|
Этап жизненного цикла
|
|
Системное планирование и анализ
|
|
Техническое задание
|
01. 04.2015 - 15. 04.2015
|
|
Выбор модели ЖЦ ПО
|
16. 04.2015 - 20. 04.2015
|
|
Системный анализ и проектирование
|
|
Проектирование системы
|
06. 04.2015 - 30. 04.2015
|
|
Конструирование и тестирование
|
|
Конструирование ПО
|
01. 05.2015 - 18. 05.2015
|
|
Тестирование ПО
|
19. 05.2015 - 22. 05.2015
|
|
Документирование и оценка ПО
|
|
Документирование ПО
|
23. 05.2015 - 10. 06.2015
|
|
Оценка качественных характеристик ПО
|
23. 05.2015 - 25. 05.2015
|
|
Оценка трудоемкости разработки ПО
|
01. 06.2015-05. 06.2015
|
2. Проект
автоматизации
2.1
Функциональная структура
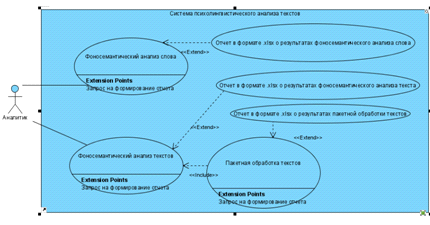
Рисунок 11. Диаграмма вариантов использования.
На рисунке 11 представлена Use Case диаграмма в нотации UML.
На диаграмме наглядно представлено какой функционал системы доступен.
Функции фоносемантического анализа слов и текстов и пакетной
обработки текстов расширяют функции составления отчетов о результатах
соответствующего анализа.
.2
Информационное обеспечение
Для наиболее удобного конструирования системы и ее
дальнейшего функционирования было принято решение для работы с данными
использовать технологию ADO.net, являющейся наиболее удобной для работы с
базами данных Microsoft Access. Для извлечения данных из БД было использовано
пространство имен System. Text. RegularExpressions содержит классы,
обеспечивающие доступ к обработчику регулярных выражений платформы.net
Framework. Пространство имен обеспечивает функциональные возможности регулярный
выражений, которые могут быть использованы из любой платформы или языка,
работающих в рамках Microsoft.net Framework.
В базе данных содержатся две самостоятельные таблицы,
составленные на основе исследований А. Журавлева: "Частотность"
(содержит поля: Код (число), Звук (текст), Частотность (число)), в которой
указано, сколько раз в среднем на тысячу звукобукв встречается каждая звукобуква
в обычной разговорной речи, и "Значимость" (содержит поля: Код
(число), Буква (текст), Значение (число), Признак (текст)) [5].
2.3
Математическое обеспечение
Частотность звука и его информативность
("заметность") находятся в обратной зависимости. Отсюда следует, что
в слове наименее информативен звук с максимальной частотностью, а все остальные
звуки во столько раз информативнее, во сколько раз их частотность меньше
максимальной для звуков данного слова [5].
Значит, при расчете фонетической значимости звукового
комплекса слова нужно увеличить вес средних оценок не только для первого и
ударного звуков, но и для всех звуков, кроме максимально частотного в слове.
Иначе говоря, нужно считать не просто среднее арифметическое
средних оценок всех звуков слова, а сначала приписать каждому звуку свой вес,
свой весовой коэффициент, в зависимости от места в слове и частотности, а уже
затем вычислять среднее арифметическое [3].
Так, если частотность любого (i-того) звука слова обозначить
как Pi, а максимальную частотность звука в данном слове как Pmax,
то коэффициент, учитывающий разницу частотностей звуков слова (ki),
можно вычислить как отношение:

Теперь нужно учесть место каждого звука в слове. Для этого
коэффициент первого звука слова (k1) увеличим в четыре раза:

А для ударного (kуд) - в два раза:
После всех этих приготовлений можно сконструировать формулу
для теоретического расчета фонетической значимости слова:

Где F - фонетическая значимость слова; fi -
фонетическая значимость очередного (i-тoro) звука слова; ki -
коэффициент для очередного (i-того) звука [1].
Но как из получившейся оценки понять, в какую сторону по
шкале двигается оценка?
На основании исследований Журавлева ясно, что если оценка
попадает в диапазон (1; 2,5) - ставим положительную оценку (например, по шкале
"красивый-отталкивающий" это будет красивый), [2,5 до 3,5] - не
учитываем оценку по данной шкале в общей оценке, [3,5; ∞) - ставим
отрицательную оценку (по шкале "красивый-отталкивающий" это будет
отталкивающий) [5].
Всего исследования проведены по 25 шкалам. Введенное слово
нужно оценить по каждой из этих шкал последовательно. Учитываются только те
оценки, которые попадают в зоны существенных отклонений, т.е. которые либо
меньше 2,5, либо больше 3,5. Если оценка попадает в нейтральную зону, ее
результат не выводится вообще (т.е. оценка слова по данной шкале не имеет
значительной фонетической значимости).
При проведении оценки текста используются те же таблицы базы
данных и показатели, что и для анализа слова, однако дополнительно необходимо
еще подсчитать количество каждой звукобуквы в тексте, границы колебаний
частотностей звукобукв (по законам теории вероятностей и статистики нормальные
колебания не превышают ±2σ), выразить через σ отклонения частотностей звукобукв в тексте от нормальных,
посчитать общие суммы положительных и отрицательных отклонений. Если в тексте
модуль суммы положительных отклонений больше отрицательных, то в качестве
оценки текста берется положительный признак соответствующей шкалы, наоборот -
отрицательный. Журавлев в своих исследованиях не проводит зависимости между
границей нейтральности оценок и количеством символов анализируемого текста,
однако в ходе проведенных в результате проектирования и тестирования системы
экспериментов, было установлено, что при анализе текста с количеством символов
меньшим или равным 1000, учитываются отклонения, превышающие ±1σ, и с увеличением количества символов в тексте на тысячу эта
граница увеличивается на |1| как в положительном, так и в отрицательном
направлениях.
2.4
Программное обеспечение
На рисунке 12 представлена диаграмма классов разрабатываемого
модуля.
Класс Program является классом входа в систему, Form1 отвечает
за вспомогательные методы анализа текстов, Analyzer - класс, содержащий
основные методы анализа текстов, WordAnalitic содержит методы для реализации
анализа слов, ExelWorker отвечает за выгрузку данных и формирование отчетов в
Excel, а MSAcces - за корректную работу БД.
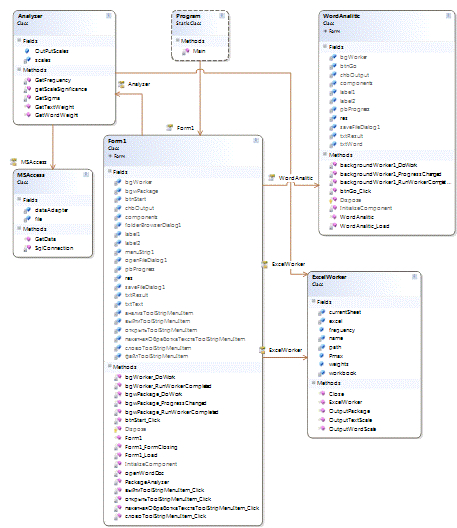
Рисунок 12. Диаграмма классов.
Все алгоритмические задачи и базовый функционал вынесен в
отдельные классы. Такая структура делает систему более гибкой и адаптивной.
На рисунке 13 представлена диаграмма последовательности
фоносемантического анализа слова. Пользователь вводит слово для анализа, а
система, в свою очередь, вызывает методы анализа слова, извлекает необходимые
для математических расчетов данные из БД, формирует отчета формата. xlsx.
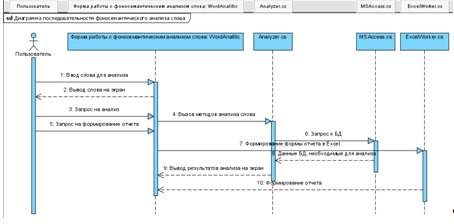
Рисунок 13. Диаграмма последовательности фоносемантического
анализа слова.
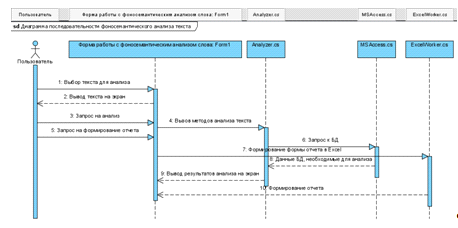
Рисунок 14. Диаграмма последовательности фоносемантического
анализа текста.
На рисунке 14 представлена диаграмма последовательности
фоносемантического анализа текста. Пользователь загружает текст для анализа, а
система, в свою очередь, вызывает методы анализа слова, извлекает необходимые
для математических расчетов данные из БД, формирует отчета формата. xlsx.

Рисунок 15. Диаграмма последовательности пакетной обработки
текстов.
На рисунке 15 представлена диаграмма последовательности
пакетной обработки текстов. Пользователь выбирает директорию, содержащую тексты
для анализа, а система, в свою очередь, вызывает методы анализа слова,
извлекает необходимые для математических расчетов данные из БД, формирует
отчета формата. xlsx.
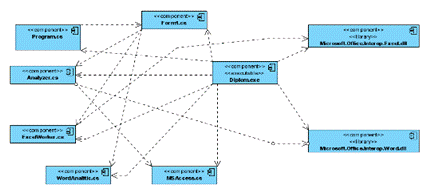
Рисунок 16. Диаграмма компонентов модуля.
На рисунке 16 представлена диаграмма компонентов системы.
Каждый разработанный класс находится в отдельном файле с расширением".
cs". Система взаимодействует с внешними библиотеками Microsoft. Office.
Interop. Word и Microsoft. Office. Interop. Excel для организации корректной
загрузки текстов в форматах. doc и. docx и вывода отчетов в формате. xlsx.
2.5
Техническое обеспечение
При работе с системой психолингвистического анализа текстов
на рабочем месте аналитика разворачивается исполняемая среда MS Access, через
которую осуществляется работа с базой данных.
2.6
Технологическое обеспечение
Для осуществления математических расчетов методов расчета
значимости звукового комплекса слова и оценки звуковой содержательности
необходимо использование достаточно большого перечня параметров, которые
хранятся в БД MS Access. Работа с БД организована с использованием технологии
ADO.net..net - технология, предоставляющая доступ к данным для приложений,
основанных на Microsoft.net. Является не развитием более ранней технологии ADO,
а самостоятельной технологией, частью фреймворка.net. В отличие от классической
ADO, которая была в основном предназначена для тесно связанных клиент-серверных
систем, ADO.net больше нацелена на автономную работу с помощью объектов
DataSet. Эти типы представляют локальные копии любого количества
взаимосвязанных таблиц данных, каждая из которых содержит набор строк и
столбцов. Объекты DataSet позволяют вызывающей сборке работать с содержимым
DataSet, изменять его, не требуя подключения к источнику данных.
2.7 Контрольный
пример
Для проведения анализа текста в качестве контрольного примера
было взято стихотворение А.С. Пушкина "Зимнее утро".
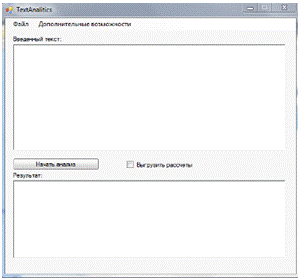
Рисунок 17. Начало работы с программой.
На рисунке 17 представлено начало работы с программой. Сразу
после открытия программы отображается форма для фоносемантического анализа
текстов.
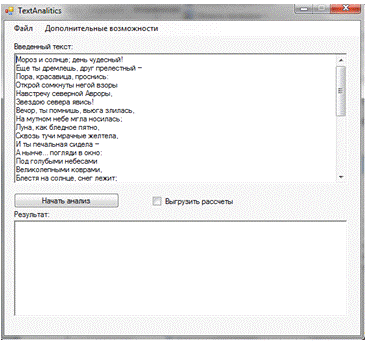
Рисунок 18. Загрузка текста в систему.
На рисунке 18 представлен вывод текста на экран после
загрузки его в систему.
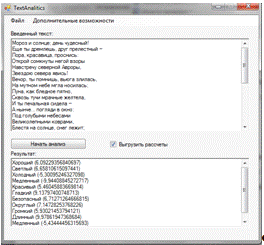
Рисунок 19. Вывод результатов анализа на экран.
На рисунке 19 представлена выгрузка результатов анализа
текстов на экран. Так как пользователь дополнительно проставил
"галочку" у опции выгрузки расчетов, системой был сформирован отчет
формата. xlsx. Его внешний вид представлен на рисунках 20-22.
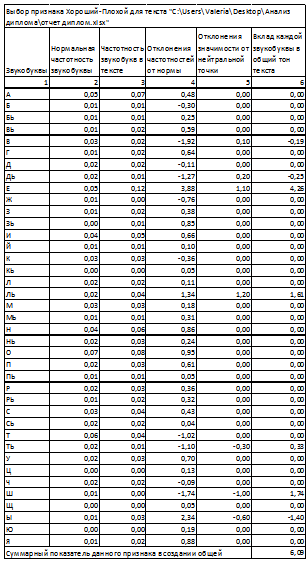
Рисунок 20. Анализ текста по шкале
"Хороший-плохой".
Так как пользователь дополнительно проставил
"галочку" у опции выгрузки расчетов, системой был сформирован отчет
формата. xlsx.
Листинг разработанного программного продукта представлен в
Приложении А "Листинг исходного кода проекта".
3. Оценка
эффективности проекта
3.1 Оценка
совокупной стоимости владения
Планируется массовое распространение системы
психолингвистического анализа текстов, стоимость одного экземпляра определяется
из предпочтительной прибыли. Аргументация запланированных размеров прибыли, а
так же расчет себестоимости системы не приводится, так как не имеют прямого
отношения к данной работе.
Определять цену одного экземпляра было решено исходя из
планируемого объема прибыли равного одному миллиону рублей с десяти проданных
коробок. Затраты на тиражирование и реализацию одной коробки были условно взяты
равными 10% от себестоимости системы. Себестоимость системы равна 461 500
рублей.
Определим себестоимость продукта с учетом затрат на
тиражирование и реализацию:
Цзатр=Цразраб + 10%; (5)
Цзатр= 461 500 + 10% = 507 650 рублей.
Определим цену одного экземпляра продукта, исходя из
необходимой прибыли:
Цэкз= Цзатр / Т + П / Т, (6)
где Т - тираж, П - прибыль.
Цэкз = 507 650/10 + 1 000 000/10 = 150 765 рублей.
При расчете отпускной цены учитывается величина налога на
добавленную стоимость НДС (18%). В данном случае воспользуемся формулой:
Цэкз отп = Цэкз* (1+0,18); (7)
Цэкз отп= 150 765 * 1,18= 177 902,7 рублей.
Таким образом цена продажи одной коробки составляет 177 902,7
рублей.
Совокупная стоимость владения равна затратам на внедрение,
так как закупка дополнительной техники предприятием не требуется.
Затраты на внедрение программного продукта (КВПР)
рассчитываются по формуле:
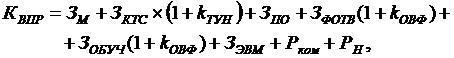 (8)
(8)
где ЗМ - затраты на приобретение материалов,
руб.;
ЗКТС - затраты на приобретение комплекса технических средств, руб.;
ЗПО
- затраты на приобретение программного обеспечения (включают стоимость
разработанного ПП, а также других существующих ПП, необходимых для
функционирования системы), руб.;
ЗФОТВ - затраты на оплату труда работников, занятых внедрением проекта,
руб.;
ЗОБУЧ - затраты на оплату труда работников, занятых освоением ПП, руб.
ЗЭВМ - затраты, связанные с эксплуатацией ЭВМ при внедрении проектного
решения, руб.;
Рком - командировочные расходы, руб.;
РН
- накладные расходы, руб.;
kТУН - коэффициент транспортирования, установки и наладки комплекса
технических средств, определяется действующими нормативами организации, а также
спецификой конкретного проекта.
Так как техника и программное обеспечение для эксплуатации системы
уже закуплены, установлены и готовы к эксплуатации, затраты на приобретение
материалов, техники и дополнительного программного обеспечения равны нулю.
Командировочные расходы так же не планируются. С учетом данных условий получим
следующую формулу:
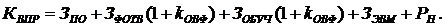 (9)
(9)
Затраты на приобретение программного обеспечения ЗПО =
474212 руб.
Внедрением занят один системный инженер с окладом 20000 руб. Время
внедрения - 0,3 месяцев. Совокупные затраты на оплату труда системного инженера
с учетом отчислений во внебюджетные фонды.
ЗФОТВ = оклад * tВН * (1+ kД) * (1+kОВФ),
(10)
где kД - коэффициент дополнительной зарплаты работников,
занятых внедрением проекта, kД = 0,2;
kОВФ - коэффициент отчислений во внебюджетные фонды, kОВФ
=0,302;
tВН - общее время на внедрение проектного решения, затрачиваемое
сотрудником, мес.
ЗФОТВ = 20 000*0,3* (1+0,2) (1+0,302) = 9 374,4 руб
.
Затраты на оплату труда работников, занятых освоением ПП:
ЗОБУЧ = n*оклад* tОБ* (1+ kД) * (1+ kОВФ)
/21/8, (11)
где n - количество сотрудников, занятых в обучении, чел., n=1
чел.;ОБ - время обучения, час., tОБ = 10 час.
ЗОБУЧ = 1*20000*10* (1+0,2) * (1+0,302) /21/8 = 3 720 руб.
Затраты, связанные с эксплуатацией ЭВМ при внедрении проектного
решения, при условии, что время работы каждой ЭВМ составит 30 % от времени
внедрения:
ЗЭВМ = 0,3*tВН * 21*8* СМ-Ч *n,
(12)
где СМ-Ч - стоимость машино-часа эксплуатации
оборудования, руб. /час., СМ-Ч =16,24 руб. /час.
ЗЭВМ = 0,3*0,3*21*8*16,24*1 = 245 руб.
Накладные расходы
РН
= (ЗФОТВ + ЗОБУЧ) * kНР,
(13)
РН
= (9 374,4 +3 720) *0,7 = 9166 руб.
Суммарные затраты на внедрение
КВПР = 461 500 + 9 374,4 + 3 720 + 245 + 9166= руб.
Таким образом, затраты на внедрение программного продукта
составили 484 005 рублей и равны балансовой стоимости продукта (или общей
стоимости владения).
3.2 Анализ
качественных и количественных факторов воздействия проекта на
бизнес-архитектуру организации
Внедрение системы психолингвистического анализа текстов
позволит:
автоматизировать процесс фоносемантического анализа текстов;
снизить трудоемкость процесса фоносемантического анализа
текстов;
уменьшит затраты на заработную плату лингвиста-аналитика.
Таким образом, внедрение вышеуказанной системы позволит
исключить ошибки, связанные с восприятием текста конкретным лингвистом ввиду
сведения человеческого фактора при анализе к минимуму [5].
Заключение
В результате выполнения выпускной квалификационной работы
были построены модели предметной области и разработанной системы. Модель
предметной области включает в себя диаграммы бизнес-процессов
"Как-есть" в нотациях IDEF0 и IDEF3 (всего 4 диаграммы), диаграммы
бизнес-процессов "Как-должно-быть" в нотациях IDEF0 и IDEF3 (всего 6
диаграмм). Модель системы (7 диаграмм) проектировалась в нотации UML и включает
в себя описание функциональных возможностей системы, ее логической и физической
структуры, а так же схему взаимодействия модулей. В системе реализовано более 7
сложных объектов, объем кода составляет более 1000 строк.
Полученный программный продукт отвечает всем требованиям
пользователей, а так же выполнил все задачи и цель ВКР. Разработанный модуль,
позволяет пользователю производить психолингвистический анализ текстов и
автоматически формировать отчеты в формате. xlsx. Таким образом, время,
необходимое для осуществления анализа, сокращается во много раз.
В настоящий момент времени система работает только с русскоязычными
текстами, потому база данных для математических расчетов есть только на русском
языке. В дальнейшем планируется провести масштабное исследование для
составление базы данных для англоязычных текстов и реализовать модуль анализа
текстов на английском языке (и соответственно локализовать систему для
англоязычных пользователей) [22].
Список
литературы
1.
Белоусов
К.И., Блазнова Н.А. Введение в экспериментальную. лингвистику: учеб. пособие /
К.И. Белоусов, Н.А. Блазнова. - М.: Флинта: Наука, 2005. - 136 с.
2.
Воронин
С.В. Фоносемантика как самостоятельная дисциплина. Исходные теоретические
положения // Общая психолингвистика: Хрестоматия. Учебное пособие / Сост.к.Ф.
Седова. - М.: Лабиринт, 2004. - 320 с.
3.
Гендер
и язык: сборник научных статей / Московский гос. лингвистический ун-т;
Лаборатория гендерных исследований. - М.: Языки славянской культуры, 2005 - 624
с.
4.
Дридзе
Т.М. Социально-психологические аспекты порождения и интерпретации текстов в
деятельности речевого общения. // Аспекты изучения текста. М., 1981. С.
129-136.
Журавлев
А.Н. Звук и смысл: Кн. для внеклассного чтения. - М.: Просвещение, 1981 - 160
с., ил.
5.
Залевская
А.А. Проблемы психолингвистики: вопросы теории и истории: лекции. - Алматы,
2006. - 56 с.
6.
Залевская
А.А. Психолингвистические исследования. Слово. Текст: Избранные труды. - М.:
Гнозис, 2005. - 543 с.
Имшинецкая
И. Фоносемантика в рекламе [Электронный ресурс] / И. Имшинецкая. - Режим
доступа: http://evartist. narod.ru/text11/60. htm, 1. 06.2015 г.
7.
Исследование
речевого мышления в психолингвистике: сборник научных трудов/ Отв. Ред. Е.Ф.
Тарасов. - М.: Наука, 1985. - 240 с.
8.
Котлячков
А., Горин С. Оружие - слово. - М.: 2001. - 215 с.
9.
Леонтьев
А.А. Психолингвистические единицы и порождение речевого высказывания: Монография.
- М.: Едиториал УРСС, 2003. - 312 с.
10.Настин И.В. Психолингвистика: учебно-методическое пособие. - М.:
Московский психолого-социальный институт, 2007. - 211 с.
11.Петренко В.Ф. Основы психосемантики: Учеб. пособие. - М.: Изд-во
Моск. ун-та, 1997. - 400 с.
12.Психолингвистические проблемы семантики: сборник научных трудов/
Отв. Ред.А. А. Леонтьев, А.М. Шахнарович. - М.: Наука, 1983. - 286 с.
13.Секерина И.А. Психолингвистика // Фундаментальные направления
современной американской лингвистики: сборник научных трудов. - М., 1997. - С.
231 - 256 с.
14.Фоносемантика [Электронный ресурс] / Материал из Википедии -
свободной энциклопедии. - Режим доступа: https: // ru.
wikipedia.org/wiki/фоносемантика, 1. 06.2015 г.
15.Фрумкина Р.М. Психолингвистика: Учеб. пособие для студ. высш.
учеб. заведений. - М.: Издательский центр "Академия", 2003. - 320 с.
16.Хроленко А.Т. Введение в лингвофольклористику: Учебное пособие
[Текст] / А.Т. Хроленко. - М.: Флинта: Наука, 2010. - 234 с.
17.Черемных, С.В. Моделирование и анализ систем. I DEF-технологии:
практикум / С.В. Черемных, И.О. Семенов, B. C. Ручкин. - М.: Финансы и
статистика, 2006. - 192 с: ил. - (Прикладные информационные технологии).
18.Языковое сознание: формирование и функционирование: сборник
научных трудов. - М., 1998. - 455 с.
19.Contemporary linguistics / Ed. by W. O'Grady, M. Dobrovolsky, M.
Aronoff. Boston, 1997.Р. 389-508.
20.Osgood Charles E. Method and Theory in Experimental Psychology
[Text] / Ch. E. Osgood. - Oxford, 1956. - 297 p.
Приложения
Приложение А.
Листинг исходного кода проекта
using System;System. Collections.
Generic;System.componentModel;System. Data;System. Drawing;System. Linq;System.
Text;System. Windows. Forms;System. IO;Word = Microsoft. Office. Interop.
Word;System. Text. RegularExpressions;Diplom
{partial class Form1: Form
{Form1 ()
{();
}string openWordDoc (string path) // открытие текстового
документа соответствующего формата
{. Application wordapp = new Word. Application ();. Visible =
false;filename = path;confirmConversions = true;readOnly =
true;addToRecentFiles = true;passwordDocument = Type. Missing;passwordTemplate
= Type. Missing;revert = false;writePasswordDocument = Type.
Missing;writePasswordTemplate = Type. Missing;format = Type. Missing;encoding =
Type. Missing;;oVisible = Type. Missing;openConflictDocument = Type.
Missing;openAndRepair = Type. Missing;documentDirection = Type.
Missing;noEncodingDialog = false;xmlTransform = Type. Missing;extention = path.
Split ('. ') [1];result="";(extention)
{"txt": result = File. ReadAllText (path);
break;"doc":"docx": Word. Document wordDoc = wordapp.
Documents. Open (ref filename,confirmConversions, ref readOnly, ref
addToRecentFiles,passwordDocument, ref passwordTemplate, ref
revert,writePasswordDocument, ref writePasswordTemplate,format, ref encoding,
ref oVisible,openAndRepair, ref documentDirection, ref noEncodingDialog, ref
xmlTransform);= wordDoc. Range (). Text;. Quit (); break;
}result;
}void словоToolStripMenuItem_Click (object sender, EventArgs
e)
{wordForm = new WordAnalitic ();. ShowDialog ();
}void открытьToolStripMenuItem_Click (object sender,
EventArgs e)
{(openFileDialog1. ShowDialog () == DialogResult. OK).
Text=openWordDoc (openFileDialog1. FileName);
}void выйтиToolStripMenuItem_Click (object sender, EventArgs
e)
{. Close ();
}void Form1_FormClosing (object sender, FormClosingEventArgs
e)
{(MessageBox. Show ("Вы точно хотите выйти из
программы?", "Вы покидаете программу.", MessageBoxButtons.
YesNo)! = DialogResult. Yes). Cancel = true;
}void btnStart_Click (object sender, EventArgs e)
{( (chbOutput. Checked) && (saveFileDialog1.
ShowDialog ()! = DialogResult. OK));. Text = "";<string> bgData
= new List<string> ();. Add (txtText. Text);. Add (saveFileDialog1. FileName);.
Enabled = false;.runWorkerAsync (bgData);. Visible = true;. Value = 25;
}<string> res;void bgWorker_DoWork (object sender,
DoWorkEventArgs e)
{<string> data = (List<string>) e.
Argument;(chbOutput. Checked)= Analyzer. GetTextWeight (data [0], new ExcelWorker
(data [1], data [1]));= Analyzer. GetTextWeight (data [0]);
}void bgWorker_RunWorkerCompleted (object sender,
RunWorkerCompletedEventArgs e)
{(res! = null)(string result in res)(! result. Contains
("--")). Text = txtResult. Text + result + "\n";(String.
IsNullOrEmpty (txtResult. Text)). Text = "Текст не имеет сильной
эмоциональной окрашенности. ";. Visible = false;. Enabled = true;. Value =
0;
}void пакетнаяОбработкаТекстаToolStripMenuItem_Click (object
sender, EventArgs e)
{( (folderBrowserDialog1. ShowDialog () == DialogResult. OK)
&& (saveFileDialog1. ShowDialog () ==DialogResult. OK))
{. Text = "";<string> bgData = new
List<string> ();. Add (folderBrowserDialog1. SelectedPath);. Add
(saveFileDialog1. FileName);. Enabled = false;.runWorkerAsync (bgData);.
Visible = true;
}
}void bgwPackage_DoWork (object sender, DoWorkEventArgs e)
{<string> data = (List<string>) e.
Argument;(sender as BackgroundWorker, data [0], data [1]);
}void bgwPackage_RunWorkerCompleted (object sender,
RunWorkerCompletedEventArgs e)
{. Show ("Пакетная обработка файлов успешно
завершена!");. Enabled = true;. Value = 0;. Visible = false;
}void PackageAnalyzer (BackgroundWorker bg, string OpenPath,
string SavePath)
{<string> files = Directory. GetFiles (OpenPath +
"\\", "*. txt"). ToList ();. AddRange (Directory. GetFiles
(OpenPath + "\\", "*. doc?"). ToList ());step = 100/files.
Count;ew = new ExcelWorker (SavePath, "", true);. OutputPackage
("Шкала \\ Текст", Analyzer. OutPutScales. ToList ());(string file in
files)
{<string> result = Analyzer. GetTextWeight (openWordDoc
(file));. ReportProgress (step);. OutputPackage (file, result);
}. Close ();
}void bgwPackage_ProgressChanged (object sender,
ProgressChangedEventArgs e)
{. Value += e. ProgressPercentage;
}System;System. Collections. Generic;System. Linq;System.
Text;System. Data;System. Data. OleDb;System. Data. SqlClient;System.
Windows;System. Windows. Forms;Diplom
{MSAccess
{static OleDbDataAdapter dataAdapter = new OleDbDataAdapter
();string file = "MyDB. mdb";static OleDbConnection SqlConnection ()
{
// string file = "DBTeis. db";con = new
OleDbConnection ();
// SqlConnectionStringBuilder conString = new
SqlConnectionStringBuilder ();conString = "Provider=Microsoft. Jet. OLEDB.
4. 0; Data Source=" + file + "; User Id=admin; Password=; ";.
ConnectionString = conString. ToString ();con;
}static DataTable GetData (string selectCommand)
{con = SqlConnection ();table = new DataTable ();
{. Open ();comm = new OleDbCommand (selectCommand, con);= new
OleDbDataAdapter (comm);commandBuilder = new OleDbCommandBuilder
(dataAdapter);. Locale = System. Globalization. CultureInfo. InvariantCulture;.
Fill (table);. Close ();
}(Exception e)
{. Show ("При выполнении запроса к базе данных произошла
ошибка: " + e. Message);
}table;
}
}
}System;System. Collections.
Generic;System.componentModel;System. Data;System. Drawing;System. Linq;System.
Text;System. Windows. Forms;System. Text. RegularExpressions;Diplom
{partial class WordAnalitic: Form
{WordAnalitic ()
{();
}void btnGo_Click (object sender, EventArgs e)
{matches = Regex. Matches (txtWord. Text, "
[^\\*а-яА-Я]", RegexOptions. IgnoreCase);(matches. Count! = 0)
{. Show ("Некорректно введено слово!!!!");;
}( (chbOutput. Checked) && (saveFileDialog1.
ShowDialog ()! = DialogResult. OK));. Text = "";<string> bgData
= new List<string> ();. Add (txtWord. Text);. Add (saveFileDialog1.
FileName);. Enabled = false;.runWorkerAsync (bgData);. Visible = true;. Value =
45;
}<string> res;void backgroundWorker1_DoWork (object
sender, DoWorkEventArgs e)
{<string> data = (List<string>) e.
Argument;(chbOutput. Checked)= Analyzer. GetWordWeight (data [0], new
ExcelWorker (data [1], data [1]));= Analyzer. GetWordWeight (data [0]);
}void backgroundWorker1_ProgressChanged (object sender,
ProgressChangedEventArgs e)
{
}void backgroundWorker1_RunWorkerCompleted (object sender,
RunWorkerCompletedEventArgs e)
{(res! = null)(string result in res). Text = txtResult. Text
+ result + "\n";(String. IsNullOrEmpty (txtResult. Text)). Text =
"Текст не имеет сильной эмоциональной окрашенности. ";. Visible =
false;. Enabled = true;. Value = 0;
}void WordAnalitic_Load (object sender, EventArgs e)
{
}
}
}System;System. Collections. Generic;System. Linq;System.
Text;System. Text. RegularExpressions;System. Data;System. Windows.
Forms;Diplom
{Analyzer
{static string [] scales = { "1. Хороший-плохой",
"2. Большой-маленький", "3. Нежный-грубый", "4.
Женственный-мужественный","5. Светлый-темный", "6.
Активный-пассивный", "7. Простой-сложный", "8.
Сильный-слабый","9. Горячий-холодный", "10.
Быстрый-медленный", "11. Красивый-отталкивающий", "12.
Гладкий-шероховатый","13. Легкий-тяжелый", "14.
Веселый-грустный", "15. Безопасный - страшный", "16. Величественный-низменный","17.
Яркий-тусклый", "18. Округлый-угловатый","19. Радостный -
печальный", "20. Громкий-тихий","21.
Длинный-короткий", "22. Храбрый-трусливый", "23.
Добрый-злой", "24. Могучий-хилый", "25.
Подвижный-медленный"};static string [] OutPutScales = {
"Хороший-Плохой", "Большой-Маленький",
"Нежный-Грубый", "Женственный-Мужественный","Светлый-Темный",
"Активный-Пассивный", "Простой-Сложный",
"Сильный-Слабый","Горячий-Холодный",
"Быстрый-Медленный", "Красивый-Отталкивающий",
"Гладкий-Шероховатый","Легкий-Тяжелый",
"Веселый-Грустный", "Безопасный-Страшный", "Величественный-Низменный","Яркий-Тусклый",
"Округлый-Угловатый","Радостный-Печальный",
"Громкий-Тихий","Длинный-Короткий",
"Храбрый-Трусливый", "Добрый-Злой",
"Могучий-Хилый", "Подвижный-Медленный"};MSAccess MSAccess
{
{new System. NotImplementedException ();
}
{
}
}ExcelWorker ExcelWorker
{
{new System. NotImplementedException ();
}
{
}
}static List<string> GetWordWeight (string word,
ExcelWorker output = null)
{
{= word + " ";<string> Result = new
List<string> ();<string, double> frequency = new
Dictionary<string, double> ();<string, double> weights = new
Dictionary<string, double> ();letters = MSAccess. GetData ("Select *
from Частототность where звук not like '_ [’юёяие] '");(DataRow letter in
letters. Rows)
{matches;goodletter = letter [1]. ToString (). Replace
("*", @"\*");teststring =
"АаОоЁёЕеИиУуЭэЯяЫыЮюЙйЧчЩщЖжШшЦц";( (letter [1]. ToString (). Length
== 1) && (! teststring. Contains (letter [1]. ToString ())))= Regex.
Matches (word, goodletter. ToString () + " [^\\*ьюёяие]",
RegexOptions. IgnoreCase); // Ищет в указанной входной строке все вхождения
заданного регулярного выражения.
{pattern = goodletter. Replace ("Ь", "
['ьюёяие] ");= Regex. Matches (word, pattern, RegexOptions. IgnoreCase);
// Ищет в указанной входной строке все вхождения заданного регулярного
выражения, используя указанные параметры сопоставления.
}(Match match in matches)
{(frequency. ContainsKey (letter [1]. ToString ()))
{[letter [1]. ToString ()] += 1;;
}. Add (letter [1]. ToString (), double. Parse (letter [2].
ToString ()));(match. Index == 0)
{. Add (letter [1]. ToString (), 4);;
}(match. Value. Contains ('*')). Add (letter [1]. ToString
(), 2);. Add (letter [1]. ToString (), 1);
}
}Pmax = frequency. Values. Max ();summKi = 0;(string sound in
frequency. Keys)
{[sound] = weights [sound] * Pmax / frequency [sound];+=
weights [sound];
}(output! = null)
{. weights = weights;. Pmax = Pmax;. frequency = frequency;
}(int i = 0; i < scales. Length; i++)
{scaleRes = getScaleSignificance (i, weights, summKi,
output);(! String. IsNullOrEmpty (scaleRes)). Add (scaleRes);
}(output! = null). Close ();Result;
}(Exception e)
{. Show ("При выполнении расчетов произошла ошибка,
проверьте введенные данные. ");null;
}
}static string getScaleSignificance (int scale,
Dictionary<string, double> frequency, double summ, ExcelWorker output =
null) // значение шкал
{F = 0;significance = MSAccess. GetData ("Select Буква,
Значение from Значимость where Признак = '"+ scales [scale]
+"'");<string, double> fk = new Dictionary<string,
double> ();(KeyValuePair<string, double> sound in frequency)
{[] sign = significance. Select ("Буква = '"+sound.
Key. Replace ("*","") +"'");. Add (sound. Key,
double. Parse (sign [0] [1]. ToString ()) * sound. Value);
}(output! = null). OutputWordScale (OutPutScales [scale],
fk);= fk. Values. Sum () /summ;(F <= 2. 5)OutPutScales [scale]. Split ('-')
[0];(F >= 3. 5)OutPutScales [scale]. Split ('-') [1];"";
}static List<string> GetTextWeight (string text,
ExcelWorker output = null) // анализ текста
{
{<string, double> frequency = new Dictionary<string,
double> ();<string, double> realFrequency = GetFrequency (text, ref
frequency);<string, double> sigma = new Dictionary<string, double>
();<string> result = new List<string> ();[] separator = { ' ',
'\n', '\r' };<string> words = text. Split (separator, StringSplitOptions.
RemoveEmptyEntries). ToList ();blockLength = words. Count / 5;(blockLength! =
0)
{<Dictionary<string, double>> realFreq = new
List<Dictionary<string, double>> ();. Add (realFrequency);(int i =
4; i >= 0; i--)
{<string, double> partFreq = new Dictionary<string,
double> ();[] tmp = new string [words. Count - blockLength * i];. CopyTo
(blockLength * i, tmp, 0, words. Count - blockLength * i);. Add (GetFrequency
(String. Concat (tmp), ref partFreq));. RemoveRange (words. Count - tmp.
Length, tmp. Length);
}= GetSigma (realFreq);
}
{. Show ("В выбранном документе менее 5 слов. Корректно
провести анализ невозможно. ");null;
}<string, double> midDeviation = new
Dictionary<string, double> ();(string sound in frequency. Keys). Add
(sound, (realFrequency [sound] - frequency [sound]) / sigma [sound]);(int i =
0; i < scales. Length; i++)
{<string, double> signDeviation = new
Dictionary<string, double> ();<string, double> contribution = new
Dictionary<string, double> ();significance = MSAccess. GetData
("Select Буква, Значение from Значимость where Признак = '" + scales
[i] +
"' and Буква not like '_ [юёяие] '");(string sound
in frequency. Keys)
{( (midDeviation [sound] < - 1) || (midDeviation [sound]
> 1))
{[] sign = significance. Select ("Буква = '" +
sound + "'");. Add (sound, 3. 0 - double. Parse (sign [0] [1].
ToString ()));. Add (sound, midDeviation [sound] * signDeviation [sound]);
}
{. Add (sound, 0);. Add (sound, 0);
}
}(output! = null)
{. frequency = frequency;. weights = realFrequency;.
OutputTextScale (OutPutScales [i], midDeviation, signDeviation, contribution);
}sum = contribution. Values. Sum ();fringe = 5;(text. Length
> 1000)+= text. Length / 1000;(sum > fringe). Add (OutPutScales [i].
Split ('-') [0] + " (" + sum. ToString () + ")");
{(sum < 0-fringe). Add (OutPutScales [i]. Split ('-') [1]
+ " (" + sum. ToString () + ")");. Add (" - (" +
sum. ToString () + ")");
}
}(output! = null). Close ();result;
}(Exception e)
{. Show ("При выполнении расчетов произошла ошибка,
проверьте введенные данные. ");null;
}
}static Dictionary<string, double> GetSigma
(List<Dictionary<string, double>> realFreq) // вычисление сигмы для
статистики
{<string, double> sigma = new Dictionary<string,
double> ();(string sound in realFreq [0]. Keys)
{midSound = 0;(int i = 1; i < 6; i++)(realFreq [i].
ContainsKey (sound))+= realFreq [i] [sound];/= 5;. Add (sound, 0);(int i = 1; i
< 6; i++)
{(realFreq [i]. ContainsKey (sound))[sound] += Math. Pow (
(realFreq [i] [sound] - midSound), 2);[sound] += Math. Pow (midSound, 2);
}[sound] = Math. Pow (sigma [sound] * 0. 2, 0. 5);
}sigma;
}static Dictionary<string, double> GetFrequency (string
text, ref Dictionary<string, double> frequency) // вычисление частотности
{soundcount = 0;= text + " ";<string, double>
realFrequency = new Dictionary<string, double> ();letters = MSAccess.
GetData ("Select * from Частототность where звук not like '_ [*’юёяие]
'");teststring = "АаОоЁёЕеИиУуЭэЯяЫыЮюЙйЧчЩщЖжШшЦц";(DataRow
letter in letters. Rows)
{matches;( (letter [1]. ToString (). Length == 1) &&
(! teststring. Contains (letter [1]. ToString ())))= Regex. Matches (text,
" (" + letter [1] + @" [^ьюёяие])", RegexOptions.
IgnoreCase);
{pattern = letter [1]. ToString (). Replace ("Ь",
" [ьюёяие] ");= Regex. Matches (text, pattern, RegexOptions.
IgnoreCase);
}(Match match in matches)
{(frequency. ContainsKey (letter [1]. ToString ()))
{[letter [1]. ToString ()] += 1;++;;
}. Add (letter [1]. ToString (), double. Parse (letter [2].
ToString ()));. Add (letter [1]. ToString (), 1);++;
}
}(string sound in frequency. Keys)[sound] /=
soundcount;realFrequency;
}
}
}System;System. Collections. Generic;System. Linq;System.
Text;System. Windows. Forms;Excel = Microsoft. Office. Interop. Excel;Diplom
{ExcelWorker
{path;Excel. Application excel;currentSheet;. Workbook
workbook;Dictionary<string, double> frequency;Dictionary<string,
double> weights;double Pmax;name;ExcelWorker (string path, string name, bool
package=false)
{. path = path;. name = name;= new Excel. Application ();(!
package). SheetsInNewWorkbook = 25; // количество листов в книге.
SheetsInNewWorkbook = 1;. Workbooks. Add (Type. Missing); // добавляем книгу=
excel. Workbooks [excel. Workbooks. Count]; // получам ссылку на первую
открытую книгу= 1;
}void OutputPackage (string fileName, List<string>
scales)
{columns = "ABCDEFGHIJKLMNOPQRSRUVWXY";. Worksheet
sheet = workbook. Worksheets. get_Item (1);. Cells [1, currentSheet] =
fileName;(int i=0; i<scales. Count; i++). Cells [i+2, currentSheet] = scales
[i];. Range rng = (Excel. Range) sheet. Cells. get_Range (columns
[currentSheet-1]. ToString () + 1. ToString (), columns [currentSheet-1].
ToString () + (scales. Count+1). ToString ());. Borders. LineStyle = Excel.
XlLineStyle. xlContinuous;. Borders. Weight = Excel. XlBorderWeight. xlMedium;.
ColumnWidth = rng. ColumnWidth * 2;. WrapText = true;++;
}void OutputTextScale (string scale, Dictionary<string,
double> midDeviation, Dictionary<string, double> signDeviation,
Dictionary<string, double> contribution) // вывод отчета по тексту
{
{. Worksheet sheet = workbook. Worksheets. get_Item
(currentSheet); // получаем ссылку на лист. Range header = (Excel. Range)
sheet. get_Range ("A1", "F2"). Cells;. Merge (Type.
Missing);. Value = "Выбор признака " + scale + " для текста
\"" + name + "\"";. Cells [3, 1] =
"Звукобуквы";. Cells [3, 2] = "Нормальная частотность
звукобуквы";. Cells [3, 3] = "Частотность звукобукв в тексте";.
Cells [3, 4] = "Отклонения частотностей от нормы";. Cells [3, 5] =
"Отклонения значимости от нейтральной точки";. Cells [3, 6] =
"Вклад каждой звукобуквы в общий тон текста";(int i = 1; i < 7;
i++). Cells [4, i] = i;row = 5;(string sound in frequency. Keys)
{. Cells [row, 1] = sound;. Cells [row, 2] = frequency
[sound];. Cells [row, 3] = weights [sound];. Cells [row, 4] = midDeviation
[sound];. Cells [row, 5] = signDeviation [sound];. Cells [row, 6] =
contribution [sound];++;
}. Range end = (Excel. Range) sheet. get_Range ("A"
+ row, "E" + row). Cells;. Merge (Type. Missing);. Value =
"Суммарный показатель данного признака в создании общей фонетической
значимости текста";. Cells [row, 6] = contribution. Values. Sum ();.
Cells. get_Range ("A1", "F" + row). Borders. LineStyle =
Excel. XlLineStyle. xlContinuous;. Cells. get_Range ("A1",
"F" + row). Borders. Weight = Excel. XlBorderWeight. xlMedium;.
Cells. get_Range ("A1", "F" + (row + 1)). WrapText =
true;++;
}(Exception e)
{. Show ("При формировании отчета произошла
ошибка");;
}
}void OutputWordScale (string scale, Dictionary<string,
double> fk) // отчет по слову
{
{. Worksheet sheet = workbook. Worksheets. get_Item
(currentSheet); // получаем ссылку на лист. Range header = (Excel. Range)
sheet. get_Range ("A1", "F2"). Cells;. Merge (Type.
Missing);. WrapText = true;. Value = "Вычисление фонетической значимости
слова " + name + " по шкале \"" + scale +
"\"";. Range thletter = (Excel. Range) sheet. get_Range
("A3", "A4"). Cells;. Merge (Type. Missing);. Value =
"Звукобуквы";. Range thstart = (Excel. Range) sheet. get_Range
("B3", "C3"). Cells;. Merge (Type. Missing);. Value =
"Исходные данные";. Range thmid = (Excel. Range) sheet. get_Range
("D3", "F3"). Cells;. Merge (Type. Missing);. Value =
"Промежуточные данные";. Cells [4, 2] = "fi";. Cells [4, 3]
= "pi";. Cells [4, 4] = "pmax/pi";. Cells [4, 5] =
"ki";. Cells [4, 6] = "fi*ki";row = 5;(string sound in fk.
Keys)
{. Cells [row, 1] = sound;. Cells [row, 2] = fk [sound] /
weights [sound];. Cells [row, 3] = frequency [sound];. Cells [row, 4] = Pmax /
frequency [sound];. Cells [row, 5] = weights [sound];. Cells [row, 6] = fk
[sound];++;
}. Cells [row, 1] = "Сумма: ";. Cells [row, 5] =
weights. Values. Sum ();. Cells [row, 6] = fk. Values. Sum ();++;. Range res =
(Excel. Range) sheet. get_Range ("A" + row, "F" + row).
Cells;. Merge (Type. Missing);. Value = "F = " + fk. Values. Sum () +
" / " + weights. Values. Sum () + " = " + fk. Values. Sum
() / weights. Values. Sum ();. Cells. get_Range ("A1", "F"
+ row). Borders. LineStyle = Excel. XlLineStyle. xlContinuous;. Cells.
get_Range ("A1", "F" + row). Borders. Weight = Excel.
XlBorderWeight. xlMedium;. Cells. get_Range ("A1", "F" +
(row + 1)). WrapText = true;++;
}(Exception e)
{. Show ("При формировании отчета произошла
ошибка");;
}
}void Close ()
{
{. SaveAs (path);. Quit ();
}(Exception e)
{. Show ("При сохранении отчета произошла
ошибка");;
}
}
}