|
Номер рейса
|
Дни недели
|
Пункт отправл.
|
Время вылета
|
Пункт назнач.
|
Время прибыт.
|
Тип самолета
|
Стоимость билета
|
|
138
|
2_4_7
|
Минск
|
21.12
|
Москва
|
0.52
|
ИЛ-86
|
115.00
|
|
57
|
3_6
|
Ереван
|
7.20
|
Киев
|
9.25
|
ТУ-154
|
92.00
|
|
1234
|
2_6
|
Москва
|
22.40
|
Минск
|
23.50
|
ТУ-134
|
73.50
|
|
242
|
1 по 7
|
Киев
|
14.10
|
Москва
|
16.15
|
ТУ-154
|
|
86
|
2_3_5
|
Минск
|
10.50
|
Сочи
|
13.06
|
ИЛ-86
|
78.50
|
|
137
|
1_3_5
|
Москва
|
17.15
|
Минск
|
18.44
|
ИЛ-86
|
115.00
|
|
241
|
1 по 7
|
Москва
|
9.05
|
Киев
|
11.05
|
ТУ-154
|
57.00
|
|
577
|
1_3_5
|
Рига
|
21.53
|
Таллинн
|
22.57
|
АН-24
|
21.50
|
|
78
|
3_6
|
Сочи
|
18.25
|
Минск
|
20.12
|
ТУ-134
|
44.00
|
|
578
|
2_4_6
|
Таллинн
|
6.30
|
Рига
|
7.37
|
АН-24
|
21.50
|
Рис. 1. Разделение данных и их интерпретации
Применение компьютеров для хранения и обработки данных обычно
приводит к еще большему разделению данных и их интерпретации. Компьютер
работает с данными как таковыми. Большая часть интерпретирующей информации
вообще не фиксируется в явной форме (компьютер не "знает", что
означает 21.50 - время вылета или стоимость билета).
Такое разделение может быть объяснено исторически. Во-первых,
ЭВМ не обладали достаточными возможностями для обработки текстов на
естественном языке - основном языке интерпретации данных. Во-вторых, стоимость
памяти ЭВМ была первоначально весьма велика. Память использовалась для хранения
самих данных, а интерпретация традиционно возлагалась на пользователя.
Пользователь закладывал интерпретацию данных в свою программу. Это существенно
повышало роль программы, так как вне интерпретации данные представляют собой не
более чем совокупность битов на запоминающем устройстве.
Жесткая зависимость между данными и использующими их
программами создает серьезные проблемы в ведении данных и делает их
использование менее гибким.
Нередки случаи, когда пользователи одной и той же ЭВМ создают
и используют в своих программах разные наборы данных, содержащие сходную
информацию. Иногда это связано с тем, что пользователь не знает, что за
соседним столом сидит сотрудник, который уже давно ввел в ЭВМ нужные данные. Но
чаще потому, что при совместном использовании одних и тех же данных возникает
масса проблем.
Разработчики прикладных программ (написанных, например, на
Бейсике, Паскале или Си) размещают нужные им данные в файлах, организуя их
наиболее удобным для себя образом. При этом одни и те же данные могут иметь в
разных приложениях совершенно разную организацию (разную последовательность
размещения в записи, разные форматы одних и тех же полей и т.п.). Обобществить
такие данные чрезвычайно трудно: например, любое изменение структуры записи
файла, производимое одним из разработчиков, приводит к необходимости изменения
другими разработчиками тех программ, которые используют записи этого файла.
Концепция баз
данных
Активная деятельность по разработке эффективных способов
обработки непрерывно растущего объема информации привела к созданию в начале
60-х годов специальных программных комплексов, называемых системами управления
базами данных (СУБД).
Основная особенность СУБД - это наличие процедур не только
для ввода, хранения и обработки самих данных, но и для описания их структуры.
Файлы, снабженные описанием хранимых в них данных и находящиеся под управлением
СУБД, стали называть банками данных, а затем базами данных.
Пусть, например, требуется хранить расписание движения самолетов
(рис. <1-1.shtml.htm>) и ряд других данных, связанных с организацией
работы аэропорта (база данных "Аэропорт"). Используя для этого СУБД,
можно подготовить следующее описание расписания (мы начинаем демонстрировать
элементы языка структурированных запросов SQL (Structured Query Language),
который используется большинством современных СУБД):
СОЗДАТЬ ТАБЛИЦУ Расписание (Номер_РейсаЦелое, Дни_НеделиТекст (8),
Пункт_Отправления Текст (24), Время_ВылетаВремя, Пункт_НазначенияТекст (24),
Время_Прибытия Время, Тип_Самолета Текст (8), Стоимость_Билета Денежный);
и хранить его вместе с данными в файле базы данных
"Аэропорт".
Язык запросов СУБД позволяет формулировать задачу поиска данных,
например, запрос
ВЫБРАТЬ Номер_Рейса, Дни_Недели, Время_Вылета ИЗ ТАБЛИЦЫ
Расписание ГДЕ Пункт_Отправления = 'Москва' И Пункт_Назначения = 'Минск' И
Время_Вылета > ‘17’;
позволяет получить расписание "Москва-Минск" на вечернее
время, а по запросу
ВЫБРАТЬ КОЛИЧЕСТВО (Номер_Рейса) ИЗ ТАБЛИЦЫ Расписание ГДЕ
Пункт_Отправления = 'Москва' И Пункт_Назначения = 'Минск';
получим количество рейсов "Москва-Минск".
Язык запросов применяется и для изменения таблиц. Например,
расширить таблицу можно следующим способом:
ДОБАВИТЬ В ТАБЛИЦУ Расписание Длительность_Полета Время;
Однако дополнительные возможности, которые предоставляет СУБД,
требуют дополнительных ресурсов машины - на обмен данными через СУБД требуется
большее время, чем на обмен аналогичными данными прямо из файлов, специально
созданных для того или иного приложения.
Программно-техническая реализация концепции баз данных позволяет
на их основе создавать различные приложения - прикладные программы, которые
служат интерфейсами между пользователем и СУБД. Схема взаимодействия
пользователя с базой данных показана на рис.2 В основе ее лежит модель
"клиент-сервер". Приложения, предназначенные для создания запросов,
форм и отчетов, стали неотъемлемой частью многих коммерческих СУБД. Более
специфические приложения создаются непосредственно пользователями. Например,
для получения и обработки результатов измерений или реализации логики задачи.
Основные
функции СУБД
В отличие от приложений, почти все СУБД являются
коммерческими продуктами, причем, подавляющую часть рынка захватили пять
систем: Oracle, Access и SQL Server (Microsoft), FoxPro (Borland) и DB2 (IBM).
К числу основных функций СУБД принято относить следующие:
· модификация объектов и структур базы
данных;
· ввод, чтение и изменение данных;
· обеспечение целостности данных;
· обеспечение безопасности данных;
· управление параллельной обработкой данных;
· создание резервных копий.
Для реализации этих функций, СУБД снабжены специальными
устройствами и компонентами. Рассмотрим некоторые из них.
Непосредственное управление данными во внешней памяти
Эта функция поддерживает структуры внешней памяти,
используемые как для хранения данных, непосредственно входящих в базу данных,
так и для служебных целей, например, для ускорения доступа к данным в некоторых
случаях (обычно для этого используются индексы).
Управление
буферами оперативной памяти
СУБД обычно работают с базами данных значительного размера,
по крайней мере, этот размер может быть больше доступного объема оперативной
памяти. Если при обращении к любому элементу данных будет производиться обмен с
внешней памятью, то вся система будет работать со скоростью доступа к
устройствам внешней памяти. Практически единственным способом реального увеличения
скорости работы является буферизация данных в оперативной памяти. Поэтому в
развитых СУБД поддерживается собственный набор буферов оперативной памяти с
собственной дисциплиной замены буферов.
Управление
транзакциями
Транзакция - это последовательность операций над базой
данных, рассматриваемых СУБД как единое целое. Либо транзакция успешно
выполняется и СУБД фиксирует во внешней памяти изменения базы данных,
произведенные этой транзакцией, либо ни одно из этих изменений никак не
отражается на состоянии базы данных. Понятие транзакции необходимо для
поддержания логической целостности (или согласованности) баз данных, которая
обеспечивается возможностью восстановления базы данных, если какой-либо сбой
сделал текущее состояние неправильным или подозрительным.
Существуют простые транзакции, такие как создание, изменение
или удаление одной записи в одном файле. Но, как правило, транзакции
представляют собой более сложные операции. Предположим, что в базе данных
существует два банковских счета и необходимо перевести средства с одного счета
на другой. Для этого нужно уменьшить на заданную сумму баланс одного счета и
увеличить на ту же сумму баланс второго. Чтобы это сделать, потребуется
выполнить две отдельные операции. Сбой в базе данных в момент между выполнением
этих двух операций может привести к несогласованности данных: баланс второго
счета не будет увеличен, в то время как баланс первого счета уменьшится.
Нарушится целостность транзакции как логически неделимого целого. В таком
случае лучше, чтобы не был выполнен ни один из операторов. Принцип целостности
транзакций требует, чтобы транзакция выполнялась полностью или не выполнялась
вовсе.
Каждая транзакция начинается при согласованном состоянии базы
данных и оставляет это состояние согласованным после своего завершения.
Система, поддерживающая процесс транзакции, обеспечивает гарантию, что если во
время выполнения неких обновлений произошла ошибка (по любой причине), то все
эти обновления будут аннулированы. Таким образом, транзакция или выполняется
полностью, или полностью отменяется (как будто она вообще не выполнялась). Это
свойство транзакции обеспечивается операторами commit и rollback. Оператор
commit выполняется, если обновления прошли успешно, изменения в базе данных
выполнены и стали постоянными. Если что-то не так, если обновление прервано
каким-либо условием ошибки, то выполняется оператор rollback и любые изменения
отменяются.
Транзакции обладают четырьмя важными свойствами:
- Атомарность - транзакции атомарны
(выполняется все или ничего).
- Согласованность - транзакции защищают базу
данных согласованно. Это означает, что транзакции переводят одно согласованное
состояние базы данных в другое без обязательной поддержки согласованности во
всех промежуточных точках.
- Изоляция - транзакции отделены одна от
другой. Это означает, что, если даже будет запущено множество конкурирующих
друг с другом транзакций, любое обновление определенной транзакции будет скрыто
от остальных до тех пор, пока эта транзакция выполняется. Другими словами, для
любых двух отдаленных транзакций Т1 и Т2 справедливо следующее утверждение: Т1
сможет увидеть обновление Т2 только после выполнения Т2, а Т2 сможет увидеть
обновление Т1 только после выполнения Т1.
- Долговечность. Когда транзакция выполнена,
ее обновления сохраняются, даже если в следующий момент произойдет сбой
системы.
Журнализация
Одним из основных требований к СУБД является надежность
хранения данных во внешней памяти. Под надежностью хранения понимается то, что
СУБД должна быть в состоянии восстановить последнее согласованное состояние
базы данных после любого аппаратного или программного сбоя. Обычно
рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие
сбои, которые можно трактовать как внезапную остановку работы компьютера
(например, аварийное выключение питания), в результате чего некоторая
транзакция остается незавершенной, и жесткие сбои, характеризуемые потерей
информации на носителях внешней памяти.
Очевидно, что в любом случае для восстановления базы данных
нужно располагать некоторой дополнительной информацией. Другими словами,
поддержание надежности хранения данных в базе требует избыточности хранения
данных, причем та часть данных, которая используется для восстановления, должна
храниться особо надежно. Наиболее распространенным методом поддержания такой
избыточной информации является ведение журнала изменений базы данных.
Журнал - это особая часть базы данных, недоступная
пользователям СУБД и поддерживаемая с особой тщательностью, в которую поступают
записи обо всех изменениях основной части базы данных (иногда поддерживаются
две копии журнала, располагаемые на разных физических дисках).
При ведении журнала придерживаются стратегии
"упреждающей" записи (так называемого протокола Write Ahead Log -
WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении
любого объекта базы данных должна попасть во внешнюю память журнала раньше, чем
измененный объект попадет во внешнюю память основной части базы данных. Если в
СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все
проблемы восстановления базы данных после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат
транзакции. При мягком сбое во внешней памяти основной части базы данных могут
находиться объекты, модифицированные транзакциями, не закончившимися к моменту
сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к
моменту сбоя успешно завершились (по причине использования буферов оперативной
памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола
WAL во внешней памяти журнала должны гарантированно находиться записи,
относящиеся к операциям модификации обоих видов объектов. Целью процесса
восстановления после мягкого сбоя является состояние внешней памяти основной
части базы данных, которое возникло бы при фиксации во внешней памяти изменений
всех завершившихся транзакций и которое не содержало бы никаких следов
незаконченных транзакций. Для того, чтобы этого добиться, сначала производят
откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те
операции завершенных транзакций, результаты которых не отображены во внешней
памяти.
Для восстановления базы данных после жесткого сбоя используют
журнал и архивную копию базы данных. Грубо говоря, архивная копия - это полная
копия базы данных к моменту начала заполнения журнала. Конечно, для нормального
восстановления базы данных после жесткого сбоя необходимо, чтобы журнал не
пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД
предъявляются особо повышенные требования. Тогда восстановление базы данных
состоит в том, что исходя из архивной копии, по журналу воспроизводится работа
всех транзакций, которые закончились к моменту сбоя.
Поддержка
языков баз данных
Для работы с базами данных используются специальные языки, в
целом называемые языками баз данных. В ранних СУБД поддерживалось несколько
специализированных по своим функциям языков. Чаще всего выделялись два языка -
язык определения схемы базы данных (SDL - Schema Definition Language) и язык манипулирования
данными (DML - Data Manipulation Language). SDL служил, главным образом, для
определения логической структуры базы данных, т.е. той структуры базы данных,
какой она представляется пользователям. DML содержал набор операторов
манипулирования данными, т.е. операторов, позволяющих заносить данные в базу,
удалять, модифицировать или выбирать существующие данные. В современных СУБД
обычно поддерживается единый интегрированный язык, содержащий все необходимые
средства для работы с базами данных, начиная от ее создания, и обеспечивающий
базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее
распространенных в настоящее время реляционных СУБД является язык SQL
(Structured Query Language).
Язык SQL сочетает средства SDL и DML, т.е. позволяет
определять схему реляционной базы данных и манипулировать данными. Язык SQL
содержит специальные средства определения ограничений целостности базы данных.
Специальные операторы языка SQL позволяют определять так называемые
представления баз данных, которые фактически являются хранимыми в базах данных
запросами (результатом любого запроса к реляционной базе данных является
таблица с именованными столбцами). Для пользователя представление является
такой же таблицей, как любая базовая таблица, хранимая в базе данных, но с
помощью представлений можно ограничить или, наоборот, расширить видимость базы
данных для конкретного пользователя. Поддержание представлений производится
также на языковом уровне. Наконец, авторизация доступа к объектам базы данных
производится также на основе специального набора операторов SQL. Идея состоит в
том, что для выполнения операторов SQL разного вида пользователь должен
обладать различными полномочиями. Пользователь, создавший таблицу базы данных,
обладает полным набором полномочий для работы с этой таблицей. В число этих
полномочий входит полномочие на передачу всех или части полномочий другим
пользователям, включая полномочие на передачу полномочий. Полномочия
пользователей описываются в специальных таблицах-каталогах, контроль полномочий
поддерживается на языковом уровне.
Трехуровневая
модель архитектуры систем баз данных
Разработка алгоритма выполнения функций СУБД начинается, как
правило, с всестороннего описания данных.
Естественно, что проект базы данных надо начинать с анализа
предметной области и выявления требований к ней отдельных пользователей
(например, сотрудников организации, для которых создается база данных), набор
которых представляет внешний уровень архитектуры базы данных (рис. 3).
Другими словами, внешний уровень архитектуры - это содержимое базы данных,
каким его видит определенный пользователь (для этого пользователя внешний
уровень и есть база данных).
Проектирование базы данных выполняет обычно один или
несколько специалистов - администраторы базы данных. Ими могут быть как
специально выделенные сотрудники организации, так и будущие пользователи базы
данных, достаточно хорошо знакомые с компьютерной обработкой данных.
Объединяя частные внешние представления о содержимом базы
данных, полученные в результате изучения потребностей пользователей, и свои
представления о данных, которые могут потребоваться в будущих приложениях,
администратор базы данных сначала конструирует обобщенное неформальное описание
создаваемой базы данных. Это описание, выполненное с использованием
естественного языка, математических формул, таблиц, графиков и других средств,
понятных всем людям, работающим над проектированием базы данных, называют информационно-логической
или инфологической (infological) моделью данных. Такая модель является
основой концептуального уровня архитектуры базы данных. Концептуальный
уровень - это полное инфологическое представление базы данных. Одна и та же
концептуальная схема должна служить основой для множества внешних схем. Она
полностью независима от физических параметров среды хранения данных. Этой
средой может быть память человека, а не компьютера. Поэтому инфологическая
модель не должна изменяться до тех пор, пока какие-то изменения в реальном
мире, которые отражаются во внешнем уровне модели, не потребуют ее изменения
для того, чтобы эта модель продолжала отражать предметную область.
Третьим уровнем архитектуры является внутренний уровень,
связанный со способами сохранения информации на физических устройствах хранения
данных. Он обеспечивает доступ к хранимым данным лишь по их именам, не заботясь
о физическом расположении этих данных. Концептуальная схема может быть
реализована в различных внутренних схемах, в зависимости от того, какие
операционные системы и программные средства используются.
Нужные данные отыскиваются СУБД на внешних запоминающих
устройствах по физической модели данных.
Трехуровневая архитектура проясняет роль моделирования данных
в проектировании систем баз данных и обеспечивает независимость хранимых
данных от использующих их программ. Администратор базы данных может при
необходимости переписать хранимые данные на другие носители информации или
реорганизовать их физическую структуру, изменив лишь физическую модель данных.
Он может подключить к системе любое число новых пользователей (новых
приложений). Такие изменения физической модели не должны быть замечены
существующими пользователями системы, так же как не будут замечены и новые
пользователи. Следовательно, независимость данных обеспечивает возможность
развития системы баз данных без разрушения существующих приложений.
Модели данных
Итак, инфологическая модель отображает реальный мир в
некоторые понятные человеку концепции, полностью независимые от параметров
среды хранения данных. Существует множество подходов к построению таких
моделей: графовые модели, семантические сети, модель "сущность-связь"
и т.д. Наиболее популярной из них является модель "сущность-связь" (Entity-Relationship или ER-диаграмма),
которая была предложена Питером Ченом (Peter Chen) в 1975 году. Различные
варианты этой модели используются для построения концептуальных схем. Ее
базовыми элементами являются сущности, атрибуты, ключи и связи.
Сущность - любой различимый объект (объект, который мы
можем отличить от другого), информацию о котором необходимо хранить в базе
данных. Сущностями могут быть люди, места, самолеты, рейсы, вкус, цвет и т.д.
Необходимо различать такие понятия, как тип сущности и экземпляр сущности.
Понятие тип сущности относится к набору однородных личностей, предметов,
событий или идей, выступающих как целое. Экземпляр сущности относится к
конкретной вещи в наборе. Например, типом сущности может быть ГОРОД, а
экземпляром - Минск, Варшава и т.д.
Сущности имеют атрибуты, которые описывают их характеристики.
Атрибут - поименованная характеристика сущности. Его наименование должно
быть уникальным для конкретного типа сущности, но может быть одинаковым для
различного типа сущностей (например, ЦВЕТ может быть определен для многих
сущностей - СОБАКА, АВТОМОБИЛЬ, ДЫМ и т.д.) Атрибуты используются для
определения того, какая информация должна быть собрана о сущности. Примерами
атрибутов для сущности АВТОМОБИЛЬ могут быть ТИП, МАРКА, НОМЕРНОЙ ЗНАК, ЦВЕТ и
т.д. Здесь также существует различие между типом и экземпляром. Тип атрибута
ЦВЕТ имеет много экземпляров или значений: Красный, Синий, Банановый, Белая
ночь и т.д., однако каждому экземпляру сущности присваивается только одно
значение атрибута. Идентификатором или ключом называется минимальный
набор атрибутов, по значениям которых можно однозначно найти требуемый
экземпляр сущности. Минимальность означает, что исключение из набора любого
атрибута не позволяет идентифицировать сущность по оставшимся атрибутам. Связи
отражают взаимоотношения между сущностями. Связь - это ассоциирование
двух или более сущностей. Степень связи указывает на количество ассоциированных
сущностей. Связи, соединяющие две сущности, наиболее часто встречаются на
практике и называются бинарными. Если бы назначением базы данных было только
хранение отдельных, не связанных между собой данных, то ее структура могла бы
быть очень простой. Однако одно из основных требований к организации базы
данных - это обеспечение возможности поиска одних сущностей по значениям
других, для чего необходимо установить между ними определенные связи. А так как
в реальных базах данных могут содержаться сотни или даже тысячи сущностей, то
теоретически между ними может быть установлено более миллиона связей. Наличие
такого множества связей и определяет сложность инфологических моделей и, в
конечном счете, баз данных.Характеристика связей
Между двумя сущностями А и В возможны три типа связей.
1.
Связь
"один-к-одному" (1:
2.
1): в
каждый момент времени каждому представителю сущности А соответствует 1 или 0
представителей сущности В, а каждому представителю сущности В соответствует 1
или 0 представителей сущности А (рис.4).
Взаимосвязь между данными при отношении между объектами 1:1
|
Студенты
|
|
Личное дело
|
|
|
|
Код студента (номер зачетной книжки)
|
Фамилия
|
|
0125
|
Ильин
|
|
0134
|
Петров
|
|
|
|
Код студента
|
Личное дело
|
|
0134
|
№1
|
|
0125
|
№2
|
|
|
|
|
Рис. 4.
1.
Связь
"один-ко-многим" (1: М): одному представителю сущности А
соответствуют 0, 1 или несколько представителей сущности В, а любому
представителю сущности В соответствует 1 или 0 представителей сущности А (рис.
5).
Взаимосвязь между данными при отношении между объектами 1: М
|
Студенты
|
|
Номер группы
|
|
|
|
|
|
Код студента
|
Фамилия
|
Номер группы
|
|
0125
|
Ильин
|
1
|
|
0134
|
Петров
|
1
|
|
0086
|
Комаров
|
|
|
|
|
Номер группы
|
Кафедра
|
|
|
1
|
|
|
|
2
|
|
|
|
|
|
|
|
|
Рис. 5.
1.
Связь
"многие-ко-многим" (N: М): каждому представителю сущности А может соответствовать
множество представителей сущности В, а каждому представителю сущности В может
соответствовать множество представителей сущности А (рис. 6).
Взаимосвязь между данными при отношении между объектами N: М
|
Фамилия
|
|
Изучаемые дисциплины
|
|
|
|
Фамилия
|
|
Ильин
|
|
Петров
|
|
Комаров
|
|
|
|
Изучаемые дисциплины
|
|
Топография
|
|
Молекулярная биология
|
|
Этика
|
|
|
|
|
Рис.6.
Тип связи "многие-ко-многим" не позволяет
однозначно устанавливать соответствие между данными, поэтому при построении баз
данных такой тип связи реализуют путем создания дополнительной ассоциативной
сущности, имеющей связи типа "один-ко-многим" с базовыми сущностями.
Иногда тип связи называют кардинальностью.
Компьютерно-ориентированные модели данных
Инфологическая модель должна быть отображена в
компьютерно-ориентированную модель. В процессе развития теории и практического
использования баз данных, а также средств вычислительной техники, были созданы
четыре типа моделей данных - иерархические, сетевые, реляционные и объектно-ориентированные.
В 1968 году компания IBM предложила первую СУБД - систему
управления информацией IMS (Information Manager System), которая основана на иерархической модели
данных.
Такие модели строятся по принципу иерархии типов объектов, в которых должен
быть только один корневой тип. На рис.7показан пример иерархической модели, в
которой хранятся данные о клиентах (имя, фирма, адрес, телефон и т.п.), товарах
(наименование, производитель, цена, количество в наличии и т.п.) и заказах на
товары (дата, товар, количество, кто принял, кто выполнил, скидки и т.п.).
Корневой тип объекта - КЛИЕНТЫ, который соединен связями "владения" с
подчиненным (дочерним) объектом ЗАКАЗЫ. Он, в свою очередь, также владеет
подчиненным объектом ТОВАРЫ. В такой модели можно создавать связи типа
"один-ко-многим" и только в одном направлении. Все связи в модели
сводятся к одной корневой сущности КЛИЕНТЫ.
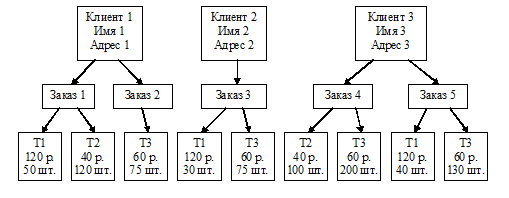
Рис. 7. Иерархическая модель данных
Простота организации, наличие заранее заданных связей между
сущностями, сходство с физическими моделями данных позволяли добиваться
приемлемой производительности иерархических СУБД на медленных ЭВМ с весьма
ограниченными объемами памяти. Но если данные не имеют древовидной структуры,
то возникает масса сложностей при построении иерархической модели с желаемой
производительностью.
В примере видны недостатки модели. Во-первых, невозможно
избежать дублирования информации о товарах. Во-вторых, нельзя ввести информацию
о товарах, на которые нет заказов. В-третьих, нельзя вести учет запаса товаров
на складе. Эти недостатки можно преодолеть, если создать дополнительную базу
данных для запасов и задать множество связей между базами данных клиентов и
запасов. Такая модель данных была создана в 1975 году и названа сетевой
моделью.
Любой объект в сетевой модели может одновременно выступать и
в роли главного, и в роли подчиненного, участвуя в связях различного типа.
Связи - это набор физических указателей, которые задают отношения владения
между сущностями без ограничения направления владения. На рис. 8 изображена
сетевая модель, в которой сущность КЛИЕНТЫ участвует в связи типа
"один-ко-многим" с сущностью ЗАКАЗЫ, а она, в свою очередь, - в связи
такого же типа с сущностью КОЛИЧЕСТВО. Одновременно связь типа "один-ко-многим"
организована между сущностями ТОВАРЫ и КОЛИЧЕСТВО. Связи типа
"многие-ко-многим" с сетевых моделях непосредственно не задаются, а
реализуются через третий объект. В нашем примере базовые сущности ЗАКАЗЫ и
ТОВАРЫ, которые имеют тип связи "многие-ко-многим", соединены через
сущность КОЛИЧЕСТВО двумя встречными наборами связей типа
"один-ко-многим".
Видно, что в сетевой модели устранена избыточность данных о
товарах, сведения о товарах можно вносить в базу данных независимо от наличия
заказов, организован учет запасов на складе. Но это достигнуто за счет
сложности системы, которая содержит немного информации, но много указателей.
Даже простые запросы требуют сложной навигации между записями.
С помощью сетевой модели, которая, также как и иерархическая,
создавалась для малоресурсных ЭВМ, можно представить практически любые
структуры данных. Однако созданные по такой модели базы данных сложны и их
сложность возрастает при увеличении количества сущностей или атрибутов. Более
того, даже новые манипуляции с данными потребуют создания новых связей. По этой
причине один из разработчиков операционной системы UNIX писал, что сетевая база
- это самый верный способ потерять данные.
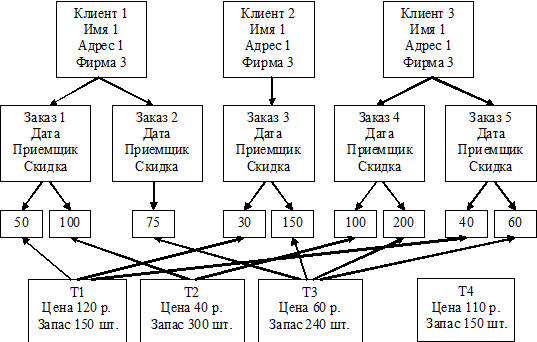
Рис. 1.6.5. Сетевая модель данных
Сложность практического использования иерархических и сетевых
СУБД заставляла искать иные способы представления данных. Реляционная модель
данных была предложена Е. Коддом (E. F. Codd) в 1970 году и в 80-х годах
получила признание как наиболее эффективная модель разработки СУБД. Название
"реляционная" возникло от английского термина "relation" - отношение. Это,
по существу, математическое название для таблицы. Поэтому в большинстве случаев
термины "отношение" и "таблица" можно считать синонимами.
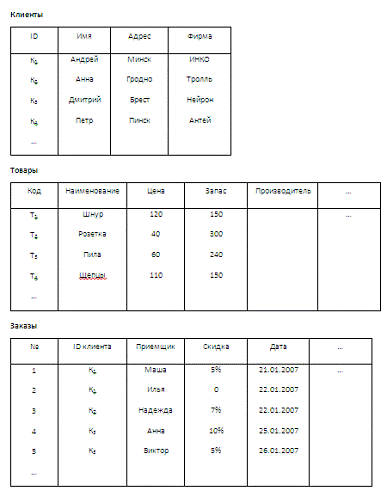
В реляционной модели данные на концептуальном уровне
представляются в виде двумерных таблиц, в которых хранится информация о
сущностях. Строки называются кортежами или записями и содержат информацию об
экземплярах сущности, а в столбцах, которые называются полями, представлена информация
об атрибутах сущности.
Идея реляционной модели данных состоит в том, что строки
таблицы с n
колонками, состоящими из элементов множеств A1, A2, …, An, можно представить как
подмножество в прямом произведении A1´A2´… ´An. Строки образуют список
из n элементов, по одному из
каждого множества Ai, а вся таблица представляет собой n-арное отношение.
Например, таблица КЛИЕНТЫ можно рассматривать как подмножество множества A1´A2´A3´A4, где A1 - множество кодов
клиентов, A2
- множество имен клиентов, A3 - множество их адресов, An - множество названий
организаций. Один из элементов этого отношения - строка К1, Андрей, Минск,
ИНКО. Представленные таким образом таблицы можно обрабатывать, используя
алгебру отношений на множествах.
Рассматриваемый нами пример можно представить в виде
реляционной модели, изображенной на рис.9. Все данные хранятся в таблицах, в
которых описаны сущности КЛИЕНТЫ, ТОВАРЫ и ЗАКАЗЫ, а таблица СПЕЦИФИКАЦИЯ
устанавливает связи между этими тремя сущностями. В реляционной базе данных
можно задавать связи между двумя атрибутами, которые имеют сопоставимые по
смыслу значения данных. При правильном проектировании базы данных можно
избежать дублирования данных и ограничения на ввод и удаление данных.
Реляционные системы представляют более простую среду для
разработки баз данных, чем иерархические или сетевые, а программное
обеспечение, основанное на реляционной алгебре, позволяет организовать
практически любое манипулирование данными. Описанные выше методы реализации
СУБД называются классическими и критикуются, в первую очередь, за то, что
основаны на идее пассивного множества данных. В них невозможно моделировать
реальное поведение данных. Их семантические возможности также сильно
ограничены, поэтому трудно представлять действительный смысл данных.
Предполагается, что эти ограничения удастся преодолеть при помощи
объектно-ориентированных технологий. В настоящее время, несмотря на многолетние
усилия, не удалось создать эффективные коммерческие объектно-ориентированные
СУБД.
Имеющиеся программные продукты представляют собой не чисто
объектно-ориентированные СУБД, а скорее реляционные СУБД, сделанные по
объектно-ориентированным технологиям. С другой стороны, большинство реляционных
СУБД используют возможности объектно-ориентированных технологий для реализации
своих функций.
Реляционный
подход
Мы будем придерживаться, как правило, терминологии и
представлений, предложенных К. Дж. Дейтом, внесшим значительный вклад в
развитие теории баз данных, и Е.Ф. Коддом, предложившим реляционную модель
данных.
база реляционная управление файл
Основные термины, касающиеся объектов баз данных, показаны на
рис. 10.
Отношение соответствует тому, что обычно называется
таблицей. Кортеж отношения или запись соответствует строке
этой таблицы, а атрибут отношения или поле - столбцу. Количество
кортежей называется кардинальным числом отношения, а количество
атрибутов - степенью или арностью (n-арное) отношения.
Отношение первой степени называется унарным, второй степени - бинарным, третьей
- тернарным, а степени n - n-арным. Кардинальное число отношения,
в отличие от его степени, изменяется во времени. Значения атрибутов выбираются
из соответствующих доменов.
Значение наименьшей семантической единицы данных, которая
предполагается отдельным значением данных (таким как отдельный табельный номер,
отдельная фамилия или отдельная зарплата в примере на рис.10), принято называть
скаляром. Скалярные значения атомарны, т.е. у них нет внутренней
структуры при рассмотрении в реляционной СУБД (несмотря на то, что фамилия
состоит их букв, для базы данных она неделима). Тогда домен можно
определить как именованное множество скалярных значений одного типа. Например,
домен кодов отделов - это множество всех возможных значений, которые могут
использоваться для кодирования отделов, домен фамилий - это множество текстовых
данных с количеством знаков от 1 до, например, 20. Итак, домены - это общая
совокупность значений, из которых берутся реальные значения атрибутов, или,
другими словами, значения атрибутов должны браться из соответствующего домена.
Наиболее важное значение доменов состоит в том, что домены
ограничивают сравнения. Если значение двух атрибутов взяты из одного и того же
домена, тогда их сравнение и, следовательно, соединения, объединения и другие
операции скорее всего имеют смысл. Если же значение двух атрибутов взяты из
разных доменов, тогда их сравнение и другие операции скорее всего не будут
иметь смысла. Поэтому система поддержки доменов способна предотвратить грубые
ошибки.
Пример создания и удаления доменов:
CREATE DOMAIN Фамилия CHAR (20);DOMAIN Зарплата NUMERIC
(5);DOMAIN Зарплата;
Можно сказать, что домен тождественен типу данных (как это
понимается в современных языках программирования) .
Отношение определяется на множестве доменов и состоит из заголовка
(интерпретация данных) и тела (набора данных). Тело содержит множество
кортежей (кардинальное число) и атрибутов (степень). Основные свойства
отношений:
·
Нет
одинаковых кортежей;
·
Кортежи
не упорядочены сверху вниз;
·
Атрибуты
не упорядочены слева направо;
·
Все
значения атрибутов атомарны.
Сейчас становится более понятным различие между отношением и
таблицей. В реляционной модели основной абстрактный объект отношение имеет
простое реальное представление - таблицу, которое делает реляционные системы
простыми и понятными. Однако, в отличие от отношения, в таблице строки
(кортежи) и столбцы (атрибуты) расположены в определенном порядке.
Именованное отношение называется базовым,
если оно является непосредственной частью базы данных. Производные отношения
определяются через базовые отношения посредством реляционных выражений и, как
правило, неименованные. Именованное производное отношение называется представлением.
Различие между базовой таблицей и представлением часто характеризуется так: базовые
таблицы реально существуют в том смысле, что они представляют данные, которые
действительно хранятся в базе данных; представления, наоборот, реально не
существуют, а просто предоставляют различные способы просмотра реальных данных.
Для каждого отношения есть связанная с ним интерпретация, или
предикат, составляющий критерий возможности обновления для этого
отношения. В любой момент времени отношение содержит в точности те кортежи, при
которых предикат является истиной.
Например, предикат отношения, изображенного на рис.10, может
быть следующим: Сотрудник с определенным табельным номером (атрибут Табель)
имеет определенную фамилию (атрибут Фамилия), определенную зарплату (атрибут
Зарплата) и зарегистрирован в определенном отделе (атрибут Код_отдела); кроме
того, нет двух сотрудников с одинаковыми табельными номерами. При
обновлении атрибута Зарплата в кортеже
Табель='В3'; Фамилия= 'Котов'; Код_отдела='А3';
Зарплата='200';
предикат имеет значение истина, а в кортеже
Табель='В3'; Фамилия= 'Котов'; Код_отдела='А1';
Зарплата='200';
предикат имеет значение ложь, т.к. в базе данных этот
сотрудник зарегистрирован в отделе А3, и в этом случае СУБД не позволит сделать
изменения.
Ключи и
целостность реляционных данных
Реляционная модель базы данных связана с тремя аспектами
данных: структурой, обработкой и целостностью. Первые два аспекта были кратко
рассмотрены в разделе 1. Целостность (от англ. integrity - неприкосновенность,
сохранность, целостность) - понимается как правильность данных в любой момент
времени. Эта цель может быть достигнута лишь в определенных пределах: СУБД не
может контролировать правильность каждого отдельного значения, вводимого в базу
данных (хотя каждое значение можно проверить на правдоподобность). Например,
при вводе номера дня недели нельзя обнаружить, что вводимое значение 5 в
действительности должно быть равно 3. Но значение 9 явно будет ошибочным и СУБД
должна его отвергнуть. Для этого ей следует сообщить, что номера дней недели
должны выбираться из домена (1,2,3,4,5,6,7).
Поддержание целостности базы данных может рассматриваться как
защита данных от неверных изменений или разрушений (в отличие от
несанкционированных изменений и разрушений, являющихся проблемой безопасности
баз данных). Современные СУБД имеют ряд средств для обеспечения целостности
(так же, как и средств обеспечения безопасности).
Основные механизмы обеспечения целостности данных связаны с
понятием первичных и внешних ключей.
Первичный ключ является частным случаем более общего понятия
- потенциального ключа. Потенциальный ключ K для некоторого отношения R - это подмножество
множества атрибутов R, обладающее следующими свойствами:
1.
Свойством
уникальности (нет двух различных кортежей в отношении R с одинаковым значением K).
2.
Свойством
неизбыточности (никакое из подмножеств K не обладает свойством
уникальности).
Каждое отношение имеет хотя бы один потенциальный ключ, так
как не содержит одинаковых кортежей - по крайней мере, комбинация всех
атрибутов обладает свойством уникальности (как правило, подходит некоторая меньшая
комбинация). На практике отношения чаще всего имеют один потенциальный ключ,
хотя их может быть и несколько. Например, в отношении, представляющем таблицу
химических элементов, может присутствовать уникальное имя элемента, уникальное
обозначение, уникальный порядковый номер и уникальное атомное число. Т.е., в
таком отношении есть четыре потенциальных ключа и из них может быть выбран
первичный ключ. Остальные потенциальные ключи будут называться альтернативными
ключами.
С понятием первичного ключа в реляционной модели связывают
правило целостности объектов: Ни один элемент первичного ключа базового
отношения не может быть Null-значением. Понятие Null-значения было предложено Е.
Коддом для представления отсутствующей информации: если данный кортеж имеет Null-значение
данного атрибута, то это означает, что в таком кортеже значение атрибута по
некоторой причине отсутствует. Null-значения - это не то же самое, что пробел
или числовой ноль. Это не реальные значения, а маркеры. Правило целостности
объектов применяется только для базовых отношений и только для первичных
ключей.
Причина значимости потенциальных ключей в реляционной системе
заключается в том, что они обеспечивают основной механизм адресации на уровне
кортежей. Для примера вновь используем отношение, изображенное на рис.10. С
помощью выражения
мы гарантированно получим отношение, содержащее не более
одного кортежа. Но с помощью выражения
Сотрудники WHERE Код_отдела=’А1'
мы можем получить любое количество кортежей. Таким образом,
потенциальные ключи имеют такое же фундаментальное значение для успешной работы
реляционной системы, как адресация основной памяти для успешной работы
компьютера, на котором эта система установлена.
Итак, потенциальный ключ - это минимальный
набор атрибутов, по значениям которых можно однозначно найти требуемый кортеж
отношения. Минимальность означает, что исключение из набора любого атрибута не
позволяет идентифицировать кортеж по оставшимся атрибутам. Каждое отношение
обладает хотя бы одним потенциальным ключом. Один из них принимается за
первичный ключ. При выборе первичного ключа следует отдавать предпочтение
несоставным ключам или ключам, составленным из минимального числа атрибутов.
Нецелесообразно также использовать ключи с длинными текстовыми значениями
(предпочтительнее использовать целочисленные атрибуты). Так, для идентификации
студента можно использовать либо уникальный номер зачетной книжки, либо набор
из фамилии, имени, отчества, номера группы и, может быть, дополнительных
атрибутов, так как не исключено появление в одной группе двух студентов с
одинаковыми фамилиями, именами и отчествами. Не допускается, чтобы первичный
ключ отношения (любой атрибут, участвующий в первичном ключе) принимал
неопределенное значение (Null-значение). Иначе возникнет противоречивая
ситуация: появится не обладающий индивидуальностью кортеж отношения (экземпляр
сущности). По тем же причинам необходимо обеспечить уникальность первичного
ключа.
Основное назначение внешних ключей - организация связей между
отношениями. Связь создается по данным, хранящимся в поле первичного ключа
одной таблицы и в поле внешнего ключа другой таблицы с данными, такими же по
смыслу и типу. Можно сформулировать условия необходимости выбора внешних
ключей:
1.
Если
сущность С связывает сущности А и В, то она должна включать внешние ключи,
соответствующие первичным ключам сущностей А и В.
2.
Если
сущность В обозначает сущность А, то она должна включать внешний ключ,
соответствующий первичному ключу сущности А.
С понятием внешнего ключа реляционная модель связывает
правило целостности по ссылкам: База данных не должна содержать
несогласованных значений внешних ключей. Другими словами, правило
утверждает, что если В ссылается на А, то А должно существовать.
Правило целостности по ссылкам позволяет поддерживать базу
данных в корректном состоянии. Чтобы такое состояние сохранилось, надо либо
запретить любые операции, приводящие к некорректному состоянию, либо разрешить
такие операции, но выполнить некоторые компенсирующие действия. Для каждого внешнего
ключа необходимо ответить на два вопроса:
. Что должно случиться при попытке удалить объект
ссылки внешнего ключа (например, отдел, в котором числятся сотрудники)?
2. Что должно случиться при попытке обновить
потенциальный ключ, на который ссылается внешний ключ (например, изменить номер
отдела)?
В общем случае существует по меньшей мере две возможности:
- ограничение - "ограничить"
операции до момента появления первой ссылки;
- каскадирование - "каскадировать"
операции, удаляя или обновляя все соответствующие атрибуты.
Разработчик при проектировании внешних ключей базы данных
должен указать не только атрибут или комбинацию атрибутов, составляющую данный
внешний ключ, но и ответить на эти вопросы, т.е. указать специальные правила
внешних ключей для данного внешнего ключа.
Реляционная модель допускает появление Null-значений среди атрибутов
внешних ключей. Например, в некоторых организациях допускается, чтобы отдельные
сотрудники не числились ни в одном отделе. В таком случае в соответствующем
кортеже отношения "Сотрудники" будет отсутствовать код отдела,
который должен быть значением для внешнего ключа. Поэтому значение внешнего
ключа должно либо быть равным значению первичного ключа цели, либо быть
полностью неопределенным. В связи с этим, более строгое определение внешнего
ключа может быть таким: Внешний ключ FK в отношении R2 - это подмножество
множества атрибутов R2 такое, что существует базовое отношение R1 с
потенциальным ключом CK, для которого каждое значение FK в текущем значении R2
или является Null-значением, или совпадает со значением CK некоторого кортежа
в текущем значении R1.
В дополнении к целостности отношений и целостности по ссылкам
существует целостность, определяемая пользователем. Для любой конкретной базы
данных существует ряд дополнительных специфических правил, которые относятся к
ней одной и определяются разработчиком. Чаще всего контролируется уникальность
тех или иных атрибутов, диапазон значений (экзаменационная оценка от 1 до 10),
принадлежность набору значений (пол "М" или "Ж"). В этом
случае средством обеспечения целостности являются домены. С ними связано такое
понятие, как целостность атрибута: Значение каждого атрибута берется из
соответствующего домена. Это более фундаментальное правило, чем первые два.
Моделирование
концептуальной схемы базы данных
Рассмотрим основные элементы метода концептуального
моделирования "сущность-связь" на следующем примере. Некоторая
банковская компания хранит информацию о своих счетах (№счета, баланс), клиентах
(№клиента, имя, адрес, статус) и филиалах банка (название, адрес, директор).
Счета могут быть двух типов - депозитные и текущие. Клиенты могут иметь
произвольное число счетов. Несколько клиентов могут совместно использовать
общий счет. Каждый счет обрабатывается одним филиалом.
Можно выделить три сущности - ФИЛИАЛЫ, КЛИЕНТЫ, СЧЕТА. На
ER-диаграмме сущности обозначаются прямоугольником (рис 11).
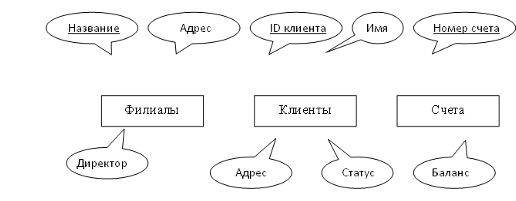
Атрибуты описывают сущность и изображаются именованными
овалами, прикрепленными к сущности. В нашем примере все атрибуты простые.
Возможны и многозначные атрибуты, например, если у клиента два адреса. Ключевые
атрибуты (т.е. та часть сущности, которая однозначно идентифицирует ее)
выделяются подчеркиванием. Возможны составные ключи, состоящие из комбинации простых
атрибутов.
Связи представляют взаимодействие между сущностями и на
диаграмме изображаются ромбом, который соединяет сущности. В нашем примере
существуют бинарные связи между клиентами и счетами и между счетами и
филиалами. Мы предположили, что каждый счет обрабатывается одним филиалом и
каждый филиал обрабатывает произвольное количество счетов, поэтому тип связи
между филиалом и счетами будет "один-ко-многим" Поскольку счет может
совместно использоваться несколькими клиентами и клиент может иметь несколько
счетов, то между ними связь имеет кардинальность "многие-ко-многим".
ER-диаграмма нашего примера представлена на рис. 12.

Рис. 12. Модель данных «сущность-связь»
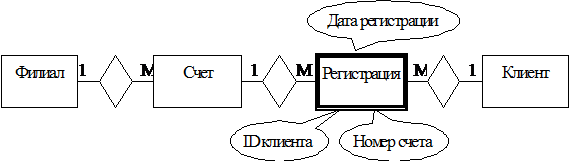
Связь типа "многие-ко-многим" может быть заменена
двумя связями типа "один-ко-многим": каждый счет может иметь
множество регистраций для каждого клиента, использующего данный счет, и каждый
клиент может иметь множество регистраций для каждого используемого счета. Такой
вид связи называется слабой сущностью. Она не существует самостоятельно, а
только при наличии связей, в которых участвует. Для создания ключа слабой
сущности желательно использовать атрибуты связываемых сущностей. В нашем
примере ключом может быть комбинация атрибутов ID_клиента и Номер_счета.
Слабая сущность может иметь и собственные атрибуты, например, Дата_регистрации,
Поручитель и т.п. На рис.13 слабая сущность изображена двойной линией.
Такая диаграмма не отражает одно условие нашего примера -
разделение счетов на текущие и депозитные. Для реализации этого условия
создается расширенная ER-модель. Наиболее важным расширением
инфологической модели является введение понятия подтип (рис.13).
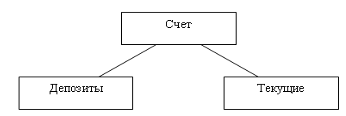
Рис. 1.8.4. Создание подтипов
При изменении внешнего уровня архитектуры базы данных наша ER-модель может быть
реконструирована. Например, если необходимо дополнить базу данных информацией о
сотрудниках филиала, то это легко сделать, организовав связь кардинальности
"один-ко-многим" между имеющейся сущностью Филиал и новой сущностью
Сотрудники. Если необходимо учесть область деятельности сотрудников, то
создаются подтипы, "Менеджер", "Экономисты",
"Системный администратор", "Программист" и т.п.
Создание подтипов позволяет отразить в ER-диаграмме генерализацию
(когда набор типов объектов объединяются в генерализованный тип) и
специализацию (противоположный процесс) данных. Примером специализации является
упомянутые подтипы "Депозиты" и "Текущие", а примером
генерализации - объединение специальностей "Системный администратор"
и "Программист" в тип "Технический персонал".
Рассмотрим пример моделирования простой базы данных. Необходимо хранить
и обрабатывать информацию о выполняемых фирмой проектах, используемых деталях
(или оборудовании) и их поставщиках. Проекты, детали и поставщики составляют
основные объекты (или сущности), о которых фирме необходимо
хранить информацию. На их основе создаются базовые отношения базы
данных. Кроме сущностей имеются и связывающие их отношения. Например,
существует отношение ДП между поставщиками и деталями: каждый поставщик
поставляет определенные детали и, наоборот, каждая деталь поставляется
определенным поставщиком; также существует отношение между проектами и деталями
(отношение ПрД). Эти отношения двусторонние - их можно рассматривать в обоих
направлениях. Следует помнить, что такие отношения, подобно сущностям, являются
частью базы данных и называются слабыми сущностями. Мы будем рассматривать их
как специальный тип объектов. ER-диаграмма, показывающая сущности и связи в
рассматриваемом примере, представлена на рис. 15.
Рис. 14. ER-диаграмма
В базе данных предлагается следующая семантика:
Таблица Проекты представляет уникальный номер проекта Пр№,
его наименование Имя_Пр, руководителя проекта Имя_Рук.
Таблица Детали представляет уникальный номер детали Д№,
название детали Имя_Д, цвет Цв, вес Вес (в граммах), город Гор, где
производится деталь. Предполагается, что каждый вид детали одного цвета и
производится в одном городе.
Таблица Поставщики представляет уникальный номер поставщика
П№, имя Имя_П (не обязательно уникальное), значение рейтинга Статус, место
расположения Гор.
Таблица ДП представляет поставки. Одно из ее назначений -
соединение таблиц Детали и Поставщики. Она может состоять из полей П№, Д№ и
поля количества поставок Кол.
Таблица ПрД представляет потребность проектов в деталях и
соединяет таблицы Проекты и Детали. Она может состоять из полей Пр№, Д№ и,
возможно, Кол.
Таким образом, можно считать, что один из возможных вариантов
инфологической модели построен. Однако очевидно, что данные, содержащиеся в
таблицах ДП и ПрД, можно представить более рационально, разместив их в одной
таблице с именем, например, Поставки, включающей поля Д№, П№, Пр№ и Кол. Эта
таблица будет является слабой сущностью и будет выполнять функцию отношений
(связей) между сущностями Проекты, Детали и Поставщики конструируемой базы
данных. На этом примере мы видим, что отношения, как и сущности, могут быть
наглядно представлены таблицами.
С учетом изложенного, схема базы данных может иметь вид,
изображенный на рис.16 (ключевые поля выделены полужирным курсивом).
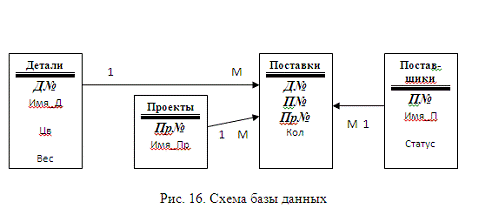
Итак, создаваемая база данных будет состоять из четырех
таблиц, изображенных на рис.1.8.7, названия которых подчеркнуты, а ключевые
поля выделены жирным шрифтом.

Определение базы данных на языке SQL может быть представлено так:
CREATE DOMAINПр№CHAR (5) CREATE DOMAINИмяCHAR (30) CREATE DOMAINД№CHAR (5) CREATE DOMAINЦвCHAR
(10) CREATE DOMAINВесNUMERIC (5) CREATE DOMAINГорCHAR (15) CREATE DOMAINКолNUMERIC (5) CREATE DOMAINП№CHAR (5) CREATE DOMAINСтатусNUMERIC
(3)BASE RELATION Проекты (Пр№DOMAIN (Пр№), Имя_ПрDOMAIN (Имя), Имя_РукDOMAIN
(Имя), PRIMARY KEY (Пр№);BASE RELATION Детали (Д№DOMAIN
(Д№), Имя_ДDOMAIN (Имя), ЦвDOMAIN (Цв), ВесDOMAIN (Вес), ГорDOMAIN
(Гор), PRIMARY KEY (Д№);BASE RELATION Поставщики (П№DOMAIN (П№), Имя_ПDOMAIN (Имя), СтатусDOMAIN (Статус), ГорDOMAIN (Гор), PRIMARY KEY (П№);BASE RELATION Поставки (П№DOMAIN (П№), Д№DOMAIN (Д№), (Пр№DOMAIN (Пр№), КолDOMAIN
(Кол), PRIMARY KEY (П№, Д№, Пр№);KEY (П№) REFERENCES Поставщики FOREIGN KEY (Пр№) REFERENCES Проекты FOREIGN KEY (Д№) REFERENCES Детали;
Представленная на рис.1.8.6 - 1.8.7 модель базы данных будет использована
нами в дальнейшем для иллюстраций различных реляционных операций.
Литература
1.
MySQL руководство администратора; М.: Вильямс, 2009. - 621 c.
.
Oracle 8. Администрирование баз данных. Учебное пособие; Oracle, 2012. - 649 c.
.
Александров, В. В.; Вишняков, Ю. С.; Горская, Л.М. и др. Информационное
обеспечение интегрированных производственных комплексов; Л.: Машиностроение,
2009. - 511 c.
.
Аткинсон, Леон MySQL. Библиотека профессионала; М.: Вильямс, 2010. - 624 c.
.
Бек, Кент Шаблоны реализации корпоративных приложений; М.: Вильямс, 2008. - 369
c.
.
Веймаер, Р.; Сотел, Р. Освой самостоятельно Microsoft SQL Server 2000 за 21
день (+ CD-ROM); М.: Вильямс, 2013. - 549 c.
.
Гандерлой, Майк; Харкинз, Сьюзан Сейлз Автоматизация Microsoft Access с помощью
VBA; М.: Вильямс, 2013. - 416 c.
.
Гетц, Кен; Джинберт, Майкл; Литвин, Пол Access 2000. Руководство разработчика.
Том 1. Настольные приложения. том 1; Киев: BHV, 2008. - 576 c.
.
Голицына, О.Л. и др. Базы данных; Форум; Инфра-М, 2013. - 399 c.
.
Гринченко, Н.Н. и др. Проектирование баз данных. СУБД Microsoft Access; Горячая
Линия Телеком, 2012. - 613 c.
.
Дейт, К. Дж. Введение в системы баз данных; К.: Диалектика; Издание 6-е, 2012.
- 360 c.
.
Дэвидсон, Луис проектирование баз данных на SQL Server 2000; Бином, 2009. - 631
c.
.
Дюваль, Поль М. Непрерывная интеграция. Улучшение качества программного
обеспечения и снижение риска; М.: Вильямс, 2008. - 497 c.
.
Каратыгин, С.; Тихонов, А. Работа в Paradox для Windows 5.0 на примерах; М.:
Бином, 2011. - 512 c.
.
Каратыгин, Сергей Access 2000 на примерах. Руководство пользователя с
примерами; М.: Лаборатория Базовых Знаний, 2012. - 376 c.
.
Кауфельд, Джон Microsoft Office Access 2003 для "чайников"; М.:
Диалектика, 2013. - 439 c.
.
Каучмэн, Джейсон; Швинн, Ульрике Oracle 8i CertifiedProfessionaql DBA
Подготовка администраторов баз данных; ЛОРИ, 2009. - 510 c.
.
Луни, Кевин; Брила, Боб Oracle 10g. Настольная книга администратора баз данных;
М.: Лори, 2008. - 365 c.