Средства объектно-ориентированного программирования в задачах защиты информации
Введение
В начале 1980-ых годов появились персональные компьютеры. Они
быстро вошли во все сферы человеческой жизни, но вместе с ними появилось много
разнообразных проблем. Одна из них - защита информации. По данным статистики,
более 90% компаний и агентств несут огромные финансовые убытки именно из-за
нарушения безопасности данных.
Защита информации в процессе ее хранения, сбора, а также
обработки имеет огромное значение.
Проблема защиты информации от несанкционированного доступа
есть совокупность проблем в областях права, организации управления, разработки
технических средств, программирования и математики.
Под защитой информации имеют в виду решение следующих задач:
проверка целостности информации; исключение незаконного доступа к программам и
данным, которые защищаются; защита программ от копирования.
Причинами проблем защиты информации являются следующие:
высокие темпы роста парка ПЭВМ; широчайшее применение ПЭВМ в различных сферах
человеческой деятельности; большая концентрация информации в ПЭВМ; множество
способов доступа пользователей к ресурсам ПЭВМ.
Возможности программирования всегда были ограничены либо
возможностями компьютера, либо возможностями человека. В прошлом веке главным
ограничением были низкие производительные способности компьютера. В настоящее
время физические ограничения отошли на второй план. Со всё более глубоким
проникновением компьютеров во все сферы человеческой деятельности, программные
системы становятся всё более простыми для пользователя и сложными по внутренней
архитектуре. Программирование стало делом команды и на смену алгоритмическим
идеологиям программирования пришли эвристические, позволяющие достичь
положительного результата различными путями.
Базовым способом борьбы со сложностью программных продуктов
стало объектно-ориентированное программирование (ООП), являющееся в настоящее
время наиболее популярной парадигмой. ООП предлагает способы мышления и
структурирования кода.
ООП - методология программирования, основанная на
представлении программного продукта в виде совокупности объектов, каждый из
которых является экземпляром конкретного класса. ООП использует в качестве
базовых элементов эвристическое взаимодействие объектов.
Практическая и теоретическая значимость изучения средств
объектно-ориентированного программирования в задачах защиты информации
заключается в том, что представленные в работе теоретические аспекты изучаемого
вопроса могут быть использованы при изучении данной темы, а практические
разработки могут применяться на практике при обеспечении защите информации.
Цель курсовой работы - изучить средства
объектно-ориентированного программирования в задачах защиты информации.
В соответствии с целью работы необходимо решить следующие
задачи:
проанализировать теоретические аспекты
объектно-ориентированного программирования;
раскрыть программную реализацию стека на языке С++;
показать криптопреобразования на языке Turbo Pascal.
Структура работы: состоит из введения, двух глав, заключения,
списка использованных источников и приложения. Содержит 26 страниц, 3 рисунка,
1 приложение, 12 литературных источников.
1.
Теоретические аспекты объектно-ориентированного программирования
1.1 Понятие объектно-ориентированного
программирования
По мере развития вычислительной техники создавались новые
подходы, помогающие справляться с растущим усложнением программ. Использование
структурного программирования при написании умеренно сложных программ принесло
свои результаты, но оказывалось несостоятельным тогда, когда программа
достигала определенной длины. Чтобы писать более сложные программы, были
разработаны принципы объектно-ориентированного программирования (ООП). ООП -
это новый подход к созданию программ.
ООП позволяет разложить проблему на составные части. В этом
случае вся процедура упрощается, и появляется возможность оперировать с гораздо
более объемными программами. Каждая составляющая становится самостоятельным
объектом, содержащим свои собственные коды и данные, относящиеся к нему.
Объект - замкнутая независимая сущность, взаимодействующая с
внешним миром через строго определенный интерфейс в виде принимаемых сообщений.
Объекты обладают определенным набором свойств, методов и
способностью реагировать на события (нажатие кнопок мыши, интервалы времени и
т.д.). В отличие от процедурного программирования, где порядок выполнения
операторов программы определяется порядком их следования и командами
управления, в ООП порядок выполнения процедур и функций определяется событиями.
Объекты с одинаковыми свойствами и поведением объединяются в
классы. Программа на объектно-ориентированном языке представляет собой
совокупность описаний классов. Классы, в свою очередь, представляют собой
описания свойств и поведения составляющих их объектов. Свойства представляются
другими, более простыми объектами. Поведение описывается обменивающимися сообщениями
объектами.
Объект - реальная именованная сущность, обладающая свойствами
и проявляющая свое поведение.
В применении к объектно-ориентированным языкам
программирования понятие объекта и класса конкретизируется, а именно:
Объект - обладающий именем набор данных (полей объекта),
физически находящихся в памяти компьютера, и методов, имеющих доступ к ним. Имя
используется для доступа к полям и методам, составляющим объект. В предельных
случаях объект может не содержать полей или методов, а также не иметь имени.
Любой объект относится к определенному классу. Класс содержит
описание данных и операций над ними. В классе дается обобщенное описание
некоторого набора родственных, реально существующих объектов. Объект -
конкретный экземпляр класса.
Объектно-ориентированное программирование основано на
принципах:
абстрагирования данных;
инкапсуляции;
наследования;
полиморфизма;
«позднего связывания».
Инкапсуляция (encapsulation) - принцип, объединяющий данные и
код, манипулирующий этими данными, а также защищающий в первую очередь данные
от прямого внешнего доступа и неправильного использования. Другими словами,
доступ к данным класса возможен только посредством методов этого же класса.
Наследование (inheritance) - это процесс, посредством
которого один объект может приобретать свойства другого. Точнее, объект может
наследовать основные свойства другого объекта и добавлять к ним свойства и
методы, характерные только для него.
Наследование бывает двух видов:
одиночное - класс (он же подкласс) имеет один и только один
суперкласс (предок);
множественное - класс может иметь любое количество предков (в
Java запрещено).
Полиморфизм (polymorphism) - механизм, использующий одно и то
же имя метода для решения двух или более похожих, но несколько отличающихся
задач.
Целью полиморфизма применительно к ООП является использование
одного имени для задания общих для класса действий. В более общем смысле
концепцией полиморфизма является идея «один интерфейс, множество методов».
Механизм «позднего связывания» в процессе выполнения программы
определяет принадлежность объекта конкретному классу и производит вызов метода,
относящегося к классу, объект которого был использован.
Механизм «позднего связывания» позволяет определять версию
полиморфного метода во время выполнения программы. Другими словами, иногда
невозможно на этапе компиляции определить, какая версия переопределенного
метода будет вызвана на том или ином шаге программы.
Краеугольным камнем наследования и полиморфизма предстает
следующая парадигма: «объект подкласса может использоваться всюду, где
используется объект суперкласса».
При вызове метода класса он ищется в самом классе. Если метод
существует, то он вызывается. Если же метод в текущем классе отсутствует, то
обращение происходит к родительскому классу и вызываемый метод ищется у него.
Если поиск неудачен, то он продолжается вверх по иерархическому дереву вплоть
до корня (верхнего класса) иерархии.
1.2 Языки
объектно-ориентированного программирования
Из огромного числа языков
программирования, появившихся за период развития информационных технологий,
лишь наиболее удобные и совершенные были приняты обществом разработчиков и
отстояли свое право на существование. Анализируя языки программирования и
обстоятельства, сопутствующие их появлению, можно обнаружить множество общих
черт. Это позволяет сгруппировать языки по основным используемым принципам и
выделить поколения в их развитии. Романова Ю.Д. приводит следующую
классификацию:
• Первое поколение (1954-1958)
FORTRAN I Математические формулы
ALGOL-58 Математические формулы
Flowmatic Математические формулы
IPL V Математические формулы
• Второе поколение (1959-1961)
FORTRAN II Подпрограммы, раздельная
компиляция
ALGOL-60 Блочные структуры,
типы данных
COBOL Описание данных, работа
с файлами
Обработка списков, указатели, сборка
мусора
• Третье поколение (1962-1970)
PL/1 FORTRAN+ALGOL+COBOL
ALGOL-68 Более строгий
преемник ALGOL-60
Pascal Более простой преемник ALGOL-60
Simula Классы, абстрактные
данные
Многие идеи, лежащие в основе современных
языков программирования, появились в том или ином виде уже к 1970 году. Все
последующие языки, за редким исключением, являются потомками или результатом
обобщения и развития вышеперечисленных. Этому во многом способствовало как
широкое распространение мини- и микро-ЭВМ и связанный с ним рост числа
разработчиков программного обеспечения, так и многообразие операционных систем
и различных сфер применения информационных технологий.
Первое поколение языков программирования
были ограничены следующими особенностями:
• Малым объем оперативной памяти.
• Несовершенством системы ввода-вывода.
Ввиду данных ограничений, а также малого
количества и дороговизны этих машин, на них работали исключительно
высококвалифицированные специалисты, способные управлять ими непосредственно на
уровне двоичных кодов. Для облегчения процесса программирования вскоре были
созданы языки первого поколения. Это были первые языки, которые приближали
программирование к предметной области и отдаляли его от конкретной машины. Их
словарь практически полностью был математическим. Топология языков первого и
начала второго поколения, приведена на рисунке 1.

Рисунок 1 - Топология первого и начала
второго поколения языков программирования
Программы, реализованные на языках первого
и начала второго поколения, имели относительно простую структуру, состоящую из
подпрограмм и данных, лежащих в глобальной области видимости. Механизмы языков
не поддерживали разделения разнотипных данных, что сильно осложняло написание
больших программ. Основная сложность при этом заключалась в том, что ошибка или
любые изменения в одной
На момент своего появления, подпрограммы
расценивались лишь как средство облегчающее процесс написания программ. Будучи
минимальными единицами переиспользования, они стали «кирпичиками» для
построения первых библиотек. Постепенно они стали играть фундаментальную роль в
декомпозиции программных систем.
Выделение подпрограмм, как механизм
абстрагирования, имело следующие важные последствия. Были разработаны различные
механизмы передачи параметров. Были заложены основания для структурного
программирования, что выражалось в появлении языковой поддержки механизмов
вложенности подпрограмм и научной разработке структур управления и областей
видимости. Возникли методы структурного проектирования, основой которых служило
использование процедур или подпрограмм в качестве отдельных строительных блоков
(рисунок 2).
Рисунок 2 - Топология языков
программирования конца второго и начала третьего поколения
Разрастание программных проектов требовало
увеличения коллективов разработчиков и появления механизмов, позволяющих этим
коллективам независимо работать над разными частями проекта. Так появились
модули.
Модуль - отдельно компилируемая части
программы, состоящая из наборов данных и подпрограмм.
В модули, как правило, собирались
подпрограммы, которые, как предполагалось, должны разрабатываться и изменяться
совместно. Туда же собирались и данные, которые использовались этими
подпрограммами. Постепенно модули стали новым, более крупным механизмом
абстракции программных систем.
Первоначально языки программирования не
имели достаточно развитых механизмов защиты данных одного модуля от
использования их процедурами другого. Во многом эта задача ложилась на
коллективы разработчиков. Появившиеся различные подходы в разработке
программных систем благоприятствовали возникновению огромного количества
языков, имеющих те или иные сильные и слабые стороны в реализации этих
принципов. Одним из наиболее развитых представителей языков третьего поколения
стал язык ALGOL-68. Будучи универсальным и реализуя почти все разработанные к
тому времени механизмы в алгоритмических языках, он был достаточно труден для
первоначального освоении, однако позволял разрабатывать системы корпоративного
масштаба для больших ЭВМ.
Благодаря распространению малых ЭВМ,
огромную популярность приобрели более простые потомки ALGOL-60 - язык Pascal, до сих пор наиболее
широко используемый в академический и учебной среде, и появившийся во второй
половине 70-х годов язык C, который приобрел наибольшую популярность среди
профессиональных программистов. Pascal изначально служил средством обучения
структурному программированию, а язык C был разработан для написания
операционной системы Unix.
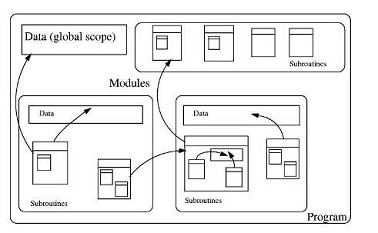
Рисунок 3 - Топология языков конца
третьего поколения
программный язык объектный ориентированный
Классическим потомком языка Pascal, предназначенным для
профессионального написания сложных программных комплексов, стал язык Ada, имеющий встроенную
поддержку модульности и абстрактных типов данных.
Язык C, имеющий гибкий лаконичный
синтаксис и простую алгоритмическую структуру (в нем отсутствуют вложенные
процедуры), стал очень популярным языком как системного, так и прикладного
программирования. Наличие возможности низкоуровневого управления памятью
(преобразование типов, наличие указателей на данные и функции), препроцессор и
поддержка макросов делают его языком системного программирования, предоставляя
средства, ранее доступные для малых ЭВМ только на уровне языка ассемблера.
Простота в освоении и чрезвычайная гибкость делают его многофункциональным
средством прикладного программирования.
Процедурно-ориентированные языки мало
подходят для написания программных систем, где центральным место занимают
данные, а не алгоритмы. С определенного момента возникла острая необходимость в
языковой поддержке описания произвольных объектов окружающего мира. Вводятся
абстрактные типы данных. Как хорошо сказал Шан-кар: «Абстрагирование,
достигаемое посредством использования процедур, хорошо подходит для описания
абстрактных действий, но не годится для описания абстрактных объектов. Это серьезный
недостаток, так как во многих практических ситуациях сложность объектов, с
которыми нужно работать, составляет основную часть сложности всей задачи».
Первым языком, в котором нашли свое
выражение идеи построения программ на основе данных и объектов стал язык Simula 67. Концепции,
заложенные в языке Simula получили свое развитие в серии языков Smalltalk-72, - 74, - 76, - 80, а
также в языках C++ и Objective C. При внесении объектно-ориентированного
подхода в язык Pascal появился язык Object Pascal. В 90-х годах компания Sun представила миру язык Java, как воплощение идеи
платформенной независимости и наиболее полную реализацию концепций
объектно-ориентированного программирования, положенных в основу языков Simula 67, Smalltalk, C++.
2. Практическая
разработка средств объектно-ориентированного программирования в задачах защиты
информации
.1 Программная реализация
стека на языке С++
В случае использования механизмов языка C,
стратегия может быть следующей - мы объявляем набор операций для работы со стеком
и заводим некоторую структуру для хранения его содержимого. Ниже приведен
пример заголовочного файла для стека, а также файл модуля, где реализованы
функции работы со стеком, объявленные в заголовке.
/* file simple_stack.h 7
#ifndef _SIMPLE_STACK_H
#define _SIMPLE_STACK_H
#define MAX_STACK_SIZE
200
typedef struct {top;*
content [MAX_STACK_SIZE];
} SimpleStack;
/* returns -1 if overflow
7push (SimpleStack *pstack, void *pobj);
/* returns NULL if empty
7* pop (SimpleStack *pstack);
*
allocateStack();freeStack (SimpleStack *pstack);
#endif/*_SIMPLE_STACK_H */
/* file simple_stack.c */
#include <malloc.h>
#include <stdlib.h>
#include «simple_stack.h»
* allocateStack()
{* pstack =
(SimpleStack*) malloc
(sizeof (SimpleStack));>top = 0;pstack;
}
freeStack (SimpleStack
*pstack)
{(pstack);
}
push (SimpleStack
*pstack, void *pobj)
{(pstack->top <
MAX_STACK_SIZE) {>content[(pstack->top)++] = pobj;0;
} else {-1; /* overflow
*/
}
}
* pop (SimpleStack
*pstack)
{(pstack->top > 0)
{pstack->content[- (pstack->top)];
} else {
return NULL; /* underflow */
}
}
Данная реализация имеет множество
недостатков, хотя и может сгодиться для небольших программ. Главными являются
следующие два:
Данные экземпляров структуры не защищены
от недобросовестного использования. Следующий код может непоправимо нарушить
работу программы:
SimpleStack pStack = allocateStack();
pStack->top = -10;
Стек реализован в виде массива, и нет
простого способа заменить его реализацию в программах, уже использующих данную
версию.
Мы можем существенно усовершенствовать наш
стек, если воспользуемся средствами модульного программирования, имеющимися в
языке С++.
// Файл advanced_stack.h
// Усовершенствованный вариант стека,
использующий
// механизм модульности языка C++
#ifndef _ADVANCED_STACK_H
#define _ADVANCED_STACK_H
// Таким образом мы определяем функциональный
// контракт модульной реализации стека
namespace advanced_stack {
struct Stack_impl;struct
Stack_impl AdvancedStack;
// returns -1 if overflowpush
(AdvancedStack *pstack, void *pobj);
// returns NULL if empty*
pop (AdvancedStack *pstack);
*
allocateStack();freeStack (AdvancedStack* pstack);
}
#endif //
_ADVANCED_STACK_H
// Файл
advanced_stack.cpp
// Реализация контракта модульной
реализации стека
namespace advanced_stack
{int MAX_STACK_SIZE =
200;Stack_impl {top;* content [MAX_STACK_SIZE];
};
_impl* allocateStack()
{_impl *pstack = new
Stack_impl();>top = 0;pstack;
}
freeStack (Stack_impl
*pstack)
{pstack;
}
push (Stack_impl *pstack,
void *pobj)
{(pstack->top <
MAX_STACK_SIZE) {>content[(pstack->top)++] = pobj;0;
} else {-1; // overflow
}
}
* pop (Stack_impl
*pstack)
{(pstack->top > 0)
{pstack->content[- (pstack->top)];
} else {
return 0; //underflow
}
}
}
В данной реализации решены обе упомянутые
выше проблемы. Примером использования модульной организации стека может стать
следующая программа:
#include <stdio.h>
#include
«advanced_stack.h»
main()
{namespace
advanced_stack;*pstack = allocateStack();
//pstack->top = 10; //
Данная строка вызвала бы ошибку компиляции,*letters
[3] = {«one», «two», «three»}; int i;(pstack, (void*) (letters[0]));(pstack,
(void*) (letters[1]));(pstack, (void*) (letters[2]));(i = 0; i < 3; i++)
{(«\n % s\n», (char*) pop(pstack));
}
freeStack(pstack);
}
Если в будущем потребуется заменить
реализацию стека, то это можно сделать изменив реализацию структуры Stack_impl и функции работы с ней,
реализованные в файле advanced_stack.cpp. Также можно объявить новое пространство имен (namespace), например dynamic_stack например, в котором
будет реализован стек изменяемого размера. В прежней программе, использующей
модульную реализацию стека, достаточно будет заменить строку
using namespace
advanced_stack;
на строку namespace dynamic_stack;
Это можно сделать при условии, что новое
пространство имен имеет контракт, совпадающий с предыдущим.
Таким образом, мы вплотную подошли к идее
объединения данных и кода, предназначенного для обработки этих данных, в одну
концептуально целостную единицу. Следующим шагом является объектная реализация
стека.
// Файл object_stack.h
#ifndef _OBJECT_STACK_H
#define _OBJECT_STACK_H
// Объектная модель стека class
ObjectStack
{:const int
MAX_STACK_SIZE;top;**content;:
// Вместо allocateStack(…), используется
конструктор ObjectStack();
// Вместо freeStack() используется
деструктор ~ObjectStack(); int push (void* pobj);
void* pop();
};
#endif // _OBJECT_STACK_H
// Файл
object_stack.cpp
#include «object_stack.h»
// Реализация объектной модели стекаint
ObjectStack:MAX_STACK_SIZE = 200;
: ObjectStack()
:top(0)
{= new
void*[MAX_STACK_SIZE];
}
:~ObjectStack()
{[] content;
}
* ObjectStack:pop()
{(top > 0)
{content[-top];
} else {0; // underflow
}
}
ObjectStack:push (void*
pobj)
{(top <
MAX_STACK_SIZE) {[top++] = pobj;0;
} else { -1; // overflow
}
}
Примером использования такого стека может
служить следующая программа:
int main()
{*pstack = new
ObjectStack();*letters [3]= {«one», «two», «three»}; int i;
// Доступ к членам данным в принципе
невозможен извне
// pstack->top = -10; // Ошибка времени
компиляции
pstack->push ((void*)
letters[0]);>push ((void*) letters[1]);>push ((void*) letters[2]);(i= 0;
i<3; i++) {(«\n % s\n», (char*) pstack->pop());
}
delete pstack;
}
Пользоваться такой реализацией стека
гораздо удобней, кроме того, она надежней предыдущих. Код лаконичен и прост для
понимания.
2.2 Криптопреобразования на языке Turbo Pascal
Криптографические преобразования строк сводятся к
перестановкам (перемещениям), заменам (подстановкам) символов в строке или
комбинациям обоих методов. Поскольку при перестановках коды символов не
меняются, то для шифрования текстовых файлов в большинстве случаев их можно
использовать без всяких ограничений. Пример криптозащиты с помощью перестановок
показан в листинге 1.
Листинг 1CryptDemo_1;
(*********************************)
(*Шифрование строки текста случайной перестановкой
символов.*)
(* Turbo Pascal 3.xx *)
(*********************************)= 'Мама мыла Машу мылом.
Маша мыло не любила. '#10;
TestTxt2 = 'Шифрование перестановкой символов.';
FileName = 'DEMO.TXT';
var
I: byte;
C: char;
Line: string [$FF];
CryptTab: array [1..255] of byte;
F: text;
begin
TextBackGround (Black);
(* шифруемый текст *)
Line:= TestTxt1 + TestTxt2;
TextColor (Yellow);
WriteLn (Line);
(* ввод-вывод строки через файл *)
TextColor (LightGreen);
Assign (F, FileName);
Rewrite (F);
WriteLn (F, Line);
Close (F);
Reset (F);
ReadLn (F, Line);
Close (F);
Erase (F);
WriteLn (Line);
(* восстановление строки *)
Line:= TestTxt1 + TestTxt2;
(* рандомизация ключа шифрования *)
Randomize;
(* подготовка таблицы перестановок *)
for I:= 1 to Length (Line) do
CryptTab [I]:= Succ (Random (Length (Line)));
(* шифрование перестановкой символов *)
for I:= 1 to Length (Line) do begin
C:= Line [I];
Line [CryptTab [I]]:= C
end;
TextColor (LightCyan);
WriteLn (Line);
(* дешифрирование перестановки символов *)
for I:= Length (Line) downto 1 do begin
C:= Line [I];
Line [I]:= Line [CryptTab [I]];
Line [CryptTab [I]]:= C
end;
TextColor (White);
Write (Line);
TextColor (LightGray);
Writeln;
Halt
end. (* CryptDemo_1 *)
Здесь таблица перестановок CryptTab (играющая роль гаммы
шифра) создается случайным образом при каждом вызове программы. Номер элемента
I и соответствующее значение CryptTab указывают положение в строке
переставляемых элементов. Шифрование и дешифрирование отличаются направлением
перебора символов строки. Программа выводит четыре текстовые строки (каждую
своим цветом): исходную (желтый), из текстового файла (зеленый), шифровку исходной
(циан) и результат ее расшифровки (белый). Обратите внимание на действие
преднамеренно введенного управляющего символа перевода строки.
Криптозащиту с помощью замен рассмотрим на примере шифра Гая
Юлия Цезаря, описываемого преобразованиями, соответственно прямым:
X = Y + (N - Shift) (mod N) (1)
и обратным:
Y = X + Shift, (mod N) (2)
где X и Y - позиция исходного и кодированного символа в
N-символьном алфавите; - сдвиг 1,2…N-1, не зависящий от номера позиции символа
в строке. И взятие по (mod N) напоминает, что соответствующее значение берется
по модулю N числа символов в алфавите. Заметим, что всегда
К сожалению, напрямую подобное преобразование неприменимо
из-за несовпадения способа нумерации строчных символов в алфавите с их кодами в
таблице ASCII. Однако преобразованием можно пользоваться, если положение в
алфавите символа C с кодом Ord (C) из диапазона 20 h..FFh считать равным:
= Ord (C) - 32 (4)
Число символов в таком алфавите (N) равно 224. Для
фиксированного значения сдвига программа шифрования / дешифрирования может быть
построена, как показано в листинге 2.
Листинг 2 CryptDemo_2;
(****************************)
(*Шифрование строки текста заменой символов 32..255.*)
(* Turbo Pascal 3.xx *)
(****************************)
const
TestTxt1 = 'Мама мыла Машу мылом. Маша мыло не любила.
'#10;
TestTxt2 = 'Шифрование заменой символов.';
var
I: byte;
C: char;
Line: string [$FF];
Shift: byte;
begin
TextBackGround (Black);
(* шифруемый текст *)
Line:= TestTxt1 + TestTxt2;
TextColor (Yellow);
WriteLn (Line);
(* рандомизация ключа шифрования *)
Randomize;
Shift:= 1 + Random (223);
(* шифрование заменой символов *)
for I:= 1 to Length (Line) do
if Line [I] >= #32 then
Line [I]:= Chr ((Ord (Line [I]) + 192 - Shift)
mod 224 + 32);
TextColor (LightCyan);
WriteLn (Line);
(* дешифрирование замены символов *)
for I:= 1 to Length (Line) do
if Line [I] >= #32 then
Line [I]:= Chr ((Ord (Line [I]) - 32 + Shift) mod
224 + 32);
TextColor (White);
Write (Line);
TextColor (LightGray);
WriteLn;
Halt
end. (* CryptDemo_2 *)
По сути дела, сдвиг и порождает фиксированную таблицу
соответствия между символами исходного и зашифрованного сообщений. Всего таких
таблиц, т.е. способов расшифровки, для N-символьного алфавита может быть ровно
N. Причем каждая таблица имеет простое устройство, и все они могут быть
проверены даже вручную.
Усиление криптостойкости шифра Цезаря достигается в том
случае, если считать сдвиги зависящими от положения шифруемого символа в
строке. Тогда каждому положению символа соответствует своя шифровальная
таблица. Число различных таблиц по-прежнему равно N, однако для расшифровки уже
необходимо знать порядок следования таблиц. Последнее и обусловливает повышение
надежности шифра. При этом достаточно хранить только таблицу сдвигов,
выполняющую функцию гаммы шифра, а сами таблицы преобразований символов
реконструировать по мере надобности, используя приведенные выше формулы. Способ
реализации такого подхода показан в приложении.
Мы рассмотрели применение лишь простейшего способа шифрования
текстов Гая Юлия Цезаря на основе перестановок и циклических замен. Надежность
каждого из подобных шифров невысока. В то же время их последовательное и
многократное применение может повысить криптостойкость шифра. Однако
использование одних лишь перестановок или только замен не повышает устойчивости
шифра ко взлому и даже способно привести к его вырождению. Комбинация
перестановок и подстановок гораздо устойчивее, и применяется в профессиональных
системах шифрования.
Заключение
Стиль программирования - это способ
построения программ, основанный на определенных принципах программирования, и
выбор подходящего языка, который делает понятными программы, написанные в этом
стиле. Концептуальной базой объектно-ориентированного стиля программирования является
объектная модель, основывающаяся на четырех главных принципах: абстрагирование;
инкапсуляция; модульность; иерархия. Имеются еще три дополнительных принципа,
которые не являются обязательными, но полезны: типизация; парллелизм;
сохраняемость.
Инкапсуляция - означает, что объекты скрывают детали своей
работы. Инкапсуляция позволяет разработчику объекта изменять принципы его
функционирования, не оказывая никакого влияния на пользователя объекта.
Наследование - означает, что новый объект можно определить на
основе уже существующих объектов, при этом он будет содержать все свойства и
методы родительского. Наследование полезно, когда требуется создать новый
объект, обладающий дополнительными свойствами по сравнению со старым.
Полиморфизм - многие объекты могут иметь одноименные методы,
которые могут выполнять разные действия для разных объектов.
Типизация имеет очень большое значение как
в языке Java (сильная типизация), так и в C++, (типизация также является
сильной, но существуют правила неявного преобразования типов, определяемых
пользователем). В отличие от С++, в Java присутствует непосредственная языковая поддержка
принципов параллелизма и сохраняемости.
Без соблюдения данных принципов
выразительные способности объектно-ориентированных языков будут при этом
потеряны или искажены, и их использование не по назначению приведет к
усложнению, а не облегчению решения поставленной задачи.
Список использованных источников
1. Архангельский А.Я. Программирование в C++Builder 5.-M.: БИНОМ, 2000. - 1152 с:
ил + CD.
2. В.П. Румянцев. Азбука программирования в Win 32 API. - 3-е изд.: - Москва,
«Горячая линия - телеком», 2001.
. Вильяме А. Системное программирование в Windows 2000 /Пер. с англ. П.
Анджан.-СПб. - М. - Харьков - Минск: Питер, 2001. - 621 с: ил. + CD-ROM.
. Дейл Н., Уимз Ч., Хедингтон М. Программирование на
C++: Пер. с англ..-М.: ДМК, 2000. - 672 с.
. Жельников В., Криптография от папируса до
компьютера. М.: ABF, 1996.
. Шилдт. Самоучитель С++:Пер. с англ. - 3-е изд.: -
СПб.:БХВ-Петербург, 2001. -688 с.
. Круглински Д.Д., Уингоу С, Шеферд Д.
Программирование на Microsoft Visual C++ 6.0: Пер. с англ..-СПб. - М. Харьков -
Минск: Питер; Русская редакция, 2000. - 821 с: ил. + CD-ROM.
. Мешков А., Тихомиров Ю. Visual C++ и MFC.:B трех томах. Том 3 - Cn6.:BHV - Санкт - Петербург,
1997. - 384 с., ил.
. Подбельский В.В., Фомин С.С. Программирование на
языке Си: - 2-е изд., доп..-M.: Финансы и статистика, 2001. - 600 с.
. Ричард Лейнекер. Энциклопедия Visual C++ - СПб.: Питер, 1999.
- 1147 с.
11. Романова Ю.Д. Информатика
и информационные технологии: учебное пособие/Ю.Д. Романова, И.Г. Лесничая, В.И.
Шестаков, И.В. Миссинг, П.А. Музычкин; под ред. Ю.Д. Романовой. - 3-е изд.,
перераб. и доп. - М.:Эксмо, 2008.-592 с.
12. Франка П. C++: 26 уроков для освоения языка; Учебный курс
/Пер. с англ. П. Бибиков.-СПб.: Питер, 2000. - 521 с.