Программирование на языке Object Pascal
Элементы языка Object
Pascal
Алфавит: буквы ((a-z)
- верхний и нижний регистр), цифры, 16-тиричные цифры, специальные символы и
зарезервированные слова. Pascal
- не чувствителен к регистрам (а = А), арабские цифры (0 - 9), 16-тиричные
цифры (0 - 9 - а - f),
специальные знаки (=, +, -, *, /, , , ‘, :, ;, (, ), {, }, [, ], ^, @, $, #),
пары символов (<=, >=, <>, :=, (*, *), .., _).
Пробел с кодом ASCII
0 - 32. Зарезервированные слова не могут использоваться в качестве
идентификатора (название операции, функции, переменных, констант).
Директивы - связанные со стандартными
объявлениями в программе, их нельзя использовать в качестве идентификаторов
переменных программ.
{$1-} - отключить контроль ошибок ввода-вывода.
{$1+} - включить контроль ошибок ввода-вывода.
Идентификатор - имена (константы, метки),
переменные (объекты, процедуры, функции, модули, программы…)
Идентификатор может иметь произвольную длину, но
значащими для компилятора являются первые 255 символов. Он должен начинаться с
буквы латинского алфавита или с символа ( _ ), за которым могут следовать
буквы, цифры и _ :
X1; 1X;
_1X
Переменная - число, которое может принимать
какое-либо значение; в языках высокого уровня с каждой переменной ассоциировано
ее имя (идентификатор). Значение переменной хранится в ячейке оперативной
памяти с определенным адресом. Каждая переменная имеет свой тип. Тип определяет
диапазон значения переменной и количество байтов, занимаемое ей в памяти.
Константы
Константа - переменная, не имеющая своего
значения в ходе выполнения программы. Они бывают именные и неименные.
Именные - символ или набор символов с
присвоенным им значением.
Неименные - любое число. Константы могут быть
целого типа, вещественного, шестнадцатеричное число, вещественное число,
логическая константа, символ, строка символов, конструктор множества и признак
неопределенного показателя (NIL).
Целые числа - записываются со знаком (или без) в
десятичной системе счисления, в диапазоне (от -10263 до 10-263 - 1),
вещественное число, записанное в экспоненциальной форме имеет вид: (±#.###…# )
- мантисса, (E±###...#) -
экспонента (порядок).
Экспоненциальный формат - формат с плавающей
запятой.
=(2,5*100)=2,5*E+2
E+2=102
,0125=1,25* E-2
E-2=10-2
Шестнадцатеричное число:
Для их записи используются шестнадцатеричные числа,
которым соответствует знак $ (00000000 = FFFFFFFF)
$10 =16
байт ($00 - $FF
= 0 - 255)
Логические константы имеют два значения: истина
(1) и лож (0), логические константы занимаю 1 байт, хотя задействован 1 бит.
Символьные константы (любой символ ASCII
таблицы) 1 символ = 1 байт. Символы заключаются в апострофы (‘ ’), а также
допустима их запись, используя ASCII
код (‘ABC’=#65#66#67=‘A’#66#‘C’).
В OPascal есть возможность
работать с символами в системе кодирования Unicode
(отличается от ASCII
тем, что занимает 2 байта).
Конструктор множества - список элементов
множества обрамленный в ([ ]): ([1.2-1.7],[red,
green, blue],
[ ]).
Выражения
Основными элементами, из которых состоит
составляющая часть программы, являются константы, переменные и обращения к
функции. Каждый из этих элементов характеризуется типом и значением. С помощью
знаков, операций и скобок из них можно составить выражение. Выражение, значение
и его тип определены типом входящих в него операндов (2+а: 2,а - операнды, + -
операция).
Значение выражения определяется порядком
выполнения операций. Порядок выполнения операций определяется их приоритетом (с
начала выполняются операции, имеющие максимальный приоритет, операции, имеющие
одинаковый приоритет выполняются в порядке встречаемости в выражение слева на
право; скобки позволяют увеличить приоритет операций до максимального).
Приоритет определяется в порядке убывания:
). Унарные операции: +, -, not
). Мультипликативные: *, /, mod,
div(\), and,
SHL, SHR
). Аддитивные: +, -, or,
xor
). Операции отношения: =, <>, <, >,
<=, >=, in
Структура управления операциями:
При запуске среды Delphi
инициализируется новый проект (по умолчанию новый проект считается приложением,
т.е. при его компиляции будут созданы исполнители _.exe
файлы).
Delphi позволяет
создавать и другие приложения: приложения Web,
элементы приложения ActiveX…
Структура проекта Delphi
Проект состоит из нескольких типов файлов:
Файл проекта (расширение _.dpr)
Файл форм (расширение _.dfm)
Файл модулей (расширение _.pas)
Файлы проекта выполняют роль главной
подпрограммы, из него выполняется вызов файлов модулей и файлов форм, а также
запуск всего приложения. Он связывает все остальные файлы. Между файлами модуля
и формы существует однозначное соответствие. С каждым файлом ассоциирован один
объект формы и значение свойств объекта. Для сохранения приложения необходимо
сохранить все три файла.
Пример файла проекта (файл проекта создается
автоматически):
Program Project1., Unit1 in ‘Unit
1.pas’ {Form 1}. Initialize;. Createform (TForm 1, Form 1);.
Run;
End;
В Delphi
существует возможность создавать консольные приложения. Это создано для
совместимости с программами на Pascal.
Program
ABC;
{Appupe Console}in (‘Hello!’);;
Среда Delphi
предназначена для создания приложений, работающих над управлением Windows.
Однако существуют возможности создавать приложения работающие под Dos.
В Delphi предусмотрены
средства для создания 32-разрядных консольных приложений, которые могут
выполняться в MS-DOS.
Для создания консольного приложения:
Файл \ new
\
consol application
Структура модуля исходного кода
В OPascal
исходный код каждой программы разбит на модули.
Модуль состоит из 4 разделов:
Обязательные:
). Интерфейсный;
). Раздел реализации;
Не обязательные:
). Раздел инициализации;
). Раздел завершения.
Интерфейсный раздел, и раздел реализации
являются обязательными и должны присутствовать в каждом модуле. В начале файл
модуля - его заголовок, в котором указывается имя модуля; затем все указанные
разделы:
Unit имя модуля;
Interface;
Uses список модулей;
(1);;список
модулей;
(2);;
(3);
Finalization;
(4);
End
В интерфейсном разделе описывается информация,
которая будет доступна из других модулей программы.
В разделе реализации содержится информация,
которая из других модулей недоступна. В нем содержатся все процедуры и функции
(их исходные коды).
Модули, из которых состоят приложения, делятся
на: созданные разработчиком и созданные в Delphi.
Встроенные модули.
System - содержит
основные функции Delphi,
его не нужно подключать с использованием слова Uses,
т.к. он подключается к каждому модулю по умолчанию.
Модули, подключенные к интерфейсному разделу по
умолчанию, доступны в любом месте данного модуля. Модули, подключенные в
разделе реализации, доступны во всем этом разделе за исключением интерфейсного
раздела. В разделах инициализации и завершения расположен код, выполняемый
только один раз, в начале и конце работы модуля. Если модулей в программе
несколько, то последовательность выполнения их разделов инициализации
соответствует порядку их следования после ключевого слова Uses.
Разделы завершения выполняются в обратном порядке.
Структура программной единицы на
языке OPascal
К программным единицам относятся: раздел
описания, процедура, функция.
Все они имеют единую структуру:
<Объявление программной единицы>;
<Раздел описания>
Implementation
(begin - для процедур и
функций)
<Список исполняемых операторов>
End. (; - для
процедур и функций)
Раздел описания состоит из (порядок следования
различен):
). Блок используемых модулей (uses
<список модулей>);
). Блок описания типов (type);
). Описание пользовательских типов;
). Описание констант (const
<описание констант>);
). Блок описания переменных (var
<список переменных>);
). Блок описания меток (label
<список меток>);
). Блок описания процедур и функций пользователя.
Любого из этих блоков может не быть (они не
обязательны).
Программные единицы:
(Описание модуля)
Unit
Unit 1;
InterfaceWindows, Massages,
SysUnits, Classes, Forms;1 = class (TForm)1: TButton;1: TLabel;Button 1 click
(sender, TObject);1: TForm 1;, y: integer;: string;=100;
(1)ABC;: array [1…n] of byte;x:= 1
to n do[x]:=x;
end;
(Тело модуля)
ImplementationTForm 1. Button 1.
Click (Sender: TObject);1. Caption := ‘Hello!’;;
end;
END.
Операторы языка OPascal
). Присваивание (:=):
<переменная>:=<выражение>;
). Пустой оператор (;): (ставится после вызова
каждого оператора или процедуры функции);
Составной оператор - последовательность
произвольных операторов программы, заключенная в операторные скобки:
Begin
…
End
OPascal
не накладывает ограничений на характер операторов входящих в составной
оператор. Внутри составного оператора может находится 1 или несколько составных
операторов. Допускается произвольная глубина вложенности составных операторов.
Условный оператор:
If
<условие> then
<оператор 1> [else
<оператор 2>]…
If x>0 then y:=3
x:= ABS(x);
y:= SQR(x);.
Операторы повторения
Цикл со счетчиком:
For
<параметр> = <начальное значение> to/down
to <конечное
значение> do
<оператор>;
В операторе For
на каждом шаге цикла происходит увеличение/уменьшение (по умолчанию) параметра
цикла на 1. Параметром цикла может быть только переменная порядкового типа.
Вещественные типы имеют конечное число значений,
которое определяется форматом внутреннего представления числа.
Любому из порядковых типов применима функция:
ORD(x)
- которая возвращает порядковый номер значения;
PRED(x)
- возвращает предыдущее значение;
SUCC(x)
- возвращает следующее значение.
Оператор цикла с предусловием.
While
<условие> do
<оператор>;
Оператор выполняется до тех пор, пока условие
истинно.
Procedure ABC, n: integer;
n:= 100;
i:= 0;i<=n do begin:= i+2;.
(.nes. Add (IntToStr (i)));;
End.
Программа выводит все четные числа от 0 до 100.
Оператор цикла с пост условием.
Repeat
<список операторов>
Until
<условие>;
Список операторов выполняется пока условие
ложно.
Var, i, n: integer;:= 0;:= 100;:=
0;:= i + 1;:= s + 1;i = n;. Lines. Add (‘s=’ + IntToSrt (s));;
Программа вычисляет сумму чисел натурального
ряда до (n).
Оператор выбора.
Case <ключ
выбора> of
<список выбора>;
[else
<оператор>];
End;
Этот оператор позволяет выбрать одно из
нескольких возможных продолжений программы.
Параметром, по которому осуществляется выбор,
служит ключ выбора. (Это выражение любого порядкового типа).
Список выбора - одна или более конструкций вида:
<константа выбора 1>: <оператор 1>;
.
.
<константа выбора N>:
<оператор N>;
Константа выбора должна быть того же типа, что и
ключ выбора.
Оператор Case
работает в следующем порядке:
· Вычисляется выражение (ключ выбора);
· В последовательности операторов
находится такой, которому предшествует константа, равная вычисленному значению;
· Найденный оператор выполняется,
после чего Case завершает
работу.
Если в списке выбора не найдена константа
соответствующая ключу, управление передается оператору, который следует за else.
Часто операторы, включающие в себя else
можно опустить и тогда, при отсутствие нужной константы, ничего не произойдет и
Case завершает свою
работу.
Procedure Calk (a, b: integer);:
integer;: char;:= edit: text;op of
‘+’ c:= a + b;
‘-’ c:= a - b;
‘*’ c:= a * b;
‘/’ c:= a dir b;begin1.Lines.Add
(‘указан неверный арифметический оператор’);
Exit;;.Lines.Add (‘c=’+IntToStr(c));;
Процедура имитирует процедуру арифметического
калькулятора.
Метки и оператор перехода go
to.
Go
to <метка>;
Этот оператор позволяет передать управление
оператору, следующему за меткой.
Метка располагается, непосредственно, перед
оператором, которому передается управление и отделяется от него (:). Перед
появлением в коде программы, метка должна быть объявлена в блоке описания (label).
Метка, описанная в блоке label,
обязательно должна быть объявлена.
Метки, объявленные в процедуре или функции,
локализуются в ней, поэтому передача управления извне процедуры или функции на
внутреннюю метку невозможна.
to <метка>;ABC;:
integer;, ab
…:
…to ab;
…:
…;
Типы данных языка OPascal
Любые константы, переменные и значения функций OPascal
характеризуются своими типами. Тип определяет множество допустимых значений,
которые можно иметь тот или иной объект, а так же множество операций допустимых
над этим объектом. Тип определяет формат представления переменной или константы
в память ЭВМ.. Простые:
1). Порядковый тип.
Порядковый тип - отличается тем, что имеет
конечное число возможных значений, эти значения можно упорядочить и каждому из
них поставить в соответствие некоторое число (порядковый номер значения).
Ø Целый тип.
Диапазон возможных значений целых типов зависит
от их внутреннего представления, которое может занимать в памяти: 8, 16, 32, 64
бита.
|
Тип
|
Диапазон
|
Размер
(в битах)
|
|
Shortint
|
-128…127
|
8
(со знаком)
|
|
Smallint
|
-32768…32767
|
16
(со знаком)
|
|
Integer
|
-2147483648…2147483647
|
32
(со знаком)
|
|
INT64
|
≈-10263…10263-1
|
64
(со знаком)
|
|
Byte
|
0…255
|
8
(без знака)
|
|
Word
|
0…65535
|
16
(без знака)
|
|
LongWord
|
0…4294967295
|
32
(без знака)
|
Во всех выражениях, функциях и процедурах
использующих целые числа действует правило вложенности: вместо значения с
большим диапазоном, может использоваться значение с меньшим диапазоном.
Функции применимые к целым типам:
ABS(x)
- возвращает модуль числа;
CHR(x)
- возвращает символ с ASCII
кодом;
Inc(x,[i])
- увеличивает переменную x
на значение i;
DEC(x,[i])
- уменьшает переменную x
на значение i;
HI(x)
- возвращает старший байт аргумента;
LO(x)
- возвращает младший байт аргумента.
В памяти ЭВМ младший и старший байт хранятся в
обратном порядке.
байта составляют машинное слово.
машинных слова составляют 2-ное слово.
Машинное слово состоит из старшего и младшего
слова, которые в памяти хранятся в обратном порядке.
ODD(x)
- возвращает (истина), если аргумент не четное число и (ложь) - если четное;
Random(x)
- возвращает случайное число в диапазоне от 0 до x;
SQR(x)
- возвращает квадрат числа (x);
Swap(x)
- меняет местами старший и младший байт аргумента.
При действие с целыми числами, тип результата
соответствует типу операнда, если операнды имеют разный тип, то тип результата
будет соответствовать типу операнда с максимальным запасом значения. OPascal
не контролирует возможные переполнения выполнения операции.
Ø Логический тип.
Значением логического типа может быть одна из
двух констант: false(0),
true(1).
Pred(true)=false(false)=true
Типы данных:
(bytebool) - false, true = 8 битbool
- false, true 16 битbool
- false, true 32 бита
Логический тип является порядковым и может быть
использован в качестве параметра четного цикла.
Логические операции допустимые над этими
числами:
Not -
инвертирует значения (false
ó true)
Or - оператор
выбора (false или true)
And - оператор
объединения (false и true)
Xor - обратно
инвертирует значения (true
ó false)
Ø Символьный тип.
Значением символьного типа является множество
всех символов персонального компьютера, каждому символу соответствует его код
(0-255 (код ASCII), 0-65535
(код Unicode)).
Для кодирования основных и управляющих символов
достаточно 7 бит (1 половина таблицы ASCII).
Кодируется значение 0-127. Эта часть является
стандартной и неизменной для всех персональных компьютеров. Управляющие коды
имеют значение 0-32.
Символьный тип - Char
1 байт (ASCII), Wide
Char 2 байта (Unicode):
Var:=Char;:= Wide Char;
…:= ‘a’:= ‘b’x= ‘a’ to z do
Для символьного типа определены следующие
функции:
Chr(x)
- возвращает символ ASCII
кода = x
Ord(x)
- возвращает код определенного символа x
Apcase(x)
- переводит в верхний регистр значение x
Locase(x)
- переводит в нижний регистр значение x
Значение функций Apcase
и Locase работают только
для символов латинского алфавита.
Ø Перечисляемый тип.
Передается перечислением тех значений, которые
он может иметь. Каждое значение именуется идентификатором и располагается в
списке обрамленном круглыми скобками. При записи идентификатора работает
правило их именования.
Соответствие между значениями перечисляемого
типа и их порядковыми номерами устанавливается порядком перечисления. Первое
значение имеет номер 0. Максимальная мощность 65535.
Порядковые типы объявляются в блоке описания
типов:
Type
Имя типа (идентификатор1, идентификатор2…)
Day=(mon, tue, wen, thu, fri, sat,
sun);=(white, red, black);:=day;:=color;
…:=tue:=redx:=mon to fri do …
Ø Тип диапазон.
Тип диапазон - является подмножеством базового
типа. В качестве базового типа может выступать любой порядковый тип, кроме типа
диапазона. Тип диапазон задается границами своих значений внутри базового типа.
Синтаксис записи:
Type
Имя типа = <минимальное
значение>..<максимальное значение>;
Оценка = <1..5>
Цифра = <0..9>
Малая буква = <a..z>
Day2 = <tue..wed>
Тип диапазон также может быть объявлен в разделе
описания переменных:
Var
X:=otcenka;
Y:=2..5;
Правила записи типа диапазона:
). Двойная точка воспринимается как единый
символ без пробела;
). Левая граница диапазона не должна превышать
правую;
). Тип диапазон использует все свойства базового
типа, но с ограничением связанным с меньшей мощностью.
2). Вещественный тип.
В отличие от порядковых типов, значение которых
сопоставляется с рядом целых чисел и представляет в памяти абсолютно точно,
значение вещественных типов определяет произвольное число с некоторой конечной
точностью. Точность зависит от внутреннего формата вещественного числа. Все
вещественные числа представляются в памяти в экспоненциальной форме записи
(т.е. состоят из двух частей: мантиссы и экспоненты, в каждой из которых есть
целое число).
Currency
- предназначен для хранения информации о деньгах. Все вычисления компилятор для
вещественных переменных осуществляет в виде типа Extended,
все остальные типы получает из Extended
путем его усечения (применяются, как правило, для экономии памяти).
Встроенные функции для работы с вещественными
числами:
Abs(x)
- модуль (x);
Cos(x)
- косинус (x);
Sin(x)
- синус (x);
Exp(x)
- экспонента;
Pi -
возвращает число π;
Sqrt(x)
- квадратный корень из (x);
Ceil(x)
- возвращает наименьшее целое большее или равно (x);
Floar(x)
- возвращает наибольшее целое меньшее или равное (x);
Frac(x)
- возвращает дробную часть числа типа Extended;
Int(x)
- возвращает целую часть числа (округляет);
IntPower(x,y)
- возводит число (x) в степень
(y);
Ldxep(x)
- ex*π;
Ln(n)
- натуральный логарифм числа (x);
Ln(xp1)
- Ln(x+1)
- натуральный логарифм от числа (x+1);
Log10(x)
- 10-ный логарифм числа (x);
Log2(x)
- 2-ичный логарифм числа (x);
LogN(n,x)
- Lognx;
max(x,y)
- нахождение максимального;
min(x,y)
- нахождение минимального;
Power(x,y)
- возводит в степень (y)
число (x) (с дробными
степенями);
Randomize
- включает генератор случайных чисел;
Trunk(x)
- отсекает дробную часть;
Rondom(x)
- (x) - целое число
(0..x);
Round(x)
- округляет вещественное значение до ближайшего целого (результат имеет тип Int64;
если число ровно по середине, то результат всегда четный);
Random -
возвращает случайное вещественное число (0..1);
|
Название:
|
Диапазон:
|
Количество
значений 10-ных чисел:
|
Размер
(в битах):
|
|
Real 48 Single Real (Double)
Extended Currency
|
От
2,9*10-19 до 1,7*1038 От 1,5*10-45 до 3,4*1038 От 5,0*10-324 до 1,7*10308 От
3,6*10-4951 до 1,1*104938 От -9*1014,### до 9*1014,###
|
10-12
7-8 15-16 19-20 19-20
|
32
48 69 80 64
|
II. Структурированные типы:
Любая переменная структурированного типа всегда
имеет несколько компонентов. Структурированные типы могут быть вложенными.
Ограничений на суммарную длину структурированного типа не накладываются.
Компилятор OPascal
автоматически компактно хранит все структуры в памяти.
1). Массивы.
Массивы бывают двух типов: статические и
динамические.
Ø Статические.
Статические имеют фиксированный размер и тип,
которые остаются неизменными в течение хода выполнения программы, а
динамические - могут изменить свой тип и размер в процессе выполнения
программы. Статические, во многом похожи на массивы в языке QBasic.
Все компоненты имеют одинаковый тип, доступ к каждому компоненту осуществляется
по его уникальному индексу.
Синтаксис записи:
Type
Имя типа = array
[диапазон 1, [диапазон 2]…] of
тип;
Пример:
= array [1..10] of byte;= array
[2..4] of extended;= array [0..5,1..20] of int 64;,b:vector;:matrix;:array
[1..15] of
bualean;
Если массивы имеют одинаковый тип a=b,
то значение массива b переходит в
массив a.
a:=b
Все массивы хранятся в памяти линейно. Для
обращения к элементу массива используют: [ ].
a[3]:=2;
x[0.17]:=a[2]/4;
Ø Динамические массивы.
Динамический массив может менять в ходе
выполнения программы размер.
Он объявляется следующим образом:
Var
Имя: array
of тип;
Многомерный динамический массив задается
аналогично статическому, но без указания границы:
Var
A: array
of byte
Задание размера массива и выделение для него памяти
выполняется с помощью процедуры: SetLenght
(имя, длина) длина - выражение целого типа. После выполнения этой процедуры
выделяется память под этот массив и его индекс может измениться от 0 до -1.
SetLenght
- может быть вызвана произвольное количество раз, каждый вызов приводит к
изменению длины массива, при этом содержимое массива сохраняется.
Если, при вызове, длинна массива увеличивается,
то добавленные элементы заполняются произвольными значениями. Если уменьшается,
то содержимое отброшенных элементов теряется:
Var
A: array
of array
of int64;
Beginlength (a; s);[1]:=1; [???][2]:=2; [312][3]:=3;(a;2); [31]
(a;3); [31?]
Организуется с использованием динамической
памяти массива.
Поскольку динамические массивы являются
динамической структурой данных, то по окончанию работы с ним необходимо удалить
их из памяти компьютера.
Существует три способа удаления динамической
памяти из системы:
). Установка длинны динамического массива в (0)
SetLenght
(имя; 0);
). Присвоение значению длины массива nil:
имя:= nil;
). Присвоение имени finalize
(имя);
В OPascal
для работы с динамическими массивами предусмотрены встроенные функции:
Copy (имя,
начальный индекс, количество элементов) - восстановление начального имени;
High -
возвращает максимальное значение индекса массива;
Многомерный динамический массив - представляется
как массив из массивов:
Var: array of array of byte(a; 4);(a
[0]; 3); [???](a [1]; 1); [?](a[2];2); [??](a[3];5); [?????]
2).
Записи:
Запись - структура данных, состоящая из
фиксированного числа компонентов (полей записи). В отличие от массива,
компоненты поля могут быть разного типа, каждое поле записи именуется.
Описание структуры записи происходит в разделе (type).
Type
Имя = record;
Список полей;
End;
Список полей представляет собой
последовательность разделов записи следующего вида:
Имя1: type1;
Имя2: type2;
Имя3: type3;=
record
FIO: string;
Gr: word;
Pol: Boolean;: string [10];
Rost: real;
Ves: real;;
...: student;.FIO: ‘Иванов
Иван
Иванович’;.Gr:
1987;.Pol: true;
...A do begin:= 180.5;:=98.2;
End;
… Доступ к каждому из компонентов записи
осуществляется с использованием спецификатора.
Структура записи спецификатора:
спецификатор 1. [спецификатор 2 ...]
идентификатор.
В данном случае спецификатором будет переменная
типа (student),
а идентификатором (pole).
… Для упрощения доступа к полям записи
используются оператор:
With
<переменная> do
<оператор>
Записи с вариантными полями
Вариантная запись содержит поля, предназначенные
для различных типов данных, причем, в одном экземпляре записи никогда не
используются все такие поля.
Модифицируем запись студент для хранения
информации о местных студентах и приезжих, т.е. проживающих о общежитии:
Местные: улица, дом, квартира.
Приезжие: номер комнаты.
Type= record;
FIO: string;
Gr: word;
Pol: Boolean;: string [10];
Rost: real;
Ves: real;mesting: Boolean of
True: (ul: string [20]; dom: string
[5]; kv: word);
Fals: (N_Komn: word);;;
Часть записи, следующая после ключевого слова (case)
содержит вариантную часть объявления. Вариантная часть обязательно должна
располагаться после объявления всех остальных полей.
В памяти, запись хранится линейно.
Синтаксис записи:
Имя = record
Список полей:
Case <поле
переключатель> : <тип> of
Вариант 1:(поле1: тип1;… полеN:
типN);
End;
Тип поля переключателя обязательно должен быть
порядковым. В памяти под запись с вариантными полями компилятор выделяет
столько свободного места, сколько необходимо для хранения записи самым длинным
из возможных вариантов. Из программы возможен доступ к записи любого варианта,
в не зависимости от значения поля-переключателя.
Ячейка (Название улицы или № комнаты) самая
большая по количеству байтов.
3). Множества.
Множества - наборы однотипных, логически
связанных друг с другом объектов. Характер связи между ними контролируется
только программистом, а не компьютером. Максимальное количество элементов в
множестве 256 минимальное 0.
Множества отличаются от массивов и записей
непостоянством своих элементов. Элементы могут включаться в множество и
выключаться из него. Механизм работы и множествами в Delphi
схож с механизмом работы в математике.
Два множества считаются равными - если они
содержат одинаковые элементы.
A {a,
b, c,
x}
B {c,
x, y}
Пересечением - называются общие элементы двух
множеств.
A
∩
B = {c,
x} - пересечение.
A
U B
= {a, b,
c, x,
y} - объединение.
C = { } - пустое
множество.
Если все элементы одного и того же множества
входят в другое, то говорят, что A
входит в B.
Формат записи множеств:
Type
<имя>= set
of <базовый
тип>
В качестве базового типа может использоваться
любой подходящий тип кроме integer,
int 64 …
Type= set of ‘a’…‘z’;, s2, s3:
mnozh:= [‘a’, ‘b’, ‘t’, ‘x’];:= [‘a’..‘k’, ‘x’..‘z’];
Над множествами определены следующие операции:
* - пересечение; s1*s2
[‘a’,
‘b’, ‘x’]
- разность; s1-s2 [‘t’]
= - проверка эквивалентности (возвращает true,
если они эквивалентны);
<> - проверка не эквивалентности
(возвращает true, если они
эквивалентны);
+ - объединение множеств;
<= - проверка вхождения (возвращает true,
если s1 входит в s2);
[s1<=s2]
>= - проверка вхождения (возвращает true,
если s2 входит в s1);
[s1>=s2]
in - проверка
принадлежности (возвращает true,
если указанный элемент входит в множество);
<элемент> in
<множество>
Некоторые алгоритмы для работы с массивами:
) Заполнение массива случайными числами:
Var
a: array
of integer;
i: integer;;(a, 10);i = 1 to n-1 do
a[i]:= random (101);;
s := (k * si-1) mod N,
где k
- начальное значение (стартовое число).
) Алгоритм поиска минимального и максимального
элемента массива:
Var: array of integer;: integer;,
max, n: integer;, nmax: integer;:= 10(a, n);i = 1 to n-1 do
a[i]:= random (101);;
Max:= a[0]; nmax:= 0;
Min:= a[0]; nmin:= 0;i:= 1 to n-1 do
begin
if a[i] > max then begin
max:= a[i];
nmax:= i;
End;
if a[i] < min then begin
min:= a[i];
nmin:= i;
End;
End;
End;
3) Алгоритм сортировки массива:
Существует множество способов сортировки
массива:
· Метод min
или max элемента;
· Метод пузырька;
· Метод Шелла;
· Метод бинарного поиска;
· ...
Метод min
или max элемента:
Const= 100: array [1..n] of
integer;, max, nmax, i, j: integer;:= 100(a, n);i := 1 to n-1 do
a[i]:= random (101);;
max:= a[1], nmax:=1;i:= 1 to n-1 do
begin
For j:= 2 to n do max < a[j] do
begin:= a[j];:= j;;max > a[i] then begin := a[i];[i]:= max;[nmax]:= temp;;:=
a[i+1];:= i+1;
End;; ;
4) Алгоритм исключения элементов из
отсортированного массива:
Var: array of byte;, n1, p, x, i:
integer;:= 100(a, n);i = 1 to n-1 do
a[i]:= random (101);;
max:= a[1], nmax:=1;i:= 1 to n-1 do
begin
For j:= 2 to n do max < a[j] do
begin:= a[j];:= j;;max > a[i] then begin := a[i];[i]:= max;[nmax]:= temp;;:=
a[i+1];:=
i+1;
End;
End;
d:= 7; [исключенный
элемент]
p:= -1;i:= 0 to n-1 dox=a[i] then
p:=i;p=-1 then begin(‘такой элемент
отсутствует’);;;i:=
p to n-1 do[i]:= a [i+1];(a,n-1);;
End;
5) Добавление элемента в отсортированный массив:
Var: array of integer;, p, x, i:
integer;:= 100(a, n);i = 1 to n-1 do
a[i]:= random (101);;
max:= a[1], nmax:=1;i:= 1 to n-1 do
begin
For j:= 2 to n do max < a[j] do
begin:= a[j];:= j;;max > a[i] then begin := a[i];[i]:= max;[nmax]:= temp;;:=
a[i+1];:= i+1;
End;; := StrToInt (Edit1.
text);x<= a[0] then (a, n+1);i:=n-1 down to 0 do
a[i+1]:=a[i];[0]:=x;x>a [n-1]
then begin(a, n+1);[n]:=x;;(x>=a[0]) and (x<=a[n-1]) then begini:= 0 to
n-2 do
if (x>=a[i]) and (x<=a[i+1])
then
p:= i+1;i:= n-1 down to p do
a[i+1]:= a[i]
a[p]:=x
End;
End;
) Пример алгоритма работы с множествами:
Программа выделяет из 1 сотни натуральных чисел
(все простые числа). Алгоритм заимствован из приема “Решето Эратосфена”.
Const
N=100;
Type
SetOfNamber
= set of
1..n;
Var, next, i: word;, PrimSet:
SetOfNamber;:= [1..n];:=[1];:= 2;begin set <> [ ] do begin:=next;n1<=n
do begin:=BeginSet - [n1];:= n1+next;;:=PrimSet+[next];(next);(next in
BeginSet) or (next>n);;
) Заполнение случайным образом двумерного
массива (матрицы):
Var: array [1..n; 1..m] of bytei:=1
to n doj:= 1 to m do
a[i,
j]:= random
(11);
Совместимость и преобразование типов.
Два типа являются совместными если:
· Оба одинаковы;
· Один тип является типом-диапазоном
другого;
· Оба вещественны;
· Оба целые;
· Оба являются типами-диапазонами
одного и того же базового типа;
· Оба являются множествами,
составленными из элементов одного и того же базового типа.
Пусть t1
- тип переменной, а t2 - тип
выражения. Операция t1:=t2
возможна, если выполняются перечисленные 6 правил и t1,t2
- не являются файлами, массивами файлов и записями, содержащими поля файлов. А
так же диапазон t2 лежит
внутри диапазона t1. Или
существует функция преобразования типов.
t1:=t2, [где
t1: integer; а t2: real ]
[integer:=
round(real)]
4). Файлы.
Под файлами понимается либо именованная область
внешней памяти ПВЭМ, либо логическое устройство, которое является потенциальным
источником или приемником информации (адаптер интерфейса - USB…).
Любой файл имеет три характерных особенности:
1. он обладает именем (это дает возможность
работать одновременно с несколькими файлами в программе);
2. он содержит компоненты одного и того же
типа (типом может быть любой тип OPascal
кроме файла);
. длина файла в OPascal
не регламентируется (ограничение накладывает только емкость внешнего
устройства).
По способу организации файлы делятся на:
1. файлы прямого доступа;
2. файлы последовательного доступа.
При работе с файлами существует понятие
указатели (это виртуальный элемент, который указывает на текущую позицию в
файле (то место, с которого будет считана информация при последующем обращение
к файлу)). При открытие файла, указатель устанавливается в начало файла.
У файлов прямого доступа можно установить
указатель на любую запись и прочитать ее.
У файлов последовательного доступа каждая
следующая запись может быть прочитана только после прочтения предыдущей записи,
т.е. что бы получить запись с номером (N)
надо прочитать (N-1) записей.
В OPascal
существует три типа файлов:
1. текстовые;
2. типизированные;
. не типизированные.
Типизированные файлы являются файлами прямого
доступа, а не типизированные и текстовые - файлы последовательного доступа.
Доступ к файлам
Любые файлы и логические устройства становятся
доступны в модуле после процедуры открытия.
Эта процедура заключается:
1. в связывании ранее объявленной файловой
переменной с именем файла;
2. в открытии файла для чтения и (или)
записи.
Файловая переменная (дескриптор файла).
Объявление файловой переменной.
Var
F: TextFile;
{текстовый файл}
F1: file of integer; {типизированный
файл}:
file of string [20]; {типизированный
файл}3:
file; {не
типизированный файл}
AssignFile
- процедура связывания файловой переменной с именем файла:
AssignFile
(<файловая переменная>, <имя файла или логическое устройство>);
Пример:
(f, ‘c:\alpha.txt’);
(f1, ‘PRN’);
Именем файла может являться любое выражение
строкового типа, которое строится по правилам определения имени в операционной
системе Windows.
Логические устройства в OPascal
К ним относятся стандартные аппаратные средства
(клавиатура, экран, принтер, коммуникационные каналы). Аппаратные средства
определяются специальными именами и называются логическими устройствами:
CON - консоль
(клавиатура / экран; допустима передача в двух направлениях);
PRN - принтер
(допустима передача в одном направлении);
COM 1 = (AUX)
- последовательный интерфейс;
COM 2 -
последовательный интерфейс;
LPT 1 -
параллельный интерфейс;
LPT 2 -
параллельный интерфейс.
Инициализация файла
Под инициализацией понимается указание
направления передачи данных, для этого существуют специальные процедуры:
1. reset
(<файловая переменная>); - открытие файла для чтения;
2. rewrite
(<файловая переменная>); - открытие файла для записи (при открытии rewrite
файл стирается и создается заново).
3. append
(<файловая переменная>); - открытие файла для записи (при открытии append
происходит добавление в файл; работает только для текстовых файлов).
Процедуры инициализации должны следовать после
того, как с именем файла связана файловая переменная.
Закрытие файла
Закрытие осуществляется с помощью процедуры CloseFile
(<файловая переменная>).
Эта процедура закрывает файл, но закрывает связь
файловой переменной с именем файла. При создании нового или расширении старого
файла процедура CloseFile
обеспечивает сохранение всех новых записей в файле и регистрирует файл в
каталоге.
При нормальном завершении работы приложения всех
действий, выполняемые этой процедурой, производятся автоматически для всех
открытых файлов.
Процедуры и функции для работы с файлами:
Eof(<файловая
переменная>); - возвращает true
если достигнут конец файла;
Eoln(<файловая
переменная >); - возвращает true
если достигнут конец строки;
SeekEof(<файловая
переменная >); - возвращает true
если до конца файла остались только символы разделители (‘ ’, tab);
SeekEoln(<файловая
переменная >);- возвращает true
если до конца строки остались только символы разделители (‘ ’, tab);
AssignPRN(<файловая
переменная >); - процедура присваивает дескриптор текстового файла принтеру;
Erase(<файловая
переменная >); - процедура стирает файл (перед стиранием необходимо закрыть
файл);
Flush(<файловая
переменная >); - процедура очищает внутренний буфер файла (при этом все
изменения сохраняются на диске);
ReName(<файловая
переменная >,<новое имя>); - процедура переименовывает файл…
Процедуры чтения записей:
Read(<файловая
переменная >,<список вывода>); - читает информацию из файла;
ReadLn(<файловая
переменная >,<список вывода>); - читает информацию из файла;
Write(<файловая
переменная >,<список ввода>); - записывает информацию в файл;
WriteLn(<файловая
переменная >,<список ввода>); - записывает информацию в файл.
Ø Текстовые файлы.
Текстовые файлы связываются с файловыми
переменными, принадлежащими стандартному типу TextFile,
используются для хранения текстовой информации. В файлах такого типа так же
могут храниться целые вещественные числа. Запись текстового файла имеет
переменную длину, поэтому файлы такого типа относятся файлам последовательного
доступа. При создании текстового файла, в конце каждой строки автоматически
ставится специальный символ, который называется EoLn,
который состоит из 2-х байтов.
В конце файла ставится специальный символ Eof.
Текстовые файлы открываются с помощью трех
процедур:
Reset - для
чтения;
RewRite
- для записи;
Append - для
добавления.
Чтение осуществляется с помощью процедуры Read
и ReadLn, запись - Write
и WriteLn.
Пример:
WriteLn(f,‘ABC’;12;‘x’;0,5); [ABC12x5E-1]
При переводе переменных типа String
количество считываемых процедурой и помещенных в строки символов равно
максимальной длине строки, если раньше не встретится признак EoLn;
этот признак в строку не помещается. Если количество символов во входном потоке
данных больше максимальной длинны строки, то лишние символы отбрасываются. При
вводе числовых переменных процедура Read
работает следующим образом: все ведущие знаки разделители и признаки конца
строк пропускаются до появления первого значащего символа (и наоборот: любой из
перечисленных символов, а так же признак конца файла считается концом
подстроки). Выделенная таким образом подстрока рассматривается как строковое
выражение числовой переменной; затем она конвертируется во внутреннее
представление числа и результат присваивается переменной.
Ansistr = 256 символов.
WriteStr = 4 Гб.
|
‘ ’ a b c ‘ ’ EoLn ‘ ’ ‘ ’ ‘ ’ 209
‘ ’ EoLn 2 ‘ ’ 3 ‘ ’ a5 ‘ ’2,5 Eof
|
Var: TextFile;: string;: string
[2];, b, c: integer;: real;(f,‘c:\FEI\alpha.txt’);(f);(f,s) [s=‘_abc ’](f,a); [a=209](f,b,c); [b=2
c=3](f,x);
[ошибка a5 перевести нельзя]
End;
Работа с текстовыми файлами.
)._Пример Вывод текстового файла на экран:
Procedure TForm1.Button1.Click (…);:
TextFile;: string;(f,‘c:\alpha.txt’);
Reset(f);not Eof(f) do begin(f,
s);.Lines.Add(s);;
End;
Если в конвертируемой строке был нарушен
требуемый формат - возникнет ошибка ввода / вывода.
Процедура Write
и WriteLn обеспечивает вывод
информации в текстовый файл. Список вывода аналогичен процедуре Read,
за исключением числовых значений, для которых существует специальный формат:
элемент [:m [: n]];
m - минимальная
ширина поля, в которое будет помещен элемент;
n - максимальное
количество знаков после ( , ).
Процедура WriteLn
аналогична процедуре Write,
но в конце добавляется признак конца строки.
)._Пример Слияние двух текстовых файлов в
третий:
Procedure TForm1.Button1.Click (…);,
f2, f3: TextFile;:
string;(f1,‘c:\Fei\alpha1.txt’);(f2,‘c:\Fei\alpha2.txt’);(f3,‘c:\Fei\alpha3.txt’);(f1);(f2);(f3);not
Eof(f1) do begin(f1,s);(f3,s);;not Eof(f2) do begin(f2,s);(f3,s);;(f1);(f2);(f3);(‘OK!’);;
Обработка ошибок при работе с
файлами
При обращение к файлам (т.е. к диску) могут
возникать ошибки, приводящие к ненормальному завершению работы приложения. Эти
ошибки необходимо предусмотреть и соответствующим образом обработать. В
основном ошибки возникают при открытии файла, реже при чтении и записи из них.
Что бы обрабатывать ошибки ввода / вывода (ошибки при работе с файлами)
необходимо использовать соответствующую директиву компилятора (специальным
образом оформленные указания компилятору внутри кода программы). Директиву
заключают в { }, внутри ставится обозначение соответствующей директивы, + или
-:
{<обозначение>,<+ или ->}:
отключить контроль ошибок ввода / вывода: {I-};
включить контроль ошибок ввода / вывода: {I+}.
Если делается попытка чтения несуществующего
файла или логического устройства, то возникает ошибка времени выполнения (from
time error).
Тип ошибки можно определить с помощью использования встроенной функции - IOResult:
word; (эта функция
возвращает результат последней операции ввода / вывода; если операция прошла
успешно, функция возвращает (0), иначе возвращает код ошибки ввода / вывода).
Для использования этой функции необходимо
отключить контроль ошибок ввода / вывода.
TForm1.Button1.Click (…);:
TextFile;: string;(f, Edit1.Text);
{I-}(f);IOResult<>0 then
begin(‘неверное
имя
файла’);;;
{I+}not Eof(f) do
begin(f,s);.Lines.Add(s);;
End;
В Delphi
существуют объекты для работы с файлами. В частности объекты TOpenDialog
и TSaveDialog. Эти объекты
позволяют открывать и использовать стандартные диалоговые окна открытия и
сохранения файла.
Вызов диалогового окна осуществляется с помощью
метода ExeCute:
Boolean; (который
возвращает true если окно
открывалось успешно и false
в противном случает).
3)._Пример
Открытие
файла:
…OpenDialog1.Execute then
begin(f,OpenDialog.FileName);
…(f);;
)._Пример Процедура подсчитывает количество
строк и символов в текстовом файле:
Procedure TForm1.Button1.Click(…);:
TextFile;: string;, k: int64;(f,'alpha.txt');(f);:=0;:=0;not Eof(f) do begin(f,
s);(i);:= k + length(s);;.Lines.Add (‘alpha.txt содержит’
+ IntToStr(k) + ‘символов’
+ ‘и’+IntToStr(i)
+ ‘строк’);;
Использование объекта TStringList
(набор строк и является потомком объекта TStrings,
каждая строка имеет свой индекс, к ней можно обратиться с помощью свойства *.strings[i]
- i - необходимая
строка).
Пример:
: TStringList;
...TForm1.Button1.Click(...);:=TStringList.Create(...);.LoadFromFile
(‘c:\alpha.txt’);.Lines.Add(t.StringList[0]);.Lines.Add(t.StringList[1]);
...
// по окончании работы объект t
надо уничтожить
t.Free;;
Методы объекта
StringList:
*.Count
- возвращает количество строк в этом объекте;
*.SaveToFile
- позволяет скинуть объект в файл.
Ø Типизированные
файлы.
Длинна, любого компонента типизированного файла,
постоянна, что дает возможность организовать прямой доступ к каждому из них.
Каждая запись файла может быть доступна путем указания ее порядкового номера.
После открытия файла, указатель стоит в его начале и указывает на первый
компонент с номером (0). После каждого чтения или записи указатель смещается на
одну позицию, т.е. на одну запись. Перемещение в списках ввода / вывода
процедур read / write
должны иметь тот же тип, что и компоненты файла (работает правило приведения
типов). Если переменных в списках ввода / вывода несколько, то указатель будет
смещаться после каждой операции обмена данными между переменными и фалом.
Работа с типизированными файлами
)._Пример Объявление типизированного файла:
Var: file of integer;: file of
string [20];: integer;: byte;: int64;: string [20];
...TForn1.Button1.Click
(...);(f,‘c:\int.dat’);(f,‘c:\string.txt’);(f);(t);(f,a,b);(t,x,‘abcdef’);(f);(t);(f,c);(t,x);(t,‘stuvw’);;
Процедура Reset
применима к типизированным файлам, открывает как для записи, так и для чтения
одновременно. ReWrite
работает аналогично текстовым.
Процедуры для работы с файловыми переменными:
Seek(<файловая
переменная>,<номер записи>); - процедура смещает указатель файла к
требуемой записи.
<файловая переменная> - дескриптор файла.
<номер записи> - выражение типа int64
содержащее номер записи.
FileSize(<файловая
переменная>):int64;
- функция возвращает количество записей в файле.
SizeOf(<экземпляр
структуры>); - позволяет определить размер объекта:
Var: word; [2]
...(z);
...
FilePos(<файловая
переменная>):int64;
- функция возвращает порядковый номер записи, которая будет обработана
следующей операцией ввода / вывода:
)._Пример Создание базы данных содержащих
информацию о погоде (база данных состоит из одной таблицы):
|
Месяц
|
День
|
0С
|
Скорость
ветра
|
Направление
ветра
|
|
byte
|
byte
|
real
|
real
|
String[3]
|
|
|
|
|
|
Type=recode;:bute;:bute;:real;:real;:string[3];;:file
of pogoda;,b:pogoda;:int64;TForm1.Button1.Click(...);
{заполнение файла}(f,‘c:\pogoda.dat’);(f);

Procedure TForm1.Button2.Click(...);
{просмотр
файла}(f);not
Eof(f) do begin(f,b);=i+1;StringGrid1 do
begin[1,i]:=IntToStr(b.m);[2,i]:=IntToStr(b.d);[3,i]:=FloatToStr(b.t);[4,i]:=
FloatToStr(b.sv);[5,i]:=b.nv;;;;
Ø
Не
типизированные файлы (бинарные).
Объявляются как переменные типа файл:
Var
f:file;
…
Отличаются тем, что для них не указан тип
компонента. Файл воспринимается как набор байтов. Отсутствие типов данных дает
ряд преимуществ:
ü Эти файлы
совместимы с любыми другими;
ü Высокая скорость
обмена данными между диском и памятью.
Инициализация не типизированного файла
осуществляется процедурами Reset
и ReWrite:
Reset(<файловая
переменная>[,<длинна записи>]);
Длинна записи не типизированного файла
измеряется в байтах и по умолчанию равна 128 байт.
Тип данных Word(<длинна
записи>) - 0..65535 максимальная длинна записи 64 Кбайт. Delphi
не накладывает ограничений на длину записи не типизированного файла, за
исключением ограничения на целый тип Word.
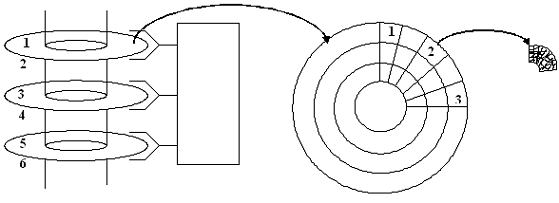
Жесткий диск состоит из нескольких дисков,
которые в свою очередь состоят из секторов, состоящих из доменов. Размер
физического сектора на жестком диске 512 байт. Для обеспечения максимальной
скорости обмена данными длину записи не типизированного файла следует задавать
кратной размеру физического сектора на диске (512 байт). Кроме того на
логическом уровне каждому файлу выделяется как минимум 1 кластер. Каждый
кластер занимает 2 или более смежных секторов. Как правило, на большинстве дисков
1 кластер читается или записывается за один оборот диска, по-этому,
максимальную скорость обмена данными можно получить, если указать длину записи
не типизированного файла равной размеру кластера в байтах.
Процедуры и функции для работы с не
типизированными файлами
Для этих файлов могут применяться все процедуры
и функции, предназначенные для типизированных, за исключением Read
и Write, которые
заменяются высокоскоростными процедурами BlokRead
и BlokWrite:
BlokRead(<файловая
переменная 1>,<2>,<3>[,<4>]);
BlokWrite(<файловая
переменная 1>,<2>,<3>[,<4>]);
- файловая переменная;
- буфер (т.е. имя переменной, которая будет
участвовать в обмене данными с диском);
- количество записей, которые должны быть
прочитаны или записаны за одно обращение к диску;
- возвращает при выходе из процедуры количество
фактически обработанных записей.
Buff: array [1..1024] of byte;:
(f,buff,2,x); [x=1]
За одно обращение к процедуре BlokRead
/ BlokWrite может быть
передано n*(длинна записи)
байт. Передача идет начиная с первого файла к переменной Buff.
Программист должен заботиться о том, что бы длинна внутреннего представления
переменной Buff была
достаточной для размещения всех n*(длинна
записи) байт. Если длинна буфера будет недостаточной или место на диске
закончится то выведется: ‘ОШИБКА!’
Ø Потоки.
Stream - поток
данных.
Thread - отдельно
выполняющаяся программа (отдельный процесс); программный поток.
TSream - объект
потока данных. Является базовым для потоков данных разного типа. В нем
реализованы все необходимые свойства и методы, используемые для чтения и записи
данных на различные типы носителей (память, диск, сеть …). Благодаря ему,
доступ к различным типам носителей становится унифицированным (единым,
одинаковым …). У объектов TSream
существует несколько потомков одного уровня позволяющих работать с различными
носителями информации.
Потомки TSream:
TFileStream
- применяется для получения доступа к файлам.
TMemoryStream
- применяется для получения доступа к памяти.
TStringStream
- применяется для получения доступа к строкам, хранящимся в динамической
памяти.
TWinSocketStream
- применяется для получения доступа к данным из сети.
TOleStream
- применяется для получения доступа к COM-интерфейсу
(component
object model).
Для всех этих объектов действуют основные методы
и свойства родительского объекта TSream.
Основные свойства объекта TSream:
Position
- указывает на текущую позицию курсора в потоке (начиная с нее будет
происходить чтение файла).
Size - размер
данных в потоке.
Методы объекта TSream:
1. указатель
на поток, из которого надо копировать;
2. размер
данных (байт) подлежащих копированию.
Read - позволяет
прочитать данные из потока, начиная с текущей позиции курсора:
1. буфер, в который будет происходить чтение;
2. количество читаемых байтов.
Write - позволяет
записывать данные в буфер (по параметрам аналогичен read);
Seek - позволяет
переместиться в новую позицию в потоке:
1. число, указывающее на сколько байт нужно
передвинуться;
2. от куда надо двигаться (не обязательные
параметр). Может принимать 3-и значения:
· soFromBegining - от
начала;
· soFromCurrent
- с текущей позиции (по умолчанию);
· soFromEnd - с
конца.
SetSize
- устанавливает размер потока (один параметр - число указывающее новый размер
потока (байт)).
Пример Работа с объектом TFileStream
- чтение информации:
…: TFileStream;: array [1..1024] of
byte;OpenDialog1.Exwcute then :=TFileStream.Create (OpenDialog1.FoleName,
fmOpenRead);.Read(buf,1024);.Free;;
end;
fmOpenRead
- режим работы с файлом.
Режимы работы с файлом для объектов TFileStream:
fmCreate
- создает новый файл (если файл уже существует, то он открывает его в режиме
записи);
fmOpenRead
- открывает файл только для чтения;
fmOpenWrite
- открывает файл только для записи (вся предыдущая информация стирается);
fmOpenReadWrite
- добавляет информация в файл не удаляя предыдущую;
fmShareExclusive
- при работе с файлами в таком режиме не одно приложение, кроме вашего не
сможет его открыть;
fmDenyWrite
- при работе с файлами в таком режиме другие приложения не могут писать в файл,
но могут его читать;
fmDenyRead
- при работе с файлами в таком режиме другие приложения могут только писать, но
не открывать приложения.. Строки.
Строки используются для обработки текста:
Var
Имя: string;
Этот тип похож на одномерный массив символов, но
в отличие от него количество элементов в строке может меняться в ходе
выполнения программы.
Максимальное количество символов в строке 255.
Пример:
: string; [0-255]:
string [10]; [0-10]
В OPascal
строка выглядит как цепочка символов, к каждому символу можно обратиться как к
элементу одномерного массива указав его индекс:
s: “это_строка”;
s1:=s6;
[т]
Строка хранится в памяти компьютера следующим
образом - самый первый элемент строки имеет индекс 0 и содержит значение
текущей длинны строки:
( это_строка ) - для человека
A (ASCII
код символов) - для компьютера
Над длинной строки можно производить необходимые
действия оперируя с нулевым байтом строки.
Над строками допустимы следующие операции:
). Сравнение (результат - истина, если строки
идентичны).
2). Сложение.
:= “ab”;:= “12”:=s1+s2; [“ab12”]
При записи строки допустимо использовать ASCII
коды символов:
S:= “abs”;
S:= #65#66#67;
S:= “a”#66
“c”
Если, при сцепление строк, длинна строки более
255 символов, то лишние символы отсекаются.
Правила сравнения строк:
<,> - допустимо использование при работе
со строками. Строки сравниваются поэлементно в соответствие с их ASCII
кодами. Если коды соответствующих символов строк отличаются от операций <
или > выдают истина или ложь.
s1:= “abcde”; [65 66
67 68 69]:= “abcae”; [65 66 67 65 69]>S2:= “abc”; [65 66
67]:= “abcde”; [65 66 67 68 69]>S1
Процедуры и функции для работы со строками:
Concat (s1,
s2 … sn):
string; - сцепление строк
в списке параметра, возвращает результат функция string;
Copy (st, index, count): string; - возвращает
из
st count символов:
:= “конкатспация”;:=
copy (s1, 4, 3); [“кат”]
Delete (st, index, count): string; -
удаляет
из
строки
st с
позиции
index count символов:
:= “процедура”;:=
delete (s1, 1, 5); [“дура”]
nsert (s1,
st, index);
- возвращает в строку s1
строку st начиная с
позиции index:
s:= “дверь”;:=
“е”;:=insert
(s, s2, 2); [“деверь”]
(s):
byte - возвращает
начальную длину строки.
Pos (s1,
s): byte
- возвращает позицию первого вхождения подстроки s
в s1:
s1:= “колокол”;:=
“ол”;:=
pos(s1;s) [2]
Если подстрока s1
отсутствует внутри строки s,
то pos возвращает (0).
Comparestr
(s1,s2):
Boolean; - сравнивает 2
строки с учетом регистра:
Comparestr (“Abc”; “abc”) [false](s1,s2):
Boolean - сравнивает
2 строки
без
учета
регистра:
(“Abc”; “abc”) [true]
Stingofchar
(s,count):
string - возвращает
строку с повторяющимся количеством повторяющихся символов:
Stingofchar
(‘f’,5); [fffff]
Sting
replace (s1,
s2, s3)
- возвращает строку с заменой вхождений одной подстроки в другую. (s1
- в какой?, s2- что?, s3
- на что?)
Trim (строка): string
- удаляет из строки пробелы и управляющие символы находящиеся в начале и в
конце строки.
TrimLeft
(строка): string - удаляет
из строки пробелы и управляющие символы находящиеся слева в строке.
TrimRight
(строка): string - удаляет
из строки пробелы и управляющие символы находящиеся справа в строке.
Str (x,
s); - эта процедура
преобразует целое или вещественное число (x)
к строковому формату и сохраняет результат в (s):
Var: real;: string;:= 230.561;(x,
s);:=
s+ ‘a’; [‘230.561a’]
Val (s,
x, c)
- процедура преобразует строку (s)
во внутреннее представление целой или вещественной переменной (x).
Параметр (c) после завершения
работы процедуры содержит (0), если преобразование прошло успешно, или содержит
номер позиции в которой произошла ошибка:
Var: integer;: real;: string;:=
‘232’;(s, x, c); (x = 2.32 E + 2; c = 0.):= ‘58*2’;(s, x, c); (x
= 5.8 E + 1; c = 3.)
(string): integer - преобразует
строку
в
целое
число.(string):
extended - преобразует число
в
строку.
(string, integer) - переводит
строку
в
целое
число,
при
ошибке
выдает
число
по
умолчанию.
(string): Boolean
- попытка перевести число в строку.. Процедуры.
Процедуры и функции играют важную роль при
написании программ и называются одним общим словом - подпрограммы. Они
представляют собой относительно самостоятельные фрагменты кода, оформленные
особым образом и снабженные именем. Упоминание этого имени в ходе программы -
называются вызовом процедуры или функции.
Отличие функции от процедуры в том, что
результатом исполнения операторов, образующих тело функции, всегда является
некоторое значение, поэтому функцию можно использовать в выражениях наряду с
переменными и константами.
Процедуры и функции представляют собой средство,
с помощью которого программа может быть разбита на ряд относительно-независимых
друг от друга частей. Это позволяет сэкономить память, т.к. код подпрограммы
существует в единственном экземпляре, а обращаться к ним можно из разных точек
программы.
У каждой подпрограммы существует набор
параметров, который позволяет модифицировать реализуемый ей алгоритм. При
вызове, параметры указываются в скобках, после вызова подпрограммы.
Локализация имен
Все подпрограммы, вызываемые в модуле, должны
быть предварительно объявлены:
· Либо упоминанием заголовка в интерфейсном
разделе;
· Либо полным описанием в разделе
реализации своего модуля.
Каждая подпрограмма имеет структуру, схожую со
структурой основной программы, модуля и проекта:
Procedure/Function
имя [(параметры)] [<тип, результаты и другие функции>]
Type
<объявление типов>;
Const
<объявление констант>;
Var
<объявление переменной>;
Label
<объявление меток>;
Begin
<тело подпрограммы>;
End;
Процедура выполняет только тело подпрограммы, а
функция возвращает еще и значение результата.
Подпрограмма любого уровня имеет, как правило,
много констант, переменных, типов и вложенных в нее подпрограмм низшего уровня.
Считая, что все имена, описанные внутри подпрограммы, локализуются в ней, т.е.
они не видимы снаружи, таким образом, со стороны операторов использующих
обращение к подпрограмме она трактуется как черный ящик, в котором реализован
тот или иной алгоритм; все детали реализации этого алгоритма скрыты для высшего
модуля или подпрограммы. При входе в подпрограмму низшего уровня становятся
доступными не только объявленные в ней имена, но и сохраняется доступ ко всем
именам верхнего уровня.
Пример:
Primer;
.
.V1…;
.
.AV2;;;B;V3
Procedure B1;
Var V4;B2;
Var V5;
Begin;
.
.;
.
.;
Begin
.
.
End;
End;
End.
Из процедуры (B2)
доступны переменные (V1,
V3, V4,
V5).
Из процедуры (V1)
доступны переменные (V1,
V3, V4).
Из процедуры (B)
доступны переменные (V1,
V3).
Из процедуры (A)
доступны переменные (V1,
V2).
На уровне модуля доступна переменная (V1).
В случае если локальный идентификатор совпадает
с глобальным, то локальное объявление перекрывает глобальное.
Пример:
A;;: string;B;: string;
s: ‘bbb!’;
Label1; Caption:= ‘внутри
процедуры
B s=’+s;;: ‘aaa’;; Caption:= ‘до
выбора
в
процедуре
B s=’+s;;
Label0 [‘до
входа ... ааа’]
Label1 [‘внутри
процедуры ... bbb!’]
Label2 [после
процедуры ... ааа]
Из внутренней процедуры можно обратиться к
одинаковому идентификатору внешней, с помощью спецификатора:
pascal идентификатор константа массив
<имя процедуры. Имя идентификатора.> A.S.
.
.
s: ‘bbb!’
label1. Caption:
‘внутри процедуры B
s=’ + s
+ ‘а внутри процедуры A
s=’ + A.S.;
.
.
При взаимодействие подпрограмм одного и того же
уровня иерархии вступает в действие следующее правило:
Любая подпрограмма перед ее использованием
должна быть объявлена.
Пример:
PrimerC; [или
A, B]A;B;A;
.
.;B
. [A];
.;C;
. [A, B];
.;.
Замечание:
1). Если
процедуры были объявлены в интерфейсном разделе модуля (одной строкой), то их
можно вызвать любую из любой и в любом порядке.
). Если процедуры объявлены в интерфейсном
разделе, то в разделе реализации они могут располагаться в произвольном порядке
и вызывать любую из любой.
Формальные и фактические параметры
Параметры, указанные в описание заголовка
программы называются формальными, а параметры, указанные при вызове
подпрограммы, называются фактическими.
Пример:
A;, b: real;Add (x, y: real;): real; (x,
y - формальные
параметры):=
x + y;;
a:=3
b:= Add(a,11);
[14] (Add
- фактический параметр)
End;
Синтаксис записи процедур и функций
Procedure
<имя> [([var]
<имя> : <тип>; [[var]
<имя1, имя2…> : <тип1 …>])];
Function
<имя> [([var]
<имя1> : <тип1>, [var]
<имя2, имя3…> : <тип3>)] : <тип результата>
Функция в отличие от процедуры обязательно
возвращает значение указанного типа и может использоваться только в выражение.
В теле функции (Begin
… End;) обязательно
должна присутствовать следующая строка:
имя функции := ...;
Эта переменная хранит результат, возвращаемый
функцией, и может быть использована только один раз.
Так же, внутри каждой функции существует
объявленная, по умолчанию, переменная с именем Result.
Эта переменная так же хранит значение функции, но может использоваться сколько
угодно.
Function Sum (n: integer): integer;,
s: integer;:= 0;i = 1 to n do s:= s + i;:= s;;Sum (n: integer): integer;:
integer;:= 0;i = 1 to n do result:= result + i;;
Способы передачи параметров подпрограммы:
· Передача по ссылке (в подпрограмму передается
ссылка(адрес фактического параметра));
· Передача по значению (в качестве
параметра передается копия значения фактического параметра);
· Передача по названию (подпрограмме
передается имя той переменной, которая является фактической переменной (в
современных языках программирования этот способ не применяется)).
Первые два способа применяются в OPascal,
каким способом передавать параметры, принимает решение программист. Следует
учитывать, что параметры, передаваемые по ссылке, могут возвращать значение при
выходе из процедуры или функции, т.е. могут быть изменены внутри подпрограммы.
Параметры, передаваемые по значению, внутри
подпрограммы изменить нельзя.
Для передачи параметра по ссылке необходимо
указать в заголовке подпрограммы ключевое слово Var,
перед именем требуемого параметра. По умолчанию параметры передаются по значению.
Пример:
Procedure
ABC;
Var
x, y:
integer;
Procedure Test (p1: integer; var p2:
integer);:= p1 + 1, p2:= p2 + 1;. Caption:= ‘p1=’ + IntToStr(p1); [p1
= 2]. Caption:= ‘p2=’ + IntToStr(p2); [p2 = 6];:=1, y:= 5;(x,
y);. Caption:= ‘x=’ + IntToStr(x); [x = 1]. Caption:= ‘y=’ +
IntToStr(y); [y = 6];
Комментарий к подпрограмме: В данном примере в
процедуру Test передается
два параметра (p1, p2):
(p1 - по значению, p2
- по ссылке), соответствующие им фактические параметры x
и y, после выхода из
процедуры Test, принимают
следующие значения: (x
= 1, т.е. остается неизмененной, т.к. в процедуре изменялась лишь его копия; y
- меняет свое значение, т.к. в процедуру был передан его адрес и изменения
производились по этому адресу).
Для передачи в подпрограмму больших структур
данных (например, массивов) следует применять передачу по ссылке, т.к. это
позволит сэкономить память.
Механизм работы подпрограмм
Использование аппаратного стека.
Для моделирования семантики (логики построения)
блочной структуры программы в ПВЭМ в настоящее время используется механизм -
стек. Стеком называется следующая структура данных, которая организована по
принципу LIEO (последний
ушел - первым пришел).
Стек заполнятся следующим образом: первый
элемент кладется на дно стека, второй - по верх первого ...
Элемент, занесенный в аппаратный стек последним
- верхушка стека.
Извлечение происходит в обратном порядке:
сначала извлекается элемент с верхушки стека, а за ним все остальные. Изъять
элемент из середины стека невозможно.
Программы ПВЭМ строятся по сегментному принципу.
Сегмент - участок памяти размером 64 Кбайт,
адрес любой ячейки равен адресу ячейки + адрес смещения.
Сегменты бывают трех типов:
· (CS)
кода
- есть всегда;
· (DS
или ES) занятый -
если ячейка занята данными;
· (SS)
стека - если используется процесс или константа (параметр, переменные, адрес
возврата).
При запуске программы в оперативной памяти
автоматически образуется стек, который занимает один сегмент. Стек применяется
для работы с подпрограммами. В архитектуре современных компьютеров существует
аппаратный стек. Основой его служит регистр указателя стека SR.
SR содержит адрес
того элемента, который был занесен в стек последним, по традиции при записи
элементов в стек, значение регистра SR
уменьшается. Таким образом, стек растет в сторону уменьшения адресов.
При вызове подпрограммы в аппаратный стек
заносятся:
· Фактические параметры (в том порядке, в котором
они указанны);
· Адрес возврата;
· Блок локальных переменных.
Занесение в стек происходит именно в таком порядке.
Пример:
, y: integer;Two (p1, p2);, z:
integer;Three (p);, a: integer;
Two (z, p); [@M4];Four;,
a: integer;
Three (y); [@M3];(Two)
Four [@M2];Batton1.
Click (...)
Two (x, y); (@M1);
End.
По завершении работы программы происходит извлечение
из аппаратного стека в обратном порядке.
Указатели
Указатели и динамическая память.
Все переменные объявленные в программе
размещаются в пределах непрерывной области оперативной памяти, которая
называется сегмент данных (1 сегмент равен 64 Кбайт). При обработке больших
объемов данных все переменные могут не поместиться в один сегмент. Для
использования памяти находящейся вне сегмента памяти, используется механизм
динамической памяти. Динамической считается все оперативная память за вычетом
сегмента данных, сегмента стека и сегмента с кодом программы. Память называется
динамической, т.к. она выделяется непосредственно в процессе работы программы.
Память, расположенная в сегменте данных - статическая и выделяется на этапе
компиляции программы.
Динамическая память основана на работе с
адресами. При динамическом выделении памяти, заранее не известно: не тип, не
количество размещаемых данных. В динамической памяти нельзя обращаться по
именам, а только по адресам.
Адреса и указатели
Операционная память представляет собой
совокупность элементарных ячеек для хранения информации. Каждая ячейка может
хранить один байт информации и обладает уникальным номером, который называется
адресом.
Указатель - переменная, которая в качестве
своего значения содержит адрес байта памяти:
p: pointer; [@]
В ПЭВМ адреса задаются совокупностью двух
шестнадцатеричных слов:
. первое слово - сегмент;
. второе слово - смещение.

Структура адреса ячейки на примере 20-и
разрядной адресации:

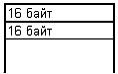
Объявление указателей
Существует два типа указателей:
1. типизированные (связываются с некоторым
типом данных);
2. не типизированные (просто хранят адрес
определенного участка памяти). Указатели объявляются в разделе описания
переменных и в разделе описания типов (Type
и Var).
Объявление типизированных указателей.
имя: ^название типа;
Var: ^integer;: ^real;
...=^PersonRecord;=Record;: string
[20];: byte;: PersonPeinter;;
В OPascal
любой идентификатор или тип, перед его использованием должен быть
предварительно объявлен (исключение сделано только для указателей, которые
могут ссылаться на еще не объявленный тип данных). Это связано с тем, что
динамическая память дает возможность организовывать данные в виде списка.
Объявление не типизированных указателей.
имя: painter;
Var: painter;,p2: ^byte; [1
байт]3,p4:
^real; [8
байт]
Типизированные и не типизированные указатели
хранят значение адресов, однако, значение одного указателя не всегда можно
передавать другому. В OPascal
передавать значение можно только между указателями, которые связаны с одним и
тем же типом данных, исключение составляют не типизированные указатели, которые
совместимы со всеми типами данных.
Var: painter;,p2: ^byte;,p4: ^real;
...:=p2;:=p4;1:=p3;
p4:=p2;
p1:=p1;
p3:=p;
Обнуление указателя
p:=Nil;
- после выполнения этой операции указатель продолжает занимать место в памяти,
но указывает в никуда (т.е. ни на одну ячейку).

p:=Nil;

Выделение и высвобождение
динамической памяти
Вся динамическая память в OPascal
рассматривается как сплошной массив байт, который называется куча (HEAP).
Физически она располагается в старших адресах памяти сразу за областью, которую
занимает код программы.

При работе с кучей используются стандартные,
объявленные по умолчанию переменные:
1. HeapOrg
- хранит адрес начала кучи;
2. HeapEnd
- хранит адрес конца кучи;
3. HeapPTR
- хранит адрес начала незанятого участка кучи.
Выделение в памяти для типизированных указателей
осуществляется с помощью процедуры New
(имя указателя):
Var
p: ^byte;
New(p);
p^:=2;
1. Администратор кучи просматривает ее
содержимое и если есть свободный байт - выделяет его, а адрес этого байта
записывается в переменную (p).
2. Запись числа (2) в свободное место с
адресом (p).
p^ - разадресация
указателя, т.е. обращение к значению хранящемуся по адресу, который лежит в (p).
Процедура New
выделяет динамическую память для требуемого указателя и только после этого
указатель можно использовать. Указатели можно использовать только в операциях
соответствующего типа, т.е. в операциях с адресами.
Разадресованные указатели могут использоваться в
любых выражениях и операциях:
Var:^byte;:real;(p);^:=2;:=SQRT(p^)+2*p^/3
Высвобождение динамической памяти.
После использования динамических переменных,
память занятую ими необходимо высвободить, для этого используется процедура dispose(имя
указателя):
Dispose(p);
После процедуры dispose
указателю снова можно выделить память.
После процедуры dispose
значение переменной высвобождается, а указателю присваивается значение Nil.
При работе с указателями ответственность за
высвобождение памяти ложится на программиста, т.к. Pascal
при завершении работы приложения, самостоятельно занятую память не
высвобождает, это может привести к утеске динамической памяти.
Для не типизированных указателей выделение
памяти осуществляется процедурой: GetMem
(имя указателя, размер). Размер - количество байт, которые будут помечены как
занятые. Он может быть от 1 до 65535 байт.
Высвобождение памяти для не типизированных
указателей:
FreeMem
(имя указателя, размер);
Пример:
Var: pointer;
…(p,400);
…
FreeMem
(p,400);
…
Процедуры для высвобождения динамической памяти:
Mark (p)
- запоминает адрес указателя (p);
Release
(p) - высвобождает
динамическую память начиная от адреса хранящегося в (p)
до конца кучи.
Эти процедуры могут применяться к типизированным
и не типизированным указателям.
Пример:
, p2, p3, p4, p5:
^integer;(p1);(p2);(p3);(p4);(p5);
…
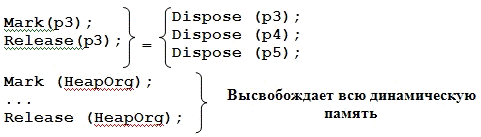
Процедуры и функции для работы с динамической
памятью:
Addr(x):
pointer; - функция
возвращает результат типа pointer
в котором содержится адрес аргумента (x),
где (x) - любой объект
программы (переменная, массив, объект указателя);
CSeg: word;
- (возвращает значение хранящееся в регистре CS)
в начале работы программы в регистре программы (CS)
хранится сегмент кода;
DSeg: word;
- (возвращает значение регистра DS)
в начале работы программы в регистре (DS)
хранится сегмент данных;
MaxAvail:
int64; - (возвращает в
байтах размер наибольшего непрерывного участка кучи);
MemAvail:
int64; - (возвращает в
байтах размер общего свободного пространства кучи);
Ofs(x):
word; - (возвращает
значение смещения адреса для указанного объекта (x))
(x) - выражение
любого типа или имя процедуры;
Seg(x):
word; - (возвращает
значение содержащее сегмент адреса указанного объекта);
PTR(s,
o: word):
pointer; - (s
- сегмент, o - смещение)
возвращает значение типа pointer
по заданному сегменту (s)
и смещению (o).
Динамические структуры памяти
Преимущества динамической памяти становятся
особенно очевидными при организации динамических структур. Элементы этих
структур связанны через адреса. К таким структурам относятся: стеки, очереди,
деревья, сети, …
Основой моделирования динамических структур
являются списки (конечно множество динамических элементов размещающихся в
разных областях памяти и объединенных в логически упорядоченную
последовательность с помощью специальных указателей, адресов связи). В списке
каждый элемент имеет информационное поле и ссылку, т.е. адрес другого элемента
списка.
Список - линейная структура данных, с помощью
которой задаются одномерные отношения.
Структуры элемента одномерного
списка
Однонаправленный список:

Двунаправленный список:

Порядок расположения информационных и ссылочных
полей в элементе произволен.
Информационная часть может содержать поля
различных типов.
Ссылки должны быть однотипны.
В зависимости от числа ссылок список бывает
однонаправленный и двунаправленный.
Линейный однонаправленный список:

- голова списка.
Список называется пустым, если указатель на
первый элемент равен Nil:
First=Nil;
Линейный двунаправленный список:

- голова списка.
Last - хвост
списка.
Так же существуют кольцевые списки, у которых
последний элемент указывает на первый.
Пример Описание элемента однонаправленного
списка:
Type Type=^zap;
point=^zap;=record; zap=record;: integer;
int1: integer;: string; int2: string; :
EL; next: point;; prev:
point;
End;
Все действия над элементами списка (вставка,
удаление, перестановка) сводятся к действиям со ссылками. Сами элементы при
этом своего физического положения в памяти не меняют.
Задачи для работы с линейным списком.
1_Создание
пустого
списка:
Create_Empty_List (var first: EL);
First:= nil;
End;
_Добавление элемента в список:
Procedure Create_New_Elem (var p:
EL);(p);^: inf1:= StrToInt (Edit1.text);^: inf2:= Edit2.text;^: next:=
nil;;_Empty_List (first);_New_Elem (p1);:= p1;_New_Elem (p2);^.next:=p2
3_Подсчет количества элементов в списке:
Function Count_El (first: EL):
integer;: integer;: EL;first=nil then k:=0:=1;:= first;q^.next <> nil
do:=k+1;:=q*next;;;;:= k;;
Аналогично записывается процедура: 1. вывода
списка на экран;
. поиск внутри списка…
_Вставка элемента в начало списка:
Procedure ins_Bea_List (p: EL; var
first: EL);first=nil then:= p;^.next:= nil;;^.next:=first;:=p;
End;
End;
_Добавление элемента в конец списка:
Procedure ins_End_List (p: EL; var
first: EL);: EL;first=nil then:=p;^.next:=nil;;:=first;q^.next<>nil do=q^.next;^.next:=p;^.next:=nil;;
End;
_Добавление элемента в середину списка (после i-того
элемента):

ins_After_i (p: EL; first: EL; i:
integer);,q: EL;,n: integer;:= Count_EL (first);(i<1) or (i>n) then;(‘i, задано
не
корректно’);;;i=1
then:=first;:=t^.next;^.next:=p;^.next:=q;;i=n
then:=p;:=first;q^.next<>nil do:=q^.next;^.next:=p;;;:=first;:=1;k<i
do:=k+1;:=t^.next;;:=t^.next; //в
t:=i, a в
q:=i+1^.next:=p;^.next:=q;;
End;

7_Удаление первого элемента в списке:
Procedure Del_Beg_List (var first:
EL);: EL;first<>nil then:=first;p^.next=nil
then(p);:=nil;;:=first;:=first^.next;(p);;
End;

_Удаление последнего элемента в списке:
Procedure Del_End_List (var first:
EL);,g: EL;first=nil then exit;first^.next=nil
then:=first;(t);:=nil;;:=first;:=first;q^.next<>nil do:=q;:=q^.next;;
// t
- предпоследний, q -
последний.
Dispose (q);^.next:=nil;;
End;

9_Удаление i-того
элемента из середины списка:
Procedure Del (var first: EL; i:
integer);, q: EL;, n: integer;first=nil then exit;:=count_EL(first);(i<1) or
(i>n) then(‘I задано не
корректно’);;;
If
i=1 then
Begin
// удаление первого элемента в списке (процедура
выше)
End;i=n then
// удаление последнего элемента в списке
(процедура выше)
End;:= first;:= nil;:=1;k<I
do:=k+1;:=t;:=t^.next;;:=t^.next; //(i-1):=q, (i):=t, (i+1):=k^.next:=k;(t);;
End;

10_Удаление
всего
списка:
Del_List (var first: EL);; q:
EL;first=nil then exit;:=first;:=nil;q<>nil do:=q;:=q^.next;(p);;:=nil;;
Кроме линейных структур, с помощью указателей
можно реализовать не линейные структуры (деревья).
Простейшим видим деревьев, являются бинарные
(двоичные) деревья (конечное множество элементов, которые либо пустые, либо
содержат одни элементы (корень дерева), а остальные элементы делятся на два не
пересекающихся подмножества, каждое из которых само является бинарным деревом
(эти подмножества - правые и левые поддеревья исходного дерева)).
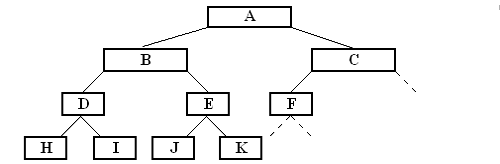
np: ^node;=record;: string;: np;:
np;;
Графика в Delphi
Delphi позволяет
использовать графические возможности операционной системы Windows.
В операционной системе Windows
графические возможности предоставляет графический интерфейс Win32.
в частности интерфейс известный как GDI.
Интерфейс GDI
используется в системе Win32
для рисования и раскраски изображений. До появления Delphi
для программирования графики в среде Windows
необходимо было напрямую работать с функциями и процедурами GDI.
В Delphi существует объект TCanvas
(холст), который инкапсулирует и упрощает использование функций и инструментов
(методов) GDI.
Представление рисунка в Delphi
TImage - компонент
с таким же названием доступен на палитре компонентов Inditional.
С помощью компонента TImage
можно загрузить и отобразить на экране любой рисованный файл (*.bmp,
*.wmf (16-и разрядный
метафайл Windows),
*.emf (32-х разрядный
расширенный формат метафайла), *.ico,
*.jpeg, а так же файлы
других графических форматов поддерживаемых надстройками класса TGraphic).
Графические данные хранятся в свойстве picture
объекта TImage.Picture.
Определение размеров графического файла:
1. размер (количество пикселей) ×
координата (x) ×
координата (y);
2. размер (длинна по (x))
×
размер (длинна по (y)) ×
количество пикселей × цвет.
Растровая графика
Позволяет хранить изображение в виде матрицы пикселей.
Основной недостаток - плохая масштабируемость (Paint,
Photoshop…).
Векторная графика.
Позволяет хранить изображение в виде набора
графических объектов, каждый из которых описывается математической формулой (Coral
Draw).
Delphi работает
только с растровой графикой.
Существует два типа растров:
). Зависимые от устройства (DDB);
). Не зависимые от устройства (DIB).
Delphi работает
только с независимыми от устройств растрами, т.к. они работают со всеми
устройствами.
Загрузка изображения на форму.
Сохранение изображения.
Для этого используется класс TPicture.
Он представляет собой контейнерный класс для инкапсуляции абстрактного класса TGraphic.
Контейнерный означает, что класс TPicture
может хранить ссылки на объекты: TBitmap,
TMetafile, TIcon.
Пример Изображение на форме какой-либо картинки:
Procedure TForm1.Button1.Click
(sender: object);

Imege1.Picture.LoadFromFile
(‘c:\*.bmp’);;
Для сохранения используется метод SaveToFile:
Image1.Picture.SaveToFile (‘c:\*.bmp’);
Для работы с файлами формата JPEG
необходимо в строке используемых модулей записать модуль JPEG.
Класс TBitmap
Класс TBitmap
предназначен для хранения растрового изображения. Он инкапсулирует объект
растров и палитры системы Win32.GPI.
Создание объекта:
Var
b: TBitmap;
……:=TBitmap.Create;
…:=nil // или
b.Destray;;
Методы объекта TBitmap:
1. .LoadFromFile
- загрузить
в объект;
2. .SaveToFile - сохранить;
. .Assign
- позволяет скопировать один растр в другой.
Var, b2: TBitmap;:=
TBitmap.Create;:= TBitmap.Create;.LoadFromFile(…);2.Assign(b1);
End;
При использование метода *.Assign
копирование происходит следующим образом: в объект (b2)
записывается ссылка на объект (b1),
что позволяет сэкономить память; в случае внесения изменений в объект (b2)
происходит автоматическое копирование объекта (b1).
4. .CopyRect
- позволяет скопировать прямоугольную часть растрового изображения из одного
объекта Bitmap в другой
или на форму.
Типы данных в OPascal:
TPaint - точка;
TRect -
прямоугольник;
Пример:
Var
a: TPaint;
b: TRect;
….x:=100;.y:=150;
….left:=10;.top:=10;.right:=100;.botton:=100;
Пример Нарисовать прямоугольник:
Var: TRect;.top:=0; //
левая.left:=0; //верхняя.night:=90; //правая.botton:=90; //нижняя.Convas.CopyRect
(ClientRect, Bitmap2.Canvas, r1);;
Существует еще один метод, позволяющий
копировать целый растр на канву формы со сжатием или расширением изображения,
так, что бы оно помещалось и полностью заполняло пространство внутри границ
канвы - StretchDraw.
Пример:
: TRect;:
TBitmap;:=TBitmap.Create;.LoadFromFile(‘c:\picture1.bmp’);.left:=0;.top;=0;.right:=Bitmap1.Width;.botton:=Bitmap1.
Leight;.Canvas.StretchDrow (r1, Bitmap1);;
Использование свойств класса TCanvas:
1. TPen
- перо (объект отвечает за способ и цвет рисования линий на канве): Image1.Canvas.Pen.
Свойства объекта TPen:
Цвет (color):
With Image1.Convas.Pen.Color do
Color:=clRed;
End;
Или выбор цвета случайным образом
Color:=RGB(random (256), random
(256), random (256));
Тип линии
(style):
.Style:=psSolid;
Виды линий:-
сплошная;-
пунктир;-
точка
/ пунктир;-
пунктир
/ точка
/ точка
- точки;
psClear
- бесцветная.
Pen.Mode
- режим работы пера (задает способ изображения линии на канве; способ смешения
цветов при накладывание объектов).
Режим работы пера задается логическими
операциями (pnCopy - по
умолчанию).
2. TBrush
- кисть (обладает тремя основными свойствами: color,
style, bitmap):
Свойства объекта TBrush:
Цвет (color):
With Image1.Convas.Brush.Color do
Color:=clRed;
End;
Или выбор цвета случайным образом
Color:=RGB(random (256), random
(256), random (256));
Тип линии
(style):
.Style:=psSolid;
Виды линий:-
сплошная;-
снизу
вверх;-
сверху
вниз;-
решетка
по
диагонали;
- решетка;
bsHorizontal
- горизонтальные линии;
bsVertical
- вертикальные линии;
bsClear
- бесцветная.
bitmap (позволяет
закрашивать область, заданным из реестра цветом):
Bitmap1.loadFromFile(‘...’);.Convas.Brush.Bitmap:=Bitmap1;
Основные методы объекта Canvas:
Canvas.MoveTo(a:
TPaint); - перемещает (но
не рисует) перо в указаннуюточку;
Canvas.LineTo(a:
TPaint); - рисует линию
от текущего указателя пера до точки (a);
Canvas.Rectangle
(a: TRect);
- рисует прямоугольник;
Canvas.Rectangle
(a1:TPaint;
a2:TPaint);
- рисует прямоугольник;
Canvas.Ellipse
(e: TRect);
- рисует овал вписанный в прямоугольник;
Canvas.Arc
(e: TRect);
- рисует дугу;
Canvas.FillRect
(a: TRect);
- рисует прямоугольник текущим пером и закрашивает его текущей кистью;
Canvas.FloodFill (x, y: integer; c:
TColor; f {fsSurfase, fsBorder}) - способ заливки;
fsSurfase
- залить вся область, где цвет равен цвету указанному в третьем параметре;
fsBorder
- залить вся область, где цвет не равен цвету указанному в третьем параметре.
Canvas.TextOut
(x, y:
integer; s:
TString); - выводит в
указанном месте текст на канву; шрифт задается при помощи Convas.Front.
Объект Screen
(экран).
Этот объект существует всегда, вне зависимости
от других объектов. Объект так же может использоваться для графики.