Идентификация в криптографии
МИНОБРНАУКИ
РОССИИ
Федеральное
государственное бюджетное образовательное учреждение
Высшего
профессионального образования
«Ижевский
государственный технический университет
имени
М.Т.Калашникова»
(ФГБОУ
ВПО «ИжГТУ имени М.Т.Калашникова»)
Кафедра
«Радиотехника»
Курсовая
работа
По
дисциплине: "Общая теория связи"
На
тему:" Идентификация в криптографии "
Выполнил студент:
группы Б05-283-1
Ворсина А.С.
Проверил:
Шишаков К.В.
Ижевск
2014
Содержание
идентификация криптография пароль
протокол
Введение
Фиксированные
пароли (слабая идентификация)
Атаки
на фиксированные пароли
“Запрос-ответ”
(сильная идентификация)
Протоколы
с нулевым разглашение
Атаки
на протоколы идентификации
Заключение
Список
литературы
Приложение
Введение
В наше время, в век информационных технологий и
различных носителей информации, имеет большое значение сохранение личных и
важных данных. Для того, чтобы информации не попала на всеобщее обозрение и
пользование, существуют различные методы идентификации.
Идентификация означает доказательство того, что
вы тот, за кого себя выдаете, кем (или чем) бы вы ни были - конкретное лицо,
сотрудник или представитель организации, устройство или даже программный
процесс, такой как система продаж акций или система заказов на базе Web.
Идентификация неизвестного нам объекта производится стандартно на основании
того, что он есть, имеет или знает что-то, его идентифицирующее. Все протоколы
идентификации включают двух участников:
) А - доказывающего - участника, проходящего
идентификацию,
) В - проверяющего - участника, проверяющего
аутентичность доказывающего.
Целью протокола является проверка того, что
проверяемым действительно является тем кем нужно.
С точки зрения проверяющего возможными исходами
протокола являются либо принятие решения об идентичности доказывающего А, либо
завершение протокола без принятия такового решения.
Протоколы идентификации могут быть разбиты на
три большие категории в зависимости от того, на чем основана идентификация.
. Протоколы, основанные на известной обеим
сторонам информации. Такой информацией могут быть пароли, личные
идентификационные номера (PIN
от английского personal
identification
number), секретные или
открытые ключи, знание которых демонстрируется во время выполнения протокола.
. Протоколы, использующие некоторые физические
приборы, с помощью которых и проводится идентификация. Таким прибором может
быть магнитная или интеллектуальная пластиковая карта, или прибор, генерирующий
меняющиеся со временем пароли.
. Протоколы, использующие физические параметры, составляющие
неотъемлемую принадлежность доказывающего. В качестве таковых могут выступать
подписи, отпечатки пальцев, характеристики голоса, геометрия руки и т. д.
Протоколы, использующие такие параметры, не носят криптографического характера
и не будут далее рассматриваться.
Одной из основных целей идентификации является
обеспечение контроля доступа к определенным ресурсам, таким, как банковские
счета, телекоммуникационные каналы, компьютерные программы, базы данных,
здания, сооружения и т.д. Идентификация также обычно является неотъемлемой
частью протокола распределения ключей.
Протоколы идентификации тесно связаны с
протоколами цифровой подписи, но проще их. Последние имеют дело с меняющимися
по содержанию сообщениями и обычно включают элементы, обеспечивающие
невозможность отказа от подписанного сообщения. Для протоколов идентификации
содержание сообщения, по существу, фиксировано - это заявление об аутентичности
доказывающего А в текущий момент времени.
Фиксированные пароли (слабая идентификация)
Обычная парольная схема основывается на не
зависящих от времени паролях и устроена следующим образом. Для каждого
пользователя имеется пароль, обычно представляющий собой последовательность
длиной от 6 до 10 знаков алфавита, которую пользователь в состоянии запомнить.
Эта последовательность выступает в качестве
общего секрета пользователя и системы. Для того чтобы получить доступ к
системному ресурсу (база данных, принтер и т.д.), пользователь представляет
свой идентификатор и пароль и прямо или косвенно определяет необходимый ресурс.
При этом идентификатор пользователя выступает как заявка на идентификацию, а
пароль - как подтверждение этой заявки. Различные парольные схемы отличаются
между собой по методам хранения парольной информации в системе и методам ее
проверки.
В число угроз данной схеме идентификации,
допускающих возможность проникновения в систему, входят раскрытие пароля (вне
системы) и перехват информации с линий связи (внутри системы). Угрозой является
также опробование паролей, в том числе с использованием словарей.
Остановимся подробнее на методах хранения
паролей в системе. Наиболее очевидным из них является хранение паролей в
открытом виде в файле, защищенном от записи и считывания системными средствами.
При обращении пользователя система сравнивает введенный пароль с паролем
данного пользователя, хранимым в файле. Недостаток этого метода состоит в том,
что пароли не защищены от привилегированных пользователей системы.
Для устранения этого недостатка используются
зашифрованные файлы паролей пользователей. При этом может использоваться либо
непосредственное зашифровывание паролей с помощью того или иного
криптографического алгоритма, либо вычисление значения хэш-функции пароля.
Заметим, что использование шифрования перед передачей пароля по незащищенному
каналу связи хотя и защищает сам пароль, но не защищает от возможности
вхождения противника в систему путем навязывания перехваченного зашифрованного
пароля. Поскольку степень защиты указанной системы определяется сложностью
перебора паролей, то на практике используется целый ряд приемов для усложнения
противнику этой процедуры.
Правила составления паролей.
Типичным требованием, предъявляемым при
составлении паролей, является ограничение на минимальную длину паролей.
Примером может служить требование, чтобы пароль имел длину не менее 9 букв или
цифр. Другими требованиями могут быть наличие в пароле хотя бы одного символа
из каждого регистра (верхнего, числового, не алфавитно-цифрового и т. д.), а
также требование, чтобы пароль не мог быть словом из имеющегося словаря или
частью идентификационной информации доказывающего.
Очевидно, что сложность проникновения в систему
определяется сложностью простейшего из паролей зарегистрированных
пользователей. Лучшими из возможных паролей являются те, которые выбираются
случайно и равновероятно из всех слов в данном алфавите. Такой выбор может быть
реализован с помощью физического датчика случайных чисел.
Усложнение процедуры проверки паролей
Для того чтобы усложнить атаки, включающие
опробование большого числа паролей, функция, обеспечивающая проверку паролей
(например, однонаправленная функция), может быть усложнена путем применения
нескольких итераций более простых функций. Вместе с тем число этих итераций не
должно быть слишком большим, чтобы не затруднить доступ в систему законным
пользователям. Необходимо также следить за тем, чтобы в результате этих
процедур не упростилась задача определения паролей.
“Подсоленные” пароли
Для уменьшения эффективности атак с
использованием словаря каждый пароль, при помещении его в словарь, может быть
дополнен «-битовой случайной последовательностью, называемой “солью” (она
изменяет “вкус” пароля) перед применением однонаправленной функции. Как
хэшированный пароль, дополненный “солью”, так и “соль” записываются в файл паролей.
Когда в последующем пользователь предъявляет пароль, система находит “соль” и
применяет однонаправленную функцию к паролю, дополненному “солью”.
Хотя сложность опробования каждого варианта
пароля при дополнении “солью” не изменяется, тем не менее добавление “соли”
усложняет атаку с целью получения хотя бы одного пароля из многих. Это
происходит потому, что в словаре должно содержаться 2n
вариантов каждого опробуемого слова, что влечет за собой большие требования к
памяти, содержащей зашифрованный словарь, и соответственно увеличивает время на
его изготовление.
Парольные фразы
Для того чтобы увеличить неопределенность
используемых паролей и вместе с тем не нарушить такое их важное качество, как
возможность запоминания человеком, часто используются парольные фразы. В этом
случае в качестве пароля используется целое предложение вместо короткого слова.
Парольные фразы хэшируются до фиксированной длины и играют ту же роль, что и
обычные пароли. При этом фраза не должна просто сокращаться до фиксированной длины.
Идея этого метода состоит в том, что человеку легче запомнить фразу, чем
случайную последовательность букв или цифр. Парольные фразы обеспечивают
большую безопасность, чем короткие пароли, но требуют большего времени для
ввода.
Атаки на фиксированные пароли
Повторное использование паролей.
Принципиальной слабостью схем, неоднократно
использующих фиксированные пароли, является возможность получения противником
этих паролей одним из следующих способов:
путем просмотра при введении с клавиатуры,
путем получения документов, содержащих эти
пароли,
путем перехвата их из каналов связи,
используемых пользователями для связи с системой, или из самой системы,
поскольку пароли используются в открытом виде.
Все это дает возможность противнику осуществить
доступ к системе, имитируя законного пользователя. Таким образом, фиксированные
пароли нельзя использовать в случае их передачи по незащищенным каналам связи,
в особенности по эфиру.
Заметим, что при использовании процедуры
идентификации на абонентском пункте для получения доступа к ресурсу сервера
(например, при идентификации кредитной карточки банкоматом в режиме on-line)
системный ответ (“идентификация А” или “завершение протокола без
идентификации”) должен быть также защищен, как и представляемый пароль. Он должен
меняться во времени, чтобы не дать противнику возможность использовать
системный ответ “идентификация А”.
Тотальный перебор паролей.
Простейшей атакой противника на систему с
фиксированными паролями является перебор всех возможных вариантов до тех пор,
пока истинный пароль не будет найден. Особенно опасна эта атака в режиме off-line,
поскольку в этом случае не требуется непосредственного контакта доказывающего с
проверяющим, и поэтому число безуспешных попыток проверки пароля в единицу
времени не может быть ограничено, как это обычно делается при проверке в режиме
on-line.
Эффективность указанной атаки впрямую зависит от
числа попыток до обнаружения первого пароля, обеспечивающего доступ в систему
или к ее ресурсу, а также от временной сложности реализации каждой из таких
попыток.
Атаки с помощью словаря.
Вместо тотального перебора всех возможных
паролей противник может прибегнуть к их перебору в порядке убывания вероятности
их использования. Этот метод обычно эффективен в том случае, когда пароли
выбираются пользователем и, как правило, являются неравновероятными. Во многих
случаях эти пароли выбираются из словаря. Обычные словари содержат, как
правило, не более 150 тыс. слов, что намного меньше числа всех всего лишь
6-буквенных паролей.
В этом случае противником может быть реализована
так называемая атака с использованием словаря. Для повышения эффективности
атаки противником создается и записывается на диск хэшированный файл слов из
используемого для выбора паролей словаря. Хэшированные значения из файла
системных паролей могут быть отсортированы (используя обычные алгоритмы
сортировки) и сравнены со словами из созданного файла. Атаки с использованием
словаря, как правило, приводят не к нахождению пароля фиксированного
пользователя, а к нахождению одного или нескольких паролей, обеспечивающих
доступ в систему.
Личные идентификационные номера относятся к
категории фиксированных паролей. Они обычно используются в приложениях,
связанных с пластиковыми картами, для доказательства того, что данный участник
является действительным владельцем карты и как таковой имеет право доступа к
определенным системным ресурсам. Ввод личного идентификационного номера
требуется во всех случаях, когда используется пластиковая карта. Это обеспечивает
дополнительный рубеж безопасности, если карта утеряна или похищена.
В
силу исторических обстоятельств (и для удобства пользователей) личный
идентификационный номер является цифровым и содержит от 4-х до 8 цифр. Для того
чтобы обеспечить защиту от его тотального перебора, применяются дополнительные
организационные меры. Например, большинство банкоматов при троекратном вводе
неправильного номера блокируют кредитную
карту. Для ее разблокирования требуется ввести уже более длинный номер.
Поскольку люди, как правило, не могут запомнить ключи настолько длинные, чтобы
с их помощью можно было бы обеспечить необходимую информационную безопасность
системы, часто используется следующая двухступенчатая процедура идентификации
пользователя.
Сначала с помощью личного идентификационного
номера проверяется личность лица, вводящего пластиковую карту, а затем
содержащаяся в пластиковой карте дополнительная ключевая информация
используется для идентификации его в системе (как действительного владельца
пластиковой карты, имеющего определенные права доступа в системе). Таким
образом, пользователь, имеющий пластиковую карту, должен помнить только
короткий личный идентификационный номер, в то время как более длинный ключ,
содержащийся на карте, обеспечивает необходимый уровень криптографической
безопасности при идентификации в системе, использующей незащищенные каналы
связи.
Одноразовые пароли.
Повышению надежности идентификации служит
использование одноразовых паролей, то есть паролей, которые могут быть
использованы для идентификации только один раз. Такие схемы обеспечивают защиту
от противника, использующего перехват паролей из незащищенного канала.
Существуют
три схемы использования одноразовых паролей:
) пользователи системы имеют общий список
одноразовых паролей, который доставляется по защищенному от перехвата каналу
связи;
) первоначально пользователь и система имеют
один общий секретный пароль. Во время идентификации, использующей пароль /,
пользователь создает и передает в систему новый пароль (t
+ 1), зашифрованный на ключе, полученном из пароля i;
) пользователи системы используют одноразовые
пароли на основе однонаправленной функции.
При использовании третьей схемы пользователь
начинает с секретного пароля w
и с помощью однонаправленной функции H(w)
вырабатывает итерации H(w),H(H{w)),…,H(H(...(H(w)...)=Hn(W).
Паролем для і -й идентификации, 1 < і < n,
является W1=Hn-l(W).
Для того чтобы идентифицировать себя при і -й
попытке, А передает В строку (А, і, W1).
В проверяет соответствие полученного і номеру попытки и равенство H(wi)
= wi-1. Если оба
равенства выполнены, В идентифицирует А и запоминает (і, wi)
для следующей попытки идентификации.
Заметим, что последний протокол не защищает от
активного противника, который перехватывает, сохраняет и блокирует передачу информации
от А к В для последующей попытки подмены собой пользователя А. Поэтому этот
протокол может быть использован только для идентификации пользователя системой,
идентичность которой уже установлена.
“Запрос-ответ” (сильная идентификация)
Идея построения криптографических протоколов
идентификации типа “запрос-ответ” состоит в том, что доказывающий убеждает
проверяющего в своей аутентичности путем демонстрации своего знания некоторого
секрета без предъявления самого секрета. Знание секрета подтверждается выдачей
ответов на меняющиеся с течением времени запросы проверяющего. Обычно запрос -
это число, выбираемое проверяющим при каждой реализации протокола. Если канал
связи контролируется противником, любое допустимое число реализаций протокола
идентификации не должно давать противнику возможность извлечения информации,
необходимой для последующей ложной идентификации. В таких протоколах обычно
используются либо случайные числа, либо числа из неповторяющихся (обычно
возрастающих) последовательностей, либо метки времени.
Остановимся подробно на последних двух
вариантах. Числа из неповторяющихся последовательностей используются как
уникальные метки сообщений, обеспечивающие защиту от навязывания ранее
переданных сообщений. Такие последовательности чисел используются независимо
для каждой пары доказывающего и проверяющего. Кроме того, при передаче
информации от А к В и от В к А также используются различные последовательности
чисел.
Стороны следуют заранее определенной политике по
выработке таких последовательностей. Сообщение принимается только тогда, когда
его число (метка сообщения) не было использовано ранее (или в определенный
предшествующий период времени) и удовлетворяет согласованной политике.
Простейшей политикой является такая:
последовательность начинается с нуля и каждое следующее число увеличивается на
единицу. Менее жесткая политика состоит в том, что принятые числа должны только
монотонно возрастать. Это позволяет работать с учетом возможности потери
сообщений из-за ошибок в каналах связи.
Недостатком метода использования
последовательностей чисел является необходимость запоминания информации,
касающейся каждого доказывающего и каждого проверяющего, а также невозможность
обнаружения сообщений, специально задержанных противником.
Метки времени используются для обеспечения
гарантий своевременности и единственности сообщений, а также для
идентификация
обнаружения
попыток навязывания ранее переданной информации. Они также могут быть
использованы для обнаружения попыток задержки информации со стороны противника.
Протоколы, использующие метки времени,
реализуются следующим образом. Сторона, направляющая сообщение, снимает
показания своих системных часов и криптографически “привязывает” их к
сообщению. Получив такое сообщение, вторая сторона снимает показания своих
системных часов и сравнивает их с показаниями, содержащимися в сообщении.
Сообщение принимается, если его временная метка находится в пределах
приемлемого временного окна - фиксированного временного интервала, выбранного
из расчета времени, необходимого для обработки и передачи максимально длинного
сообщения и максимально возможной рассинхронизации часов отправителя и
получателя. В отдельных случаях для приема сообщения необходимо, кроме
указанного выше, обеспечить выполнение условия, чтобы та же самая (или более
ранняя) метка времени не приходила ранее от того же самого абонента.
Надежность методов, основанных на метке времени,
зависит от надежности и точности синхронизации системных часов, что является
главной проблемой в таких системах. Преимуществами указанных систем является
меньшее число передаваемых для идентификации сообщений (как правило, одно), а
также отсутствие требований по сохранению информации для каждой пары участников
(как в числовых последовательностях). Временные метки в протоколах могут быть
заменены запросом, включающим случайное число, и ответом.
“Запрос-ответ” с использованием симметричных
алгоритмов шифрования
Механизм реализации идентификации с помощью
алгоритмов “запрос-ответ” требует, чтобы доказывающий и проверяющий имели общий
секретный ключ. В небольших системах такими ключами может быть обеспечена
каждая пара корреспондентов заблаговременно. В больших системах установление
общего ключа может быть обеспечено путем передачи его по защищенному каналу
обоим корреспондентам из доверенного центра.
Для описания алгоритмов введем следующие
обозначения:
ZA - случайное
число, вырабатываемое А;
tA - временная
метка А;
k - общий секретный
ключ для А и В;
Ek - алгоритм
шифрования на ключе k;
id (В) -
идентификатор В.
. Односторонняя идентификация с использованием
временной метки.
Доказывающий А передает проверяющему В свою
временную метку и идентификатор, зашифрованные на общем ключе:
А-> В:Еk
(tA id(B)).
Проверяющий В, расшифровав данное сообщение,
проверяет соответствие допустимому интервалу временной метки и совпадение
полученного и собственного идентификаторов. Последнее необходимо для того,
чтобы не дать противнику возможности немедленно переадресовать сообщение к А.
. Односторонняя идентификация с использованием
случайных чисел.
Временные метки могут быть заменены случайными
числами с помощью дополнительной пересылки:
(1) А <- В: zB
(2) A->
В: Ek (zB,
id(B)).
В данном протоколе проверяющий В, расшифровав
сообщение, проверяет, соответствует ли полученное число случайному числу,
переданному им на шаге (1). После этого он проверяет, соответствует ли его
идентификатор полученному идентификатору.
Для предотвращения криптоанализа Ek
с помощью специально подобранных открытых текстов А может ввести в (2) свое
случайное число так же, как в следующем протоколе.
. Взаимная идентификация с использованием
случайных чисел.
Эта процедура описывается с помощью следующего
протокола:
(1) А <- В: zB
(2) A-> B:Ek(zA,zB,id(B)),
(3) А<- В: Ek
(zA,zB).
Получив сообщение на шаге (2), проверяющий В
расшифровывает его и осуществляет те же проверки, что и выше. После этого он
использует zA на шаге
(3). Доказывающий A,
расшифровав (3), проверяет соответствие полученных случайных чисел тем, которые
использовались ранее в (1) и (2).
“Запрос-ответ" с использованием
асимметричных алгоритмов шифрования
В протоколе идентификации, построенном на основе
шифр системы с открытым ключом, доказывающий может продемонстрировать владение
секретным ключом одним из двух способов:
при расшифровании запроса, зашифрованного на его
открытом ключе;
при проставлении под запросом своей цифровой
подписи (см. гл. 15).
Рассмотрим эти два способа более подробно.
Пусть h
- некоторая однонаправленная функция и EA
и DA - алгоритмы
зашифрования и расшифрования абонента A.
Первый способ основан на следующем протоколе:
1) A <- B : h(z), id(B), EA (z,
id(B)),
(2) A
-> B : z
) Проверяющий В выбирает случайное число Z,
вычисляет h(z)
и запрос с = EA (z,
id(B)).
Доказывающий А расшифровывает с и проверяет совпадение значений хэш-функции и
идентификаторов. Если получено различие, то А прекращает протокол. В противном
случае А посылает z
проверяющему В. В идентифицирует Л, если полученное от А число z
совпадает с имеющимся у него числом.
Использование однонаправленной хэш-функции предотвращает
попытки криптоанализа с помощью выбранного открытого текста.
Рассмотрим
теперь протокол, использующий цифровую подпись. Пусть zA,
tA обозначают
соответственно случайное число и метку времени доказывающего A,
SA обозначает
алгоритм цифровой подписи А. Будем считать, что алгоритм проверки цифровой
подписи доказывающего известен проверяющему.
Для идентификации могут быть использованы
следующие три протокола.
. Односторонняя идентификация с использованием
временных меток:
(1) A->B: tA, id(B), SA(tA,
id(B)).
Получив сообщение, пользователь В проверяет, что
временная метка находится в допустимом интервале, id
(В) совпадает с его собственным идентификатором, а также то, что цифровая
подпись под этими двумя полями верна.
. Односторонняя идентификация с использованием
случайных чисел:
(1) А <- В : zB
(2) А -> В: zA,
id (В), SA
(zA , zB,
id (В)).
Получив сообщение, пользователь В проверяет, что
id (В) соответствует
его идентификатору и что цифровая подпись под строкой (zA,
zB, id
(В)) верна.
. Взаимная идентификация с использованием
случайных чисел:
(1) A<-B:zB
(2) А-+В: zA, id(B), SA (zA, zB,
id(B)),
(3) А <- В : id(A),SB(zB, zA
,id(A)).
Протоколы с нулевым разглашением
Недостатком протоколов с фиксированным паролем
является то, что доказывающий А передает проверяющему В свой пароль, вследствие
чего В может в последующем выдать себя за А. Протоколы типа “запрос-ответ”
ликвидируют этот недостаток. При их выполнении А отвечает на запросы B9
меняющиеся во времени, не давая В информации, которую тот может использовать,
чтобы выступать от имени А. Тем не менее А может выдать некоторую частичную
информацию о своем секрете.
Протоколы с нулевым разглашением призваны решить
эту проблему, давая возможность доказывающему продемонстрировать знание
секрета, не выдавая о нем никакой информации. Точнее говоря, выдается только
один бит информации, обозначающий то, что доказывающий знает секрет.
В протоколах с нулевым разглашением термин
“доказательство” имеет смысл, отличный от традиционно принятого в математике.
Доказательство имеет вероятностный характер. Это означает, что утверждение
имеет место с некоторой вероятностью, которая может быть выбрана сколь угодно
близкой к единице.
А доказывает В знание секрета s
с помощью t итераций следующего
трехшагового протокола.
Доверенный центр T
выбирает модуль n=pq
и сообщает его всем доказывающим. При этом числар и q
остаются секретными.
Каждый доказывающий А выбирает секрет S,
которым является число, взаимно простое с n,
1 < s < n
- 1, вычисляет значение v
= S2 mod
n и объявляет v
своим открытым ключом.
Следующие три шага производятся независимо t
раз, причем В принимает доказательство владения А секретом s,
если все эти итерации приводят к положительному ответу.
. А выбирает случайно Z,
1 <z<n-
1, и посылает В число х = Z2
mod n.
. В случайно выбирает бит с и направляет его А.
. А вычисляет и направляет В число у, равное
либо z, если с =
0,
либо zs
mod n,
если с =1. В дает положительный ответ, если y
не равен 0 и у2 = xvc
(mod n).
Заметим, что в зависимости от значения бита с
выполнено одно из двух условий: у2 = x(mod
n) или у2 = xv(mod
n), так как v
= s2 (mod
n). Проверка
равенства y = O
исключает случай z = 0.
Корректность протокола может быть обоснована следующими рассуждениями. Наличие
запроса с требует, чтобы А был в состоянии ответить на любой из двух вопросов,
ответ на один из которых требует знания секрета S,
а ответ на другой предотвращает попытку обмана. Противник, выдающий себя за A,
может попытаться обмануть проверяющего, выбрав любое число z
и передав В число х = z2/v.
Тогда он сможет ответить на запрос “с = 1”,
направив правильный ответ “у = z”,
но не сможет ответить на запрос “с = 0”, ответ на который требует знания корня
квадратного из числах по модулю п.
Доказывающий A,
знающий s, в состоянии
ответить на оба вопроса. Если же он не знает S,
то в лучшем случае - на один из двух вопросов. Таким образом, обман удается с
вероятностью, не превышающей 1/2. При кратной итерации протокола вероятность
обмана может быть доведена до величины, не превышающей 2-t
.
Ответ “у = z”
не зависит от секрета s
доказывающего A, а ответ У = zs
mod n”
также не несет информации о S,
так как случайное z не известно
проверяющему В.
Идеи, лежащие в основе протоколов с нулевым
разглашением, могут быть сформулированы следующим образом.
Доказывающий А выбирает случайный элемент из
заранее оговоренного множества, как свой секретный ключ для данной итерации
протокола, вычисляет, используя его как аргумент некоторой однонаправленной
функции, ее значение, и предъявляет это значение проверяющему. Этим
обеспечивается случайность и независимость различных итераций протокола и
определяется набор вопросов, на каждый из которых доказывающий готов дать
ответ. Протокол построен так, что только доказывающий A,
владеющий секретом S, в
состоянии ответить на все эти вопросы, и ни один ответ не дает информации о
секрете. На следующем этапе В выбирает один из этих вопросов и А дает на него
ответ, который затем проверяется В. Осуществляется необходимое число итераций
протокола с целью снизить до приемлемого уровня вероятность обмана.
Другими
словами, в основе протоколов с нулевым разглашением лежит комбинация идей
протоколов типа “режь и выбирай” (этот термин происходит от стандартного
метода, которым дети делят кусок пирога: один режет, а другой выбирает) и
протоколов типа “запрос-ответ”.
Атаки на протоколы идентификации
В заключение приведем перечень атак на протоколы
идентификации и методов их отражения, часть из которых уже упоминалась выше.
. Подмена - попытка подменить одного пользователя
другим.
Методы
противодействия состоят в сохранении в тайне от
противника информации, определяющей алгоритм идентификации.
. Повторное навязывание сообщения (replay)
- подмена или другой метод обмана, использующий информацию ранее проведенного протокола
идентификации того же самого или другого пользователя. Методы противодействия
включают использование протоколов типа “запрос-ответ”, использование временных
меток, случайных чисел или возрастающих последовательностей чисел.
. Комбинированная атака (interleaving
attack) - подмена или
другой метод обмана, использующий комбинацию данных из ранее выполненных
протоколов, в том числе протоколов, ранее навязанных противником.
Метод противодействия состоит в обеспечении
целостности проводимых протоколов и отдельных сообщений.
. Атака отражением - комбинированная атака,
использующая посылку части информации только что проведенного протокола
доказывающему. Методы противодействия включают введение в протокол
идентификационной информации проверяющего, использование различных ключей для
приема и передачи сообщений.
. Задержка передачи сообщения (forced
delay) - перехват
противником сообщения и навязывание его в более поздний момент времени.
Методы противодействия включают использование
случайных чисел совместно с ограничением временного промежутка для ответа,
использование временных меток.
. Атака с использованием специально подобранных
текстов-• атака на протоколы типа “запрос-ответ”, при которой противник по
определенному правилу выбирает запросы с целью получить информацию о
долговременном ключе доказывающего. Эта атака может включать специально
подобранные открытые тексты, если доказывающий должен подписать или зашифровать
запрос, и специально подобранные шифрованные тексты, если доказывающий должен
расшифровать запрос.
Методы противодействия этой атаке состоят во
включении случайных чисел в запросы или ответы, а также в использовании
протоколов с нулевым разглашением.
. Использование противником своих средств в
качестве части телекоммуникационной структуры - атака, при которой в протоколе
идентификации между AwB
противник С входит в телекоммуникационный канал и становится его частью при
реализации протокола между Aw
В. При этом противник может подменить информацию, передаваемую между AwB.
Эта атака особенно опасна в случае установления AwB
общего ключа по протоколу Диффи - Хеллмана.
Противодействие этой атаке состоит в
использовании защищенного канала для установления общего ключа между AwB.
В заключение заметим следующее. Идентификация
может быть гарантирована только в момент времени после завершения протокола.
При этом имеется опасность того, что противник подключится к линии связи после
окончания процесса идентификации, выдавая себя за законного пользователя. Для
исключения этой возможности следует совместить процесс идентификации с
процессом установления общего сеансового ключа, который должен быть использован
для защиты передаваемой информации до следующей реализации протокола
идентификации.
Заключение
В физическом мире мы вынуждены иногда идентифицировать
себя на основании того, что знаем. Такими общими секретами могут быть девичья
фамилия матери или номер школы. В рассмотренной работе я показала какие
существуют методы идентификации, какие бывают атаки на протоколы идентификации
и как можно защититься от этих атак.
Список литературы
Алферов
А.П.: Основы криптографии Учебное пособие, 2 изд., испр. и доп. - М.. Гелиос
АРВ, 2002. - 480 стр.
Брюс
Шнайер.: Прикладная криптография, 2 изд. Протоколы, алгоритмы и исходные тексты
на языке С
Приложения
Упрощенная схема идентификации с нулевой
передачей знаний
Прежде всего выбирается значение модуля n,
который является произведением двух больших простых чисел. Модуль n
должен иметь длину 512...1024 бит. Это значение n
представляют группе пользователей, которым придется доказывать свою
подлинность. В процессе идентификации участвуют две стороны:
сторона A,
доказывающая свою подлинность;
сторона B,
проверяющая подлинность A.
Для того, чтобы сгенерировать открытый и
секретный ключи для стороны A,
доверенный арбитр (Центр) выбирает такое число V,
что сравнение
х2
V
( mod n
)
имеет решение. Число V
при этом называют квадратичным
вычетом по модулю n.
Кроме того должно существовать целое число
V-1
(
mod n
) .
Выбранное значение V
является открытым ключом для А. Затем вычисляют наименьшее значение S,
для которого
S sqrt (V-1)( mod n ).
Это значение S
является секретным ключом для А.
Теперь можно приступить к выполнению протокола
идентификации.
. Сторона А выбирает некоторое случайное число r,
r < n.
Затем она вычисляет
х = r2
mod n
и отправляет х стороне В.
. Сторона В посылает А случайный бит b.
. Если b
= 0, тогда А отправляет r
стороне В. Если b = 1, то А
отправляет стороне В
у = r
* S mod
n .
. Если b
= 0, сторона В проверяет, что
х = r2
mod n
,
чтобы убедиться, что А знает sqrt
(х). Если b = 1, сторона В
проверяет,что
х = у2 *
V mod
n ,
чтобы быть уверенной, что А знает sqrt
(V-1).
Эти шаги образуют один цикл протокола,
называемый аккредитацией.
Стороны А и В повторяют этот цикл t
раз при разных случайных значениях r
и b до тех пор, пока В
не убедится, что А знает значение S.
Если сторона А не знает значения S,
она может выбрать такое значение r,
которое позволит ей обмануть сторону В, если В отправит ей b
= 0, либо А может выбрать такое r,
которое позволит обмануть В, если В отправит ей b
= 1. Но этого невозможно сделать в обоих случаях. Вероятность того, что А
обманет В в одном цикле, составляет 1/2. Вероятность обмануть В в t
циклах равна (1/2)t.
Для того чтобы этот протокол работал, сторона А
никогда не должна повторно использовать значение r.
Если А поступила бы таким образом, а сторона В отправила бы стороне А на шаге 2
другой случайный бит b,
то В имела бы оба ответа А. После этого В может вычислить значение S,
и для А все закончено.
Симметричное шифрование
Работа по симметричному шифрованию в большой
степени начинается с того же, что и работа с функциями хэширования, в том
смысле, что требуется создать и подготовить симметричный ключ и буфер его
объекта. Эти действия должны быть знакомы: создание поставщика алгоритма,
определение размера буфера объекта ключа посредством запроса свойства BCRYPT_OBJECT_LENGTH
поставщика и выделение буфера этого размера. При обращении к функции BCryptGenerateSymmetricKey
с использованием секрета для ее инициализации создается симметричный ключ. Эта
процедура проиллюстрирована на рис. 6.
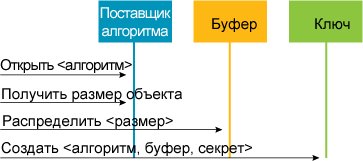
Рис. 6 Создание
объекта симметричного ключа
Поскольку открытие поставщиков алгоритмов и
создание буферов уже обсуждалось в предыдущих разделах, двинемся дальше и
сосредоточимся на генерации симметричного ключа.
Асимметричное шифрование
Асимметричное шифрование разрешает проблемы,
связанные с совместным использованием секретов и векторов инициализации,
посредством использования подхода с применением открытого ключа, в котором обе
стороны поддерживают закрытый и открытый ключи. Открытые ключи создаются
доступными всем. Ключи связаны таким образом, что только закрытый ключ может
использоваться для расшифровки данных, зашифрованных с помощью открытого ключа.
Естественно, такая дополнительная мощь требует затрат, и асимметричное
шифрование с точки зрения вычислений оказывается значительно более
дорогостоящим по сравнению с симметричным шифрованием. Тем не менее, ему нет
цены, как только речь заходит об установлении взаимодействия с предоставлением
участвующим сторонам механизма безопасного совместного использования информации
о ключе симметричного шифрования. На рис. 7
проиллюстрирован процесс создания асимметричных ключей.
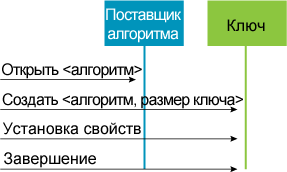
Рис. 7 Создание
асимметричного ключа
|
Функция
|
Что шифруется?
|
Чем шифруется?
|
Чем дешифруется?
|
Преимущества
|
|
Цифровая подпись
|
Хэш сообщения
|
Личный ключ отправителя
|
Открытый ключ отправителя
|
Гарантия
того, что сообщение не было изменено. Отправитель не может отказаться от
авторства сообщения.
|
|
Идентификация
|
Хэш пароля
|
Личный ключ отправителя
|
Открытый ключ отправителя
|
Подтверждение
знания отправителем пароля без пересылки пароля по незащищенным линиям.
|
|
Шифрование
|
Сообщение или секретный ключ
|
Открытый ключ получателя
|
Личный ключ получателя
|
Обеспечение
конфиденциальности, потому что содержимое не поддается дешифровке; только
получатель может это сделать.
|