|
Задача интеллектуального анализа данных
|
Алгоритмы интеллектуального анализа данных
|
|
Классификация
|
Для задачи классификации используются следующие алгоритмы Microsoft: упрошенный алгоритм Байеса,
алгоритм дерева принятия решений, алгоритм нейронной сети.
|
|
Регрессия
|
Для задачи регрессии используются следующие алгоритмы Microsoft: алгоритм дерева принятия решений,
алгоритм линейной регрессии, алгоритм временных рядов, алгоритм нейронной
сети, алгоритм логической регрессии.
|
|
Кластеризация
|
Для задачи кластеризации используются следующие алгоритмы Microsoft: алгоритм кластеризации, алгоритм
кластеризации последовательностей.
|
|
Поиск взаимосвязей
|
Для задачи поиска взаимосвязей используются следующие
алгоритмы Microsoft: алгоритм дерева принятия решений,
алгоритм взаимосвязей.
|
1.4.3.1 Упрощенный алгоритм Байеса
Упрощенный алгоритм Байеса - это алгоритм классификации, основанный на
вычислении условной вероятности значений прогнозируемых атрибутов.
Предполагается, что входные атрибуты являются независимыми и определен хотя бы
один выходной атрибут.
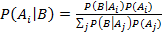 . (24)
. (24)
Формула
Байеса позволяет вычислить условные (апостериорные) вероятности.
Для
СУБД MS SQL Server
2008 описание модели интеллектуального анализа хранится в виде иерархии узлов.
Для упрощенного алгоритма Байеса иерархия имеет 4 уровня. Среда разработки BI Dev Studio позволяет просмотреть
содержимое модели.
Для
корректного использования этого алгоритма необходимо учитывать:
1. входные атрибуты должны быть взаимно независимыми;
. атрибуты могут быть только дискретными или дискретизованными (в
процессе дискретизации множество значений непрерывного числового атрибута
разбивается на интервалы и далее идет работы с номером интервала);
. алгоритм требует меньшего количества вычислений, чем другие
алгоритмы интеллектуального анализа для MS SQL Server 2008, поэтому он часть используется для
первоначального исследования данных. По этой же причине алгоритм предпочтителен
для анализа больших наборов данных с большим числом входных атрибутов.
.4.3.2 Алгоритм дерева принятия решений
Алгоритм представляет собой алгоритм регрессии и алгоритм классификации,
предоставляемый службами Microsoft SQL Server Службы Analysis Services для
использования в прогнозирующем моделировании как дискретных, так и непрерывных
атрибутов.
Для дискретных атрибутов алгоритм осуществляет прогнозирования на основе
связи между входными столбцами в наборе данных. Он использует значения этих
столбцов (известные как состояния) для прогнозирования состояний столбца,
который обозначается как прогнозируемый. Алгоритм идентифицирует входные
столбцы, которые коррелированы с прогнозируемым столбцом.
Для непрерывных атрибутов алгоритм использует линейную регрессию для
определения места разбиения дерева решений.
Если несколько столбцов установлены как прогнозируемые или если входные
данные содержат вложенную таблицу, которая задана как прогнозируемая, то
алгоритм строит отдельное дерево решений для каждого прогнозируемого столбца.
Принцип работы алгоритма
Алгоритм дерева принятия решений строит модель интеллектуального анализа
данных путем создания ряда разбиений в дереве. Эти разбиения представлены как
узлы. Алгоритм добавляет узел к модели каждый раз, когда выясняется, что
входной столбец имеет значительную корреляцию с прогнозируемым столбцом.
Способ, которым алгоритм определяет разбиение, отличается в зависимости от
того, прогнозирует ли он непрерывный столбец или дискретный столбец.
Прогнозирование дискретных столбцов
Способ, которым алгоритм дерева принятия решений строит дерево для
дискретного прогнозируемого столбца, можно продемонстрировать с использованием
гистограммы. Показана гистограмма, на которой построен прогнозируемый столбец
«Покупатели велосипедов» в сравнении с входным столбцом «Возраст». Гистограмма
«Б» показывает, что возраст человека помогает определить, купит ли этот человек
велосипед.

Рис. 16. Гистограмма «А»
Корреляция, показанная на диаграмме, приведет к тому, что алгоритм дерева
принятия решений создаст новый узел в модели.
Добавление алгоритмом новых узлов к модели приводит к созданию
древовидной структуры. Верхний узел дерева описывает разбиение прогнозируемого
столбца для всех заказчиков. При продолжении роста модели алгоритм
рассматривает все столбцы.

Рис. 17. Гистограмма «Б»
Прогнозирование непрерывных столбцов
Когда алгоритм дерева принятия решений строит дерево, основанное на
непрерывном прогнозируемом столбце, каждый узел содержит регрессионную формулу.
Разбиение осуществляется в точке нелинейности в этой регрессионной формуле.

Рис. 18. Диаграмма данных
Диаграмма содержит данные, которые можно моделировать либо используя
одиночную линию, либо используя две соединенные линии. Однако одиночная линия
не обеспечит надлежащего представления данных. Вместо этого при использовании
двух линий модель обеспечит гораздо более точное приближение данных. Точка
соединения этих двух линий является точкой нелинейности и представляет собой точку,
в которой разобьется узел в модели дерева решений. Эти два уравнения
представляют регрессионные уравнения для этих двух линий.

Рис. 19. Регрессионные уравнения
.4.3.3 Алгоритм линейной регрессии
Алгоритм линейной регрессии позволяет представить зависимость между
входной и выходной переменными как линейную, а затем использовать полученный
результат при прогнозировании. Линия на диаграмме является наилучшим линейным
представлением данных.

Рис. 20. Пример использования линейной регрессии
В случае одной независимой переменной (одного регрессора), задача может
быть сформулирована следующим образом.
Уравнение,
описывающее прямую на плоскости: 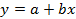 . Для
. Для  й точки
будет справедливо
й точки
будет справедливо 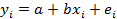 , где
, где 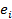 -
разница между фактическим значением
-
разница между фактическим значением 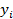 и
вычисленным в соответствии уравнением линии. Каждой точке соответствует ошибка,
связанная с ее расстоянием от линии регрессии. Нужно с помощью подбора
коэффициентов
и
вычисленным в соответствии уравнением линии. Каждой точке соответствует ошибка,
связанная с ее расстоянием от линии регрессии. Нужно с помощью подбора
коэффициентов 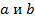 получить
такое уравнение, чтобы сумма ошибок, связанных со всеми точками, стала
минимальной. Для решения этой задачи может использоваться, в частности, метод
наименьших квадратов.
получить
такое уравнение, чтобы сумма ошибок, связанных со всеми точками, стала
минимальной. Для решения этой задачи может использоваться, в частности, метод
наименьших квадратов.
Линейная
регрессия является полезным и широко известным методом моделирования, особенно
для случаев, когда известен приводящий к изменениям базовый фактор, и есть основания
ожидать линейный характер зависимости.
.4.3.4 Алгоритм анализа временных рядов
В общем случае, временной ряд - это набор числовых значений, собранных в
последовательные моменты времени. Целью анализа временного ряда может быть
выявление имеющихся зависимостей текущих значений параметров от предшествующих,
с последующим использованием их для прогнозирования новых значений.
Ряд
можно представить как упорядоченное множество элементов или событий 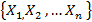 , каждое
из которых в общем случае может быть описано набором атрибутов:
, каждое
из которых в общем случае может быть описано набором атрибутов: 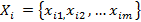 . На
практике чаще всего используется один атрибут. При описании варианта для
интеллектуального анализа данных, отметка времени (или номер элемента во
временном ряде) вводится как один из атрибутов. Как правило, предполагается,
что отметка времени - дискретное числовое значение, а предсказываемый атрибут -
непрерывный.
. На
практике чаще всего используется один атрибут. При описании варианта для
интеллектуального анализа данных, отметка времени (или номер элемента во
временном ряде) вводится как один из атрибутов. Как правило, предполагается,
что отметка времени - дискретное числовое значение, а предсказываемый атрибут -
непрерывный.
Выделяют два основных формата представления временных рядов - столбчатый
и чередующийся. С данными в столбчатом формате несколько проще работать, но
этот формат менее гибкий.
Рассмотрим теперь некоторые особенности реализации алгоритма в SQL Server
2008. Алгоритм временных рядов (Microsoft Time Series) предоставляет собой
совокупность двух алгоритмов регрессии, оптимизированных для прогноза рядов
непрерывных числовых значений.
По умолчанию службы Analysis Services для обучения модели используют
каждый алгоритм отдельно, а затем объединяют результаты, чтобы получить
наиболее точный прогноз. В зависимости от имеющихся данных и требований к
прогнозам, можно выбрать для использования только один алгоритм.
Точность прогноза для временного ряда может повысить указание известной
периодичности.
Авторегрессия
отличается от обычной регрессии тем, что текущее значение параметра 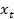
выражается
через его значения в предыдущие моменты времени. Если использовать линейные
зависимости, то алгоритм имеет решение в виде:
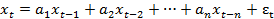 . (25)
. (25)
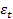 -
погрешность, которую надо минимизировать путем подбора коэффициентов
-
погрешность, которую надо минимизировать путем подбора коэффициентов 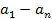 , в чем и
заключается обучение модели. Использование аналитическими службами SQL Server
дерева авторегрессии позволяет менять формулу путем разбиения в точках
нелинейности.
, в чем и
заключается обучение модели. Использование аналитическими службами SQL Server
дерева авторегрессии позволяет менять формулу путем разбиения в точках
нелинейности.
1.4.3.5 Алгоритм кластеризации
Кластеризация позволяет снизить размерность задачи анализа предметной
области, путем «естественной» группировки вариантов в кластеры. Таким образом,
кластер будет объединять близкие по совокупности параметров элементы, и в некоторых
случаях, его можно рассматривать как единое целое
В случаях, когда для группировки используются значения одного-двух
параметров, задача кластеризации может быть относительно быстро решена вручную
или, например, обычными средствами работы с реляционными базами данных. Когда
параметров много, возникает потребность в автоматизации процесса выявления
кластеров.
Предоставляемый аналитическими службами SQL Server 2008 алгоритм
кластеризации (Microsoft Clustering), использует итерационные методы для
группировки вариантов со сходными характеристиками в кластеры. Алгоритм сначала
определяет имеющиеся связи в наборе данных и на основе этой информации
формирует кластеры.
Идею можно проиллюстрировать с помощью диаграмм на рисунке 21. На первом
этапе (рисунок 21, а) имеется множество вариантов, далее (рисунок 21, b) идет итерационный процесс
формирования кластеров, и в итоге получен относительно небольшой набор
кластеров, которым можно задать идентификаторы и продолжить анализ.
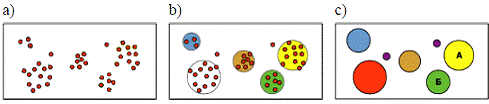
Рис. 21. Переход от отдельных вариантов к кластерам
Microsoft
Clustering содержит реализацию двух алгоритмов кластеризации. Первый из них,
алгоритм  средних
(англ.
средних
(англ.  means),
реализует, так называемую жесткую кластеризацию. Это значит, что вариант может
принадлежать только одному кластеру. Идея алгоритма заключается в следующем:
means),
реализует, так называемую жесткую кластеризацию. Это значит, что вариант может
принадлежать только одному кластеру. Идея алгоритма заключается в следующем:
.
Выбирается число кластеров 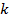 .
.
.
Из исходного множества данных случайным образом выбираются записей,
которые будут служить начальными центрами кластеров.
.
Для каждой записи исходной выборки определяется ближайший к ней центр кластера.
При этом записи, «притянутые» определенным центром, образуют начальные
кластеры.
.
Вычисляются центроиды - центры тяжести кластеров. Каждый центроид - это вектор,
элементы которого представляют собой средние значения признаков, вычисленные по
всем записям кластера. Центр кластера смещается в его центроид.
Шаги
3 и 4 итеративно повторяются, при этом может происходить изменение границ
кластеров и смещение их центров. В результате минимизируется расстояние между
элементами внутри кластеров. Остановка алгоритма производится тогда, когда
границы кластеров и расположения центроидов не перестанут изменяться от
итерации к итерации, т. е. на каждой итерации в каждом кластере будет
оставаться один и тот же набор записей.
Второй
метод, реализованный в Microsoft Clustering, это максимизация ожиданий (англ. Expectation-maximization, EM). Он относится к методам мягкой кластеризации, т. е.
вариант в этом случае принадлежит к нескольким кластерам, а для всех возможных
сочетаний вариантов с кластерами вычисляются вероятности.
При
кластеризации методом EM алгоритм итеративно уточняет начальную модель
кластеризации, подгоняя ее к данным, и определяет вероятность принадлежности
точки данных кластеру. Этот алгоритм заканчивает работу, когда вероятностная
модель соответствует данным. Функция, используемая для установления
соответствия, - логарифм функции правдоподобия данных, вводимых в модель.
Если
в процессе формируются пустые кластеры или количество элементов в одном или
нескольких кластерах оказывается меньше заданного минимального значения,
малочисленные кластеры заполняются повторно с помощью новых точек и алгоритм EM
запускается снова. Результаты работы алгоритма максимизации ожидания являются
вероятностными: каждая точка данных принадлежит всем кластерам, но с разной
вероятностью. Поскольку метод допускает перекрытие кластеров, сумма элементов
всех кластеров может превышать число элементов обучающего набора.
.4.3.6 Алгоритм взаимосвязей
Алгоритм взаимосвязей или ассоциативных правил (Association Rules)
позволяет выявить часто встречающиеся сочетания элементов данных и использовать
обнаруженные закономерности для построения прогноза.
Для
выявления часто встречающихся наборов объектов может использоваться алгоритм
Apriori, реализация которого лежит в основе алгоритма Microsoft Association Rules, использующегося в SQL Server 2008. Алгоритм Apriori последовательно выделяет часто
встречающиеся одно-, двух-, …, n-элементные наборы. На м этапе
выделяются 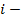 элементные
наборы. Для этого сначала выполняется формирование наборов-кандидатов, после
чего для них рассчитывается поддержка.
элементные
наборы. Для этого сначала выполняется формирование наборов-кандидатов, после
чего для них рассчитывается поддержка.
Поддержка
(от англ. support) используется для измерения популярности набора элементов.
Например, поддержка набора элементов 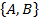 - общее
количество транзакций, которые содержат как
- общее
количество транзакций, которые содержат как 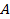 , так и
, так и .
.
Чтобы
количественно охарактеризовать правило, используется вероятность (англ.
probability). Этот же показатель иногда называется достоверностью.
Probability 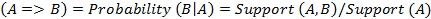 . (26)
. (26)
Вероятность
для набора рассчитывается
как отношение числа транзакций, содержащих этот набор, к общему числу
транзакций.
Чтобы
оценить взаимную зависимость элементов используется важность (англ. importance)
или показатель интереса.
Importance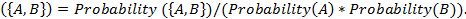 (27)
(27)
Если
Importance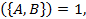 то и
то и 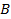 -
независимые элементы. Importance
-
независимые элементы. Importance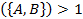 означает, что и имеют
положительную корреляцию (клиент купивший товар A вероятно купит и B).
Importance
означает, что и имеют
положительную корреляцию (клиент купивший товар A вероятно купит и B).
Importance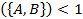 указывает на отрицательную корреляцию.
указывает на отрицательную корреляцию.
Для
правил важность рассчитывается как логарифм отношения вероятностей:
Importance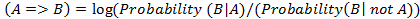 (28)
(28)
В
данном случае равная 0 важность означает, что между и нет
взаимосвязи. Положительная важность означает, что вероятность повышается,
когда справедливо ;
отрицательная - вероятность понижается,
когда справедливо .
Настройками
пороговых значений можно регулировать максимальное число элементов в
рассматриваемых наборах, минимальную вероятность, при которой правило будет
рассматриваться,
минимальную поддержку для рассматриваемых наборов и т. д.
.4.3.7 Алгоритм кластеризации последовательностей
Задача кластеризации последовательностей - выявить часто встречающиеся
последовательности событий. Важное различие заключается в том, что в данном
случае учитывается, в какой очередности события происходят (или элементы добавляются
в набор). Схожие последовательности объединяются в кластеры. Кроме анализа
характеристик кластеров, возможно решение задачи прогнозирования наступления
событий на основании уже произошедших ранее.
Используемый аналитическими службами SQL Server 2008 алгоритм Microsoft
Sequence Clustering - это гибридный алгоритм, сочетающий методы кластеризации с
анализом марковских цепей. Анализируемое множество вариантов формируется с
использованием вложенных таблиц.
Важно, чтобы вложенная таблица содержала собственный идентификатор,
который позволил бы определить последовательность элементов.
С
помощью марковских моделей анализируется направленный граф, хранящий переходы
между различными состояниями. Алгоритм Microsoft Sequence Clustering использует
марковские цепи 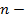 го
порядка. Число
го
порядка. Число 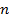 говорит
о том, сколько состояний использовалось для определения вероятности текущего
состояния. В модели первого порядка вероятность текущего состояния зависит
только от предыдущего состояния. В марковской цепи второго порядка вероятность
текущего состояния зависит от двух предыдущих состояний, и так далее.
говорит
о том, сколько состояний использовалось для определения вероятности текущего
состояния. В модели первого порядка вероятность текущего состояния зависит
только от предыдущего состояния. В марковской цепи второго порядка вероятность
текущего состояния зависит от двух предыдущих состояний, и так далее.
Вероятности
перехода между состояниями хранятся в матрице переходов. По мере удлинения
марковской цепи, размер матрицы растет экспоненциально, соответственно растет и
время обработки, что надо учитывать при решении практических задач.
Далее
алгоритм изучает различия между всеми возможными последовательностями, чтобы
определить, какие последовательности лучше всего использовать в качестве
входных данных для кластеризации. Созданный алгоритмом список вероятных
последовательностей используется в качестве входных данных для применяемого по
умолчанию EM-метода кластеризации (англ. Expectation Maximization, максимизации
ожидания).
Целями
кластеризации являются как связанные, так и не связанные с последовательностями
атрибуты. У каждого кластера есть марковская цепь, представляющая полный набор
путей, и матрица, содержащая переходы и вероятности последовательности
состояний. На основе начального распределения используется правило Байеса для
вычисления вероятности любого атрибута, в том числе - последовательности, в
конкретном кластере.
.4.3.8 Алгоритм нейронных сетей
В случае наличия в данных сложных зависимостей между атрибутами,
«быстрые» алгоритмы интеллектуального анализа, такие как упрощённый алгоритм
Байеса, могут давать недостаточно точный результат. Улучшить ситуацию может
применение нейросетевых алгоритмов.
Нейронные сети - это класс моделей, построенных по аналогии с работой
человеческого мозга. Существуют различные типы сетей, в частности, в SQL Server
алгоритм нейронной сети использует сеть в виде многослойного персептрона, в
состав которой может входить до трех слоев нейронов, или персептронов. Такими
слоями являются входной слой, необязательный скрытый слой и выходной слой.

Рис. 22 Пример схемы нейронной сети
Каждый нейрон получает одно или несколько входных значений (входов) и
создает выходное значение (один или несколько одинаковых выходов). Каждый выход
является простой нелинейной функцией суммы входов, полученных нейроном. Входы
передаются в прямом направлении от узлов во входном слое к узлам в скрытом
слое, а оттуда передаются на выходной слой. Нейроны в составе слоя не соединены
друг с другом. Скрытый слой может отсутствовать (в частности, это используется
алгоритмом логистической регрессии).
В используемом аналитическими службами SQL Server 2008 алгоритме
Microsoft Neural Network, имеющий более двух состояний дискретный входной
атрибут модели интеллектуального анализа приводит к созданию одного входного
нейрона для каждого состояния и одного входного нейрона для отсутствующего
состояния (если обучающие данные содержат какие-либо значения NULL).
Непрерывный входной атрибут «создает» два входных нейрона: один нейрон для
отсутствующего состояния и один нейрон для значения самого непрерывного
атрибута. Входные нейроны обеспечивают входы для одного или нескольких скрытых
нейронов.
Выходные нейроны представляют значения прогнозируемых атрибутов для
модели интеллектуального анализа данных. Дискретный прогнозируемый атрибут,
имеющий более двух состояний, «создает» один выходной нейрон для каждого состояния
и один выходной нейрон для отсутствующего или существующего состояния.
Непрерывные прогнозируемые столбцы «создают» два выходных нейрона: один нейрон
для отсутствующего или существующего состояния и один нейрон для значения
самого непрерывного столбца.
Нейрон получает входы от других нейронов или из других данных, в
зависимости от того, в каком слое сети он находится. Входной нейрон получает
входы от исходных данных. Скрытые нейроны и выходные нейроны получают входы из
выхода других нейронов нейронной сети. Входы устанавливают связи между
нейронами, и эти связи являются путем, по которому производится анализ для
конкретного набора вариантов.
Каждому
входу присвоено значение, именуемое весом, которое описывает релевантность или
важность конкретного входа для скрытого или выходного нейрона. Значения веса
могут быть отрицательными; это означает, что вход может подавлять, а не
активировать конкретный нейрон. Чтобы выделить важность входа для конкретного
нейрона, значение входа умножается на вес. В случае отрицательных весов
умножение значения на вес служит для уменьшения важности входа. Схематично это
представлено на рисунке 23, где 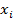 - вход,
- вход, 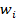 -
соответствующий ему вес.
-
соответствующий ему вес.

Рис.
23 Формальное представление нейрона
Каждому нейрону сопоставлена простая нелинейная функция, называемая
функцией активации, которая описывает релевантность или важность определенного
нейрона для этого слоя нейронной сети. В качестве функции активации в алгоритме
Microsoft Neural Network крытые нейроны используют функцию гиперболического
тангенса (tanh), а выходные нейроны - сигмоидальную (логистическую) функцию.
Обе функции являются нелинейными и непрерывными, позволяющими нейронной сети
моделировать нелинейные связи между входными и выходными нейронами.
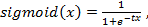 (29)
(29)
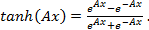 (30)
(30)
Обучение
модели интеллектуального анализа данных производится по следующей схеме.
Алгоритм сначала оценивает обучающие данные и резервирует определенный процент
из них для использования при определении точности сети.
Затем
алгоритм определяет количество и сложность сетей, включаемых в модель
интеллектуального анализа данных. Определяется число нейронов в каждом слое.
Процесс обучения строится по следующей схеме:
.
На начальной стадии случайным образом присваиваются значения всем весам всех
входов в сети.
.
Для каждого обучающего варианта вычисляются выходы.
.
Вычисляются ошибки выходов. В качестве функции ошибки может использоваться
квадрат остатка (квадрат разности между спрогнозированным и фактическим значением).
Шаги
2, 3 повторяются для всех вариантов, используемых в качестве образцов. После
этого, веса в сети обновляются таким образом, чтобы минимизировать ошибки.
В
процессе обучения может выполняться несколько итераций. После прекращения роста
точности модели обучение завершается.
.4.3.9 Алгоритм логической регрессии
Логистическая регрессия является известным статистическим методом для
определения влияния нескольких факторов на логическую пару результатов.
Например, задача может быть следующей.
Предположим, что прогнозируемый столбец содержит только два состояния, и
необходимо провести регрессионный анализ, сопоставляя входные столбцы с
вероятностью того, что прогнозируемый столбец будет содержать конкретное
состояние. Результаты, полученные методами линейной и логистической регрессии,
представлены на рисунке 24a) и 24b) соответственно. Линейная регрессия не
ограничивает значения функции диапазоном от 0 до 1, несмотря на то, что они
должны являться минимальным и максимальным значениями этого столбца. Кривая,
формируемая алгоритмом логистической регрессии, в этом случае более точно
описывает исследуемую характеристику.

Рис. 24. Сравнение результатов, полученных методами линейной «А» и
логистической регрессии «В»
В реализации Майкрософт, для моделирования связей между входными и
выходными атрибутами применяется видоизмененная нейронная сеть, в которой
отсутствует скрытый слой. Измеряется вклад каждого входного атрибута, и в
законченной модели различные входы снабжаются весовыми коэффициентами. Название
«логистическая регрессия» отражает тот факт, что кривая данных сжимается путем
применения логистического преобразования, чтобы снизить эффект экстремальных
значений.
1.5 Анализ результатов главы 1 и уточнение постановки задачи
В данной главе выполнен обзор технологий бизнес-аналитики, в частности -
обзор оперативного анализа данных, построенного на базе OLAP, и интеллектуального анализа данных,
для реализации которого может быть использован Data Mining, и указана основная их цель и преимущество.
Рассматривается концепция хранилищ данных и их классификация с кратким обзором.
В первой части работы приведена подробная архитектура СУБД для улучшения
понимания происходящих процессов.
Также приведено подробное описание моделей, используемые средствами СУБД SQL Server. В данном разделе подробно рассказывается о методах и
алгоритмах, заложенных в анализе данных, а также их формализация. Конкретно
приведены и рассмотрены Майкрософтовские алгоритмы интеллектуального анализа
данных.
Формальное представление задачи классификации и регрессии:
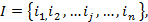
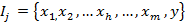 ,
,
где
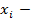 атрибуты-независимые переменные,
атрибуты-независимые переменные,
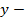 зависимая.
зависимая.
Формальное
представление задачи кластеризации:
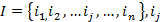 -
исследуемый объект;
-
исследуемый объект; 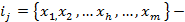 набор
параметров.
набор
параметров.
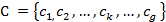 ,
, 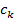 --
кластер, содержащий похожие друг на друга объекты из множества
--
кластер, содержащий похожие друг на друга объекты из множества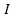 :
:
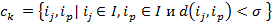 .
.
Формальное
представление задачи поиска ассоциативных правил:
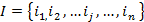 ,
, 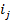 -
объекты, входящие в анализируемые наборы;
-
объекты, входящие в анализируемые наборы;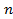 - общее
количество объектов.
- общее
количество объектов.
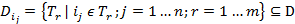 ,
множество транзакций, в которые входит объект
,
множество транзакций, в которые входит объект 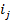 .
.
При
поиске ассоциативных правил требуется найти множество всех частых наборов:
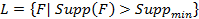 .
.
Следующая
глава будет посвящена разделу с языковыми средствами для СУБД SQL Server.
2. Языковые средства бизнес-аналитики: языки MDX и DMX
.1 Базовые понятия языка MDX
(MultiDimensional eXpressions - язык многомерных выражений)
является языком запросов, используемым для извлечения данных из многомерных баз
данных. Он используется для запрашивания данных из баз данных OLAP с помощью
Analysis. Изначально MDX был разработан компанией Microsoft и был введен в 1998
году.
Основой многомерной базы данных является куб. Каждый куб
обычно содержит более двух измерений. Куб Adventure Works в учебной базе данных
содержит 21 измерение.
Объект Measures (размерности) представляет собой специальное
измерение, которое является набором размерностей. Размерности являются
количественными сущностями, которые используются для анализа. Каждая
размерность представляет собой часть категории, называющейся размерной группой
(measure group). Размерные группы используются инструментами разработки или
клиентскими инструментами главным образом для навигационных целей, чтобы
улучшить читабельность или облегчить использование конечным пользователям. Они
никогда не используются в запросах MDX при обращении к размерностям. Тем не
менее, они могут использоваться в определенных функциях MDX. По умолчанию
служба анализа генерирует размерную группу для каждой таблицы фактов.
Каждая иерархия измерения содержит один или несколько
элементов, называемых членами (members). Каждый член соответствует одному или
нескольким вхождениям этого значения в базовую таблицу измерений.
В MDX каждый член иерархии представлен уникальным именем.
Уникальные имена помогают идентифицировать определенные члены.
Ячейка (cell) представляет собой элемент, из которого
извлекаются данные, соответствующие пересечению членов измерения. Число ячеек
внутри куба данных определяется числом иерархий в каждом из измерений куба
данных и числом членов каждой иерархии. Ячейки хранят значения всех
размерностей в кубе. Если для какой-нибудь размерности недоступно значение
данных в ячейке, считается, что соответствующим значением размерности является
значение Null (т.е. пустое значение).
Кортеж (tuple) уникально идентифицирует ячейку или раздел куба
данных. Кортеж представлен членами измерений куба данных, разделенными
запятыми. Кортеж заключается в круглые скобки. Кортеж совсем необязательно
должен явно содержать члены всех измерений куба данных.
Поскольку кортеж уникально идентифицирует ячейку, он может
содержать не более одного члена от каждого измерения. Кортеж, представленный
единственным членом, называют простым кортежем. Простой кортеж можно не
заключать в круглые скобки. Если кортеж представлен членами нескольких
измерений, то такой кортеж требуется заключать в круглые скобки. Совокупности
кортежей формируют новые объекты (называемые наборами), которые часто
используются в запросах и выражениях MDX.
Набор (set) - это совокупность кортежей, которые определены с
использованием одинакового количества одних и тех же измерений. Набор обычно
заключается в фигурные скобки ({}).
.2 Создание структуры многомерного анализа
Запрос на языке MDX представляет собой набор команд, который
выглядит следующим образом:
[WITH
<formula_expression> [, <formula_expression>
...]][<axis_expression>,
[<axis_expression>...]][<cube_expression>]
[WHERE
[slicer_expression]]
где:
· axis_specification -
содержит описание осей куба;
· cube_specification -
содержит название куба;
· slicer_specification -
содержит описание срезов куба.
Ключевые слова WITH, SELECT, FROM и WHERE в сочетании
с выражениями, следующими за ними, принято называть предложениями (clause). В
представленном выше шаблоне запроса MDX в квадратные скобки заключены необязательные
элементы, которые могут присутствовать в одних запросах и отсутствовать в
других.
.2.1 Выражение SELECT
Инструкция SELECT языка MDX используется для
извлечения подмножества многомерных данных из сервера OLAP. Используется
следующий синтаксис для инструкции SELECT:
SELECT [<axis_expression>, [<axis_expression>...]]
Выражение axis_expression, указанное после ключевого слова SELECT, ссылается на измерение,
представляющее те данные, которые надо извлечь. Эти измерения называют осевыми
измерениями (axis dimensions), поскольку представленные ими данные проецируются
на соответствующие оси. Для выражения axis_expression используется следующий
синтаксис:
<axis_expression> := <набор> ON Axis (номер оси)
Язык MDX предоставляет возможность указать до 128 осей
в инструкции SELECT. Первые пять осей имеют псевдонимы. Это оси COLUMNS
(столбцы), ROWS (строки), PAGES (страницы), SECTIONS (разделы) и CHAPTERS
(главы). Последующие оси указываются с помощью слова Axis, за которым следует
номер оси. Рассмотрим следующий пример.Measures. [Internet Sales Amount] ON COLUMNS,
[Customers]. [Country].MEMBERS on
ROWS,
[Product]. [Product Line].MEMBERS on
PAGES
В приведенной выше инструкции SELECT указаны три оси. В этом примере данные из измерений Measures, Customers и Product отображаются на трех осях, чтобы сформировать осевые
измерения.
При определении инструкции SELECT создается осевое
измерение. Инструкция SELECT назначает набор осям COLUMNS и ROWS. Осевое
измерение извлекает и содержит данные для нескольких членов, а не для
единственного члена.
.2.2 Выражение FROM
Предложение FROM в запросе MDX определяет куб, из
которого извлекаются данные для анализа. Предложение FROM обязательно для
любого запроса MDX.
Для предложения FROM используется следующий синтаксис:<cube_expression>
Выражение cube_expression обозначает имя куба или
подраздела куба, из которого извлекаются данные. Куб, указанный в предложении
FROM, называют контекстом куба (cube context), и запрос MDX выполняется внутри
этого контекста.
SELECT [Measures]. [Internet Sales
Amount] ON COLUMNS
FROM [Adventure Works]
Выше приведен пример правильного запроса MDX, который
извлекает размерность [Internet Sales Amount] по оси X. Указанная размерность
извлекается из контекста куба [Adventure Works].
2.2.3 Выражение WHERE
Для задания условия отбора применяется предложение WHERE. Инструкция WHERE ограничивает набор результатов запроса с помощью
некоторого критерия.
SELECT Measures. [Sales] ON COLUMS,
[Product]. [Product Line].MEMBERS on
ROWSProductsCube([Product]. [Color].[Silver])
Два столбца, выбираемых запросом SQL, теперь представлены по осям COLUMNS и ROWS.
Измерение среза (slicer dimension) создается при
определении предложения WHERE; это фильтр, который исключает нежелательные
измерения и члены. Измерение среза включает и все те оси куба, которые не
включены явно в оси, указанные в определении запроса. Заданные по умолчанию
члены иерархий, которые не включены в оси запроса, используются в осях среза
данных. результатом измерения среза является один кортеж. Если в оси среза
определено несколько кортежей, то они будут обработаны как набор, а их значения
- агрегированы с использованием размерности, заданной в запросе, и функции
агрегации из этой размерности.
.2.4 Выражение WITH
Типичными вычислениями, которые создаются с использованием предложения WITH, являются именованные наборы и
вычисляемые члены. Кроме этого, предложение WITH обеспечивает возможность определять вычисления по
ячейкам, загружать куб в кэш Analysis Services для
улучшения выполнения запроса, изменять содержимое ячеек с помощью вызова
функций из внешних библиотек.
Для предложения WITH используется следующий синтаксис.
[WITH <formula_expression> [,
<formula_expression> ...]]
Предложение WITH позволяет
определять несколько вычислений внутри одной инструкции. Выражение formula_expression варьируется в зависимости от типа
вычислений. При использовании в предложении WITH нескольких вычислений они отделяются друг от друга
запятыми.
.2.5 Именованные наборы
Именованный набор - это просто псевдоним для обычного выражения MDX,
описывающего набор. Такой псевдоним можно использовать в любом месте внутри
запроса вместо того, чтобы вводить реальное выражение, описывающее набор.
Для именованного набора выражение formula_expression в предложении WITH
выглядит следующим образом:
Formula_expression := SET <псевдоним_набора>
AS [']<набор>[']
В качестве псевдонима можно использовать любое имя, которое обычно
заключают в квадратные скобки. В выражении, определяющем именованный набор,
используются ключевые слова SET и AS. Набор кортежей не обязательно
заключать в одинарные кавычки ('').
.2.6 Вычисляемые члены
Вычисляемые члены представляют собой вычисления, определяемые выражениями
MDX. Таким образом, вычисляемые члены позволяют получить результат, основанный
на вычислении выражений MDX, а не просто извлечь исходные фактические данные. В
языке MDX для создания вычисляемых членов в предложении WITH используются
ключевые слова MEMBER и AS.
WITH MEMBER [MEASURES].[Profit] AS '([Measures].[Internet
Sales Amount] - [Measures].[Total Product Cost])'[MEASURES].[Profit] ON
COLUMNS,
[Customer].[Country].MEMBERS ON ROWS[Adventure Works]
В примере вычисляемый член Profit (Прибыль) определен как разность
размерностей [Internet Sales Amount] (Сумма Интернет-продаж) и [Total Product
Cost] (Общая стоимость товара). При выполнении данного запроса для каждой
страны вычисляемый член будет получен на основе вычисления выражения MDX.
.3 Выражения MDX
Выражения MDX представляют
собой инструкции языка MDX,
которые вычисляют определенные значения. Обычно они используются для вычисления
или определения значений для таких объектов, как заданный по умолчанию член и
заданная по умолчанию размерность, либо применяются при определении выражений
безопасности, позволяющих или запрещающих доступ к некоторой информации. Обычно
выражения MDX используют в качестве параметра член, кортеж или набор и
возвращают некоторое значение. Если в результате выполнения выражения не
получено значение, то возвращается значение Null.
Язык MDX также поддерживает возможность размещения комментариев в
запросах и выражениях MDX. На текущий момент существует три различных способа
добавления комментариев в код MDX.
Эти способы продемонстрированы ниже:
// (две косые черты) здесь следует комментарий
- (два дефиса) здесь следует комментарий
/* здесь следует комментарий */ (две пары символов косой черты и
звездочки)
2.3.1 Операторы
Язык MDX включает несколько операторов. Оператор представляет собой
функцию, которая выполняет специфическое действие и использует аргументы. В MDX
используются операторы нескольких типов. MDX содержит арифметические операторы,
логические операторы и специальные операторы MDX.
Обычные арифметические операторы, такие как «+», «-», «*» и «/», входят в
состав арифметических операторов MDX. Эти операторы могут применяться для
выполнения арифметических операций с двумя числами.
Операторы «+», «-» и «*» помимо того, что являются арифметическими
операторами, также могут использоваться для выполнения операций с наборами
кортежей MDX. Оператор «+» применяется для объединения двух наборов, оператор
«-» используется для вычисления разности двух наборов, а оператор «*» позволяет
найти векторное произведение двух наборов. Результатом векторного произведения
двух наборов являются все возможные комбинации кортежей в каждом наборе.
Векторное произведение позволяет извлечь данные в матричном формате.
Язык MDX поддерживает такие операторы сравнения, как «<», «<=»,
«>», «>=», «=» и «<>». Эти операторы используют два выражения MDX в
качестве аргументов и возвращают значения TRUE (Истина) или FALSE (Ложь) в
зависимости от результатов сравнения величин, полученных в результате
вычисления выражений MDX.(Customer.[Country].members) > 3
В приведенном выше примере функция Count используется для подсчета
количества членов в иерархии Country измерения Customer. Поскольку иерархия
Country содержит больше трех членов, результатом рассматриваемого выражения MDX
будет значение TRUE.
Язык MDX поддерживает такие логические операторы, как AND, OR, NOT и IS,
которые используются для логической конъюнкции (операция И), логической
дизъюнкции (операция ИЛИ), логического отрицания и сравнения. Эти операторы
используют два выражения MDX в качестве аргументов и возвращают значение TRUE
или FALSE как результат логической операции. Данные логические операторы обычно
используются в выражениях MDX, предназначенных для обеспечения защиты ячейки
или измерения от несанкционированного доступа.
.3.2 Функции
Функции MDX могут использоваться в выражениях или запросах MDX. Функции
MDX помогают обращаться к некоторым общим операциям, которые требуются в ваших
запросах или выражениях MDX.
Функции набора применяются для выполнения операций с
наборами кортежей. Такие функции используют в качестве аргументов наборы
кортежей, и зачастую результатом их выполнения также является набор. Наиболее
широко применяемыми из функций набора являются функции CrossJoin и Filter.
Для функции CrossJoin используется следующий
синтаксис.(Выражение_набора [, Выражение_набора ...])
Функция CrossJoin возвращает все возможные комбинации
членов наборов, указанных в качестве ее аргументов.
SELECT Measures.[Internet Sales
Amount] ON COLUMNS,( {Product.[Product Line].[Product Line].MEMBERS},
{[Customer].[Country].MEMBERS}) on
ROWS[Adventure Works]
Этот запрос создает векторное произведение каждого
члена в измерении Product (Товар) с каждым членом измерения Customer (Клиент) и
возвращает для каждой полученной пары значение размерности Internet Sales
Amount (Сумма Интернет-продаж).
Функция Filter использует два аргумента: выражение,
задающее набор, и логическое выражение, определяющее условие отбора. Логическое
выражение применяется к каждому элементу набора и возвращает набор элементов,
удовлетворяющий логическому условию. Для функции Filter используется следующий
синтаксис.( Выражение_набора, {Логическое_выражение |
[CAPTION | KEY | NAME] = Строковое_выражение})
SELECT Measures.[Internet Sales
Amount] ON COLUMNS,(CrossJoin( {Product.[Product Line].[Product Line].MEMBERS},
{[Customer].[Country].MEMBERS}),[Internet
Sales Amount] >2000000) on ROWS [Adventure Works]
Этот запрос возвращает информацию только о тех
товарах, для которых суммы продаж по каждой из стран (и общая сумма по всем
странам) превышают $2000000.
Функции члена измерения используются для выполнения
операций с членами, таких как извлечение текущего члена, предыдущего,
родительского, дочернего, следующего члена и т.д. Все функции данной категории
возвращают член. Одна из наиболее часто используемых функций этой категории
называется ParallelPeriod.
Функция ParallelPeriod позволяет извлечь член
измерения типа Time (Время), основываясь на заданном члене и определенных
условиях. Для функции ParallelPeriod используется следующий
синтаксис.([Выражение_уровня [, Числовое_выражение [,
Выражение_члена]]])
Функция ParallelPeriod используется для сравнения
значений размерности относительно различных временных периодов.
Числовые функции чрезвычайно полезны при определении
параметров запроса MDX или создании вычисляемых размерностей. В данной группе
представлено множество статистических функций, включая функции для расчета
стандартного среднеквадратичного отклонения, выборочной дисперсии и корреляции.
Наиболее часто применяемыми из числовых функций являются простая функция под
названием Count и DistinctCount. Функция Count используется для подсчета количества элементов в
таком объекте, как измерение, кортеж, набор или уровень. Функция DistinctCount в свою очередь использует в качестве
аргумента выражение, задающее набор кортежей, и возвращает число индивидуальных
(недублирующихся) элементов в указанном наборе, а не общее число элементов.
Ниже показан синтаксис, используемый обеими упомянутыми функциями.(Измерение |
Кортеж | Набор| Уровень)(Выражение_набора)
Чтобы извлечь имена наборов, кортежей и членов в форме
строки, можно использовать специальные функции, например,
MemberToStr(<Выражение_члена>). А для выполнения обратного
преобразования, т.е. преобразования строкового значения в выражение,
возвращающее член измерения, можно использовать функцию StrToMember(<Строка>).MEMBER Measures.CustomerCount
AS DistinctCount(([Customer].[Customer].MEMBERS,
[Product].[Product
Line].Mountain,"Internet Sales"))Measures.CustomerCount ON
COLUMNS[Adventure Works]
Функция DistinctCount подсчитывает число
неповторяющихся членов измерения Customer (Клиент), которые соответствуют
клиентам, приобретавшим товары из товарной линии Mountain (Горные). Если клиент
приобретал товар дважды, то функция DistinctCount посчитает этого клиента
только один раз. Функция MDX Exists используется для отбора только тех
клиентов, которые приобретали товары из товарной линии Mountain через Интернет.
Результатом выполнения функции Exists является набор записей о клиентах,
которые приобрели товары из товарной линии Mountain.
2.4 Базовые понятия языка DMX
Наименьшей логической единицей работы с
данными при интеллектуальном анализе является атрибут, который содержит
некоторую "элементарную" информацию об анализируемом примере. Для
алгоритмов Data Mining существует два основных типа атрибутов:
· категориальные
(дискретные), принимающие значения из некоторого фиксированного конечного
набора значений;
· непрерывные числовые
атрибуты.
Дополнительные типы атрибутов основаны на
базовых. К ним, в частности, относятся упорядоченный (или циклический) тип.
Такой атрибут является категориальным, но для него задан определенный порядок
значений (например, размеры одежды).
Дискретизированные атрибуты - это
специальный вариант категориального типа, полученный из непрерывного путем
разбиения на диапазоны. Например, упрощенный алгоритм Байеса не может обрабатывать
непрерывные атрибуты, поэтому потребуется дискретизация.
С каждым категориальным атрибутом связан
набор его значений (или состояний). На этапах подготовки и изучения данных
важно провести анализ множества состояний атрибутов и, при необходимости, внести
коррективы.
Вариант определяется как отдельный пример,
предоставляемый алгоритму интеллектуального анализа данных. Он состоит из
набора атрибутов с соответствующими значениями и во многих случаях описывает
объект или событие. Вариант можно представить строкой в таблице, столбцы
которой - атрибуты.
В то же время, MS SQLServer и DMX позволяют
использовать вложенные таблицы, что позволяет описывать более сложные по
структуре варианты.
Ключ варианта используется для
идентификации варианта. В этом качестве может использоваться исходный ключ
таблицы, из которой берутся данные для анализа. Вложенный ключ позволяет
идентифицировать объект, описываемый во вложенной таблице.
Атрибут может рассматриваться алгоритмом
интеллектуального анализа в качестве входа, выхода или входа и выхода
одновременно. Язык DMX позволяет это указать в процессе описания модели. На
стадии обучения алгоритму предоставляются как входные, так и выходные данные.
На стадии прогнозирования - алгоритм получает входные данные и возвращает выходные.
Анализировать данные можно из реляционных
таблиц и других источников, если они специальным образом описаны в качестве
представления источника данных в службах AnalysisServices. Сначала определяется
источник данных (DataSource), а потом его представление (DataSourceView).
Представление источника данных позволяет сочетать различные источники данных и
работать с вложенными таблицами. Один из способов определить источник данных -
использование соответствующего мастера в среде BI DevStudio.
Службы AnalysisServices считывают данные
из источника в специальный кэш. Помещенные в кэш данные можно сохранить и
использовать при создании других моделей интеллектуального анализа или удалить,
чтобы освободить место в хранилище.
.5 Создание структуры интеллектуального анализа данных
Структура интеллектуального анализа данных
может быть представлена как совокупность исходных данных и описания способов их
обработки. Структура содержит модели, которые используются для анализа ее
данных.
Рассмотрим конструкции языка DMX, позволяющие
создавать структуры.
Для этого используется оператор CREATE
MININGSTRUCTURE. В обобщенном виде его формат представлен ниже:
CREATE [SESSION] MINING STRUCTURE
<structure>
[(<column definition list>)]
)
[WITH HOLDOUT (<holdout-specifier>
[OR <holdout-specifier>])]
[REPEATABLE(<holdout seed>)]
где
<holdout-specifier>::=<holdout-maxpercent>
PERCENT |
<holdout-maxcases> CASES
Приведённые в описании атрибуты имеют следующие
значения:
· Structure - уникальное имя
структуры;
· column definition list -
cписок определений столбцов с разделителями-запятыми;
· holdout-maxpercent - целое
число от 1 до 100, которое показывает процентную долю данных, выделяемых для
проверки;
· holdout-maxcases - целое
число, показывающее максимальное число вариантов, используемых для проверки.
Если указанное значение больше числа входных вариантов, для проверки будут
использованы все варианты и отобразится соответствующее предупреждение. В
случае, если указаны как процентная доля, так и число вариантов, применяется
меньшее из ограничений;
· holdoutseed - целое число,
которое используется как начальное значение при начале секционирования данных.
Если оно равно 0, в качестве начального значения используется хэш
идентификатора структуры интеллектуального анализа данных. Если надо
гарантировать возможность повторного создания такого же разбиения (при условии,
что исходные данные остались прежними), необходимо в скобках указать ненулевое
целое значение.
Необязательное ключевое слово SESSION показывает, что
структура является временной и ее можно использовать только в течение текущего
сеанса работы с SQL Server. После завершения сеанса структура и любые модели на
ее основе удаляются. Чтобы создать временные структуры и модели
интеллектуального анализа данных, необходимо сначала задать свойство базы
данных Allow Session Mining Models. При использовании для анализа инструментов
TableAnalysisTools из надстроек интеллектуального анализа данных для Microsoft
Excel создаются именно такие структуры.
Для определения столбца используется следующий формат:
<column name><data type>
[<Distribution>] [<Modeling Flags>] <Content Type>
[<column relationship>],
где обязательно указываются <columnname> - имя
столбца,
<datatype> - тип данных,
<ContentType> - тип содержимого.
Для определения столбца с вложенной таблицей
используется следующий синтаксис:
<columnname>TABLE ( <column
definition list> )
Флаг Distribution позволяет указать на распределение
для столбца с числовым значением.
Флаги моделирования Modeling Flags можно использовать
для указания дополнительных сведений о соответствующем атрибуте. Алгоритм может
их использовать для создания более точной модели интеллектуального анализа
данных. Некоторые флаги могут быть определены на уровне структуры, другие на
уровне столбца модели интеллектуального анализа.
К любому определению столбца можно добавить
предложение, описывающее связь между двумя столбцами (column relationship).
Делается это с помощью ключевого слова RELATED TO, что показывает иерархию
значений. Назначением столбца RELATED TO может быть ключевой столбец вложенной
таблицы, столбец с дискретными значениями из строки вариантов или какой-либо
другой столбец с предложением RELATED TO, указывающим на более глубокий уровень
иерархии.
.5.1 Создание модели интеллектуального анализа данных
Создание модели интеллектуального анализа данных можно
осуществить одним из следующих способов:
1. после создания структуры интеллектуального
анализа данных можно добавлять в нее модели с помощью инструкции ALTER MINING
STRUCTURE;
2. можно использовать инструкцию CREATE MINING
MODEL, в результате выполнения которой создается модель и автоматически
формируется лежащая в ее основе структура интеллектуального анализа данных. Имя
структуры интеллектуального анализа данных формируется путем добавления
строки"_structure" к имени модели.
Первый способ является более предпочтительным,
особенно когда планируется создать на основе одной структуры несколько моделей
(использующих разные наборы столбцов, алгоритмы и т.д.). Формат оператора представлен ниже.
MINING STRUCTURE
<structure>MINING MODEL <model>
<column definition list>
[(<nested column definition
list>) [WITH FILTER (<nested filter criteria>)]]
)<algorithm> [(<parameter
list>)]
[WITH DRILLTHROUGH]
[,FILTER(<filter criteria>)] ,
Таблица 4. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
structure
|
имя структуры интеллектуального анализа данных, к которой
будет добавлена модель;
|
|
model
|
уникальное имя модели интеллектуального анализа данных;
|
|
column definition list
|
список определений столбцов с разделителями-запятыми;
|
|
nestedcolumn definition list
|
список с разделителями-запятыми столбцов вложенной таблицы,
если применимо;
|
|
nested filter criteria
|
определение фильтра, применяющегося к столбцам вложенной
таблицы;
|
|
algorithm
|
название используемого моделью алгоритма интеллектуального
анализа данных;
|
|
parameter list
|
список параметров алгоритма (через запятую);
|
|
filter criteria
|
определение фильтра, применяющегося к столбцам таблицы
вариантов.
|
Если структура интеллектуального анализа данных содержит
составные ключи, то модель интеллектуального анализа данных должна включать в
себя все ключевые столбцы, определенные в структуре.
Если модели не требуется прогнозируемый столбец
(например, при кластеризации), то в инструкцию не нужно включать определение
столбца.
В общем случае определение столбца выполняется в
соответствии со следующим форматом:
<structure column name> [AS
<model column name>] [<modeling flags>] [<prediction>]
Таблица 5. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
structure column name
|
имя столбца в соответствии с определение структуры;
|
|
model column name
|
псевдоним (необязательный параметр, позволяющий в модели
использовать);
|
|
modeling flags
|
флаги моделирования, о которых говорилось выше: значение
REGRESSOR указывает, что алгоритм регрессии может использовать заданный
столбец в формуле регрессии; значение MODEL_EXISTENCE_ONLY указывает, что
само присутствие атрибута важнее, чем значения столбца атрибута;
|
|
prediction
|
флаг прогнозирования (или флаг использования), указывающий,
что данный столбец содержит прогнозируемую величину. Может принимать значение
PREDICT (столбец является как входом, так и выходом) или PREDICT_ONLY
(столбец является только выходом). Столбец без флага считается входом.
|
Если в определении модели стоит WITH DRILLTHROUGH, то
пользователям разрешается проводить детализацию (т.е. просматривать не только
параметры модели, но и данные вариантов в этой модели).
Определение фильтров позволяет использовать при
обработке модели только варианты, соответствующие условиям фильтрации.
После определения структур и моделей, следующим шагом
является обработка, включающая заполнение структуры интеллектуального анализа
данными. Это делается с помощью инструкции INSERT INTO, формат которой приведен
ниже:
INSERT INTO [MINING MODEL]|[MINING
STRUCTURE] <model>|<structure> (<mapped model columns>)
<source data query>
или
INSERT INTO [MINING MODEL]|[MINING
STRUCTURE] <model>|<structure>.COLUMN_VALUES (<mapped model
columns>) <source data query>
Таблица 6. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
model
|
название модели;
|
|
structure
|
название структуры;
|
|
mapped model columns
|
список через запятую с названиями столбцов, в т.ч.
вложенных таблиц с их столбцами;
|
|
source data query
|
запрос, описывающий загружаемый набор исходных данных.
|
Если в операторе указана структура интеллектуального
анализа данных, обрабатывается эта структура и все связанные с ней модели. Если
задана модель, инструкция обрабатывает только эту модель. Если не указан
аргумент MININGMODEL или MININGSTRUCTURE, службы
AnalysisServices производят поиск типа объекта на основе имени, и затем
обрабатывается корректный объект. Если сервер содержит структуру и модель
интеллектуального анализа данных с одинаковыми именами, возвращается ошибка.
Форма INSERT INTO<объект>.COLUMN_VALUES,
позволяет производить вставку данных непосредственно в столбцы модели без ее
обучения. При использовании этого метода, данные столбцов поставляются модели в
сжатом и упорядоченном виде, что полезно при работе с наборами данных,
содержащими иерархии или упорядоченные столбцы.
Элементы списка <mapped model columns>
представимы в виде:
<column identifier> | SKIP |
<table identifier> (<column identifier> | SKIP)
Таблица 7. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
<columnidentifier>
|
название столбца;
|
|
<tableidentifier>
|
название вложенной таблицы;
|
Ключевое слово SKIP указывает на то, что
соответствующий столбец исходного запроса (исходных данных) не будет
использоваться для заполнения структуры или модели (т.е. пропускается).
.5.2 Листинг
Удалить данные, модель или структуру можно с помощью
оператора DELETE. Его синтаксис приведен ниже:
DELETE FROM [MINING MODEL]
<model>[.CONTENT]FROM [MINING STRUCTURE]
<structure>[.CONTENT]|[.CASES]
Таблица 8. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
model
|
имя модели;
|
|
structure
|
имя структуры.
|
Если не указан аргумент MININGMODEL или
MININGSTRUCTURE, Analysis Services производит поиск типа объекта на основе
имени и затем обрабатывает корректный объект.
Если сервер содержит структуру и модель
интеллектуального анализа данных с одинаковыми именами, возвращается ошибка.
Инструкция DROP позволяет удалить модель или структуру
интеллектуального анализа данных из базы данных. Синтаксис для того и другого
случая соответственно приведен ниже.
DROP MINING MODEL<model>
или
DROP MINING STRUCTURE
<structure>
Таблица 9. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
model
|
имя модели;
|
|
structure
|
имя структуры.
|
Инструкции EXPORT и IMPORT позволяют соответственно
сохранить модель или структуру интеллектуального анализа в файл резервной копии
служб AnalysisServices (*.abf) и восстановить модель или структуру из файла.
Синтаксис команд:
<object type><object
name>[, <object name>] [<object type><object name>[,
<object name] ] TO <filename> [WITH DEPENDENCIES] FROM<filename>
Таблица 10. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
objecttype
|
тип экспортируемого объекта (модель или структура
интеллектуального анализа данных);
|
|
objectname
|
|
filename
|
имя и расположение файла для экспорта (аргумент типа
string, берется в одинарные кавычки).
|
Если инструкция указывает модель интеллектуального
анализа данных, итоговый файл также содержит связанную структуру
интеллектуального анализа данных. Если инструкция указывает WITH DEPENDENCIES,
все объекты, необходимые для обработки объекта (например, источник данных и
представление источника данных), включаются в ABF-файл. Чтобы экспортировать
или импортировать объекты базы данных служб Microsoft SQLServer Службы AnalysisServices,
необходимо иметь права администратора базы данных или сервера.
.5.3 Работа с данными и построение прогнозов
Следующая задача - это работа с данными и построение
прогнозов. Для этого используется оператор SELECT.
При интеллектуальном анализе данных с помощью
оператора SELECT можно решить следующие задачи:
· просмотр вариантов, загруженных в структуру интеллектуального
анализа данных;
· просмотр содержимого существующей модели;
· создание прогнозов по существующей модели;
· создание копии существующей модели.
Для решения первых двух задач используется следующий
формат записи оператора:
SELECT [FLATTENED] [TOP<n>]
<selectlist><model/structure>[.aspect]
[WHERE <condition expression>]
[ORDER BY
<expression>[DESC|ASC]]
Инструкция FLATTENED указывает на необходимость
преобразования, возвращаемых запросом SELECT результатов в "плоский"
набор строк (т.е. преобразование к обычной таблице). Она используется, когда
представление вариантов с вложенными таблицами в используемом по умолчанию иерархическом
формате неприемлемо.
Инструкции
ORDER BY и TOP<n> позволяют упорядочить возвращаемый набор по указанному
параметру и вернуть только первые  значений.
Это может быть полезно в сценариях вроде целевых рассылок, где результаты нужно
отправлять только наиболее вероятным получателям. Для этого можно упорядочить
результаты прогнозирующего запроса целевой рассылки по вероятности, а затем
вернуть только верхние n результатов.
значений.
Это может быть полезно в сценариях вроде целевых рассылок, где результаты нужно
отправлять только наиболее вероятным получателям. Для этого можно упорядочить
результаты прогнозирующего запроса целевой рассылки по вероятности, а затем
вернуть только верхние n результатов.
В
список выбора <selectlist> могут входить ссылки на скалярные столбцы,
прогнозирующие функции и выражения. Доступные параметры зависят от алгоритма и
следующих условий:
· выполняется запрос к структуре или модели интеллектуального
анализа;
· запрос выполняется к содержимому или к вариантам;
· источник данных является реляционной таблицей или кубом;
· делается ли прогнозирование.
Если вместо списка выбора стоит символ «*», то будут
выбраны все столбцы из модели или структуры.
Инструкция WHERE позволяет ограничить перечень возвращаемых
результатов только теми, что соответствуют указанному логическому условию.
Синтаксис будет следующий:
WHERE <condition expression>
2.5.4 Детализация структуры
Рассмотрим инструкцию FROM. Если в ней стоит
<structure>.CASES, где <structure> - имя структуры
интеллектуального анализа, то будут возвращаться варианты, использованные для
создания структуры. Если детализация для структуры не включена, выполнение
данной инструкции завершится сбоем. Но по умолчанию детализация включена. Явное
указание для работы со структурой - с помощью ключевых слов MINING STRUCTURE.
.5.5 Детализация модели
Формат оператора выглядит следующим образом:
SELECT [FLATTENED] [TOP <n>]
<expression list> FROM <model>.CASES
[WHERE <condition
expression>][ORDER BY <expression> [DESC|ASC]]
Если детализация для модели интеллектуального анализа
данных не включена, выполнение данной инструкции завершится ошибкой. Для
расширений интеллектуального анализа данных активировать детализацию можно
только при создании модели (с помощью инструкции WITHDRILLTHROUGH). В среде BI
DevStudio можно добавить детализацию и в существующую модель, но прежде чем
будет можно просматривать варианты, необходимо выполнить повторную обработку
модели.
Если детализация включена как для модели, так и для структуры
интеллектуального анализа данных, пользователи, являющиеся членами роли с
разрешением на детализацию модели и структуры, могут обращаться к столбцам в
структуре интеллектуального анализа данных, которые не включены в модель.
2.5.6 Запрос значений столбца
Ниже приведен синтаксис оператора, позволяющего
получить значения указанных столбцов модели.
SELECT [FLATTENED] DISTINCT [TOP
<n>] <expression list> FROM <model>
[WHERE <condition list>][ORDER
BY <expression>]
При этом для дискретного столбца будут введены все
возможные значения, для непрерывного - среднее значение, для дискретизованного
- среднее значение для каждого из определённых в процессе дискретизации
интервалов.
.5.7 Построение прогнозов
Задача прогнозирования в языке DMX также решается с
помощью оператора SELECT. При этом чаще всего используется конструкция
прогнозирующего соединения - PREDICTION JOIN. С ее помощью шаблонам модели
сопоставляется набор данных из внешнего источника, что позволяет определить
значение для прогнозируемого столбца.
Для обработки модель получает входные данные из
внешнего источника, определяет наиболее соответствующий шаблон и выдает
результат.
Запрос с использованием функции OPENQUERY
В том случае, когда требуется сделать прогноз для
множества вариантов, которые берутся из таблицы базы данных, можно использовать
функцию OPENQUERY. При этом предварительно требуется создать представление
источника данных.
Использование функции Predict
Функция Predict возвращает спрогнозированное значение
или набор значений для заданного столбца. Синтаксис будет следующим:
Predict(<scalar column
reference>, [option1], [option2], [option n], [INCLUDE_NODE_ID], n)
(<table column reference>, [option1], [option2], [option n],
[INCLUDE_NODE_ID], n)
В то же время просто выбор прогнозируемого столбца в
заголовке SELECT аналогичен вызову функции PREDICT с параметрами по умолчанию.
.5.8 Создание копии модели - оператор SELECT INTO
Рассмотрим создание копии существующей модели
интеллектуального анализа данных. Для этого используется синтаксис:
SELECT INTO <new
model><algorithm> [(<parameter list>)] [WITH DRILLTHROUGH[,]
[FILTER(<expression>)]]
FROM <existingmodel>
Таблица 11. Значения приведенных атрибутов
|
Атрибут
|
Описание
|
|
newmodel
|
имя для новой создаваемой модели;
|
|
algorithm
|
название используемого новой моделью алгоритма
интеллектуального анализа данных;
|
|
parameterlist
|
cписок через запятую параметров алгоритма;
|
|
expression
|
выражение, определяющее фильтр для значений, попадающих в
новую модель;
|
|
existingmodel
|
имя существующей модели для копирования.
|
Если существующая модель является обученной, новая
модель автоматически обрабатывается при выполнении этой инструкции. В противном
случае новая модель оставляется необработанной.
2.6 Анализ результатов главы 2
В данной главе описываются языковые средства, с помощью которых будут
реализованы методы и алгоритмы, указанные в первой главе. Для оперативного
анализа данных (OLAP) используется
язык MDX, а для интеллектуального анализа
данных (Data Mining) - DMX.
Оба языка SQL-подобные, но отличия от стандартного
языка для реляционных таблиц присутствуют.
Во второй части рассматриваются основные базовые понятия и выражения для
языков, а также операторы и различные функции, чтобы проще понимать способ
реализации практической части.
В следующей главе (практической части) будет рассмотрена непосредственно
сама реализация поставленных задач в приложении. Будут использоваться выше
написанные языковые конструкции для создания наглядного представления анализа
данных.
В практической части будет использован образец информационных баз
компании Microsoft, который описывает торговую компанию
Adventure Works Cycles. Это производственная компания, производящая и
реализующая металлические и композитные велосипеды для рынков Северной Америки,
Европы и Азии.
3. Использование Microsoft SQL Server для аналитической обработки данных
.1 Постановка задача для экспериментальной части работы
Цель экспериментальной части работы - показать возможные применение
технологий бизнес-аналитики на предприятии.
Решаемые задачи:
1. Формирование источника данных, представление источника данных, в
проекте служб Analysis Services, спроектировать измерения, куб,
создать структуры и модели интеллектуального анализа данных, провести
развертывание проекта и обучение моделей.
. Создание на основе сформированных структур и моделей:
а) классификации клиентов вымышленной компании Adventure Works на основе оценки их доходов - высоко прибыльные
клиенты или нет;
б) кластеризации клиентов;
в) анализа точности предсказания
г) предсказания по продажам определенного товара в заданном регионе;
.2 Описание используемой базы данных
Службы SSAS позволяют анализировать большие
объемы данных. С их помощью можно проектировать, создавать и управлять
многомерными структурами, которые содержат подробные и статистические данные из
нескольких источников данных.
Для управления кубами OLAP и данными интеллектуального анализа и работы с
ними используется среда SQL Server Management Studio. Для создания новых
структур используется среда Business Intelligence Development Studio.
Установка надстроек и процесс развертывания инфраструктуры, что
соответствует первым двум пунктам поставленной экспериментальной задачи,
довольно просты для понимания и выполнения, за счет чего быстро достигается
успешное их выполнение.
Конкретно для моей задачи был установлен Microsoft SQL Server 2008 редакции Enterprise и учебная база данных AdventureWorksDW2008.
Рис. 25. Проверка конфигурации операционной системы на предмет
возможности установки SQL Server
Формировать и проектировать источник данных, представление источника
данных, измерения, структуры и модели будем в среде BI Dev Studio.
Единицей развертывания является весь проект, представляющий собой базу
данных аналитических служб. Для развертывания проекта надо обладать правами
администратора аналитических служб экземпляра SQL Server, на который производится развертывание.
Исходным источником данных, который был создан, является Adventure Works DW.ds, который
указывает на реляционную базу AdventureWorksDW.
Представление источника данных определяется как абстрактное
представление, которое позволяет модифицировать способ рассмотрения источника
данных, либо описать схему и в дальнейшем менять фактический источник данных.
В реляционной базе данных AdventureWorksDW есть представление dbo.vTargetMail, которое позволяет получить
информацию о клиенте (идентификаторы, имя, фамилию, регион и т.д.) и о том,
купил он велосипед или нет. А также есть представление dbo.vDMPrep,
которое описывает категорию и модель продукта, и клиента, который его купил
(регион, возраст, доход и т.д.).
Если в исходной БД открыть в конструкторе представление vTargetMail, то получим следующий код на языке SQL:
SELECT c.[CustomerKey], c.[GeographyKey], c.[CustomerAlternateKey],
c.[Title], c.[FirstName], c.[MiddleName], c.[LastName], c.[NameStyle],
c.[BirthDate], c.[MaritalStatus], c.[Suffix], c.[Gender], c.[EmailAddress],
c.[YearlyIncome], c.[TotalChildren], c.[NumberChildrenAtHome],
c.[EnglishEducation], c.[SpanishEducation], c.[FrenchEducation],
c.[EnglishOccupation], c.[SpanishOccupation], c.[FrenchOccupation],
c.[HouseOwnerFlag], c.[NumberCarsOwned], c.[AddressLine1], c.[AddressLine2],
c.[Phone], c.[DateFirstPurchase], c.[CommuteDistance], x.[Region], x.[Age],
CASE x.[Bikes] WHEN 0 THEN 0 ELSE 1 AS [BikeBuyer][dbo].[DimCustomer] c INNER
JOIN (
[CustomerKey],[Region],[Age],Sum(CASE [EnglishProductCategoryName]
'Bikes' THEN 1 ELSE 0 END) AS [Bikes][dbo].[vDMPrep] BY
[CustomerKey],[Region],[Age]) AS [x] ON c.[CustomerKey] = x.[CustomerKey]
Отсюда видно, что часть информации о клиенте берется из таблицы
dbo.DimCustomer.
Аналогичным образом и для второго представления - dbo.vDMPrep, которое будет использоваться в дальнейшем для
создания структур и моделей.
Следующим шагом является создание структур и моделей.
Для каждой поставленной задачи будет создаваться своя структура и свои
модели. Например, для задачи кластеризации клиентов создана структура vTargetMail_structure2.dmm, которая использует единый для всех поставленных
задач в практической части работы источник данных Adventure Works DW.ds и представление
источника данных TargetMail_dsv2.dsv. Таким образом, имеется один источник данных, 4
представления источника данных, 4 структуры и построенные на их основе модели.
Из контекстного меню можно запустить обработку структуры и всех моделей.
В процессе обработки данные будут загружены в структуру, и пройдет обучение
моделей.
Существуют разные типы обработки объекта:
- Полная обработка (объект полностью обрабатывается, обработка структуры
и всех ее моделей);
- Обработка по умолчанию (сервер выполняет действия, необходимые для
приведения данного объекта в обработанное состояние)
Обработка структуры;
Очистка структуры (кэш структуры будет очищен от исходных данных, но
модели сохранятся в обработанном виде);
Отмена обработки (переводит объект в необработанное состояние).
.3 Задача кластеризации клиентов базы данных AdventureWorks
Пусть необходимо разделить всех клиентов на несколько групп, сходных по
значениям параметров. Подобная задача называется - кластеризацией.
Необходимо создать структуру, основанную на реляционной БД, и модель
интеллектуального анализа данных. Для решения поставленной задачи потребуется
модель, использующая алгоритм кластеризации. Используемое представление источника
данных будет - vTargetMail_dsv.dsv.
В качестве входных атрибутов будем использовать:
· Age (Возраст)
· BikeBuyer (Покупка велосипеда)
· CommuteDistance (Расстояние ежедневных поездок)
· EnglishEducation (Образование)
· Gender (Пол)
· NumberCarOwned (Число имеющихся машин)
· NumberChildrenAtHome (Число детей дома)
· Region (Регион)
· YearlyIncome (Годовой доход)
В результате, получим модель - vTargetMail_Cl.
После обработки структуры и модели, можно увидеть выявленные
характеристики кластеров. Кластер 5 объединяет людей, проживающих только в
Европе, у которых, в среднем, 1 ребенок, и, в основном, нет машины. И именно в
этом кластере почти у всех есть велосипеды.
3.4 Задача классификации клиентов на основе оценки их
доходов
Пусть, используя имеющиеся данные компании Adventure Works, необходимо определить, к какому типу относится
клиент - высоко прибыльный или нет. Это пример задачи классификации, которую
можно решить с помощью прощенного алгоритма Баейса.
Создадим структуру интеллектуального анализа и модель, использующую
алгоритм Байеса. Назовем структуру v DMPrep_structure4.dmm, а модель - v DM Prep_NB2. Представление источника данных будем использовать DMPrep_dsv.dsv, а
источник данных прежний - Adventure Works DW.ds.
Предсказываемый атрибут выберем - IncomeGroup (доход). В нашем случае доход у
клиентов бывает высокий (High),
средний (Moderate) и низкий (Low). Для того, чтобы определить является ли клиент
высоко прибыльным, достаточно только два значения - High и Low.
Далее определяем какие атрибуты оказывают на него влияние - Age и Region.
Таким образом, самым прибыльным районом из всех является Северная
Америка, люди возрастом от 44 до 52 лет. А самым бедным по прибыли является -
Европа, возрастом младше 44 лет. Следовательно, если необходимо определить
каким является определенный клиент (прибыльный для компании или нет), то
достаточно определить его географический район, а для более точного результата
- уточнить его возраст.
3.5 Задача анализа точности предсказания
На основе задачи классификации о том, купит ли клиент велосипед или нет,
с помощью разных алгоритмов, можно узнать точность предсказания. Данную задачу
будем исследовать с помощью алгоритма Байеса, нейронных сетей и деревьев
решений.
Создадим одну структуру, а на ее базе 3 различных модели. Предсказываемый
атрибут будет BikeBuyer.
После того, как структура и модели созданы и обработаны, можно выяснить,
какая модель дает более точный прогноз, используя диаграммы точности.
Предсказания будем выполнять относительно клиента, который купил велосипед.
На диаграмме роста (рис.26) верхняя линия соответсвует идеальной модели,
линия под углом 45 градусов - случайный выбор. В данном случае, примерно 50%
вариантов имеют значение BikeBuyer = 1, то есть клиент, купивший велосипед. Чем
ближе результат к иедальной модели, тем точнее прогноз. Наилучший результат
дает алгоритм деревьев решений.
Более подробно ознакомиться с содержимым модели позволяет средство
просмотра Microsoft Generic Content Tree Viewer. В данном случае, для модели
алгоритма Байеса, в случае отсутсвия у клмента машины - 1889 клиентов купили
велосипед, приблизительно 63%.
Построим прогноз для отдельного варианта - купит ли человек, заполнивший
анкету, велосипед.
Выберем одноэлементный запрос и зададим набор параметров, характеризующих
нового клиента. Целью запроса будет - узнать значение атрибута BikeBuyer. Чтобы
узнать оценку вероятности для выполняемого прогноза, используем функцию
PredicyProbability() с указанием столбца [vTargetMail_DT].[BikeBuyer] в
качетсве аргумента.
Таким образом, предсказываемое значение и оценка вероятности покупки
велосипеда клиентом будет примерно 0,7:

Рис.26. Результаты анализа точности предсказания
Полученный запрос можно представить на языке DMX:
[vTargetMail_DT].[Bike Buyer], PredictProbability([vTargetMail_DT].[Bike
Buyer])
[vTargetMail_DT]PREDICTION JOIN
(SELECT 39 AS [Age], '0-1 Miles' AS [Commute Distance], 'Bachelors' AS
[English Education], 'F' AS [Gender], 1 AS [Number Cars Owned], 2 AS [Number
Children At Home], 'Europe' AS [Region],
AS [Total Children], NULL AS [Yearly Income]) AS t
.6 Задача предсказания по продажам определенного товара в
заданном регионе
Пусть нам необходимо узнать сколько клиентов купило велосипед
определенной модели Mountain-100 в определенном регионе, то есть в Европе.
Для этого необходимо создать новое представление источника данных, так
как на основе предыдущих этот анализ выполнить невозможно. После исследования
имеющихся представлений и таблиц на сервере, можно сделать следующий вывод: для
реализации поставленной задачи необходимо на базе источника данных Adventure
Works DW.ds создать представление источника данных, которое включает в себя
представление dbo.vDMPrep и таблицы DimProduct, DimProductCategory, DimProductSubcategory.
Полученную структуру назовем v DM Prep_structure5.dmm. На базе этой
струтуры будут созданы 3 модели, использующие алгорит Байеса, деревьев решений
и нейронных сетей.
Предсказываемый атрибут будет Amount (количество).
Таком образом, получается, что именно эту модель велосипеда в Европе
купила группа людей с низким доходом, младше 44 лет. За всю историю компании
Adventure Works велосипед Mountain-100 купило приблизительно 221 человек.
Заключение
В поисках возможностей извлечения данных и выделения
из них информации, позволяющей делать прогнозы и принимать меры, компании часто
тратят значительные средства на приобретение больших и сложных приложений
бизнес-аналитики.
Целью выпускной работы бакалавра было исследование математических
моделей, методов и средств бизнес-аналитики СУБД SQL Server.
В ходе решения поставленной цели были решены следующие задачи:
. Рассмотрены теоретические основы различных технологий в
бизнес-аналитике на примере СУБД SQL Server.
. Рассмотрены основные принципы используемых математических
моделей.
. Проведен анализ языковых средств, с помощью которых реализованы
методы и алгоритмы для СУБД SQL Server.
. Разработана практическая задача классификации клиентов по
доходу.
. Проведен анализ точности предсказания по продажам определенных
товаров в заданных регионах.
. Применена задача кластеризации клиентов и предложены
рекомендации по применению полученных результатов.
архитектура server аналитика бизнес
Библиографический список
1. Барсегян А.А. Анализ данных и процессов: учеб.
пособие / А.А. Барсегян, М.С. Куприянов, И.И. Холод, М.Д. Тесс, С.И. Елизаров. ‒
3-е изд., перераб. и доп. ‒ СПб.: БХВ-Петербург, 2009. ‒ 512 с.
. Полубояров В.В. Использование MS SQL Server Analysis
Services 2008 для построения хранилищ данных. [Электронный ресурс] Режим
доступа:
https://www.facultyresourcecenter.com/curriculum/RU/8621-MS-SQL-Server-An.aspx?c1=ru-ru&c2=RU
. Паклин Н.Б., Орешков В.И. Бизнес-аналитика: от
данных к знаниям: учебное пособие. 2-е изд., испр. - СПб.: Питер, 2013. - 704
с.: ил.
. Нестеров С.А. Базы данных. Интеллектуальный анализ
данных: учеб.пособие / С.А.Нестеров - Спб.: Изд-во Политехн. ун-та, 2011. -
272с.
. Семченков С.Ю. Формальное представление структуры
систем аналитической обработки данных, основанных на OLAP-технологии.
[Электронный ресурс] Режим доступа:
http://www.unn.ru/pages/issues/vestnik/99999999_West_2010_6/30.pdf
. Миронов В.В., Макарова Е.С. Агрегация показателей в
OLAP-кубе при сведении по зависимым измерениям. [Электронный ресурс] Режим
доступа: http://journal.ugatu.ac.ru/index.php/vestnik/article/view/85/95
. Олифер В., Олифер Н. Введение в BackOffice 2.5.
[Электронный ресурс] Режим доступа:
http://citforum.ru/ofis/backoffice/index.shtml
. Анализ современной технологии реализации баз данных.
Языки и стандарты. [Электронный ресурс] Режим доступа:
http://www.unn.ru/pages/e-library/publisher_db/files/43/8.pdf
. Торбен Бэч, Кристиан Йенсен. Технология многомерных
баз данных. [Электронный ресурс] Режим доступа:
http://www.olap.ru/basic/multi_dim_DWH.asp
. Планирование и архитектура служб Analysis Services.
[Электронный ресурс] Режим доступа:
http://technet.microsoft.com/ru-ru/library/bb510500(v=sql.100)
. Алексей Федоров, Наталия Елманова. Введение в OLAP,
часть 8. Обзор MDX. [Электронный ресурс] Режим доступа:
http://www.olap.ru/basic/olap_intro8.asp
. Майкл Гандерлой, Джозеф Джорден, Дейвид Чанц. SQL
Server 2005 Analysis Services и MDX для профессионалов. [Электронный ресурс]
Режим доступа: http://www.dialektika.com/PDF/978-5-8459-1316-6/part.pdf
. Алгоритмы интеллектуального анализа данных (службы
Analysis services). [Электронный ресурс] Режим доступа:
http://msdn.microsoft.com/ru-ru/library/ms175312.aspx
. Соловьев С.В., Цой Р.И., Гринкруг Л.С. Технология
разработки прикладного программного обеспечения. [Электронный ресурс] Режим
доступа: http://www.rae.ru/monographs/141-4638