Изучение возможностей массивно-параллельных вычислений в применении к задачам математической физики
СОДЕРЖАНИЕ
Введение
. Литературный обзор
. Методы и методики исследований
. Задача о малых колебаниях
.1 Постановка задачи. Вывод
уравнения
3.2 Решение задачи методом Фурье
. Вычисление коэффициентов с помощью
быстрого преобразования Фурье
.1 Дискретный подход к вычислению
коэффициентов
.2 Быстрое преобразование Фурье и
библиотека CUFFT
4.3 Реализация FFT
для задачи о колебаниях струны и мембраны
. Вычисление методом Лежандра-Гаусса
.1 Квадратуры Лежандра-Гаусса
.2 Расчет узлов и весовых
коэффициентов
.3 Реализация на С
. Параллельный расчёт амплитуд
.1 Массивно-параллельный расчёт
амплитуд
.2 Оценка выигрыша во времени
Заключение
Список использованных источников
Приложение
ВВЕДЕНИЕ
В настоящее время круг научных задач, требующих
использования значительных вычислительных ресурсов для своего решения, все
время расширяется, и в первую очередь это связано с тем, что сама организация
научных исследований претерпела существенные изменения в сторону увеличения
масштабности экспериментов и количества обрабатываемых данных. А, как известно,
чем масштабнее поставленная задача, тем мощнее должны быть вычислительные
ресурсы, которые используются для работы над ней.
Одной из главных характеристик любого
вычислительного устройства является его быстродействие. Для оценки
производительности компьютеров обычно используется единица flops
(от английского Floating Point
Operations per
Second), показывающая количество операций с плавающей запятой в секунду,
которое выполняет оцениваемая вычислительная система.
Однако, как правило, производительность всей
системы сильно зависит от типа выполняемой задачи. Значительно снижают
вычислительную мощность такие операции, как обмен данных между элементами
вычислительной системы и также частое обращение к памяти. Поэтому для оценки
производительности вводится новое понятие - пиковая вычислительная мощность -
теоретическое максимальное количество операций над данными типа float
в секунду, которое способно произвести данное устройство.
Сегодня принято относить к суперкомпьютерам
системы с пиковой мощностью более 10 Терафлопс (среднестатистический
современный персональный компьютер несёт в себе производительность порядка 0.1
Терафлопс). На самом деле реальное быстродействие всегда оказывается заметно
ниже пикового /2/.
Для персонального компьютера быстродействие
обычно напрямую связано с тактовой частотой центрального процессора (CPU).
Однако если внимательно изучить динамику роста частоты CPU, то нетрудно
заметить, что в последние годы скорость роста частоты существенно снизилась, но
зато появилась новая тенденция - создание многоядерных процессоров и систем и
увеличение числа ядер в процессоре. В первую очередь это связано с
ограничениями технологии производства микросхем, но немалую роль играет и тот
факт, что энергопотребление устройства, а значит и количество выделяемого им
тепла, пропорционально четвертой степени частоты. Таким образом, увеличивая
тактовую частоту всего лишь вдвое, мы тем самым увеличиваем тепловыделение в
шестнадцать раз. До сих пор с этим удавалось справляться за счет уменьшения
размеров отдельных элементов микросхем, однако существуют серьезные препятствия
для дальнейшей миниатюризации (в частности, миниатюризация ограничена
минимальными контролируемыми размерами топологии фотоповторителя).
Кроме того, для некоторых задач последовательные
архитектуры обработки становятся неэффективными при увеличении тактовой частоты
в связи с существованием так называемого «фон-неймановского узкого места» в
канале пересылки данных между центральным процессором и памятью, что ведёт к ограничению
производительности при последовательном потоке вычислений /6/.
Поэтому сейчас рост быстродействия идет в
значительной степени за счет увеличения числа параллельно работающих
процессорных ядер, то есть через параллелизм.
Максимальное ускорение, которое можно получить
от распараллеливания программы на N процессоров, дается законом Амдала /2, 7/:

В этой формуле T
- это часть времени выполнения программы, которая может быть распараллелена на
N ядер. Таким образом, если мы можем распараллелить три четверти всей
программы, то максимальный выигрыш составит уменьшение времени вычислений в
четыре раза. Именно поэтому крайне важно использование хорошо
распараллеливаемых алгоритмов и методов. Распараллеливание программ - процесс
адаптации алгоритмов, записанных в виде программ, для их эффективного
исполнения на вычислительной системе параллельной архитектуры.
Цель работы
Изучение возможностей массивно-параллельных
вычислений в применении к задачам математической физики.
Задачи исследований
Для достижения указанной цели были поставлены
следующие задачи:
) построение оптимального алгоритма
параллельного расчета при решении задач о колебаниях струны и мембраны с
использованием технологии NVIDIA
CUDA;
) вычисление коэффициентов с помощью алгоритмов
быстрого преобразования Фурье средствами библиотеки CUFFT;
) параллельное вычисление коэффициентов методом
квадратур Лежандра-Гаусса;
) визуализация задачи с использованием
библиотеки OpenGL;
) сравнительный расчёт времени вычисления.
1. ЛИТЕРАТУРНЫЙ ОБЗОР
В последние годы производители вычислительных
устройств были вынуждены пересмотреть взгляды на традиционные методы увеличения
их производительности. Из-за разнообразных фундаментальных ограничений при
изготовлении интегральных схем, полагаться на увеличение тактовых частот для
существующих архитектур более не представляется возможным.
В свою очередь производители суперкомпьютеров
достигли значительных улучшений производительности путём увеличения числа
процессоров. Для самых быстрых суперкомпьютеров сотни и даже тысячи
процессорных ядер, работающих согласованно, не являются редкостью, и со
временем многоядерность проникла и в индустрию персональных компьютеров,
позволив тем самым повышать производительность, не увеличивая тактовых частот.
В то же время настоящая революция произошла в
области обработки графических данных. В начале 90-х рост популярности
графических операционных систем дал толчок для создания рынка процессоров
нового типа - 2D-ускорителей, которые позволяли выполнять аппаратно операции с
растровыми изображениями, что способствовало повышению качества отображения
/10/.
Вообще термин «графический процессор» (GPU,
Graphics Processing Unit) по легенде был впервые использован корпорацией
Nvidia. Сейчас современные GPU представляют из себя массивнопараллельные
вычислительные устройства с очень высоким быстродействием (свыше одного
терафлопа) и большим объемом собственной памяти /2/.
Всё началось с Voodoo Graphics - графического
ускорителя, созданного в 1995 году компанией ЗDFх, простого растеризатора,
переводящего треугольники в массивы пикселов, который получал на вход уже
спроецированные центральным процессором вершины. Этот незамысловатый ускоритель
мог обрабатывать до одного миллиона полигонов и выводить на экран до сорока пяти
миллионов пикселей в секунду, тем самым легко обгоняя CPU. Причина такой
производительности кроется в одновременности обработки пикселов. Это,
собственно, и привело к широкому распространению графических ускорителей ЗD
графики.
В связи с тем, что все вершины и все фрагменты,
получающиеся при растеризации, можно обрабатывать совершенно независимо друг от
друга, традиционные задачи рендеринга прекрасно накладываются на архитектуру
параллельной обработки. /2, 10/
Быстрая эволюция графических процессоров после
появления Voodoo привела к
созданию ускорителей, которые могли самостоятельно обрабатывать вершины и
накладывать текстуры. Выпуск карты GeForce
256 компанией NVIDIA
способствовал расширению возможностей GPU
в еще большей степени, теперь графические процессоры умели совершать
геометрические преобразования, рассчитывать освещение сцены и выполнять
некоторые другие несложные, но весьма полезные операции. /2, 21/
Если же рассматривать развитие GPU
с точки зрения параллельности вычислений, то самым большим прорывом стал выпуск
в 2001 году GeForce
3 - процессора, отвечавшего тогда еще только появившемуся стандарту Microsoft
DirectX 8.0, согласно
которому графическое оборудование должно было предоставлять возможность
программируемой обработки вершин. Фактически это значило, что разработчики
программного обеспечения получили возможность самостоятельно решать, какие
именно типы расчетов будут производится на видеокарте.
Вообще основным назначением GPU
в начале 2000-x было вычисление
цвета отдельного пикселя с помощью так называемых пиксельных шейдеров. На вход
пиксельного шейдера подаются координаты точки и набор дополнительных данных,
таких как начальный цвет, текстурные координаты или прочие атрибуты, а на
выходе получается цвет этой точки. Но так как всякая арифметика, производимая
над входными параметрами, теперь полностью определялась программистом, в роли
цвета могли выступать любые данные. Так, если входные данные имели числовой
тип, то программист мог написать шейдер, который выполнял бы над ними
произвольные операции.
Так графические ускорители превратились в
SIМD-процессоры. SIMD (Single Instruction Multiple Data) или векторный
процессор - это параллельный процессор, в котором операндами некоторых команд
могут выступать упорядоченные массивы данных - векторы, в отличие от скалярных
процессоров, которые могут работать только с одним операндом в единицу времени.
SIМD-процессор получает на вход поток однородных данных и параллельно выполняет
над ними одну и ту же инструкцию. Возникло абсолютно новое в программировании
направление - GPGPU (General Purpose Computing on Graphics Processing Units,
GPU общего назначения) - техника использования графических процессоров для
решения не связанных с графикой задач, решением которых обычно занимается
центральный процессор. /10, 21/
Скорости вычисления на GPU
были гигантскими, однако модель программирования значительно ограничивалась
рамками стандартной задачи рендеринга. Входные параметры обязательно должны
были быть приведены к формату цветов или текстурных блоков, кроме того, не
поддерживались операции с памятью типа scatter,
позволяющие записывать данные в произвольные ячейки. Было сложно предугадать
поведение GPU в отношении
чисел с плавающей точкой. И, самое главное - «общение» разработчика с
графическим процессором осуществлялось исключительно посредством одного из
графических интерфейсов программирования приложений (API,
Application
Programming
Interface), в числе которых
были OpenGL и DirectX,
поскольку никакого другого способа взаимодействия с видеокартой не существовало.
Это означало, что программист должен был обладать навыками в написании программ
на шейдерных языках, что было достаточно неудобным условием.
В ноябре 2006 года компания NVIDIA
анонсировала серию графических акселераторов GeForce 8, базирующихся на архитектуре
CUDA (Compute Unified
Device Architecture). Эта новая архитектура включала в себя особую шейдерную
доработку, которая позволяла каждому арифметически-логическому устройству (ALU,
Arithmetic
Logic Unit)
в микросхеме быть использованным при вычислениях общего назначения в
соответствии со стандартом чисел одинарной точности. Кроме того, CUDA
обеспечивала произвольный доступ к памяти и к программно-управляемому кэшу, так
называемой разделяемой памяти (shared
memory).
Позже, чтобы облегчить процесс программирования,
компания NVIDIA создала
специальный язык CUDA
C. По своей сути,
это расширение стандартного языка C,
содержащее в себе новые функции, обеспечивающие взаимодействие с архитектурой CUDA.
Помимо этого языка был также предложен специальный драйвер, который позволил
избежать «общения» с видеопроцессором через графические API
и уйти от представления общей задачи в формате задачи рендеринга. /10/
CUDA базируется
на том соображении, что графический процессор (в среде GPGPU называемый также
устройством, device) может
служить сопроцессором к CPU
(host). Программа,
написанная на языке CUDA
C использует и
графический, и центральный процессоры, и последовательный код выполняется CPU.
За распараллеленную часть вычислений отвечает видеокарта.
Всякое GPU,
выпускаемое NVIDIA, включает в
себя нескольких кластеров текстурных процессоров. Каждый такой кластер - это
текстурный блок и два или три потоковых мультипроцессора. Мультипроцессоры, в
свою очередь, содержат до восьми вычислительных устройств, а также два функциональных
блока. Одна операция одновременно выполняется всеми потоками в варпе (warp).
Варп - это группа, включающая 32 потока-нити, минимальное количество потоков,
которое обрабатывают мультипроцессоры. По аналогии с SIMD
такой способ обработки назвали SIMT
(Single Instruction
Multiple
Threads).
Мультипроцессор обладает шестнадцатью
килобайтами разделяемой памяти, которая позволяет обмениваться данными потокам,
которые исполняются им. Потоки, исполняемые разыми мультипроцессорами,
взаимодействовать друг с другом не могут, это одна из особенностей архитектуры
/10, 12, 13/.
Функция, выполняемая видеокартой, обычно
называется ядром (kernel).
Каждый параллельно выполняемый экземпляр ядра получил название блока (block);
всякий блок исполняется только одним мультипроцессором, но мультипроцессор
может исполнять несколько блоков. Блоки обычно дробятся на потоки - нити (threads).
В силу особенностей разделяемой памяти обмениваться данными могут только нити
одного блока. Все блоки и их нити объединяются в сетку (grid),
которая может быть одно- и двумерной. Блоки по отношению к нитям также могут
иметь несколько измерений (до трёх включительно). В настоящее время существуют
аппаратные ограничения на количество нитей в блоке - до 512 (всего) и на
количество блоков в сетке - до 65535 (по каждому измерению).
Файлы программ, написанных на CUDA C, имеют
расширение *.cu, и могут содержать в себе как функции, выполняемые CPU, так и
функции-ядра. Для их разграничения в языке существуют особые спецификаторы:
служебное слово  перед названием функции указывает
на то, что она будет выполнятся GPU и вызываться может только из
GPU.
Спецификатор
перед названием функции указывает
на то, что она будет выполнятся GPU и вызываться может только из
GPU.
Спецификатор 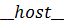 означает полную принадлежность
функции к центральному процессору. А для того чтобы обеспечить запуск
фрагмента, выполняемого видеокартой, с CPU
используется спецификатор
означает полную принадлежность
функции к центральному процессору. А для того чтобы обеспечить запуск
фрагмента, выполняемого видеокартой, с CPU
используется спецификатор  .
.
На функции, исполняемые графическим
процессором, накладывается ряд определённых ограничений. В частности, не
разрешается брать адрес -функций, не поддерживается рекурсия
и внутренние переменные типа static. Также все функции,
исполняемые GPU, должны
иметь строго постоянное число аргументов. /2/
Вызов функции-ядра 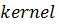 осуществляется при помощи
синтаксического правила:
осуществляется при помощи
синтаксического правила:
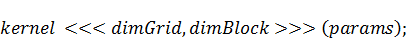
где 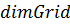 - размер сетки в блоках,
- размер сетки в блоках, 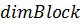 - размер блока в нитях,
- размер блока в нитях, 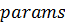 - список аргументов функции
- список аргументов функции 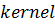 . Переменные и должны соответствовать типу
. Переменные и должны соответствовать типу  , который можно представить себе как
набор из трёх чисел-размерностей. Для сетки в качестве третьей размерности
должна всегда указываться единица, так как на сегодняшний момент сетка может
быть только двумерной. Кроме размеров сетки и блока в директиве запуска также
может быть указан размер разделяемой памяти, по умолчанию равный нулю, и имя
потока.
, который можно представить себе как
набор из трёх чисел-размерностей. Для сетки в качестве третьей размерности
должна всегда указываться единица, так как на сегодняшний момент сетка может
быть только двумерной. Кроме размеров сетки и блока в директиве запуска также
может быть указан размер разделяемой памяти, по умолчанию равный нулю, и имя
потока.
Вообще тип является одним из добавленных в CUDA C типов.
Кроме него в этом языке появились и другие типы-векторы, например 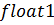 ,
,  ,
,  ,
, 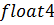 , базирующиеся на стандартном типе
, базирующиеся на стандартном типе  . Удобный для работы с двумерными
структурами, тип активно использовался в этой
работе.
. Удобный для работы с двумерными
структурами, тип активно использовался в этой
работе.
Кроме спецификаторов, некоторых
новых типов и директивы запуска ядра в CUDA C добавлен
также набор дополнительных функций. Так, для того чтобы функция-ядро
выполнялась над набором данных, необходимо выделить некоторое количество памяти
на GPU, и это
осуществляется при помощи аналога стандартной функции 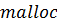 -
- 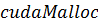 . Чтение и запись в область памяти,
выделенную этой особой функцией, разрешается только из кода, выполняемого
устройством; разыменовывать указатель, возвращаемый ей, с центрального процессора
нельзя. Поэтому еще одним очевидным расширением языка должна стать специальная
функция, которая освобождает память устройства, аналог
. Чтение и запись в область памяти,
выделенную этой особой функцией, разрешается только из кода, выполняемого
устройством; разыменовывать указатель, возвращаемый ей, с центрального процессора
нельзя. Поэтому еще одним очевидным расширением языка должна стать специальная
функция, которая освобождает память устройства, аналог  . Она получила название
. Она получила название 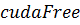 и вызывается из кода, выполняемого CPU. Функция
и вызывается из кода, выполняемого CPU. Функция  в свою очередь позволяет копировать
данные из памяти CPU в память GPU и обратно,
что является одним из основных способов обмена данными между процессором и
устройством. Подробнее синтаксис вызова и использование всех этих функций будут
рассмотрены в четвёртой главе.
в свою очередь позволяет копировать
данные из памяти CPU в память GPU и обратно,
что является одним из основных способов обмена данными между процессором и
устройством. Подробнее синтаксис вызова и использование всех этих функций будут
рассмотрены в четвёртой главе.
Практически во всех программах,
которые выполняются многопоточно, в их параллельной части необходимо
осуществлять какие-то операции с номером текущего потока. В архитектуре CUDA номер
потока - это номер текущей нити, который можно получить, зная размер блока,
номер блока в сетке и номер нити в блоке. За эти параметры отвечают встроенные
переменные 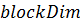 ,
,  и
и  соответственно.
соответственно.
Для примера рассмотрим задачу,
которая прекрасно накладывается на архитектуру параллельных вычислений. Найдем
приближённое значение интеграла:

применяя метод прямоугольников. Как
известно, точное значение такого интеграла равно числу 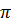 .
.
Простейший пример кода на C++ может
выглядеть так:
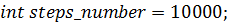
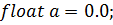

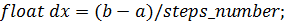
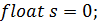

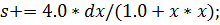

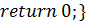
Тот же код, преобразованный для
работы с технологией CUDA:
) часть, выполняемая CPU:

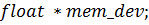

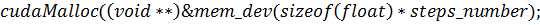
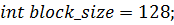
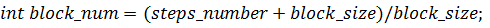

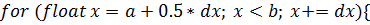

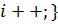
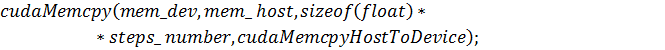
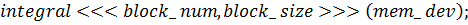
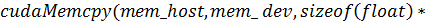
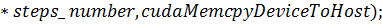

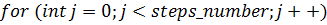

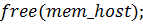
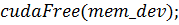
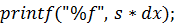
) функция
выполняемая
на
GPU:
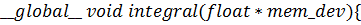
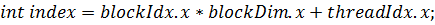
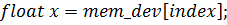

Результат работы программы:
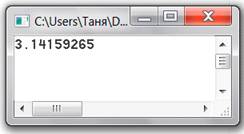
Рассмотренный пример очень хорошо иллюстрирует
использование CUDA, которое, как легко заметить, сводится к следующему
алгоритму:
) выделение памяти на GPU;
) копирование данных из памяти CPU в выделенную
память GPU;
) осуществление запуска ядра;
) копирование результатов вычислений обратно в
память CPU;
) освобождение выделенной памяти GPU.
Фактически для каждого допустимого индекса
входных массивов запускается отдельная нить для осуществления нужных
вычислений. Все эти нити выполняются параллельно, и каждая нить может получить
информацию о себе через встроенные переменные. /10, 13/
Что касается выигрыша во времени, то, согласно
эксперименту, для одного миллиона разбиений интервала интегрирования время
вычисления с помощью CUDA
по сравнению с временем исполнения аналогичной CPU-программы
сократилось более, чем в десять раз.
В современном мире области возможного применения
технологии CUDA невероятно
широки. Массивно-параллельные вычисления успешно используются в некоторых
областях медицины, в обработке изображений, в науках об окружающей среде. В
гидродинамике, например, очень сложное движение обтекающих потоков воздуха или жидкости
сделало невероятно ресурсоёмким процесс конструирования рабочих механизмов, а с
применением параллельного вычисления появилась возможность значительно
сократить время, а значит и стоимость расчетов. /10/
В наше время значительная часть стоящих перед
человечеством физических задач не может быть решена за обозримое время, если
использовать для решения только параллельные алгоритмы. Поэтому в данной
дипломной работе предлагается проверить возможности технологии CUDA
в задачах математической физики. Для примера была взята задача о колебаниях,
которая прекрасно накладывается на параллельную архитектуру.
2. МЕТОДЫ И МЕТОДИКИ ИССЛЕДОВАНИЙ
В процессе работы над поставленными задачами
использовались следующие математические методы:
) для решения уравнения колебаний - метод
разделения переменных;
) для расчёта входящих в решение коэффициентов -
быстрое преобразование Фурье;
) для альтернативного расчета коэффициентов -
метод квадратур Лежандра-Гаусса.
Также использовались следующие средства:
) для написания кода и компиляции -
интегрированная среда разработки Microsoft
Visual Studio
9.0;
) для создания кода, выполняемого GPU,
и его компиляции - набор инструментов CUDA
Toolkit 4.0 и комплекс
средств разработки CUDA
SDK 4.0;
) для пошаговой проверки результатов, для
расчёта узлов и весовых коэффициентов метода квадратур Гаусса - математический
пакет Maple 13;
) для вычисления коэффициентов Фурье -
библиотека CUFFT;
) для оценки времени расчёта коэффициентов Фурье
на процессоре - библиотека FFTW;
) для визуализации результата - открытая
графическая библиотека OpenGL
4.2.
Видеокарта, на которой производились расчёты: NVIDIA
GeForce 9200M
GS.
3. ЗАДАЧА О МАЛЫХ КОЛЕБАНИЯХ
колебание задача коэффициент
амплитуда
Для демонстрации возможностей параллельного
вычисления в общем и технологии CUDA
в частности была выбрана задача о малых колебаниях. Такой выбор основан на
исключительной простоте задачи, что позволяет найти несколько разных алгоритмов
вычисления и остановиться на оптимальном, а также с помощью дополнительных независимых
расчётов легко проверить точность получаемого решения. Также задача о
колебаниях хороша тем, что даёт прекрасную возможность для визуализации
результата, что послужит лишним подтверждением корректности вычислений и
наглядной демонстрацией их производительности.
На начальном этапе работы все расчёты
производились на примере одномерной задачи о колебаниях струны. После
достижения положительного результата они были распространены на случай
двумерной мембраны. Именно этот двумерный случай впоследствии и был
визуализирован.
.1 Постановка задачи. Вывод уравнения
Возьмём натянутую струну (под струной здесь и
далее понимается тонкая упругая нить) и немного отклоним её от положения
равновесия, а затем отпустим. Получив некоторое количество энергии струна начнёт
колебательный процесс, который - в идеальном случае отсутствия сопротивления
среды - будет продолжаться бесконечно долго.
В последующих рассуждениях остановимся именно на
этом простейшем случае свободных поперечных колебаний и найдем уравнение, иллюстрирующее
поставленную задачу.
Пусть есть струна, которая способна
совершать малые колебания в плоскости  около некоторого равновесного
положения, совпадающего, положим, с осью
около некоторого равновесного
положения, совпадающего, положим, с осью  . Пусть также существует некоторая
функция координаты и времени
. Пусть также существует некоторая
функция координаты и времени  , которая определена для всех точек
струны и несёт в себе смысл отклонения её в точке
, которая определена для всех точек
струны и несёт в себе смысл отклонения её в точке  в момент времени
в момент времени  от равновесного положения.
Допустим, что натяжение достаточно велико и можно пренебречь сопротивлением при
изгибе и силой тяжести. Вместе с этим будем опускать все величины высшего
порядка малости по сравнению с
от равновесного положения.
Допустим, что натяжение достаточно велико и можно пренебречь сопротивлением при
изгибе и силой тяжести. Вместе с этим будем опускать все величины высшего
порядка малости по сравнению с 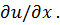
Так как струна изгибу не
сопротивляется, сила её натяжения  в любой точке будет направлена по касательной
этой точке /4/. В силу нашего приближения любой участок струны даже после
отклонения от равновесия своей длины не изменит. Действительно, длина плоской кривой,
заданной уравнением
в любой точке будет направлена по касательной
этой точке /4/. В силу нашего приближения любой участок струны даже после
отклонения от равновесия своей длины не изменит. Действительно, длина плоской кривой,
заданной уравнением  , опирающейся на точки с
координатами
, опирающейся на точки с
координатами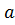 и
и  , как известно, равна:
, как известно, равна:

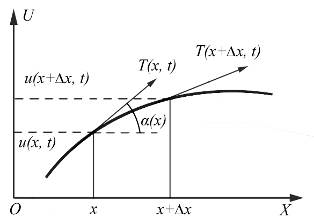
Рисунок 1
что, при учёте пренебрежения малым
слагаемым, даст 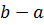 , то есть длину участка струны в
положении равновесия. Определяемое законом Гука абсолютное значение силы
натяжения
, то есть длину участка струны в
положении равновесия. Определяемое законом Гука абсолютное значение силы
натяжения 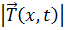 напрямую зависит от удлинения
струны, а значит в контексте данной задачи будет постоянным, не зависящим ни от
координаты, ни от времени, и равным некоторому значению
напрямую зависит от удлинения
струны, а значит в контексте данной задачи будет постоянным, не зависящим ни от
координаты, ни от времени, и равным некоторому значению  .
.
Согласно второму закону Ньютона,
сумма сил, приложенных к элементу струны 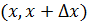 , равна произведению ускорения
такого элемента на его массу (рисунок 1). Массу выразим через линейную
плотность
, равна произведению ускорения
такого элемента на его массу (рисунок 1). Массу выразим через линейную
плотность 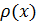 , а сила натяжения, действующая на
участок струны, может быть представлена разностью:
, а сила натяжения, действующая на
участок струны, может быть представлена разностью:
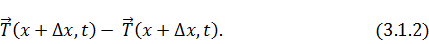
Таким образом, уравнение движения в
проекции на ось, перпендикулярную оси , запишется так:
, запишется так:
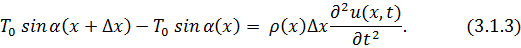
Теперь выразим синус угла через
производную смещения:
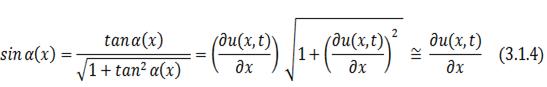
и получим:
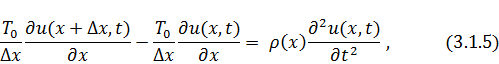
что в пределе при 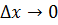 даёт необходимое нам одномерное
волновое уравнение:
даёт необходимое нам одномерное
волновое уравнение:
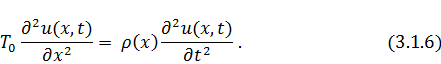
Еще более упростим задачу, положив плотность
струны постоянной:

Аналогичное уравнение можно получить и для
двумерного случая малых колебаний мембраны:
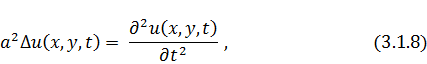
где 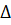 - двумерный оператор Лапласа. Из
физических соображений очевидно, что одного только уравнения
- двумерный оператор Лапласа. Из
физических соображений очевидно, что одного только уравнения 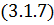 недостаточно для однозначного
определения функции отклонения, и необходимо дополнить картину заданием начальных
условий и режима на концах струны.
недостаточно для однозначного
определения функции отклонения, и необходимо дополнить картину заданием начальных
условий и режима на концах струны.
В качестве первого начального
условия положим:

Функция 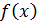 здесь будет иметь смысл положения
струны в момент времени, когда она была отпущена. Второе начальное условие, в
качестве которого задают первую производную от
здесь будет иметь смысл положения
струны в момент времени, когда она была отпущена. Второе начальное условие, в
качестве которого задают первую производную от 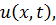 сделаем нулевым:
сделаем нулевым:

что будет означать, что в начальный момент
времени струна покоилась. Рассматривая краевые условия, также ограничимся
простейшим случаем закреплённой на концах струны:

Все те же самые рассуждения можно распространить
и на случай мембраны:

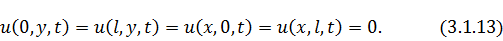
Поставленная таким образом смешанная задача для
уравнения гиперболического типа может быть решена несколькими способами, но мы
будем рассматривать метод разделения переменных, ибо вид получаемого таким
образом решения позволит дополнительно продемонстрировать некоторые возможности
распараллеливания вычислений.
3.2 Решение задачи
методом Фурье
Суть метода Фурье заключается в представлении
искомого решения в виде произведения двух независимых функций, каждая из
которых будет зависеть только от своей переменной /4/. В нашем случае это:

Подставляя такое решение в волновое
уравнение , получаем:


Равенство 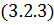 должно тождественно выполняться для
любых аргументов и
должно тождественно выполняться для
любых аргументов и 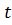 , поэтому из математических
соображений ясно, что левая и правая его части равны некоторой константе
, поэтому из математических
соображений ясно, что левая и правая его части равны некоторой константе  . В результате из одного уравнения
мы получаем два независимых:
. В результате из одного уравнения
мы получаем два независимых:


Теперь получим граничные с учётом
представления 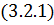 :
:
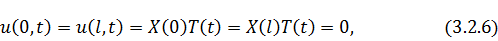
Общее решение уравнения 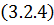 для функции
для функции  имеет вид:
имеет вид:
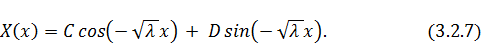
Добавим граничные условия и получим:

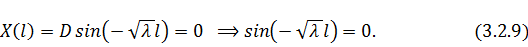
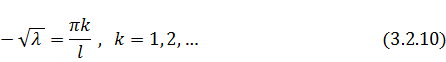
Константу положим равной единице и получим
множество
положим равной единице и получим
множество  - нетривиальных решений
- нетривиальных решений задачи
задачи  :
:

Аналогично для  :
:

Таким образом частное решение
уравнения :

а так как это уравнение является линейным и
однородным, можно утверждать, что сумма частных решений тоже ему удовлетворяет:
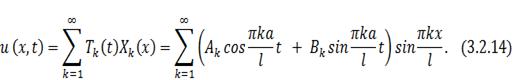
Недостающие коэффициенты находятся из учёта
начальных условий:


Выражение 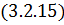 по своей сути является разложением
функции в тригонометрический ряд Фурье,
коэффициенты которого, как известно, вычисляются по формуле:
по своей сути является разложением
функции в тригонометрический ряд Фурье,
коэффициенты которого, как известно, вычисляются по формуле:
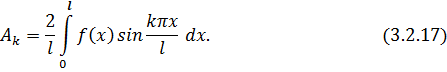
В той же последовательности ищется
решение и для двумерного случая, и для прямоугольной мембраны размерами  оно выражается двойным рядом:
оно выражается двойным рядом:
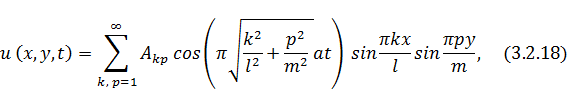

В силу подобного представления решения
становится возможным распараллеливание сразу двух процессов - расчета амплитуд
для каждой точки струны или мембраны и вычисления коэффициентов Фурье.
Единожды задав функцию начального
положения , можно сразу рассчитать зависящие
только от неё коэффициенты  , поэтому построение оптимального
алгоритма для их вычисления станет первым этапом работы с CUDA.
, поэтому построение оптимального
алгоритма для их вычисления станет первым этапом работы с CUDA.
В двух последующих главах будем
рассматривать расчёт коэффициентов Фурье двумя независимыми способами - при
помощи быстрого преобразования Фурье и через квадратурные формулы
Гаусса-Лежандра. В обоих случаях используются методы массивно-параллельного
вычисления.
4. ВЫЧИСЛЕНИЕ КОЭФФИЦИЕНТОВ С ПОМОЩЬЮ БЫСТРОГО
ПРЕОБРАЗОВАНИЯ ФУРЬЕ
4.1 Дискретный подход к
вычислению коэффициентов
Коэффициенты , выражение для которых было
получено в предыдущей главе, как уже говорилось, программно могут быть
рассчитаны несколькими способами. Один из них - дискретное преобразования
Фурье.
Для этого сначала весь интервал
интегрирования необходимо разбить на 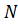 элементарных равных промежутков и
интегралы заменить дискретными суммами по формуле левых прямоугольников:
элементарных равных промежутков и
интегралы заменить дискретными суммами по формуле левых прямоугольников:
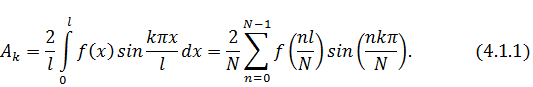
В последующих преобразованиях будем опускать
двойку перед суммой, учитывая, что добавим её позже в окончательное решение.
Теперь обратим своё внимание на формулы прямого
и обратного дискретного преобразования Фурье:
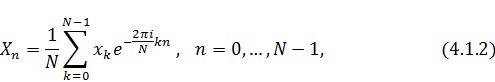
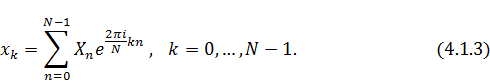
Согласно именно такому определению
преобразования Фурье функционирует большинство математических библиотек, в том
числе и та, которая была использована в этой работе. Значит, теперь задача
состоит в том, чтобы каким-то образом изменить результаты, получаемые программно,
согласно формулам  и
и 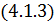 , чтобы можно было использовать их в
расчете . Рассмотрим обратное
преобразование. Для начала разложим экспоненту по формуле Эйлера:
, чтобы можно было использовать их в
расчете . Рассмотрим обратное
преобразование. Для начала разложим экспоненту по формуле Эйлера:


Несложно заметить, что если положить
в качестве 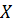 набор значений функции
набор значений функции  (заведомо вещественных), то мнимая
часть обратного дискретного преобразования Фурье даст выражение довольно
похожее на выражение для коэффициентов . Сравним:
(заведомо вещественных), то мнимая
часть обратного дискретного преобразования Фурье даст выражение довольно
похожее на выражение для коэффициентов . Сравним:
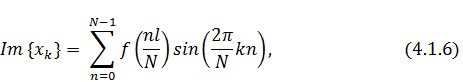
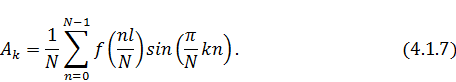
Теперь в выражении 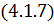 умножим и разделим аргумент синуса
на двойку:
умножим и разделим аргумент синуса
на двойку:

Воспользуемся тем замечательным
преимуществом, что входные значения для преобразования Фурье мы можем задавать
какими угодно, и предположим, что существует некоторый набор 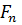 , содержащий всего 2
, содержащий всего 2 элементов, первых значений которого
действительно вычисляются по формуле:
элементов, первых значений которого
действительно вычисляются по формуле:
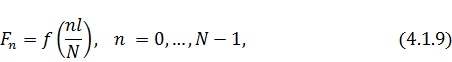
остальные же значения  положим равными нулю. Очевидно, что
добавление нулевых членов не изменит суммы:
положим равными нулю. Очевидно, что
добавление нулевых членов не изменит суммы:
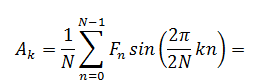
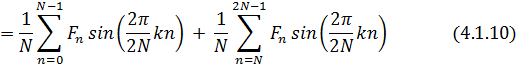
и мы приходим к выражению:
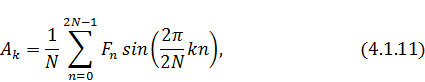
что является по своей сути
умноженной на коэффициент мнимой частью обратного дискретного преобразования
Фурье для двойного набора значений. Для ясности можем положить  и получим:
и получим:
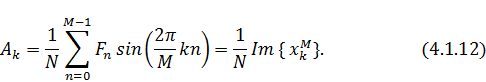
Таким образом мы приходим к простому
алгоритму вычисления коэффициентов Фурье, входящих в решение поставленной в
предыдущих главах задачи. Согласно этому алгоритму для нахождения требуется выполнить следующие
действия:
) разбить промежуток интегрирования
(то есть длину струны) на равных частей, для каждой из
которых вычислить значение функции начального положения (по левой границе интервала);
) сформировать набор , первых значений которого совпадают
со значениями , полученными в предыдущем пункте, а
остальные равны нулю;
) выполнить обратное преобразование
Фурье для ;
) взять нормированную мнимую часть
от полученных коэффициентов.
При этом очевидно, что на выходе
преобразования Фурье образуется массив из 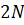 значений, но нас интересует только
первые из них, так как именно они будут
давать значений . Вторая половина массива, вообще
говоря, будет зеркальным отображением первой, это является одним из свойств
дискретного преобразования Фурье и справедливо для всех случаев, когда на его
вход подаётся набор вещественных данных.
значений, но нас интересует только
первые из них, так как именно они будут
давать значений . Вторая половина массива, вообще
говоря, будет зеркальным отображением первой, это является одним из свойств
дискретного преобразования Фурье и справедливо для всех случаев, когда на его
вход подаётся набор вещественных данных.
Теперь задача свелась к выполнению
непосредственно обратного дискретного преобразования Фурье. В следующем пункте
рассмотрим, как с помощью технологии CUDA можно
сделать это с минимальными затратами ресурсов.
4.2 Быстрое
преобразование Фурье и библиотека CUFFT
В набор разработчика CUDA Toolkit, по
обыкновению, входят две дополнительные библиотеки, связанные с наиболее часто
встречающимися задачами. Первая из них, CUBLAS
- реализация стандарта BLAS
(Basic Linear
Algebra Subprograms)
- содержит в себе фундаментальные алгоритмы осуществления базовых операций
линейной алгебры. О второй, CUFFT,
и пойдёт речь в этом подразделе.
Библиотека CUFFT
- это CUDA-адаптированный
вариант набора инструментов для осуществления быстрого преобразования Фурье,
предоставляющий несложный интерфейс для эффективных вычислений на графическом
процессоре широкого круга задач фильтрации сигналов и спектрального анализа.
Вот некоторые пункты из длинного списка тех операций, которые поддерживает
последняя версия библиотеки:
) операции с комплексными и вещественными
данными;
) одномерные, двумерные и трёхмерные
преобразования;
) выполнение преобразований над массивами
размером до шестидесяти четырёх миллионов элементов с одинарной точностью и до
ста двадцати восьми миллионов элементов с двойной точностью;
) поддержка in-place
преобразований, при которых используется минимум места для хранения данных, а
входной массив замещается результирующим, и out-of-place
преобразований;
) двойная точность вычислений на некоторых
совместимых видеокартах;
) поддержка потокового выполнения, позволяющего
несинхронные вычисления и перемещение данных /17/.
Вообще быстрое преобразование Фурье
(Fast Fourier Transform, FFT) -
собирательное название группы алгоритмов вычисления дискретного преобразования
Фурье. Главной отличительной чертой этих алгоритмов является значительное
уменьшение числа шагов, необходимых для расчёта коэффициентов, по сравнению со
стандартными способами преобразования. Впервые такой метод был предложен
Джеймсом У.Кули из Исследовательского центра имени Томаса Уотсона корпорации
IBM и Джоном У.Тьюки из Bell Telephone Laboratories /3/. Основная идея их
работы заключалась в том, чтобы разделить сумму из 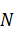 слагаемых на две суммы с числом
слагаемых, равным
слагаемых на две суммы с числом
слагаемых, равным 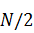 , а затем вычислить обе суммы по
отдельности. В свою очередь вычисление этих сумм производилось тем же самым
способом, иначе говоря, рекурсивно. Постоянное деление оставшегося отрезка
пополам в конце концов приводило к двухточечному преобразованию Фурье. Несложно
заметить, что длина входного вектора для реализации такого алгоритма
должна быть степенью двойки, однако это не накладывает особого ограничения на
входные данные, ибо всегда существует возможность дополнить вектор с
, а затем вычислить обе суммы по
отдельности. В свою очередь вычисление этих сумм производилось тем же самым
способом, иначе говоря, рекурсивно. Постоянное деление оставшегося отрезка
пополам в конце концов приводило к двухточечному преобразованию Фурье. Несложно
заметить, что длина входного вектора для реализации такого алгоритма
должна быть степенью двойки, однако это не накладывает особого ограничения на
входные данные, ибо всегда существует возможность дополнить вектор с 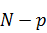 элементами до необходимой длины,
добавив к нему
элементами до необходимой длины,
добавив к нему 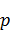 нулевых коэффициентов, наличие
которых не повлияет на результат.
нулевых коэффициентов, наличие
которых не повлияет на результат.
Различают так называемое
«прореживание по времени», при котором в первую сумму включаются чётные
слагаемые, а во вторую - нечётные, и «прореживание по частоте», для которого в
первой сумме оставляют первые слагаемых, а во второй -
оставшиеся. Оба варианта при этом равноценны.
Выведем быстрое преобразование Фурье
напрямую из дискретного преобразования на примере прореживания по времени. ДПФ
для вектора 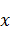 длины
длины 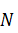 с точностью до нормировочного
множителя имеет следующий вид:
с точностью до нормировочного
множителя имеет следующий вид:
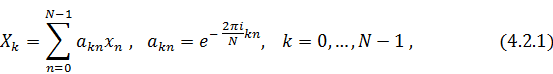
где 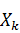 - набор комплексных амплитуд
синусоидальных сигналов, образующих входной сигнал. Для случая, когда - чётно, имеем:
- набор комплексных амплитуд
синусоидальных сигналов, образующих входной сигнал. Для случая, когда - чётно, имеем:
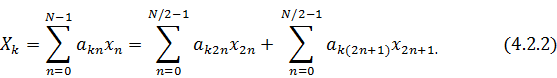
Очевидно, что коэффициенты 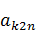 и
и  можно представить в виде:
можно представить в виде:
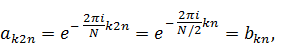

где 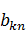 - аналогичные
- аналогичные 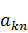 коэффициенты дискретного
преобразования Фурье для входного вектора длиной . В итоге получаем:
коэффициенты дискретного
преобразования Фурье для входного вектора длиной . В итоге получаем:

то есть
линейную комбинацию двух дискретных преобразований Фурье над «половинными»
векторами. Продолжая рекурсивное разделение, приходим к двухточечному
преобразованию, которое, с учётом выражения (4.2.4) и того факта, что значение  равно минус единице, будет
вычисляться по формулам:
равно минус единице, будет
вычисляться по формулам:

Количество единичных операций
умножения, которое требуется выполнить для вычисления дискретного
преобразования Фурье, уменьшается в два раза при соответствующем уменьшении
длины входного вектора. К примеру, для вектора в шестнадцать элементов нам
потребовалось бы шестнадцать в квадрате, то есть двести пятьдесят шесть
операций. Разделив же вектор пополам и получив два по восемь элементов, для
каждого мы выполним по восемь в квадрате умножений, в сумме дающих сто двадцать
восемь. Таким образом, результирующая асимптотическая сложность быстрого
алгоритма вычисления преобразования Фурье равна 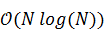 вместо сложности
вместо сложности 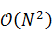 стандартного алгоритма.
стандартного алгоритма.
Именно такому быстрому алгоритму
вычисления соответствует набор функций библиотеки CUFFT и именно им
резонно воспользоваться для получения коэффициентов, входящих в решение
поставленной задачи.
Интерфейс программирования CUFFT API (Application Programming Interface) базируется
на свободно распространяемой библиотеке FFTW, которая считается одной из
наиболее эффективных библиотек быстрого преобразования Фурье в среде CPU-программирования.
FFTW
предоставляет простой механизм конфигурации, так называемый plan, который
полностью предопределяет оптимальную схему выполнения расчета для определённого
размера и типа входных данных. При вызове функции вычисления преобразования
производятся точно по предписанному плану. Преимущество такого подхода
заключается в том, что единожды создав подобную схему, система сохраняет
состояние, необходимое для множественного выполнения преобразований без
пересчёта конфигурации.
Итак, первым шагом выполнения
быстрого преобразования Фурье будет создание плана. Для этого в первую очередь
необходимо выделить некоторый объём памяти на GPU, что
осуществляется стандартной функцией CUDA -  :
:
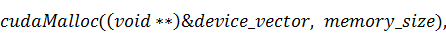
где 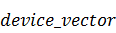 - указатель на массив входных
данных на видеокарте, а
- указатель на массив входных
данных на видеокарте, а  - размер этого массива в байтах.
Если же набор входных данных хранится в памяти, относящейся к центральному
процессору, то необходимо скопировать его в память видеокарты следующей
командой:
- размер этого массива в байтах.
Если же набор входных данных хранится в памяти, относящейся к центральному
процессору, то необходимо скопировать его в память видеокарты следующей
командой:
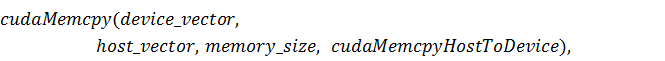
где  - указатель на массив входных
данных, созданный CPU. Далее нужно объявить объект типа
- указатель на массив входных
данных, созданный CPU. Далее нужно объявить объект типа  :
:

в котором будет сохранён план, и
определить его:
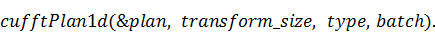
Первым аргументом функции 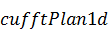 является указатель на объект типа ,
является указатель на объект типа ,  - количество элементов входного
вектора,
- количество элементов входного
вектора,  - число преобразований, которые
требуется выполнить. Аргумент
- число преобразований, которые
требуется выполнить. Аргумент 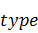 обозначает тип данных
преобразования и может принимать следующие значения:
обозначает тип данных
преобразования и может принимать следующие значения:
) 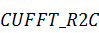 - преобразование вещественных
данных в комплексные;
- преобразование вещественных
данных в комплексные;
) 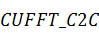 - преобразование комплексных данных
в комплексные;
- преобразование комплексных данных
в комплексные;
) 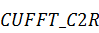 - комплексно-вещественное
преобразование,
- комплексно-вещественное
преобразование,
а также соответствующие им значения 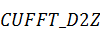 ,
, 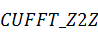 и
и  , отвечающие за преобразования с
двойной точностью. Вместо можно использовать функции
, отвечающие за преобразования с
двойной точностью. Вместо можно использовать функции 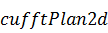 и
и  , в случае, если набор входных
данных является двумерным или трёхмерным, но мы в дальнейшем ограничимся
одномерными преобразованиями.
, в случае, если набор входных
данных является двумерным или трёхмерным, но мы в дальнейшем ограничимся
одномерными преобразованиями.
И, наконец, непосредственно
выполнением расчёта занимается группа функций 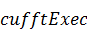 , расширенное название которых
содержит в себе информацию о типе данных и о точности вычислений. Рассмотрим
расчёт на примере функции, выполняющей комплексное преобразование с единичной
точностью:
, расширенное название которых
содержит в себе информацию о типе данных и о точности вычислений. Рассмотрим
расчёт на примере функции, выполняющей комплексное преобразование с единичной
точностью:
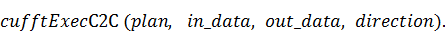
Здесь 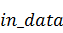 и
и 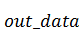 - указатели на массивы комплексных
данных в памяти GPU, - исходный сигнал и
- указатели на массивы комплексных
данных в памяти GPU, - исходный сигнал и 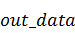 - полученный. В нашем случае роль
этих аргументов будет играть преобразованная к типу указателя на
- полученный. В нашем случае роль
этих аргументов будет играть преобразованная к типу указателя на  переменная (выполняем in-place
преобразование).
переменная (выполняем in-place
преобразование).
Параметром  типа
типа 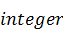 можно задать направление
преобразования, его значение
можно задать направление
преобразования, его значение  даёт прямое преобразование Фурье,
даёт прямое преобразование Фурье,  - обратное.
- обратное.
Всё, что осталось сделать - это
скопировать данные из памяти GPU в память, доступную CPU, «убить»
план функцией  и освободить занимаемое место на
видеокарте:
и освободить занимаемое место на
видеокарте:


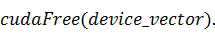
На этом знакомство с быстрым
преобразованием Фурье и основным функциональным аппаратом библиотеки CUFFT будем
считать законченным и перейдём непосредственно к их использованию в
поставленной задаче.
4.3
Реализация FFT для задачи о колебаниях струны и мембраны
Для того чтобы осуществить обратное
преобразование Фурье над набором вещественных данных будем использовать complex-to-complex
преобразование, заполняя мнимую часть входного массива нулями. Необходимость
именно такого типа преобразования заключается в том, что функция  , которая, казалось бы, лучше
соответствует задаче, вообще говоря, выполняет только прямое преобразование
Фурье. Функция
, которая, казалось бы, лучше
соответствует задаче, вообще говоря, выполняет только прямое преобразование
Фурье. Функция 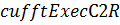 , выполняющая только обратное
преобразование, не подойдет по типу, ибо на выходе мы получим массив
вещественных данных. Использование же функции
, выполняющая только обратное
преобразование, не подойдет по типу, ибо на выходе мы получим массив
вещественных данных. Использование же функции 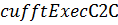 , которая строго следует определению
дискретного преобразования Фурье и может быть выполнена в обоих
направлениях, не несёт в себе никаких неучтённых последствий, поэтому мы будем
пользоваться именно ей.
, которая строго следует определению
дискретного преобразования Фурье и может быть выполнена в обоих
направлениях, не несёт в себе никаких неучтённых последствий, поэтому мы будем
пользоваться именно ей.
Начиная реализацию FFT для случая
струны, прежде всего зададим функцию её начального положения:
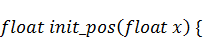
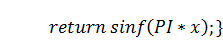
Здесь для примера мы положили, что 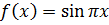 , а длина струны
, а длина струны  равна единице. Константа
равна единице. Константа 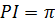 была определена заранее, глобально.
Теперь зададим число отрезков разбиения , а заодно и . Нельзя забывать о том, что число
элементов, подаваемых на вход преобразования Фурье, должно являться степенью
двойки:
была определена заранее, глобально.
Теперь зададим число отрезков разбиения , а заодно и . Нельзя забывать о том, что число
элементов, подаваемых на вход преобразования Фурье, должно являться степенью
двойки:


Ясно, что в готовой программе функции и
определения будут следовать в ином порядке, здесь же будем приводить их именно
в той последовательности, которая кажется наиболее логичной.
Сейчас необходимо набрать массив
входных данных для преобразования. Как оговаривалось в начале этого пункта, эти
данные формально должны быть комплексными, но с нулевой мнимой частью. Для
работы с комплексными данными на CUDA существует подходящий тип , определённый как структура из двух
элементов, первый из которых несет информацию о действительной части, а второй
- о мнимой. Сначала создадим указатель на массив типа и выделим место:

Теперь вспомним соображения из пункта 4.1.1,
согласно которым первая половина входного массива должна заполнятся значениями
функции начального положения на левых границах интервалов разбиения, а вторая -
нулями, и осуществим это:
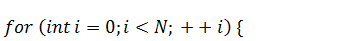

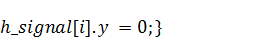
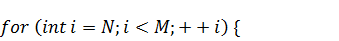


Все готово к тому, чтобы приступить
непосредственно к преобразованию. Выделяем память на видеокарте и копируем туда
массив 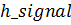 :
:
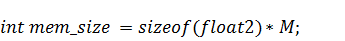

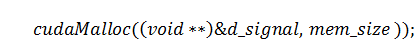
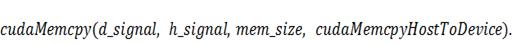
Создаём CUFFT
план:


Выполняем обратное дискретное преобразование
Фурье:

Копируем данные из памяти видеокарты:
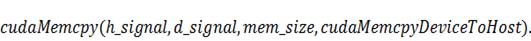
Теперь те самые коэффициенты,
которые непосредственно входят в решение, могут быть найдены из данных массива . Для этого достаточно взять его
мнимую часть, то есть 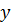 -компоненту структуры, и первые элементов, деленные на , дадут искомые .
-компоненту структуры, и первые элементов, деленные на , дадут искомые .
Абсолютно аналогичные действия
приведут нас к нахождению коэффициентов для мембраны. В этом случае
предлагается функцию начального положения задавать как произведение двух - для
координаты и координаты , тогда интеграл (3.2.19)
распадается на два, и появляется возможность рассчитать коэффициенты для двух
осей независимо друг от друга, а потом найти окончательные просто их
перемножив. Такой подход был выбран исключительно из соображений экономии
времени на преобразовании программы одномерного случая в программу двумерного.
Если же по какой-то причине представить функцию 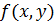 в виде такого произведения не
представляется возможным, то программа подлежит доработке, а вместо двух
одномерных преобразований Фурье должно быть выполнено одно двумерное.
в виде такого произведения не
представляется возможным, то программа подлежит доработке, а вместо двух
одномерных преобразований Фурье должно быть выполнено одно двумерное.
Вот окончательный набор операций,
который приведёт к получению коэффициентов для задачи о мембране:

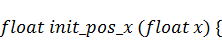
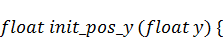


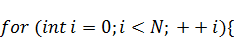
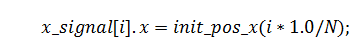
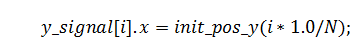
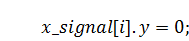

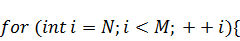
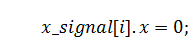




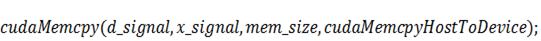

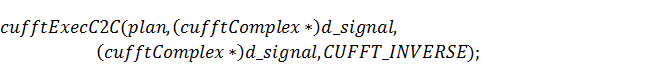



Итак, с помощью некоторых
математических приёмов и быстрого преобразования Фурье из библиотеки CUFFT были
получены коэффициенты , входящие в решение одномерной
задачи и соответствующие им коэффициенты двумерной. Оставшиеся действия,
которые необходимо выполнить для построения конечного решения, будут
рассмотрены в шестой главе.
Не стоит забывать, что несмотря на
всю эффективность вычисления с помощью FFT,
использованная замена интегралов суммами даёт не самые точные значения. Поэтому
в следующей главе будет изложен более точный метод вычисления интегралов - с
помощью квадратур Лежандра-Гаусса.
5. ВЫЧИСЛЕНИЕ МЕТОДОМ ЛЕЖАНДРА-ГАУССА
5.1 Квадратуры
Лежандра-Гаусса
Квадратурными формулами вообще называют
выражения, используемые для численной оценки значений интегралов. Обычно такие
выражения имеют следующий вид:
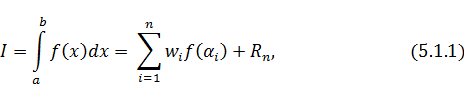
то есть представляют собой сумму
значений интегрируемой функции, взятой в определённых точках, умноженных на
некоторые коэффициенты, называемые также весовыми коэффициентами или просто
весами. Точки 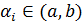 , в которых берётся функция, называют
узлами, а
, в которых берётся функция, называют
узлами, а  здесь представляет собой остаточный
член.
здесь представляет собой остаточный
член.
Именно выбор узлов и весовых
множителей определяет точность той или иной квадратурной формулы. Например,
метод левых прямоугольников, который был применён в предыдущей главе, имеет
первый порядок точности, метод средних прямоугольников, использующий те же
веса, но другие узлы - второй. В связи с этим возникает вопрос о поиске
наилучшей формулы для числа 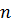 узлов. Гаусс сформулировал
постановку такой задачи следующим образом: нужно найти квадратурную формулу с
заданным числом узлов , которая будет точно описывать
интеграл от всякого полинома степени
узлов. Гаусс сформулировал
постановку такой задачи следующим образом: нужно найти квадратурную формулу с
заданным числом узлов , которая будет точно описывать
интеграл от всякого полинома степени 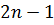 или любой более низкой степени.
или любой более низкой степени.
Для удобства будем рассматривать
интеграл на отрезке 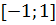 , поиск результатов для других
отрезков интегрирования будет осуществляется простым пересчётом. Представляя последовательно как
, поиск результатов для других
отрезков интегрирования будет осуществляется простым пересчётом. Представляя последовательно как 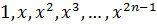 , и полагая, что должно равняться нулю, запишем:
, и полагая, что должно равняться нулю, запишем:
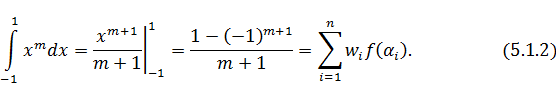
Выражение 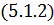 представляет собой линейную систему
из
представляет собой линейную систему
из 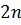 уравнений, которую, вообще говоря,
довольно сложно решить для произвольного числа узлов. Поэтому мы поступим
следующим образом.
уравнений, которую, вообще говоря,
довольно сложно решить для произвольного числа узлов. Поэтому мы поступим
следующим образом.
Представим, что нам известен
некоторый полином 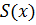 степени
степени 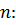

корнями которого являются
необходимые нам для построения квадратурной формулы узлы. Возьмём любой другой
полином 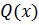 степени
степени 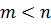 , умножим его на
, умножим его на  и результат проинтегрируем на
отрезке от минус единицы до единицы, используя при этом формулу
и результат проинтегрируем на
отрезке от минус единицы до единицы, используя при этом формулу  :
:

Так как степень произведения
полиномов 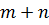 меньше, чем - максимальная степень, для которой
применима формула Гаусса, выражение
меньше, чем - максимальная степень, для которой
применима формула Гаусса, выражение 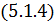 не несёт в себе противоречий.
не несёт в себе противоречий.
Из следует вывод о том, что полином ортогонален всякому полиному
степени . Но это значит, что с точностью до
некоторого множителя полином совпадает с полиномом Лежандра
соответствующей степени. Действительно, полиномы Лежандра, определяемые
выражением:
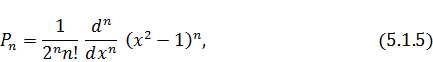
образуют систему, ортогональную на , это их известное свойство /1/.
Известно также, что всякая система полиномов, обладающая свойством
ортогональности на некотором отрезке, определена однозначно с точностью до
множителя. Поэтому можно утверждать, что искомый полином представим в виде:

а это значит, что необходимые нам
узлы 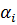 могут быть найдены как корни
соответсвующего полинома Лежандра.
могут быть найдены как корни
соответсвующего полинома Лежандра.
Осталось получить веса квадратурной
формулы. Для этого воспользуемся системой некоторых полиномов 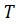 степени
степени 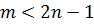 , для каждого из которых
выполняется:
, для каждого из которых
выполняется:

Тогда очевидно:
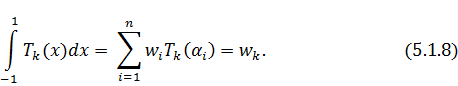
Чтобы получить все весовых коэффициентов, удобнее
всего положить 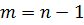 и представить
и представить 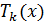 в виде:
в виде:
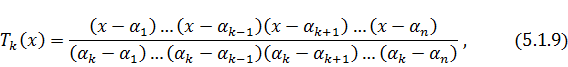
тогда 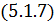 будет выполняться. Запишем
окончательное выражение для весов:
будет выполняться. Запишем
окончательное выражение для весов:
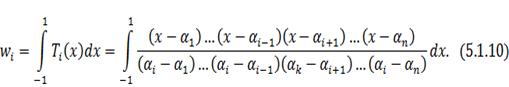
В связи с тем, что узлы и веса
вообще никак не зависят от начального условия - функции  произведём их расчёт
заблаговременно.
произведём их расчёт
заблаговременно.
5.2 Расчёт узлов и
весовых коэффициентов
Для расчёта узлов и весов
квадратурной формулы был использован математический
пакет Maple. Ниже
разберём пример кода, с помощью которого можно получить результат.
Прежде всего необходимо подключить
пакет ортогональных полиномов, который позволит использовать полиномы Лежандра
как уже определённые функции:

Поставим задачу не только вычислить веса и узлы,
но и проверить их на каком-нибудь простом интеграле. В качестве подынтегральной
функции выберем косинус:
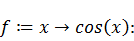
Интегрирование будем осуществлять на
отрезке 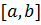 , количество узлов положим равным
ста. Также отдельно зададим границы интервала
, количество узлов положим равным
ста. Также отдельно зададим границы интервала 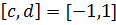 , чуть позже это будет полезным:
, чуть позже это будет полезным:
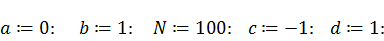
Получим узлы, находя корни полинома
Лежандра 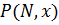 сотой степени:
сотой степени:
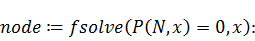
Посчитаем веса:
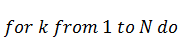
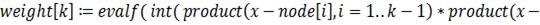
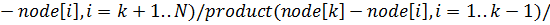
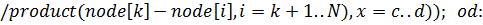
Найдем значение интеграла с помощью квадратурной
формулы Гаусса, учитывая, что интервал интегрирования не совпадает с интервалом
для этой формулы, а значит необходимо перераспределить узлы на новом отрезке,
масштабируя расстояния между ними:
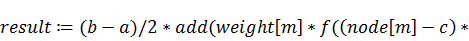
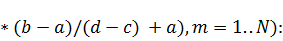
Теперь вычислим интеграл стандартными средствами
Maple и сравним
результаты:
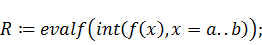
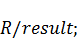
Последнее действие даёт единицу, что означает
адекватность узлов и весов.
5.3 Реализация на C++
Сейчас нужно экспортировать
полученные результаты в программу на С++. Для этого просто сохраним данные в
двух текстовых файлах -  и
и  и будем подгружать содержимое этих
файлов в самом начале работы программы с помощью функций:
и будем подгружать содержимое этих
файлов в самом начале работы программы с помощью функций:
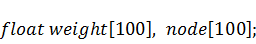
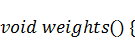
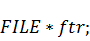
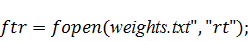


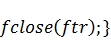

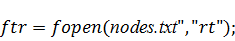
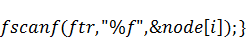
Для того чтобы вычислить
коэффициенты , которые с учётом соображений,
изложенных в пунктах  и
и 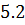 , определяются формулой:
, определяются формулой:
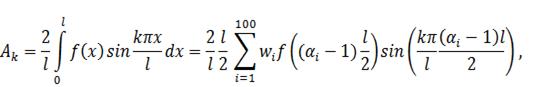
также удобно воспользоваться
распараллеливанием. Как и в предыдущей главе, зададим функцию в виде 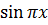 , длину струны положим равной
единице, а количество коэффициентов оставим равным двумстам пятидесяти
шести:
, длину струны положим равной
единице, а количество коэффициентов оставим равным двумстам пятидесяти
шести:

Расчёт будем осуществлять при помощи CUDA.
Создаём вспомогательную функцию, которая будет выполняться процессором и
отвечать за перенос данных из памяти CPU
в память GPU и обратно,
а также за вызов функции-ядра:

В качестве аргументов будем
передавать указатели на массивы, содержащие веса и узлы квадратурной формулы, а
также указатель на массив, в который будем сохранять получившиеся коэффициенты.
Внутри функции  прежде всего произведем копирование
данных из памяти процессора в память видеокарты:
прежде всего произведем копирование
данных из памяти процессора в память видеокарты:

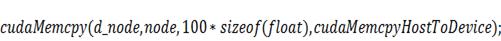
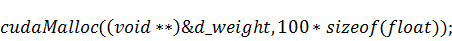
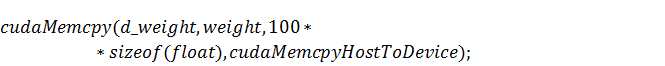
а также выделим в памяти GPU
место под массив коэффициентов:
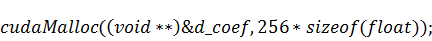
Необходимо посчитать всего двести пятьдесят
шесть коэффициентов, для чего будем использовать соответствующее число нитей.
Сгруппируем все эти нити в одномерные блоки по сто двадцать восемь нитей в
каждом и сформируем сетку из блоков:
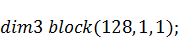
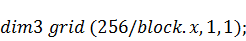
Вызовем функцию-ядро, которая будет
называться  :
:
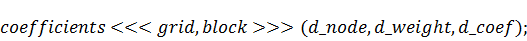
и после того, как она отработала, скопируем
результаты обратно в память процессора и освободим память видеокарты:




Функция будет выполняться видеопроцессором
и осуществлять одни и те же действия для множества нитей. Вот её листинг:
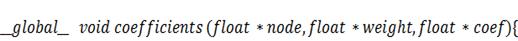
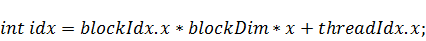

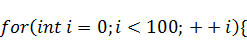
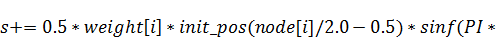
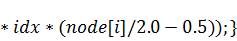

Коэффициенты двумерного случая будем
представлять, как и в главе  , в виде произведения коэффициентов
каждого измерения. Удобно в такой ситуации сохранять получаемые результаты в
массиве типа , где -компонента будет содержать
коэффициенты, насчитанные для -измерения, а -компонента - для
, в виде произведения коэффициентов
каждого измерения. Удобно в такой ситуации сохранять получаемые результаты в
массиве типа , где -компонента будет содержать
коэффициенты, насчитанные для -измерения, а -компонента - для  Текст исполняющих функций при этом
меняется мало: массив
Текст исполняющих функций при этом
меняется мало: массив  объявляется как -массив, и это необходимо учитывать
каждый раз, когда осуществляется выделение места под коэффициенты, перенос
данных в память видеокарты или обратно. Листинг функции :
объявляется как -массив, и это необходимо учитывать
каждый раз, когда осуществляется выделение места под коэффициенты, перенос
данных в память видеокарты или обратно. Листинг функции :
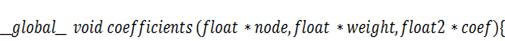
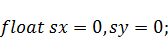
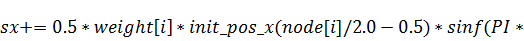

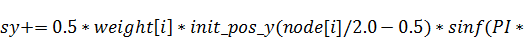

В этом случае процесс вычисления
коэффициентов распараллеливается на двести пятьдесят шесть нитей, каждая из
которых выполняет расчёт одного - и одного -коэффициента. Можно поступить и
по-другому: не меняя типа массива 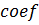 , сделать двумерной сетку и
двумерными же блоки нитей:
, сделать двумерной сетку и
двумерными же блоки нитей:
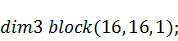
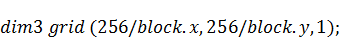
тогда процесс распараллеливается на 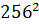 нитей, и каждая нить рассчитывает
только один коэффициент. Функция будет выглядеть так:
нитей, и каждая нить рассчитывает
только один коэффициент. Функция будет выглядеть так:
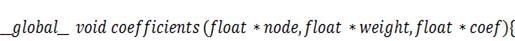
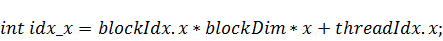
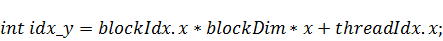
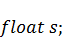
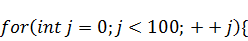
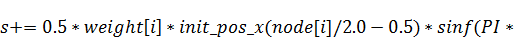

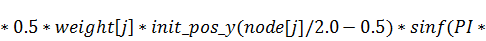

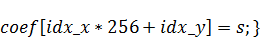
В случае, если функция начального состояния
мембраны по какой-то причине не представима в виде произведения двух
независимых функций по двум измерениям, последний способ особенно удобен.
Итак, в этой главе был предложен метод получения
входящих в решение коэффициентов с помощью квадратурной формулы
Лежандра-Гаусса. В следующей главе рассмотрим оставшиеся до получения решения
шаги.
6. ПАРАЛЛЕЛЬНЫЙ РАСЧЕТ АМПЛИТУД
6.1
Массивно-параллельный расчет амплитуд
Вернемся к решению задачи о колебаниях:

для которого уже найдены 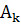 . Так как бесконечное суммирование
осуществить программно, вообще говоря, невозможно, оборвем ряд на некотором
. Так как бесконечное суммирование
осуществить программно, вообще говоря, невозможно, оборвем ряд на некотором  :
:

В четвертой и пятой главах при
расчёте коэффициентов было задано равным двумстам
пятидесяти шести; при желании несложно сделать это число значительно больше, но
мы остановимся на этом значении.
Далее предлагается описывать
положение струны  точками и рассчитывать их
отклонения от положения равновесия в каждый момент времени, делая это с помощью
массивно-параллельных вычислений. Итак, разобьем всю длину струны точками, тогда, если известен номер
точками и рассчитывать их
отклонения от положения равновесия в каждый момент времени, делая это с помощью
массивно-параллельных вычислений. Итак, разобьем всю длину струны точками, тогда, если известен номер
 точки, то её координату можно
выразить как
точки, то её координату можно
выразить как 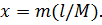 Создадим процедуру, которая
подготавливает запуск функции-ядра и осуществляет его:
Создадим процедуру, которая
подготавливает запуск функции-ядра и осуществляет его:

В качестве аргументов она будет
принимать указатель на массив , куда будут записываться
рассчитанные амплитуды, указатель на массив коэффициентов, число коэффициентов,
число точек и время, для которого необходимо
выполнить расчёт. Листинг функции:
, куда будут записываться
рассчитанные амплитуды, указатель на массив коэффициентов, число коэффициентов,
число точек и время, для которого необходимо
выполнить расчёт. Листинг функции:
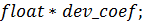

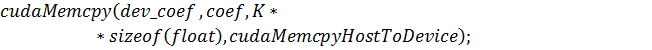
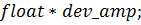
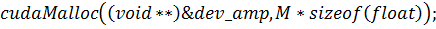

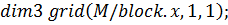
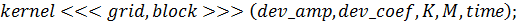
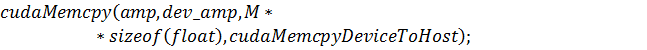
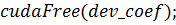

И, наконец, сама функция-ядро:
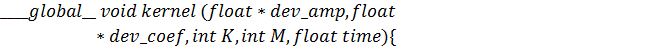


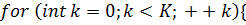
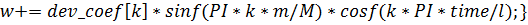

Осуществляя эти действия для случая,
когда коэффициенты были получены быстрым преобразованием Фурье, нужно помнить,
что результат должен быть удвоен, так как при изложении метода в пункте 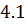 для простоты была опущена двойка.
для простоты была опущена двойка.
По аналогии рассмотрим двумерную
ситуацию:

Так как для мембраны были получены
два набора коэффициентов по обоим измерениям, будем хранить их в двух массивах
типа 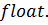 Предполагая, что мембрана
разбивается точками по -измерению и - по , сформируем функцию подготовки и
запуска ядра:
Предполагая, что мембрана
разбивается точками по -измерению и - по , сформируем функцию подготовки и
запуска ядра:



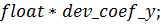
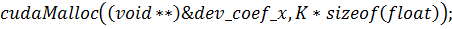
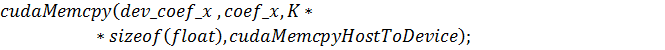
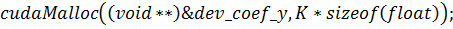
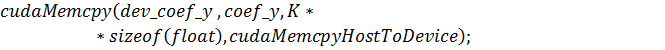

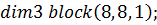




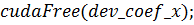

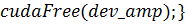
Здесь, как и в одномерном случае,
константа 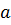 была положена равной единице.
Примечательно, что для построения двумерного алгоритма удобнее пользоваться
двумерными блоками и сеткой.
была положена равной единице.
Примечательно, что для построения двумерного алгоритма удобнее пользоваться
двумерными блоками и сеткой.
Соответствующая функция-ядро будет
выглядеть так:

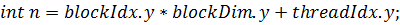
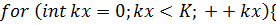
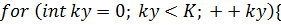

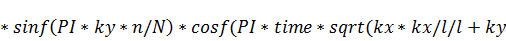 *
*
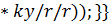

После выполнения любой из этих
программ результаты хранятся в одномерном массиве 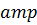 . Таким образом был получен
программный код, с помощью которого отклонения всех точек струны или мембраны
рассчитываются параллельно, что позволяет значительно сократить время расчетов
и сделать возможной визуализацию колебательного процесса. В данной работе
визуализация колебаний осуществляется с помощью открытой графической библиотеки
OpenGL.
Параллельно рассчитанный трехмерный массив координат точек проецируется на
двумерную плоскость с учётом задаваемой в программе перспективы и отображается
на экран. Время, через которое расчет повторяется заново, чтобы получить новые
координаты точек по вертикальной оси, было положено равным одной сотой секунды.
. Таким образом был получен
программный код, с помощью которого отклонения всех точек струны или мембраны
рассчитываются параллельно, что позволяет значительно сократить время расчетов
и сделать возможной визуализацию колебательного процесса. В данной работе
визуализация колебаний осуществляется с помощью открытой графической библиотеки
OpenGL.
Параллельно рассчитанный трехмерный массив координат точек проецируется на
двумерную плоскость с учётом задаваемой в программе перспективы и отображается
на экран. Время, через которое расчет повторяется заново, чтобы получить новые
координаты точек по вертикальной оси, было положено равным одной сотой секунды.
6.3 Оценка выигрыша во
времени
Для того чтобы в полной мере оценить
преимущества технологии CUDA
перед вычислениями на центральном процессоре, было сделано несколько простых
сравнений. Сначала эксперимент был проведен при участии программы для
нахождения значения интеграла методом прямоугольников, описанной в первой
главе. Была создана абсолютно аналогичная, но непараллельная программа, которая
выполнялась исключительно на CPU.
Оценка времени выполнения производилась с помощью функций-расширений CUDA
для программы, написанной на CUDA
C, и стандартными
средствами языка С - для обыкновенной. Как показало сравнение для одного
миллиона разбиений интервала интегрирования, время, затраченное на вычисления CPU,
в десять раз превосходило время, затраченное при расчете видеокартой (точные
значения времени для разного числа разбиений находятся в приложении A).
Далее тестированию подверглось быстрое
преобразование Фурье. Для чистоты эксперимента при создании последовательного
кода была использована библиотека FFTW,
именно та, на основе которой была написана CUFFT,
описанная в четвёртой главе. Для входного вектора длиной в восемь тысяч сто
девяносто два элемента CUDA
сработала в восемь раз быстрее.
При наблюдении за временем вычисления четырёх
тысяч девяносто шести интегралов методом Лежандра-Гаусса параллельные расчеты
оказались выгоднее в тридцать один раз.
И, наконец, расчёт отклонений от положения
равновесия тысячи двадцати четырёх точек струны при использовании CUDA
выполнился в двадцать пять раз быстрее.
ЗАКЛЮЧЕНИЕ
В данной работе на примере одной из задач
математической физики - задаче о малых колебаниях - были рассмотрены
возможности технологии CUDA.
В соответствии с разработанным алгоритмом,
решение задачи о малых колебаниях производилось в два этапа: сначала
параллельно рассчитывались входящие в решение коэффициенты, а затем уже для
всех точек струны или мембраны одновременно находились амплитуды. В качестве
методов вычисления коэффициентов были использованы быстрое преобразование Фурье
и квадратурные формулы Лежандра-Гаусса.
Для осуществления быстрого преобразования Фурье
было предложено использовать библиотеку CUFFT,
которая может производить расчеты параллельно. Также были проделаны некоторые
математические преобразования, которые позволили использовать результат
применительно к решению задачи.
В качестве альтернативы быстрому преобразованию
Фурье был составлен алгоритм вычисления коэффициентов с помощью квадратур
Лежандра-Гаусса. Получены узлы и весовые коэффициенты квадратурной формулы,
которые затем использовались при параллельном расчете интегралов.
Наконец, был написан код, позволяющий
одновременное вычисление отклонений для множества точек, что и являлось главной
задачей работы.
Для наглядности результат был визуализирован с
помощью графической библиотеки, и колебательный процесс выводится на экран
динамически.
По результатам сравнения времени вычисления на GPU
и на CPU можно
заключить, что с применением массивно-параллельных архитектур скорость
вычислений возрастает в десятки раз, из чего следует, что технологии, подобные CUDA,
позволят существенно облегчить процесс расчетов в физике, что, в свою очередь,
при массовом использовании скажется на организации процесса научных исследований
и наверняка снизит их стоимость.
Календарный график
подготовки к защите ВКР
студента-выпускника гр. Ф - 71. Кальницкой
Татьяны Борисовны.
На тему: Применение технологии CUDA
в решении задач математической физики
|
Этапы
работы
|
Выполнение
|
|
планируемый
период (дата контроля)
|
по
факту
|
|
1.
|
Закрепление
за руководителем, выдача задания на практику
|
09. 09. 2011
|
|
|
2.
|
Сдача
отчета по научно-производственной практике
|
09. 01. 2012
|
|
|
3.
|
Утверждение
темы ВКР, подготовка приказа
|
01. 03. 2012
|
|
|
4.
|
Составление
плана ВКР, совместно с руководителем
|
09. 03. 2012
|
|
|
5.
|
Готовность
к 1-му этапу контроля ВКР = выполнение 30 % (минимум: 20-30 стр.)
|
31. 03. 2012
1300
|
|
|
6.
|
Готовность
ко 2-му этапу контроля ВКР = выполнение 70 % (минимум: 40-50 стр.)
|
30. 04. 2012 1300
|
|
|
7.
|
Готовность
к 3-му этапу контроля ВКР = выполнение 95 % (минимум: 55-75 стр.)
|
19. 05. 2012 1300
|
|
|
8.
|
Утверждение
и подписание разделов ВКР у консультантов
|
21
- 29.
05. 2012
|
|
|
9.
|
Утверждение
и подписание ВКР у руководителя (получение отзыва) = выполнение 100%
(минимум: 60-80 стр.)
|
24
- 31.
05. 2012
|
|
|
10.
|
Прохождение
нормоконтроля, получение подписи Пагубко А.Б. (выполнение ВКР - 100% )
|
24
- 31.
05. 2012
|
|
|
11.
|
Получение
рецензии на ВКР
|
25
- 30. 05. 2012
|
|
|
12.
|
Предварительное
заслушивание докладов по ВКР на кафедре
|
30
- 31.
05. 2012
|
|
|
13.
|
Получение
подписи зав. кафедрой
|
30 - 31. 05. 2012
|
|
|
14.
|
Сдача
готового комплекта ВКР секретарю ГАК
|
30.05
- 01. 06. 2012
|
|
|
15.
|
Защита
ВКР
|
14 - 15. 06. 2012
|
|
Руководитель ВКР / / . Подпись
Фамилия, инициалы Дата
cтудент-выпускник
ВКР / / . Подпись Фамилия, инициалы Дата
ПРИЛОЖЕНИЕ А
Время вычислений на CPU
и на GPU
|
Вычисление
определённого интеграла методом прямоугольников
|
|
Количество
разбиений
|
Время
CPU, мс
|
Время
GPU, мс
|
|
10000
|
0.280701
|
0.048032
|
|
50000
|
0.543859
|
0.106976
|
|
100000
|
1.105263
|
0.194208
|
|
500000
|
5.736842
|
0.876561
|
|
1000000
|
10.684210
|
1.757601
|
|
Быстрое
преобразование Фурье
|
|
Длина
входного вектора
|
Время
CPU, мс
|
Время
GPU, мс
|
|
8
|
0.027480
|
0.023072
|
|
32
|
0.035407
|
0.026144
|
|
128
|
0.096631
|
0.034561
|
|
512
|
0.380318
|
0.036384
|
|
2048
|
0.463209
|
0.050624
|
|
4096
|
0.864361
|
0.110688
|
|
8192
|
1.839091
|
0.228481
|
|
Расчет
коэффициентов с помощью квадратур Лежандра-Гаусса
|
|
Кол-во
коэффициентов
|
Время
CPU, мс
|
Время
GPU, мс
|
|
8
|
0.280713
|
0.226272
|
|
32
|
1.912281
|
0.233504
|
|
128
|
7.385964
|
0.299296
|
|
512
|
29.543859
|
0.972000
|
|
2048
|
121.526315
|
3.811360
|
|
4096
|
236.192982
|
7.621276
|
|
8192
|
474.561403
|
16.063521
|
|
Параллельный
расчет амплитуд
|
|
Число
точек
|
Время
CPU, мс
|
Время
GPU, мс
|
|
256
|
0.625792
|
15.714285
|
|
512
|
1.235568
|
31.142857
|
|
1024
|
2.457760
|
62.434581
|
|
2048
|
4.898496
|
118.139178
|
|
4096
|
9.777280
|
236.284141
|
|
8192
|
19.567682
|
464.154172
|
ПРИЛОЖЕНИЕ Б
Визуализация результата

|
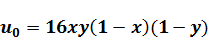
|
|
0
|
 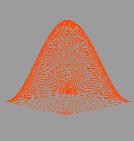
|
 
|
|
2
|
 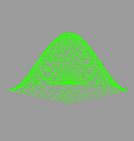
|
 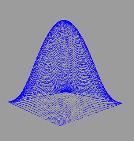
|
|
4
|
 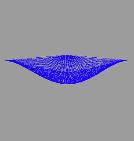
|
 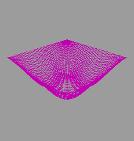
|
|
6
|
 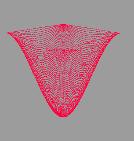
|
 
|
|
8
|
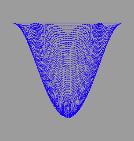 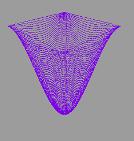
|
 
|
|
Время,
мс
|
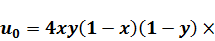 
|
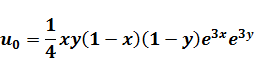
|
|
|
0
|
 
|
 
|
|
|
2
|
 
|
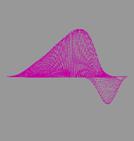 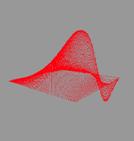
|
|
|
4
|
 
|
 
|
|
|
6
|
 
|
 
|
|
|
8
|
 
|
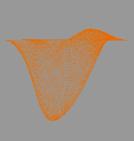 
|
|
|
|
|
|
|
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1.
Беляев, Н. Введение в теорию приближённых вычислений. Конспект лекций / Н.Р.
Беляев, И. В. Танатаров. - Харьков: ФТФ ХНУ им. В.Н. Каразина, 2011. - 215 с.
.
Боресков, А. Основы работы с технологией CUDA / А.В Боресков, А.А. Харламов. -
М.: ДМК ПРЕСС, 2010. - 232 с.
.
Брейсуэлл, Р. Преобразование Фурье / Р.Н. Брейсуэлл // Scientific American. -
1989. - №8. - C. 48-56.
.
Владимиров, В. Уравнения математической физики / B.C. Владимиров. - 4-е изд. -
М.: Наука, 1981. - 512 с.
.
Гергель, В. Теория и практика параллельных вычислений / В.П. Гергель. - М.:
Бином. Лаборатория знаний, 2007. - 424 с.
.
Мухин, О. Моделирование систем. Конспект лекций / О.И. Мухин. - Пермь: РЦИ
ПГТУ, 1999.
.
Хамахер, К. Организация ЭВМ / К. Хамахер, З. Враншевич, С. Заки. - 5-е изд. -
СПб.: Питер, 2003. - 848 с.
.
Хорошевский, В. Архитектура вычислительных систем / В.Г. Хорошевский. - М.:
МГТУ им. Баумана, 2008. - 520 с.
.
Kirk, D. Programming Massively Parallel Processors / D.B. Kirk, Wen-Mei Hwu. -
USA: Elsevier Inc., 2010. - 255 c.
.
Sanders, J. CUDA by Example: an introduction to general-purpose GPU programming
/ J. Sanders, E. Kandrot. - USA: NVIDIA Corporation, 2011. - 311 c.
.
Whitehead, N. Precision & Performance: Floating Point and IEEE 754
Compliance for NVIDIA GPUs / N.Whitehead, A. Fit-Florea. - USA: NVIDIA
Corporation, 2011. - 7 c.
.
CUDA C Best Practices Guide. - USA: NVIDIA Corporation, 2010. - 63 c.
.
CUDA C Programming Guide. - USA: NVIDIA Corporation, 2010. - 154 c.
.
CUDA Toolkit Performance Report. - USA: NVIDIA Corporation, 2011. - 17 c.
.
CUDA: Getting Started Guide. - USA: NVIDIA Corporation, 2012. - 15 c.
.
CUDA API Referenced Manual. - USA: NVIDIA Corporation, 2012. - 593 c.
.
CUDA Toolkit 4.1 CUFFT Library. - USA: NVIDIA Corporation, 2012. - 33 c.
.
CUDA C SDK 4.2 Release Notes. - USA: NVIDIA Corporation 2012.
19.
Официальный сайт компании NVIDIA: http://www.nvidia.com/
.
Сайт разработчиков NVIDIA: http://www.developer.nvidia.com/
.
Использование видеокарт для вычислений, статьи разработчиков:
http://www.gpgpu.ru/