Алгоритми генерації та оцінки стійкості паролів (Delphi)
ДИПЛОМНА РОБОТА
«Алгоритми
генерації та оцінки стійкості паролів»
Вступ
Пароль - це секретне слово або набір символів,
призначений для підтвердження особи або повноважень. Паролі часто
використовуються для захисту інформації від несанкціонованого доступу. У
більшості обчислювальних систем комбінація «ім'я користувача - пароль»
використовується для посвідчення користувача.
Паролі є найбільш поширеним інструментом,
використовуваним для отримання доступу до інформаційних ресурсів. Для користувачів
це один з найзручніших варіантів, який, до того ж, не вимагає наявність
якого-небудь додаткового устаткування або спеціальних навиків.
На жаль, з погляду комп'ютерної безпеки парольну
аутентифікацію далеко не завжди можна назвати вдалим вибором. Як і багато
технічних рішень, вона страждає від двох проблем: людського чинника і технічної
недосконалості.
Людський чинник (помилки користувачів). Багато
людей не можуть (або просто не хочуть, не бачать сенсу) запам'ятовувати стійкі
паролі, оскільки це об'єктивно складно. Тому вони використовують прості,
нестійкі паролі, або, якщо їх все ж таки примушують використовувати стійкі,
записують їх на килимках для мишки, на обороті клавіатури або на стікерах,
приклеєних до монітора.
Технічна недосконалість (помилки розробників), що
найчастіше полягає в помилках, допущених на етапах проектування та/чи
реалізації програмного забезпечення, що здійснює перевірки паролів.
Заслуга конструювання довгих пceвдoвипадкових рядів з
хорошими статистичними властивостями повністю належить криптографії. Для
забезпечення безпеки комп'ютерних систем критично важливо мати алгоритми, що
задовольняють такому критерію як непередбачуваність. Іншими словами, навіть
знаючи алгоритм генератора й всі попередні елементи послідовності, повинне бути
максимально трудомістким обчислення наступних елементів.кpeтні ключі є основою
криптографічних перетворень, для яких, слідуючи правилу Кepкхoфa, стійкість
хорошої шифрувальної системи визначається лише секретністю ключа. Однак, на
практиці створення, розподіл і зберігання ключів рідко були складними технічно,
хоч і дорогими завданнями.
Головна проблема класичної криптографії довгий
час полягала в трудності генерування непередбачуваних двійкових послідовностей
великої довжини із застосуванням короткого випадкового ключа. Для її вирішення
широко використовуються генератори двійкових пceвдoвипадкових послідовностей.
Суттєвий прогрес в розробці і аналізі цих генераторів був досягнутий лише на
початку шістдесятих років.
Метою дипломної роботи є дослідження алгоритмів
генерації та оцінки стійкості паролів. Розроблена система призначена для
генерації криптостійких паролів з використанням двох типів алгоритмів - на
основі псевдовипадкової послідовності та ключової фрази. Також розроблена
система дозволяє визначити вагу стійкості пароля.
Система генерації та оцінки стійкості паролів
була створена за допомогою середовища прискореної розробки програмного
забезпечення Delphi. Система програмування Delphi має широкі можливості по створенню
різноманітного програмного забезпечення, володіє необхідним набором драйверів
для доступу до найвідоміших форматів баз даних, зручними й розвиненими засобами
для доступу до інформації, розташованої як на локальному диску, так і на
вилученому сервері, а також великою колекцією візуальних компонентів для
побудови відображуваних на екрані вікон, що необхідно для створення зручного
інтерфейсу між користувачем і виконавчим кодом.
1. Постановка завдання
.1 Найменування та галузь використання
Найменування розробки: система генерації та оцінки
стійкості паролів.
Розроблена система призначена для генерації
криптостійких паролів з використанням двох типів алгоритмів - на основі
псевдовипадкової послідовності та ключової фрази. Також розроблена система
дозволяє визначити вагу стійкості пароля.
Розроблений в процесі виконання дипломної роботи
програмний продукт може бути застосований в навчальному процесі в якості
ілюстрації особливостей роботи алгоритмів генерації паролів та критеріїв оцінки
їх стійкості при викладанні дисципліни « Захист інформації».
1.2 Підстава для створення
Підставою для розробки є наказ №55С-01 від 1 листопада 2011 р. по Криворізькому
інституту КУЕІТУ.
Початок робіт: 03.11.11. Закінчення робіт:
03.05.12.
1.3 Характеристика розробленого програмного забезпечення
Система генерації та оцінки стійкості паролів
була створена за допомогою середовища прискореної розробки програмного
забезпечення Delphi. При розробці інтерфейсу користувача були використані
компоненти пакету AlphaControls 2010.
Склад розробленої системи:
· password.exe - виконавчий
файл системи;
· my.ini - ini-файл, що містить
інформацію про поточні налаштування системи;
· NextAlpha.asz - skin-файл інтерфейсу
системи;
· help.hlp - файл довідки.
1.4 Мета й призначення
Метою дипломної роботи є дослідження алгоритмів генерації
та оцінки стійкості паролів. В результаті експериментальних досліджень була
розроблена система, яка виконує наступні функції:
. генерація пароля на основі псевдовипадкової
послідовності;
. генерація пароля на основі ключової фрази;
. оцінка стійкості пароля на основі алгоритму
Password Strength Meter.
1.5 Загальні вимоги до розробки
Вимоги до програмного забезпечення:
· робота в середовищі
операційних систем Windows 2000/XP/Vista/7;
· відсутність додаткових
вимог до розміщення здійсненних файлів, простота та зрозумілість інтерфейсу
користувача;
Мінімальні вимоги до апаратного забезпечення:
· IBM-сумісний комп'ютер,
не нижче Pentium IІ, RAM-128Mb, SVGA-800*600*16bit;
· вільний простір на
жорсткому диску не менш 2 Мб;
· монітор, клавіатура,
маніпулятор типу «миша».
1.6 Джерела розробки
Джерелами розробки дипломної роботи є:
· технічне завдання на
реалізацію проекту;
· довідкова література;
· наукова література;
· технічна література;
· програмна документація.
2. Огляд алгоритмів генерації псевдовипадкових послідовностей
.1 Проблема генерації випадкових чисел в історичному аспекті
програмний пароль тестування алгоритм
Протягом багатьох років ті, кому випадкові числа
були необхідні для наукової праці, змушені були тягати кулі з урни, попередньо
добре перемішавши їх, або кидати гральні кості, або розкладати карти. Таблиця,
що містить більше 40 000 узятих навмання випадкових цифр зі звітів про перепис,
була опублікована в 1927 році Л. X. К. Типпеттом.
З тих пор були побудовані механічні генератори випадкових
чисел. Перша така машина була використана в 1939 році М.Ж. Кендаллом і Б.
Бабінгтон-Смітом (В. Babington-Smith) для побудови таблиці, що містить 100 000
випадкових цифр. Комп'ютер Ferranti Mark I, уперше запущений в 1951 році, мав
вбудовану програму, що використовувала резисторний генератор шуму та поставляла
20 випадкових бітів на суматор. Цей метод був запропонований А.М. Тьюрингом. В
1955 році. RAND Corporation опублікувала широко використовувані таблиці, у яких
утримувався мільйон випадкових цифр, отриманих за допомогою інших спеціальних
пристроїв. Відомий генератор випадкових чисел ERNIE застосовувався протягом
багатьох років для визначення виграшних номерів британської лотереї.
Після винаходу комп'ютерів почалися дослідження
ефективного способів одержання випадкових чисел, убудованих програмно в
комп'ютери. Можна було застосовувати таблиці, але користі від цього методу було
мало через обмежену пам'ять комп'ютера й необхідного часу введення, тому
таблиці могли бути лише занадто короткими; крім того, було не дуже приємно
укладати таблиці й користуватися ними.
Генератор ERNIE міг бути убудований у комп'ютер,
як в Ferranti Mark I, але це виявилося незручно, оскільки неможливо точно
відтворити обчислення навітьвідразу по закінченні роботи програми; більше того,
такі генератори часто давали збої, що було вкрай важко виявити.
Технологічний прогрес дозволив повернутися до
використання таблиць в 90-ті роки, тому що мільярди тестованих випадкових
байтів можна було розмістити на компакт-дисках. Дж. Марсалья (George Marsaglia)
допоміг пожвавити табличний метод в 1995 році, підготувавши демонстраційний
диск із 650 Мбайт випадкових чисел, при генеруванні яких запис шуму діодного
ланцюга сполучалася з певним чином скомпонованою музикою в стилі «реп». (Він
назвав це «білим і чорним шумом».)
Недосконалість перших механічних методів спочатку
розбудило інтерес до одержання випадкових чисел за допомогою звичайних
арифметичних операцій, закладених у комп'ютер. Джон фон Нейман (John von
Neumann) першим запропонував такий підхід близько 1940 року. Його ідея полягала
у тому, щоб піднести до квадрата попереднє випадкове число й виділити середні
цифри. Метод середин квадратів фон Неймана фактично є порівняно бідним джерелом
випадкових чисел, однак він послужив відправною точкою наступних досліджень у
цій області.
2.2 Загальні характеристики генераторів псевдовипадкових чисел
ГПВЧ - алгоритм, що генерує послідовність чисел,
елементи якої майже незалежний друг від друга й підкоряються заданому
розподілу.
Якщо вимогливим фахівцям із криптографії АГВЧ
буквально необхідні, то для обчислювальних завдань інженерів і вчених, що
спеціалізуються на рішенні різноманітних задач прикладної математики,
найчастіше подібні технологічні хитрування надлишкові. Тут достатній просто
дуже гарний програмний генератор псевдовипадкових чисел ГПВЧ.
У більшості завдань прикладної математики,
розв'язуваних стохастичними методами, винятково важливим є досить специфічна
властивість «рівномірності розподілу» випадкових чисел, що генерують ГПВЧ.
Специфічне тому, що воно радикально відрізняється від поняття, описуваного тим
же терміном у математичній статистиці. Щоб не було подібної плутанини, термін
«рівномірність розподілу» часто заміняють на «гарну розподіленість» і
підкреслюють, що він ставиться саме до послідовності чисел («добре розподілена
послідовність» або «well distributed sequence»). Як й у випадках з АГВЧ, коли
хоча й неявно, але малося на увазі, що за апаратними засобами ГВЧ стоїть
потужна й складна програмна підтримка, так й в обчислювальних застосуваннях
ГПВЧ навіть над таким майже ідеальним генератором, як Mersenne Twister (Вихор
Мерсенна), для одержання високих показників треба «надбудовувати» програмний
прошарок, що формує з послідовності випадкових чисел добре розподілену
послідовність.
Ніякий детермінований алгоритм не може генерувати
повністю випадкові числа, він може тільки апроксимувати деякі властивості
випадкових чисел.
Будь-який ГПВЧ із обмеженими ресурсами рано або
пізно зациклюється - починає повторювати ту саму послідовність чисел. Довжина
циклів ГПВЧ залежить від самого генератора й у середньому становить близько 2n/2,
де n - розмір внутрішнього стану в бітах, хоча лінійні конгруентні й
LFSR-генератори мають максимальні цикли порядку 2n. Якщо ГПВЧ може
сходитися до занадто коротких циклів, такий ГПВЧ стає передбачуваним й є
непридатним.
Більшість простих арифметичних генераторів хоча й
мають велику швидкість, але страждають від багатьох серйозних недоліків:
· занадто короткий період;
· послідовні значення не є
незалежними;
· деякі біти «менш
випадкові», чим інші;
· нерівномірний одномірний
розподіл;
· зворотність.
Зокрема, алгоритм RANDU, що десятиліттями
використовувався на мейнфреймах, виявився дуже поганим, що викликало сумнів у
вірогідності результатів багатьох досліджень, що використали цей алгоритм.
Різновидом ГПВЧ є ГПВБ - генератори
псевдо-випадкових біт, а так само різних потокових шифрів. ГПВБ, як і потокові
шифри, складаються із внутрішнього стану (звичайно розміром від 16 біт до
декількох мегабайт), функції ініціалізації внутрішнього стану ключем або
насінням (англ. seed), функції відновлення внутрішнього стану й функції виводу.
ГПВБ підрозділяються на прості арифметичні, зламані криптографічні й
криптостойкі. Їхнє загальне призначення - генерація послідовностей чисел, які неможливо
відрізнити від випадкових обчислювальними методами.
Хоча багато які криптостійкі ГПВБ або потокові
шифри пропонують набагато більше «випадкові» числа, такі генератори набагато
повільніше звичайних арифметичних і можуть бути непридатні у всякого роду
дослідженнях, що вимагають, щоб процесор був вільний для більше корисних
обчислень.
У військових цілях й у польових умовах
застосовуються тільки засекречені синхронні криптостойкі ГПВЧ (потокові шифри),
блокові шифри не використаються. Прикладами відомих криптостойких ГПВЧ є RC4,
ISAAC, SEAL, Snow, зовсім повільний теоретичний алгоритм Блюма, Блюма й Шуба, а
так само лічильники із криптографічними кеш-функціями або криптостійкими
блоковими шифрами замість функції виводу.
2.3 Випадкові числа й теорія імовірності
Подія називається випадковою, якщо в результаті
випробування вона може відбутися, а може й не відбутися.
Приклади:
1.
випробування - кидання монети, випадкова подія - випадання герба;
2.
випробування - участь у грі «Російське лото», випадкове подія -
виграш;
3.
випробування - стрибок з парашутом, випадкова подія - удале
приземлення;
4.
випробування - народження дитини, випадкова подія - стать дитини -
чоловіча;
5.
випробування - спостереження за погодою протягом дня, випадкова
подія - протягом дня був дощ.
Як бачимо настання випадкової події в результаті
випробування, загалом кажучи, не можна пророчити заздалегідь у принципі. Цей
факт - непередбачуваність настання - можна в деяких випадках вважати головною
відмітною властивістю випадкової події. Проте, є можливість деякі випадкові
події піддати аналізу методами математики.
Нехай деяке випробування зроблене 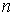 раз й у результаті цього пов'язана з ним
випадкова подія (позначимо її через А) відбулася
раз й у результаті цього пов'язана з ним
випадкова подія (позначимо її через А) відбулася 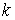 раз. Тоді відносною частотою
раз. Тоді відносною частотою 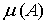 випадкової події А, назвемо
відношення до Іншими словами
випадкової події А, назвемо
відношення до Іншими словами 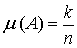 .
.
Для багатьох випадкових подій відносна частота має
властивість стійкості, тобто в різних довгих серіях випробувань відносні
частоти той самої випадкової події мало відрізняються друг від друга. Випадкові
події, відносні частоти яких мають властивість стійкості, називаються
регулярними.
Стійкість відносної частоти була виявлена й багаторазово
підтверджена експериментально натуралістами в 17-19 століттях. Найбільш
вражаючим є результат К. Пирсона, що кидав монету 12000 разів, потім здійснив
ще одну серію кидань - 24000 разів. У цих серіях він підраховував кількість
випадань герба й одержав значення відносної частоти для нього 0,5016 й 0,5005,
що відрізняються друг від друга на 0,0011.
Для випадкових подій, що мають властивість стійкості,
відносну частоту настання події природно вважати ступенем можливості настання
випадкової події.
При використанні відносної частоти як міри можливості
настання випадкової події виникають наступні труднощі. Перша - у різних серіях
випробувань виходять різні значення частоти, незрозуміло яке з отриманих
значень «більш істинно». Друга - відносну частоту можна знайти тільки після
випробувань, причому бажано отримати досить довгу серію, тому що властивість
стійкості проявляється тим виразніше, чим довше серія. Все це разом узяте
змушує шукати способи однозначного визначення міри можливості настання
випадкової події, причому до випробування.
Спочатку визначимо ймовірність регулярної випадкової події
як число, біля якого коливається відносна частота в довгих серіях випробувань.
Потім уведемо поняття рівноможливості, рівноймовірності двох подій. Зміст цього
поняття ясний інтуїтивно, ціль введення - ми хочемо визначити математично
поняття ймовірності зводячи його до більш простого не обумовленого поняття
рівноможливості. Наявність рівноймовірності деяких подій що є результатами
деякого випробування встановлюється з «загальних міркувань», не доводиться
математично й не може бути доведено, не має потреби в доказі як первинне.
Наприклад, при киданні гральної кістки випадання 1, 2, …, 6 очків уважають
подіями рівноймовірності (або «майже» рівноймовірності) виходячи з
передбачуваної фізичної однорідності матеріалу кості й геометричної
правильності, тобто вважаючи кістку ідеальним кубом. Якщо в результаті
випробування можливе настання рівноможливих подій, ніякі дві з яких не можуть наступити
одночасно, то ймовірність кожного із цих подій визначається як 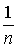 , а самі події називаються елементарними
подіями або елементарними результатами.
, а самі події називаються елементарними
подіями або елементарними результатами.
Якщо, подія А ініціюється одним з 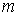 елементарних результатів, а самих
результатів по колишньому , то ймовірність події А
позначувана як
елементарних результатів, а самих
результатів по колишньому , то ймовірність події А
позначувана як 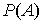 , визначається як відношення к. Інакше:
, визначається як відношення к. Інакше: 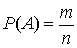 .
.
Це і є формула класичної ймовірності, яку ми будемо надалі
використати в наших дослідженнях.
Зародження теорії ймовірностей і формування перших понять
цієї галузі математики відбулося в середині 17 століття, коли Паскаль, Ферма,
Бернуллі спробували здійснити аналіз завдань, пов'язаних з азартними іграми
новими методами. Незабаром стало ясно, що виникаюча теорія знайде широке коло
застосування для рішення багатьох завдань виникаючих у різних сферах діяльності
людини.
2.4. Алгоритми генерації псевдовипадкових чисел
Метод середини квадрата
Першим алгоритмічний метод одержання рівномірно
розподілених псевдовипадкових чисел запропонував Джон фон Нейман (один з
основоположників кібернетики). Метод одержав назву «метод середини квадрата».
Суть методу: попереднє випадкове число зводиться
у квадрат, а потім з результату витягаються середні цифри.
Наприклад:
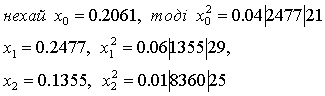 (2.1)
(2.1)
і т.д.
Як видно метод середини квадрата досить добре повинен
«перемішувати» попереднє число. Однак він має недоліки:
· якщо який-небудь член
послідовності виявиться рівним нулю, то всі наступні члени також будуть нулями;
· послідовності мають
тенденцію «зациклюватися», тобто зрештою, утворять цикл, що повторюється
нескінченне число раз.
Властивість «зациклюватися» стосується всіх
послідовностей, побудованих по рекурентній формулі xi+1=f(xi).
Повторюваний цикл називається періодом. Довжина періоду в різних послідовностей
різна. Чим період більше, тим краще.
Метод середин квадратів фон Неймана, як було
показано, фактично є порівняно бідним джерелом випадкових чисел. Небезпека
полягає в тому, що послідовність прагне ввійти у звичну колію, тобто короткий
цикл повторюваних елементів. Наприклад, кожна поява нуля як числа послідовності
приведе до того, що всі наступні числа також будуть нулями.
Деякі вчені експериментували з методом середин
квадратів на початку 50-х років. Працюючи із чотиризначними числами замість
восьмизначних, Дж.Е. Форсайт випробував 16 різних початкових значень і виявив,
що 12 з них приводять до циклічних послідовностей, що закінчуються циклом 6100.
2100, 4100, 8100, 6100…., у той час як два з них приводять до послідовностей,
що вироджується в нульові.
Більш інтенсивні дослідження, головним чином у
двійковій системі числення, провів Н.К. Метрополис. Він показав, що якщо
використати 20-розрядне число, то послідовність випадкових чисел, отримана
методом середин квадратів, вироджується в 13 різних циклів, причому довжина
найбільшого періоду дорівнює 142.
Лінійний конгруентний метод
У цей час найбільш популярними генераторами
випадкових чисел є генератори, у яких використається схема, запропонована Д.Г.
Лехмером в 1949 році - лінійний конгруентний метод.
Виберемо чотири «чарівних числа»:
m, модуль; 0 < m;
а, множник; 0 < a < m;
с, приріст; 0 < з < m;
X0, початкове значення; 0 < X0
< m.
Потім одержимо бажану послідовність випадкових
чисел (Хn), маючи на увазі
n+1 = (а* Xn+ с)
mod m, n > 0. (2.2)
Ця послідовність називається лінійною
конгруентною послідовністю. Одержання залишків по модулю m почасти
нагадує зумовленість, коли кулька попадає в осередок колеса рулетки. Наприклад,
для m = 10 й X0 = а = с = 7 одержимо послідовність:
,6,9,0,7,6,9,0,…. (2.3)
Як показує цей приклад, така послідовність не
може бути «випадковою» при деяких наборах чисел m, а, с і Х0.
У прикладі ілюструється той факт, що конгруентна послідовність завжди утворить
петлі, тобто обов'язково існує цикл, що повторюється нескінченне число раз. Ця
властивість є загальною для всіх послідовностей виду Хn+1 = f(Хn),
де f перетворить кінцеву множину саме в себе.
Цикли, що повторюються, називаються періодами;
довжина періоду послідовності (2.3) дорівнює 4. Безумовно, послідовності, які
ми будемо використати, мають відносно довгий період.
Заслуговує на увагу випадок, коли с = 0,
тому що числа, що генеруються, будуть мати менший період, чим при с ≠
0. Ми переконаємося надалі, що обмеження с = 0 зменшує довжину
періоду послідовності, хоча при цьому усе ще можливо зробити період досить
довгим. В оригінальному методі, запропонованому Д.Г. Лехмером, с
вибиралося рівним нулю, хоча він і допускав випадок, коли с ≠ 0,
як один з можливих. Той факт, що умова с ≠ 0 може приводити до
появи більш довгих періодів, був установлений В.Е. Томсоном (W. Е. Thomson) і
незалежно від нього А. Ротенбергом (А. Rotenberg). Багато авторів називають
лінійну конгруентну послідовність при с = 0 мультиплікативним
конгруентним методом, а при с ≠ 0 - змішаним конгруентним
методом. Для спрощення формул уводимо константу: b = а-1.
Можна відразу відкинути випадок, коли а = 1,
при якому послідовність Хn може бути представлена у вигляді Хn
= (Х0 + с) mod m і поводиться явно не як випадкова
послідовність. Випадок, коли а = 0 навіть гірше. Отже, для практичних
цілей припускаємо, що:
а>2, b>1. (2.4)
Зараз можна узагальнити формулу (2.2):
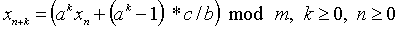 (2.5)
(2.5)
де (n + k) - й член виражається безпосередньо через n-й.
Лінійний конгруентний метод застосовується в простих
випадках і не має криптографічну стійкість. Входить у стандартні бібліотеки
різних компіляторів.
При практичній реалізації лінійного конгруентного методу
вигідно вибирати m = 2e, де e - число біт у машинному
слові, оскільки це дозволяє позбутися відносно повільної операції приведення по
модулю. Машинне слово - машиннозалежна й платформозалежна величина, вимірювана
в бітах або байтах, рівна розрядності регістрів процесора й/або розрядності
шини даних.
У таблиці нижче наведені найбільш часто використовувані
параметри лінійних конгруентних генераторів, зокрема, у стандартних бібліотеках
різних компіляторів.
Таблиця 2.1. Параметри лінійних конгруентних генераторів
|
Компілятор
|
m
|
a
|
c
|
|
Numerical
Recipes
|
232
|
1664525
|
1013904223
|
|
Borland C/C+ +
|
232
|
22695477
|
1
|
|
GNU Compiler
Collection
|
232
|
69069
|
5
|
|
ANSI
C: Open Watcom, Digital Mars, Metrowerks, IBM VisualAge C/C+ +
|
232
|
1103515245
|
12345
|
|
Borland Delphi,
Virtual Pascal
|
232
|
134775813
|
1
|
|
Microsoft
Visual/Quick C/ C+ +
|
232
|
214013
|
2531011
|
|
Apple CarbonLib
|
231
- 1
|
16807
|
0
|
RANDU - сумно відомий
лінійний конгруентний генератор псевдовипадкових чисел, що ввійшов у вживання в
1960-х. Він визначається рекурентним співвідношенням:
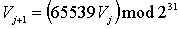 (2.6)
(2.6)
де V0 - непарне.
Псевдовипадкові числа обчислюються в такий
спосіб:
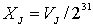 (2.7)
(2.7)
Популярна думка, що даний алгоритм - один з найменш
продуманих генераторів псевдовипадкових чисел серед коли-небудь,
запропонованих. Так, він не проходить спектральний тест при кількості вимірів,
що перевищує 2.
Підставою для вибору параметрів генератора послужило те, що
в рамках цілочисельної 32-бітної машинної арифметики
операції по модулі 231, зокрема, множення довільного числа на 65539
= 216 + 3, виконуються ефективно. У той же час, такий вибір володіє
й принциповим недоліком. Розглянемо наступне вираження (будемо думати, що всі
операції виконуються по модулю 231).
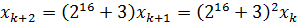 (2.8),
(2.8),
звідки, розкривши квадратичний співмножник, одержуємо:
 (2.9),
(2.9),
що, у свою чергу, показує наявність лінійної залежності (а
отже, і повної кореляції) між трьома сусідніми елементами послідовності:
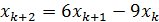 (2.10)
(2.10)
Метод Фібоначчі із запізненням
Особливості розподілу
випадкових чисел, що генеруються лінійним конгруентним алгоритмом,
унеможливлюють їхнє використання в статистичних алгоритмах, що вимагають
високої роздільної здатності.
У зв'язку із цим лінійний
конгруентний алгоритм поступово втратив свою популярність і його місце зайняло
сімейство алгоритмів Фібоначчі, які можуть бути рекомендовані для використання
в алгоритмах, критичних до якості випадкових чисел. В англомовній літературі
датчики Фібоначчі такого типу називають звичайно «Subtract-with-borrow
Generators» (SWBG).
Найбільшу популярність
датчики Фібоначчі одержали у зв'язку з тим, що швидкість виконання арифметичних
операцій з речовинними числами зрівнялася зі швидкістю цілочисельної
арифметики, а датчики Фібоначчі природно реалізуються в речовинній арифметиці.
Один із широко розповсюджених датчиків Фібоначчі
заснований на наступній ітеративній формулі:
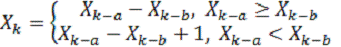 (2.11),
(2.11),
де Xk - речовинні
числа з діапазону (0,1), a, b - цілі позитивні числа, називані лагами.
Для роботи датчику Фібоначчі потрібно знати max {a, b} попередніх
генерованих випадкових чисел. При програмній реалізації для зберігання
генерованих випадкових чисел використається кінцева циклічна черга на базі
масиву. Для старту датчику Фібоначчі потрібно max {a, b} випадкових
чисел, які можуть бути генеровані простим конгруентним датчиком.
Лаги a й b
- «магічні» й їх не слід вибирати довільно. Рекомендуються вибирати наступні
значення лагів: (a, b)=(55,24), (17,5) або (97,33). Якість
одержуваних випадкових чисел залежить від значення константи a. Чим воно
більше, тим вище розмірність простору, у якому зберігається рівномірність
випадкових векторів, утворених з отриманих випадкових чисел. У той же час, зі
збільшенням величини константи a збільшується об'єм використовуваної
алгоритмом пам'яті.
Значення (a, b) =
(17,5) можна рекомендувати для простих додатків, що не використовують
вектори високої розмірності з випадковими компонентами. Значення (a, b) =
(55,24) дозволяють одержувати числа, задовільні для більшості алгоритмів,
вимогливих до якості випадкових чисел. Значення (a, b) = (97,33)
дозволяють одержувати дуже якісні випадкові числа й використаються в
алгоритмах, що працюють із випадковими векторами високої розмірності. Описаний
датчик Фібоначчі випадкових чисел (з лагами 20 й 5) використається в широко
відомій системі Matlab.
Одержувані випадкові числа мають гарні
статистичні властивості, причому всі біти випадкового числа рівнозначні по
статистичних властивостях. Період датчика Фібоначчі може бути оцінений по
наступній формулі:
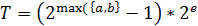 (2.12),
(2.12),
де е - число бітів
у мантисі дійсного числа.
Алгоритм Блюма - Блюма - Шуба
Цей генератор псевдовипадкових чисел був
запропонований в 1986 році Ленор Блюм, Мануелем Блюмом і Майклом Шубом.
Математичне формулювання алгоритму виглядає в
такий спосіб:
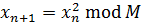 (2.13)
(2.13)
де M = p*q є добутком двох більших простих
p й q. На кожному кроці алгоритму вихідні дані виходять із xn
шляхом узяття або біта парності, або одного або більше найменш значимого біту xn.
Два простих числа, p й q, повинні
бути обоє порівнянні з 3 по модулю 4 (це гарантує, що кожне квадратичне
відхилення має один квадратний корінь, що також є квадратичним відхиленням) і
найбільший загальний дільник НЗД повинен бути малий (це збільшує довжину
циклу):
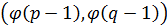 (2.14)
(2.14)
Цікавою особливістю цього алгоритму є те, що для
одержання xn необов'язково обчислювати всі n-1
попередніх чисел, якщо відомо початковий стан генератора x0 і
числа p й q, n-не значення може бути обчислене «прямо»
використовуючи формулу:
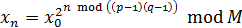 (2.15)
(2.15)
Цей генератор підходить для криптографії, але не
для моделювання, тому що він недостатньо швидкий. Однак, він має надзвичайно
високу стійкість, що забезпечується якістю генератора виходячи з обчислювальної
складності задачі факторизації чисел.
Вихор Мерсенна
Із сучасних ГПВЧ широке поширення одержав вихор
Мерсенна, запропонований в 1997 році Мацумото й Нишимурой. Їхня робота
ґрунтується на властивостях простих чисел Мерсенна (звідси назва) і забезпечує
швидку генерацію високоякісних псевдовипадкових чисел.
Перевагами цього методу є колосальний період
(219937-1), рівномірний розподіл в 623 вимірах (лінійний конгруентний метод дає
більш-менш рівномірний розподіл від сили в 5 вимірах), швидка генерація
випадкових чисел (в 2-3 рази швидше, ніж стандартні ГПВЧ, що використають
лінійний конгруентний метод). Однак існують складні алгоритми, що розпізнають
послідовність, породжувану за допомогою вихрячи Мерсенна як невипадкову. Це
робить вихор Мерсенна невідповідним для використання в криптографії.
Вихор Мерсенна є вітковим регістром зрушення з
узагальненою віддачею (twisted generalised feedback shift register, TGFSR).
«Вихор» - це перетворення, що забезпечує рівномірний розподіл псевдовипадкових
чисел в 623 вимірах. Тому кореляція між послідовними значеннями у вихідній
послідовності алгоритму «Вихор Мерсенна» дуже мала.
Існують ефективні реалізації алгоритму «Вихор
Мерсенна», що перевершують по швидкості багато стандартні ГПВЧ (зокрема, в 2-3
рази швидше лінійних конгруентних генераторів). Вихор Мерсенна реалізований у
бібліотеці gLib і стандартних бібліотеках для PHP, Python і Рубі.
Генеровані алгоритмом «Вихор Мерсенна»
псевдовипадкові числа успішно проходять тести DIEHARD, що говорить про їх гарні
статистичні властивості.
2.5 Статистичні
критерії оцінки якості алгоритмів
Наша основна мета - одержати послідовність, що
поводиться так, начебто вона є випадковою. Вище розповідалося, як зробити період
послідовності настільки довгим, що при практичних застосуваннях він ніколи не
буде повторюватися. Це важливий критерій, але він не дає гарантії, що
послідовність буде використатися в додатках. Як вирішити, чи досить випадковою
буде послідовність?
Якщо дати навмання обраній людині олівець і папір
і попросити її написати 100 десяткових цифр, т о дуже мало шансів, що буде
отриманий задовільний результат. Люди прагнуть уникати дій, що приводять до
результатів, які здаються невипадковими, таким, наприклад, як поява пари рівних
суміжних цифр (хоча приблизно одна з 10 цифр повинна рівнятися попередньої). І,
якщо показати тій же людині таблицю дійсно випадкових чисел, вона. імовірно,
скаже, що ці числа не випадкові. Вона помітить багато гаданих закономірностей.
Теоретична статистика надає деякі кількісні міри
випадковості. Існує буквально нескінченне число критеріїв, які можна
використати для перевірки того, чи буде послідовність випадковою. Обговоримо
критерії, на наш погляд, найбільш корисні, найбільш повчальні й найбільш
пристосовані до обчислень на комп'ютерах.
Якщо критерії 1, 2,…, Тп підтверджують,
що послідовність поводиться випадковим образом, це ще не означає, загалом
кажучи, що перевірка за допомогою Тп+1 - го критерію буде
успішною. Однак кожна успішна перевірка дає усе більше й більше впевненості у
випадковості послідовності. Звичайно до послідовності застосовується біля
напівдюжини статистичних критеріїв, і якщо вона задовольняє цим критеріям, то
послідовність уважається випадковою (це презумпція невинності до доказу
провини).
Кожну послідовність, що буде широко
використатися, необхідно ретельно перевірити. Розрізняються два види критеріїв:
емпіричні критерії, при використанні яких комп'ютер маніпулює групами
чисел послідовності й обчислює певні статистики, і теоретичні критерії,
для яких характеристики послідовності визначаються за допомогою
теоретико-числових методів, заснованих на рекуррентних правилах, які
використовуються для утворення послідовності.
Тести Diehard - це набір статистичних
тестів, заснованих на емпіричних критеріях, які призначені для виміру якості
набору випадкових чисел. Вони були розроблені Джорджем Марсалья (George
Marsaglia) протягом декількох років і вперше опубліковані на CD-ROM,
присвяченому випадковим числам. Разом вони розглядаються як один з найбільш
строгих відомих наборів тестів.
Далі надамо короткий опис тестів, що входять у
набір.
Дні народження (Birthday Spacings) -
вибираються випадкові точки на великому інтервалі. Відстані між крапками
повинні бути асимптотическі розподілені по Пуассону. Назва цей тест одержала на
основі парадокса днів народження.
Парадокс днів народження - твердження, що якщо
дано групу з 23 або більше людин, то ймовірність того, що хоча б у двох з них
дні народження (число й місяць) збіжаться, перевищує 50%. Для групи з 60 або
більше людин імовірність збігу днів народження хоча б у двох її членів
становить більше 99%, хоча 100% вона досягає, тільки коли в групі не менш 366
чоловік (з урахуванням високосних років - 367).
Таке твердження може здатися суперечним здоровому
глузду, тому що ймовірність одному народитися в певний день року досить мала, а
ймовірність того, що двоє народилися в конкретний день - ще менше, але є вірним
відповідно до теорії ймовірностей. Таким чином, воно не є парадоксом у строгому
науковому змісті - логічного протиріччя в ньому ні, а парадокс полягає лише в
розходженнях між інтуїтивним сприйняттям ситуації людиною й результатами
математичного розрахунку.
Розподіл Пуассона моделює випадкову величину, що
представляє собою число подій, що відбулися за фіксований час, за умови, що
дані події відбуваються з деякою фіксованою середньою інтенсивністю й незалежно
друг від друга.
Пересічні перестановки (Overlapping
Permutations) - аналізуються послідовності п'яти послідовних випадкових чисел.
120 можливих перестановок повинні виходити зі статистично еквівалентною
ймовірністю.
Ранги матриць (Ranks of matrices) -
вибираються деяка кількість біт з деякої кількості випадкових чисел для
формування матриці над {0,1}, потім визначається ранг матриці. Підраховуються
ранги.
Ранг матриці - найвищий з порядків мінорів цієї
матриці, відмінних від нуля. Ранг матриці дорівнює найбільшому числу лінійно
незалежних рядків (або стовпців) матриці.
Мавпячі тести (Monkey Tests) -
послідовності деякої кількості біт інтерпретуються як слова. Уважаються
пересічні слова в потоці. Кількість «слів», які не з'являються, повинні
задовольняти відомому розподілу. Назва цей тест одержала на основі теореми про
нескінченну кількість мавп.
Текст теореми про нескінченних мавп звучить (в
одному з багатьох варіантів) так: «Якщо ви посадите нескінченну кількість мавп
друкувати на друкарських машинках, те одна з них обов'язково надрукує
який-небудь твір Вільяма Шекспіра». Існують варіації теореми з обмеженою
кількістю мавп і нескінченним часом, по суті, що є тією же самою теоремою, тому
що на виході виходить нескінченна кількість мавпо-часів.
Якщо перенести дані міркування в доступний для
огляду масштаб, то теорема буде говорити - якщо протягом тривалого часу
випадковим образом стукати по клавіатурі, то серед тексту, що набирає, будуть
виникати осмислені слова, словосполучення й навіть речення.
Ця теорема не пояснює нічого щодо інтелекту
конкретної випадкової мавпи, який пощастить набити правильний текст. Немає
ніякої необхідності в мавпах і друкарських машинках, експеримент може бути
реалізований, наприклад, підключенням генератора випадкових чисел до принтера.
Підрахунок одиничок (Count the 1’s) -
уважаються одиничні біти в кожному з наступний або обраних байт. Ці лічильники
перетвориться в «літери», і вважаються випадки «слів» з п’яти літер.
Тест на паркування (Parking Lot Test) -
випадково розміщаються одиничні окружності у квадраті 100х100. Якщо окружність
перетинає вже існуючу, спробувати ще. Після 12000 спроб, кількість успішно «припаркованих»
окружностей повинне бути нормально розподіленою.
Тест на мінімальну відстань (Minimum
Distance Test) - 8000 крапок випадково розміщаються у квадраті 10000х10000,
потім знаходиться мінімальна відстань між будь-якими парами. Квадрат цієї
відстані повинен бути експоненціально розподілений з деякою медіаною.
Тест випадкових сфер (Random Spheres Test) -
випадково вибираються 4000 точок у кубі з ребром 1000. У кожній точці міститься
сфера, чий радіус є мінімальною відстанню до іншої крапки. Мінімальний об'єм
сфери повинен бути експоненціально розподілений з деякою медіаною.
Тест стиску (The Squeeze Test) - 231
множиться на випадкові дійсні числа в діапазоні (0,1) доти, поки не вийде 1.
Повторюється 100000 разів. Кількість дійсних чисел необхідних для досягнення 1
повинне бути розподілено певним чином.
Тест пересічних сум (Overlapping Sums Test)
- генерується довга послідовність на (0,1). Додаються послідовності з 100
послідовних дійсних чисел. Суми повинні бути нормально розподілені з
характерною медіаною й сигмою.
Тест послідовностей (Runs Test) -
генерується довга послідовність на (0,1). Підраховуються висхідні й спадні
послідовності. Числа повинні задовольняти деякому розподілу.
Тест гри в кістки (The Craps Test) -
грається 200000 ігор у кістки, підраховуються перемоги й кількість кидків у
кожній грі. Кожне число повинне задовольняти деякому розподілу.
3. Дослідження методів тестування та оцінки стійкості паролів
.1 Парольна система як захист від несанкціонованого доступу
Злом пароля є одним з поширених типів атак на
інформаційні системи, що використовують аутентифікацію по паролю або парі «ім'я
користувача-пароль». Суть атаки зводиться до заволодіння зловмисником паролем
користувача, що має право входити в систему.
Привабливість атаки для зловмисника полягає в
тому, що при успішному отриманні пароля він гарантовано отримує всі права
користувача, обліковий запис якого був скомпрометований, а крім того вхід під
існуючим обліковим записом звичайно викликає менше підозр у системних
адміністраторів.
Технічно атака може бути реалізована двома
способами: багатократними спробами прямої аутентифікації в системі, або
аналізом хешей паролів, одержаних іншим способом, наприклад перехопленням
трафіку.
При цьому можуть бути використані наступні
підходи.
. Прямий перебір. Перебір всіх можливих поєднань
допустимих в паролі символів.
. Підбір по словнику. Метод заснований на
припущенні, що в паролі використовуються існуючі слова якої-небудь мови або їх
поєднання.
. Метод соціальної інженерії. Заснований на
припущенні, що користувач використовував в якості пароль особисті відомості,
такі як його ім'я або прізвище, дата народження і т. п.
Парольна система як невід'ємна складова
підсистеми управління доступом системи захисту інформації (СЗІ) є частиною
«переднього краю оборони» всієї системи безпеки. Тому парольна система стає
одним з перших об'єктів атаки при вторгненні зловмисника в захищену систему.
Підсистема управління доступом СЗІ має на увазі
наступні поняття.
Ідентифікатор доступу - унікальна ознака
суб'єкта або об'єкту доступу.
Ідентифікація - привласнення суб'єктам
і об'єктам доступу ідентифікатора і (або) порівняння ідентифікатора, що
пред'являється, з переліком привласнених ідентифікаторів.
Пароль - ідентифікатор суб'єкта доступу, який є
його (суб'єкта) секретом.
Аутентифікація - перевірка
приналежності суб'єкту доступу пред'явленого їм ідентифікатора; підтвердження
достовірності.
Можна також зустріти і такі тлумачення термінів
ідентифікатор і пароль користувача.
Ідентифікатор - деяка унікальна
кількість інформації, що дозволяє розрізняти індивідуальних користувачів
парольної системи (проводити їх ідентифікацію). Часто ідентифікатор також
називають ім'ям користувача або ім'ям облікового запису користувача.
Пароль - деяка секретна кількість інформації,
відома тільки користувачу і парольній системі, що пред'являється для
проходження процедури аутентифікації.
Обліковий запис - сукупність
ідентифікатора і пароля користувача.
Одним з найбільш важливих компонентів парольної
системи є база даних облікових записів (база даних системи захисту). Можливі
наступні варіанти зберігання паролів в системі:
· у відкритому вигляді;
· у вигляді хэш-значень
(hash (англ.) - суміш, мішанина);
· зашифрованими на деякому
ключі.
Найбільший інтерес представляють другий і третій
способи, які мають ряд особливостей.
Хешування не забезпечує захист від підбору
паролів по словнику у разі отримання бази даних зловмисником. При виборі
алгоритму хешування, який буде використаний для обчислення хеш-значень паролів,
необхідно гарантувати неспівпадання хеш-значень, одержаних на основі різних
паролів користувачів.
Крім того, слід передбачити механізм, що
забезпечує унікальність хеш-значень в тому випадку, якщо два користувачі
вибирають однакові паролі. Для цього при обчисленні кожного хеш-значення звичайно
використовують деяку кількість «випадкової» інформації, наприклад, видаваної
генератором псевдови-падкових чисел.
При шифруванні паролів особливе значення має
спосіб генерації і зберігання ключа шифрування бази даних облікових записів.
Можливі наступні варіанти:
· ключ генерується
програмно і зберігається в системі, забезпечуючи можливість її автоматичного
перезавантаження;
· ключ генерується
програмно і зберігається на зовнішньому носії, з якого прочитується при кожному
запуску;
· ключ генерується на основі
вибраного адміністратором пароля, який вводиться в систему при кожному запуску.
Найбільш безпечне зберігання паролів
забезпечується при їх хешуванні і подальшому шифруванні одержаних хеш-значень,
тобто при комбінації другого і третього способів зберігання паролів в системі.
Як пароль може потрапити до рук зловмисника?
Найбільш реальними виглядають наступні випадки:
· записаний нами пароль був
знайдений зловмисником;
· пароль був підглянений
зловмисником при введенні легальним користувачем;
· зловмисник дістав доступ
до бази даних системи захисту.
Заходи протидії першим двом небезпекам очевидні.
В останньому випадку зловмиснику буде потрібно
спеціалізоване програмне забезпечення, оскільки, записи в такому файлі украй
рідко зберігаються у відкритому вигляді. Стійкість парольної системи
визначається її здатністю протистояти атаці зловмисника, що оволодів базою
даних облікових записів і що намагається відновити паролі, і залежить від
швидкості «максимально швидкої» реалізації використовуваного алгоритму хешування.
Відновлення паролів полягає в обчисленні хеш-значень по можливих паролях і
порівнянні їх з наявними хеш-значеннями паролів з подальшим їх уявленням в
явному вигляді з урахуванням регістра.
З бази даних облікових записів пароль може бути
відновлений різними способами: атакою по словнику, послідовним (повним)
перебором і гібридом атаки по словнику і послідовного перебору.
При атаці по словнику послідовно обчислюються
хеш-значення для кожного із слів словника або модифікацій слів словника і
порівнюються з хеш-значеннями паролів кожного з користувачів. При збігу
хеш-значень пароль знайдений. Перевага методу - його висока швидкість.
Недоліком є те, що таким чином можуть бути знайдені тільки дуже прості паролі,
які є в словнику або є модифікаціями слів словника. Успіх реалізації даної
атаки безпосередньо залежить від якості і об'єму використовуваного словника
(нескладно відшукати подібні готові словники в Інтернеті).
Послідовний перебір всіх можливих комбінацій
(brute force (англ.) - груба сила, рішення «в лоб») використовує набір символів
і обчислює хеш-значення для кожного можливого пароля, складеного з цих
символів. При використанні цього методу пароль завжди буде визначений, якщо
складові його символи присутні у вибраному наборі. Єдиний недолік цього методу
- велика кількість часу, який може знадобитися на визначення пароля. Чим більша
кількість символів (букв різного регістра, цифр, спецсимволів) міститься у
вибраному наборі, тим більше часу може пройти, поки перебір комбінацій не
закінчиться.
При відновленні паролів гібридної атаки по
словнику і послідовного перебору до кожного слова або модифікації слова
словника додаються символи справа та/або зліва (123parol). Крім цього
може здійснюватися перевірка використання: імен користувачів як паролів;
повторення слів (dogdog); зворотного порядку символів слова (elpoep);
транслітерації букв (parol); заміну букв кирилиці латинською розкладкою
(gfhjkm).
Для кожної комбінації, що вийшла, обчислюється
хеш-значення, яке порівнюється з хеш-значеннями паролів кожного з користувачів.
Який пароль можна однозначно назвати слабким в
усіх відношеннях (за винятком можливості запам’ятати)? Типовий приклад: пароль
з невеликої кількості (до 5) символів/цифр. За деякими даними, з 967 паролів
одного із зламаних поштових серверів мережі Інтернет 335 (майже третина)
складалася виключно з цифр.
Кількість паролів, що включають букви і цифри
виявилося рівним 20. Решта паролів складалася з букв в основному в нижньому
регістрі за рідкісним виключенням (в кількості 2 паролів) тих, що включають
спецсимволи («*», «_»). Символ «_», проте, часто зустрічався в іменах
користувачів. У 33 випадках ім'я і пароль користувача співпадали.
Найпопулярнішим виявився пароль 123 (зустрічався 35 разів, майже кожен 27
пароль). На другому місці пароль qwerty (20 паролів). Далі слідують: 777 (18
разів), 12 (17 разів), hacker (14 разів) і 1, 11111111, 9128 (по 10 разів). 16
паролів складалися з одного символу / цифри.
Підвищення вимог до пароля виникає із-за ступеня
його важливості. Прикладом «важливого пароля» служить пароль, вживаний для
роботи в автоматизованих системах, що обробляють інформацію обмеженого доступу
(державна таємниця, конфіденційна інформація).
3.2 Ентропія як міра стійкості паролів
Мірою стійкості паролів традиційно є ентропія - міра
невизначеності, вимірювана звичайно в бітах. Ентропія в 1 біт відповідає
невизначеності вибору з двох паролів, в 2 біта - з 4 паролів, в 3 біта - з 8
паролів і т.д. Ентропія в N біт відповідає невизначеності вибору з 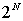
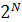 паролів. У разі використання випадкових паролів (наприклад,
випадкових чисел, що згенеровані за допомогою генератора) ентропія обчислюється
досить просто: вона залежить від кількості можливих паролів для заданих
параметрів. Так, для випадкового пароля завдовжки N символів, складеного
з алфавіту, що містить M букв, ентропія буде рівна:
паролів. У разі використання випадкових паролів (наприклад,
випадкових чисел, що згенеровані за допомогою генератора) ентропія обчислюється
досить просто: вона залежить від кількості можливих паролів для заданих
параметрів. Так, для випадкового пароля завдовжки N символів, складеного
з алфавіту, що містить M букв, ентропія буде рівна:
 (3.1)
(3.1)
Значення ентропії для деяких довжин паролів і
наборів символів представлені в таблиці 3.1.
Якщо ж пароль був згенерований не неупередженим
генератором випадкових чисел, а людиною, то обчислити його ентропію набагато
важче. Найпоширенішим підходом до підрахунку ентропії в цьому випадку є підхід,
який був запропонований американським інститутом NIST:
· ентропія першого символу
пароля складає 4 біта;
· ентропія наступних семи
символів пароля складає 2 біта на символ;
· ентропія символів з 9-го
по 20-го складає 1,5 біта на символ;
· всі подальші символи
мають ентропію 1 біт на символ;
· якщо пароль містить
символи верхнього регістра і неалфавітні символи, то його ентропія збільшується
на 6 біт.
Таблиця 3.1. Значення ентропії для деяких довжин
паролів
|
Довжина
пароля
|
Цифри
(10) (1)
|
Латинські
букви без урахування регістра (26)
|
Цифри і
латинські букви без урахування регістра (36)
|
Латинські
букви з урахуванням регістра (52)
|
Цифри і
латинські букви з урахуванням регістра (62)
|
Цифри,
латинські букви і спеціальні символи (96)
|
|
6
|
19,9
|
28,2
|
31,0
|
34,2
|
35,7
|
39,5
|
|
7
|
23,3
|
32,9
|
36,2
|
39,9
|
41,7
|
46,1
|
|
8
|
26,6
|
37,6
|
41,4
|
45,6
|
47,6
|
52,7
|
|
9
|
29,9
|
42,3
|
46,5
|
51,3
|
53,6
|
59,3
|
|
10
|
33,2
|
47,0
|
51,7
|
57,0
|
59,5
|
65,8
|
|
11
|
36,5
|
51,7
|
56,9
|
62,7
|
65,5
|
72,4
|
|
12
|
39,9
|
56,4
|
62,0
|
68,4
|
71,5
|
79,0
|
Стійкість того або іншого пароля повинна
розглядатися тільки в контексті конкретної системи парольної аутентифікації:
пароль, що є стійким для однієї системи, може виявитися абсолютно не стійким
при використанні іншої. Це відбувається через те, що різні системи різною мірою
реалізують (або зовсім не реалізують) механізми протидії атакам, направленим на
злом паролів, а також тому, що деякі системи містять помилки або використовують
ненадійні алгоритми.
Основний спосіб протидії злому паролів - штучно
уповільнити процедуру їх перевірки. Дійсно, чи займе перевірка 10 наносекунд
або 10 мілісекунд - для користувача різниця буде непомітною, а з погляду злому
швидкість впаде дуже істотно - з 100 мільйонів до 100 паролів в секунду.
Уповільнення звичайно досягається за рахунок багатократного обчислення
криптографічних функцій, причому ці обчислення побудовані так, щоб атакуюча сторона
не могла перевірити пароль без повторення обчислень (тобто недостатньо просто
додати виклик Sleep в процедурі перевірки пароля). Вперше такий варіант був
запропонований в 1997 році в роботі «Secure Applications of Low-Entropy Keys».
Системи, що реалізовують подібні уповільнення, збільшують
ефективну ентропію пароля на величину 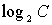 , де C - кількість ітерацій при обчисленні
кри-птографічного перетворення. Приклади подібних систем приведені в таблиці
3.2.
, де C - кількість ітерацій при обчисленні
кри-птографічного перетворення. Приклади подібних систем приведені в таблиці
3.2.
Таблиця 3.2. Системи, що збільшують ефективну ентропію
пароля
|
Де
застосовується
|
Кількість
ітерацій, алгоритм
|
Зміни
ефективної ентропії пароля
|
|
WPA
|
4x4096
SHA-1 (PBKDF2)
|
+14 біт
|
|
MS
Office 2007
|
50 000
SHA-1
|
+15,6
біт
|
|
WinRAR
3.0+
|
~100
000 SHA-1
|
+16,6
бит
|
|
PGP
9.0+
|
2x1024
SHA-1
|
+11 біт
|
|
Adobe
Acrobat 5.0 - 8.0
|
50 MD5
+ 20 RC4
|
+6,1
біт
|
Як було сказано вище, системи можуть містити
помилки, що знижують їх стійкість. Наприклад, для шифрування даних може
використовуватися алгоритм з ключем недостатньої довжини або сама процедура
перетворення пароля може бути ненадійною. Так, всі версії Microsoft Word і
Excel, починаючи з 97 і до 2003 включно, для шифрування документів за
умовчанням використовують потоковий алгоритм RC4 з довжиною ключа 40 біт.
Стійкість системи визначається стійкістю
найслабкішої ланки, тому якщо відомо, що для шифрування використовується
40-бітовий ключ, немає ніякого сенсу використовувати пароль з більшою
ентропією. Інший, що став вже класичним, приклад - алгоритм перевірки паролів в
операційній системі Windows NT/2000/XP/2003. Ці системи підтримують два
алгоритми - LM і NTLM. При створенні користувача або зміні його пароля ці
системи обчислюють LM- і NTLM-хеші пароля і зберігають його в базі даних
облікових записів.
Алгоритм обчислення LM-хеша виглядає таким чином:
· символи пароля
приводяться до верхнього регістра і перетворяться в OEM-кодування;
· якщо пароль коротше 14
символів, він доповнюється пропусками до цієї величини;
· одержана послідовність з
14 символів ділиться на дві частини по 7 символів;
· одержані в результаті
шифрування блоки об'єднуються - це і є LM-хеш пароля.
3.3 Засоби злому паролів
Проблему безпеки комп'ютерних мереж надуманою не
назвеш. Практика показує: чим більше мережа і чим цінніша інформація
довіряється підключеним до неї комп'ютерам, тим більше знаходиться охочих
порушити її нормальне функціонування ради матеріальної вигоди або просто з
цікавості. Йде постійна віртуальна війна, в ході якої організованості системних
адміністраторів протистоїть винахідливість комп'ютерних зломщиків.
Основним захисним рубежем проти зловмисних атак в
комп'ютерній мережі є система парольного захисту, який є у всіх сучасних
програмних продуктах. Відповідно до сталої практики, перед початком сеансу
роботи з операційною системою користувач зобов'язаний реєструватися,
повідомивши їй своє ім'я і пароль. Ім'я потрібне для ідентифікації користувача,
а пароль служить підтвердженням правильності проведеної ідентифікації.
Інформація, введена користувачем в діалоговому режимі, порівнюється з тією, що
є у розпорядженні операційної системи. Якщо перевірка дає позитивний результат,
то користувачу стають доступні всі ресурси операційної системи, пов'язані з його
ім'ям.
Найбільш ефективним є метод злому парольного
захисту операційної системи (надалі - ОС), при якому атаці піддається системний
файл, що містить інформацію про легальних користувачів і їх паролі. Проте
будь-яка сучасна ОС надійно захищає призначені для користувача паролі, які
зберігаються в цьому файлі, за допомогою шифрування. Крім того, доступ до таких
файлів, як правило, за умовчанням заборонений навіть для системних
адміністраторів, не говорячи вже про рядових користувачів операційної системи.
Проте, у ряді випадків зловмиснику вдається шляхом різних хитрувань одержати в
своє розпорядження файл з іменами користувачів і їх зашифрованими паролями. І
тоді йому на допомогу приходять так звані парольні зломщики - спеціалізовані
програми, які служать для злому паролів операційних систем.
Криптографічні алгоритми, вживані для шифрування
паролів користувачів в сучасних ОС, використовують необоротне шифрування, що
робить неможливим ефективніший алгоритм злому, чим тривіальний перебір можливих
варіантів. Тому парольні зломщики іноді просто шифрують всі паролі з
використанням того ж самого криптографічного алгоритму, який застосовується для
їх засекречування в ОС, що атакується. Потім вони порівнюють результати
шифрування з тим, що записане в системному файлі, де знаходяться шифровані
паролі користувачів цієї системи. При цьому як варіанти паролів парольні
зломщики використовують символьні послідовності, що автоматично генеруються з
деякого набору символів. Даний спосіб дозволяє зламати всі паролі, якщо відоме
їх уявлення в зашифрованому вигляді, і вони містять тільки символи з даного
набору.
За рахунок дуже великого числа комбінацій, що
перебираються, яке росте експоненціально із збільшенням числа символів в
початковому наборі, такі атаки парольного захисту ОС можуть віднімати дуже
багато часу. Проте добре відомо, що більшість користувачів операційних систем
особливо не утрудняють себе вибором стійких паролів, тобто таких, які важко
зламати. Тому для ефективнішого підбору паролів зломщики звичайно використовують
спеціальні словники, які є наперед сформованим списком слів, найбільш часто
використовуваних на практиці як паролі.
До кожного слова із словника парольний зломщик
застосовує одне або декілька правил, відповідно до яких воно видозмінюється і
породжує додаткову безліч видозмінених паролів:
· проводиться зміна
буквеного регістра, в якому набране слово;
· порядок проходження букв
в слові міняється на зворотний;
· у початок і в кінець
кожного слова приписується цифра 1;
· деякі букви змінюються на
близькі по зображенню цифри (в результаті, наприклад, із слова password можна
одержати pa55w0rd).
Це підвищує вірогідність знаходження пароля,
оскільки в сучасних ОС, як правило, розрізняються паролі, набрані заголовними і
рядковими буквами, а користувачам цих систем настійно рекомендується вибирати
такі, в яких букви чергуються з цифрами.
Одні парольні зломщики по черзі перевіряють кожне
слово із спеціального словника, застосовуючи до нього певний набір правил для
генерації додаткової безлічі видозмінених паролів.
Інші заздалегідь обробляють весь словник за
допомогою цих же правил, одержуючи новий словник більшого розміру, з якого
потім черпають паролі, що перевіряються. Враховуючи, що звичайні словники
природних людських мов складаються всього з декількох сотень тисяч слів, а
швидкість шифрування паролів достатньо висока, парольні зломщики, що здійснюють
пошук по словнику, працюють достатньо швидко (до однієї хвилини).
Люди використовують деякі слова як паролі частіше
за інших. Частотні словники перераховують найбільш популярні слова. Хороші
словники містять сотні тисячі слів. Хороший частотний словник містить назви
корпорацій, заголовків кінофільмів, торгові марки і т.д. Злом за допомогою
словника звичайно відбувається дуже швидко, навіть якщо використовується
величезний словник.
Атака «в лоб» (пошук всіх можливих паролів) не
підходить для довгих паролів, тому що потрібно дуже багато часу. Головним чином
є комбінації подібно до jkqmzwd, які є повністю безглуздими серед мільярдів і
квінтильйонів шуканих паролів. Посилена «атака в лоб» - оптимізований алгоритм
дослідження, який тільки пробує «розумні» паролі. В результаті час злому
скорочується.
Швидкість перебору може сильно розрізнятися для
різних випадків. Наприклад у випадку якщо швидкість перебору 1,000 паролів в
секунду час в таблиці треба помножити на 10,000. Якщо швидкість перебору 15
млн. паролів в секунду, вказаний час потрібно поділити на 1.5. На щастя
швидкості перебору в 100 млн. паролів в секунду на сьогоднішньому устаткуванні
не зустрічаються. Отже скорочення максимального часу знаходження пароля на
порядок від вказаного в таблиці вже неможливо.
«На щастя», тому що все-таки парольні системи
покликані захищати. Такий великий час злому буде нам дуже не на щастя якщо ми
забудемо пароль до власних даних.
Якщо зловмисник не може припустити довжину вашого
пароля і вимушений буде перебирати всі варіанти паролів завдовжки скажемо від 5
до 8 символів, то час такого повного перебору очевидно може бути оцінений як
сума часів перебору 5-ти, 6-ти, 7-ми, і 8-ми символьних паролів.
В результаті проведеного аналізу встановлений
максимальний час злому паролів. Швидкість перебору паролів 106000 паролів в
секунду (Pentium III/550).
Таблиця 3.3. Загальна оцінка часу, необхідного
для злому методом «грубої сили»
|
Довжина
паролю
|
Довжина
набору 26 (тільки літери)
|
36
(літери та цифри)
|
70 (всі
друковані символи)
|
Російські
літери
|
|
4
|
Негайно
|
Негайно
|
3
хвилини
|
Негайно
|
|
5
|
1
хвилина 48 секунд
|
9
хвилин
|
3
години
|
5
хвилин
|
|
6
|
50
хвилин
|
5 годин
48 хвилин
|
10 днів
17 годин
|
2
години 53 хвилини
|
|
7
|
22 години
|
8 днів
17 годин
|
2 роки
3 дні
|
26
годин
|
|
8
|
24 дні
|
314
днів 17 годин
|
138
років
|
123 дні
12 годин
|
|
9
|
1 рік
248 днів
|
30
років
|
9363
роки
|
10
років
|
Підрахунок часу злому здійснювався програмою
PwlTool.
3.4 Огляд деяких алгоритмів оцінки стійкості пароля
Аналізатор
паролів SeaMonkey
Цей аналізатор паролів розроблений як частина
проекту - вільного набору програм для роботи в Internet, створеного і
підтримуваного організацією Seamonkey Council, що виділилася з Mozilla
Foundation. Сам механізм аналізу пароля є частиною JavaScript бібліотеки при
роботі з паролями. Алгоритм його роботи полягає в обчисленні ваги пароля, що
ґрунтується на даних про символи, з яких цей пароль складений. Вага пароля
обчислюється за наступною формулою:
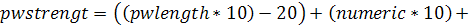
 (3.2)
(3.2)
де:
· pwlength рівне 5, якщо
кількість символів в паролі більше 5, або рівно довжині пароля;
· numeric рівне 3, якщо
кількість цифр в паролі більше 3, інакше - рівно кількості цифр;
· numsymbols вважається рівним
3, якщо число символів в паролі, відмінних від букв, цифр і знаків
підкреслення, більше 3, інакше - кількості таких символів;
· upper рівне 3, якщо
кількість букв у верхньому регістрі більше 3, або кількості заголовних букв в
іншому випадку.
Після обчислення вага пароля нормується так, щоб
його значення полягало в інтервалі від 0 до 100. Нормування проводиться у тому
випадку, коли значення ваги не потрапляє в цей діапазон. У разі, коли pwstrength
менше 0, значення pwstrength прирівнюють до нуля, а коли більше 0,
значення ваги встановлюють рівним 100. Ранжирування ж пароля по ступеню
стійкості залишене на розсуд розробників.
Описаний аналізатор не використовує ніяких
перевірок з використанням словників, що робить його оцінки дещо однобокими, і,
ймовірно, менш точними.
Password Strength Meter (jQuery plugin)
Ще одним варіантом оцінювача пароля, що працює на
клієнтській стороні, є Password Strength Meter - плагін, розроблений для
JavaScript фреймворку jQuery.
Процедура оцінки працює таким чином. Відома
безліч якостей, володіючи якими пароль збільшує або зменшує свою стійкість до
підбору. Кожне така якість має свою строго певну вагу. Алгоритм полягає в
поетапній перевірці наявності у пароля цих якостей і, у разі їх присутності
відбувається збільшення сумарної ваги пароля, по величині якого після
проглядання всіх характеристик робиться висновок про рівень стійкості пароля.
Розглянемо повний алгоритм процедури оцінки
пароля:
1. Вага пароля встановлюється рівною нулю.
2. Якщо довжина пароля менше 4 символів, то
робота алгоритму закінчується і повертається результат «дуже короткий пароль».
Інакше переходимо до кроку 3.
3. Вагу пароля збільшуємо на величину 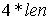
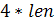 - довжину пароля.
- довжину пароля.
. Здійснюється спроба стиснення пароля по наступному
алгоритму. Якщо в паролі зустрічається підрядок виду SS, де S -
рядок довжини 1, то перша частина цього підрядка видаляється і стиснення
продовжується з позиції початку другій частині цього підрядка. Наприклад,
застосовуючи цей алгоритм до рядка aaabbcab, на виході одержимо рядок abcab.
Після виконання операції стиснення вага пароля зменшується на величину len - lenCompress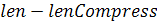 - довжину пароля після стиснення.
- довжину пароля після стиснення.
. Проводяться спроби стиснення пароля для випадків
рядків S довжиною 2, 3 і 4 символів. Вага пароля зменшується аналогічно
на величину len - lenCompress.
Відзначимо, що стиснення кожного разу проводиться
на паролі, що перевіряється, а не рядках, одержаних на попередніх спробах.
6. Якщо пароль містить не менше 3 цифр, то
збільшити вагу на 5.
7. Якщо пароль містить не менше 2 знаків,
то збільшити вагу на 5.
. Якщо пароль містить букви, як у
верхньому, так і в нижньому регістрах, то збільшити вагу пароля на 10.
. Якщо пароль містить букви і цифри, то
збільшити вагу пароля на 15.
10. Якщо пароль містить знаки і цифри, то
збільшити вагу на 15.
11. Якщо пароль містить букви і знаки, то
збільшити вагу на 15.
. Якщо пароль складається тільки з букв
або тільки з цифр, то зменшити вагу пароля на 10.
. Якщо вага пароля менше 0, то встановити
його рівним 0. Якщо більше 100, то встановити рівним 100.
. Пароль, вага якого менше 34, визнається
«слабким». Якщо вага від 34 до 67, то пароль відноситься до категорії «добрий»,
а якщо більше 67, то пароль вважається «відмінним».
Cornell University - Password Strength Checker
Офіційний алгоритм, що надається центром безпеки
Корнельського університету (Ітака, США). З його допомогою користувачі можуть
перевірити свій пароль, заповнивши web-форму і відправивши його на перевірку.
Оцінка пароля, як і у випадку з сервісом Google, проводиться на стороні
сервера.
Реалізація алгоритму не розкрита для загального
доступу, проте в описі сервісу вказані вимоги, яким повинен задовольняти
пароль, щоб перевірка пройшла успішно:
1. Пароль повинен мати довжину не менше 8
символів.
2. При складанні пароля використовуються
символи, принаймні, трьох алфавітів з наступного списку:
· заголовні латинські
букви;
· рядкові латинські букви;
· цифри;
· спеціальні знаки (такі
як! * (): |);
3. Пароль не повинен містити слів із словника.
4. Пароль не повинен містити послідовностей
букв (наприклад, ААА), що повторюються, і послідовностей виду abc, qwerty,
123, 321.
Ці вимоги повинні строго виконуватися. Якщо хоч
би якась вимога не виконується, то пароль визнається ненадійним.
Password Strength Tester
JavaScript аналізатор паролів, який розробляється
і підтримується в рамках проекту Rumkin.com.
Алгоритм оцінки, реалізований в даному
аналізаторі, ґрунтується на загальних положеннях теорії інформації. Як основна
оцінка пароля використовується його ентропія, обчислення якої проводиться з
використання таблиць діаграм для англійської мови.
Під ентропією (інформаційною місткістю) пароля
розуміється міра випадковості вибору послідовності символів, що становлять
пароль, оцінена методами теорії інформації.
Інформаційна місткість E вимірюється в бітах і
характеризує стійкість до підбору пароля методом повного перебору за умови
відсутності апріорної інформації про характер пароля і застосування
зловмисником оптимальної стратегії перебору, при якій середня очікувана
кількість спроб до настання вдалої дорівнює 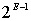
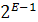 . За твердженням автора цього оцінювача, з метою зменшення
завантажуваного на клієнтську сторону об'єму інформації всі небуквені символи
були об'єднані в одну групу. Ця група виступає якимсь універсальним символом,
який і використовується в частотній таблиці.
. За твердженням автора цього оцінювача, з метою зменшення
завантажуваного на клієнтську сторону об'єму інформації всі небуквені символи
були об'єднані в одну групу. Ця група виступає якимсь універсальним символом,
який і використовується в частотній таблиці.
Як відзначає розробник, при даному допущенні значення
одержуваної ентропії буде менше, ніж у разі, коли в частотній таблиці всі
символи представлені роздільно.
Залежно від набутого значення ентропії паролю
привласнюється відповідна характеристика його стійкості.
Таблиця 3.4. Залежність рівня стійкості пароля від значення
ентропії
|
Ентропія
|
Рівень
стійкості
|
Коментар
|
|
< 28
біт
|
Дуже
слабкий
|
Допустимо
захищати тільки не цінну інформацію
|
|
28-35 біт
|
Слабкий
|
Здатний
зупинити велике число зломщиків, ідеально підходить для використання в якості
desktop-паролю
|
|
36-59
біт
|
Середній
|
Цілком
придатний для комп'ютерів в корпо-ративній
мережі
|
|
60-127
біт
|
Високий
|
Може
бути використаний, щоб охороняти фінансову інформацію
|
|
>
128 біт
|
Наднадійний
|
Пароль
володіє дуже великою стійкістю до підбору.
|
У плагіні Password Strength Meter для jQuery при
оцінці здійснюється виявлення паролів побудованих шляхом повторення груп
символів. Особливо слід зазначити проект Password Strength Tester, в якому
використовується математична модель, побудована на основі положень теорії
інформації.
Необхідно сказати, що в розглянутих програмних
рішеннях існують ряд проблем, що не дозволяють рахувати оцінку рівня надійності
пароля повною. Так on-line аналізатори, реалізовані засобами сценаріїв
JavaScript, що виконуються на клієнтській стороні, обмежені в своїх ресурсах,
що виключає можливість здійснювати перевірку по словниках великих об'ємів. У
теж час варіант перевірки пароля на стороні сервера хоч і вирішує проблему
використання словників, проте залишає відкритим питання про надійність передачі
і, головне, захищеності оцінюваного пароля від несанкціонованого використання.
У останньому випадку користувач може сподіватися лише на те, що обробку пароля
проводить сервер, що виконує лише «чисті» операції, а не використовується в
якості постачальника інформації для зловмисників.
Окрім цього, слід зазначити, що всі розглянуті
програмні продукти не підтримують оцінку паролів, що містять букви кирилиці.
Алгоритм оцінки стійкості пароля від Microsoft
Аналіз коду показав, що алгоритм використовує два
аналізатори стійкості пароля - основні, достатньо спрощені, і допоміжний -
глибший.
Почнемо з поточного алгоритму, по якому
аналізатор працює в черговому режимі.
1. Рівень стійкості пароля дається в діапазоні
[0; 4] залежно від обчислюваної «бітової стійкості» bits.
· bits ≥ 128 - 4;
· 128 > bits ≥ 64 - 3;
· 64 > bits ≥ 56 - 2;
· bits < 56 - 1;
· порожній пароль - 0.
2. Для оцінки «бітової стійкості»
використовується формула (3.3).
 (3.3)
(3.3)
де:
· bits - бітова стійкість;
· log - натуральний
логарифм;
· length - довжина пароля;
· charset - сумарний розмір
множин для кожного з типів нижче, якщо вони присутні в рядку.
1. Малі англійські букви
[abcdefghijklmnopqrstuvwxyz].
2. Заголовні англійські букви
[A-Z].
3. Спеціальні символи
[~`!@#$%^&*()-_+=»].
4. Цифри [1234567890].
5. Решта символів.
Розглянемо алгоритм роботи допоміжного аналізатора.
Для аналізу стійкості використовуються наступні
показники:
· довжина пароля;
· кількість
використовуваних типів символів: заголовні латинські, малі латинські, цифри,
спеціальні символи;
· відсутність слова в
словнику (слова завдовжки від 3 до 16 символів) з урахуванням подібності
символів;
· близькість слова до
словарного слова з певною вірогідністю.
Стійкість пароля підрозділяється на п'ять класів:
1. Відмінний (Best).
· довжина пароля - не менше
14;
· кількість
використовуваних різних типів символів - не менше 3;
· у словнику відсутньо
близьке з вірогідністю 0.6 слово з урахуванням подібності символів.
2. Стійкий (Strong).
· довжина пароля - не менше
8;
· кількість
використовуваних різних типів символів - не менше 3;
· у словнику відсутньо
близьке з вірогідністю 0.6 слово з урахуванням подібності символів.
3. Середній (Medium).
· довжина пароля - не менше
8;
· кількість
використовуваних різних типів символів - не менше 2;
· слово відсутнє в словнику
з урахуванням подібності символів;
4. Слабкий (Weak).
· пароль складається як
мінімум з одного довільного символу.
5. Ніякий.
· вся решта паролів.
4. Опис функціональних можливостей та програмної реалізації
проектованої системи
.1 Функціональне призначення та технологічні особливості розробки
Паролі є найбільш поширеним інструментом,
використовуваним для отримання доступу до інформаційних ресурсів. Для
користувачів це один з найзручніших варіантів, який, до того ж, не вимагає
наявність якого-небудь додаткового устаткування або спеціальних навиків.
Метою роботи є дослідження алгоритмів генерації
та оцінки стійкості паролів. Розроблена система призначена для генерації
криптостійких паролів з використанням двох алгоритмів - на основі
псевдовипадкової послідовності та ключової фрази. Також розроблена система
дозволяє визначити вагу стійкості пароля на основі алгоритму Password Strength Meter.
Згідно запропонованому в дипломні роботі
алгоритму користувач в змозі одержати криптростійкий, практично непіддатливої
злому пароль, що не потребує запам'ятовування. У будь-який момент, коли він нам
знадобиться, ми використовуючи нашу систему, зможемо легко його відновити.
Для роботи системи необхідно: IBM-сумісний
комп'ютер, не нижче Pentium - IІ, з ОЗУ рівним 128 Мб, з SVGA - відеоадаптером
і монітором 15 дюймів.
Система генерації та оцінки стійкості паролів
була створена за допомогою середовища прискореної розробки програмного
забезпечення Delphi. При розробці інтерфейсу користувача були використані
компоненти пакету AlphaControls 2010.
Склад розробленої системи:
· password.exe - виконавчий
файл системи;
· my.ini - ini-файл, що містить
інформацію про поточні налаштування системи;
· NextAlpha.asz - skin-файл інтерфейсу
системи;
· help.hlp - файл довідки.
4.2 Розробка
логіко-функціональної схеми роботи користувача з системою
На рис. 4.1 наведена логіко-функціональна схема
роботи користувача з системою.
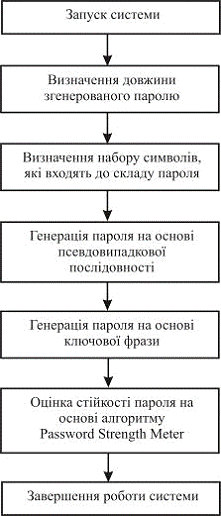
Рис. 4.1 Логіко-функціональна схема роботи
користувача з системою
4.3 Опис інтерфейсу
користувача
Після запуску на екрані з’являється головне вікно
системи (рис. 4.2). По-перше, необхідно визначити довжину пароля, що буде
згенерований. Значення за умовчанням завантажується з ini-файлу системи,
мінімальна довжина паролю - 4 символи.
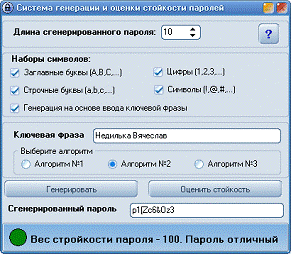
Рис. 4.2 Робоче вікно системи
Також необхідно визначити набір символів, які
будуть включені в пароль. Це можуть бути заголовні та рядкові латинські букви,
цифри або спеціальні символи. При установці прапорця «Символы», на екрані з'явиться
додаткове вікно (рис. 4.3), де користувач може додати або видалити символи,
які міститиме згенерований
пароль.
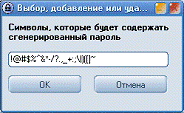
Рис. 4.3 Вибір, додавання або видалення символів
Якщо вибраний варіант генерації на основі
псевдовипадкових послідовностей, ми відразу ж натискаємо кнопку «Генерировать» і одержуємо
необхідний пароль. Якщо він нас не влаштовує, натискаємо кнопку ще раз і
одержуємо інші варіанти. Після цього одержаний пароль ми можемо скопіювати в
буфер обміну і використовувати за призначенням.
Кнопка «Оценить стойкость» дозволяє по описаному
нами надалі алгоритму на основі методу Password Strength Meter оцінити вагу
стійкості паролю і його категорію. Візуальний індикатор, що відображається в
лівій частині панелі приймає зелений колір, якщо пароль відмінний, жовтий, якщо
пароль хороший, і червоний, якщо пароль слабкий. Також ми можемо ввести свій
власний пароль і оцінити згідно вказаному алгоритму його стійкість.
Розглянемо генерацію пароля на основі введення ключової
фрази. Після установки цього прапорця стає доступним поле введення ключової
фрази і вибору алгоритму. Усі три алгоритми є різновидами спеціально
розробленого алгоритму шифрування.
Символи, які містить ключова фраза можуть бути
довільними. Але ключ, на основі якого буде згенерований пароль містить лише
латинські та кириличні літери, або цифри. Інші цифри будуть видалені. Також не
має різниці в регістрі, великі та маленькі літери у фразі будуть сприйматися
однаково.
Обравши відповідний алгоритм, тиснемо кнопку «Генерировать» та отримаємо
необхідний пароль.
Також в системі передбачена довідка, побачити яку
ми зможемо натиснувши відповідну кнопку в головному вікні. Довідка зберігається
в форматі hlp, вікно довідкової системи має вигляд, наведений на рис. 4.4.
Довідка про систему містить основні відомості про
засоби її використання, алгоритми генерації та оцінки стійкості паролів, які
були використані, а також відомості про автора.
Таким чином, ми одержуємо криптростійкий,
практично непіддатливої злому пароль, що не потребує запам'ятовування. У
будь-який момент, коли він нам знадобиться, ми використовуючи нашу систему,
зможемо легко його відновити.
Рис. 4.4 Вікно довідкової системи
4.4 Розробка алгоритмів та програмна реалізація системи
При створені головного вікна системи зчитуємо
дані з ini-файлу та формуємо змінні-послідовності символів.
procedure TForm1. FormCreate (Sender:
TObject);i:integer;; // ініціалізуємо генератор псевдовипадкових
чисел
ini:= TIniFile. Create (ExtractFilePath(ParamStr(0)) + 'my.ini'); // створюємо
посилання на ini-файл
znak:=ini. ReadString ('nabor', 'znaki',
'!@#$%^&*-/?.,_+:;\|) ([]~'); // зчитуємо з ini-файлу множину
спеціальних знаків, що будуть використовуватися при генерації паролю
sSpinEdit1. Value:=ini.readinteger ('dlina_pas', 'len', 10); // зчитуємо
довжину паролю
ini. Free;
for i:=65 to 90 do // формуємо множину
великих латинських літер
insert (char(i), eng_big, i-64); i:=97 to 122 do // формуємо множину
маленьких латинських літер
insert (char(i), eng_small, i-96); i:=192 to 223 do // формуємо множину
великих кириличних літер
insert (char(i), rus_big, i-191); i:=224 to 255 do // формуємо множину
маленьких кириличних літер
insert (char(i), rus_small, i-223);:='0123456789'; // формуємо множину
цифор
end;
При закритті програми зберігаємо дані в ini-файлі.
procedure TForm1. FormDestroy (Sender:
TObject);:= TIniFile. Create (ExtractFilePath(ParamStr(0)) + 'my.ini');.
WriteString ('nabor', 'znaki', znak); // записуємо поточну послідовність
спеціальних знаків
ini. WriteInteger ('dlina_pas', 'len',
sSpinEdit1. Value); // записуємо довжину паролю
ini. Free;;
Система дозволяє користувачеві дозвільно
формувати послідовність спеціальність знаків. Процедура, що відбувається при
виборі відповідного перемикача.
procedure TForm1.sCheckBox4Click (Sender:
TObject);sCheckBox4. Checked then znaki. ShowModal // на екрані з’являється
вікно формування послідовності символів
end;
Після натиснення кнопки «ОК» послідовність
зберігається у відповідній змінній.
procedure Tznaki.but_closeClick (Sender:
TObject);:=sEdit1. Text; // змінна, що містить текст послідовності
спеціальних символів
close;
Процедура генерації паролів на основі
псевдовипадкових послідовностей відбувається на основі наступного алгоритму.
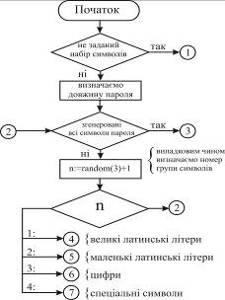
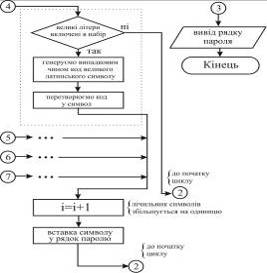
Рис. 4.5 Алгоритм генерації паролю на основі
псевдовипадкової послідовності
Якщо не заданий набір символів, на основі яких
буде згенерований пароль, робота процедури завершується. Далі визначаємо
довжину пароля. Цикл виконуватиметься, поки не будуть згенеровані всі символи
пароля. Потім ми випадковим чином визначаємо номер групи символів. Якщо 1 - це
великі латинські букви, 2 - маленькі латинські букви, 3 - цифри, 4 - спеціальні
символи.
Далі ми перевіряємо, якщо заголовні букви
включені в набір, то генеруємо випадковим чином код заголовного латинського
символу. Після цього перетворюваний код в символ. Аналогічно поступаємо з
іншими групами символів. Після цього лічильник символів збільшується на одиницю
і відбувається вставка символу в рядок пароля. Далі повертаємося в початок
циклу. Після його завершення виводимо рядок пароля на екран.
Далі наведений програмний код, що дозволяє
реалізувати цей алгоритм.
if not sCheckBox5. Checked then // якщо не обраний
режим генерації на основі ключової фрази
beginnot (sCheckBox1. Checked) or (sCheckBox2.
Checked) or (sCheckBox3. Checked) or (sCheckBox4. Checked) then // якщо не
заданий набір символів виводимо відповідне повідомлення та завершуємо роботу
процедури
begin. Visible:=true; Label1. Caption:='Не задан
набор символов';;;:=sSpinEdit1. Value; // визначаємо довжину паролю
pas:=''; // змінна, що зберігає
пароль
i:=0;i<=len do begin // цикл виконується, доки
не будуть згенеровані всі символи паролю
n:=random(3)+1; // випадковим чином
визначаємо номер групи символів
i:=i+1;n of
: // великі латинські літери
if sCheckBox1. Checked then begin // якщо
відповідний прапорець обраний
a:=random (90-65)+65; // генеруємо випадковим
чином код літери
ch:=char(a); // перетворюємо код в
символ
end;
: // маленькі латинські літериsCheckBox2.
Checked then:=random (122-97)+97;:=char(a);;
:// цифри
if sCheckBox3. Checked then:=random
(57-48)+48;:=char(a);;
: // спеціальні знакиsCheckBox4. Checked
then:=random (24-1)+1; // випадковим чином генеруємо порядковий номер знаку
в масиві символів
ch:=znak[a]; // привласнюємо буферній
змінній знак
end;i:=i-1;;(ch, pas, i); // вставляємо в
строку паролю у відповідній позиції згенерований символ
end;. Text:=pas; // виводимо згенерований
пароль у відповідне текстове поле
end;;
Для генерації паролю на основі випадкової фрази
був розроблений наступний алгоритм.
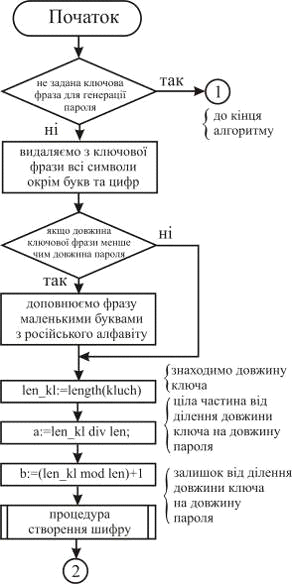
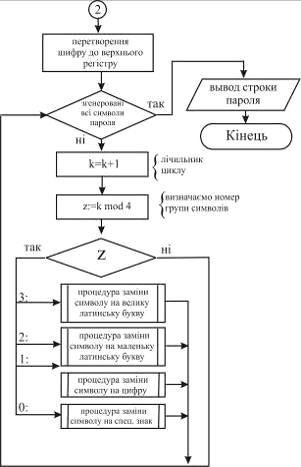
Рис. 4.6 Алгоритм генерації паролю на основі
ключової фрази
Наведемо алгоритм однієї ї з процедур - заміни
символу шифру на велику латинську букву.


Рис. 4.7 Алгоритм процедури заміни символу шифру
на велику латинську букву
Розглянемо цей алгоритм генерації паролю на
основі
ключової
фрази. Спершу видаляємо
з ключової фрази всі символи окрім букв і цифр. Якщо довжина ключової фрази
менше ніж довжина пароля (цей варіант не рекомендується, проте допустимий)
доповнюємо фразу маленькими буквами з російського алфавіту. Знаходимо цілу
частину від ділення довжини ключа на довжину пароля і залишок від ділення
довжини ключа на довжину пароля. Приступаємо до процедури генерації шифру. Схема створення
шифру на основі ключа наведена на рис. 4.8.

Рис. 4.8 Схема створення шифру на основі ключа
Припустимо, після видалення непотрібних символів
ми одержали наступний ключ (рис. 4.8). У шифр будуть включені символи,
починаючи із значення змінної b з кроком, який рівний змінній а. У результаті
одержимо рядок шифру, який містить таку ж кількість символів, як і необхідна
довжина пароля.
Наступний етап - генерація пароля на основі рядка
шифру. Всі символи шифру будуть перетворені до верхнього регістра. Далі
починається цикл, який виконуватиметься, поки не будуть згенеровані всі символи
пароля. Визначаємо номер групи символів і викликаємо відповідну процедуру.
Розглянемо алгоритм на прикладі заміни символу
шифру на велику латинську букву. Спочатку ми перевіряємо, чи включені великі
букви в набір, якщо ні, то виходимо з процедури. Потім ми перевіряємо букву
шифру, якщо символ шифру - кирилична буква, то знаходимо номер цієї букви в
російському алфавіті. Так само поступаємо з англійськими буквами і цифрами.
Потім визначаємо номер символу в англійському
алфавіті і вставляємо велику англійську букву в пароль.
Наступний фрагмент коду реалізує наведені вище
алгоритми.
else // якщо обраний режим
генерації паролю на основі ключової фрази
beginsEdit1. Text='' then // якщо не задана
ключова фраза для генерації паролю. Visible:=true;. Caption:='Для генерации
пароля введите ключевую фразу!';; // завершення процедури;:=sEdit1.
Text; // текст ключової фразиi:=1 to length(kluch) do // видаляємо
із ключової фрази усі символи окрім літер або цифр
if not (kluch[i] in ['A'..'Z', 'a'..'z',
'А'..'Я', 'а'..'я', '0'..'9']) then delete (kluch, i, 1);:=0;
len_kl:=length(kluch); // довжина ключової фразиlen_kl<len then // якщо
довжина ключової фрази менш ніж довжина паролю, що генерується, доповнюємо
фразу маленькими літерами російської абетки
for i:=len_kl+1 to len do:=j+1;(rus_small[j],
kluch, i);;_kl:=length(kluch);:=len_kl div len; // ціла частина від
ділення довжини ключової фрази на довжину паролю
b:=(len_kl mod len)+1; // залишок від
ділення довжини ключової фрази на довжину паролю
i:=b; shifr:=''; j:=0;j<=len do // створюємо шифр на
основі ключової фрази:=j+1;(kluch[i], shifr,
j);:=i+a;;:=Ansiuppercase(shifr); // переводимо рядок шифру до верхнього
регістру
if sRadioGroup1. ItemIndex=0 then // якщо обраний
перший алгоритм:=0; i:=1; pas:='';i<=len do // цикл продовжується,
доки не буде згенеровані всі символи паролю
begin:=k+1;:=k mod 4; // визначаємо,
символ з якої групи буде виводитисяz of
: if sCheckBox1. Checked then // великі латинські
літери(ord (shifr[i])>=192) and (ord (shifr[i])<=223) then // якщо
літера шифру кирилицею
for j:=1 to length (rus_big) do // перебираємо усі
літери алфавітуshifr[i]=rus_big[j] then n:=j; // шукаємо номер цієї
літери за абеткою(ord (shifr[i])>=65) and (ord (shifr[i])<=122) then //
якщо літера шифру латиницею
for j:=1 to length (eng_big)
doshifr[i]=eng_big[j] then n:=j;(ord (shifr[i])>=48) and (ord
(shifr[i])<=57) then // якщо символ в шифрі є цифрою
for j:=1 to 10 do // перебираємо усі цифри
if shifr[i]=cifra[j] then n:=j; // знаходимо номер
відповідноїn>26 then // якщо номер символу більше, ніж літер в
англійської абетці
n:=32-n+1;:=length (eng_big) - n+1; // визначаємо номер
літери, яка буде включена в пароль в англійській абетці
insert (eng_big[n], pas, i); // вставляємо
відповідний символ в рядок паролю
i:=i+1; // перехід до наступного
символу паролю;
: if sCheckBox2. Checked then // великі латиньські
літери(ord (shifr[i])>=192) and (ord (shifr[i])<=223) then // якщо
літера шифру кирилицею
for j:=1 to length (rus_big)
doshifr[i]=rus_big[j] then n:=j;(ord (shifr[i])>=65) and (ord
(shifr[i])<=122) then // якщо літера шифру латиницею
for j:=1 to length (eng_big)
doshifr[i]=eng_big[j] then n:=j;(ord (shifr[i])>=48) and (ord
(shifr[i])<=57) then // якщо символ в шифрі є цифрою
for j:=1 to 10 doshifr[i]=cifra[j] then
n:=j;n>26 then // якщо номер символу більше, ніж літер в
англійської абетці
n:=32-n+1;:=length (eng_small) -
n+1;(eng_small[n], pas, i);:=i+1; // перехід до наступного символу паролю;
: if sCheckBox3. Checked then // цифри(ord
(shifr[i])>=192) and (ord (shifr[i])<=223) then // якщо літера шифру
кирилицею
for j:=1 to length (rus_big)
doshifr[i]=rus_big[j] then n:=j;(ord (shifr[i])>=65) and (ord
(shifr[i])<=122) then // якщо літера шифру латиницею
for j:=1 to length (eng_big)
doshifr[i]=eng_big[j] then n:=j;(ord (shifr[i])>=48) and (ord
(shifr[i])<=57) then // якщо символ в шифрі є цифрою
for j:=1 to 10 doshifr[i]=cifra[j] then n:=j;:=n
mod 10; // визначаємо номер цифри в масиві, що буде використана для
підстановки
insert (cifra[n+1], pas, i);:=i+1; // перехід до
наступного символу паролю;
: if sCheckBox4. Checked then // спеціальні
символи:='!@#$%^&*-/?.,_+:;\|) ([]~'; // задаємо фіксований рядок
символів(ord (shifr[i])>=192) and (ord (shifr[i])<=223) then // якщо
літера шифру кирилицею
for j:=1 to length (rus_big)
doshifr[i]=rus_big[j] then n:=j;(ord (shifr[i])>=65) and (ord
(shifr[i])<=122) then // якщо літера шифру латиницею
for j:=1 to length (eng_big)
doshifr[i]=eng_big[j] then n:=j;(ord (shifr[i])>=48) and (ord
(shifr[i])<=57) then // якщо символ в шифрі є цифрою
for j:=1 to 10 doshifr[i]=cifra[j] then
n:=j;n>24 then // якщо номер перевищує кількість символів в
фіксованому масиві
n:=32-n+1; n:=24-n+1;(znak[n], pas, i); i:=i+1;;;
// кінець структури case; // кінець циклу; // кінець
програмної реалізації першого алгоритму.
if sRadioGroup1. ItemIndex=1 then // програмна
реалізація другого алгоритму
begin
…
end;sRadioGroup1.
ItemIndex=1 then // програмна реалізація третьго алгоритму
begin
…
end;
Розглянемо алгоритм процедури оцінки стійкості
пароля. На початковому етапі вага пароля встановлюється рівною нулю. Якщо
довжина пароля менше 4 символів, то повертається результат «дуже короткий
пароль» і робота алгоритму закінчується.
На наступному кроці вагу пароля збільшуємо на величину , де - довжина пароля. На подальших етапах вагу пароля визначає набір
символів, з яких він складається. Наприклад, якщо пароль містить не менше 3
цифр, то вага збільшується на 5 одиниць, якщо пароль містить букви, як у
верхньому, так і в нижньому регістрах, то вага пароля збільшується на 10.
Далі виконується процедура стиснення пароля, яка полягає у
видаленні символів, що повторюються. Алгоритм процедури наведений на рис. 4.9.
Після виконання операції стиснення вага пароля зменшується
на величину len-lenCompress, де len - довжина пароля, а lenCompress
- довжина пароля після стиснення. Пароль, вага якого менше 34, визнається
«слабким». Якщо вага від 34 до 67, то пароль відноситься до категорії «добрий»,
а якщо більше 67, то пароль вважається «відмінним».
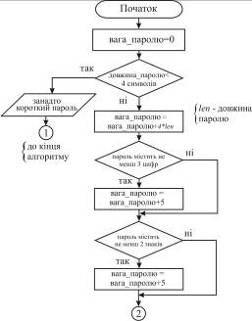
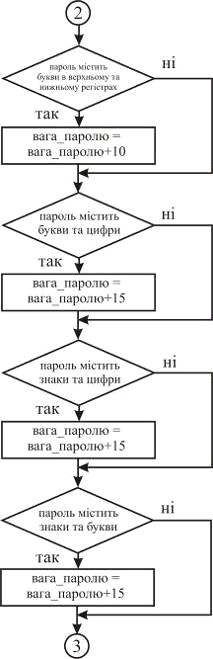
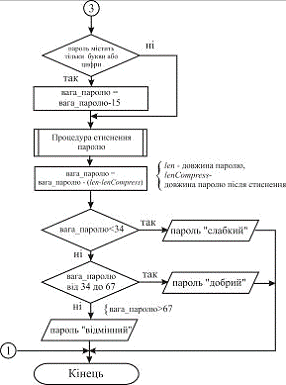
Рис. 4.9 Алгоритм оцінки стійкості паролю на основі методу
Password Strength Meter
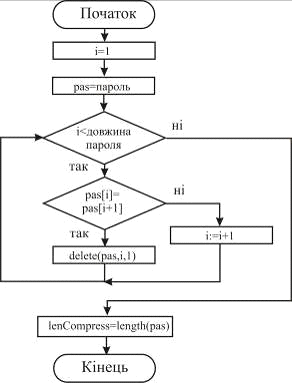
Рис. 4.10 Алгоритм процедури стиснення паролю
Наступний код демонструє реалізацію процедури
оцінки стійкості паролів.
if length(pas)<4 then // якщо довжина
пароля менш ніж 4 символа. Caption:='Слишком короткий пароль!'; // процедура
завершується;:=0; // початкове значення ваги паролю
ves:=ves+length(pas)*4;
// якщо пароль містить не менше 3 цифр, то вага
збільшується на 5 одиниць
k:=0; // лічильник кількості цифр
for i:=1 to length(pas) do // перебираємо в
циклі усі символи паролю
if (pas[i] in ['0'..'9']) then // якщо символ є
цифрою
k:=k+1; // рахуємо кількість цифр
if k>=3 then ves:=ves+5; // збільшуємо
вагу паролю
k:=0;
// якщо пароль містить не менш 2 знаків, то вага
збільшується на 5 одиниць
for i:=1 to length(pas) do(pas[i] in ('!', '@',
'#', '$', ' % ', '^', '&', '*', '+', '-
', '/', '?', '.', ',', '_', '+', ':', ';', '\',
'|', ')', ' (', ' [', ']', '~',#32]) // множина, що містить
спеціальні символи
then:=k+1;k>=2 then ves:=ves+5;:=0; m:=0;
// якщо пароль містить букви в верхньому та
нижньому регістрах, то вага збільшується на 10 одиниць
for i:=1 to length(pas) do(ord (pas[i])>=65)
and (ord (pas[i])<=90) then // якщо символ є латинською літерою в
верхньому регістрі
k:=k+1;(ord (pas[i])>=97) and (ord
(pas[i])<=122) then // якщо символ є латинською літерою в нижньому
регістрі
m:=m+1;;(k<>0) and (m<>0) then
ves:=ves+10;
// пароль містить букви та цифри, то вага
збільшується на 15 одиниць
k:=0; m:=0;i:=1 to length(pas) do(ord
(pas[i])>=65) and (ord (pas[i])<=90) or (ord (pas[i])>=97) and (ord
(pas[i])<=122) then // якщо символ є літерою
k:=k+1;(pas[i] in ['0'..'9']) then // якщо символ є
цифрою:=m+1;;(k<>0) and (m<>0) then ves:=ves+15;
// якщо пароль містить знаки та цифри, то вага
збільшується на 15 одиниць
k:=0; m:=0;i:=1 to length(pas) do(pas[i] in ('!',
'@', '#', '$', ' % ', '^', '&', '*', '+', '-'
'/', '?', '.', ',', '_', '+', ':', ';', '\', '|',
')', ' (', ' [', ']', '~',#32]) // множина спеціальних символів
then:=k+1;(pas[i] in ['0'..'9']) then // якщо символ є
цифрою:=m+1;;(k<>0) and (m<>0) then ves:=ves+15;
// якщо пароль містить спеціальні знаки та букви,
то вага збільшується на 15 одиниць
k:=0; m:=0;i:=1 to length(pas) do(pas[i] in ('!',
'@', '#', '$', ' % ', '^', '&', '*', '+', '-'
'/', '?', '.', ',', '_', '+', ':', ';', '\', '|',
')', ' (', ' [', ']', '~',#32]) // множина спеціальних символів:=k+1;(ord
(pas[i])>=65) and (ord (pas[i])<=90) or (ord (pas[i])>=97) and (ord
(pas[i])<=122) then // якщо символ є літерою
m:=m+1;;(k<>0) and (m<>0) then
ves:=ves+15;
// якщо пароль містить тільки букви або цифри,
вага паролю зменшується на 10 одиниць
k:=0; m:=0;i:=1 to length(pas) do(ord
(pas[i])>=65) and (ord (pas[i])<=90) or (ord (pas[i])>=97) and (ord
(pas[i])<=122) then // якщо символ є літерою:=k+1;(pas[i] in
['0'..'9']) then // якщо символ є цифрою:=m+1;;(k=0) or (m=0) then ves:=ves-10;:=pas;
// далі виконується процедура стиснення
пароля, яка полягає у видаленні символів, що повторюються:=1; // номер
символу
while i<length(pas) do // перебираємо усі
символи паролю
beginpas1 [i]=pas1 [i+1] then // якщо поточний
символ ідентичний наступному
delete (pas1, i, 1) // видаляємо символ
else i:=i+1;;:=ves - (length(pas) -
length(pas1)); // зменшуємо вагу паролю
if ves>100 then ves:=100; if ves<0 then
ves:=0;ves<34 then // пароль, вага якого менше 34, визнається «слабким».
Brush. Color:=clRed; // змінюємо колір індикатору
s:='слабый';ves>67 then // якщо вага більше
67, то пароль вважається «відмінним». Brush. Color:=clGreen;:='отличный';//
якщо вага від 34 до 67, то пароль відноситься до категорії «добрий».
Brush. Color:=clYellow;:='хороший';;
// виводимо інформацію щодо стійкості паролю
Label1. Caption:='';. Visible:=true;.
Caption:='Вес стройкости пароля - '+inttostr(ves)+'. Пароль '+s;
Спершу необхідно ввести заголовок довідкового
вікна (Title). У поле Header вводимо назву пункту довідки, а потім сам текст
довідки.
При цьому ми можемо вставляти в текст графічні
зображення і гіперпосилання на інші пункти довідки.


Щоб додати сторінку можна вибрати в меню Edit -
New Page або натиснути на кнопку «+» на панелі інструментів. Кнопка «-» видаляє
непотрібний розділ.
Рис. 4.11 Головне вікно програми shalomhelp.exe
Щоб згрупувати сторінки по розділах необхідно
натиснути кнопку Page Organizer на панелі інструментів або F5.

Натиснувши на кнопку Header, ми додаємо заголовок
розділу. Вікно менеджеру сторінок довідкової системи наведено на рис. 4.12.
Кнопками Up і Down можна змінювати порядок
проходження сторінок довідки.
Рис. 4.12 Менеджер сторінок довідкової системи
Щоб змінити текст заголовка необхідно його
виділити і натиснути на Enter. На екрані з'явиться вікно, в якому можна
відредагувати текст.
Рис. 4.13 Вікно редагування заголовку розділу
Для коректного відображення символів кирилиці
потрібно вибрати в меню Options - Project Options, перейти на вкладку Language
і вибрати із списку кодувань Russian.
Для компіляції файлу необхідно натиснути F9 або
кнопку на панелі інструментів. Перед компіляцією файл необхідно зберегти.

У результаті ми повинні одержати файл з
розширенням hlp.
Щоб підключити довідкову систему до додатку
необхідно:
. Помістити hlp-файл і файл з розширенням cnt в
той же каталог, що і здійснимий файл.
. У властивості HelpFile форми ввести ім'я файлу
(наприклад, help.hlp), у властивості HelpKeyword гарячу клавішу виклику довідки
(F1), HelpContext = 1 (номер розділу довідки за умовчанням).
. Для виклику довідки за допомогою кнопки
необхідно написати в обробнику OnClick:
winhelp (Form1. Handle, 'help.hlp', HELP_CONTEXT,
1);
5. Економічне обґрунтування доцільності розробки програмного
продукту
Метою дипломної роботи є дослідження алгоритмів
генерації та оцінки стійкості паролів. Розроблена система призначена для
генерації криптостійких паролів з використанням двох алгоритмів - на основі
псевдовипадкової послідовності та ключової фрази.
Також розроблена система дозволяє визначити вагу
стійкості пароля на основі алгоритму Password Strength Meter.
Економічна доцільність розробки полягає в
економії витрат порівняно з придбанням комерційних програмних продуктів,
здатних виконувати аналогічні функції.
В ході розробки програмного продукту було
використане програмне забезпечення Turbo Delphi 2006 Explorer, яке є
безкоштовним.
Визначення витрат на створення програмного
продукту
Оскільки середа розробки є безкоштовною, витрати
на створення програмного продукту складаються з витрат по оплаті праці
розробника програми і витрат по оплаті машинного часу при відладці програми:
Зспп=Ззпспп +Змвспп
де:
Зспп - витрати на створення
програмного продукту;
Ззпспп - витрати на оплату
праці розробника програми;
Змвспп - витрати на оплату
машинного часу.
Витрати на оплату праці розробника програми (Ззпспп)
визначаються шляхом множення трудомісткості створення програмного продукту на
середню годинну оплату програміста (з урахуванням коефіцієнта відрахувань на
соціальні потреби):
Ззпспп=t•Tчас
Розрахунок трудомісткості створення програмного
продукту
Трудомісткість розробки програмного продукту
можна визначити таким чином:
= to+ tа+ tб+ tп+
tд+ tвід,
де:o - витрати праці на підготовку
опису завдання;а - витрати праці на розробку алгоритму рішення
задачі;б - витрати праці на розробку блок-схеми алгоритму рішення
задачі;п - витрати праці на складання програми по готовій
блок-схемі;д - витрати праці на підготовку документації завдання;від
- витрати праці на відладку програми на ЕОМ при комплексній відладці
завдання.
Складові витрат можна виразити через умовне число
операторів Q. У нашому випадку число операторів у відлагодженій програмі Q=950.
Розрахунок витрат праці на підготовку опису
завдань
Оцінити витрати праці на підготовку опису
завдання не можливо, оскільки це пов'язано з творчим характером роботи,
натомість оцінимо витрати праці на вивчення опису завдання з урахуванням
уточнення опису і кваліфікації програміста:
o= Q•B/(75…85•K),
де:- коефіцієнт збільшення витрат праці унаслідок
недостатнього опису завдання, уточнень і деякої недоробки, B=1,2…5;- коефіцієнт
кваліфікації розробника, для тих, що працюють до 2 років K=0.8;
Коефіцієнт В приймаємо рівним 3.
Таким чином отримаємо:o=
950•3/(78•0,8) = 45,67 (люд-год).
Розрахунок витрат праці на розробку алгоритму
Витрати праці на розробку алгоритму рішення
задачі:
а = Q/(60…75•K)а =
950/(70•0,8)=16,96 (люд-год).
Розрахунок витрат праці на розробку блок-схеми
Витрати праці на розробку блок-схеми алгоритму
рішення задачі обчислимо таким чином:
б= Q/(60…75•K)б =
950/(71•0,8)=16,73 (люд-год).
Розрахунок витрат праці на складання програми
Витрати праці на складання програми по готовій
блок-схемі обчислимо таким чином:
п= Q/(60…75•K)п =
950/(72•0,8)=16,49 (люд-год).
Розрахунок витрат праці на відладку програми
Витрати праці на відладку програми на ЕОМ при
комплексній відладці завдання:
від=1.5• tAвід,
де tAвід - витрати праці на
відладку програми на ЕОМ при автономній відладці одного завдання;
Aвід= Q/(40…50•K)Aвід
= 950/(48•0,8)=24,74 (люд-год).
Звідси tвід=1,5•24,74=37,11 (люд-год).
Розрахунок витрат праці на підготовку
документації
Витрати праці на підготовку документації по
завданню визначаються:
д= tдр+ tдо,
де:др - витрати праці на підготовку
матеріалів в рукопису;до - витрати на редагування, друк і оформлення
документації;
др= Q/(150…200•K)др =
950/(180•0.8) = 6,59 (люд-год)до=0.75•tдр
tдо =0.75•6,59=4,95 (люд-год)
Звідси:д=6,59+4,95=11,54 (люд-год).
Отже, загальну трудомісткість розробки
програмного продукту можна розрахувати:
= to+ tа+ tб+ tп+
tд+ tвід,= 45,67+16,96+16,73+16,49+11,54+37,11 = 144,5 (люд-год).
Розрахунок середньої зарплати програміста
Середня зарплата програміста в сучасних ринкових
умовах може варіюватися в широкому діапазоні. Для розрахунку візьмемо середню
годинну оплату праці програміста, яка складає Тчас=10 грн/година. Це
означає, що вартість розробки буде становитиму 1445 грн.
Витрати на оплату праці програміста складаються
із зарплати програміста і нарахувань на соціальні потреби.
Єдине соціальне нарахування становить 37,2%.
Тобто 1445 грн•37,2%= 537,54 грн.
Звідси витрати на оплату праці програміста
складають:
Ззпспп= 1445+537,54= 1
982,54 грн.
Витрати на оплату машинного час
Витрати на оплату машинного часу при відладці
програми визначаються шляхом множення фактичного часу відладки програми на ціну
машино-години орендного часу:
Змвспп =Счас• tеом,
де:
Счас - ціна машино-години, грн/год;еом
- фактичний час відладки програми на ЕОМ.
Розрахунок фактичного часу відладки
Фактичний час відладки обчислимо за формулою:
еом = tп + tдо + tвід;еом
=16,49 +4,95 +37,11 = 58,55 години
Розрахунок ціни машино-години
Ціну машино-години знайдемо по формулі:
Сгод = Зеом/Теом,
де:
Зеом - повні витрати на експлуатацію
ЕОМ на протязі року;
Теом - дійсний річний фонд часу ЕОМ,
год/рік.
Розрахунок річного фонду часу роботи ПЕОМ
Загальна кількість днів в році - 365. Число
святкових і вихідних днів - 114 (10 святкових і 52•2 - вихідні).
Час простою в профілактичних роботах визначається
як щотижнева профілактика по 3 години.
Разом річний фонд робочого часу ПЕОМ складає:
Теом = 8•(365-114) - 52•3=1852 год.
Розрахунок повних витрат на експлуатацію ЕОМ
Повні витрати на експлуатацію можна визначити по
формулі:
Зеом = (Ззп+ Зам+
Зел+ Здм+ Зпр+ Зін),
де:
Ззп - річні витрати на заробітну плату
обслуговуючого персоналу, грн/рік;
Зам - річні витрати на амортизацію,
грн/рік;
Зел - річні витрати на електроенергію,
споживану ЕОМ, грн/рік;
Здм - річні витрати на допоміжні
матеріали, грн/рік;
Зпр - витрати на поточний ремонт
комп'ютера, грн/рік;
Зін - річні витрати на інші і накладні
витрати, грн/рік.
Амортизаційні відрахування
Річні амортизаційні відрахування визначаються по
формулі:
Зам=Сбал•Нам,
де: Сбал - балансова вартість
комп’ютера, грн/шт.;
Нам - норма амортизації, %;
Нам =25%.
Балансова вартість ПЕОМ включає відпускну ціну,
витрати на транспортування, монтаж устаткування і його відладку:
Сбал = Срин +Зуст;
де:
Срин - ринкова вартість комп’ютеру,
грн/шт.,
Зуст - витрати на доставку і установку
комп'ютера, грн/шт.;
Комп'ютер, на якому велася робота, був придбаний
за ціною Срин =5000 грн, витрати на установку і наладку склали
приблизно 10% від вартості комп'ютера.
Зуст = 10%• Срин
Зуст =0.1•5000=500 грн.
Звідси, Сбал = 5000 +500
=5500 грн./шт.,
а Зам=5500•0,25= 1375 грн/год.
Розрахунок витрат на електроенергію
Вартість електроенергії, споживаної за рік,
визначається по формулі:
Зел = Реом • Теом •
Сел • А,
де:
Реом - сумарна потужність ЕОМ,
Теом - дійсний річний фонд часу ЕОМ,
год/рік;
Сел - вартість 1кВт•год
електроенергії;
А - коефіцієнт інтенсивного використання
потужності машини.
Згідно технічному паспорту ЕОМ Реом =0.22
кВт, вартість 1кВт•год електроенергії для споживачів Сел =0,2802
грн., інтенсивність використання машини А=0,98.
Тоді розрахункове значення витрат на
електроенергію:
Зел = 0,22 • 1852• 0,2802•
0,30 = 34,25 грн.
Розрахунок витрат на поточний ремонт
Витрати на поточний і профілактичний ремонт
приймаються рівними 5% від вартості ЕОМ:
Зпр = 0.05• Сбал
Зпр = 0,05• 5500 = 275 грн.
Розрахунок витрат на допоміжні матеріали
Витрати на матеріали, необхідні для забезпечення
нормальної роботи ПЕОМ, складають близько 1% від вартості ЕОМ:
Звм =0,01• 5500 =55 грн.
Інші витрати по експлуатації ПЕОМ
Інші непрямі витрати, пов'язані з експлуатацією
ПЕОМ, складаються з вартості послуг сторонніх організацій і складають 5% від
вартості ЕОМ:
Зпр = 0.05• 5500 =275 грн.
Річні витрати на заробітну плату обслуговуючого
персоналу
Витрати на заробітну плату обслуговуючого
персоналу складаються з основної заробітної плати, додаткової і відрахувань на
заробітну плату:
Ззп = Зоснзп +Здодзп
+Звідзп.
Основна заробітна плата визначається, виходячи із
загальної чисельності тих, що працюють в штаті:
Зоснзп =12 •∑Зіокл,
де:
Зіокл - тарифна ставка і-го
працівника в місяць, грн;
- кількість місяців.
У штат обслуговуючого персоналу повинні входити
інженер-електронщик з місячним окладом 1500 грн. і електрослюсар з окладом 1200
грн. Тоді, враховуючи, що даний персонал обслуговує 20 машин, маємо витрати на
основну заробітну плату обслуговуючого персоналу, які складуть:
Зоснзп =
12•(1500+1200)/20=1620 грн.
Додаткова заробітна плата складає 60% від
основної заробітної плати:
Здодзп = 0,6 •1620 = 972
грн.
Відрахування на соціальні потреби складають 37,2%
від суми додатковою і основною заробітних плат:
Звідзп = 0,372•(1620 + 972)
= 959,04 грн.
Тоді річні витрати на заробітну плату
обслуговуючого персоналу складуть:
Ззп = 1620 +972 +959,04 =
3551,04 грн.
Повні витрати на експлуатацію ЕОМ в перебігу року
складуть:
Зеом = 3551,04 + 1375+ 29,78 + 55 +
275+ 275= 5560,82 грн.
Тоді ціна машино-години часу, що орендується,
складе
Сгод = 5560,82 /1852 = 3 грн.
А витрати на оплату машинного часу складуть:
Змвспп =Сгод•tеом
Змвспп = 3 • 58,55= 175,65
грн.
Розрахунок економічного ефекту
Зспп=Ззпспп +Змвспп
Зспп =1928,96+ 175,65= 2104,61
грн.
Тобто собівартість програмного продукту 2104,61
грн.
А зараз визначимо ціну програмного продукту:
Ц = Зспп + Р,
Где Ц - ціна програмного продукту;
Р - 15% від витрат на створення програмного
продукту.
Ц = 2104,61 + 315,69= 2420,3 грн.
Ціна розробки програмного продукту дорівнює
2420,3 грн.
Оскільки робота є науково-дослідницькою, на ринку
програмного немає аналогічних розробок. Але аналіз програмних продуктів, що
здатні виконувати схожі функції та мають вартість орієнтовно $50 дозволяє зробити
висновок, що розроблена програма за умови тиражування обійдеться значно
дешевше, ніж аналоги.
Якщо буде реалізовано 100 копій розробленого
програмного продукту, економічний прибуток становитиме:
ЕК = 50 $ * 8,0 * 50 - 2420,3 = 37 579,7 грн.,
де 8,0 - курс долара Національного банку України
6. Охорона праці
Державна політика з охороні праці випливає з
конституційного права кожного громадянина на належні безпечні й здорові умови
праці, пріоритету життя й здоров'я працівника стосовно результатів виробничої
діяльності. Реалізація цієї політики повинне забезпечувати постійне поліпшення
умов і безпеки праці, зниження рівня травматизму й професійних захворювань.
В Україні діють закони, які визначають права й
обов'язки її громадян, а також організаційну структуру органів влади і
промисловості. Конституція України декларує рівні права й свободи всім жителям
країни: вільний вибір роботи, що відповідає безпечним і здоровим умовам, на
відпочинок, на соціальний захист у випадку втрати працездатності й старості.
Всі закони й нормативні документи повинні узгоджуватися, базуватися й
відповідати статтям Конституції.
Законодавча база охорони праці України має ряд
законів, основним з яких є Закон України «Про охорону праці» і Кодекс законів
про працю (КЗпП). До законодавчої бази також належать Закони України: «Про
загальнообов'язкове страхування від нещасних випадків на виробництві й
професійних захворювань, які викликали втрату працездатності», «Про охорону
здоров'я», «Про пожежну безпеку», «Про забезпечення санітарного й
епідеміологічного добробуту населення», «Про використання ядерної енергії й
радіаційну безпеку», «Про дорожній рух», «Про обов'язкове страхування у зв'язку
з тимчасовою втратою працездатності й витратами, обумовленими народженням й
похоронами». Їх доповнюють державні галузеві й міжгалузеві нормативні акти - це
стандарти, інструкції, правила, норми, положення, статути й інші документи які
мають статус правових норм, обов'язкових для виконання всіма установами й
працівниками України.
Найбільш повним нормативним документом по
забезпеченню охорони праці користувачів ПК є «Державні санітарні правила й
норми роботи з візуальними дисплейними терміналами (ВДТ)
електронно-обчислювальних машин» ДСанПіН 3.3.2.007-98.
В Україні затверджене положення про створення
державних нормативних актів по охороні праці ДНАОП. Це норми, інструкції,
вказівки й інші види державних нормативних актів по охороні праці обов'язкові
по виконанню й керівництво підприємствами й установами, на які поширюється
сфера дії цих актів.
6.1 Аналіз небезпечних й шкідливих виробничих факторів в
обчислювальному центрі
Гігієнічні вимоги до параметрів робочої зони
включають вимоги до параметрів мікроклімату, освітлення, шуму й вібрації,
рівнів електромагнітного й іонізуючого випромінювання
До основних параметрів метеорологічних умов
робочої зони приміщення відносять температуру, відносну вологість, швидкість
переміщення повітря й барометричний тиск (таблиця 6.1). Метеоумови в робочій
зоні приміщення визначаються ГОСТ 12.0.005.88 «Загальні санітарно-гігієнічні
вимоги до повітря робочої зони».
Таблиця 6.1. Оптимальні норми температури,
відносної вологості і швидкості руху повітря
|
Період
року
|
Категорія
роботи
|
Температура,°С
|
Відносна
вологість повітря, %
|
Швидкість
руху повітря, не більше м/с
|
|
Холодний
і перехідний
|
легка
|
21-24
|
40-60
|
0,1
|
|
Теплий
|
легка
|
22-25
|
40-60
|
0,2
|
Вищевказані оптимальні норми виходять з принципу
забезпечення максимальної комфортності для людини. Відхилення даних параметрів
від оптимальних призводить до підвищення ризику захворюваності працівників.
У зв'язку із застосуванням у приміщенні великої
кількості ПК із електронно-променевими дисплеями й іншого офісного й
друкарського встаткування в теплий період року спостерігається порушення
мікрокліматичних параметрів робочого простору, зокрема значне підвищення
температури повітря, зниження відносної вологості повітря.
Підвищення температури негативно позначається на
роботі деяких вузлів ПК й іншої апаратури. Для охолодження перегрітих вузлів ПК
використаються вентилятори, що у свою чергу підвищують швидкість руху повітря.
Освітлення робочого місця - найважливіший фактор
створення нормальних умов праці. Освітленню варто приділяти особливу увагу,
тому що при роботі з монітором найбільшу напругу одержують очі. При організації
освітлення необхідно мати на увазі, що збільшення рівня освітленості приводить
до зменшення контрастності зображення на дисплеї. У таких випадках вибирають
джерела загального освітлення, по їхній яскравості й спектральному складу
випромінювання. Загальна чутливість зорової системи збільшується зі збільшенням
рівня освітленості в приміщенні, але лише доти, поки збільшення освітленості не
приводить до значного зменшення контрасту.
Приміщення комп’ютерного класу має природне й
штучне освітлення. Природне освітлення здійснюється через віконні прорізи, що
виходять на південний схід, тим самим у ясну погоду забезпечує достатній рівень
освітлення без використання світильників. У вечірній час і несприятливу погоду,
коли освітленість робочого місця має значення нижче 300 лк освітленість
забезпечується системою загального рівномірного освітлення, а робочі місця
операторів додатково обладнані люмінесцентними світильниками місцевого
освітлення, розташованими безпосередньо на робочому столі. Вони мають
непросвічуючий відбивач і розташовуються нижче лінії зору оператора, щоб не
викликати осліплення.
Робоче місце перебуває поруч із вікном, тому
екран монітора розташовується під прямим кутом до нього (це виключає відблиски
на екрані). Щоб уникнути відбиттів, які можуть знизити чіткість сприйняття,
розташовуємо робоче місце не прямо під джерелом верхнього світла, а небагато
осторонь. Стіна й будь-яка поверхня за комп'ютером освітлена приблизно так
само, як й екран. Необхідно остерігатися дуже світлого або блискучого
фарбування на робочому місці - воно може стати джерелом відбитків, що
заподіюють занепокоєння.
Крім освітленості, великий вплив на діяльність
оператора роблять кольори фарбування приміщення й спектральних характеристик
використовуваного світла. Рекомендується, щоб стеля відбивала 80-90%, стіни -
50-60%, підлога - 15-30% падаючого на них світла. Тому приміщення оператора
пофарбоване в сині кольори, що відноситься до кольорів «холодного» тону (синій,
зелений, фіолетовий), що створює враження спокою й викликає в людини відчуття
прохолоді.
Незадовільне освітлення стомлює не тільки зір,
але й викликає стомлення всього організму в цілому. Неправильне освітлення
часто є причиною травматизму (погано освітлені небезпечні зони, засліплюючі
лампи й відблиски від них). Різкі тіні погіршують або викликають повну втрату
орієнтації працюючих, а також викликають втрату чутливості очних нервів, що
приводить до різкого погіршення зору.
Підвищення рівня шуму на робочому місці
викликається за рахунок застосування безлічі вентиляторів у системах
охолодження ПК, також кондиціонерами, електронагрівальними приладами,
акустичними системами й т.д. Шум погіршує умови праці, впливаючи на організм
людини. При тривалому впливі шуму на організм людини відбуваються небажані
явища:
1) знижується гострота зору, слуху;
2) підвищується кров'яний тиск;
) знижується увага.
Сильний тривалий шум може бути причиною
функціональних змін серцево-судинної й нервової систем, що приводить до
захворювань серця й підвищеної нервозності. У робочих приміщеннях фахівців
операторів ЕОМ рівень шуму згідно норм не повинен перевищувати 65 дб. На
робочих місцях у приміщеннях для розміщення шумних агрегатів обчислювальних
машин (АЦПУ, роботи, принтери й т.і.) рівень шуму не повинен перевищувати 75
дб.
При використанні дисплеїв випромінюються
електромагнітні хвилі які негативно впливають на здоров'я людини. Спектр
випромінювання комп'ютерного дисплея містить у собі рентгенівські,
ультрафіолетову й інфрачервону області, а також широкий діапазон
електромагнітних хвиль інших частот. У ряді експериментів було виявлено, що
електромагнітні поля із частотою 50 Гц (що виникають навколо ліній
електропередач, відеодисплеїв і навіть внутрішньої електропроводки) можуть
ініціювати біологічні зрушення (аж до порушення синтезу ДНК) у клітках тварин.
На відміну від рентгенівських променів електромагнітні хвилі мають незвичайну
властивість: небезпека їхнього впливу зовсім не обов'язково зменшується при
зниженні інтенсивності опромінення, певні електромагнітні поля діють на клітки
лише при малих інтенсивностях випромінювання або на конкретних частотах - в
«вікнах прозорості». Джерело високої напруги комп'ютера - строковий
трансформатор - міститься в задній або бічній частині термінала, рівень
випромінювання з боку задньої панелі дисплея вище, причому стінки корпуса не
екранують випромінювання. Тому користувач повинен перебувати не ближче чим на
1,2 м від задніх або бічних поверхонь сусідніх терміналів.
За результатами виміру електромагнітних
випромінювань встановлено, що максимальна напруженість електромагнітного поля
на кожусі відеотермінала становить 3.6 В/м, однак у місці знаходження оператора
її величина відповідає фоновому рівню (0.2-0.5 В/м); градієнт електростатичного
поля на відстані 0.5 м менш 300 В/см є в межах припустимого. На відстані 5 см
від екрана інтенсивність електромагнітного випромінювання становить 28-64В/м
залежно від типу приладу. Ці значення знижуються до 0.3-2.4 В/м на відстані 30
см від екрана (мінімальна відстань очей оператора до площини екрана). Також
джерелами електромагнітних випромінювань на робочому місці є: кондиціонери,
джерела резервного живлення ПК, телефони, приймально-передаючі антени, лінії
зв'язку мережі Інтернет й інше електронне устаткування. Рівень випромінювання
кожного окремо взятого джерела випромінювання не несе шкоди здоров'ю людини,
але накопичення складної техніки в закритому просторі веде до збільшення
сумарної кількості електромагнітних випромінювань.
Все устаткування комп’ютерного класу приєднане до
мережі змінного струму (220 В, 50 Гц). Кабельне розведення виконане відповідно
до вимог
ДНАОП 0.00-1.31-99 і Правилами побудови й експлуатації електроустановок.
Підведення електроживлення до робочих місць виконано системою із закритою
проводкою, що забезпечує додаткову безпеку працівників від поразки електричним
струмом і підвищує пожежобезпечність. Все устаткування, використовуване в
лабораторії при дотриманні елементарних вимог електробезпечності виключає
можливість поразки електричним струмом. Для виключення можливого короткого
замикання й поразки електрострумом у лабораторії застосовується устаткування й
розетки із захисним заземленням.
6.2 Заходи щодо нормалізації небезпечних і шкідливих факторів
Для забезпечення нормальних метеоумов у
комп’ютерному класі встановлений кондиціонер, що постійно підтримує задані
кліматичні параметри в робочому просторі. У зимовий період у доповненні до
центрального опалення використаються електрообігрівачі масляного типу. У літній
період при зниженні в повітрі кількості водяної пари (низкою вологості повітря)
застосовується зволожувач повітря.
При тривалій роботі за комп'ютером користувач
отримує не тільки фізичне, але й психо-емоційне навантаження на організм. Це
пов'язане із тривалою монотонною сидячою роботою, розумовими перенапругами,
емоційними перевантаженнями. Для нормалізації стану працівників передбачене
окреме приміщення для відпочинку, де працівник може відпочити від роботи,
виконати легкі фізичні вправи, прийняти тонізуючі напої (кава, чай).
Освітленість у приміщенні передбачена більш
низька, ніж за робочим місцем, для відпочинку зорового апарата людини.
Як джерела загального освітлення використаємо
лампи типу ЛБ і ДРЛ із індексом передачі кольору не менш 70 (R>70), як
світильники - установки з переважно відбитим або розсіяним світлом. Світильники
загального освітлення розташовуємо над робочим столом у рівномірно прямокутному
порядку.
Для запобігання відблисків екрана дисплея прямими
світловими потоками застосовуємо світильники загального призначення,
розташовані між рядами робочих місць. При цьому лінії світильників
розташовуються паралельно світлоприйому. Освітлювальні установки забезпечують
рівномірну освітленість за допомогою приглушеного або неуважного
світлорозподілу.
Для виключення відблисків застосовуємо спеціальні
фільтри для екранів, захисні козирки або розташовуємо джерела світла паралельно
напрямку погляду на екран монітора по обидва боки. Місцеве освітлення
забезпечується світильниками, установленими безпосередньо на столі або на його
вертикальній панелі, а також вмонтованими в козирок пульта. При природному
освітленні застосовуємо сонцезахисні засоби, що знижують перепади яскравості
між природним світлом і світінням екрана дисплея. При такому засобі,
використаємо регульовані жалюзі.
Для захисту від дії зовнішнього випромінювання на
персонал ведуться заходи щодо збільшення відстані між оператором і джерелом
випромінювання, скорочення тривалості роботи в полі випромінювання, екранування
джерела випромінювання. На дисплеях застосовуються заземлені свинцеві екрани,
що практично повністю нейтралізують несприятливу дію дисплея на очі людини.
Для зменшення негативної дії негативних іонів
застосовується кондиціонер з іонізатором, що нейтралізує дію негативних іонів і
наповнює приміщення благотворно впливають на організм людини позитивними
аероіонами.
Для забезпечення оптимального освітлення в літню
пору, на віконних прорізах передбачені жалюзі, що регулюють необхідний напрямок
сонячної світлової хвилі.
Для забезпечення безпеки при перевантаженнях
живильної мережі на уведенні електропроводки в приміщення встановлений
розподільний щит з автоматичними вимикачами С-16, які автоматично розмикають
ланцюг при перевищенні силою струму значення 16 А.
Для запобігання поразки персоналу електричним
струмом всі розетки й вимикачі оснащені написами «Напруга 220 V». Передбачено
щоквартальні профілактичні огляди стану електроустаткування й проводки, а також
2 рази в рік виміри опору ґрунту в місцях монтажу заземлюючого пристрою.
Електропостачання підстанції здійснюється
напругою 6кВ трипровідними лініями з ізольованою нейтраллю.
Розподіл електроенергії виконується від
понижуючої підстанції напругою 380В чотирьох-провідними лініями із
глухозаземленою нейтралью.
Захист від небезпеки переходу напруги з мережі
6кВ у мережу низької напруги здійснюється за допомогою з'єднання нейтралі
силових трансформаторів підстанції до робочого заземлення, а нульовий провідник
багаторазово заземлюється по трасі електропостачання.
Величину розрахункового струму замикання на землю
визначаємо по наближеній емпіричній формулі:
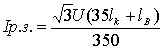 (6.1)
(6.1)
де U - фазна напруга мережі, кВ;k - довжина
кабельних ліній, км;- довжина повітряних ліній, електрично об'єднаних в одну
мережу, км.
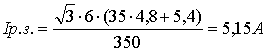 (6.2)
(6.2)
Звідси опір заземлюючого пристрою дорівнює:
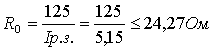 (6.3)
(6.3)
Тому приймаємо згідно ППЕ R0=4 Ом
Для виконання робочого заземлення приймаємо металеві труби
довжиною l=1 м і діаметром d=50 мм, з'єднаних металевою смугою 48 мм².
Опір відстані струму визначаємо по наступній емпіричній
формулі:
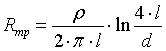 , (6.4)
, (6.4)
де r =1×104 Ом×см - питомий опір глинистого
ґрунту;- довжина провідника;- діаметр провідника.
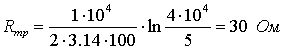 , (6.5)
, (6.5)
З огляду
на сезонні коливання питомого опору ґрунту, приймаємо коефіцієнт 1.2 тоді:
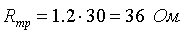 (6.6)
(6.6)
Необхідне
число трубних стрижнів визначаємо зі співвідношення:
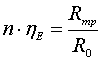 ,(6.7)
,(6.7)
де
n-число трубних стрижнів;
hЕ=0,88 - коефіцієнт використання
труб, що враховує їхню екрануючу взаємодію, при розташуванні між ними до 6 м,
тоді:
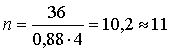 (6.8)
(6.8)
Довжина
смуги, що поєднує труби:
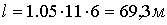 (6.9)
(6.9)
Опір
розтікання струму смуги буде:
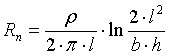 (6.10)
(6.10)
де h=1,2
- глибина на якій перебуває смуга:=80 - ширина смуги.
З
урахуванням коливання питомого опору ґрунту:
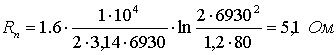 (6.11)
(6.11)
Опір
розтікання всього заземлюючого робочого пристрою в цілому буде:
(6.12)
де heл=0,91 - коефіцієнт використання сполучної
смуги.
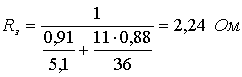 (6.13)
(6.13)
Опір розтікання захисного заземлення повинен бути
не більше 4 Ом. У такий спосіб розрахований контур заземлення забезпечить
надійний захист від поразки електричним струмом.
6.3 Пожежна безпека
Пожежі в лабораторіях та комп’ютерних класах
становлять особливу небезпеку, тому що пов’язані з великими матеріальними
збитками. Як відомо, пожежа може виникнути при взаємодії горючих речовин,
окислювача й джерела запалювання. У приміщенні комп’ютерного класу присутні всі
три фактори, необхідні для виникнення пожежі.
Будинок у якому перебуває комп’ютерний клас,
можна віднести до категорії «В» пожежної небезпеки із третім ступенем
вогнестійкості - будинок з несучими й обгороджуючими конструкціями, з природних
або штучних матеріалів, бетону або залізобетону.
Виникнення пожежі в розглянутому приміщенні
найбільше ймовірно із причин несправності електроустаткування, до яких
відносять: іскріння в місцях з'єднання електропроводки, короткі замикання в
ланцюгах, перевантаження проводів й обмоток трансформаторів, перегрів джерел
безперебійного живлення й інші фактори. Тому підключення комп'ютерів до мережі
відбувається через розподільні щити, що дозволяють робити автоматичне
відключення навантаження при аварії.
Особливістю сучасних ЕОМ є дуже висока щільність
розташування елементів електронних схем, висока робоча температура процесора й
мікросхем пам'яті. Отже, вентиляція й система охолодження, передбачені в
системному блоці комп'ютера повинні бути постійно в справному стані, тому що в
противному випадку можливий перегрів елементів, що не виключає їхнє займання.
Надійна робота окремих елементів й електронних
схем у цілому забезпечується тільки в певних інтервалах температури, вологості
й при заданих електричних параметрах. При відхиленні реальних умов експлуатації
від розрахункових, також можуть виникнути пожежонебезпечні ситуації.
Серйозну небезпеку представляють різні
електроізоляційні матеріали. Широко застосовувані компаунди на основі
епоксидних смол складаються з горючих смол, що виділяють при горінні задушливі
гази. Материнські плати електронних пристроїв, а також плати всіх додаткових
пристроїв ЕОМ виготовляють із гетинаксу або склотекстоліта. Пожежна небезпека
цих ізоляційних матеріалів невелика, вони ставляться до групи важко горючих, і
можуть запалитися тільки при тривалому впливі вогню й високої температури.
Оскільки в розглянутому випадку, при загоряннях
електропристрої можуть перебувати під напругою, то використовувати воду й піну
для гасіння пожежі неприпустимо, оскільки це може привести до електричних
травм. Іншою причиною, по якій небажане використання води, є те, що на деякі
елементи ЕОМ неприпустиме влучення вологи. Тому для гасіння пожеж у
розглянутому приміщенні можна використати або порошкові состави, або установки
вуглекислотного гасіння. Але оскільки останні призначені тільки для гасіння
невеликих вогнищ загоряння, то область їхнього застосування обмежена. Тому для
гасіння пожеж у цьому випадку застосовуються порошкові состави, тому що вони
мають наступні властивості: діелектрики, практично не токсичні, не роблять
корозійного впливу на метали, не руйнують діелектричні лаки.
Установки порошкового пожежогасіння можуть бути
як переносними, так і стаціонарними, причому стаціонарні можуть бути з ручним,
дистанційним й автоматичним включенням.
Автоматична установка й установка з механічним
включенням відрізняється тільки засобами відкриття запірного крана. В
автоматичних установках використаються різні датчики виявлення пожежі (по диму,
тепловому й світловому випромінюванню), а в механічних спеціальні тросові
системи з легкоплавкими замками. У цей час освоєні модульні порошкові установки
ОПА-50, ОПА-100, УАПП.
Для забезпечення гасіння пожежі в прилеглому
складському приміщенні застосовується автоматична стаціонарна установка порошкового
пожежогасіння УПС-500. Установка порошкового гасіння складається з посудини для
зберігання порошку, балонів зі стисненим газом, редуктора, запірної апаратури,
трубопроводів і порошкових зрошувачів. Саме приміщення оператора оснащене
порошковим вогнегасником.
У приміщенні комп’ютерного класу застосовуються
сповіщувачі типу ИП 104, які спрацьовують при перевищенні температури в
приміщенні +600С. І сповіщувачі типу ИП 212, які спрацьовують при
скупченні диму в приміщенні. На стелях приміщення встановлені ручні пожежні
сповіщувачі про загоряння, що передають сигнал на пульт пожежної охорони. На
всіх поверхах встановлені пожежні щити з необхідним інвентарем (ПК, рукава,
ящики з піском, лопати, сокири й т.д.) і номером телефону пожежної охорони.
Для профілактики пожежної безпеки організоване
навчання виробничого персоналу (обов'язковий інструктаж із правил пожежної
безпеки не рідше одного разу в рік), видання необхідних інструкцій з доведенням
їх до кожного працівника лабораторії, випуск і вивіска плакатів із правилами
пожежної безпеки й правилами поведінки при пожежі. Також у загальнодоступних
місцях перебувають покажчики, що інформують людей про розташування в будинку
пожежних щитів, і засобів пожежогасіння аварійних виходів з будинку у випадку
виникнення пожежі, план евакуації людей в аварійних ситуаціях.
План евакуації людей в аварійних ситуаціях
розписує оптимальний маршрут слідування від поточного місця знаходження людини
до виходу з приміщення.
Висновки
Ні для кого не є секретом той факт, що сьогодні
на переважній більшості комп'ютерів для аутентифікації користувачів
використовується парольний захист. Це стосується практично всіх, у тому числі і
корпоративних ПК.
Тим часом парольний захист не задовольняє
сучасним уявленням про інформаційну безпеку. Причина цьому - дуже сильна
залежність даного виду аутентифікації від так званого людського чинника.
Надійність парольної аутентифікації повністю
залежить від того, яке ключове слово вибрав собі користувач і як він його
зберігає.
Все це робить паролі уразливими перед різними
атаками зловмисників. Так, наприклад, використання в якості паролю осмислених
виразів робить можливим їх підбір по словнику. Ну а застосування всюди єдиного
ключового слова дозволяє зловмисникам проникати в добре захищені інформаційні
системи шляхом злому «слабких» в плані безпеки сервісів.
Розглянуті алгоритми оцінки стійкості пароля
дозволяють за якою-небудь певною ознакою оцінити стійкість пароля до злому. Для
цього кожним алгоритмом оцінки стійкості використовуються свій комплекс процедур,
званий аналізатором в алгоритмі, який направлений на вивчення самого пароля,
відповідність пароля яким-небудь поширеним «заготовкам». Незалежно від того, чи
використовується для порівняння база даних найпоширеніших паролів, звана
словником, до пароля пред'являються досить жорсткі вимоги, такі, як наявність
цифр, заголовних і рядкових букв, спеціальних символів, знаку підкреслення, а
так само фіксована довжина - починаючи з 8 символів (гарантує досить низьку
оцінку з боку аналізатора).
Не дивлячись на достатню кількість алгоритмів і
аналізаторів, лише одиниці з них надають клієнту можливість допустимості
генерації паролів, що містять кирилицю. Зміст символів різних шрифтів сприяє
багатократному збільшенню стійкості пароля, а рівно його ентропії.
В результаті виконання дипломної роботи була
розроблена система, яка виконує наступні функції:
. генерація пароля на основі псевдовипадкової
послідовності;
. генерація пароля на основі ключової фрази;
. оцінка стійкості пароля на основі алгоритму
Password Strength Meter.
Таким чином, ми одержуємо криптростійкий,
практично непіддатливої злому пароль, що не потребує запам'ятовування. У
будь-який момент, коли він нам знадобиться, ми використовуючи нашу систему,
зможемо легко його відновити.
Список літератури
1. Бобровский С. Delphi 7 - CПб.: Питер, 2005.
2. Бpaccap Ж. Coвpeмeннaя
кpиптoлoгия: Пep. c aнгл. М.: ПOЛИМEД, 1999.
. Гаевский А. Разработка
программных приложений на Delphi 6 - М.: Киев, 2000.
. Галисеев, Г.В. Программирование в
среде Delphi 8 for.NET. Самоучитель.: - М.: Издательский дом «Вильямс», 2004.
. Глинский Я.Н., Анохин В.Е.,
Ряжская В.А. Turbo Pascal 7.0 и Delphi. Учебное пособие. СПб.:
ДиаСофтЮП, 2003.
. Гофман В., Хомоненко А. Delphi 6. CПб.:
БХВ-Петербург, 2004.
. Дарахвелидзе П.Г., Марков Е.П.
Delphi - среда визуального программирования. СПб.: BHV - Санкт-Петербург, 1999.
. Жукoв И.Ю., Ивaнoв М.A.,
Ocмoлoвcкий C.A. Пpинципы пocтpoeния кpиптocтoйких гeнepaтopoв пceвдocлучaйных
кoдoв // Пpoблeмы инфopмaциoннoй бeзoпacнocти. Кoмпьютepныe cиcтeмы. 2001, №1.
. Зeнзин O.C., Ивaнoв М.A. Cтaндapт
кpиптoгpaфичecкoй зaщиты - AES. Кoнeчныe пoля. Cepия CКБ (cпeциaлиcту пo
кoмпьютepнoй бeзoпacнocти). Книгa 1. М.: КУДИЦ-OБPAЗ, 2002.
. Ивaнoв М.A., Чугункoв И.В.
Тeopия, пpимeнeниe и oцeнкa кaчecтвa гeнepaтopoв пceвдocлучaйных
пocлeдoвaтeльнocтeй. Cepия CКВ (cпeциaлиcту пo кoмпьютepнoй бeзoпacнocти).
Книгa 2. М.: КУДИЦ-OБPAЗ, 2003. 240 c. Гepacимeнкo В.A., Мaлюк A.A. Ocнoвы
зaщиты инфopмaции. М.: МИФИ, 1997.
. Калверт Ч. Delphi 5. Энциклопедия
пользователя. СПб.: ДиаСофтЮП, 2003.
. Климова Л.М. «Delphi 7.
Самоучитель. М.: ИД КУДИЦ-ОБРАЗ, 2005.
. Коцюбинский А.О., Грошев С.В.
Язык программирования Delphi 5 - М.: «Издательство Триумф», 1999.
. Леонтьев В. Delphi 5 - М.: Москва
«Олма-Пресс», 1999.
. Мадрел Тео. Разработка
пользовательского интерфейса/ Пер. с англ. - М.:ДМК, 2001.
. Немнюгин С.А. Программирование - CПб.: Питер, 2000.
. Озеров В. Delphi. Советы
программистов (2-е издание). - СПб.: Символ - Плюс, 2002.
. Пономарев В. Самоучитель Delphi 7. CПб.: БХВ-Петербург,
2005.
. Ревнич Ю.В. Нестандартные приемы
программирования на Delphi. - СПб.: БХВ-Петербург, 2005.
. Ремизов Н. Delphi - CПб.: Питер, 2000.
. Фараонов В. Система
программирования Delphi. CПб.: БХВ-Петербург, 2005.
. Ханекамп Д. Вилькен П. Программирование
под Windows/ Пер. с нем. - М.: ЭКОМ, 1996.
. Хомоненко А. Д Delphi 7. CПб.:
БХВ-Петербург, 2005.
24. Fluhrer S.R. Statistical analysis
of the alleged RC4 keystream generator / S.R. Fluhrer, D.A. McGrew // Fast
Software Encryption, Cambridge Security Workshop Proceedings. - 2000.
25. Golic J. Dj. Linear models for
keystream generators / J. Dj. Golic // IEEE Transactions on Computers. - 1996.
26. j@alba.ua - адрес автора
. http://www.delphikingdom.ru // Королевство Delphi. Виртуальный клуб
программистов
. http://www.delphiworld.narod.ru
// Профессиональные
программы для разработчиков
. http://www.delphisources.ru // Программирование на Delphi
. http://www.delphibasics.ru // Справочник - «Основы Delphi»
31. http://www.delphimaster.ru //
Мастера Delphi