Сетевая технология публикации и обработки данных в муниципальном учреждении Д/С №176
Министерство
образования РФ
Самарский
государственный аэрокосмический университет
им. С.П.
Королева
Тольяттинский
филиал
Кафедра
радиоэлектроники и системотехники.
Сетевая
технология публикации и обработки данных в муниципальном учреждении Д/С №176
Пояснительная
записка к курсовому проекту по курсу «Сети ЭВМ и телекоммуникаций»
Тольятти 2011
Реферат
WEB-ПРИЛОЖЕНИЕ,
SQL-СЕРВЕР, МНОГОЗВЕННАЯ АРХИТЕКТУРА,
ТЕХНОЛОГИЯ, HTML-СТРАНИЦА, СЕРВЛЕТ, КОНТЕЙНЕР
СЕРВЛЕТОВ, JSP-СТРАНИЦА, JDBC-ДРАЙВЕР, СЕРВЕР ПРИЛОЖЕНИЙ, WEB-СЕРВЕР, ИНТЕРФЕЙС.
Объектом исследования является муниципальное учреждение детского
воспитания Д/С №176 «Белочка».
Цель работы - разработка сетевой технологии публикации и обработки данных
для работников указанного учреждения.
В процессе работы будет создано web-приложение, доступное разработаны основные интерфейсные формы.
Введение
В данном курсовом проекте необходимо провести анализ рассматриваемого
предприятия, выявить слабые места существующей технологии обработки данных и документооборота.
После проведенного анализа будет спроектирована и разработана новая технология,
соответствующая современным требованиям, а так же удовлетворяющая в полной мере
требованиям рассматриваемой организации.
Актуальностью темы является увеличение эффективности работы предприятия
за счет использования сетевой технологии публикации и обработки данных.
Новизна заключается в том, что данная технология еще не использовалась в
рамках рассматриваемой организации «ЛАДА», в частности у дет/сада №176.
Целью данной работы является изучение и анализ публикации данных с
помощью web-технологий, и, на основе полученных
знаний, создание собственного web-приложения
с функциональностью, определенной в «Требованиях к ПП».
В ходе работы необходимо реализовать следующие задачи:
1) Изучить ведущие web-технологии
на сегодняшний день;
2) Провести проектирование разрабатываемого ПП для Заказчика;
) Определить основной функционал разрабатываемого ПП;
) Разработать технологию в соответствии с определенными к нему
требованиям;
) Провести анализ полученного результата;
) Провести оценку проделанной работы и выявить дальнейшие пути
улучшения технологии.
1. Анализ поставленной задачи и постановка задачи на проектирование
В данной главе проводится анализ поставленной задачи, рассматриваются
имеющиеся на данный момент времени технологии по созданию web-приложений и
проводится их сравнение, а также осуществляется выбор методов и средств
решения, с помощью которых можно осуществить реализацию проекта.
1.1 Анализ существующей технологии обработки информации
Учреждение Д/С №176 «Белочка», именуемом далее как Заказчик, является
одним из представителей организации «ЛАДА», занимающейся образовательным
воспитанием детей дошкольного возраста в Самарской области.
Рассмотрим структурную схему рассматриваемой организации, отраженную на
рисунке 1.
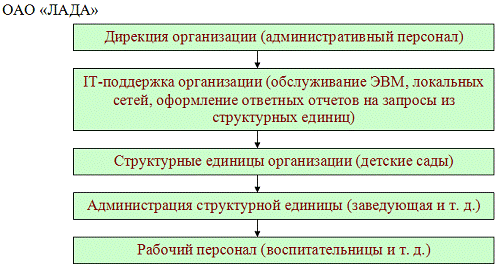
Рисунок
1- организационно-структурная схема организации ОАО «ЛАДА»
В ходе исследования организационной деятельности предприятия были
выявлены следующие механизмы работы с данными информационной системы:
1) Имеется БД по всем структурным единицам организации (детским
садам) на главном сервере. У Заказчика отсутствует онлайн режим по работе с БД,
так как обслуживание детского сада в вопросах, связанных с ЭВМ (обслуживание,
работа с потоками информации) осуществляется отдельной структурной единицей - IT-поддержкой;
2) Для получения информации (например, по ребенку) необходимо делать
запрос в соответствующий IT-отдел,
отвечающий за работу с БД;
) Локальная информация в рамках одной структурной единицы хранится
в бумажном виде;
4) Ввод локальной информации происходит вручную.
На рисунке 2 была отображена последовательность действий, необходимых для
получения информации из центральной БД.
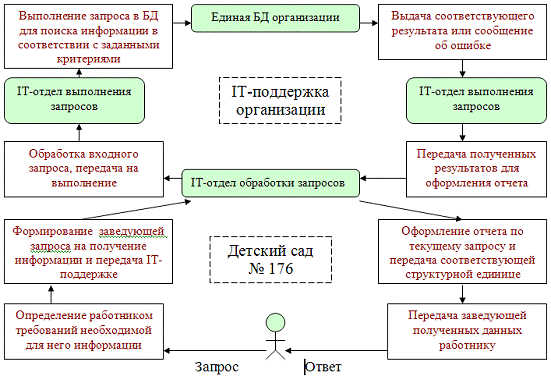
Рисунок
2 - жизненный цикл запроса в действующей ИС
Данный подход показывает, что для получения требуемой
информации необходимо создать запрос определенного формата, который принимается
заведующей дет/сада. Далее этот запрос проходит цепочку обработки в
IT-поддержке, где по заданным параметрам во входном запросе получается отчет с
требуемой информацией и передачей ее обратно отправителю. После этого
полученный отчет передается работнику.
Преимуществами данного подхода являются:
1) Высокий уровень дифференциации обязанностей;
2) Заказчик не участвует в процессе генерации необходимой
информации, а только предъявляет параметры запроса;
Но кроме положительных моментов сразу можно отметить и недостатки
использования данного подхода:
1) Данный ЖЦ запроса приводит к увеличению времени предоставления
информации требующему лицу. Это время включает в себя не только оборот запроса
внутри предприятия; большая часть этого времени состоит из формирования отчета
на стороне IT-поддержке;
2) Из первого недостатка вытекает и следующий: в связи с большим
временем отклика на сформированный запрос падает актуальность требуемой
информации (а порой эта информация требуется немедленно);
) В связи с удаленным расположением Заказчика и IT-поддержки, повышается риск не
получения ответа из-за физических или механических причин (оборвался кабель,
сбой технических средств).
Помимо центрального репозитория существует и локальное хранение
информации в рамках каждого дет/сада. Для этого у Заказчика ведется система
отчетности по разным областям деятельности предприятия (история болезней,
информация о ребенке, информация о работающем персонале). Отчетность ведется в
письменном виде, что также вносит свои недостатки.
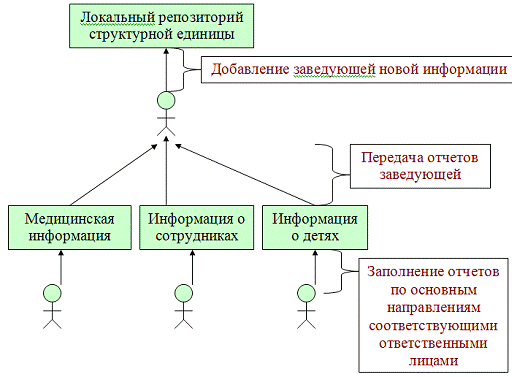
Рисунок
3- процесс локального обновления информации
В большинстве случаев именно этот механизм используется на предприятии,
поскольку получение требуемой информации ведется за более быстрый период, ее
актуальность сохраняется. Кроме того, чаще всего к числу требуемой информации
относятся общераспространенные данные (ФИО, адрес, телефон), которые в полной
мере описаны в рамках локального репозитория. Опишем ЖЦ запроса при
использовании локального подхода:
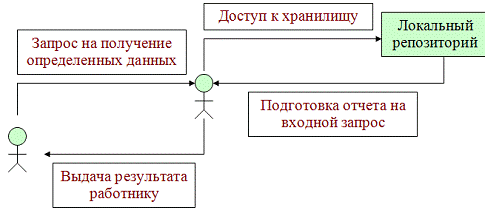
Рисунок
4- жизненный цикл запроса в локальной системе обработки данных
Положительными моментами такой организации работы являются:
) Малое время ожидания получения конечного ответа на запрос
работника;
) Сохранение актуальности полученных данных.
Результатом данной организации обработки данных являются следующие
недостатки:
1) Бумажное ведение локальной информации также ведет к увеличению
времени ее получения;
2) Оформление имеющихся данных происходит ручным способом,
соответственно велика вероятность человеческого фактора - ошибка при
заполнении, неразборчивость почерка и т. д.;
) Бумажное хранение информации весьма небезопасно - любая ЧС
(пожар) может привести к необратимой потере всей информации, т. к. не имеется
ее копии.
) Для централизованного хранения всего объема информации в рамках
Заказчика выделяется специальное место, что также делает очень уязвимым
хранение… Кроме того, данное место можно было бы использовать более
рационально;
) Ограниченность информации - при переводе ребенка в другую
структурную единицу «ЛАДА» необходимо:
а) Найти локальную информацию о ребенке;
б) Передать в соответствующий дет/сад;
в) Согласовать изменение данных с центральным сервером;
г) Удалить эту информацию из местного локального хранения.
Это приводит к затруднениям при переводе ребенка в другую структурную
единицу, например, при переезде на другое место жительство;
6) В связи с тем, что работу с репозиторием ведет один человек, то в
случае его увольнения время на получение нужной информации резко возрастет, так
как новому лицу потребуется много больший период на ее поиск;
7) Недостаточная полнота хранимых данных в отличии от центрального
репозитория.
Итого, в рамках Заказчика происходит большие объемы потоков информации.
Каждый день работниками предприятия происходит ведение учета, оформление
разного рода документов, заполнение отчетов мед/персоналом. Разумеется, что
почти вся эта информация касается конкретных детей, любо событий, связанных с
ними. Это в свою очередь означает, что необходим быстрый, легкий, а главное
полный набор необходимых сведений о ребенке в читабельном виде.
Существует два основных подхода для получения этой информации:
1) Создание специализированного запроса в IT-отдел по обработке и выдаче информации.
2) Использование локальных методов ведения и учета информации,
который заключается в ведении бумажных отчетов по той или иной области
деятельности предприятия.
Очевидно, что оба этих метода не предоставляют в должной мере того
удобства, которое необходимо для оптимальной работы: необходимы большие затраты
времени, что порой бывает критическим показателем, наглядность и читабельность
предоставляемых данных в первом случае не зависит от Заказчика, а во втором
случае и вовсе, зависит от конкретных людей, ведущих учет этих данных (плохой
почерк, ошибки при заполнении, невнимательность в результате усталости от
рутинной работы).
Проведенный анализ показывает необходимость изменения текущего состояния
информационной системы Заказчика, что подтверждает и сам персонал данного
предприятия.
1.2
Разработка новой технологии обработки информации
1.2.1 Выбор методологии проектирования
Чем детальнее будет рассмотрено построение разрабатываемой технологии,
тем качественнее и надежнее можно будет ее реализовать. Поэтому очень важным
является выбрать такую технологию проектирования, которая в полной мере
позволит нам декомпозировать единую систему на необходимое число составляющих
для дальнейшей разработки. На данном этапе необходимо определить все
ограничения и требования к системе.
Для описания функционирования разрабатываемой мною технологии будет
выбрана методология DFD, основанная на
графическом представлении систем. Она является одной из составляющих более
общей IDEF методологии. DFD - диаграмма потоков данных. Так
называется методология графического структурного анализа, описывающая внешние
по отношению к системе источники и адресаты данных, логические функции, потоки
данных и хранилища данных, к которым осуществляется доступ. Другой составляющей
является IDEF0 и IDEF3 методологии. Они являются методологиями
функционального моделирования и графической нотации, предназначенной для
формализации и описания бизнес-процессов. Поэтому данные методология не
позволит нам описать функциональную часть системы.
Вывод: методология DFD
наиболее полно подходит для описания процессов сетевой технологии, описания
движения информационных потоков и документации, поэтому выбор будет оставлен за
нею. Кроме того, важным фактором является мой личный опыт работы с данной
методологией.
1.2.2 Описание текущей модели обработки информации
Необходимо описать модель того подхода, который используется на
сегодняшний день у Заказчика, с целью определения основных потоков информации и
документов, а так же лиц, задействованных в том или ином процессе.
Для составления модели важно определить, для чего она создается, для
каких позиций она описывается.
Модель призвана ответить на следующий ряд вопросов:
- Что необходимо для выполнения отчетности сотрудником
дет/сада?
- Какие необходимы первоначальные данные?
- Как осуществляется метод доступа к требуемым данным?
- Как происходит документооборот при данном процессе?
Исходя из поставленных вопросов можно определить цель создаваемой модели:
определить основные этапы для ведения отчетности работниками дет/сада.
Рассматриваемая модель создается из списка позиций:
- Заведующая дет/садом;
- Мед/персонал;
- Работник по кадрам;
- Родители;
- Воспитатели.
Для дальнейшего анализа системы будет выбрана точка зрения родителей и
заведующей дет/садом, так как именно родители являются главными лицами,
требующими вести учет состояния их ребенка, а контакт с предприятием
осуществляется через заведующую.
Таким образом мною были определены цель и точка зрения разрабатываемой
модели, которая отражена на рисунке 5.

Рисунок
5 - описание цели и точки зрения модели
Следующим шагом является определение основных функций системы, а так же
описание основных входных данных системы:
- Данные по детям;
- Данные по кадрам;
- Мед/информация;
- Стандарт и тип отчета.
Функциями системы являются:
- Ввод информации в центральную БД;
- Актуализация данных БД;
- Доступ к информации в БД;
- Оформление отчетности.
Отразим эти параметры на рисунке 6.
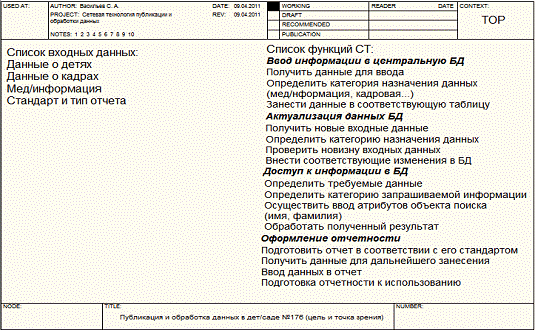
Рисунок
6 - определение функций модели
После определения основных понятий можно переходить к непосредственной
контекстной модели. Для этого сначала опишем уровень А-0, где определяются
основные процессы, подсистемы ИС, управляющие элементы, а также входные и
выходные элементы.
Основным процессом автоматизации будет процесс ведения отчетности
работниками дет/сада. Поэтому управляющими элементами будут являться
ответственные лица по областям. На вход текущей технологии обработки информации
поступают разного рода данные по областям (о детях, кадрах), после работы с
которыми составляются соответствующие отчеты на выходе системы. Разумеется, что
внутри предприятия существуют разного рода стандарты и правила, в соответствии
с которыми и происходит оформление результирующих отчетов.
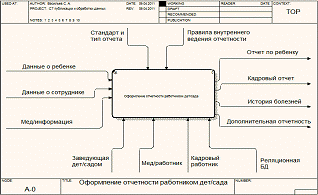
Рисунок
7 - описание работы текущей технологии обработки информации
Построив общую модель описания рассматриваемого процесса важно
декомпозировать его с целью выявления основных этапов и действий, реализуемых в
нем. После декомпозиции получаем модель типа А0.
Для нормального функционирования системы обработки информации в текущей
системе используются следующие этапы:
- Занесение новых входных данных бумажном виде;
- Актуализация имеющихся данных отдельным работником;
- Создание отчетов на основе имеющихся данных по
категориям: «Отчетность по ребенку», «Отчетность по кадрам»; «История
болезней»;
- Выполнение дополнительных видов отчетности по
требованию.
Отразим данный подход в модели А0 на рисунке 8.
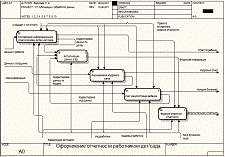
Рисунок
8 - декомпозиция текущего процесса обработки информации
Очень затруднительным этапом из рассмотренных является актуализация
имеющихся данных. Это вызвано тем, что данные хранятся в бумажном виде, что
усложняет процесс поиска нужной информации. Кроме потери времени на описанный
поиск, существует проблема внесения изменений в записи. Поэтому данный этап
нуждается в срочной автоматизации.
Исходя из описанных проблем, определим последовательность действий,
выполняемых сотрудником для внесения изменений в базе данных. Эту
последовательность отразим на рисунке 9, получив следующий тип модели А2.
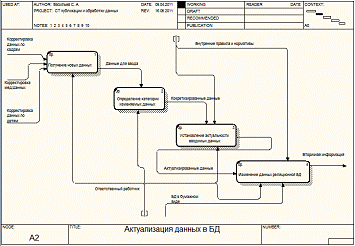
Рисунок
9 - декомпозиция этапа актуализации данных в текущей системе
В ходе произведенной декомпозиции мною определены следующие участники
процесса обработки информации в текущей системе:
- Заведующая дет/садом;
- Работник по кадрам;
- Мед/персонал;
- Ответственное лицо по актуализации данных.
Подведем итог, описав полный функционал текущей системы и выделив его
отрицательные стороны:
- В текущей системе хранение данных осуществляется в
бумажном виде. Резервирование данных занимает большие временные периоды,
большие затраты со стороны ответственного лица, отсутствие синхронизации данных
в настоящей и резервной БД;
- Хранение БД в бумажном виде приводит к большим
временным затратам на поиск необходимой информации, что снижает актуальность
информации до момента ее получения;
- Большая часть хранимых данных заносится ответственным
лицом ручным способ. Разумеется, что почерк человека может привести к
затруднению читабельности данных, а его увольнение и вообще, к потере данных.
- Как было отмечено на этапе декомпозиции этапа
актуализации данных на рисунке 9, данной задачей занимается отдельное
физическое лицо. Естественно, это приводит не только к потерям времени на
получение измененных данных, но и на возможность человеческого фактора.
Человек, не работающий в сфере медицины, будет испытывать затруднения и, возможно,
допускать ошибки при столкновении со специфическими понятиями и определениями.
- Родитель для получения информации о своем ребенке
должен обратиться с запросом к заведующей, после чего начнется процесс
обработки запроса, описанный ранее на рисунке 2. Разумеется, доступ к данной
информации в домашних условиях значительно усовершенствовал бы систему.
Описанные проблемы и должна решить разрабатываемая технология.
1.2.3 Описание разрабатываемой модели обработки информации
В связи с недостатками, определенными в пункте 1.1 и 1.2.2 необходимо
определить возможные пути их устранения, а так же функции и свойства новой
технологии.
На основе выбранной в предыдущем пункте методологии необходимо описать
процесс функционирования разрабатываемой технологии, а после произвести его
декомпозицию с целью выявления основополагающим моментов разработки системы. В
результате этого мы сможем увидеть и определить основные звенья, из которых
будет состоять технология, а значит более детально описать и разработать
выполняемые ими функции. В итоге, при таком подходе можно получить
отказоустойчивую и надежную систему, обеспечивающую в полной мере те
требования, которые к ней были предъявлены в рамках данного курсового проекта.
Опишем основу функционирования разрабатываемой технологии с помощью
контекстной модели, изображенной на рисунке 10.
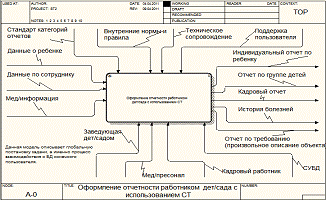
Рисунок
10 - описание работы разрабатываемой ИС обработки информации
Как
видно из предыдущего рисунка, основной функцией и направлением разрабатываемой
технологии будет являться обработка и учет потоков информации (данных) в рамках
Заказчика. Результатом работы в этими потоками будут служит разного рода
отчеты. Процесс оформления отчетности является сложным процессом, поэтому его
необходимо декомпозировать на следующие этапы:
- Ввод новой информации в реляционную БД;
- Актуализация существующих данных БД;
- Работа с БД и получение разного рода информации;
- Подготовка отчетности.
Исходя из этой декомпозиции, отразим основной этап функционирования
системы на рисунке 11.
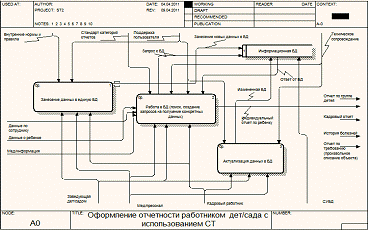
Рисунок
11 - декомпозиция процесса ведения отчетности дет/сада
На вход системы поступает запрос на получение определенного рода
информации из центрального репозитория. Данный запрос обрабатывается
ответственным лицом (заведующая, мед/работник, кадровый работник). Данное лицо
на основе полученного запроса заполняет необходимую форму, позволяющую получить
информацию из центральной БД с помощью специальных средств взаимодействия с
ней. Полученная информация обрабатывается этим же лицом, составленный отчет
подготавливается к выдаче.
Определив этапы разрабатываемой технологии, становится возможным
определить основные лица, участвующие на конкретном этапе, а так же его
основные действия.
Для начала рассмотрим этап занесения данных в БД. Сотрудник, получая
новую информацию, соответствующую его области ответственности, получает доступ
к БД с помощью средств доступа и взаимодействия с БД. После соединения с
центральным хранилищем происходит непосредственный ввод информации с помощью
пользовательского интерфейса. Отразим данные операции на рисунке 12.
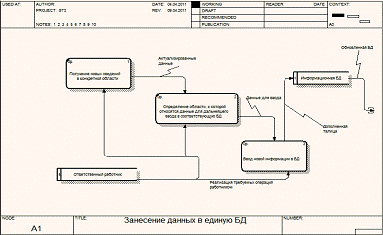
Рисунок
12 - декомпозиция этапа занесения данных в БД
Описанную выше декомпозицию процесса ввода данных отразим на рисунке 13.
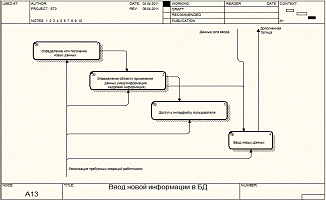
Рисунок
13 - элементарные операции работника на этапе занесения данных
Следующим рассматриваемым этапом является непосредственная работа с БД
ответственным работником. В ходе реализации данного этапа работник получает
разного рода информацию об объекте, по которому необходимо произвести поиск
соответствующей информации. Для получения запрашиваемых данных работник
производит доступ к БД с помощью специальных средств и методом взаимодействия с
ней. После этого, получив доступ к пользовательскому интерфейсу, происходит
заполнение входных параметров объекта, отправляется запрос в БД. Получив ответ
от БД, работник анализирует результат, на основе которого происходит процесс
оформления отчета по той или иной категории.
Данную декомпозицию отразим на рисунке 14.
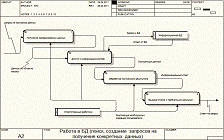
Рисунок
14 - декомпозиция этапа работы с БД конечного пользователя
Вышеописанную декомпозицию процесса доступа к БД опишем на рисунке 15.
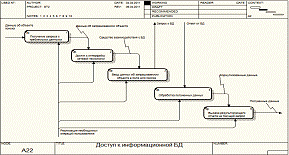
Рисунок
15 - элементарные операции работника на этапе доступа к БД
Наконец, последним рассматриваемым этапом является актуализация БД. На
данном этапе, в отличии от текущей технологии, актуализация осуществляется не
отдельным лицом, а ответственным в своей области человеком (заведующая,
мед/персонал, работник по кадрам). Данное лицо, получив новую информацию об уже
описанном объекте в БД, с помощью специальных средств проверяет новизну
вводимых данных. Если полученная информация действительно является актуальной,
то происходит ее корректировка, после доступа работника к пользовательскому
интерфейсу. Опишем данный этап на рисунке 16.
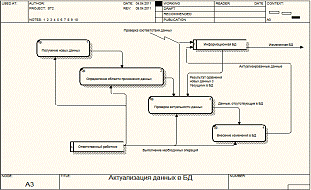
Рисунок
16 - декомпозиция этапа актуализации данных в центральной БД
Результирующий отчет должен содержать следующую информацию:
- ФИО человека, сгенерировавшего запрос;
- ФИО человека, обработавшего запрос;
- Время получение информации из БД (с целью анализа и
последующего улучшения метода доступа к БД);
- Непосредственно сами запрашиваемые данные.
Ожидаемый эффект от внедрения данной технологии позволить избавиться от
установленных проблем и добавить следующий функционал:
1) Скорость получения данных с центрального репозитория уменьшится в
несколько раз, а их актуальность значительно повысится. Скорость добавления и
редактирования данных также уменьшится;
2) Вероятность искажения данных в результате человеческого фактора
уменьшится в несколько раз, а значит, достоверность информации повысится;
) Доступ к информации будет доступен не только локально, а так же
посредством сети Интернет путем публикации этих данных через web-интерфейс (после аутенфикации и
идентификации) при соответствующем запросе.
) Безопасность хранения данных будет существенно увеличена, как от
бытовых угроз (воспламенение и т. д.), так и информационная (будет реализовано
резервирование данных).
) Мобильность системы позволит не только быстро и легко заменять
компоненты всей системы (СУБД, контейнеры сервлетов), но и переносить ее на
разные платформы, что расширит круг возможного применения.
) Этап актуализации будет выполняться не отдельным лицом, а непосредственно
ответственным по категориям:
- Заведующая - занимается оформлением и учетом
информации, связанной непосредственно с ребенком - посещаемость, адрес
проживания и т. д.
- Кадровый работник - ведет отчетность по сотрудникам
текущего предприятия.
- Мед/персонал - занимается описанием мед/обследований
ребенка, его состояние здоровья, историю болезней и т. д.
7) Хранения данных в электронном виде позволит значительно расширить
список хранимых атрибутов объектов по сравнению с бумажным. Кроме того, станет
возможным избежать повторяемости данных в одной таблице. Наконец, станет
незатруднительным хранение данных указанный период после ухода ребенка в общей
БД.
Итак, в данной главе были описаны основные направления, по которым будет
вестись работа. Но для начала необходимо определиться с выбором архитектуры
технологии и используемого ПО.
Необходимо реализовать следующие программные модули в разрабатываемой
технологии:
- Модуль ввода данных в БД;
- Модуль резервирования текущей БД;
- Модуль редактирования данных;
- Модуль анализа и статистической обработки данных о
болезнях детей, позволяющий заранее предугадать болезнь ребенка и предпринять
меры по ее предостережению.
1.3 Выбор и разработка архитектуры сетевой технологии
В источнике #"526851.files/image017.gif">
Рисунок
17 - представление многоуровневой архитектуры клиент-сервер
Как видно из рисунка 17, система предусматривает использование доступа к
реляционной БД 3 пользователей в рамках одного детского сада:
- Заведующая. Доступ для нее необходим в первостепенную
очередь, так как она ведет многочисленные работы, в которых ведутся отчетности
с использованием разного рода информации, которая и будет храниться в БД.
Поэтому своевременный и быстрый доступ к нужной ей информации является важным
критерием;
- Всвязи с частым медицинскими обследованиями,
прививками и другим оздоровительными мероприятиями для детей, важно вести учет
этой информации, а так же историю болезней. Эти данные заносятся в мед/карту
ребенка, которая будет использоваться им в будущем, поэтому требуется тщательно
и точно вести все ключевые моменты в его здоровье.
- Работник по кадрам несет ответственность за
актуализацию и своевременное изменение существующей информации по кадрам,
работающим в детском саду №176. Поэтому он должен иметь доступ к
внесению/изменению данных в реляционной БД.
Терминал - это интерфейсный (обычно графический) компонент, который
представляет первый уровень, собственно приложение для конечного пользователя.
Первый уровень не должен иметь прямых связей с базой данных (по требованиям
безопасности), быть нагруженным основной бизнес-логикой (по требованиям масштабируемости)
и хранить состояние приложения (по требованиям надежности). На первый уровень
может быть вынесена и обычно выносится простейшая бизнес-логика: интерфейс
авторизации, алгоритмы шифрования, проверка вводимых значений на допустимость и
соответствие формату, несложные операции (сортировка, группировка, подсчет
значений) с данными, уже загруженными на терминал. Сервер приложений
располагается на втором уровне. На втором уровне сосредоточена большая часть
бизнес-логики. Вне его остаются фрагменты, экспортируемые на терминалы, а также
погруженные в третий уровень хранимые процедуры и триггеры. Сервер базы данных
обеспечивает хранение данных и выносится на третий уровень. Обычно это
стандартная реляционная или объектно-ориентированная СУБД. Если третий уровень
представляет собой базу данных вместе с хранимыми процедурами, триггерами и
схемой, описывающей приложение в терминах реляционной модели, то второй уровень
строится как программный интерфейс, связывающий клиентские компоненты с
прикладной логикой базы данных. В "правильной" (с точки зрения
безопасности, надежности, масштабирования) конфигурации сервер базы данных
находится на выделенном компьютере (или кластере), к которому по сети
подключены один или несколько серверов приложений, к которым, в свою очередь,
по сети подключаются терминалы.
Плюсами данной архитектуры являются:
- клиентское ПО не нуждается в администрировании;
- масштабируемость;
- конфигурируемость - изолированность уровней друг от
друга позволяет быстро и простыми средствами переконфигурировать систему при
возникновении сбоев или при плановом обслуживании на одном из уровней;
- высокая безопасность;
- высокая надежность;
- низкие требования к скорости канала (сети) между
терминалами и сервером приложений;
- низкие требования к производительности и техническим
характеристикам терминалов, как следствие снижение их стоимости.
К недостаткам многозвенной сетевой архитектуры относят следующие
показатели:
- растет сложность серверной части и, как следствие,
затраты на администрирование и обслуживание;
- более высокая сложность создания приложений;
- сложнее в разворачивании и администрировании;
- высокие требования к производительности серверов
приложений и сервера базы данных, а, значит, и высокая стоимость серверного
оборудования;
- высокие требования к скорости канала (сети) между
сервером базы данных и серверами приложений.
1.4 Выбор технологии и программного обеспечения для
реализации новой сетевой технологии
В данной главе необходимо описать все необходимое ПО и технологию, которые
будут мною использованы для создания результирующей системы.
1.4.1 Выбор технологии создания web-приложения
Основой создания web-приложения
html-страница, содержимое которой
создается динамически и после отображается на стороне клиента (в браузере). В ходе
развития web-технологий, имели место разные
подходы к формированию контента страницы. Поэтому необходимо провести анализ
технологий и выбрать ту, которая позволит решить поставленные задачи.
Анализируя современные технологии, мой выбор был остановлен на следующих
актуальных подходах:
1) PHP - Personal Home Page tools
2) Java Servlets
3) JSP - Java Server Pages
4) JSF - Java Server Faces
5) ASP.NET - Active Server Pages
Данные технологии являются широко используемыми на сегодняшний день,
поэтому важно определить достоинства каждой из них. Для этого проведем
критический отбор, который сведем в таблицу 1. Оценка будет проводиться по
10-бальной шкале, где 10 - наилучшее выполнение критерия.
Таблица
1 - критическая оценка технологий разработки web-приложений
|
Критерий оценки
|
PHP
|
Java Servlet
|
JSP
|
JSF
|
ASP.NET
|
|
Кроссплатформенность
|
8
|
10
|
10
|
10
|
7
|
|
Возможности масштабируемости приложения
|
4
|
10
|
10
|
9
|
10
|
|
Простота в использовании
|
10
|
5
|
8
|
7
|
8
|
|
Наличие бесплатных библиотек
|
10
|
9
|
10
|
8
|
8
|
|
Производительность
|
6
|
10
|
8
|
9
|
10
|
|
Распространенность в использовании
|
8
|
10
|
8
|
5
|
8
|
|
ИТОГО
|
46
|
55
|
55
|
48
|
51
|
В ходе анализа были выбраны две технологии, набравшие наибольшие
показатели:
1) Java Servlets
2) Java Server Pages
В связи с личными предпочтениями, а так же навыками работы с данными
технологиями, за основу мною будет выбрана технология JSP. Но достоинства Java Servlets так же будут мною использованы при
реализации определенных функций, что позволит повысить показатели надежности
системы.
1.4.2
Выбор сервера базы данных
Поскольку данный проект основан на работе с большими потоками данных, то
ключевым моментом является место, где эти данные хранятся. Кроме того,
поскольку разрабатываемая технология является сетевой, то необходимо
предусмотреть множественный доступ к одним ресурсом. Поэтому очень важно
выбрать именно ту БД, которая в полной мере позволит реализовать определенные
нами функции.
На основе анализа современных БД выбор будет осуществлен между следующими
серверами:
1) FireBird;
2) MySQL;
3) Oracle;
4) MS SQL;
5) PostgreSQL.
Для оценки проведем критериальную оценку данных серверов по 10-бальной
шкале, где 10 - наивысший балл, то есть наилучшее соответствие критерию и
сведем результаты в таблицу 2.
Таблица
2 - критическая оценка серверов БД
|
Критерий оценки
|
FireBird
|
MySQL
|
Oracle Database 10g
|
MS SQL
|
PostgreSQL
|
|
Поддержка обслуживания большого числа пользователей (до
тысячи)
|
8
|
10
|
10
|
10
|
8
|
|
Бесплатное распространение
|
10
|
10
|
0
|
0
|
10
|
|
Многоплатформенность
|
10
|
10
|
10
|
0
|
10
|
|
Защита от несанкционированного доступа
|
8
|
5
|
10
|
7
|
8
|
|
Возможности БД (view, procedure,
backup)
|
6
|
10
|
10
|
10
|
6
|
|
Унификация используемого SQL-языка
|
10
|
9
|
10
|
10
|
8
|
|
Простота настройки, администрирования, отсутствие
требования наличия специально обученного персонала
|
8
|
10
|
2
|
5
|
8
|
|
Перспективы развития БД, выпуск новых релизов, стабильность
фирмы производителя
|
8
|
10
|
10
|
10
|
8
|
|
ИТОГО
|
68
|
74
|
62
|
52
|
66
|
В ходе анализа был выбран сервер БД MySQL, который превзошел конкурирующие сервера за счет
мощности, стабильности, многопоточности, а главное - бесплатного сопровождения.
Кроме того, у меня есть навыки работы с данным сервером, что также значимо в
последующей разработке.
1.4.3 Выбор метода доступа к базе данных
Разумеется, что помимо выбора сервера БД необходимо определить средства,
с помощью которых будет осуществляться доступ к данным, хранящимся на нем.
Всвязи с выбором языка Java
для реализации web-приложения
удобно использовать встроенные в него средства доступа к серверам БД. Таким
являются драйвер JDBC.
JDBC -
платформенно-независимый стандарт взаимодействия Java приложений с различными СУБД. Данный стандарт
позволяет создать соединение с БД по специально описанному URL. Данный драйвер загружается
динамически во время работы программы. Кроме того, при использовании JDBC увеличивается переносимость
приложения, так как не требуется регистрация драйвера, а так же запрос к БД
осуществляется непосредственно в коде JAVA (в котором описывается SQL-запрос
для отправки), что существенно увеличивает быстродействие обмена данными с
центральным хранилищем.
1.4.4 Выбор сервера приложений
Важным аспектом является выбор сервера приложений, который играет
связывающее звено между клиентом и центральной БД, что видно из рисунка 5.
Исходя из этого очевиден факт, что какими бы не были быстродейственными и
мощными БД, клиентская часть web-приложения,
при использовании слабого сервера приложений обмен данными и обработка запросов
пользователя будут сведены к минимуму.
Поэтому в роли сервера приложений могут быть использованы только новейшие
технологии, использующие современные подходы к реализации, а так же использующие
возможности современных языков программирования. Под эту оценку подходят
следующие сервера:
1) GlassFish;
2) JBoss;
4) WebSphere.
Для оценки выбранных серверов проведем оценку по критериям, которую
сведем в таблицу 3. Используемая 10-бальная шкала показывает, что наилучшее
соответствие выбранному критерию описывается присвоение серверу 10 баллов.
Таблица
3 - критическая оценка серверов приложений
|
Критерий оценки
|
GlassFish
|
JBoss
|
WebLogic
|
WebSphere
|
|
Многоплатформенность
|
10
|
10
|
9
|
7
|
|
Бесплатное распространение
|
10
|
10
|
2
|
4
|
|
Перспективы развития БД, выпуск новых релизов, стабильность
фирмы производителя
|
10
|
8
|
10
|
8
|
|
Поддержка обслуживания большого числа пользователей (до
тысячи)
|
7
|
9
|
10
|
10
|
|
Независимость от параметров ЭВМ (RAM, многопроцессорность)
|
9
|
10
|
5
|
8
|
|
Встроенные web-сервер
и контейнер сервлетов
|
10
|
10
|
8
|
5
|
|
ИТОГО
|
56
|
57
|
44
|
42
|
Исходя из проведенного анализа мною был выбран сервер приложений JBoss Application Server, ввиду своих производительных показателей,
бесплатного распространения и хорошей поддержке и сопровождению со стороны
разработчиков.
1.4.5 Выбор WEB-сервера
Наконец, необходимо определить с WEB-сервером, который будет обрабатывать http-запросы пользователя, и генерировать
ответную web-страницу для визуального отображения
запрашиваемой информации.
Среди всех существующих на сегодняшний день WEB-серверов вне конкуренции остается Apache HTTP Server. Данное ПО является свободно распространяемым, а это
является критическим критерием при выборе компонентов технологии. Кроме того,
данный сервер является кроссплатформенным и гибким в конфигурации, поддерживает
IPv6.
1.5 Обоснование требований к разрабатываемой сетевой
технологии
В данной главе мною будут описаны требования, которым должна будет
соответствовать сетевая технология.
Как уже было отражено в пункте 1.3 пользователями данной технологии
будут:
- Заведующая (выполняет учет, обработку и актуализацию
данных по ребенку, то есть информацией об самом ребенке: ФИО, адрес проживания,
контактные данные родителей, посещаемость и т. д.);
- Мед/работник (выполняет учет, обработку и актуализацию
данных по состоянию здоровья ребенка, возникающим отклонениям, истории
болезней, сделанные прививки и т. д.);
- Кадровый работник (выполняет учет, обработку и
актуализацию данных по кадровому составу организации: ФИО, адрес проживания,
должность, дата приема, стаж и т. д.).
1.5.1 Требования к защищенности системы
Опишем требования к защищенности системы:
- Система аутенфикации и идентификации пользователя;
- Ограничение одновременно передаваемого трафика по сети
при выполнении запроса пользователем (web-страницы не должны быть грузоемкими).
Разрабатываемая технология рассчитана на выполнение обработки данных по
разным категориям, взаимодействие с которыми осуществляет соответствующее лицо,
описанное выше. Поэтому важно обеспечить доступ строго определенно лица к
данным, во избежание влияния другого лица на целостность и достоверность
информации. Поэтому в системе будет введена система аутенфикации и
идентификации пользователя, после завершения которой ему будет
разрешен/запрещен доступ к ресурсам системы. Разумеется, в зависимости от
зарегистрированного имени пользователя, ему будет предоставлен соответствующий
интерфейс работы с системой.
Система авторизации будет заключаться в вводе пользователем уникального
имени, выданного и зарегистрированного специально для него, а также пароля,
подтверждающего личность пользователя. С целью устранения проблемы с утратой,
забыванием личных идентификационных данных, будет организован подход, при
котором именем пользователя будет являться фамилия пользователя на латинице с
добавлением инициалов без пробела с заглавной буквы. Пример - Иванов Дмитрий
Сергеевич будет иметь имя IvanovDS. В качестве пароля будет выбран код и номер паспорта пользователя.
Например, 3605999999. Это позволит:
- В любой момент пользователю на основе ассоциативных
данных при утере вспомнить параметры авторизации;
- Защищенность авторизации повышается за счет того, что
знанием параметров паспорта обладает только его владелец.
Ограничение трафика будет осуществлено посредством правильного
конфигурирования web-страниц, при
котором пользователь сможет оправить запрос только с указанным количеством
параметров. Это позволит вести контроль за рациональным использованием сети.
Загрузка web-страницы не должна превышать 1с, а
отправляемый запрос с одной страницы не должен превышать 64кб данных.
1.5.2 Требования к интерфейсу системы
Опишем требования к интерфейсу системы:
- Правильный выбор цветовой гаммы системы;
- Расположение и размеры компонентов системы;
- Возможность дополнительной настройки пользователем
интерфейса под собственные предпочтения.
Выбор правильной цветовой схемы определяет удобство работы пользователя с
системой, возможность легкого восприятия информации на ней. Цвет текста не
должен быть ярким, он должен сочетаться с фоновым цветом, быть легко
прочитанным. Для определения цветовой схемы используем следующую таблицу. По
5-бальной шкале проведем анализ рассмотренных цветовых гамм и выберем наиболее
удачную.
Таблица
4 - определение цветовой схемы интерфейса
|
№
|
Цвет
|
Критерии
|
Итого
|
|
|
Цвет не раздражает глаз
|
Сочетание цветов
|
Читаемость шрифта
|
|
|
1
|
Передний план
|
Ш
|
1
|
3
|
3
|
7
|
|
Фон
|
Ш
|
|
|
|
|
|
2
|
Передний план
|
Ш
|
2
|
2
|
4
|
8
|
|
Фон
|
Ш
|
|
|
|
|
|
3
|
Передний план
|
Ш
|
5
|
4
|
5
|
14
|
|
Фон
|
Ш
|
|
|
|
|
|
4
|
Передний план
|
Ш
|
5
|
3
|
5
|
13
|
|
Фон
|
Ш
|
|
|
|
|
В итоге наибольшие баллы набрала схема под номером 3 - сизый фон,
сиреневая канва, цвет шрифта - коричневый.
Рисунок
18 - цветовая схема разрабатываемой технологии
Компоненты системы должны удовлетворять требованиям пользователя для
удобного использования. Для этого между компонентами должны быть расстояние,
достаточное, например, для случайного нажатия на соседнюю кнопку. Текстовые
поля должны быть максимально развернуты, чтобы пользователь меньше использовал
скролл для прокрутки. Каждому компоненту должен соответствовать свой лейбл,
чтобы пользователь знал предназначение поля или кнопки. При использовании
списков, в заголовке по умолчанию должно быть, по возможности, установлено
наиболее вероятное значение для этого поля, что позволит пользователю экономить
время.
Но описанные требования являются общими. Так как каждый пользователь
обладает собственными требованиями, то будет очень полезным предоставить ему
возможности самостоятельного регулирования некоторых аспектов интерфейса.
Например, цветовые схемы интерфейса, цвет шрифта и т. д. Кроме того, если у
пользователя плохое зрение, то будет полезным предусмотреть возможность
регулирования размеров компонентов.
1.5.3 Требования к разграничению прав и действий
пользователей системы
Опишем требования к разграничению прав пользователей:
- Каждому пользователю выделяется собственная учетная
запись;
- Каждый пользователь имеет свою область
ответственности, а значит и доступ только к определенной части БД;
- Ограничение ручного ввода пользователем данных (использование
выплывающих списков с заранее известными значениями поля).
Поскольку было определено, что работу с системой будут осуществлять три
человека, то важно устранить возможность влияния каждого из них друг на друга,
т. е. заведующая не может корректировать мед/данные и т. д. Для этого каждому
пользователю будет выделена собственная учетная запись с соответствующим
логином и паролем. В зависимости от прошедшей авторизации будут выделены права
под данную учетную запись.
В связи с вышесказанным будет реализован подход, при котором каждый
пользователь сможет иметь доступ только к необходимым для него таблицам и
данным в БД.
Использование методов автоматизации при вводе данных позволит свести к
минимуму вероятность внесения некорректных данных. В частности, использование
списков, например, для указания даты рождения, адреса проживания и т. д.
1.5.4 Требования к производительности системы
Опишем требования к производительности системы:
- Возможность одновременной обработки запросов сразу от
каждого из трех описанных пользователей системы при локальном доступе, а так же
пропускную способность до 1000 человек при web-запросах через сеть Интернет;
- Время ответа не должно превышать 0,1 секунды, т. е.
пользователь должен воспринимать работу системы как «мгновенную»;
- Система должна быть отказоустойчива при ошибочных
действиях пользователя или сбоях аппаратных средств;
- Разрабатываемую технологию необходимо сделать
кроссплатформенной, а параметры и конфигурация ЭВМ конечного пользователя не
должна иметь значение.
Система должна позволять одновременный доступ к ее ресурсам сразу
нескольких пользователей системы. Это будет достигаться за счет использования
архитектуры, описанной в пункте 1.3. Этот критерий является обязательным в
современном уровне развития IT-технологий.
Кроме того, пользователь не должен ощущать задержки при работе, каждый
его запрос должен быть обработан в узкие сроки. Данное требование так же
является критическим на сегодняшний день для сетевой технологии.
Кроссплатформенность системы будет достигаться за счет использования
современных методов обработки данных, многозвенной архитектуры и ЯВУ - Java.
Итого, в данной главе были определены конечные требования к
разрабатываемой сетевой технологии, которые и будут реализованы в ходе
разработки системы.
1.6 Постановка задачи
В первом разделе был проведен анализ информационной системы детского сада
№176. В ходе анализа было выявлено, что у данной организации отсутствует онлайн
режим доступа к БД по учету детей, кадров и т.д. Кроме того было установлено,
что в данном предприятии используется широко используется подход по ручному
ведению БД по следующим направлениям:
- Ведения отчетности по детям, их личной информации,
контактной информации их родителей;
- Учет и актуализация кадровой информации внутри организации
«ЛАДА»;
- Ведение отчетов по истории болезней детей, прививкам и
т. д.
Были выявлены основные недостатки данной системы, которые отражены в
пункте 1.1 и 1.2.1.
После определения основных этапов, из которых строится текущая технология
обработки информации в пункте 1.2.1, было проведено описание того, как должна
работать система учета и обработки информации в рамках рассматриваемого
предприятия. Данное описание приведено в пункте 1.2.2. Для реализации описанной
системы нужно было определить основных участников документооборота, основные
модули системы, ПО и АО. Для разрабатываемой системы была выбрана многозвенная
архитектура, позволяющая в полной мере создать сетевую технологию современного
уровня. Описание компонентов данной архитектуры приведено на рисунке 17 пункта
1.3.
Ключевыми лицами в работе с разрабатываемой системой были выделены:
- Заведующая дет/садом №176 (выполняет учет, обработку и
актуализацию данных по ребенку);
- Мед/работник (выполняет учет, обработку и актуализацию
данных по состоянию здоровья ребенка);
- Кадровый работник (выполняет учет, обработку и
актуализацию данных по кадровому составу организации).
При выборе ПО были определены основные критерии, по которым производился
отбор. Основными из них являлись:
- Бесплатное распространение;
- Многоплатформенность;
- Соответствие современным стандартам разработки сетевых
технологий.
В результате основными компонентами были определены:
1) В качестве технологии разработки web-приложений были выбраны Java Servlet и Java Server Page (описание критериальной оценки в
пункте 1.4.1);
2) В качестве сервера БД был выбран MYSQL (описание критериальной оценки в пункте 1.4.2);
) В качестве метода доступа к серверу БД был выбран JDBC (описание критериальной оценки в
пункте 1.4.3);
) В качестве сервера приложений был выбран JBoss Application Server (описание критериальной оценки в пункте 1.4.4);
) В качестве web-сервера
был выбран Apache HTTP Server (описание критериальной оценки в пункте 1.4.5).
Наконец, были сформулированы основные требования, предъявляемые к
разрабатываемой системе:
1. Требования к защищенности системы:
а) Система аутенфикации и идентификации пользователя;
б) Шифрование данных, передаваемых внутри системы;
в) Защита от копирования web-страниц пользователем на локальную машину;
г) Ограничение одновременно передаваемого трафика по сети при
выполнении запроса пользователем (web-страницы не должны быть грузоемкими);
д) Выполнение резервирования данных (back-up
системы).
2. Требования к интерфейсу системы:
а) Правильный выбор цветовой гаммы системы;
б) Расположение и размеры компонентов системы;
в) Возможность дополнительной настройки пользователем интерфейса под
собственные предпочтения.
3. Требования к разграничению прав и действий пользователя системы:
а) Каждому пользователю выделяется собственная учетная запись;
б) Каждый пользователь имеет свою область ответственности, а значит
и доступ только к определенной части БД;
в) Ограничение ручного ввода пользователем данных (использование
выплывающих списков с заранее известными значениями поля).
4. Требования к производительности системы:
а) Возможность одновременной обработки запросов сразу от каждого из трех
описанных пользователей системы при локальном доступе, а так же пропускную
способность до 1000 человек при web-запросах
через сеть Интернет;
б) Время ответа не должно превышать 0,1 секунды, т. е. пользователь
должен воспринимать работу системы как «мгновенную»;
в) Система должна быть отказоустойчива при ошибочных действиях
пользователя или сбоях аппаратных средств;
г) Разрабатываемую технологию необходимо сделать кроссплатформенной, а
параметры и конфигурация ЭВМ конечного пользователя не должна иметь значение.
2. Разработка информационной технологии
В данной главе на основе требований, определенных в предыдущем разделе, а
так же на основе выбранных методов и технологий разработки, будет осуществлена
формализация предметной области, разработана структура и архитектура
программного продукта, будет осуществлено непосредственное кодирование.
2.1 Разработка логической модели БД
Для разработки информационной системы необходимо реализовать построение
модели БД, которая будет реализовываться в системе. При построения будет
использоваться среда ERwin
4.1, позволяющая отразить как логическую, так и физическую модель базы данных.
На основе ненормализованных данных, определенных в Приложении 1, можно
реализовать построение логической модели создаваемой БД.
информация
данные приложение публикация
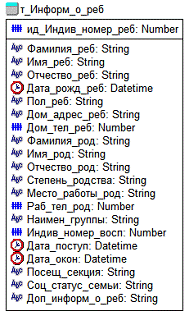
Рисунок
19 - ненормализованная сущность таблицы «Информация о ребенке»

Рисунок
20 - ненормализованная сущность таблицы «Кадровая информация»
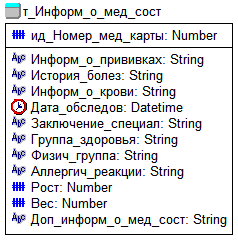
Рисунок
21 - ненормализованная сущность таблицы «Медицинская информация»
После определения ненормализованных сущностей необходимо выполнить их
нормализацию.
В результате нормализации была получена следующая логическая модель,
отраженная на рисунке 25.
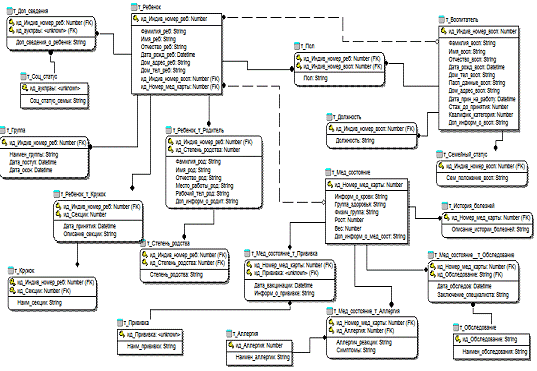
Рисунок
22 - логическая модель разрабатываемой технологии
2.2
Разработка физической модели БД
На основе полученной логической модели, отраженной на рисунке 25, можно
перейти к физической модели разрабатываемой технологии. В ERwin 4.1 физическая
модель является графическим представлением реально реализованной базы данных. Физическая
база данных будет состоять из таблиц, столбцов и связей. Физическая модель
зависит от платформы, выбранной для реализации, и требований к использованию
данных.
Компонентами физической модели данных являются таблицы, столбцы и
отношения. Сущности логической модели станут таблицами в физической модели.
Логические атрибуты станут столбцами. Логические отношения станут ограничениями
целостности связей.
|
Тип
данных логической модели
|
Тип данных физической модели
|
|
string
|
varchar (30)
|
|
number
|
int
|
|
datetime
|
datetime
|
Рисунок
23 - определение соответствий типов данных логической и физической моделей
технологии
После определения БД, в которой будет осуществляться непосредственное
хранение данных и их обработка, можно определить физическую модель данных разрабатываемой
технологии.
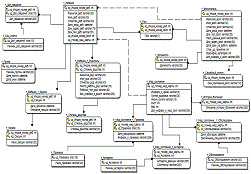
Рисунок 24 - физическая модель данных разрабатываемой технологии
2.3
Разработка основных форм и интерфейсов
В данной главе необходимо определить основные формы и интерфейсы, которые
будут использоваться в разрабатываемой системе.
Всвязи с тем, что с системой будут работать пользователи без больших
умений владения ПК, то важно разработать такой интерфейс взаимодействия его с
системой, который бы позволил при минимальных действиях человека выполнить
наибольшее количество действий системы. Для разрабатываемой технологии был
выбран диалоговый, графический тип интерфейса.
Отразим на следующем рисунке схему взаимодействия всех необходимых форм
пользовательского интерфейса.
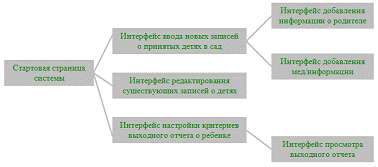
Рисунок
25 - схема взаимодействия форм и интерфейсов системы
Как было определено в требованиях к разрабатываемой системе, необходимо
предоставить интерфейс, позволяющий пользователю получить возможность работы с
системой. Данный интерфейс должен включать:
- Интерфейс для ввода новых данных;
- Интерфейс для актуализации БД;
- Интерфейс для получения отчета по запрашиваемым
параметрам.
Для этого необходимо создать навигационное меню, позволяющее пользователю
выполнить необходимую функцию. Это необходимо реализовать на стартовой
странице, на которую попадает пользователь после удачной авторизации.
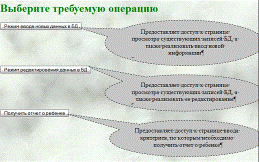
Рисунок
26 - страница главного навигационного меню системы
Рассмотрим теперь конкретно интерфейс работы пользователя в каждой из
приведенных подсистем.
Для начала опишем интерфейс пользователя для ввода новой информации. Он
отражен на следующем рисунке.
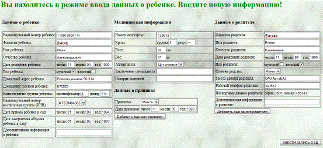
Рисунок
27 - страница ввода новых данных в систему
Далее отразим интерфейс пользователя для редактирования данных.
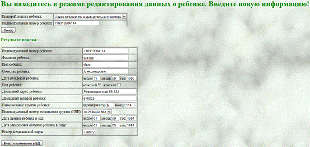
Рисунок
28 - страниц редактирования данных в системе
Наконец, необходимо показать интерфейс пользователя для получения отчета
о ребенке. Данный интерфейс приведен на следующем рисунке.
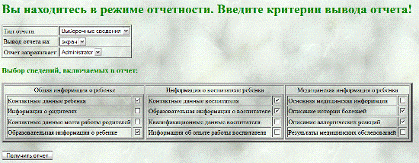
Рисунок
29 - страница получения отчета о ребенке
На приведенной выше странице пользователю предоставляются разного рода
настройки результирующего отчета. Эти настройки позволяют вывести отчет как на
экран для быстрого ознакомления, так и вывести на принтер. Кроме того,
пользователю предоставляется возможность как выполнения полной отчетности о
ребенке, которая включит все сведения из БД о ребенке, так и выборочную
отчетность, приведенную для примера на рисунке выше.
Выборочная отчетность включает три основных области описания информации
ребенка в БД:
- Общая информация о ребенке;
- Информация о воспитателе ребенка;
- Медицинская информация о ребенке.
В результате настройки запрашиваемых данных система должна представить
отчет о ребенке. Пример такого отчета представлен на следующем рисунке.
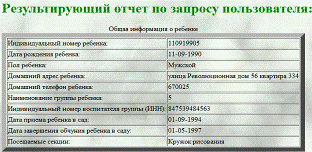
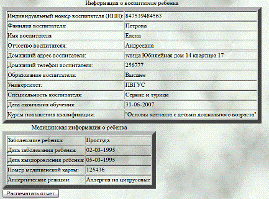
Рисунок
30 - страница результирующего отчета по запросу пользователя
2.4 Разработка основных алгоритмов обработки информации
В данной главе мною будут рассмотрены основные алгоритмы обработки
информации.
2.4.1 Разработка алгоритмов работы между клиентом и БД с
помощью сервлетов
Основу работы пользователя с системой будут составлять сервлеты. Поэтому
важно качественно и эффективно реализовать их инициализацию init(), тело сервлета doGet(), doPost(), а также их уничтожение destroy() после завершения их использования.
Рисунок
31 - принцип работы сервлетного приложения
Пользователь реализует доступ к БД посредством JSP-страниц, на которых он заполняет определенные данные,
которые передаются параметрами объекта REQUEST. После нажатия кнопки на JSP странице происходит вызов определенного сервлета, в
котором извлекаются переданные параметры и используются при работе с БД. После
получения ответа от SQL-сервера
происходит формирование ответа в виде объекта RESPONSE, в который полученный результат
также записывается параметрами этого объекта.
Вызов сервлета происходит по следующему циклу:
1) Происходит создание сервлета методом init(). Данный метод был переопределен для выполнения
определенных нужд, а именно, в нем происходит создание пула соединения с БД, по
которому и происходит пересылка sql-скриптов,
описанных в пункте 2.4.1. Создание соединение происходит следующим образом:
а) java.sql.DriverManager - создает класс для подключения драйвера JDBC для соединения с MySQL;
б) java.sql.Connection - описывает URL, по которому будет загружена определенная БД, а также
указывает авторизационные данные к ней;
в) java.sql.Statement - создает пул, по которому будет происходить
передача sql-скрипта на SQL-сервер;
г) java.sql.ResultSet - описывает непосредственно сам sql-скрипт, который будет передан на SQL-сервер.
Полученное соединение используется пользователем в дальнейшем. Разрыв
соединения происходит после завершения сервлета в методе destroy().
Опишем Java код, используемый для выполнения
описанных этапов:
DriverManager.registerDriver(new com.mysql.jdbc.Driver());con
= DriverManager.getConnection("jdbc:mysql://localhost:3306/mysql",
"root", "SQLpassword1");st = con.createStatement();rs =
st.executeQuery("SQL запрос");
2) После инициализации сервлета происходит описание функционал,
который несет сервлет. Для этого используется следующие объекты:
а) определяются кодировки описанных объектов REQUEST и RESPONSE;
б) java.io.PrintWriter - создание объекта, который будет формировать
JSP страницу с ответом на запрос
пользователя;
в) request.getParameter() - данный метод позволяет извлечь
переданные пользователем параметры для их использования при работе с БД;
г) out.println() - данный метод позволяет непосредственно
реализовать запись ответа клиенту в виде тегов, данных и т. п.
Опишем код, используемый для выполнения описанных этапов:
request.setCharacterEncoding("Cp1251");out = response.getWriter();.println("<html><head>");.println("<title>Start
page</title></head><body
background=IMAGES/Backcolor.jpg>");.println("<h1
align=\"center\"><font color=\"green\">Welcome to
InFly technology!</font></h1>");.println("<form
method=\"get\" action=\"" + request.getContextPath() +
"/StartPage.jsp\">");.println("<table
border=\"0\"><tr><td
align=\"top\">");.println("<input
type=\"submit\" value=\"Enter to
system\"></td></tr>");.println("</table></form>");.println("<form
method=\"get\" action=\"" + request.getContextPath() +
"/AdministrativeTools.jsp\">");.println("<table
border=\"0\"><tr><td
align=\"top\">");.println("<input
type=\"submit\" value=\"Administrative
tools\"></td></tr>");.println("</table></form>");.println("</body></html>");
3) Наконец, после формирования сервером ответа клиенту необходимо
закрыть открытое на текущий момент соединения с БД во избежание возникновения
ошибок разного рода, связанные с передачей некорректных данных, а также
освобождение памяти, которую занимает это соединение. Для этого используется
метод connection.close().
После того, как была выполнена отправка на SQL сервер запроса, будет получен объект RESPONSE, хранящий полученный результат. Для
того, чтобы извлечь из него данные используется метод next() в сочетании в методом getString(“имя_столбца”). Первый возвращает
булевское значение, по которому можно судить, если еще строки записей в RESPONSE. Второй метод позволяет извлечь
конкретно значение столбца, имя которого передается в метод.
Опишем код, используемый для выполнения описанных этапов:
if (rs.next())
{rezult = rs.getString("Фам_ребенка");.println("<html><head>");.println("<title>Rezult
page</title></head><body
background=IMAGES/Backcolor.jpg>");.println("<h1><font
color=\"red\">Фамилия ребенка: rezult </font></h1>");.println("</body></html>");
}.close();
2.4.2
Разработка алгоритмов доступа к БД и ее редактирования с помощью SQL-запросов
Основой работы разрабатываемой системы является передача данных,
заполняемых пользователем в интерфейсе, посредством параметров в в объекте query. Это значит, что их можно извлечь
методом getParameter(“имя_переменной”) и вставить в SQL запрос.
2.4.2.1 Реализация функции ввода данных главного меню
системы
Первая функция главного меню системы вызывается кнопкой «Режим ввода
данных в БД». После ее нажатия пользователю предоставляется соответствующая JSP страница, отображенная на рисунке
29. Здесь пользователь заполняет форму, данные которой поместятся в таблицу БД
после нажатия кнопки «Внести запись в БД» на данной JSP. Именно на событие нажатия этой кнопки будет вызван
соответствующий сервлет, в котором будет реализован доступ к БД, а так же в
помощью оператора INSERT будут
добавлены данные в требуемые столбцы таблиц.
Опишем sql-скрипт, выполняемый в данном
сервлете:
INTO т_Ребенок AS реб, т_Родитель AS род, т_Мед_инф AS мед, т_Прививка AS
прив
VALUES (реб.Инд_номер_ребенка =
getParameter("id_Num_child"),
реб.Фамилия =
getParameter("Surname_child"),
реб.Имя =
getParameter("Name_child"),
реб.Отчество = getParameter("Midname_child"),
реб.Дата_рожд = getParameter("Date_born_child"),
реб.Дом_адрес = getParameter("Home_address_child"),
реб.Наим_группы = getParameter("Group_child"),
реб.Инд_номер_воспит =
getParameter("Num_teacher_child"),
род.Фамилия =
getParameter("Surname_parent"),
род.Имя =
getParameter("Name_parent"),
род.Отчество =
getParameter("Midname_parent"),
род.Дата_рожд = getParameter("Date_born_parent"),
род.Работа =
getParameter("Workplace_parent"),
род.Паспорт = getParameter("Pasport_parent"),
род.Раб_телефон = getParameter("Work_phone_parent"),
мед.Номер_карты = getParameter("Num_card"),
мед.Кровь = getParameter("Blood"),
мед.Рост = getParameter("Height"),
мед.Вес = getParameter("Weight"),
прив.Наим_прививки = getParameter("Name_vakcination"),
прив.Дата_вакцинации = getParameter("Date_vakcin"))
Структура и иерархия имен таблиц была описана на рисунке 25.
2.4.2.2 Реализация функции редактирования данных
главного меню системы
Вторая функция главного меню системы вызывается кнопкой «Режим
редактирования данных в БД». После ее нажатия пользователю предоставляется
соответствующая JSP страница,
отображенная на рисунке 30. Здесь пользователь выбирает критерий, по которому
он ищет запись в БД для ее дальнейшего редактирования. Для принятия изменений
пользователь жмет кнопку «Внести изменения в БД» на данной JSP. Именно на событие нажатия этой
кнопки будет вызван соответствующий сервлет, в котором будет реализован доступ
к БД, а так же в помощью оператора SELECT будет определена запись в БД, UPDATE предоставит возможность изменения записи.
Опишем sql-скрипт, выполняемый в данном
сервлете:
SELECT * FROM Ребенокинд_Номер_ребенка =
getParameter("id_Num_child")
Используя данный запрос пользователю предоставляется информация о
ребенке, которую он может изменить на web-странице, после чего при нажатии кнопки «Внести изменения в БД» будет
выполнен следующий SQL запрос.
т_Ребенок AS реб, т_Мед_инф AS мед, т_Прививка AS прив
SET (реб.Фамилия =
getParameter("Surname_child"),
реб.Имя =
getParameter("Name_child"),
реб.Отчество =
getParameter("Midname_child"),
реб.Дата_рожд = getParameter("Date_born_child"),
реб.Дом_адрес = getParameter("Home_address_child"),
реб.Наим_группы = getParameter("Group_child"),
реб.Инд_номер_воспит =
getParameter("Num_teacher_child"),
мед.Номер_карты = getParameter("Num_card"),
мед.Кровь = getParameter("Blood"),
мед.Рост = getParameter("Height"),
мед.Вес = getParameter("Weight"),
прив.Наим_прививки = getParameter("Name_vakcination"),
прив.Дата_вакцинации = getParameter("Date_vakcin"))ид_Номер_ребенка =
getParameter("id_Num_child")
После выполнения этого запроса в БД произойдет изменение записи,
удовлетворяющей условие поиска (например, при выборе поиска ребенка по
индивидуальному номеру).
2.4.2.3 Реализация функции отчетности главного меню
системы
Третья функция главного меню системы вызывается кнопкой «Получить отчет о
ребенке». После ее нажатия пользователю предоставляется соответствующая JSP страница, отображенная на рисунке
31. Здесь пользователь выбирает критерии, по которым будет сформирован
дальнейший отчет. Для принятия изменений пользователь жмет кнопку «Получить
отчет» на данной JSP. Именно на
событие нажатия этой кнопки будет вызван соответствующий сервлет, в котором
будет реализован доступ к БД, а так же в помощью оператора SELECT будет определена запись в БД.
Опишем sql-скрипт, выполняемый в данном
сервлете:
реб.Инд_номер_ребенка, реб.Фамилия, реб.Отчество, реб.Дата_рожд,
реб.Дом_адрес, реб.Наим_группы, реб.Инд_номер_воспит, род.Фамилия, род.Имя,
род.Отчество, род.Дата_рожд, род.Работа, род.Паспорт, род.Раб_телефон,
мед.Номер_карты, мед.Кровь, мед.Рост, мед.Вес, прив.Наим_прививки,
прив.Дата_вакцинациит_Ребенок AS реб, т_Родитель AS род, т_Мед_инф AS мед,
т_Прививка AS прив
WHERE инл_Номер_ребенка = getParameter("id_Num_child")
Результат поиска будет отображен на новой JSP странице, как показано на рисунке 32.
2.4.3 Разработка алгоритма обработки мед/информации для
проведения вероятностного анализа заболевания детей
В ходе накопления информации по всем детям в саду, становится возможным
вести обработку данной информации для получения разного рода дополнительной
информации.
В БД храниться история болезней каждого ребенка с указанием сроков, в
которые проходила та или болезнь. Имея данные сведения, становится возможным
вести статистическое определение вероятности очередного заболевания ребенка, а
значит и возможность своевременного принятия мер по предотвращению болезни.
Опишем алгоритм, реализующий определение вероятности заболевания ребенка
на основе предшествующего периода, на следующей схеме.
Рисунок
32 - схема получения статистической диаграммы заболеваний ребенка
Рисунок
33 - схема расчета вероятности повторения заболевания ребенка
На основе полученной диаграммы становится возможным сопоставить период
заболеваний ребенка и заключения мед/сестры и определить вероятность очередной
болезни, а также принять меры по ее предотвращению. Опишем данный алгоритм:
На основе полученных результатов становится возможным для мед/специалиста
определение необходимости принятие тех или иных мер в определенный период для
предотвращения заболевания ребенка.
2.5 Описание разработанной сетевой технологии
Структура разработанной технологии представлена на следующем рисунке.
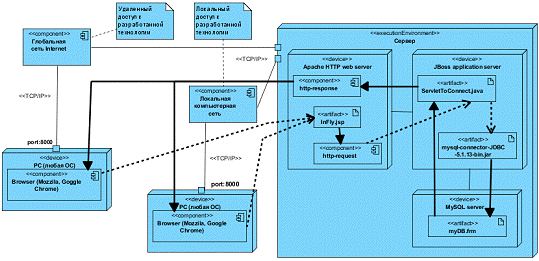
Рисунок
34 - диаграмма развертывания разработанной сетевой технологии
В ходе проделанной работы была получена сетевая технология со следующей
структурой. Пользователями разработанной системы могут являться как удаленные
клиенты, так и локальные. К локальным пользователям относятся заведующая
дет/садом, мед/работник.
Для начала работы с системой пользователь открывает браузер на РС (Mozzila, Google Chrome, IE), в
котором прописывают URL: http:/InFly:8000/InFly.jsp. После этого он получает доступ к
функциям системы. В ходе работы пользователь выбирает ту функцию, которая ему
необходима. При этом ему предоставляется соответствующая web-страница, в которой он манипулирует
теми или иными данными (например, добавление нового ребенка в БД). После
окончания заполнения формы с данными о ребенка формируется http-request, который передается в сервлет ServletToConnect.java на стороне JBoss сервера. В данном сервлете происходит получение переданных данных,
которые подставляются в соответствующий sql запрос.
После формирования sql
запроса сервлет использует mysql-connector-JDBC-5.1.13-bin.jar драйвер для получения соединения по
работе с файлом БД myDB.frm, в котором хранятся все таблицы с
данными о детях. После получения соединения сервлет передает серверу MySQL сформированный sql запрос, на который получает ответ в
виде объекта ResultSet.
После получения ответа от SQL
сервера, сервлет начинает извлекать из полученного объекта запрашиваемые
данные, на основе которых будет сформирован http-request,
который передает обратно Apache HTTP серверу.
WEB
сервер на основе принятого http-request формирует ответную web-страницу с запрашиваемыми
пользователем данными, которую передает обратно браузеру клиента.
. Оценка эффективности разработанного
проекта
Результатом процесса реализации, описанного в предыдущей главе, стало
создание работоспособного приложения, с помощью которого осуществляется
публикация и обработка данных о детях в дет/саде №176 «Белочка».
Оценка эффективности функционирования разработанной системы будет
осуществляться с помощью следующих критериев:
1. Скорость работы системы;
2. Защита от ошибочных действий пользователя;
. Скорость обучения работы с системой;
. Удовлетворенность пользователя от работы с системой.
Скорость работы с системой определяется временем, складывающимся из
времени доступа пользователя к функциям системы, времени отображения экранных
интерфейсов, времени получения ответа на созданный запрос, времени восприятия
полученной информации.
Миним_общее_время = Тавт + Тотобр + Тотв + Твоспр
где Миним_общее_время - минимально возможное время, Тавт - время
авторизации пользователя, Тотобр - время отображения веб-страницы, Тотв - время
получения ответа от системы, Твоспр - время восприятия информации
пользователем.
Доступ к функциям системы предоставляется пользователю сразу после
прохождения удачной авторизации, на которую тратиться не более 10 секунд. Время
отображения веб-страницы занимает не более 1 секунды. Время получения ответа
системы занимает не более секунды. За счет удачного использования таблиц на
веб-странице информация является читабельной и наглядной, поэтому для
восприятия информации требуется не более 20 секунд.
Миним_общее_время = 10 + 1 + 1 + 20 =32 сек
Итого, для получения отчета о ребенке без работы в системе пользователю
потребуется не более 32 секунд.
Защита от ошибочных действий пользователя достигается за счет
использования специальных обработчиков за вводимыми данными, использование
ненулевых полей для важной информации, а также максимально возможное использование
дополнительных методов защиты от некорректных действий пользователя
(использование выплывающих списков, подсказок и т. д.).
Скорость обучения работы системой измеряется количеством дней, которое
необходимо пользователю для уверенного использования системы. За счет большого
количества подсказок в виде выплывающего текста и т. п., а также интуитивно
понятного интерфейса, пользователь сможет самостоятельно использовать систему
за сутки. Кроме того, справка при нажатии клавиши F1 всегда поможет ответить на возникшие вопросы.
Заключение
В рамках курсового проекта была поставлена задача: разработать
web-приложение, функциональной возможностью которого будет публикация и
обработка данных дет/сада №176 «Белочка». В качестве исходных данных была использована
информационная система в бумажном виде о детях. В результате проведенного
анализа поставленной задачи и обзора современных технологий создания
web-приложений, было решено использовать технологию создания приложений с
помощью JSP-страниц и сервлетов с использованием
JDBC-драйвера для доступа к базе данных, размещенной на сервере MySQL.
Для реализации веб-приложения необходимо было выполнить:
- Перенести сведения из бумажного вида в БД сервера MySQL;
- Формирование запросов, с помощью которых будет осуществляться
запись/чтение запрашиваемой информации;
- Разработка сервлетов, с помощью которых будет
осуществляться доступ к БД;
- Разработка JSP-страниц, выполняющих роль интерфейса по работе пользователя с системой.
В качестве инструмента по разработке веб-приложения была выбрана среда IDE NetBeans 7.0, язык программирования Java.
Результатом процесса реализации стало создание работоспособного
web-приложения, с помощью которого можно публиковать и обрабатывать данные о
детях дет/сада №176 «Белочка».
Для оценки эффективности функционирования разработанного web-приложения,
было проведено его тестирование заведующей дет/сада, результаты которого
описаны в главе 3.
Литература
1. Вязовик
Н.А. Программирование на Java:
Учебный курс. - М.: Издательство «Открытые системы», «Craftway Computers», 2003. - 592с;
2. Хабибуллин
И.Ш. Самоучитель Java: Учебник для
вузов. - Спб: Издательство «БХВ-Петербург», 2001. - 464с.: ил;
3. Основные виды
архитектур программных приложений. - электронный источник: http://www.intuit.ru/department/database/databases/, 2009;
. Буди Курняван.
Создание web-приложений на языке Java с помощью сервлетов, JSP и EJB:
Руководство для разработчиков масштабируемых приложений J2EE. - М.:
Издательство «Лори», 2008. - 880с;
. Изучение технологии JSP.
- электронный источник: <http://java.sun.com/products/jsp/docs.html>,
2009.
Приложение 1
Таблица
5 - перечень данных, используемых в разрабатываемой технологии
|
Категория
|
Наименование атрибута
|
Тип поля
|
|
Информация о ребенке
|
Индивидуальный номер ребенка
|
Простое
|
|
Фамилия ребенка
|
Простое
|
|
Имя ребенка
|
Простое
|
|
Отчество ребенка
|
Простое
|
|
Дата рождения ребенка
|
Простое
|
|
Пол ребенка
|
Простое
|
|
Домашний адрес ребенка
|
Простое
|
|
Домашний телефон ребенка
|
Простое
|
|
Фамилия родителя
|
Простое
|
|
Имя родителя
|
Простое
|
|
Отчество родителя
|
Простое
|
|
Степень родства
|
Простое
|
|
Место работы родителя
|
Простое
|
|
Рабочий телефон родителя
|
Простое
|
|
Наименование группы ребенка
|
Простое
|
|
Индивидуальный номер воспитателя группы
|
Простое
|
|
Дата приема в сад ребенка
|
Простое
|
|
Дата завершения обучения в саде ребенка
|
Простое
|
|
Дата окончания обучения ребенка
|
Простое
|
|
Посещаемый кружок/секция
|
Простое
|
|
Социальный статус семьи
|
Простое
|
|
Дополнительная информация о ребенке
|
Составное
|
|
Кадровая информация
|
Индивидуальный номер сотрудника (ИНН)
|
Простое
|
|
Фамилия сотрудника
|
Простое
|
|
Имя сотрудника
|
Простое
|
|
Отчество сотрудника
|
Простое
|
|
Дата рождения сотрудника
|
Простое
|
|
Пол сотрудника
|
Простое
|
|
Домашний адрес сотрудника
|
Простое
|
|
Должность
|
Простое
|
|
Образование сотрудника
|
Простое
|
|
Специальность
|
Простое
|
|
Семейное положение
|
Простое
|
|
Паспортные данные
|
Составное
|
|
Дата приема на работу сотрудника
|
Простое
|
|
Стаж работы до устройства на работу
|
Простое
|
|
Дата проходимой аттестации
|
Простое
|
|
Наименование аттестации
|
Составное
|
|
Квалификационная категория
|
Простое
|
|
Дополнительная информация о сотруднике
|
Составное
|
|
Медицинская информация
|
Сведения о прививках
|
Составное
|
|
История болезней
|
Составное
|
|
Резус-фактор и группа крови
|
Простое
|
|
Дата последнего мед/осмотра
|
Простое
|
|
Группа здоровья
|
Простое
|
|
Физкультурная группа
|
Простое
|
|
Аллергические реакции
|
Составное
|
|
Обследования специалистов
|
Составное
|
|
Рост
|
Простое
|
|
Вес
|
Простое
|
|
Дополнительная мед/информация о ребенке
|
Составное
|