Управление памятью компьютера
Введение
программа память компьютер свопинг
В теоретической части курсовой работы мы
рассмотрим идеологию построения системы управления памятью в современных ОС.
Центральная концепция управления памятью - система виртуальной памяти -
обеспечивает поддержку и защиту больших виртуальных адресных пространств
процессов, составленных из нескольких логических сегментов. Тщательное
проектирование аппаратно-зависимых и аппаратно-независимых компонентов
менеджера памяти, базирующееся на анализе поведения программ (локальности
ссылок), дает возможность организовать их производительную работу.
В практической части мы рассмотрим
программную реализацию визуальной модели структуризации адресного пространства
оперативной памяти страницами переменной длины. Мы рассмотрим основные классы,
необходимые для построения данной модели, а также разберем логику процесса
структуризации адресного пространства.
1.
Организация памяти компьютера. Простейшие схемы управления памятью.
Главная задача компьютерной системы -
выполнять программы. Программы вместе с данными, к которым они имеют доступ, в
процессе выполнения должны (по крайней мере, частично) находиться в оперативной
памяти. Операционной системе приходится решать задачу распределения памяти
между пользовательскими процессами и компонентами ОС. Эта деятельность
называется управлением памятью. Таким образом, память (storage, memory) является важнейшим
ресурсом, требующим тщательного управления. В недавнем прошлом память была
самым дорогим ресурсом.
Часть ОС, которая отвечает за управление
памятью, называется менеджером памяти.
.
Физическая организация памяти компьютера.
Запоминающие устройства компьютера
разделяют, как минимум, на два уровня: основную (главную, оперативную,
физическую) и вторичную (внешнюю) память.
Основная память представляет собой
упорядоченный массив однобайтовых ячеек, каждая из которых имеет свой
уникальный адрес (номер). Процессор извлекает команду из основной памяти,
декодирует и выполняет ее. Для выполнения команды могут потребоваться обращения
еще к нескольким ячейкам основной памяти. Обычно основная память
изготавливается с применением полупроводниковых технологий и теряет свое
содержимое при отключении питания.
Вторичную память (это главным образом
диски) также можно рассматривать как одномерное линейное адресное пространство,
состоящее из последовательности байтов. В отличие от оперативной памяти, она
является энергонезависимой, имеет существенно большую емкость и используется в
качестве расширения основной памяти.
Эту схему можно дополнить еще несколькими
промежуточными уровнями, как показано на рис. 1. Разновидности памяти могут
быть объединены в иерархию по убыванию времени доступа, возрастанию цены и
увеличению емкости.
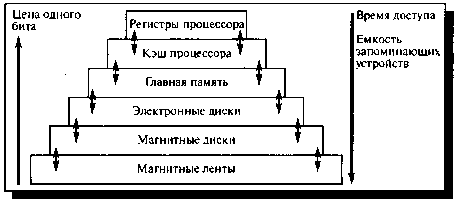
Рисунок 1. Уровни памяти
Многоуровневую схему используют следующим
образом. Информация, которая находится в памяти верхнего уровня, обычно
хранится также на уровнях с большими номерами. Если процессор не обнаруживает
нужную информацию на i-м уровне, он начинает искать ее на следующих уровнях. Когда
нужная информация найдена, она переносится в более быстрые уровни.
.
Локальность
Оказывается, при таком способе организации
по мере снижения скорости доступа к уровню памяти снижается также и частота
обращений к нему.
Ключевую роль здесь играет свойство
реальных программ, в течение ограниченного отрезка времени способных работать с
небольшим набором адресов памяти. Это эмпирически наблюдаемое свойство известно
как принцип локальности или локализации обращений.
Свойство локальности (соседние в
пространстве и времени объекты характеризуются похожими свойствами) присуще не
только функционированию ОС, но и природе вообще. В случае ОС свойство
локальности объяснимо, если учесть, как пишутся программы и как хранятся
данные, то есть обычно в течение какого-то отрезка времени ограниченный
фрагмент кода работает с ограниченным набором данных. Эту часть кода и данных
удается разместить в памяти с быстрым доступом. В результате реальное время
доступа к памяти определяется временем доступа к верхним уровням, что и обусловливает
эффективность использования иерархической схемы. Надо сказать, что описываемая
организация вычислительной системы во многом имитирует деятельность
человеческого мозга при переработке информации. Действительно, решая конкретную
проблему, человек работает с небольшим объемом информации, храня не относящиеся
к делу сведения в своей памяти или во внешней памяти (например, в книгах).
Кэш процессора обычно является частью
аппаратуры, поэтому менеджер памяти ОС занимается распределением информации
главным образом в основной и внешней памяти компьютера. В некоторых схемах
потоки между оперативной и внешней памятью регулируются программистом (см.,
например, далее оверлейные структуры), однако это связано с затратами времени
программиста, так что подобную деятельность стараются возложить на ОС.
Адреса в основной памяти, характеризующие
реальное расположение данных в физической памяти, называются физическими
адресами. Набор физических адресов, с которым работает программа, называют
физическим адресным пространством.
4.
Логическая память
Аппаратная организация памяти в виде
линейного набора ячеек не соответствует представлениям программиста о том, как
организовано хранение программ и данных. Большинство программ представляет
собой набор модулей, созданных независимо друг от друга. Иногда все модули,
входящие в состав процесса, располагаются в памяти один за другим, образуя
линейное пространство адресов. Однако чаще модули помещаются в разные области
памяти и используются по-разному.
Схема управления памятью, поддерживающая
этот взгляд пользователя на то, как хранятся программы и данные, называется
сегментацией. Сегмент - область памяти определенного назначения, внутри которой
поддерживается линейная адресация. Сегменты содержат процедуры, массивы, стек
или скалярные величины, но обычно не содержат информацию смешанного типа.
По-видимому, вначале сегменты памяти
появились в связи с необходимостью обобществления процессами фрагментов
программного кода (текстовый редактор, тригонометрические библиотеки и т.д.), без
чего каждый процесс должен был хранить в своем адресном пространстве
дублирующую информацию. Эти отдельные участки памяти, хранящие информацию,
которую система отображает в память нескольких процессов, получили название
сегментов. Память, таким образом, перестала быть линейной и превратилась в
двумерную. Адрес состоит из двух компонентов: номер сегмента, смещение внутри
сегмента. Далее оказалось удобным размещать в разных сегментах различные
компоненты процесса (код программы, данные, стек и т.д.). Попутно выяснилось,
что можно контролировать характер работы с конкретным сегментом, приписав ему
атрибуты, например, права доступа или типы операций, которые разрешается
производить с данными, хранящимися в сегменте.
Некоторые сегменты, описывающие адресное
пространство процесса, показаны на рис. 2.
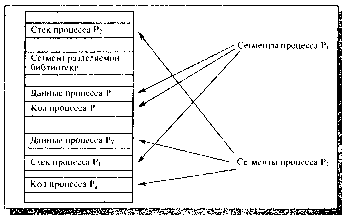
Рисунок 2. Сегменты, описывающие адресное пространство процесса
Большинство современных ОС поддерживают сегментную организацию
памяти. В некоторых архитектурах (Intel,
например) сегментация поддерживается оборудованием.
Адреса, к которым обращается процесс, таким образом, отличаются от
адресов, реально существующих в оперативной памяти. В каждом конкретном случае
используемые программой адреса могут быть представлены различными способами.
Например, адреса в исходных текстах обычно символические. Компилятор связывает
эти символические адреса с перемещаемыми адресами (такими, как п байт от начала
модуля). Подобный адрес, сгенерированный программой, обычно называют логическим
(в системах с виртуальной памятью он часто называется виртуальным) адресом.
Совокупность всех логических адресов называется логическим (виртуальным)
адресным пространством.
.
Связывание адресов
Итак, логические и физические адресные
пространства ни по организации, ни по размеру не соответствуют друг другу.
Максимальный размер логического адресного пространства обычно определяется
разрядностью процессора (например, 232) и в современных системах
значительно превышает размер физического адресного пространства. Следовательно,
процессор и ОС должны быть способны отобразить ссылки в коде программы в
реальные физические адреса, соответствующие текущему расположению программы в
основной памяти. Такое отображение адресов называют трансляцией (привязкой)
адреса или связыванием адресов (см. рис. 3).
Связывание логического адреса,
порожденного оператором программы, с физическим должно быть осуществлено до
начала выполнения оператора или в момент его выполнения. Таким образом,
привязка инструкций и данных к памяти в принципе может быть сделана на
следующих шагах [Silberschatz, 2002].
· Этап компиляции (Compile time). Когда на стадии
компиляции известно точное место размещения процесса в памяти, тогда
непосредственно генерируются физические адреса. При изменении стартового адреса
программы необходимо перекомпилировать ее код. В качестве примера можно
привести.com программы MS-DOS, которые связывают ее с физическими адресами на
стадии компиляции.
· Этап загрузки (Load time). Если информация о
размещении программы на стадии компиляции отсутствует, компилятор генерирует
перемещаемый код. В этом случае окончательное связывание откладывается до
момента загрузки.
·
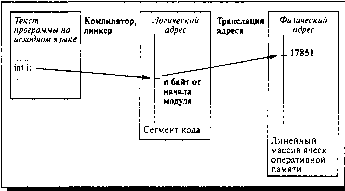
Рисунок 3. Формирование логического адреса и связывание с
физическим
Если стартовый адрес меняется, нужно всего
лишь перезагрузить код с учетом измененной величины.
• Этап выполнения (Execution time). Если процесс может
быть перемещен во время выполнения из одной области памяти в другую, связывание
откладывается до стадии выполнения. Здесь желательно наличие
специализированного оборудования, например регистров перемещения. Их значение
прибавляется к каждому адресу, сгенерированному процессом. Большинство
современных ОС осуществляет трансляцию адресов на этапе выполнения, используя для
этого специальный аппаратный механизм.
6.
Функции системы управления памятью
Чтобы обеспечить эффективный контроль
использования памяти, ОС должна выполнять следующие функции:
· отображение адресного
пространства процесса на конкретные области физической памяти;
· распределение памяти
между конкурирующими процессами;
· контроль доступа к
адресным пространствам процессов;
· выгрузка процессов
(целиком или частично) во внешнюю память, когда в оперативной памяти
недостаточно места;
· учет свободной и занятой
памяти.
В следующих разделах лекции
рассматривается ряд конкретных схем управления памятью. Каждая схема включает в
себя определенную идеологию управления, а также алгоритмы и структуры данных и
зависит от архитектурных особенностей используемой системы. Вначале будут
рассмотрены простейшие схемы. Доминирующая на сегодня схема виртуальной памяти
будет описана в последующих лекциях.
7.
Простейшие схемы управления памятью
Первые ОС применяли очень простые методы
управления памятью. Вначале каждый процесс пользователя должен был полностью
поместиться в основной памяти, занимать непрерывную область памяти, а система
принимала к обслуживанию дополнительные пользовательские процессы до тех пор,
пока все они одновременно помещались в основной памяти. Затем появился «простой
свопинг» (система по-прежнему размещает каждый процесс в основной памяти
целиком, но иногда на основании некоторого критерия целиком сбрасывает образ
некоторого процесса из основной памяти во внешнюю и заменяет его в основной
памяти образом другого процесса). Такого рода схемы имеют не только
историческую ценность. В настоящее время они применяются в учебных и
научно-исследовательских модельных ОС, а также в ОС для встроенных (embedded) компьютеров.
8.
Схема с фиксированными разделами
Самым простым способом управления
оперативной памятью является ее предварительное (обычно на этапе генерации или
в момент загрузки системы) разбиение на несколько разделов фиксированной
величины. Поступающие процессы помещаются в тот или иной раздел. При этом
происходит условное разбиение физического адресного пространства. Связывание
логических и физических адресов процесса происходит на этапе его загрузки в
конкретный раздел, иногда - на этапе компиляции.
Каждый раздел может иметь свою очередь
процессов, а может существовать и глобальная очередь для всех разделов (см.
рис. 4).
Эта схема была реализована в IBM OS/360 (MFT), DEC RSX-11 и ряде других систем.
Подсистема управления памятью оценивает
размер поступившего процесса, выбирает подходящий для него раздел, осуществляет
загрузку процесса в этот раздел и настройку адресов.
Очевидный недостаток этой схемы - число
одновременно выполняемых процессов ограничено числом разделов.
Другим существенным недостатком является
то, что предлагаемая схема сильно страдает от внутренней фрагментации - потери
части памяти, выделенной процессу, но не используемой им. Фрагментация
возникает потому, что процесс не полностью занимает выделенный ему раздел или
потому, что некоторые разделы слишком малы для выполняемых пользовательских
программ.
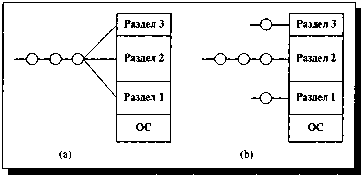
Рисунок 4. Схема с фиксированными разделами: (а) - с общей
очередью процессов, (b) - с
отдельными очередями процессов
9.
Один процесс в памяти
Частный случай схемы с фиксированными
разделами - работа менеджера памяти однозадачной ОС. В памяти размещается один
пользовательский процесс. Остается определить, где располагается
пользовательская программа по отношению к ОС - в верхней части памяти, в нижней
или в средней. Причем часть ОС может быть в ROM (например, BIOS, драйверы устройств).
Главный фактор, влияющий на это решение, - расположение вектора прерываний,
который обычно локализован в нижней части памяти, поэтому ОС также размещают в
нижней. Примером такой организации может служить ОС MS-DOS.
Защита адресного пространства ОС от
пользовательской программы может быть организована при помощи одного граничного
регистра, содержащего адрес границы ОС.
10.
Оверлейная структура
Так как размер логического адресного
пространства процесса может быть больше, чем размер выделенного ему раздела
(или больше, чем размер самого большого раздела), иногда используется техника,
называемая оверлей (overlay) или организация структуры с перекрытием. Основная идея - держать
в памяти только те инструкции программы, которые нужны в данный момент.
Потребность в таком способе загрузки
появляется, если логическое адресное пространство системы мало, например 1
Мбайт (MS-DOS) или даже всего 64 Кбайта (PDP-11), а программа относительно
велика. На современных 32-разрядных системах, где виртуальное адресное
пространство измеряется гигабайтами, проблемы с нехваткой памяти решаются
другими способами (см. раздел «Виртуальная память»).
Коды ветвей оверлейной структуры программы
находятся на диске как абсолютные образы памяти и считываются драйвером
оверлеев при необходимости. Для описания оверлейной структуры обычно
используется специальный несложный язык (overlay description language). Совокупность файлов
исполняемой программы дополняется файлом (обычно с расширением. odl), описывающим дерево
вызовов внутри программы. Для примера, приведенного на рис. 8.5, текст этого
файла может выглядеть так:
А - (В, С) C - (D, E)
Синтаксис подобного файла может
распознаваться загрузчиком. Привязка к физической памяти происходит в момент
очередной загрузки одной из ветвей программы.

Рисунок 5. Организация структуры с перекрытием
Оверлеи могут быть полностью реализованы
на пользовательском уровне в системах с простой файловой структурой. ОС при
этом лишь делает несколько больше операций ввода-вывода. Типовое решение -
порождение линкером специальных команд, которые включают загрузчик каждый раз,
когда требуется обращение к одной из перекрывающихся ветвей программы.
Тщательное проектирование оверлейной
структуры отнимает много времени и требует знания устройства программы, ее
кода, данных и языка описания оверлейной структуры. По этой причине применение
оверлеев ограничено компьютерами с небольшим логическим адресным пространством.
Как мы увидим в дальнейшем, проблема оверлейных сегментов, контролируемых
программистом, отпадает благодаря появлению систем виртуальной памяти.
Заметим, что возможность организации
структур с перекрытиями во многом обусловлена свойством локальности, которое
позволяет хранить в памяти только ту информацию, которая необходима в
конкретный момент вычислений.
11.
Динамическое распределение. Свопинг
Имея дело с пакетными системами, можно
обходиться фиксированными разделами и не использовать ничего более сложного. В
системах с разделением времени возможна ситуация, когда память не в состоянии
содержать все пользовательские процессы. Приходится прибегать к свопингу (swapping) - перемещению процессов
из главной памяти на диск и обратно целиком. Частичная выгрузка процессов на
диск осуществляется в системах со страничной организацией (paging) и будет рассмотрена
ниже.
Выгруженный процесс может быть возвращен в
то же самое адресное пространство или в другое. Это ограничение диктуется
методом связывания. Для схемы связывания на этапе выполнения можно загрузить
процесс в другое место памяти.
Свопинг не имеет непосредственного
отношения к управлению памятью, скорее он связан с подсистемой планирования
процессов. Очевидно, что свопинг увеличивает время переключения контекста.
Время выгрузки может быть сокращено за счет организации специально отведенного
пространства на диске (раздел для свопинга). Обмен с диском при этом
осуществляется блоками большего размера, то есть быстрее, чем через стандартную
файловую систему. Во многих версиях Unix свопинг начинает работать только тогда, когда
возникает необходимость в снижении загрузки системы.
12.
Схема с переменными разделами
В принципе, система свопинга может
базироваться на фиксированных разделах. Более эффективной, однако,
представляется схема динамического распределения или схема с переменными
разделами, которая может использоваться и в тех случаях, когда все процессы
целиком помещаются в памяти, то есть в отсутствие свопинга. В этом случае
вначале вся память свободна и не разделена заранее на разделы. Вновь
поступающей задаче выделяется строго необходимое количество памяти, не более.
После выгрузки процесса память временно освобождается. По истечении некоторого
времени память представляет собой переменное число разделов разного размера
(рис. 6). Смежные свободные участки могут быть объединены.
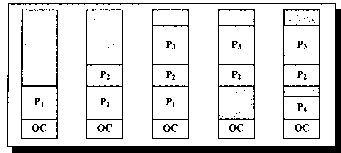
Рисунок 6. Динамика распределения памяти между процессами (серым
цветом показана неиспользуемая память)
В какой раздел помещать процесс? Наиболее
распространены три стратегии:
· Стратегия первого
подходящего (First fit). Процесс помещается в первый подходящий по размеру раздел.
· Стратегия наименее
подходящего (Worst fit). При помещении в самый большой раздел в нем остается достаточно
места для возможного размещения еще одного процесса.
Моделирование показало, что доля полезно
используемой памяти в первых двух случаях больше, при этом первый способ
несколько быстрее. Попутно заметим, что перечисленные стратегии широко
применяются и другими компонентами ОС, например для размещения файлов на диске.
Типовой цикл работы менеджера памяти
состоит в анализе запроса на выделение свободного участка (раздела), выборе его
среди имеющихся в соответствии с одной из стратегий (первого подходящего,
наиболее подходящего и наименее подходящего), загрузке процесса в выбранный раздел
и последующих изменениях таблиц свободных и занятых областей. Аналогичная
корректировка необходима и после завершения процесса. Связывание адресов может
осуществляться на этапах загрузки и выполнения.
Этот метод более гибок по сравнению с
методом фиксированных разделов, однако ему присуща внешняя фрагментация -
наличие большого числа участков неиспользуемой памяти, не выделенной ни одному
процессу. Выбор стратегии размещения процесса между первым подходящим и
наиболее подходящим слабо влияет на величину фрагментации. Любопытно, что метод
наиболее подходящего может оказаться наихудшим, так как он оставляет множество
мелких незанятых блоков.
Статистический анализ показывает, что
пропадает в среднем 1/3 памяти! Это известное правило 50% (два соседних
свободных участка в отличие от двух соседних процессов могут быть объединены).
Одно из решений проблемы внешней
фрагментации - организовать сжатие, то есть перемещение всех занятых
(свободных) участков в сторону возрастания (убывания) адресов, так, чтобы вся
свободная память образовала непрерывную область. Этот метод иногда называют
схемой с перемещаемыми разделами. В идеале фрагментация после сжатия должна
отсутствовать. Сжатие, однако, является дорогостоящей процедурой, алгоритм
выбора оптимальной стратегии сжатия очень труден и, как правило, сжатие
осуществляется в комбинации с выгрузкой и загрузкой по другим адресам.
13.
Страничная память
Описанные выше схемы недостаточно
эффективно используют память, поэтому в современных схемах управления памятью
не принято размещать процесс в оперативной памяти одним непрерывным блоком.
В самом простом и наиболее
распространенном случае страничной организации памяти (или paging) как логическое адресное
пространство, так и физическое представляются состоящими из наборов блоков или
страниц одинакового размера. При этом образуются логические страницы (page), а соответствующие
единицы в физической памяти называют физическими страницами или страничными
кадрами (page frames). Страницы (и страничные кадры) имеют фиксированную длину, обычно
являющуюся степенью числа 2, и не могут перекрываться. Каждый кадр содержит
одну страницу данных. При такой организации внешняя фрагментация отсутствует, а
потери из-за внутренней фрагментации, поскольку процесс занимает целое число
страниц, ограничены частью последней страницы процесса.
Логический адрес в страничной системе -
упорядоченная пара (р, d), где р - номер страницы в виртуальной памяти, ad - смещение в рамках
страницы р, на которой размещается адресуемый элемент. Заметим, что разбиение
адресного пространства на страницы осуществляется вычислительной системой
незаметно для программиста. Поэтому адрес является двумерным лишь с точки
зрения операционной системы, а с точки зрения программиста адресное
пространство процесса остается линейным.
Описываемая схема позволяет загрузить
процесс, даже если нет непрерывной области кадров, достаточной для размещения
процесса целиком. Но одного базового регистра для осуществления трансляции
адреса в данной схеме недостаточно. Система отображения логических адресов в
физические сводится к системе отображения логических страниц в физические и
представляет собой таблицу страниц, которая хранится в оперативной памяти.
Иногда говорят, что таблица страниц - это кусочно-линейная функция отображения,
заданная в табличном виде.
Интерпретация логического адреса показана
на рис. 7. Если выполняемый процесс обращается к логическому адресу v = (p, d), механизм отображения
ищет номер страницы р в таблице страниц и определяет, что эта страница находится
в страничном кадре р', формируя реальный адрес из р' и d.
Таблица страниц (page table) адресуется при помощи
специального регистра процессора и позволяет определить номер кадра по
логическому адресу. Помимо этой основной задачи, при помощи атрибутов,
записанных в строке таблицы страниц, можно организовать контроль доступа к
конкретной странице и ее защиту.
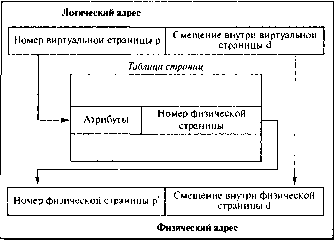
Рисунок 7. Связь логического и физического адресов при страничной
организации памяти
Отметим еще раз различие точек зрения
пользователя и системы на используемую память. С точки зрения пользователя, его
память - единое непрерывное пространство, содержащее только одну программу.
Реальное отображение скрыто от пользователя и контролируется ОС. Заметим, что
процессу пользователя чужая память недоступна. Он не имеет возможности
адресовать память за пределами своей таблицы страниц, которая включает только
его собственные страницы.
Для управления физической памятью ОС
поддерживает структуру таблицы кадров. Она имеет одну запись на каждый
физический кадр, показывающий его состояние.
Отображение адресов должно быть
осуществлено корректно даже в сложных случаях и обычно реализуется аппаратно.
Для ссылки на таблицу процессов используется специальный регистр. При
переключении процессов необходимо найти таблицу страниц нового процесса,
указатель на которую входит в контекст процесса.
14.
Сегментная и сегментно-страничная организация памяти
Существуют две другие схемы организации
управления памятью: сегментная и сегментно-страничная. Сегменты, в отличие от
страниц, могут иметь переменный размер. Идея сегментации изложена во введении.
При сегментной организации виртуальный адрес является двумерным как для
программиста, так и для операционной системы, и состоит из двух полей - номера
сегмента и смещения внутри сегмента. Подчеркнем, что в отличие от страничной
организации, где линейный адрес преобразован в двумерный операционной системой
для удобства отображения, здесь двумерность адреса является следствием представления
пользователя о процессе не в виде линейного массива байтов, а как набора
сегментов переменного размера (данные, код, стек…).
Программисты, пишущие на языках низкого
уровня, должны иметь представление о сегментной организации, явным образом
меняя значения сегментных регистров (это хорошо видно по текстам программ,
написанных на Ассемблере). Логическое адресное пространство - набор сегментов.
Каждый сегмент имеет имя, размер и другие параметры (уровень привилегий,
разрешенные виды обращений, флаги присутствия…). В отличие от страничной схемы,
где пользователь задает только один адрес, который разбивается на номер
страницы и смещение прозрачным для программиста образом, в сегментной схеме
пользователь специфицирует каждый адрес двумя величинами: именем сегмента и
смещением.
Каждый сегмент - линейная
последовательность адресов, начинающаяся с 0. Максимальный размер сегмента
определяется разрядностью процессора (при 32-разрядной адресации это 232
байт или 4 Гбайт). Размер сегмента может меняться динамически (например,
сегмент стека). В элементе таблицы сегментов помимо физического адреса начала
сегмента обычно содержится и длина сегмента. Если размер смещения в виртуальном
адресе выходит за пределы размера сегмента, возникает исключительная ситуация.
Логический адрес - упорядоченная пара v = (s, d), номер сегмента и
смещение внутри сегмента.
В системах, где сегменты поддерживаются
аппаратно, эти параметры обычно хранятся в таблице дескрипторов сегментов, а
программа обращается к этим дескрипторам по номерам-селекторам. При этом в
контекст каждого процесса входит набор сегментных регистров, содержащих
селекторы текущих сегментов кода, стека, данных и т.д. и определяющих, какие
сегменты будут использоваться при разных видах обращений к памяти. Это позволяет
процессору уже на аппаратном уровне определять допустимость обращений к памяти,
упрощая реализацию защиты информации от повреждения и несанкционированного
доступа.
Аппаратная поддержка сегментов
распространена мало (главным образом на процессорах Intel). В большинстве ОС
сегментация реализуется на уровне, не зависящем от аппаратуры.
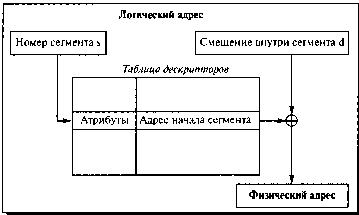
Рисунок 8. Преобразование логического адреса при сегментной
организации памяти
Хранить в памяти сегменты большого размера
целиком так же неудобно, как и хранить процесс непрерывным блоком.
Напрашивается идея разбиения сегментов на страницы. При сегментно-страничной
организации памяти происходит двухуровневая трансляция виртуального адреса в
физический. В этом случае логический адрес состоит из трех полей: номера
сегмента логической памяти, номера страницы внутри сегмента и смещения внутри
страницы. Соответственно, используются две таблицы отображения - таблица
сегментов, связывающая номер сегмента с таблицей страниц, и отдельная таблица
страниц для каждого сегмента.
Сегментно-страничная и страничная
организация памяти позволяют легко организовать совместное использование одних
и тех же данных и программного кода разными задачами. Для этого различные
логические блоки памяти разных процессов отображают в один и тот же блок
физической памяти, где размещается разделяемый фрагмент кода или данных.
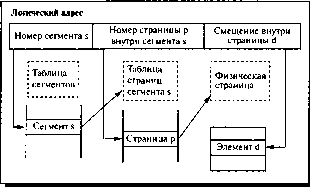
Рисунок 9. Упрощенная схема формирования физического адреса при
сегментно-страничной организации памяти
15.
Виртуальная память. Архитектурные средства поддержки виртуальной памяти
Понятие
виртуальной памяти
Разработчикам программного обеспечения
часто приходится решать проблему размещения в памяти больших программ, размер
которых превышает объем доступной оперативной памяти. Один из вариантов решения
данной проблемы - организация структур с перекрытием - рассмотрен в предыдущей
лекции. При этом предполагалось активное участие программиста в процессе
формирования перекрывающихся частей программы. Развитие архитектуры компьютеров
и расширение возможностей операционной системы по управлению памятью позволило
переложить решение этой задачи на компьютер. Одним из главных достижений стало
появление виртуальной памяти (virtual memory). Впервые она была реализована в 1959 году на
компьютере «Атлас», разработанном в Манчестерском университете.
Суть концепции виртуальной памяти
заключается в следующем. Информация, с которой работает активный процесс,
должна располагаться в оперативной памяти. В схемах виртуальной памяти у
процесса создается иллюзия того, что вся необходимая ему информация имеется в
основной памяти. Для этого, во-первых, занимаемая процессом память разбивается
на несколько частей, например страниц. Во-вторых, логический адрес (логическая
страница), к которому обращается процесс, динамически транслируется в
физический адрес (физическую страницу). И наконец, в тех случаях, когда
страница, к которой обращается процесс, не находится в физической памяти, нужно
организовать ее подкачку с диска. Для контроля наличия страницы в памяти
вводится специальный бит присутствия, входящий в состав атрибутов страницы в
таблице страниц.
Таким образом, в наличии всех компонентов
процесса в основной памяти необходимости нет. Важным следствием такой
организации является то, что размер памяти, занимаемой процессом, может быть
больше, чем размер оперативной памяти. Принцип локальности обеспечивает этой
схеме нужную эффективность.
Возможность выполнения программы,
находящейся в памяти лишь частично, имеет ряд вполне очевидных преимуществ:
· Программа не ограничена
объемом физической памяти. Упрощается разработка программ, поскольку можно
задействовать большие виртуальные пространства, не заботясь о размере
используемой памяти.
· Поскольку появляется
возможность частичного помещения программы (процесса) в память и гибкого
перераспределения памяти между программами, можно разместить в памяти больше
программ, что увеличивает загрузку процессора и пропускную способность системы.
· Объем ввода-вывода для
выгрузки части программы на диск может быть меньше, чем в варианте
классического свопинга, в итоге каждая программа будет работать быстрее.
Таким образом, возможность обеспечения
(при поддержке операционной системы) для программы «видимости» практически
неограниченной (характерный размер для 32-разрядных архитектур 232 =
4 Гбайт) адресуемой пользовательской памяти (логическое адресное пространство)
при наличии основной памяти существенно меньших размеров (физическое адресное
пространство) - очень важный аспект.
Но введение виртуальной памяти позволяет
решать другую, не менее важную задачу - обеспечение контроля доступа к
отдельным сегментам памяти и, в частности, защиту пользовательских программ
друг от друга и защиту ОС от пользовательских программ. Каждый процесс работает
со своими виртуальными адресами, трансляцию которых в физические выполняет
аппаратура компьютера. Таким образом, пользовательский процесс лишен
возможности напрямую обратиться к страницам основной памяти, занятым
информацией, относящейся к другим процессам.
Например, 16-разрядный компьютер PDP-11/70 с 64 Кбайт
логической памяти мог иметь до 2 Мбайт оперативной памяти. Операционная система
этого компьютера тем не менее поддерживала виртуальную память, которая
обеспечивала защиту и перераспределение основной памяти между пользовательскими
процессами.
Напомним, что в системах с виртуальной
памятью те адреса, которые генерирует программа (логические адреса), называются
виртуальными, и они формируют виртуальное адресное пространство. Термин
«виртуальная память» означает, что программист имеет дело с памятью, отличной
от реальной, размер которой потенциально больше, чем размер оперативной памяти.
Хотя известны и чисто программные
реализации виртуальной памяти, это направление получило наиболее широкое развитие
после соответствующей аппаратной поддержки.
Следует отметить, что оборудование
компьютера принимает участие в трансляции адреса практически во всех схемах
управления памятью. Но в случае виртуальной памяти это становится более сложным
вследствие разрывности отображения и многомерности логического адресного
пространства. Может быть, наиболее существенным вкладом аппаратуры в реализацию
описываемой схемы является автоматическая генерация исключительных ситуаций при
отсутствии в памяти нужных страниц (page fault).
Любая из трех ранее рассмотренных схем
управления памятью - страничной, сегментной и сегментно-страничной - пригодна
для организации виртуальной памяти. Чаще всего используется
сегментно-стра-ничная модель, которая является синтезом страничной модели и
идеи сегментации. Причем для тех архитектур, в которых сегменты не
поддерживаются аппаратно, их реализация - задача архитектурно-независимого
компонента менеджера памяти.
Сегментная организация в чистом виде
встречается редко.
Архитектурные
средства поддержки виртуальной памяти
Очевидно, что невозможно создать полностью
машинно-независимый компонент управления виртуальной памятью. С другой стороны,
имеются существенные части программного обеспечения, связанного с управлением
виртуальной памятью, для которых детали аппаратной реализации совершенно не
важны. Одним из достижений современных ОС является грамотное и эффективное
разделение средств управления виртуальной памятью нааппаратно-независимую и
аппаратно-зависимую части. Коротко рассмотрим, что и каким образом входит в
аппаратно-зависимую часть подсистемы управления виртуальной памятью. Компоненты
аппаратно-независимой подсистемы будут рассмотрены в следующей лекции.
В самом распространенном случае необходимо
отобразить большое виртуальное адресное пространство в физическое адресное
пространство существенно меньшего размера. Пользовательский процесс или ОС
должны иметь возможность осуществить запись по виртуальному адресу, а задача ОС
- сделать так, чтобы записанная информация оказалась в физической памяти
(впоследствии при нехватке оперативной памяти она может быть вытеснена во
внешнюю память). В случае виртуальной памяти система отображения адресных
пространств помимо трансляции адресов должна предусматривать ведение таблиц,
показывающих, какие области виртуальной памяти в данный момент находятся в
физической памяти и где именно размещаются.
Страничная
виртуальная память
Как и в случае простой страничной
организации, страничная виртуальная память и физическая память представляются состоящими
из наборов блоков или страниц одинакового размера. Виртуальные адреса делятся
на страницы (page), соответствующие единицы в физической памяти образуют страничные
кадры (page frames), а в целом система поддержки страничной виртуальной памяти называется
пейджингом (paging). Передача информации между памятью и диском всегда
осуществляется целыми страницами.
После разбиения менеджером памяти
виртуального адресного пространства на страницы виртуальный адрес преобразуется
в упорядоченную пару (р, d), где р - номер страницы в виртуальной памяти, ad - смещение в рамках
страницы р, внутри которой размещается адресуемый элемент. Процесс может
выполняться, если его текущая страница находится в оперативной памяти. Если
текущей страницы в главной памяти нет, она должна быть переписана (подкачана)
из внешней памяти. Поступившую страницу можно поместить в любой свободный
страничный кадр.
Поскольку число виртуальных страниц
велико, таблица страниц принимает специфический вид (см. раздел «Структура
таблицы страниц»), структура записей становится более сложной, среди
атрибутов страницы появляются биты присутствия, модификации и другие
управляющие биты.
При отсутствии страницы в памяти в
процессе выполнения команды возникает исключительная ситуация, называемая страничное
нарушение (page fault) или страничный отказ. Обработка страничного нарушения
заключается в том, что выполнение команды прерывается, затребованная страница
подкачивается из конкретного места вторичной памяти в свободный страничный кадр
физической памяти и попытка выполнения команды повторяется. При отсутствии
свободных страничных кадров на диск выгружается редко используемая страница.
Проблемы замещения страниц и обработки страничных нарушений рассматриваются в
следующей лекции.
Для управления физической памятью ОС
поддерживает структуру таблицы кадров. Она имеет одну запись на каждый
физический кадр, показывающий его состояние.
В большинстве современных компьютеров со
страничной организацией в основной памяти хранится лишь часть таблицы страниц,
а быстрота доступа к элементам таблицы текущей виртуальной памяти достигается,
как будет показано ниже, за счет использования сверхбыстродействующей памяти,
размещенной в кэше процессора.
Сегментно-страничная
организации виртуальной памяти
Как и в случае простой сегментации, в
схемах виртуальной памяти сегмент - это линейная последовательность адресов,
начинающаяся с 0. При организации виртуальной памяти размер сегмента может быть
велик, например может превышать размер оперативной памяти. Повторяя все ранее
приведенные рассуждения о размещении в памяти больших программ, приходим к
разбиению сегментов на страницы и необходимости поддержки своей таблицы страниц
для каждого сегмента.
На практике, однако, появления в системе
большого количества таблиц страниц стараются избежать, организуя
неперекрывающиеся сегменты в одном виртуальном пространстве, для описания
которого хватает одной таблицы страниц. Таким образом, одна таблица страниц
отводится для всего процесса. Например, в популярных ОС Linux и Windows 2000 все сегменты
процесса, а также область памяти ядра ограничены виртуальным адресным
пространством объемом 4 Гбайт. При этом ядро ОС располагается по фиксированным
виртуальным адресам вне зависимости от выполняемого процесса.
16.
Структура таблицы страниц
Организация таблицы страниц - один из
ключевых элементов отображения адресов в страничной и сегментно-страничной
схемах. Рассмотрим структуру таблицы страниц для случая страничной организации
более подробно.
Итак, виртуальный адрес состоит из
виртуального номера страницы и смещения. Номер записи в таблице страниц
соответствует номеру виртуальной страницы. Размер записи колеблется от системы
к системе, но чаще всего он составляет 32 бита. Из этой записи в таблице
страниц находится номер кадра для данной виртуальной страницы, затем
прибавляется смещение и формируется физический адрес. Помимо этого запись в
таблице страниц содержит информацию об атрибутах страницы. Это биты присутствия
и защиты (например, 0 - read/write, 1 - read only…). Также могут быть
указаны: бит модификации, который устанавливается, если содержимое страницы
модифицировано, и позволяет контролировать необходимость перезаписи страницы на
диск; бит ссылки, который помогает выделить малоиспользуемые страницы; бит,
разрешающий кэширование, и другие управляющие биты. Заметим, что адреса страниц
на диске не являются частью таблицы страниц.
Основную проблему для эффективной
реализации таблицы страниц создают большие размеры виртуальных адресных
пространств современных компьютеров, которые обычно определяются разрядностью
архитектуры процессора. Самыми распространенными на сегодня являются
32-разрядные процессоры, позволяющие создавать виртуальные адресные
пространства размером 4 Гбайт (для 64-разрядных компьютеров эта величина равна
264 байт). Кроме того, существует проблема скорости отображения,
которая решается за счет использования так называемой ассоциативной памяти (см.
следующий раздел).
Подсчитаем примерный размер таблицы
страниц. В 32-битном адресном пространстве при размере страницы 4 Кбайт (Intel) получаем 232/212
= 220, то есть приблизительно миллион страниц, а в 64-битном и того
более. Таким образом, таблица должна иметь примерно миллион строк (entry), причем запись в строке
состоит из нескольких байтов. Заметим, что каждый процесс нуждается в своей
таблице страниц (а в случае сегментно-страничной схемы желательно иметь по
одной таблице страниц на каждый сегмент).
Понятно, что количество памяти, отводимое
таблицам страниц, не может быть так велико. Для того чтобы избежать размещения
в памяти огромной таблицы, ее разбивают на ряд фрагментов. В оперативной памяти
хранят лишь некоторые, необходимые для конкретного момента исполнения фрагменты
таблицы страниц. В силу свойства локальности число таких фрагментов относительно
невелико. Выполнить разбиение таблицы страниц на части можно по-разному.
Наиболее распространенный способ разбиения - организация так называемой
многоуровневой таблицы страниц. Для примера рассмотрим двухуровневую таблицу с
размером страниц 4 Кбайт, реализованную в 32-разрядной архитектуре Intel.
Таблица, состоящая из 220
строк, разбивается на 210 таблиц второго уровня по 210
строк. Эти таблицы второго уровня объединены в общую структуру при помощи одной
таблицы первого уровня, состоящей из 2Ш строк. 32-разрядный адрес
делится на 10-разрядное поле p1, 10-разрядное поле Р2 и 12-разрядное смещение d. Поле p1 указывает на нужную
строку в таблице первого уровня, поле Р2 - второго, а поле d локализует нужный байт
внутри указанного страничного кадра (см. рис. 9.1).
При помощи всего лишь одной таблицы
второго уровня можно ох-ватить4 Мбайт (4 Кбайтх 1024) оперативной памяти. Таким
образом, для размещения процесса с большим объемом занимаемой памяти достаточно
иметь в оперативной памяти одну таблицу первого уровня и несколько таблиц
второго уровня. Очевидно, что суммарное количество строк в этих таблицах много
меньше 220. Такой подход естественным образом обобщается на три и
более уровней таблицы.
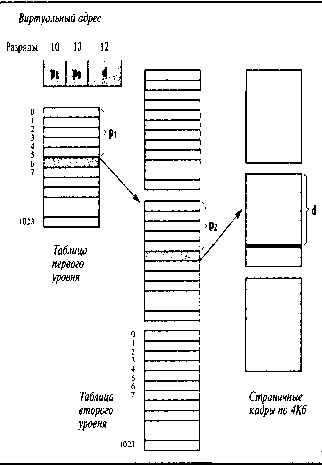
Рисунок 10. Уровни
Наличие нескольких уровней, естественно,
снижает производительность менеджера памяти. Несмотря на то что размеры таблиц
на каждом уровне подобраны так, чтобы таблица помещалась целиком внутри одной
страницы, обращение к каждому уровню - это отдельное обращение к памяти. Таким
образом, трансляция адреса может потребовать нескольких обращений к памяти.
Количество уровней в таблице страниц
зависит от конкретных особенностей архитектуры. Можно привести примеры
реализации одноуровневого (DEC PDP-11), двухуровневого (Intel, DEC VAX), трехуровневого (Sun SPARC, DEC Alpha) пейджинга, а также
пейджинга с заданным количеством уровней (Motorola). Функционирование RISC-процессора MIPS R2000 осуществляется
вообще без таблицы страниц. Здесь поиск нужной страницы, если эта страница
отсутствует в ассоциативной памяти, должна взять на себя ОС (так называемый zero level paging).
17.
Ассоциативная память
Поиск номера кадра, соответствующего
нужной странице, в многоуровневой таблице страниц требует нескольких обращений
к основной памяти, поэтому занимает много времени. В некоторых случаях такая
задержка недопустима. Проблема ускорения поиска решается на уровне архитектуры
компьютера.
В соответствии со свойством локальности
большинство программ в течение некоторого промежутка времени обращаются к
небольшому количеству страниц, поэтому активно используется только небольшая
часть таблицы страниц.
Естественное решение проблемы ускорения -
снабдить компьютер аппаратным устройством для отображения виртуальных страниц в
физические без обращения к таблице страниц, то есть иметь небольшую, быструю
кэш-память, хранящую необходимую на данный момент часть таблицы страниц. Это
устройство называется ассоциативной памятью, иногда также употребляют термин
буфер поиска трансляции (translation lookaside buffer - TLB).
Одна запись таблицы в ассоциативной памяти
(один вход) содержит информацию об одной виртуальной странице: ее атрибуты и
кадр, в котором она находится. Эти поля в точности соответствуют полям в
таблице страниц.
Так как ассоциативная память содержит
только некоторые из записей таблицы страниц, каждая запись в TLB должна включать поле с
номером виртуальной страницы. Память называется ассоциативной, потому что в ней
происходит одновременное сравнение номера отображаемой виртуальной страницы с
соответствующим полем во всех строках этой небольшой таблицы. Поэтому данный
вид памяти достаточно дорого стоит. В строке, поле виртуальной страницы которой
совпало с искомым значением, находится номер страничного кадра. Обычное число
записей в TLB от 8 до 4096. Рост количества записей в ассоциативной памяти
должен осуществляться с учетом таких факторов, как размер кэша основной памяти
и количества обращений к памяти при выполнении одной команды.
Вначале информация об отображении
виртуальной страницы в физическую отыскивается в ассоциативной памяти. Если
нужная запись найдена - все нормально, за исключением случаев нарушения
привилегий, когда запрос на обращение к памяти отклоняется.
Если нужная запись в ассоциативной памяти
отсутствует, отображение осуществляется через таблицу страниц. Происходит
замена одной из записей в ассоциативной памяти найденной записью из таблицы
страниц. Здесь мы сталкиваемся с традиционной для любого кэша проблемой
замещения (а именно - какую из записей в кэше необходимо изменить). Конструкция
ассоциативной памяти должна организовывать записи таким образом, чтобы можно
было принять решение о том, какая из старых записей должна быть удалена при
внесении новых.
Число удачных поисков номера страницы в
ассоциативной памяти по отношению к общему числу поисков называется hit (совпадение) ratio (пропорция, отношение).
Иногда также используется термин «процент попаданий в кэш». Таким образом, hit ratio - часть ссылок, которая
может быть сделана с использованием ассоциативной памяти. Обращение к одним и
тем же страницам повышает hit ratio. Чем больше hit ratio, тем меньше среднее
время доступа к данным, находящимся в оперативной памяти.
Предположим, например, что для определения
адреса в случае кэш-промаха через таблицу страниц необходимо 100 не, а для
определения адреса в случае кэш-попадания через ассоциативную память - 20 не. С
90% hit ratio среднее время определения адреса - 0,9x20 + 0,1x100 = 28 не.
Вполне приемлемая производительность
современных ОС доказывает эффективность использования ассоциативной памяти.
Высокое значение вероятности нахождения данных в ассоциативной памяти связано с
наличием у данных объективных свойств: пространственной и временной
локальности.
Необходимо обратить внимание на следующий
факт. При переключении контекста процессов нужно добиться того, чтобы новый
процесс «не видел» в ассоциативной памяти информацию, относящуюся к предыдущему
процессу, например очищать ее. Таким образом, использование ассоциативной
памяти увеличивает время переключения контекста.
Рассмотренная двухуровневая (ассоциативная
память + таблица страниц) схема преобразования адреса является ярким примером
иерархии памяти, основанной на использовании принципа локальности, о чем
говорилось во введении к предыдущей лекции.
18.
Инвертированная таблица страниц
Несмотря на многоуровневую организацию,
хранение нескольких таблиц страниц большого размера по-прежнему представляют
собой проблему. Ее значение особенно актуально для 64-разрядных архитектур, где
число виртуальных страниц очень велико. Вариантом решения является применение
инвертированной таблицы страниц (inverted page table). Этот подход
применяется на машинах PowerPC, некоторых рабочих станциях Hewlett-Packard, IBM RT, IBM AS/400 и ряде других.
В этой таблице содержится по одной записи
на каждый страничный кадр физической памяти. Существенно, что достаточно одной
таблицы для всех процессов. Таким образом, для хранения функции отображения
требуется фиксированная часть основной памяти, независимо от разрядности
архитектуры, размера и количества процессов. Например, для компьютера Pentium с 256 Мбайт оперативной
памяти нужна таблица размером 64 Кбайт строк.
Несмотря на экономию оперативной памяти,
применение инвертированной таблицы имеет существенный минус - записи в ней (как
и в ассоциативной памяти) не отсортированы по возрастанию номеров виртуальных
страниц, что усложняет трансляцию адреса. Один из способов решения данной
проблемы - использование хеш-таблицы виртуальных адресов. При этом часть
виртуального адреса, представляющая собой номер страницы, отображается в
хеш-таблицу с использованием функции хеширования. Каждой странице физической
памяти здесь соответствует одна запись в хеш-таблице и инвертированной таблице
страниц. Виртуальные адреса, имеющие одно значение хеш-функции, сцепляются друг
с другом. Обычно длина цепочки не превышает двух записей.
19.
Размер страницы
Разработчики ОС для существующих машин
редко имеют возможность влиять на размер страницы. Однако для вновь создаваемых
компьютеров решение относительно оптимального размера страницы является
актуальным. Как и следовало ожидать, не существует одного наилучшего размера.
Скорее есть набор факторов, влияющих на размер. Обычно размер страницы - это
степень двойки от 29 до 214 байт.
Чем больше размер страницы, тем меньше
будет размер структур данных, обслуживающих преобразование адресов, но тем
больше будут потери, связанные с тем, что память можно выделять только
постранично.
Как следует выбирать размер страницы?
Во-первых, нужно учитывать размер таблицы страниц, здесь желателен большой
размер страницы (страниц меньше, соответственно и таблица страниц меньше). С
другой стороны, память лучше утилизируется с маленьким размером страницы. В
среднем половина последней страницы процесса пропадает. Необходимо также
учитывать объем ввода-вывода для взаимодействия с внешней памятью и другие
факторы. Проблема не имеет идеального решения. Историческая тенденция состоит в
увеличении размера страницы.
Как правило, размер страниц задается
аппаратно, например в DEC PDP-11 - 8 Кбайт, в DEC VAX - 512 байт, в других
архитектурах, таких как Motorola 68030, размер страниц может быть задан
программно. Учитывая все обстоятельства, в ряде архитектур возникают
множественные размеры страниц, например в Pentium размер страницы
колеблется от 4 Кбайт до 8 Кбайт. Тем не менее большинство коммерческих ОС
ввиду сложности перехода на множественный размер страниц поддерживают только
один размер страниц.
20.
Аппаратно-независимый уровень управления виртуальной памятью
Исключительные
ситуации при работе с памятью
Из материала предыдущей лекции следует,
что отображение виртуального адреса в физический осуществляется при помощи
таблицы страниц. Для каждой виртуальной страницы запись в таблице страниц
содержит номер соответствующего страничного кадра в оперативной памяти, а также
атрибуты страницы для контроля обращений к памяти.
Что же происходит, когда нужной страницы в
памяти нет или операция обращения к памяти недопустима? Естественно, что
операционная система должна быть как-то оповещена о происшедшем. Обычно для
этого используется механизм исключительных ситуаций (exceptions). При попытке выполнить
подобное обращение к виртуальной странице возникает исключительная ситуация
«страничное нарушение» (page fault), приводящая к вызову специальной
последовательности команд для обработки конкретного вида страничного нарушения.
Страничное нарушение может происходить в
самых разных случаях: при отсутствии страницы в оперативной памяти, при попытке
записи в страницу с атрибутом «только чтение» или при попытке чтения или записи
страницы с атрибутом «только выполнение». В любом из этих случаев вызывается
обработчик страничного нарушения, являющийся частью операционной системы. Ему
обычно передается причина возникновения исключительной ситуации и виртуальный
адрес, обращение к которому вызвало нарушение.
Нас будет интересовать конкретный вариант
страничного нарушения - обращение к отсутствующей странице, поскольку именно
его обработка во многом определяет производительность страничной системы. Когда
программа обращается к виртуальной странице, отсутствующей в основной памяти,
операционная система должна выделить страницу основной памяти, переместить в
нее копию виртуальной страницы из внешней памяти и модифицировать
соответствующий элемент таблицы страниц.
Повышение производительности
вычислительной системы может быть достигнуто за счет уменьшения частоты
страничных нарушений, а также за счет увеличения скорости их обработки. Время
эффективного доступа к отсутствующей в оперативной памяти странице складывается
из:
· обслуживания исключительной ситуации (page fault);
· чтения (подкачки)
страницы из вторичной памяти (иногда, при недостатке места в основной памяти,
необходимо вытолкнуть одну из страниц из основной памяти во вторичную, то есть
осуществить замещение страницы);
· возобновления выполнения
процесса, вызвавшего данный page fault. Для решения первой и третьей задач ОС выполняет
до нескольких
сот машинных инструкций в течение
нескольких десятков микросекунд. Время подкачки страницы близко к нескольким
десяткам миллисекунд. Проведенные исследования показывают, что вероятности page fault 5х107
оказывается достаточно, чтобы снизить производительность страничной схемы
управления памятью на 10%. Таким образом, уменьшение частоты page faults является одной из
ключевых задач системы управления памятью. Ее решение обычно связано с
правильным выбором алгоритма замещения страниц.
Стратегии
управления страничной памятью
Программное обеспечение подсистемы
управления памятью связано с реализацией следующих стратегий:
Стратегия выборки (fetch policy) - в какой момент
следует переписать страницу из вторичной памяти в первичную. Существует два основных
варианта выборки - по запросу и с упреждением. Алгоритм выборки по запросу
вступает в действие в тот момент, когда процесс обращается к отсутствующей
странице, содержимое которой находится на диске. Его реализация заключается в
загрузке страницы с диска в свободную физическую страницу и коррекции
соответствующей записи таблицы страниц.
Алгоритм выборки с упреждением
осуществляет опережающее чтение, то есть кроме страницы, вызвавшей
исключительную ситуацию, в память также загружается несколько страниц,
окружающих ее (обычно соседние страницы располагаются во внешней памяти
последовательно и могут быть считаны за одно обращение к диску). Такой алгоритм
призван уменьшить накладные расходы, связанные с большим количеством
исключительных ситуаций, возникающих при работе со значительными объемами
данных или кода; кроме того, оптимизируется работа с диском.
Стратегия размещения (placement policy) - в какой участок
первичной памяти поместить поступающую страницу. В системах со страничной
организацией все просто - в любой свободный страничный кадр. В случае систем с
сегментной организацией необходима стратегия, аналогичная стратегии с
динамическим распределением.
Стратегия замещения (replacement policy) - какую страницу нужно
вытолкнуть во внешнюю память, чтобы освободить место в оперативной памяти.
Разумная стратегия замещения, реализованная в соответствующем алгоритме
замещения страниц, позволяет хранить в памяти самую необходимую информацию и
тем самым снизить частоту страничных нарушений. Замещение должно происходить с
учетом выделенного каждому процессу количества кадров. Кроме того, нужно
решить, должна ли замещаемая страница принадлежать процессу, который
инициировал замещение, или она должна быть выбрана среди всех кадров основной
памяти.
Алгоритмы
замещения страниц.
Итак, наиболее ответственным действием
менеджера памяти является выделение кадра оперативной памяти для размещения в
ней виртуальной страницы, находящейся во внешней памяти. Напомним, что мы
рассматриваем ситуацию, когда размер виртуальной памяти для каждого процесса
может существенно превосходить размер основной памяти. Это означает, что при
выделении страницы основной памяти с большой вероятностью не удастся найти
свободный страничный кадр. В этом случае операционная система в соответствии с
заложенными в нее критериями должна:
· найти некоторую занятую
страницу основной памяти;
· переместить в случае
надобности ее содержимое во внешнюю память;
· переписать в этот
страничный кадр содержимое нужной виртуальной страницы из внешней памяти;
· должным образом
модифицировать необходимый элемент соответствующей таблицы страниц;
· продолжить выполнение
процесса, которому эта виртуальная страница понадобилась.
Заметим, что при замещении приходится
дважды передавать страницу между основной и вторичной памятью. Процесс
замещения может быть оптимизирован за счет использования бита модификации (один
из атрибутов страницы в таблице страниц). Бит модификации устанавливается
компьютером, если хотя бы один байт был записан на страницу. При выборе
кандидата на замещение проверяется бит модификации. Если бит не установлен, нет
необходимости переписывать данную страницу на диск, ее копия на диске уже
имеется. Подобный метод также применяется к read-only-страницам, они никогда
не модифицируются. Эта схема уменьшает время обработки page fault.
Существует большое количество
разнообразных алгоритмов замещения страниц. Все они делятся на локальные и
глобальные. Локальные алгоритмы, в отличие от глобальных, распределяют
фиксированное или динамически настраиваемое число страниц для каждого процесса.
Когда процесс израсходует все предназначенные ему страницы, система будет
удалять из физической памяти одну из его страниц, а не из страниц других
процессов. Глобальный же алгоритм замещения в случае возникновения
исключительной ситуации удовлетворится освобождением любой физической страницы,
независимо от того, какому процессу она принадлежала.
Глобальные алгоритмы имеют ряд
недостатков. Во-первых, они делают одни процессы чувствительными к поведению
других процессов. Например, если один процесс в системе одновременно использует
большое количество страниц памяти, то все остальные приложения будут в
результате ощущать сильное замедление из-за недостатка кадров памяти для своей
работы. Во-вторых, некорректно работающее приложение может подорвать работу
всей системы (если, конечно, в системе не предусмотрено ограничение на размер
памяти, выделяемой процессу), пытаясь захватить больше памяти. Поэтому в
многозадачной системе иногда приходится использовать более сложные локальные
алгоритмы. Применение локальных алгоритмов требует хранения в операционной
системе списка физических кадров, выделенных каждому процессу. Этот список
страниц иногда называют резидентным множеством процесса. В одном из следующих
разделов рассмотрен вариант алгоритма подкачки, основанный на приведении
резидентного множества в соответствие так называемому рабочему набору процесса.
Эффективность алгоритма обычно оценивается
на конкретной последовательности ссылок к памяти, для которой подсчитывается
число возникающих page faults. Эта последовательность называется строкой
обращений (reference string). Мы можем генерировать строку обращений
искусственным образом при помощи датчика случайных чисел или трассируя
конкретную систему. Последний метод дает слишком много ссылок, для уменьшения
числа которых можно сделать две вещи:
· для конкретного размера
страниц можно запоминать только их номера, а не адреса, на которые идет ссылка;
· несколько подряд идущих
ссылок на одну страницу можно фиксировать один раз.
Как уже говорилось, большинство
процессоров имеют простейшие аппаратные средства, позволяющие собирать
некоторую статистику обращений к памяти. Эти средства обычно включают два
специальных флага на каждый элемент таблицы страниц. Флаг ссылки (reference бит) автоматически
устанавливается, когда происходит любое обращение к этой странице, а уже
рассмотренный выше флаг изменения (modify бит) устанавливается, если производится запись в
эту страницу. Операционная система периодически проверяет установку таких
флагов, для того чтобы выделить активно используемые страницы, после чего
значения этих флагов сбрасываются.
Рассмотрим ряд алгоритмов замещения
страниц.
Алгоритм
FIFO. Выталкивание первой пришедшей страницы
Простейший алгоритм. Каждой странице
присваивается временная метка. Реализуется это просто созданием очереди
страниц, в конец которой страницы попадают, когда загружаются в физическую
память, а из начала берутся, когда требуется освободить память. Для замещения
выбирается старейшая страница. К сожалению, эта стратегия с достаточной
вероятностью будет приводить к замещению активно используемых страниц, например
страниц кода текстового процессора при редактировании файла. Заметим, что при
замещении активных страниц все работает корректно, но page fault происходит немедленно.
Аномалия Билэди (Belady)
На первый взгляд кажется очевидным, что
чем больше в памяти страничных кадров, тем реже будут иметь место page faults. Удивительно, но это не
всегда так. Как установил Билэди с коллегами, определенные последовательности
обращений к страницам в действительности приводят к увеличению числа страничных
нарушений при увеличении кадров, выделенных процессу. Это явление носит
название «аномалии Билэди» или «аномалии FIFO».
Система с тремя кадрами (9 faults) оказывается более
производительной, чем с четырьмя кадрами (10 faults), для строки обращений к
памяти 012301401234 при выборе стратегии FIFO.

Аномалия Билэди: (а) - FIFO с тремя страничными
кадрами; (b) - FIFO с четырьмя страничными
кадрами
Аномалию Билэди следует считать скорее
курьезом, чем фактором, требующим серьезного отношения, который иллюстрирует
сложность ОС, где интуитивный подход не всегда приемлем.
Оптимальный
алгоритм (ОРТ)
Одним из последствий открытия аномалии
Билэди стал поиск оптимального алгоритма, который при заданной строке обращений
имел бы минимальную частоту page faults среди всех других алгоритмов. Такой алгоритм был
найден. Он прост: замещай страницу, которая не будет использоваться в течение
самого длительного периода времени.
Каждая страница должна быть помечена
числом инструкций, которые будут выполнены, прежде чем на эту страницу будет
сделана первая ссылка. Выталкиваться должна страница, для которой это число
наибольшее.
Этот алгоритм легко описать, но
реализовать невозможно. ОС не знает, к какой странице будет следующее
обращение. (Ранее такие проблемы возникали при планировании процессов -
алгоритм SJF)
Зато мы можем сделать вывод, что для того,
чтобы алгоритм замещения был максимально близок к идеальному алгоритму, система
должна как можно точнее предсказывать обращения процессов к памяти. Данный
алгоритм применяется для оценки качества реализуемых алгоритмов.
Выталкивание
дольше всего не использовавшейся страницы. Алгоритм LRU
Одним из приближений к алгоритму ОРТ
является алгоритм, исходящий из эвристического правила, что недавнее прошлое -
хороший ориентир для прогнозирования ближайшего будущего.
Ключевое отличие между FIFO и оптимальным алгоритмом
заключается в том, что один смотрит назад, а другой вперед. Если использовать
прошлое для аппроксимации будущего, имеет смысл замещать страницу, которая не
использовалась в течение самого долгого времени. Такой подход называется least recently used алгоритм (LRU). Работа алгоритма
проиллюстрирована на рис. 10.2. Сравнивая рис. 10.1 b и 10.2, можно увидеть,
что использование LRU алгоритма позволяет сократить количество страничных нарушений.

Пример работы алгоритма LRU
LRU - хороший, но
труднореализуемый алгоритм. Необходимо иметь связанный список всех страниц в
памяти, в начале которого будут хранится недавно использованные страницы.
Причем этот список должен обновляться при каждом обращении к памяти. Много
времени нужно и на поиск страниц в таком списке.
В [Таненбаум, 2002] рассмотрен вариант
реализации алгоритма LRU со специальным 64-битным указателем, который
автоматически увеличивается на единицу после выполнения каждой инструкции, а в
таблице страниц имеется соответствующее поле, в которое заносится значение
указателя при каждой ссылке на страницу. При возникновении page fault выгружается страница с
наименьшим значением этого поля.
Как оптимальный алгоритм, так и LRU не страдают от аномалии
Би-лэди. Существует класс алгоритмов, для которых при одной и той же строке
обращений множество страниц в памяти для п кадров всегда является подмножеством
страниц для п+1 кадра. Эти алгоритмы не проявляют аномалии Билэди и называются
стековыми (stack) алгоритмами.
Выталкивание
редко используемой страницы. Алгоритм NFU
Поскольку большинство современных
процессоров не предоставляют соответствующей аппаратной поддержки для
реализации алгоритма LRU, хотелось бы иметь алгоритм, достаточно близкий
к LRU, но не требующий
специальной поддержки.
Программная реализация алгоритма, близкого
к LRU, - алгоритм NFU (Not Frequently Used).
Для него требуются программные счетчики,
по одному на каждую страницу, которые сначала равны нулю. При каждом прерывании
по времени (а не после каждой инструкции) операционная система сканирует все
страницы в памяти и у каждой страницы с установленным флагом обращения
увеличивает на единицу значение счетчика, а флаг обращения сбрасывает.
Таким образом, кандидатом на освобождение
оказывается страница с наименьшим значением счетчика, как страница, к которой
реже всего обращались. Главный недостаток алгоритма NFU состоит в том, что он
ничего не забывает. Например, страница, к которой очень часто обращались в
течение некоторого времени, а потом обращаться перестали, все равно не будет
удалена из памяти, потому что ее счетчик содержит большую величину. Например, в
многопроходных компиляторах страницы, которые активно использовались во время
первого прохода, могут надолго сохранить большие значения счетчика, мешая
загрузке полезных в дальнейшем страниц.
К счастью, возможна небольшая модификация
алгоритма, которая позволяет ему «забывать». Достаточно, чтобы при каждом
прерывании по времени содержимое счетчика сдвигалось вправо на 1 бит, а уже
затем производилось бы его увеличение для страниц с установленным флагом обращения.
Другим, уже более устойчивым недостатком
алгоритма является длительность процесса сканирования таблиц страниц.
Другие
алгоритмы
Для полноты картины можно упомянуть еще
несколько алгоритмов.
Например, алгоритм Second-Chance - модификация алгоритма FIFO, которая позволяет
избежать потери часто используемых страниц с помощью анализа флага обращений
(бита ссылки) для самой старой страницы. Если флаг установлен, то страница, в
отличие от алгоритма FIFO, не выталкивается, а ее флаг сбрасывается, и
страница переносится в конец очереди. Если первоначально флаги обращений были
установлены для всех страниц (на все страницы ссылались), алгоритм Second-Chance превращается в алгоритм FIFO. Данный алгоритм
использовался в Multics и BSD Unix.
В компьютере Macintosh использован алгоритм NRU (Not Recently-Used), где страница -
«жертва» выбирается на основе анализа битов модификации и ссылки. Интересные
стратегии, основанные на буферизации страниц, реализованы в VAX/VMS и Mach.
Имеется также и много других алгоритмов
замещения. Объем этого курса не позволяет рассмотреть их подробно. Подробное
описание различных алгоритмов замещения можно найти в монографиях [Дейтел,
1987], [Цикритис, 1977], [Таненбаум, 2002] и др.
Итак, что делать, если в распоряжении
процесса имеется недостаточное число кадров? Нужно ли его приостановить с
освобождением всех кадров? Что следует понимать под достаточным количеством
кадров?
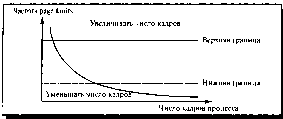
Трешинг
(Thrashing)
Хотя теоретически возможно уменьшить число
кадров процесса до минимума, существует какое-то число активно используемых
страниц, без которого процесс часто генерирует page faults. Высокая частота страничных
нарушений называется трешинг (thrashing, иногда употребляется русский термин
«пробуксовка», см. рис. 10.3). Процесс находится в состоянии трешинга, если при
его работе больше времени уходит на подкачку страниц, нежели на выполнение
команд. Такого рода критическая ситуация возникает вне зависимости от
конкретных алгоритмов замещения.
Часто результатом трешинга является
снижение производительности вычислительной системы. Один из нежелательных
сценариев развития событий может выглядеть следующим образом. При глобальном
алгоритме замещения процесс, которому не хватает кадров, начинает отбирать
кадры у других процессов, которые в свою очередь начинают заниматься тем же. В
результате все процессы попадают в очередь запросов к устройству вторичной
памяти (находятся в состоянии ожидания), а очередь процессов в состоянии
готовности пустеет. Загрузка процессора снижается. Операционная система
реагирует на это увеличением степени мультипрограммирования, что приводит к еще
большему трешингу и дальнейшему снижению загрузки процессора. Таким образом,
пропускная способность системы падает из-за трешинга.
Частота page faults в зависимости от
количества кадров, выделенных процессу
Эффект трешинга, возникающий при
использовании глобальных алгоритмов, может быть ограничен за счет применения
локальных алгоритмов замещения. При локальных алгоритмах замещения если даже
один из процессов попал в трешинг, это не сказывается на других процессах.
Однако он много времени проводит в очереди к устройству выгрузки, затрудняя
подкачку страниц остальных процессов.
Критическая ситуация типа трешинга
возникает вне зависимости от конкретных алгоритмов замещения. Единственным
алгоритмом, теоретически гарантирующим отсутствие трешинга, является рассмотренный
выше не реализуемый на практике оптимальный алгоритм.
Итак, трешинг - это высокая частота
страничных нарушений. Необходимо ее контролировать. Когда она высока, процесс
нуждается в кадрах. Можно, устанавливая желаемую частоту page faults, регулировать размер
процесса, добавляя или отнимая у него кадры. Может оказаться целесообразным
выгрузить процесс целиком. Освободившиеся кадры выделяются другим процессам с
высокой частотой page faults.
Для предотвращения трешинга требуется
выделять процессу столько кадров, сколько ему нужно. Но как узнать, сколько ему
нужно? Необходимо попытаться выяснить, как много кадров процесс реально
использует. Для решения этой задачи Деннинг использовал модель рабочего
множества, которая основана на применении принципа локальности.
21.
Модель рабочего множества
Рассмотрим поведение реальных процессов.
Процессы начинают работать, не имея в
памяти необходимых страниц. В результате при выполнении первой же машинной
инструкции возникает page fault, требующий подкачки порции кода. Следующий page fault происходит при
локализации глобальных переменных и еще один - при выделении памяти для стека.
После того как процесс собрал большую часть необходимых ему страниц, page faults возникают редко.
Таким образом, существует набор страниц (P1, P2,… Рп),
активно использующихся вместе, который позволяет процессу в момент времени t в течение некоторого
периода Т производительно работать, избегая большого количества page faults. Этот набор страниц
называется рабочим множеством W (t, T) (working set) процесса. Число страниц в рабочем множестве
определяется параметром Т, является неубывающей функцией Т и относительно
невелико. Иногда Т называют размером окна рабочего множества, через которое
ведется наблюдение за процессом (см. рис. 10.4).

Пример рабочего множества процесса
Легко написать тестовую программу, которая
систематически работает с большим диапазоном адресов, но, к счастью,
большинство реальных процессов не ведут себя подобным образом, а проявляют свойство
локальности. В течение любой фазы вычислений процесс работает с небольшим
количеством страниц.
Когда процесс выполняется, он двигается от
одного рабочего множества к другому. Программа обычно состоит из нескольких
рабочих множеств, которые могут перекрываться. Например, когда вызвана
процедура, она определяет новое рабочее множество, состоящее из страниц,
содержащих инструкции процедуры, ее локальные и глобальные переменные. После ее
завершения процесс покидает это рабочее множество, но может вернуться к нему
при новом вызове процедуры. Таким образом, рабочее множество определяется кодом
и данными программы. Если процессу выделять меньше кадров, чем ему требуется
для поддержки рабочего множества, он будет находиться в состоянии трешинга.
Принцип локальности ссылок препятствует
частым изменениям рабочих наборов процессов. Формально это можно выразить
следующим образом. Если в период времени (t - Т, t) программа обращалась к
страницам W (t,
T), то при надлежащем
выборе Т с большой вероятностью эта программа будет обращаться к тем же
страницам в период времени (t, t + Т). Другими словами, принцип локальности утверждает, что если
не слишком далеко заглядывать в будущее, то можно достаточно точно его
прогнозировать исходя из прошлого. Понятно, что с течением времени рабочий
набор процесса может изменяться (как по составу страниц, так и по их числу).
Наиболее важное свойство рабочего
множества - его размер. ОС должна выделить каждому процессу достаточное число
кадров, чтобы поместилось его рабочее множество. Если кадры еще остались, то
может быть инициирован другой процесс. Если рабочие множества процессов не
помещаются в память и начинается трешинг, то один из процессов можно выгрузить
на диск.
Решение о размещении процессов в памяти
должно, следовательно, базироваться на размере его рабочего множества. Для
впервые инициируемых процессов это решение может быть принято эвристически. Во
время работы процесса система должна уметь определять: расширяет процесс свое
рабочее множество или перемещается на новое рабочее множество. Если в состав
атрибутов страницы включить время последнего использования tj (для страницы с номером i), то принадлежность i-й страницы к рабочему
набору, определяемому параметром t в момент времени t будет выражаться неравенством: t - Т < tj < t. Алгоритм выталкивания
страниц WSClock, использующий информацию о рабочем наборе процесса, описан в
[Таненбаум, 2002].
Другой способ реализации данного подхода
может быть основан на отслеживании количества страничных нарушений, вызываемых
процессом. Если процесс часто генерирует page faults и память не слишком
заполнена, то система может увеличить число выделенных ему кадров. Если же
процесс не вызывает исключительных ситуаций в течение некоторого времени и
уровень генерации ниже какого-то порога, то число кадров процесса может быть
урезано. Этот способ регулирует лишь размер множества страниц, принадлежащих
процессу, и должен быть дополнен какой-либо стратегией замещения страниц.
Несмотря на то что система при этом может пробуксовывать в моменты перехода от
одного рабочего множества к другому, предлагаемое решение в состоянии
обеспечить наилучшую производительность для каждого процесса, не требуя никакой
дополнительной настройки системы.
.
Страничные демоны
Подсистема виртуальной памяти работает
производительно при наличии резерва свободных страничных кадров. Алгоритмы,
обеспечивающие поддержку системы в состоянии отсутствия трешинга, реализованы в
составе фоновых процессов (их часто называют демонами или сервисами), которые
периодически «просыпаются» и инспектируют состояние памяти. Если свободных
кадров оказывается мало, они могут сменить стратегию замещения. Их задача -
поддерживать систему в состоянии наилучшей производительности.
Примером такого рода процесса может быть
фоновый процесс - сборщик страниц, реализующий облегченный вариант алгоритма
откачки, основанный на использовании рабочего набора и применяемый во многих
клонах ОС Unix (см., например, [Bach, 1986]). Данный демон производит откачку
страниц, не входящих в рабочие наборы процессов. Он начинает активно работать,
когда количество страниц в списке свободных страниц достигает установленного
нижнего порога, и пытается выталкивать страницы в соответствии с собственной
стратегией.
Но если возникает требование страницы в
условиях, когда список свободных страниц пуст, то начинает работать механизм
свопинга, поскольку простое отнятие страницы у любого процесса (включая тот,
который затребовал бы страницу) потенциально вело бы к ситуации thrashing, и разрушало бы рабочий
набор некоторого процесса. Любой процесс, затребовавший страницу не из своего
текущего рабочего набора, становится в очередь на выгрузку в расчете на то, что
после завершения выгрузки хотя бы одного из процессов свободной памяти уже
может быть достаточно.
В ОС Windows 2000 аналогичную роль
играет менеджер балансного набора (Working set manager), который вызывается раз
в секунду или тогда, когда размер свободной памяти опускается ниже
определенного предела, и отвечает за суммарную политику управления памятью и
поддержку рабочих множеств.
.
Программная поддержка сегментной модели памяти процесса
Реализация функций операционной системы,
связанных с поддержкой памяти, - ведение таблиц страниц, трансляция адреса,
обработка страничных ошибок, управление ассоциативной памятью и др. - тесно связана
со структурами данных, обеспечивающими удобное представление адресного
пространства процесса. Формат этих структур сильно зависит от аппаратуры и
особенностей конкретной ОС.
Чаще всего виртуальная память процесса ОС
разбивается на сегмен ты пяти типов: кода программы, данных, стека, разделяемый
и сегмен файлов, отображаемых в память (см. рис.).
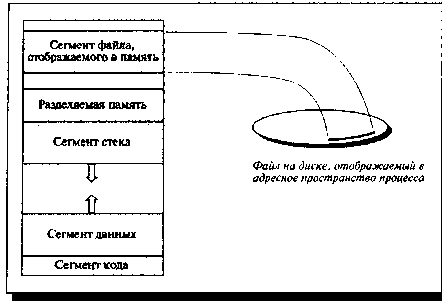
Сегмент программного кода содержит только
команды. Сегмент программного кода не модифицируется входе выполнения процесса,
обычно страницы данного сегмента имеют атрибут read-only. Следствием этого
является возможность использования одного экземпляра кода для разны процессов.
Сегмент данных, содержащий переменные
программы и сегмент стекг содержащий автоматические переменные, могут
динамически менять cboi размер (обычно данные в сторону увеличения адресов, а стек - в
сторон уменьшения) и содержимое, должны быть доступны по чтению и запис: и
являются приватными сегментами процесса.
С целью обобществления памяти между
несколькими процессам: создаются разделяемые сегменты, допускающие доступ по
чтению и записи. Вариантом разделяемого сегмента может быть сегмент файла,
отображаемого в память. Специфика таких сегментов состоит в том, что из ни
откачка осуществляется не в системную область выгрузки, а непосредственно в
отображаемый файл. Реализация разделяемых сегментов основан на том, что
логические страницы различных процессов связываются с од ними и теми же
страничными кадрами.
Сегменты представляют собой непрерывные
области (в Linux они так и называются - области) в виртуальном адресном
пространстве процесса, выровненные по границам страниц. Каждая область состоит
из набора страниц с одним и тем же режимом защиты. Между областями в
виртуальном пространстве могут быть свободные участки. Естественно, что
подобные объекты описаны соответствующими структурами (см., например, структуры
mm_struct и vm_area_struct в Linux).
Часть работы по организации сегментов
может происходить с участием программиста. Особенно это заметно при низкоуровневом
программировании. В частности, отдельные области памяти могут быть поименованы
и использоваться для обмена данными между процессами. Два процесса могут
общаться через разделяемую область памяти при условии, что им известно ее имя
(пароль). Обычно это делается при помощи специальных вызовов (например, тар и unmap), входящих в состав
интерфейса виртуальной памяти.
Загрузка исполняемого файла (системный
вызов exec) осуществляется обычно через отображение (mapping) его частей (кода,
данных) в соответствующие сегменты адресного пространства процесса. Например,
сегмент кода является сегментом отображаемого в память файла, содержащего
исполняемую программу. При попытке выполнить первую же инструкцию система
обнаруживает, что нужной части кода в памяти нет, генерирует page fault и подкачивает эту часть
кода с диска. Далее процедура повторяется до тех пор, пока вся программа не
окажется в оперативной памяти.
Как уже говорилось, размер сегмента данных
динамически меняется. Рассмотрим, как организована поддержка сегментов данных в
Unix. Пользователь,
запрашивая (библиотечные вызовы malloc, new) или освобождая (free, delete) память для динамических
данных, фактически изменяет границу выделенной процессу памяти через системный
вызов brk (от слова break), который модифицирует значение переменной brk из структуры данных
процесса. В результате происходит выделение физической памяти, граница brk смещается в сторону
увеличения виртуальных адресов, а соответствующие строки таблиц страниц
получают осмысленные значения. При помощи того же вызова brk пользователь может
уменьшить размер сегмента данных. На практике освобожденная пользователем
виртуальная память (библиотечные вызовы free, delete) системе не
возвращается. На это есть две причины. Во-первых, для уменьшения размеров
сегмента данных необходимо организовать его уплотнение или «сборку мусора». А
во-вторых, незанятые внутри сегмента данных области естественным образом будут
вытолкнуты из оперативной памяти вследствие того, что к ним не будет обращений.
Ведение списков занятых и свободных областей памяти в сегменте данных
пользователя осуществляется на уровне системных библиотек.
Более подробно информация об адресных
пространствах процессов в Unix изложена в [Кузнецов], [Bach, 1986].
.
Отдельные аспекты функционирования менеджера памяти
Корректная работа менеджера памяти помимо
принципиальных вопросов, связанных с выбором абстрактной модели виртуальной
памяти и ее аппаратной поддержкой, обеспечивается также множеством нюансов и
мелких деталей. В качестве примера такого рода компонента рассмотрим более
подробно локализацию страниц в памяти, которая применяется в тех случаях, когда
поддержка страничной системы приводит к необходимости разрешить определенным
страницам, хранящим буферы ввода-вывода, другие важные данные и код, быть
блокированными в памяти.
Рассмотрим случай, когда система
виртуальной памяти может вступить в конфликт с подсистемой ввода-вывода.
Например, процесс может запросить ввод в буфер и ожидать его завершения.
Управление передастся другому процессу, который может вызвать page fault и, с отличной от нуля
вероятностью, спровоцировать выгрузку той страницы, куда должен быть
осуществлен ввод первым процессом. Подобные ситуации нуждаются в дополнительном
контроле, особенно если ввод-вывод реализован с использованием механизма
прямого доступа к памяти (DMA). Одно из решений данной проблемы - вводить
данные в невытесняемый буфер в пространстве ядра, а затем копировать их в
пользовательское пространство.
Второе решение - локализовать страницы в
памяти, используя специальный бит локализации, входящий в состав атрибутов
страницы. Локализованная страница замещению не подлежит. Бит локализации
сбрасывается после завершения операции ввода-вывода.
Другое использование бита локализации
может иметь место и при нормальном замещении страниц. Рассмотрим следующую цепь
событий. Низкоприоритетный процесс после длительного ожидания получил в свое
распоряжение процессор и подкачал с диска нужную ему страницу. Если он сразу
после этого будет вытеснен высокоприоритетным процессом, последний может легко
заместить вновь подкачанную страницу низкоприоритетного, так как на нее не было
ссылок. Имеет смысл вновь загруженные страницы помечать битом локализации до
первой ссылки, иначе низкоприоритетный процесс так и не начнет работать.
Использование бита локализации может быть
опасным, если забыть его отключить. Если такая ситуация имеет место, страница
становится неиспользуемой. SunOS разрешает использование данного бита в качестве
подсказки, которую можно игнорировать, когда пул свободных кадров становится
слишком маленьким.
Другим важным применением локализации
является ее использование в системах мягкого реального времени. Рассмотрим
процесс или нить реального времени. Вообще говоря, виртуальная память -
антитеза вычислений реального времени, так как дает непредсказуемые задержки
при подкачке страниц. Поэтому системы реального времени почти не используют
виртуальную память. ОС Solaris поддерживает как реальное время, так и
разделение времени. Для решения проблемы page faults Solaris разрешает процессам
сообщать системе, какие страницы важны для процесса, и локализовать их в
памяти. В результате возможно выполнение процесса, реализующего задачу
реального времени, содержащего локализованные страницы, где временные задержки
страничной системы будут минимизированы.
Помимо системы локализации страниц, есть и
другие интересные проблемы, возникающие в процессе управления памятью. Так,
например, бывает непросто осуществить повторное выполнение инструкции,
вызвавшей page fault. Представляют интерес и алгоритмы отложенного выделения памяти
(копирование при записи и др.). Ограниченный объем данного курса не позволяет
рассмотреть их более подробно.
Описанная система управления памятью
является совокупностью программно-технических средств, обеспечивающих производительное
функционирование современных компьютеров. Успех реализации той части ОС,
которая относится к управлению виртуальной памятью, определяется близостью
архитектуры аппаратных средств, поддерживающих виртуальную память, к
абстрактной модели виртуальной памяти ОС. Справедливости ради заметим, что в
подавляющем большинстве современных компьютеров аппаратура выполняет функции,
существенно превышающие потребности модели ОС, так что создание
аппаратно-зависимой части подсистемы управления виртуальной памятью ОС в
большинстве случаев не является чрезмерно сложной задачей.
25.
Классовая декомпозиция предметной области
В данной курсовой работе необходимо написать программу,
моделирующую разбиение исходного неделимого адресного пространства ОП на
страницы переменной длины. Исходя из этого было выделено 3 основных класса,
необходимых для построения модели:
1) AddressSpace - класс, представляющий
исходное адресное пространство ОП;
2) AddressSpacePage - класс, представляющий
страницу структурированного адресного пространства ОП;
3) AddressSpacePages - класс, представляющий
страницы структурированного адресного пространства с доступом по индексу [a, b], где a номер страницы, а b смещение.
Исходя из необходимости визуального отображения результатов
структуризации АП ОП, было введено еще 2 класса, являющиеся компонентами:
1) AddressSpaceVisualizerControl - компонента для
отображения состояния экземпляра класса AddressSpace и AddressSpacePages
2) VisualizerControl компонента для
отображения состояния экземпляра класса AddressSpacePage
Далее рассмотрим эти классы более подробно.
Класс AddressSpacePage
Данный класс предназначен для представления страницы
структурированного адресного пространства ОП. Для задания параметров страницы в
классе предусмотрены свойства Size и BaseMemoryAddress, устанавливающие
соответственно размер страницы и базовый адрес в исходном неструктурированном
АП, смещение адреса задаётся свойством Displacement.
Класс AddressSpacePages
Данный класс предназначен для представления страниц
структурированного адресного пространства ОП как единого целого. Он хранит в
себе список страниц addressSpasePage, и максимальный размер
страницы maxPageSize. Также для распределения размеров страниц содержится генератор
случайных величин g. Так как этот класс является как бы посредником
между АП и страницей он не иимет свойств, но имеет индексатор this, который позволяет
получить доступ к странице по индексу [a, b], где a номер страницы, а b
смещение.
Класс
AddressSpace
Для задания параметров АП в классе предусмотрены свойства Size и MaxPageSize, устанавливающие
соответственно размер исходного неструктурированного АП и максимальный размер
страницы структурированного АП.
При создании экземпляра класса структуризация автоматически
не производится. Чтобы выполнить структуризацию необходимо вызвать метод Structuring, который имеет всего
один параметр - Generator. В качестве этого параметра должен быть передан экземпляр
класса, наследованного от абстрактного класса Generator, и реализующего его
абстрактные методы и свойства. По умолчанию используется случайный генератор
чисел.
После вызова метода Structuring, исходное адресное
пространство будет разбито на произвольное количество страниц случайного
размера, доступ к которым можно получить через свойство addressSpacepages. Необходимо отметить,
что в случае вызова метода Structuring для уже структурированного адресного
пространства, перед выполнением разбиения будет выполнен сброс всех результатов
предыдущей структуризации.
Generator
Так как генератор случайных чисел Random плохо
генерирует случайные величины и не справляется со своей работой, пришлось
прибегнуть к библиотеке Troschuetz. Random.dll.
Эта библиотека содержит абстрактные базовые классы для
генераторов случайных чисел и случайных распределений чисел. В данной работе
использовались 4 генератора.
|
Реализация
|
Описание
|
|
ALFGenerator
|
Метод Фибоначчи с запаздываниями
|
|
MT19937Generator
|
Вихрь Мерсенна
|
|
StandardGenerator
|
Стандартный генератор Random
|
Xorshift
|
Класс VisualizerControl
Данный класс компоненты предназначен для отображения
пользователю состояния страницы структурированного и неструктурированного
адресного пространства. Отображаемая страница задается через свойство addressSpacePage.
Область контрола разделена на четыре составляющих:
) Область базового адреса - отображает базовый адрес
страницы в исходном неструктурированном адресном пространстве;

2) Область прямоугольника размера страницы - в данной области
отрисовывается закрашенный прямоугольник, ширина которого соответствует размеру
отображаемой страницы.
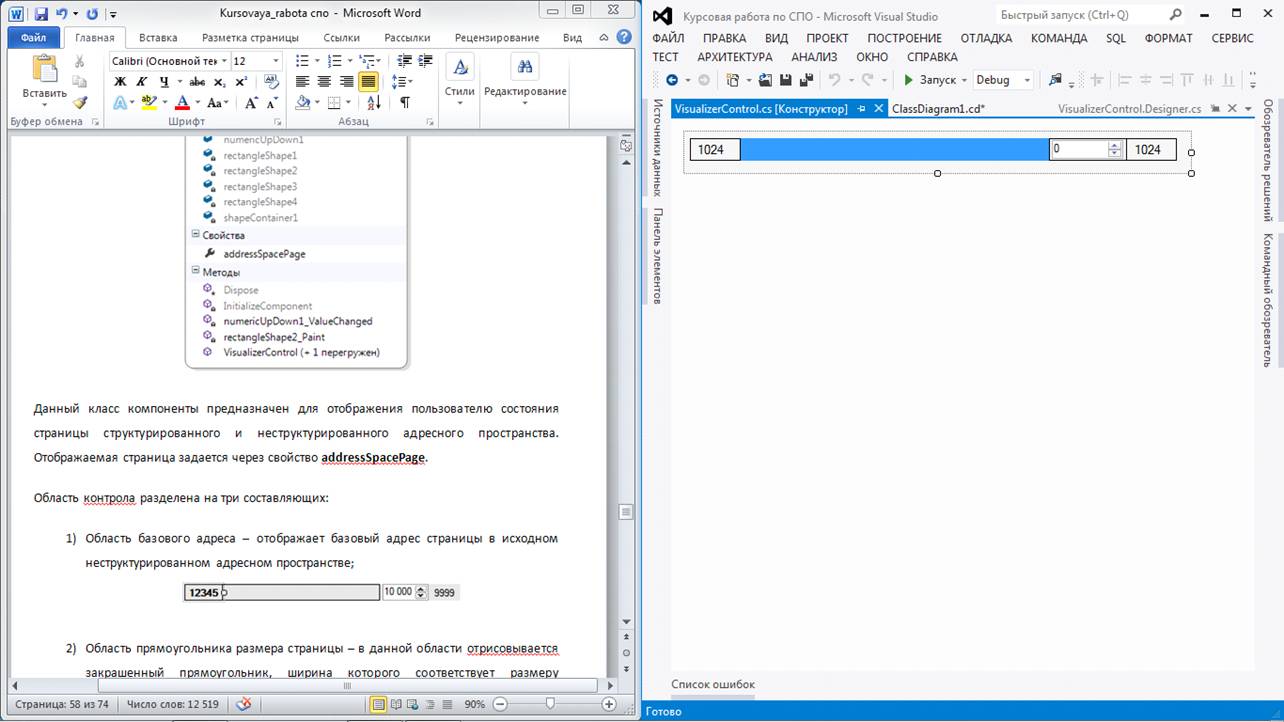
3) Область задания смещения - содержит поле для задания
смещения на текущей странице

) Последнее поле показывает исходный адрес текущего
элемента в неструктурированном АП

Класс AddressSpaceVisualizerControl
Данный класс компоненты предназначен для отображения
пользователю состояния адресного пространства. Отображаемое адресное
пространство задается через свойство AddressSpace. Также сдесь содержится
список компонент VisualizerControl которые отображают страницы текущего АП.
Область компоненты разделена на три составляющих:
) Информационная строка - предназначена для
отображения информации о размере исходного АП, количестве страниц, на которое
оно было разбито, и среднем размере страницы;
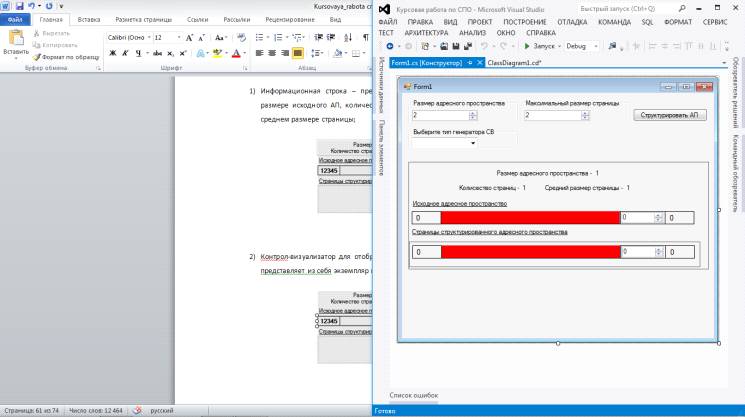
2) Компонента для отображения исходного
неструктурированного АП - представляет из себя экземпляр класса VisualizerControl;
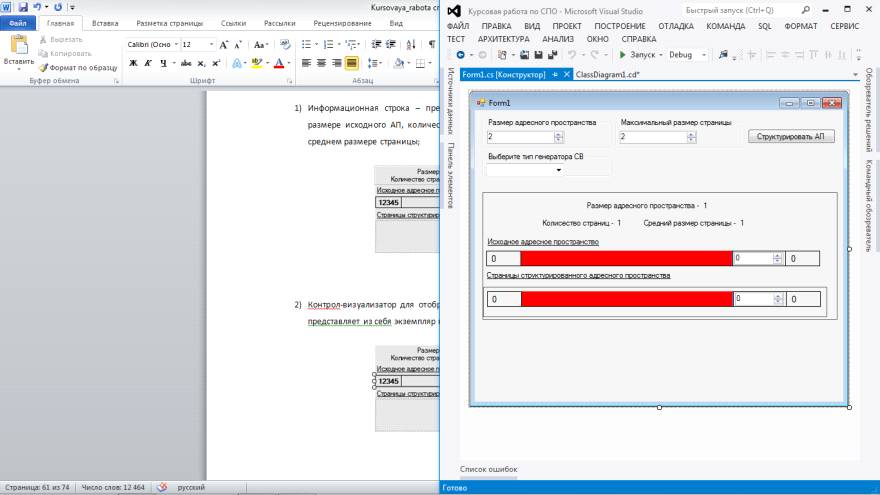
) Зона страниц структурированного адресного
пространства - предназначена для вывода компонент страниц структурированного
АП.

Разбиение
адресного пространства ОП на страницы переменной длины
Разбиение АП ОП осуществляется методом Structuring класса AddressSpace. Который создаст класс AddressSpacePages и разобьёт АП. Разбор
логики работы данного метода выполнен в комментариях в исходном коде.
// базовый адрес страницыindex=0;
// Проверка текущего генератора, иначе
поставить стандартный
if (g == null)
{= new StandardGenerator();
}
// пока базовый адрес страницы меньше обьёма
ОП(index < size)
{
// расчитать длину страницы
int i=g. Next (1, maxPageSize);
// проверить чтобы новая страница не
оказалась больше АП
if (index + i > size)
{= size - index;
}
// Создать страницу. Add (new AddressSpacePage (index, i));
// увеличить базовый адресс новой страницы+=
i;
}
.
Описание работы с программой
Задание
параметров

Настройка параметров позволяет задать «Размер адресного
пространства», «Максимальный размер страницы» структурированного АП и
«Генератор случайных чисел», используемый для разбиения АП.
Выполнение
структуризации

Выполнение структуризации выполняется нажатием на кнопку
«Структурировать АП.
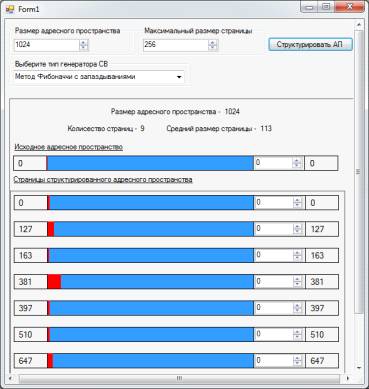
Поиск
адреса в исходном неструктурированном АП и наоборот.
При указании смещения внутри страницы, интересующий вас адрес
выделяется на самой странице, а его адрес в исходном пространстве отображается
рядом.

При указании смещения внутри АП, интересующий вас адрес
выделяется на самой странице.
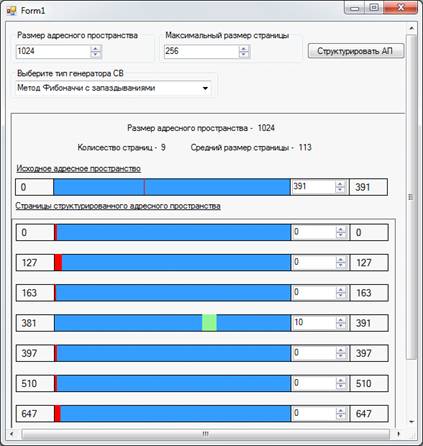
Примеры
работы программы.
Размер адресного пространства: 1024
Максимальный размер страницы: 256
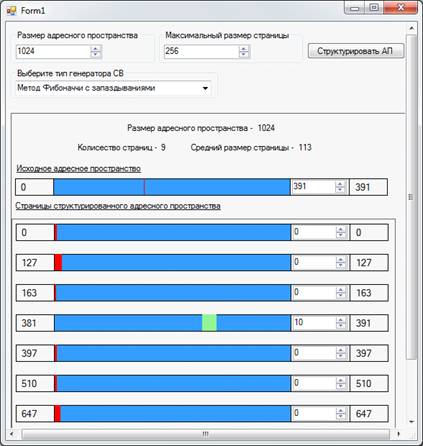
Размер адресного пространства: 512
Максимальный размер страницы: 256
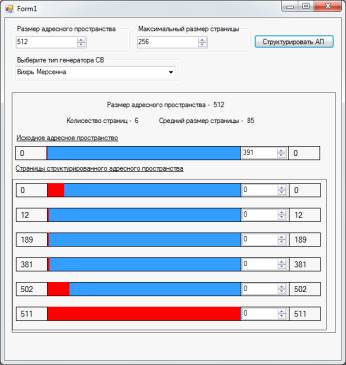
Размер адресного пространства: 512
Максимальный размер страницы: 128
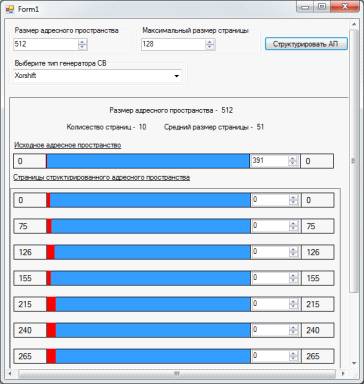
Выводы
В теоретической части курсовой работы мы
рассмотрели идеологию построения системы управления памятью в современных
операционных системах.
В практической части мы рассмотрели
программную реализацию визуальной модели структуризации адресного пространства
оперативной памяти страницами переменной длины. Построенная модель позволяет
задать параметры адресного пространства (его размер) и параметры структуризации
(максимальный размер страницы и генератор СВ, использующийся при разбиении).
Также созданная модель позволяет по значению смещения внутри страницы найти
адрес в исходном неструктурированном адресном пространстве.
Список использованных источников
1 Операционные
системы: Учебник для вузов. 2-е изд. / А.В. Гордеев. - СПб.: Питер, 2011. - 416
с.
2 Эффективное
администрирование. Ресурсы Windows Server 2010, Windows Server: Пер. с англ. - М.:
Изд-во «Русская Редакция» / В.В. Мельников СПб.: БХВ - Петербург, 2009. - 768
с.
Эффективная
работа: Windows - Сулацкая И.М.СПб.: Питер, 2008. - 1069 с.