Теория языков программирования и методы трансляции
Введение
программа анализатор автоматный
Для интерпретации языков программирования
необходимы компиляторы, в основе которых лежат синтаксические и семантические
анализаторы. Для построения простейшего компилятора целесообразно использовать
современные утилиты для лексического разбора такие как flex и bison,
позволяющие на основе набора лексем, описании грамматики языка, сгенерировать
программный код, выполняющий разбор введенного текста.
Лисп - семейство языков программирования,
основанных на представлении программы системой линейных списков символов,
которые притом являются основной структурой данных языка. Лисп считается вторым
после Fortran старейшим высокоуровневым языком программирования.
Большим достоинством Лиспа является его
функциональная направленность, т. е. программирование ведется с помощью
функций. Причем функция понимается как правило, сопоставляющее элементам
некоторого класса соответствующие элементы другого класса. Сам процесс
сопоставления не оказывает никакого влияния на работу программы, важен только
его результат - значение функции. Это позволяет относительно легко писать и
отлаживать большие программные комплексы. Ясность программ, четкое
разграничение их функций, отсутствие каверзных побочных эффектов при их
выполнении является обязательными требованиями к программированию таких
логически сложных задач, каковыми являются задачи искусственного интеллекта.
Дисциплина в программировании становится особенно важной, когда над программой
работает не один человек, а целая группа программистов.
Сферы применения языка Лисп многообразны:
наука и промышленность, образование и медицина, от декодирования генома
человека до системы проектирования авиалайнеров. [2]
1. Постановка задачи
Разработать программу синтаксического и
семантического анализа для подмножества Lisp. Синтаксический разбор реализовать
с использованием детерминированного автомата с магазинной памятью.
Семантические аспекты описать грамматикой свойств.
Выбранное мной подмножество языка
извлекает голову от головы исходного списка: (car
(car '((12 12) (7 8) 3)))
2. Описание исходного языка
Описание регулярной грамматики,
описывающей лексемы языка:
"setq"
{return stq;}
"list"
{return lst;}
"cons"
{return cns;}
[0-9]+
{return Number;}
[A-Za-z][A-Za-z0-9]*
{return id;}
\' {return
APOST;}
\ {return
SPACE;}
\( {return
LSC;}
\) {return
RSC;}
Описание КС-грамматики, описывающей
синтаксис языка:
Если (V,T,P,S) - КС- грамматика (V - множество
нетерминальных символов, T - множество терминальных символов, P - множество порождающих
правил, Form - аксиома), то
V::={<stq, lst,cns
>};::={ LSC RSC id Number SPACE APOST};
Form::= program|program SPACE form
;:
stroka1
;: LSC
fun SPACE id SPACE arg RSC
;: LSC
fun SPACE arg SPACE arg RSC
;:
cns|stq|lst|
;:
Number|id|fun1
;:
cns1|stq1|lst1|
;: LSC
cns SPACE arg SPACE arg RSC
;: LSC
stq SPACE arg SPACE Number RSC
;: LSC
lst SPACE arg SPACE arg RSC
;
3. Детерминированная автоматная модель синтаксического
анализатора
В ходе работы над курсовым проектом была
использованная модель детерминированного автомата с магазинной памятью
Детерминированный автомат с магазинной
памятью может использоваться в качестве распознавателя некоторых частных видов
КС-языков. (КС-язык это язык, который может быть описан КС-грамматикой, а
КС-грамматика, по классификации Хомского, - это грамматика, правила которой в
левой части содержат по одному нетерминалу, а в правой - произвольные строки
терминалов, нетерминалов или пустые строки).
Управляющая таблица содержит в своих
клетках команды, которые должен выполнить автомат. Координаты клетки, из
которой следует выбрать очередную команду, определяются содержанием вершины
стека (координата строки) и обозреваемым на входной ленте символом
анализируемой строки (координата столбца). Управляющая таблица автомата,
реализующего алгоритм типа «сдвиг-приведение», естественно, содержит команды
типа «сдвиг» и типа «приведение», а также две команды завершения работы
алгоритма: успешное завершение синтаксического разбора входной строки и
обнаружение синтаксической ошибки во входной строке. LR(1)-грамматика и
грамматика предшествования являются частными видами КС-грамматик, для которых
может быть построен детерминированный автомат, реализующий алгоритм типа
«сдвиг-приведение».
В ходе работы над курсовым проектом была
использована LR(1)-реализация алгоритма «сдвиг-приведение»
В заголовки строк управляющей таблицы LR(1)-автомата
выносятся индексы его внутренних состояний, а в заголовки строк - все
терминальные и нетерминальные символы грамматики, а также маркер конца входной
строки. Записи стека содержат два поля: поле символа и поле внутреннего
состояния. Содержание поля состояния верхней записи стека определяет текущее
внутреннее состояние автомата и, следовательно, координату строки управляющей
таблицы, из которой должна быть выбрана очередная команда. Перед началом работы
распознавателя в стек следует поместить запись, содержащую индекс начального
состояния в поле состояния. Команда типа «сдвиг» должна указывать, в какое
внутреннее состояние переходит автомат одновременно с чтением символа из входной
ленты. В результате выполнения этой команды курсор входной ленты перемещается
на один символ влево, а стек пополняется записью с прочитанным из ленты
символом в поле символа и индексом внутреннего состояния, указанного в команде,
в поле состояния. Команда типа «приведение» должна указывать правило
грамматики, например, в виде его номера, по которому следует выполнить
приведение. В результате выполнения этой команды из стека удаляются записи,
соответствующие правой части правила, по которому делается приведение, и
подготавливается имитация установки курсора входной ленты на нетерминальный
символ левой части этого правила. По команде «допуск» разбор считается успешно
завершенным. По команде «ошибка» разбор также прекращается, но входная строка
объявляется синтаксически неверной.
Для вышеприведенного фрагмента грамматики
с правилами i) - iii) управляющая таблица LR(1)-автомата может
быть такой.
|
<описания>
|
<список имен>
|
вещественное
|
,
|
идентификатор
|
маркер конца
|
|
1
|
допуск
|
|
сдвиг2
|
|
|
|
|
2
|
|
сдвиг3
|
|
|
сдвиг6
|
|
|
3
|
|
|
|
сдвиг4
|
|
приведение i
|
|
4
|
|
|
|
|
сдвиг5
|
|
|
5
|
|
|
|
приведение ii
|
|
приведение ii
|
|
6
|
|
|
|
приведение iii
|
|
приведение iii
|
Таблица построена в предположении, что
нетерминал <описания> является начальным символом фрагмента грамматики
(его аксиомой). Числами 1 - 6 в таблице обозначены внутренние состояния
автомата, при этом состояние 1 является начальным. Соответственно, в командах
типа «сдвиг» этими числами указываются внутренние состояния, в которые должен
переходить автомат, выполняя такие команды. Команды типа «приведение» снабжены
номерами правил, по которым следует выполнять приведение. Пустые клетки таблицы
считаются содержащими команду «ошибка».
Содержание полей символа и внутреннего состояния указаны через
запятую. Символом  обозначена пустая строка. Так запись ,1 означает, что поле символа пусто, а в
поле внутреннего состояния находится индекс 1.
обозначена пустая строка. Так запись ,1 означает, что поле символа пусто, а в
поле внутреннего состояния находится индекс 1.
Для того, чтобы построить управляющую таблицу для LR(1)-автомата, нужно определить множество
его внутренних состояний. Внутренние состояния автомата ставятся в соответствие
позициям правых частей правил LR(1)-грамматики
в результате так называемой разметки этих правил.
В простейшем случае разметка выполняется следующим образом.
. Индексы внутренних состояний следует поместить между соседними
символами, перед первым символом (в начальную позицию) и после последнего
символа (в конечную позицию) правой части каждого правила.
. В начальные позиции всех правых частей правил для аксиомы
следует поместить индекс начального состояния автомата.
. Если в процессе разметки индекс какого-либо состояния оказался
перед нетерминальным символом, его следует распространить на начальные позиции
всех правых частей правил для этого нетерминального символа.
. Если в процессе разметки в двух или более правилах слева от
одного и того же символа оказался один и тот же индекс внутреннего состояния,
то в этих правилах и справа от этого символа следует поместить одинаковые
индексы.
Рассмотренная в этом разделе LR(1)-таблица была построена на основе такой разметки правил
грамматики:
i) <описания>::= 1
вещественное 2 <список имен> 3
iii) <список имен>::= 2 идентификатор
6
Для разметки понадобилось шесть различных
индексов. Следовательно, у автомата должно быть шесть внутренних состояний.
Заполнение таблицы с использованием
разметки выполняется по следующим правилам.
1. Команда «сдвиг k» помещается в клетку
таблицы с координатами (j,символ), если позиция слева от символа отмечена индексом k, а позиция справа от
символа - индексом j.
2. Команда «приведение m» помещается в клетку
таблицы с координатами (n,символ), если конечная позиция правой части m-го правила грамматики
отмечена индексом n, а символ является символом-следователем для нетерминала левой
части m-го
правила грамматики, т.е. может следовать за этим нетерминалом в какой-либо
сентенциальной форме. (Сентенциальной формой называются аксиома и все строки
нетерминальных и терминальных символов, которые из нее выводятся).
. Команда «допуск» помещается в
клетку таблицы с координатами (l,аксиома), где l - индекс начального внутреннего состояния автомата.
. После заполнения таблицы по
правилам 1 - 3 в клетки, оставшиеся пустыми, помещается команда «ошибка».
В результате применения этих правил к
размеченному фрагменту грамматики и получается вышеприведенная управляющая
таблица LR(1)-автомата.[1]
4. Структура разработанной программы
Программа состоит из:
· Сгенерированного файла
утилитой FLEX(flex.cpp);
· Файлов, сгенерированных
утилитой BISON (bisonout.cpp, bisonout.hpp);
· Файла исходного текста
(parcerin.txt).
5. Результаты тестирования
В качестве входных данных программе были
предложены данные:
(car '((1 2) 3)) и (car ((1 2) 3)).
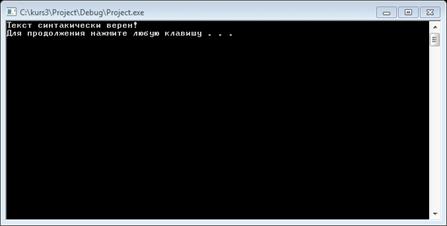
Ответная реакция программы на строку (car '((1 2) 3))

Ответная реакция программы на строку (car ((1 2) 3))
6. Руководство пользователя
Написанная мною программа распознаёт
команды car и cdr (возможны вариации Car, CAR, Cdr, CDR) и список их аргументов (цифры, числа, буквы
латинского алфавита). Список может содержать также вложенные списки и функции
(только указанные выше).
Запуск программы осуществляется через
проект(Project.sln) с несением входных данных в файл parserin.txt (включён в
проект).
Реакция программы на входные данные:
· сообщение «Синтаксическая
ошибка!», означает наличие синтаксических ошибок в исходном тексте;
· сообщение «Текст
синтаксически верен!», означает отсутствие синтаксических ошибок в исходном
тексте.
Заключение
В ходе работы над курсовым проектом была
разработана программа, позволяющая анализировать синтаксис и лексику исходного
кода на языке Lisp.
Достоинствами такой программы является
анализ текста с вложенными функциями и списками различной глубины, а также
простой интерфейс. В качестве недостатков стоит указать наличие только
синтаксического и лексического анализа, небольшой набор определяемых функций, а
также отсутствие возможности указывать в качестве аргументов функций
переменные.
Библиографический список
1. Т.М. Максимова. Теория языков программирования и методы
трансляции. Методические указания к выполнению курсовых работ. - СПб.: СПбГУАП,
2011.
2. http://progopedia.ru
. http://ru.wikipedia.org
Приложение
Содержание файла описания для flex:
%option noyywrap
%option yylineno
%option never-interactive
%{
#include <string>
#include <iostream>
#include
"bisonout.hpp"namespace std;FILE *yyin, *yyout; // referenced from
flex-generated scannerint yylineno;yylex();yyval;tmpstr = "";
%}[0-9] [1-9]({DIGIT})*[a-zA-Z]
%%
{DIGIT} {return
DIGIT;}
{NAME} {return
NAME;}
{NUMBER} {return
NUMBER;}
"car" {return
CAR;}
"Car" {return
CAR;}
"CAR" {return
CAR;}
"cdr" {return
CDR;}
"Cdr" {return
CDR;}
"CDR" {return
CDR;}
\' {return
APOST;}
\ {return
SPACE;}
\( {return
LSC;}
\) {return
RSC;}
Содержание файла описания для bison:
%{
#include <iostream>
#include <stdio.h>
#include <string>
#include <stdlib.h>
#include
<Windows.h>
namespace std;yyerror(char
const* msg);yylex();lineno();yyparse();
%}
%token DIGIT NAME NUMBER
CAR CDR APOST SPACE LSC RSC
%%: LSC func RSC;: CAR
SPACE prog | CDR SPACE prog | CAR SPACE arg | CDR SPACE arg;: APOST val;: LSC
lists RSC;: atomes | LSC lists RSC | lists SPACE atomes | lists SPACE LSC lists
RSC;: atom | atomes SPACE atom;: NUMBER | DIGIT | NAME;
%%
FILE *yyin;yyerror(char
const* msg)
{0;
}main()
{(LC_ALL,"RUS");=fopen("c:\\kurs3\\parserin.txt","r");
(yyparse()!=0)
printf("Синтаксическая ошибка!\n");
else printf("Текст синтакcически
верен!\n");
("pause");0;