|
Обмін
|
|
Семантика
|
|
Повідомлення
|
|
Протоколи
|
|
Передача/прийом
|
|
Дані
|
Рис. 6. Концептуальне подання
інформаційного обміну
Навіть під час вражаючого росту
Інтернету із середини 1990-х років єдиним найбільш популярним напрямком
розробки програмістів була життєво важлива передача повідомлень. По суті,
функціональна сумісність, що є «бойовим кличем» моделей з веб-службами,
заснована на простій ідеї поміщення об'єкта в контейнер так, щоб зробити його
повідомленням. Фактично це є суттю моделі з веб-службами: перетворення зручних
для читання людиною веб-сторінок у повідомлення. Після того як дані відображені
і перетворені в повідомлення, може бути почата передача таких повідомлень
одному або декільком приймачам (для якої може бути необхідна маршрутизація на
транспортному рівні моделі ОSI 7 чи вище).
Передача повідомлень є основою всіх
видів передачі даних, до яких відносяться як віддалений виклик процедури RРС,
так і об’єкти, що виконуються. Коли вузол вирішує здійснити доступ або спільно
використовувати дані, відсутні в його пам'яті, але, перебувають у межах
фізичної досяжності (тобто за межами високошвидкісної шини чи внутрішнього
механізму передачі даних), то необхідно передавати повідомлення. Хоча існує
багато цікавих і корисних варіантів, ця проста концепція є фундаментальною
складовою частиною МРО.
Передача повідомлень у МРО може
приймати багато форм. Певний тип переданих даних повинен підходити для певної
операції, і це ж справедливо відносно форми їхньої передачі. Реалізація
широкомовного розсилання повідомлення, наприклад, багато в чому відрізняється
від передачі «один до одному». На природу повідомлень, природно, впливають
часові співвідношення. Із простої передавальної моделі виникає складний набір
реалізацій, що базується на трьох загальних поглядах на повідомлення:
- перетворення даних;
синхронність;
маршрутизація.
Ці три погляди спричиняють різні особливості
схем передачі повідомлень, які широко використовуються сьогодні.
Спільно використовувана пам'ять у
порівнянні з оброблюваними повідомленнями
Взагалі, повідомлення МРО
використовуються одним із двох способів, як показано на рис.: вузол бачить або
загальну пам'ять, семантика доступу до якої не відрізняється значно від тої, що
використовується для локальної пам'яті, або різні результати опрацювання
внаслідок маніпуляцій і перетворень самих повідомлень; це є причиною створення
загальної пам'яті. У кожної з цих схем відбувається подальша спеціалізація з
урахуванням поглядів на передачу повідомлень, наведених вище.
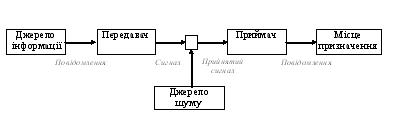
Рис. 7. Схеми передачі повідомлень
У кожній точці цього шляху важлива
матеріалізація повідомлення, з концептуальної позиції, як функція точок
опрацювання, у яких відбувається перетворення повідомлення. Загалом, потік
повідомлень у часі не прив'язаний до конкретної або одиночної операції або
встановленого порядку в кожній з можливих точок опрацювання. Тут також немає
якого-небудь певного обмеження на операції в точці опрацювання. Як така,
класифікація типу даних або перетворення, наприклад, теоретично може
відбуватися в ряді точок зупинки на даному шляху, навіть у синхронному
середовищі передачі повідомлень. Те ж саме можна сказати про можливі операції
маршрутизації.
Концепція перетворення типу даних,
імовірно, більш точно визначається як перетворення типу документа; типізація
даних на мовному рівні ортогонально співвідноситься з перетворенням даних, що
відбувають при передачі повідомлень. Але перетворення даних для кожного
документа операційно важливо для передачі повідомлень в Інтернеті і його
вузлів. Наприклад, для шифрування і дешифрування повідомлень необхідно
здійснювати складні перетворення даних, які повинні виконуватися надійним,
упорядкованим образом. Таке опрацювання відбувається в множині точок,
розподілених у часі і між ресурсами.
Крім шифрування, іншими прикладами
перетворення документів служать опрацювання Java-в-ХМL, оболонки і контейнери
метаданих і перетворення таблиць стилів у таких підходах, як XSLT.
Завдяки розширенню ХМL, роботі зі
стандартизації і зростаючої доступності інструментів, що підтримують ці
стандарти зараз стало можливим генерувати множину типів документів. Наприклад,
технологія перетворення документів ХМL полегшила розробку спеціалізованих
генераторів коду в проектах по розробці додатків. При цьому теоретично
поліпшується функціональна сумісність платформ і інфраструктур.
Переваги підходу із провайдером
передачі повідомлень
Очевидно, що підхід із провайдером
передачі повідомлень обумовив поширення асинхронної моделі передачі повідомлень
у МРО-середовищах. При використанні провайдеру передачі повідомлень
повідомлення можна посилати в одне або кілька проміжних місць призначення перед
тим, як воно піде до кінцевого одержувача; затримка передачі повідомлення може
бути невизначеною. Такі проміжні місця призначення (вузли-оперотори), визначені
в об'єкті повідомлення (заголовок). Якщо проміжні вузли-оператори визначені, то
повинні враховуватися часові співвідношення.
Тобто, асинхронна передача
повідомлень по своїй суті є складнішою від снхронної.
Провайдер передачі повідомлень також
створює можливість більше високої надійності їхньої передачі, залежно від
характеристик вузлів, що беруть участь.
Маршрутизація є одним з аспектів
передачі повідомлень у МРО і є завданням мережного рівня. Динамічне визначення
шляху проходження інформації в сучасному Інтернеті як і раніше функціонально
здійснюється в протоколах передачі даних нижнього рівня моделі ОSI 7.
Широкомовне і групове розсилання
Для МРО широкомовна і групова
передача може надати гнучкий вибір варіантів передачі “один-до-багатьох”. В
Інтернеті можливі три типи передачі:
одноадресна: звичайна
“один-до-одному”;
широкомовна: глобальна “один-до-багатьох”
(проходить через маршрутизатор);
багатоадресна, або групова: локальна
“один-до-багатьох” (зупиняється біля маршрутизатора).
Широкомовні МРО-системи висувають
багато унікальних і важких задач в області мережного керування. Таким системам,
загалом, необхідна висока пропускна здатність (до 20 Мбіт/сек на канал), і до
них пред'являються жорсткі вимоги по якості обслуговування для надійної
гарантованої доставки; деякі види такої передачі можуть коштувати мільйони
доларів за годину. Групове розсилання на основі ТСР/ІР використовувалися в
деяких стандартних прикладних інфраструктурах, таких як мережна технологія
Jini, і певною мірою в проекті JХТА.
Тема 5. GRID - технології
Питання:
1. Вступ до Грід-технологій
. Концепція Грід
. Архітектура Грід
. Понятие про віртуальну організацію
. Про розподіленя ресурсів в Грід
. Інструментальні засоби Грід
. Програмне забезпечення Грід
. Користувач в Грід
. Глобальна інфраструктура Грід для науки
. Грід в НУ “Львівська політехніка”
Технологія Грід (Grid - сітка) використовується для створення
географічно розподіленої обчислювальної інфраструктури, що поєднує ресурси
різних типів з колективним доступом до цих ресурсів у рамках віртуальних
організацій, що складаються з підприємств і фахівців, що спільно використовує
ці загальні ресурси.
Ідейною основою технології Грід є об'єднання ресурсів шляхом
створення комп'ютерної інфраструктури, що забезпечує глобальну інтеграцію
інформаційних і обчислювальних ресурсів на основі мережних технологій і
спеціального програмного забезпечення проміжного рівня (між базовим і
прикладним ПЗ), а також набору стандартизованих служб для забезпечення
надійного спільного доступу до географічно розподілених інформаційних і
обчислювальних ресурсів: окремим комп'ютерам, кластерам, сховищам інформації і
мережам.
Є три напрямки розвитку технології Грід:
обчислювальний Грід;
Грід для інтенсивного опрацювання даних;
семантичний Грід для оперування даними з різних баз даних.
Метою першого напрямку є досягнення максимальної швидкості
обчислень за рахунок глобального розподілу цих обчислень між комп'ютерами -
наприклад, проект DEISA (www.desia.org), у якому об'єднуються суперкомп'ютерні
центри.
Метою другого напрямку є опрацювання величезних обсягів даних відносно
нескладними програмами за принципом «одне завдання - один процесор». Доставка
даних для опрацювання і пересилання результатів у цьому випадку є досить
складним завданням. Для цього напрямку інфраструктура Грід є об'єднанням
кластерів. Один із проектів, метою якого є створення виробничої Грід-системи
для опрацювання наукових даних, є проект EGEE (Enabling Grids for E-scienc), що
виконується під егідою Європейського Союзу (www.eu-egee.org
<#"792213.files/image007.gif">
Базовий рівень (Fabric Layer) описує служби, що безпосередньо
працюють із ресурсами (рис.9). Є такі ресурси:
- обчислювальні ресурси;
- ресурси зберігання даних;
- інформаційні ресурси,
каталоги;
- мережні ресурси.
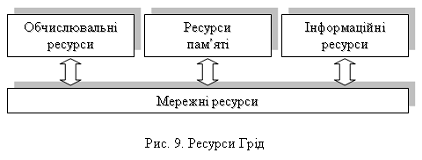
Обчислювальні ресурси надають
користувачеві процесорні потужності; можуть бути як кластери, так і окремі
робітники станції. Необхідною умовою для цього є наявність спеціального ПЗ, ПЗ
проміжного рівня (middleware), що реалізує стандартний зовнішній інтерфейс із
ресурсом. Основною характеристикою обчислювального ресурсу є продуктивність.
Ресурси пам'яті - простір для
зберігання даних. Для доступу до ресурсів пам'яті використовується ПЗ
проміжного рівня, що реалізує уніфікований інтерфейс керування і передачі
даних. Як і у випадку обчислювальних ресурсів, фізична архітектура ресурсу
пам'яті не принципова для Грід-системи. Основною характеристикою ресурсу
пам'яті є його обсяг.
Інформаційні ресурси і каталоги є
особливим видом ресурсів пам'яті. Вони служать для зберігання і надання
метаданих і інформації про інші ресурси Грід-системи. Інформаційні ресурси
дозволяють структуровано зберігати величезний обсяг інформації про поточний
стан Грід-системи і ефективно виконувати завдання пошуку.
Мережний ресурс є сполучною ланкою
між розподіленими ресурсами Грід-системи. Основною характеристикою мережного
ресурсу є швидкість передачі даних.
Рівень зв'язку (Connectivity Layer) визначає комунікаційні
протоколи і протоколи аутентифікації.
Комунікаційні протоколи забезпечують обмін даними між
компонентами базового рівня.
Протоколи аутентифікації, ґрунтуючись
на комунікаційних протоколах, надають криптографічні механізми для
ідентифікації і перевірки дійсності користувачів і ресурсів.
Незважаючи на існуючі альтернативи,
на даний час протоколи рівня зв'язку в Грід-системах припускають використання
тільки стеку протоколів TCP/IP, зокрема: на мережному рівні - IP і ICMP,
транспортному рівні - TCP, UDP, на прикладному рівні - HTTP, FTP, DNS, RSVP.
Для забезпечення надійного транспорту
повідомлень у Грід-Системі повинні використовуватися рішення, що передбачають
гнучкий підхід до безпеки комунікацій (можливість контролю над рівнем захисту,
обмеження делегування прав, підтримка надійних транспортних протоколів). У цей
час ці рішення ґрунтуються як на існуючих стандартах безпеки, споконвічно
розроблених для Інтернет (SSL, TLS), так і на нових розробках.
Ресурсний рівень (Resource Layer)
побудований над протоколами комунікації і аутентифікації рівня зв'язку
архітектури Грід. Ресурсний рівень реалізує протоколи, що забезпечують
виконання таких функцій:
- узгодження політик безпеки
використання ресурсу;
- процедура ініціації ресурсу;
- моніторинг стану ресурсу;
- контроль над ресурсом;
- облік використання ресурсу.
Протоколи цього рівня опираються на
функції базового рівня для доступу і контролю над локальними ресурсами. На
ресурсному рівні протоколи взаємодіють із ресурсами, використовуючи
уніфікований інтерфейс і не розрізняючи архітектурні особливості конкретного
ресурсу.
Розрізняють два основних класи
протоколів ресурсного рівня:
інформаційні протоколи - одержують
інформацію про структуру і стан ресурсу (про його конфігурацію, що біжуче
завантаження, політику використання);
протоколи керування -
використовуються для узгодження доступу до поділюваних ресурсів, визначаючи
вимоги і припустимі дії стосовно ресурсу (наприклад, підтримка резервування,
можливість створення процесів, доступ до даних). Протоколи керування повинні
перевіряти відповідність запитуваних дій політиці поділу ресурсу, включаючи
облік і можливу оплату. Вони можуть підтримувати функції моніторингу статусу і
керування операціями.
Колективний рівень (Collective Layer) відповідає за глобальну
інтеграцію різних наборів ресурсів, на відміну від ресурсного рівня,
сфокусованому на роботі з окремо взятими ресурсами. У колективному рівні
розрізняють загальні і специфічні (для додатків) протоколи. Загальні протоколи
- протоколи виявлення і виділення ресурсів, системи моніторингу і авторизації
співтовариств. Специфічні протоколи створюються для різних додатків Грід -
протокол архівації розподілених даних, протоколи керування завданнями
збереження стану тощо).
Компоненти колективного рівня
пропонують різні методи спільного використання ресурсів. Функції і сервіси, які
реалізовані в протоколах даного рівня такі:
- сервіси каталогів дозволяють
віртуальним організаціям виявляти вільні ресурси, виконувати запити по іменах і
атрибутах ресурсів, таким як тип і завантаження;
- сервіси спільного виділення,
планування і розподілу ресурсів забезпечують виділення одного або більше
ресурсів для певної мети, а також планування виконуваних на ресурсах завдань;
- сервіси моніторингу і
діагностики відслідковують аварії, атаки і перевантаження.
- сервіси дублювання
(реплікації) даних координують використання ресурсів пам'яті в рамках
віртуальних організацій, забезпечуючи підвищення швидкості доступу до даних
відповідно до обраних метрик, такими як час відповіді, надійність, вартість і
т.п.;
- сервіси керування робочим
завантаженням застосовуються для опису і керування багатокроковими,
асинхронними, багатокомпонентними завданнями;
- служби авторизації
співтовариств сприяють поліпшенню правил доступу до поділюваних ресурсів, а
також визначають можливості використання ресурсів співтовариства. Подібні
служби дозволяють формувати політики доступу на основі інформації про ресурси,
протоколи керування ресурсами і протоколах безпеки зв’язуючого рівня;
- служби обліку і оплати
забезпечують збір інформації про використання ресурсів для контролю обігів
користувачів;
- сервіси координації
підтримують обмін інформацією в потенційно великому співтоваристві
користувачів.
Прикладний рівень (Application Layer) описує
користувальницькі додатки, що працюють у середовищі віртуальної організації.
Додатка функціонують, використовуючи сервіси, визначені на нижчих рівнях. На
кожному з рівнів є певні протоколи, що забезпечують доступ до необхідних служб,
а також прикладні програмні інтерфейси (Application Programming Interface -
API), що відповідають даним протоколам.
Для полегшення роботи із прикладними
програмними інтерфейсами користувачам надаються набори інструментальних засобів
для розробки програмного забезпечення (Software Development Kit - SDK).
Інфраструктура Грід базується на
наданні ресурсів у загальне користування, з одного боку, і на використанні
привселюдно доступних ресурсів, з іншого. В існуючих Грід-Системах віртуальна
організація являє собою об'єднання (колаборацію) фахівців з деякої прикладної області,
які об’єднуються для досягнення загальної мети.
Кожна ВО має у своєму розпорядженні
певну кількість ресурсів, які надані зареєстрованими в ній власниками (деякі
ресурси можуть одночасно належати декільком ВО). Кожна ВО самостійно встановлює
правила роботи для своїх учасників, виходячи з дотримання балансу між потребами
користувачів і наявним обсягом ресурсів.
Грід-система є середовищем
колективного комп’ютинга, у якому кожний ресурс має власника, а доступ до
ресурсів відкритий з розділенням за часом і за простором режимі множини вхідних
у ВО користувачів. Віртуальна організація може утворюватися динамічно і мати
обмежений час існування.
Таким чином, можна визначити
Грід-систему як просторово розподілене операційне середовище із гнучким,
безпечним і скоординованим поділом ресурсів для виконання додатків у рамках
певних віртуальних організацій.
Ефективний розподіл ресурсів і їх
координація є основними завданнями системи Грід, і для їхнього розв’язання
використовується планувальник (брокер ресурсів). Користуючись інформацією про
стан Грід-Системи, планувальник визначає найбільш підходящі ресурси для кожного
конкретного завдання і резервує їх для її виконання. Під час виконання завдання
може запитати в планувальника додаткові ресурси або звільнити надлишкові. Після
завершення завдання всі відведені для неї обчислювальні ресурси звільняються, а
ресурси пам'яті можуть бути використані для зберігання результатів роботи.
Вся робота з керування, перерозподілу
і оптимізації використання ресурсів лягає на планувальник і виконується
непомітно для користувача.
Для системи такої складності дуже
важлива проблема забезпечення надійного функціонування і відновлення при збоях.
Завдання контролю над помилками у Грід покладається на систему моніторингу.
Дані про стан заносяться в інформаційні ресурси, звідки вони можуть бути
прочитані планувальником і іншими сервісами, що дозволяє мати достовірну
інформацію, що постійно обновляється, про стан ресурсів.
У Грід-системах використовується
складна система виявлення і класифікації помилок. Якщо помилка відбулася з вини
завдання, то завдання буде зупинена, а відповідна діагностика спрямована її
власникові (користувачеві). Якщо причиною збою послужив ресурс, то планувальник
зробить перерозподіл ресурсів для даного завдання і запустить знову її.
Збої ресурсів є не єдиною причиною
відмов у Грід-системах. Через величезну кількість завдань і постійно мінливої
складної конфігурації системи важливо вчасно визначати перевантажені і вільні
ресурси, роблячи перерозподіл навантаження між ними. Перевантажений мережний
ресурс може стати причиною відмови значної кількості інших ресурсів.
Планувальник, використовуючи систему моніторингу, постійно стежить за станом
ресурсів і автоматично вживає необхідних заходів для запобігання перевантажень
і простою ресурсів.
У розподіленому середовищі, який є
Грід-система, важливою властивістю є відсутність так званої єдиної точки збою.
Це означає, що відмова будь-якого ресурсу не повинна приводити до збою в роботі
всієї системи. Саме тому планувальник, система моніторингу і інші сервіси
Грід-системи розподілені і продубльовані.
Розглянемо набір інструментальних
засобів, використовуваних при реалізації проектів Грід і розроблених у рамках
проекту Глобус (Globus Project), які дозволяють побудувати повнофункціональну
Грід-Систему:
- GRAM (Globus Resource
Allocation Manager), відповідальний за створення/видалення процесів.
Встановлюється на обчислювальному вузлі (наприклад, робоча станція,
обчислювальний кластер) Грід-системи. Користувальницькі додатки формують запити
до GRAM спеціальною мовою RSL (Resource Specification Language).
- MDS (Monitoring and Discovery
Service) забезпечує способи подання інформації (наприклад, дані про
конфігурацію або стан як всієї системи, так і окремих її ресурсів - тип
ресурсу, доступний дисковий простір, кількість процесорів, обсяг пам'яті,
продуктивність та інше) про Грід-Систему. Вся інформація логічно організована у
вигляді дерева, і доступ до неї здійснюється по стандартному протоколі LDAP
(Lightweight Directory Access Protocol).
- GSI (Globus Security
Infrastructure) забезпечує захист, що включає шифрування даних, а також
аутентифікацію (перевірка достовірності, при якій установлюється, що користувач
чи ресурс дійсно є тим, за кого себе видає) і авторизацію (процедура перевірки,
при якій установлюється, що аутентифікований користувач або ресурс дійсно має
права доступу) з використанням цифрових сертифікатів Х.509.
- GASS (Global Access to
Secondary Storage) надає можливість зберігання масивів даних у розподіленому
середовищі і доступу до цих даних. Визначає різні стратегії розміщення даних.
- Бібліотеки globus_io і Nexus
використовуються як прикладними програмами так і компонентами Globus Toolkit
для мережної взаємодії вузлів у гетерогенному середовищі.
Архітектура засобів керування
ресурсами (Globus Resource Management Architecture - GRMA) має багаторівневу
структуру (рис. 10).
Запити користувальницьких додатків
виражаються на RSL і передаються брокерові ресурсів, що відповідає за
високорівневу координацію використання ресурсів (балансування завантаження) у
певному домені. На основі переданого користувальницьким додатком запиту і
політики (права доступу, обмеження по використанню ресурсів) відповідального
адміністративного домена брокер ресурсів ухвалює рішення щодо того, на яких обчислювальних
вузлах буде виконуватися завдання, який відсоток обчислювальної потужності
вузла вона може використовувати і ін.
При виборі обчислювального вузла
брокер ресурсів повинен визначити, які вузли доступні в даний момент, їхнє
завантаження, продуктивність і інші параметри, зазначені в RSL-запиті, вибрати
найбільш оптимальний варіант (це може виявитися один чи кілька обчислювальних
вузлів), згенерувати новий RSL-Запит (ground RSL) і передати його
високорівневому менеджерові ресурсів (co-allocator). В запиті будуть вже більш
конкретні дані, такі, як імена конкретних вузлів, необхідне кількість пам'яті і
др. Основні функції високорівневого менеджера ресурсів такі:
- колективне виділення
ресурсів;
- додавання/видалення ресурсів;
- одержання інформації про стан
задач;
- передача початкових
параметрів задачам.
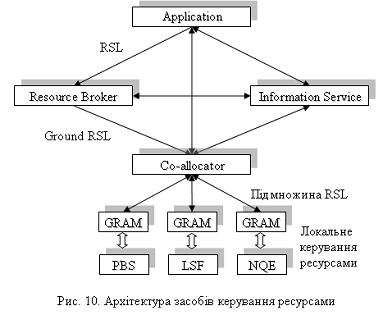
Високорівневий менеджер ресурсів
робить декомпозицію запитів ground RSL на множину простіших RSL-запитів і
передає ці запити GRAM. Далі, при відсутності повідомлень про помилки від GRAM,
завдання користувача запускається на виконання. У випадку, якщо один з GRAM
повертає помилку, завдання або знімається з виконання, або спроба запуску
виробляються повторно.
Менеджер GRAM надає верхнім рівням універсальний API для керування
ресурсами вузла Грід. Сам GRAM взаємодіє з локальними засобами керування
ресурсами вузла.
Організація доступу до ресурсів
GRAM - досить низькорівневий
компонент Globus Toolkit, що є інтерфейсом між високорівневим менеджером
ресурсів і локальною системою правління ресурсами вузла і може взаємодіяти з
такими локальними системами керування ресурсами:
- PBS (Portable Batch System) -
система керування ресурсами і завантаженням кластерів. Працює на платформах:
Linux, FreeBSD, NetBSD, Digital Unix, Tru64, HP-UX, AIX, IRIX, Solaris.
- LSF (Load Sharing Facility) -
аналогічна PBS. Розроблена компанією Platform Computing.
- NQE (Network Queuing
Environment) - продукт компанії Cray Research, що використовується як менеджер
ресурсів на суперкомп'ютерах, кластерах і системах Cray, може працювати і на
інших платформах.
- LoadLeveler - продукт
компанії IBM, керуючий балансом завантаження великих кластерів.
Використовується в основному на кластерах IBM.
- Condor - вільно доступний
менеджер ресурсів, розроблений студентами університетів Європи і США.
Аналогічний перерахованим вище. Працює на платформах UNIX і Windows NT.
- Easy-LL - спільна розробка
IBM і Cornell Theory Center, призначена для керування великим кластером IBM у
цьому центрі. По суті є об'єднанням LoadLeveler і продукту EASY лабораторії
Argonne National Lab.
- fork - найпростіший
стандартний засіб запуску процесів в UNIX.
Структура GRAM представлена на рис.
11.

Щоб на даному обчислювальному вузлі
можна було віддалено запускати на виконання програми, на ньому повинен
виконуватися спеціальний процес Gatekeeper, який працює в привілейованому
режимі і виконує такі функції:
- проводить взаємну
аутентифікацію із клієнтом;
- аналізує RSL запит;
- відображає клієнтський запит
на обліковий запис деякого локального користувача;
- запускає від імені локального
користувача спеціальний процес Job Manager, і передає йому список необхідних ресурсів.
Після того, як Gatekeeper виконає
свою роботу, Job Manager запускає завдання (процес або кілька процесів) і
робить його подальший моніторинг, повідомляючи клієнта про помилки і інші
події. Gatekeeper запускає тільки один Job Manager для кожного користувача, що
керує всіма завданнями даного користувача. Коли завдань більше не залишається,
Job Manager завершує роботу.
Всі перераховані компоненти, включаючи користувальницькі
додатки, можуть використовувати інформаційний сервіс (Information Service) для
одержання всієї необхідної інформації про стан Грід-системи. В Globus Toolkit
роль інформаційного сервісу грає MDS. Цей компонент відповідає за збір і
надання конфігураційної інформації, інформації про стан Грід-системи і її
підсистем, а також забезпечує універсальний інтерфейс одержання необхідної
інформації. MDS має децентралізовану, легко масштабовану структуру і працює як
зі статичними, так і з динамічними даними, необхідними користувальницьким
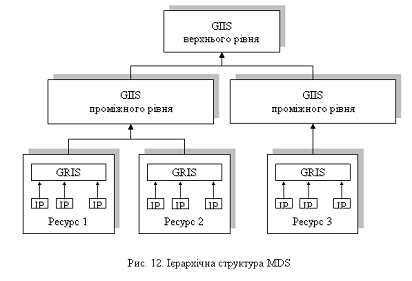
додаткам і різним сервісам Грід-системи. Ієрархічна структура MDS наведена на
рис. 12.
MDS складається із трьох основних
компонентів:
- IP (Information Provider) - є джерелом інформації про
конкретний ресурс або частину ресурсу;
GRIS (Grid Resource Information Service) - надає інформацію
про вузол Грід-системи. GRIS опитує індивідуальні IP і об’єднує отриману від
них інформацію в межах єдиної інформаційної схеми;
GIIS (Grid Index Information Service) - об’єднує інформацію з
різних GRIS або інших GIIS. Для зменшення часу реакції на запит і зниження
мережного трафіка GIIS кешу дані. GIIS верхнього рівня містить всю інформація
про стан даної системи Грід.
Інфраструктура безпеки Грід (Grid Security Infrastructure -
GSI) забезпечує безпечну роботу в незахищених мережах загального доступу
(Інтернет), надаючи такі сервіси, як аутентифікація, конфіденційність передачі
інформації і єдиний вхід у Грід-систему. заснована на надійній і широко
використовуваній інфраструктурі криптографії з відкритим ключем (Public Key
Infrastructure - PKI).
Як ідентифікатори користувачів і ресурсів в GSI
використовуються цифрові сертифікати X.509, в процедурі видачі/одержання
сертифікатів задіяні:
центр сертифікації (Certificate Authority - CA) - спеціальна
організація, що володіє повноваженнями видавати (підписувати) цифрові
сертифікати;
підписчик - це людина або ресурс, що користується
сертифікаційними послугами CA. CA включає в сертифікат дані, надавані
передплатником (ім'я, організація та ін.) і ставить на ньому свій цифровий
підпис.
користувач - це людина або ресурс, що покладається на
інформацію із сертифіката при одержанні його від передплатника. В Globus
Toolkit використовуються два типи сертифікатів X.509: сертифікат користувача
(User Certificate), сертифікат вузла (Host Certificate) - вказується доменне
ім'я конкретного обчислювального вузла.
Подальший розвиток інструментальних засобівToolkit був першим
повноцінним набором інструментальних засобів для розробок в області технології
Грід і став стандартом де-факто. Однак навіть найпоширеніша друга версія Globus
Toolkit не була позбавлена недоліків, основним з яких була відсутність
уніфікованих засобів розробки інтероперабельних додатків, здатних взаємодіяти
між собою і надавати один одному різні послуги (сервіси).
Для рішення цієї проблеми на Global Grid Forum (GGF) була
запропонована Відкрита архітектура сервісів Грід (Open Grid Services
Architecture - OGSA). Стандарт OGSA визначає основний набір послуг, які надають
Грід-системи, і описує їхню архітектуру.
Стандарт OGSA пропонує проектувати Грід-системи за принципом
сервіс-орієнтованої архітектури, що визначає метод побудови програмних систем у
вигляді набору незалежних або слабко зв'язаних сервісів. Передбачається, що
кожний сервіс виконує свою строго певну функцію і має тверду семантику. Сервіси
допускають багато реалізацій, але мають стандартний, строго специфікований
інтерфейс, через який можуть взаємодіяти як один з одним, так і з додатками
Грід. У такий спосіб в OGSA Грід-система представляється як набір сервісів, що
реалізують різні послуги.
Рівні архітектури OGSA наведені на рис. 13.

Нижній рівень представлений ресурсами, які можуть входити в
Грід-систему.
Середній рівень являє собою послуги на якому здійснюється
узагальнення (віртуалізація) ресурсів. Користувачеві надаються високорівневі
послуги із чітко визначеними інтерфейсами.
Верхній рівень представляє додатки, що використовують послуги
для виконання різних завдань. Цей рівень в OGSA не специфікований.
Більша частина деталей, пов'язаних з конкретною реалізацією
сервісів, в OGSA не обумовлюється. Замість цього OGSA опирається на сімейство
технологій веб-сервісів (Web-services) Архітектура OGSA зосереджується на
визначенні послуг у вигляді набору взаємодіючих сервісів.
Архітектура розроблялася з врахуванням таких ключових вимог,
отриманих шляхом аналізу сценаріїв використання Грід-Систем. Цими вимогами є:
. Інтероперабельність. Більшість Грід-Систем є розподіленими
і гетерогенними, тобто можуть містити в собі велику кількість платформ,
операційних систем і мереж. Для ефективної роботи в таких умовах Грід-система
повинна відповідати таким вимогам:
віртуалізація ресурсів (представлення ресурсів в узагальненій
формі, що дозволяє абстрагуватися від непринципових розходжень ресурсів, що
виконують ту саму функцію);
загальні способи керування (узагальнені механізми керування
різнорідними ресурсами для спрощення адміністрування Грід-систем);
виявлення ресурсів (механізми забезпечення пошуку ресурсів з
необхідними властивостями в гетерогенному оточенні);
стандартні протоколи (стандартизація протоколів для побудови
гетерогенної інтероперабельної системи).
. Поділюваний доступ. Грід-система повинна дозволяти
організовувати поділюваний доступ до ресурсів, що належать різним організаціям.
. Безпека включає такі вимоги:
аутентифікація і авторизація;
інтеграція із системами безпеки (різні адміністративні домени
можуть використовувати різні моделі і системи забезпечення безпеки, при цьому
Грід-системи повинні взаємодіяти з ними і забезпечувати їхню інтеграцію).
делегування прав (механізми делегування прав користувача, що
дозволяють уникати багаторазової аутентифікації.
. Запуск завдань. Можливість запуску завдань на віддалених
обчислювачах. При цьому пред'являються такі вимоги:
підтримка різних типів завдань;
керування завданнями;
диспетчеризація - завдання повинні автоматично направлятися
на підходящі обчислювальні ресурси з урахуванням певних вимог (тип ОС,
наявність бібліотек, кількість одночасно доступних обчислювачів тощо);
забезпечення ресурсами (засоби для автоматичного виділення
потрібних завданню ресурсів і підготовки до їхнього використання).
. Маніпуляція даними. Повинні забезпечувати ефективні методи
роботи з величезною кількістю даних. Необхідне виконання таких умов:
цілісність даних - механізми кешування і реплікації, що не
приводять до одержання застарілих даних;
інтеграція даних - механізми для забезпечення одночасної
роботи з декількома джерелами даних;
пошук даних.
. Гарантії якості обслуговування. Повинні забезпечуватися
такі умови: мінімально допустима пропускна здатність мережі, гарантована
продуктивність обчислювача, гарантований рівень безпеки тощо. При цьому можуть
висуватися такі додаткові вимоги:
угода про якість обслуговування;
міграція (можливість міграції додатків, що виконуються, з
одних ресурсів на інші).
. Оптимізація виділення ресурсів. Грід-системи повинні вміти
ефективно використовувати наявні ресурси і уміти оптимізувати їхнє виділення.
Повинні використовуватися гнучкі механізми, наприклад, розподіл ресурсів на
невеликі інтервали часу з наступним переглядом параметрів виділення.
. Зниження вартості підтримки шляхом автоматизації багатьох
задач і ефективного адміністрування та підтримки різнорідних ресурсів, що
робить необхідним наявність механізмів автоматичного виявлення можливих проблем
і оповіщення про них.
. Надійність. Забезпечується шляхом використання запасних
ресурсів, резервного копіювання даних, моніторингу ресурсів, автоматичного
відновлення від збоїв, наявністю механізмів відновлення, наприклад, з
використанням контрольних точок.
. Простота використання і розширюваність.
. Масштабованість.
Для побудови повністю функціональної Грід-системи необхідне
ПЗ проміжного рівня, побудоване на базі існуючих інструментальних засобів і що
надає високорівневі сервіси задачам і користувачам.
Прикладом такого ПЗ може бути ПЗ LCG (LHC Computing Grid) -
розробник: Європейський центр ядерних досліджень CERN.
Пакет LCG складається з кількох частин - елементів. Кожний
елемент є самостійним набором програм (ті самі програми можуть входити в кілька
елементів), що реалізують деякий сервіс, і призначений для установки на
комп'ютер під керуванням ОС Scientific Linux.
Основні елементи LCG і їхнє призначення:
CE (Computing Element) - набір програм, призначений для
установки на керуючий вузол обчислювального кластера. Надає універсальний
інтерфейс до системи керування ресурсами кластера і дозволяє запускати на
кластері обчислювальні завдання;
SE (Storage Element) - набір програм, призначений для
установки на вузол зберігання даних. Надає універсальний інтерфейс до системи
зберігання даних і дозволяє управляти даними (файлами) у Грід-системі;
WN (Worker Node) - набір програм, призначений для установки
на кожний обчислювальний вузол кластера. Надає стандартні функції і бібліотеки
LCG задачам, що виконуються на даному обчислювальному вузлі;
UI (User Interface) - набір програм, що реалізують
користувальницький інтерфейс Грід-cистеми (інтерфейс командного рядка). У цей
елемент входять стандартні команди керування задачами і даними;
RB (Resource Broker) - набір програм, що реалізують систему
керування завантаженням (брокер ресурсів). Це найбільш складний і об'ємний
елемент LCG, що надає всі необхідні функції для скоординованого автоматичного
керування завданнями в Грід-системі;
PX (Proxy) - набір програм, що реалізують сервіс
автоматичного відновлення сертифікатів (myproxy);
LFC (Local File Catalog) - набір програм, що реалізують
файловий каталог Грід-системи. Файловий каталог необхідний для зберігання
інформації про копії (репліках) файлів, а також для пошуку ресурсів, що містять
необхідні дані;
BDII (Infornation Index) - набір програм, що реалізують
інформаційний індекс Грід-системи. Інформаційний індекс містить всю інформацію
про поточний стан ресурсів, одержувану з інформаційних сервісів, і необхідний
для пошуку ресурсів;
MON (Monitor) - набір програм для моніторингу обчислювального
кластера. Даний елемент збирає і зберігає в базі даних інформацію про стан і
використання ресурсів кластера.
VOMS (VO Management Service) - набір програм, що реалізують
каталог віртуальних організацій. Даний каталог необхідний для керування
доступом користувачів до ресурсів Грід-системи на основі членства у ВО.
На один комп'ютер можлива установка відразу декількох
елементів LCG, мінімальна кількість вузлів, необхідних для розгортання повного
набору ПЗ LCG, дорівнює трьом.
В основі ПЗ LCG лежать розробки, виконані в рамках
європейського проекту EDG (European DataGrid) кілька років назад. Да ний час
проект LCG активно розвивається переходячи до нової, більш функціональної
інфраструктури ПЗ, що носить назву gLite.
Система входу користувача в
Грід-Систему досить складна. Це визначено багатьма факторами, але головною
проблемою є рішення питань безпеки. Аутентифікаційні рішення для середовищ
віртуальних організацій повинні мати такі властивості:
єдиний вхід. Користувач повинен
реєструватися і аутентифікуватися тільки один раз на початку сеансу роботи;
делегування прав. Користувач повинен
мати можливість запуску програм від свого імені і делегувати частина своїх прав
іншим програмам;
довірче відношення до користувача.
Якщо користувач запросив одночасну роботу з ресурсами декількох постачальників,
то при конфігурації захищеного середовища користувача система безпеки не
повинна вимагати взаємодії постачальників ресурсів один з одним.
Для входу в Грід-систему користувач
повинен:
бути легальним користувачем
обчислювальних ресурсів у своїй організації;
мати персональний цифровий
сертифікат, підписаний центром сертифікації;
бути зареєстрованим хоча б в одній
ВО.
Веб-інтерфейси Грід
Прикладом веб-інтерфейсу до Грід-системи може бути GENIUS,
розроблений в італійському інституті INFN (grid-demo.ct.infn.it), основною
метою при створенні якого є:
ознайомлення користувача з технологією Грід;
надання доступу до сервісів Грід-системи через Інтернет;
простий і зручний графічний інтерфейс;
ефективний моніторинг поточного стану Грід-системи.
Веб-Інтерфейс GENIUS дозволяє виконувати всі основні операції
по керуванню задачами і даними в Грід-системі, причому всі ці дії користувач
може робити прямо із браузера.
Проект GILDA складається з таких частин:
GILDA Testbed - набір сайтів із установленим ПЗ LCG;
Grid Demonatrator - веб-інтерфейс GENIUS, що дозволяє
працювати з певним набором додатків;
GILDA CA - центр сертифікації, що видає 14-денні сертифікати
для роботи з GILDA;
GILDA VO - ВО, що об’єднує всіх користувачів GILDA;
Grid Tutor - веб-інтерфейс GENIUS, використовується для
демонстрації можливостей технології Грід;
Monitoring System - система моніторингу для GILDA Testbed.
Користувальницькі веб-інтерфейси до Грід-системам є досить
перспективним напрямком, тому що можуть бути легко адаптовані під конкретне
завдання або предметну область і не вимагають навичок роботи з командним рядком
unix. Авторизація користувачів на таких інтерфейсах відбувається за допомогою
завантажених у браузер цифрових сертифікатів.
Як приклад, розглянемо одну з найпотужніших у світі
інфраструктура Грід, що реалізована в рамках проекту EGEE (Enable Grid
E-scienc).
Мета проекту EGEE - об'єднати існуючі національні,
регіональні і тематичні Грід-розробки в єдину цільну Грід-інфраструктуру для
підтримки наукових досліджень. Користуватися інфраструктурою зможуть
географічно розподілені співтовариства дослідників, які мають потребу в
спільних для них обчислювальних ресурсах, готові об'єднати свої власні обчислювальні
інфраструктури і згодні із принципами загального доступу.
Для відпрацьовування, офіційної оцінки експлуатаційних
якостей і функціональності системи обрані дві практичні області. Одна -
опрацювання даних від експериментів на прискорювачі LHC, де Грід-Інфраструктура
забезпечує зберігання і аналіз петабайтів (1015 байтів) реальних і
змодельованих даних експериментів з фізики високих енергій, що ведуться в CERN.
Інша - біомедичні Гріди, де декілька колаборацій розв’язують однаково складні
завдання, наприклад, пошук у геномних базах даних і індексування лікарняних баз
даних, що становить декілька терабайтів у рік для однієї лікарні.
У рамках цієї інфраструктури створено понад 60 ВО.
У проекті EGEE беруть участь більше 90 організацій з 32
країн. Ці організації об'єднані в регіональні Гріди (федерації). У проекті
беруть участь 13 федерацій. Сумарна обчислювальна потужність даної
Грід-інфраструктури становить у даний момент понад 20 тисяч процесорів.
Проект EGEE має партнерські відносини з більш ніж 70 учасниками,
що не входять у даний проект, у тому числі через ряд інших проектів Грід (рис.
14).

У завдання проекту входить:
- поширення інформації про технологію
Грід;
- залучення нових користувачів,
навчання;
- підтримка додатків;
- підтримка і обслуговування
інфраструктури Грід і взаємодія з основними провайдерами;
- розробка і інтеграція програмного
забезпечення проміжного рівня;
- забезпечення безпеки;
- розробка мережних сервісів.
У рамках проекту працюють:
Служба поширення інформації і розширення кола користувачів
(Dissemination and Outreach Activity) тримає зібрані воєдино всі головні
відомості про проект разом з посиланнями на відповідні регіональні веб-сайти
(див. www.eu-egee.org). Крім того, ключові користувальницькі групи і групи
потенційних користувачів можуть одержувати повідомлення зі спеціалізованих
списків розсилання інформації з електронної пошти;
Служба навчання і включення до числа користувачів (Training
and Induction Activity) випускає комплект навчальних матеріалів і курсів
англійською мовою. Навчання організоване за регіональним принципом, і ключові
матеріали можуть бути перекладені на відповідну європейську мову.
Служба розробки і інтеграції проміжного ПЗ для Грід (Grid
Middleware Engineering and Integration Activity) підтримує і постійно
вдосконалює набір програмних засобів, завдяки якому Грід-сервіси промислового
рівня доступні основному колу користувачів. Діяльність, пов'язана із проміжними
програмними засобами EGEE, полягає, головним чином, у їхньому перепроектуванні
в плані їхньої функціональності. Проміжне програмне забезпечення розвивається в
напрямку сервісно-орієнтованої архітектури, яка базується на стандартах,
розроблених у рамках веб-сервісів. Центри перепроектування проміжного
програмного забезпечення відповідають за такі ключові сервіси: доступ до
ресурсів (Італія), організація даних (CERN), пошук і збір інформації
(Великобританія), брокерські операції з ресурсами і облік ресурсів (Італія),
безпека (країни Північної Європи). Безпосереднє відношення до цієї роботи мають
групи забезпечення якості і безпеки Гридов (Quality Assurance and Grid
Security). Центр інтеграції і тестування проміжного програмного забезпечення
(Middleware Integration and Testing Center) перебуває в CERN.
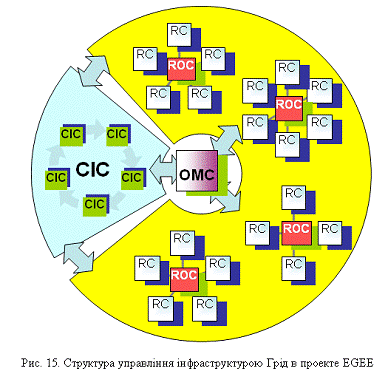
Групи, що забезпечують експлуатацію Грід, гарантують високий
рівень Грід-сервісів. Основними якостями, що визначають такий рівень
Грід-Сервісів, є їхня керованість, стійкість до збоїв і різного роду
несправностям, єдиний підхід до забезпечення безпеки, а також їхня
розширюваність, необхідна для включення в роботу нових ресурсів негайно в міру
їхньої появи. Головні завдання цих груп: підтримка базових сервісів
інфраструктури, моніторинг і контроль Гридів, розміщення проміжного програмного
забезпечення, підключення ресурсів, підтримка ресурсів і користувачів, загальне
керування Гридами і міжнародне співробітництво. Оперативний центр (Operations
Management Centre - ОМС) в CERN погоджує роботу п'яти центрів базової
інфраструктури (Core Infrastructure Centre - CIC), розташованих в CERN,
Франції, Італії, Росії, Великобританії, і восьми регіональних оперативних
центрів (Regional Operation Centre - ROC), які, у свою чергу, координують
роботу ресурсних центрів (Resource Cerntre - RC). Структура керування
інфраструктурою Грід у проекті EGEE наведена на рис. 15.
Робота EGEE для масового користувача базується на проміжному
програмному забезпеченні і сервісах проекту LCG (www.cern.ch/lcg).
Для контролю за функціонуванням цієї інфраструктури
функціонують різні засоби моніторингу (проходження функціональних тестів,
монітори завдань, стану сайтів і інформаційної системи).
Як транспортне середовище для передачі даних і програми
інфраструктури EGEE використовує дослідницьку мережу GEANT і підключені до неї
регіональні мережі.
Для включення в Грід-інфраструктуру EGEE нових користувачів і
наукових співтовариств діють Служби прийому заявок і підтримки (Application
Identification and Support Activity), які ідентифікують і підтримують
починаючих користувачів із широкого кола академічних дисциплін і галузей
економіки.
Проект створення національної Grid - інфраструктури
для розвитку інформаційного суспільства в Україні, її склад і задачі вперше
були озвучені академіком НАНУ Згуровським М.З на самітті WSIS (World Summit on
Information Societу) у 2004 році. Мова йшла про необхідність створення
освітнього і дослідницького сегменту інформаційного суспільства України з двома
головними напрямками: широке використання інформаційних і комунікаційних
технологій на всіх стадіях наукових досліджень і освіти, а також інформаційне
управління відповідними галуззями.
Запропоновані цілі і задачі знайшли своє відображення вже у
2005 році в Державній цільовій програмі «Інформаційні та комунікаційні
технології в освіті й науці на 2006-2010 роки», прийнятій Кабінетом Міністрів
України (Постанова КМ України №1153 від 7 грудня 2005 року). Національний
технічний університет «Київський політехнічний інститут виграв тендер проектів
з реалізації завдання « Створення національної Grid - інфраструктури для
підтримки наукових досліджень» цієї Державної цільової програми, оголошений
Міністерством освіти і науки України.
Grid сегмент МОНУ на відміність від Grid сегменту НАНУ, який
є Grid обчислювального типу (Computing Grid), можна віднести до Grid
інформаційного типу (Data Grid), тому що проект Ugrid головним чином пов’язаний
з забезпеченням обслуговування Української філії Світового Центру Даних (УФ
СЦД), надавши його клієнтам віддалений доступ до світових сховищ наукових
даних, можливості ефективного сумісного використання комп’ютерів, унікальних
експериментальних установок і приладів.
Згідно з рішенням Академії наук України від 3 квітня 2006 р.
Українська філія СЦД є головною структурою на Україні, яка здійснює
накопичення, збереження й обробку національних і світових даних, наданих
відповідними організаціями (Інститут геофізики ім. С.І. Суботіна НАН України
(Відділ сейсмічної небезпеки, Відділ геотермії й сучасної геодинаміки, Відділ
геомагнетизму, Відділ глибинних процесів Землі і гравіметрії, Відділ фізичних
властивостей речовини Землі і т.д.), Кримська експертна рада з оцінювання
сейсмічної небезпеки й прогнозування землетрусів, Міністерство архітектури і
будівельної політики АР Крим, Полтавська гравіметрична обсерваторія,
Геомагнітні обсерваторії (Київ, Львів, Одеса), Іоносферні станції, Національний
антарктичний науковий центр Міністерства освіти і науки України (Геомагнітна
обсерваторія - Аргентина, Айленд), Головна Астрономічна обсерваторія НАНУ,
Львівський державний університет (Обсерваторія Львів), Одеський державний
університет (Обсерваторія Одеса), Кримська Астрофізична обсерваторія НДІ
Міністерства освіти і науки України (Обсерваторія КРАО),Харківський інститут
радіоелектроніки (ХНУРЕ)та ін.).
Проект Ugrid виконує команда з 10 : різних українських
організацій (2-х академічних, 6-ти освітянських і 2-х промислових), яку
очолюють Інститут Системного Аналізу (ІПСА) Національного Технічного
Університету “Київський політехнічний Інститут”. Науковим керівником проекту є
Михайло Захарович Згуровський, ректор НТУУ”КПІ”, академік НАНУ, один з
ініціаторів впровадження Grid технологій в Україні.
Серед виконавців проекту, крім НТУУ”КПІ”, є Інститут проблем
моделювання в енергетиці імені Г.Є. Пухова НАНУ (ІПМЕ), Харківський
національний університет радіоелектроніки (ХНУРЕ), Львівський національний
технічний університет „Львівська політехніка” (НУЛП),, Запорізький національний
технічний університет (ЗНТУ), Донецький національний політехнічний інститут
(ДонНПІ), Дніпропетровський національний гірничий університет (ДНГУ), державне
підприємство ”Львівський науково-дослідний радіотехнічний інститут”(ЛНДРІ) і
підприємство ЮСТАР.
Поточні обчислювальні ресурси проекту наведені в табл. 7.
Табл. 7. Власні обчислювальні ресурси проекту UGrid
|
Cluster
|
Proces-sors
|
NODs/ CPU
|
RAM/NOD (GB)
|
HD (GB)
|
STO-RAGE (TB)
|
|
1.
|
KPI Cluster, Национальный технический университет
Украины «Киевский политехнический институт»
|
336
|
84/4
|
2
|
|
36
|
|
2.
|
ХНУРЕ, Харківський національний університет
радіоелектроніки
|
10
|
10/1
|
1
|
20
|
0,2
|
|
3.
|
ЗНТУ, Запоріжський національний технічний
університет
|
25
|
2/10
|
1
|
200
|
|
|
4.
|
НТУ Львівська політехніка
|
8
|
2/4
|
3
|
200
|
|
|
5.
|
ДонНТУ, Донецький національний технічний університет
|
12
|
1/12
|
1
|
|
2
|
|
6.
|
|
|
|
|
|
|
Після модернізації кластеру НУТУ „КПІ” він буде складатися з
586 процесорів з піковою потужністю вище 6 Тфлопс.
Оскільки більшість вищих навчальних закладів, академічних
інститутів і промислових підприємств поки не мають суперкомп’ютерів, то в
проекті передбачено розробку заходів віртуалізації ресурсів звичайних персональних
комп’ютерів з допомогою Grid технологій.
Передбачається створити Grid інфраструктуру з 6-ю
ресурсно-операційними центрами (в Києві, Харкові, Донецьку, Дніпропетровську,
Запоріжжі і Львові) і розпочати відділене обслуговування майбутніх користувачів
- науковців з університетів та наукових установ України. ділянці.
1. В червні 2007 року підписана Угода з європейською
організацією DANTE про підключення Національної науково-освітньої мережі УРАН
(www.uran.net.ua <#"792213.files/image015.gif">
Рис. 16. Отримання доступу користувачем через Web-портал SDGrid
. Встановлено програмного забезпечення NetSolve на кластері НТУУ “КПІ”
для надання дослідникам можливості використання ресурсів Grid при проведенні
обчислень в звичних для них робочих середовищах
MATLAB/Mathematica/OctaveFortran/C/, встановлених на персональних комп’ютерах.
Користувач не піклується тепер про те, де знаходиться, як виявляється і
викликається потрібний йому Grid ресурс; він тільки вказує ті критерії, за
якими необхідно підібрати йому цей ресурс, і взаємодіє далі з цим ресурсом так
само, як і з локальними ресурсами (процедурами, класами, програмами) його
робочого середовища.
Докладніше дослідження, що проводяться, виглядають так
НТУУ”КПІ”: Створення порталу знань, дослідження сумісності
(inetroperability) проміжного програмного слою, створення Grid-додатка для
моделювання сучасних мікро-електронно-механічних систем (МЕМС);
НТУ Львівська політехніка: створення потужної системі збереження даних
на базі з використанням системи IBM BladeCenter QS21, що складається з 14
обчислювальних блейд-серверів на базі процесорів Cell та одного координуючого
вузла;
- ЗНТУ, Запоріжський національний технічний університет: паралельна програмна модель
нейронної мережі, дослідження паралельної реалізації методу молекулярної
динаміки;
- ХНУРЕ, Харківський національний університет
радіоелектроніки: програмне забезпечення для тестування продуктивності
бібліотеки PVM.
Аналіз характеристик та напрямків застосування GRID-порталу у
Львівському центрі GRID
Дослідження вимог та характеристик Grid-порталупортал
забезпечує доступ користувачів до ресурсів, що є основними поняттями
Grid-систем, та повинен відповідати таким вимогам [5]:
. Доступність. Доступ до Grid-порталу повинен
здійснюватись з будь-якого місця та не залежати від типу обладнання
користувача;
2. Доступ до різних служб повинен здійснюватись,
використовуючи один той самий інтерфейс користувача;
3. Безпека. Необхідною умовою роботи в Grid є безпека
інформації на всіх рівнях взаємодії користувача із системою, зокрема:
захищена передача даних по Web;
захищеність параметрів доступу користувача;
аутентифікація користувача;
захищеність на рівні віртуальної організації;
4. Інтерфейс користувача має бути достатньо простим та
зрозумілим.
По суті будь-який Grid-портал являє собою графічний
Web-інтерфейс, основними функціями якого є:
1. Навчання користувачів технології Grid-обчислень;
. Ефективний моніторинг біжучого стану Grid-системи.
Тобто Grid-портал дозволяє здійснювати управління завданнями
та даними в Grid-системі безпосередньо з браузера.
Доступ користувачів до ресурсів Grid-систем, зокрема до
ресурсів Центру Суперкомп’ютерних Обчислень НТУУ «КПІ» здійснюється шляхом
авторизації користувача за допомогою цифрових сертифікатів. Для надання
сертифікатів в Україні відкрито Сертифікаційний центр відкритих ключів, який
обслуговує всю національну Grid-інфраструктуру.
Отримання сертифікату є головним та необхідним кроком для
отримання доступу до Grid-системи. Цифровий сертифікат є аналогом паспорту та
дозволяє однозначно ідентифікувати користувача. Доступ до Grid-системи може
бути здійснений з будь-якої точки (терміналу), в якій наявне відповідне
програмне забезпечення (ПЗ).
При доступі до ресурсів Центру Суперкомп’ютерних Обчислень
НТУУ «КПІ» користувач має можливість:
· Користуватись віддаленим доступом до кластеру по
захищеному каналу для завантаження своїх прикладних програм чи їх вихідних
кодів, призначених для запуску на системі кластерного типу;
· Створювати прикладні програми з
вихідних кодів за допомогою компіляторів, встановлених в системі;
· Використовувати наявні стандартні
прикладні програми та бібліотеки;
· Отримувати перелік прикладних
програм, компіляторів та бібліотек, встановлених в системі;
· Виконувати програми на кластері; отримувати та
зберігати результати їх роботи в межах виділеного дискового простору.
Сьогодні для користувачів надаються такі програмні засоби,
дуже поширені серед наукової спільноти:
- MPI - OpenMPI (бібліотека для паралельного програмування)
Компілятори GCC (C/C++, Fortran-77, Fortran-95, інш.)
Паралельні пакети лінійної алгебри:
Інші пакети:
FFTW - C програма дискретного перетворення Фур’є <#"792213.files/image016.gif">
Рис. 17. Приклад використання системи збереження даних ІВМ
DS3400 при підключенні до 4 серверів.
Таблиця 11. Конфігурація блейд-шасі ІBM eServer BladeCenter H
|
Складові
|
Конфігурація
|
|
Шасі
|
ІBM eServer BladeCenter(tm) H Chassis або еквівалент
|
|
Вентилятори
|
Дубльовані із гарячою заміною
|
|
З’єднувальна плата
|
Пасивне дублювання
|
|
Блоки живлення
|
2 дубльованих блока живлення (загальна к-сть 4)
2900W
|
|
Модуль комутатори BladeCenter
|
2 х 20 портові Nortel Networks Layer 2/3 Copper GbE
Switch Module for BladeCenter або еквівалент
|
|
Fiber Channel комутатори
|
2 x QLogic(R) 4Gb 20-port FC Switch Module for IBM
eServer BladeCenter або еквівалент
|
|
Модуль управління
|
Дубльований BladeCenter Redundant KVM/Advanced
Management Module або еквівалент
|
Остаточна схема розгортання комплексу в складі системи
збереження даних, блейд-серверів, які забезпечують доступ до неї та SAN-мережі.
архітектура протокол грід інтернет

Рис. 18. Схема розгортання комплексу в складі системи
збереження даних, блейд-серверів, які забезпечують доступ до неї та SAN-мережі
без використання окремого SAN-комутатора
Після запуску цього комплексу разом із системою резервного копіювання
даних на основі бібліотеки на магнітних стрічках IBM System Storage TS3100 Tape
Library планується перенесення сюди загальноуніверситетських сервісів, в тому
числі і обчислювальних, які на даний момент виконуються на серверах типу HP,
ІВМ, Intel та SuperMicro.
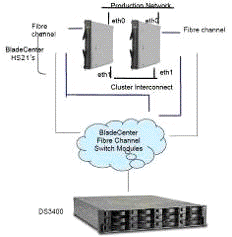
Рис. 19. Схема зображенням з’єднань між блейд-серверами та
системою збереження даних
Литература
1. I. Foster, C. Kesselman. The Grid: Blueprint for
a New Computing Infrastructure. - Morgan Kaufmann Publishers, 1998.
2. I. Foster,
C. Kesselman, S. Tuecke. The Anatomy of the Grid: Enabling Scalable Virtual
Organizations. - International J. Supercomputer Applications, 15(3), 2001,
<http://www.globus.org/research/papers/anatomy.pdf>
. I. Foster,
C. Kesselman, S. Tuecke, J.M. Nick. The Physiology of the Grid: An Open Grid
Services Architecture for Distributed Systems Integration. - Morgan Kaufmann
Publishers, 2002.
. I. Foster,
H. Kishimoto, A. Savva, D. Berry et al. The Open Grid Services Architecture. -
Global Grid Forum, 2005
. А.К.
Кирьянов, Ю.Ф. Рябов Введение в технологию Грид // Петербургский институт
ядерной физики им. Б.П. Константинова РАН. - 2006. - 39 с.
. Петренко
А.І. Національна Grid - інфраструктура для забезпечення наукових досліджень і
освіти // Системні дослідження і інформаційні технології. - Київ. - №1 - 2008.
- C.79-92.
. M. Z.
Zgurovsky. Development of Educational and Research Segment of Information
Society in Ukraine. - //Proc. WSIS.-Tunis.- 2004.-P.103-107.
. M. Z.
Zgurovsky. Development of Educational and Research Segment of Information
Society in Ukraine. - //Системні дослідження та інформаційні технології. -
Київ. - 2006. - №1. - С.7-17.
. Petrenko
A.I. Development of Grid -infrastructure\for Educational and Research segment
of Information Society in Ukraine with focus on Ecological monitoring and
Telemedicine. - // Data Science Journal.- Volume 6.- Supplement, 14 April 2007.
- P.583-590.