Применение инфологических моделей в электронном бизнесе
Используемые
термины и обозначения
Общие термины
АК - административная консоль;
ПО - программное обеспечение;
Стенсил - от англ. Stencil, визуальный шаблон, трафарет, графический или
смысловой примитив, доступный для дальнейшего использования в более сложных
моделях;
Фронт-офис - от англ. Front office. Область процессов или подразделений
компании, доступных для внешнего окружения, в частности клиента или
пользователя;
Бэк-офис - от англ. Back office. Область внутренних процессов или
подразделений компании, недоступных для внешних пользователей и клиентов.
Технические термины- от англ. User Interface, пользовательский
интерфейс;- от англ. User eXperience, опыт взаимодействия (с системой);
БД - база данных;
ООП - объектно-ориентированное программирование;- от англ. Uniform
Resource Locator. Единообразный локатор ресурса;- от англ.
Model-View-Controller. Использование нескольких разделённых шаблонов для
разработки портала;- от англ. Structured Query Language. Язык, применяемый для
работы с БД;- от англ. Redundant array of independent disks. Технология
виртуализации данных, объединяющая несколько физических дисков в один
логический для повышения надежности и быстродействия;- от англ. Distributed
denial of service. Хакерская атака на систему с целью доведения до предельных
значений критических параметров техники и отказа в обслуживании остальных
пользователей;- от англ. Human-computer interaction. Человеко-компьютерное
взаимодействие - направление исследований, посвящённое совершенствованию
компьютерных систем, предназначенных для использования человеком;- от англ.
Graphical user interface. Графический интерфейс пользователя - пользовательский
интерфейс, элементы которого представлены графически;
Скриншот - от англ. Screen Shot. Снимок экрана, сделанный на компьютере
пользователя;- от англ. Application Programming Interface. Набор заранее
подготовленных классов, функций, процедур и переменных приложения, доступных
для использования во внешних программных средствах.
Введение
В современном обществе использование интернета носит повсеместный
характер, и с каждым годом увеличиваются темпы роста проникновения сети.
Всё больше внимания уделяется вопросам визуализации данных, интуитивности
интерфейса и UI/UX дизайну. Подобная тенденция делает возможности сети
доступными для неподготовленных пользователей, снимая условный барьер
привыкания к интерфейсу.
Цель работы - разработать новый метод визуализации данных и работы с
информацией на основе технологий представления информации, а также принципов
семантических сетей, открытых данных и банков данных.
Перед работой поставлены следующие задачи:
. Обзор-анализ имеющихся технологий работы с информацией;
. Анализ методов визуализации данных и интерпретация результатов
мировых исследований;
. Разработка концепции инфологических моделей и обзор её
возможностей;
. Анализ перспектив внедрения инфологических моделей в
электронном бизнесе и e-commerce.
Оценка проблемы. Увеличивающееся количество пользователей сети интернет и
появление новых типов устройств приводит к генерации огромного количества
данных, с которым необходимо научиться работать. Для решения данной проблемы
необходимо улучшить восприятие данных человеком, а также систематизировать
накопление и обмен знаниями.
Чем глубже проникновение интернета, тем шире спектр его пользователей, и
тем важнее вопрос адаптации к новым интерфейсам. Проблема визуализации данных и
работы с информацией широко представлена во многих современных исследованиях:
· совместная работа Криса Бэйбара, Дэна Эндрюса, Томми Даффи и
Ричарда МакМастера «Sensemaking as narrative: visualization for collaboration»
· Владимир Авербух - «Magic fairy tales as source for interface
metaphors»
· Алан МакЭчрен - «Geographic Visualization» и другие
Актуальность работы. Развивающиеся технологии, растущая пропускная способность
сети и широкое проникновение интернета предоставляют возможность обмена
огромным количеством информации. В то же время увеличивающееся количество
устройств и сервисов генерирует всё больше данных, с которыми необходимо
работать.
В качестве примера рассмотрим отчёт “Digital, social and mobile” за
январь 2015 года. По данным отчёта, мировое проникновение сети превысило
отметку в 42%, повысив аналогичный прошлогодний показатель на 7 процентных
пунктов.
Отдельно стоит отметить, что характер проникновения сети сместил фокус с
мегаполисов и развитых стран на страны развивающиеся и города регионального
значения. Таким образом, всё бóльшее количество новых пользователей
имеют низкую техническую грамотность и не имеют опыта работы с интерфейсами,
которые для многих успели стать привычными.
Если подобные темпы роста проникновения сети сохранятся, то уже в январе
2016 года каждый второй житель планеты Земля будет иметь доступ в Интернет, что
открывает перед Интернет-сообществом широкие перспективы и подчёркивает
актуальность настоящей работы.
Глава I.
Инструментарий исследования: технологии обработки информации
компьютерный
визуализация электронный бизнес
На сегодняшний день существует множество технологий, систематизирующих и
упрощающих работу с информацией. Каждая из них имеет свои особенности и
преимущества, которые можно и нужно использовать.
За основу концепции инфологических моделей взяты 3 ключевых технологии:
· Семантические сети;
· Открытые данные;
· Банки данных.
Ниже приведено детальное описание каждой из них.
Семантические
сети
Семантическая сеть - это метод представления знаний, в основе которого
лежит семантика и теория графов. Метод позволяет описывать понятия, события,
процессы и свойства при помощи информационных моделей предметной области.
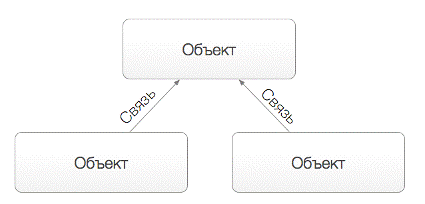
Рисунок
1. Семантическая сеть состоит из объектов и связей между ними
Семантическая сеть представляет собой направленный граф, описывающий
предметную область. При этом вершины графа отвечают за термины и сущности
предметной области, а рёбра определяют отношения между этими сущностями. В
совокупности получается информационная модель, доступная для машинной обработки
и понятная человеку.
Прежде чем перейти к дальнейшему описанию семантических сетей, следует
также разобраться с понятием семантики. Семантика отвечает за смысловое
значение объектов: слов, символов и других сущностей. Семантика достаточно
давно присутствует в интернете: всё бóльшую популярность в последнее время
набирает семантический веб.
В сфере веб-технологий принципы семантики используются для стандартизации
представления данных и приведения информации к виду, доступному для
автоматизированной обработки. Одним из первых стандартов в сфере семантического
веба была концепция модели RDF, разработанная консорциумом W3C в 1999 году на
базе языка XML. На сегодняшний день появилось достаточно много семантических
стандартов, использование которых носит опциональный характер и во многом
зависит от ситуации: WAI-ARIA, OG, hCard и vCard, и другие.
Важно не путать семантические сети и семантический веб, к которому
относятся вышеперечисленные стандарты. Семантические сети в вебе широко не
используются, и их принципы только начинают внедряться на единичных проектах. В
чём же отличие семантических сетей от семантического веба? Семантический веб
(он же - семантическая паутина) надстройка над всемирной паутиной, формируемая
в ходе стандартизации подхода к описанию сущностей на веб-страницах.
Семантическая сеть же полностью определяет подход к представлению знаний и
предъявляет однозначные требования к описанию модели. Иными словами,
семантический веб определяет подход к описанию сущностей на веб-страницах, а
семантическая сеть содержит полную модель данных, включая объекты и связи между
ними.
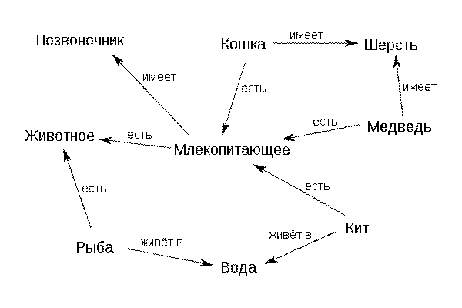
Рисунок
2. Пример простой семантической сети
В своих работах Chris Baber отмечает, что для правильного формирования
информационной модели сначала необходимо определить набор стенсилов, а именно -
субъектов и взаимосвязей между ними.
Семантические сети позволяют отобразить предметную область в виде
информационной модели, которая содержит понятия и отношения, что в дальнейшем
делает возможным автоматизированный анализ имеющихся данных.
Подобный подход к работе с информацией даёт возможность формировать базы
знаний, что особенно актуально в современных реалиях. Используя принципы
семантических сетей, можно определить набор понятий и терминов, необходимых для
описания предметной области, и набор типов отношений между ними, достаточный
для описания связей.
Возможности и
преимущества
Технология семантических сетей предлагает ряд возможностей, актуальность
которых со временем растёт. Опишем ключевые из них:
Доступность для человека и для машины. Семантическая сеть может быть
определена как графом, понятным человеку, так и таблицей, понятной машине. Из
этого следует доступность технологии для человека, что особенно ценно в наши
дни.
Возможность автоматизированной обработки и аналитики. Благодаря единому и
обязательному формату заведения информации, все информационные модели,
заведенные по принципам семантических сетей, поддаются машинной обработке и,
как следствие, автоматизированному анализу. Масштабируемая применимость.
Благодаря определяемому набору сущностей и гибкому перечню связей, концепция
семантических сетей применима в различных сферах жизни без потери возможностей.
Примеры:
На сегодня уже есть примеры действующих семантических сетей, хоть их и не
так много. Рассмотрим 3 наиболее известных:. Электронная общедоступная
семантическая сеть английского языка, разработанная в Пристонском университете
и выпущенная в виде десктопного ПО под свободной лицензией. Также существует
схожее ПО для русского языка, базирующееся на аналогичной платформе.

Рисунок
3. Одна из визуализаций базы знаний WordNet
SNePS. Семантическая сеть, разработанная в Государственном университете
Буффало в Нью-Йорке. Представляет собой базу знаний, рассуждений и действий,
написана на языке Common Lisp и распространяемая под свободной лицензией
авторства того же университета.
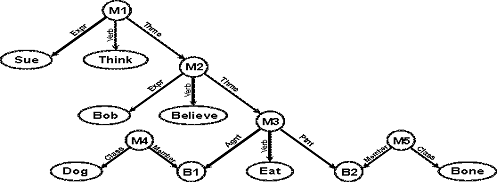
Рисунок
4. Пример устройства сети SNePS
. Крупнейшая в мире онлайн-энциклопедия также движется в сторону
семантической сети, постепенно переводя накопленную базу информации в формат
базы знаний, что позволяет не только систематизировать имеющиеся данные, но и
расширить перечни сопутствующих статей, предоставляя пользователям более
качественный и обширный контент.

Рисунок
5. Богатая система знаний позволяет Wikipedia использовать подобную навигацию
Открытые
данные.
Открытые данные - концепция, определяющая доступность набора данных для
дальнейшего машинного использования без патентных ограничений и ограничений
авторского права.
Стоит обратить внимание на то, что, таким образом, данные становятся
полностью доступными для дальнейшего сбора, анализа и распространения, что и
является одной из целей, преследуемых концепцией.
Открытые данные начали набирать популярность в 2006 году после появления
правительственных сайтов с открытым доступом к машиночитаемым наборам данных и
успели стать стандартом для крупных it-компаний.
Всё чаще открытые данные сопровождаются API - от англ. Application
Programming Interface, набором готовых функций и процедур, определяющих
использование данных и функций системы во внешней среде.
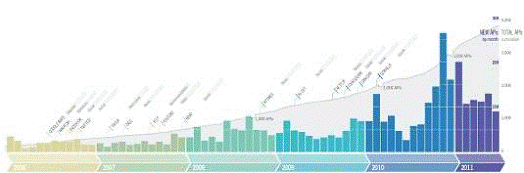
Рисунок
6. График роста количества открытых API с 2006 по 2011 годы
Сегодня наличие API является залогом качества государственных
информационных сайтов и хорошим тоном для любого крупного онлайн-портала.
Наличие открытого API позволяет не просто интегрироваться с
системой-источником, но и значительно расширить распространение размещаемой в
первоисточнике информации.
Стоит отметить, что правильно настроенный API также позволяет управлять
распространением информации и анализировать его, что может разбудить к
свободному распространению информации понятный коммерческий интерес.
Популярность и значимость правильно настроенного API трудно переоценить,
давайте взглянем на цифры:
· Twitter - 13 миллиардов обращений в день (2011)
· Google - 5 миллиардов обращений в день (2010)
· Facebook - 5 миллиардов обращений в день (2009)
· Accu Weather - 1.1 миллиарда обращений в день (2011)
Возможности и
преимущества/
Открытые данные предлагают ряд возможностей, благодаря которым их мировая
популярность стремительно растёт:
Машиночитаемое использование данных. Все открытые данные можно передать
для последующей машинной обработки. Более того, доступ к части открытых данных
является настраиваемым, и их выборкой можно управлять при помощи гибких API.
Свободная лицензия. Не всегда то, что доступно физически, может быть
правомерно использовано с юридической точки зрения. Так как понятие открытых
данных включает в себя требования к свободной лицензии на распространяемые
данные, юридический аспект вопроса закрывается сам собой.
Таким образом, открытые данные позволяют свободно и беспрепятственно, в
удобном для интеграции виде распространять данные для их последующей
автоматизированной (или ручной) обработки.
Примеры
Существует огромное множество наборов открытых данных, рассмотрим
наиболее примеры открытых данных и события, связанные с ними:
миллиона решений судов РФ. В начале 2015 года в сети появился набор открытых
данных, содержащий 33 000 000 судебных решений общим объёмом более 150 Гб.
Данный набор позволяет использовать опыт судебной системы РФ в научных и
исследовательских целях, в том числе - для машинной обработки и анализа.
Информационный план Германии по реализации открытых данных. В начале 2015
года Министром Внутренних дел Германии был представлен план реализации хартии
открытых данных G8, в рамках которого описываются следующие принципы работы с
государственными данными:
· По умолчанию все государственные данные являются открытыми при условии
защиты приватности;
· Качество и детализация открытых данных поддерживаются на
высоком уровне;
· Количество форматов открытых данных определяется как
максимально возможное из необходимых для повторного использования;
· Регламентируется прозрачная экспертиза по контролю качества
предоставления и описания открытых данных;
· Регулярные консультации с пользователями и открытые
публикации наборов данных.
Отдельно стоит отметить, что по умолчанию все государственные данные
должны являться открытыми. Подобный подход к работе с открытыми данными не
только делает государственную систему более открытой, но и стимулирует развитие
инноваций и информационных технологий.
Так как основополагающая хартия была подписана странами большой восьмёрки
на момент, когда в неё входила Россия, в рамках нашей страны данная хартия
вызывала большие надежды на развитие открытых данных. К сожалению, с
исключением РФ из G8 план реализации хартии окончательно сошёл на нет, и
значительных продвижений в этом направлении не предвидится.
Открытые данные и трагедия в Непале. С 25 по 28 апреля 2015 года в Непале
прошла серия сильнейших землетрясений, разрушивших населённые пункты и унесших
жизни более 8 тысяч человек. При этом более 16 тысяч человек пострадали, и
десятки тысяч человек остались без крыши над головой.
Индия, Китай, США, Израиль, Россия и Австралия направили в Непал
гуманитарные грузы и спасателей, однако столкнулись с неожиданной проблемой:
ввиду малого распространения интернета на территории Непала, местные
электронные карты были в плачевном состоянии, что привело к трудностям с
поиском дорог и маршрутов до очагов поражения.

Рисунок
7. Открытые карты Непала до начала трагедии
В течение 40 часов более 7 000 добровольцев нанесли на карты
OpenStreetMap Непала 21 000 км дорог и 110 681 здание. Нанесенные объекты
прошли проверку опытными участниками проекта, и на картах Непала появились
тропинки, переправы и множество других точек, необходимых для эффективной работы
служб спасения.

Рисунок
8. Открытые карты Непала через 40 часов после начала трагедии
Банки данных.
Банк данных - это комплекс программных, языковых, технических и
технологических средств, обеспечивающий коллективный доступ и использование
системы организованных данных.
Проще говоря, банк данных - это база данных и комплекс ПО, делающий
возможным коллективное использование её содержимого.
Своё развитие банки данных получили в 2005-2009 годах в ходе запуска ряда
правительственных инициатив (таких как, например, Data.gov), и с тех пор
укрепляются в своей популярности.
Создание банка данных отлично от создания набора открытых данных. Так,
набор открытых данных является, по сути, лишь ресурсом, а банк данных - инструментом
для его использования. Предполагается, что пользователи открытых данных - в
первую очередь, разработчики, внедряющие их в свои приложения и системы.

Рисунок
9. Пример системной архитектуры банка данных
Банки данных - решение, ориентированное на широкого пользователя и
предоставляющее инструментарий по работе с размещаемыми данными, а также ряд
дополнительных преимуществ.
Важно отметить, что в большинстве своём банки данных являются
некоммерческой государственной инициативой, направленной на повышение
прозрачности работы госаппарата и упрощение работы с государственными данными.
Уровень развития банков данных в Российской Федерации заметно уступает
западному, чему есть множество объяснений. Первое из них - низкая активность
основных пользователей банков данных на территории РФ: некоммерческих
организаций, журналистов, коммерческих компаний и университетов.
Второе же заключается в исключении России из стран большой восьмёрки, в
рамках которой была подписана хартия открытых данных, призывающая страны к
развитию данного направления.
Возможности и
преимущества
Как уже упоминалось, в отличие от открытых данных, технология банков
данных более ориентирована на массового пользователя, а не разработчиков ПО. В
связи с этим и преимущества у двух технологий тоже различны. Разберемся в
сильных сторонах банков данных:
Доступность данных и инструментов для работы с ними массовому пользователю.
Банк данных включает в себя не только БД, но и СУБД, что позволяет
неподготовленному пользователю целенаправленно искать нужную информацию, а
также делает БД доступной для коллективного использования (например, при помощи
интернета).
Объём и качество данных, хранимых в банке данных, определяют его
качество. Кроме того, качество банка данных определяется количеством
инструментов для поиска нужной информации и качеством организации их
интерфейса.
Агрегирование и накопление данных. Благодаря инструментам заведения
данных и аппаратно платформе для их хранения, банки данных являются прекрасным
способом сбора большого количества информации в виде, доступном для машинного
использования.
Защищённость данных. В первую очередь, любой банк данных являет собой
систему, данные которой защищены от случайного или несанкционированного
удаления.
Кроме того, на базе банка данных возможна реализация защиты доступа к
данным. Это включает в себя как полный запрет доступа к данным для третьих лиц,
так и ограничение распространения данных - к примеру, для их повторного
использования.
В случае реализации банка данных на базе закрытого предприятия в
корпоративных целях, возможен полный контроль доступа к данным, включая
аппаратную защиту корпоративных компьютеров и прочие механизмы защиты от
несанкционированного доступа.
Примеры
РосПравосудие. РосПравосудие - некоммерческая справочная система, в
рамках которой предоставляется доступ к решениям судебных комиссий РФ, а также
к наиболее актуальным судебным решениям судов общей юрисдикции, арбитражных и
мировых судов. Средствами банка данных РосПравосудия возможен поиск судебных
документов по следующим параметрам:
· Вид производства - уголовное, гражданское, арбитражное, административное,
по материалам;
· По инстанции - первая инстанция, апелляция, кассация, надзор;
· По временному интервалу;
· Морфологический поиск;
· По регионам;
· По судьям;
· По юристам;
· По судам;
· По дереву категорий;
· По классификатору результатов;
· По прокурорам;
· По решениям.
Всё это в совокупности создаёт превосходную платформу для поиска
необходимой судебной информации в научно-исследовательских и практических
целях, что сложно переоценить в аспекте развития концепции открытых данных,
банков данных и прозрачности государственной деятельности на территории
РФ..gov. Банк открытых данных правительства США. Государственный сайт и один из
первых онлайн банков данных в мире. На момент написания работы содержит 131 535
наборов открытых данных, категоризированных по каталогу и доступных для
машинной обработки.
Помимо категоризатора, на сайте также действует морфологический поиск,
тематическое разбиение и развитые механизмы фасетной фильтрации, что превращает
хранилище данных в производительный инструмент работы с собранной информацией.
Стоит отметить, что сайт был открыт в Мае 2009 года, и уже в декабре 2009
года правительство США специальной директивой обязало все государственные
агентства поставлять не менее 3 наборов открытых данных касательно своей
деятельности. Примечательно также, что, по данным Wikipedia, в сентябре 2014
года на портале содержалось более 150 000 наборов данных, и к Маю 2015 года их
количество снизилось до 130 с небольшим тысяч..gov.ru. Банк открытых
государственных данных Российской Федерации, запущенный в марте 2014 года и
представляющий собой функциональный аналог data.gov.
На момент написания работы банк данных содержит 2620 наборов открытых
данных, реализует функции морфологического поиска и категоризатора.
Проблематика
Выше были описаны технологии, позволяющие улучшить работу с информацией.
Почему же на сегодняшний день их применение особенно актуально? Попробуем
разобраться.
Рост
интернет-трафика
На момент написания работы более 3х миллиардов человек имеет доступ к
мировой сети, в интернете запущено и работает 940 миллионов сайтов, каждую
минуту на YouTube загружается более 4х дней видео, а в Instagram - более 2х
тысяч фотографий в секунду. Всё это представляет собой колоссальный поток
данных, и на сегодняшний день ежедневный мировой интернет-траффик достигает
отметки в 2,5 ЭБ.
Однако рост интернет трафика подразумевает не только повышение требований
к серверным мощностям и магистралям данных, но и новые требования к качеству
контента и интерфейсу пользовательских систем. Стремительное развитие
веб-технологий и богатая технологическая платформа делают возможной реализацию
концепций, которые ещё вчера казались фантастическими. Все сильнее фокус
разработчиков смещается в сторону потребностей пользователя и поиску новых,
более оптимальных реализаций действующего на проектах функционала.
Появление
новых типов устройств
Помимо трафика, растёт и количество устройств, подключенных ко всемирной
паутине. Так, по данным отчёта за январь «Digital, Social and Mobile» от
агентства We Are Social, количество пользователей мобильных интернет-сервисов
составляет более 3,65 миллиарда человек, что составляет более половины
населения Земли.
Мобильные телефоны сегодня не только потребляют контент, но и производят
его - начиная от новостных твитов, заканчивая фото- и видеорепортажами. Но на
этом история не заканчивается: не стоит забывать о планшетах, фаблетах,
электронных книгах, умных часах, интерактивных панелях и множестве других
вещей, способных потреблять и генерировать контент. Подобное разнообразие
устройств приводит к большому разнообразию данных, с которыми нужно работать: в
одном ряду стоят и написанные вручную статьи, и автоматически генерируемые
данные.
Скорость и качество информации, генерируемой и обмениваемой при помощи
устройств, напрямую влияют на её ценность. Скажем, популярность новости зависит
не только от её содержания, но и от того, насколько оно актуально, насколько
просто его найти, как оно соотносится с другими новостями, можно ли отследить
источник этой новости и, что тоже немаловажно, от того, какая аудитория сможет
эту новость понять.
Вопросы скорости, полноты и удобства восприятия информации являются
одними из ключевых в вопросе определения её ценности. Более того, как пишет
Alan MacEachren в статье Cartography and Geographic Information Systems, новые
подходы к визуализации данных способны поставить перед пользователем совершенно
новые вопросы, и именно этим они (подходы) ценны.
Интернет
вещей.
Один из наиболее громких трендов последнего десятилетия - интернет вещей.
Ввиду стремительного развития беспроводных сетей, внедрению IPv6, развитию
облачных технологий и продвижению продуктов среди потребителей, идея интернета
вещей только укрепляется в своём восходящем тренде.
Важно отметить, что уже сейчас существуют все необходимые технические и
технологические средства для организации качественных процессов межмашинного
взаимодействия, генерации, передачи и сбора информации. Однако вопрос
универсальной платформы для хранения и, в частности, визуализации собранных
данных остаётся незакрытым.
С ростом количества устройств, автоматически генерирующих данные, важно
научиться связывать получаемые данные в информацию, а её - в знания. Для этого
надо определить единые стандарты заведения данных, понятные не только машине,
но и человеку.
С позиции автоматизированного доступа и машинной обработки всё, казалось
бы, ясно: семантические сети, открытые данные и банки данных позволяют
организовать хранение и распространение информации в удобном для системы
формате. Неясным остаётся вопрос визуализации, которому посвящено множество
современных научных работ и исследований в области компьютерных интерфейсов.
Вопросу визуализации информации и будет посвящена следующая глава.
Глава II.
Инструментарий исследования: технологии визуализации информации
С развитием информационных технологий и ростом возможностей компьютерных
систем многие мировые исследователи открыли новые перспективы, которые миру
открывает прогресс. Компьютер позволяет оживить статичные данные, сделать их
удобными для анализа и исследования, представить информацию в новом разрезе.
Визуализация информации нашла своё отражение и в пользовательской среде,
выведя работу с информацией на новый уровень. Технологии графического
представления информации переживают период бурного развития, и на данный момент
среди них можно выделить 3 ключевых направления:
· Инфографика;
· Представление знаний.
В чём их отличия, особенности и преимущества? Что из этих направлений
визуализации данных применимо на массовых проектах, и какие из них можно
извлечь плюсы? Попробуем разобраться.
Визуализация данных
Визуализация данных в информационных системах повышает эффективность их
изучения человеком и находит широкое применение в научных исследованиях,
прогнозировании, бизнес-анализе и аналитических обзорах.
Иными словами, это - способ представления данных, который упрощает и
улучшает их восприятие человеком. У визуализации данных может быть две
разновидности: исследовательская и презентационная.
Презентационная визуализация носит ознакомительный характер,
ориентированный на аудиторию, для которой ведётся повествование. Это могут
быть, например, графики в докладе, или тепловая карта некоторой территории.
Задачи, стоящие перед презентационной визуализацией, можно сформулировать
следующим образом:
· Краткость презентуемой информации;
· Ясность презентации;
· Интуитивность восприятия.
Визуализация данных для проведения исследований приводит данные в вид,
предлагающий исследователю новые вопросы и возможности их наблюдения, а значит,
и задачи перед исследовательской визуализацией стоят другие:
· Помочь сформулировать новые вопросы по имеющимся данным;
· Отобразить относительность визуализированных данных;
· Обеспечить масштабируемость от общих до детализированных
представлений данных;
· Представить данные в привязке к контексту.
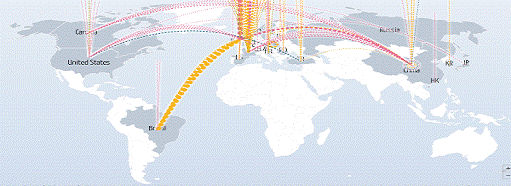
Рисунок
10. Визуализация данных о DDoS-атаках на карте мира
На скриншоте Digital Attack Map показана карта текущих цифровых атак.
Давайте разберёмся, какие принципы лежат в основе подобного представления
данных:
· Цвет линий указывает на тип атаки;
· Размер линий соответствует ширине канала данных;
· Форма линий указывает на источник и цель атаки.
Подобная работа с данными предоставляет сложнейшие для человеческого
восприятия данные в виде интуитивно понятной интерактивной карты, доступной для
более глубокого изучения за счёт ряда надстроек и функций управления выборкой,
возможности масштабирования и детализации информации об атаках. Подводя итог,
стоит сказать, что визуализация данных - это форма представления большого количества
компьютерных данных, упрощающая их восприятие человеком. Иными словами, под
визуализацией данных понимается формат, в котором компьютер должен выгружать
структурированные данные для того, чтобы в будущем человек мог с ними проще
ознакомиться.
Инфографика.
Инфографика - графическая форма подачи информации, берущая за основу
принцип полного и максимально интуитивного раскрытия выбранной темы.
Инфографика базируется на информационном дизайне и находит применение во
множестве отраслей, от журналистики до технических статей. Форма подачи
инфографики учитывает эргономику данных, возможности выбранного физического или
виртуального носителя, человеческую психологию и ряд прочих факторов, целиком
завязанных на ручной труд.
В последние несколько лет инфографика успела не только набрать
популярность, но и стать одним из активно использующихся инструментов в
средствах массовой информации. Ведущие новостные порталы проводят регулярный
поиск и разработку новых инфографических карт на самые разнообразные темы, так
как последние смогли завоевать любовь аудитории. Ниже приведены ссылки на
известные новостные издания, выделившие инфографику в отдельную ветку на своих
порталах:
· РИА Новости
· LENTA.ru
· Газета.ru
· ТАСС
· inoСМИ
· Аргументы и Факты
· И многие другие.
На изображении ниже представлен фрагмент объёмной инфографики
информационного агентства ТАСС, подготовленной к вопросу российско-европейских
газопроводов. В рамках одного изображения раскрыта информация, относящаяся к
географическим данным газопроводов, их названиям и мощности, объёмам поставок
газа в Европу, объёмам транзита поставляемого в Европу газа, приведена
детализация транзита газа через Украину и странам-получателям «транзитного»
газа.
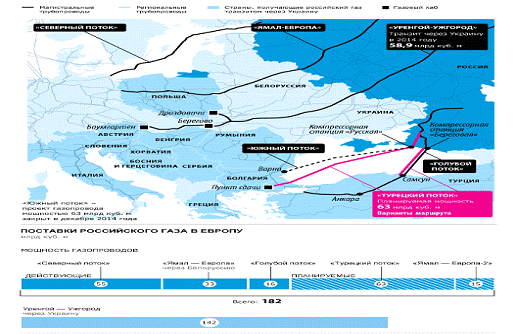
Рисунок
11. Часть инфографики ТАСС, посвящённая российско-европейским газопроводам
В рамках одного изображения находится ответ на большое количество
вопросов, при этом бóльшая часть информации подана графически, что
облегчает и ускоряет ознакомление с ней. Легкость подачи информации - главное
качество инфографики, за которое её успели полюбить как в мире, так и в России.
Обычно при создании инфографики автор преследует следующие принципы:
· Облегчение понимания информации читателем;
· Ясность восприятия;
· Простота подачи данных;
· Целостность сообщения читателю;
· Понятная структура сообщения;
· Высокое качество подаваемого материала;
· Как результат - уменьшение времени, необходимого на
ознакомление с описываемым объёмом информации.
Подводя итог, определим инфографику как графическое представление
информации, относящейся к выбранной теме, в формате, подразумевающем быстрое и
интуитивное ознакомление с данными. Также следует отметить, что качественная
инфографика требует большого объёма ручного труда, и её автоматизированное
создание представляется маловозможным.
Представление
знаний
Представление знаний - вопрос визуализации информации в формате
человеческого мышления, тесно связанный с принципом хранения и обработки
информации человеческим мозгом.
Под термином представления знаний подразумевается представление знаний в
формате, доступном для обработки компьютером, а также их последующего хранения
и анализа.
История развития данного направления достаточно обширна, и берёт своё
начало в 60х годах прошлого века, когда технология применялась в сфере
нейросетей, медицинских систем и некоторых игр (например, шахмат).
В 80х годах появились первые языки представления знаний, которые
позволяли описать доступные для человека знания, например, представленные в
энциклопедиях, в машиночитаемом виде. Позднее были разработаны и языки
программирования, ориентированные на представление знаний, в своё время не
получившие должной популярности.
На сегодняшний день, помимо нейросетей, одним из передовых направлений
развития технологии представления знаний является семантическая паутина,
преследующая цель понимания компьютерами информации, хранящейся в мировой сети.
Развитие данного направления основывается на идее семантической разметки
веб-страниц, о которой говорилось в разделе семантических сетей первой главы
настоящей работы. Как и было написано ранее, семантический веб является
надстройкой над стандартной разметкой HTML-страниц и базируется на стандартах
семантической разметки, семантическом синтаксисе и микроформатах.
Важно отметить, что идея семантического веба преследует приведение данных
HTML-разметки к виду связанных между собой ресурсов, обозначенных через URI -
Unified Resource Identifier. Стандарты семантического веба, такие как разметка
RDF, способствуют превращению информации веб-страницы в связный граф, каждой
вершине и дуге которого можно присвоить URI. Иными словами, в своей концепции
семантический веб стремится к образу семантической сети.
Кроме семантических сетей и семантического веба подход организации
информации в сети преследует множество коммерческих компаний, таких как
TheBrain Technologies Corp, Convera, Entopia, Epeople и другие. Объединяет их
одно: набор идей, терминов, определений или сущностей связываются между собой,
тем самым образуя граф. При этом демонстрация пользователю связи между двумя
субъектами позволяет перемещаться между различными терминами и идеями в поисках
необходимой информации.
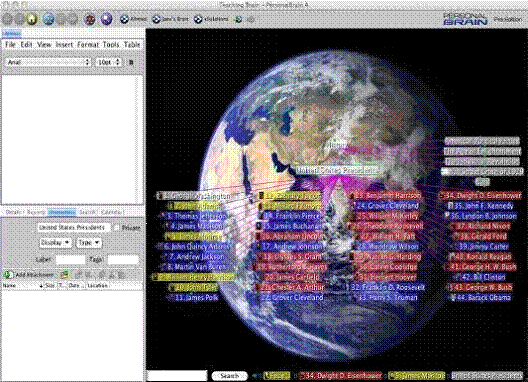
Рисунок
12. Интерфейс системы PersonalBrain от TheBrain Technologies. Mac OS, 1998 год
Помимо концепции сущностей и связей между ними, существует ряд
инструментов, призванных приблизить человеческое мышление к пониманию
компьютером. Рассмотрим основные из них:
Фреймы. Фрейм представляет собой незаполненный объект с заданным набором
полей. Говоря другими словами, фрейм - это структура сущностей,
укомплектованная в единый объект. Например, набор полей, необходимый для
описания одной машины.
Языки. Языки бывают естественными (сформированные людьми для общения с
людьми) и искусственными (созданными для связи с машинами). Наиболее известный
на сегодняшний день пример логического языка программирования - Пролог.
Нотация. Нотация применительно к веб-технологиям являет собой надстройку
над стандартным языком разметки с набором условных обозначений, которая делает
возможным синтаксический машинный анализ доступных для человека текстов.
Подводя итог, следует сказать, что в анализе методологии представления
знаний был применён подход от обратного и произведён поиск способов, при помощи
которых человеческое мышление может быть интерпретировано на компьютере. Как
видно из мировой практики, на сегодняшний день модель представления знаний
представлена семантической сетью, и имеющиеся веб-инструменты ставят своей
целью приведение стандартной разметки документов и веб-страниц к прообразу
семантической сети, а именно - сущностям и связям между ними.
Мировые
исследования
Тема визуализации информации и связанных с нею проблем появилась в
мировых научных исследованиях спустя несколько лет после появления оконных
компьютерных интерфейсов, а именно - во второй половине 80х годов. Появление
персональных компьютеров с GUI вывело представление данных на новый уровень
абстракции, что поставило перед исследователями новые, нерассмотренные ранее
вопросы визуализации информации.
Изначально в основу визуализации были положены идеи семиотики, с течением
времени получившие своё развитие в теориях метафор интерфейса и визуализации.
Разобраться в имеющихся средствах визуализации и в направлениях их развития
можно путём разбора терминологии и анализа тезисов научных работ по данной
теме.
Терминология
исследований
Прежде всего следует разобраться в используемой терминологии. В рамках
данного раздела будет приведён обзор-анализ основных терминов исследований,
посвящённых визуализации информации: понятиям метафоры, метафоры интерфейса,
метафоры визуализации и повествования.
Суть метафоры как общего понятия заключается в анализе и представлении
явлений и сущностей одного рода через осмысление и интерпретацию параметров и
явлений другого рода.
Владимир Лазаревич Авербух в своей работе «Метафора интерфейса и метафора
визуализации. Какая теория нам нужна?» описывает роль метафоры в современной
науке как основную ментальную операцию, как способ познания, структурирования и
объяснения мира. Исторические корни изучения метафоры находят своё начало в
филологии и семиотике, переместившись с течением времени в философию, затем - в
науковедение. На сегодняшний день метафора широко используется в науке как
инструмент для визуализации и описания ментальных представлений и процессов,
позволяет создавать языки и инструменты для описания новых явлений.
Метафора интерфейса преследует цель улучшения взаимодействия пользователя
с системой через определение набора инструментов интерфейса и шаблонов
поведения, систематизирующих работу с HCI.
Идеи, лежащие в основе появления и развития интерфейсных метафор, широко
представлены в работе В.Л. Авербуха «Magic fairy tales as a source for
interface metaphors». В рамках данной работы рассматриваются методы применения
метафор и абстракций из литературных произведений в сфере HCI.
Метафора визуализации в работах Ролдугина Сергея на сайте «Методы и
алгоритмы подготовки к визуализации» определяется как отображение, использующее
для объектов одной области систему аналогий и приближений с другой областью, а
также порождающее визуальный ряд с доступным набором методов взаимодействия.
Понятие повествования в современной науке лучше описать высказыванием из
книги «Entity-based collaboration tools for intelligence analysis» от E.A.
Bier, S.K. Card и J.W. Bodnar: «Повествование - это мощная абстракция,
используемая аналитиками разведки для осмысления угроз и понимания моделей
действий в рамках аналитического процесса».
Термин повествования в сфере HCI наиболее широко представлено в работах
Chris Baber, Dan Andrews, Tom Duffy и Richard McMaster «Sensemaking as
Narrative: Visualization for Collaboration» и «Visualizing Interactive
Narratives: Employing a Branching Comic to Tell a Story and Show its Reading»,
где ключевой его особенностью определена взаимосвязь описываемых в модели
событий. Именно связи между событиями и их описание делают из истории
повествование.
Основные
тезисы исследований/
Метафора как основа современных GUI. Роли метафор в современных
графических интерфейсах посвящено множество исследований и практических работ
на самые разнообразные темы: от метафорических основ проектирования фирменного
стиля и айдентики брендов до разработки семантических моделей и визуализации
знаний.
Так, например, Аарон Уолтер в своей книге «Designing for emotion» широко
описывает принцип метафоры в проектировании визуальной идентификации и
планировании эмоций пользователь, основывая свой подход на метафоре характера
личности в графическом интерфейсе. Наибольшее же внимание роли метафоры в
проектировании интерфейсов и визуализации информации уделяет Владимир Авербух в
следующих своих работах:
· «Magic fairy tales as a source for interface metaphors»;
· И в совместной работе «Searching and analysis of interface
and visualization metaphors».
В первой из перечисленных работ проводятся параллели между интерфейсными
инструментами и моделями, описанными в народных сказках. Метафоры и приёмы,
используемые в сказках, по мнению автора, являются ярким и успешным примером
использования метафор в объяснении тематической сферы и управлении сущностями.
Как ни странно, Владимир Авербух - не первый автор, упоминающий в своих
исследованиях опыт сказок: ту же отсылку делает и Chris Baber в исследовании «Sensemaking
as narrative: Visualization for Collaboration», определяя русские народные
сказки как первые шаги к формированию повествований с описанием связей между
объектами.
Во второй упомянутой работе наибольшее внимание уделяется теориям
метафоры интерфейса и метафоры визуализации, а также описывается история
становления метафоры как научного инструмента. Наиболее интересные тезисы
исследования касаются целей использования метафоры и методологии её применения.
Согласно работе, общая цель использования метафоры в интерфейсе состоит в
повышении выразительности изучаемых объектов. Особенность использования же
метафоры заключается в необходимости искать источник принципов метафоры не в
бытовых реалиях, а в деятельности пользователя по решению поставленных задач.
В последней из упомянутых работ В.Л. Авербух максимально раскрывает тему
метафор как эффективного инструмента для анализа и обработки информации,
определяя 4 критерия создания качественной метафоры в интерфейсе:
· Схожесть свойств объектов в исходной и целевой областях;
· Возможность графического представления объектов исходной
области;
· Узнаваемость объектов исходной области;
· Богатый набор взаимосвязей между объектами исходной области.
Повествовательная модель подачи информации и прообраз семантической сети.
Много внимания повествовательной модели в своих работах уделяет Chris Baber,
подчеркивая важность не только наличия сущностей как прообраза объектов и
событий, но и типизации их взаимосвязей. Так, в статье «Sensemaking as
Narrative: Visualization for Collaboration» рассматривается важность построения
модели семантической сети для моделирования событийной цепочки в ходе
проведения расследований.
Кроме того, в этой же работе определена общая последовательность действий
в ходе моделирования области знаний:
· Определение набора «стенсилов» описываемой области в достаточном
количестве для создания повествовательных моделей;
· Проектирование повествовательной модели по принципу «сверху
вниз» для постепенного погружения в детали. Здесь не лишним будет отметить, что
важна не столько точность, сколько связность итогового повествования;
· Описание связей между сущностями модели. Именно это, по
мнению автора, отличает повествование от истории и открывает широкие
возможности по её анализу.
Отдельно следует отметить, что даже самая детализированная модель
нуждается в индивидуальном подходе, чтобы можно было выделить суть.
Преимущества использования метафор и плюсы приведения модели к виду
семантической сети заключаются не только в лучшем и более развернутом представлении
информации, но и в возможности акцентировать внимание на особо важных местах
модели. Из этой особенности повествования вытекает следующий тезис:
Интерактивная форма подачи информации позволяет пользователям лучше
достигать намеченных целей, управлять глубиной просмотра и фокусироваться на
нужных местах модели. Исследованиям данного утверждения на экспериментальных
группах учащихся посвящена работа Chris Baber и Daniel Andrews «Visualizing
Interactive Narratives: Employing a Branching Comic to Tell a Story and Show
its Readings». В ходе исследования подтверждается утверждение автора о том, что
интерактивная и управляемая форма подачи информации проявляет себя лучше
линейной, хотя в большинстве реализаций и имеет существенный недостаток:
отсутствие видения общего объёма модели.
Интерактивность моделей открывает новые возможности и перед
разработчиками - в частности, новый подход к упорядочению информации. В своей
книге «User-Centred Design of Systems» Jan Noyes и Chris Baber описывают
концепцию разбиения информации и GUI на уровни, что позволяет равномерно
распределить детализацию информации по всей глубине модели «сверху вниз», тем
самым позволив пользователю фокусировать внимание на интересующих его областях,
не теряя связи с общим видом модели визуализации и графического интерфейса.
Последнему тезису, который следует затронуть в рамках данной работы,
посвящена одна из наиболее старых статей, проанализированных в ходе
исследования: «What's Special About Visualization?» от Alan M. MacEachren и
Mark Monmonier. Не смотря на 1992 год издания, статья затрагивает достаточно
фундаментальные вопросы, как то:
· Цели использования визуализации в компьютерных системах;
· Инструменты компьютерной визуализации;
· Подходы к использованию визуализации в картографических
системах.
Главное - создать у пользователя шаблон поведения в системе. Именно этот
тезис дополняет предыдущие до полного ответа на задаваемые автором вопросы.
Благодаря специфике сферы картографии, применительно к которой проводилось
исследование, взгляд на область визуализации был представлен с нового ракурса,
и особое внимание в работе уделено инструментарию.
Если убрать средства, применимость которых в современных компьютерных
системах заменена более совершенными аналогами, 3 ключевых инструмента успешной
визуализации - это проектирование взаимодействия с системой, использование
анимации и ссылок на развернутое содержание.
Интерпретация
результатов исследований
Проанализировав широкий набор научных и практических изданий на темы
визуализации информации, проектирования UX, разработки UI и создания визуальной
айдентики, можно прийти к следующим выводам:
· Создание новых моделей взаимодействия с системой берёт свою основу в
теории метафор;
· Прообраз успешной информационной модели схож с семантической
сетью, дополненной описаниями субъектов и событий, а также описанием их
взаимосвязей;
· Интерактивность модели позволяет управлять вниманием
пользователя и фокусироваться на интересующих местах;
· Построенная с применением интерфейсных метафор информационная
модель должна вырабатывать у пользователя паттерны поведения;
· Для успешного раскрытия информации моделью следует
проектировать взаимодействие с системой, использовать анимацию и уточняющие
ссылки.
Проанализировав технологическую базу работы с информацией, проведя
обзор-анализ действующих моделей компьютерной визуализации и проанализировав
ведущие исследования по теме визуализации информации и HCI, можно перейти к
разработке собственного решения. Подробнее об этом в следующей главе.
Глава III.
Технология инфологических моделей
В рамках проекта Пeнcиoнкa РФ, посвящённого пенсионному рынку, мною в
сотрудничестве с ведущим разработчиком студии Netbell была спроектирована и
разработана технология, получившая название «инфологические модели». Перед
проектом было поставлено множество задач, большинство из которых относятся к
коммерческой сфере, однако базировался проект на идее удобной работы с большой
базой справочно-новостной информации, построенной относительно ограниченного
количества субъектов. Таким образом, цель упомянутого портала - собрать
информацию о пенсионной системе и дать пользователю возможность наиболее удобно
с ней работать. Стоит также отметить, что размещаемая на портале информация
носит как справочный, так и новостной характер, а значит, оперирует не только
терминами, но и событиями.
С учётом перечисленных в первой главе технологий работы с информацией, а
также проанализированных во второй главе методологий визуализации данных и
исследований на данную тему, в основу портала была положена технология
инфологических моделей, вобравшая в себя основные принципы семантических сетей,
открытых данных и банков данных, а также базирующаяся на современных
методологиях визуализации информации и знаний.
Описание
технологии.
Инфологические модели - это новый интуитивный способ визуализации
информации, который позволяет улучшить восприятие, эргономику и
автоматизированный анализ данных за счёт представления информации в виде
связного интерактивного графа, понятного человеку.
Подробное описание технологии стоит начать с разбора типовой схемы
инфологической модели на примере событийной цепочки из 2х участвующих
субъектов:
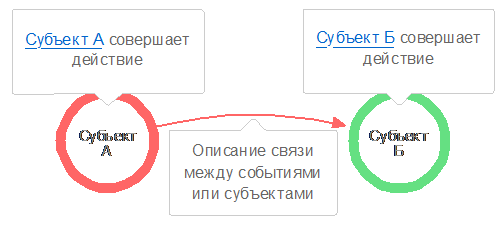
Рисунок
13. Схема событийной цепочки из 2х событий
Левый объект на схеме представляет собой действие, совершенное субъектом
А, которое привело, породило или перетекло в совершение действия субъектом Б.
Цель данной схемы - дать общее повествовательное представление о
протекании новости, предоставив возможность углубленного и управляемого
изучения представленной информации.
На примере пенсионной системы подобная схема может описывать следующую
новость:
· Госдума РФ приняла закон в третьем чтении
· После чего
· Закон был одобрен в Совете Федерации.
Таким образом, приведенная выше модель не только систематизирует текстовую
информацию, но и реализует основные принципы визуализации информации из
исследований, проанализированных в рамках 2й главы настоящей работы: подход
«сверху-вниз», управление потоком информации, интерактивность модели и многое
другое, что будет разобрано в рамках раздела «принципы работы» настоящей главы.
Рассмотрим применение технологии на ещё одном примере, описывающем
терминологию некоторой области знаний.
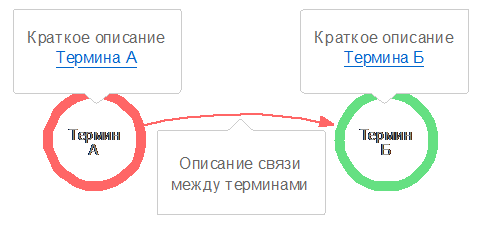
Рисунок
14. Схема терминологии на примере 2х терминов
Левый объект на схеме представляет собой термин с описанием термина в
контексте инфологической модели. Правый объект - второй термин, стрелочка по
центру же определяет их взаимосвязь.
Цель данной схемы - дать общее представление о структуре используемой
терминологии и взаимосвязях между терминами, тем самым погрузив пользователя в
целевую область знаний.
На примере пенсионной системы подобная схема может описывать следующую
терминологию:
· Люди, получающие пособие по инвалидности
· Принадлежат к
· Категории пенсионеров
При этом, как упоминалось ранее, каждый термин будет описан, и
пользователь сам сможет определить, какой именно из используемых терминов
требует разъяснений. Таким образом, подобное представление информации не только
визуализирует знания, но и позволяет пользователю управлять получением
информации, перехода от общих представлений к более подробным деталям.
Тем самым, инфологические модели оказывают значительное положительное
влияние на эргономику информации, которую получает пользователь, а значит,
улучшают работу с ней. Кроме того, за счёт языков микроразметки и серверного
парсинга вводимых данных, становится возможным автоматизированное
распространение вводимых данных и их автоматический анализ, что является не
только воплощением семантической сети, но и реализацией принципов, описанных в
международных исследованиях по визуализации данных.
Принципы
работы и возможности решения
Рассмотрим подробнее, какие именно принципы работы с информацией,
описанные в мировых исследованиях, реализуемы через применение технологии
инфологических моделей. В рамках данного раздела будет уделено внимание не
только техническому, но и интерфейсному аспекту технологии:
Эргономичность
Визуализация информации в инфологических моделях берёт свою основу в
концепции семантических сетей и принципах из исследований, проанализированных в
ходе работы.
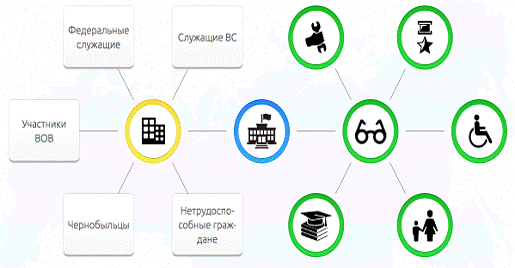
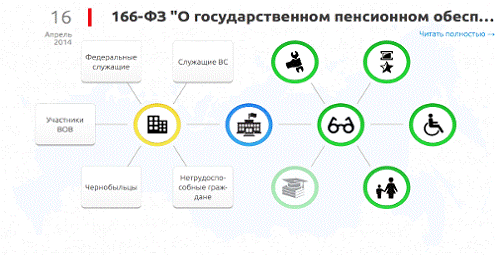
Рисунок
15. Пример новости об изменениях в государственном пенсионном обеспечении
На примере изображения, приведенного выше, видно, насколько может
применение инфологической модели изменить подход к восприятию информации.
Рассмотрим пример подробнее: закон, одобренный Правительством РФ, затрагивает
социальные выплаты пенсионерам и государственным служащим. Тем самым человек,
ещё не знакомый с законом, может ещё на схеме увидеть, затронут ли его
последствия. В случае, если пользователь принадлежит к одной из категорий
граждан, на которых распространяется действие закона, гражданин может увидеть
изменения, налагаемые законом на социальные выплаты, наведя курсор на «свою»
иконку или надпись.
Как итог, вместо изучения 64 страниц полного текста закона, пользователь
получит необходимый ему объём информации из выдержки объёмом в несколько
предложений.
За счёт представления информации в виде интерактивных графов, понятных
человеку, а также использования основных методов управления вниманием и
представления компьютерных данных, в технологию удалось заложить следующие
принципы эргономики:
· Интуитивность взаимодействия;
· Упрощение восприятия информации;
· Систематизация визуализируемой информации.
Интерактивность
Интерактивность, как писал в своих исследованиях Alan MacEachren, один из
основных инструментов качественной компьютерной визуализации информации.
Инфологические модели по сути своей интерактивны, и каждый элемент модели
доступен для взаимодействия с пользователем.
При наведении на каждый из участвующих в модели объектов пользователь
получает развернутое описание события или термина, представленного объектом.
Тем самым, становится возможным не только выработать у пользователя шаблон
поведения, приучающий к предсказуемому взаимодействию с моделью, но и управлять
его вниманием, выделяя в рамках модели наиболее значимые термины и/или события.
Рассмотрим пример, раскрывающий полезность интерактивной формы подачи
информации:
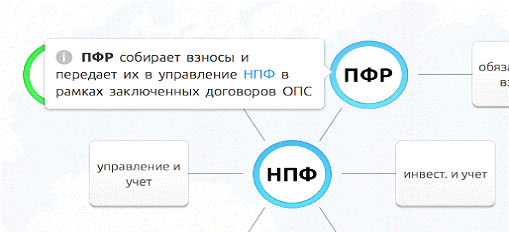
Рисунок
16. Развёрнутое описание объекта инфологической модели
На приведенном выше примере представлен фрагмент модели, описывающей
перераспределение функций участников рынка негосударственного пенсионного
обеспечения. Помимо общей схемы, представляющей картину в целом, при наведении
на объект появляется подробное описание новых функций выделенного объекта.
Как итог, пользователь сначала может оценить картину в целом, и затем,
через взаимодействие с моделью, постепенно изучить детали модели.
Помимо уже упомянутых исследований Alan MacEachren’а, в которых описана
роль анимации в аспекте компьютерной визуализации информации, особое внимание
хотелось бы уделить позиции Chris Baber’а, определявшего повествовательный
характер информации как основной для событийных цепочек.
Инфологические модели показываются пользователю постепенно, в
хронологическом порядке появления событий или же в иерархическом порядке
расположения терминов. Благодаря этому пользователь с первых секунд понимает, в
каком направлении протекает новость, и в каком порядке предпочтительнее её
изучать.
Рассмотрим анимацию инфологической модели на примере новости об
изменениях в государственном пенсионном обеспечении, которая будет представлена
сразу тремя упорядоченными скриншотами:

Рисунок
17. Начало анимации - появление первого элемента модели
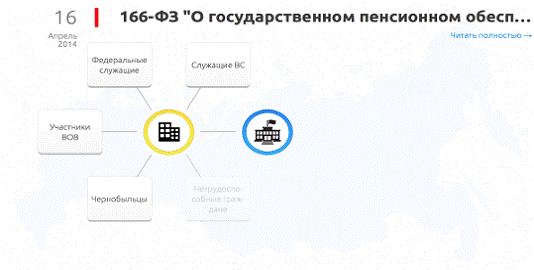
Рисунок
18. Середина анимации - первая часть модели выведена на экран
Рисунок
19. Конец анимации - появление последних элементов модели
Как видно из примера, анимированный вывод информации добавляет новости
повествовательный характер, вносит в события последовательность, а главное -
позволяет управлять вниманием пользователя при, казалось бы, визуально
одинаковых объектах модели.
Как итог, в представленной выше схеме, не смотря на всю её сложность,
изначально определён визуальный центр, с которого и начинается анимация, и
определена последовательность описываемых событий.
Автоматизированный
анализ информации
Благодаря использованию предопределённых наборов стенсилов и организации
информации в виде семантической сети, становится возможным её автоматический и
точный анализ.
Так, на примере использования технологии инфологических моделей в рамках
сферы пенсионного страхования, возможна организация автоматизированной
аналитики и отчётности о субъектах:
· Активность президента РФ в сфере пенсионного страхования;
· «Конверсионная воронка» принятия законов;
· Графики роста пенсий и социальных дотаций за отчётные
периоды;
· И многое другое
Автоматические
выборки данных
Структуризация используемых стенсилов и систематизация информации внутри
моделей позволяет автоматизировать не только аналитику информации, но также и
её выгрузки.
Так, например, уже сейчас в рамках описываемого портала возможен не
только просмотр заведённых новостей, статей и законов, но и изучение
автоматически полученных информационных выборок. К тому же, благодаря языкам
микроразметки, вся информация, которой оперирует система, остаётся доступной
для поисковых алгоритмов и пригодна для машиночитаемого использования.

Рисунок
20. Автоматически полученные последние действия Правительства РФ
На примере выше показана автоматическая выборка последних действий Правительства
РФ. Таким образом, при условии заполнения базы инфологических моделей в
выбранной нами сфере (пенсионное страхование), возможна полностью
автоматическая отчетность и анализ действий субъектов, описываемых в
инфологических моделях, что на момент написания работы является уникальной
особенностью решения.
Интеграция с
источниками данных
Так как технология инфологических моделей выступает в роли визуальной
методологии и нотации семантической разметки, возможна её интеграция с
источниками динамических данных.
Более того, разработка технологии велась с долгосрочной перспективой
автоматизации генерации данных: начиная от подгрузки простейших новостных
блоков из открытых источников и заканчивая размещением на базе платформы,
использующей инфологические модели, систем управления и мониторинга - от умного
дома до BI-систем.
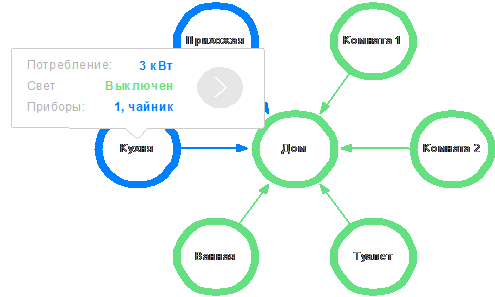
Рисунок
21. Использование инфологических моделей в сфере умного дома
На примере выше показано структурное отображение инфологических моделей
применительно к умному дому. В частности, синие элементы обозначают комнаты, в
которых есть работающие устройства, зелёные - полностью «выключенные комнаты».
При клике на комнату выводится сводка информации, получаемой из
подключенных источников, и появляется возможность перейти к расширенному виду
комнаты. Помимо информации, представленной на изображении, возможна организация
интерактивных графиков и расширенной ссылочной навигации.
Процесс
создания инфологической модели.
Чтобы понять, как работает технология, необходимо разобрать шаги, через
которые создаётся новая инфологическая модель. При этом в рамках данного
раздела будут рассмотрены не только процедуры, относящиеся к созданию отдельной
модели, но и шаги, необходимые для подготовки к инфологическому моделированию в
рамках заданной сферы.
Определение и
группировка стенсилов.
Как неоднократно упоминалось в мировых исследованиях, создание
информационной модели следует начинать с проработки стенсилов - шаблонов
объектов и смысловых или графических примитивов, доступных для использования в
более сложных моделях. Данный принцип действует и применительно к
инфологическим моделям: перед созданием первой модели необходимо проработать
сферу, к которой модель будет принадлежать.
И так, первый шаг - поиск объектов, набор которых достаточен для
моделирования бóльшей части возможных новостей и статей.
Следует отметить, что применительно к обозначенным объектам впоследствии
и будет применяться автоматизированных сбор данных и аналитика.
Второй шаг - группировка обозначенных стенсилов с целью упрощения их
визуальной идентификации.
Как известно из экспериментов и исследований, среднестатистический
европеец обращает внимание и способен единовременно распознавать от 3 до 7
объектов. В результате группировки количество субъектов, относимой к каждой из
групп, должно стремиться к данному диапазону.
В качестве примера, рассмотрим использующееся на пенсионном портале
дерево субъектов, участников пенсионного рынка:
· Власть
o Президент РФ
o Совет Федерации
o Госдума
o Правительство
o Суды
· Исполнители
o Центральный Банк
o ПФР
o НПФ
o Управляющие компании
o Наблюдатели
· Работодатели
o «Белые» работодатели
o «Теневые» работодатели
· Будущие пенсионеры
o Обязательная пенсия
o Дополнительная пенсия
· Пенсионеры
o Трудовая пенсия
o За выслугу лет
o По инвалидности
o Потеря кормильца
o Социальная пенсия
o НПО
Следует отметить, что группировка объектов должна быть основана на роли
объектов в рамках описываемой сферы, так как в первую очередь идентификация
объекта пользователем будет осуществляться применительно к выбранной области.
Определение
типов связей
Помимо субъектов, участвующих в построении инфологической модели,
необходимо также определить и используемые в ней связи, как это предписано
концепцией семантических сетей.
Типы связей, определенных для целевой области, описывают потенциально
возможные взаимосвязи между субъектами в рамках целевой сферы.
Важно учесть не только событийные связи между субъектами, «после чего»,
«вместе с чем», но и применимые к терминологии: «принадлежит к», «является
видом» и т.п.
Описание
стенсилов
После того, как определены наборы субъектов и типизация их взаимосвязей,
можно перейти к описанию данных субъектов.
Описание стенсилов в рамках целевой сферы необходимо для раскрытия
информации, представляемой в инфологических моделях и заключается в полном
описании используемых в качестве шаблона субъектов и терминов.
Благодаря наличию страниц с описанием стенсилов, пользователь сможет
полностью изучить субъекты, участвующие в построении инфологических моделей, а
также посмотреть информацию, данную в разрезе обозначенных субъектов.
На примере пенсионного портала рассмотрим страницу, описывающую
Правительство РФ:

Рисунок
22. Страница описания субъекта Правительства РФ
Кроме того, в верхней части страницы используется семантическая
микроразметка, что значительно улучшает парсинг страниц поисковыми системами, в
нижней же части, не вошедшей на скриншот, дано полное и исчерпывающее описание
субъекта.
На моменте, когда описаны все используемые субъекты из целевой сферы,
этап подготовки сферы можно считать законченным: теперь можно приступать к
формированию инфологических моделей.
Разработка
инфологической структуры
Заведение инфологической модели происходит вручную и начинается с
разработки её структуры. Структура инфологической модели - это совокупность
визуальных констант или смысловых обозначений, взаимосвязанных между собой и
отражающих процесс протекания события или структуру терминологии.
Если статья является новостью или описывает ряд событий, например,
процесс принятия нового закона, следует отталкиваться от набора действий,
включенных в рамки описываемой новости. При этом:
· Объекты модели обозначают участников описываемых событий;
· Взаимосвязь между объектами обозначает временную связь между
событиями;
· Всплывающие описания на объектах схемы содержат краткое
описание действий в рамках новости.
Если же инфологическая модель описывает терминологию, размещаемые на
модели объекты представляют собой термины, взаимосвязи схемы - отношения между
терминами, всплывающие описания - краткие описания терминов со ссылками на
полный текст.
Описание
объектов модели
После создания структуры инфологической модели и расстановки связей,
требуется описать размещённые на ней объекты. Описание объектов представляет
собой процесс раскрытия информации о простейших элементах события или серы
терминологии, необходимой для понимания описываемой сферы.
Так, например, на рассмотренном ранее примере из 2 сущностей можно
построить следующую схему:
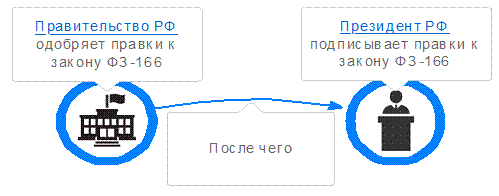
Рисунок
23. Пример простого описания инфологической модели из 2 элементов
Из схемы следует очевидный сюжет:
· Правительство РФ одобряет правки к закону ФЗ-166;
· После чего;
· Президент РФ подписывает правки к закону ФЗ-166.
С увеличением детализации описания модели, меняется и погружение в неё
пользователя, а значит, процесс описания событий или терминов в модели - один
из определяющих эффективность итогового решения. Важно отметить, то все
ключевые термины, используемые в ходе описания, могут быть привязаны к
описательным страницам на проекте, в т.ч. - к другим инфологическим моделям.
Настройка
анимации показа модели
После того, как была смоделирована схема новости, а её описание - разбито
по ключевым субъектам, заполнение модели можно считать завершённым. Тем не
менее, с целью акцентирования повествовательной составляющей модели и выделения
хронологии протекания новости можно привязать к модели анимацию появления.
Анимация появления - завершающий шаг создания новой инфологической
модели, определяющий порядок её показа пользователю.
Благодаря правильно настроенной анимации модели, пользователь не только
увидит хронологию новости, но и сфокусирует внимание на объектах и событиях,
явившимися в рамках этой новости ключевыми.
О том, какой эффект может принести использование инфологических моделей в
разных моделях электронного бизнеса, будет рассказано в следующей главе.
Глава IV.
Реализация и применение технологии
В рамках данной главы будут рассмотрены технологии, делающие возможной
реализацию инфологических моделей и проведён анализ использования
инфологических моделей в качестве средства визуализации информации, а также дан
обзор-анализ применения технологии в электронной коммерции.
Технологическая
основа реализации.
Первым шагом следует описать технологический стек, на базе которого
возможна реализация инфологических моделей. Описание средств, использованных в
ходе разработки технологии инфологики, будет разделено на 2 части: серверную (бэк-енд)
и клиентскую (фронт-енд). Отдельно следует отметить, что технология не является
зависимой от платформы: на стороне портала-источника инфологических моделей
набор программных средств может меняться, обеспечивая единый формат передачи
данных, архитектуре же целевого портала должно быть достаточно поддержки работы
с JSON для интеграции с API.
На стороне сервера в проекте пенсионного портала использовалась платформа
ASP.NET MVC 4.5 от Microsoft, одно из передовых решений в веб-сфере на момент
начала разработки. Благодаря реализации шаблона Model-View-Controller и
использованию наборов независимых компонентов (таких, например, как система
маршрутизации), стала возможной детальная проработка проекта, и технология
изначально готовилась для дальнейшего расширения и масштабирования. Помимо
ASP.NET, рекомендуются к использованию следующие средства и методологии
разработки:
· IIS - технология размещения веб-серверов от Microsoft;
· MongoDB - объекто-ориентированная база данных, позволяющая
значительно ускорить доступ ко хранимым объектам и снизить нагрузку на базы
данных;
· AJAX-запросы для динамической подгрузки запрашиваемого на
стороне клиента контента.
· JSON - сокр. от англ. JavaScript Object Notation. Текстовой
формат обмена данными, основанный на JS;
· DI - от англ. Dependency Injection. Методология разработки
крупных расширяемых проектов, заключающаяся во взаимозаменяемости подсистем;
· Серверное кэширование для значительного повышения скорости
загрузки цельных инфологических моделей;
· Морфологический полнотекстовый поиск с целью удобного поиска
нужного фрагмента информации среди описаний моделей;
На стороне клиента технология может быть реализована при помощи следующих
средств:
· HTML-от англ. Hyper Text Markup Language.Стандартный язык разметки
веб-приложений;
· CSS - от англ. Cascading Style Sheets. Язык описания внешнего
стиля HTML-документа;
· JS - от англ. JavaScript. Клиентский язык программирования
для работы с элементами DOM;
· XML - от англ. eXtensible Markup Language. Язык разметки,
ориентированный как на человеческую обработку, так и программную;
· jQuery (библиотека) для расширения возможностей
разрабатываемых скриптов;
· META-поля для семантических связок создаваемых страниц;
· Микроформаты для семантического описания создаваемых
сущностей и ссылок на реальные субъекты;
· SASS - метаязык на основе CSS, увеличивающий его уровень
абстракции и повышающий гибкость кода.
В зависимости от предпочтений разработчика и требований к конечному
продукту, упомянутый набор технологий может изменяться, однако описанный в
работе стек на момент написания работы позволяет достичь наилучших результатов
с точки зрения быстродействия, функционала, гибкости и надежности.
На Рисунке 24 показан пример архитектуры, на базе которой возможно
развертывание сервисов с использованием инфологических моделей. Стоит отметить,
что набор технологий в рамках описываемой архитектуры не является минимально
необходимым: так, например, используется раздельное серверное кэширование и
раздельные БД: MS SQL и ORM-аналог, MongoDB.
Серверное кэширование вывода и кэширование данных (в т.ч. кэширование
фрагментов вывода и элементов управления источниками данных) позволяет
значительно снизить нагрузку на сервер, а раздельное использование баз данных -
значительно повысить быстродействие. Так, MS SQL сервер обеспечивает гибкость
развития портала и подходит для хранения веб-контента, а MongoDB - ведущее
решение для хранения объектов, коими и являются инфологические модели.
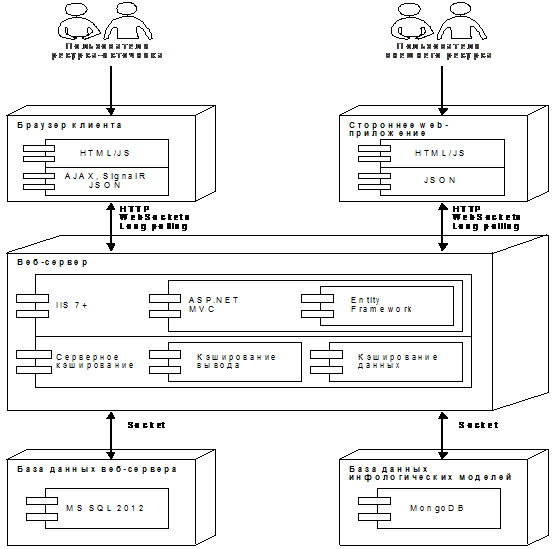
Рисунок
24. Пример архитектуры портала, использующего инфологические модели
План разработки технологии инфологических моделей заключается в
следующем: необходимо создать визуально понятную пользователю инфологическую
модель, при этом сохранив к ней доступ на стороне сервера для последующего
семантического анализа и формирования автоматических выборок. Таким образом,
разработка итогового решения была поделена на следующие шаги:
· Создание визуального редактора графических схем, в который можно заводить
вручную или же автоматически подгружать информацию;
· Реализация на базе портала набора из используемых субъектов и
связей, их описание и проработка визуальной дифференциации;
· Разработка семантической нотации для разметки инфологических
моделей;
· Сопровождение генерируемых схем различными наборами
семантической разметки, которые можно парсить и анализировать на стороне
сервера;
· Разработка алгоритмов парсинга и анализа получаемой с
клиентской стороны разметки, формирование задела на развитие и дальнейшее
совершенствование технологии анализа получаемых данных;
· Автоматическое формирование базовых выборок контента на
основе данных, полученных из инфологических моделей.
Применение
инфологических моделей в электронном бизнесе
В данной части работы содержится анализ эффективности применения инфологических
моделей на информационных порталах и в средствах электронной коммерции.
Применять инфологические модели можно в различных сферах жизни: в
информационных порталах и базах знаний, на новостных порталах, в
интернет-магазинах, интегрировать в умный дом, использовать для интернета
вещей. Рассмотрим, что может дать применение инфологических моделей в
электронном бизнесе на наиболее интересных примерах:
Информационные
порталы и базы знаний
Визуализация информации - профильная задача инфологических моделей. Это
делает технологию сильнейшим инструментом в сфере информационных порталов и баз
знаний.
Инфологические модели не только визуализируют информацию и упрощают её
восприятие, но также позволяют значительно сократить время, необходимое для
привязки данных, автоматизации выборок контента и обмена информацией, что
положительно сказывается как на качестве фронт-офисных сервисов, так и на
оптимизации процессов бэк-офиса.
Среди возможностей, которые предлагает технология для информационных
порталов и баз знаний, как наиболее значимые можно выделить следующие:
Связность данных. Все термины и статьи, заведенные в систему,
взаимосвязаны между собой. Модели, в которых используются данные сущности,
также объединены в единую семантическую сеть и доступны для автоматического
анализа.
Полнота данных. Связность данных обуславливает полноту предоставляемых
пользователю данных, так как помимо описания самого термина, легко можно найти
описания смежных с ним терминов, детализацию описания самого термина или общую
модель сферы с участием термина.
Раздача информации. Инфологические модели, дополненные правильно
настроенным API, позволяют автоматизировать раздачу информации. Особенность же
данного применения заключается в связности распространяемой информации:
портал-получатель данных не ограничен передаваемой инфологической моделью и
может предоставить пользователям связный с нею контент.
Новостные
порталы
Качество новостного портала определяется не только качеством размещаемых
на нём новостных статей, но также их достоверностью и временем появления. На
сегодняшний день скорость индексации поисковыми системами крупнейших новостных
порталов занимает считанные минуты от начала индексации до попадания страницы в
поисковые выборки, а значит, вопрос оперативности и контроля источника новостей
стоит особенно остро.
Благодаря устройству технологии инфологических моделей, их применение
может предложить новостным порталам ряд неоспоримых преимуществ: высокое
качество визуализации информации, оперативность распространения данных, высокую
достоверность заимствованных фрагментов статей, полноту предлагаемых
пользователю данных и возможность автоматизированной аналитики размещаемого
контента.
В качестве наиболее важных возможностей, предлагаемых технологией
новостным порталам, можно выделить следующие:
Быстрое распространение информации. За счёт автоматизации процесса
распространения инфологических моделей и их фрагментов, становится возможным
полуавтоматическое заведение новостных статей на порталы, что значительно
снижает время, необходимое на подготовку новости к размещению на сайте
агентства.
Управление раздачей информации. Правильно настроенные API позволяют
автоматизировать процесс распространения информации и управлять им, определяя
политику доступа и заимствования данных. Благодаря этому становится также
возможным автоматизированный мониторинг и анализ распространения информации,
что открывает перед новостными агентствами новые перспективы.
Контроль источника данных. Для всех инфологических моделей а также их
элементов, заимствованных со сторонних ресурсов, сохраняется обозначение
источника данных, что позволяет контролировать источник и отслеживать каналы
появления информации.
Интернет-магазины
Дерево каталога, его интерфейс, а также сервис автоматических
рекомендаций были и остаются одними из ключевых вопросов в техническом аспекте
развития интернет-магазинов. Благодаря широким возможностям автоматического
анализа размещаемой информации, инфологические модели выступают в роли сильного
инструмента применительно к вышеобозначенным проблемам.
Помимо уже описанного ранее высокого качества визуализации данных,
использование инфологических моделей может принести интернет-магазину ряд
весомых преимуществ: информативность описания товаров и товарных категорий,
гибкость используемого на сайте дерева каталога, автоматизацию процессов работы
с информацией, размещаемой на сайте, широкие возможности автоматизированной
аналитики товарной сетки и управляемый обмен данными.
Среди возможностей, доступных для интернет-магазина в ходе применения
технологии инфологических моделей, можно выделить 3 ключевые:
«Умные» cross-sale модули, заполняемые на основе анализа товарной сетки и
рекомендаций пост-продажной аналитики. Благодаря правильной настройки
инфологических моделей возможна автоматизация рекомендаций целых комплектов
дополнительных аксессуаров.
Структурированный и управляемый каталог товаров. Становится возможным
использование как нового интерфейса доступа к каталогу для клиентов
интернет-магазина, так и новый интерфейс управления деревом для внутренних
сотрудников. Смену дерева каталога можно превратить в перепривязку узлов
инфологической модели каталога к новым пунктам меню на сайте.
Умный дом и
интернет вещей
Концепция интернета вещей переживает бурный рост, однако перед полной
реализацией идеи удобного управления вещами через интернет встаёт ряд проблем,
основная из которых - несогласованность производителей и разработчиков
относительно используемых API и интерфейсов.
Из-за различий в аппаратных и программных интерфейсах становится
невозможным создание единой платформы для управления подконтрольными
предметами, что, в свою очередь, негативно сказывается на развитии области в
целом.
Применение инфологических моделей как средства мониторинга и визуализации
показателей помогло бы решить часть обозначенных проблем, привнеся в интернет
вещей следующие преимущества: высокий уровень юзабилити, информативность
рабочих моделей, унификацию пользовательского интерфейса работы с предметами,
автоматизированный мониторинг и аналитику показателей, а также высокую степень
адаптивности под новые устройства.
В перспективе применения инфологических моделей для интернета вещей можно
выделить следующие значительные возможности:для систематизации и обмена данными
на платформе единого решения. Так как инфологические модели могут быть
представлены самостоятельным уровнем визуализации информации с устройств
интернета вещей, агрегируемые данные становятся доступными для любого машинного
анализа через настраиваемые API.
Мониторинг и анализ показателей. Интуитивный интерфейс и высокая
информативность предоставляют пользователю удобный инструмент по отслеживанию
агрегируемых показателей. Кроме того, связность и машиночитаемость данных
делают возможным автоматизированный анализ собранных показателей. Например,
можно определить, в какой из комнат неоправданно завышено потребление
электроэнергии или узнать, все ли электрические приборы выключены.
На примере Рисунка 21, «Использование инфологических моделей в сфере
умного дома», показано, как мог бы выглядеть интерфейс для умного дома,
построенный на базе инфологической модели. Зелёный цвет обозначает низкое
энергопотребление, синий - повышенное. При этом данные, попадающие на модель,
динамические, и обновляются в режиме реального времени.
Что будет, если опуститься в концепте на следующий уровень детализации,
до отдельной комнаты? Можно увидеть включенные в состав выбранной комнаты
предметы и перейти к управлению ими. Следующий пример раскрывает вид отдельной
комнаты на базе интерфейса инфологических моделей:
Рисунок
25. Концепт интерфейса умного дома, детализация до уровня комнаты
Протоколирование происходящих событий.
Помимо уже обозначенных возможностей, в отдельный субъект инфологической
модели может быть записан перечень зафиксированных событий, связанных с
выбранным субъектом. Например, периоды работы чайника и график потребленной им
энергии. Историчность предоставляемых данных при сохранении высокого уровня
юзабилити - явное преимущество технологии.
Таким образом, применимость технологии имеет широкий характер - от
точечного инструмента для коммерческих сайтов до универсальной платформы,
объединяющей стандарты и технологии. Отчасти это вызвано новым подходом к
визуализации информации и вытекающему отсюда улучшенному восприятию данных
человеком, отчасти - возможностями обработки информации, которые открывает
применение инфологических моделей в современных сферах бизнеса и жизни.
Заключение
В ходе работы были проанализированы современные технологии обработки
данных и методологии визуализации информации, а также интерпретированы
результаты исследований и трудов, нашедших своё отражение в мировой научной
литературе.
Проанализированный материал и полученные в ходе исследования результаты
послужили основой для проектирования и разработки технологии инфологических
моделей, воплотившей в себе ключевые возможности обработки и визуализации
информации. Тем самым были решены поставленные перед исследованием задачи, а
также достигнута обозначенная цель создания нового эффективного метода
визуализации данных и работы с информацией.
Первая глава содержит обзор-анализ современных технологий обработки
информации, а также преимущества и примеры семантических сетей, открытых данных
и банков данных, принципы которых нашли применение в технологии инфологических
моделей.
Во второй главе дан обзор методов визуализации данных, основанных на
мировом научном опыте. В ходе главы разобраны и интерпретированы результаты
исследовательских работ ведущих мировых специалистов, таких как Chris Baber,
Alan MacEachren, Владимир Авербух и другие.
В третьей главе с использованием полученных в ходе исследования выводов
спроектирована и реализована технология инфологических моделей, обладающая
следующими возможностями и преимуществами, в том числе - в перспективе
дальнейших исследований:
· Высокая оперативность обмена новостями и данными;
· Контроль источников данных;
· Управление потоками распространения
информации;
· Целостность и связность
предоставляемых данных;
· Автоматическая генерация
клиенто-ориентированных страниц;
· Автоматизированная аналитика
заводимой информации;
· И многие другие, в зависимости от
сферы применения технологии.
Последняя глава настоящей работы содержит анализ эффекта от внедрения
инфологических моделей в электронном бизнесе на примере информационных
порталов, баз знаний, новостных порталов, интернет-магазинов, интернета вещей и
умного дома, а также описание технической базы, необходимой для реализации
технологии.
Следует отметить, что использование технологии инфологических моделей
возможно уже сегодня и открывает ряд значимых перспектив: улучшение восприятия
информации человеком, развитие «умной» коммерции, а также систематизацию и
автоматизацию обработки информации.
Используемая
литература
1. Baber
C., Andrews D., Duffy T., McMaster R. Sensemaking as narrative: Visualization
for collaboration. // VAW2011, University London College, 2011, С. 7-8
2. Averbukh
V.L. Magic fairy tales as source for interface metaphors // arXiv preprint CoRR
abs/0811.1974, 2008.
. MacEachren
AM, Monmonier M. Geographic Visualization: Introduction // Cartography and
Geographic Information Science, vol.19, 1992.
C. 197-200
. Авербух
В.Л. Метафора интерфейса и метафора визуализации. Какая теория нам нужна? //
International Conference Graphicon, Novosibirsk, 2006.
. Baber
C., Andrews D. Visualizing Interactive Narratives: Employing a Branching Comic
to Tell a Story and Show its Readings // Proceedings of the 32nd annual ACM
conference on Human factors in computing systems, 2014, С. 1895-1904
. Andrews
D., Baber C., Efremov S., Komarov M. Creating and using interactive narratives:
reading and writing branching comics // Proceedings of the SIGCHI Conference on
Human Factors in Computing Systems, 2012, С. 1703-1712
. MacEachren
A.M. How maps work: representation, visualization, and design. New York:
Guilford Press, 1995.
. Noyes
J., Baber C. User-centred design of systems. 1999
. Segel
E., Heer J. Narrative Visualization: Telling Stories with Data // Visualization
and Computer Graphics, IEEE Transactions, vol.16, 2010. C. 1139-1148
. Bier
E.A., Card S.K., Bodnar, J.W. Entity based collaboration tools for intelligence
analysis // Visual Analytics Science and Technology, VAST '08. IEEE Symposium,
2008. C. 99-106
. Pirolli,
P. and Russell, D.M. Introduction to this special issue on sensemaking
HUMAN-COMPUTER INTERACTION, vol.26, 2011. C. 1-8
. Blackwell
A.F. The Reification of Metaphor as a Design Tool // JournalACM Transactions on
Computer-Human Interaction (TOCHI), vol. 13, 2005. C. 490-530
. Greimas
A.J., McDowell D., Velie A.R. Structural Semantics: an attempt at a method //
University of Nebraska Press Lincoln, 1983
. Cooper
A. The Inmates Are Running the Asylum: Why High-Tech Products Drive Us Crazy
and How to Restore the Sanity // Sams: Pearson Education, 1998 and 2004
. Treder
M. UX Design for Startups. UXPin, 2013
. Walter
A. Designing for emotion. 2011
. Marcotte
E. Responsive web design. 2011
18. Chimero
F. The Shape of Design. Minnesota: Shapco Printing, 2012
19. Newson
D. & Haynes J. Public Relations Writing: Form & Style. Belmont: Thomson
Higher Education, 2007
. Иван
Бегтин - Открытые данные как основа открытого государства. 2013.
. Иван
Бегтин - Открытые данные. Государство как платформа. 2013.