|
№
п/п
|
Предложение
|
Пример
|
|
1
|
NP + Vi
|
Bobworked.
|
|
2
|
NP + Vt + NP
|
Bobpaid the bill.
|
|
3
|
NP + be + subs
|
Bob is a boss.
|
|
4
|
NP + be + AdvP
|
Bob is in the bathroom.
|
|
5
|
NP + Vb + subs
|
Bob became a hero.
|
|
6
|
NP + Vs + Adj
|
Bobfeltsad.
|
|
7
|
NP + Vh + NP
|
Bobhas a car.
|
Таким образом, исследование простых предложений в английском языке будет
проводиться в соответствии с заданными пределами языковых конструкций. Данный
выбор обусловлен тем, что в указанных конструкциях возможно автоматическое
определение предикативного ядра. В частности, может выделить некоторые правила
семантического анализа простых английских предложения:
1) Порядок следования: сказуемому в повествовательном предложении
предшествует подлежащее. Однако имеются следующие исключения:
- придаточные предложения, сравнения и условия с ограниченным числом
глаголов движения и с целью обособления наречий, как правило, негативных (в
обратном порядке ставятся части составного глагольного сказуемого);
- смысловое выделение слов, усиление значения.
2) Правило согласования по числу: сказуемое и подлежащее обладают
одинаковой характеристикой числа. Однако имеются следующие исключения:
- омонимия формы имени существительного (например, The cowwasgrazing –
The cowweregrazing);
- омонимия в виде глагола во временах, которые отличны от настоящего,
исключая глагол «tobe» (The womanspoke
– The womenspoke);
- использование как подлежащее слов, которые означают группу: «board»,
«company», «crowd», «family», «group», «infantry», «Parliament», «people» и
пр.;
- использование как подлежащее местоимений «all», «none», «who»;
- использование в качестве подлежащего сочинительного словосочетания (SamandTonyaaresohappytogether.)
1.2. Правила и последовательность
семантического анализа простого английского предложения: основные модели и их
правила
Автоматический семантический анализ простого
английского предложения является тесно связанным с задачей понимания текста.
При этом под смыслом текста в настоящей работе понимается описание знаний,
которые содержатся в нем, решающий широкий круг задач, которые связаны с
анализом простого английского предложения. При этом в качестве основной задачи
семантического анализа выступает трансляция на язык представления знаний
языкового выражений.
Одним из наиболее распространенных способов
семантического анализа является представление простого английского предложения
на языке логики. Создателем данной модели является Р. Монтегю, который первый
показал, что английский язык может транслироваться в формальный язык[2].
Он считал, что на теоретическом уровне естественные и формальные языки главным
образом не различаются, а значение английского простого предложения - это
условие его истинности. В этом случае значение предложения складывается из
значений его элементов. Ученый сформировал правила грамматики семантики, в
основу которой лежит исчисление предикатов первого порядка, которое расширено
интенсиональной логикой, включающей в себя лямбда-исчисление, типы функций и
расширенную структуру типов.
В работе данного ученого выдвигается гипотеза,
согласно которой каждое синтаксическое правило обладает своим аналогом в
семантике, и для семантического анализа формальную грамматику можно совместить.
На рис. 1 изображен пример дерева, отражающие правила проведения семантического
анализа простого английского предложения на основе применения формальной
интегрированной семантической грамматики, согласно которой осуществляется вывод
формулы высказывания
«Every cafes closed».

Рисунок 1 – Результатразборапоформальнойсемантическойграмматикепредложения «Every cafes closed»
Работа Р. Монтегю дала начало целому направлению, в рамках которого
исследуются подходы моделирования на формальном языке временных аспектов
английского языка: выражений событий, характеристик объектов в тексте, идиом,
метафор и др. На практике известны попытки применения формальной семантики в
задаче машинного перевода[3]. Однако на сегодняшний день, из-за
неоднозначности и гибкости английского языка применение аппарата формальной
семантики на практике, с одной стороны, проблематично из-за его сложности, а с
другой стороны, недостаточно для решения современных задач обработки простых
английских предложений.
Одной из самых старых моделей семантики английских предложений считается
модель, основанная на ролевой структуре предложения. Ч. Филлмор ввел понятие
глубинного падежа – универсальной (тематической) роли, которую могут исполнять
участники ситуации, обозначенной в предложении глаголом. Глубинные падежи было
предложено рассматривать как «универсальные врожденные понятия,
идентифицирующие типы суждений, которые человек способен делать о событиях,
происходящих вокруг него, – суждений о вещах такого рода, как «кто сделал
нечто», «с кем нечто случилось», «что подверглось некоему изменению». Всего
было введено около двенадцати подобных понятий, которые, как предполагалось,
позволяют представить в обобщенном виде все возможные смыслы участников ситуаций.
На сегодняшний день среди исследователей нет согласия о составе инвентаря ролей
и о том, по каким принципам их необходимо выделять и различать. Тем не менее,
существует ряд ролей, которые довольно часто используются в литературе (таблица
3)[4].
Таблица 3 – Некоторые часто
используемые тематические роли
|
Тематическая
роль
|
Определение
|
|
Агенс
|
Одушевленный инициатор действия, контролирующий его.
|
|
Пациенс
|
Участник, больше остальных вовлеченный в действие и
претерпевающий в ходе него наиболее существенные изменения.
|
|
Бенефактив
|
Участник ситуации, чьи интересы каким-то образом затронуты
в процессе ее осуществления, получающий от нее пользу или вред.
|
|
Экспериенцер
|
Участник – носитель чувств и восприятий, переживающий действие.
|
|
Стимул
|
Источник информации при глаголах чувственного восприятия
или источник непроизвольного переживания.
|
|
Инструмент
|
Неодушевленный объект, с помощью которого осуществляется
действие, но который сам не претерпевает изменений при его осуществлении.
|
|
Адресат
|
Получатель сообщения.
|
|
Источник
|
Место, из которого осуществляется движение.
|
|
Цель
|
Место, в которое осуществляется движение.
|
Реляционно-ситуационная модель текста формализует глубинные семантические
структуры текста с помощью аппарата неоднородных семантических сетей.
Реляционно-ситуационная модель опирается на теорию коммуникативной грамматики
Г.А. Золотовой[5].
В теории коммуникативной грамматики важную роль играет понятие
синтаксемы. Синтаксема представляет собой минимальную синтактико- семантическую
единицу языка, несущую обобщенный, категориальный смысл и характеризующуюся
взаимодействием морфологических, семантических и функциональных признаков.
Категориальный смысл синтаксемы называется ее значением. В отличие от ролей,
которые в лингвистических теориях чаще всего ассоциируются с аргументами
предикатных слов (например, таких как глаголы) и тесно с ними связаны, значения
синтаксем в этой теории являются в некоторой степени автономными.
Реляционно-ситуационная модель формализует значения синтаксем предложения
и их семантические отношения в виде семантической сети. Вершинами этой сети
являются синтаксемы. Синтаксемы могут быть двух видов – именные синтаксемы
(выраженные именной или предложной группой) и предикатные синтаксемы. Значение
предикатных синтаксем – это смысл предиката, который они выражают. Значения
именных синтаксем в тексте можно представить в виде:
- связей между именными синтаксемами и предикатными синтаксемами;
- связей между именными синтаксемами и служебной вершиной.
Существует два основных подхода к решению задачи определения ролевых
структур высказываний:
- с помощью машинного обучения с учителем на семантически размеченных
корпусах;
- подход, в котором применяются различные методы обучения без учителя
(кластеризация) или с частичным привлечением учителя.
Однако, на наш взгляд, наиболее предпочтительным способом семантического
анализа простого английского предложения является формирование вручную базовых
семантических шаблонов, но количество подобных шаблонов значительно меньше
числа шаблонов, сопоставление с которыми осуществляется по классическим
алгоритмам, не подразумевающим последовательное сокращение анализируемых
предложений. Вследствие небольшого числа базовых семантических шаблонов работа
над семантически анализом значительно ускоряется. Рассмотрим правила данного
метода.
Базовым семантическим шаблоном является правило, по которому в анализируемых
простых предложениях находится семантическая зависимость. Такой шаблон имеет 4
основные части:
1) последовательность слов или неделимых смысловых единиц, для которых
указаны их морфологические признаки, а в некоторых случаях приведены названия
этих слов и смысловых единиц;
2) название семантического отношения, которое должно быть сформировано в
случае обнаружения в тексте последовательности, описанной в предыдущем пункте;
3) последовательность чисел, определяющая позиции в последовательности из
п. 1, элементы которой должны быть добавлены в очередь с приоритетом, в
соответствии с которой впоследствии будут удаляться слова из анализируемого
предложения, подаваемого на вход семантическому анализатору;
4) число, обозначающее значение приоритета, группы семантических
зависимостей, к которой относится данное семантическое отношение.
Порядок применения данного шаблона указан на рисунке 2.

Рис. 2 -
Пример базового семантического шаблона
1.3. Признаки семантического
согласования и выделение семантических связей и объектов.
Предложение на уровне синтаксиса
определяется как единая, автономная синтаксическая единица, выявляющая
законченную мысль, а также реализующая совокупность обязательных грамматических
связей, входящих в состав таковой, чуть более мелких объединений (членов
предложения).
К этим признакам, квалифицирующим
предложение в аспекте его формы, приобщаются два базисных содержательных
признака – предикативность и модальность.
Предикативность будучи основным
содержательным признаком предложения зачастую рассматривается в качестве
свойства, определяющего не целое предложение, а исключительно структурное ядро
такового, именуемое моделью предложения, ядерным предложением или структурной
схемой: под предложением понимается синтаксическая структура коммуникативного
направления, в основе которой находится одна из присутствующих в системе языка
применимых форм, имеющих категорию предикативности[6].
Сообразно с такой постановкой задачи
предикативность рассматривается в качестве признака основы предложения,
структурной схемы, реализуемой с использованием синтаксических приемов
диссеминации в целую структурную модель. Общепринятые структурные
систематизации предложения базировались на противопоставлении двусоставных
предложений односоставным. В существе двусоставных преодолений находится
подлежащно-сказуемостная конструкция, односоставные обладают одним главным
членом, не являющийся ни сказуемым, ни подлежащим.
Структурное деление предложения
расширялось его делением на неполные и полные, нераспространенные и
распространенные. В итоге были найдены более дискретные структурные
классификации. Например, в границах двусоставных предложений начали выделять
ядерные, как то сочетания членов предложения, удаление которые невозможно без
повреждения структурного содержания предложения. Примечательно, что разные
исследователи следовали различным принципам, в следствие чего изменялось
допустимое число ядерных предложений. В иностранной англистике наибольшее
признание получила семичленная систематика ядерных предложений, маркируемая в
зависимости от метода морфологического проявления предикативного члена.
Как следует из приведенного ранее
перечня образцов ядерных предложений, часть из них[7]
модифицируются не по структуре синтаксиса, а по методу морфологического
отображения предикативного члена. Образцы 4 и 3 имеют одинаковый вид, хоть и
различны по синтаксической сущности[8].
Таблица 4 – Образцы ядерных предложений
|
1
|
NV
|
Bearsroar.
|
|
2
|
NVN
|
Henrybroke the
sculpture.
|
|
3
|
NVNN
|
He gave me a truck.
|
|
4
|
NVNN
|
TheyshoutedhimLiam.
|
|
5
|
NVLN
|
Liamis a broker.
|
NVLA
|
Liamistall.
|
|
7
|
NVLAdv
|
Liamisthere.
|
Г. Г. Почепцов считает ядром предложения,
конструктивным центром оного - глагол-сказуемое. Конструктивно-значимые части
(компоненты) предложения непосредственно связаны с этим предложением
дистрибутивной связью, следовательно невозможно изъять их из него не нарушая
структурной целостности предложения. Учитывая различные комбинации
конструктивно-значимых элементов предложения Г. Г. Почепцов обозначил 39 форм
ядерных предложений: десять первых форм основываются на разной совместимости
глаголов с дополнениями; другие 14 форм предлагают различную совместимость
глагола с обстоятельствами. Далее идут формы, использующие глагол-сказуемое в
конструкции страдательного залога, конструкциях here is,
there is,
глаголе-связке, и заканчивает список форма односоставного предложени[9]. Отечественная
лингвистика обладает и иным подходом, согласно которому формы предложения
определяют по видам синтаксической связи. В английских предложениях различаются
следующие виды связи: подчинительная (субординативная), координативная,
предикативная, вторично – предикативная и интродуктивная. Разные комбинации
указанных видов синтаксической связи образуют юнкционные модели. К примеру
предложение«She was attracted by them.
Theiorotatesroundthejupiter. Sheattractedthem»
используют одну и ту же юнкционную модель, включающую два вида связи –
предикативный и субординативный. Описательно модель можно изобразить следующим
образом[10]:

Рис.
3 Описательная модель
Вектор указывает тип
связи:
Другой принцип устройства структурных
форм предложения
был создан отечественными лингвистами: основой выделения моделей стал
функционално-позиционный признак, соответственно учитывались
назначение и положение члена предложения.
Было создано шесть моделей английского двусоставного (простого) предложения:
Таблица 5 – Модели простого предложения
двусоставного
|
1
|
SP
|
The boyscreams.
|
|
2
|
SP Comps
|
She is a girl
(young).
|
|
3
|
SPO1
|
The archer killed a
lion.
|
|
4
|
SPO2O1
|
Liam gave him a
laptop.
|
|
5
|
SPO1CompO
|
She painted the stand
black.
|
|
6
|
There PrS
|
There is a hook in
the wall
|
Эти модели включают только компоненты,
имеющие необходимые позиции в предложении. За счет элементов с факультативным
положением[11] они могут сделаться
распространенными.
Синтаксическая структура предложения
являет собой сеть связей частей предложения. Учитывая, характеристики отношения
частей предложения устанавливающих сеть взаимотношений, допустимо выделить
несколько типов грамматик:
1) грамматики, организующие отношения
исключительно между особыми минимальными синтаксическими единицами (МСЕ)
(грамматика зависимостей);
2) грамматики, отношения в которых
устанавливаются как между МСЕ, так и между совокупностью их комплексов,
представляющих собой цепочки означенных единиц (грамматика непосредственно
составляющих – НС).
 На
этом основании синтаксическую конструкцию предложений в грамматике зависимостей
возможно отобразить в образе ориентированного графа, дерева зависимостей,
узлами которого считаются МСЕ, в грамматике же - НС – в виде специфической
совокупности двухэлементных графов, учитывая, что их узлами выступают различные
цепочки. Так, к примеру, синтаксическая конструкция предложения a
big boy is lying at a high bedвыглядит следующим образом[12]:
На
этом основании синтаксическую конструкцию предложений в грамматике зависимостей
возможно отобразить в образе ориентированного графа, дерева зависимостей,
узлами которого считаются МСЕ, в грамматике же - НС – в виде специфической
совокупности двухэлементных графов, учитывая, что их узлами выступают различные
цепочки. Так, к примеру, синтаксическая конструкция предложения a
big boy is lying at a high bedвыглядит следующим образом[12]:
Рис. 4 Синтактическая конструкция
1. В грамматике зависимостей (рис. 5):

Узлами графа (элементами связи)
выступают МСЕ, которые в грамматике зависимостей представляют словоформы,
причем, в качестве элемента связи выступает непременно каждая из МСЕ, и
взаимосвязи устанавливаются напрямую между МСЕ.
2. В грамматике НС (рис. 6):

Узлами графа считаются линейные
взаимосвязи из нескольких или одной МСЕ: лишь в трех ситуациях синтаксическая
связь может устанавливаться прямо между МСЕ[13]:
1.4. Объектно-атрибутная
архитектура в семантическом анализе простого предложения
В настоящее время переносимость программного обеспечения
(далее - ПО) обеспечивается посредством кроссплатформенных языков
программирования: переносимость на уровне компиляции (C, C++, FreePascal), на
уровне выполнения программы (Java, C#) и интерпретируемые языки (PHP, Perl,
Tcl). Но средства, которые обеспечивают переносимость ПО, являются довольно
громоздкими, и в связи с эти переносимое ПО может осуществлять свою работуисключительно
на довольно мощных вычислительных узлах. В таком же положении находятся
организации распределенных вычислений, т.к. существующие технологии обмена
информацией между вычислительными узлами (RPC, DCOM, CORBA, MPI) являются также
негибкими. Формирование же распределенных и переносимых программ является
весьма сложным процессом, доступнымтолько профессиональным программистам.
Рассмотрим совершенно новый подход к обеспечению
переносимости ПО, моделированию и организации вычислений распределенных вычислительных
систем (далее – ВС), которые отличаются простотой и гибкостью: формирование
подобных систем будет под силу даже начинающим программистам.
Данный подход основывается на применении новой
объектно-атрибутной (далее - ОА) архитектуры ВС. Построенная по данной
архитектуре системафункционирует по принципу управления вычислениями посредством
потока данных (dataflow), то есть алгоритм задается не с помощью
последовательности команд, а посредством описания обмена данными между
виртуальными функциональными устройствами (далее - ФУ). Обмен информацией между
ФУ происходит через виртуальную шину данных/атрибута (далее - ШДА), по которойосуществляется
передача информационных пар (ИП), являющиеся совокупностью данных (нагрузки) и
описывающего их ярлыка (тега). Действия, осуществляемые ФУ над данными,
задаются последовательностью ИП, приходящих по ШДА. ФУ осуществляет выполнение
операции только после того, когда к нему приходят все данные, необходимые для
выполнения операции; то есть действия, которые выполняет ФУ, описываются посредством
потока данных, а не задаются извне.
Например, Box{Long=10 Wide=20 Depth=5}, где Box – название ИК, «=»
- обозначение ИП (до «=» помещается мнемоника атрибута, после – обозначение
нагрузки, фигурные скобки ограничивают множество ИП, относящееся к ИК; перед
описанием ИК может помещаться название (в нашем случае «Box»). В
вышеприведенном примере мнемоники атрибутов ИП обозначают: «Long» - длина, «Wide» - ширина, «Depth» - глубина.
ОА-система включает в себя два компонента: платформу
(программное описание логики работы ФУ) и ОА- образ – алгоритм вычислений, который
задается посредством описания обмена информацией между ФУ. Платформа является зависимой
от конкретной аппаратной архитектуры вычислительного узла, ОА-образ независимот
аппаратной архитектуры (ОА-образ способен задавать последовательность
элементарных вычислений, а также описывать сложные абстрактные модели,
наподобие того, как это делается в объектно-ориентированном программировании;
это существенно повышает технологичность написания ОА- образа, и существенно
расширяет возможности для создания интеллектуальных систем). Для обеспечения
работы ФУ на новой аппаратной платформе, требуется под новую платформу написать
весьма простые программы реализации логики работы ФУ-в. Виртуальные ФУ, которые
запущены на вычислительных узлах распределенной ВС, образуют ОА-вычислительное
пространство, которое способно работать в качестве единого целого. Причем
вычислительные узлы, которые объединены линиями коммуникации, могут являться не
только различной аппаратной архитектуры, но и различной вычислительной мощности.
ОА-архитектура имеет еще одно полезное свойство:
удобство имитационного моделирования распределенных ВС. Имея легкую
переносимость ОА-платформы виртуальные ФУ могут быть запушены не только на
вычислительных узлах создаваемый системы (система автоматизации, сетевая ВС,
система управления техническим объектом и т.п.), но и на обычном персональном
компьютере. Входной поток информации (например, сигналы с датчиков системы
автоматизации) весьма просто эмулируется (входной сигнал с датчика есть не что
иное, как ИП: значение, снабженное специальным атрибутом, по которому ФУ
ОА-системы будут идентифицировать данные). И программист весьма просто может
создать ОА-образ будущей распределенной ВС, отладить образ, а затем
«переселить» его в реальную распределенную ВС.
Таким образом, ОА-архитектура является оптимальным
решением при автоматической обработке текста.
1.5. Этапы семантического анализа в соответствии
с объектно-атрибутной архитектурой
Основой системы анализа является
семантико-морфологический словарь, имеющий в своем составе описание лексем.
Описание одной лексемы - это ОА-список всех возможных толкований. Каждое
толкование лексемы является совокупностью двух по крайней мере связанных между
собой информационных капсул (ИК): капсула с описанием морфологических свойств
толкования лексемы (падеж, род, число и т.п.) и капсула с семантическими
свойствами. При анализе текста происходит поиск лексем в этом словаре, и из
найденных описаний формируется ОА-список толкований лексем исходного текста.
Далее осуществляется
преобразование данного списка в семантическую сеть (ОА-граф), представляющая
собой онтологическую базу знаний, которая сформирована исходя из информации,закладываемойв
анализируемомтексте.Преобразование реализуется в несколько этапов отпростогок
сложному.
На каждом этапе
осуществляется «склейка» второстепенных лексем в словосочетании (синтагме) с
лексемой главной.
Например, при анализе
первого предложения из фрагмента текста «There is the chair. The chairisblue» описание объекта «chair»
попадет в тематический словарь; при анализе же второго предложения для слова «chair»
будет найден объект, который уже упоминался в тексте и к нему будет добавлено
свойство «blue».
Далее осуществляютсяэтапы
анализа синтаксических конструкций с союзами, и заключительный проход – склейка
существительных и глаголов. Для анализа смысловых связей между предложениями
в ОА-системе применяется так называемый тематическийсловарь. Схема синтеза
семантического графа из текста приведена на рис. 7.
Рис. 7 – Схема построения ОА-графа из
списка лексем исходного текста[14]
 Алгоритмпреобразованиятекста в
семантическийграфзадается с помощьюправилпреобразования (ОА-грамматика),
основойкоторыхсталиформальныеграмматикиХомского. ОА-грамматика в отличие от своего прототипа оперирует
не с цепочкой символов, а с цепочкой (списком) капсул с описанием лексем
(список исходных лексем) и служит для формирования семантического ОА-графа.
Формально ОА-грамматику можно описать как четверку OAG = {A,L,P,G}, где A – алфавит атрибутов; L – алфавит нагрузок ИП (в этот
алфавит входят не только числа и строки, но и ссылки на ИК; G – ОА-граф (список описаний лексем
исходного языка); P – правила
преобразования ОА-графа[15].
Алгоритмпреобразованиятекста в
семантическийграфзадается с помощьюправилпреобразования (ОА-грамматика),
основойкоторыхсталиформальныеграмматикиХомского. ОА-грамматика в отличие от своего прототипа оперирует
не с цепочкой символов, а с цепочкой (списком) капсул с описанием лексем
(список исходных лексем) и служит для формирования семантического ОА-графа.
Формально ОА-грамматику можно описать как четверку OAG = {A,L,P,G}, где A – алфавит атрибутов; L – алфавит нагрузок ИП (в этот
алфавит входят не только числа и строки, но и ссылки на ИК; G – ОА-граф (список описаний лексем
исходного языка); P – правила
преобразования ОА-графа[15].
Например, для обработки
предлога «in» в английском языке применяются правила (цифрами обозначены 1-й и
2-й проходы анализа):
1. in
NOUN , temp{Location ={Subj={NOUN*{Location=temp}} Location=in };
2. NOUN1
in*{ Location=temp} , NOUN1*{ Location=temp*{Obj=NOUN1}}; где Location - атрибутместарасположениячего-либо, Obj - объект, Subj - субъект.
Рассмотрим в качестве
примера предложение с тремя связями: объект, субъект, инструмент.
Так, для предложения «Mikeplayingwithball» будет синтезирован следующий
ОА-граф (жирным выделены атрибуты ИП, которые одновременно обозначают
семантические роли/валентности):
{ Object
= Mike
Subject = { Object = ball
with Subject
, temp{Location ={ Subject ={Subject *{Location=temp}}
Location=with}
}
Act = playing
}
Для совпадения графов
необходимо, чтобы ИП из капсул из вершин графа-запроса полностью совпали с ИП
из капсул в вершинах графа-текста. Для ускорения поиска подграфа была
разработана методика спектра атрибутов. По этой методике происходит подсчет
всех атрибутов, встречающихся в ОА-графе, и далее поиск подграфа начинается с
тех вершин, в которых обнаружено наименьшее количество совпадений в обоих
ОА-графах. В ОА-графе используются двусторонние связи между узлами для того,
чтобы можно было произвести обход графа начиная с любой его вершины. Таким
образом, удастся значительно снизить число переборов во время поиска (рис.8).
Рис. 8 – Поиск подграфа в
семантическом ОА-графе текста[16]
В настоящее время
требуется расширение семантико-морфологического словаря и увеличение числа
правил обработки списка лексем. В результате данной работы будет возможность
обработки ОА-системой адаптированных текстов.
Глава 2. Вычислительная часть
2.1. Разработка
формата семантико-морфологического словаря
В рамках настоящего исследования необходимо
разработать формат семантико-морфологического словаря.
С учетом имеющихся недостатков существующих словарей,
мы считаем, что требуется новая структура семантико-морфологического словаря.
За основу будет взять стандартный словарь. При этом главными задачами выступали
преобразование содержательной части с учетом особенностей использования
разрабатываемого словаря и формальная организация словаря с учетом потребностей
адресата.
Данный словарь является двуязычным электронным
словарем, предназначенным для анализа простых английских предложений.
Рассмотрим основные этапы составления такого словаря.
Таблица 6 - Этапы составления словаря

Разрабатываемый словарь должен выполнять следующие
функции:
1) решение проблемы омонимии (многозначности слов);
2) обеспечение описания семантических и
морфологических характеристик каждого слова;
3) хранение признак для согласования слов в простом
английском предложении, лица;
4) обеспечение наиболее простой трансформации списка
толкований слов исходного предложения.
Лексикографическая статья в данном словаре должна
обладать максимум лексико-семантической и синтаксической информацией, которая
будет релевантна для будущих задач автоматической обработки простых
предложений. Для каждого лексикографических типов должна указываться следующая
информация:
- транскрипция;
- написание в полной форме;
- орфографические варианты;
- перевод на русский и английский языки;
- толкование;
- синтаксическая и семантическая модель;
- сочетаемость с грамматическими модификаторами;
- возможность употребления в различных синтаксических
позициях;
- стандартная сочетаемость;
- синонимы.
Данный словарь будет состоять из описания вышеуказанной
информации (рис. 9). В капсулу
с описанием морфологических свойств толкования лексемы (падеж, род, число и
т.п.) предлагается разместить вышеуказанную информацию. В информационную капсулу (далее – ИК)[17]описания слова будет помещаться
информационная пара (далее – ИП)[18]
словоформы. В ИК с описанием указанной информации будут помещаться ИП с
описанием морфологических свойств толкования словоформы. Для согласования
словоформ в описание толкования словоформы добавим ИП со ссылкой на список
согласований, который обеспечит автоматическое согласование. Каждая ИП будет
состоять из двух линий: в первой хранятся признаки синтаксического
согласования, во второй – признака семантического согласования.
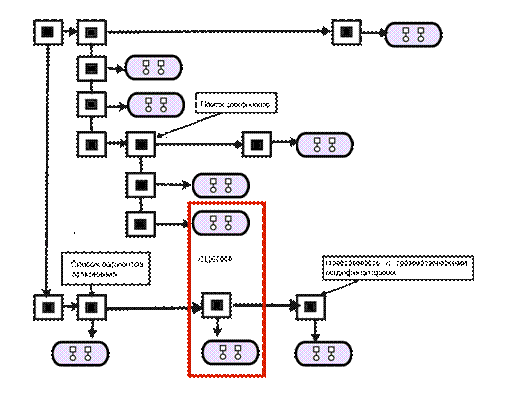
Рис. 9. Формат
семантико-морфологического словаря
Описания всех словоформ, которые присутствуют в списке
толкований слов исходного текста будут скопированы в список слов исходного
текста.
Ниже представлен пример поиска слов, зависимых от
главного слова,словарем (рис. 10).

Рис. 10 Поиск зависимого слова существительным
2.2. Алгоритм семантического анализа
простых предложений в английском языке посредством предлагаемого словаря
В настоящее время имеет распространение методика преобразования списка
исходных словоформ, происходящая за несколько этапов: на каждом этапе
анализируется та или иная языковая конструкция[19]. Конструкции
классифицируются следующим образом: атомарные – это те конструкции, которые
присутствуют в простых предложениях изначально – к примеру, части речи;
комплексные – это те конструкции, образуемые после объединения нескольких
языковых конструкций. Объединение языковых конструкций называется операцией
сцепки. К примеру, сцепка может возникнуть при объединении глагола с наречием:
свойство, описываемое наречием, является описанием действия, заданного
глаголом, в качестве атрибута (например, gofast). Данная сцепка будет осуществляться на этапе анализа
наречия – т.е. в перечне ищется наречие, затем ищется близлежащее
существительное. При данной операции будет производиться автоматическое
семантическое согласование данных словоформ.

Рис.11. Пример сцепки
Приведем пример.
Одна из проблем, которые могут возникнуть при сцепке, является омонимия.
Для ее решения используется преобразование списка толкований слов в новый
список, в который будут состоять из линий, содержащих все возможные комбинации
толкований слов.
Алгоритм семантического анализа по правилу в тексте
заключается в следующей последовательности этапов:
1 этап: Выполняется поиск слова в словаре начальных
форм. Если слово в словаре найдено, то этап 5.
2 этап: Слово считывается посимвольно в обратном
порядке (начиная с конца слова). Если слово закончилось, то работа алгоритма
завершается. На основе текущего списка аффиксов, префиксов, суффиксов и пр.
формируется список гипотетических частей слова.
3 этап: Выполняется поиск всех гипотетических
аффиксов, префиксов, суффиксов и пр. в словаре. Все найденные аффиксов,
префиксов, суффиксов и пр. добавляются в список аффиксов, префиксов, суффиксов
и пр.. Если ни один новый аффикс не найден, то переходим к этапу 2.
4 этап: Выполняется поиск начальной части слова в
словаре начальных форм. Если слово не найдено, то переходим к этапу 2.
5 этап: В результат добавляется найденная основа и
сопутствующий набор аффиксов, префиксов, суффиксов и пр. Переход к этапу 2.
После нормализации, для каждого найденного слова
осуществляется вычисление его семантических и морфологических характеристик на
основе его аффиксов, префиксов, суффиксов и пр. и морфологического класса
основы.
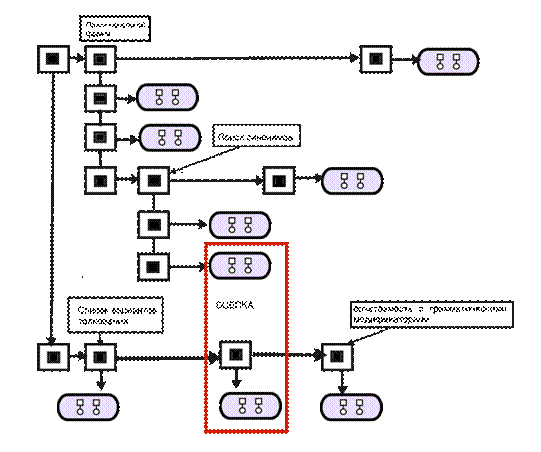
Рис. 12. Алгоритм семантического анализа по правилу в
тексте
Разберем указанный алгоритм в соответствии с описанным
в главе 1 подходами.
Предложения «Mikeplayingwithball.
Hilikessport» будет
синтезирован следующий ОА-граф:
{Object
= Mike = Hi
Subject1 = { Object = ball
Subject2 = { Object = sport
with Subject1,
temp{Location ={ Subject1 ={Subject1 *{Location=temp}}
Location=with}
}
Act1 = playing
Act2 =likes
}
Таким образом, предложенный словарь, учитывающий
синонимы, будет производить семантический анализ по нескольким семантическим
единицам.
[1]
Ермоленко Т.В. Формализация правил выделения предикативного ядра предложений,
используемых синтаксическим парсером английских текстов [Электронный ресурс] //
URL:
#"#_ftnref2" name="_ftn2" title="">[2] Montague,
Richard (1970b). Universal grammar. Theoria 36:373-398.
[3] Montague, Richard (1970b).
Universal grammar. Theoria
36:373-398.
[4]Мещанинов, И.И. Проблемы развития языка. СПб.: Питер, 2015.
С. 61.
[5]
О структуре простого предложения // Вопросы языкознания. 1967. № 6.
[6] Теоретическая
грамматика английского языка / под ред. В. В. Бурлакова. л.: наука, 1983. С.
62.
[7]Бурлакова В. В.
Синтаксические структуры современного английского языка. М.: Просвещение, 1984.
[8] Теоретическая
грамматика английского языка / под ред. В. В. Бурлакова. л.: наука, 1983.
[9]Долинина И. Б.
Системный анализ предложения. М: Высшая школа, 1977.
[11]Бурлакова В. В.
Синтаксические структуры современного английского языка. М.: Просвещение, 1984.
[12]Долинина И. Б.
Системный анализ предложения. М: Высшая школа, 1977.
[13]Долинина И. Б.
Системный анализ предложения. М: Высшая школа, 1977.
[14]Салибекян
С.М., Халькина С.Б., Тиновицкий К.Д. Объектно-атрибутный подход для
семантического анализа естественного языка // Объектные системы. 2014. №1 (8)
С.80-86.
[15]
Там же. С. 84
[16]Салибекян
С.М., Халькина С.Б., Тиновицкий К.Д. Объектно-атрибутный подход для
семантического анализа естественного языка // Объектные системы. 2014. №1 (8)
С.80-86.
[17] Капсула – это совокупность
информационных пар, служащих для описания определенного объекта (с помощью
капсулы обеспечивается абстракция данных). Каждая ИП, входящая в капсулу,
задает один из критериев описываемого объекта.
[18] Информационная пара (ИП) (атрибутированные
данные) – совокупность нагрузки(данных или ссылки на данные), и ярлыка
(атрибута/уникального идентификатора),описывающего нагрузку. Указатель,
хранящийся в нагрузке ИП, может ссылаться наинформационные конструкции любой
сложности (переменные, массивы, списки, другие ИП и т.д.). Тип данных,
помещенных в нагрузке, определяется по ярлыку ИП.
[19]Варьева.
А.В. О синтаксической форме слова // Мысли о языке. — М., 2017.