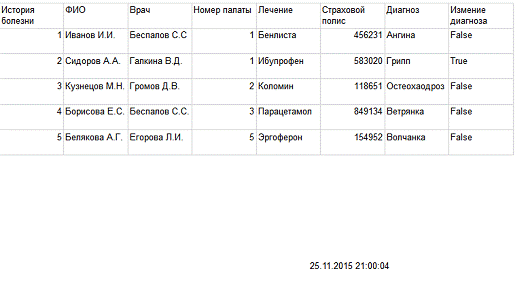
База данных для учета больных
Введение
Больница - это большая организация ежедневно работающая с огромным
количеством информации. Каждый день туда поступают сотни пациентов с различными
диагнозами, лечащими врачами и способами лечения. Вся эта информация требует
какой-то систематизации для согласования работы всех сотрудников больницы.
Именно эта задача и решается в данном курсовом проекте.
Разработанная база данных поможет вести учет всех больных, своевременно и
точно узнавать о ходе лечения конкретных пациентов, вести учет мест в палатах.
Она значительно упростит ведение документации, так как предусматривает
возможность добавления, обновления и удаления новых данных о пациентах.
1. Постановка задачи
В данном курсовом проекте требуется разработать базу данных для учета
больных.
Решаемые задачи:
1. Упорядочение по полям: ФИО больных, диагноз, распределение по
палатам.
2. Поиск: сведения о больных по первым буквам фамилии; по № палаты.
. Выборка: по дню поступления больных, по дню выписки, по
диагнозу..
. Вычисления: количество больных , поступивших в январе, феврале и
т.д.; количество больных, выписавшихся в январе, феврале и т.д.
. Коррекция: удаление данных о больных, выписавшихся в прошлом
году; количество больных с изменением первоначального диагноза на конечный.
Для разработки бд была выбрана программная среда SQL Server Management
Studio.
2. Проектирование структуры БД
Существует два основных способа проектирования структуры БД метод
информационного моделирования IDEF1x и метод нормальных форм:
1. Метод IDEF1X определяет стандарты терминологии, используемой при
информационном моделировании, и графического изображения типовых элементов на
диаграммах. Компонентами IDEF1X-модели являются сущности, связи между
сущностями и атрибуты сущностей.
2. Процесс проектирования БД с использованием метода нормальных форм
является итерационным и заключается в последовательном переводе отношений из
первой нормальной формы в нормальные формы более высокого порядка по
определенным правилам. Каждая следующая нормальная форма ограничивает определенный
тип функциональных зависимостей, устраняет соответствующие аномалии при
выполнении операций над отношениями БД и сохраняет свойства предшествующих
нормальных форм.
.1 Метод информационного моделирования IDEF1x
X является методом для разработки реляционных баз данных и использует
условный синтаксис, специально разработанный для удобного построения
концептуальной схемы. Концептуальной схемой мы называем универсальное
представление структуры данных в рамках коммерческого предприятия, независимое
от конечной реализации базы данных и аппаратной платформы.
Сущность в IDEF1X описывает собой совокупность или набор экземпляров
похожих по свойствам, но однозначно отличаемых друг от друга по одному или
нескольким признакам. Каждый экземпляр является реализацией сущности. Примером
сущности IDEF1X может быть сущность "Pacient", которая представляет
собой всех пациентов больницы, а один из них, скажем, Иванов Иван Иванович,
является конкретной реализацией этой сущности. В примере, приведенном на рис.
1, каждый экземпляр сущности Pacient содержит следующую информацию: История
болезни, ФИО, Врач и т.п. В IDEF1X модели эти свойства называются атрибутами
сущности. Каждый атрибут содержит только часть информации о сущности.
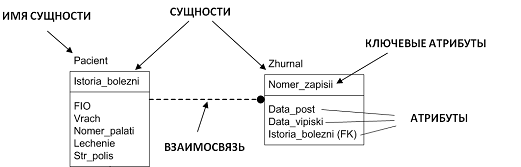
Рисунок 1
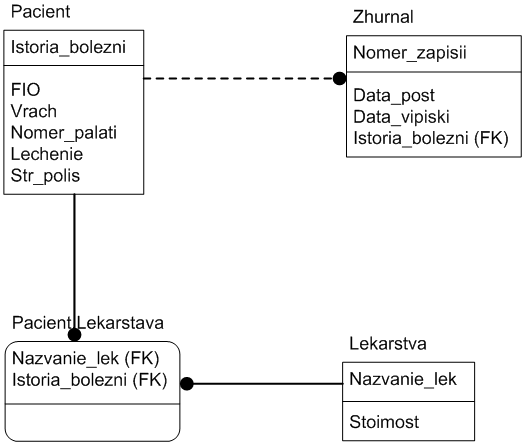
Связи в IDEF1X представляют собой ссылки, соединения и ассоциации между
сущностями. Связи это суть глаголы, которые показывают, как соотносятся
сущности между собой. Ниже приведен ряд примеров связи между сущностями:
· Пациенты <заносятся> в Журнал
· Пациенты <принимают> Лекарства
Каждая сущность может обладать любым количеством связей с другими
сущностями.
Виды отношений между сущностями:
· один ко многим - один экземпляр одной сущности связан с несколькими
экземплярами другой сущности;
· многие ко многим - многие экземпляры одной сущности связаны
со многими экземплярами другой сущности (обычно на первоначальных стадиях
проектирования) позже такие отношения приводятся к отношениям один ко многим.
Первичный ключ - это набор атрибутов, выбранных для идентификации
уникальных экземпляров сущности. Атрибуты первичного ключа располагаются над
линией в ключевой области. Как следует из названия, неключевой атрибут - это
атрибут, который не был выбран ключевым. Неключевые атрибуты располагаются под
чертой, в области данных.
Если сущности в IDEF1X диаграмме связаны, связь передает ключ (или набор
ключевых атрибутов) дочерней сущности. Эти атрибуты называются внешними
ключами. Внешние ключи определяются как атрибуты первичных ключей родительского
объекта, переданные дочернему объекту через их связь. Передаваемые атрибуты
называются мигрирующими.
При разработке модели, зачастую, приходится сталкиваться с сущностями,
уникальность которых зависит от значений атрибута внешнего ключа. Для этих
сущностей (для уникального определения каждой сущности) внешний ключ должен
быть частью первичного ключа дочернего объекта. Дочерняя сущность, уникальность
которой зависит от атрибута внешнего ключа, называется зависимой сущностью.
Сущности, независящие при идентификации от других объектов в модели,
называются независимыми сущностями.
В IDEF1X концепция зависимых и независимых сущностей усиливается типом
взаимосвязей между двумя сущностями. Если вы хотите, чтобы внешний ключ
передавался в дочернюю сущность (и, в результате, создавал зависимую сущность),
то можете создать идентифицирующую связь между родительской и дочерней
сущность. Идентифицирующие взаимосвязи обозначаются сплошной линией между
сущностями.
Неидентифицирующие связи, являющиеся уникальными для IDEF1X, также
связывают родительскую сущность с дочерней. Неидентифицирующие связи
используются для отображения другого типа передачи атрибутов внешних ключей -
передача в область данных дочерней сущности (под линией). Неидентифицирующие
связи отображаются пунктирной линией между объектами.
Основным преимуществом IDEF1X, по сравнению с другими многочисленными
методами разработки реляционных баз данных, такими как ER и ENALIM является
жесткая и строгая стандартизация моделирования. Установленные стандарты
позволяют избежать различной трактовки построенной модели, которая несомненно
является значительным недостатком ER.
.2 Метод нормальных форм
Основные понятия:
1. Атрибут - свойство некоторой сущности. Часто называется полем
таблицы.
2. Домен атрибута - множество допустимых значений, которые может
принимать атрибут.
. Кортеж - конечное множество взаимосвязанных допустимых значений
атрибутов, которые вместе описывают некоторую сущность (строка таблицы).
. Отношение - конечное множество кортежей (таблица).
. Схема отношения - конечное множество атрибутов, определяющих
некоторую сущность. Иными словами, это структура таблицы, состоящей из
конкретного набора полей.
. Проекция - отношение, полученное из заданного путём удаления и
(или) перестановки некоторых атрибутов.
. Нормальная форма - требование, предъявляемое к структуре таблиц
в теории реляционных баз данных для устранения из базы избыточных
функциональных зависимостей между атрибутами (полями таблиц).
Аномалией называется такая ситуация в таблице БД, которая приводит к
противоречию в БД либо существенно усложняет обработку БД. Причиной является
излишнее дублирование данных в таблице, которое вызывается наличием
функциональных зависимостей от не ключевых атрибутов. Аномалии разделяются на:
1. Аномалии-модификации проявляются в том, что изменение одних данных
может повлечь просмотр всей таблицы и соответствующее изменение некоторых
записей таблицы.
2. Аномалии-удаления - при удалении какого либо кортежа из таблицы
может пропасть информация, которая не связана на прямую с удаляемой записью.
. Аномалии-добавления возникают, когда информацию в таблицу нельзя
поместить, пока она не полная, либо вставка записи требует дополнительного
просмотра таблицы.
Цель нормализации: исключить избыточное дублирование данных, которое
является причиной аномалий, возникших при добавлении, редактировании и удалении
кортежей(строк таблицы).
Первая нормальная форма - отношение находится в 1НФ, если все его
атрибуты являются простыми, все используемые домены должны содержать только
скалярные значения. Не должно быть повторений строк в таблице.
Вторая нормальная форма - отношение находится во 2НФ, если оно находится
в 1НФ и каждый не ключевой атрибут неприводимо зависит от Первичного Ключа(ПК).
Неприводимость означает, что в составе потенциального ключа отсутствует меньшее
подмножество атрибутов, от которого можно также вывести данную функциональную
зависимость.
Третья
нормальная форма - отношение находится в 3НФ, когда находится во 2НФ и каждый
не ключевой атрибут нетранзитивно зависит от первичного ключа. Проще говоря,
второе правило требует выносить все не ключевые поля, содержимое которых может
относиться к нескольким записям таблицы в отдельные таблицы.
3.
Обоснование выбора СУБД
Система
управления базами данных (СУБД) - совокупность программных и лингвистических
средств общего или специального назначения, обеспечивающих управление созданием
и использованием баз данных.
Основные
функции СУБД:
. управление
данными во внешней памяти (на дисках);
2. управление
данными в оперативной памяти с использованием дискового кэша;
3. журнализация
изменений, резервное копирование и восстановление базы данных после сбоев;
4. поддержка
языков БД (язык определения данных, язык манипулирования данными).
По способу
организации взаимодействия с базой данных через сеть, СУБД делят на:
. СУБД с
централизованной архитектурой;
2. СУБД
с архитектурой файл-сервер;
. СУБД
с архитектурой клиент-сервер;
. СУБД
с трехуровневой архитектурой: «тонкий клиент» - сервер приложений - сервер базы
данных.
В СУБД с
централизованной архитектурой, СУБД и сама БД располагаются и функционируют на
центральном компьютере (мэйнфрейме), а пользователи получают доступ к БД при
помощи обычных терминалов: компьютер рассматривается просто как устройство
ввода и отображения информации: на мэйнфрейм передаются нажатия клавиш, в
обратном направлении передаются данные, отображаемые непостредственно на
мониторах пользователей.
В СУБД с
архитектурой файл-сервер база данных хранится на сервере, а копии СУБД
устанавливаются на компьютерах пользователей. Файл базы данных, находящийся на
сервере, совместно используется всеми пользователями одновременно, при помощи
сетевого программного обеспечения и самой операционной системы. Такая
архитектура позволяет добиться приемлемой производительности, т.к. в
распоряжении каждой копии СУБД находятся все ресурсы компьютера пользователя. С
другой стороны, производительность такой схемы для каждого пользователя зависит
от характеристик компьютера пользователя. Кроме этого, такая архитектура
значительно нагружает работу сети, поскольку при такой схеме пользователю
передается вся копия БД.
При
архитектуре клиент-сервер база данных хранится на сервере, а СУБД
подразделяется на две части: клиентскую и серверную. Клиентская часть СУБД
выполняется на стороне пользователя (клиента) и обеспечивает интерактивное
взаимодействие с пользователем и формирование запросов к БД (на языке SQL).
Серверная часть работает на сервере и взаимодействует с БД, обеспечивая
выполнение запросов клиентской части. При этом пользователю будут переданы
только запрашиваемые строки, а не вся БД. Недостаток заключается в том, что ели
необходимо часто изменять деловую логику, то приходится переделывать и
переустанавливать клиентскую часть. Если рабочих мест много, то это уже несет
большие затраты.
При
трехуровневой архитектуре в функции клиентской части («тонкий клиент») входит
только интерактивное взаимодействие с пользователем, а вся деловая логика
вынесена на сервер приложений, который собственно и обеспечивает формирование
запросов к БД, передаваемых на выполнение серверу БД. «Тонкий клиент» чаще
всего находится на стороне пользователя и представляет собой Web-броузер с
применением в соответствующей HTML-странице Java-апплетов или компонентов
ActiveX. Сервер приложений находится на сервере и может являться
специализированной программой или обычным web-сервером, который вызывает для
обработки запроса внешнюю программу CGI.
Преимущества
трехуровневой архитектуры очевидны: при необходимости изменений в деловой
логике, изменения вносятся на сервере приложений, переустанавливать клиентские
части не надо.
СУБД
Microsoft Access - система управления базами данных, которую фирма Microsoft
неизменно включает в состав профессиональной редакции Microsoft Office. СУБД
Access занимает одно из ведущих мест среди систем для проектирования, создания
и обработки баз данных.
Достоинства:
1. очень
простой графический интерфейс, который позволяет не только создавать
собственную базу данных, но и разрабатывать приложения, используя встроенные
средства,
2. хранит
все данные в одном файле, хотя и распределяет их по разным таблицам, как и
положено реляционной СУБД. К этим данным относится не только информация в
таблицах, но и другие объекты базы данных.
. предлагает
большое количество Мастеров, которые выполняют основную работу за пользователя
при работе с данными и разработке приложений, помогают избежать рутинных
действий и облегчают работу неискушенному в программировании пользователю.
. распространенность,
которая обусловлена тем, что Access является продуктом компании Microsoft,
. постоянно
обновляется производителем, поддерживает множество языков,
. полностью
совместим с операционной системой Windows,
. ориентированность
на пользователя с разной профессиональной подготовкой, что выражается в наличии
большого количества Мастеров, развитую систему справки и понятный интерфейс.
. широкие
возможности по импорту/экспорту данных в различные форматы, от таблиц Excel и
текстовых файлов, до практически любой серверной СУБД через механизм ODBC,
9. Наличие
развитых встроенных средств разработки приложений. Большинство приложений,
распространяемых среди пользователей, содержит тот или иной объем кода VBA
(Visual Basic for Applications),
10. Наличие
встроенного языка макрокоманд.
Недостатки:
1. ограничены
возможности по обеспечению многопользовательской среды.
. В ранних
версиях (до Access 2003) отсутствуют такие средства как триггеры и хранимые
процедуры, что заставляет разработчиков возлагать поддержание бизнес логики БД
на клиентскую программу или разрабатывать процедуры с помощью встроенного
средства VBA.
3. обладает
несложными способами защиты с использованием пароля БД (возможно применения
дополнительных мер по защите от несанкционированного доступа с использованием
процедур VBA),
. В
вопросах поддержки целостности данных отвечает только моделям БД небольшой и средней
сложности.
. Не
распространяется бесплатно.
СУБД
Microsoft SQL Server - система управления реляционными базами данных (СУРБД),
разработанная корпорацией Microsoft. Основной используемый язык запросов -
Transact-SQL, создан совместно Microsoft и Sybase.
Достоинства:
. Независимость
от конкретной СУБД. Несмотря на наличие диалектов и различий в синтаксисе, в
большинстве своём тексты SQL-запросов, содержащие DDL и DML, могут быть
достаточно легко перенесены из одной СУБД в другую.
2. Наличие
стандартов. Наличие стандартов и набора тестов для выявления совместимости и
соответствия конкретной реализации SQL общепринятому стандарту только
способствует «стабилизации» языка.
3. Декларативность.
С помощью SQL программист описывает только то, какие данные нужно извлечь или
модифицировать. То, каким образом это сделать, решает СУБД непосредственно при
обработке SQL-запроса.
Недостатки:
. Несоответствие реляционной модели данных:
· Повторяющиеся строки
· Неопределённые значения
· Явное указание порядка колонок слева направо
· Колонки без имени и дублирующиеся имена колонок
· Отсутствие поддержки свойства «=»
· Использование указателей
· Высокая избыточность
2. Сложность. Хотя SQL и задумывался как средство работы конечного
пользователя, в конце концов он стал настолько сложным, что превратился в
инструмент программиста.
3. Отступления от стандартов. Несмотря на наличие международного
стандарта ANSI SQL-92, многие компании, занимающиеся разработкой СУБД, вносят
изменения в язык SQL, применяемый в разрабатываемой СУБД, тем самым отступая от
стандарта. Таким образом, появляются специфичные для каждой конкретной СУБД
диалекты языка SQL.
. Сложность работы с иерархическими структурами. Ранее диалекты
SQL большинства СУБД не предлагали способа манипуляции древовидными
структурами. Некоторые поставщики СУБД предлагали свои решения. В настоящее
время в ANSI стандартизована рекурсивная конструкция WITH из диалекта SQL DB2.
В MS SQL Server рекурсивные запросы появились лишь в версии MS SQL Server 2005.
В данном курсовом проекте в качестве реализации БД была выбрана среда
Microsoft SQL Server. Она бесплатная, имеет независимость от конкретной СУБД,
поэтому тексты SQL запросов, написанные в данной среде могут быть легко
перенесены на другие СУБД - это очень удобно и эффективно. Также эта среда
имеет стандарты - запросы написанные совершенно другим разработчиком можно
легко понять, производить их изменение и доработку.
4. Физическая реализация
.1 Построение таблиц и схемы данных средствами СУБД
Для создания таблицы в режиме конструктор необходимо раскрыть контекстное
меню "Базы данных", выбрать свою базу данных, в нашем случае -
Больница (рис.2). Затем также раскрыть контекстное меню, выбрать пункт
"Таблицы", щелкнуть правой кнопкой мыши по нему, после чего появится
выпадающий список, где нужно выбрать пункт "Создать таблицу".

Рисунок 2
Далее появится следующий интерфейс (рис. 3). Он разделен на три части.
Под пунктом "Имя столбца" вы указываете непосредственно имена своих
столбцов. "Тип данных" предназначен для указания типов ваших
столбцов. Третий пункт разрешает использование или запрещает использование
нулевых значений.
Рисунок 3
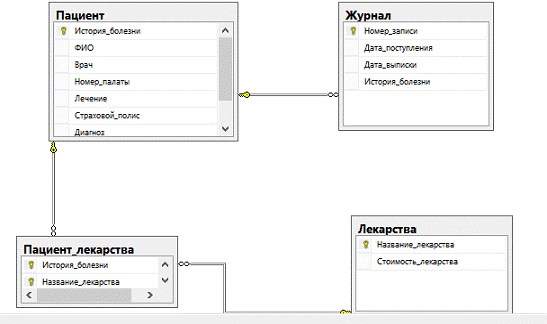
В данной базе данных используется три основные таблицы и одна промежуточная.
Основные:
· Пациенты
· Лекарства
· Журнал
Промежуточная:
· Пациент_лекарства
Таблица 1 "Пациент"
|
Имя поля
|
Тип данных
|
Признак ключевого поля
|
|
История_болезни
|
INT
|
Primary key
|
|
ФИО
|
NCHAR(30)
|
-----
|
|
Врач
|
NCHAR(30)
|
-----
|
|
Номер_палаты
|
INT
|
-----
|
|
Лечение
|
NCHAR(30)
|
-----
|
|
Страховой_полис
|
INT
|
-----
|
|
Диагноз
|
NCHAR(30)
|
-----
|
|
Измение_диагноза
|
bit
|
-----
|
Таблица 2 "Журнал"
|
Имя поляТип данныхПризнак
ключевого поля
|
|
|
|
Номер_записи
|
INT
|
-----
|
|
Дата_поступления
|
DATE
|
-----
|
|
Дата_выписки
|
DATE
|
-----
|
|
История_болезни
|
INT
|
Foreign key
|
Таблица 3 "Лекарства"
|
Имя поля
|
Тип данных
|
Признак ключевого поля
|
|
Название_лекарства
|
NCHAR(30)
|
Primary key
|
|
Стоимость_лекарства
|
INT
|
-----
|
Таблица 4 "Пациент_лекарства"
|
Имя поляТип данныхПризнак
ключевого поля
|
|
|
|
История_болезни
|
INT
|
Foreign key
|
|
Название_лекарства
|
NCHAR(30)
|
Foreign key
|
Для установления связей между таблицами нужно открыть созданную диаграмму
(рис. 4). Нажать левой кнопкой мыши на ключ у главной таблицы, в нашем случае
"Пациент", и, держа кнопку, перетащить курсор мыши на дочернюю
таблицу "Журнал".

После этого откроется следующий интерфейс (рис. 5). Здесь выбираются
таблицы для первичных и внешних ключей, а также необходимые для этого поля.
После автоматически создается связь.
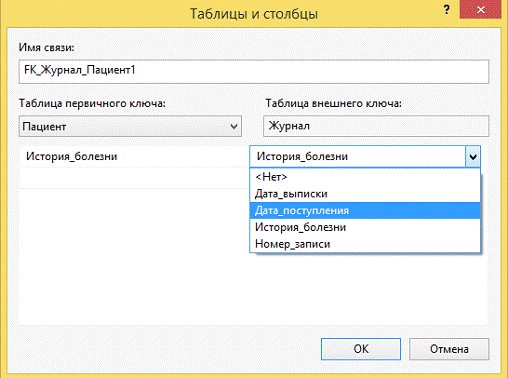
Рисунок 5
.2 Создание запросов на языке SQL
- это универсальный язык для создания, модификации и управления
информацией, которая входит в состав реляционных баз данных. Первоначально SQL
был основным способом работы с данными. С помощью него пользователь мог
выполнять следующие действия:
· создание новой таблицы в базе данных (БД);
· добавление новых записей в существующие таблицы;
· редактирование записей;
· полное удаление записей;
· выбор записи из разных таблиц, в соответствии с заданными
условиями;
· изменение вида и структур одной или нескольких таблиц.
· и д.р.
В разрабатываемой системе используются следующие запросы:
Упорядочение по полям: ФИО больных, диагноз, распределение по палатам.
Запрос:
Пациент.*ПациентBY Пациент.ФИОПациент.*ПациентBY
Пациент.ДиагнозПациент.*ПациентBY Пациент.Номер_палаты
Результат:

Рис. 6
Поиск: сведения о больных по первым буквам фамилии; по № палаты. Данные
запросы были выполнены с помощью хранимых процедур.
Запрос на поиск №1:
USE [Больница]
/****** Object: StoredProcedure [dbo].[Поиск по фамилии] Script Date: 25.11.2015 19:54:27
******/ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE [dbo].[Поиск по фамилии]
@Введите_фамилию nvarchar(30)*ПациентФИО like '%' + @Введите_фамилию
+ '%'
Результат:

Рис. 7
Запрос на поиск №2:
[Больница]
GO
/****** Object: StoredProcedure [dbo].[Поиск_по_палате] Script Date: 25.11.2015
19:58:46 ******/ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE [dbo].[Поиск_по_палате]
@Введите_палату int*ПациентПациент.Номер_палаты=@Введите_палату
END
Результат:

Рис. 8
Выборка: по дню поступления больных, по дню выписки, по диагнозу.
Запрос:
*ПациентДиагноз = 'Грипп'Пациент.*Журнал, ПациентДата_поступления = '03.05.2014'
AND Журнал.История_болезни = Пациент.История_болезниПациент.*Журнал,
ПациентДата_выписки = '20.03.2015' AND Журнал.История_болезни =
Пациент.История_болезни
Результат:
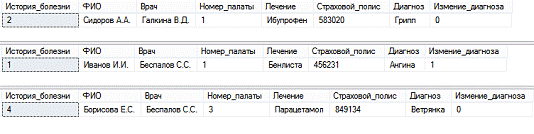
Рис. 9
Вычисления: количество больных, поступивших в январе, феврале и т.д.;
количество больных, выписавшихся в январе, феврале и т.д. Данные запросы были
выполнены с помощью хранимых процедур.
Запрос на вычисление №1:
[Больница]
GO
/****** Object: StoredProcedure [dbo].[Вычисление_1] Script Date: 25.11.2015 20:06:49
******/ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE [dbo].[Вычисление_1]
@Количество_больных int=0 OUTPUT
SELECT @Количество_больных=count(*)ЖурналMONTH(Журнал.Дата_поступления) =
'01' OR MONTH(Журнал.Дата_поступления) = '02';
Результат:

Рис. 10
Запрос на вычисление №2:
[Больница]
GO
/****** Object: StoredProcedure [dbo].[Вычисление_2] Script Date: 25.11.2015 20:09:38
******/ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE [dbo].[Вычисление_2]
@Количество_больных int=0 OUTPUT@Количество_больных=count(*)ЖурналMONTH(Журнал.Дата_выписки) = '01' OR MONTH(Журнал.Дата_выписки) = '02';
END
Результат:
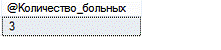
Рис. 11
Коррекция: удаление данных о больных, выписавшихся в прошлом году;
количество больных с изменением первоначального диагноза на конечный.
Запрос на коррекцию №1:
USE
[Больница]
GO
/****** Object: StoredProcedure [dbo].[Удаление] Script Date: 25.11.2015 20:29:01
******/ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE [dbo].[Удаление]
@количество int OUTPUT@количество=Журнал.История_болезни
FROM ЖурналYEAR(Журнал.Дата_поступления) < '2015'
DELETEПациентПациент.История_болезни=@количество
END

Рис.12
Запрос на коррекцию №2:
USE
[Больница]
GO
/****** Object: StoredProcedure [dbo].[Количество_больных_с_изм] Script Date: 25.11.2015 20:11:36
******/ANSI_NULLS ONQUOTED_IDENTIFIER ONPROCEDURE [dbo].[Количество_больных_с_изм]
@Количество_больных int=0 OUTPUT@Количество_больных=count(*)Пациент Пациент.Измение_диагноза = 'TRUE'
Результат:

Рис. 13
Также в данном курсовом проекте был разработан триггер. При удалении
записей он проверяет условие "Изменения диагноза" и если оно истинно,
то появляется сообщение об ошибке.
Триггер:
USE [Больница]
/****** Object: Trigger [dbo].[primer2] Script Date:
25.11.2015 20:15:14 ******/ANSI_NULLS ONQUOTED_IDENTIFIER ONTRIGGER
[dbo].[primer2][dbo].[Пациент]DELETENOCOUNT ON;(select Измение_диагноза from deleted) = '1'
print'Нельзя удалять запись!'
Запрос:ПациентИзмение_диагноза = '1'
Результат:

Рис. 14
Было предусмотрено ограничение целостности: каждый больной лечится в
одной из существующих палат (рис. 15).
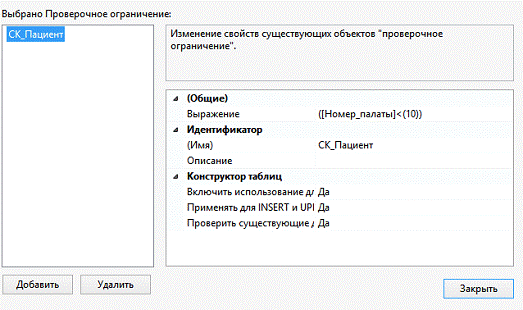
Рисунок 15
Если пользователь вводит номер палаты, который больше 10, то появляется
следующее сообщение об ошибке (рис. 16).
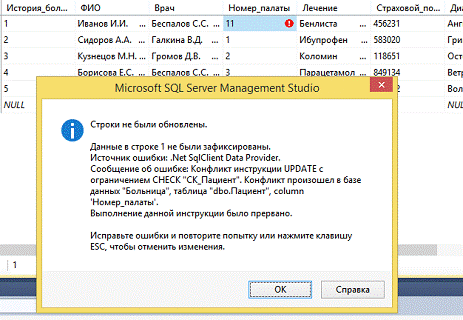
Рисунок 16
4.3 Создание форм и отчетов
В общей структуре информационной системы формы служат для упрощения
работы пользователя с базами данных. Формы делают работу более простой и
наглядной. В данном курсовом проекте для создания форм и отчетов была
использована программа "Построитель отчетов 3.0". Для того чтобы
приступить к разработке отчета необходимо выбрать наш SQL-сервер и базу данных
(рис. 17).
Рисунок 17
После чего нажать "Ок", а затем кнопку далее. В
"Проектировании запроса" вам предложат выбрать интересующие вас таблицы,
которые будут участвовать в отчете и нажать кнопку далее (рис. 18).
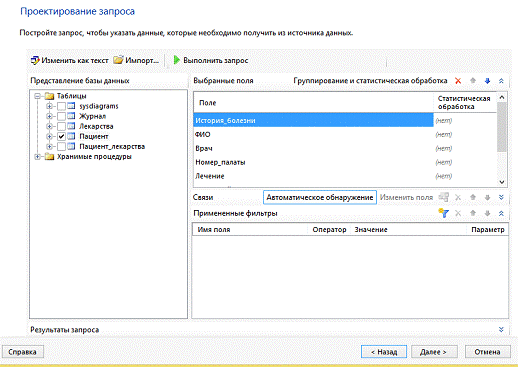
Рисунок 19
Как только вы завершили проектирование запроса вам предложат выбрать
стиль отчета, в нашем случае был выбран стиль "Универсальный"
Конечный вариант отчета представлен в Приложении В.
Список литературы
1) ГОСТ 2.106-96. Текстовые документы. М.: Изд-во
стандартов, 1996.-40с.- (Единая система конструкторской документации).
2) ГОСТ 2.105-95. Общие требования к текстовым
документам. М.:Изд-во стандартов, 1995.-20с.- (Единая система конструкторской
документации).
) Базы данных: теория, разработка и использование :
учебное пособие / Е.Г. Бершадская, Н.А. Филиппова. - Пенза : Изд-во Пенз. гос.
технол. акад., 2012. - 107 с.
Приложение А
управление запрос информационный
Приложение Б
Приложение В