Анализ эффективности функционального программирования на языке F# для многоядерных процессоров
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ РЕСПУБЛИКИ БЕЛАРУСЬ БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ
Факультет
радиофизики и электроники
Кафедра
информатики и компьютерных систем
Дипломная
работа по теме:
Анализ
эффективности функционального программирования на языке F# для многоядерных
процессоров
Минск
ВВЕДЕНИЕ
В настоящее время разработка и использование
сложных программных систем невозможно без учета существующей тенденции
увеличения ядер в процессорах. Вследствие этого возникает необходимость в инструментах
для параллельного программирования, которые бы обеспечили быструю и
качественную разработку программного обеспечения. Повсеместно использующийся
объектно-ориентированный подход затрудняет написание параллельных программ,
поэтому в последнее время растет интерес к парадигме функционального
программирования и оно начинает интенсивнее использоваться в индустрии
разработки программного обеспечения. В частности корпорация Microsoft включила
в состав своей последний среды разработки Visual Studio 2010 функциональный
язык F#, много функциональных возможностей добавилось в язык C#, включая
функциональное ядро LINQ.
Целями данной работы являются:
Определение эффективности главной концепции
мультипарадигменного языка F# - функционального программирования.
Исследование эффективности параллельного
программирования на функциональном языке F#.
Для реализации целей была поставлена задача по
сравнению эффективности программирования на различных .NET языках (С++, С#, F#)
на примере оконного приложения, реализующего графическую обработку изображения
недетерминированного фрактала - множества Мандельброта. Построение данного
множества является стандартной задачей для анализа параллельных возможностей
языка. В качестве критерия эффективности будет выступать скорость работы
программ, в качестве дополнительных критериев - удобство написания и повторного
использования кода, его безопасность.
1. ФУНКЦИОНАЛЬНОЕ ПРОГРАММИРОВАНИЕ
НА ЯЗЫКЕ F#
.1 Анализ существующих
функциональных языков
язык программирование функция
матрица
История
Время появления теоретических работ, которые
обосновывают функциональный подход, относится к 20-м - 30-м годам XX столетия.
Истоки математических основ функционального
подхода к программированию следует искать в ранних работах М. Шенфинкеля (Moses
Schönfinkel),
которые,
нужно отметить, малоизвестны, т.к. довольно далеки по времени от работ,
непосредственно связанных с функциональным подходом. Еще в 1924 году он
разработал простую (simple) теорию функций, которая фактически являлась
исчислением объектов-функций и предвосхитила появление лямбда-исчисления.
Затем, в 1934 году, А. Черч (Alonso Church)
предложил лямбда-исчисление и применил его для исследования теории множеств. Не
вызывает сомнений тот факт, что разработанная им теория конечных последовательностей
в форме исчисления лямбда-конверсий положила начало математическому исчислению,
формализующему понятие функции. Вклад ученого был настолько фундаментальным,
что теория до сих пор называется лямбда-исчислением и часто именуется в
литературе лямбда-исчислением Черча.
Дальнейшее развитие функциональный подход
получает в работах, посвященных типизированному лямбда-исчислению, согласно
которым аргументам функций и самим функциям можно назначать (или, иначе,
приписывать) тот или иной тип. Типизация существенно увеличивает вычислительную
стройность и значимость любой математической формализации, и, естественно, без
нее немыслимы современные языки программирования.
Теорию и практику программирования существенно
обогатило моделирование среды вычислений в форме абстрактной машины,
построенной на основе категориальной комбинаторной логики, созданной Х. Карри
(Haskell B. Curry). В 1940 году он предложил теорию функций без переменных
(иначе называемых комбинаторами), известную в настоящее время как комбинаторная
логика. Эта теория является развитием лямбда-исчисления и представляет собой
формальный язык, аналогичный языку функционального программирования и
позволяющий более наглядно моделировать вычисления в среде абстрактных машин, в
значительной мере схожих с виртуальной машиной .NET.
В 50-х годах XX столетия появилась первая
реализация функционального языка программирования в виде языка LISP. Он был
предложен Джоном Мак-Карти (John McCarthy) в качестве средства исследования
границ применимости компьютеров, в частности, методом решения задач
искусственного интеллекта. Лисп послужил эффективным инструментом
экспериментальной поддержки теории программирования и развития сферы его
применения.
Позднее, уже в 60-х г.г. Р. Хиндли (Roger
Hindley) разработал выводимость типов (type inference), т.е. возможность неявно
определить тип выражения, исходя из типов выражений, которые его окружают.
Именно эта возможность широко используется в современных языках
программирования, таких как SML и Haskell.
Также в 60-х г.г. П. Лендин (Peter Landin)
создал первую абстрактную машину на основе расширенного лямбда-исчисления.
Машина получила название SECD и формализовала вычисления на языке
программирования ISWIM (If you See What I Mean), который впоследствии стал
прообразом языка функционального программирования ML.
Наконец, в 70-х г.г. Р. Милнер (Robin Milner)
создал полиморфную систему типизации для языка функционального программирования
ML, которая вместе с развернутым описанием того же автора положила начало
стандартизации этого языка программирования. В 1971 г теория решеток Д. Скотта
(Dana S. Scott) стала основой для моделирования вычисления значения функции
(или семантики) языка программирования [1].
Функциональный подход породил целое семейство
языков, родоначальником которых, как уже отмечалось, стал язык программирования
LISP. Позднее, в 70-х годах, был разработан первоначальный вариант языка ML,
который впоследствии развился, в SML, а также ряд других языков, из которых,
пожалуй, самым «молодым» является созданный совсем недавно - в 2006 году
мультипарадигменный язык Nemerle.
Рассмотрим эволюцию языков программирования,
развивающихся в рамках функционального подхода, в частности семейства Lisp, ML,
Haskell.
1.2 Семейства функциональных языков
Семейство Lisp
Ранние языки функционального программирования,
которые берут свое начало от классического языка LISP (LISt Processing;
современное написание: Lisp). Традиционный Лисп имеет динамическую систему
типов. Язык является функциональным, но многие поздние версии обладают также
чертами императивности, к тому же, имея полноценные средства символьной
обработки становится возможным реализовать объектно-ориентированность, примером
такой реализации является платформа CLOS.
Основной механизм языка Лисп - инкапсулированная
в список определяющая голова списка и подключённый к ней хвост списка, который
рекурсивно также может быть списком. Любая программа на языке Лисп состоит из
последовательности выражений (форм). Результат работы программы состоит в
вычислении этих выражений. Все выражения записываются в виде списков - одной из
основных структур Лиспа, поэтому они могут легко быть созданы посредством
самого языка. Это позволяет создавать программы, изменяющие другие программы
или макросы, позволяющие существенно расширить возможности языка.
Одной из необычных особенностей семейства языков
Лисп является возможность использования макросов для создания встроенного
предметно-ориентированного языка программирования. Обычно, в большом количестве
проектов, написанных на языке Лисп, модуль может быть написан на множестве
подобных миниязыков, то есть, один может использовать SQL-диалект языка Лисп, а
другой может быть написан на диалекте, ориентированном на графический интерфейс
пользователя или вывод на принтер и т. д. [3].
Первые области применения языка Лисп были
связаны с символьной обработкой данных и процессами принятия решений. Наиболее
популярный сегодня диалект Common Lisp является универсальным языком
программирования. Он широко используется в самых разных проектах:
Интернет-серверы и службы, серверы приложений и клиенты, взаимодействующие с
реляционными и объектными базами данных, научные расчёты и игровые программы.
Одно из направлений использования языка Lisp -
его использование в качестве скриптового языка, автоматизирующего работу в ряде
прикладных программ:используется как язык сценариев в САПР AutoCAD (диалект
AutoLISP);
его диалект - SKILL - используется для написания
скриптов в САПР Virtuoso Platform компании Cadence Design Systems;является
одним из базовых средств текстового редактора Emacs (диалект
EmacsLISP);используется как язык сценариев в издательском программном
обеспечении Interleaf/Quicksilver (диалект Interleaf Lisp);
в оконном менеджере Sawfish применяется
специальный диалект Лиспа Rep, который в значительной степени повторяет диалект
Лиспа от Emacs;
диалект Scheme используется в качестве одного из
скриптовых языков в графическом процессоре Gimp;
диалект GOAL используется для высокодинамичных
трёхмерных игр;может использоваться для написания скриптов в аудиоредакторе
Audacity [4].
Семейство ML(Meta Language) - семейство строгих
языков функционального программирования с развитой полиморфной системой типов и
параметризуемыми модулями. Подобная система типов была раньше предложена
Роджером Хиндли в 1969 году и сейчас часто называется системой Хиндли-Милнера.
Не является чистым функциональным языком, так как он включает и императивные
инструкции.
В основе строгой и статической системы типов
языка лежит лямбда-исчисление, к которому добавлена строгая типизация. Строгая
система типов делает возможности для оптимизации, поэтому вскоре появляется
компилятор языка. В системе типов Хиндли-Милнера ограниченно полиморфная
система типов, где большинство типов выражений может быть выведено
автоматически. Это дает возможность программисту не описывать явно типы
функций, но сохранить строгий контроль типов.
Можно выделить особенности ML:является
интерактивным языком. Каждое введенное предложение анализируется, компилируется
и исполняется, и значение, полученное в результате исполнения предложения, вместе
с его типом выдается пользователюимеет полиморфную систему типов. Каждое
допустимое предложение языка обладает однозначно определяемой наиболее общей
типизацией, которая определяет контексты, в которых предложение может быть
использовано.поддерживает абстрактные типы данных. Абстрактные типы весьма
полезный механизм в модульном программировании. Новые типы данных могут быть
определены вместе с набором операций над значениями этих типов в ML области
действия идентификаторов определяются статически. Смысл всех идентификаторов в
программе определяется статически, что позволяет создавать более модульные и
более эффективные программысодержит надежно типизированный механизм обработки
исключительных событийсодержит средства разбиения программ на модули, обеспечивающие
возможность разработки больших программ по частям [5].
В середине 80-х годов ML распался на два
диалекта, которые в данный момент обычно рассматривают как различнные языки:
Objective CaML и Standard ML.
Язык CaML поддерживает функциональную, императивную
и объектно-ориентированную парадигмы программирования. Был разработан в 1985
году во французском институте INRIA, который занимается исследованиями в
области информатики. Самый распространённый в практической работе диалект языка
ML. Его реализация содержит много возможностей, не имеющих прямого отношения к
функциональному подходу, но необходимых для практического языка
программирования:
Компилятор в байт-код (генерирует компактный и
достаточно эффективный код)
Компилятор в машинный код для многих платформ (в
том числе x86, SPARC, Alpha etc.). Порождаемый транслятором код обладает
эффективностью сравнимой с С ( различие в скорости как правило от двукратного
проигрыша до 3-кратного выигрыша - последнее имеет место за счет более
эффективной работы с кучей).
Как нативный (native), так и байт-код
порождаются в виде исполняемого файла.
Текстовый отладчик (с функциональностью близкой
к GNU Debugger)
Генераторы лексических и синтаксических
анализаторов (OCamlLex, OCamlYacc) [6].
К достоинствам языка относят строгую типизацию,
развитую систему модулей, автоматическую сборку мусора, эффективность,
кроссплатформенность.ML - модульный функциональный язык программирования общего
назначения.
По сравнению с ранними функциональными языками,
SML обладает рядом несомненных достоинств. К ним, в первую очередь, относятся:
безопасность программного кода, т.е. гарантия
отсутствия переполнения памяти (в случае корректно написанной программы) и,
соответственно, защиты от потенциальной неустойчивости работы системы
посредством искусственного создания этого переполнения;
статическая типизация: все ошибки несоответствия
типов выявляются уже на стадии контроля соответствия типов в ходе трансляции (а
не во время выполнения программы, как в LISP и Scheme);
выводимость типов (нет необходимости явно
указывать тип каждого выражения, при этом результирующий программный код
становится более удобочитаемым, его легче хранить и повторно использовать).
К числу других преимуществ языка функционального
программирования SML следует отнести параметрический полиморфизм (возможность
обрабатывать аргументы абстрактного типа). При этом трудозатраты на разработку
программного обеспечения сокращаются за счет универсальности разрабатываемых
функций (скажем, становится возможным написать унифицированную функцию для
упорядочения по возрастанию элементов списка, которая сможет упорядочивать и
список из целочисленных элементов, и список из символьных строк).
Еще одним мощным средством, облегчающих
символьную обработку (в частности, декомпозицию и верификацию программ),
является механизм сопоставления с образцом.
Построение программ из модулей способствует
разделению интерфейсной части (описательной части) и реализации (содержательной
части) функций, что обеспечивает унификацию и сокращает время создания сложных
программных проектов, облегчая тестирование на соответствие спецификациям
заказчика.
Обработка исключительных ситуаций, которые
описывают ход выполнения программы в случае возникновения тех или иных
относительно редких событий, а также теоретически интересного механизма
продолжений, создают возможность реализации программных систем,
взаимодействующих с пользователем в реальном времени.
Из последних реализаций нужно отметить
мультипарадигменный язык Nemerle, который в функциональном подходе будет
родственен языкам семейства ML, включая их особенности:
функции высшего порядка;
сопоставление с образцом (pattern matching);
алгебраические типы;
локальные функции;
кортежи и анонимные типы;
частичное применение;
мощный вывод типов;
Вдобавок к императивным и функциональным
парадигмам, Nemerle обладает мощной системой макросов, которые предоставляют
пользователю возможность добавлять новые конструкции в язык и описывать решение
задач в декларативном стиле с помощью создания собственных
предметно-ориентированных языков программирования (DSL).
Основные концепции языка Nemerle:
Типобезопасные «гигиеничные» макросы и
квазицитирование c возможностью расширения синтаксиса.
Наличие локальных функций (лексических
замыканий). Функция является полноправным объектом, то есть может быть
сохранена в переменной, передана в качестве аргумента в другую функцию или
возвращена из функции.
Гарантированная оптимизация хвостовой рекурсии,
то есть хвостовая рекурсия всегда заменяется циклом при компиляции.
Выведение типов. В частности, возможно выведение
типов локальных переменных и выведение сигнатуры локальных функций.
Отсутствие четкой границы между инструкцией
(statement) и выражением (expression). «Everything is expression». Например,
условный оператор может находиться внутри арифметического выражения. Нет
необходимости в инструкциях return, break, continue.
Алгебраические типы данных, кортежи и
сопоставление с образцом.
Упрощенный синтаксис работы со списками.
Списочные литералы.
Частичное применение операторов и функций -
простая генерация обёртки некоторой функции, в которой часть параметров
подставлена заранее, а часть передаётся непосредственно при вызове функции.
Основные недостатки - сложность синтаксиса,
непривычность принятых соглашений и ограничений, практическая невозможность макротрансформаций.,
Miranda, Haskell
Язык Hope появился в 70х годах в Эдинбургском
Университете. Hope является первым языком, в котором появились отложенные
вычисления и алгебраические типы, но в нем отсутствует возможность неявного
объявления типов. В последующих версиях языка добавилась поддержка отложенных
вычислений[7]. Язык является важным этапом в жизни функционального
программирования, он послужил основой для таких языков как Miranda и Haskell,
но сам распространения не получил.
Язык Miranda был разработан в 1985 году, он стал
первым коммерчески поддерживаемым чисто функциональным языком программирования.
Его чистая функциональность обеспечивает отсутствие побочных эффектов, так как
в языке нет состояния, нет переменных. Выделим также другие особенности
языка:поддерживает функции в качестве данных.является «ленивым» (нестрогим)
языком, поддерживаются нестрогие функции и бесконечные размерности.
Реализованы генераторы списков (list
comprehensions), т.е. создание списков при помощи математических выражений.
В основе языка лежит полиморфная строгая
типизация.
Абстрактные типы данных и модули.
Программа на языке Miranda является набором
уравнений, которые описывают разнообразные математические функции и
алгебраические типы данных. Важным здесь является слово «набор» - порядок
вычисления уравнений, в общем, не определен, и до их вычисления не нужно
объявлять каких либо сущностей.
Так как при синтаксическом анализе программы
используется интеллектуальный разбор, редко появляется необходимость
использовать скобки или другие ограничители при ее написании. Также в Miranda
не нужно описывать типы при объявлении переменных так как в языке присутствует
система вывода типов. В языке существует лишь несколько встроенных типов:
числа (целые неограниченной размерности и числа
с плавающей точкой двойной точности)
символы
списки
кортежи
функции[8]была относительно популярна в 1980-х
годах, но оставалась проприетарным программным обеспечением. Это затрудняло
развитие и исследования возможностей ленивого функционального программирования,
поэтому буквально за пару лет появилось более десятка схожих языков. Чтобы
объединить усилия разных разработчиков, в 1987 г. на конференции по
функциональным языкам программирования и компьютерной архитектуре в Орегоне
(FPCA’87) было решено создать комитет для разработки открытого стандарта.
В 1990 г. была предложена первая версия языка
Haskell 1.0. В дальнейшем работа комитета продолжилась, и в 1999 г. был
опубликован «The Haskell 98 Report», который стал стабильным стандартом языка
на много лет. Язык, однако, продолжал бурно развиваться, компилятор GHC
(Glasgow Haskell Compiler) был фактическим стандартом в отношении новых
возможностей. Последняя версия языка - Haskell 2010 - была объявлена в конце
2009 г, но последней «значительной» версией (стандартом) остаётся Haskell 98
[9].является чисто функциональным языком программирования общего назначения,
который включает много последних инноваций в разработке языков
программирования. Haskell обеспечивает функции высокого порядка, нестрогую
семантику, статическую полиморфную типизацию, определяемые пользователем
алгебраические типы данных, сопоставление с образцом, описание списков,
модульную систему, монадическую систему ввода - вывода и богатый набор
примитивных типов данных, включая списки, массивы, целые числа произвольной и
фиксированной точности и числа с плавающей точкой. Haskell является и
кульминацией, и кристаллизацией многих лет исследования нестрогих
функциональных языков [10].
В качестве основных характеристик языка Haskell
можно выделить следующие:
возможность использования лямбда-абстракции;
функции высшего порядка;
частичное применение;
недопустимость побочных эффектов (чистота
языка);
ленивые вычисления (lazy evaluation);
сопоставление с образцом, функциональные образцы
(pattern matching);
параметрический полиморфизм (в т.ч.
абстрагирование от конструктора типа) и полиморфизм классов типов;
статическая типизация;
автоматическое выведение типов (основано на
модели типизации Хиндли - Милнера);
алгебраические типы данных;
параметризуемые типы данных;
рекурсивные типы данных;
абстрактные типы данных (инкапсуляция);
генераторы списков (list comprehensions);
охраняющие выражения (guards) - выражения,
которые предназначены для ограничения вычислительных процессов и направления их
по определённому направлению в зависимости от условия охраны[11];
возможность писать программы с побочными
эффектами без нарушения парадигмы функционального программирования с помощью
монад;
возможность интеграции с программами,
реализованными на императивных языках программирования посредством открытых
интерфейсов (стандартное расширение языка Foreign Function Interface);
Среди возможностей компилятора GHC нужно
отметить три варианта компиляции: непосредственно в машинные коды целевой
архитектуры, компиляция через промежуточный код на языке C или C--, компиляция
в язык LLVM (Low Level Virtual Machine).
Со времени принятия последнего стандарта языка
(Haskell98) прошло много времени, и с тех пор ведущие реализации языка (ghc и
hugs) были расширены множеством дополнительных возможностей:
Полиморфизм 2-го и высших рангов (rank-2 and
rank-N polymorphism)
Функциональные зависимости (FD, functional
dependencies)
В 2009 году сформировалась концепция Haskell
Platform - стандартного дистрибутива языка, включающего кроме компилятора
(GHC), также дополнительный инструментарий (систему сборки и развёртывания
пакетов Cabal) и набор популярных библиотек. Сейчас Haskell Platform - это
рекомендованный базовый дистрибутив для разработчиков. Готовые сборки Haskell
Platform доступны для Windows, MacOS X и ряда дистрибутивов Linux.
Развитием ранних языков программирования стали
языки функционального программирования с сильной типизацией, характерным
примером которых является классический ML, и далее, его прямой потомок, SML. В
языках с сильной типизацией каждая конструкция (или выражение) должно иметь
тип. При этом в более поздних языках функционального программирования, однако,
нет необходимости явного приписывания типа, и типы изначально неопределенных
выражений могут выводиться (до запуска программы), исходя из типов связанных с
ними выражений.
Следующим шагом в развитии языков
функционального программирования стала поддержка полиморфных функций, т.е.
функций с параметрическими аргументами (аналогами математической функции с
параметрами). В частности, полиморфизм поддерживается в языках SML, Miranda и
Haskell.
На современном этапе развития возникли языки
функционального программирования «нового поколения» со следующими расширенными
возможностями: сопоставление с образцом (Scheme, F#, Nemerle), параметрический
полиморфизм (SML) и так называемые «ленивые» (по мере необходимости) вычисления
(Haskell, Miranda, F#,)[12].
1.3 Преимущества функционального
программирования
Важным преимуществом реализации языков
функционального программирования является автоматизированное динамическое
распределение памяти компьютера для хранения данных. При этом программист
избавляется от рутинной необходимости контролировать данные, а при
необходимости может запустить функцию «сборки мусора» - очистки памяти от тех данных,
которые больше не потребуются программе.
Сложные программы при функциональном подходе
строятся посредством агрегирования функций. При этом текст программы
представляет собой функцию, некоторые аргументы которой можно также
рассматривать как функции. Таким образом, повторное использование кода сводится
к вызову ранее описанной функции, структура которой, в отличие от процедуры
императивного языка, прозрачна математически.
Типы отдельных функций, используемых в
функциональных языках, могут быть переменными. При таком подходе обеспечивается
возможность обработки разнородных данных (например, упорядочение элементов
списка по возрастанию для целых чисел, отдельных символов и строк) или
полиморфизм. Таким образом, при создании программ на функциональных языках
программист сосредотачивается на предметной области и в меньшей степени
заботится о рутинных операциях (обеспечении правильного с точки зрения
компьютера представления данных и т.д.).
Поскольку функция является естественным
формализмом для языков функционального программирования, реализация различных
аспектов программирования, связанных с функциями, существенно упрощается.
Интуитивно прозрачным становится написание рекурсивных функций, т.е. функций,
вызывающих самих себя в качестве аргумента. Естественной становится и
реализация обработки рекурсивных структур данных.
Благодаря реализации механизма сопоставления с
образцом, такие языки функционального программирования как ML и Haskell весьма
хорошо применимы для символьной обработки.
Близость к математической формализации и
изначальная функциональная ориентированность являются причиной следующих
преимуществ функционального подхода:
простота тестирования и верификации программного
кода на основе возможности построения строгого математического доказательства корректности
программ;
унификация представления программы и данных
(данные могут быть инкапсулированы в программу как аргументы функций,
означивание или вычисление значения функции может производиться по мере
необходимости);
безопасная типизация: недопустимые операции над
данными исключены;
динамическая типизация: возможно обнаружение
ошибок типизации во время выполнения;
независимость программной реализации от
машинного представления данных и системной архитектуры программы (программист
концентрирует внимание на деталях реализации, а не особенностях машинного
представления данных).
Основной особенностью функционального
программирования, определяющей как преимущества, так и недостатки данной
парадигмы, является то, что в ней реализуется модель вычислений без состояний.
Если императивная программа на любом этапе исполнения имеет состояние, то есть
совокупность значений всех переменных, и производит побочные эффекты, то чисто
функциональная программа ни целиком, ни частями состояния не имеет и побочных
эффектов не производит. То, что в императивных языках делается путём
присваивания значений переменным, в функциональных достигается путём передачи
выражений в параметры функций. Непосредственным следствием становится то, что
чисто функциональная программа не может изменять уже имеющиеся у неё данные, а
может лишь порождать новые путём копирования и/или расширения старых.
Следствием того же является отказ от циклов в пользу рекурсии.
Привлекательная сторона вычислений без состояний
- повышение надёжности кода за счёт чёткой структуризации и отсутствия
необходимости отслеживания побочных эффектов. Любая функция работает только с
локальными данными и работает с ними всегда одинаково, независимо от того, где,
как и при каких обстоятельствах она вызывается. Невозможность мутации данных
при пользовании ими в разных местах программы исключает появление
труднообнаруживаемых ошибок (таких, например, как случайное присваивание
неверного значения глобальной переменной в императивной программе).
Поскольку функция в функциональном
программировании не может порождать побочные эффекты, менять объекты нельзя как
внутри области видимости, так и снаружи (в отличие от императивных программ,
где одна функция может установить какую-нибудь внешнюю переменную, считываемую
второй функцией). Единственным эффектом от вычисления функции является
возвращаемый ей результат, и единственный фактор, оказывающий влияние на
результат - это значения аргументов.
Таким образом имеется возможность протестировать
каждую функцию в программе, просто вычислив её от различных наборов значений
аргументов. При этом можно не беспокоиться ни о вызове функций в правильном
порядке, ни о правильном формировании внешнего состояния. Если любая функция в
программе проходит модульные тесты, то можно быть уверенным в качестве всей
программы. В императивных программах проверка возвращаемого значения функции
недостаточна: функция может модифицировать внешнее состояние, которое тоже
нужно проверять, чего не нужно делать в функциональных программах[13].
Традиционно упоминаемой положительной
особенностью функционального программирования является то, что оно позволяет
описывать программу в так называемом «декларативном» виде, когда жесткая
последовательность выполнения многих операций, необходимых для вычисления
результата, в явном виде не задаётся, а формируется автоматически в процессе
вычисления функций. Это обстоятельство, а также отсутствие состояний даёт
возможность применять к функциональным программам достаточно сложные методы
автоматической оптимизации.
Ещё одним преимуществом функциональных программ
является то, что они предоставляют широчайшие возможности для автоматического
распараллеливания вычислений. Поскольку отсутствие побочных эффектов
гарантировано, в любом вызове функции всегда допустимо параллельное вычисление
двух различных параметров - порядок их вычисления не может оказать влияния на
результат вызова.
Естественно, языки функционального
программирования не лишены и некоторых недостатков.
Часто к ним относят нелинейную структуру
программы и относительно невысокую эффективность реализации. Второй недостаток
постепенно исправляется с новыми версиями компиляторов. Тем не менее,
программирование с использованием математического понятия функции вызывает
некоторые трудности, поэтому функциональные языки, в той или иной степени
предоставляют и императивные возможности [2].
Отсутствие присваиваний и замена их на
порождение новых данных приводят к необходимости постоянного выделения и
автоматического освобождения памяти, поэтому в системе исполнения
функциональной программы обязательным компонентом становится высокоэффективный
сборщик мусора.
Для преодоления недостатков функциональных
программ уже первые языки функционального программирования включали не только
чисто функциональные средства, но и механизмы императивного программирования
(присваивание, цикл)[14].
В качестве обобщения сравним функциональный и
императивный подходы к программированию.
Нужно понимать, что принципы функционального
программирования формулировались специально для поддержки функционального,
декларативного подхода к решению проблем. Напротив, при императивном подходе
разработчик пишет код, подробно определяющий шаги, которые должен выполнить
компьютер для достижения цели.
Основные усилия программиста при императивном
подходе направлены на способы выполнения (алгоритмы) задач и отслеживания
изменений в их состоянии, при функциональном - на требуемые данные и их
преобразования. В императивном подходе важное значение имеют состояние и
порядок вычисления, в функциональном состояния не существует, а порядок маловажен.
Императивный подходи использует циклы, условия и вызовы методов, а
функциональный - лишь вызовы функций, в том числе рекурсивный.
Основными единицами обработки в императивном
программировании являются экземпляры структур или классов, в функциональном -
функции как полноценные объекты и коллекции данных.
Чтобы решить задачу, разработчики
объектно-ориентированных приложений проектируют иерархии классов, добиваются
правильной инкапсуляции и мыслят в терминах контрактов между классами. Для них
первостепенное значение имеет обеспечение правильного поведения и состояния
типов объектов, а для достижения этого используются такие возможности языка,
как классы, интерфейсы, наследование и полиморфизм.
В отличие от этого, в функциональном
программировании применяется подход к вычислительным проблемам как к
определению чисто функциональных преобразований коллекции данных. В
функциональном программировании приходится отказываться от применения состояний
и изменяющихся данных, а вместо этого сосредоточиваться на применении
функции[15].
1.4 Язык F#: особенности,
преимущества, недостатки, области применения
Функциональный язык F# был разработан в 2002 г.
Доном Саймом (Don Syme) в Microsoft Research в Кембридже. В настоящее время его
разработку ведет Microsoft Developer Division, и распространяется вместе с .NET
Framework и Visual Studio как часть Visual Studio 2010.# входит в семейство
ML-языков, унаследовав все преимущества этого семейства, а также поддерживает
большинство функциональных возможностей нестрогих языков (например Haskell),
таких как отложенные вычисления, бесконечные последовательности, монады. Одной
из важных особенностей языка является поддержка Microsoft, что служит хорошим
подспорьем для его развития и расширения сферы применения. Перечислим важнейшие
характеристики этого языка:# - мультипарадигменный язык программирования.
Акцент сделан на функциональности, но на нем можно писать функциональный,
императивный и объектно-ориентированный код. Это предоставляет программисту
возможность ухода от табий ООП и более гибко рассматривать проблему.#
использует вывод типов, что приводит к более лаконичным программам.# - это
.NET-язык программирования.# - компилируемый язык программирования, при этом в
качестве промежуточного языка используется язык Common Intermediate Language
(CIL), так же как и в программах, написанных на языках C# или VB.NET.# включен
в стандартный набор Visual Studio 2010
У него есть интерактивная среда программирования
(REPL) как для Ruby и Python, называемая F# Interactive Window.
Рассмотрим технические особенности F#, которые
делают его особенно привлекательным для написания программ:
Статически типизированный. F# является
статически типизированным языком, в отличие, например, от динамически
типизированного Ruby. Это означает, что информация о типах известна во время
компиляции. Благодаря этому код исполняется намного быстрее и есть возможность
узнавать о большинстве ошибок еще на этапе компиляции.
Лаконичный. В дополнение к выведению типов, F#
также использует значимые пробелы. Если сместить строки под if-конструкцией на
несколько пробелов вправо, компилятор расценит их как тело оператора (light
синтаксис). Это избавляет от необходимости засорять код фигурными скобками и
сохраняет вертикальное пространство. Меньше кода на странице означает
возможность одновременно видеть большую часть программы, и меньше переключать
контекст просматривая код.
Расширяемый. Это означает возможность
использования F# в крупных проектах уровня предприятий
Исследуемый. В F# вам нет необходимости
обращаться к дизайну, чтобы понять, как все работает. Можно быстро
прототипировать решения F#, а также экспериментировать с алгоритмами и
подходами с помощью F# Interactive Window. Опираясь на лаконичную природу F#,
не нужно писать много кода, чтобы экспериментировать с программами.
Библиотеки. F# поставляется со своей собственной
библиотекой для написания функционального или другого кода[16]. Платформа .NET
позволяет использовать множество уже существующих библиотек.
В языке используются такие функциональные
инструменты как каррирование (определение функции нескольких аргументов как
функции высшего порядка), функциональные типы, кортежи, связывание имен,
цитирования (метапредставление абстрактного синтаксического дерева программы),
вычислительные выражения (computation expressions).интегрировала среду
разработки F# в Visual Studio 2010 и планирует активно внедрять данный язык в
разработку программных систем, которые сами с течением времени смогут
масштабироваться, например в зависимости от количества пользователей, данное достоинство
нельзя просто реализовать в императивных языках программирования.
Области применения F#:
Симуляция.
Вычислительные финансы.
Обработка крупномасштабных данных.
Языково-ориентированное программирование.
Написание анализаторов кода.
Расширяемый F# код.
Многопоточное программирование.
Параллельное программирование.
Асинхронное программирование.
Примером использования F# является коммерческий
продукт WebSharper фирмы IntelliFactory. Это платформа для создания клиентских
web-приложений. Она позволяет писать клиентский код на F#, который затем будет
оттранслирован на JavaScript. Такая трансляция распространяется на достаточное
большое подмножество F#, включая функциональное ядро языка, алгебраические типы
данных, классы, объекты, исключения и делегаты. Также поддерживается
значительная часть стандартной библиотеки F#, включая работу с
последовательностями (sequences), событиями и асинхронными вычислительными
выражениями (async workflows). Всё может быть автоматически оттранслировано на
целевой язык JavaScript. Кроме того, поддерживается некоторая часть стандартных
классов самого .NET, и объём поддержки будет расти [17].
2. ПРОГРАММИРОВАНИЕ ДЛЯ МНОГОЯДЕРНЫХ
ПРОЦЕССОРОВ
.1 Параллельное программирование для
многоядерных процессоров
Сегодняшнее программирование разделено на две
практически непересекающиеся области: программирование высокоскоростных
вычислений и создание программ общего назначения. Десятилетиями
программирование для персональных компьютеров существовало в оранжерейных
условиях: оптимизация программ находилась если не на последнем, то далеко не на
первом месте. Много внимания уделялось процессу групповой разработки, объектным
шаблонам программирования, сокращению времени создания программ. Считалось, что
скорость работы программы увеличивается независимо от разработчика, просто в
силу постоянного роста мощности процессора, ускорения обмена данными с памятью
и периферией.
Действительно, примерно с 1970-го по 1985 год
производительность процессоров росла преимущественно за счет совершенствования
элементной базы и увеличения тактовой частоты. Затем, вплоть до 2000 года,
основную роль стали играть архитектурные усовершенствования - конвейеризация,
специализация, суперскалярность, спекулятивные вычисления, кэширование,
увеличение разрядности. Все эти факторы не влияли на процесс проектирования
большинства программ, которые продолжали оставаться прозрачными, линейными и
преимущественно объектно-ориентированными. Даже без перекомпиляции они
исполнялись на новых платформах значительно быстрее, и программисты считали,
что так будет продолжаться вечно.
В 2001 году был исчерпан ресурс повышения
тактовой частоты процессора. Для рядового пользователя это прошло незамеченным,
поскольку организация массового производства процессоров с тактовой частотой
более 3 ГГц растянулась на несколько лет. К 2005 году был освоен серийный
выпуск 3-гигагерцевых процессоров, и оказались в основном исчерпанными ресурсы
архитектурного совершенствования отдельно взятого процессора. В апреле 2005
года Intel и AMD одновременно приступили к продаже двухъядерных процессоров для
персональных компьютеров - по сути, двух процессоров на одной подложке. Теперь
забота о повышении скорости исполнения программ полностью ложится на плечи
кодировщиков.
Программирование на нескольких процессорах - проблема
не новая, но для ее решения от разработчика требуются специальная подготовка,
особый образ мышления и высокая квалификация.
Параллельная обработка имеет две разновидности:
конвейерность и собственно параллельность. В том и другом случаях предполагается
архитектурное вычленение из системы отдельных физических компонентов.
Идея конвейерности заключается в разбиении
операции на последовательные этапы длительностью в такт с последующей
реализацией каждого из них отдельным физическим блоком. Если организовать
работу таких блоков в виде конвейера (каждый блок, выполнив работу, передает
результат вычислений следующему блоку и одновременно принимает новую порцию
данных), то получится очевидный выигрыш.
Идея распараллеливания по данным еще проще. Если
имеется каждому из N процессоров предоставить равную часть данных для
обработки, то производительность увеличится в N раз. Если в задаче нельзя
выделить участки, допускающие параллельную обработку, или массив однотипных
операндов для конвейеризации, то сократить время ее выполнения не удастся. Это
описывается законом Амдала, который определяет максимально достижимую
производительность.
Кроме конвейеризации и физического
распараллеливания используются следующие методы:
специализация (применение внутри процессоров блоков,
оптимизированных под определенный вид вычислений, например математических
сопроцессоров);
кэширование;
спекулятивные вычисления.
Серийно изготавливаемые компьютеры позволяют
создать дешевую альтернативу суперкомпьютерам, например кластерную систему. При
этом основная задача сводится к программированию созданной системы.
Простота идеи программирования физически
параллельных систем выливается на практике в целый ряд сложных методик и
условий.
Алгоритм должен допускать распараллеливание.
При вычленении параллельных участков, как
правило, приходится придавать алгоритму специальную форму. Например, если
необходимо определить сумму массива, при распараллеливании на первом шаге
одновременно суммируются соседние четные и нечетные элементы массива, а на втором
попарно суммируются результаты, полученные на первом шаге, и т.д. Компактно
записать параллельный вариант на языке Си невозможно. В общем случае приведение
алгоритма к форме, позволяющей сократить время вычислений, означает отход от
формы, обеспечивающей наиболее наглядное представление.
В многопроцессорной системе разбиение на слишком
крупные части не позволяет равномерно загрузить процессоры и добиться
минимального времени вычислений, а излишне мелкая «нарезка» означает рост
непроизводительных расходов на связь и синхронизацию.
Физическому параллелизму присуща зависимость
глобальной структуры алгоритма от топологии вычислительной платформы. Процесс
создания максимально эффективного алгоритма практически не автоматизируется и
связан с большими трудозатратами на поиск специфической структуры алгоритма,
оптимальной для конкретной топологии целевой системы. Найденная структура
обеспечит минимальное время получения результата, но, скорее всего, будет
неэффективна для другой конфигурации. Более суровое следствие зависимости
структуры алгоритма от вычислительной платформы - тотальная непереносимость не
только исполняемых кодов, но и самого исходного текста.
Рассуждая о специфике физического параллелизма,
следует упомянуть вопросы надежности. Программист, пишущий физически
параллельную программу, обязательно должен иметь представление о следующих
вещах:
взаимные блокировки параллельных участков;
несинхронный доступ, или гонки;
возможность зависания параллельных участков;
опасность использования сторонних процедур и
библиотек;
набор специализированных средств отладки
физически параллельных программ;
нелокальный характер ошибок;
динамический характер ошибок и, как следствие,
влияние средств отладки программ на корректность исполнения последних.
Если параллельные (а вернее, независимые)
сущности выделяются на основе соображений удобства программирования (в первую
очередь, для снижения сложности описания системы), то говорят о логическом
параллелизме.
Логический параллелизм на уровне операционных
систем является многозадачным; при этом имеется выделенная задача
(планировщик), которая занимается переключением процессора с одной задачи на
другую. Алгоритмы переключений могут быть как примитивными, так и весьма
сложными. Самый простой - алгоритм разделения по времени. Планировщик работает
с очередью задач и активизируется по прерываниям от таймера с некоторым
заданным периодом. После активизации он сохраняет контекст текущей задачи,
ставит ее в конец очереди, восстанавливает контекст следующей задачи из очереди
и запускает ее на исполнение.
Поскольку задачи различны по исполняемым
функциям и ресурсоемкости, то возникает проблема распределения вычислительной
мощности процессора соразмерно задачам. В этом случае базовый алгоритм может
усложняться, например за счет механизма приоритетов: задачам присваиваются
приоритеты, и при смене задач управление передается наиболее приоритетной. В
системе может быть предусмотрено динамическое изменение приоритетов.
Планировщик допускается вызывать по прерываниям не только от таймера, но и от других
источников, а также по требованию активной задачи, после выполнения необходимых
высокоприоритетных операций. Однако получаемая гибкость сопровождается
повышением накладных расходов на планирование, сильно зависящих от числа
обслуживаемых задач.
Задача с уникальным набором данных и функций
достаточно тяжеловесна для вызова и обслуживания. Многозадачный логический
параллелизм предполагает небольшое количество задач (обычно в пределах одного
десятка). Между тем существуют области, в которых необходим «мелкозернистый»
логический параллелизм - разбиение задачи на множество небольших независимо
исполняемых частей. В серверах баз данных, на новостных порталах, в мобильных
сервисах, которые обслуживают распределенные системы, предназначенные для
нескольких сотен тысяч абонентов, требуется механизм независимого обслуживания
тысяч одновременно поступающих запросов. В таких системах надо не только не
пропустить поступивший запрос, но и обслужить его, возможно, организовав
интерактивный диалог, контроль над достоверностью и перезапрос информации в
случае ошибки.
«Мелкозернистый» логический параллелизм
эффективен в задачах управления сложным промышленным оборудованием.
Необходимость отражения параллелизма процессов, осуществляемых на объекте
управления, требует создания по меньшей мере сотни параллельно исполняемых
процессов. Сжатие информации достигается при логическом параллелизме за счет
упрощенного описания комбинаций независимых случаев: описание алгоритма как
набора независимых частей - это описание суммы ситуаций, а монолитное описание
- это описание произведения ситуаций.
Преимущества «мелкозернистого» логического
параллелизма заставляют искать пути снижения накладных расходов, присущих
многозадачности. Известные решения для операционных систем - легковесные процессы
(light-weight process). Переключение процессора на поток минимизировано вплоть
до операций сохранения/восстановления этих указателей. Планировщик по-прежнему
присутствует и активизируется по прерываниям от таймера.
Минимизировать или даже полностью исключить
накладные расходы, присущие многозадачности можно при многопоточности. Простота
организации делает многопоточность привлекательной для обеспечения
«мелкозернистого» логического параллелизма с гранулярностью на уровне
нескольких инструкций. Получаемый выигрыш компенсирует риск возможных ошибок
(которые могут возникнуть, например, из-за работы с общей областью данных).
Ведущие изготовители микроэлектронных
компонентов, пытаясь сохранить тенденцию роста производительности, предлагают
радикальные изменения в базовой архитектуре персональных компьютеров -
многоядерные процессоры. Эти архитектурные изменения предполагают коррекцию
подходов к созданию программ, а именно - активное использование физического
параллелизма. Однако он, с одной стороны, неприменим к большому классу
существующих последовательных алгоритмов, а с другой, означает возврат к
низкоуровневому программированию со всеми вытекающими отсюда последствиями (от
повышения квалификационных требований к разработчикам до увеличения затрат на
создание и реинжиниринг программ) [18].
К моменту появления многоядерных процессоров уже
существовали такие технологии как OpenMP (Open Multi-Processing) и MPI(Message
Passing Interface) для многопроцессорных систем. Обе они могут применяться для
написания программ для многоядерных процессоров. Сравним эти технологии.
Достоинства OpenMP:
На OpenMP программы легче писать и отлаживать
чем на MPI
Поэтапное распараллеливание - директивы могут
постепенно добавляться в программу
Программы могут выполняться также последовательно
Для того чтобы сделать программу параллельной
обычно не требуется никаких изменения последовательно кода.
Программы просты для понимания, облегчена их
поддержка
Недостатки OpenMP:
Программы могут быть исполнены лишь на
многопроцессорных или многоядерных системах с общей памятью.
Необходим компилятор поддерживающий openMP.
В основном можно использовать только для
распараллеливания циклов.
Достоинства MPI:
Программы могут выполняться на многопроцессорных
системах как с распределенной так и с общей памятью.
Каждый процесс имеет свои локальные переменные.
Покрывает больший спектр задач чем openMP.
Недостатки MPI:
Требуется вносить достаточно много изменений для
перехода от последовательной программы к параллельной.
Трудно отлаживать.
Производительность ограничена связями между
вычислительными узлами [19].
Обе этих технологии имеют довольно значительные
недостатки, которые осложняют широкое их распространение в программирование для
многоядерных процессоров.
Разработки компании Microsoft избавляют программиста
от необходимости управления потоками и взаимоблокировками на низком уровне.
Visual Studio 2010 и .NET Framework 4 улучают поддержку параллельного
программирования, путем предоставления новой среды выполнения, новых типов
библиотек класса и новых средств диагностики. Эти функциональные возможности
упрощают параллельную разработку, что позволяет разработчикам писать
эффективный, детализированный и масштабируемый параллельный код с помощью
естественных выразительных средств без необходимости непосредственной работы с
потоками или пулом потоков [20].
Параллельная модель программирования в .NET 4.0
включает две возможности:(Task Parallel Library) - улучшенное средство для
работы с потоками - программист работает не с потоками а с задачами. Содержит
два главных класса: Task и Parallel. Класс Parallel в частности библиотека
содержит параллельные реализация таких конструкций как For, Foreach,
Invoke.(Parallel Language-Integrated Query) - известная библиотеки LINQ с
возможностью параллельного исполнения запросов [21].
Язык F# может использовать эти возможности .NET
для написания параллельных программ, но в его активе имеются и свои инструменты
для этих целей.
Асинхронные потоки операций - один из самых
интересных примеров практического использования вычислительных выражений. Код,
выполняющий какие либо неблокирующие операции ввода-вывода, как правило сложен
для понимания, поскольку представляет из себя множество callback-методов,
каждый из которых обрабатывает какой-то промежуточный результат и возможно
начинает новую асинхронную операцию. Асинхронные потоки операций позволяют
писать асинхронный код последовательно, не определяя callback-методы явно. Для
создания асинхронного потока операций используется блок async:
System.IO
open
System.NetMicrosoft.FSharp.Control.WebExtensionsgetPage (url:string) ={req =
WebRequest.Create(url)! res = req.AsyncGetResponse()stream =
res.GetResponseStream()reader = new StreamReader(stream)! result =
reader.AsyncReadToEnd()result
}
Построитель асинхронного потока операций,
работает следующим образом. Встретив оператор let! или do!, он начинает
выполнять операцию асинхронно, при этом метод, начинающий асинхронную операцию,
получит оставшуюся часть блока async в качестве функции обратного вызова. После
завершения асинхронной операции переданный callback продолжит выполнение
асинхронного потока операций, но, возможно, уже в другом потоке операционной
системы (для выполнения кода используется пул потоков). В результате код
выглядит так, как будто он выполняется последовательно. То, что может быть с
легкостью записано внутри блока async с использованием циклов и условных
операторов, достаточно сложно реализуется с использованием обычной техники,
требующей описания множества callback-методов и передачей состояния между их
вызовами.- это класс из стандартной библиотеки F#, реализующий один из
паттернов параллельного программирования. MailboxProcessor является агентом,
обрабатывающим очередь сообщений, которые поставляются ему извне при помощи
метода Post. Вся конкурентность поддерживается реализацией класса, который
содержит очередь с возможностью одновременной записи несколькими писателями и
чтения одним единственным читателем, которым является сам агент [17].
let agent =
MailboxProcessor.Start(fun inbox ->{true do! msg = inbox.Receive()"message
received: '%s'" msg
})
2.2 Анализ эффективности
программирования на F# для многоядерных процессоров
Для исследования эффективности программирования
на языке F# была выбрана одна из базовых операций работы процессора - умножение
матриц для чисел с плавающей точкой. Одним из критериев является тот, что
умножение матриц легко поддается распараллеливанию. Были выбраны алгоритмы
эффективного умножения, которые также способствуют написанию параллельной
программы. Для сравнения, аналогичные программы были написаны на императивных
языках С++ и C#.
Существует множество алгоритмов перемножения
матриц: алгоритм Штрассена, алгоритм Пана, алгоритм Бини, алгоритмы Шёнхаге,
алгоритм Копперсмита-Винограда, алгоритмы с использованием теории групп.
Данные алгоритмы предусматривают оптимизацию по
способу умножения, но существуют также алгоритмы, оптимизирующие доступ к
памяти и позволяющие лучше распараллеливать задачу. Среди таких алгоритмов
можно выделить:
ленточный алгоритм;
алгоритм Фокса;
алгоритм Кэннона;преобразование (Morton-order);
В программе для анализа эффективности
параллельного программирования использовались алгоритмы Штрассена и
Z-преобразования матриц. Рассмотрим их подробней.
Пусть A, B - две квадратные матрицы над кольцом
R. Матрица C получается по формуле:
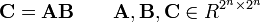
Если размер умножаемых матриц n не является
натуральной степенью двойки, мы дополняем исходные матрицы дополнительными
нулевыми строками и столбцами. При этом мы получаем удобные для рекурсивного
умножения размеры, но теряем в эффективности за счёт дополнительных ненужных
умножений.
Разделим матрицы A, B и C на равные по размеру
блочные матрицы
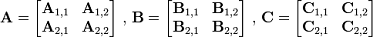
где
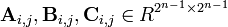
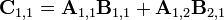
Однако с помощью этой процедуры нам не удалось
уменьшить количество умножений. Как и в обычном методе, нам требуется 8
умножений.
Теперь определим новые матрицы
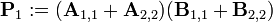
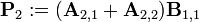
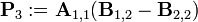
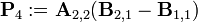
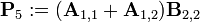
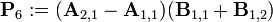

которые затем используются для выражения Ci,j.
Таким образом, нам нужно всего 7 умножений на каждом этапе рекурсии. Элементы
матрицы C выражаются из Pk по формулам
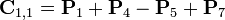

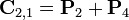
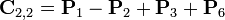
Итерационный процесс продолжается n раз, до тех
пор пока матрицы Ci,j не выродятся в числа (элементы кольца R). На практике
итерации останавливают при размере матриц от 32 до 128 и далее используют
обычный метод умножения матриц. Это делают из-за того, что алгоритм Штрассена
теряет эффективность по сравнению с обычным на малых матрицах из-за
дополнительных копирований массивов [22].преобразование, или код Мортона
(рис.1) впервые был предложен в 1966 году Г.М. Мортоном, он представляет собой
пространственную кривую, часто использующуюся в информатике. Благодаря сохраняющему
локальность поведению он используется в структурах данных для перевода
многомерной информации в одно измерение. Z-значение точки легко вычисляется с
помощью бинарного представления значений координат. Как только данные
отсортированы в этом порядке, к ним может быть применена любая одномерная
структура, например деревья двоичного поиска, B-деревья, списки или
хэш-таблицы.

Рис. 1 - Графическое представление
Z-преобразования
Для исследования были написаны программы,
реализующие умножение матриц на языках С++ и С# с использованием OpenMP и
Parallel Extensions, а также на языке F# с использованием асинхронных
выражений. Исследование проводилось на двухъядерном процессоре Inter Core 2
Duo, 2.4 Ghz, 3Mb Cache, 3Gb оперативной памяти, среда Visual Studio 2008 Team
System, операционная система Microsoft Windows Vista Home Edition, библиотека
для параллельных вычислений ParallelExtensions_Jun08CTP, сборка F# 1.9.6.16.
Для исследования были реализованы следующие
алгоритмы умножения матриц:
Классический (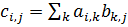 ).
).
Классический с использованием Z-преобразования.
Штрассена с использованием Z-преобразования.
Результаты измерения времени работы этих
алгоритмов для выбранных языков программирования представлены на рисунках 2-6.
На рисунке 7 для сравнения был добавлен график зависимости времени выполнения
программы от размера матриц для встроенного метода умножения матриц библиотеки
Math платформы .NET.

Рис. 2 - График зависимости времени выполнения
от размера матриц для классического алгоритма умножения
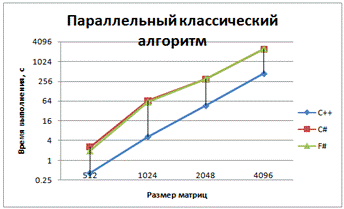
Рис. 3 - График зависимости времени выполнения
от размера матриц для параллельной версии классического алгоритма умножения
Рис. 4 - График зависимости времени выполнения
от размера матриц для классического алгоритма умножения с использованием
Z-преобразования матриц
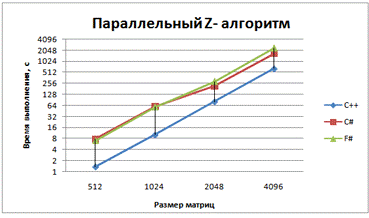
Рис. 5 - График зависимости времени выполнения
от размера матриц для параллельной версии классического алгоритма умножения с
использованием Z-преобразования матриц
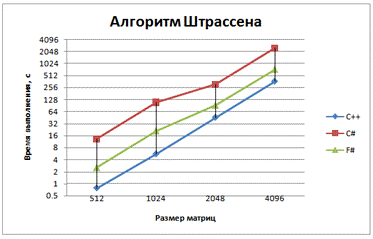
Рис. 6 - График зависимости времени выполнения
от размера матриц для алгоритма Штрассена с использованием Z-преобразования
матриц
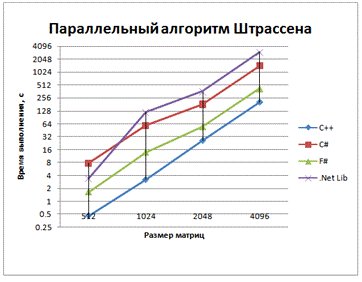
Рис. 7 - График зависимости времени выполнения
от размера матриц для параллельной версии алгоритма Штрассена с использованием
Z-преобразования матриц
После проведенного эксперимента проанализируем
полученные результаты:
При обычном и обычном параллельном умножениях
.NET языки показали одинаковую производительность, чего и следовало ожидать.
Здесь и далее С++ намного опережает их по производительности, что доказывает
целесообразность использования для приложений, требующих высокой скорости
вычислений компилируемых языков, а F# и C# - интерпретируемые языки. .NET
совместимые языки компилируются во второй, кроссплатформенный язык, который
называется CIL (Common Intermediate Language). А уже зависимая от платформы
среда CLR (Common Language Runtime) компилирует CIL в машинный код, который
может быть выполнен на данной платформе.
Умножение с использованием Z-преобразования
матриц лучше проходит на С#, чем на F#, но значительно хуже распараллеливается
(всего 20-25%).
Массивы располагаются линейно в оперативной
памяти, благодаря Z-преобразованию доступ к ним осуществляется последовательно,
ниже процент cache-misses, это приводит к уменьшению времени выполнения
умножений.
Использование метода Штрассена, как и ожидалось,
привело к ускорению работы программы.
В умножении с использованием метода Штрассена F#
показывает лучшие результаты, чем C#. Следует полагать, что это происходит
благодаря отходу от императивного способа создания новых матриц и использования
связывания имен let.
На основе полученных результатов можно сделать
вывод, что язык F# позволяет эффективно распараллеливать и решать такую
стандартную задачу как умножение матриц, обходя при этом по эффективности
другой язык работающий на платформе .NET - C#, но уступая языку С++,
работающему с неуправляемой памятью.
3. АНАЛИЗ ЭФФЕКТИВНОСТИ
ФУНКЦИОНАЛЬНОГО ПРОГРАММИРОВАНИЯ НА ЯЗЫКЕ F# ДЛЯ РЕШЕНИЯ ЗАДАЧИ ОБРАБОТКИ
ИЗОБРАЖЕНИЙ ДЛЯ МНОГОЯДЕРНЫХ ПРОЦЕССОРОВ
.1 Описание задачи
Задача умножения матриц является достаточно
абстрактной и не привязана к конкретной проблеме из реального мира, а для
исследования эффективности определенного языка необходимо учитывать возможность
его применения на практике. В связи с этим для исследования нужно было найти
задачу, обладающую следующими свойствами:
Актуальность. Для того чтобы определить язык как
эффективный, необходимо убедиться, что он может решать актуальные задачи и
получать убедительные результаты.
Реализуемость. Для анализа языка задача не
должна быть слишком сложной, но она должна охватывать базовые требования,
которые должны обязательно реализовываться в современном языке.
Возможность распараллеливания. Поскольку анализ
языка проводится в частности для многоядерных процессоров, нужно убедиться в
том, что язык позволяет эффективно распределять нагрузку на данный тип
вычислительных систем.
Наглядность. Хорошей практикой для описания
новых языков является реализация наглядных примеров, так как это способствует
восприятию его как альтернативы существующим языкам.
В архиве Microsoft был найден набор таких
примеров от 2009-12-09. Описание примеров можно найти в источнике [22]. Из этих
примеров для исследования была выбрана задача построения и обработки
классического множества Мандельброта.
В математике множество Мандельброта - это
фрактал, определённый как множество точек С на комплексной плоскости, для
которых итеративная последовательность
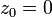
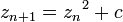
не уходит на бесконечность.
Впервые множество Мандельброта было описано в
1905 году Пьером Фату (Pierre Fatou), французским математиком, работавшим в
области аналитической динамики комплексных чисел. Фату изучал рекурсивные
процессы вида 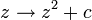
Начав с точки на комплексной плоскости, можно
получить новые точки, последовательно применяя к ним эту формулу. Такая последовательность
точек называется орбитой при преобразовании
Фату нашел, что орбита при этом преобразовании
показывает достаточно сложное и интересное поведение. Существует бесконечное
множество таких преобразований - своё для каждого значения. Основываясь на
своих расчётах, он доказал, что орбита точки, лежащей на расстоянии больше 2 от
начала координат, всегда уходит в бесконечность.
Фату никогда не видел изображений, которые мы
сейчас знаем как изображения множества Мандельброта, потому что необходимое
количество вычислений невозможно провести вручную. Профессор Бенуа Мандельброт
был первым, кто использовал для этого компьютер.
Фракталы были описаны Мандельбротом в 1975 году
в его книге «Les Objets Fractals: Forme, Hasard et Dimension» («Фрактальные
объекты: форма, случайность и размерность») [24].
Фрактал (лат. fractus - дробленый, сломанный,
разбитый) - сложная геометрическая фигура, обладающая свойством самоподобия, то
есть составленная из нескольких частей, каждая из которых подобна всей фигуре
целиком. В более широком смысле под фракталами понимают множества точек в
евклидовом пространстве, имеющие дробную метрическую размерность (в смысле
Минковского или Хаусдорфа), либо метрическую размерность, строго большую топологической
[25].
Одной из идей, выросших из открытия фрактальной
геометриим, была идея нецелых значений для количества измерений в пространстве.
Конечно, мы не можем осознать четырехмерные вещи, хотя Lucky Tesseract и
активно работает в этом направлении. Мандельброт назвал нецелые измерения такие
как 2.76 фрактальными измерениями. Обыкновенная евклидова геометрия утверждает,
что пространство ровное и плоское. Свойства такого пространства такого
пространства задают точки, линии, углы, треугольники, кубы, сферы, тетраэдры и
т. д.
Мандельброт верил, что действительный ландшафт
пространства не ровный и что в нашем мире нет ничего, что было бы совершенно
плоским, круглым, то есть все фрактально. Следовательно, объект, имеющий точно
3 измерения невозможен. Поэтому концепция фрактального измерения была нужна для
измерения степени неровности вещей.
Первыми открытыми фракталами были т.н.
детерминированные фракталы. Их отличительной чертой является свойство
самоподобия, обусловленное особенностями метода их генерации.
Такие фракталы называются классическими,
геометрическими фракталами или линейными фракталами. Эти фракталы обычно
формируются начиная с инициатора - фигуры, к которой применяется определенный
основной рисунок. Во всех детерминированных фракталах, само-подобие проявляется
на всех уровнях. Это значит, что независимо от того насколько вы приближаете
фрактал, вы увидите все тот же узор. Для сложных фракталов, которые будут
рассмотрены позже, это не так. Детерминистские фракталы образуются в процессе,
называемом итерацией, которая применяет основной рисунок к инициатору, после
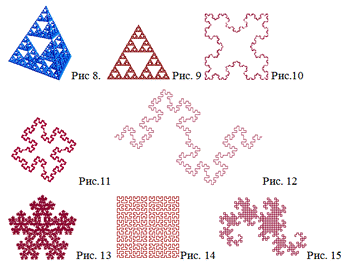
чего применяет его к результату и так далее. Из примеров можно выделить решетку
Серпинского (рис. 8), фрактал Серпинского (рис. 9),крест Коха (рис. 10),
фрактал Мандельброта (рис. 11), колбасу Минковского (рис. 12), пятиугольник
Дарера (рис. 13), кривую Гильберта (рис 14), кривую Дракона (рис 15). Их
фрактальные размерности находятся в пределах от 1.26 до 2.0.
Большая часть встречающихся сегодня фракталов не
являются детерминированными. Они не линейны и не собраны из повторяющихся
геометрических форм. Такие фракталы называются сложными. Если увеличить малую
область фрактала до размера большей области то получатся два изображения,
которые будут очень похожи в деталях, но они не будут полностью идентичными.
Детерминистские фракталы являются линейными,
тогда как сложные фракталы таковыми не являются. Будучи нелинейными, эти
фракталы генерируются нелинейными алгебраическими уравнениями.
Из самых известных недетерминированных фракталов
можно выделить множества Мандельброта (рис. 16) и Жулиа (рис. 17).

Большинство фракталов, которые можно найти на
сегодняшний день, представлены в богатой цветовой схеме. Возможно, фрактальные
изображения получили такое большое эстетическое значение именно благодаря этой
особенности. После того, как уравнение посчитано, начинается применение цвета.
Если результаты остаются стабильными, или колеблются вокруг определенного
значения, точка обычно принимает черный цвет. Если значение на том или ином
шаге стремится к бесконечности, точку закрашивают в другой цвет, может быть в
синий или красный. Во время этого процесса, компьютер назначает цвета для всех
скоростей движения.
Фракталы находят все большее и большее
применение в науке. Основная причина этого заключается в том, что они описывают
реальный мир иногда даже лучше, чем традиционная физика или математика. Вот
несколько примеров:
Наиболее полезным использованием фракталов в
компьютерной науке является фрактальное сжатие данных. В основе этого вида
сжатия лежит тот факт, что реальный мир хорошо описывается фрактальной
геометрией. При этом, картинки сжимаются гораздо лучше, чем это делается
обычными методами (такими как jpeg или gif). Другое преимущество фрактального
сжатия в том, что при увеличении картинки, не наблюдается эффекта пикселизации
(увеличения размеров точек до размеров, искажающих изображение). При
фрактальном же сжатии, после увеличения, картинка часто выглядит даже лучше,
чем до него.
Изучение турбулентности в потоках очень хорошо
подстраивается под фракталы. Турбулентные потоки хаотичны и поэтому их сложно
точно смоделировать. И здесь помогает переход к из фрактальному представлению,
что сильно облегчает работу инженерам и физикам, позволяя им лучше понять
динамику сложных потоков.
При помощи фракталов также можно смоделировать
языки пламени.
Пористые материалы хорошо представляются в
фрактальной форме в связи с тем, что они имеют очень сложную геометрию. Это
используется в нефтяной науке.
Для передачи данных на расстояния используются
антенны, имеющие фрактальные формы, что сильно уменьшает их размеры и вес.
Фракталы используются для описания кривизны
поверхностей. Неровная поверхность характеризуется комбинацией из двух разных
фракталов.
Биосенсорные взаимодействия и биения сердца в
медицине.
Моделирование хаотических процессов, в частности
при описании моделей популяций в биологии.
Применение фракталов в стеганографии и для
шифрования данных.
Сегодня Мандельброт и другие ученые, такие как
Клиффорд А. Пикковер (Clifford A. Pickover), Джеймс Глейк (James Gleick) или Г.
О. Пейтген (H.O. Peitgen) пытаются расширить область фрактальной геометрии так,
чтобы она могла быть применена практически ко всему в мире, от предсказания цен
на рынке ценных бумаг до совершения новых открытий в теоретической физике [26].
Тем не менее и сама задача построения фракталов
не завершилась а продолжила развитие в 3D-масштабах. Далее приведены примеры
изображений, построенных с использованием фракталов.

Рис. 18 - 3D-изображения, построенные при помощи
фракталов
Анализ эффективности параллельного
программирования на F# для задачи обработки графического представления
фрактальных функций
Задача графической реализации фрактального
множества была выбрана не случайно, ведь, как и в большинстве задач по
обработке изображений, в данной присутствует возможность для распараллеливания
вычислений по данным. В программе было использовано распараллеливание по
независимым рядам пикселей, что позволило равномерно распределить нагрузку
между ядрами процессоров.
Для исследования эффективности использования
языка F#, было реализовано 2D-изображение множества Мандельброта на 256 цветах
в окне Windows. В качестве дополнительного функционала были реализованы такие
функции как масштабирование окна, приближение и удаление картинки,
восстановление первоначального приближения, перемещение по изображению.
Для тестирования было использовано следующее
оборудование:Core 2 Duo, 2.4 Ghz, 3Mb Cache, 3Gb оперативной памяти, среда
Visual Studio 2010 Ultimate, операционная система Microsoft Windows Vista Home
Edition 32x.Intel Core i7, 2.6 Ghz, 6Mb Cache, 6Gb оперативной памяти, среда
Visual Studio 2010 Ultimate, операционная система Microsoft Windows 7 Home Premium
64x.
Для тестирования исходное изображение
десятикратно увеличивалось и сравнивалось время его перерисовки для языков F#,
C++/CLR, C#.
Так выглядит окно программы после применения
нескольких увеличений.

Рис. 19 - Окно программы Interactive
Fractal
В результате исследования были представлены
несколько графиков, которые отображают количество обработанных пикселей в
миллисекунду на 10 шагах приближения множества Мандельброта.
Результаты тестирования на первом оборудовании:
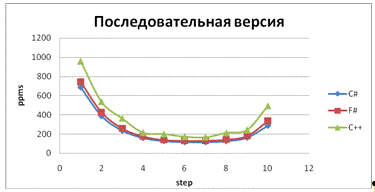
Рис. 20 - Скорость обработки пикселей на десяти
шагах приближения для последовательной версии программы
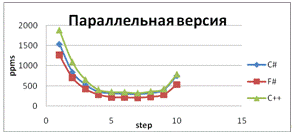
Рис. 21 - Скорость обработки пикселей на десяти
шагах приближения для параллельной версии программы
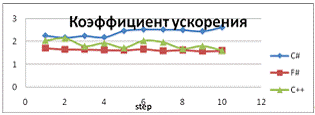
Рис. 22 - Коэффициент ускорения работы программы
на десяти шагах приближения
Результаты тестирования на втором оборудовании:
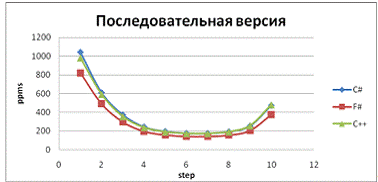
Рис. 23 - Скорость обработки пикселей на десяти
шагах приближения для последовательной версии программы
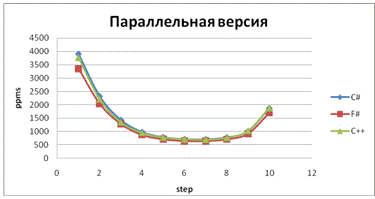
Рис. 24 - Скорость обработки пикселей на десяти
шагах приближения для параллельной версии программы
Рис. 25 - Коэффициент ускорения работы программы
на десяти шагах приближения
По полученным результатам можно сделать c
выводы:
Результаты отличаются для двух- и
четырехъядерных процессоров. Лучшие результаты язык F# показывает при
тестировании параллельной версии программы на четырех ядрах.
Использование языка F# не дает выигрыша в
скорости выполнения программы.
Так как все языки компилируются в CLI,
результаты работы программы обработки изображения примерно одинаковы.# показывает
лучший коэффициент ускорения на многоядерном процессоре, чем другие языки
В ряде тестов ускорение при работе нескольких
ядер превышало их количество.
Проанализируем код программ для получения
объяснения результатов эксперимента.
С++^ rrd = gcnew
RenderImageData(position, width, height);(parallel)
{^options = gcnew
ParallelOptions();>CancellationToken = cancellationToken;::For(0,
rrd->ImageHeight, options, gcnew Action<int>(rrd,
&RenderImageData::RenderRow));
}
{(int row = 0; row <
rrd->ImageHeight; row++)
{.ThrowIfCancellationRequested();>RenderRow(row);
}
}
…= gcnew
array<Byte>(Pixels);RenderRow(int row)
{initialY = row * RowToYTranslation
+ Top;(int col = 0, currentPixelIndex = row * ImageWidth; col < ImageWidth;
col++, currentPixelIndex++)
{c = *(gcnew Complex(col *
ColToXTranslation + Left, initialY));z = c;(int iteration = 0; iteration <
MaxIterations; iteration++)
{(z.Magnitude > 4)
{[currentPixelIndex] = iteration;
break;
}= (z * z) + c;
}
}
}
Видно, что основные вычисления происходят в циклах
по высоте изображения, ширине и количеству итераций для определения цвета
точки. Для осуществления распараллеливания используется конструкция for класса
Parallel библиотеки TPL. Также очевиден и недостаток такой реализации - все
процессы обращаются к общей структуре, что теоретически допускает возможность
конфликтов между записывающими потоками. Из неудобств написания программы нужно
выделить отсутствие поддержки IntelliSense, необходимость инициализации и
выделения памяти массиву данных до его использования.
C#(parallelRendering)
{options = new ParallelOptions {
CancellationToken = cancellationToken };.For(0, imageHeight, options, row =>
{initialY = row * rowToYTranslation
+ top;(byte* ptr = data)
{* currentPixel = &ptr[row *
imageWidth];(int col = 0; col < imageWidth; col++, currentPixel++)
{c = new Complex(col *
colToXTranslation + left, initialY);z = c;(int iteration = 0; iteration <
maxIterations; iteration++)
{(z.Magnitude > 4)
{
*currentPixel = (byte)iteration;;
}= (z * z) + c;
}
}
}
});
}
{(int row = 0; row < imageHeight;
row++)
{.ThrowIfCancellationRequested();initialY
= row * rowToYTranslation + top;(byte* ptr = data)
{* currentPixel = &ptr[row *
imageWidth];(int col = 0; col < imageWidth; col++, currentPixel++)
{c = new Complex(col * colToXTranslation
+ left, initialY);z = c;(int iteration = 0; iteration < maxIterations;
iteration++)
{(z.Magnitude > 4)
{
*currentPixel = (byte)iteration;
break;
}= (z * z) + c;
}
}
}
};
}
Этот же способ был реализован и на C#, что в
конечном итоге приводит к тем же проблемам. Кроме того, используется
unsafe(небезопасный) код с указателями. Из-за того большая часть кода
повторяется дважды, программа становится громоздкой и неудобной для повторного
использования. Повторное написание кода вызвано использованием многих
переменных класса, т.е. состояния программы.
F#rec drawBit (z : Complex) c
curIter =curIter withwhen x = maxIterations ->byte 0
|_ ->z withwhen x.Magnitude >
4.0 -> byte curIter
|_ -> drawBit (z*z+c) c
(curIter+1)getbyte initialY j =.ThrowIfCancellationRequested()c = new
Complex((float j) * colToXTranslation + left, initialY)c c 0data
=parallelRendering then.Parallel.init imageHeight (fun i -> Array.init
newImageWidth (fun j -> getbyte ((float i) * rowToYTranslation + top)
j)).init imageHeight (fun i -> Array.init newImageWidth (fun j -> getbyte
((float i) * rowToYTranslation + top) j))
Версия на F# имеет следующие отличия:
Отсутствуют операторы присваивания, что
автоматически устраняет проблему конфликта между процессами
Циклы заменяются рекурсией, которая, в силу
того, что она «хвостовая» компилируется обратно в цикл
Легче производить функциональную декомпозицию,
код становится короче
Параллельная версия отличается от
последовательной одним словом
Отсутствует необходимость инициализировать
массив до его заполнения, так как эти операции можно выполнить одновременно
Результаты эксперимента несколько различаются
для 2х и 4х ядерного процессора, наиболее эффективно проявляет себя
параллельная версия программы на 4х ядерном процессоре
В этом эксперименте также проявился эффект
сверхлинейного ускорения - скорость работы программы при подключении двух и
четырех ядер увеличивалась более чем в два и четыре раза соответственно. Это
объясняется использованием общего кэша L2 на процессоре Core 2 Duo и L3 на
процессоре i7. Можно выделить следующие преимущества систем с общим кэшем:
Увеличивается коэффициент использования кэша.
Уменьшается сложность согласования кэшей.
Уменьшается количество промахов кэша.
Уменьшается расход памяти - одни и те же данные
для нескольких процессоров записываются единожды.
Уменьшается нагрузка на шину данных - проблемы
доступа к данным разрешаются на уровне кэша [27].
Так как массив бит для изображения в памяти
располагается линейно, то достигается высокий процент попаданий в кэш, что
серьезно увеличивает производительность уже для двухъядерного процессора. Для
четырехъядерного процессора это приводит к сверхлинейному ускорению,
невозможному без участия кэша.
ЗАКЛЮЧЕНИЕ
В результате проделанной работы можно
утверждать, что язык F# является эффективным .NET языком программирования для
реализации параллельных вычислений или параллельной обработки данных. В
эксперименте с умножением матриц по алгоритму Штрассена с использованием
Z-порядка реализация на F# оказалась эффективней другого .NET языка C#. В
эксперименте с оконным приложением для обработки изображения
недетерминированного фрактала язык показал лучший коэффициент ускорения при
переходе с одного ядра на четыре, при этом обеспечивая безопасный доступ
потоков различных ядер к общим данным. Кроме того, возможности асинхронной
работы потоков, интеграции с другими .NET приложениями, интерактивного
выполнения кода, статическая типизация, функциональная основа делают его
незаменимым инструментов в руках профессионального разработчика. Поддержка
своих механизмов и библиотек .NET для параллельного программирования для
многоядерных процессоров позволяет F# успешно конкурировать с другими мощными
языками поддерживающими возможности параллельной разработки.
ЛИТЕРАТУРА
1. <http://www.ict.edu.ru/ft/005135//ch3.pdf>
. <http://ru.wikipedia.org/wiki/Язык_функционального_программирования>
. <http://ru.wikipedia.org/wiki/Препроцессор>
. <http://ru.wikipedia.org/wiki/Lisp>
. <http://progopedia.ru/language/ml/>
. <http://oops.math.spbu.ru/~msk/languages.functional.html>
. <http://en.wikipedia.org/wiki/Hope_(programming_language)>
. <http://progopedia.ru/language/miranda/>
. <http://ru.wikipedia.org/wiki/Haskell>
. <http://www.intuit.ru/department/pl/haskel98/1/>
. <http://ru.wikipedia.org/wiki/Охрана_(программирование)>
. <http://www.uchi-it.ru/7/2/3.html>
. <http://www.rsdn.ru/article/funcprog/fp.xml>
. <http://ru.wikipedia.org/wiki/Функциональное_программирование>
. <http://msdn.microsoft.com/ru-ru/library/bb669144.aspx>
. <http://habrahabr.ru/blogs/net/71656/>
. <http://fprog.ru/2010/issue5/maxim-moiseev-et-al-fsharp-intro/>
. <http://www.realcoding.net/article/view/2764>
. <http://www.dartmouth.edu/~rc/classes/intro_mpi/parallel_prog_compare.html>
. <http://msdn.microsoft.com/en-us/library/dd460693.aspx>
. <http://ru.wikipedia.org/wiki/Алгоритм_Штрассена>
. <http://blogs.msdn.com/b/pfxteam/archive/2009/12/09/9934811.aspx>
. <http://ru.wikipedia.org/wiki/Множество_Мандельброта>
. <http://ru.wikipedia.org/wiki/Фрактал>
. <http://www.chaostarantula.narod.ru/ToC/1.htm>
. <http://drdobbs.com/embedded-systems/196902836>
27. Tomas Petricek,Jon Skeet
Functional Programming for the Real World/Manning/2009
28. Сошников
Д.В. - лекции (“Функциональное программирование”)/2008/Lect1, видео (“F# :
Новый язык программирования .NET”)/Платформа/ 2009
. Тим
Мэттсон, Андрей Чернышев Введение в технологии параллельного программирования
/Intel® Software Network/2009
30. Don Syme, Adam Granicz, and
Antonio Cisternino Expert F#/Apress/2010
ПРИЛОЖЕНИЕ 1
Тексты программ на F#
А. Программа для умножения матриц
#light//включение
light-синтаксисаSystemSystem.Threading
/// Измерение времени выполнения функции
let Time f =timer =
System.Diagnostics.Stopwatch.StartNew ()y = f ()"Time taken = %O"
timer.ElapsedMatrixMultiplyDemo () =
/// Обыкновенное
умножениеMultiply
(A: float[,]) (B: float[,])(C: float[,]) =n = Array2D.length1 Ai = 0 to (n-1)
doj=0 to n-1 dok=0 to n-1 do.[i,j] <- C.[i,j] + A.[i,k] * B.[k,j]
/// Простое
умножениеMultiplyX
(A: matrix) (B: matrix) =
(fun x y -> x * y) A B //анонимная функция
/// Быстрое умножение с использованием алгоритма
Parallel-FX
let PFXMultiply (A: float[,]) (B:
float[,]) (C: float[,]) =n = Array2D.length1 ARowTask i =j=0 to n-1 dok=0 to
n-1 do.[i,j] <- C.[i,j] + A.[i,k] * B.[k,j]
//далее
идет
инструкия
из
Parallel Extensions .NET.For(0, (n-1), new Action<int>(RowTask))
///Создание
Z-матрицCreateZMatrix
(A: float[,]) (B: float[,]) (C: float[,] ) =n = Array2D.length1 AzMaskSize =
int(Math.Log(float(n*n),float(2)))DecalcZ z =mutable z1 = zmutable i = 0mutable
j = 0mutable bit = 1(bit <= z1) do<- j ||| (z1 &&& bit)<-
z1 >>> 1<- i||| (z1 &&& bit)<- bit <<< 1
(i,j) //возвращается
tuplef i (M: float[,]) =(i1,j1)=DecalcZ i.[i1,j1]zA=Array.init
(1<<<zMaskSize) (fun i -> f i A)zB=Array.init
(1<<<zMaskSize) (fun i -> f i B)mutable zC=Array.init
(1<<<zMaskSize) (fun i -> f i C)
(zA,zB,zC) //массив zC теперь изменяемый
///параллельное Z-умножениеPZMatrixMultiply
(zA:float[]) (zB:float[]) (zC:float[]) =
let n=Array.length zAZCode =
0MaskBits = int(Math.Log(float(n),float(2)))rec zMultiply (aZCode,aMaskBits)
(bZCode,bMaskBits) (cZCode,cMaskBits)=aMaskBits >=2 thenGetSubcells (zCode,
maskBits) = //разбиение на
4 ячейкиsubMaskBits
= maskBits - 2zI =
[|
(zCode , subMaskBits)
(zCode |||
(1<<<subMaskBits), subMaskBits)
(zCode |||
(2<<<subMaskBits), subMaskBits)
(zCode |||
(3<<<subMaskBits), subMaskBits)
|]c1sub = GetSubcells
(aZCode,aMaskBits)c2sub = GetSubcells (bZCode,aMaskBits)cRsub = GetSubcells
(cZCode,aMaskBits)c1sub.[0] c2sub.[0] cRsub.[0]c1sub.[1] c2sub.[2] cRsub.[0]c1sub.[0]
c2sub.[1] cRsub.[1]c1sub.[1] c2sub.[3] cRsub.[1]c1sub.[2] c2sub.[0]
cRsub.[2]c1sub.[3] c2sub.[2] cRsub.[2]c1sub.[2] c2sub.[1] cRsub.[3]c1sub.[3]
c2sub.[3] cRsub.[3].[cZCode] <- zA.[aZCode] * zB.[bZCode] +
zC.[cZCode]PzMultiply (aZCode,aMaskBits) (bZCode,bMaskBits)
(cZCode,cMaskBits)=aMaskBits >=2 thenGetSubcells (zCode, maskBits)
=subMaskBits = maskBits - 2zI =
[|
(zCode , subMaskBits)
(zCode |||
(1<<<subMaskBits), subMaskBits)
(zCode |||
(2<<<subMaskBits), subMaskBits)
(zCode ||| (3<<<subMaskBits),
subMaskBits)
|]c1sub = GetSubcells
(aZCode,aMaskBits)c2sub = GetSubcells (bZCode,aMaskBits)cRsub = GetSubcells
(cZCode,aMaskBits)
let tasks = [//разбиение на асинхронные потоки
async
{c1sub.[0] c2sub.[0]
cRsub.[0]c1sub.[1] c2sub.[2] cRsub.[0]
}
{c1sub.[0] c2sub.[1]
cRsub.[1]c1sub.[1] c2sub.[3] cRsub.[1]
}
{c1sub.[2] c2sub.[0]
cRsub.[2]c1sub.[3] c2sub.[2] cRsub.[2]
}
{c1sub.[2] c2sub.[1]
cRsub.[3]c1sub.[3] c2sub.[3] cRsub.[3]
}
]|> Async.Parallel |>
Async.RunSynchronously |>ignore.[cZCode] <- zA.[aZCode] * zB.[bZCode] +
zC.[cZCode]
//вычисление
на
последнем
уровне(ZCode,MaskBits)(ZCode,MaskBits)(ZCode,MaskBits)
///простое
Z-умножениеZMatrixMultiply
(zA:float[]) (zB:float[]) (zC:float[]) =n=Array.length zAZCode = 0MaskBits =
int(Math.Log(float(n),float(2)))rec zMultiply (aZCode,aMaskBits)
(bZCode,bMaskBits) (cZCode,cMaskBits)=aMaskBits >=2 thenGetSubcells (zCode,
maskBits) =subMaskBits = maskBits - 2zI =
[|
(zCode , subMaskBits)
(zCode |||
(1<<<subMaskBits), subMaskBits)
(zCode ||| (2<<<subMaskBits),
subMaskBits)
(zCode |||
(3<<<subMaskBits), subMaskBits)
|]c1sub = GetSubcells
(aZCode,aMaskBits)c2sub = GetSubcells (bZCode,bMaskBits)cRsub = GetSubcells
(cZCode,cMaskBits)c1sub.[0] c2sub.[0] cRsub.[0]c1sub.[1] c2sub.[2]
cRsub.[0]c1sub.[0] c2sub.[1] cRsub.[1]c1sub.[1] c2sub.[3] cRsub.[1]c1sub.[2]
c2sub.[0] cRsub.[2]c1sub.[3] c2sub.[2] cRsub.[2]c1sub.[2] c2sub.[1]
cRsub.[3]c1sub.[3] c2sub.[3] cRsub.[3].[cZCode] <- zA.[aZCode] * zB.[bZCode]
+ zC.[cZCode](ZCode,MaskBits)(ZCode,MaskBits)(ZCode,MaskBits)
zC
///Умножение с использование метода Штрассена
let StrassenMultiply (zA:float[])
(zB:float[]) (zC:float[]) =n=Array.length zAZCode = 0MaskBits =
int(Math.Log(float(n),float(2)))rec Strassen (aZCode,aMaskBits)
(bZCode,bMaskBits) (cZCode,cMaskBits)=GetSubcells (zCode, maskBits)
=subMaskBits = maskBits - 2zI =
[|
(zCode , subMaskBits)
(zCode |||
(1<<<subMaskBits), subMaskBits)
(zCode |||
(2<<<subMaskBits), subMaskBits)
(zCode |||
(3<<<subMaskBits), subMaskBits)
|]aMaskBits >= 3 thenc1sub =
GetSubcells (aZCode,aMaskBits)c2sub = GetSubcells (bZCode,aMaskBits)cRsub =
GetSubcells (cZCode,aMaskBits)c1sub.[0] c2sub.[0] cRsub.[0]c1sub.[1] c2sub.[2]
cRsub.[0]c1sub.[0] c2sub.[1] cRsub.[1]c1sub.[1] c2sub.[3] cRsub.[1]c1sub.[2]
c2sub.[0] cRsub.[2]c1sub.[3] c2sub.[2] cRsub.[2]c1sub.[2] c2sub.[1]
cRsub.[3]c1sub.[3] c2sub.[3] cRsub.[3]a0code=aZCodea1code=aZCode |||
1a2code=aZCode ||| 2a3code=aZCode ||| 3b0code=bZCodeb1code=bZCode |||
1b2code=bZCode ||| 2b3code=bZCode ||| 3c0code=cZCodec1code=cZCode ||| 1c2code=cZCode
||| 2c3code=cZCode ||| 3p1=(zA.[a0code]+zA.[a3code])*(zB.[b0code]+
zB.[b3code]);p2=(zA.[a2code]+zA.[a3code])* zB.[b0code];p3=zA.[a0code]
*(zB.[b1code]- zB.[b3code]);p4=zA.[a3code] *(zB.[b2code]-
zB.[b0code]);p5=(zA.[a0code]+zA.[a1code])* zB.[b3code];p6=(zA.[a2code]-zA.[a0code])*(zB.[b0code]+
zB.[b1code]);p7=(zA.[a1code]-zA.[a3code])*(zB.[b2code]+ zB.[b3code]);.[c0code]
<- p1+p4-p5+p7+zC.[c0code];.[c1code] <- p3+p5+zC.[c1code];.[c2code] <-
p2+p4+zC.[c2code];.[c3code] <- p1-p2+p3+p6+zC.[c3code];(ZCode,MaskBits)(ZCode,MaskBits)(ZCode,MaskBits)
zC
///Параллельная версия умножения с
использованием метода штрассена
let ParStrassenMultiply (zA:float[])
(zB:float[]) (zC:float[]) =n=Array.length zAZCode = 0MaskBits =
int(Math.Log(float(n),float(2)))rec Strassen (aZCode,aMaskBits)
(bZCode,bMaskBits) (cZCode,cMaskBits)=GetSubcells (zCode, maskBits)
=subMaskBits = maskBits - 2zI =
[|
(zCode , subMaskBits)
(zCode |||
(1<<<subMaskBits), subMaskBits)
(zCode |||
(2<<<subMaskBits), subMaskBits)
(zCode |||
(3<<<subMaskBits), subMaskBits)
|]aMaskBits >= 3 thenc1sub =
GetSubcells (aZCode,aMaskBits)c2sub = GetSubcells (bZCode,aMaskBits)cRsub =
GetSubcells (cZCode,aMaskBits)c1sub.[0] c2sub.[0] cRsub.[0]c1sub.[1] c2sub.[2]
cRsub.[0]c1sub.[0] c2sub.[1] cRsub.[1]c1sub.[1] c2sub.[3] cRsub.[1]c1sub.[2]
c2sub.[0] cRsub.[2]c1sub.[3] c2sub.[2] cRsub.[2]c1sub.[2] c2sub.[1]
cRsub.[3]c1sub.[3] c2sub.[3] cRsub.[3]a0code=aZCodea1code=aZCode |||
1a2code=aZCode ||| 2a3code=aZCode ||| 3b0code=bZCodeb1code=bZCode ||| 1b2code=bZCode
||| 2b3code=bZCode ||| 3c0code=cZCodec1code=cZCode ||| 1c2code=cZCode |||
2c3code=cZCode ||| 3p1=(zA.[a0code]+zA.[a3code])*(zB.[b0code]+
zB.[b3code]);p2=(zA.[a2code]+zA.[a3code])* zB.[b0code];p3=zA.[a0code]
*(zB.[b1code]- zB.[b3code]);p4=zA.[a3code] *(zB.[b2code]-
zB.[b0code]);p5=(zA.[a0code]+zA.[a1code])*
zB.[b3code];p6=(zA.[a2code]-zA.[a0code])*(zB.[b0code]+
zB.[b1code]);p7=(zA.[a1code]-zA.[a3code])*(zB.[b2code]+ zB.[b3code]);.[c0code]
<- p1+p4-p5+p7+zC.[c0code];.[c1code] <- p3+p5+zC.[c1code];.[c2code] <-
p2+p4+zC.[c2code];.[c3code] <- p1-p2+p3+p6+zC.[c3code];rec ParStrassen
(aZCode,aMaskBits) (bZCode,bMaskBits) (cZCode,cMaskBits)=GetSubcells (zCode,
maskBits) =subMaskBits = maskBits - 2zI =
[|
(zCode , subMaskBits)
(zCode ||| (1<<<subMaskBits),
subMaskBits)
(zCode |||
(2<<<subMaskBits), subMaskBits)
(zCode |||
(3<<<subMaskBits), subMaskBits)
|]aMaskBits >= 3 thenc1sub =
GetSubcells (aZCode,aMaskBits)c2sub = GetSubcells (bZCode,aMaskBits)cRsub =
GetSubcells (cZCode,aMaskBits)tasks = [
{c1sub.[0] c2sub.[0]
cRsub.[0]c1sub.[1] c2sub.[2] cRsub.[0]
}
{c1sub.[0] c2sub.[1]
cRsub.[1]c1sub.[1] c2sub.[3] cRsub.[1]
}
{c1sub.[2] c2sub.[0]
cRsub.[2]c1sub.[3] c2sub.[2] cRsub.[2]
}
{c1sub.[2] c2sub.[1]
cRsub.[3]c1sub.[3] c2sub.[3] cRsub.[3]
}
]|> Async.Parallel |>
Async.RunSynchronously |>ignorea0code=aZCodea1code=aZCode ||| 1a2code=aZCode
||| 2a3code=aZCode ||| 3b0code=bZCodeb1code=bZCode ||| 1b2code=bZCode |||
2b3code=bZCode ||| 3c0code=cZCodec1code=cZCode ||| 1c2code=cZCode |||
2c3code=cZCode ||| 3p1=(zA.[a0code]+zA.[a3code])*(zB.[b0code]+
zB.[b3code]);p2=(zA.[a2code]+zA.[a3code])* zB.[b0code];p3=zA.[a0code]
*(zB.[b1code]- zB.[b3code]);p4=zA.[a3code] *(zB.[b2code]-
zB.[b0code]);p5=(zA.[a0code]+zA.[a1code])*
zB.[b3code];p6=(zA.[a2code]-zA.[a0code])*(zB.[b0code]+
zB.[b1code]);p7=(zA.[a1code]-zA.[a3code])*(zB.[b2code]+ zB.[b3code]);.[c0code]
<- p1+p4-p5+p7+zC.[c0code];.[c1code] <- p3+p5+zC.[c1code];.[c2code] <-
p2+p4+zC.[c2code];.[c3code] <-
p1-p2+p3+p6+zC.[c3code];(ZCode,MaskBits)(ZCode,MaskBits)(ZCode,MaskBits)n = 512
//1024,2048,4096mutable rand= new Random()rand1 = ref randGenerate i j (rand:
Random ref) =.Value <- new Random(i+j)x = rand.Value.NextDouble()A =
Array2D.init n n (fun i j -> Generate i j rand1)B = Array2D.init n n (fun i
j -> Generate i j rand1)C = Array2D.create n n 0.0"[Lib multiply of
%dx%d matrix] " n nx =A1= Math.Matrix.of_array2 AB1= Math.Matrix.of_array2
B(fun () -> MultiplyX A1 B1)|>ignore.GC.Collect()(Za,Zb,Zc) =
CreateZMatrix A B CZc1= Array.copy ZcZc2= Array.copy ZcZc3= Array.copy
Zc"[Ordinary multiply of %dx%d matrix] " n n(fun () -> Multiply A
B C) |> ignore"[Fast multiply of %dx%d matrix] " n n(fun () ->
PFXMultiply A B C)|>ignore"[Z multiply of %dx%d matrix] " n nx0
=Math.Vector.of_array (Time(fun () ->ZMatrixMultiply Za Zb Zc))"[Parallel
Z multiply of %dx%d matrix] " n nx1 =Math.Vector.of_array (Time(fun ()
->PZMatrixMultiply Za Zb Zc1))"[Strassen multiply of %dx%d matrix]
" n nx2 =Math.Vector.of_array (Time(fun () ->StrassenMultiply Za Zb
Zc2))"[Parallel Strassen multiply of %dx%d matrix] " n nx3
=Math.Vector.of_array (Time(fun () ->ParStrassenMultiply Za Zb Zc3))error =
(x0-x2)+(x1-x3)"error = ".Write(Array.sum (Math.Vector.to_array
error))PrintWithHeading s =line = String.replicate(s |> String.length)
"=""%s\n%s" s line"RFE 2010\nVladimir
Shchur\n""Matrix Multiply"()"\n\nPress any key to
finish"
ПРИЛОЖЕНИЕ 2
Программа по обработке графического
изображения множества Мандельброта
.fs - файл запуска Windows-приложения
module Program
=SystemSystem.Windows.FormsMandelbrotFormModule
#if COMPILED
[<STAThread>]Application.EnableVisualStyles()Application.SetCompatibleTextRenderingDefault(false)Application.Run(new
MandelbrotForm())
#endif.fs -в этом файле производятся обработка
пользовательских событий и вывод изображения на экран
module
MandelbrotFormModuleSystemSystem.Windows.FormsSystem.DrawingSystem.Drawing.ImagingSystem.DiagnosticsSystem.Runtime.InteropServicesSystem.ThreadingSystem.Threading.TasksSystem.Collections.ConcurrentSystem.IOMandelbrotGeneratorModule
/// <summary>Describes the
bounds of the fractal to render.</summary>mutable _mandelbrotWindow =
MandelbrotPosition( 2.9, 2.27, -0.75, 0.006)
/// <summary>The last known
size of the main window.</summary>mutable _lastWindowSize = Size.Empty
/// <summary>The last known
position of the mouse.</summary>mutable _lastMousePosition = Point(0,0)
/// <summary>The most recent
cancellation source to cancel the last task.</summary>mutable
_lastCancellation = new CancellationTokenSource()
/// <summary>The last time the
image was updated.</summary>mutable _lastUpdateTime = DateTime.MinValue
/// <summary>Whether the left
mouse button is currently pressed on the picture box.</summary>mutable
_leftMouseDown = false
/// <summary>
/// The format string to use for the
main form's title; {0} should be set to the number of
/// pixels per second rendered.
/// </summary>_formTitle =
"Interactive Fractal F# ({0}x) - PPMS: {1} - Time: {2}";
/// <summary>Whether to use
parallel rendering.</summary>mutable _parallelRendering =
false;MandelbrotForm() as this =Form(ClientSize = new System.Drawing.Size(521,
452),= new System.Drawing.SizeF(8.0f, 16.0f),=
System.Windows.Forms.AutoScaleMode.Font,= new System.Windows.Forms.Padding(4,
4, 4, 4),= "MainForm",= "Mandelbrot in F#")pictureBox = new
PictureBox(BackColor = System.Drawing.Color.Black,=
System.Windows.Forms.DockStyle.Fill,= Point(0, 0),= Padding(4, 4, 4, 4),=
"mandelbrotPb",= Size(410, 369),=
System.Windows.Forms.PictureBoxSizeMode.CenterImage,= 0,= false)statusStrip =
new StatusStrip( Location = Point(0, 427),= "statusStrip",=
Padding(1, 0, 19, 0),= Size(521, 25),= 2,=
"statusStrip")toolStripStatusLabel = new ToolStripStatusLabel(Name =
"toolStripStatusLabel1",= Size(386, 20),= "P: parallel mode, S:
sequential mode, Double-click: zoom")countProc flag =flag with
| false -> 1
| true ->
Environment.ProcessorCountUpdateImageAsync () =
// If there's currently an active
task, cancel it! We don't care about it anymore.not
(_lastCancellation.Equals(null))_lastCancellation.Cancel()
// Get the current size of the picture
boxrenderSize = pictureBox.Size
// Keep track of the time this
request was made. If multiple requests are executing,
// we want to only render the most
recent one available rather than overwriting a more
// recent image with an older
one.timeOfRequest = DateTime.UtcNow;
// Start a task to asynchronously
render the fractal, and store the task
// so we can cancel it later as
necessary
_lastCancellation <- new
CancellationTokenSource()token = _lastCancellation.Token
// Start a task to asynchronously
render the fractaltask ={
// For diagnostic reasons, time how
long the rendering takessw = Stopwatch.StartNew()
// Render the fractalbmp = Create
_mandelbrotWindow renderSize.Width renderSize.Height token
_parallelRenderingnot (bmp.Equals(null))sw.Stop()ppms =
(Convert.ToDouble(renderSize.Width * renderSize.Height)) / (double)
sw.ElapsedMilliseconds;
// Update the fractal image
asynchronously on the UI
// If this image is the most recent,
store it into the picture box
// making sure to free the resources
for the one currently in use.
// And update the form's title to
reflect the rendering time.(timeOfRequest >
_lastUpdateTime)//pictureBox.Image.Dispose().Image <- bmp
//_lastUpdateTime <-
timeOfRequest.Text <- String.Format(_formTitle,_parallelRendering,.ToString("F2"),
sw.ElapsedMilliseconds.ToString())file = new
FileStream("D:/Result/F#.txt", FileMode.Append)strw = new
StreamWriter(file).WriteLine(this.Text).Flush().Close()
// If the image isn't the most
recent, just get rid of itbmp.Dispose()
}.StartAsTask(task,cancellationToken
= token) |> ignore
// Add
Handlersthis.SuspendLayout()this.Controls.Add(pictureBox)statusStrip.Items.Add(toolStripStatusLabel)|>ignorethis.Controls.Add(statusStrip)pictureBox.VisibleChanged.AddHandler(new
EventHandler(fun s e -> this.pictureBox_VisibleChanged
(s,e)))pictureBox.MouseDoubleClick.AddHandler(new MouseEventHandler(fun s e
-> this.pictureBox_DoubleClick(s,e)))pictureBox.MouseDown.AddHandler(new
MouseEventHandler(fun s e -> this.pictureBox_MouseDown(s,e)))pictureBox.MouseUp.AddHandler(new
MouseEventHandler(fun s e ->
this.pictureBox_MouseUp(s,e)))pictureBox.MouseMove.AddHandler(new
MouseEventHandler(fun s e ->
this.pictureBox_MouseMove(s,e)))pictureBox.Resize.AddHandler(new EventHandler(fun
s e ->
this.pictureBox_Resize(s,e)))this.ResumeLayout()this.pictureBox_VisibleChanged
(s, e) =(pictureBox.Visible)_lastWindowSize <- this.Size|>
ignorethis.pictureBox_DoubleClick (s, e) =
// Center the image on the selected
location
_mandelbrotWindow.CenterX <-
_mandelbrotWindow.CenterX + (float (e.X - (pictureBox.Width / 2)) / (float
pictureBox.Width)) * _mandelbrotWindow.Width
_mandelbrotWindow.CenterY <-
_mandelbrotWindow.CenterY + (float (e.Y - (pictureBox.Height / 2)) / (float
pictureBox.Height)) * _mandelbrotWindow.Height
// If the left mouse button was
used, zoom in by a factor of 2; if the right mouse button, zoom
// out by a factor of 2factor
=(e.Button = MouseButtons.Left)0.52.0;
_mandelbrotWindow.Width <-
_mandelbrotWindow.Width*factor
_mandelbrotWindow.Height <-
_mandelbrotWindow.Height*factor
// Update the
image()this.pictureBox_MouseDown (s, e) =
// Record that mouse button is being
pressed(e.Button = MouseButtons.Left)_lastMousePosition <- e.Location
_leftMouseDown <-
truethis.pictureBox_MouseUp (s, e) =
// Record that the mouse button is
being released(e.Button = MouseButtons.Left)_lastMousePosition <- e.Location
_leftMouseDown <-
falsethis.pictureBox_MouseMove (s, e) =
// Determine how far the mouse has
moved. If it moved at all...delta = new Point(e.X - _lastMousePosition.X, e.Y -
_lastMousePosition.Y)not (delta = Point.Empty)// And if the left mouse button
is down...(_leftMouseDown)
// Determine how much the mouse
moved in fractal coordinatesfractalMoveX = (float delta.X) * _mandelbrotWindow.Width
/ (float pictureBox.Width)fractalMoveY = (float delta.Y) *
_mandelbrotWindow.Height / (float pictureBox.Height)
// Shift the fractal window
accordingly
_mandelbrotWindow.CenterX <-
_mandelbrotWindow.CenterX - fractalMoveX
_mandelbrotWindow.CenterY <-
_mandelbrotWindow.CenterY - fractalMoveY
// And update the image()
// Record the new mouse position
_lastMousePosition <-
e.Locationthis.pictureBox_Resize (s, e) =
// If the window has been resizednot
(this.Size = _lastWindowSize)
// Scale the mandelbrot image by the
same factor so that its visual size doesn't changenot (_lastWindowSize.Width =
0)xFactor = (float this.Size.Width) / (float _lastWindowSize.Width)
_mandelbrotWindow.Width <-
_mandelbrotWindow.Width * xFactornot (_lastWindowSize.Height = 0)yFactor =
(float this.Size.Height) / (float _lastWindowSize.Height)
_mandelbrotWindow.Height <-
_mandelbrotWindow.Height * yFactor
// Record the new window size
_lastWindowSize <- this.Size
// Update the image()this.OnKeyDown
e =
// Handle the key pressed.OnKeyDown
ee.KeyCode with.R ->
_mandelbrotWindow <- new
MandelbrotPosition( 2.9, 2.27, -0.75, 0.006)tempForm = new
MandelbrotForm()xFactor = (float this.Size.Width) / (float
tempForm.Width)yFactor = (float this.Size.Height) / (float tempForm.Height)
_mandelbrotWindow.Width <-
_mandelbrotWindow.Width * xFactor
_mandelbrotWindow.Height <-
_mandelbrotWindow.Height * yFactor()
|Keys.S ->
_parallelRendering <- false()
|Keys.P ->
_parallelRendering <- true()
|_ -> ().fs -в этом файле производятся
расчеты цвета пикселей для построения множества Мандельброта
module MandelbrotGeneratorModule
#nowarn
"9"SystemSystem.IOSystem.Windows.FormsSystem.DrawingSystem.Drawing.ImagingSystem.DiagnosticsSystem.Runtime.InteropServicesSystem.ThreadingSystem.Threading.TasksSystem.NumericsMicrosoft.FSharp.NativeInteropMicrosoft.FSharp.CollectionsSystem.Collections.Concurrent
/// <summary>Represents the
bounds and location of the mandelbrot fractal to be
rendered.</summary>public MandelbrotPosition =mutable public Width:
floatmutable public Height: floatmutable public CenterX: floatmutable public
CenterY: float(width: float, height: float, centerX: float, centerY: float) =
{ Width = width ; Height = height;
CenterX = centerX; CenterY = centerY }
/// <summary>Create the color
palette to be used for all fractals.</summary>
/// <returns>A 256-color array
that can be stored into an 8bpp Bitmap's
ColorPalette.</returns>CreatePaletteColors : Color[] =paletteColors :
Color[] = Array.init 256 (fun i -> Color.FromArgb(0, i * 5 % 256, i * 5 %
256))
/// <summary>The 256 color
palette to use for all fractals.</summary>_paletteColors =
CreatePaletteColors
/// <summary>Copy our
precreated color palette into the target Bitmap.</summary>
/// <param
name="bmp">The Bitmap to be updated.</param>UpdatePalette
(bmp : Bitmap) =p = bmp.Palette.Array.Copy(_paletteColors, p.Entries,
_paletteColors.Length).Palette <- p// The Bitmap will only update when the
Palette property's setter is used
/// <summary>Renders a
mandelbrot fractal.</summary>
/// <param
name="position">The MandelbrotPosition representing the fractal
boundaries to be rendered.</param>
/// <param
name="imageWidth">The width in pixels of the image to
create.</param>
/// <param name="imageHeight">The
height in pixels of the image to create.</param>
/// <param
name="parallelRendering">Whether to render the image in
parallel.</param>
/// <returns>The rendered
Bitmap.</returns>Create (position : MandelbrotPosition ) imageWidth
(imageHeight : int) (cancellationToken: CancellationToken) parallelRendering =
// The maximum number of iterations
to perform for each pixel. Higher number means better
// quality but also
slower.maxIterations = 256
// In order to use the Bitmap ctor
that accepts a stride, the stride must be divisible by four.
// We're using imageWidth as the
stride, so shift it to be divisible by 4 as necessary.newImageWidth =imageWidth
% 4 = 0imageWidth(imageWidth / 4) * 4
// Based on the fractal bounds,
determine its upper left coordinateleft = position.CenterX - (position.Width /
2.0)top = position.CenterY - (position.Height / 2.0)
// Get the factors that can be
multiplied by row and col to arrive at specific x and y valuescolToXTranslation
= position.Width / (float newImageWidth)rowToYTranslation = position.Height /
(float imageHeight)
// Get Pixel Color for each complex
numberrec drawBit (z : Complex) c curIter =curIter withwhen x = maxIterations
->byte 0
|_ ->z withwhen x.Magnitude >
4.0 -> byte curIter
|_ -> drawBit (z*z+c) c (curIter+1)getbyte
initialY j =.ThrowIfCancellationRequested()c = new Complex((float j) *
colToXTranslation + left, initialY)c c 0
// Fill dataArray with pixel
colorsdata =parallelRendering then.Parallel.init imageHeight (fun i ->
Array.init newImageWidth (fun j -> getbyte ((float i) * rowToYTranslation +
top) j)).init imageHeight (fun i -> Array.init newImageWidth (fun j ->
getbyte ((float i) * rowToYTranslation + top) j))
// Create the bitmapbitMap = new
Bitmap(newImageWidth,imageHeight,PixelFormat.Format8bppIndexed)
// Get the bitmap data for bitmap
with a Read Write lockbitData =
bitMap.LockBits(Rectangle(0,0,bitMap.Width,bitMap.Height),ImageLockMode.ReadWrite,PixelFormat.Format8bppIndexed)
// Setup the pointermutable
(p:nativeptr<byte>) = NativePtr.ofNativeInt (bitData.Scan0)i in
0..bitMap.Height-1 doj in 0..bitMap.Width-1 do.set p 0 (data.[i].[j])<-
NativePtr.add p 1tempBitmap = new
Bitmap(newImageWidth,imageHeight,newImageWidth,PixelFormat.Format8bppIndexed,bitData.Scan0)
// Needed to avoid memory errorsnewBitMap
= tempBitmap.Clone(new Rectangle(0, 0, tempBitmap.Width, tempBitmap.Height),
PixelFormat.Format8bppIndexed).UnlockBits(bitData)
// Change colorsnewBitMap
newBitMap