|
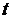 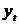 
|
|
|
|
|
|
|
|
|
|
|
|
|
1
|
509
|
507
|
-
|
7
|
520
|
512
|
+
|
15
|
514
|
519
|
-
|
|
2
|
507
|
508
|
-
|
8
|
519
|
514
|
+
|
16
|
510
|
520
|
-
|
|
3
|
508
|
509
|
-
|
9
|
512
|
515
|
-
|
17
|
516
|
521
|
-
|
|
4
|
509
|
509
|
-
|
10
|
511
|
516
|
-
|
18
|
518
|
524
|
+
|
|
5
|
518
|
510
|
+
|
11
|
517
|
517
|
+
|
19
|
524
|
524
|
+
|
|
6
|
515
|
511
|
-
|
12
|
524
|
518
|
+
|
20
|
521
|
526
|
+
|
|
|
|
|
13
|
526
|
+
|
|
|
|
|
|
|
|
|
14
|
519
|
519
|
+
|
|
|
|
|
)Значение каждого уровня исходного ряда 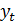 сравнивается
со значением медианы. Если
сравнивается
со значением медианы. Если 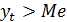 , то
, то 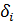 принимает
значение «+», если меньше, то «-»;
принимает
значение «+», если меньше, то «-»;
) v(20)=8- число серий;
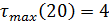 - протяженность
самой большой серии. В соответствии с (5) делаем проверку:
- протяженность
самой большой серии. В соответствии с (5) делаем проверку:

Оба неравенства выполняются. С вероятностью 0,95
тренд во временном ряду отсутствует, что согласуется с выводом, сделанным с
помощью метода Фостера-Стюарта.
2. Сглаживание временных рядов
Следующим шагом в исследовании свойств ряда
динамики является обнаружение характера его тенденций с последующей
пролонгацией таковой в будущее, если конечно тенденция существует. При решении
такого рода задач исследователь может воспользоваться хорошо разработанным
инструментарием сглаживания временных рядов, методы которого условно можно
разделить на две группы:
аналитические, при использовании которых заранее
предполагается вид зависимости, описывающей тенденцию ряда, с последующей
оценкой параметров модели сглаживания;
алгоритмические, которые не предполагают
априорных знаний сглаживающей кривой, ориентируясь лишь на алгоритм расчета
сглаженных уровней ряда.
Суть различных приемов сглаживания сводится к
замене фактических уровней временного ряда расчетными уровнями, которые
подвержены колебаниям в меньшей степени. Это способствует более четкому
проявлению тенденции развития.
Метод скользящих средних
Скользящие средние позволяют сгладить как
случайные, так и периодические колебания, выявить имеющуюся тенденцию в
развитии процесса, и поэтому, являются важным инструментом при фильтрации
компонент временного ряда.
Алгоритм сглаживания по простой скользящей
средней может быть представлен в виде следующей последовательности шагов:
Определяют длину интервала сглаживания g,
включающего в себя g последовательных уровней ряда (g<n). При этом надо
иметь в виду, что чем шире интервал сглаживания, тем в большей степени
взаимопогашаются колебания, и тенденция развития носит более плавный,
сглаженный характер. Чем сильнее колебания, тем шире должен быть интервал
сглаживания.
Разбивают весь период наблюдений на участки, при
этом интервал сглаживания как бы скользит по ряду с шагом, равным 1.
Рассчитывают арифметические средние из уровней
ряда, образующих каждый участок.
. Заменяют фактические значения ряда,
стоящие в центре каждого участка, на соответствующие средние значения.
При этом удобно брать длину интервала
сглаживания g в виде нечетного числа: g=2p+l, т.к. в этом случае полученные
значения скользящей средней приходятся на средний член интервала.
Наблюдения, которые берутся для расчета среднего
значения, называются активным участком сглаживания.
При нечетном значении g все уровни активного
участка могут быть представлены в виде:
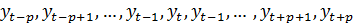 , а скользящая
средняя определена по формуле 6:
, а скользящая
средняя определена по формуле 6:
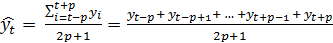 , (6)
, (6)
где 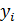 -
фактическое значение i-ro уровня;
-
фактическое значение i-ro уровня;
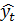 - значение
скользящей средней в момент t;
- значение
скользящей средней в момент t;
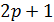 - длина интервала
сглаживания.
- длина интервала
сглаживания.
Процедура сглаживания приводит к полному
устранению периодических колебаний во временном ряду, если длина интервала
сглаживания берется равной или кратной циклу, периоду колебаний.
Для устранения сезонных колебаний желательно
было бы использовать четырех- и двенадцатичленную скользящие средние, но при
этом не будет выполняться условие нечетности длины интервала сглаживания.
Поэтому при четном числе уровней принято первое и последнее наблюдение на
активном участке брать с половинными весами:
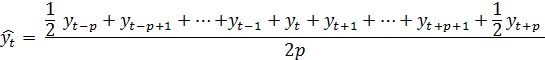
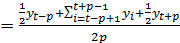 (7)
(7)
Тогда для сглаживания сезонных колебаний при
работе с временными рядами квартальной или месячной динамики можно использовать
следующие скользящие средние:
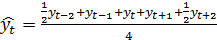 (8)
(8)
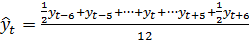 (9)
(9)
При использовании скользящей средней с длиной
активного участка g=2p+l первые и последние p уровней ряда сгладить нельзя, их
значения теряются. Очевидно, что потеря значений последних точек является
существенным недостатком, т.к. для исследователя последние "свежие"
данные обладают наибольшей информационной ценностью. Рассмотрим один из
приемов, позволяющих восстановить потерянные значения временного ряда. Для
этого необходимо:
) Вычислить средний прирост на последнем
активном участке
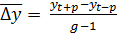 ,
,
где g - длина активного участка;
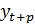 - значение
последнего уровня на активном участке;
- значение
последнего уровня на активном участке;
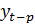 - значение первого
уровня на активном участке;
- значение первого
уровня на активном участке;
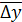 - средний
абсолютный прирост.
- средний
абсолютный прирост.
) Получить Р сглаженных значений в конце
временного ряда путем последовательного прибавления среднего абсолютного
прироста к последнему сглаженному значению.
Аналогичную процедуру можно реализовать для
оценивания первых уровней временного ряда. Метод простой скользящей средней
применим, если графическое изображение динамического ряда напоминает прямую.
Когда тренд выравниваемого ряда имеет изгибы, и для исследователя желательно
сохранить мелкие волны, применение простой скользящей средней нецелесообразно.
Если для процесса характерно нелинейное
развитие, то простая скользящая средняя может привести к существенным искажениям.
В этих случаях более надежным является использование взвешенной скользящей
средней.
При сглаживании по взвешенной скользящей средней
на каждом участке выравнивание осуществляется по полиномам невысоких порядков.
Чаще всего используются полиномы 2-го и 3-его порядка. Так как при простой
скользящей средней выравнивание на каждом активном участке производится по
прямой (полиному первого порядка), то метод простой скользящей средней может
рассматриваться как частный случай метода взвешенной скользящей средней.
Простая скользящая средняя учитывает все уровни ряда, входящие в активный
участок сглаживания, с равными весами, а взвешенная средняя приписывает каждому
уровню вес, зависящий от удаления данного уровня до уровня, стоящего в середине
активного участка.
Выравнивание с помощью взвешенной скользящей
средней осуществляется следующим образом.
Для каждого активного участка подбирается
полином вида
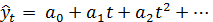 ,
,
параметры которого оцениваются по методу
наименьших квадратов. При этом начало отсчета переносится в середину активного
участка. Например, для длины интервала сглаживания g=5, индексы уровней
активного участка будут следующими i : -2, -1, 0, 1, 2.
Тогда сглаженным значением для
уровня, стоящего в середине активного участка, будет значение параметра 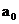 подобранного
полинома.
подобранного
полинома.
Нет необходимости каждый раз заново
вычислять весовые коэффициенты при уровнях ряда, входящих в активный участок
сглаживания, т.к. они будут одинаковыми для каждого активного участка. Причем
при сглаживании по полиному k-ой нечетной степени весовые коэффициенты будут
такими же, как при сглаживании по полиному (k-1) степени.
Экспоненциальное сглаживание
Для экспоненциального сглаживания
ряда используется рекуррентная формула
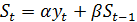 , (10)
, (10)
Где  - значение экспоненциальной средней
в момент t;
- значение экспоненциальной средней
в момент t;
α - параметр сглаживания, α = const,
0< α <l;
β=1 - α.
Если последовательно использовать
соотношение (10), то экспоненциальную среднюю можно выразить через предшествующие
значения уровней временного ряда. При 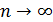
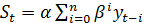 (11)
(11)
Таким образом, величина оказывается
взвешенной суммой всех членов ряда. Причем веса отдельных уровней ряда убывают
по мере их удаления в прошлое соответственно экспоненциальной функции (в
зависимости от "возраста" наблюдений). Именно поэтому величина
названа экспоненциальной средней.
Предположим, что модель временного
ряда имеет вид:
 .
.
Английский математик Р. Браун
показал, что математические ожидания ряда и экспоненциальной средней совпадут,
но в то же время дисперсия экспоненциальной средней D[] меньше
дисперсии временного ряда (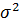 )
)
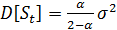 . (12)
. (12)
Из (12) видно, что при высоком
значении 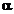 дисперсия
экспоненциальной средней незначительно отличается от дисперсии ряда. С
уменьшением α дисперсия
экспоненциальной средней сокращается, возрастает ее отличие от дисперсии ряда.
Тем самым, экспоненциальная средняя начинает играть роль «фильтра»,
поглощающего колебания временного ряда.
дисперсия
экспоненциальной средней незначительно отличается от дисперсии ряда. С
уменьшением α дисперсия
экспоненциальной средней сокращается, возрастает ее отличие от дисперсии ряда.
Тем самым, экспоненциальная средняя начинает играть роль «фильтра»,
поглощающего колебания временного ряда.
Таким образом, с одной стороны,
следует увеличивать вес более свежих наблюдений, что может быть достигнуто
повышением α
(согласно(11)), с другой стороны, для сглаживания случайных отклонений величину
α нужно
уменьшить. Эти два требования находятся в противоречии. Поиск компромиссного
значения параметра сглаживания составляет задачу оптимизации
модели.
Иногда поиск этого значения
параметра осуществляется путем перебора. В этом случае в качестве оптимального
выбирается то значение α, при
котором получена наименьшая дисперсия ошибки. Например, при построении этих
моделей с помощью пакета "Мезозавр" в меню предусмотрена ветвь
"оптимизация", реализующая поиск значения по этой схеме.
При использовании экспоненциальной
средней для краткосрочного прогнозирования предполагается, что модель ряда
имеет вид:
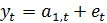 ,
,
где  - варьирующий во времени средний
уровень ряда,
- варьирующий во времени средний
уровень ряда,
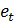 случайные неавтокоррелированные
отклонения с нулевым математическим ожиданием и дисперсией .
случайные неавтокоррелированные
отклонения с нулевым математическим ожиданием и дисперсией .
Прогнозная модель определяется
равенством:
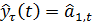 ,
,
где 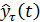 - прогноз, сделанный в момент t на τ единиц
времени (шагов) вперед;
- прогноз, сделанный в момент t на τ единиц
времени (шагов) вперед;
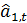 - оценка (знак
- оценка (знак 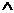 над
величиной означает оценку).
над
величиной означает оценку).
Единственный параметр модели определяется
экспоненциальной средней:
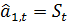
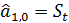
Выражение (10) можно представить
по-другому, перегруппировав члены:
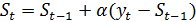 (13)
(13)
Величину 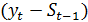 можно
рассматривать как погрешность прогноза. Тогда новый прогноз
можно
рассматривать как погрешность прогноза. Тогда новый прогноз 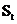 получается
в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и
состоит адаптация модели.
получается
в результате корректировки предыдущего прогноза с учетом его ошибки. В этом и
состоит адаптация модели.
Экспоненциальное сглаживание
является примером простейшей самообучающейся модели. Вычисления чрезвычайно
просты, выполняются итеративно, причем массив прошлой информации уменьшен до
единственного значения.
Полиномиальные модели
Понятие экспоненциальной средней
можно обобщить в случае экспоненциальных средних более высоких порядков.
Выравнивание p-го порядка:
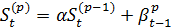 (14)
(14)
является простым экспоненциальным
сглаживанием, примененным к результатам сглаживания (p-l)-гo порядка.
Если предполагается, что тренд
некоторого процесса может быть описан полиномом степени n, то коэффициенты
предсказывающего полинома могут быть вычислены через экспоненциальные средние
соответствующих порядков.
В случае, когда исследуемый процесс,
состоящий из детерминированной и случайной компоненты, описывается полиномом
n-го порядка, прогноз на τ шагов
вперед осуществляется по формуле:
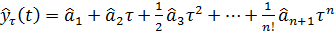 , (15)
, (15)
где 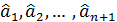 - оценки параметров.
- оценки параметров.
Фундаментальная теорема метода
экспоненциального сглаживания и прогнозирования, впервые доказанная Р. Брауном
и Р. Майером, говорит о том, что (n+1) неизвестных коэффициентов полинома n-го
порядка могут быть
оценены с помощью линейных комбинаций экспоненциальных средних 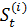 , где
, где 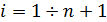 .
.
Следовательно, задача сводится к
вычислению экспоненциальных средних, порядок которых изменяется от 1 до (n+1),
а затем через их линейные комбинации - к определению коэффициентов полинома.
На практике обычно используются
полиномы не выше второго порядка. Например, при использовании полинома первого
порядка адаптивная модель временного ряда имеет вид:
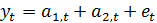 , (16)
, (16)
где - значение текущего t-го уровня;
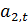 - значение текущего прироста.
- значение текущего прироста.
Процедура прогнозирования временных
рядов по методу экспоненциального сглаживания сравнительно проста и состоит из
следующих этапов:
Выбирается вид модели
экспоненциального сглаживания, задается значение параметра сглаживания α. При выборе
порядка адаптивной полиномиальной модели могут использоваться различные
подходы, например, графический анализ, метод изменения разностей и др.
Определяются начальные условия.
Например, для полиномиальной модели первого порядка необходимо определить 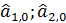 .
.
Чаще всего в качестве этих оценок
берут коэффициенты соответствующих полиномов, полученные методом наименьших
квадратов. Начальные условия для модели нулевого порядка обычно получают
усреднением нескольких первых уравнений ряда. Зная эти оценки, с помощью
указанных в таблице формул находят начальные значения экспоненциальных средних.
Производится расчет значений
соответствующих экспоненциальных средних.
Находятся оценки коэффициентов
модели.
Осуществляется прогноз на одну точку
вперед, находится отклонение фактического значения временного ряда от
прогнозируемого. Шаги с 3 по 5 данной процедуры повторяются для всех 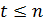 , где n -
длина ряда.
, где n -
длина ряда.
Окончательная прогнозная модель
формируется на последнем шаге в момент t=n. Прогноз получается на базе
выражения (15) путем подстановки в него последних значений коэффициентов и
времени упреждения τ.
К положительным особенностям
рассмотренных моделей следует отнести то, что при поступлении новой, свежей
информации расчеты повторять не придется. Достаточно принять в качестве
начальных условий последние значения функций сглаживания и
продолжить вычисления.
3. Анализ периодических колебаний во
временных рядах
Часто на практике встречаются процессы, носящие
периодический характер и связанными с определенной циклической природой тех или
иных социально-экономических явлений. После формального исключения из
соответствующих исходных уровней статистического ряда уровней, определяемых
общей долгосрочной тенденцией развития (тренда), исследователь в качестве
материала своего изучения имеет остаток по ряду наблюдений - вектор .
(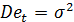 ).
Часто даже визуального наблюдения за распределением уровней ряда бывает
достаточно, чтобы заметить тенденции в их разбросе, колебания относительно
некого среднего уровня. В этой связи может возникнуть мысль о наличии в ряду
остатков возможной зависимости от фактора времени t, которая может фактически
носить как циклическую, так и сезонную природу. Однако, несмотря на различную
природу такого рода явлений, на принципиальную разницу их генезиса, формально
мы можем попытаться идентифицировать произвольные колебательные движения
социально-экономических процессов с помощью схожего аппарата формализации, в
частности, попытаться представить изучаемый ряд (для дальнейшего рассмотрения
примем вновь обозначение yt) разложением Фурье.
).
Часто даже визуального наблюдения за распределением уровней ряда бывает
достаточно, чтобы заметить тенденции в их разбросе, колебания относительно
некого среднего уровня. В этой связи может возникнуть мысль о наличии в ряду
остатков возможной зависимости от фактора времени t, которая может фактически
носить как циклическую, так и сезонную природу. Однако, несмотря на различную
природу такого рода явлений, на принципиальную разницу их генезиса, формально
мы можем попытаться идентифицировать произвольные колебательные движения
социально-экономических процессов с помощью схожего аппарата формализации, в
частности, попытаться представить изучаемый ряд (для дальнейшего рассмотрения
примем вновь обозначение yt) разложением Фурье.
Пусть имеется N наблюдений над переменной Y (для
упрощения дальнейших выкладок примем, что N - четное).- период колебаний, т.е.
промежуток времени, через который наша искомая функция в точности повторит свои
значения.
За исходное примем, что в N укладывается целое
число (h) периодов длины m, т.е. h = N/m или N=h*m. Например, если аналитик
изучает динамику некоторого явления, описанного показателем Y за три года с
помесячной регистрацией статистики, то в наших обозначениях это запишется
следующим образом: длина наблюдаемого ряда N=36 месяца; предполагаемая длина
периода m=12; целое число периодов наблюдаемой статистики h=3).
Заданную числовую последовательность Yt можно
попытаться представить в виде:
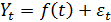 ,
,
где 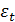 -
случайная составляющая изучаемого ряда (
-
случайная составляющая изучаемого ряда (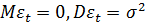 );
);
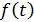 - некоторая
периодическая функция с периодом m.
- некоторая
периодическая функция с периодом m.
Утверждение. Если числовая последовательность
y1, y2, … yN имеет период m, тогда эту последовательность можно представить как
сумму m периодических тригонометрических функций, имеющих период m и меньше.
Иначе говорят: функция разложима в ряд
Фурье вида:
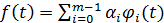 (17)
(17)
где 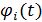 -
i-я тригонометрическая функция.
-
i-я тригонометрическая функция.
4. Сезонность. Аддитивная и
мультипликативная модели
Многие экономические временные ряды содержат
периодические сезонные колебания. Такие ряды могут быть описаны моделями двух
типов - моделями с мультипликативными (18) и с аддитивными коэффициентами
сезонности (19):
 (18)
(18)
 , (19)
, (19)
Где -
характеристика тенденции развития,
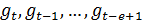 - аддитивные
коэффициенты сезонности,
- аддитивные
коэффициенты сезонности,
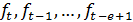 - мультипликативные
коэффициенты сезонности,
- мультипликативные
коэффициенты сезонности,
- количество фаз в
полном сезонном цикле (для ежемесячных наблюдений =12,
для квартальных - =4),
- случайная
компонента с нулевым математическим ожиданием.
Очевидно, что можно составить множество
адаптивных сезонных моделей, перебирая различные комбинации типов тенденций в
сочетании с сезонными эффектами аддитивного и мультипликативного вида. Выбор
той или иной модели будет продиктован характером динамики исследуемого
процесса. В качестве примера рассмотрим модель Уинтерса с линейным характером
тенденции и мультипликативным сезонным эффектом. Эта модель является
объединением двухпараметрическои модели линейного роста Хольта и сезонной
модели Уинтерса, поэтому ее чаще всего называют моделью Хольта-Уинтерса.
Прогноз по модели Хольта-Уинтерса на τ
шагов вперед определяется выражением:
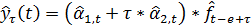 (20)
(20)
Обновление коэффициентов осуществляется
следующим образом:
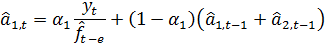
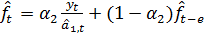 (21)
(21)
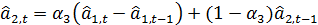
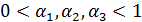
Из (20) видно, что является
взвешенной суммой текущей оценки 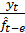 ,
полученной путем очищения от сезонных колебаний фактических данных и
предыдущей оценки
,
полученной путем очищения от сезонных колебаний фактических данных и
предыдущей оценки 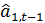 . В качестве
коэффициента сезонности
. В качестве
коэффициента сезонности 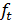 берется его
наиболее поздняя оценка, сделанная для аналогичной фазы цикла (
берется его
наиболее поздняя оценка, сделанная для аналогичной фазы цикла (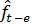 ).
).
Затем величина ,
полученная по первому уравнению, используется для определения новой оценки
коэффициента сезонности по второму уравнению. Оценки  модифицируются
по процедуре, аналогичной экспоненциальному сглаживанию.
модифицируются
по процедуре, аналогичной экспоненциальному сглаживанию.
Оптимальные значения для  Уинтерс
предлагает находить экспериментальным путем, задавая сетку значений этих
параметров. Критерием сравнения при этом выступает стандартное отклонение
ошибки.
Уинтерс
предлагает находить экспериментальным путем, задавая сетку значений этих
параметров. Критерием сравнения при этом выступает стандартное отклонение
ошибки.
Адаптивные сезонные модели являются важной
составной частью современных пакетов прикладных программ, ориентированных на
решение задач прогнозирования.
5. Понятие о стационарных временных
рядах
Реализация временного ряда - это выборка типа
{…, y-2, y-1, y0, y1, y2, …}. Обычно наблюдения упорядочены во времени - отсюда
следует и название: временной ряд, хотя при более тщательном подходе это не
всегда так.
В теории его реализация начинается в
неопределенном прошлом и продолжается до неопределенного будущего, но на практике,
очевидно, наблюдаемые данные - это конечное подмножество реализации временного
ряда {y1, …, yN}, которое называют выборочной
траекторией. И если бы основная вероятностная структура ряда со временем
изменялась, мы были бы обречены - не было бы никакого способа точно предсказать
будущее, основываясь на прошлом, потому что законы, действующие в будущем
отличались бы от действующих в прошлом. Если мы хотим строить прогнозы значений
временного ряда, мы как минимум желаем, чтобы его математическое ожидание и ковариация
(то есть ковариация между текущими и прошлыми значениями) были постоянны во
времени. В этом случае мы говорим, что рассматриваемый ряд является
стационарным в широком смысле. То есть, стационарные в широком смысле временные
ряды yt характеризуются тем, что их средние значения Myt, дисперсии Dyt и
ковариации 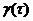 = M[(yt - Myt)(yt+t -Mxt+t)] не зависят от t, для
которого они вычисляются.
= M[(yt - Myt)(yt+t -Mxt+t)] не зависят от t, для
которого они вычисляются.
Стохастический процесс называется
строго стационарным (strictly stationary) или стационарным в узком смысле, если
его свойства не зависят от изменения начала отсчета времени. Иными словами,
если совместное распределение вероятностей m наблюдений  , сделанные
в любые моменты времени
, сделанные
в любые моменты времени  , такое же,
как и для m наблюдений
, такое же,
как и для m наблюдений  сделанных в
моменты времени
сделанных в
моменты времени 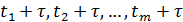 .
.
Поэтому, чтобы дискретный процесс
был строго стационарным, взаимное распределение любой совокупности наблюдений
не должно изменяться при сдвиге всех времен наблюдений вперед или назад на
любое целое число k.
Другими словами, свойства строго
стационарного временного ряда не меняются при изменении начала отсчета времени.
Часто используется понятие слабой
стационарности (weak stationary) или стационарности в широком смысле, которое
состоит в том, что среднее, дисперсия и ковариация yt не зависят от момента
времени t.
Рассмотрим свойство стационарности
временных рядов подробнее. Первое требование стационарности ряда - это
постоянство среднего значения ряда во времени. Среднее значение ряда в момент t
записывается как
 (22)
(22)
Если среднее значение не изменяется
с течением времени, как того требует условие стационарности, то мы можем
записать
 (23)
(23)
для любых t. Поскольку среднее не изменяется со
временем, нет никакой необходимости помечать его индексом времени.
Вторым требованием стационарности ряда является
постоянство ковариации во времени. Для отслеживания этого факта используется
понятие автоковариационной функции. Автоковариация при сдвиге τ
- это ковариация для различных значений одного и того же временного ряда и
 .
Значение этой функции будет, конечно, зависеть от t,
но может также зависеть от t, поэтому в общем случае пишут
.
Значение этой функции будет, конечно, зависеть от t,
но может также зависеть от t, поэтому в общем случае пишут
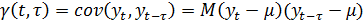 (24)
(24)
Если ковариация не зависит от времени, как того
требует условие стационарности, а зависит только от величины сдвига по времени τ,
то мы можем записать 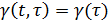 , для любого t.
, для любого t.
Автоковариационная функция важна,
потому что она отражает основное понятие циклической динамики в стационарном
ряде. Исследуя автоковариационную структуру ряда, мы узнаем о ее поведении в
изменяющихся условиях. Это весьма удобно сделать, исследуя график поведения
автоковариации как функции от τ. Обратим внимание на то, что
автоковариационная функция симметричная; то есть 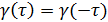 для всех τ. Как
правило, мы рассматриваем только неотрицательные значения
для всех τ. Как
правило, мы рассматриваем только неотрицательные значения 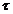 . Симметрия
отражает тот факт, что автоковариация стационарного ряда зависит только от
смещения. Не имеет значения, смещаемся мы вперед или назад. Обратите внимание
также, что
. Симметрия
отражает тот факт, что автоковариация стационарного ряда зависит только от
смещения. Не имеет значения, смещаемся мы вперед или назад. Обратите внимание
также, что 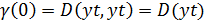 .
.
Еще одно специальное требование
стационарности - требование конечности дисперсии ряда (автоковариация при
нулевом смещении 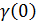 ). Можно
показать, что никакая автоковариация не может быть больше по модулю чем , так если
). Можно
показать, что никакая автоковариация не может быть больше по модулю чем , так если 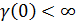 , то также
ведут себя и все остальные автоковариации.
, то также
ведут себя и все остальные автоковариации.
Может показаться, что требования для
стационарности весьма строгие и не предвещают ничего хорошего для наших
прогностических моделей, почти все из которых требуют, так или иначе,
стационарность. На самом деле, многие экономические, деловые, финансовые ряды и
т.д. - не являются стационарными. Тенденция к росту, например, соответствует
устойчиво увеличивающемуся среднему значению, а сезонность предполагает
изменение среднего значения в зависимости от периода времени года. Оба случая -
примеры нарушения стационарности.
Но хотя многие ряды не стационарны,
часто бывает возможно работать с моделями, которые дают специальную интерпретацию
нестационарным компонентам вроде тенденции и сезонности, так, чтобы циклический
компонент, вероятно, оставался стационарным. Мы часто принимаем эту стратегию.
Для этого с помощью простых преобразований можно привести нестационарные ряды к
стационарному виду. Например, многие ряды, которые являются определенно
нестационарными в абсолютных единицах (уровнях), выглядят стационарными в
относительных (темпах роста). Для этого используются специальные процедуры,
именуемые интегрированием динамических рядов.
Кроме того, хотя стационарность
требует, чтобы средние и ковариации были устойчивыми и конечными, она не
накладывает никаких ограничений на другие характеристики распределения ряда,
например, асимметрию и эксцесс. По этой причине, такую стационарность часто
называют стационарностью второго порядка, или слабой стационарностью. Таким
образом, работаем ли мы непосредственно в уровнях и включаем специальные
компоненты для нестационарных элементов наших моделей, или мы работаем на
преобразованных данных типа темпов роста, предположение о стационарности не
столь нереалистично, как это может показаться.
Вспомним, что корреляция между двумя
случайными переменными x и у (коэффициент парной корреляции) определяется как
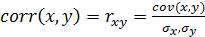 (25)
(25)
То есть корреляция переменных x и y
- это просто их ковариация, "нормализованная", или
"стандартизированная", произведением стандартных отклонений x и y. И
корреляция, и ковариация - меры измерения тесноты линейной связи между двумя
случайными переменными. Тем не менее, корреляция часто бывает более
информативна и легко интерпретируется, потому что конструкция коэффициента
корреляции гарантирует, что corr(x, y) Î[-1,1], в то время как ковариация между теми же
самыми двумя случайными переменными может принимать любое значение. Корреляция,
кроме того, не зависит от единиц, в которых переменные x и у измерены, тогда
как ковариация зависит. Вследствие лучшей интерпретируемости корреляции по
сравнению с ковариацией, исследователи часто работают с корреляцией охотнее,
чем с ковариацией, между и . То есть
работа с функцией автокорреляции, 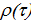 , предпочтительней, чем с функцией
автоковариации,
, предпочтительней, чем с функцией
автоковариации, 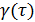 . Функцию
автокорреляции можно получить, разделив автоковариационную функцию на дисперсию
. Функцию
автокорреляции можно получить, разделив автоковариационную функцию на дисперсию
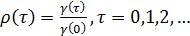 (26)
(26)
ормула для автокорреляции - это
обычная формула корреляции, только для измерения тесноты взаимосвязи между
членами одного и того же временного ряда, т.е. между и . Это
объясняется тем, что дисперсия равна , и
вследствие стационарности, дисперсия в любое другое время - также . Таким
образом,
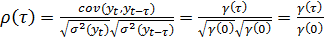 (27)
(27)
Следует иметь в виду, что 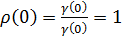 ,
потому что любой ряд совершенно коррелируется сам с собой. Таким образом,
только значения автокорреляции при ненулевых сдвигах информируют нас
относительно динамической структуры рядов.
,
потому что любой ряд совершенно коррелируется сам с собой. Таким образом,
только значения автокорреляции при ненулевых сдвигах информируют нас
относительно динамической структуры рядов.
Наконец, иногда полезной является частная
автокорреляционная функция,  , так как -
только коэффициент при в совокупности
линейной регрессии на
, так как -
только коэффициент при в совокупности
линейной регрессии на 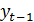 .,…,
.
Такие регрессии именуют авто- регрессиями, потому что переменная регрессирована
на своих же лаговых значениях. Легко видеть, что автокорреляция и частная
автокорреляция, хотя и связаны, но отличаются важным образом. Автокорреляции -
только "простые" или "регулярные" корреляции между и
.
Частные автокорреляции, с другой стороны, измеряют тесноту взаимосвязи между и
при
устранении влияния промежуточных членов ,…,
.,…,
.
Такие регрессии именуют авто- регрессиями, потому что переменная регрессирована
на своих же лаговых значениях. Легко видеть, что автокорреляция и частная
автокорреляция, хотя и связаны, но отличаются важным образом. Автокорреляции -
только "простые" или "регулярные" корреляции между и
.
Частные автокорреляции, с другой стороны, измеряют тесноту взаимосвязи между и
при
устранении влияния промежуточных членов ,…,
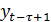 этого
ряда; то есть они измеряют “очищенную” корреляцию между и
.
этого
ряда; то есть они измеряют “очищенную” корреляцию между и
.
Можно показать, что любой стационарный ряд
должен иметь автокорреляционную и частную автокорреляционную функции, которые
каким либо образом приближаются к 0 при увеличивающемся смещении.
6. Понятие белого шума в моделях
динамики временных рядов
Перед тем, как оценить параметры прогностической
модели временного ряда, необходимо изучить ее совокупные свойства, предполагая,
что выбранная модель значима. Простейшим из такого рода процессов временного
ряда является основным стандартным блоком, из которого можно получить все
остальные процессы. Записать его можно следующим образом =
et,
где et
~
(0, s2)
и et
некоррелирован во времени. В данной ситуации говорят, что et,
и следовательно, , последовательно
(серийно) некоррелированы (т.е. отсутствует корреляция внутри ряда). Во всех
ситуациях, если не установлено другое, мы будем полагать, что s2
< ¥.
Такой процесс, с нулевым математическим ожиданием, постоянной конечной
дисперсией и отсутствием корреляции внутри ряда, называется белым шумом с
нулевым средним, или просто белым шумом (white noise). Иногда для краткости
пишут et
~
WN (0, s2)
и следовательно ~
WN (0, s2).
Следует обратить внимание, что et
и аналогично , последовательно
некоррелированны, но они необязательно последовательно независимы, потому что
они необязательно распределены нормально. Если в добавлении к последовательной
некоррелированности является и серийно
независимым, тогда мы можем сказать, что -
это независимый белый шум. Таким образом, записывается
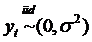 (28)
(28)
и говорится, что “значения независимо
и одинаково распределены с нулевым математическим ожиданием постоянной
дисперсией”. Если в ряду отсутствует
корреляция и ряд распределен нормально, то из этого следует, что ряд уt также
независимо распределен. Тогда мы говорим, что уt - это нормальный белый шум,
или белый шум Гаусса:  . Мы читаем
“ уt - это независимо, одинаково нормально распределенный ряд с нулевым средним
и постоянной дисперсией” или просто “Гауссовский белый шум”.
. Мы читаем
“ уt - это независимо, одинаково нормально распределенный ряд с нулевым средним
и постоянной дисперсией” или просто “Гауссовский белый шум”.
Возмущения в регрессионной модели
рассматриваются как белый шум в том или ином роде. Тем не менее, имеется одно
важное различие. Возмущения в регрессионной модели не поддаются наблюдению, тогда
как временные ряды наблюдаемы. Позже, тем не менее, мы увидим, как все наши
модели для наблюдаемых рядов могут быть применены для не поддающихся наблюдению
переменных, таких как регрессионные возмущения.
Охарактеризуем динамическую
стохастическую структуру белого шума уt ~
WN (0, s2). По
построению, безусловное математическое ожидание уt будет M(уt) = 0, а
безусловная дисперсия D (уt) = s2.
Чтобы полностью понять линейную
динамическую структуру стационарного процесса временного ряда, нам требуется
рассчитать и проверить его среднее значение и автоковариационную функцию. Так
как белый шум, по определению, не коррелирован во времени, все автоковариации
и, следовательно, все автокорреляции, равны нулю, за исключением значения,
зависящего от нулевого сдвига. Формально автоковариационная функция для
процесса белого шума записывается так
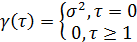 (29)
(29)
Автокорреляционная функция для этого
процесса запишется следующим образом
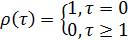 (30)
(30)
Рассмотрим частную
автокорреляционную функцию (ЧАКФ) для рядов содержащих белый шум. Так как АКФ
при сдвиге равном 0 всегда равна 1, ЧАКФ при нулевом смещении принимает то же
значение. Для белого шума, все значения ЧАКФ при больших, чем нуль, сдвигах
равны нулю. Это следует опять-таки из того, что белый шум, по построению,
серийно не коррелирован. Совокупные регрессии yt на yt-1, или на yt-1 и yt-2,
или на другие лаги, приводит к нулевым коэффициентам, потому что процесс
серийно не коррелирован. Формально, ЧАКФ процесса белого шума записывается так
(31)
Это снова вырожденная функция и выглядит так же
как АКФ.
Из определения процесса типа «белый шум» ясно,
что попытки спрогнозировать независимый белый шум, обречены на провал. Так как
мы не можем сказать, что происходит с рядом, содержащим белый шум в любое
время, не связанное с прошлым, и аналогично, что происходит в будущем, не
связанным с настоящим или прошлым. Но понимание белого шума чрезвычайно важно
как минимум по двум причинам. Во-первых, процессы с более ощутимой динамикой
получаются простой трансформацией белого шума. Во-вторых, ошибки прогноза на
один период вперед должны быть белым шумом. Так как, если эти ошибки не
являются белым шумом, то они коррелированны, что означает, что прогностическая
модель построена некорректно, а если это имеет место, то прогноз не может быть
хорошим. Поэтому важно понимание и распознавание этого явления.
Таким образом, мы охарактеризовали
белый шум через его среднее значение, дисперсию, АКФ и ЧАКФ. Другая
характеристика динамики с важными выводами для прогнозирования, включает
среднее и дисперсию процесса, обусловленные прошлой истории этого процесса. В
частности, мы часто можем понять сущность динамики процесса, анализируя его
условное математическое ожидание, которое является ключевым объектом для
прогнозирования. Для сравнения безусловных и условных математических ожиданий и
дисперсий, чтобы облегчить нашу попытку, рассмотрим пример независимого белого
шума, 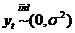 с теми же
аргументами: безусловным средним 0 и безусловной дисперсией s2. Рассмотрим теперь условные
среднее и дисперсию, где исходными ретроспективными данными является
информационное множество Wt-1, которое
по существу содержит или прошлую историю наблюдаемого ряда, т.е. Wt-1 = {…yt-1, yt-2,…}, или
прошлую историю возмущений ряда, т.е. Wt-1
= { et-1, et-2,… }. В сравнении с
безусловными средним и дисперсией, которые должны быть постоянными, согласно
требованиям стационарности, условные среднее и дисперсия необязательно
постоянные, и в общем случае мы должны считать их непостоянными. Для
независимого белого шума условное среднее имеет вид
с теми же
аргументами: безусловным средним 0 и безусловной дисперсией s2. Рассмотрим теперь условные
среднее и дисперсию, где исходными ретроспективными данными является
информационное множество Wt-1, которое
по существу содержит или прошлую историю наблюдаемого ряда, т.е. Wt-1 = {…yt-1, yt-2,…}, или
прошлую историю возмущений ряда, т.е. Wt-1
= { et-1, et-2,… }. В сравнении с
безусловными средним и дисперсией, которые должны быть постоянными, согласно
требованиям стационарности, условные среднее и дисперсия необязательно
постоянные, и в общем случае мы должны считать их непостоянными. Для
независимого белого шума условное среднее имеет вид
М(yt | Wt-1) = 0, (32)
а условная дисперсия выглядит как
(yt | Wt-1) = М[(yt - М(yt | Wt-1))2 | Wt-1] = s2. (33)
Условные и безусловные дисперсии и
средние идентичны для рядов, содержащих белый шум. Рассматриваемый процесс не
содержит динамики и, следовательно, нет динамики в условных моментах, которую
можно моделировать.
7. Модель случайного блуждания
Важным примером стационарного
временного ряда является процесс
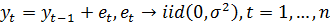 (34)
(34)
называемый случайным блужданием
(random walk). Учитывая, что ошибка et
некоррелирована с yt-1, можно получить:
М(yt) = М(yt-1)
+0; D(yt ) = D(yt-1) + s2.
(35)
Отсюда ясно, что случайное блуждание
нестационарно, так как
 (36)
(36)
Если положить, что процесс начинается с момента
t=1 и М(y1) =m, D(y1) = s2, то М(yt) =m,
D(yt) = s2t,
при t=1,2,…, т.е. дисперсия неограниченно возрастает во времени.
8. Понятие оператора лагового сдвига
Оператор сдвига и связанные с ним структурные
компоненты - это язык, на котором описываются прогностические модели. Оператор
сдвига, обозначим его символом L, оперирует рядом, вводя в него запаздывания (лаги),
так что
 . (37)
. (37)
Аналогично,
 (38)
(38)
и так далее. Однако в общем случае будем
говорить, что речь идет об использовании полиномов от оператора сдвига. Полином
от оператора сдвига степени m - это линейная функция различных степеней L до
m-й степени
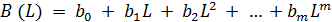 . (39)
. (39)
Пример полинома от оператора сдвига m-й степени,
оперирующего с рядами, например, 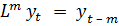 .
Хорошо известный оператор разности первого порядка D
- это в действительности полином первой степени от оператора сдвига:
.
Хорошо известный оператор разности первого порядка D
- это в действительности полином первой степени от оператора сдвига:
 .
.
Например, если необходимо рассмотреть полином
второй степени от оператора сдвига вида (1 + 0.78L + 0.65L2), оперирующего с
рядом yt. Эквивалентно это условие можно записать как равенство
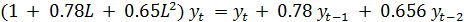 ,
,
которое представляет собой взвешенную сумму, или
распределенный лаг, настоящих и прошлых значений ряда yt.
Все ранее рассмотренное относится к полиномам
конечной степени. Полином бесконечного порядка можно записать так
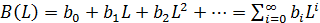 (40)
(40)
Таким образом, например, для представления
распределенного лага текущих и прошлых возмущений бесконечного порядка, можно
записать
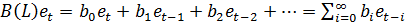 (41)
(41)
Модели, содержащие бесконечное количество
распределенных лагов, занимают центральное место в моделировании и
прогнозировании временных рядов. Это находит выражение в так называемой теореме
Уолда.
Многие модели временных рядов не противоречат
условиям стационарности. Так что, если мы знаем, что ряд стационарен, это ещё
не дает четкого ответа на вопрос, какой вид модели мы можем применить для
описания динамики ряда. Тренд и сезонные модели, которые мы уже изучили, здесь
неприменимы, так они описывают специфические нестационарные компоненты.
Исследователю необходима подходящая модель для имитации стационарных остатков
динамического ряда. Теорема о представлении Уолда указывает на соответствующий
вид модели.
Теорема. Пусть {yt} будет любым стационарным
процессом с нулевым средним, не содержащим никаких детерминированных компонент.
Тогда этот процесс можно записать как
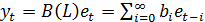 , где
, где 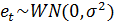 ,
при
,
при 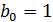 и
и
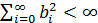 (42)
(42)
Иначе говоря, моделью для любого стационарного
ряда является бесконечно распределенный лаг белого шума, называемый
представлением Уолда. Такое представление ряда называется - общим линейным
процессом. Общим, потому что любой стационарный ряд может быть записан в такой
форме, а линейный, потому что представление Уолда изображает ряд в виде
линейной комбинации его инноваций (т.е. его предшествующих значений).
Ввиду особой важности для прогнозирования общего
линейного процесса рассмотрим его условные и безусловные моменты. Зная средние
и дисперсии по ряду, мы легко можем получить его безусловные моменты, т.е.
математическое ожидание ряда
 (43)
(43)
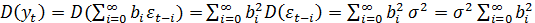 (44)
(44)
Условное математическое ожидание ряда
определяется как
М(yt | Wt-1) = М(et
| Wt-1)
+b1М(et-1
| Wt-1)
+ b2М(et-2
| Wt-1)
+….=
= 0 + b1et-1 + b2et-2 +…= 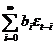 (45)
(45)
и условная дисперсия ряда
(yt | Wt-1)
= М[ (yt - М(yt | Wt-1))2 | Wt-1]
= М(et 2| Wt-1)
= М(et
2) = s2
(46)
Существенным является то, что условное среднее
смещается во времени в ответ на изменение информационного пространства. Модель
фиксирует изменения процесса, и изменяющееся среднее - это один из способов
интегрировать эти изменения. Важная цель при моделировании временных рядов,
особенно для прогнозистов, - это уловить динамику условного среднего (т.к.
безусловное среднее постоянно, это один из признаков стационарности ряда), а
условное среднее изменяется в ответ на эволюцию исходного информационного
пространства.
9. Оценка и вывод среднего,
автокорреляционной и частной автокорреляционной функций
Предположим, что у нас есть выборка данных
временного ряда, и мы не знаем вида модели, которая генерирует эти данные, т.е.
среднее, АКФ, или ЧАКФ, связанные с истинной моделью. Вместо этого, мы хотим
использовать данные, чтобы оценить среднее, АКФ и ЧАКФ, которые мы можем потом
использовать, чтобы помочь нам изучить лежащую в основе динамику, а потом
решить, какая модель или набор моделей нам подходят.
Оценка выборочного среднего
Среднее стационарного ряда определяется как 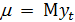 .
Основной принцип оценивания, который называется принципом аналогии,
предполагает, что мы улучшаем формулу оценки (оценочную функцию) путем
замещения математического ожидания выборочными средними. Так что наша оценка
среднего совокупности, представленной как выборка размерностью Т, называется
выборочным средним
.
Основной принцип оценивания, который называется принципом аналогии,
предполагает, что мы улучшаем формулу оценки (оценочную функцию) путем
замещения математического ожидания выборочными средними. Так что наша оценка
среднего совокупности, представленной как выборка размерностью Т, называется
выборочным средним
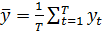 (47)
(47)
Обычно нас прямо не интересует оценка среднего,
но она нужна для оценки автокорреляционной функции.
Оценка выборочной автокорреляции
Значение автокорреляции при сдвиге уровней ряда
на величину t для стационарных рядов уt равно
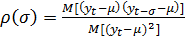 (48)
(48)
Применяя принцип аналогии, получим в результате
оценочную формулу
временной ряд сдвиг динамика
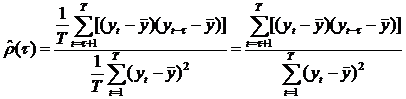 (49)
(49)
Эта формула, которая выглядит как
функция от t, называется
выборочной автокорреляционной функцией, а ее графическое представление
коррелограммой. Заметим, что некоторые суммы начинаются с t= t + 1, а не с t= 1; это
необходимо из-за наличия в формуле yt-t.
Обратим внимание на то, что производится деление одних и тех же суммы на Т,
хотя в сумме только (Т- t) членов,
т.е. происходит некоторое искажение числа степеней свободы. Деление на Т или на
(Т- t) дает почти
одинаковый результат в виду более чем существенной разницей между Т и t, поэтому для практических
целей это не имеет большого значения; кроме того, есть хорошие математические
причины для предпочтения деления на Т.
Часто требуется оценить, является ли
исследуемый ряд возможной аппроксимацией к белому шуму, тогда можно сказать,
равны ли нулю автокорреляции в совокупности. Лучшим результатом будет ряд
белого шума. Тогда распределение выборочных автокорреляций в больших выборках
будет
 (50)
(50)
Выборочные автокорреляции ряда,
содержащего белый шум, распределены приблизительно нормально, а нормальное
распределение всегда “удобное” распределение. Среднее значение равно 0, и это
говорит о том, что выборочные автокорреляции являются несмещенными оценками
автокорреляции генеральной совокупности, которая на самом деле равна 0.
Дисперсия выборочных автокорреляций приблизительно равна  (стандартное
отклонение »
(стандартное
отклонение » 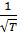 ). Выясним,
является ли ряд белым шумом, то есть, равны ли все автокорреляции 0
одновременно. Простое расширение позволяет нам проверить эту гипотезу.
). Выясним,
является ли ряд белым шумом, то есть, равны ли все автокорреляции 0
одновременно. Простое расширение позволяет нам проверить эту гипотезу.
Литература
1.
Арженовский С.В., Молчанов И.Н. Статистические методы прогнозирования. Учебное
пособие /Рост. гос. экон. унив. - Ростов-н/Д. - 2001. - 74 с.
.
Афанасьев В.Н., Юзбашев М.М. Анализ временных рядов и прогнозирование. -
Москва: "Финансы и статистика", 2001. -228 с.
.
Большаков А.А., Каримов Р.Н. Методы обработки многомерных данных и временных
рядов Учебное пособие для вузов. -М.: Горячая линия-Телеком, 2007. --522 с.
.
Дуброва Т.А. Статистические методы прогнозирования в экономике . -М.: МЭСИ,
2001. - 50 с.
.
Керимов А.К. Анализ и прогнозирование временных рядов. Учеб. пособие. - М.:
Изд-во РУДН, 2005. - 138 с.
.
Лукашин Ю.П. Адаптивные методы краткосрочного прогнозирования временных рядов.
Учеб. пособие. -М.: Финансы и статистика, 2003 г. - 416 с.
.
Орлов А.И. Статистические методы прогнозирования. - В кн.: Малая российская
энциклопедия прогностики. - М.: Институт экономических стратегий, 2007. -
С.148-153.
.
Рунова Л.П., Рунов И.Л. Анализ временных рядов и прогнозирование.
Учебно-методические материалы по дисциплине “Методы социально-экономического
прогнозирования” для студентов специальности “Математические методы в
экономике”. -Ростов-на-Дону, РГУ, 2006. -109с.
.
Татаренко С.И. Методы и модели анализа временных рядов: методические указания к
лабораторным работам. -Тамбов: Изд-во Тамб. гос. техн. ун-та, 2008. - 32 с.