Сумісність материнської плати і відеокарти. Технологія підвищення продуктивності SLI і CrossFire
ВСТУП
Теоретична продуктивність сучасних
відеокарт досягає одного трильйона операцій з плаваючою комою в секунду. Це в
десятки разів більше, ніж у найшвидших процесорів. Оскільки потужності сучасних
відеокарт недостатньо для високоякісної динамічної графіки, то часто
використовують технології Scan Line Interleaving (SLI) і CrossFire, що
дозволяють застосовувати відразу дві і більше відеокарт в одній системі для
спільної роботи над одним зображенням.
1.
ПОСТАНОВКА ЗАДАЧІ
Тема курсової роботи: «Сумісність материнської
плати і відеокарти (Технологія збільшення продуктивності SLI
та AMD Crossfire)».
Мета курсової роботи: Дослідження
сумісності материнської плати і відеокарти при використання технологій
збільшення продуктивності SLI
NVIDIA
та AMD Crossfire.
Порівняльний аналіз технологій SLI
та AMD Crossfire.
Згідно з метою курсової роботи
необхідно розглянути такі питання:
- Інтерфейс взаємодії
материнської плати та відеокарти
- Технологія AMD(ATI)
Crossfire;
- Дослідження
побудови і організації CrossFire
системи;
- Технологія NVIDIA
SLI;
- Побудова і
організація SLI
системи;
- Дослідження
технічних характеристик спеціалізованих відеокарт;
На технічному аналізі обох
технологій збільшення продуктивності отримаємо результат сумісності
материнської плати і відео карт, за даними якого ми зможемо надати рекомендації
по використанню оптимальних відео карт та технологій.
1.1 Ідея створення одночасного
режиму роботи декількох відеокарт
В процесі створення комп’ютерної
техніки перед дослідниками-розробниками поставали питання взаємодії людини та
персональної електронної обчислювальної машини (ПЕОМ). Загалом вони ділилися на
два напрямки: введення інформації в ПЕОМ та виведення інформації.
Людиною,
близько 90% інформації сприймається очима. Тому постало питання представлення
інформації у вигляді зображення.
Одним з перших графічних адаптерів
для ПЕОМ IBM
PC став MDA
(Monochrome
Display Adapter)
e 1981 році. Він
працював тільки в текстовому режимі з роздільною здатністю 80 ×
25 символів (фізично 720 ×
350 точок) і підтримував п`ять атрибутів тексту:
звичайний, яскравий, інверсний, підкреслений і миготливий. Ніякої колірної або
графічної інформації він передавати не міг, і те, якого кольору будуть літери,
визначалося моделлю використовувався монітора. Зазвичай вони були білими,
бурштиновими або смарагдовими на чорному тлі. Фірма Hercules в 1982 році
випустила подальший розвиток адаптера MDA, відеоадаптер HGC (Hercules Graphics
Controller - графічний адаптер Геркулес), який мав графічне дозвіл 720 ×
348 точок і підтримує дві графічні сторінки. Але він
все ще не дозволяв працювати з кольором.[1,2]
Першою кольоровий відкритий стала
CGA (Color Graphics Adapter), випущена IBM і яка стала основою для подальших
стандартів відеокарт. Вона могла працювати або в текстовому режимі з дозволами
40 × 25 знакомест і
80 × 25 знакомест
(матриця символу - 8 × 8), або
в графічному з дозволами 320 × 200 точок
або 640 × 200 точок.
У текстових режимах доступно 256 атрибутів символу - 16 кольорів символу і 16
кольорів фону (або 8 кольорів фону і атрибут миготіння), в графічному режимі
320 × 200 було
доступно чотири палітри по чотири кольори кожна, режим високого дозволу 640 ×
200 був монохромним. У розвиток цієї карти з'явився
EGA (Enhanced Graphics Adapter) - поліпшений графічний адаптер, з розширеною до
64 кольорів палітрою, і проміжним буфером. Було покращено здатність до 640 ×
350, в результаті додався текстовий режим 80 ×
43 при матриці символу 8 ×
8. Для режиму 80 ×
25 використовувалася велика матриця - 8 ×
14, одночасно можна було використовувати 16
кольорів, кольорова палітра була розширена до 64 кольорів. Графічний режим
також дозволяв використовувати при дозволі 640 ×
350 16 кольорів з палітри в 64 кольори. Був
сумісний з CGA і MDA. [1]
Далі відеокарти почали стрімко
розвиватися, напрямки розвитку: збільшення роздільної здатності, кількості
кольорів, швидкість оброблення інформації, кількість інформаціє, яка
зберігається в пам’яті відеокарт, кількість технологій які оброблюються відео
процесором автоматично і інш.
Для приклада, сучасна офісна відеокарта
(Intel HD Graphics 5000), яка вбудована в центральний процесор, маєть
можливість працювати з трьома моніторами з роздільною здатністю до 3840x2160
крапок та глибиною кольору Truecolor (24-бітний Truecolor-колір використовує по
8 біт для представлення червоною, синьою і зеленою складових) який надає
16700000 різних кольорів. [1]
Повертаючись до теми дослідження,
відмітимо, що основною силою, яка штовхає виробників на збільшення
продуктивності роботи відеокарт це програмне забезпечення. Постійний розвиток
програмного забезпечення, завдяки якому наприклад з’являються нові методи
обробки відеоданих, створення все більш реалістичних відео ефектів для
кінематографа, розробка технологічних об’єктів та об’єктів будівництва у
віртуальному просторі, відображення фільмів з високою роздільною здатністю,
відтворення сучасних відеоігор і інш.. Виходячи з цього, при визначенні
продуктивності відеокарт в більшості випадків використовують цифрове значення
кількості кадрів при фіксованій роздільній здатності, та однакових параметрах
згладжування.
Підвищення продуктивності роботи
відеокарт можливо за допомогою багатьох елементів. Виділимо основні напрямки:
збільшення тактової частоти
роботи відео процесора (англ. Graphics Proccesing Unit, GPU);
зміна архітектури графічного
процесора (додавання графічних блоків, розробка нових інтелектуальних блоків,
виборок паралельних розрахунків і інш.);
збільшення пропускної
здатності шини «пам’ять-графічний» процесор;
збільшення кількості та
тактової частоти роботи графічної пам’яті;
використання технології
NVIDIA SLI, AMD CrossFireX (декілька відеокарт об’єднані спеціальним кабелем
оброблюють дані паралельно);
використання спеціальних
відео процесорів для оптимізованого програмного забезпечення (графічні
процесори PNY Quadro).
Термін SLI почала використовувати
компанія 3DFX, яка вивела на ринок технологію SLI (тоді розшифровувалося як
Scan-Line Interleave - англ. чергування рядків). У режимі SLI дві плати Voodoo2
з'єднувалися спеціальним кабелем, при цьому кожна з них обробляла половину
рядків на екрані. За вартість другої плати Voodoo2 користувачі отримували
істотне поліпшення продуктивності. Також при використанні SLI збільшувалося
максимальний робочий дозвіл до 1024 × 768. Однак
через високу вартість і громіздкість конструкції з трьох плат (дві відеокарти
Voodoo2 і звичайна двомірна відеокарта) технологія SLI, революційна в той час,
надала мінімальний ефект на ринкове становище 3dfx і, на відміну від власне
Voodoo2, чи не була визнала комерційно успішною.
«Пляшковим горлом», що обмежив
потенційні можливості Voodoo2 SLI стала недостатня потужність ЦП комп'ютерів
того часу. Стійкі в часі переваги цієї технології стають очевидними завдяки
успішному застосуванню Voodoo2 SLI в комп'ютерних іграх аж до кінця 2004 року,
через 6 років після виходу на ринок.
Однак, технологія SLI була
недоступною в конфігурації деяких плат сторонніх виробників, заснованих на
чіпсетах 3dfx. Також SLI використовувалася для з'єднання мікросхем VSA-100 у
відеокарті Voodoo5.
Після покупки більшості активів 3dfx,
в 2004 році Nvidia здійснила перезапуск бренду SLI (тепер: Scalable Link
Interface - англ. Масштабований інтерфейс) при виведенні на ринок відеокарт
серії GeForce 6. Своє бачення технології з'єднання декількох відеокарт під
назвою Crossfire вивели на ринок і ATI Technologies. Хоча Nvidia SLI і ATI
Crossfire засновані на одній ідеї спільної обробки зображення декількома
відеокартами, реалізація на практиці проведена по-різному. [3]

Рисунок 1 - Відеокарта Voodoo 1 SLi (дата
виходу 1 жовтня 1996 року) [3]

Рисунок 2
- Відеокарта Voodoo 2
SLi (дата виходу 1 березня 1998 року) [3]

Рисунок 3 - Дві відеокарти Voodoo 2
об’єднані спеціальним кабелем для роботи в режимі SLi [4]
Відеокарти використовували
надсучасну на той час шину - PCI.
1.2 Історія розвитку інтерфейсу
взаємодії відеокарти та материнської плати
Розгляд інтерфейсу почнемо з моделі
VESA.
VESA local
bus
- VL-Bus
або VLB
- тип локальної шини, розроблений асоціацією VESA для ПК. Шина VLB, по суті, є
розширенням внутрішньої шини процесора Intel 80486. Вона зазвичай об'єднує
процесор, пам'ять, схеми буферизації для системної шини та її контролер, а
також деякі інші допоміжні схеми. Перша специфікація на стандарт локальної шини
з'явилася в 1992 році.
Головною метою її розробки була
дешева альтернатива шинам MicroChannel і EISA, придатна для впровадження в
масові настільні комп'ютери. З цією роллю шина VLB успішно впоралася. Було
випущено велику кількість плат контролерів, які використовували цю шину, на
основі випущених раніше мікросхем, які працювали до цього з шиною ISA. Навіть
за 16-бітної архітектури міг бути отриманий виграш по тактовій частоті від 4
раз і більше.не розрахована на використання з процесорами, що прийшли на заміну
486-у або з тими, що існували паралельно з ними: Alpha, PowerPC тощо. Тому в
середині 1993 року з асоціації VESA вийшли ряд виробників на чолі з Intel. Ці
фірми створили спеціальну групу для розробки нового альтернативного стандарту,
названого Peripheral Component Interconnect (PCI). [5]

Рисунок 4 - З'єднувачі шин VLB
(ліворуч) та ISA (праворуч) [5]
Навесні 1991 р. компанія Intel
завершує розробку першої макетної версії шини PCI. Перед інженерами було
поставлене завдання розробити недороге й продуктивне рішення, що дозволило б
реалізувати можливості процесорів 486, Pentium і Pentium Pro. Окрім того, треба
було врахувати помилки допущені VESA при проектуванні шини VLB (електричне
навантаження не дозволяло підключати більше 3 плат розширення), а також
реалізувати автоконфігурування пристроїв за прикладом протоколу Autoconfig для комп'ютерів
Amiga.
року з'являється перша версія шини
PCI, Intel повідомляє, що стандарт шини буде відкритим і створює PCI Special
Interest Group. Завдяки цьому, будь-який зацікавлений розробник отримує
можливість створювати пристрої для шини PCI без необхідності придбання
ліцензії. Перша версія шини мала тактову частоту 33 МГц, могла бути 32 або 64
бітною, а пристрої могли працювати з сигналами в 5 V або 3,3 V. Теоретично,
пропускна здатність шини 133 Мбайт/сек, однак у реальності пропускна здатність
становила біля 80 Мбайт/сек.
В середині 1993 року, компанія Intel
виходить із асоціації VESA і починає вживати активних заходів по просуванню
шини PCI на ринку. Відповіддю на критику з боку фахівців з конференцій Usenet і
компаній конкурентів стала PCI 2.0.
В 1995 р., з'являється версія PCI
2.1 («паралельна шина PCI»), яка забезпечила передачу даних по шині з частотою
66 МГЦ і максимальну швидкість передачі в 533 МБ/сек (для 64 бітного варіанта з
частотою 66 МГц). Крім того, ця шина вже була підтримана на рівні ОС Windows 95
(технологія Plug and Play). Згодом завдяки популярності, версія шини PCI 2.1
була перенесена на платформи з процесорами Alpha, MIPS, PowerPC, SPARC та ін.
В 1997 р., у зв'язку з розвитком
комп'ютерної графіки й розробкою шини AGP, шина PCI перестала задовольняти
підвищені вимоги до відеокарт і стала витіснятися продуктивнішою AGP. [6](від
англ. Accelerated Graphics Port, прискорений графічний роз'єм) - розроблена в
1997 році компанією Intel, спеціалізована 32-бітова системна шина для відеокарти.
З'явилася одночасно з чипсетами для процесора Intel Pentium MMX чипсет MVP3,
MVP5 з Super Socket 7. Основним завданням розробників було збільшення
продуктивності та зменшення вартості відеокарти, за рахунок зменшення кількості
вбудованої відеопам'яті. За задумом «Intel», великі обсяги відео пам'яті для
AGP-карт були б не потрібні, оскільки технологія передбачала високошвидкісний
доступ до загальної пам'яті.
Її відмінності від попередниці, шини
PCI:
робота на тактовій частоті
66 МГц;
збільшена пропускна
здатність;
режим роботи з пам'яттю DMA
і DME;
поділ запитів на операцію і
передачу даних;
можливість використання
відеокарт з енергоспоживанням більшим, ніж PCI.
У наш час материнські плати із
слотами AGP практично не випускаються, стандарт AGP був повсюдно витіснено на
ринку більш швидким і універсальним PCI Express.
Розвитком стандарту PCI Express
займається організація PCI Special Interest Group (PCI-SIG).
На відміну від шини PCI, що
використала для передачі даних загальну шину, PCI Express, в загальному
випадку, є пакетною мережею з топологією типу зірка, пристрої PCI Express
взаємодіють між собою через середовище, утворене комутаторами, при цьому кожен
пристрій безпосередньо зв'язаний з'єднанням типу точка-точка з комутатором.
Крім того, шиною PCI Express
підтримується:
гаряча заміна карт;
гарантована смуга пропускання (QoS);
управління енергоспоживанням;
контроль цілісності даних, які
передаються.
Розробка стандарту PCI Express була
почата фірмою Intel після відмови від шини InfiniBand. Офіційно перша базова
специфікація PCI Express з'явилася в липні 2002 року.
Шина PCI Express націлена на
використання тільки як локальна шина. Оскільки програмна модель PCI Express
багато в чому успадкована від PCI, то існуючі системи і контролери можуть бути
допрацьовані для використання шини PCI Express заміною тільки фізичного рівня,
без доопрацювання програмного забезпечення. Висока пікова продуктивність шини
PCI Express дозволяє використовувати її замість шин AGP і тим більше PCI і
PCI-X, очікується, що PCI Express замінить ці шини в персональних комп'ютерах.
[7]

Рисунок 5 - Зовнішній вигляд
комп’ютерних шин. [8]
На сучасному етапі використовуються
шини PCI-Express x 16, PCI Express x4 та PCI-Express x 1. [9]
1.3 Технологія збільшення
продуктивності відео AMD CrossFireX
CrossFireX (рос. Перехресний вогонь)
- технологія, що дозволяє одночасно використовувати потужності двох і більше
(до чотирьох графічних процесорів одночасно) відеокарт Radeon для побудови
тривимірного зображення.
Рисунок 6 - Зовнішній вигляд трьох
відеокарт об’єднаних за технологією CrossFireX. [10]

Рисунок 7
- Зовнішній вигляд конектора для об’єднання
відеокарт за технологією CrossFireX. [11]
Для побудови на комп'ютері
CrossFireX-системи необхідно мати:
материнську плату з двома або більше
роз'ємами PCI Express x16 (до версій R9-285, R9-290 або R9-290X ще й з чіпсетом
AMD або Intel певної моделі, що підтримує CrossFireX);
потужний блок живлення, як правило,
потужністю від 700Вт;
відеокарти з підтримкою CrossFireX;
Спеціальний гнучкий місток
CrossFireX для з'єднання відеокарт.
Відкрите повинні бути однієї серії
(за деякими винятками), але не обов'язково однієї моделі. При цьому швидкодію і
частота CrossFire-системи визначаються характеристиками чіпа найменш
продуктивної відеокарти.систему 2015 року можна організувати наступними
способами:
відеокарти AMD Radeon R9 380 2 ГБ,
з'єднані за технологією AMD CrossFireX. Внутрішнє з'єднання - відеокарти
об'єднуються за допомогою спеціального гнучкого містка CrossFireX, при цьому
для з'єднання більш, ніж двох відеокарт не потрібно використовувати
спеціалізовані багаторознімних містки (типу NVIDIA 3-way SLI або 4-way SLI),
відеокарти з'єднуються послідовно простими CrossFireX містками. З'єднання
ведеться приблизно так: від першої до другої - від другої до третьої - від
третього до четвертої (для з'єднання 4 відеокарт); від першої до другої - від
другої до третьої (для 3 карт); від першої до другої (для 2 карт). Слід
зауважити, що на однопроцесорних відкритих по 2 роз'єми CrossFireX, тому у
випадку з системою з двох відеокарт об'єднувати їх можна як одним, так і двома
містками (від першої до другої - від першої до другої), різниці в
продуктивності не буде.
Програмний метод - відеокарти не
з'єднуються, обмін даними йде по шині PCI Express x16, при цьому їх взаємодія
реалізується за допомогою драйверів. Недоліком даного способу є втрати в
продуктивності на 10-15% в порівнянні з вищеназваним способом. На даний момент
практично повністю загубив актуальність, залишившись способом з'єднання
нізкопроїзводітельних відеокарт, для яких відсутність сполучного містка не є
значущою втратою. Високопродуктивні відеокарти можна об'єднати, тільки
використовуючи містки, так як без них драйвер не зрозуміє, що таке об'єднання
можливе.- обмін між відеокартами виробляється, як і в попередньому випадку, по шині
PCI Express, але за допомогою спеціалізованого апаратного блоку XDMA, наявного
в GPU починаючи з R9-285, R9-290 або R9-290X.
Завдяки апаратно-керованого обміну
даними досягається скорочення втрат продуктивності в порівнянні з
програмно-керованим обміном. Тим не менш, втрати продуктивності можуть виникати
через особливості побудови системи PCI Express, наприклад, за наявності між
відеокартамі декількох мостів [12].
Алгоритми побудови зображень:
Картинка розбивається на квадрати
32x32 пікселя і приймає вид шахової дошки. Кожен квадрат обробляється однією
відеокартою.

Рисунок 7 - Схема алгоритму
SuperTiling
Схема алгоритму Scissor
Зображення розбивається на кілька
частин, кількість яких відповідає кількості відеокарт у зв'язці. Кожна частина
зображення обробляється однією відеокартою повністю, включаючи геометричну і
піксельну складові.
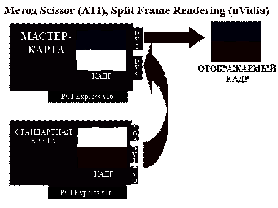
Рисунок 8 - Схема алгоритму Scissor
Аналог в nVidia SLI - алгоритм Split
Frame RenderingFrame Rendering
Обробка кадрів відбувається по
черзі: одна відеокарта обробляє тільки парні кадри, а друга - тільки непарні.
Однак, у цього алгоритму є недолік. Справа в тому, що один кадр може бути
простим, а інший складним для обробки.
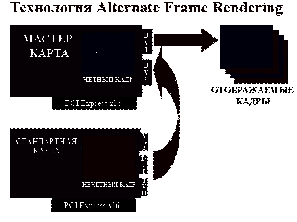
Рисунок 9 - Схема алгоритму
Alternate Frame Rendering
Цей алгоритм, запатентований ATI ще
під час випуску двочіпової відеокарти, використовується також в nVidia SLI.
Даний алгоритм націлений на
підвищення якості зображення. Одна і та ж картинка генерується на всіх
відеокартах з різними шаблонами згладжування. Відеокарта робить згладжування
кадру з деяким кроком щодо зображення іншої відеокарти. Потім отримані
зображення змішуються і виводяться. Таким чином досягається максимальна
чіткість і деталізованість зображення. Доступні наступні режими згладжування:
8x, 10x, 12x и 14x.
Аналог в nVidia SLI - SLI
AA.GraphicsGraphics (раніше Hybrid CrossFireX) - унікальна здатність APU
лінійки Fusion A-серії Llano значно (принаймні в теорії) збільшувати загальну
продуктивність відеопідсистеми, коли інтегрований GPU працює спільно з
підключеною дискретною відеоплатой, доповнюючи її. Ще більш дивною є здатність
Llano працювати з GPU, які швидше або повільніше ніж його власне інтегроване
відеоядро - для коректної роботи Dual Graphics не вимагає ідентичного GPU і при
цьому він не шкодить швидшому GPU, якщо його продуктивність нижче, як
відбувається в CrossFire. Фактично, він приводить в рівновагу доступне апаратне
забезпечення для більшої продуктивності (наприклад, якщо дискретний GPU вдвічі
швидше вбудованого, драйвер бере один кадр від APU на кожні два кадри від
дискретної карти).
При всій спокусливості подібної
асиметричної реалізації CrossFire, є серйозні недоліки:
По-перше, це працює тільки в
додатках, що використовують DirectX 10 або 11. І якщо використовується DirectX
9 або більш ранній ігровий рушій, то продуктивність погіршується до самої
повільної з двох встановлених графічних карт (проте, згідно з останніми заявами
AMD, при використанні DirectX нижче 10 версії програми повинні звертатися до
більш швидкої з двох встановлених графічних карт).
По-друге, щоб Dual Graphics
працювала, коефіцієнт графічної продуктивності повинен бути принаймні «два до
одного», якщо відеокарта в три рази швидше GPU Llano, то Dual Graphics
працювати не буде.
В OpenGL Dual Graphics не
підтримується, і він завжди працює на GPU, керуючому основним виходом дисплея.
І хоча ця функція дійсно працює і
результати тесту показують вищу частоту кадрів в чистому вигляді.
Приклад: ПЄОМ з відеокартою AMD
Radeon R9 380 2 ГБ, материнською платою MSI A88XM-P33 (процесорний слот Socket
FM2 +), процесор AMD A8-7670K (інтегрований графічний прискорювач AMD Radeon
R7).
2. ТЕХНОЛОГІЯ ЗБІЛЬШЕННЯ
ПРОДУКТИВНОСТІ ВІДЕО NVIDIA SLI
SLI (англ. Scalable link interface,
рос. Масштабований інтерфейс зв'язку) - технологія, що дозволяє використовувати
потужності декількох відеокарт для обробки тривимірного зображення.
У 2001 році NVIDIA купує 3dfx за 110
млн доларів. З введенням специфікації PCI-E стає знову можливим використання
декількох графічних карт для обробки зображення. У 2004 році, з виходом перших
рішень на базі нової шини PCI Express, NVIDIA повідомляє про підтримку у своїх
продуктах технології мультичіпової обробки даних SLI, що розшифровується вже
по-іншому - Scalable Link Interface (масштабований інтерфейс).
Подальшим розвитком технології став
вихід в 2006 році технології Quad SLI дозволяє об'єднати пару двох чіпових
відеокарт (тоді для GeForce 7900GX2). А наприкінці 2007 року введена в експлуатацію
технологія 3-Way SLI, що дозволяє об'єднувати у зв'язці 3 відеокарти Nvidia.
Для побудови комп'ютера на базі SLI
необхідно мати:
материнську плату з двома і більше
роз'ємами PCI Express x16, що підтримує технологію SLI;
якісний блок живлення потужністю
мінімум 550 ват (рекомендуються блоки SLI-Ready);
відеокарти GeForce 6/7/8/9, GT (S /
X) 200/300/400/500/600/700/800/900 або Quadro FX з шиною PCI Express;
міст, що поєднує відеокарти.
Підтримка чипсетів для роботи з SLI
здійснюється програмно. Відкрите повинні бути однієї моделі, при цьому версія
BIOS плат, їх виробник, частота ядра, частота відео пам'яті і обсяг відео
пам'яті значення не мають.систему можна організувати двома способами:
За допомогою спеціального містка
SLI;
Програмним шляхом.
В останньому випадку навантаження на
шину PCIe зростає, що погано позначається на продуктивності.
Набула поширення система Quad SLI.
Вона передбачає об'єднання в SLI-систему двох двочіпових плат (GeForce 7950GX2,
GeForce 9800GX2, GeForce GTX295 або GeForce GTX 590) або чотирьох одночіпових
(в даному випадку вона іменується 4-Way SLI). Таким чином, виходить, що в
побудові зображення беруть участь 4 чіпи. Примітка: Quad SLI поки коректно
працює тільки в операційній системі Windows 7 і Windows Vista, в Windows XP її
не можна використовувати через обмеження в ОС.
Робоча пам'ять.
Багато виробників «подвійних»
відеокарт воліють писати сумарний обсяг локальної пам'яті (наприклад, EVGA або
Palit). Насправді ж такі відеоадаптери, фактично будучи SLI-картами, можуть використовувати
тільки власну, встановлену на друкованій платі, пам'ять. Тобто в побудові
зображенні, наприклад, відеокарта GeForce GTX295 зможе використовувати тільки
896 Мб пам'яті. Кожен її чіп має в своєму розпорядженні тільки половину від
заявленої виробником.
Процесорозалежність
Зв'язка з відеокарт SLI спочатку є
досить продуктивним рішенням, наприклад, з пари GeForce GTX260. Але тут виникає
проблема процесорозалежності, оскільки багато сучасні ігри дуже інтенсивно
використовують ЦП, так само, як і сам SLI. Тому, щоб зв'язка SLI повністю
розкрила свій потенціал, необхідний відповідний потужний процесор з високою
тактовою частотою; в іншому випадку приросту від використання SLI буде набагато
менше очікуваного.
Оптимальним (на 2015 рік) для
більшості ігор на систему SLI з двох GeForce GTX275 є процесор рівня Core 2 Duo
E8400-E8600, розігнаний до 4 ГГц. Менша частота процесора призводить до падіння
кадрової частоти, а більш висока частота процесора (порядку 4,5-5 ГГц) кадрову
частоту вже не збільшує.
3. ВИКОРИСТАННЯ
СПЕЦІАЛІЗОВАНИХ РІШЕНЬ ДЛЯ
ПРОМИСЛОВИХ ДОДАТКІВ
Серія відеокарт Quadro призначена
для вирішення професійних графічних завдань, тому тут виробник передбачив
наявність сертифікованих драйверів, оптимізованих під такі програми, як CAD або
DCC. Таким чином, продуктивність OpenGL повинна істотно зрости, в порівнянні з
серією GeForce.
Що стосується рівня продуктивності
Quadro K2100M, то його можна порівняти з GT 750M, але при цьому відеокарта
поступається Quadro K3000M. Таким чином, потужності вистачить на програвання
вимогливих ігор 2013 року на середніх і високих налаштуваннях.
Розширений набір додаткових функцій
дозволяє зробити роботу даного графічного адаптера набагато продуктивніше. З
відеокартою NVIDIA Quadro K2100M доступні підтримка дисплеїв з високою
роздільною здатністю (3840х2160 пікселів) і одночасне підключення до чотирьох
активних моніторів. Це можливо за допомогою DisplayPort 1.2 або HDMI 1.4a. Крім
того, через HDMI можна передавати деякі формати аудіокодеків - Dolby TrueHD і
DTS-HD. Проте слід врахувати, що в ноутбуках з підтримкою технології Optimus
інтегрована графіка отримує повний контроль над портами дисплея, оранічівая,
таким чином, доступні можливості дискретної графіки.
Для реалізації функції
картинка-в-картинці можуть одночасно розшифровуватися два потоки. Крім того,
відеопроцесор п'ятого покоління PureVideo HD (VP5) виконує апаратне декодування
відео HD, обробляючи MPEG-1/2, MPEG-4 ASP, H.264 і VC1 / WMV9 повністю в
дозволі до 4К, а VC1 і MPEG-4 до 1080р . Модуль кодування схожий на Intel
QuickSync, і доступний через API NVENC.
Продуктивність роботи в останніх
версіях Autodesk® AutoCAD, Autodesk® Inventor і Autodesk® 3ds Max з
використанням відеокарт Quadro. Це означає, що користувач з легкістю можете
збільшити складність своїх проектів, візуалізувати швидше і виправляти помилки
на більш ранніх етапах проектування.
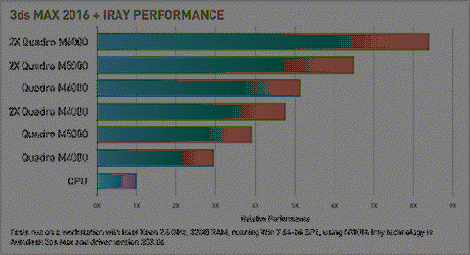
Рисунок 10 - Продуктивність роботи
графічної карти в ПЗ 3ds
MAX відносно
розрахунків з допомогою процесора Intel
Xeon 2.6 GHz,
32 GB RAM
[13]
Звернемо увагу на те, що для
виконання графічного проектування у програмних продуктах як то 3ds
MAX необхідно
використовувати не тільки спеціалізовані відеокарти, а й спеціалізовані
процесори (Intel
Xeon 2.6 GHz
- процесор з 6 ядрами та з можливістю роботи з 12 потоками).
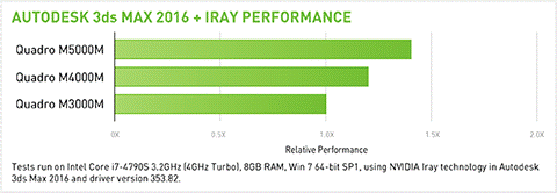
Рисунок 11
- Відносна продуктивність роботи графічної карти
в ПЗ AUTODESK
3ds MAX
[13]
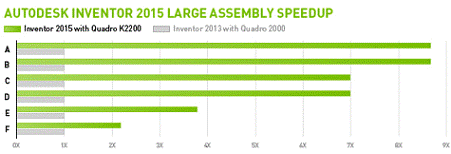

Рисунок 12
- Продуктивність роботи графічної карти Quadro
K2200 в ПЗ AUTODESK
INVENTOR в
залежності від важкості моделі [13]
відеокарта материнський
плата інтерфейс
Розглянемо продуктивність роботи
відеокарт при відео монтажі в ПЗ Adobe Premiere Pro CS5.5.
Тестування відбувалося на робочих
станціях: HP Z600 (2х чотирьохядерних процесора Intel Xeon E5640, 2.66ГГц) і
Z400 (чотирьохядерний процесор Intel Xeon W3520, 2.66ГГц), 24Гб оперативної
пам'яті. Відеокарти тестувалися класу Quadro: Quadro 2000, Quadro 4000, Quadro
5000, Quadro FX 4800.
В результаті відзначені важливі
речі: прискорення роботи залежить як від використовуваного формату відео, від
конфігурації комп'ютера, так і від прийомів роботи і налаштувань системи.
Таблица 1
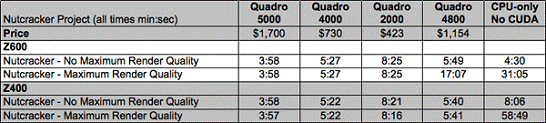
Відзначмо чотирнадцяти кратне
зростання продуктивності професійної відеокарти Quadro +5000 на робочій станції
HP Z400. [14]
Для рішення від AMD - FirePro ми
маємо наступні технічні характеристики:
архітектура GCN: Призначена для
рендеринга і використання графічного процесора в обчисленнях;
технологія AMD Eyefinity: Можливість
підключення шести дисплеїв з роздільною здатністю 4K1;Express 3.0: Більше
продуктивності з більшою пропускною здатністю.
Продуктивність можливо оцінити за
допомогою порівняльних графіків.
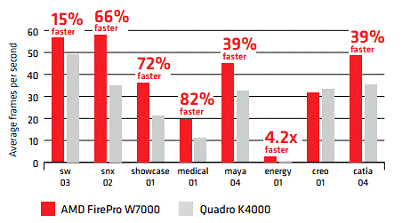
Рисунок 13 - Продуктивність роботи
графічної карти AMD FirePro W7000
в ПЗ SolidWorks
2013, Siemens
PLM Soft,
Medical-01, Catia
та ін.. в порівнянні з Quatro
K4000 [15]

Рисунок 13 - Продуктивність роботи
графічної карти AMD FirePro W5000
в ПЗ SolidWorks
2013, Siemens
PLM Soft,
Medical-01, Catia
та ін.. в порівнянні з Quatro
K2000 [15]
Результати порівняння продуктивності
T-FLEX CAD 12 на професійних відкритих Quadro K620 і Quadro K2200 при різних
рівнях згладжування anti-aliasing. У ході тестування вимірювалося середня
кількість кадрів в секунду.
Таблиця 2
- Результат тесту відеокарт Quadro у програмному
пакеті T-FLEX CAD 12 [13]
|
ВИДЕОКАРТА
|
QUADRO K620 <#"871861.files/image018.gif">
Рисунок 14 -
Зовнішній вигляд відеокарти AMD FirePro™ W5000
Память
§ Объем/Тип: 2 ГБ
GDDR5
§ Интерфейс: 256 бит
§ Пропускная
способность: 102,4 ГБ
Производительность вычислений
§ 1,3 терафлопс для
чисел с одинарной точностью и 79,2 гигафлопс для чисел с двойной точностью с
плавающей запятой
Параметры вывода
§ DisplayPort: Два
стандартных
§ DVI:
Один
DVI-I (dual-link)
§ Максимальное
разрешение DisplayPort 1,2: 4096x2160
§ Максимальное
разрешение DisplayPort 1.1: 2560x1600
§ Максимальное
разрешение DVI: 2560x1600/Характеристики/Поддержка ОС
§ DirectX® 11.1
§ OpenGL 4,2
§ OpenCL™ 1,2
§ Шейдерная модель:
5.0
§ Поддержка
технологии AMD Eyefinity: Да
§ Поддержка AMD
CrossFire™ Pro: Да
§ Поддержка AMD HD3D
Pro: Да (через стереоскопический 3-штырьковый разъем mini-DIN)
§ Поддерживаемые
операционные системы: Microsoft® Windows 8, Microsoft® Windows® 7, Windows® XP,
Windows Vista® и Linux® (32- или 64-разрядные)3
Потребляемая
мощность/Форм-фактор
§ Максимальная
мощность: < 75 Вт
§ Разъемы: Один
§ Форм-фактор: Полная
высота / уменьшенная длина
§ Интерфейс шины:
PCIe® x16, 3.0 для оптимальной производительности
§ Охлаждение:
Активный вентилятор
§

Рисунок 15 -
Зовнішній вигляд відеокарти QUADRO K2200
Технічні характеристики
ГПУ пам'яті 4 ГБ GDDR5
Інтерфейс пам'яті 128-біт
Пропускна здатність пам'яті 80.0 Гб
/ сCUDA Cores 640
Інтерфейс системи PCI Express 2.0
x16
Максимальна споживана потужність 68
Вт
Системи охолодження безшумний
Активний кулер
Форм-фактор 4,376 "Н ×
7,97" L, Одномісний
Роз'єми DVI-I DL + 2 DP 1.2
Макс Одночасне відображення 3
Direct, 4 DP 1.2
Макс DP 1.2 Дозвіл 3840 х 2160 при
60 Гц
Макс DVI-I Дозвіл DL 2560 ×
1600 при 60 Гц
Макс DVI-I Дозвіл SL 1920 ×
1200 при 60 Гц
Максимальна роздільна здатність VGA
2048 × 1536 при 85 Гц
Графіка інтерфейси Shader Model 5.0,
OpenGL 4.53,DirectX 11.24
Обчислити інтерфейси CUDA,
DirectCompute,OpenCL ™
На завершення аналізу наведемо
тестування роботи спеціалізованих відеокарт FirePro та QUADRO в режимі одна
карта, дві карти SLI
або CrossFire
у порівнянні з топовим неспеціалізованим рішенням Geforce
GTX Titan
віртістю 1150$ на
19.12.2015 року.

Рисунок 16 - Швидкість рендерингу
відео сцени для відеокарт FirePro, QUADRO та Geforce
GTX Titan
в режимі Single
або Dual
(більше - гірше) [16]
Для порівняння ціна Quadro
K5000 складає
близько
2200$ на 19.12.2015 року.
Для функціонування відеокарт в
режимі Sli
або
CrossFire
необхідними
умовами є:
наявність шини PCI-E
16х у кількості рівній кількості відеокарт які планується об’єднати;
наявність підтримки Bios
або EFI BIOS материнською плати режимів Sli
та CrossFire;
наявність конектора Sli
або CrossFire
(для топових сучасних відеокарт опціонально);
наявність блока живлення, потрібної
потужності.
Доцільність використання режимів
NVIDIA SLI та AMD CrossFireX для ігрових систем для підвищення продуктивності
роботи ПЕОМ є в тому випадку, коли в системі вже встановлена відеокарта
середнього або топового класу. При цьому витрати у 200-400 умовних одиниць
нададуть підвищення кількості кадрів при тестуванні ігрового програмного
забезпечення на 50-80% в залежності від оптимізації ПЗ.
При плануванні придбання сучасного
ПЕОМ за вартість двох відеокарт доцільніше придбати одну, але вищого класу. Це
дозволить зменшити навантаження на блок живлення та у подальшому надасть
можливість апгрейду.
При використанні спеціалізованого ПЗ
- рішень для промисловості, рішень для відеорендерингу та монтажу доцільно
використовувати спеціалізовані відеокарти.
Для NVidia
це лінійка Quadro, для AMD це лінійка FirePro.
У цьому випадку підвищення
продуктивності з використанням режимів NVIDIA SLI та AMD CrossFireX надасть
суттєвих переваг при економії робочого часу, та прискорення виробничого
процесу.
Але остаточне рішення необхідно
приймати порівнявши всі варіанти виходячи з суми, яку передбачаються витратити
на апаратне та програмне забезпечення робочих станцій ПЕОМ.
ПЕРЕЛІК ПОСИЛАНЬ
1. Електронний ресурс. Матеріал з Вікіпедії -
вільної енциклопедії. https://ru.wikipedia.org/wiki/Видеокарта
. Архитектура компьютера - Эндрю Таненбаум, Т.
Остин.
Издательство: Питер. 2015. 816 стр.
3.
Електронний
ресурс. Архів 3dfx.
http://www.x86-secret.com/articles/divers/v5-6000/v56kgb-2.htm
. Електронний ресурс. Зарождение и первые шаги
3D-ускорителей. <http://www.compbegin.ru/articles/view/_122>
. Електронний ресурс. Video Electronics
Standards Association (VESA) <https://uk.wikipedia.org/wiki/VLB>
6. Електронний
ресурс. PCI <https://uk.wikipedia.org/wiki/PCI>
7. Електронний
ресурс. Матеріал з Вікіпедії - вільної енциклопедії. <https://uk.wikipedia.org/wiki/PCI_Express>
8. Електронний
ресурс.
Порівняння
шин. <http://organic-store.com.ua>
. Большая энциклопедия компьютера - Леонов
Василий. Издательство: Эксмо. 2012. 592 стр.
. Електронний ресурс. AMD CrossFireX™ multi-GPU
technology. http://www.club-3d.com/
. Електронний ресурс. AMD CrossFireX - bridge
connector. wikimedia.org
. Електронний ресурс. Технлогія AMD CrossFireX.
<https://uk.wikipedia.org>
.
Електронний
ресурс.
РАСКРОЙТЕ ПОЛНЫЙ ПОТЕНЦИАЛ AUTODESK PRODUCT DESIGN SUITE С ГРАФИЧЕСКИМИ
ПРОЦЕССОРАМИ NVIDIA. http://www.nvidia.ru/object/autodesk-design-suite-ru.html#myTabListID=0
<http://www.nvidia.ru/object/autodesk-design-suite-ru.html>
.
Електронний
ресурс.
Тестируем Quadro. <http://www.efxi.ru/more/premiere_cuda6.html>
. Електронний ресурс. AMD-FirePro-specviewperf. http://www.amd.com/Documents/AMD-FirePro-specviewperf12.pdf
16. Електронний ресурс. Adobe
Premiere Pro CC Professional GPU Acceleration.
<https://www.pugetsystems.com/labs/articles/Adobe-Premiere-Pro-CC-Professional-GPU-Acceleration-502/>
Похожие работы на - Сумісність материнської плати і відеокарти. Технологія підвищення продуктивності SLI і CrossFire
|