Розробка алгоритму ідентифікації різних видів складних об’єктів моніторингу при веденні інформаційної роботи
ЗМІСТ
ПЕРЕЛІК УМОВНИХ ПОЗНАЧЕНЬ
ВСТУП
. ТАКТИКО − ТЕХНІЧНЕ
ОБГРУНТУВАННЯ НЕОБХІДНОСТІ РОЗРОБКИ АЛГОРИТМУ ІДЕНТИФІКАЦІЇ СКЛАДНИХ ОБ’ЄКТІВ
МОНІТОРИНГУ НА ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ КЛАСТЕРНОГО АНАЛІЗУ
.1 Методи та алгоритми
кластеризації
.2 Постановка задачі
дослідження
. РОЗРОБКА АЛГОРИТМУ
ІДЕНТИФІКАЦІЇ СКЛАДНИХ ОБ’ЄКТІВ МОНІТОРИНГУ НА ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ
КЛАСТЕРНОГО АНАЛІЗУ
.1 Основні ознаки, що
дозволяють здійснювати ідентифікацію складних об’єктів моніторингу на основі
нечітких алгоритмів кластерного аналізу
.2 Вибір доцільного алгоритму
кластеризації складних об’єктів моніторингу
.3 Синтез математичної моделі
кластеризації об’єктів за результатами роботи засобів радіомоніторингу
.4 Алгоритм ідентифікації
складних об’єктів моніторингу на основі нечітких алгоритмів кластерного аналізу
. АПРОБАЦІЯ АЛГОРИТМУ
ІДЕНТИФІКАЦІЇ РІЗНИХ ТИПІВ СКЛАДНИХ ОБ’ЄКТІВ НА ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ
КЛАСТЕРНОГО АНАЛІЗУ
. ОХОРОНА ПРАЦІ
.1 Аналіз умов праці на
робочому місці
.2 Вимоги безпеки при роботі з
ПЕОМ
ВИСНОВКИ
ПЕРЕЛІК ПОСИЛАНЬ
Додаток. Програма реалізації
алгоритму ідентифікації складних ОМ на основі нечітких алгоритмів кластерного
аналізу
ПЕРЕЛІК УМОВНИХ ПОЗНАЧЕНЬ
¾ ГІС геоінформаційна
система
¾ ДРВп джерело
радіовипромінювання
¾ ЗС збройні
сили
¾ ІР інформаційна
робота
¾ ОМ об’єкт
моніторингу
¾ РЕО радіоелектронна
обстановка
¾ РЛС радіолокаційна
станція
¾ РМ радіомоніторинг
¾ РТМ радіотехнічний
моніторинг
ВСТУП
Об’єктом дослідження кваліфікаційної
роботи є процес ведення інформаційної роботи підрозділами радіомоніторингу
(РМ). Предметом дослідження є програмно - алгоритмічне забезпечення
інформаційної роботи (ІР) ідентифікації об’єктів моніторингу (ОМ) за
результатами роботи засобів РМ. Ведення ІР має на меті обробку даних від
добуваючих підрозділів. Зокрема, підвищення інформаційного забезпечення
застосування військ, у підрозділах і частинах збройних сил (ЗС) передбачається
за рахунок підвищення точності визначення місцеположення джерела
радіовипромінювання (ДРВп) засобами моніторингу з подальшою їх ідентифікацією
та створенням відповідних моделей їх діяльності.
Метою роботи є розробка алгоритму
ідентифікації різних видів складних ОМ при веденні ІР, внаслідок роботи якого
збільшується швидкість обробки інформації, яка надходить від засобів РМ та
збільшується час для прийняття рішення оператором.
Робота виконувалась методом
кластерного аналізу, адже одним з найефективніших варіантів побудови моделі
розміщення складних об’єктів моніторингу в умовах відсутності апріорної вибірки
є застосування кластерного аналізу. Використання алгоритмів кластеризації
дозволяє здійснювати побудову можливих варіантів розміщення об’єктів
моніторингу з врахуванням особливостей рельєфу місцевості на основі
геоінформаційних систем (ГІС) з меншими затратами часу.
Отримані результати відображають
бойовий порядок, тип підрозділу та радіоелектронну обстановку (РЕО) в ньому.
Для побудови моделі розміщення складних об’єктів моніторингу застосовується
принцип статистичного детермінованого розміщення простих об’єктів. Застосування
даного принципу зводиться до послідовного отримання засічок для побудови моделі
відображення РЕО.
Результати роботи можуть бути
використані для ведення ІР підрозділами РМ.
Розвиток даної роботи полягає у
збільшенні кількості ознак ідентифікації, що в свою чергу призведе до
збільшення ймовірності правильного розпізнавання складних ОМ.
1. ТАКТИКО - ТЕХНІЧНЕ ОБГРУНТУВАННЯ
НЕОБХІДНОСТІ РОЗРОБКИ АЛГОРИТМУ ІДЕНТИФІКАЦІЇ СКЛАДНИХ ОБ’ЄКТІВ МОНІТОРИНГУ НА
ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ КЛАСТЕРНОГО АНАЛІЗУ
Сьогодні, основою досягнення
переваги над противником є технологічна перевага та збільшення інформаційної
складової забезпечення бойових дій ЗС, а головною рисою сучасної збройної
боротьби - інтеграція процесів ведення моніторингу, передачі даних, управління
військами та зброї, вогневої поразки противника в масштабі часу близькому до
реального.
Цим питанням присвячено чимало
розробок закордонних і вітчизняних фахівців. Їх успішність радикально
пов’язують з можливостями добувати й доставляти споживачеві необхідну
інформацію для вирішення визначених збройним силам завдань.
Метою даного розділу є обґрунтування
необхідності удосконалення процесу розпізнавання та вибір доцільного алгоритму
ідентифікації складних ОМ.
Даний алгоритм повинен забезпечити
вибір найкращого рішення з множини можливих рішень при проведенні ідентифікації
складних ОМ. Процес прийняття рішення при веденні РМ характеризується частковою
невизначеністю, неповнотою і недостовірністю інформації, малим резервом часу та
динамічною зміною РЕО. Крім того, він повинен враховувати існуючі недоліки
процесу ідентифікації складних ОМ.
Враховуючи особливості ведення РМ:
умови невизначеності та відсутність апріорної інформації про груповий об’єкт,
що робить не можливим використання класичної теорії ідентифікації
(класифікації), в даній роботі мною запропоновано рішення даної задачі за
допомогою кластерного аналізу [3].
Згідно [9] кластерний аналіз - це
спосіб групування багатовимірних об’єктів, оснований на представленні
результатів окремих спостережень точками геометричного простору з подальшим
виділенням груп як «згустків» цих точок.
Таким чином, основна мета аналізу -
виділити у вхідних багатовимірних масивах даних такі однорідні підмножини, щоб
об’єкти всередині груп були схожі між собою, а об’єкти з різних груп - не
схожі. Під «схожістю» розуміється близькість об’єктів в багатовимірному
просторі ознак, і тоді задача зводиться до виділення в цьому просторі скупчень
об’єктів, які вважаються однорідними групами. В даному розділі розглянуто
існуючі алгоритми кластеризації та проведено їх аналіз [7], а також здійснено
постановку задачі дослідження. Задача ідентифікації вирішується в умовах
невизначеності, адже для кожного окремого завдання необхідно вибрати
відповідний алгоритм і міри відстаней. Вибір метрики повністю лежить на операторі,
оскільки результати кластеризації можуть істотно відрізнятися при використанні
різних способів визначення ступеня схожості. Візуалізація великої кількості
просторових даних займає тривалий час. Дана проблема вирішується за допомогою
вибору найбільш доцільного методу кластеризації, що дозволить багато в чому
покращити процес відображення просторових даних і полегшить роботу з ними.
1.1 Методи
та алгоритми кластеризації
кластеризація моніторинг
складний об'єкт
З аналізу літератури [2] визначено,
що загальноприйнятої класифікації методів кластеризації не існує. Але якщо
узагальнити різні методи кластеризації, то можна виділити ряд груп.
Об'єднання схожих об'єктів у групи
може бути здійснене різними способами. Серед таких груп, згідно
[18] виділяються наступні:
а) ієрархічні групи - будують не
одне розбиття вибірки на кластери, що не перетинаються, а систему вкладеного
розбиття. За допомогою таких груп можна виділити кластери, об’єднуючи менші
кластери та розподіляючи більші. Тобто на виході створюється дерево кластерів,
на різних рівнях якого можна отримати різне розподілення на кластери. Серед
груп ієрархічної кластеризації виділяються два основні типи: висхідні і
низхідні алгоритми.
низхідні типи груп кластеризації
працюють за принципом «згори-вниз»: на початку усі об'єкти поміщаються в один
кластер, який потім розбивається на дрібніші кластери.
висхідні типи, які на початку роботи
поміщають кожен об'єкт в окремий кластер, а потім об'єднують кластери у більші,
поки усі об'єкти вибірки не будуть міститись в одному кластері.
б) неієрархічні (плоскі) - будують
одне розбиття об’єктів на кластери. Плоскі групи вважаються досить швидкими та
простими в дії. До того ж одноразове розбиття дозволяє уникнути необхідності
зберігати велику кількість проміжних даних. Серед таких груп кластеризації
виділяються наступні типи:
типи, які ґрунтовані на теорії
графів. Суть їх полягає в тому, що вибірка об'єктів представляється у вигляді
графа G= (V, E), вершинам (V) якого відповідають об'єкти, а ребра (E) мають
вагу, яка дорівнює «відстані» між об'єктами. Перевагою даних типів
кластеризації є наочність, відносна простота реалізації і можливість внесення
різних удосконалень, які ґрунтовані на геометричних міркуваннях.
EM - тип. Алгоритм EM - типу
використовують в математичній статистиці для пошуку оцінок максимальної
правдоподібності параметрів ймовірнісних моделей, коли модель залежить від
деяких прихованих змінних. Кожна ітерація EM-типу алгоритму складається з двох
кроків. На E-кроку (expectation) обчислюється очікуване значення функції
правдоподібності, при цьому приховані змінні розглядаються як спостережувані.
На M-кроку (maximization) обчислюється оцінка максимальної правдоподібності,
таким чином збільшується очікувана правдоподібність, що обчислюється на
E-кроці. Потім це значення використовується для E-кроку на наступній ітерації.
Алгоритм виконується до збіжності.
K - середніх (k - means) - тип.
Алгоритм цього типу будує задане число кластерів, розташованих якнайдалі один
від одного. Робота алгоритму ділиться на декілька етапів: випадковий вибір k
точок, що є початковими «центрами мас» кластерів; віднесення кожного об'єкта до
кластера з найближчим «центром мас»; перерахування «центрів мас» кластерів
згідно з їх поточним складом; якщо критерій зупинки алгоритму не задоволений,
то повернутися до віднесення кожного об'єкта до кластера з найближчим «центром
мас». В якості критерію зупинки роботи алгоритму зазвичай вибирають мінімальну
зміну середньоквадратичної похибки. Так само можливо зупиняти роботу алгоритму,
якщо при спробі віднести об'єкт до кластера з найближчим «центром мас», не було
об'єктів, що перемістилися з кластера в кластер. До недоліків цього алгоритму
можна віднести необхідність задавати кількість кластерів для розбиття.
C - середніх (c - means) - найбільш
популярний тип нечіткої кластеризації. Він є модифікацією типу k- середніх.
Кроки роботи алгоритму даного типу:
) вибір початкового нечіткого
розбиття n об'єктів k кластерів шляхом вибору матриці приналежності U розміру n
* k;
) використовуючи матрицю U, пошук
значення критерію нечіткої помилки; кожне спостереження «приписується» до
одного з n кластерів - того, відстань до якого найкоротша;
)розрахунок нового центра кожного
кластера як елемент, ознаки якого розраховуються як середнє арифметичне ознак
об’єктів, що входять у цей кластер.
Відбувається стільки ітерацій
(повторюються кроки 3-4), поки кластерні центри не стануть стійкими.
Не дивлячись на значні відмінності
між перерахованими методами всі вони спираються на початкову « гіпотезу
компактності»: у просторі об’єктів всі близькі об’єкти повинні відноситись до
одного кластера, а всі різні (відмінні) об’єкти відповідно повинні знаходитись
у різних кластерах відповідно. Для вирішення основної задачі, тобто
ідентифікації ОМ за допомогою алгоритмів кластерного аналізу доцільним буде
застосування алгоритму C - середніх - типу. Адже даний тип алгоритму має ряд
особливостей та переваг, він дозволяє одному і тому ж об’єкту належати
одночасно кільком кластерам з різним ступенем приналежності, а також він
простий і швидкий та легко реалізується на практиці.
1.2
Постановка задачі дослідження
Процес прийняття рішення при веденні
РМ характеризується частковою невизначеністю і недостовірністю інформації,
малим резервом часу та динамічною зміною РЕО. Проаналізувавши теоретичний
матеріал було встановлено, що на сучасному етапі існує велика кількість типів
кластеризації, які використовують різні принципи та підходи. Але, незважаючи на
це, проблема актуальна, розробляються нові алгоритми для вирішення тих чи інших
завдань. Для роботи над кваліфікаційною роботою необхідно проаналізувати методи
і алгоритми кластеризації, розібратися в області застосування кожного з них і
вибрати найбільш доцільний для даного завдання алгоритм, який повинен
забезпечувати: вибір найкращого рішення з множини можливих рішень ідентифікації
складних ОМ, головним елементом якого є кластеризація.
Підвищення вимог до достовірності та
оперативності прийнятих рішень в процесі ведення ІР потребують комплексування
даних різних видів моніторингу. Тим часом,
існуючі способи визначення місця положення ОМ та їх ідентифікації неоптимальні
стосовно основних показників ефективності. Такими показниками є ймовірність
правильного ухвалення рішення і час його прийняття. В ідеалі потрібно домогтися
покращення даних параметрів, але через їхній взаємозв’язок це неможливо.
Підвищення достовірності потребує обробки й аналізу додаткової інформації, що
неминуче призводить до збільшення часу.
Задачу підвищення достовірності
своєчасного і правильного рішення для визначення місцеположення ОМ та його
ідентифікації можна вирішити шляхом автоматизації процесу обробки інформації і
формування рекомендацій, що призведе до значного зменшення часу інформаційної
підготовки прийняття рішення. Його зменшення дасть оператору більше часу на
прийняття рішення, що дозволить більш детально аналізувати інформацію, яка
надходить про ОМ, і дасть можливість використання додаткової інформації. Це, у
свою чергу, призведе до підвищення ймовірності правильного прийняття рішення
при тому ж часі виконання алгоритму прийняття рішення. Вироблення рекомендацій
оператору дасть можливість істотно спростити наступний етап його роботи - етап
безпосереднього прийняття рішення.
Отже, задачу дослідження по
ідентифікації ОМ з використанням різних видів ДРВп в загальному вигляді можна
сформулювати таким чином: необхідно за певними показниками РЕО провести
ідентифікацію ОМ з максимальною достовірністю за заданий час.
Часові витрати на прийняття рішення
в автоматизованій системі управління (АСУ) з аналізу наявних матеріалів можливо
відобразити за допомогою діаграми (рис.1.1).

Рисунок 1.1 − Часова
діаграма прийняття рішень
На
рис. 1.1 прийняті такі умовні позначення:
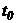 - час збору
інформації технічними засобами;
- час збору
інформації технічними засобами;
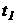 - час, що
витрачається на обробку інформації і формування первинних гіпотез;
- час, що
витрачається на обробку інформації і формування первинних гіпотез;
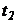 - час, що
витрачається на вибір рішення;
- час, що
витрачається на вибір рішення;
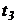 - час,
необхідний для реалізації прийнятого рішення.
- час,
необхідний для реалізації прийнятого рішення.
Як
видно з діаграми (рис.1.1), значна частина часу йде на обробку інформації і
формування гіпотез. На вибір рішення приділяється досить малий час, що може
привести до низької його імовірності. Це може викликати прийняття неадекватних
рішень.
Отже, задача комплексування даних
різних видів радіомоніторингу сформульована таким чином: необхідно за
показниками 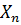 оцінити
місцеположення ОМ та провести його ідентифікацію D за допустимий час з
максимальною достовірністю. У формалізованому вигляді її можна представити:
оцінити
місцеположення ОМ та провести його ідентифікацію D за допустимий час з
максимальною достовірністю. У формалізованому вигляді її можна представити:
 ,
(1.1)
,
(1.1)
де 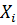 − показник з визначеної множини
− показник з визначеної множини  ;
;
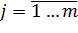 −
варіанти оцінки місцеположення ОМ;
−
варіанти оцінки місцеположення ОМ;
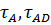 −
час і допустимий час аналізу відповідно.
−
час і допустимий час аналізу відповідно.
Висновок до першого розділу
На основі визначених недоліків та
обґрунтованого методу ідентифікації ОМ у межах даної кваліфікаційної роботи
необхідно провести наступні дослідження: визначити ознаки, що характеризують
процес iдентифiкацiї складних об’єктів по різних видах РМ, розробити модель
iдентифiкацiї складних ОМ по різних видах РМ, розробити програмно-алгоритмічне
забезпечення.
2. РОЗРОБКА АЛГОРИТМУ ІДЕНТИФІКАЦІЇ
СКЛАДНИХ ОБ’ЄКТІВ МОНІТОРИНГУ НА ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ КЛАСТЕРНОГО АНАЛІЗУ
В даному розділі здійснюється
розробка алгоритму ідентифікації об’єктів моніторингу на основі нечітких
алгоритмів кластерного аналізу. Розробка охоплює чотири етапи. На першому етапі
проаналізовано методи розрахунку відстаней між об’єктами і центрами кластерів,
обґрунтовано який для вирішення задачі кваліфікаційної роботи буде
найдоцільнішим. На другому етапі вибрано сукупність алгоритмів кластеризації,
на основі яких буде будуватись математична модель. На третьому етапі
розраховано математичну модель кластеризації ОМ за результатами роботи засобів
РМ та РТМ. На завершальному четвертому етапі побудовано власне алгоритм
ідентифікації складних ОМ на основі нечітких алгоритмів кластерного аналізу.
2.1 Основні
ознаки, що дозволяють здійснювати ідентифікацію складних об’єктів моніторингу
на основі нечітких алгоритмів кластерного аналізу
Відомі [2] деякі етапи
кластеризації. Початковим етапом кластеризації є необхідність складання вектора
характеристик для кожного об’єкта - як правило, це набір ознак з невеликими
числовими значеннями. Однак існують також алгоритми, що працюють з якісними
(категорійними) характеристиками. Вихідними даними для здійснення кластеризації
ОМ буде вектор характеристик географічних координат просторових даних
розміщення ДРВ; частотний діапазон та інтенсивність їх роботи. Визначивши
вектор характеристик, можна провести його нормалізацію, щоб всі компоненти
давали однаковий внесок при розрахунку «відстані». У процесі нормалізації всі
значення приводяться до деякого діапазону, наприклад, [-1, -1] або [0, 1]. Для
кожної пари об’єктів вимірюється «відстань» між ними - ступінь схожості. Існує
безліч метрик, ось лише основні з них:
відстань Евкліда. Найбільш поширена
функція відстані. Є геометричною відстанню у багатовимірному просторі. Такий
метод шукає кластери як сфери однакового розміру.
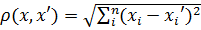 ,
(2.1)
,
(2.1)
де 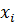 − центр i-го кластера;
− центр i-го кластера;
 −
і-ий об’єкт кластеризації;
−
і-ий об’єкт кластеризації;
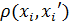 −
відстань між об’єктами з вихідної матриці даних і центрами кластерів;−
кількість елементів у вибірці.
−
відстань між об’єктами з вихідної матриці даних і центрами кластерів;−
кількість елементів у вибірці.
квадрат евклідової відстані.
Застосовується для надання більшої ваги віддаленішим один від одного об’єктам.
Ця відстань обчислюється таким чином:
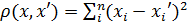 ;
(2.2)
;
(2.2)
відстань міських кварталів
(манхеттенська відстань). Ця відстань є середньою різниць по координатах. У
більшості випадків застосування такої відстані призводить до таких же
результатів, як і для звичайної відстані Евкліда. Проте при його застосуванні
вплив окремих великих різниць (викидів) зменшується (оскільки вони не зводяться
в квадрат). Формула для розрахунку манхеттенскої відстані:
 ;
(2.3)
;
(2.3)
відстань Чебишева. Ця відстань може
виявитися корисною, коли треба визначити два об'єкти як «різні», якщо вони
розрізняються по будь - якій одній координаті. Відстань Чебишева обчислюється
за формулою:
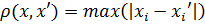 ;
(2.4)
;
(2.4)
степенева відстань. Застосовується у
разі, коли необхідно збільшити або зменшити вагу, що відноситься до
розмірності, для якої відповідні об’єкти сильно відрізняються. Степенева
відстань обчислюється за наступною формулою:
 ,
(2.5)
,
(2.5)
де r і p - параметри, що визначаються
користувачем. Параметр p відповідальний за поступове зважування різниць по
окремих координатах, параметр r відповідальний за прогресивне зважування
великих відстаней між об’єктами. Якщо обидва параметри - r і p - рівні 2, то ця
відстань співпадає з відстанню Евкліда.
Вибір метрики повністю лежить на
досліднику, оскільки результати кластеризації можуть істотно відрізнятися при
використанні різних метрик [19].
Для даного випадку найбільш доцільна
метрика - Евклідова [5], так як дана міра ідеально підходить для розрахунку
географічних відстаней та бойових порядків. Решта метрик менш доцільніші, так
як вони застосовуються для вирішення інших специфічних завдань, і не придатні
для здійснення кластеризації просторових даних. Основні характеристики бойових
порядків засобів ППО і ознаки по яких можливо здійснювати кластеризацію
представлені у табл. 2.1.
Таблиця 2.1
Основні характеристики бойових
порядків засобів ППО і ознаки по яких можливо здійснювати кластеризацію
|
Назва дивізіону
|
Кількість бойових батарей, шт.
|
Відстань між бойовими батареями, км
|
Віддаленість від переднього краю, км
|
Дальність зв’язку, км
|
|
“Чапарел - Вулкан”
|
3
|
8-15
|
>15
|
8-30
|
|
“Петріот”
|
6
|
30-50
|
>40
|
30-100
|
|
“Удосконалений Хок”
|
3-4
|
15-40
|
>35
|
15-80
|
Ознаки, по яким здійснюється
кластеризація:
кількість бойових батарей - N;
відстань між бойовими батареями 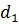 ;
;
віддаленість від переднього краю 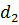 ;
;
дальність зв’язку
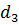 .
.
2.2 Вибір
доцільного алгоритму кластеризації складних об’єктів моніторингу
Проаналізувавши відомі алгоритми
кластеризації [4] , для вирішення задачі ідентифікації, найбільш доцільними є
нечіткі алгоритми. Нечіткі методи кластеризації, на відміну від чітких,
дозволяють одному і тому ж об’єкту належати одночасно кільком кластерам з
різним ступенем приналежності. Нечітка кластеризація в багатьох ситуаціях
переважає чітку, зокрема для об’єктів, розташованих на грані кластерів.
Алгоритм кластеризації складається з
ряду блоків:
вибір початкового нечіткого розбиття
n об’єктів k кластерів шляхом вибору матриці приналежності U розміру n x k;
пошук значення критерію нечіткої
помилки, використовуючи матрицю U:
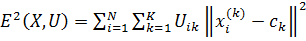 ,
(2.6)
,
(2.6)
де  -
«центр мас» нечіткого кластера k :
-
«центр мас» нечіткого кластера k :
 ;
(2.7)
;
(2.7)
кожне спостереження «приписується»
до одного з n кластерів - того, відстань до якого найкоротша;
розраховується новий центр кожного
кластера як елемент, ознаки якого розраховуються як середнє арифметичне ознак об’єктів,
що входять у цей кластер.
Відбувається така кількість ітерацій
(повторюються кроки 3-4), поки кластерні центри не стануть стійкими (тобто при
кожній ітерації в кожному кластері виявлятимуться одні й ті самі об’єкти). Це
повторення грунтоване на мінімізації цільової функції, яка представляє собою
відстань від будь-якого елемента кластера у центрі самого кластеру, зважених
щодо членства класу, відносно іншого елемента кластера. Дисперсія всередині
кластера буде мінімізована, а між кластерами - максимізована. Цей алгоритм може
не підійти, якщо заздалегідь невідоме число кластерів, або необхідно однозначно
віднести кожен об'єкт до одного кластера.
Переваги:
простота та швидкість виконання.
Недоліки:
результат кластеризації у найбільшій
мірі залежить від випадкових початкових позицій кластерних центрів;
алгоритм чутливий до аномальних
вимірів (викидів), які можуть викривлювати середнє.
Існують наступні алгоритми нечіткого
кластерного аналізу:
FCM (Fuzzy c-means - нечітких
c-середніх);
гірської кластеризації;
поступово зростаючого розбиття.
Алгоритм FCM
Алгоритм нечіткої кластеризації
називають FCM - алгоритмом (Fuzzy Classifier Means, Fuzzy C-Means). Метою FCM -
алгоритму кластеризації є автоматична класифікація безлічі об'єктів, які
задаються векторами ознак в просторі ознак. Іншими словами, такий алгоритм
визначає кластери і відповідно класифікує об'єкти. Кластери представляються
нечіткими множинами, і, крім того, межі між кластерами також є
нечіткими.алгоритм кластеризації припускає, що об'єкти належать усім кластерам
з певним ступенем приналежності. Ступінь приналежності визначається відстанню
від об'єкта до відповідних кластерних центрів. Даний алгоритм ітераційно
обчислює центри кластерів і нові ступені приналежності об'єктів.
Алгоритм нечіткої кластеризації
виконується наступним чином :
а) ініціалізація.
Вибираються наступні параметри:
необхідна кількість кластерів N, 2
<N <К;
міра відстаней (Евклідова);
фіксований параметр q;
початкова (на нульовій ітерації)
матриця приналежності  об'єктів
об'єктів
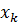 з
урахуванням заданих початкових центрів кластерів
з
урахуванням заданих початкових центрів кластерів 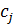 .
.
б) регулювання позицій 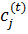 центрів
кластерів.
центрів
кластерів.
На t-му ітераційному кроці при
відомій матриці 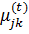 обчислюється відповідно
до викладеного вище рішенням системи диференціальних рівнянь.
обчислюється відповідно
до викладеного вище рішенням системи диференціальних рівнянь.
в) корегування значень приналежності
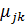 .
.
Враховуючи відомі ,
вираховуються , якщо 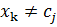 ,
в іншому випадку:
,
в іншому випадку:
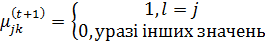 ;
(2.8)
;
(2.8)
г) зупинка алгоритму.
Алгоритм нечіткої кластеризації
зупиняється при виконанні наступної умови:
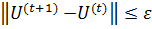 ,
(2.9)
,
(2.9)
де || || − матрична норма
(Евклідова);
ε −
заздалегідь заданий рівень точності.
Алгоритм гірської кластеризації
Алгоритм пікового групування
(гірської кластеризації), запропонований Р. Ягером та Д. Фільовим, не вимагає
задавання кількості кластерів. Кластеризація гірським алгоритмом не є нечіткою,
однак, її часто використовують при синтезі нечітких правил з даних.
Ідея алгоритму полягає в тому, що
спочатку визначають точки, які можуть бути центрами кластерів. Далі для кожної
такої точки розраховується значення потенціалу, що показує можливість
формування кластера в її околиці. Чим щільніше розташовані об’єкти в околиці
потенційного центра кластера, тим вище значення його потенціалу. Після цього
ітераційно вибираються центри кластерів серед точок з максимальними
потенціалами. Алгоритм гірської кластеризації можна записати як послідовність
таких кроків:
а) формування потенційних центрів
кластерів, число яких Q повинно бути кінцевим. Центрами кластерів можуть бути
об'єкти кластеризації - екземпляри вибірки х. Тоді Q = S, де S - кількість
екземплярів у вибірці x. Другий спосіб вибору потенційних центрів кластерів
полягає в дискретизації простору вхідних ознак. Для цього діапазони зміни
вхідних ознак розбивають на кілька інтервалів. Проводячи через точки розбиття
прямі, паралельні координатним осям, одержуємо «сітковий» гіперкуб. Вузли цієї
сітки і будуть відповідати центрам потенційних кластерів. Позначимо через 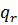 -
кількість значень, що можуть приймати центри кластерів за r-ою координатою, r =
1,2,...N. Тоді кількість можливих кластерів буде дорівнювати:
-
кількість значень, що можуть приймати центри кластерів за r-ою координатою, r =
1,2,...N. Тоді кількість можливих кластерів буде дорівнювати:
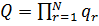 ;
(2.10)
;
(2.10)
б) розрахунок потенціалу центрів
кластерів за формулою:
 ,
(2.11)
,
(2.11)
де 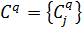 -
потенційний центр q-го кластера;
-
потенційний центр q-го кластера;
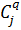 −
значення j-ої ознаки для q-го кластера;
−
значення j-ої ознаки для q-го кластера;
α −
додатня константа;
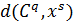 −
відстань (Евклідова) між потенційним центром кластера
−
відстань (Евклідова) між потенційним центром кластера  та
об’єктом кластеризації
та
об’єктом кластеризації 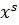 .
.
У випадку, коли об’єкти
кластеризації задані двома ознаками (N = 2), графічне зображення розподілу
потенціалу буде являти собою поверхню, що нагадує гірський рельєф (рис. 2.1).
Звідси і назва - гірський алгоритм кластеризації.

Рисунок 2.1 −
Розподіл
потенціалу при кластеризації гірським алгоритмом
в) вибір центрами кластерів
координати «гірських» вершин. Для цього, центром першого кластера призначають
точку з найбільшим потенціалом. Звичайно, найвища вершина оточена декількома
досить високими піками. Тому призначення центром наступного кластера точки з
максимальним потенціалом серед вершин, що залишилися, призвело б до виділення
великого числа близько розташованих центрів кластерів.
Щоб вибрати наступний центр кластера
необхідно спочатку виключити вплив щойно знайденого кластера. Для цього
значення потенціалу для можливих центрів кластерів, що залишилися, перераховується
в такий спосіб: від поточних значень потенціалу віднімають внесок центра щойно
знайденого кластера (тому кластеризацію за цим алгоритмом іноді називають
субтрактивною). Перерахунок потенціалу відбувається за формулою:
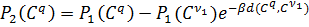 ,
(2.12)
,
(2.12)
де  − потенціал на першій ітерації;
− потенціал на першій ітерації;
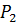 −
потенціал на другій ітерації;
−
потенціал на другій ітерації;
β −
додатня константа;
 −
номер першого знайденого центра кластера:
−
номер першого знайденого центра кластера:
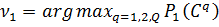 .
(2.13)
.
(2.13)
Номер центра другого кластера
визначається за максимальним значенням оновленого потенціалу:
 .
(2.14)
.
(2.14)
Потім знову перераховуються значення
потенціалів:
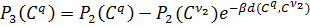 .
(2.15)
.
(2.15)
д) якщо максимальне значення
потенціалу перевищує деякий поріг, то здійснюється перехід до пункту б), у
іншому випадку - зупинка. Алгоритм гірської кластеризації є ефективним, якщо
розмірність вхідного вектора не є занадто великою. У іншому випадку (при
великій кількості ознак) число потенційних центрів наростає лавиноподібно, і
процес розрахунку чергових пікових функцій стає занадто тривалим, а процедура
кластеризації - малоефективною.
Алгоритм гірської кластеризації
можна використовуватись для синтезу нечіткої бази знань. Нехай ми маємо 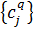 -
центри кластерів, знайдені в результаті гірської кластеризації, кожному з яких
зіставлене значення цільової ознаки
-
центри кластерів, знайдені в результаті гірської кластеризації, кожному з яких
зіставлене значення цільової ознаки 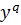 .
Тоді кожному центру кластера ставиться у
відповідність правило: якщо
.
Тоді кожному центру кластера ставиться у
відповідність правило: якщо  , то
, то 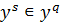 ,
де нечіткі терми та характеризуються
гаусівськими функціями приналежності:
,
де нечіткі терми та характеризуються
гаусівськими функціями приналежності:
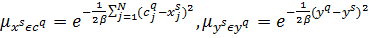 . (2.16)
. (2.16)
Алгоритм поступово зростаючого
розбиття IDA
Алгоритм поступово зростаючого
розбиття IDA (incremental decomposition algorithm) полягає в наступному. На
першій ітерації є одне продукційне правило, що має як область свого впливу
(область, у якій значення результуючої функції приналежності передумови
нечіткого правила перевищує задану величину) усю множину припустимих вхідних
значень (рис. 2.2).
На другій ітерації дане правило
розбивається на два двома способами (показані стрілками). Проводиться навчання
і вибирається, який зі способів розбиття дає найменшу погрішність (даний
перехід відзначений чорною стрілкою). Серед наявних правил вибирається те, для
якого складова похибки в загальній похибці є найбільшою (область його впливу
заштриховано). Воно і підлягає розбиттю на два правила двома способами
(ітерація 3). Описаний процес продовжується до досягнення необхідної точності
або поки не буде згенеровано задане число продукційних правил.
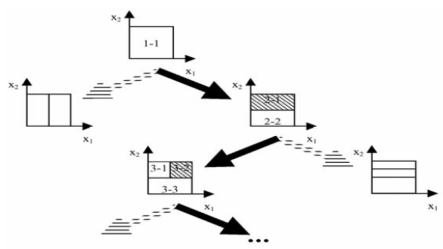
Рисунок 2.2 − Схема роботи
методу IDA
Інформація про ДРВп, що надходить
від пеленгаторних постів записується до бази даних. Після чого, сукупність
даних, що досліджується представляє собою кінцеву множину ДРВп  ,
кожен елемент якої характеризується множиною кількісних та якісних
характеристик
,
кожен елемент якої характеризується множиною кількісних та якісних
характеристик 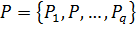 , наприклад: координати
розташування ДРВп, вид зв’язку (КХ, УКХ), інтенсивність роботи (частота виходу
в ефір впродовж 12 годин), які у свою чергу після проведення аналізу і
кластеризації дадуть змогу оператору відобразити реальну РЕО, на якій чітко
буде відображатись кількість підрозділів (бойових батарей в даному випадку) N,
відстань між ними , віддаленість від
переднього краю , дальність зв’язку
.
Для ідентифікації складних ОМ необхідно вибрати оптимальний алгоритм
кластеризації. В даній роботі пропонується вибрати алгоритм C-means та усунути
його основний недолік - необхідність попереднього задання кількості кластерів.
Для усунення даного недоліку мною запропоновано частково поєднати алгоритм C -
means та алгоритм гірської кластеризації, адже перевагою останнього є те, що
він не вимагає задавання кількості кластерів, а сам їх шукає і встановлює для
них центри, які можуть бути КП (командним пунктом) в бойовому порядку
підрозділу. Ця умова є необхідною для вирішення задачі кваліфікаційної роботи,
тому для ідентифікації складних об’єктів моніторингу буде використано саме це
поєднання методів. Для застосування цього алгоритму необхідно розрахувати
математичну модель та визначити характеристики ДРВп, які підлягають обробці.
, наприклад: координати
розташування ДРВп, вид зв’язку (КХ, УКХ), інтенсивність роботи (частота виходу
в ефір впродовж 12 годин), які у свою чергу після проведення аналізу і
кластеризації дадуть змогу оператору відобразити реальну РЕО, на якій чітко
буде відображатись кількість підрозділів (бойових батарей в даному випадку) N,
відстань між ними , віддаленість від
переднього краю , дальність зв’язку
.
Для ідентифікації складних ОМ необхідно вибрати оптимальний алгоритм
кластеризації. В даній роботі пропонується вибрати алгоритм C-means та усунути
його основний недолік - необхідність попереднього задання кількості кластерів.
Для усунення даного недоліку мною запропоновано частково поєднати алгоритм C -
means та алгоритм гірської кластеризації, адже перевагою останнього є те, що
він не вимагає задавання кількості кластерів, а сам їх шукає і встановлює для
них центри, які можуть бути КП (командним пунктом) в бойовому порядку
підрозділу. Ця умова є необхідною для вирішення задачі кваліфікаційної роботи,
тому для ідентифікації складних об’єктів моніторингу буде використано саме це
поєднання методів. Для застосування цього алгоритму необхідно розрахувати
математичну модель та визначити характеристики ДРВп, які підлягають обробці.
2.3 Синтез
математичної моделі кластеризації об’єктів за результатами роботи засобів
радіомоніторингу
Для заданої множини ДРВп K, що
характеризується вхідними векторами і
N визначених кластерів передбачається, що
будь-яка належить
будь-якому з приналежністю в
інтервалі [0,1], де j - номер кластера, а k − номер вхідного вектора.
Для забезпечення однозначності в
розрахунках при розробці математичної моделі приймаються до уваги наступні
умови нормування для :
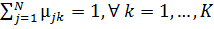 ;
(2.17)
;
(2.17)
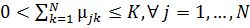 .
(2.18)
.
(2.18)
Для забезпечення найбільшої ймовірності
приналежності ДРВп до кластеру необхідно мінімізувати суми всіх зважених
відстаней  :
:
 ,
(2.19)
,
(2.19)
де q − фіксований параметр,
заданий перед ітераціями.
Для досягнення вищезазначеної мети
необхідно вирішити наступну систему рівнянь:
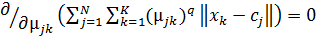 (2.20)
(2.20)
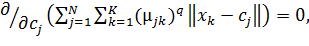
де N − кількість кластерів;−
кількість ДРВп;
 −
ймовірність входження
−
ймовірність входження  до кластеру .
до кластеру .
Сумісно з умовами нормування дана
система диференціальних рівнянь має наступний розв’язок:
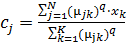 ,
(2.21)
,
(2.21)
де − зважений центр мас.
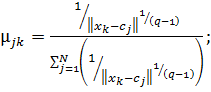 (2.22)
(2.22)
Таким чином представлено математичну
модель, яка забезпечує процес кластеризації ОМ з заданою приналежністю в умовах
невизначеності, за визначеними ознаками з використанням алгоритму C-means, на
основі якої створено алгоритм ідентифікації складних ОМ.
2.4
Алгоритм ідентифікації складних об’єктів моніторингу на основі нечітких
алгоритмів кластерного аналізу
На даний час розроблена велика
кількість програмних пакетів, які забезпечують вирішення задач в різних галузях
науки. Найбільш всеохоплюючим різноманітних галузей науки є програмний пакет
Matlab.
Для вирішення поставлених задач
ідентифікації ОМ доцільно використовувати функції кластеризації програмного
пакету Matlab.
В даному програмному пакеті
необхідно розробити алгоритм, щоб забезпечити виконання наступних вимог до
кластеризації складних ОМ:
автоматичного визначення кількості
кластерів, що розглядаються з заданої множини ДРВ;
автоматичного визначення
приналежності кожного ДРВ до кожного з кластерів;
зручне для оператора представлення
даних для подальшої їх обробки та аналізу;
визначення кількості засобів зв’язку
і типу зв’язку, який вони реалізовують;
визначення інтенсивності роботи
засобу зв’язку, яка є передумовою для надання її статусу основного ДРВп в
підрозділі.
На основі розробленої математичної
моделі розроблений алгоритм, що реалізує вимоги для виконання поставленого
завдання в програмному середовищі MatLab. В додатку А
представлена блок - схема алгоритму кластеризації, що забезпечує вирішення
поставлених задач.
Алгоритм побудований на основі
функціональних блоків. Робота функціонального блоку розрахована по певних
функціях, які мають вхідні аргументи. Аргументом функції може виступати як
сукупність ДРВп з їхніми параметрами, що підлягають кластеризації, так і окремі
характеристики, що визначають роботу даного алгоритму.
В даному алгоритмі показано процес
кластеризації ОМ з використанням двох функцій кластеризації subclust та fcm,
які входять до програмного пакету Matlab.
Після того, як головна функція
отримала вхідні дані про ОМ, (додаток А, блок 1), вона викликає функцію
subclust, або метод субтрактивної нечіткої кластеризації (додаток А, блок 3),
який забезпечує визначення кількості кластерів.
Ідея методу субтрактивної
кластеризації полягає в тому, що кожна точка даних передбачається як центр
потенційного кластера, після чого обчислюється деяка міра здатності кожної
точки даних представляти центр кластера. Ця кількісна міра заснована на оцінці
щільності точок даних довкола відповідного центру кластера.
Даний алгоритм заснований на
виконанні наступних дій:
а) вибір точки даних з максимальним
потенціалом для представлення центру першого кластера.
б) видалення всіх точки даних в
околиці центру першого кластера, величина якої задається параметром radii, щоб
визначити наступний нечіткий кластер і координати його центру. Тобто цей
параметр дозволяє вибрати максимальний радіус кластера, в даному випадку на
вибір тактичного нормативу бойового порядку.
Ці дві процедури повторюються до тих
пір, поки всі точки даних не виявляться всередині околиць радіусу radii шуканих
центрів кластерів.
Функція командного рядка subclust
знаходить центри кластерів методом субтрактивної кластеризації. Вона
використовується в наступному форматі:
[C, S] = subclust (X, radii,
xBounds, options)
Розглянемо вхідні аргументи:
Матриця X містить дані кластеризації
щодо ДРВп, а також їх характеристики. Перші дві колонки матриці X відповідають
координатам окремих точок даних, решта колонок це якісні показники ДРВп..
Параметр radii є вектором,
компоненти якого набувають значень з інтервалу [0, 1] і задають діапазон
розрахунку центрів кластерів по кожній з ознак вимірів, тобто ним задаються
дані щодо радіусу ОМ. При цьому робиться припущення, що всі дані містяться в
деякому одиничному гіперкубі. Можливо задавати радіус для кожної характеристики
ДРВп окремо. У загальному випадку малі значення параметра radii призводять до пошуку
великої кількості малих бойових формувань (взвод, рота).
Аргумент xBounds є матрицею
розмірності (2*q), яка визначає спосіб відображення матриці даних X в деякому
одиничному гіперкубі. Тут q - кількість ознак, що розглядаються в множині
даних. Цей аргумент є необов’язковим, якщо матриця X вже нормалізована. Перший
рядок матриці xBounds містить мінімальні значення інтервалу виміру кожної з
ознак, а другий рядок - максимальні значення виміру кожної з ознак. Приклад
задання аргументу “xBounds=[-10_-5; 10_5]”. При проведенні кластеризації перша
характеристика знаходитиметься в межах [-10 +10], а друга [-5 +5].
Для зміни заданих за умовчанням
параметрів алгоритму кластеризації може бути використаний додатковий вектор
options. Компоненти цього вектора можуть набувати наступних значень:
options (1) = quashFactor -
параметр, використовуваний як коефіцієнт для множення значень radii, які
визначають околицю центру кластера. Це здійснюється з метою зменшення впливу
потенціалу граничних точок, що розглядаються як частина нечіткого кластера;
options (2) = acceptRatio -
параметр, що встановлює потенціал як частину потенціалу центру першого
кластера, вище за який інша точка даних може розглядатися як центр іншого
кластера;
options (3) = rejectRatio -
параметр, що встановлює потенціал як частину потенціалу центру першого
кластера, нижче за який інша точка даних не може розглядатися як центр іншого
кластера;
options(4) = verbose - якщо значення
цього параметра не дорівнює нулю, то на екран монітора виводиться інформація про
виконання процесу кластеризації.
Вихідними значеннями функції будуть
змінні [C, S]:
а) Функція subclust повертає матрицю
С значень координат центрів нечітких кластерів. При цьому кожен рядок цієї
матриці містить координати одного центру кластера.
б) Ця функція також повертає вектор
S, компоненти якого представляють значення s, які визначають діапазон впливу
центру кластера по кожній з ознак, що розглядаються. При цьому всі центри
кластерів володіють однаковою множиною значень s, які призначені для визначення
правильності розбиття кластерів.
Отримані значення центрів кластерів
з параметру “C” передаються у функцію fcm. Синтаксис функції fcm має наступний
вигляд:
[center, U, obj_fcn] = fcm(data,
cluster_n, options)
Вхіднимн аргументами цієї функції є:
data: матриця початкових даних ДРВп
X кластеризації, s-рядок якої представляє інформацію про один об’єкт нечіткої
кластеризації у формі вектора xs = (xs1, xs2, ..., xsN), xsj - кількісне
значення ознаки для об’єкта даних ДРВп, s=1, 2,..., S - кількість екземплярів
кластеризації, N - кількість параметрів (ознак), що описують один екземпляр
(або кластер);
cluster_n: кількість шуканих
нечітких кластерів (більше одиниці).
Вихідними аргументами цієї функції
[center, U, obj_fcn] є :
center: матриця центрів шуканих нечітких
кластерів ДРВп, кожен рядок якої представляє собою координати центру одного з
нечітких кластерів у формі вектора;
U: матриця значень функцій
приналежності шуканого нечіткого розбиття, або матриця ймовірностей;
obj_fcn: значення цільової функції
на кожній з ітерацій роботи алгоритму FCM.
Функція fcm (data, cluster_n,
options) може бути викликана з додатковими аргументами options, які призначені
для управління процесом нечіткої кластеризації, а також для зміни критерію
зупинки роботи алгоритму і відображення інформації на екрані монітора.
Ці додаткові аргументи мають
наступні значення:
options (1) : експоненціальна вага m
для розрахунку матриці нечіткого розбиття U (за умовчанням це значення дорівнює
т=2);
options (2): максимальне число
ітерацій k (за умовчанням це значення дорівнює k=100);
options (3): мінімально допустиме
значення покращення цільової функції за одну ітерацію алгоритму (за замовчанням
це значення дорівнює e=0.00001);
options (4): інформація про поточну
ітерацію, що відображується на екрані монітора (за умовчанням це значення
дорівнює 1).
Якщо будь-яке із значень додаткових
аргументів дорівнює NAN (не число), то для цього аргументу використовується
значення за умовчанням. Функція fcm закінчує свою роботу, коли алгоритм FCM
виконає максимальну кількість ітерацій , або коли різниця між значеннями
цільових функцій на двох послідовних ітераціях буде менше заданого апріорі
значення параметра збіжності алгоритму e.
Функція fcm реалізована у вигляді
m-файла і використовує, у свою чергу, три інші функції:
функцію initfcm для формування
матриці вихідного розбиття деяким випадковим чином;
функцію distfcm розрахунку матриці
відстаней між точками даних і центрами кластерів;
функцію stepfcm для розрахунку
значень цільової функції і функцій приналежності об’єктів нечітким кластерам на
кожній ітерації роботи алгоритму FCM. Всі ці функції також реалізовані у
вигляді m-файлів.
Представлений алгоритм ідентифікації
забезпечує проведення кластеризації ОМ. Також існує можливість задання
параметрів кластеризації. Проте використання лише одного алгоритму для
ідентифікації ОМ не може в достатній мірі забезпечувати розв’язання всього
спектра задач ідентифікації ОМ. Таким чином, для успішного проведення
ідентифікації необхідно використовувати різні алгоритми аналізу даних.
Висновок до другого розділу
В даному розділі було розглянуто всі
існуючі методи кластеризації, серед яких було обрано найбільш доцільний
алгоритм для виконання задачі ідентифікації ОМ. Таким алгоритмом є поєднання
алгоритму С-means. та алгоритму гірської кластеризації Для застосування цього
алгоритму було розраховано математичну модель, де запропоновано використання
формули Евклідової відстані, що найбільш підходить для розрахунку по
координатах.
. АПРОБАЦІЯ АЛГОРИТМУ
ІДЕНТИФІКАЦІЇРІЗНИХ ТИПІВ СКЛАДНИХ ОБ’ЄКТІВ НА ОСНОВІ НЕЧІТКИХ АЛГОРИТМІВ
КЛАСТЕРНОГО АНАЛІЗУ
Проведення апробації є необхідним
для перевірки в реальних умовах, на практиці, теоретично розроблених
математичних моделей та алгоритмів. Апробація дозволяє на практиці оцінити
можливості створених моделей та знайти їхні недоліки для різних вихідних даних
та умов застосування. Математична модель алгоритму реалізована на основі
математичного моделювання у середовищі MatLab.
Розглянемо вирішення задачі
ідентифікації ОМ для множини вхідних даних, що є матрицею даних ДРВп X
розмірністю (28x4) (таблиця 3.1), яка міститься у файлі point 6 (База даних
21:00 25.12.2012).
Рисунок 3.1 − Вибір бази даних
Таблиця 3.1
Вхідні дані для розрахунків
|
Координати по х
|
Координати по
y
|
Робоча частота
|
Інтенсивність виходу в ефір
|
|
43
|
39
|
19
|
12
|
|
44
|
40
|
13
|
15
|
|
44
|
41
|
49
|
45
|
|
43,5
|
45
|
768
|
536
|
|
44
|
67
|
423
|
445
|
|
41
|
68
|
436
|
421
|
|
42
|
70
|
752
|
523
|
|
44
|
72
|
12
|
19
|
|
69
|
31
|
56
|
72
|
|
68,5
|
34
|
23
|
17
|
|
71
|
32
|
643
|
336
|
|
70
|
35
|
679
|
698
|
|
70
|
75
|
15
|
63
|
|
71
|
76
|
14
|
54
|
|
72
|
78
|
876
|
563
|
|
68
|
80
|
55
|
47
|
39
|
25
|
36
|
|
89
|
40
|
32
|
45
|
|
90
|
41
|
12
|
21
|
|
91
|
45
|
36
|
54
|
|
91
|
67
|
74
|
78
|
|
89
|
68
|
67
|
89
|
|
89
|
70
|
44
|
51
|
|
90
|
72
|
15
|
30
|
|
68
|
52
|
15
|
42
|
|
69
|
55
|
46
|
16
|
|
56
|
59
|
79
|
95
|
|
58
|
63
|
20
|
17
|
Побудуємо на графіку точки з
координатами, які містяться у перших двох колонках масиву. На рис. 3.2
представлений варіант розміщення ДРВп.
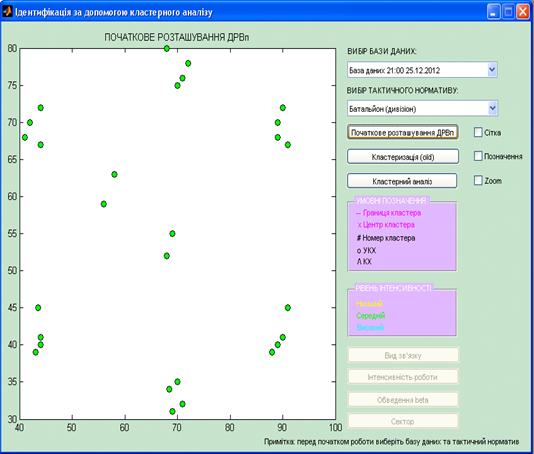
Рисунок 3.2 − Варіант
розміщення ДРВп
З врахуванням всіх особливостей,
деякі параметри для проведення розрахунків були встановлені загальним чином:
- аргумент squashFactor = 1.25
вказує на те, що необхідно визначити кластери, недалеко розташовані один від
одного.
аргумент acceptRatio=0.5 вказує на
те, що для пошуку центрів кластерів дуже високий потенціал не є необхідним.
аргумент rejectRatio=0.15 не виключає
з розгляду точки даних, що не володіють високим потенціалом.
аргумент verbose = 1 дозволяє
виведення інформації про виконання процесу кластеризації на екран монітора.
Наступним кроком був підбір
тактичного нормативу для ідентифікації ОМ. Він обирається довільним чином,
відповідно до того який підрозділ ми хочемо ідентифікувати. На рис. 3. 3
показано як обирається тактичний норматив на прикладі ОМ − батальйон або
дивізіон.
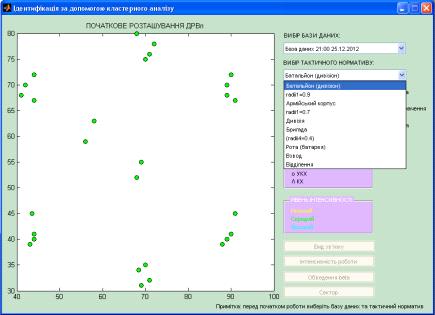
Рисунок 3.3 − Вибір тактичного
нормативу
Потім була здійснена кластеризація,
в результаті виконання якої були отримані наступні якісні показники (рис. 3.4).
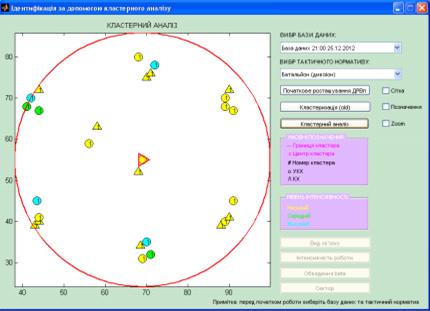
Рисунок 3.4 − Результат
вирішення задачі нечіткої субтрактивної кластеризації в системі MatLab
З рис. 3.4 видно, що в результаті
проведення кластеризації по дальності зв’язку ми виявили один батальйон
(дивізіон) з центром з координатами (70,55), який позначений трикутником,
повернутим в праву сторону. Межею цього підрозділу є коло, яке намальоване
навколо нього. Цифри, колір, та умовне позначення на кожного ДРВп мають
інформативний характер. Цифри означають номер підрозділу, до якого належить
ДРВп, колір - інтенсивність виходу в ефір, а умовне позначення - вид зв’язку,
який забезпечує кожне ДРВп.
Для ідентифікації групового ОМ
проведеться більш детальна кластеризація і вибереться в пошуку тактичних
нормативів роту (батарею) для ідентифікації їх в отриманому батальйоні
(дивізіоні).

Рисунок 3.5 − Вибір тактичного
нормативу (батарея)
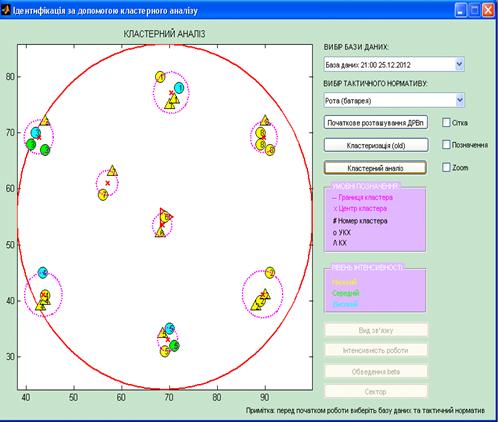
Рисунок 3.6 − Результат
ідентифікації рот (батарей) як ОМ
Як можна відмітити, для вказаних
значень аргументів функція субтрактивної кластеризації, що розглядається,
знаходить вісім нечітких кластерів і відображає координати їх центрів в вікні
системи MatLab. Із ідентифікованих восьми кластерів 6 являються бойовими
батереями, а 2 інші шта і штабна батерея відповідно.
Як видно з рис 3.6, дальність від
переднього краю складає більше, ніж 40 км, що дозволяє нам остаточно сказати
про завершення ідентифікації ОМ.
Висновок до третього розділу
Таким чином, дана програма на основі
системи MatLab дозволяє вирішувати завдання нечіткої кластеризації з
параметрами, які нас задовольняють.
Результати нечіткої кластеризації
мають наближений характер і можуть служити лише для попередньої структуризації
інформації, що міститься в множині вихідних даних. Вирішуючи завдання нечіткої
кластеризації, потрібно пам’ятати про особливості і обмеження процесу виміру
ознак у сукупності об’єктів кластеризації. Оскільки нечіткі кластери формуються
на основі метрики Евкліда, відповідний простір ознак повинен задовольняти
аксіомам метричного простору. В той же час для пошуку закономірностей в
проблемній області, що мають неметричний характер, необхідно використовувати
спеціальні засоби та інструменти, розроблені для інтелектуального аналізу даних
(Data Mining).
. ОХОРОНА ПРАЦІ
Охорона праці - це система правових,
соціально - економічних, організаційно - технічних, санітарно - гігієнічних і
лікувально - профілактичних заходів та засобів, спрямованих на збереження
життя, здоров'я і працездатності людини у процесі трудової діяльності.
Законодавчими актами, що визначають
основні положення з охорони праці, є загальні закони України, а також
спеціальні законодавчі акти, які приймаються або затверджуються іншими
державними органами і Кабінетом Міністрів України, Міністерством охорони
здоров'я України та іншими відомствами.
Загальними законами України, що
визначають основні положення з охорони праці, є Конституція України, Кодекс
законів про працю України та Закон України " Про охорону праці".
Спеціальними законодавчими актами є
міжгалузеві та галузеві нормативні акти про охорону праці.
Державна політика в галузі охорони
праці базується на принципах:
пріоритету життя і здоров'я
працівників;
підвищення рівня промислової безпеки
шляхом суцільного технічного контролю;
комплексного розв’язання завдань
охорони праці на основі загальнодержавної програми з цього питання;
соціального захисту працівників,
повного відшкодування шкоди особи, які потерпіли від нещасних випадків;
встановлення єдиних вимог з охорони
праці для всіх підприємств;
використання економічних методів
управління охороною праці;
забезпечення координації діяльності
органів державної влади в галузі охорони праці;
використання світового досвіду
організації роботи щодо підвищення безпеки праці.
4.1 Аналіз
умов праці на робочому місці
Аналіз умов праці на робочому місці
характеризується такими параметрами як мікроклімат та вентиляція приміщення,
освітленість, можливість враження електричним струмом, стан пожежної безпеки.
Мікроклімат приміщення та робочих
місць має значний вплив на самопочуття людини, її здоров'я та працездатність.
Підвищена або понижена температура повітря, надмірна його вологість або сухість,
значна швидкість руху повітря або його застій призводить до погіршення умов
праці, знижують її продуктивність, збільшують захворюваність. Для виключення
вказаних несприятливих наслідків розроблені санітарно-гігієнічні вимоги до
параметрів мікроклімату. Ці вимоги викладені у ГОСТ 12.1.005-76 ″Повітря
робочої зони. Загальні вимоги″. Оптимальні значення параметрів
мікроклімату наведені у табл. 4.1
Таблиця 4.1
Оптимальні значення параметрів
мікроклімату
|
Сезон року
|
Категорії робіт
|
Температура, С°
|
Відносна вологість, %
|
Швидкість руху повітря, м/с
|
|
Холодний та перехідний
|
Легка - I Сер. Важкості - II а Сер. Важкості -
II б Важка - III
|
20 - 23 10 - 20 17 - 19 16 - 18
|
60 - 40 60 - 40 60 - 40 60 - 40
|
0,2 0,2 0,3 0,3
|
|
Теплий
|
Легка - I Сер. Важкості - II а Сер. Важкості -
II б Важка - III
|
22 - 25 21 - 23 20 - 22 10 - 21
|
60 - 40 60 - 40 60 - 40 60 - 40
|
0,2 0,3 0,4 0,5
|
Оптимальні параметри мікроклімату
визначаються тільки за період року та за ступенем важкості роботи, яка
виконується.
Теплий період року характеризується
середньодобовою температурою 100 С і вище, а холодний - нижче 100
С.
Робота з ПЕОМ відносяться до
категорії робіт як легка, тобто роботи, які виконуються сидячи, стоячи або
пов’язані з ходьбою, але не вимагають систематичного фізичного напруження та
перенесення вантажів, енергозатрати - 150 ккал/г. Параметри для даної категорії
робіт наведені в табл. 4.1.
Важливою умовою підтримання праці
особового складу на високому рівні є забезпечення приміщення належною
вентиляцією, яка призначена для видалення з приміщення надмірної теплоти, пилу,
вологи, шкідливих газів. Вентиляція може бути природною та механічно. Механічна
вентиляція забезпечується осьовими або відцентровими вентиляторами. Природна
вентиляція, у свою чергу, може бути організованою, тобто обмін повітря
проводиться через вікна та світлові ліхтарі та неорганізованою, тобто
повітрообмін проводиться через нещільності у конструкції будівель та
матеріалів.
У приміщенні для роботи організована
природна припливно-витяжною вентиляцією. Така організація вентиляції приміщення
здатна забезпечувати вимоги, які висуваються до приміщення.
Освітлення приміщення здійснюється
як природним так і штучним освітленням. Причому природне освітлення
здійснюється через вікно у зовнішніх стінах. В даному випадку природна освітленість
залежить також і від світлих тонів фарб, якими пофарбовані стіни та столи.
Якість освітлення залежить також від
рівномірності освітлення, яке визначається за виразом:
 (4.1)
(4.1)
де  -
мінімальне значення показання люксметра;
-
мінімальне значення показання люксметра;
 - максимальне
значення показання люксметра.
- максимальне
значення показання люксметра.
Проведене дослідження показало, що
коефіцієнт нерівномірності складає 0,45. Тоді як мінімальне значення для того,
щоб задовольняти гігієнічні вимоги має складати не менше 0,3.
Штучне освітлення реалізовується за
допомогою ламп денного освітлення (газорозрядні лампи), які сумісно
використовуються з освітлюваною арматурою. Дані лампи мають світлові
характеристики, які найбільш повно відповідають гігієнічним вимогам.
Електрична безпека приміщень є
важливим заходом захисту особового складу від враження електричним струмом. В
зв’язку з цим в приміщенні організовано контурне заземлення та щит швидкого
зняття напруги. Для кожного робочого місця передбачено гумовий килимок.
Дане приміщення належить до
категорії з підвищеною небезпекою, оскільки має можливість одночасного дотику
особового складу до металевих частин ПЕОМ та металоконструкцій будівлі, які
з’єднані із землею.
Важливе значення для безпеки життя,
здоров'я та матеріальних цінностей під час виконання лабораторної роботи є
забезпечення пожежної безпеки в приміщенні. Враховуючи це, в приміщенні
передбачено ряд протипожежних заходів. Як засіб сигналізації використовується
сигналізаційна димова пожежна установка СДПУ-1, яка призначена для виявлення
диму, для автоматичної сигналізації про пожежу. Вона розрахована на включення
10 променів, із паралельними підключенням на кожен промінь 10 пожежних
комбінованих випромінювачів або димових датчиків.
4.2 Вимоги
безпеки при роботі з ПЕОМ
До роботи на ПЕОМ допускаються
особи, які пройшли спеціальне навчання, медичне обстеження, вступний інструктаж
з охорони праці, інструктаж на робочому місці та інструктаж по пожежній
безпеці.
Оператор (користувач) повинен:
виконувати правила внутрішнього
трудового розпорядку;
не допускати в робочу зону сторонніх
осіб;
не виконувати вказівок, які
суперечать правилам охорони праці;
пам'ятати про особисту
відповідальність за виконання правил охорони праці та безпеку товаришів по
роботі;
уміти надавати першу медичну
допомогу потерпілим від нещасних випадків;
уміти користуватись первинними
засобами пожежегасіння;
виконувати правила особистої
гігієни.
Основні небезпечні та шкідливі
виробничі фактори, які діють на оператора (користувача):
підвищений рівень шуму на робочому
місці (від вентиляторів, процесорів та аудіоплат);
підвищене значення напруги в
електричному ланцюзі, замикання якого може статися через тіло людини;
підвищений рівень статичної
електрики;
підвищений рівень електромагнітного
випромінення;
підвищена напруженість електричного
поля;
пряма та відбита від екранів
близькість;
несприятливий розподіл яскравості в
полі зору;
фізичні перевантаження статичної та
динамічної дії;
нервово-психічні перевантаження (розумове
перенапруження, перенапруження аналізаторів, монотонність праці, емоційні
перевантаження).
При виборі приміщення для розміщення
робочих місць ПЕОМ необхідно враховувати, що вікна можуть давати близькість
екранах дисплеїв і викликати значне осліплення в тих, хто сидить перед ними,
особливо влітку та в сонячні дні. Приміщення з ПЕОМ повинні мати природне і
штучне освітлення. При незадовільному освітленні знижується продуктивність
праці оператора ПЕОМ, можливі короткозорість, швидка втомленість.
Розміщення робочих місць
оператора (користувача) повинно відповідати ГОСТ 22269-76 «Рабочее место
оператора. Взаимное расположение злементов рабочего места.». Не допускається
розташування робочих місць ПЕОМ в підвальних приміщеннях, а учбових закладів і
дошкільних установ у підвальних і цокольних поверхах. Робочі місця з ПЕОМ при
виконанні творчої роботи, яка потребує значної розумової активності чи великої
концентрації уваги, слід ізолювати одне від одного перегородкою висотою 1,5 -
2,0 м. Робочі місця з ПЕОМ рекомендується розміщувати в окремих приміщеннях. У
разі розміщення робочих місць із ПЕОМ у залах або приміщеннях з джерелами
небезпечних та шкідливих факторів вони повинні розташовуватись у повністю
ізольованих кабінетах із природним освітленням та організованим повітрообміном.
Площа, на якій розташовується одне робоче місце з ПЕОМ, повинна становити не
менше як 6.0 м , об'єм
приміщення - не менше як 20 м
, об'єм
приміщення - не менше як 20 м . Поверхня підлоги має бути рівною,
без вибоїн, неслизькою, зручною для очищення та вологого прибирання, мати
антистатичні властивості. При розміщенні робочих місць необхідно виключити
можливість прямого засвічування екрана джерелом природного освітлення.
. Поверхня підлоги має бути рівною,
без вибоїн, неслизькою, зручною для очищення та вологого прибирання, мати
антистатичні властивості. При розміщенні робочих місць необхідно виключити
можливість прямого засвічування екрана джерелом природного освітлення.
Вимоги до освітлення для
візуального сприймання операторами інформації з двох різних носіїв (з екрана
ПЕОМ та паперового носія) різні.
Надто низький рівень
освітленості погіршує сприймання інформації при читанні документів, а надто
високий призводить до зменшення контрасту зображення знаків на екрані. Тому
відношення яскравості екрана ПЕОМ до яскравості оточуючих його поверхонь не
повинно перевищувати у робочій зоні 3:1.
Штучне освітлення у
приміщеннях з ПЕОМ треба здійснювати у вигляді комбінованої системи освітлення
з використанням люмінесцентних джерел світла у світильниках загального
освітлення, які слід розташовувати над робочими поверхнями у
рівномірно-прямокутному порядку.
Для запобігання освітленню
екранів ПЕОМ прямими світловими потоками, лінії світильників повинні бути
розташовані з достатнім бічним зміщенням відносно рядів робочих місць або зон,
а також паралельно до світлових отворів. Бажане розміщення вікон з одного боку
робочих приміщень. При цьому кожне вікно повинно мати світлорозсіюючі штори з
коефіцієнтом відбивання 0,5- 0,7. Штучне освітлення повинно забезпечити на
робочих місцях ПЕОМ освітленість 300 - 500 лк. При природному освітленні слід
передбачити наявність сонцезахисних засобів, з цією метою можна використовувати
плівки з металізованим покриттям або жалюзі з вертикальними ламелями, що
регулюються.
Розташовувати робоче місце
обладнане ПЕОМ, необхідно таким чином, щоб в поле зору оператора не потрапляли
вікна або освітлювальні прилади; вони не повинні знаходитися й безпосередньо за
його спиною. На робочому місці має бути забезпечена рівномірна освітленість за
допомогою переважно відбитого або розсіяного розподілу світла.(рис 4.1)

Рисунок 4.1 − Напрямки
освітлення робочого місця
Світлових відблисків з
клавіатури, екрана та від інших частин ПЕОМ у напрямку очей оператора не
повинно бути. Для їх виключення необхідно застосовувати спеціальні екранні
фільтри, захисні козирки або розташовувати джерела світла паралельно напрямку
погляду на екран ПЕОМ з обох сторін. Для запобігання засліплення світильники
місцевого освітлення повинні мати відбивачі з непрозорого матеріалу чи скло
молочного кольору. Захисний кут відбивача повинен бути не менше 40 градусів.
Не бажано, щоб одяг оператора
був світлим і особливо блискучим. Для оздоблення приміщень з ПЕОМ повинні
використовуватися дифузно-відзеркалюючі матеріали з коефіцієнтами відбиття:
стелі - 0,7 - 0,8; стін - 0,4 - 0,5; підлоги - 0,2 - 0,3.
Забороняється застосовувати
для оздоблення інтер'єру полімерні матеріали, що виділяють у повітря шкідливі
хімічні речовини.
Вміст шкідливих хімічних речовин у приміщеннях з ПЕОМ не повинен перевищувати
концентрацій вказаних у ГОСТ 12.1.005-88 «Общие санитарно-гигиенические
требования к воздуху рабочей зоны». Робочі місця з ПЕОМ повинні розташовуватись
на відстані не менше як 1,5 м від стіни з віконними прорізами, від інших стін -
на відстані 1м; між собою на відстані не менше як 1,5 м.
Основним обладнанням робочого
місця оператора ПЕОМ є монітор, клавіатура, робочий стіл, стілець (крісло);
допоміжним - пюпітр, підставка для ніг, шафи, полиці та інше.
При розташуванні елементів
робочого місця слід враховувати:
робочу позу оператора;
простір для розміщення
оператора;
можливість огляду елементів
робочого місця;
можливість огляду простору за
межами робочого місця;
можливість робити записи,
розміщення документації і матеріалів, які використовує оператор (користувач).
Взаємне розташування
елементів робочого місця не повинно заважати виконанню всіх необхідних рухів та
переміщень для експлуатації ПЕОМ; сприяти оптимальному режиму праці і
відпочинку, зниженню втоми оператора (користувача).
При використанні допоміжних
пристосувань під ПЕОМ, повинна бути передбачена можливість переміщення
останнього відносно вертикальної осі в межах ± 30 градусів (вправо-вліво). Для
забезпечення точного і швидкого зчитування інформації поверхню екрана ПЕОМ слід
розташовувати в оптимальній зоні інформаційного поля в площині,
перпендикулярній нормальній лінії погляду оператора (користувача), який
знаходиться в робочій позі. Допускається відхилення від цієї площини - не
більше 45 градусів; допускається кут відхилення лінії погляду від нормального -
не більше 30 градусів.
Розташовувати ПЕОМ на
робочому місці необхідно так, щоб поверхня екрана знаходилася на відстані 500 -
600 мм від очей оператора (користувача), в залежності від розміру екрана.
Необхідно стало розташовувати клавіатуру на робочому столі, не допускаючи її
хитання або на окремому столі на відстані 100 - 300 мм від краю ближче до
працюючого. Положення клавіатури та кут її нахилу повинен відповідати
побажанням операторі (користувача) - кут нахилу в межах 5 - 15°.
Принтер треба розташовувати
так, щоб доступ до нього оператора (користувача) та його колег був зручним; щоб
максимальна відстань до клавіш управління принтером не перевищувала довжину
витягнутої руки (по висоті 900 - 1300 мм, по глибині 400 - 500 мм).
Конструкція робочого столу
повинна забезпечувати можливість оптимального розміщення на робочій поверхні
обладнання (рис. 4.2), що використовується, з урахуванням його кількості,
розмірів, конструктивних особливостей (розмір ПЕОМ, клавіатури, принтера та
інше) та характеру його роботи. Висота робочої поверхні столу повинна
регулюватися у межах 680 - 800 мм; у середньому вона повинна становити 725 мм.
Ширина і глибина робочої поверхні повинні забезпечувати можливість виконання
трудових операцій в межах моторного поля, межа якого визначається зоною в межах
видимості приладів і досяжності органів керування. Перевагу слід віддавати
модульним розмірам столу, на основі яких розраховуються конструктивні розміри;
ширину слід вважати: 600, 800, 1000, 1200, 1400; глибину - 800, 1000 мм, при
нерегульованій його висоті - 725 мм.
Рисунок 4.2 −
Розміщення обладнання на робочому місці
Поверхня столу має бути
матовою з малим відбиттям та теплоізолюючою. Робочий стіл повинен мати простір
для ніг висотою не менше як 600 мм, шириною не менше як 500 мм, глибиною на
рівні колін але не менше як 450 мм та на рівні витягнутої ноги - не менше як
650 мм.
Конструкція робочого крісла
повинна задовольняти вимогам ГОСТ 22889-6 «Кресло человека-оператора» із
змінами № 2 ИУС 7-28.
Крісло повинно забезпечувати
підтримування раціональної робочої пози під час виконання основних виробничих
операцій, створювати умови для зміни пози. З метою попередження втоми крісло
повинно забезпечувати зниження статичного напруження м'язів шийно-плечової
ділянки та спини. Тип робочого крісла повинен обиратися залежно від характеру
та тривалості роботи. Воно має бути підйомно-поворотним і регулюватися по висоті
та кутах нахилу сидіння і спинки, а також відстані спинки від переднього краю
сидіння. Регулювання кожного параметра має бути незалежним і мати надійну
фіксацію. Усі важелі та ручки пристосування (для регулювання) мають бути
зручними в управлінні. Висота поверхні сидіння повинна регулюватись у межах 400
- 550 мм. Ширина та глибина його поверхні має бути не менше як 400 мм. Поверхня
сидіння має бути плоскою, передні краї - закругленими. Сидіння та спинка крісла
мають бути напівм'яким, такими, що не електризуються та з повітронепроникним
покриттям, матеріал якого забезпечує можливість легкого очищення від
забруднення. Зміна кута нахилу поверхні сидіння повинна бути в межах від 15°
уперед та 5° назад. Опорна поверхня спинки крісла повинна мати висоту 280 - 300
мм, ширину - не менше як 380 мм та радіус кривизни горизонтальної площини - 400
мм. Кут нахилу спинки у вертикальній площині повинен регулюватися у межах (-30
°) - (+30 °) від вертикального положення. Відстань спинки від переднього краю
сидіння повинна регулюватися у межах 260 - 400 мм. Крісла повинні мати
стаціонарні або підлокітники довжиною не менше як 250 мм, шириною у межах 50 -
70 мм, що можуть регулюватися по висоті над сидінням у межах 200 - 260 мм та
регулюватися по параметру внутрішньої відстані між підлокітниками у межах 350 -
500 мм.
Робоче місце має бути
обладнане стійкою підставкою для ніг, параметри якої просто регулюються.
Підставка повинна мати ширину не менше як 300 мм, глибину не менше як 400 мм, з
регулюванням, по висоті до 150 мм та по куту нахилу опорної поверхні підставки
до 20°. Поверхня підставки має бути рифленою, а по передньому краю мати бортик
висотою 10 мм. Дані вимоги представлені на рис.4.3.
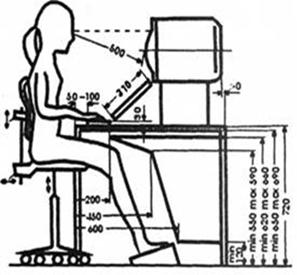
Рисунок 4.3 − Положення
оператора за робочим місцем
Робоче місце оператора
(користувача) має бути обладнане легко переміщуваним пюпітром для розташування
на ньому документів, розміщеним на одному рівні з екраном та віддалений від
очей оператора (користувача) приблизно на таку ж відстань (припустима
розбіжність цих відстаней не більше як 100 мм).
Пюпітр не повинен вібрувати і
має бути стійким.
Величина площини пюпітра має
бути не меншою за розміри найбільшого з джерел інформації, що застосовується
оператором (користувачем). При необхідності перегортання оригіналу обидві його
сторони повинні розташовуватися на підставці. Рукопис повинен слабо прилипати
до підставки або кріпитися за допомогою спеціальних зажимів. Поверхня пюпітра
має бути матовою. Пюпітр повинен мати лінійку, що легко пересувається по рядках,
прозору та зручну для використання.
Раціональна поза оператора
(користувача): розташування тіла при якому ступні працівника розташовані на
площині підлоги або на підставці для ніг, стегна зорієнтовані у горизонтальній
площині, верхні частини рук - вертикальні, кут ліктьового суглоба коливається у
межах 70° - 90°, зап'ястя зігнуті під кутом не більше ніж 20°, нахил голови - у
межах 15° - 20°, а також виключені часті її повороти.
Для забезпечення оптимальної
робочої пози оператора (користувача) необхідно:
засоби праці, з якими
оператор (користувач) має тривалий або найбільш частий зоровий контакт, повинні
розташовуватися у центрі зони зорового спостереження та моторного поля;
забезпечити відстань між
найважливішими засобами праці, з якими оператор (користувач) працює найбільш
часто близько до 500 мм;
трудові завдання операторів
(користувачів) розробляти з урахуванням мінімізації перепадів яскравості між
найбільш важливими об'єктами зорового спостереження.
При розташуванні екрана ПЕОМ
на технологічному обладнанні необхідно передбачити зручність зорового нагляду в
вертикальній площині під кутом ±30° від нормальної лінії погляд оператора
(користувача) ПЕОМ, відстань від екрана до ока працівника повинна складати 500
- 900 мм в залежності від розміру екрана.
Для нейтралізації зарядів
статичної електрики в приміщенні, де виконуються роботи на ПЕОМ, рекомендується
збільшувати вологість повітря за допомогою кімнатних зволожувачів. Відстань від
екрана до ока працівника повинна складати 500 - 900 мм в залежності від
розмірів екрана. Крім даної інструкції оператор (користувач) повинен виконувати
інструкцію по безпечній експлуатації ПЕОМ заводу - виробника.
Висновок до четвертого
розділу
Таким чином розділ охорона
праці є важливим елементом даної роботи, оскільки життя і здоров’я людини є
головними чинниками у виконанні поставлених завдань та робіт.
ВИСНОВКИ
В ході виконання
кваліфікаційної роботи обґрунтовано необхідність розробки алгоритму
ідентифікації складних об’єктів моніторингу на основі нечітких алгоритмів кластерного
аналізу.
У першому розділі було
проведено обґрунтування необхідності розробки алгоритму ідентифікації складних
об’єктів моніторингу на основі нечітких алгоритмів кластерного аналізу при
веденні ІР та розглянуто основні завдання дослідження, які вирішуються в
кваліфікаційній роботі. А також було здійснено перерахунок існуючих алгоритмів
кластеризації та проведено їх аналіз.
Перерахунок існуючих метрик
для визначення відстані між кластерами та окремими ДРВ було здійснено у другому
розділі. А також було проведення перерахунку, аналізу та вибору
найоптимальнішого алгоритму кластеризації ОМ.
В третьому розділі було
представлено приклад програмного продукту, який підтверджує коректну роботу
алгоритму та забезпечує розв’язання задачі ідентифікації складних ОМ за
допомогою нечітких алгоритмів кластерного аналізу. Отже, за допомогою
розробленого алгоритму можна в подальшому проводити ідентифікацію складних ОМ
за допомогою даних, отриманих внаслідок роботи пеленгаторних постів РМ.
ПЕРЕЛІК ПОСИЛАНЬ
1.
Айвазян С.А., Бухштабер В.М., Енюков И.С., Мешалкин Л.Д. / Прикладная
статистика: классификация и снижение размерности,- М.: Финансы и статистика,
1989.
.
Бериков В. С., Лбов Г. С. Современные тенденции в кластерном анализе //
Всероссийский конкурсный отбор обзорно-аналитических статей по приоритетному
направлению «Информационно-телекоммуникационные системы», 2008. - 26 с.
.
Воронцов К. В. Алгоритмы кластеризации и многомерного шкалирования. Курс
лекций. МГУ, 2007.
.
Герасимов Б.М., Дивизинюк М.М., Субач И.Ю., Системы поддержки принятия решений:
проектирование, применение, оценка эффективности. Монография. 2004.
.
Журавльов Ю.І., Рязанов В.В., Сенько О.В. «Розпізнавання». Математичні методи.
Програмна система. Практичні застосування. - М.: Фазiс, 2006.
6. Інтернет енциклопедія. - Режим доступу:
<http://ru.wikipedia.org/wiki>
. Информационно-аналитический ресурс,
посвященный машинному обучению, распознаванию образов и интеллектуальному
анализу данных - www.machinelearning.ru/
8.
Котов А., Красильников Н. Кластеризация даних. 2006
.
Мандель И. Д. Кластерный анализ. - М.: Финансы и статистика, 1988. - 176 с.
.
Ротштейн А.П. Интелектуальные технологии идентификации
.
Тарасов В.О., Герасимов Б. М., Левін І. О., Корнійчук В. О. Інтелектуальні
системи підтримки прийняття рішень: Теорія, синтез, ефективність.- К.:
МАКНС, 2007.= 336с. - Рос. мовою.
12. Чубукова И.А. Курс лекций «Data Mining»,
Интернет-университет информационных технологий -
www.intuit.ru/department/database/datamining/
<http://www.intuit.ru/department/database/datamining/>
13.
Чекмарев B.B. Книга об экономическом пространстве. Кострома: КГУ им. H.A.
Некрасова, 2001. 341 с.
.
Чемберлин Э. Теория монополистической конкуренции. М.: Изд-во ин. лит-ры, 1959.
С. 393.
.
Черковец В.Н. Общетеоретические и российские проблемы воспроизводства //
Воспроизводство и экономический рост/ Под ред. проф. В.Н. Чер-ковца, доц. В.А.
Бирюкова. М.: Экономический факультет, ТЕИС, 2001. С. 31.
.
Четыркин В.М. Проблемные вопросы экономического районирования. Ташкент, 1967.
.
Шарыгин М.Д. Дробное районирование и локальные территориально-производственные
комплексы. Пермь, 1975
.
Шерешева М.Ю. О кластерах / М.Ю. Шерешева //Сетевые формы межфирменной
кооперации: стратегические вызовы и конкурентные преимущества новых организаций
XXI века. Интернет-ресурс: www.ecsocman.edu.ru/db/msg/154728.
19. Шмитц X. Маленькие обувщики и гиганты Форда:
рассказ о суперкластере //Интернет-ресурс:
www.ideas.repec.org/a/eee/wdevel/v23yl995ilp9-28.html
<http://www.ideas.repec.org/a/eee/wdevel/v23yl995ilp9-28.html>
. Jain A., Murty M., Flynn P. Data clustering: A
Review.// ACM Computing Surveys. 1999. Vol. 31, no. 3.
ДОДАТОК
Програма реалізації
алгоритму ідентифікації складних ОМ на основі нечітких алгоритмів кластерного
аналізу
function varargout = Forma_Claster(varargin)
% FORMA_CLASTER M-file for
Forma_claster.fig
% singleton*.
% H = FORMA_CLASTER returns the
handle to a new FORMA_CLASTER or the handle to
% the existing singleton*.
%
FORMA_CLASTER('CALLBACK',hObject,eventData,handles,...) calls the local
% function named CALLBACK in
FORMA_CLASTER.M with the given input arguments.
%
FORMA_CLASTER('Property','Value',...) creates a new FORMA_CLASTER or raises the
% existing singleton*. Starting from
the left, property value pairs are
% applied to the GUI before
Forma_claster_OpeningFcn gets called. An
% unrecognized property name or
invalid value makes property application
% stop. All inputs are passed to
Forma_claster_OpeningFcn via varargin.
% *See GUI Options on GUIDE's Tools
menu. Choose "GUI allows only one
% instance to run (singleton)".
% See also: GUIDE, GUIDATA,
GUIHANDLES
% Edit the above text to modify the
response to help Forma_claster
% Last Modified by GUIDE v2.5
30-Jun-2013 11:41:58
% Begin initialization code - DO NOT
EDIT_Singleton = 1;_State = struct('gui_Name', mfilename, ...
'gui_Singleton', gui_Singleton, ...
'gui_OpeningFcn',
@Forma_claster_OpeningFcn, ...
'gui_OutputFcn',
@Forma_claster_OutputFcn, ...
'gui_LayoutFcn', [] , ...
'gui_Callback', []);nargin
&& ischar(varargin{1})_State.gui_Callback =
str2func(varargin{1});nargout
[varargout{1:nargout}] =
gui_mainfcn(gui_State, varargin{:});_mainfcn(gui_State, varargin{:});
% End initialization code - DO NOT
EDIT
% --- Executes just before
Forma_claster is made visible.Forma_claster_OpeningFcn(hObject, eventdata,
handles, varargin)
% This function has no output args,
see OutputFcn.
% hObject handle to figure
% eventdata reserved - to be defined
in a future version of MATLAB
% handles structure with handles and
user data (see GUIDATA)
% varargin command line arguments to
Forma_claster (see VARARGIN)
% Choose default command line output
for Forma_claster.output = hObject;
% Update handles structure(hObject,
handles);
% UIWAIT makes Forma_claster wait
for user response (see UIRESUME)
% uiwait(handles.figure1);
% --- Outputs from this function are
returned to the command line.varargout = Forma_claster_OutputFcn(hObject,
eventdata, handles)
% varargout cell array for returning
output args (see VARARGOUT);
% hObject handle to figure
% eventdata reserved - to be defined
in a future version of MATLAB
% handles structure with handles and
user data (see GUIDATA)
% Get default command line output
from handles structure{1} = handles.output;
% --- Executes during object
creation, after setting all properties.axes1_CreateFcn(hObject, eventdata,
handles)
% hObject handle to axes1 (see
GCBO)pushbutton1_Callback(hObject, eventdata,
handles)=handles.data1;=[pointc(:,1),point(:,2)];;(pointcl(:,1),
pointcl(:,2),'o','markersize',7,'MarkerFaceColor','g','color','m');('ПОЧАТКОВЕ
РОЗТАШУВАННЯ
ДРВп')
% --- Executes on selection change
in popupmenu1.popupmenu1_Callback(hObject, eventdata, handles)('D:\\Паньків_Кваліфікаційна_робота\\Forma_Claster\\point1.mat');('D:\\Паньків_Кваліфікаційна_робота\\Forma_Claster\\point2.mat');('D:\\Паньків_Кваліфікаційна_робота\\Forma_Claster\\point3.mat');('D:\\Паньків_Кваліфікаційна_робота\\Forma_Claster\\point4.mat');('D:\\Паньків_Кваліфікаційна_робота\\Forma_Claster\\point5.mat');('D:\\Паньків_Кваліфікаційна_робота\\Forma_Claster\\point6.mat');=get(hObject,'Value');val1.data1=point1;2.data1=point2;3.data1=point3;4.data1=point4;5.data1=point5;6.data1=point6;(hObject,handles);
% --- Executes during object
creation, after setting all properties.popupmenu1_CreateFcn(hObject, eventdata,
handles)ispc && isequal(get(hObject,'BackgroundColor'),
get(0,'defaultUicontrolBackgroundColor'))(hObject,'BackgroundColor','white');
% --- Executes on selection change
in popupmenu2.popupmenu2_Callback(hObject, eventdata,
handles)=get(hObject,'Value');val1.data2=1;2.data2=0.9;3.data2=0.8;4.data2=0.7;5.data2=0.6;6.data2=0.5;7.data2=0.4;8.data2=0.3;9.data2=0.2;10.data2=0.15;(hObject,handles);
% --- Executes during object
creation, after setting all properties.popupmenu2_CreateFcn(hObject, eventdata,
handles)ispc && isequal(get(hObject,'BackgroundColor'),
get(0,'defaultUicontrolBackgroundColor'))(hObject,'BackgroundColor','white');
% --- Executes on button press in
pushbutton12.pushbutton12_Callback(hObject, eventdata, handles)=handles.data1;(point);
% --- Executes on button press in
pushbutton13.pushbutton13_Callback(hObject, eventdata,
handles)=handles.data1;=handles.data2;(point,g);
% --- Executes on button press in
checkbox3.checkbox3_Callback(hObject, eventdata, handles)(get(hObject,'Value'))onoff
% --- Executes on button press in
checkbox5.checkbox5_Callback(hObject, eventdata,
handles)(get(hObject,'Value'))onoff
% --- Executes on button press in
checkbox6.checkbox6_Callback(hObject, eventdata, handles)(get(hObject,'Value'))on
elseoff
Основна функція програми
function
clustering(point,g)=[point(:,1),point(:,2)];=subclust(pointcl,g);
[c,U,obj]=fcm(pointcl,size(matrix,1));=max(U);i=1:size(matrix,1)=find(U(i,:)==maxU);{i}=pointcl(B(1,:),:);
% позначення виду зв'язку та інтенсивностіon;l=1:(size(point))point(l,3)>30
&& point(l,4)>500(pointcl(l,1),
pointcl(l,2),'ko','markersize',13,'MarkerFaceColor','c');point(l,3)>30
&& point(l,4)<100(pointcl(l,1),
pointcl(l,2),'ko','markersize',13,'MarkerFaceColor','y');point(l,3)>30
&& point(l,4)<500 && point(l,4)>100(pointcl(l,1),
pointcl(l,2),'ko','markersize',13,'MarkerFaceColor','g');point(l,3)<30
&& point(l,4)>500(pointcl(l,1),
pointcl(l,2),'k^','markersize',13,'MarkerFaceColor','c');point(l,3)<30 &&
point(l,4)<100(pointcl(l,1), pointcl(l,2),'k^','markersize',13,'MarkerFaceColor','y');point(l,3)<30
&& point(l,4)<500 && point(l,4)>100(pointcl(l,1),
pointcl(l,2),'k^','markersize',13,'MarkerFaceColor','g');
end
%
надання окремим ДРВп номера кластеру
for i=1:(size(d,2))(d{i}(:,1),
d{i}(:,2),ToString(i),'color','k','FontSize',9);
end
%
визначення координат вектора від центра кластера
for
f=1:(size(d,2))=(c(f,1)-d{f}(:,1));2=(c(f,2)-d{f}(:,2));
%
знаходження значення вектора по модулю "x"i=1:1:(size(am1,1))=am1(i,1)*am1(i,1);(i)=am11;
end
%
знаходження значення вектора по модулю "y"i=1:1:(size(am2,1))=am2(i,1)*am2(i,1);(i)=am22;
% абсолютний модуль_modul=sqrt(masyv1+masyv2);
% масив найдовших векторів_obvedennya=max(absolute_modul);
% коло=0:pi/100:2*pi;=c(f,1);=c(f,2);=2*masyv_obvedennya;=2*masyv_obvedennya;=v0+A/2*sin(t);=u0+B/2*cos(t);g>0.1
&& g<0.3(u0,v0,'rx','markersize',7,'LineWidth',
2);(v,u,'-c','LineWidth',2);g>0.2 &&
g<0.4(u0,v0,'rx','markersize',8,'LineWidth',
2);(v,u,':m','LineWidth',2);g>0.3 &&
g<0.5(u0,v0,'r+','markersize',9,'LineWidth',
2);(v,u,'-.r','LineWidth',2);g>0.4 &&
g<0.6(u0,v0,'r*','markersize',10,'LineWidth',
2);(v,u,'--y','LineWidth',2);g>0.5 &&
g<0.7(u0,v0,'rd','markersize',11,'LineWidth',
2);(v,u,'-k','LineWidth',2);g>0.6 && g<0.8(u0,v0,'r>','markersize',12,'LineWidth',
2);(v,u,':g','LineWidth',2);g>0.7 &&
g<0.9(u0,v0,'rh','markersize',13,'LineWidth',
2);(v,u,'-.b','LineWidth',2);g>0.8 &&
g<1(u0,v0,'rp','markersize',14,'LineWidth',
2);(v,u,'--m','LineWidth',2);g>0.9 && g<1.1(u0,v0,'r>','markersize',15,'LineWidth',
2);(v,u,'-r','LineWidth',2);equal('КЛАСТЕРНИЙ АНАЛІЗ')
end