Разработка алгоритмов динамического масштабирования вычислительных сетей
ПЕРЕЧЕНЬ УСЛОВНЫХ ОБОЗНАЧЕНИЙ
ВС - вычислительная сеть
СУ - система управления
ИВС - информационно-вычислительные сети
СПД - сети передачи данных
ПО - программное обеспечение
ОС - операционная система
НСИ - несанкционированный сбор информации
БД - база данных
ССОП - сеть связи общего пользования
СЗИ - средство защиты информации
НДВ - недекларированная возможность
ТКС - телекоммуникационная система
ССОП - сеть связи общего пользования
ИБ - информационная безопасность
VPN - Virtual Private Network (виртуальная частная сеть)
СПРУ - Система принятия решения на управление
ЕСЭ - Единая сеть электросвязи
СС - Система связи
ПДВ - Предпринятые деструктивные воздействия
ВВЕДЕНИЕ
В настоящее время мир стоит на пути перехода к информационному обществу,
в котором производство и потребление информации являются важнейшим видом
деятельности, информация признается наиболее значимым ресурсом, а
информационная среда наряду с социальной и экологической становится новой
средой обитания человека.
Современный этап развития (ВС) предполагает их цифровизацию, интеграцию и
глобализацию, которые приводят к неизбежности применения широкого диапазона
открытых протоколов информационного обмена (сетевого взаимодействия), а также
технологий и оборудования преимущественно иностранных разработок (в том числе и
средств защиты), имеющих уязвимости и недекларированные возможности.
Естественным в условиях интеграции Единой сети электросвязи РФ и
международных телекоммуникаций, бурного развития технологий является рост
количества угроз информационной безопасности распределенным вычислительным
сетям (ВС) различных организаций, органов государственной власти, силовых и
других ведомств. Существенно возрастают потенциальные возможности
террористических организаций, отдельных злоумышленников по идентификации
элементов ВС и вскрытию ее структуры. Например, концепция «сетецентричной
войны» США предполагает использование (ВС) как арены боевых действий. В то же
время существующие методы и средства защиты предполагают лишь разграничение
доступа и обнаружение вторжений в локальные сегменты сетей, т. е.
осуществляется попытка установить границы на уровне локальных сегментов, а
информация о построении и развитии ВС остается незащищенной в виду
незащищенности технологической информации (информации развития) ВС и
отображения процессов ее обработки на информационном поле противодействующей
стороны. Информацией развития ВС являются топология и алгоритмы
функционирования ВС и ее элементов, используемое оборудование и программное
обеспечение, схемы информационных потоков и роль отдельных сегментов. Более
того, иерархия элементов и узлов ВС отражает структуру системы управления (СУ),
в интересах которой она создается. Это связано с тем, что элементы ВС и
процессы управления обладают характерными признаками. Наиболее ярким примером
этого является возможность с помощью перехвата и анализа информационных потоков
распределенной ВС получить их схему, отражающую в свою очередь структуру ВС, а
значит и структуру ее СУ.
Несмотря на значительные результаты теоретических и прикладных
исследований в области защиты информации в информационно-вычислительных
системах, в частности криптографическими методами, резервированием, методами
контроля межсетевого взаимодействия и т. п., недостаточно проработанной
остается проблема защиты распределенных ВС, использующих сети связи общего
пользования.
Учитывая, что во многих случаях объекты ВС оснащаются разнотипными
вычислительными средствами, существующие методы обеспечения информационной
безопасности с помощью шлюзов («защитных оболочек») не всегда эффективны и
легко подвержены деструктивным воздействиям типа «отказ в обслуживании». Это
связано с тем, что элементы распределенных ВС легко обнаруживаются при помощи
анализа информационных потоков, циркулирующих в каналах связи
телекоммуникационных систем.
Одним из основных требований к современной компьютерной сети является
требование к их масштабируемости, предполагающее способность сети быть
достаточно большой и сложной без снижения требуемого уровня ее
производительности, безопасности и управляемости.
Масштабируемость компьютерных сетей обеспечивается возможностью их
наращивания и объединения при наличии эффективных средств поддержки
информационно-компьютерной безопасности и сетевого управления.
В связи с разновидностью сетей, промежуточный канал может иметь различные
MTU, максимальный размер фрейма, который
может быть передан, и для того, что IP-пакеты могли передавать по сетям любых типов, предусмотрена
фрагментация, которая при необходимости передать пакет в следующую сеть
разбивает слишком длинные для конкретного типа составляющей сети сообщения на
более короткие пакеты с созданием соответствующих служебных полей, нужных для
последующей сборки фрагментов в исходное сообщение. Динамическое
масштабирование используется т.к. сеть связи общего пользования живет своей
жизнью и структура нашего объекта фактически все время меняется, в него могут
включаться разные фрагменты ССОП и соответственно с разными МТУ.
Отмеченное выше позволяет выделить сложившееся противоречие между
требованием по повышению эффективности защиты распределенных ВС от
деструктивных воздействий типа «отказ в обслуживании» и существующим уровнем
теоретических и практических исследований в этой области.
Данное противоречие позволяет констатировать проблему, заключающуюся в
разработке механизмов контроля корректности сборки пакетов.
Выявленное противоречие и существующая проблема обусловили выбор темы
данного исследования: «Разработка алгоритмов динамического масштабирования
вычислительных сетей» и ее актуальность.
1. АНАЛИЗ УСЛОВИЙ ФУНКЦИОНИРОВАНИЯ АВТОМАТИЗИРОВАННЫХ СИСТЕМ УПРАВЛЕНИЯ
.1 Анализ средств построения динамически масштабируемых вычислительных
сетей
Основная идея введения сетевого уровня состоит в следующем. Сеть в общем
случае рассматривается как совокупность нескольких сетей и называется сетью или
интерсетью (internetwork или internet). Сети, входящие в сеть, называются
подсетями (subnet), составляющими сетями или просто сетями (рис. 1).
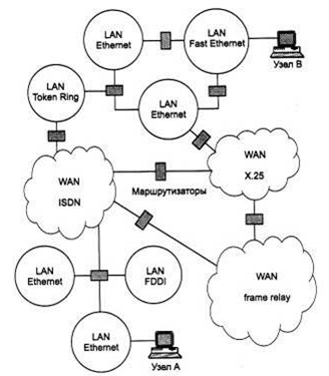
Рис. 1. Архитектура сети
Подсети соединяются между собой маршрутизаторами. Компонентами сети могут
являться как локальные, так и глобальные сети. Внутренняя структура каждой сети
на рисунке не показана, так как она не имеет значения при рассмотрении сетевого
протокола. Все узлы в пределах одной подсети взаимодействуют, используя единую
для них технологию. Так, в сеть, показанную на рисунке, входит несколько сетей
разных технологий: локальные сети Ethernet, Fast Ethernet, Token Ring, FDDI и
глобальные сети frame relay, X.25, ISDN. Каждая из этих технологий достаточна
для того, чтобы организовать взаимодействие всех узлов в своей подсети, но не
способна построить информационную связь между произвольно выбранными узлами,
принадлежащими разным подсетям, например между узлом А и узлом В на рис. 1.
Следовательно, для организации взаимодействия между любой произвольной парой
узлов этой «большой» сети требуются дополнительные средства. Такие средства и
предоставляет сетевой уровень.
Хотя многие технологии локальных сетей (Ethernet, Token Ring, FDDI, Fast
Ethernet и др.) используют одну и ту же систему адресации узлов на основе
МАС-адресов, существует немало технологий (X.25, АТМ, frame relay), в которых
применяются другие схемы адресации. Адреса, присвоенные узлам в соответствии с
технологиями подсетей, называют локальными. Чтобы сетевой уровень мог выполнить
свою задачу, ему необходима собственная система адресации, не зависящая от
способов адресации узлов в отдельных подсетях, которая позволила бы на сетевом
уровне универсальным и однозначным способами идентифицировать любой узел сети.
Естественным способом формирования сетевого адреса является уникальная
нумерация всех подсетей сети и нумерация всех узлов в пределах каждой подсети.
Таким образом, сетевой адрес представляет собой пару: номер сети (подсети) и номер
узла.
Данные, которые поступают на сетевой уровень и которые необходимо
передать через сеть, снабжаются заголовком сетевого уровня. Данные вместе с
заголовком образуют пакет. Заголовок пакета сетевого уровня имеет
унифицированный формат, не зависящий от форматов кадров канального уровня тех
сетей, которые могут входить в объединенную сеть, и несет наряду с другой
служебной информацией данные о номере сети, которой предназначается этот пакет.
Сетевой уровень определяет маршрут и перемещает пакет между подсетями.
При передаче пакета из одной подсети в другую пакет сетевого уровня,
инкапсулированный в прибывший канальный кадр первой подсети, освобождается от
заголовков этого кадра и окружается заголовками кадра канального уровня
следующей подсети. Информацией, на основе которой делается эта замена, являются
служебные поля пакета сетевого уровня. В поле адреса назначения нового кадра
указывается локальный адрес следующего маршрутизатора.
Основным полем заголовка сетевого уровня является номер сети-адресата. В
рассмотренных нами ранее протоколах локальных сетей такого поля в кадрах
предусмотрено не было - предполагалось, что все узлы принадлежат одной сети.
Явная нумерация сетей позволяет протоколам сетевого уровня составлять точную
карту межсетевых связей и выбирать рациональные маршруты при любой их
топологии, в том числе альтернативные маршруты, если они имеются, что не умеют
делать мосты и коммутаторы.
Кроме номера сети заголовок сетевого уровня должен содержать и другую
информацию, необходимую для успешного перехода пакета из сети одного типа в
сеть другого типа. К такой информации может относиться, например:
номер фрагмента пакета, необходимый для успешного проведения операций
сборки-разборки фрагментов при соединении сетей с разными максимальными
размерами пакетов;
время жизни пакета, указывающее, как долго он путешествует по интерсети,
это время может использоваться для уничтожения «заблудившихся» пакетов;
качество услуги - критерий выбора маршрута при межсетевых передачах -
например, узел-отправитель может потребовать передать пакет с максимальной
надежностью, возможно, в ущерб времени доставки.
Когда две или более сети организуют совместную транспортную службу, то
такой режим взаимодействия обычно называют межсетевым взаимодействием
(internetworking).
Важнейшей задачей сетевого уровня является маршрутизация - передача
пакетов между двумя конечными узлами в сети.
рассмотрим процесс маршрутизации на примере.
Допустим (см. рис. 2.), хосты А и В находятся в сети 1, сеть 1
соединяется с сетью 2 с помощью маршрутизатора G1. К сети 2 подключен
маршрутизатор G2, соединяющий ее с сетью 3, в которой находится хост С.

Рис. 2. Пример маршрутизации
Таблица маршрутов хоста А выглядит, например, так:
Сеть 1 А
Прочие сети G1
Это означает, что дейтаграммы, адресованные узлам сети 1, отправляет сам
хост А (так как это его локальная сеть), а дейтаграммы, адресованные в любую
другую сеть (это называется маршрут по умолчанию), хост А отправляет
маршрутизатору G1, чтобы тот занялся их дальнейшей судьбой.
Предположим, хост А посылает дейтаграмму хосту В. В этом случае,
поскольку адрес В принадлежит той же сети, что и А, из таблицы маршрутов хоста
А определяется, что доставка осуществляется непосредственно самим хостом А.
Если хост А отправляет дейтаграмму хосту С, то он определяет по IP-адреcу
C, что хост С не принадлежит к сети 1. Согласно таблице маршрутов А, все
дейтаграммы с пунктами назначения, не принадлежащими сети 1, отправляются на
маршрутизатор G1 (это называется маршрут по умолчанию). При этом хост А не
знает, что маршрутизатор G1 будет делать с его дейтаграммой и каков будет ее
дальнейший маршрут - это забота исключительно G1. G1 в свою очередь по своей
таблице маршрутов определяет, что все дейтаграммы, адресованные в сеть 3,
должны быть пересланы на маршрутизатор G2. Это может быть как явно указано в
таблице, находящейся на G1, в виде Сеть 3 G2, так и указано в виде маршрута по
умолчанию.
На этом функции G1 заканчиваются, дальнейший путь дейтаграммы ему
неизвестен и его не интересует. Маршрутизатор G2, получив дейтаграмму,
определяет, что она адресована в одну из сетей (№3), к которым он присоединен
непосредственно, и доставляет дейтаграмму на хост С.
Фрагментация IP-пакетов
Протокол IP позволяет выполнять фрагментацию пакетов, поступающих на
входные порты маршрутизаторов.
Следует различать фрагментацию сообщений в узле-отправителе и
динамическую фрагментацию сообщений в транзитных узлах сети - маршрутизаторах.
Практически во всех стеках протоколов есть протоколы, которые отвечают за
фрагментацию сообщений прикладного уровня на такие части, которые укладываются
в кадры канального уровня. В стеке TCP/IP эту задачу решает протокол TCP,
который разбивает поток байтов, передаваемый ему с прикладного уровня на
сообщения нужного размера (например, на 1460 байт для протокола Ethernet).
Поэтому протокол IP в узле-отправителе не использует свои возможности по
фрагментации пакетов.
А вот при необходимости передать пакет в следующую сеть, для которой
размер пакета является слишком большим, IP-фрагментация становится необходимой.
В функции уровня IP входит разбиение слишком длинного для конкретного типа
составляющей сети сообщения на более короткие пакеты с созданием
соответствующих служебных полей, нужных для последующей сборки фрагментов в
исходное сообщение.
В большинстве типов локальных и глобальных сетей значения MTU, то есть
максимальный размер поля данных, в которое должен инкапсулировать свой пакет
протокол IP, значительно отличается. Сети Ethernet имеют значение MTU, равное
1500 байт, сети FDDI - 4096 байт, а сети Х.25 чаще всего работают с MTU в 128
байт.пакет может быть помечен как не фрагментируемый. Любой пакет, помеченный
таким образом, не может быть фрагментирован модулем IP ни при каких условиях.
Если же пакет, помеченный как не фрагментируемый, не может достигнуть
получателя без фрагментации, то этот пакет просто уничтожается, а
узлу-отправителю посылается соответствующее ICMP-сообщение.
Протокол IP допускает возможность использования в пределах отдельной
подсети ее собственных средств фрагментирования, невидимых для протокола IP.
Например, технология АТМ делит поступающие IP-пакеты на ячейки с полем данных в
48 байт с помощью своего уровня сегментирования, а затем собирает ячейки в
исходные пакеты на выходе из сети. Но такие технологии, как АТМ более
перспективны, т.к. создают регулярный поток заявок на входы обслуживающих
приборов - узлов сети.
Процедуры фрагментации и сборки протокола IP рассчитаны на то, чтобы
пакет мог быть разбит на практически любое количество частей, которые
впоследствии могли бы быть вновь собраны. Получатель фрагмента использует поле
идентификации для того, чтобы не перепутать фрагменты различных пакетов. Модуль
IP, отправляющий пакет, устанавливает в поле идентификации значение, которое
должно быть уникальным для данной пары отправитель - получатель, а также время,
в течение которого пакет может быть активным в сети.
Поле смещения фрагмента сообщает получателю положение фрагмента в
исходном пакете. Смещение фрагмента и длина определяют часть исходного пакета,
принесенную этим фрагментом. Флаг «more fragments» показывает появление
последнего фрагмента. Модуль протокола IP, отправляющий неразбитый на фрагменты
пакет, устанавливает в нуль флаг «more fragments» и смещение во фрагменте.
Чтобы разделить на фрагменты большой пакет, модуль протокола IP,
установленный, например, на маршрутизаторе, создает несколько новых пакетов и
копирует содержимое полей IP-заголовка из большого пакета в IP-заголовки всех
новых пакетов. Данные из исходного пакета делятся на соответствующее число
частей, размер каждой из которых, кроме самой последней, обязательно должен
быть кратным 8 байт. Размер последней части данных равен полученному остатку.
Каждая из полученных частей данных помещается в новый пакет. Когда
происходит фрагментация, то некоторые параметры IP-заголовка копируются в
заголовки всех фрагментов, а другие остаются лишь в заголовке первого
фрагмента. Процесс фрагментации может изменить значения данных, расположенных в
поле параметров, и значение контрольной суммы заголовка, изменить значение
флага «more fragments» и смещение фрагмента, изменить длину IP-заголовка и
общую длину пакета, В заголовок каждого пакета заносятся соответствующие
значения в поле смещения «fragment offset», а в поле общей длины пакета
помещается длина каждого пакета. Первый фрагмент будет иметь в поле «fragment
offset» нулевое значение. Во всех пакетах, кроме последнего, флаг «more
fragments» устанавливается в единицу, а в последнем фрагменте - в нуль.
Чтобы собрать фрагменты пакета, модуль протокола IP (например, модуль на
хост - компьютере) объединяет IP-пакеты, имеющие одинаковые значения в полях
идентификатора, отправителя, получателя и протокола. Таким образом, отправитель
должен выбрать идентификатор таким образом, чтобы он был уникален для данной
пары отправитель-получатель, для данного протокола и в течение того времени,
пока данный пакет (или любой его фрагмент) может существовать в IP-сети.
Очевидно, что модуль протокола IP, отправляющий пакеты, должен иметь
таблицу идентификаторов, где каждая запись соотносится с каждым отдельным
получателем, с которым осуществлялась связь, и указывает последнее значение
максимального времени жизни пакета в IP-сети. Однако, поскольку поле
идентификатора допускает 65 536 различных значений, некоторые хосты могут
использовать просто уникальные идентификаторы, не зависящие от адреса
получателя.
Процедура объединения заключается в помещении данных из каждого фрагмента
в позицию, указанную в заголовке пакета в поле «fragment offset».
Каждый модуль IP должен быть способен передать пакет из 68 байт без
дальнейшей фрагментации. Это связано с тем, что IP-заголовок может включать до
60 байт, а минимальный фрагмент данных - 8 байт. Каждый получатель должен быть
в состоянии принять пакет из 576 байт в качестве единого куска либо в виде
фрагментов, подлежащих сборке.
Если бит флага запрета фрагментации (Don't Fragment, DF) установлен, то
фрагментация данного пакета запрещена, даже если в этом случае он будет
потерян. Данное средство может использоваться для предотвращения фрагментации в
тех случаях, когда хост - получатель не имеет достаточных ресурсов для сборки
фрагментов.
Работа протокола IP по фрагментации пакетов в хостах и маршрутизаторах
иллюстрируется на рис. 3.
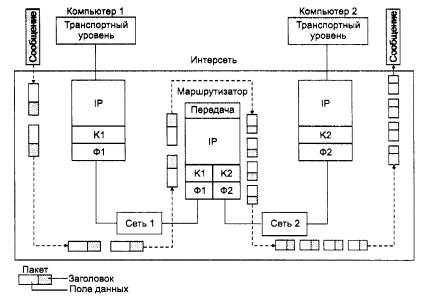
Рис.3. Фрагментация IP-пакетов при передаче между сетями с разным
максимальным размером пакетов: К1 и 01 - канальный и физический уровень сети 1;
К2 и Ф2 - канальный и физический уровень сети 2
Пусть компьютер 1 связан с сетью, имеющей значение MTU в 4096 байт,
например с сетью FDDI, При поступлении на IP-уровень компьютера 1 сообщения от
транспортного уровня размером в 5600 байт протокол IP делит его на два
IP-пакета, устанавливая в первом пакете признак фрагментации и присваивая
пакету уникальный идентификатор, например 486, В первом пакете величина поля
смещения равна 0, а во втором - 2800. Признак фрагментации во втором пакете
равен нулю, что показывает, что это последний фрагмент пакета. Общая величина
IP-пакета составляет 2800 плюс 20 (размер IP-заголовка), то есть 2820 байт, что
умещается в поле данных кадра FDDI. Далее модуль IP компьютера 1 передает эти
пакеты своему сетевому интерфейсу (образуемому протоколами канального уровня К
1 и физического уровня Ф1), Сетевой интерфейс отправляет кадры следующему
маршрутизатору.
После того, как кадры пройдут уровень сетевого интерфейса маршрутизатора
(К1 и Ф1) и освободятся от заголовков FDDI, модуль IP по сетевому адресу
определяет, что прибывшие два пакета нужно передать в сеть 2, которая является
сетью Ethernet и имеет значение MTU, равное 1500. Следовательно, прибывшие
IP-пакеты необходимо фрагментировать. Маршрутизатор извлекает поле данных из
каждого пакета и делит его еще пополам, чтобы каждая часть уместилась в поле
данных кадра Ethernet. Затем он формирует новые IP-пакеты, каждый из которых имеет
длину 1400 + 20 - 1420 байт, что меньше 1500 байт, поэтому они нормально
помещаются в поле данных кадров Ethernet.
В результате в компьютер 2 по сети Ethernet приходят четыре IP-пакета с
общим идентификатором 486, что позволяет протоколу IP, работающему в компьютере
2, правильно собрать исходное сообщение. Если пакеты пришли не в том порядке, в
котором были посланы, то смещение укажет правильный порядок их объединения.
Отметим, что IP-маршрутизаторы не собирают фрагменты пакетов в более
крупные пакеты, даже если на пути встречается сеть, допускающая такое
укрупнение. Это связано с тем, что отдельные фрагменты сообщения могут
перемещаться по интерсети по различным маршрутам, поэтому нет гарантии, что все
фрагменты проходят через какой-либо промежуточный маршрутизатор на их пути.
При приходе первого фрагмента пакета узел назначения запускает таймер,
который определяет максимально допустимое время ожидания прихода остальных
фрагментов этого пакета. Таймер устанавливается на максимальное из двух
значений: первоначальное установочное время ожидания и время жизни, указанное в
принятом фрагменте. Таким образом, первоначальная установка таймера является
нижней границей для времени ожидания при сбое. Если таймер истекает раньше
прибытия последнего фрагмента, то все ресурсы сборки, связанные с данным
пакетом, освобождаются, все полученные к этому моменту фрагменты пакета
отбрасываются, а в узел, пославший исходный пакет, направляется сообщение об
ошибке с помощью протокола ICMP.
MTU
Максимальный блок передачи
(maximum transmission unit, MTU). Большинство типов сетей определяют верхний предел.
Если IP хочет отослать датаграмму, которая больше чем MTU канального
уровня, осуществляется фрагментация (fragmentation), при этом датаграмма
разбивается на меньшие части (фрагменты). Каждый фрагмент должен быть меньше
чем MTU.
На рисунке 4 приведен список некоторых типичных значений MTU. Здесь
приведены MTU для каналов точка-точка (таких как SLIP или PPP), однако они не
являются физической характеристикой среды передачи. Это логическое ограничение,
при соблюдении которого обеспечивается адекватное время отклика при диалоговом
использовании.

Рисунок
4. Типичные значения максимальных блоков передачи (MTU)
Транспортный
MTU
Когда
общаются два компьютера в одной и той же сети, важным является MTU для этой
сети. Однако, когда общаются два компьютера в разных сетях, каждый
промежуточный канал может иметь различные MTU. В данном случае важным является
не MTU двух сетей, к которым подключены компьютеры, а наименьший MTU любого
канала данных, находящегося между двумя компьютерами. он называется
транспортным MTU (path MTU).
Когда
IP датаграмма фрагментирована, она не собирается вновь до тех пор, пока не
достигнет конечного пункта назначения. (Для некоторых других сетевых протоколов
процесс повторной сборки отличается от описанного выше, при этом повторная
сборка осуществляется на маршрутизаторе следующей пересылки, а не в конечном
пункте назначения.) На уровне IP сборка осуществляется в конечном пункте назначения.
Это сделано для того, чтобы сделать фрагментацию и повторную сборку прозрачной
для транспортных уровней (TCP и UDP), хотя это может вести к некоторой потере
производительности. Существует вероятность, что фрагмент датаграммы будет снова
фрагментирован (возможно даже несколько раз). Информации, которая содержится в
IP заголовке вполне достаточно для фрагментации и повторной сборки.
1.2 Атаки, основанные на IP-Фрагментации и защита от них
Атака крошечными фрагментами (Tiny Fragment Attack)
В случае, когда на вход фильтрующего маршрутизатора поступает
фрагментированная датаграмма, маршрутизатор производит досмотр только первого
фрагмента датаграммы (первый фрагмент определяется по значению поля
IP-заголовка Fragment Offset=0). Если первый фрагмент не удовлетворяет условиям
пропуска, он уничтожается. Остальные фрагменты можно безболезненно пропустить,
не затрачивая на них вычислительные ресурсы фильтра, поскольку без первого
фрагмента датаграмма все равно не может быть собрана на узле назначения.
При конфигурировании фильтра перед сетевым администратором часто стоит
задача: разрешить соединения с TCP-сервисами Интернет, инициируемые
компьютерами внутренней сети, но запретить установление соединений внутренних
компьютеров с внешними по инициативе последних. Для решения поставленной задачи
фильтр конфигурируется на запрет пропуска TCP-сегментов, поступающих из внешней
сети и имеющих установленный бит SYN в отсутствии бита ACK; сегменты без этого
бита беспрепятственно пропускаются в охраняемую сеть, поскольку они могут
относиться к соединению, уже установленному ранее по инициативе внутреннего
компьютера.
Рассмотрим, как злоумышленник может использовать фрагментацию, чтобы
обойти это ограничение, то есть, передать SYN-сегмент из внешней сети во
внутреннюю.
Злоумышленник формирует искусственно фрагментированную датаграмму с
TCP-сегментом, при этом первый фрагмент датаграммы имеет минимальный размер
поля данных - 8 октетов (напомним, что размеры фрагментов указываются в
8-октетных блоках). В поле данных датаграммы находится TCP-сегмент,
начинающийся с TCP-заголовка. В первых 8 октетах TCP-заголовка находятся номера
портов отправителя и получателя и поле Sequence Number, но значения флагов не
попадут в первый фрагмент. Следовательно, фильтр пропустит первый фрагмент
датаграммы, а остальные фрагменты он проверять не будет. Таким образом,
датаграмма с SYN-сегментом будет успешно доставлена на узел назначения и после
сборки передана модулю TCP.
На рис. 6. пример датаграммы из 2 фрагментов (IP-заголовки выделены серым).
В поле данных первого фрагмента находится 8 октетов TCP-заголовка. В поле
данных второго фрагмента помещена остальная часть TCP-заголовка с флагом SYN.
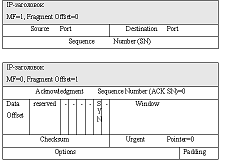
Рис. 6. Фрагментированный TCP-сегмент
Описанный выше прием проникновения сквозь фильтр называется «Tiny
Fragment Attack» (RFC-1858). Использование его в других случаях (для обхода
других условий фильтрации) не имеет смысла, так как все остальные «интересные»
поля в заголовке TCP и других протоколов находятся в первых 8 октетах заголовка
и, следовательно, не могут быть перемещены во второй фрагмент.
Для защиты от этой атаки фильтрующему маршрутизатору, естественно, не
следует инспектировать содержимое не первых фрагментов датаграмм - это было бы
равносильно сборке датаграмм на промежуточном узле, что быстро поглотит все
вычислительные ресурсы маршрутизатора. Достаточно реализовать один из двух
следующих подходов:
) не пропускать датаграммы с Fragment Offset=0 и Protocol=6 (TCP), размер
поля данных которых меньше определенной величины, достаточной, чтобы вместить
все «интересные поля» (например, 20);
) не пропускать датаграммы с Fragment Offset=1 и Protocol=6 (TCP):
наличие такой датаграммы означает, что TCP-сегмент был фрагментирован с целью
скрыть определенные поля заголовка и что где-то существует первый фрагмент с 8
октетами данных. Несмотря на то, что в данном случае первый фрагмент будет
пропущен, узел назначения не сможет собрать датаграмму, так как фильтр
уничтожил второй фрагмент.
Отметим, что поскольку в реальной жизни никогда не придется
фрагментировать датаграмму до минимальной величины, риск потерять легальные
датаграммы, применив предложенные выше методы фильтрации, равен нулю.
Второй аспект фрагментации, интересный с точки зрения безопасности, - накладывающиеся
(overlapping) фрагменты. Рассмотрим пример датаграммы, несущей TCP-сегмент и
состоящей из двух фрагментов (рис.7, IP-заголовок выделен серым цветом). В поле
данных первого фрагмента находится полный TCP-заголовок, без опций, дополненный
нулями до размера, кратного восьми октетам. В поле данных второго фрагмента -
часть другого TCP-заголовка, начиная с девятого по порядку октета, в котором
установлен флаг SYN.
Видно, что второй фрагмент накладывается на первый (первый фрагмент
содержит октеты 0-23 данных исходной датаграммы, а второй фрагмент начинается с
октета 8, потому что его Fragment Offset=1). Поведение узла назначения,
получившего такую датаграмму, зависит от реализации модуля IP. Часто при сборке
датаграммы данные второго, накладывающегося фрагмента записываются поверх
предыдущего фрагмента. Таким образом, при сборке приведенной в примере
датаграммы в TCP-заголовке переписываются поля начиная с ACK SN в соответствии
со значениями из второго фрагмента, и в итоге получается SYN-сегмент.
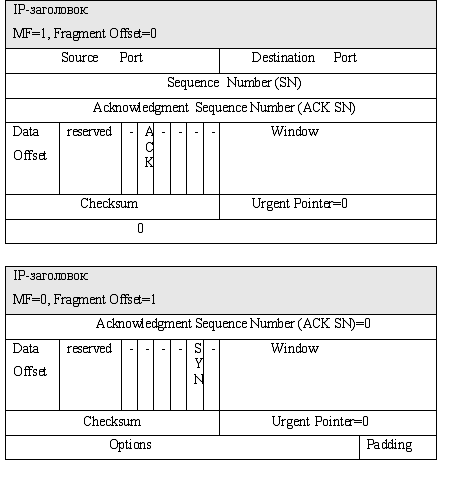
Рис. 7. Накладывающиеся фрагменты
Если для защиты от Tiny Fragment Attack применяется подход 1) из
описанных выше (инспекция первого фрагмента датаграммы), то с помощью
накладывающихся фрагментов злоумышленник может обойти эту защиту.
Маршрутизатор, применяющий второй подход, будет успешно противостоять
Tiny Fragment Attack с накладывающимися фрагментами.
Фрагментация и фильтрация пакетов.
Поскольку фильтрация подразумевает под собой пропуск в сеть одних
пакетов, и блокировку других, то при фрагментации в сеть смогут попасть только
те фрагменты, которые не содержат заголовков блокируемых пакетов (tcp, udp или
icmp), так как защищающее сеть устройство фильтрации неспособно анализировать
состояние поля заголовка. Состояние, явно говорит о том, что блокироваться
должны все фрагменты, идентификаторы которых совпадают с идентификатором
заблокированного фрагмента. Однако некоторые сетевые устройства не сохраняют
эту информацию, так как анализируют последующие после заблокированного
фрагмента пакеты, как отдельные, самостоятельные и не проводят аналогии с
предшествующими или последующими пакетами. Такой принцип работы некоторых
сетевых устройств связан с тем, что приходиться анализировать каждый пакет, на
что необходимы соответствующие ресурсы, как временные так и
программно-аппаратные, что не всегда является приемлемым для устройств
подобного класса. Намного проще создать более упрощенную архитектуру которая
будет работать во много раз быстрее.
У нас возникла ситуация, когда в сеть пропускаются пакеты, которые не
отвечают критериям блокировки, так как отсутствует заголовок идентифицирующий
принадлежность пакета к тому или иному виду трафика (tcp, udp, icmp).
Если датаграмма с установленным флагом пересекает сеть, где необходима
фрагментация, маршрутизатор выясняет это и возвращает посылающему хосту ICMP
сообщение об ошибке. Данное сообщение указывает MTU сети, требующей
фрагментации (данное ошибочное сообщение может использоваться атакующим для
выяснения MTU некоторого сегмента сети где находится интересующая его цель и
впоследствии может применять это значение для своих целей, например, для
генерирования своих пакетов с данным MTU с целью обхода брандмауэра). Некоторые
хосты в зависимости от используемой на них ОС (соответствующего стэка tcp/ip),
намеренно посылают в сеть начальную датаграмму с установленным флагом
фрагментации, определяя MTU на пути к хосту назначения. Если сообщение об
ошибке ICMP возвращается с меньшим MTU, хостом производится пакетирование
датаграмм, предназначенных для хоста назначения, в группы, которые малы, чтобы
избежать фрагментации. В связи с этим фрагментация снижает эффективность работы
сети в целом, поскольку при потере одного фрагмента нужно посылать опять их
всех (на данной особенности строятся атаки типа «затопления» фрагментированными
пакетами).
1.3 Постановка задачи на поиск новых технических решений,
выводы
Атаки отказа в обслуживании основаны на использовании большого количества
фрагментированных пакетов, что приводит к чрезмерной трате ресурсов атакованной
ИВС. Большинство систем обнаружения атак и фильтры пакетов сообщений не
поддерживают проверки фрагментированных пакетов или не выполняют их правильной
сборки и поэтому не в состоянии выявить компьютерные атаки (а значит, и
заблокировать опасный трафик), распределенные среди нескольких
фрагментированных пакетов сообщений.
Отмеченное выше позволяет выделить сложившееся противоречие между
требованием по повышению эффективности обнаружения компьютерных атак и
необходимостью агрегирования гетерогенных ИВС. Указанное противоречие
усугубляется возможностью сокрытия атак в отдельных фрагментах пакетов
сообщений.
Данное противоречие позволяет констатировать задачу, заключающуюся в
разработке алгоритмов защиты масштабируемых ИВС.
Цель исследования - повышение защищенности ИВС от деструктивных
(преднамеренных и непреднамеренных) программных воздействий, связанных с
некорректной фрагментацией пакетов сообщений.
вычислительный сеть атака фрагментированный
2. Анализ алгоритмов защиты ИВС от деструктивных программных
воздействий, связанных с некорректной фрагментацией пакетов сообщений
.1 Атаки на информационно-вычислительно сети
Атакой (attack, intrusion) на информационную систему называется действие
или последовательность связанных между собой действий нарушителя, которые
приводят к реализации угрозы путем использования уязвимостей этой
информационной системы. Другими словами, если бы можно было устранить
уязвимости информационных систем, то тем самым была бы устранена и возможность
реализации атак.
На сегодняшний день неизвестно, сколько существует методов атак. Связано
это в первую очередь с тем, что до сих пор отсутствуют какие-либо серьезные
математические исследования в этой области. Из близких по тематике исследований
можно назвать работу, написанную в 1996 году Фредом Коэном, в которой описаны
математические основы вирусной технологии. Как один из результатов этой работы
приведено доказательство бесконечности числа вирусов. То же можно сказать и об
атаках, поскольку вирусы - одно из подмножеств атак.
Модели атак
Традиционная модель атаки строится по принципу "один к одному"
(рис. 1.) или "один ко многим" (рис. 2.), т. е. атака исходит из
одного источника. Разработчики сетевых средств защиты (межсетевых экранов,
систем обнаружения атак и т. д.) ориентированы именно на традиционную модель
атаки. В различных точках защищаемой сети устанавливаются агенты (сенсоры)
системы защиты, которые передают информацию на центральную консоль управления.
Это облегчает масштабирование системы, упрощает удаленное управление и т. д.
Однако такая модель не справляется с относительно недавно (в 1998 году)
обнаруженной угрозой - распределенными атаками.

В модели распределенной или скоординированной (distributed или
coordinated attack) атаки используются иные принципы. В отличие от традиционной
модели "один к одному" и "один ко многим", в распределенной
модели используются принципы "многие к одному" и "много ко
многим" (рис. 3 и 4 соответственно).

Распределенные атаки основаны на "классических" атаках типа
"отказ в обслуживании", которые будут рассмотрены ниже, а точнее, на
их подмножестве, известном как Flood- или Storm-атаки (указанные термины можно
перевести как "шторм", "наводнение" или
"лавина"). Смысл данных атак заключается в посылке большого
количества пакетов на заданный узел или сегмент сети (цель атаки), что может
привести к выведению этого узла или сегмента из строя, поскольку он захлебнется
в лавине посылаемых пакетов и не сможет обрабатывать запросы авторизованных
пользователей. По такому принципу работают атаки SYN-Flood, Smurf, UDP Flood,
Targa3 и т. д. Однако в том случае, если пропускная способность канала до цели
атаки превышает пропускную способность атакующего или целевой узел некорректно
сконфигурирован, то "успеха" такая атака не достигнет. Скажем, с
помощью этих атак бесполезно пытаться нарушить работоспособность своего
провайдера. В случае же распределенной атаки ситуация коренным образом
меняется. Атака происходит уже не из одной точки интернета, а сразу из
нескольких, что приводит к резкому возрастанию трафика и выведению атакуемого
узла из строя. Например, по данным "России-Онлайн", в течение двух
суток, начиная с 9 часов утра 28 декабря 2000 г. крупнейший интернет-провайдер
Армении "Арминко" подвергался распределенной атаке. В данном случае к
атаке подключилось более 50 машин из разных стран, которые посылали по адресу
"Арминко" бессмысленные сообщения. Кто организовал эту атаку и в
какой стране находился хакер, установить было невозможно. Хотя атаке подвергся
в основном "Арминко", перегруженной оказалась вся магистраль, соединяющая
Армению с Всемирной Паутиной. 30 декабря благодаря сотрудничеству
"Арминко" и другого провайдера -- "АрменТел" связь была
полностью восстановлена. Компьютерная атака, правда, продолжалась, но с меньшей
интенсивностью.
Этапы реализации атак
Можно выделить следующие этапы реализации атаки: предварительные
действия, или сбор информации (information gathering), реализация атаки
(exploitation) и завершение атаки. Обычно когда говорят об атаке, то
подразумевают именно второй этап, забывая о первом и последнем. Сбор информации
и завершение атаки ("заметание следов") в свою очередь также могут
являться атакой и могут быть разделены на три этапа (рис. 5).

Основной этап - это сбор информации. Именно эффективность работы
злоумышленника на данном этапе является залогом "успешности" атаки. В
первую очередь выбирается цель атаки и собирается информация о ней (тип и
версия операционной системы, открытые порты и запущенные сетевые сервисы,
установленное системное и прикладное программное обеспечение и его конфигурация
и т. д.). Затем идентифицируются наиболее уязвимые места атакуемой системы,
воздействие на которые приводит к нужному злоумышленнику результату.
Межсетевые экраны неэффективны против множества атак.
На первом этапе злоумышленник пытается выявить все каналы взаимодействия
цели атаки с другими узлами. Это позволит выбрать не только тип реализуемой
атаки, но и источник ее реализации. Например, атакуемый узел взаимодействует с
двумя серверами под управлением ОС Unix и Windows NT. С одним сервером
атакуемый узел имеет "доверительные" отношения, а с другим - нет. От
того, через какой сервер злоумышленник будет реализовывать нападение, зависит,
какая атака будет задействована, какое средство реализации будет выбрано, и т.
д. Затем, в зависимости от полученной информации и преследуемых целей,
выбирается атака, дающая наибольший эффект. Например, для нарушения
функционирования узла можно использовать SYN Flood, Teardrop, UDP Bomb и т. д.,
а для проникновения на узел и кражи информации - CGI-скрипт PHF для кражи файла
паролей, удаленный подбор пароля и т. п. Затем наступает второй этап -
реализация выбранной атаки.
Традиционные средства защиты, такие, как межсетевые экраны или механизмы
фильтрации в маршрутизаторах, вступают в действие на втором этапе, совершенно
"забывая" о первом и третьем. Это приводит к тому, что зачастую
совершаемую атаку очень трудно остановить даже при наличии мощных и дорогих
средств защиты. Пример тому - распределенные атаки. Логично было бы, чтобы
средства защиты начинали работать еще на первом этапе, т. е. предотвращали бы
саму возможность сбора информации об атакуемой системе, что могло бы
существенно затруднить действия злоумышленника. Традиционные средства не
позволяют также обнаружить уже совершенные атаки и оценить ущерб после их
реализации (третий этап) и, следовательно, определить меры по предотвращению
подобных атак в будущем.
В зависимости от искомого результата нарушитель концентрируется на том
или ином этапе. Например, для отказа в обслуживании он в первую очередь
подробно анализирует атакуемую сеть и выискивает в ней лазейки и слабые места
для атаки на них и выведения узлов сети из строя. Для хищения информации
злоумышленник основное внимание уделяет незаметному проникновению на анализируемые
узлы при помощи обнаруженных ранее уязвимостей.
Рассмотрим основные механизмы реализации атак. Это необходимо, чтобы
разобраться в методах обнаружения этих атак. Кроме того, понимание принципов
действий злоумышленников - залог успешной обороны вашей сети.
Сбор информации
Первый этап реализации атак -- это сбор информации об атакуемых системе
или узле, т. е. определение сетевой топологии, типа и версии операционной
системы атакуемого узла, а также доступных сетевых и иных сервисов и т. п. Эти
действия реализуются различными методами.
Изучение окружения.
На этом этапе нападающий исследует сетевое окружение предполагаемой цели
атаки, например узлы интернет-провайдера атакуемой компании или узлы ее
удаленного офиса. Злоумышленник может пытаться определить адреса
"доверенных" систем (скажем, сеть партнера) и узлов, которые напрямую
соединены с целью атаки (например, маршрутизатор ISP) и т. д. Такие действия
трудно обнаружить, поскольку они выполняются в течение довольно длительного
времени, причем снаружи области, контролируемой средствами защиты (межсетевыми
экранами, системами обнаружения атак и т. п.).
Идентификация топологии сети.
Множество атак безгранично.
Многие из этих методов используются современными системами управления
(например, HP OpenView, Cabletron SPECTRUM, MS Visio и др.) для построения карт
сети. И эти же методы могут быть с успехом применены злоумышленниками для
построения карты атакуемой сети.
Идентификация узлов.
Идентификация узла (host detection), как правило, осуществляется путем
посылки при помощи утилиты ping команды ECHO_REQUEST протокола ICMP. Ответное
сообщение ECHO_REPLY говорит о том, что узел доступен. Существуют свободно
распространяемые программы, которые автоматизируют и ускоряют процесс
параллельной идентификации большого числа узлов, например, fping или nmap.
Опасность данного метода в том, что стандартными средствами узла запросы
ECHO_REQUEST не фиксируются. Для этого необходимы средства анализа трафика,
межсетевые экраны или системы обнаружения атак.
Это самый простой метод идентификации узлов, но он имеет ряд недостатков.
Во-первых, многие сетевые устройства и программы блокируют ICMP-пакеты и не
пропускают их во внутреннюю сеть (или, наоборот, не пропускают их наружу).
Например, MS Proxy Server 2.0 не разрешает прохождение пакетов по протоколу
ICMP. В результате не получается полной картины. С другой стороны, блокировка
ICMP-пакета говорит злоумышленнику о наличии "первой линии обороны" -
маршрутизаторов, межсетевых экранов и т. д. Во-вторых, использование ICMP-запросов
позволяет с легкостью обнаружить их источник, в чем, разумеется, злоумышленник
вовсе не заинтересован.
Существует еще один метод определения узлов сети - использование
"смешанного" ("promiscuous") режима сетевой карты, который
позволяет определить различные узлы в сегменте сети. Но он неприменим в тех
случаях, когда трафик сегмента сети недоступен нападающему со своего узла, т.
е. этот метод годится только для локальных сетей. Другим способом идентификации
узлов сети является так называемая разведка DNS, позволяющая идентифицировать
узлы корпоративной сети при помощи обращения к серверу службы имен.
Идентификация сервисов и сканирование портов.
Идентификация сервисов (service detection), как правило, осуществляется
путем обнаружения открытых портов (port scanning). Такие порты очень часто
связаны с сервисами, основанными на протоколах TCP или UDP. Например, открытый
80-й порт подразумевает наличие Web-сервера, 25-й порт -- почтового
SMTP-сервера, 31 337-й -- серверной части "троянского коня" BackOrifice,
12 345-й или 12 346-й - серверной части "троянского коня" NetBus и т.
д. Для идентификации сервисов и сканирования портов могут быть использованы
различные программы, в том числе и свободно распространяемые, например nmap или
netcat.
Идентификация операционной системы.
Основной механизм удаленного определения ОС (OS detection) -- анализ
ответов на запросы, учитывающие различные реализации TCP/IP-стека в различных
операционных системах. Стек протоколов TCP/IP в каждой ОС реализован по-своему,
что позволяет при помощи специальных запросов и ответов на них определить,
какая ОС установлена на удаленном узле.
Другой, менее эффективный и крайне ограниченный, способ идентификации ОС
узлов - анализ сетевых сервисов, обнаруженных на предыдущем этапе. Например,
открытый 139-й порт позволяет сделать вывод, что удаленный узел, вероятнее
всего, работает под управлением ОС семейства Windows. Для определения ОС могут
быть использованы различные программы, например nmap или queso.
Определение роли узла.
Предпоследним шагом на этапе сбора информации об атакующем узле является
определение его роли, скажем, в выполнении функций межсетевого экрана или
Web-сервера. Делается этот шаг на основе уже собранной информации об активных
сервисах, именах узлов, топологии сети и т. п. Допустим, открытый 80-й порт
может указывать на наличие Web-сервера, блокировка ICMP-пакета - на
потенциальное наличие межсетевого экрана, а DNS-имя узла proxy.domain.ru или
fw.domain.ru говорит само за себя.
Определение уязвимостей узла.
Последний шаг - поиск уязвимостей (searching vulnerabilities).
Злоумышленник при помощи различных автоматизированных средств или вручную
определяет уязвимости, которые могут быть использованы для реализации атаки. В
качестве таких автоматизированных средств могут быть использованы
ShadowSecurityScanner, nmap, Retina и т. д.
Реализация атаки
После всего вышеперечисленного предпринимается попытка получить доступ к
атакуемому узлу, причем как непосредственный (проникновение на узел), так и
опосредованный, например, при реализации атаки типа "отказ в
обслуживании". Реализация атаки в случае непосредственного доступа также
может быть разделена на два этапа: проникновение и установление контроля.
Проникновение подразумевает преодоление средств защиты периметра
(межсетевого экрана) различными путями - использованием уязвимости сервиса
компьютера, "смотрящего" наружу, или передачей враждебной информации
по электронной почте (макровирусы) или через апплеты Java. Такая информация
может быть передана через так называемые туннели в межсетевом экране (не путать
с туннелями VPN), через которые затем и проникает злоумышленник. К этому же
этапу можно отнести подбор пароля администратора или иного пользователя при
помощи специализированной утилиты (L0phtCrack или Crack).
Установление контроля.
После проникновения злоумышленник устанавливает контроль над атакуемым
узлом. Это возможно путем внедрения программы типа "троянский конь"
(NetBus или BackOrifice). После установки контроля над нужным узлом и
"заметания следов" злоумышленник может осуществлять все необходимые
несанкционированные действия дистанционно без ведома владельца атакованного
компьютера. При этом установление контроля над узлом корпоративной сети должно
сохраняться и после перезагрузки операционной системы - с помощью замены одного
из загрузочных файлов или вставки ссылки на враждебный код в файлы автозагрузки
или системный реестр. Известен случай, когда злоумышленник сумел
перепрограммировать EEPROM сетевой карты и даже после переустановки ОС повторно
реализовал несанкционированные действия. Более простой модификацией этого
примера является внедрение необходимого кода или фрагмента в сценарий сетевой
загрузки (скажем, для ОС Novell NetWare).
Цели реализации атак.
Необходимо отметить, что злоумышленник на втором этапе может преследовать
две цели. Во-первых, получение несанкционированного доступа к самому узлу и
содержащейся на нем информации. Во-вторых, получение несанкционированного
доступа к узлу для осуществления дальнейших атак на другие узлы. Первая цель,
как правило, осуществляется только после реализации второй. То есть сначала
злоумышленник создает себе базу для дальнейших атак и только после этого
проникает на другие узлы. Это необходимо для того, чтобы скрыть или существенно
затруднить нахождение источника атаки.
Завершение атаки
Завершающим этапом атаки является "заметание следов". Обычно
злоумышленник реализует это путем удаления соответствующих записей из журналов
регистрации узла и других действий, возвращающих атакованную систему в
исходное, "предатакованное" состояние.
Классификация атак
Существуют различные типа классификации атак. Например, деление на
пассивные и активные, внешние и внутренние атаки, умышленные и неумышленные.
Однако, дабы не запутать читателя большим разнообразием классификаций, мало применимыми
на практике, хотелось бы предложить более "жизненную" классификацию:
Удаленное проникновение (remote penetration). Атаки, которые позволяют
реализовать удаленное управление компьютером через сеть. Примером такой
программы является NetBus или BackOrifice.
Локальное проникновение (local penetration). Атака, приводящая к
получению несанкционированного доступа к узлу, на котором она запущена,
например программа GetAdmin.
Удаленный отказ в обслуживании (remote denial of service). Атаки,
позволяющие нарушить функционирование или перегрузить компьютер через интернет
(Teardrop или trin00).
Локальный отказ в обслуживании (local denial of service). Атаки, которые
позволяют нарушить функционирование или перегрузить атакуемый компьютер.
Примером такой атаки является "враждебный" апплет, загружающий
центральный процессор бесконечным циклом, что приводит к невозможности
обработки запросов других приложений.
Сетевые сканеры (network scanners). Программы, которые анализируют
топологию сети и обнаруживают сервисы, доступные для атаки, например система
nmap.
Сканеры уязвимостей (vulnerability scanners). Программы, которые ищут
уязвимости на узлах сети и могут быть использованы для реализации атак. К таким
сканерам можно отнести систему SATAN или ShadowSecurityScanner.
Взломщики паролей (password crackers). Программы, которые
"подбирают" пароли пользователей. Пример взломщика паролей --
L0phtCrack для Windows или Crack для Unix.
Анализаторы протоколов (sniffers). Программы, которые
"прослушивают" сетевой трафик. С их помощью можно автоматически
искать такую информацию, как идентификаторы и пароли пользователей, информацию
о кредитных картах и т. д. Из таких анализаторов протоколов стоит упомянуть
Microsoft Network Monitor, NetXRay компании Network Associates или LanExplorer.
Сократим число возможных категорий до пяти:
сбор информации (Information gathering);
попытки несанкционированного доступа (Unauthorized access attempts);
отказ в обслуживании (Denial of service);
подозрительная активность (Suspicious activity);
системные атаки (System attack).
Первые четыре категории относятся к удаленным атакам, а последняя - к
локальным, реализуемом на атакуемом узле. Можно заметить, что в данную
классификацию не попал целый класс так называемых "пассивных" атак.
Помимо "прослушивания" трафика, в эту категорию также попадают такие
атаки, как "ложный DNS-сервер", "подмена ARP-сервера" и т.
п.
Классификация атак, реализованная во многих системах обнаружения атак, не
может быть категоричной. Например, атака, реализация которой для ОС Unix
(например, переполнение буфера statd) чревата самыми плачевными последствиями
(самый высокий приоритет), для ОС Windows NT может оказаться вообще
неприменимой или иметь очень низкую степень риска..
2.2 Разработка алгоритма защиты масштабируемых информационно-вычислительных
сетей
Алгоритм может быть использован в системах защиты от
компьютерных атак путем их оперативного выявления и блокирования в
информационно-вычислительных сетях (ИВС). Например, в сетях передачи данных
(СПД) типа «Internet», основанных на семействе
коммуникационных протоколов TCP/IP
(Transmission Control Protocol / Internet Protocol)
Целью заявленного технического решения является разработка способа защиты
ИВС от компьютерных атак, обеспечивающего повышение устойчивости функционирования
ИВС в условиях несанкционированных воздействий за счет повышения достоверности
обнаружения (распознавания) компьютерных атак путем расширения признакового
пространства системы защиты, которое используется для выявления
фрагментированных пакетов поступающих в ИВС из КС и анализа их параметров.
Достижение сформулированной цели необходимо для своевременного предоставления
сервисных возможностей абонентам ИВС, а также для обеспечения доступности5
обрабатываемой информации.
Поставленная цель достигается тем, что в способе защиты ИВС от
компьютерных атак заключающемся в том, что принимают i-й, где i=1,2,3…,
пакет сообщения из КС, запоминают его, принимают (i+1)-й пакет сообщения, запоминают его, выделяют из
запомненных пакетов сообщений характеризующие их параметры, сравнивают их и по
результатам сравнения принимают решение о факте наличия или отсутствия
компьютерной атаки, предварительно задают массив {P} для запоминания P≥1 фрагментированных пакетов сообщений и массивы для запоминания
параметров, выделенных из запомненных пакетов сообщений: S≥1 значений поля данных «Общая
длина», С≥1 значений поля данных «Смещение фрагмента», E≥1 сумм значений полей данных
«Общая длина» и «Смещение фрагмента» запомненных пакетов сообщений
соответственно {S}, {C} и {E}. Кроме того, предварительно задают массив {Pдоп} для запоминания дополнительных Pдоп≥1 фрагментированных пакетов
сообщений. Причем после приема из КС i-го пакета сообщения из его заголовка выделяют значение поля данных «Флаг
фрагментации» Fi. При его значении равном нулю, передают i-й пакет сообщения в ИВС, после чего
принимают (i+1)-й пакет сообщения из КС. При
значении поля даных «Флаг фагментации» i-го пакета сообщения равным единице, запоминают i-й пакет сообщения, выделяют из его
заголовка значение поля данных «Идентификатор» Ni и запоминают его. Выделяют из
заголовка значения полей данных «Общая длина» Si и «Смещение фрагмента» Ci. Запоминают их в соответствующих массивах {S} и {C}. Вычисляют сумму Ei запомненного i-го пакета собщения Ei=Si+Ci и запоминают ее в массив {Е}. Кроме
того, приняв из КС (i+1)-й пакет
сообщения, из его заголовка выделяют значение поля данных «Идентификатор» Ni+1, сравнивают его со значением поля
данных «Идентификатор» Ni i-го
пакета сообщения. При их несовпадении передают (i+1)-й пакет сообщения в ИВС, после чего принимают из КС
очередной пакет сообщения. При совпадении значений полей данных «Идентификатор»
i-го и (i+1)-го пакета сообщений запоминают (i+1)-й пакет сообщения, выделяют из его заголовка значения
полей данных «Общая длина» Si+1, «Смещение фрагмента» Ci+1 и запоминают их в соответствующих массивах {S} и {C}.
Вычисляют сумму Ei+1=Si+1+Ci+1 и запоминают ее в массив {Е}.
Считывают из заголовка (i+1)-го
пакета сообщения значение поля данных «Флаг фрагментации» Fi+1. При его равенстве единице повторяют
действия, начиная с принятия из КС очередного пакета сообщения и сравнения
полей данных «Идентификатор», причем эти действия повторяют до приема из КС
пакета сообщения, принадлежащего совокупности Ni фрагментированых пакетов сообщений,
со значением поля данных «Флаг фрагментации» равном нулю. При значении поля
данных «Идентификатор» (i+1)-го
пакета сообщения равном нулю, из массива {Р} фрагментированных пакетов
сообщений считывают, из числа ранее запомненных пакетов сообщений, пакет
сообщения Рm, где m = 1,2,3… с наименьшим значением поля
данных «Смещение фрагмента» Сmin. Удаляют этот пакет сообщений из массива {Р} и запоминают
его в массив {Рдоп} для дополнительных фрагментированных пакетов
сообщений. После чего из числа оставшихся в массиве {Р} фрагментированных
пакетов сообщений вновь считывают пакет сообщений Рm+1 с наименьшим значением поля данных
«Смещение фрагмента» Сmin. Также удаляют этот пакет сообщений Рm+1 из массива {Р} и запоминают его в
массив {Рдоп}. После чего сравнивают сумму Еm из массива {Е}, соответствующую
запомненному в массиве {Рдоп} пакету сообщения Рm, со значением поля данных «Смещение
фрагмента» Сm+1, принадлежащим пакету сообщения Рm+1, запомненному последним в массив {Рдоп}.
При неравенстве значений Еm
и Сm+1 принимают решение о наличии
компьютерной атаки, запрещают передачу в ИВС всех пакетов сообщений,
сохраненных в массиве {Р} и удаляют все значения из массивов {Р}, {Рдоп},
{S}, {C} и {E}.
При равенстве значений Еm
и Сm+1 из массива {Рдоп} в ИВС
передают пакет сообщения Рm.
Затем считывают из заголовка пакета сообщения Рm+1, оставшегося в массиве {Рдоп},
значение его поля данных «Флаг фрагментации» F. При F
равным нулю из массива {Рдоп} передают пакет сообщения в ИВС, а при F равном единице из массива {Р}
фрагментированных пакетов сообщений считывают очередной пакет сообщений с
наименьшим значением поля данных «Смещение фрагмента» Cmin. После чего повторяют действия
начиная с запоминания очередного пакета сообщения в массив {Рдоп},
причем эти действия повторяют со всеми пакетами из множества {Р}.
Известно, что фрагментация используется при необходимости передачи IP-дейтаграммы6 через
сегмент ИВС, в которой максимально допустимая единица передачи данных (maximum transmission unit - MTU7) меньше
размера этой дейтаграммы. Если размер дейтаграммы превышает это значение, то на
маршрутизаторе, который передает данную дейтаграмму, должна быть выполнена ее
фрагментация.
Фрагменты передаются по адресу назначения, где хост8-получатель
должен выполнить их повторную сборку. На пути доставки фрагментированных
пакетов они могут подвергаться дальнейшей фрагментации, если необходима их
передача через сегмент сети с еще меньшим MTU. Значения MTU для различных технологий построения ИВС представлены в таблице 1
(рис.1). Практически во всех стеках протоколов есть протоколы, отвечающие за
фрагментацию сообщений прикладного уровня на такие части, которые укладывались
бы в кадры канального уровня. В стеке ТСР/IP эту задачу решает протокол ТСР, который разбивает поток
байтов, передаваемый ему с прикладного уровня, на сегменты нужного размера.
Протокол IP на хосте-отправителе, как правило,
не использует свои возможности по фрагментации пакетов. А вот на
маршрутизаторе, когда пакет необходимо передать из сети с большим значением MTU в сеть с меньшим значением MTU, способности протокола IP выполнять фрагментацию становятся
востребованными.
Значения MTU для наиболее
популярных технологий существенно отличаются, а это значит что в ИВС, которой
должна быть свойственна гетерогенность, фрагментация не является редким
явлением.
В функции протокола IP входит разбиение ставшего при передаче недопустимо
длинным пакета на более короткие пакеты-фрагменты, каждый из которых должен
быть снабжен полноценным IP-заголовком. Некоторые из полей заголовка -
идентификатор N, флаг фрагментации F, смещение С - непосредственно
предназначены для проведения последующей сборки фрагментов в исходное
сообщение.
Процедуры фрагментации и сборки протокола IP рассчитаны на то, чтобы
пакет сообщения можно было разбить на практически любое количество частей,
которые впоследствии могли бы быть вновь собраны. Получатель фрагмента
использует поле «Идентификатор» N для
того, чтобы опознать все фрагменты одного и того же пакета. Маршрутизатор, на
котором происходит разбиение (разбор) пакета сообщения на совокупность пакетов,
устанавливает в поле «Идентификатор» значение, которое должно быть уникальным
для данной последовательности фрагментированных пакетов.
Поле «Смещение фрагмента» сообщает хосту-получателю положение фрагмента в
исходном пакете сообщения. Сумма значений полей данных «Смещение фрагмента» и
«Общая длина» определяют часть исходного пакета, принесенную этим и предыдущими
фрагментами.
Флаг фрагментации F показывает появление последнего фрагмента. Во всех
фрагментированных пакетах одной совокупности флаг фрагментации равен единице,
за исключением последнего (флаг фрагментации равен нулю).
Нарушители также используют фрагментацию на разных этапах своих атак с
целью сокрытия своих действий и зондирования сетей, а также для запуска
вредоносных программ. Атаки отказа в обслуживании основаны на использовании
большого количества фрагментированных пакетов, что приводит к чрезмерной трате
ресурсов атакованной ИВС.
Поиск эффективных технических решений повышения устойчивости функционирования
ИВС в условиях распределенных компьютерных атак может быть осуществлен, путем
повышения эффективности функционирования системы защиты, которого можно достичь
за счет повышения достоверности обнаружения (распознавания) компьютерных атак, использующих
фрагментацию пакетов сообщений, путем расширения признакового пространства
системы защиты, которое осуществляется путем анализа информации хранящейся во
фрагментах пакетов сообщений, необходимой для успешной сборки в первоначальное
состояние на хосте-получателе:
• Каждый фрагмент единого пакета сообщений связан с другим фрагментом с
помощью общего для всех фрагментов идентификационного номера. Этот номер
копируется из поля «Идентификатор» заголовка IP-дейтаграммы, и, если пакет
фрагментирован, его называют идентификатором фрагмента (fragment ID);
• Каждый фрагмент хранит информацию о своем месте, т. е. о смещении
относительно исходного (нефрагментированного) пакета сообщения. В каждом
фрагменте указан размер передаваемых в нем данных.
• Каждый фрагмент уведомляет о наличии следующих за ним фрагментов. Для
этой цели служит флаг фрагментации F (More Fragments - следующий фрагмент).
Заявленный способ реализуют следующим образом. Структура пакетов
сообщений такова:
Пакет IP
состоит из заголовка и поля данных. Заголовок пакета имеет следующие поля:
Поле Номер версии (VERS) указывает версию протокола IP. Сейчас повсеместно используется версия 4 и готовится
переход на версию 6, называемую также IPng (IP next generation).
Поле Длина заголовка (HLEN) пакета IP занимает 4 бита и указывает значение длины заголовка, измеренное в
32-битовых словах. Обычно заголовок имеет длину в 20 байт (пять 32-битовых
слов), но при увеличении объема служебной информации эта длина может быть
увеличена за счет использования дополнительных байт в поле Резерв (IP OPTIONS).
Поле Тип сервиса (SERVICE TYPE) занимает 1 байт и задает приоритетность пакета и вид
критерия выбора маршрута. Первые три бита этого поля образуют подполе
приоритета пакета (PRECEDENCE).
Приоритет может иметь значения от О (нормальный пакет) до 7 (пакет управляющей
информации). Маршрутизаторы и компьютеры могут принимать во внимание приоритет
пакета и обрабатывать более важные пакеты в первую очередь. Поле Тип сервиса
содержит также три бита, определяющие критерий выбора маршрута. Установленный
бит D (delay) говорит о том, что маршрут должен выбираться для
минимизации задержки доставки данного пакета, бит Т - для максимизации
пропускной способности, а бит R -
для максимизации надежности доставки.
Поле Общая длина (TOTAL LENGTH) занимает 2 байта и указывает общую длину пакета с
учетом заголовка и поля данных.
Поле Идентификатор пакета (IDENTIFICATION) занимает 2 байта и используется для
распознавания пакетов, образовавшихся путем фрагментации исходного пакета. Все
фрагменты должны иметь одинаковое значение этого поля.
Поле Флаги (FLAGS) занимает 3 бита, оно указывает на возможность фрагментации пакета
(установленный бит Do not Fragment -
DF - запрещает маршрутизатору фрагментировать данный пакет), а
также на то, является ли данный пакет промежуточным или последним фрагментом
исходного пакета (установленный бит More Fragments - MF -говорит о том пакет переносит
промежуточный фрагмент).
Поле Смещение фрагмента {FRAGMENT OFFSET) занимает 13 бит, оно используется для указания в
байтах смещения поля данных этого пакета от начала общего поля данных исходного
пакета, подвергнутого фрагментации. Используется при сборке/разборке фрагментов
пакетов при передачах их между сетями с различными величинами максимальной
длины пакета.
Поле Время жизни (TIME ТО LIVE)
занимает 1 байт и указывает предельный срок, в течение которого пакет может
перемещаться по сети. Время жизни данного пакета измеряется в секундах и
задается источником передачи средствами протокола IP. На шлюзах и в других узлах сети по истечении каждой секунды
из текущего времени жизни вычитается единица; единица вычитается также при
каждой транзитной передаче (даже если не прошла секунда). При истечении времени
жизни пакет аннулируется.
Идентификатор Протокола верхнего уровня (PROTOCOL) занимает 1 байт и указывает, какому
протоколу верхнего уровня принадлежит пакет (например, это могут быть протоколы
TCP, UDP или RIP).
Поля Адрес источника (SOURCE IP ADDRESS) и Адрес назначения (DESTINATION IP ADDRESS) имеют одинаковую длину - 32 бита, и одинаковую
структуру.
Поле Резерв (IP OPTIONS) является
необязательным и используется обычно только при отладке сети. Это поле состоит
из нескольких подполей, каждое из которых может быть одного из восьми
предопределенных типов. В этих подполях можно указывать точный маршрут
прохождения маршрутизаторов, регистрировать проходимые пакетом маршрутизаторы,
помещать данные системы безопасности, а также временные отметки. Так как число
подполей может быть произвольным, то в конце поля Резерв должно быть добавлено
несколько байт для выравнивания заголовка пакета по 32-битной границе.
Максимальная длина поля данных пакета ограничена
разрядностью поля, определяющего эту величину, и составляет 65535 байтов,
однако при передаче по сетям различного типа длина пакета выбирается с учетом
максимальной длины пакета протокола нижнего уровня, несущего IP-пакеты. Если это кадры Ethernet, то выбираются пакеты с максимальной
длиной в 1500 байтов, умещающиеся в поле данных кадра Ethernet.
Протоколы транспортного уровня (протоколы TCP или UDP), пользующиеся сетевым уровнем для отправки пакетов,
считают, что максимальный размер поля данных IP-пакета равен 65535, и поэтому могут передать ему сообщение
такой длины для транспортировки через интерсеть. В функции уровня IP входит разбиение слишком длинного
для конкретного типа составляющей сети сообщения на более короткие пакеты с
созданием соответствующих служебных полей, т.е. фрагментация, нужных для
последующей сборки фрагментов в исходное сообщение.
В большинстве типов локальных и глобальных сетей
определяется такое понятие как максимальный размер поля данных кадра или
пакета, в которые должен инкапсулировать свой пакет протокол IP. Эту величину обычно называют
максимальной единицей транспортировки - Maximum Transfer Unit, MTU.
Сети Ethernet имеют значение MTU, равное 1500 байт, сети FDDI - 4096 байт, а сети Х.25 чаще всего
работают с MTU в 128 байт.
Например, на рис. 2 представлена структура заголовка IP-дейтаграммы. Полужирным шрифтом
выделены поля данных заголовка пакета сообщения, по которым определяют
правильность сборки фрагментированных пакетов.

Рис.2
На рис. 3 представлена блок-схема алгоритма,
реализующего заявленный способ защиты ИВС от компьютерных атак. Данный алгоритм
позволяет выявить и произвести анализ одной последовательности
фрагментированных пакетов. При обнаружении в канале связи нескольких
последовательностей фрагментированных пакетов, данный алгоритм будет
выполняться для каждой из обнаруженных последовательностей.

Рис. 3 Блок-схема алгоритма, реализующего заявленный
способ защиты ИВС от компьютерных атак
В блок-схеме приняты следующие обозначения:
{P} - массив для запоминания
фрагменированных пакетов сообщений;
{S} - массив для запоминания значений
полей данных «Общая длина», выделенных и запомненных фрагментированых пакетов
сообщений;
{С} - массив для запоминания значений полей данных «Смещение фрагмента»,
выделенных и запомненных фрагментированых пакетов сообщений;
{E} - массив для запоминания суммы
значений полей данных «Общая длина» и «Смещение фрагмента», выделенных и
запомненных фрагментированых пакетов сообщений;
{Pдоп} - массив для дополнительного
запоминания фрагментированных пакетов сообщений;
F -
значение поля данных «Флаг фрагментации»;
N -
значение поля данных «Идентификатор».
Предварительно задают (см. блок 1 на рис. 3) массив {P} для запоминания P≥1 фрагментированных пакетов
сообщений. Максимальная размерность данного массива будет зависеть от отношений
MTU передаваемого сегмента ИВС и
принимаемого т.е.
|
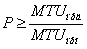 (1) (1)
|
|
Например, при передачи пакета сообщения из сегмента построенного по
технологии Token Ring (IBM,
16 Мбит/с) (MTU =17914 байта) в сегмент сети
построенный по технологии DIX Ethernet (MTU =1500 байта) максимальная
размерность массива равна двенадцати разрядам.
Также предварительно задают массивы для запоминания параметров,
выделенных из запомненных пакетов сообщений, S≥1 значений поля данных «Общая длина», С≥1
значений поля данных «Смещение фрагмента», E≥1 сумм значений полей данных «Общая длина» и «Смещение
фрагмента» запомненных пакетов сообщений {S}, {C}, {E} соответственно. Разрядность данных
массивов будет равна разрядности массива хранящего фрагментированные пакеты
сообщений одной последовательности. А также задают массив {Pдоп} для запоминания дополнительных Pдоп≥1 фрагментированных пакетов
сообщений. Разрядность данного массива будет равна двум разрядам. Кроме того,
первоначально данные множества будут пустые.
Из КС принимают (см. блок 2 на рис. 3) i-ый пакет сообщения, где i=1,2,3… и выделяют (см. блок 3 на рис. 3) из заголовка
принятого пакета значение поля данных «Флаг фрагментации» Fi. Затем выясняют (см. блок 4 на рис.
3) равно ли значение поля данных «Флаг фрагментации» нулю. Равенство при этой
проверке означает, что принятый пакет сообщений не является фрагментированным.
В этом случае принятый из КС пакет сообщений передается в ИВС (см. блок 5 на
рис. 3), а из КС принимается очередной (i+1)-й пакет сообщения, при этом в последующем осуществляется
выделение и анализ значения поля данных «Флаг фрагментации» Fi+1. Данная проверка осуществляется с
целью выявления факта поступления из КС фрагментированных пакетов в ИВС.
При получении из КС фрагментированного пакета сообщения (значение поля
данных «Флаг фрагментации» равно единице), принятый пакет сообщения запоминают
в массив {P} (см. блок 7 на рис. 3). При этом
независимо, каким из принятых из КС и проанализированных пакетов сообщений он
был первым, вторым или i-м,
он сохраняется в первую ячейку массива {P} (см. рис. 4). Из заголовка сохраненного пакета сообщения
выделяют (см. блок 8 на рис. 3) и запоминают значение поля данных «Идентификатор»,
а значения полей данных «Смещение фрагмента» и «Общая длина» сохраняют в
массивы {С} и {S} соответственно
(см. блок 9 на рис. 3). При чем значения сохраняются в первые ячейки массивов,
т.к. пакет сообщений сохранен в первую ячейку. Затем находят сумму значений
полей данных «Смещение фрагмента» и «Общая длина» запомненного пакета сообщений
E. Данная сумма показывает на сколько
должен быть смещен следующий принятый фрагментированный пакет принадлежащий
данной совокупности пакетов. Полученное значение сохраняется в первую ячейку
массива {E} (см. блок 10 на рис. 3).
Далее принимают из КС следующий пакет сообщений (см. блок 11 на рис. 3).
Установив наличие поступающих в ИВС фрагментированных пакетов сообщений,
осуществляем выделение и запоминание пакетов сообщений из поступающей
последовательности из КС, пакетов принадлежащих данной совокупности
фрагментированных пакетов. Для этого из принятого пакета сообщений выделяем
значение поля данных «Идентификатор» Ni+1 (см. блок 12 на рис. 3). Сравниваем его значение со значением поля
данных «Идентификатор» Ni пакета сообщения запомненного ранее (см. блок 13 на рис. 3). В случае
отсутствия совпадения значений полей данных «Идентификатор» принятого пакета
сообщения и пакета сообщения запомненного ранее, первый передается в ИВС (см.
блок 14 на рис. 3), а из КС принимается следующий пакет сообщения с целью
установления принадлежности к анализируемой совокупности фрагментированных
пакетов.
В случае выявления принадлежности принятого пакета сообщения к
совокупности анализируемой последовательности фрагментированных пакетов
(значения полей данных «Идентификатор» принятого и запомненного ранее пакетов
сообщений равны), не зависимо каким был принят и проанализирован данный пакет
сообщения из КС ( например, (i+k)-й пакет сообщений) запоминают
принятый пакет сообщения в следующую (вторую, третью и т.д.) ячейку массива {P} (см. блок 16 на рис. 3). Выделяют
из заголовка принятого пакета сообщения значения полей данных «Общая длина» и
«Смещение фрагмента» (см. блок 17 на рис. 3) и запоминают их значения
соответственно в массивы {S} и {C} в ячейки с номерами,
соответствующими номеру ячейки, в которую был сохранен анализируемый пакет
сообщений (см. блок 18 на рис. 3). Затем вычисляют и запоминают сумму значений
полей данных «Смещение фрагмента» и «Общая длина» запомненного пакета сообщений
(см. блок 19 на рис. 3) и сохраняют в соответствующую ячейку массива {E}. Например, если был выявлен второй
пакет сообщений, принадлежащий данной совокупности фрагментированных пакетов
сообщений ((i+k)-й пакет сообщений), он помещается во вторую ячейку массива
{P}, а значения его полей данных и
сумма этих значений, также помещаются во вторые ячейки соответствующих
массивов. Такая же процедура размещения осуществляется и с третьим (например, с
(i+k+t)-м ) и с
четвертым (например, с (i+k+t+q)-м ) пакетом
сообщений. Процесс выявления фрагментированного пакета сообщения, состоящего из
четырех фрагментов, принадлежащих одной последовательности, представлен на рис.
4.
Для определения является ли принятый пакет сообщения последним из
совокупности анализируемых фрагментированных пакетов, из заголовка принятого
пакета сообщения выделяют значение поля данных «Флаг фрагментации» (см. блок 17
на рис. 3), запоминают его (см. блок 18 на рис. 3) и выясняют (см. блок 20 на
рис. 3) равно ли значение поля данных «Флаг фрагментации» F нулю. Неравенство при этой проверке
означает, что принятый пакет сообщений не является последним пакетом сообщений
принадлежащим анализируемой совокупности фрагментированных пакетов сообщений.
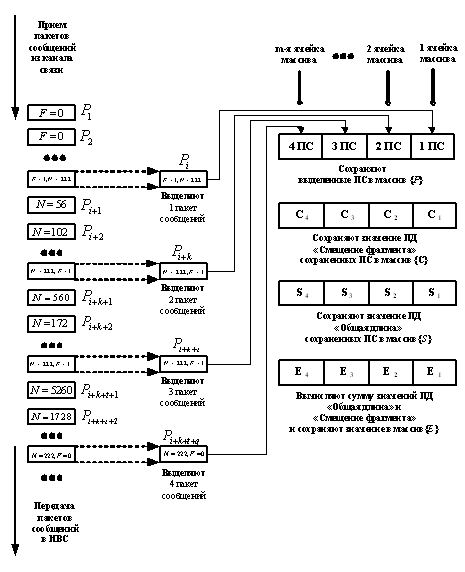
Рис. 4 Процесс выявления фрагментированных пакетов
В этом случае повторяют действия начиная с принятия из КС очередного
пакета сообщения (см. блок 11 на рис. 3) и сравнения полей данных
«Идентификатор» (см. блок 13 на рис. 3), причем эти действия повторяют до
приема из КС пакета сообщения, принадлежащего совокупности Ni фрагментированных пакетов сообщений,
со значением поля данных «Флаг фрагментации» равном нулю (см. блок 20 на рис.
3). В этом случае приступают к анализу запомненных пакетов сообщений в массив {P}, с целью определения правильности
сборки всей совокупности выявленных фрагментированных пакетов сообщений.
Для анализа запомненных пакетов сообщений в массив {P}, с целью определения правильности
сборки всей совокупности фрагментированных пакетов сообщений из совокупности
запомненных пакетов сообщений считывают из числа ранее запомненных пакетов
сообщений пакет сообщения Pm, где m=1,2,3…, которому соответствует
наименьшее значение поля данных «Смещение фрагмента» Сmin. Выделенный пакет сообщения удаляют
из массива {P} и запоминают его в массив {Pдоп} для фрагментированных пакетов
сообщений выделенных дополнительно (см. блок 22 на рис. 3). После чего из числа
оставшихся в массиве {Р} фрагментированных пакетов сообщений вновь считывают
пакет сообщений Pm+1 с наименьшим значением поля данных
«Смещение фрагмента» Сmin, и также удаляют этот пакет сообщений из массива {Р} и запоминают его в
массив {Рдоп} (см. блок 23 на рис. 3).
После сравнения суммы параметров Em из массива сумм параметров {E}, соответствующей ранее запомненному
пакету сообщений Pm в
массиве дополнительно запомненных пакетов сообщений {Pдоп} со значением поля данных «Смещение фрагмента» Сm+1 из массива значений полей данных
«Смещение фрагмента» {C},
соответствующего позднее запомненному пакету сообщений Pm+1 в массиве дополнительно запомненных
пакетов сообщений {Pдоп} (см. блок 24 на рис. 3), если
значения не равны, то после принятия решения о наличии компьютерной атаки,
запрещают передачу пакетов сообщений в ИВС (см. блок 30 на рис. 3) и производят
удаление всех фрагментированных пакетов сообщений пренадлежащих данной
совокупности фрагментированных пакетов сообщений, а также удаляют из массивов
содержащих значения параметров запомненных пакетов сообщений все данные (см.
блок 31 на рис. 3).
В случае равенства значений Еm и Сm+1 из массива {Рдоп} в ИВС передают пакет сообщения Рm (см. блок 25 на рис. 3), затем
считывают из заголовка пакета сообщения Рm+1, оставшегося в массиве {Рдоп},
значение его поля данных «Флаг фрагментации» F (см. блок 26 на рис. 3) и при F равным нулю из массива {Рдоп} передают пакет
сообщения в ИВС (см. блок 28 на рис. 3), а при F равном единице из массива {Р} фрагментированных пакетов
сообщений считывают очередной пакет сообщений с наименьшим значением поля
данных «Смещение фрагмента» (см. блок 23 на рис. 3), после чего повторяют
действия начиная с запоминания этого очередного пакета сообщения в массив {Рдоп},
причем эти действия повторяют со всеми пакетами из множества {Р}. Процесс
определения правильности сборки пакета сообщения, состоящего из четырех
фрагментов представлен на рис. 5.
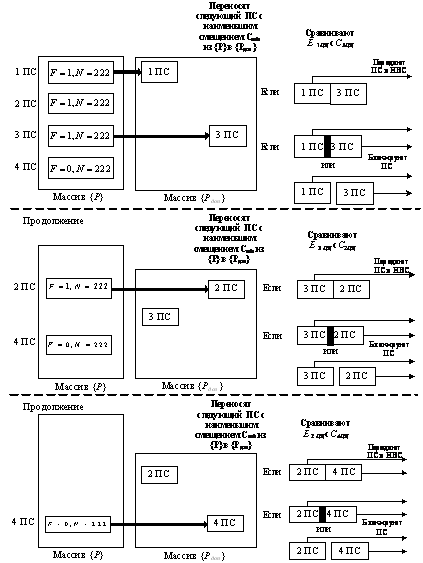
Рис. 5 Процесс определения правильности сборки
фрагментированных пакетов сообщений;
Предлагаемый способ защиты ИВС от компьютерных атак
позволяет распознавать компьютерные атаки с учетом того, что фрагменты пакета
сообщения, из-за задержек в КС (при следовании фрагментов пакета сообщения
разными маршрутами) могут поступать на хост-получатель в произвольном порядке
(на рис. 5. представлен вариант, когда третий фрагмент пакета сообщения был
выделен из КС ранее второго фрагмента).
2.3 Анализ реализации технического результата путем
создания макета программного комплекса и проведения эксперимента
Возможность реализации сформулированного технического
результата была проверена путем создания макета программного комплекса и
проведения натурного эксперимента.
Эксперимент производился следующим образом: с помощью
программно-аппаратных средств объединены три сегмента ИВС, построенных по
технологиям Token Ring (IBM,
16 Мбит/с) (MTU =17914 байта) (один сегмент) и
построенный по технологии DIX Ethernet (MTU = 1500 байта) (два сегмента). Причем
объединение произвели таким образом, чтобы на атакуемый хост поступали не
только фрагментированные пакеты сообщений, но и пакеты сообщений не
подверженные фрагментации (см. рис. 6).
В ходе эксперимента был смоделирован поток сообщений поступающий на вход
атакуемого хоста ИВС, включающий совокупности фрагментированных пакетов сообщений,
подверженные компьютерным атакам типа Teardrop и Teardrop 2, описанные в книге Норткан С, Новак Д. Обнаружение нарушений
безопасности в сетях, 3-е издание.: Пер. с англ. - М.: Издательский дом
«Вильямс», 2003. - 448 с.: ил.

Рис. 6. Схема ИВС, используемая в эксперименте.
В ходе эксперимента были выявлены следующие типы пакетов сообщений,
поступающие на атакуемый хост:
· Нефрагментированые пакеты сообщений - пакеты сообщений,
поступившие на атакуемый хост, построенный по технологии DIX Ethernet из сегмента построенного по такой же
технологии через сегмент построенный по технологии Token Ring;
· Фрагментированные пакеты сообщений, не подверженные
несанкционированным воздействиям, поступившие из сегмента построенного по
технологии Token Ring;
· Фрагментированные пакеты сообщений, подверженные
несанкционированным воздействиям, характеризующим компьютерные атаки типа Teardrop;
· Фрагментированные пакеты сообщений, подверженные
несанкционированным воздействиям, характеризующим компьютерные атаки типа Teardrop 2.
При проведении эксперимента, в первом случае блок распознавания
(обнаружения) компьютерной атаки, реализующий предлагаемый способ защиты ИВС от
компьютерных атак был отключен. В результате атаки данного типа были не
обнаружены, а операционная система хоста-получателя вышла из строя (атака Teardrop), во втором случае (атака Teardrop 2), хост-получатель был заблокирован
(атака типа «Отказ в обслуживании). Результаты эксперимента при отключенном
блоке распознавания представлены на рис. 7 а.
При повторном проведении эксперимента при включенном блоке распознавания,
были выявлены и заблокированы все смоделированные последовательности
фрагментированных пакетов сообщений несущие несанкционированные воздействия
(см. рис. 7 б.).

Рис. 7 Интерфейс пользователя программного макета
системы защиты иве от компьютерных атак с результатами эксперимента.
Из представленных результатов следуют выводы: для
повышения достоверности обнаружения (распознавания) компьютерных атак путем
расширения признакового пространства системы защиты заявленный способ
обеспечивает повышение устойчивости функционирования ИВС при воздействии
компьютерных атак, использующих фрагментированные пакеты сообщений.
Дополнительными положительными свойствами заявленного
способа являются: возможность обнаружения распределенных компьютерных атак не
только на этапе реализации атаки, но и, что очень важно на этапе сбора
нарушителем информации о ИВС.
Выводы
1. Разработан алгоритм, обеспечивающий повышение
устойчивости функционирования ИВС в условиях воздействий компьютерных атак,
использующих фрагментированные пакеты сообщений за счет повышения достоверности
обнаружения (распознавания) компьютерных атак данного типа путем расширения
признакового пространства системы защиты и выявлением из совокупности
поступающих пакетов сообщений из КС в ИВС фрагментированных пакетов сообщений,
предварительной проверки правильности их сборки и выявления компьютерных атак
определенного типа, что необходимо для обеспечения доступности обрабатываемой
информации в ИВС, так как большинство систем обнаружения вторжений и фильтры
пакетов сообщений не поддерживают проверки фрагментированных пакетов или не
выполняют их правильной сборки и поэтому не в состоянии выявить компьютерные
атаки (а значит, и заблокировать опасный трафик), распределенные среди
нескольких фрагментированных пакетов сообщений.
2. Путем создания макета программного комплекса и
проведения натурного эксперимента, была проверена возможность реализации
сформулированного технического результата.
Список литературы:
1.
Кульгин М.
Технологии корпоративных сетей. Энциклопедия. - СПб.:изд. «Питер», 1999г.
2.
Лукацкнй А.В.
Обнаружение атак.- СПб.: БХВ-Петербург, 2001 г
3.
Норткан С., Новак
Д. Обнаружение нарушений безопасности в сетях.
4.
Олифер В.Г.,
Олифер Н.А. Компьютерные сети. Принципы, технологии, протоколы: учебник для
вузов - СПб - Питер, 2003г
5.
Медведовский И.Д.
Атака на Internet.- M., 1999г.
6.
Протоколы
интернета. Александр Филимонов. СПб. 2003 г.
7.
Сергеев П.В.
Методические указания по написанию экономического обоснования дипломного
проекта. М. МГУ, 1992
8.
Правовая охрана и
коммерческая реализация программ для ЭВМ и баз данных: Методические указания по
дисциплине "Интеллектуальная собственность"/Сост.: Ю.И. Буч, И. С.
Терентьева; СПбГЭТУ. СПб., 1998.
9.
Конеев И. Р.,
Беляев А.В. Информационная безопасность предприятия. - СПб.: БХВ-Петербург,
2003.
10. Ю. Кузнецов В.Е., Лихачев А.М., Паращук И.Б., Присяжнюк С.П.
Телекоммуникации. Толковый словарь основных терминов и сокращений. Под
редакцией А.М. Лихачева. СП. Присяжнюка. СПб.: Издательство МОРФ, 2001.