|
Критерий отбора
|
k-средних
|
CURE
|
BIRCH
|
COBWEB
|
DBSCAN
|
XMEANS
|
EM
|
Иерарх. класт-ция
|
FOREL
|
|
Число настраиваемых параметров
|
1
|
4
|
1
|
1
|
2
|
2
|
1
|
3
|
3
|
|
Не требуется задание числа кластеров
|
-
|
-
|
-
|
+
|
+
|
+
|
+
|
+
|
-
|
|
Легкость реализации, вычислительная простота
|
+
|
-
|
+
|
+
|
+
|
+
|
+
|
+
|
+
|
|
Работа с большим объемом данных
|
+
|
-
|
-
|
+
|
+
|
+
|
+
|
-
|
-
|
|
Возможность выделять кластеры сложной структуры
|
-
|
+
|
-
|
+
|
+
|
-
|
+
|
+
|
-
|
|
Возможность выделять кластеры в присутствии «шума» и
выбросов
|
-
|
+
|
-
|
+
|
-
|
+
|
+
|
+
|
+
|
|
Работа с любым типом данных
|
-
|
-
|
-
|
+
|
-
|
+
|
-
|
+
|
+
|
Кластерный анализ модельных данных с использованием выбранных алгоритмов
показал хорошие результаты, поэтому именно эти алгоритмы используются для
дальнейшей кластеризации реальных данных проверяющей системы дистанционного
практикума.
Ниже представлено математическое описание выбранных алгоритмов.
Алгоритм DBSCAN - это
плотностный алгоритм для кластеризации пространственных данных с присутствием
шума, был предложен Мартином Эстер, Гансом-Питером Кригель и коллегами в 1996
году как решение проблемы разбиения данных на кластеры произвольной формы. [16]
Авторы DBSCAN экспериментально показали, что алгоритм способен распознать
кластеры различной формы, например, как на рисунке 2.1.

Рисунок 2.1 - Примеры кластеров произвольной формы
Принцип алгоритма, заключается в том, что внутри каждого кластера
наблюдается типичная плотность точек (объектов), которая заметно выше, чем
плотность снаружи кластера, а также плотность в областях с шумом ниже плотности
любого из кластеров. Ещё точнее, что для каждой точки кластера её соседство
заданного радиуса должно содержать не менее некоторого числа точек, это число
точек задаётся пороговым значением.
Алгоритм DBSCAN для заданных значений параметров исследует кластер
следующим образом: сначала в качестве затравки выбирает случайную точку,
являющуюся ядровой, затем помещает в кластер саму затравку и все точки,
плотно-достижимые из неё.
Алгоритм EM основан на вычислении расстояний, т.е.
обнаружения областей, которые являются более "заселенными", чем другие.
В процессе работы алгоритма происходит итеративное улучшение решения, а
остановка осуществляется в момент, когда достигается требуемый уровень точности
модели. [17]
В основе EM-алгоритма лежит предположение, что исследуемое
множество данных может быть смоделировано с помощью линейной комбинации
многомерных нормальных распределений. Предполагается, что данные в каждом
кластере подчиняются определенному закону распределения, а именно, нормальному
распределению.алгоритм является итеративным алгоритмом, каждая итерация
которого состоит из двух шагов: шага математического ожидания (expectation
step, E-шаг) и шага максимизации (maximization step, M-шаг).
На E-шаге вычисляется ожидаемое значение функции
правдоподобия, при этом скрытые переменные рассматриваются как наблюдаемые. На
M-шаге вычисляется оценка максимального правдоподобия, таким образом,
увеличивается ожидаемое правдоподобие, вычисляемое на E-шаге. Затем это
значение используется для E-шага на следующей итерации. Алгоритм выполняется до
сходимости. Опишем эти шаги с математической точки. Для этого рассмотрим
функцию:
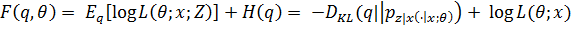 (2.1)
(2.1)
где q - распределение вероятностей ненаблюдаемых
переменных Z;
pZ|X ( · | x;θ) - условное распределение ненаблюдаемых переменных при фиксированных
наблюдаемых  и параметрах
и параметрах  ;
;
H - энтропия
<https://ru.wikipedia.org/wiki/%D0%AD%D0%BD%D1%82%D1%80%D0%BE%D0%BF%D0%B8%D1%8F_(%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D1%8F_%D0%B8%D0%BD%D1%84%D0%BE%D1%80%D0%BC%D0%B0%D1%86%D0%B8%D0%B8)>;
DKL - расстояние Кульбака-Лейблера
<https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D1%81%D1%81%D1%82%D0%BE%D1%8F%D0%BD%D0%B8%D0%B5_%D0%9A%D1%83%D0%BB%D1%8C%D0%B1%D0%B0%D0%BA%D0%B0_%E2%80%94_%D0%9B%D0%B5%D0%B9%D0%B1%D0%BB%D0%B5%D1%80%D0%B0>.
Тогда шаги EM-алгоритма можно представить как:
E-шаг:
Выбираем q, чтобы максимизировать F:
 (2.2)
(2.2)
M-шаг: Выбираем θ, чтобы максимизировать F:
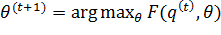 (2.3)
(2.3)
Алгоритм X-Means является одним из наиболее популярных методов кластеризации. Также
он является некоторым обобщением алгоритма k-средних и использует его в своей
реализации. Одним из главных отличий данного алгоритма можно назвать отсутствие
требования точного количества искомых кластеров, задается лишь требуемый
диапазон значений для количества кластеров. [18]
Основная идея алгоритма заключается в том, что на каждой
итерации перевычисляется центр масс для каждого кластера, полученного на
предыдущем шаге, затем векторы разбиваются на кластеры вновь в соответствии с
тем, какой из новых центров оказался ближе по выбранной метрике.
Алгоритм завершается тогда, когда на какой-то итерации не
происходит изменения центра масс кластеров. Это происходит за определенное
конечное число итераций, так как количество возможных разбиений конечного
множества конечно, а на каждом шаге суммарное квадратичное отклонение V
не увеличивается, поэтому зацикливание невозможно.
Данный алгоритм использует Байесовский критерий выбора
модели. Он вытекает из принципа максимума правдоподобия. Этот критерий
определяется формулой:
 (2.4)
(2.4)
где 𝐿𝑗 - логарифмическая
функция правдоподобия для модели;
𝑑 - длина вектора
параметров;
𝑛 - количество объектов в
выборке.
Иерархическая кластеризация - это комплекс алгоритмов, использующих
разделение крупных кластеров на более мелкие или объединение мелких в более
крупные. Соответственно, выделяют дивизивную и агломеративную кластеризации. В
данной работе использовалась агломеративная кластеризация Ланса-Уильямса.[17]
Алгоритм:
1. Cначала все кластеры одноэлементные:

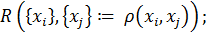 (2.6)
(2.6)
2. Для всех  (t - номер итерации):
(t - номер итерации):
. найти в 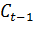 два ближайших кластера:
два ближайших кластера:

 (2.8)
(2.8)
4. Слить их в один кластер:
.
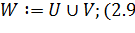
 ;(2.10)
;(2.10)
. Для всех  вычислить расстояние R(W, S) по формуле
Ланса-Уильямса.
вычислить расстояние R(W, S) по формуле
Ланса-Уильямса.
Расстояние между кластерами определяется как:
 ,(2.11)
,(2.11)
где  - числовые параметры.
- числовые параметры.
Алгоритм COBWEB - классический метод инкрементальной концептуальной кластеризации,
которая определяет кластеры как группы объектов, относящиеся к одному концепту
- определённому набору пар атрибут-значение. Он создаёт иерархическую
кластеризацию в виде дерева: каждый узел этого дерева ссылается на концепт и
содержит вероятностное описание этого концепта, которое включает в себя
вероятность принадлежности концепта к данному узлу и условные вероятности
вида[10]:
 (2.12)
(2.12)
где  - пара атрибут-значение;
- пара атрибут-значение;
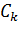 - класс концепта.
- класс концепта.
В алгоритме для построения дерева используется эвристическая
мера оценки, называемая полезностью категории - прирост ожидаемого числа корректных
предположений о значениях атрибутов при знании об их принадлежности к
определённой категории относительно ожидаемого числа корректных предположений о
значениях атрибутов без этого знания. Чтобы встроить новый объект в дерево,
алгоритм COBWEB итеративно проходит всё дерево в поисках «лучшего» узла, к
которому отнести этот объект. Выбор узла осуществляется на основе помещения
объекта в каждый узел и вычисления полезности категории получившегося среза.
Также вычисляется полезность категории для случая, когда объект относится к
вновь создаваемому узлу. В итоге объект относится к тому узлу, для которого
полезность категории больше.
В результате исследования существующих алгоритмов кластеризации для
проведения эксперимента были выбраны алгоритмы COBWEB, DBSCAN,
алгоритм иерархической кластеризации, XMEANS и EM-алгоритм.
2.2 Выбор программного пакета для проведения эксперимента
Одной из задач исследования является выбор программного комплекса для
процесса кластеризации и последующей визуализации полученных результатов.
Для этого была проведена большая работа по поиску существующих
статистических пакетов. Как удалось выяснить, все существующие приложения можно
разделить на три основные категории: частные исследовательские работы,
реализованные с помощью популярных программных математических пакетов,
дорогостоящие коммерческие решения, ориентированные на корпоративные
статистические исследования и небольшая доля статистических пакетов,
находящихся в свободном доступе.
Для того чтобы выбрать математический пакет для исследования, был
рассмотрен ряд существующих средств обработки статистических данных.
The Fuzzy Clustering and Data Analysis Toolbox
Программный комплекс для Matlab
предоставляющий три категории функций [19]:
) алгоритмы кластеризации, разбивающие данные на кластеры
различными подходами: K-means и K-medoid - алгоритмы
устойчивой кластеризации; FCMclust, GKclust и GGclust алгоритмы неустойчивой кластеризации;
) функции анализа, оценивающие, каждое фиксированное разбиение,
выполненное алгоритмом, основанные на индексах(Xie and Beni’s, Dunn, Alternative Dunn, Partition index);
) функции визуализации, реализующие модифицированный метод Sammon’а отображения данных в пространство
меньшей размерности.
Это приложение устанавливается в качестве дополнительного модуля, не
предоставляет готового интерфейса для анализа, но позволяет в дальнейшем,
использовать описанные выше функции при разработке приложений на Matlab.
Cluster Validity Analysis Platform (CVAP)
Приложение является программным инструментом, реализовано также на Matlab. Основано на удобном графическом
интерфейсе, включает в себя несколько алгоритмов кластерного анализа (K-means, hierarchical, SOM, PAM), а также наиболее широко используемые индексы оценки
их работы. Работая в этом приложении, пользователь получает возможность не
только загружать свои данные, а так же сохранять результаты работы. Несомненным
достоинством является то, что графическая часть позволяет анализировать для
одного индекса сразу несколько алгоритмов[20].
SPSS Statistics
Платный модульный, полностью интегрированный программный комплекс,
охватывающий все этапы аналитического процесса, ориентированный на решение
бизнес-проблем и сопутствующих исследовательских задач. Интуитивно понятный
интерфейс обладает множеством функций управления статистическими данными[21]. В
своем составе имеет алгоритмы кластеризации.
RapidMiner
Данный программный комплекс является средой для машинного обучения и
анализа данных, в которой пользователь ограждён от всей «черновой работы». [22]
Вместо этого ему предлагается «нарисовать» весь желаемый процесс анализа данных
в виде цепочки (графа) операторов и запустить его на выполнение. Цепочка
операторов представляется в RapidMiner в виде интерактивного графа и в виде
выражения на языке XML (основного языка системы).
Сейчас в системе реализовано более 400 операторов. Из них
. Операторы обучения по прецедентам, в которых реализованы
алгоритмы кластеризации, классификации, регрессии и поиска ассоциаций;
. Операторы предобработки (фильтрация, дискретизация, заполнение пропусков,
уменьшение размерности и т.д.);
. Операторы работы с признаками (селекция и генерация признаков);
. Мета-операторы (например, оператор оптимизации по нескольким
параметрам);
. Операторы оценки качества (скользящий контроль и т.д.);
. Операторы визуализации;
. Операторы загрузки и сохранения данных (включая работу со
специальными форматами: arff, C4.5, csv, bibtex, базы данных и т.д.).
WEKA
Программа WEKA написана на языке Java в университете Вайкато
(Новая Зеландия) и предоставляет пользователю возможность предобработки данных,
решения задач кластеризации, классификации, регрессии и поиска ассоциативных
правил, а также визуализации данных и результатов. [23] Программа очень проста
в освоении (пожалуй, имеет самый интуитивный интерфейс среди всех программ
такого типа), бесплатна и может быть дополнена новыми средствами предобработки
и визуализации данных.
Исходные данные могут представлены в виде матрицы признаковых описаний
объектов. Weka предоставляет доступ к SQL-базам через Java Database
Connectivity (JDBC) и в качестве исходных данных может принимать результат
SQL-запроса.имеет пользовательский интерфейс Explorer, но та же
функциональность доступна через компонентный интерфейс Knowledge Flow и из
командной строки. Имеется отдельное приложение Experimenter для сравнения
предсказательной способности алгоритмов машинного обучения на заданном наборе
задач.имеет несколько панелей[24]:
) панель предобработки Preprocess panel позволяет
импортировать данные из базы, CSV файла и т.д., и применять к ним алгоритмы
фильтрации, например, переводить количественные признаки в дискретные, удалять
объекты и признаки по заданному критерию;
) панель классификации Classify panel пoзволяет
применять алгоритмы классификации и регрессии к выборке данных, оценивать
предсказательную способность алгоритмов, визуализировать ошибочные
предсказания, ROC-кривые, и сам алгоритм, если это возможно (в частности,
деревья решений);
) панель поиска ассоциативных правил Associate panel решает
задачу выявления всех значимых взаимосвязей между признаками;
) панель кластеризации Cluster panel даёт доступ к
алгоритму k-средних, EM-алгоритму, COBWEB, DBSCAN и другим;
) панель отбора признаков Select attributes panel даёт
доступ к методам отбора признаков;
) панель визуализации Visualize строит матрицу
графиков разброса (scatter plot matrix), позволяет выбирать и увеличивать
графики, и т.д.
Выбор программного средства для решения задачи
кластеризации[25] Недостаток
The Fuzzy Clustering and Data Analysis Toolbox и CVAP прежде всего заключается в их
недоступности и невозможности анализа собственных алгоритмов. Данные
некоммерческие приложения реализованы в основном на Matlab, который автоматически накладывает ряд ограничений:
) приложения зависят от версии и поставленных дополнительных
библиотек;
) необходимо знать его внутреннюю структуру и правила работы;
) графическая и вычислительная реализации фиксированы;
) анализ собственных алгоритмов, если и возможен, то необходимо
создание дополнительных систем взаимодействия.
CVAP поддерживается только средствами запущенного приложения Matlab, несмотря на удобный графический
интерфейс.
Чтобы воспользоваться средствами The Fuzzy Clustering and Data Analysis Toolbox, необходимо написание дополнительных
функций, связывающих алгоритм и функции анализа.
Все подобные приложения в большинстве случаев являются персональными
исследованиями, которые зачастую были созданы для демонстрации конкретных
методов, поэтому ограничены по своему функционалу.
Сам Matlab является коммерческим продуктом, который
необходимо приобретать и устанавливать, что само по себе является длительным,
трудоемким процессом.
Коммерческие проекты, в том числе SPPP Statistics, в свою очередь успешно развиваются, но так как
ориентированы в основном на статистические исследования в бизнесе, то включают
в себя алгоритмы кластеризации как часть статистических методов, поэтому
специализированных средств для анализа работы самих алгоритмов, как правило, не
имеют. При этом стоимость подобных разработок достаточно велика. Например,
лицензионная программа SPSS Statistics для одного частного пользователя на
данный момент стоит порядка сорока тысяч рублей. Помимо этого реализация и
анализ своих алгоритмов в подобных приложениях так же не предусмотрен.
Свободные же программные комплексы (RapidMiner, WEKA) также накладывают ряд ограничений на процессы
обработки данных. В данное ПО нет возможности встроить собственные алгоритмы,
количество и разнообразие имеющихся алгоритмов кластеризации также
незначительно.
RapidMiner имеет очень хорошие средства визуализации: способов визуализации
достаточно много и все графики смотрятся очень эффектно. Но единственный минус,
из-за которого пришлось отказаться от данного ПО, это отсутствие подключения к
базе данных FireBird и отсутствие выбранных в начале
исследования алгоритмов.
Таким образом, исследовав несколько статистических пакетов, для
дальнейшего процесса кластеризации был выбран программный пакет WEKA, в котором имеются выбранные
алгоритмы, и имеется возможность подключения к БД через URL. К тому же, WEKA один из немногих продуктов, который имеет интуитивно
понятный интерфейс и техническую литературу с описанием, переведенную на
русский язык.
.3 Выбор объектов для кластеризации данных дистанционного практикума
и определение их признаков
На основе анализа концептуальной схемы базы данных
проверяющей системы дистанционного практикума, представленной на рисунке 2.2,
были выделены основные сущности - это задачи, пользователи и решения. Поэтому
было принято решение выделить следующие объекты кластеризации:
) студенты (пользователи практикума);
) задачи практикума;
) пары «студент - задача».

Рис. 2.2 - Концептуальная схема базы данных
Для того, чтобы определиться с набором признаков для
кластеризации, были исследованы имеющиеся в базе данных атрибуты выбранных
сущностей.
Для задач в базе данных хранятся следующие атрибуты:
− идентификатор задачи;
− предел использования процессорного времени и оперативной
памяти для данной задачи;
− минимальный процент уникального кода при котором решение
для данной задачи считается уникальным;
− экспертная сложность задачи;
− количество пользователей решивших данную задачу;
− количество пользователей пытавшихся решивших данную задачу;
− количество решений поступивших для данной задачи.
Каждому пользователю системы в базе данных присваивается идентификатор,
логин и пароль для входа в систему, также хранятся вычисляемые данные
количество задач, решенных пользователем и количество задач, которые
пользователь пытался решить.
Каждая попытка решения задачи студентом фиксируется в базе данных, при
этом сохраняются следующие сведения:
− идентификатор студента и номер задачи;
− дата и время получения решения задачи системой проверки;
− используемый компилятор;
− статус попытки (верное решение или код ошибки);
− характеристики верного решения - время исполнения программы
(запроса, скрипта), размер используемой памяти, процент плагиата.
Проанализировав хранящиеся в БД атрибуты объектов
кластеризации и выбрав наиболее значимые признаки, для каждого этапа
исследования был определен набор признаков для кластеризации.
Для кластеризации пользователей проверяющей системы были
выбраны следующие атрибуты, которые позволят выделить группы студентов по
уровню подготовки:
) идентификатор пользователя;
2)  - относительный
показатель уровня подготовки студента;
- относительный
показатель уровня подготовки студента;
) среднее число попыток решения задач;
) средняя сложность решаемых задач;
) год обучения (1-5, студенты прошлых лет
рассматриваются как один курс «-1»).
Для кластеризации задач проверяющей системы были выбраны
следующие атрибуты, которые позволят выделить группы задач по уровню сложности:
1) идентификатор задачи;
2)  - относительный показатель степени сложности задачи;
- относительный показатель степени сложности задачи;
) количество неуникальных решений;
) количество частично верных решений;
Для кластеризации пар «студент-задача» были выбраны следующие
атрибуты, которые позволят определить подходит задача студенту или нет:
) сложность задачи;
2) - относительный показатель степени
сложности задачи;
3) - относительный
показатель уровня подготовки студента;
) средняя сложность решенных студентом задач;
5)  - относительный
показатель с какой попытки решена задача;
- относительный
показатель с какой попытки решена задача;
) Количество дней между первой и последней попыткой
решения задачи.
В базе данных для каждой задачи выполнена экспертная оценка
сложности в баллах (1-200 баллов). Но эмпирическая оценка сложности задачи,
вычисленная на основе реальных данных о решении этой задачи множеством студентов,
не всегда может совпадать с экспертной. Поэтому стоит обратить внимание, что во
всех опытах в качестве атрибута использовалась именно эмпирическая оценка
сложности задачи.
3. ХОД И РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТА
3.1 Получение данных из хранилища базы данных дистанционного
практикума
кластеризация data mining алгоритм
В настоящее время в базе данных дистанционного практикума накоплен
достаточно большой объем информации: больше 168 000 решений отправлено
студентами на проверку за всё время эксплуатации системы, более 1500 задач
хранится в базе данных. Такой большой объем данных начал отрицательно
сказываться на производительности системы. В связи с этим было создано
хранилище данных (ХД), которое позволило разделить данные, используемые для
оперативной обработки и для решения задач анализа. ХД было организовано на базе СУБД Oracle 11g,
которая уже используется в практикуме для обучения студентов разработке SQL запросов.
Для анализа накопленных данных в ХД имеется таблица фактов, содержащая
детальную информацию о каждой попытке решения конкретной задачи конкретным
студентом. Кроме того, имеются агрегированные данные по каждой задаче и каждому
студенту. Необходимые для кластеризации множества атрибутов были извлечены
стандартными средствами выгрузки Oracle SQL Developer в файл формата .txt [26].
3.2 Загрузка данных в программный пакет WEKA
Перед тем, как начать процесс кластеризации, необходимо
загрузить данные в пакет. WEKA поддерживает определенные форматы: .arff, .csv. Полученные данные их
хранилища БД в формате .txt. Поэтому для проведения эксперимента необходим
модуль подготовки данных, который будет преобразовывать данные из формата .txt в формат .csv, текстовые данные преобразовывать в
цифровой код, так как некоторые алгоритмы работают только с числовыми типами.
Таким образом, модуль подготовки данных проверяет входные данные на наличие
строковых типов, если такие имеются, преобразует их в цифровой код. Затем
полученные данные приводит к формату .csv, т.е. первая строка содержит название атрибутов, следующие строки
представляют собой значения этих атрибутов, разделенные запятой. На выходе
получаем файл формата .csv,
готовый для загрузки в WEKA.
Обобщенный алгоритм работы модуля подготовки данных приведен на рисунке
3.1.
Моду ль подготовки данных реализован в соответствии с
алгоритмом работы в среде
разработки Microsoft Visual Studio 2008 на язык С++. [27, 28]
Кластеризация студентов

Кластеризация студентов - это первый опыт анализа данных с
целью получения скрытых знаний с помощью выбранных алгоритмов. Алгоритмы
изначально были опробованы на модельных данных, взятых из репозитория UCI,
который является крупнейшим репозиторием реальных и модельных данных машинного
обучения. Задачи (наборы данных, data set) именно этого репозитория чаще всего
используются научным сообществом для эмпирического анализа алгоритмов машинного
обучения[1].
Кластерный анализ незашумленных модельных данных с помощью
выбранных алгоритмов показал хорошие результаты. Поэтому было принято решение
для дальнейшего исследования использовать именно эти алгоритмы.
Выборка исходных данных содержала 4713 строк в соответствии с
количеством студентов, зарегистрированных в практикуме.
Результаты кластеризации студентов получились хорошо
интерпретируемыми. Если обобщить результаты, полученные различными алгоритмами,
то можно выделить следующие кластеры:
- студенты, не отправившие ни одного
решения;
- студенты, которым потребовалось для
верного решения задач средней сложности (15 баллов) две попытки;
- студенты, которые решали легкие задачи (10
баллов) с первой попытки;
- студенты, у которых число отправленных
решений для одной задачи больше десяти, средняя сложность задач 87 баллов (от
50 до 150 баллов);
- студенты, которым удалось получить верное
решение сложных задач с первого раза (100 баллов);
- студенты, выбравшие сложные задачи и не
сумевшие их решить (сложность задач 150 баллов).
Далее представлены результаты кластеризации каждого
алгоритма.
Алгоритм DBSCAN выделил 5 кластеров:
) студенты, хорошо решавшие задачи любой сложности;
) студенты, решавшие задачи средней сложности;
) студенты, выбравшие сложную задачу, но не сумевшие
ее решить;
) студенты, не отправившие не одного решения;
) студенты, решавшие сложные задачи с 2-3 попыток.
Также алгоритм не смог кластеризовать 38 элементов и выделил
их как шум. Было выявлено, что это студенты, которые отправляли решение сложной
задачи много раз.
Алгоритм иерархической кластеризации не смог кластеризовать
входные данные, при запуске процесса кластеризации программный пакет WEKA
выдавал исключительную ситуацию, связанную с нехваткой памяти.
Алгоритм COBWEB выделил 4 кластера:
) студенты, решавшие легкие задачи с первой попытки;
) студенты, решавшие задачи средней сложности с 1-2
попыток;
) студенты, выбравшие сложные задачи, но так и не
решившие их;
) студенты, решившие сложные задачи за большое
количество попыток.
EM-алгоритм выделила 4 кластера:
) студенты, не отправившие не одного решения;
) студенты, решившие несложные задачи с первой
попытки;
) студенты, решившие задачи средней сложности за 2-3
попытки;
) студенты, выбравшие сложные задачи, но не всегда
решившие их.
Алгоритм X-MEANS выделил 6 кластеров:
) студенты, решавшие легкие задачи с первой попытки;
) студенты, решавшие легкие задачи за 2-3 попытки;
) студенты, которые отправляли 1 - 2 решения задачи
средней сложности, если оно оказывалось неверным, забрасывали задачу;
) студенты, которые выбирали сложные задачи и
отправляли по 2 - 6 решений, но процент решенных задач маленький;
) студенты, решившие задачи средней сложности за 1-2
попытки;
) студенты, не отправившие ни одного решения.
Для каждого кластера также получен список студентов, входящих
в данный кластер. Все полученные данные переданы преподавателям, использующим
практикум в учебном процессе.
3.3 Кластеризация задач
Вторым этапом исследования накопленных данных в проверяющей системе была
кластеризация задач. Ожиданием было получить кластеры задач разной сложности.
Полученные в ходе эксперимента результаты представлены ниже[29].
Если обобщить результаты, полученные различными алгоритмами,
то можно выделить следующие кластеры:
- задачи, к которым не приступал ни один студент;
- задачи, у которых процент решивших студентов составляет
65-70%;
- задачи, у которых среднее количество попыток больше 5.
- задачи, которые решены с 1 попытки.
Алгоритм DBSCAN выделил 4 кластера:
) задачи, к которым не приступал ни один студент;
) задачи, которые решили два-три студента;
) задачи, для которых количество пользователей пытавшихся решить
превышает количество пользователей решивших данную задачу где-то в 2 раза;
) задачи, у которых среднее количество попыток больше 5.
Алгоритм COBWEB выделил 6 кластеров:
) задачи, у которых количество отправленных и верных решений
примерно одинаковое (относительный показатель числа решивших к числу решавших
студентов от 0.8 до 1) и среднее число попыток - 4;
) задачи, которые не решал ни один студент;
) задачи, которые решили два-три студента с одной попытки;
) задачи, которые были решены в среднем с 3 попыток;
) задачи, относительный показатель числа решивших к числу решавших
студентов составляет 0.75 и среднее число попыток составляет 2;
) задачи, у которых неверных решений больше, чем верных.
Алгоритм иерархической кластеризации выделил 5 кластеров:
) задачи, у которых количество пользователей решивших и решавших
примерно одинаковое (относительный показатель примерно 0.9, среднее число
попыток - 3, количество пользователей при этом от 20 до 40 человек;
) задачи, у которых процент решивших студентов составляет 65-70%;
) задачи, к которым студенты приступали и решали их, а среднее
количество попыток 2;
) задачи, для решения которых понадобилось в среднем 6-7 попыток,
при этом решило эти задачи не больше 20 человек;
) задачи, к которым не приступал ни один студент.
Также каждый из алгоритмов отметил достаточно большое количество задач
как шум. В основном это задачи, для которых отправлено одним человеком
множество решений (возможно с целью улучшения показателей используемого времени
и памяти задачей).
Кластеризация задач практикума на этом этапе позволила выделить группы
задач, к которым студенты вообще не приступают и которые решают практически все
студенты.
3.4 Кластеризация пар «студент - задача»
После кластеризации задач и студентов было интересно проанализировать
пары «студент - задача». По результатам эксперимента ожидалось получить ответ,
подходит задача студенту или нет. Кластеризация проводилась на основе данных об
отправленных решениях.
Этот эксперимент проводился на обновленной версии статистического пакета WEKA, в которой появился новый алгоритм
кластеризации - CANOPY. Это
быстрый алгоритм кластеризации, используемый чаще всего для анализа данных
большой размерности. Идея алгоритма заключается в том, чтобы разделить
множество исходных объектов на несколько подмножеств, которые называются Canopy.
Canopy - это такое множество элементов, у которого расстояние от центральной
точки из этого множества до всех остальных точек в множестве не превышает
некоторого значения. Данный алгоритм на входе не требует указания количества
кластеров, поэтому он может использоваться в эксперименте. [30]
Обобщенные результаты кластеризации пар «студент-задача» представлены в
таблице 3.5.
Таблица 3.5 - Обобщенные результаты кластеризации пар
«студент-задача»
|
Алгоритм
|
Время выполнения, с
|
№ кластера
|
Количество объектов
|
% соотношение объектов
|
|
EM
|
175.84
|
1 кластер
|
18 717
|
43%
|
|
|
2 кластер
|
24 885
|
57%
|
|
COBWEB
|
156.95
|
1 кластер
|
19 006
|
44%
|
|
|
2 кластер
|
24 596
|
56%
|
|
CANOPY
|
0.05
|
1 кластер
|
14 077
|
32%
|
|
|
2 кластер
|
29 525
|
68%
|
|
KMeans
|
0.63
|
1 кластер
|
19 949
|
46%
|
|
|
2 кластер
|
23 653
|
54%
|
|
Иерархическая кластеризация
|
Алгоритм не смог кластеризовать исходную выборку из-за
большого количества данных
|
Все алгоритмы, за исключением алгоритма иерархической кластеризации,
выделили два кластера. Алгоритм иерархической кластеризации не смог кластеризовать
исходную выборку из-за большого количества данных.
При разбиении исходной выборки объектов на кластеры алгоритмы за более
значимые признаки взяли две характеристики: эмпирическую степень сложности
задачи (количество пользователей решивших / количество пытавшихся решить
пользователей задачу) и показатель с какого количества попыток решена задача.
Поэтому, если обобщить результаты кластеризации всех алгоритмов, то 1
кластер - это задачи, которые решены с первой попытки или за минимальное
количество попыток, а 2 кластер - это нерешенные задачи или задачи, для
получения правильного решения которых потребовалось достаточно большое
количество попыток.
Пример формирования кластеров ЕМ-алгоритмом в зависимости от атрибутов
кластеризации представлен на рисунках 3.3, 3.4, 3.5, 3.6, 3.7.

Рис. 3.3 - Разбиение объектов на кластеры по признаку
«степень сложности задачи»

Рис. 3.4 - Разбиение объектов на кластеры по признаку
«уровень подготовки студентом»
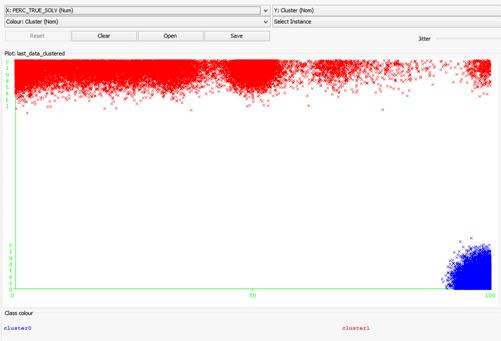
Рис. 3.5 - Разбиение объектов на кластеры по признаку «с какого
количества попыток решена задача»

Рис. 3.6 - Разбиение объектов на кластеры по признаку «количество дней
между первой и последней попыткой решения задачи»

Рис. 3.7 - Разбиение объектов на кластеры по всем атрибутам
При кластеризации пар «студент-задача» все алгоритмы, которые смогли
кластеризовать данные, выделили два примерно одинаковых кластера задач:
) задачи, которые решены с первой попытки или за минимальное
количество попыток;
) нерешенные задачи или задачи, для получения правильного решения
которых потребовалось достаточно большое количество попыток.
ЗАКЛЮЧЕНИЕ
В ходе написания выпускной квалификационной работы были решены все
поставленные задачи.
Во-первых, изучены методы интеллектуального анализа Data Mining, исходя из специфики исходных данных для дальнейшего
исследования был выбран метод кластерного анализа.
Во-вторых, были исследованы существующие алгоритмы кластеризации, а затем
на основании проведенного анализа были отобраны пять алгоритмов для дальнейшего
исследования: COBWEB, DBSCAN, алгоритм иерархической кластеризации, XMEANS и EM-алгоритм.
В-третьих, были проанализированы существующие на данный
момент статистические пакеты, включающие в себя средства для кластерного
анализа, и выбран подходящий программный пакет - WEKA.
В-четвертых, были выбраны объекты кластеризации данных
дистанционного практикума по программированию и определены множества их
признаков.
В-пятых, были подготовлены данные для трех экспериментов: это
три набора атрибутов для кластеризации, полученные из хранилища базы данных
проверяющей системы кафедры АВТ. Также был разработан модуль подготовки данных
для загрузки в пакет WEKA.
В-шестых, был выполнен вычислительный эксперимент,
зафиксированы полученные результаты, которые будут использованы для повышения
эффективности процесса обучения.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Ржеуцкая, С.Ю. Опыт применения методов кластеризации
для анализа результатов дистанционного обучения / С.Ю. Ржеуцкая, Ю.С. Басалаева
// Информатизация инженерного образования: материалы международной науч.-практ.
конф., 12-13 апр. 2016 г. / МЭИ. - Москва, 2016. - С. 617 - 620.
. Методы и модели анализ данных: OLAP и Data Mining/
А.А. Барсегян, М.С. Куприянов, В.В. Степаненко, И.И. Холод. - Санкт-Петербург:
БХВ - Петербург, 2004. - 360 с.
. Паклин, Н. Б. Бизнес-аналитика: от данных к знаниям
/ Н. Б. Паклин, В. И. Орешков. - Санкт-Петербург: Изд. Питер, 2009. - 624 с.
4. Чубукова, И.А. Data Mining: учеб. пособие / И.А. Чубукова. - Москва: МГУП, 2006.
- 328 с.
5. Басалаева, Ю.С. Проблема очистки данных
дистанционного практикума по программированию в процессе кластерного анализа/
Ю.С. Басалаева // Современные тенденции развития науки и производства. - 2016.
- № 2. - С. 119 - 120.
6. Дюк, В. Data Mining: учеб.
пособие / В. Дюк, А. Самойленко. - Санкт-Петербург: Изд. Питер, 2001. - 368 с.
7. Ian, H. Data Mining: Practical Machine
Learning Tools and Techniques / H. Ian, E. Frank, A. Hall. - San Francisco:
Morgan Kaufmann, 2011. - P. 664 - 666.
8. Айвазян, С. А. Прикладная статистика: классификация и
снижение размерности / С. А. Айвазян, В.М. Бухштабер, И.С. Енюков // Финансы и
статистика. - 2007. - № 1. - С. 50 - 57.
9. Berkhin,
P. Survey of Clustering Data Mining Techniques
<http://citeseer.ist.psu.edu/berkhin02survey.html> / P. Berkhin. - USA:
Accrue Software, 2002. - 55 p.
10. Fisher,
D.H. Knowledge acquisition via incremental conceptual clustering / D.H. Fisher.
- German: University of Tubingen, 2008. - 211 p.
. Hastie,
T. The Elements of Statistical Learning / T. Hastie, R. Tibshirani. - German:
Springer, 2011. - 70 p.
12. Информационно-аналитический
ресурс, посвященный машинному обучению, распознаванию образов и
интеллектуальному анализу данных [Электронный ресурс]: офиц. сайт. - Режим
доступа: - www.machinelearning.ru <http://www.machinelearning.ru/>.
. Котов, А.
Кластеризация данных
<http://logic.pdmi.ras.ru/%7Eyura/internet/02ia-seminar-note.pdf> / А.
Котов, Н. Красильников // Инновации. - 2015. - №1. - С.34-37.
14. McCallum,
A. Efficient Clustering of High Dimensional Data Sets with Application to
Reference Matching / A. McCallum, K. Nigam // ACM Sigkdd. 2012. - P. 169 - 178.
15. Басалаева Ю. С.
Исследование алгоритмов кластеризации с целью анализа данных проверяющей
системы // Молодые исследователи - регионам: материалы межд. научн. конф.,
20-25 апр. 2015г. / . - Вологда, 2015. - С. 50 - 51.
. Автоматическая
обработка текстов на естественном языке и компьютерная лингвистика: учеб.
пособие / Е.И. Большакова, Э.С. Клышинский, Д.В. Ландэ [и др.]. - Москва: МИЭМ,
2011. - 272 с.
. Воронцов, К.В.
Алгоритмы кластеризации и многомерного шкалирования: учеб. пособие / К. В.
Воронцов - Москва: МГУ, 2009. - 80 с.
18. Pelleg, D.
X-means: Extending K-means with Efficient Estimation of the Number of Clusters
/ D. Pelleg, A.W. Moore. - London: Graw-Hill, 2012. - 727 p.
. Balazs,
B. Fuzzy Clustering and Data Analysis Toolbox For Use with Matlab / B. Balazs,
J. Abonyi, F. Balazs. - Netherlands: Kluwer Academic Publishers, 2001. - 80 p.
. CVAP:
Cluster Validity Analysis Platform (cluster analysis and validation tool) [Электронный ресурс]:
офиц. сайт. - Режим доступа:
http://www.mathworks.com/matlabcentral/fileexchange/14620-cvap--cluster-validity-analysis-platform--cluster-analysis-and-validation-tool/.
21. SPSS Statistics
[Электронный ресурс]: офиц. сайт. - Режим доступа:
http://www-03.ibm.com/software/products/ru/spss-stats-standard.
. RapidMiner
[Электронный ресурс]: офиц. сайт. - Режим доступа: https://rapidminer.com/.
. WEKA: Data Mining
Software [Электронный ресурс]: офиц. сайт. - Режим доступа:
http://www.cs.waikato.ac.nz/ml/weka/.
24. Remco, R.
WEKA Manual / R. Remco, E. Frank, R. Kirkby. - Hamilton: University of Waikato,
2013. - 327 p.
25. Басалаева, Ю.С. Выбор
инструментов Data Mining для анализа результатов дистанционного
образования / Ю.С. Басалаева // Современные материалы, техника и технология. -
2015. - № 2. - С. 22 - 25.
26. Feuerstein,
S. Oracle PL/SQL Programming / Steven Feuerstein, Bill Pribyl. - USA: O’Reilly
Media, 2005. - 1198 p.
27. Страуструп, Б.
Программирование. Принципы и практика использования C++ / Б. Страуструп. -
Москва: Вильямс, 2015. - 1329 с.
. Шилдт, Г. C++:
базовый курс / Г. Шилдт. - Москва: Вильямс, 2010. - 536 с.
. Басалаева, Ю. С.
Кластеризация задач дистанционного практикума по программированию / Ю.С.
Басалаева, С.Ю. Ржеуцкая // Молодые исследователи - регионам: материалы
международной научной конференции. - Вологда : , - 2016. Т. 1.С. 60 - 61.
. Mahout description of Canopy-Clustering
<https://mahout.apache.org/users/clustering/canopy-clustering.html> [Электронный ресурс]: офиц. сайт. - Режим доступа: <https://mahout.apache.org/users/clustering/canopy-clustering.html>.
.
ПРИЛОЖЕНИЕ 1
Реализация функций в модуле подготовки данных
#include
"dataconverter.h"
#include
"iostream"
DataConverter::DataConverter()
{
}DataConverter::IntToString(int num)
{oss;<< num;
return
oss.str();
}DataConverter::trim(string source)
{
while(source[0]==' ' || source[0]=='\t'
|| source[0]=='\n')= source.erase(0, 1); //убираем пробелы, табулящию, перевод строки слева
while(source[source.length()-1]==' ' || source[source.length()-1]=='\t' || source[source.length()-1]=='\n')= source.erase(source.length()-1, 1); //убиаем справа
return
source;
}
bool
DataConverter::isNumeric(string source)
{
bool
res = true;
for (int i = 0; i < source.length(); i++)
{
unsigned
char ch = (unsigned
char)(source.c_str()[i]);
if
(!isdigit(ch))
{= false;
break;
}
}
return
res;
}DataConverter::encodeString(string srcstr)
{retval;
for (int i = 0; i < srcstr.length(); i++)
{+= IntToString((unsigned char)srcstr.c_str()[i]);
}
return
retval;
}<string> DataConverter::strSplit(string source, string delimiter)
{<string> res;
int
index1 = 0;
int
index2;
while (true)
{= source.find(delimiter, index1);
if
(index1 != index2)
{
if
(index2 == string::npos)
{
if
(!source.substr(index1, source.length() - index1).empty()).insert(res.end(),
source.substr(index1, source.length() - index1));
break;
}
else
{
if
(!source.substr(index1, index2 - index1).empty()).insert(res.end(), source.substr(index1,
index2-index1));
}
}= index2 + delimiter.length();
}
return
res;
}DataConverter::listToCSV(string source, string delimiter)
{retval;<string> lst = strSplit(source, "\n");
for (int i = 0; i < lst.size(); i++)
{<string> items = strSplit(trim(lst.at(i)), delimiter); // разделяем строку на айтемы, разделитель - delimiter
for (int j = 0; j < items.size(); j++)
{
if
(isNumeric(items.at(j)) || i==0) //проверяем, а не
число ли??? И уж не первая ли строка (заголовок)
{.append(items.at(j)); // да. Число. Добавляем
без изменений
}
else
{.append(encodeString(items.at(j))); // нет, не
число. Конвертим в число и добавляем.
}
if
((items.size() - 1) == j)
{.append("\n"); // если элемент последний, то добавляем в конце перевод строки
}
else
{.append(","); // элемент не последний. Добавляем после него разделитель
}
}
}
return
retval;
}