Программа для иерархической классификации веб-сайтов
Основные определения, термины и
сокращения
validation - процедура оценивания обобщающей
способности алгоритмов машинного обучения;
TF-IDF (Term Frequency - Inverted
Document Frequency) - статистическая мера, используемая для оценки важности
слова в контексте документа
<https://ru.wikipedia.org/wiki/%D0%94%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82>,
являющегося частью коллекции документов;(Uniform Resource Locator) -полный путь
к размещению ресурса в сети интернет, содержит доменное имя; может содержать
путь к конкретной странице или файлу;Mining - применение методов и алгоритмов
интеллектуального анализа данных для обнаружения и поиска зависимостей и знаний
в сети Интернет;
Ансамбль классификаторов - набор
классификаторов применяемых совместно для решения одной задачи классификации;
Дерево - структура данных,
эмулирующая древовидную структуру в виде набора связанных узлов. Является
связным графом, не содержащим циклы;
Мета теги - необязательные атрибуты,
размещенные в заголовке страницы, которые предназначены для предоставления
структурированных метаданных
<https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D1%82%D0%B0%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D0%B5>
о веб-странице
<https://ru.wikipedia.org/wiki/%D0%92%D0%B5%D0%B1-%D1%81%D1%82%D1%80%D0%B0%D0%BD%D0%B8%D1%86%D0%B0>;
Обучающая выборка - конечное
множество объектов (примеров), для которых известна их принадлежность к тем или
иным классам;
Обучение по прецедентам - вид
обучения, при котором интеллектуальной системе
<https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%82%D0%B5%D0%BB%D0%BB%D0%B5%D0%BA%D1%82%D1%83%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0>
предъявляется набор положительных и отрицательных примеров, связанных с
какой-либо заранее неизвестной закономерностью;
Стемминг - это процесс нахождения
основы слова
<https://ru.wikipedia.org/wiki/%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D0%B0_%D1%81%D0%BB%D0%BE%D0%B2%D0%B0>
для заданного исходного слова;
СУБД - система управления базами
данных
Тег - элемент языка разметки
гипертекста;
Токенизация - выделение слов и
границ предложений;
Функция высшего порядка - функция,
принимающая в качестве аргумента другие функции;
Шум (шумовой объект, шумовой выброс)
- объект, признаковое описание которого аномально отличается от типичного
объекта того же класса.
Введение
сайт данные качество
валидация
Вместе с развитие интернета и
постоянным ростом количества информации в сети возрастает потребность в
автоматической обработке и классификации этой информации. Одной из наиболее
актуальных задач в этой области является задача иерархической классификации
веб-сайтов. Программы, решающие данную задачу, могут иметь широкое применение в
организации баз знаний, проведении маркетинговых и социологических
исследований, сегментации пользователей по их действиям в сети, поиске и
извлечении информации в сети.
Задача иерархической классификации
веб-сайтов находится на стыке таких дисциплин как web mining, машинное обучение
и обработка естественного языка. В рамках этих дисциплин существуют более
популярные и хорошо изученные задачи классификации текстов (в том числе
иерархической) и веб-страниц [1] [2] [3] [4] [5]. Однако, несмотря на близость
упомянутых задач, иерархическая классификация веб-сайтов имеет ряд
особенностей, затрудняющих использование существующих решений в схожих задачах
и требующих разработки новых методов для достижения приемлемого качества
классификации.
Веб-страницы обладают четкой
структурой и гиперссылками, а также специфическим содержанием - элементами
управления, навигации, оформления. Такие элементы могут свидетельствовать о
важности содержимого каких-либо элементов (например, текст, выделенный жирным
шрифтом) или указывать путь к дополнительной информации (гиперссылки). Данные,
заключенные в мета теги зачастую гораздо важнее для понимания назначения сайта или
страницы, чем информация из других разделов. Однако значительная часть работ в
этой области [1] [3] [6] [7] применяет популярные методы из области обработки
естественного языка для классификации веб-страниц. Чаще всего в таких случаях
страница очищается от всех автоматически сгенерированных элементов (текст
разметки, javascript код) и к оставшимся словам применяется метод TF-IDF [8]
для оценки важности этих слов и представлении документа (веб-страницы) в виде
числового вектора. Недостатки такого подхода в том, что расположение данных на
странице, их форматирование и параметры отображения полностью игнорируются.
Таким образом, текст рекламного объявления может зачастую получить больший вес,
чем текст из мета тега описания страницы.
В работах [9] [10] было доказано,
что популярные алгоритмы, используемые для классификации текста, при применении
к веб-страницам показывают низкое качество работы. Также было показано, что
использование гиперссылок, информации доступной по ним, а также признаков
связанных со структурой веб-страницы следует производить крайне аккуратно - в
различных экспериментах это вело как к улучшению классификации, так и к ее
ухудшению.
Для повышения качества классификации
в данной работе предлагается метод Tag Weighting, который оценивает важность
слов на веб-странице с учетом ее структуры и параметров форматирования текста.
Также следует отметить, что задача
классификации веб-сайта как совокупности веб-страниц отличается от задачи
классификации веб-страницы, которая подразумевается в большинстве работ на эту
тему. Такая постановка задачи дает дополнительные возможности для получения
информации об объекте и расширении его признакового описания, а также для
значительного расширения обучающей выборки в целом за счет дополнительных
веб-страниц. С другой стороны, использование веб-страниц может приводить к
увеличению риска ошибок при классификации из-за зашумленности сайтов (причиной
которой может стать спам) и их политематичности (например, форумы, в которых
существуют разделы, посвященные разнообразным тематикам). Это приводит к
необходимости создания правил для получения и отбора такой информации о
веб-сайте, которая бы не повредила качеству классификации.
Отдельный раздел работы посвящен
классификации в условиях наличия иерархии категорий. В общем случае,
иерархическая модель данных в задачах классификации подразумевает древовидную
структуру хранения данных. Однако существуют некоторые различия в правилах, по
которым производится классификация. Так, документы в коллекции могут быть
организованы как дерево или как ориентированный ациклический граф (например,
каталог Yahoo [11]). Каждая категория в обоих случаях может принадлежать только
к одной родительской категории (категории верхнего уровня в иерархии) [12] или
ко многим родительским категориям [11]. Более того, документы в коллекции могут
принадлежать только конечным категориям в иерархии (категориям самого низкого
уровня) [12] или они также могут принадлежать и внутренним категориям [13].
Большинство работ в этой области [12] [14] [4] [5] посвящены классификации в
условиях, когда объекту классификации может быть присвоена только одна конечная
категория.
В силу того, что в качестве
обучающего набора данных выбран Яндекс.Каталог [15] в данной работе полагается,
что структурой данных коллекции является дерево, каждая категория может
принадлежать ко многим родительским категориям, а также допускается
принадлежность документов в коллекции к внутренним категориям. Это придает
задаче дополнительную сложность, в первую очередь за счет многозначности (политематичености)
классификации. Например, сайт habrahabr.ru в Яндекс.Каталоге может принадлежать
категориям «Интернет» и «Социальные сети», которые находятся на одном уровне в
иерархии [16]. Тот факт, что документ в коллекции может принадлежать не только
концевым, но и родительским категориям также затрудняет использование уже
существующих алгоритмов иерархической классификации.
На данный момент существует два
основных подхода к решению задачи иерархической классификации: плоский (flat) и
поэтапный (level based) [17]. Плоский подход предполагает обучение одного
классификатора для всех классов [13] [14]. При таком подходе устройство
иерархии игнорируется, для классификатора все классы находятся на одном уровне,
классификация производится один раз. Поэтапный подход предполагает обучения
отдельных классификаторов для каждого уровня в иерархии [12] [18] [19]. В общем
случае, сложно сказать о том, какой из подходов лучше - у каждого из них есть
свои преимущества и недостатки, которые будут подробно рассмотрены далее. В
данной работе предполагается создание ансамбля классификаторов, который бы
объединял в себе оба подхода для достижения наилучшего качества классификации.
В рамках выпускной квалификационной
работы была поставлена цель - разработать программу для иерархической
классификации веб-сайтов. Для достижения поставленной цели необходимо решить
следующие задачи:
Создать и предварительно обработать
обучающую выборку на основе данных Яндекс.Каталога
Изучить различные методы и алгоритмы
в области классификации веб-сайтов и иерархической классификации;
Разработать модуль загрузки и отбора
необходимой информации о веб-сайте;
Разработать модуль для построения
признакового описания веб-сайта с учетом структуры и параметров форматирования
веб-страниц;
Провести эксперименты для изучения
возможности применения различных моделей классификации и их объединения в
ансамбли для решения поставленной задачи;
Выбрать итоговую модель с наилучшими
показателями и разработать модуль для иерархической классификации признаковых
описаний веб-сайтов;
Разработать техническую
документацию.
Данная работа организована следующим
образом: во введении описаны предметная область и актуальность работы, ее цель
и задачи, а также освещены основные подходы к их решению; первая глава
описывает получение и обработку данных о веб-сайте; во второй главе рассмотрен
алгоритм построения признакового описания веб-сайта с учетом структуры и
параметров форматирования веб-страниц, третья глава посвящена построению
ансамблей для решения задачи иерархической классификации, четвертая глава
рассматривает использующиеся подходы для оценки качества работы классификатора,
пятая глава описывает общую архитектуру программы и особенности реализации, в
шестой главе приведены результаты тестирования качества работы программы и
анализ этих результатов. В заключении перечислены основные полученные
результаты и приведены пути дальнейшей работы.
В приложениях 1-3 приведена
документация к программе по ГОСТ: техническое задание, руководство оператора,
программа и методика испытаний.
1. Получение и обработка данных о
веб-сайте
.1 Получение данных
В Яндекс.Каталоге веб-сайт
представлен названием его домена или поддомена, URL адресом, его кратким
описанием, индексом цитирования, тематикой, регионом и адресом в каталоге.
Таким образом, имея адрес главной страницы веб-сайта необходимо собрать
достаточно полную информацию о сайте, которая бы в то же время не навредила
качеству классификации. Как это уже упоминалось, многие исследователи
классифицируют сайт, используя только его главную страницу, сводя, таким
образом, задачу к задаче классификации веб-страниц. Однако в ряде работ в этой
области [20] [21] демонстрируется, что использование информации доступной по
гиперссылкам с главной страницы может увеличивать качество классификации. При
этом отмечается, что такой подход следует использовать с осторожностью из-за
высокой вероятности «зашумленности» таких страниц, наличия информации, не
относящейся к тематике сайта. После проведения ряда экспериментов было
установлено, что наибольшая эффективность достигается при извлечении информации
только из мета тегов со страниц того же сайта, доступных по гиперссылкам, и
всей доступной информации с главной страницы.
1.2 Предварительная обработка данных
Загруженные данные о сайте в
дальнейшем хранятся в двух вариантах - сырые, с сохранением всего содержимого
загруженных веб-страниц, и предварительно обработанные. Второй вариант
предполагает очистку страницы от всех элементов разметки, javascript кода и
прочего автоматически сгенерированного содержимого. Также производится удаление
рекламных элементов, в разметке которых содержатся ссылки на популярные системы
рекламной аналитики, такие как «ad.yandex.ru», «adsense», «adserver»,
«adsys-tem», «adsale», «openx». Далее производится токенизация оставшихся слов,
удаление стоп-слов (предлоги, междометия, причастия, частицы), ссылок и
пунктуации.
Последним шагом в обработке
веб-страницы является стемминг. Одним из самых распространенных алгоритмов
стемминга является алгоритм Портера, опубликованный Мартином Портером в 1980
году [22]. Основной идеей алгоритма является отсечение суффиксов и окончаний
для достижения основной формы слова. Алгоритм не задействуют каких-либо баз
основ слов и ориентируется на особенности языка. Реализация алгоритма Портера
для русского и некоторых других языков носит название SnowballStemmer [23].
2. Формирование признаков
Для успешного проведения классификации
необходимо представить полученные веб-страницы в некотором пространстве
признаковых описаний. Признаком объекта X называется отображение 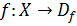 ,
где
,
где 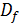 -
множество допустимых значений признака. Допустим, что заданы некоторые признаки
-
множество допустимых значений признака. Допустим, что заданы некоторые признаки
 .
Тогда признаковым описанием объекта
.
Тогда признаковым описанием объекта  будет
называться вектор
будет
называться вектор 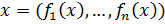 . Признаковым
пространством в таком случае будет называться множество
. Признаковым
пространством в таком случае будет называться множество 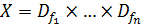
 .
.
Как уже упоминалось ранее, одним из
самых популярных методов для представления документов в признаковом
пространстве является TF-IDF (Term Frequency - Inverted Document Frequency)
[8]. Основная идея метода заключается в том, что чем чаще слово встречается в
документе, и чем реже оно встречается в других документах, тем более важным оно
является для оцениваемого документа. Более формально мера TF-IDF определяется
следующим образом:
 ,
,
где  -
частота встречи слова
-
частота встречи слова 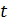 в документе
в документе  ,
а
,
а 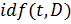 -
обратная частота встречи слова в документах
коллекции D.
-
обратная частота встречи слова в документах
коллекции D.
Каждый документ в коллекции представляется
вектором ,
где
,
где 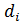 -
вектор, соответствующий i-ому документу,
-
вектор, соответствующий i-ому документу, 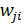 -
вес j-ого слова в i-ом документе, а n - общее количество уникальных слов в
коллекции.
-
вес j-ого слова в i-ом документе, а n - общее количество уникальных слов в
коллекции.
Однако применение данного метода к веб-страницам
не учитывает некоторые их особенности, что негативно сказывается на качестве
классификации. Так, все слова, содержащиеся на странице, считаются изначально
равными по весу, вне зависимости от их положения на странице или их
форматирования. Таким образом, может оказаться так, что слова, содержащие
рекламное объявление на сайте или слова из текста спама на форуме могут
оказаться важнее слов, указанных в мета данных или заголовке страницы. Метод
TF-IDF не учитывает, что форматирование текста тоже может указывать на важность
того или иного слова на странице.
Для решения этой проблемы был разработан метод
Tag Weighting, позволяющий учесть положение текста на странице и параметры его
форматирования при представлении документа в признаковом пространстве. Основная
идея метода заключается в том, чтобы умножать веса слов на веса тегов, в
которых они встречаются, а веса тегов вычислять обратно пропорционально к их
частоте (т.е. чем чаще тег встречается, тем наименее значимые элементы в нем
находятся). Таким образом, наиболее значительными данными априори становятся
мета данные о странице (каждый мета тег повторяется на странице только один
раз), а также те данные, которые заключены в редко встречающиеся теги (например,
выделение курсивом или жирным шрифтом). При этом в случае, когда различное
форматирование обильно используется для рекламы или без цели выделения важного
текста, значимость слов отформатированных таким образом будет низкой из-за
частоты использования форматирующих тегов.
При использовании предложенного метода вес W
i-ого слова на k-ом сайте вычисляется следующим образом:
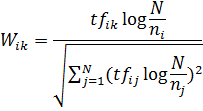
где 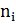 это
количество сайтов в коллекции, в которых встречается i-ое слово, N - общее
количество сайтов в выборке, а
это
количество сайтов в коллекции, в которых встречается i-ое слово, N - общее
количество сайтов в выборке, а 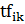 вычисляется как:
вычисляется как:
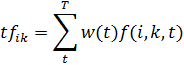
где T - множество всех тегов сайта  ,
,
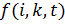 это
частота встречи i-ого слова в теге сайта ,
а
это
частота встречи i-ого слова в теге сайта ,
а  в
свою очередь вычисляется как:
в
свою очередь вычисляется как:

Далее каждый сайт представляется вектором ,
где -
вес j-ого слова в i-ом сайте, а n - общее количество уникальных слов во всех
сайтах коллекции, полученных после проведения полного цикла предобработки. Так
осуществляется представление сайта в признаковом пространстве.
3. Иерархическая классификация
После загрузки, предобработки и представления
сайта в признаковом пространстве необходимо выполнить классификацию, т.е.
отнести сайт к одной или нескольким заранее заданным категориям. Для
автоматического выполнения данной задачи необходимо построить алгоритм, который
был бы способен обучаться по прецедентам.
По условиям поставленной задачи заданные
категории образуют иерархию. Дополнительным условием является то, что сайт
может быть отнесен более чем к одной категории, а также то, что сайт может быть
отнесен и к родительской категории.
Такие условия достаточно сильно осложняют
задачу, и большая часть известных алгоритмов машинного обучения при их прямом
применении показывают низкое качество работы. Для достижения приемлемого
качества результата в данной работе предлагается создание ансамбля из уже
существующих моделей машинного обучения.
В данной главе описываются используемые
алгоритмы машинного обучения, подходы к решению задачи иерархической
классификации, а также подходы к построению ансамблей классификаторов.
3.1 Алгоритмы машинного обучения
Машина опорных векторов
В задачах классификации текстов и
веб-страниц широкое распространение получил алгоритм машины опорных векторов
(SVM) [25]. Основной идеей алгоритма является построение оптимальной
разделяющей гиперплоскости в пространстве признакового описания по обучающей
выборке.
Одним из несомненных преимуществ
данной модели является возможность работы с линейно неразделимыми данными при
помощи использования ядерных функций, реализующих отображения исходного
пространства признакового описания в некоторое пространство большей
размерности. Основными недостатками данного алгоритма является проблема
построения спрямляющего подпространства при линейной неразделимости классов, а
также высокая чувствительность к шумам [26].
Решающие деревья
Другим известным алгоритмом для
решения задач машинного обучения является решающее дерево. Данная модель
довольно проста и имеет древовидную структуру, в которой в нетерминальных
вершинах дерева содержатся предикаты - логические правила, которые разбивают
множества возможных значений вектора признаков на непересекающиеся множества. В
терминальных же вершинах дерева содержится метка класса, которая ставит объект
в соответствие одному из классов. С каждой вершиной, кроме корневой, в дереве
связано подмножество обучающей выборки. Пример такого дерева можно видеть на
рис. 1.

Рисунок 1 - Пример решающего дерева.
[27]
Процесс классификации начинается с
корневой вершины и состоит в последовательном применении предикатов, связанных
с вершинами дерева. По окончании процесса объект классификации достигает
терминальной вершины и ему присваивается метка класса, закрепленная за этой
вершиной [27].
3.2 Иерархическая классификация
На данный момент существует два
основных подхода к решению задачи иерархической классификации: плоский (flat) и
поэтапный (level based) [17]. Плоский подход предполагает обучение одного
классификатора для всех классов [13] [14]. При таком подходе иерархическая
организация категорий и связи между ними игнорируются - для классификатора все
категории находятся на одном уровне. Классификация производится в один шаг для
всех категорий. Поэтапный подход предполагает обучения отдельных
классификаторов для каждого уровня в иерархии [12] [18] [19]. Оба подхода имеют
свои существенные недостатки.
Так, в поэтапной классификации
слишком многое зависит от решений классификаторов в категориях верхнего уровня
- их ошибка приводит к тому, что объект классификации даже не доходит до нужных
классификаторов нижних уровней и на первом же шаге отправляется по неверной
ветке дерева. Но даже при наличии хорошо обученных классификаторов на верхних
уровнях с прохождением вниз по дереву иерархии вероятность ошибки итоговой
классификации увеличивается. Кроме того, поэтапный классификатор нуждается в
довольно большой обучающей выборке, которая в достаточной степени смогла бы
охватить все категории в дереве, т.к. при данном подходе необходимо обучать
классификатор для каждого уровня категории. Более того, чем меньше объектов
остается для обучения классификаторов отдельных категорий, тем больше
возрастает чувствительность к шумовым объектам и качеству выборки.
Основной недостаток плоского
классификатора заключается в том, что признаковые описания объектов,
находящихся на разных уровнях категории могут быть очень похожи (например, в
случае с категорией «Hi-tech/Сети и связь» и ее дочерней категорией
«Hi-tech/Сети и связь/Устройство сетей»). В таких ситуациях вероятность ошибки
плоского классификатора весьма высока. Другой недостаток плоского подхода
заключается в необходимости переобучать весь классификатор даже при небольшом
изменении в структуре иерархии, что зачастую требует довольно много ресурсов,
т.к. плоская модель классификации обучается на всей выборке целиком.
По условиям задачи сайт может быть
отнесен более чем к одной категории, включая родительские. Такое условие
придает задаче дополнительную сложность. Большинство упомянутых исследований в
этой области [12] [14] [4] [5] посвящены решению задач в более простых условиях
- однозначной классификации сайта (может быть отнесен только к одной категории)
и отнесения сайта только к концевым категориям. Но даже в таких условиях
результаты работы различных существующих решений могли оказаться
неудовлетворительными. Это свидетельствует о необходимости разработки нового
подхода к решению данной задачи.
Для достижения высокого качества
классификации и устранения недостатков обоих подходов в данной работе
предлагается объединить модели, построенные по разным принципам, в один
ансамбль классификаторов.
3.3 Построение ансамбля
классификаторов
Поэтапный ансамбль классификаторов
Первая часть решения заключается в построении
модели поэтапной классификации, которая содержит набор бинарных
классификаторов.
Для каждого узла дерева иерархии, к которому
принадлежит хотя бы один объект в обучающей выборке, обучается классификатор
определяющий принадлежность к категории этого узла по сравнению с категориями
узлов того же уровня (далее горизонтальный классификатор).
Помимо этого, для всех узлов имеющих дочерние
узлы обучаются отдельные классификаторы, которые определяют, принадлежит ли
объект текущей категории или он должен принадлежать одной из ее подкатегорий
(вертикальный классификатор).
Горизонтальным классификаторам в качестве
обучающей выборки с положительными примерами подаются объекты принадлежащие
непосредственно текущей категории, а в качестве отрицательной выборки - объекты
принадлежащие к категориям того же уровня и имеющие ту же родительскую
категорию.
Вертикальные классификаторы обучаются на выборке
из объектов, которые принадлежат текущей категории или ее родительским
категориям, как положительной и на выборке из объектов всех подкатегорий текущей
категории как отрицательной.
Иными словами, если вероятность принадлежности
объекта текущей и родительским категориям больше вероятности принадлежности к
детям текущей категории, то объект остается в текущей категории и наоборот.
Такой подход позволяет уменьшить вероятность
отдаления объекта от его истинной категории.
Классификация и обучение всех вертикальных и
горизонтальных классификаторов осуществляется по методу SVM, описанному ранее.
Плоские классификаторы
Бэггинг и лес решающих деревьев
Бэггинг - это метод объединения
различных классификаторов в один ансамбль, где все классификаторы работают
независимо друг от друга. При применении этого метода классификаторы могут
обучаться на различных подвыборках, различных подпространствах признаков или использовать
различные алгоритмы классификации. Результат классификации определяется путем
голосования. Чаще всего используется принцип простого большинства, который
присваивает объекту метку того класса, за который проголосовало большинство
алгоритмов [28].
В данной задаче бэггинг используется
для построения ансамбля решающих деревьев (решающего леса), каждое из которых
обучается на отдельных подвыборках обучающей выборки.
Плоский классификатор на основе SVM
В качестве третьей модели
классификации используется плоский классификатор, основанный на машине опорных
векторов. Аналогично решающему лесу, данный классификатор работает по принципу
«один против всех», т.е. для каждого класса строится отдельный бинарный
классификатор, определяющий принадлежность к этому классу. Каждый из таких
классификаторов в качестве положительной (принадлежит к классу) выборки
получает выборку объектов, принадлежащих к этому классу, а в качестве
отрицательной выборки получает выборку объектов, принадлежащих любым другим
классам, такого же размера.
Все рассмотренные модели
классификации объединяются в единую модель с помощью простого голосования - для
каждой категории решение о присвоении объекту текущей категории принимается
большинством голосов.
Подход с объединением различных
классификаторов в один ансамбль обладает следующими достоинствами:
недостатки одних подходов к
классификации компенсируются за счет других;
ошибка каждого из базовых
классификаторов в ансамбле усредняется, что делает ансамбль более устойчивым к
случайностям и шуму;
множество возможных гипотез ансамбля
расширяется за счет комбинирования гипотез базовых классификаторов, что
увеличивает обобщающую способность ансамбля;
снижается риск переобучения за счет
независимой работы моделей в ансамбле;
появляется возможность эффективной
реализации параллельной работы отдельных моделей.
В данной главе были рассмотрены
используемые алгоритмы машинного обучения, основные используемые подходы к
построению ансамблей классификаторов и к решению задачи иерархической
классификации, а также предложена модель решения задачи иерархической
классификации с помощью ансамбля классификаторов, объединяющих рассмотренные
подходы к решению задачи иерархической классификации.
4. Оценка качества работы модели
В данной главе представлены популярные
методы оценки качества работы модели классификации, которые в том числе
используются в других работах на эту тему. Приведено их описание и обоснование
используемых для данной оценки метрик.
4.1 Метрики оценки качества
Полная точность (accuracy)
Данная метрика является одной из
наиболее простых и в то же время универсальных метрик для оценки качества
работы алгоритмов классификации. Значение данного коэффициента вычисляется как
доля верно классифицированных объектов от общего числа объектов в выборке. Данная
метрика популярна благодаря своей простоте и возможности расширения на любое
число классов. Основным недостатком данной метрики является то, что она
присваивает всем документам одинаковый вес, что может быть некорректно в случае
сильного смещения документов в обучающей выборке в сторону какого-либо одного
или нескольких классов. Данная метрика может иметь высокое значение, однако
классификатор в пределах одного класса может показывать крайне низкое качество
работы. При этом метрика никак не сигнализирует об этом.
Точность, полнота и F-мера
Такие метрики, как точность
(precision) и полнота (recall) впервые получили широкое распространение в
оценке качества работы систем решающих задачу информационного поиска. Точность
системы в пределах одного класса представляет собой долю объектов действительно
принадлежащих определенному классу относительно всех объектов отнесенных
системой к этому классу. Полнота выражается как доля найденных классификатором
объектов принадлежащих классу относительно всех объектов этого класса [29].
Таблица 4 представляет собой таблицу сопряженности отдельного класса, где TP
(true positive) - истинно-положительное решение, TN (true negative) -
истинно-отрицательное решение, FP (false positive) - ложно-положительное
решение и FN (false negative) - ложно-отрицательное решение.
Таблица 1 - Таблица сопряженности
класса объектов
|
Экспертная
оценка (действительные значения класса контрольной выборки)
|
|
Положительная
|
Отрицательная
|
|
Оценка
системы
|
Положительная
|
TP
|
FP
|
|
Отрицательная
|
FN
|
TN
|
Таким образом, точность и полнота вычисляются
как:

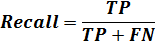
мера объединяет в себе информацию о точности и
полноте оцениваемого алгоритма. Вычисляется она как гармонические среднее
показателей точности и полноты:
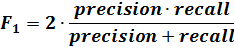
В силу того, что F-мера вычисляется
отдельно для каждого класса ее удобно использовать для поиска и анализа
конкретных ошибок алгоритма, для оценки классификации с несколькими классами.
При этом в случае большого числа классов необходима характеристика, которая бы
агрегировала полноту и точность по всем классам и характеризовала бы общее
поведение системы. В данной работе для этой цели применяется следующие
агрегированные величины: макро точность (macro precision), которая вычисляется
как среднее арифметическое значения точности по всем классам, макро полнотой
(macro recall), которая вычисляется как среднее арифметическое значение полноты
по всем классам и макро F-мера (Macro F-score), которая является гармоническим
средним между ними [30].
4.2 Кросс-валидация
Одним из наиболее распространенных
методов для проведения полноценного тестирования и оценки качества работы
различных алгоритмов машинного обучения, является скользящий контроль
(cross-validation). Для независимой выборки данный метод позволяет получить
несмещенную оценку вероятности ошибки в отличие от средней ошибки на обучаемой
выборке, которая может являться смещенной оценкой вероятности ошибки из-за
переобучения алгоритма [28]. Другим достоинством данной процедуры является
способность получения оценки вероятности ошибки алгоритма, при отсутствии
специально разработанной для тестирования контрольной выборки.
Допустим, что  - множество
признаковых описаний объектов, на котором задана конечная выборка прецедентов
- множество
признаковых описаний объектов, на котором задана конечная выборка прецедентов 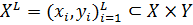 , где
, где 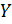 - конечное
множество классов. Задано отображение
- конечное
множество классов. Задано отображение 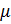 , которое произвольной выборке
прецедентов ставит в соответствие алгоритм
, которое произвольной выборке
прецедентов ставит в соответствие алгоритм  . Тогда качество работы алгоритма
. Тогда качество работы алгоритма 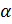 по
произвольной выборке прецедентов
по
произвольной выборке прецедентов 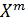 оценивается с помощью функционала
качества
оценивается с помощью функционала
качества 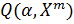 :
:
 ,
,
где  -
некоторая неотрицательная функция, которая возвращает величину ошибки алгоритма
-
некоторая неотрицательная функция, которая возвращает величину ошибки алгоритма
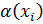 при
корректной метке класса
при
корректной метке класса  .
.
Метод получения оценки скользящего
контроля заключается в многократном разбиении общей выборки 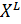 на две
непересекающиеся подвыборки
на две
непересекающиеся подвыборки 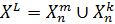 , где
, где 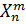 - обучающая подвыборка длины
- обучающая подвыборка длины  ,
, 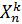 - тестовая
подвыборка длины
- тестовая
подвыборка длины  , где
, где 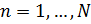 - номер
разбиения. Для каждого из
- номер
разбиения. Для каждого из  разбиений
выполняется построение алгоритма
разбиений
выполняется построение алгоритма 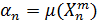 и вычисление значения функционала
качества алгоритма
и вычисление значения функционала
качества алгоритма 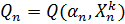 . Тогда
оценка скользящего контроля вычисляется следующим образом [28]:
. Тогда
оценка скользящего контроля вычисляется следующим образом [28]:
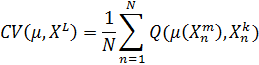
В данной главе проведен обзор
методов оценки качества работы алгоритмов машинного обучения. Приведено их
описание и обоснование используемых для данной оценки метрик. Для оценки общего
поведения системы используется макро F-мера, а также макро полнота и макро
точность. Для оценки качества классификации для отдельных классов используются
стандартные показатели точности, полноты и F-меры. Для проведения тестирования
используется алгоритм кросс-валидации.
5. Разработка программы
В данной главе приведено описание
общей структуры программы, инструментов разработки, особенностей реализации
методов и алгоритмов данной работы. Отдельный раздел посвящен реализации
параллельных вычислений в программе. Также описаны использующиеся механизмы
хранения данных.
5.1 Структура программы
Программа состоит из нескольких
отдельных модулей, каждый из которых выполняет свою функцию.
Модуль download предназначен для
загрузки веб-сайтов. Взаимодействие с базой данных и сериализация объектов
программы производится в модуле db. В модуле feature_extraction реализованы
алгоритмы формирования признаков (а именно TF-IDF и Tag Weighting) по собранным
с веб-сайта страницам, а также методы предобработки веб-страниц. Модуль
classifier содержит класс-оболочку для использования различных моделей
классификации. В модуле hierarchical_classification реализовано управлением
иерархической классификации с помощью различных моделей. Сами модели находятся
в модулях level_based_classifier (реализация поэтапного классификатора) и
ova_flat_clf (реализация плоского классификатора). Модуль preprocessing
содержит различные методы предобработки обучающей выборки и данных полученных
после загрузки веб-сайтов. Модуль tree описывает классы и структуры необходимые
для хранения дерева. Тестирование и оценка качества работы модели реализованы в
модуле evaluation. Алгоритм жадного поиска для оптимизации гиперпараметров
модели находится в модуле grid_search. Анализ обучающей выборке и вывод
статистики по ней реализован в модуле analyze_dataset.
Взаимодействие пользователя с
программой осуществляется посредством файла конфигурации config.ini, в котором
задаются необходимые параметры: путь к файлу с выборкой, режим работы, один из
двух возможных методов формирования признаков, параметры подключения к базе
данных. Для работы с файлом конфигурации выделен модуль config.
Модуль main при запуске считывает
файл конфигурации, проверяет заданные там параметры и запускает одну из функций
модуля hierarchical_classification - обучение, классификация или тестирование в
зависимости от заданного в файле конфигурации режима работы.
5.2 Инструменты разработки
Программа тесно взаимодействует с
базой данных MySQL, которая является одной из самых популярных систем
управления реляционными базами данных. Данная СУБД является свободно
распространяемым программным обеспечением, а также известна своей простотой
администрирования и гибкостью в настройках. Благодаря своему широкому
распространению MySQL хорошо документирована и обладает большим и развитым
сообществом. Основные минусы данной СУБД: MySQL не поддерживает последние
стандартны SQL (SQL-98, SQL-2003, SQL-2011) [31], ограниченный функционал
различных движков (storage engine) MySQL, ряд архитектурных ограничений [32].
Для взаимодействия с базой данных используется библиотека MySQLdb [33].
Для операций с массивами данных (в
частности, с обучающей выборкой) используется библиотека pandas. Основными
преимуществами данной библиотеки являются эффективные операции над массивами
данных, хранение массива данных в виде структурированной таблицы с
индексированием, быстрое и удобное получение данных из файла или из базы
данных. Библиотека написана на python и C [34].
Поскольку признаковое описание
объекта в данной работе основано на частоте встречаемости слов в документах
вектор, описывающий объект, будет иметь значительное количество нулей, даже в
случае большой обучающей выборки. Это объясняется известным законом Ципфа,
согласно которому при попытке упорядочить все слова языка по убыванию частоты
их использования частота n-го слова в таком списке окажется приблизительно обратно
пропорциональной его порядковому номеру n [35]. Из этого следует, что в большом
корпусе документов большинство слов встречаются один раз. Поэтому для
эффективного хранения признаковых описаний объектов следует использовать
разреженную матрицу объекты-признаки. Поскольку в ходе обучения и классификации
часто требуется получать признаковые описания объектов по индексу, разумным
решением выглядит использование матрицы формата compressed sparse row,
обеспечивающем быстрый доступ к строкам [36]. В программе используется ее
реализация из библиотеки scipy - scipy.sparse.csr_matrix.
Для стемминга используется известная
библиотека по работе с естественным языком nltk, для синтаксического разбора
веб-страниц используется библиотека BeautifulSoup. Для реализации алгоритмов
машинного обучения используется библиотека scikit-learn.
Благодаря использованию python и
свободных библиотек написанных на python или на C, программа является
кроссплатформенной и может работать как на операционных системах Windows, так и
на Mac OS X и системах семейства *nix.
5.3 Параллельные вычисления
Для достижения хороших результатов классификации
посредством предлагаемой в работе модели необходима большая обучающая выборка,
которая бы в достаточной степени охватывала все категории, к которым могут быть
отнесены сайты. В данной работе используется выборка основанная на данных
Яндекс.Каталога. Эта выборка содержит более 160 тысяч ссылок на различные
веб-сайты. При этом есть потребность загружать не только главные страницы
веб-сайтов, но и страницы сайта, доступные по гиперссылкам. Загрузка сотен
тысяч веб-страниц занимает достаточно продолжительное время.
Более того, построенная модель требует обучения
трех независимых ансамблей классификаторов, в каждом из которых происходит
обучение сотен базовых классификаторов по описанным алгоритмам машинного
обучения.
Все это указывает на необходимость какой-либо
оптимизации или изменения логики выполнения для ускорения работы программы.
Наиболее эффективным средством в данном случае видится реализация параллельного
выполнения загрузки страниц, обучения различных ансамблей, классификации с
помощью различных ансамблей. Отметим, что результаты упомянутых задач не влияют
друг на друга, задачи выполняются независимо и не требуют связи промежуточных
результатов (что часто является большим затруднением в задачах распределенных
вычислений). Такие задачи называют чрезвычайно параллельными, т.к. условия их
выполнения способствуют распараллеливанию. Поэтому для увеличения скорости
работы программы было принято решение реализовать параллельную загрузку
веб-страниц.
В языке python существуют различные
способы для выполнения многопоточных и мультипроцессорных программ. Так,
существует библиотека threading, реализующая все стандартные методы
многопоточного программирования - различного рода блокировки, семафоры,
события. Эта библиотека хорошо подходит для реализации асинхронных действий,
однако при попытке увеличить быстродействие программы данная библиотека
сталкивается с ограничением известным как GIL (Global Interpreter Lock) [37].
Основная идея GIL заключается в том, что в любой момент времени только один
поток python может выполняться процессором. GIL позволяет однопоточным
программам выполняться значительно быстрее и позволяет обеспечить определенную
потокобезопасность, однако он ограничивает возможности и эффективность
параллельных вычислений. Более того, из-за конкурирования потоков в попытке
перехватить GIL выполнение однопоточной программы может быть значительно
быстрее ее многопоточного аналога.
Из-за ограниченности многопоточного
выполнения в python необходимо прибегнуть к мультипроцессорному выполнению. Для
этого в языке python существует библиотека multiprocessing, которая позволяет
обходить ограничение, накладываемое GIL, за счет использования подпроцессов
вместо потоков. Таким образом, удается достичь значительной нагрузки на
процессоры многоядерных компьютеров. При этом API библиотеки multiprocessing
практически аналогично библиотеке threading, что облегчает переключение между
ними.
5.4 Загрузка веб-сайтов
Для решения задачи параллельной
загрузки веб-страниц применяется функциональный подход с использованием
встроенной функции высшего порядка map. Эта функция применяют заданную в
аргументе функцию к заданной последовательности, управляя итерацией по этой
последовательности. Функция map с поддержкой многопоточности присутствует в
библиотеке multiprocessing.
С использованием такого подхода код,
загружающий веб-страницы параллельно в нескольких процессах, выглядит следующим
образом:download_urls(urls): # создаем директорию кеширующую загруженные
страницы
if not
os.path.exists(CACHE_DIRECTORY): os.makedirs(CACHE_DIRECTORY).info('cache
downloaded directory created')= Pool(multiprocessing.cpu_count())=
pool.map(download, urls).close().join()bodies
В функции download_urls, принимающей
на вход список УРЛ адресов, создается директория кеширующая загруженные
страницы (если на момент вызова метода ее не существует). Далее создается
объект Pool, в параметрах которого задается количество рабочих процессов в
пуле. В данном случае этот параметр задается функцией
multiprocessing.cpu_count(), возвращающей максимальное количество процессов,
которое может быть запущено в данный момент. При вызове метода pool.map
запускаются все рабочие процессы, которые параллельно выполняют функцию
download для элементов из списка urls.
В функции download входящий УРЛ
адрес проверяется на корректность, далее проверяется был ли он скачен до этого
(с помощью кеширующей директории), далее отправляется запрос к сайту.
Предусмотрено некоторое количество ошибок и различных ситуаций при отправке
запроса и получении ответа от сайта. Так, сайты, которые возвращают код
состояния HTTP больший или равный 400, удаляются из обучающей выборки. При этом
для сайтов, код состояния которых равен 408 (истекло время ожидания), 434, 444,
503 (сервис недоступен) или 504 (шлюз не отвечает), программа пытается
выполнить повторную загрузку.
Другая проблема, возникающая при
загрузке различных данных с веб-сайтов, связана с необходимостью определения
кодировки загружаемых данных. К сожалению, далеко не все создатели веб-страниц
явно указывают их кодировку. Поэтому необходимо иметь возможность автоматически
определять кодировку для загруженного содержимого веб-страниц.
Для автоматического определения
кодировки в данной работе используется следующий метод: в случае, если
кодировка не указана явно в теле страницы, проверяются первые несколько байт
файла (там может быть указан BOM символ, свидетельствующий о принадлежности к
конкретной кодировке). После этого производится анализ частоты наиболее часто
используемых символов. В случае, когда анализ частот не позволяет сделать вывод
о кодировке, то используется класс UnicodeDammit из библиотеки BeautifulSoup,
который использует морфологический анализ и модель n-gram для определения
кодировки с некоторой вероятностью. Отметим, что в настоящий момент абсолютно
точное определение кодировки неизвестного текста считается невозможным [38].
Однако распознавание широко используемых кириллических или латинских кодировок
производится с почти 98% точностью.
5.5 Построение дерева иерархии
Для построения поэтапного
классификатора необходимо хранить информацию о структуре обучающей выборки,
которая задается пользователем. Обучающая выборка должна иметь иерархическую
структуру и храниться в следующем формате:
<имя_категории_верхнего_уровня>/<имя_подкатегории>/…/<имя_категории_сайта>;<URL
адрес сайта>
Пример содержимого
файла:Tech/Компьютеры/Компьютерная
помощь/;#"865971.files/image051.jpg">
Рисунок 2 - Распределение элементов
по корневым категориям
Концевых категорий в построенном по собранной
выборке дереве иерархии насчитывается 201. Глубина дерева иерархии равна
девяти. Среднее количество прямых потомков у категории составляет
приблизительно 4,5. Наиболее крупной категорией в выборке является категория
"Универсальное", содержащая 1000 элементов. При этом 281 категория в
выборке содержит только один элемент. Распределение элементов по всем
категориям представлено на рис. 2.
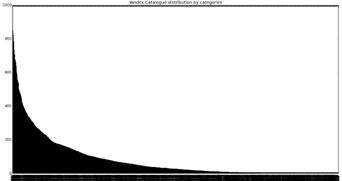
Рисунок 3 - Распределение элементов
по категориям в Яндекс.Каталоге
Как видно из рис. 3 значительная часть собранной
выборки представлена крайне малым числом сайтов. По одному или нескольким
веб-сайтам практически невозможно построить качественное признаковое описание
категории. Кроме этого, существует вероятность, что сайт был удален или во
время проведения обучения будет недоступен. После ряда экспериментов было
принято решение удалить категории, содержащие менее пяти элементов из выборки
как недостаточно хорошо представленные в ней. Всего таких категорий оказалось
728.
6.2 Оптимизация гиперпараметров
модели
Каждый из используемых в данной работе
алгоритмов машинного обучения и извлечения признаков требует задания ряда
параметров для дальнейшей работы. Машина опорных векторов нуждается в
определении метода регуляризации и размере штрафа. Эффективность работы леса
решающих деревьев зависит от количества деревьев в ансамбле, критерия
информативности признаков, максимальной глубины дерева. На формирование вектора
признаков оказать существенное влияние ограничения на максимальную и
минимальную частоту слова, метод регуляризации, возможная бинаризация
признаков, способ сглаживания частот слов.
Для оптимизации гиперпараметров модели в данной
работе используется алгоритм жадного поиска, который перебирает все возможные
наборы значений параметров в поисках комбинации дающей наилучший результат на
тестовой выборке. Отметим, что для сведения к минимуму эффекта переобучения
тестирование в данном случае также осуществляется с помощью кросс-валидации.
Плюсами использования жадного поиска является быстрая реализация и эффективное
распараллеливание. Обучения на разных наборах параметров распределяются между
различными процессами.
Оптимальные значения гиперпараметров,
определенные в ходе жадного поиска приведены в таблице 2.
Таблица 2 - Оптимальные значения гиперпараметров
модели
|
Алгоритм
|
Имя
параметра
|
Оптимальное
значение
|
|
Формирование
признаков
|
максимально
допустимая частота встречи терма в документах (в процентах от общего числа
документов)
|
0.75
|
|
Формирование
признаков
|
минимально
допустимая частота терма
|
1
|
|
Формирование
признаков
|
проводить
ли бинаризацию признаков
|
False
|
|
Формирование
признаков
|
метод
нормализации
|
l2
|
|
Формирование
признаков
|
метод
сглаживания
|
сглаживание
Лапласа
|
|
Формирование
признаков
|
диапазон
n-gram
|
(1,3)
|
|
SVM
|
размер
штрафа
|
0.0005
|
|
SVM
|
метод
регуляризации
|
l2
|
|
Лес
решающих деревьев
|
количество
деревьев
|
не
ограничено
|
|
Лес
решающих деревьев
|
критерий
информативности
|
энтропия
|
|
Лес
решающих деревьев
|
максимальная
глубина дерева
|
не
ограничена
|
6.3 Результаты экспериментов
Оценки работы отдельных моделей и их объединения
в один ансамбль находятся в таблице 3.
Таблица 3
|
Модель
|
Макро
точность
|
Макро
полнота
|
Макро
Ф-мера
|
|
Плоский
SVM
|
0.64
|
0.59
|
0.61
|
|
Плоский
лес решающих деревьев
|
0.66
|
0.64
|
0.65
|
|
Поэтапный
SVM
|
0.68
|
0.69
|
0.68
|
|
Объединенный
ансамбль
|
0.75
|
0.76
|
0.75
|
Результаты, представленные в таблице 3,
доказывают эффективность предложенного способа построения ансамбля из различных
представленных моделей классификации - объединенные в один классификатор модели
дают ощутимо лучший результат. Такой эффект достигается за счет использования
различных подходов и алгоритмов классификации в едином ансамбле, что позволяет
компенсировать недостатки отдельных подходов к поэтапной классификации, а также
уменьшить влияние шумов и случайностей на результат классификации.
При сравнении различных подходов к иерархической
классификации видно, что поэтапный классификатор с использованием алгоритма SVM
на каждом уровне работает значительно лучше, чем плоский подход с
использованием аналогичного алгоритма. Это обусловлено большим количеством
элементов в выборке в целом и в каждой категории в частности (категории с
минимальным количеством элементов были удалены), что позволило эффективно
обучить поэтапную модель классификации на всех уровнях, а также большое число
похожих друг на друга категорий на разных уровнях или в разных ветках дерева
иерархии, что вызывало значительное число ошибок у плоского классификатора.
Также отметим, что плоский лес решающих деревьев
показал себя лучше плоского классификатора с использованием алгоритма опорных
векторов по схеме «один-против-всех». В данном случае ключевую роль сыграло
использование техники бэггинга для построения леса решающих деревьев. Это
позволило снизить риск переобучения и сделать модель более устойчивое к шумовым
объектам в выборке. Для успешного обучения леса решающих деревьев также
необходима достаточно большая обучающая выборка, которая была собрана в ходе
этой работы. Вполне вероятно, что на выборке меньшего объема лес решающих
деревьев показал бы результаты худшие, чем плоский классификатор на основе SVM.
В таблице 4 приведены результаты классификации
элементов относящихся к различным корневым категориям. Значения метрик
вычислены отдельно для элементов каждой корневой категории.
Таблица 4
|
Корневая
категория
|
Макро
точность
|
Макро
полнота
|
Макро
Ф-мера
|
|
Бизнес
|
0.78
|
0.73
|
0.75
|
|
Дом
|
0.66
|
0.62
|
0.63
|
|
Культура
|
0.53
|
0.61
|
0.56
|
|
Hi-tech
|
0.62
|
0.78
|
0.69
|
|
Учеба
|
0.74
|
0.63
|
0.69
|
|
Отдых
|
0.71
|
0.52
|
0.6
|
|
Спорт
|
0.71
|
0.88
|
0.78
|
|
Авто
|
0.52
|
0.79
|
0.62
|
|
Общество
|
0.68
|
0.57
|
0.62
|
|
Развлечения
|
0.76
|
0.79
|
|
Справки
|
0.52
|
0.58
|
0.54
|
|
СМИ
|
0.46
|
0,54
|
0.5
|
|
Работа
|
0,75
|
0,78
|
0.76
|
|
Универсальное
|
0.21
|
0.34
|
0.26
|
|
Порталы
|
0.42
|
0.36
|
0,39
|
Наибольшее число ошибок наблюдается в категориях
«Универсальное» и «Порталы». После анализа выборки было установлено, что
тематики данных категорий в достаточно сильной степени пересекаются. Так, в
обеих категориях присутствует значительное количество информационных порталов,
в особенности порталов городов или других географических объектов. Другие
элементы категории «Универсальное» достаточно разнородны по составу: часть из
них являются разного рода новостными ресурсами, часть посвящена географическим
объектам или географии в целом. Также в этой категории содержатся блоги,
форумы, площадки для объявлений (например, avito.ru). Все эти факторы делают
классификации данной категории затруднительной, а также вызывают ошибки при
классификации элементов других категорий (которые иногда могут быть ошибочно
отнесены к «Универсальным»).
Дальнейший анализ ошибок классификации показал,
что многие из них были вызваны схожестью состава категорий «Спорт» и «СМИ» - в
обеих категориях присутствует достаточно большое количество сайтов посвященных
спортивной тематике, что вылилось в схожие признаковые описания объектов этих
категорий и их подкатегорий.
Заключение
В ВКР разработана программа для выполнения
иерархической классификации веб-сайтов. В основе работы программы лежит принцип
объединения различных моделей классификации в ансамбли. Помимо этого важной
особенностью программы является возможность ее обучения на заданной
пользователем выборке и предоставления пользователю возможностей по оцениванию
качества работы программы. Программа сама распознают структуру и свойства
дерева иерархии по заданной пользователем выборке. Таким образом, программа
может служить не только как прикладной продукт для решения задач по
классификации сайтов, но и как платформа для экспериментов в области машинного
обучения.
В работе предложен метод для формирования
признаков по содержимому веб-сайта и способ объединения различных моделей
классификации в ансамбль. Отметим, что работа ансамбля классификаторов в данной
работе предполагает использование не только различных алгоритмов машинного
обучения, но и различных подходов к задаче иерархической классификации -
плоского и поэтапного. Это позволяет взаимно компенсировать недостатки разных
подходов и увеличить итоговое качество работы модели.
Разработанная программа показывает достаточно
хороший результат при тестировании на данных Яндекс.Каталога, доказывая тем
самым эффективность предложенных в работе методов. При оценке качества работы
программы и отдельных алгоритмов машинного обучения использовались такие метрики
как точность, полнота и Ф-мера.
По результатам тестирования качество работы
ансамбля заметно превосходит качество работы отдельных моделей. При сравнении
классификаторов использующих разные подходы к иерархической классификации
лучшим оказался поэтапный подход. В данном случае это обусловлено большим
объемом обучающей выборки, а также рядом особенностей задачи: политематичностью
классификации, большим количеством категорий и принадлежности элементов к
внутренним категориям. Экспериментальным путем было доказано, что в таких
условиях лучше работает поэтапный подход.
Для обеспечения эффективной работы программы в
условиях обработки большого объема данных активно использовались параллельные
вычисления. Так, был реализован модуль для параллельной загрузки веб-страниц и
модуль для параллельной работы различных моделей классификации. Это позволило
добиться приемлемого времени работы при классификации новых объектов, однако
обучение модели по прежнему занимает достаточно продолжительное время. В связи
с этим, одним из направлений дальнейшей работы видится использование
распределенных систем хранения и обработки данных (например Hadoop или Spark).
Также перспективным направлением дальнейшей работы видится применение
алгоритмов тематического моделирования для формирования признаков и
классификации. Помимо этого, существует множество путей для дальнейших
экспериментов с построением ансамблей классификаторов: применение других
решающих правил (например, взвешенное голосование), использование других
методов для формирования признаков, включение в ансамбль других алгоритмов
машинного обучения.
Список
использованных
источников
1. Onan
A. Classifier and feature set ensembles for web page classification // Journal
of Information Science, 2015.
. Sebastiani
F. Machine learning in automated text categorization // CSUR, Vol. 34, No. 1,
2002. pp. 1-47.
. Qi
X., Davison. Web page classification // CSUR, Vol. 41, No. 2, 2009. pp. 1-31.
. An
W., Liu Q. Hierarchical Text Classification Based on LDA and Domain Ontology //
AMM, Vol. 411-414, 2013. pp. 1112-1116.
. Chen
X., Chen J. Class Hierarchical Structure-Based Text Classification // AMR, Vol.
255-260, 2011. pp. 2233-2237.
. Mladenic
D. Turning Yahoo into an automatic web-page classifier // Proceedings of the
European Conference on Artificial Intelligence (ECAI). 1998. pp. 473-474.
. Xin
J., Rongyan L., Xian S., Rongfang B. Automatic Web Pages Categorization with
ReliefF and Hidden Naive Bayes // DBLP.
. Aizawa
A. An information-theoretic perspective of tf-idf measures // Information
Pro-cessing & Management, Vol. 39, 2003. pp. 45-65.
. Chakrabarti
S. Mining the Web : Discovering Knowledge from Hypertext Data // MorganKaufmann
Publishers, 2003.
. Rahmani
A., Meshkizadeh S. Webpage Classification based on Compound of Using HTML
Features & URL Features and Features of Sibling Pages.
11. Yahoo
[Электронный ресурс] // Yahoo: [сайт]. URL: http://yahoo.com (дата обращения:
16.Апрель.2016).
12. Chen
H., Dumais S. Hierarchical classification of Web content // in Proc. of the
23rd ACM Int. Conf. on Research and Development in Information Retrieval.
Athens. 2000. pp. 256-263.
. He
Y., Wang K., Zhou S. Hierarchical classification of real life documents //
Proc. of the 1st SIAM Int. Conf. on Data Mining. Chicago. 2001.
. Sasaki
M., Kita K. Rule-based text categorization using hierarchical categories // In
Proc. of the IEEE Int. Conf. on Systems, Man, and Cybernetics. La Jolla. 1998.
pp. 2827-2830.
15. Яндекс.Каталог
[Электронный
ресурс]
// Яндекс.Каталог:
[сайт].
URL: https://yandex.ru/yaca/
16. Яндекс.Каталог:
habrahabr.ru [Электронный ресурс] // Яндекс.Каталог: [сайт]. URL:
https://yandex.ru/yaca/?text=habrahabr.ru
. Sun
A., Lim E., Ng W. Performance measurement framework for hierarchical text
classification // J. Am. Soc. Inf. Sci., Vol. 54, No. 11, 2003. pp. 1014-1028.
. D’Alessio
S., Murray K., Schiaffino R., Kershenbaum A. The effect of using hierarchical
classifiers in text categorization // In Proc. of the 6th Int. Conf. “Recherche
d’Information Assistee par Ordinateur”. Paris. 2000. pp. 302-313.
. Koller
D., Sahami M. Hierarchically classifying documents using very few words // In
Proc. of the 14th Int. Conf. on Machine Learning. 1997.
. Slattery
S., Ghan R., Yang Y. Hypertext categorization using hyperlink patterns and meta
data // ICML 01: Proceedings of the Eighteenth International Conference on
Machine Learning. 2001. pp. 178-185.
. Lee
M., Oh H., Myaeng S. A practical hypertext categorization method using links
and incrementally available class information // Proceedings of the 23rd Annual
International ACM SIGIR Conference on Research and Development in Information
Retrieval. 2000. pp. 264-271.
. Porter
M. An algorithm for suffix stripping // Morgan Kaufmann Publishers, 1997. pp.
313-316.
. Russian
stemming algorithm [Электронный
ресурс]
// Snowball: [сайт]. URL:
http://snowball.tartarus.org/algorithms/russian/stemmer.html
. Mitchell
T. Machine Learning. McGraw-Hill Science/Engineering/Math, 1997.
. Corinna
Cortes V.V. Support-Vector Networks // Machine Learning, No. 20, 1995. pp.
273-297.
26. Data
Analysis (Software Engineering) [Электронный ресурс] // Учебные курсы
факультета компьютерных наук: [сайт]. URL:
http://wiki.cs.hse.ru/Интеллектуальный_анализ_данных_(программная_инженерия)
(дата обращения: 1.Апрель.2016).
27. Quinlan
R. Induction of Decision Trees // Machine Learning, Vol. 1, 1985. pp. 81-106.
28. Профессиональный
информационно-аналитический ресурс, посвященный машинному обучению,
распознаванию образов и интеллектуальному анализу данных [Электронный ресурс]
// MachineLearning.ru: [сайт]. URL:
http://www.machinelearning.ru/ (дата
обращения:
1.Апрель.2016).
. Powers
D. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness,
Markedness & Correlation // Journal of Machine Learning Technologies, Vol.
1, No. 2, 2011. pp. 37-63.
. Asch
V.V. Macro- and micro-averaged evaluation measures, September 2013.
31. Справочное
руководство по MySQL [Электронный ресурс] // MySQL.RU: [сайт]. URL:
http:/www.mysql.ru/docs/man/Standards.html (дата обращения: 10.май.2016).
. Известные
ошибки и недостатки проектирования в MySQL [Электронный ресурс] // MySQL.ru:
[сайт]. URL: http:/www.mysql.ru/docs/man/Bugs.html (дата обращения:
10.май.2016).
. mysql-python.sourceforge.net
[Электронный ресурс] // sourceforge.net: [сайт]. URL:
http:mysql-python.sourceforge.net/MySQLdb.html (дата обращения: 10.май.2016).
34. Python
Data Analysis Library [Электронный
ресурс]
// pandas.pydata.org: [сайт].
URL: http:/pandas.pydata.org (дата
обращения:
10.май.2016).
. Powers
D.M.W. Proceedings of the Joint Conferences on New Methods in Language
Processing and Computational Natural Language Learning // Applications and
explanations of Zipf's law. 1998. pp. 151-160.
36. Aydin
Buluç J.T.F.M.F.J.R.G.C.E.L. SPAA '09 Proceedings of the twenty-first
annual symposium on Parallelism in algorithms and architectures // Parallel
sparse matrix-vector and matrix-transpose-vector
multiplication using compressed sparse blocks. 2009. pp. 233-244.
. Seungbeom
Kim J.P. 19th International Unicode Conference // Automatic Detection of
Character Encoding and Language. San Jose. 2001.