величинами. Необходимо
определить коэффициенты уравнения регрессии методом наименьших квадратов,
оценить тесноту связи между величинами, проверить значимость коэффициента
корреляции и спрогнозировать время нахождения поезда на участке при заданном
весе поезда (5200 т).
Решение. На величину времени нахождения поезда на участке Y,
помимо веса X, влияние оказывает профиль и качество железнодорожного полотна,
качество подвижного состава, направление и скорость ветра и другие факторы.
Поэтому зависимость между величиной времени нахождения поезда на участке Y и
веса поезда X является статистической: при одном весе поезда при различных
дополнительных условиях время нахождения поезда на участке может принимать
различные значения. Для определения вида регрессионной зависимости построим
корреляционное поле.
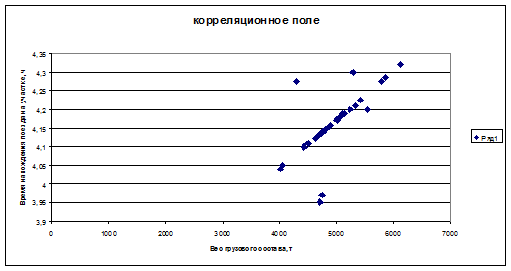
Рис. 1. Корреляционное поле
Характер расположения точек на диаграмме рассеяния позволяет
сделать предположение о линейной регрессионной зависимости 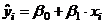 .
.
Таблица 1 - Результаты промежуточных вычислений
|
Вес грузового
состава, т, 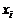 Время нахождения поезда на участке,
час., Время нахождения поезда на участке,
час.,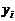 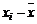  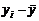  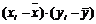
|
|
|
|
|
|
|
|
4435,68
|
4,098
|
-463,381
|
214722
|
-0,057
|
0,003
|
26,274
|
|
5100,58
|
4,190
|
201,519
|
40610
|
0,035
|
0,001
|
7,114
|
|
4885,41
|
4,156
|
-13,651
|
186
|
0,001
|
0,000
|
-0,018
|
|
5416,94
|
4,225
|
517,879
|
268198
|
0,070
|
0,005
|
36,407
|
|
4496,66
|
4,108
|
-402,401
|
161927
|
-0,047
|
0,002
|
18,792
|
|
4722,08
|
3,950
|
-176,981
|
31322
|
-0,205
|
0,042
|
36,228
|
|
5537,91
|
4,200
|
638,849
|
408128
|
0,045
|
0,002
|
28,940
|
|
5074,01
|
4,180
|
174,949
|
30607
|
0,025
|
0,001
|
4,426
|
|
4807,09
|
4,145
|
-91,971
|
8459
|
-0,010
|
0,000
|
0,892
|
|
4046,02
|
4,050
|
-853,041
|
727680
|
-0,105
|
0,011
|
89,313
|
|
4683,93
|
4,130
|
-215,131
|
46281
|
-0,025
|
0,001
|
5,314
|
|
4872,42
|
4,154
|
-26,641
|
710
|
-0,001
|
0,000
|
0,019
|
|
4003,22
|
4,040
|
-895,841
|
802532
|
-0,115
|
0,013
|
102,753
|
|
4628,01
|
4,122
|
-271,051
|
73469
|
-0,033
|
0,001
|
8,863
|
|
4293,44
|
4,274
|
-605,621
|
366777
|
0,119
|
0,014
|
-72,251
|
|
5035,70
|
4,175
|
136,639
|
18670
|
0,020
|
0,000
|
2,774
|
|
5780,28
|
4,274
|
881,219
|
776546
|
0,119
|
0,014
|
105,129
|
|
4752,14
|
3,970
|
-146,921
|
21586
|
-0,185
|
0,034
|
27,136
|
|
6115,63
|
4,320
|
1216,569
|
1480039
|
0,165
|
0,027
|
201,099
|
|
4788,77
|
4,143
|
-110,291
|
12164
|
-0,012
|
0,000
|
1,290
|
|
5140,42
|
4,189
|
241,359
|
58254
|
0,034
|
0,001
|
8,279
|
|
5856,44
|
4,285
|
957,379
|
916574
|
0,130
|
0,017
|
124,746
|
|
5243,49
|
4,200
|
344,429
|
118631
|
0,045
|
0,002
|
15,603
|
|
5007,53
|
4,170
|
108,469
|
11765
|
0,015
|
0,000
|
1,660
|
|
5321,63
|
4,210
|
422,569
|
178564
|
0,055
|
0,003
|
23,368
|
|
5296,32
|
4,300
|
397,259
|
157814
|
0,145
|
0,021
|
57,722
|
|
4046,73
|
4,050
|
-852,331
|
726469
|
-0,105
|
0,011
|
89,239
|
|
4051,41
|
4,050
|
-847,651
|
718513
|
-0,105
|
0,011
|
88,749
|
|
4795,27
|
4,146
|
-103,791
|
10773
|
-0,009
|
0,000
|
0,903
|
|
4736,68
|
4,137
|
-162,381
|
26368
|
-0,018
|
0,000
|
2,874
|
|
Итого 146972
|
125
|
0
|
8414339
|
0
|
0,239
|
1044
|
Найдем уравнение прямой линии методом наименьших квадратов
.
Средний вес грузового состава:
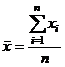 =
= 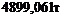 .
.
Среднее значение времени нахождения поезда на участке:
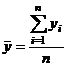 =
=
Коэффициенты уравнения:
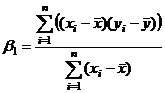
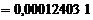
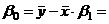
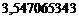
Уравнение регрессии имеет вид: 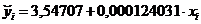 .
.
Для линейной связи коэффициенты:
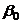 - постоянная регрессии, показывает точку пересечения прямой с осью
ординат
- постоянная регрессии, показывает точку пересечения прямой с осью
ординат
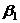 - коэффициент регрессии, показывает меру зависимости переменных y
от х, указывает среднюю величину изменения переменной у при изменении х на одну
единицу, знак В1 определяет направление этого
изменения.
- коэффициент регрессии, показывает меру зависимости переменных y
от х, указывает среднюю величину изменения переменной у при изменении х на одну
единицу, знак В1 определяет направление этого
изменения.
Вычислим линейный коэффициент корреляции
 = 0,735247869.
= 0,735247869.
Таблица 2 - Расчет значений времени нахождения поезда на
участке по уравнению регрессии
|
Вес грузового
состава, т, Время нахождения поезда на участке,
час.,
|
|
|
|
4435,68
|
4,098
|
4,097226427
|
|
5100,58
|
4,19
|
4,179694528
|
|
4885,41
|
4,156
|
4,153006814
|
|
5416,94
|
4,225
|
4,218932922
|
|
4496,66
|
4,108
|
4,104789828
|
|
4722,08
|
3,95
|
4,132748858
|
|
5537,91
|
4,2
|
4,233936932
|
|
5074,01
|
4,18
|
4,176399029
|
|
4807,09
|
4,145
|
4,143292719
|
|
4046,02
|
4,05
|
4,048896573
|
|
4683,93
|
4,13
|
4,128017082
|
|
4872,42
|
4,154
|
4,151395653
|
|
4003,22
|
4,04
|
4,043588053
|
|
4628,01
|
4,122
|
4,121081277
|
|
4293,44
|
4,274
|
4,079584282
|
|
5035,7
|
4,175
|
4,171647408
|
|
5780,28
|
4,274
|
4,263998285
|
|
4752,14
|
3,97
|
4,136477225
|
|
6115,63
|
4,32
|
|
4788,77
|
4,143
|
4,141020474
|
|
5140,42
|
4,189
|
4,184635916
|
|
5856,44
|
4,285
|
4,273444473
|
|
5243,49
|
4,2
|
4,197419774
|
|
5007,53
|
4,17
|
4,168153459
|
|
5321,63
|
4,21
|
4,207111544
|
|
5296,32
|
4,3
|
4,203972323
|
|
4046,73
|
4,05
|
4,048984635
|
|
4051,41
|
4,05
|
4,049565099
|
|
4795,27
|
4,146
|
4,141826674
|
|
4736,68
|
4,137
|
4,134559708
|
|
Итого 146971,84
|
124,641
|
124,641
|

Рис. 2. Корреляционное поле и линия регрессии
Спрогнозируем время нахождения поезда на участке при заданном
весе грузового состава (5200 т).

Качественная оценка тесноты связи между величинами выявляется по
шкале Чеддока (таблица 3).
Таблица 3 - Шкала Чеддока
|
Теснота связи
|
Значение
коэффициента корреляции при наличии
|
|
прямой связи
|
обратной связи
|
|
Слабая
|
0,1-0,3
|
(-0,1) - (-0,3)
|
|
Умеренная
|
0,3-0,5
|
(-0,3) - (-0,5)
|
|
Заметная
|
0,5-0,7
|
(-0,5) - (-0,7)
|
|
Высокая
|
0,7-0,9
|
(-0,7) - (-0,9)
|
|
Весьма высокая
|
0,9-0,99
|
(-0,9) -
(-0,99)
|
Вывод. Линейный коэффициент корреляции характеризует тесноту связи
между двумя коррелируемыми признаками в случае наличия между ними линейной
зависимости. Т.к.  = 0,735, то можно говорить о том, что
между величинами X и Y существует линейная прямая, высокая связь.
= 0,735, то можно говорить о том, что
между величинами X и Y существует линейная прямая, высокая связь.
Чтобы сделать статистический вывод о значимости коэффициента
корреляции (при проверке линейности регрессионной зависимости) выдвигается
нулевая гипотеза об отсутствии линейной зависимости между исследуемыми с. в.
против альтернативной гипотезы о наличии линейной связи.
корреляция
регрессионный распределение вариационный
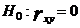 ,
,
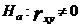 .
.
Если гипотеза H0 отклоняется, то считается, что
уравнение регрессии Y по X действительно имеет линейный вид.
Для проверки гипотезы H0 вычисляется t-статистика
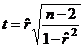 = 5,74.
= 5,74.
При условии справедливости гипотезы H0 рассчитанная
t-статистика имеет распределение Стьюдента с n - 2
степенями свободы. Найденное значение t = 5,74 сравнивается с критическим
значением ta,n при n = n
- 2 = 30-2 = 28 степенях свободы. В нашем случае ta,n = t a=0.05, n=28 =
1,701. Так как расчетное значение 5,74 по абсолютной величине превосходит
табличное 1,701 для заданного уровня значимости, то нулевая гипотеза H0
с. в. отклоняется, и с вероятностью ошибки a можно утверждать, что между исследуемыми величинами существует
линейная зависимость.