Сортировка Джона фон Неймана
Содержание
Введение
. Процедура слияние
. Сортировка
сиянием
. Восходящая
сортировка слиянием
. Гибридная
сортировка
. Естественная
сортировка
Заключение
Список литературы
Введение
слияние листинг
программирование алгоритм
В данной курсовой работе мы рассмотрим
сортировку Джона фон Неймана.
Тема нашего исследования
актуальна, она является очень важным для изучения в связи с тем, что сортировка
и поиск данных - это наиболее часто встречающиеся практические задачи,
возникающие при создании программного обеспечения. Сортировка слиянием -
вероятно, один из самых простых алгоритмов сортировки (среди
"быстрых" алгоритмов).
Сортировка слиянием -
стабильный алгоритм сортировки. Это означает, что порядок "равных"
элементов не изменяется в результате работы алгоритма. В некоторых задачах это
свойство достаточно важно.
Этот алгоритм был предложен
Джоном фон Нейманом в 1945 году
Везде элементы массивов
нумеруются с нуля.
Целью курсовой работы является
сортировка фон Неймана.
Задача изучить алгоритмы
сортировки слиянием, сортировка слиянием в целом.
Предмет и объект исследования.
Объектом исследования является сортировка фон Неймана. Предметом исследования -
сортировка слиянием, алгоритм сортировки, процедура слияния, восходящая
сортировка слиянием, гибридная сортировка и естественная сортировка.
Методы нашего исследования являются анализ,
синтез, обобщение.
Допустим, у нас есть два
отсортированных массива A и B размерами  и
и
 соответственно,
и мы хотим объединить их элементы в один большой отсортированный массив C
размером
соответственно,
и мы хотим объединить их элементы в один большой отсортированный массив C
размером 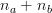 .
Для этого можно применить процедуру слияния, суть которой заключается в
повторяющемся "отделении" элемента, наименьшего из двух имеющихся в
началах исходных массивов, и присоединении этого элемента к концу
результирующего массива. Элементы мы переносим до тех пор, пока один из
исходных массивов не закончится. После этого оставшийся "хвост"
одного из входных массивов дописывается в конец результирующего массива. Пример
работы процедуры показан на рисунке:
.
Для этого можно применить процедуру слияния, суть которой заключается в
повторяющемся "отделении" элемента, наименьшего из двух имеющихся в
началах исходных массивов, и присоединении этого элемента к концу
результирующего массива. Элементы мы переносим до тех пор, пока один из
исходных массивов не закончится. После этого оставшийся "хвост"
одного из входных массивов дописывается в конец результирующего массива. Пример
работы процедуры показан на рисунке:
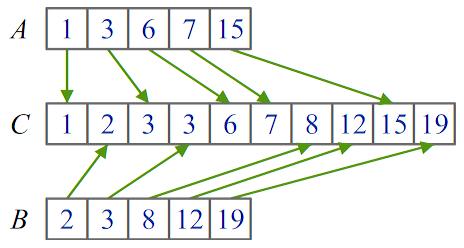
Рис. 1. Пример работы процедуры
слияния
Алгоритм слияния формально
можно записать следующим образом:
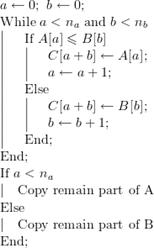 (1)
(1)
Для обеспечения стабильности
алгоритма сортировки нужно, чтобы в случае равенства элементов тот элемент, что
идёт раньше во входном массиве, попадал в результирующий массив в первую
очередь. Мы увидим далее, что если два элемента попали в разные массивы (A
и B), то тот элемент, что шёл раньше, попадёт в массив A.
Следовательно, в случае равенства элемент из массива A должен иметь
приоритет. Поэтому в алгоритме стои́т
знак  вместо
< при сравнении элементов.
вместо
< при сравнении элементов.
Недостатком представленного
алгоритма является необходимость дописывать оставшийся кусок, из-за чего при
дальнейших модификациях алгоритма нам придётся писать много повторяющегося
кода. Чтобы этого избежать, будем использовать чуть менее эффективный, но более
короткий алгоритм, в котором копирование "хвоста" встроено в основной
цикл:
 (2)
(2)
Очевидно, время работы
процедуры слияния составляет 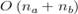 .
.
Реализация процедуры слияния на
языке программирования C++ представлена в листинге 1.
template<class T> void Merge(T
const *const A, int const nA, T const *const B, int const nB, T *const C)
{ //Выполнить слияние массива A, содержащего nA элементов, // и массива
B, содержащего nB элементов. // Результат записать в массив C. int a(0),
b(0); //Номера текущих элементов в массивах A и B while(
a+b < nA+nB ) //Пока остались элементы в массивах { if(
(b>=nB) || ( (a<nA) && (A[a]<=B[b])
) ) { //Копирую элемент из массива A C[a+b]
= A[a]; ++a; } else { //Копирую элемент из массива
B C[a+b] = B[b]; ++b; } } }
Листинг 1. Компактная (не самая
быстрая) реализация процедуры слияния
. Сортировка слиянием
Процедура слияния требует два
отсортированных массива. Заметив, что массив из одного элемента по определению
является отсортированным, мы можем осуществить сортировку следующим образом:
1. разбить имеющиеся
элементы массива на пары и осуществить слияние элементов каждой пары, получив
отсортированные цепочки длины 2 (кроме, быть может, одного элемента, для
которого не нашлось пары);
2. разбить имеющиеся
отсортированные цепочки на пары, и осуществить слияние цепочек каждой пары;
. если число
отсортированных цепочек больше единицы, перейти к шагу 2.
Проще всего формализовать этот
алгоритм рекурсивным способом (в следующем разделе мы реализуем этот алгоритм
итерационным способом). Функция 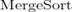 сортирует участок
массива от элемента с номером a до элемента с номером b:
сортирует участок
массива от элемента с номером a до элемента с номером b:
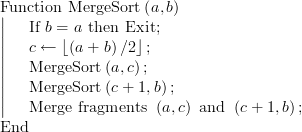 (3)
(3)
Поскольку функция сортирует
лишь часть массива, то при слиянии двух фрагментов ей не остаётся ничего, кроме
как выделять временный буфер для результата слияния, а затем копировать данные
обратно:
Листинг 2. Реализация
сортировки слиянием
Время работы сортировки
слиянием составляет 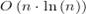 . Пример работы
процедуры показан на рисунке:
. Пример работы
процедуры показан на рисунке:
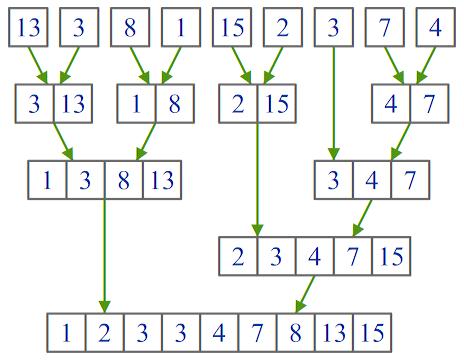
Рис. 2. Пример работы
рекурсивного алгоритма сортировки слиянием
. Восходящая сортировка
слиянием
Программа, представленная в
листинге 2, имеет серьёзные недостатки: она выделяет и освобождает много
буферов памяти, и делает копирование результатов слияния в исходный массив
вместо того, чтобы вернуть новый массив в качестве результата (она не может
вернуть новый массив в качестве результата, т.к. на входе получает зачастую
лишь часть большого массива).
Чтобы избавиться от этих
недостатков, откажемся от рекурсивной реализации, и сделаем сортировку
следующим образом:
· выделим временный
буфер памяти размером с исходный массив;
· выполним попарное
слияние элементов, записывая результат во временный массив;
· поменяем местами
указатели на временный массив и на исходный массив;
· выполним попарное
слияние фрагментов длиной 2;
· аналогично
продолжаем до тех пор, пока не останется один кусок;
· в конце работы
алгоритма удаляем временный массив.
Такой алгоритм называется
восходящей сортировкой слиянием. Реализация его на языке программирования C++
приведена в листинге 3.
template<class
T> void
MergeSortIterative(T
*&A, int
const n)
{ //Отсортировать массив A,
содержащий n элементов. // При
работе указатель на A, возможно,
меняется. // (Функция получает ссылку на указатель на A)
T *B(
new T[n]
); //Временный буфер памяти for(int
size(1);
size<n;
size*=2) {
//Перебираем все размеры кусочков для слияния: 1,2,4,8... int
start(0);
//Начало первого кусочка пары for(;
(start+size)<n;
start+=size*2)
{ //Перебираем все пары кусочков, и выполняем попарное // слияние.
(start+size)<n означает, что начало // следующего кусочка лежит внутри
массива Merge(A+start , size, A+start+size, min(size,n-start-size),
B+start ); } //Если последний кусочек остался без пары, просто
копи- // руем его из A в B: for(; start<n; ++start) B[start]=A[start];
T *temp(B); B=A; A=temp; //Меняем местами указатели }
delete[n] B; //Удаляем временный буфер }
Листинг 3. Реализация
восходящей сортировки слиянием
К сожалению, в этот алгоритм не
так просто вписать оптимизацию для случая слияния двух элементов (если нужно,
можно вписать эту оптимизацию в процедуру Merge).
Пример работы программы
листинга 3 показан на рисунке:
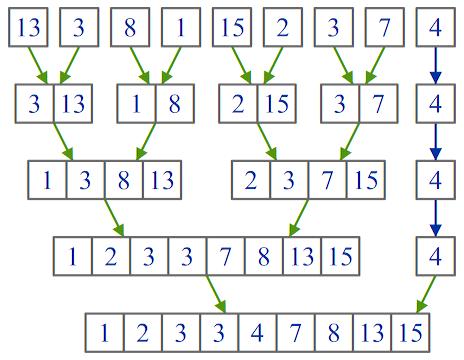
Рис. 3. Пример работы
восходящего алгоритма сортировки слиянием
template<class T> void
MergeSortIter2(T *const A, int const n) { //Отсортировать
массив
A, содержащий
n элементов.
T *B( A ); //Буфер
памяти
№1 T *C( new T[n] ); //Буфер
памяти
№2 for(int size(1); size<n; size*=2) { //Перебираем
все
размеры
кусочков
для
слияния:
1,2,4,8... int start(0); //Начало
первого
кусочка
пары
for(; (start+size)<n; start+=size*2) { //Перебираем
все
пары
кусочков,
и
выполняем
попарное
// слияние.
(start+size)<n означает,
что
начало
// следующего
кусочка
лежит
внутри
массива
Merge(B+start , size, B+start+size, min(size,n-start-size),
C+start ); } //Если
последний
кусочек
остался
без
пары,
просто
копи-
// руем
его
из
B в
C: for(; start<n; ++start) C[start]=B[start];
T *temp(B); B=C; C=temp; //Меняем
местами
указатели
} //В
данный
момент
результат
работы
находится
в
массиве
B. if( C == A ) { // Если
массив
C является
массивом
A, то
нужно
// скопировать
результат
работы
из
B в
A. for(int i(0); i<n; ++i) A[i]=B[i];
delete[n] B; //Удаляем
временный
буфер
} else { delete[n]
C; //Удаляем временный
буфер
} }
Листинг 4. Реализация
восходящей сортировки слиянием с сохранением результата работы в исходном
массиве
. Гибридная сортировка
Анализ быстродействия алгоритма
наталкивает нас на мысль объединить преимущества алгоритмов пирамидальной
сортировки и сортировки слиянием. К счастью, сделать это очень просто: нужно
разбить массив сразу на большие кусочки (например, размером 512 элементов), и
применить к ним алгоритм пирамидальной сортировки. Полученные отсортированные
кусочки затем можно "досортировать" слиянием. Используя функции из лекции
5, требуемые изменения в алгоритме минимальны (за основу взята функция из
листинга 3):
template<class
T> void
HybridSort(T
*&A, int
const n)
{ //Отсортировать массив A,
содержащий n элементов. // При
работе указатель на A, возможно,
меняется. // (Функция получает ссылку на указатель на A)
//Размер кусочка для сортировки пирамидой: // (нужно подбирать для
максимального ускорения) int
const tileSize(
4096 ); for(int
start(0);
start<n;
start+=tileSize)
HeapSort(A+start,
min(tileSize,n-start)
); if(
n <= tileSize
)
return; //Больше
сортировать не нужно T
*B(
new T[n]
); //Временный буфер памяти for(int
size(tileSize);
size<n;
size*=2) {
//Перебираем размеры кусочков для слияния, // начиная с tileSize
элементов int
start(0);
//Начало первого кусочка пары for(;
(start+size)<n;
start+=size*2)
{ //Перебираем все пары кусочков, и выполняем попарное // слияние.
(start+size)<n означает, что начало // следующего кусочка лежит внутри
массива Merge(A+start , size, A+start+size, min(size,n-start-size),
B+start ); } //Если последний кусочек остался без пары, просто
копи- // руем его из A в B: for(; start<n; ++start) B[start]=A[start];
T *temp(B); B=A; A=temp; //Меняем местами указатели }
delete[n] B; //Удаляем временный буфер }
Листинг 5. Реализация гибридной
сортировки
. Естественная сортировка
До сих пор мы рассматривали
алгоритмы сортировки, которые никак не учитывают то, что данные (или их часть)
могут быть уже отсортированы. Для алгоритма сортировки слиянием есть очень
простая и эффективная модификация, которая называется "естественная
сортировка" ("Natural Sort"). Суть её в том, что нужно образовывать
цепочки, и производить их слияние не в заранее определённом и фиксированном
порядке, а анализировать имеющиеся в массиве данные. Алгоритм следующий:
1. разбить массив на
цепочки уже отсортированных элементов (в худшем случае, когда элементы в
массиве идут по убыванию, все цепочки будут состоять из одного элемента);
2. произвести слияние
цепочек методом сдваивания.
Пример работы этого алгоритма
показан на рисунке:
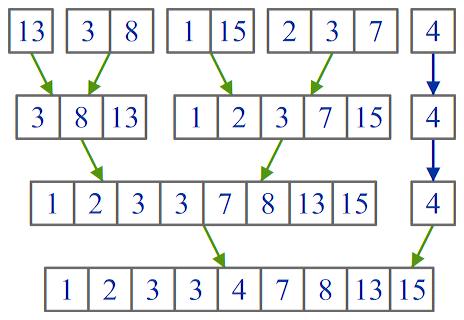
Рис. 7. Пример работы
естественного алгоритма сортировки слиянием
В отличие от ранее
рассмотренных вариантов алгоритма слияния, естественная сортировка справилась с
задачей за 3, а не за 4 итерации.
Обратите внимание, что во время
работы алгоритма не могут образоваться новые отсортированные цепочки кроме получившихся
в результате слияний, поэтому поиск отсортированных цепочек должен проводиться
только на первом этапе. Но как хранить найденные цепочки? Выделять для них
память - очень неэффективно. Самый простой способ - вообще их не хранить, а
искать каждый раз заново. Это неэффективно, зато просто:
<class T> void NaturalSort(T
*&A, int const n) { //Отсортировать массив A, содержащий n
элементов. // При работе указатель на A, возможно, меняется. // (Функция
получает ссылку на указатель на A) T *B( new T[n] );
//Временный буфер памяти while(true) //Выполняем слияния, пока не
останется один { // отсортированный участок. Выход из цикла // находится
дальше int start1 ,end1 ; //Первый отсортированный участок int start2(-1),end2(-1);
//Второй отсортированный участок while(true) { //Цикл по
всем парам отсортированных участков в массиве //Начало первого участка для
слияния находится после // конца второго участка предыдущей пары: start1 =
end2+1; end1 = start1; //Двигаемся вправо до нарушения сортировки: while(
(end1<n-1) && (A[end1]<=A[end1+1])
) ++end1; //Первый участок пары простирается до конца массива: if(
end1 == n-1 ) break; //Начало второго участка для слияния находится
после // конца первого участка текущей пары: start2 = end1+1, end2 = start2;
//Двигаемся вправо до нарушения сортировки: while( (end2<n-1)
&& (A[end2]<=A[end2+1]) )
++end2; //Выполняем слияние двух отсортированных участков Merge(A+start1,
end1-start1+1, A+start2, end2-start2+1, B+start1 ); //Второй участок
пары простирается до конца массива: if( end2 == n-1 ) break; }
//Данные полностью отсортированы и находятся в массиве A: if( (start1==0)
&& (end1==n-1) ) break; //Если последний кусочек
остался без пары, просто копи- // руем его из A в B: if( end1 == n-1 )
{ for(; start1<n; ++start1) B[start1]=A[start1];
} T *temp(B); B=A; A=temp; //Меняем местами указатели }
delete[n] B; //Удаляем временный буфер }
Листинг 8. Исходный код
алгоритма естественной сортировки слиянием
Несмотря на то, что
представленная реализация на каждой итерации примерно 25% времени проводит в
поиске отсортированных фрагментов для слияния (хотя этот поиск достаточно
произвести только в начале), она показывает неплохие результаты для случайного
набора чисел:

Рис. 8. Отношение времени
сортировки к 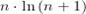 . Красный цвет -
естественная сортировка, серый цвет - восходящая сортировка слиянием
. Красный цвет -
естественная сортировка, серый цвет - восходящая сортировка слиянием
Заключение
В данной работе была изучена подробно сортировка
слиянием, алгоритм сортировки, процедура слияния, восходящая сортировка
слиянием, гибридная сортировка и естественная сортировка.
Особенностью этого алгоритма является то, что он
работает с элементами массива преимущественно последовательно, благодаря чему
именно этот алгоритм используется при сортировке в системах с различными
аппаратными ограничениями (например, при сортировке данных на жёстком диске,
или даже на магнитной ленте). Кроме того, сортировка слиянием - чуть ли не
единственный алгоритм, который может быть эффективно использован для сортировки
таких структур данных, как связанные списки. Последовательная работа с
элементами массива значительно увеличивает скорость сортировки в системах с
кэшированием.