Исследование форм структурированных данных на Lisp
Министерство образования и науки
Российской Федерации
Московский авиационный институт
(национальный исследовательский
университет)
Кафедра №304 «Вычислительные машины,
системы и сети»
Курсовая работа
по дисциплине «Программирование на
языках высокого уровня»
на тему «Исследование форм
структурированных данных на LISP»
Выполнил
студент
группы 3О-210Б
Арифуллин
А.И.
Принял
доцент
каф.304, к.т.н.
Новиков П.В.
Москва, 2015
Введение
Высокоуровневый язык программирования Lisp (от англ. List Processing -
«обработка списков») был разработан в 60-х годах XX века американским ученым Джоном Маккарти[3].
Lisp -
важнейший язык, широко применяемый в исследованиях искусственного интеллекта.
Многие методы, используемые в области разработки искусственного интеллекта,
основаны на особых свойствах этого языка. Lisp представляет собой основу для обучения методам
искусственного интеллекта, их исследования и практического применения, иными
словами, Lisp вводит в мир символьной обработки и
искусственного интеллекта [3].
Важная особенность языка Lisp -
его функциональный подход. Lisp
предоставляет возможность обработки данных, представленных в виде символов и
символьных структур, - списков. Тексты программ также представляются в виде
списков. Более того, в процессе вычислений можно формировать фрагменты
программы и выполнять их отдельно. Это позволяет легко организовывать
преобразование программ и их хранение, что удобно при организации баз знаний,
необходимых в системах искусственного интеллекта [2].
В данной курсовой работе исследуются формы структурированных данных языка
Lisp на примере конструкций Common Lisp.
Атомы и
списки
язык программирование строка данные
Атом (неделимый) - простой объект данных, который подразделяется на два
типа: символьный и числовой.
Символьные атомы представляют собой последовательность, состоящую из
букв, цифр и специальных знаков (по крайней мере должен быть один символ,
отличающую ее от числа). Как правило символ обозначает какой-либо объект или
действие.
Пример: ALPHA, DEFUN, X, COMMON_LISP
Числовые атомы представляют собой целые и вещественные числа.
Пример: 123, 132.04, 3123.3123
Символы в языке Lisp
используют буквы как нижнего, так и верхнего регистра, однако буквы в
большинстве Lisp-системах все равно будут
представляться как буквы верхнего регистра.
Атомы-константы - это все числовые данные и символы специального
назначения T и Nil, T-обозначает
логическую истину, а Nil -
соответственно логическую ложь. Так же стоит отметить, что Nil может обозначать пустой список.
Список - это основной тип данных в языке Lisp. Список - упорядоченная последовательность,
элементами которой являются атомы либо подсписки. Списки заключаются в скобки,
элементы списка обязательно разделяются пробелами.
Пример: (ALPHA BETA) ; состоит из двух элементов
(STUDENT (FIRST_NAME KHAN) (SECOND_NAME CHINGIZ)); состоит из трех элементов
Список может содержать в качестве своих элементов другие списки,
следовательно, это иерархическая структура данных, в которой открывающие и
закрывающие скобки находятся в строгом соответствии.
Список, в котором нет элементов, называется пустым обозначается
"()" или Nil.
Пример:
NIL;
то же самое, что ()
(NIL); список, состоящий из NIL или то же самое, что (())
(NIL ()); список, состоящий из двух
пустых списков
Списки в Lisp - это
рекурсивная структура, которая может быть описана с помощью правил Бэкуса-Наура[1]:
список ::=(голова . хвост); точечная пара, где голова - элемент списка,
хвост - список
элемент списка ::= элемент списка ИЛИ список
пустой список ::= NIL
Ключом к пониманию списков, является осознание того, что они, по большей
части, иллюзия, построенная на основе объектов более примитивных типов данных.
Эти простые объекты - пары значений, называемые cons-ячейкой, от имени функции
CONS, используемой для их создания.принимает 2 аргумента и возвращает новую
cons-ячейку, содержащую 2 значения. Эти значения могут быть ссылками на объект
любого типа. Если второе значение не NIL и не другая cons-ячейка, то ячейка
печатается как два значения в скобках, разделённые точкой (так называемая
точечная пара).
(cons 1 2)
(1 . 2)
Запрос к голове списка исполняется с помощью базовых функций CAR; к хвосту - CDR.
(setq list (cons 1 2))
(1 . 2)
(car list)
(cdr list)
2
Важно не отметить, что две данные функции можно писать слитно, чтобы их
можно было комбинировать:
(cadr '(2 3 4 5))
;возвращает голову хвоста
(caddr '(2 3 4 5))
;возвращает голову хвоста от хвоста
(cdar '((2 3 4)(3 4 5)))
(3 4);возвращает хвосты головы списка
(cdadr '((2 3 4)(3 4 5)))
(4 5);возвращает хвост головы хвоста
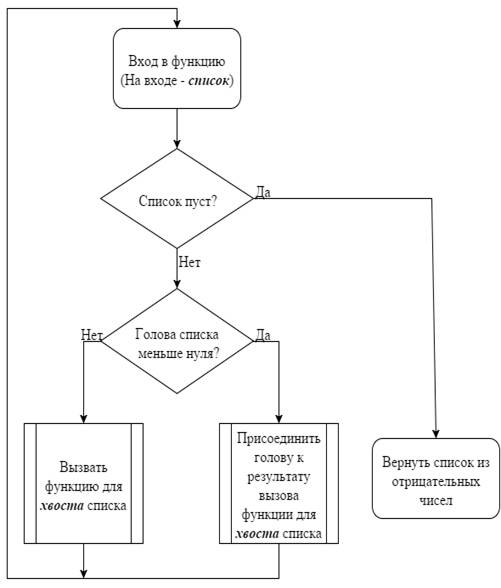
Рассмотрим несколько примеров рекурсивной обработки атомов и рекурсивных
списков:
.Функция, которая получает список чисел и выводит список из отрицательных
чисел:
(defun negative_number (list)
(cond ((null list) nil)
((> 0 (car list))(cons (car list)(negative_number (cdr
list))))
(T(negative_number(cdr list)))))_NUMBER
(NEGATIVE_NUMBER '(-3 -4 -5 1 1 3 4 -10))
(-3 -4 -5 -10)
Струтурная схема алгоритма работы программы:
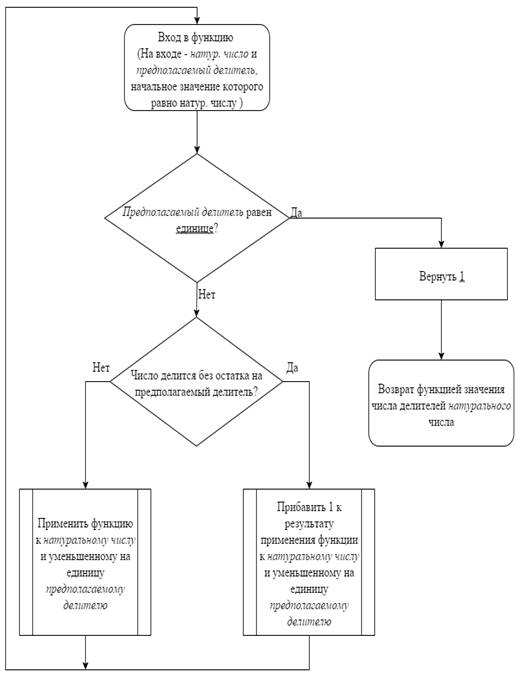
.Функция, которая получает список, состоящий из натуральных чисел, и
возвращающая список количеств простых чисел соответствующего натурального
числа. Для этого сперва нужно определить рекурсивную функцию divisor_of_number ,
высчитывающая количество делителей натурального числа n, и затем создать функцию divisor_list,
применяющая divisor_of_number для каждого
элемента списка:
(defun divisor_of_number (n x)
(cond((= x 1) 1)
(T(divisor_of_number n (1- x)))))_OF_NUMBER ;Компиляция прошла
успешно
(defun divisor_list (lst)
(mapcar (lambda (E) (divisor_of_number E E)) lst))
_LIST ;Успешная компиляция
>(DIVISOR_LIST '(100 17 13 5 6 7 10))
(9 2 2 2 4 2 4) ;Искомый список
Структурная схема алгоритма работы программы divisor_of_number:
Свойства
атомов Lisp
В Lisp любой символьный атом может быть
связан со списком свойств атома. Список свойств может быть пуст или содержать
произвольное количество свойств. Свойство представляется парой имя_свойства - значение_свойства.
Пример:
Свойства символа ТОК: (система_измерения Ампер)
Рассмотрим функции чтения, изменения и удаления свойств, определяемых
пользователем:
Чтение свойства
Значение свойства можно выяснить с помощью функции
GET(символ
свойство), например:
(GET('current 'SoU))
(GET('current 'value))
NIL
Присваивание свойства
Задать новое свойство или изменить его значение можно осуществить с
помощью функции (PUTPROP символ
значение свойство):
(PUTPROP ('current 'Amper 'SoU))
Однако в Common Lisp такой функции не существует,
для присваивания свойства атому в этой версии Lisp применяется обобщенная функция присваивания SETF и функции GET:
(SETF(GET 'current 'value) '1)
1
По сути GET возвращает ячейку памяти для данного
свойства, а SETF присваивает значение свойство
ячейке, то есть SETF изменяет
физическую структуру списка.
Удаление свойства
Удаление свойства и его значения производятся функцией
(REMPROP символ свойство) , в Common Lisp в случае успешного удаления возвращается значение T:
(REMPROP 'current 'SoU)
В случае если удаляемого свойства не существует, возвращается значение NIL:
(REMPROP 'current 'weight)
Небольшой пример, демонстрирующий работу над атомами с помощью их свойств
в Common Lisp:
(SETF (GET 'SPEED 'SYS-OF-UNITS) 'MPS)
(SETF (GET 'SPEED 'VALUE) 100)
(SETF (GET 'MASS 'SYS-OF-UNITS) 'KG)
(SETF (GET 'MASS 'VALUE) 10)
(SETF (GET 'KINETIC-ENERGY 'SYS-OF-UNTITS) 'JOULE)
(SETF (GET 'KINETIC-ENERGY 'VALUE) (/(*(*(GET 'SPEED
'VALUE)(GET 'SPEED 'VALUE))(GET 'MASS 'VALUE))2))
(REMPROP 'SPEED 'VALUE)
Массивы
Массив - структура данных, представляющая собой последовательность
данных, ячеек, имеющих одно имя, но разные номера (индексы), обеспечивающие
адресацию к этим ячейкам. Массивы в LISP используются для хранения большого количества данных.
Массивы создаются формой (MAKE-ARRAY размерность режимы), режимы -
необязательный аргумент, с помощью него можно задавать тип элементов, задать им
начальные значения или придать массиву динамический размер. Для вычислений,
осуществляемых с массивами, наряду с функцией создания массива используются
функции для выборки и изменения элементов массива. Вызов функции (AREF массив индексы) осуществляет
адресацию к элементу массива.
(setq matrix (MAKE-ARRAY '(4 4);Объявления массива
:element-type 'integer
:initial-element 0))
((0 0 0 0)(0 0 0 0)(0 0 0 0)(0 0 0 0))
(setf (aref matrix 1 2) '3);Присваиваем значение по адресу
((0 0 0 0)(0 0 3 0)(0 0 0 0)(0 0 0 0))
Рассмотрим пример, в котором проводится обработка матриц, а именно:
перемножение двух матриц размерностью [2x4] и [4x2].
В курсе линейной алгебры умножение матриц - одна из основных операций над
матрицами. Результатом умножения двух матриц размерностями 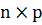 и
и 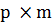 является матрица размерностью
является матрица размерностью 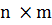 , которая называется произведением
матриц. Математическая формула имеет вид:
, которая называется произведением
матриц. Математическая формула имеет вид:

(DEFUN MULT_MATRIX (MATR1 MATR2 R1 R2 C1 C2 &OPTIONAL
TEMP RES_MATRIX)
(SETQ
TEMP 0)
(IF (/= C1 R2) '"ОШИБКА УМНОЖЕНИЯ"
(PROGN
;ОБНУЛЯЕМ МАТРИЦУ
РЕЗУЛЬТАТ
(SETQ RES_MATRIX (MAKE-ARRAY (LIST R1 C2) :ELEMENT-TYPE
'INTEGER :INITIAL-ELEMENT 0))
(DO
((I 0))
((>= I R1))
(DO
((J 0))
((>= J C2))
(SETQ TEMP 0)
(DO
((P 0))
((>= P C1))
(SETQ TEMP (+ TEMP (* (AREF MATR1 I P) (AREF
MATR2 P J))))
(SETQ P (+ P 1)))
(SETF (AREF RES_MATRIX I J) TEMP)
(SETQ J (+ J 1))
(SETQ I (+ I 1))
)_MATRIX)))_MATRIX
(setq matrix (MAKE-ARRAY '(1 2)))
#2A((0 0))
(setf (aref matrix 0 0) 3)
(setf (aref matrix 0 1) 4)
(setq matrix1 (MAKE-ARRAY '(2 3)))
#2A((0 0 0)(0 0 0))
(SETF (AREF MATRIX1 0 0) 1)
(SETF (AREF MATRIX1 1 2) 5)
(SETF (AREF MATRIX1 1 1) 6)
#2A((1 4))
#2A((1 0 0)(0 6 5))
(MULT_MATRIX MATRIX MATRIX1 1 2 2 3)
#2A((1 24 20))
Параметры TEMP и RES_MATRIX являются необязательными (опциональными), они
используются только в теле программы.
Векторы
Векторы наподобие списков содержат последовательность лисповских
объектов, таких как атомы, числа, списки или другие векторы. Внешней формой
представления векторов является:
#(x1 x2 ... xN)
Векторы нельзя обрабатывать как списки, но для них можно использовать
функции, работающие с последовательностями.
Для создания вектора применяется функция vector, в следующем примере рассмотрим объявление вектора,
обращение к его элементам по индексу через функцию elt, а так же изменения элемента в векторе с помощью
функционала setf:
(setq vect (vector 1 2 3));объявление вектора
#(1 2 3)
(elt vect 0);обращение к индексу 0
1
(setf (elt vect 0) 'A);
#(A 2 3)
Подмножество вектора выделяется с помощью:
(SUBSEQ VECT 0 2);0 - НАЧАЛО, 2 - КОНЕЦ
#(A 2)
В работах со списками обобщены функции, которые применимы для векторов:
(REVERSE VECT)
#(3 2 A)
(REMOVE 'A VECT)
#(2 3)
(LENGTH VECT)
Векторы, как и списки, очень хорошо подходят для обработки их функционалами.
Для ранее рассмотренных нами МАР-функционалов предусмотрено обобщение MAPCAR -
функции MAP, которую можно применять к любому объекту в форме
последовательности[3].
(map 'vector #'+ #(1 1 1 1 1) #(1 2 3 4 5))
#(2 3 4 5 6)
(map 'list (lambda (x) (if (oddp x) 'A 'B)) #(1 2 3 4 5))
(A B A B A)
Структуры
Структура - это объединение различных объектов, переменных (даже
различного типа данных), которому можно задать имя. Возьмем в пример класс
космических кораблей. Нас интересуют его характеристики, такие как скорость,
количество экипажа и время экспедиции на этом корабле. Такой универсальный
класс космических судов можно отобразить с помощью макроса DEFSTURCT .
Рассмотрим реализацию вышеприведенного примера в структурированном виде:
(defstruct spaceship
x_ship
y_ship
x_speed
y_speed
x_exped
y_exped)
При определении структуры автоматически генерируются функции:
. Для каждого нового типа данных генерируется MAKE- функция создания структуры данного типа. Например,
объект типа spaceship можно создать и присвоить переменной
типа space_ship_1:
(setq spaceship1 (MAKE-spaceship))
#S( SPACESHIP :X_SHIP NIL :Y_SHIP NIL :X_SPEED NIL :Y_SPEED
NIL :X_EXPED NIL :Y_EXPED NIL )
Полю, к тому же, можно присвоить начальное значение с помощью ключевого
слова, которое является имя поля с двоеточием перед ним
(setq spaceship1 (MAKE-spaceship :x_ship 1.0
:y_ship 2.0
:x_speed 300.0
:y_speed 400.0
:x_exped 2
))
#S( SPACESHIP :X_SHIP 1.0 :Y_SHIP 2.0 :X_SPEED 300.0 :Y_SPEED
400.0 :X_EXPED 2 :Y_EXPED NIL )
2. Копирование структуры с помощью функции COPY-:
(copy-spaceship spaceship1)
#S( SPACESHIP :X_SHIP NIL :Y_SHIP NIL :X_SPEED NIL :Y_SPEED
NIL :X_EXPED NIL :Y_EXPED NIL )
3. Функция-предикат, определяющая принадлежность элемента x данной структуре (ИМЯ_СТРУКТУРЫ-P ЭЛЕМЕНТ):
(spaceship-p spaceship1)
. Функция-предикат, предназначенная для проверки встроенных типов TYPEP:
(typep spaceship1 'integer)
. Функция доступа для полей, создается следующим образом:
(ИМЯ_СТРУКТУРЫ-ПОЛЕ ЭЛЕМЕНТ_ТИПА_СТРУКТУРА)
.0
Строки
Строковый тип - основной тип данных, подобно символам, числам, спискам и
т.д. В их работе применяются свои элементарные примитивные функции и предикаты.
Значением строки является произвольная последовательность знаков (знак тоже
является типом данных). Его объекты изображаются в виде #\x.
В этой записи x является
изображаемым данной записью знаком или словом в случае специального знака,
обычно не имеющего печатного изображения.
Пример:
#\e ; знак e
#\TAB; табуляция
Значением знака является сам знак:
#\e
#\e
Как проверить, является ли объект знаком? Для это есть предикат
(CHARACTERP ОБЪЕКТ):
(CHARACTERP #\x)
В строке знаки записываются в последовательности друг за другом, они
должны ограничиваться с обеих сторон знаком "(кавычки). Если строку ввести
в интерпретатор, то в качестве возвращаемого результата мы будем ту же строку,
здесь же в примере покажем работу функции-предиката (STRINGP ОБЪЕКТ), значение которой истина, если объект -
строка
"Язык LISP использует функциональный подход"
"Язык LISP использует функциональный подход"
"Лямбда-исчисление"
"Лямбда-исчисление"
(STRINGP "Лямбда-исчисление")
Работа со строками
Для работ со строками как минимум понадобятся функции чтения строк,
изменения элементов в строках и сравнение.
Элемент строки можно прочитать, сославшись на его позицию (индекс) с
помощью функции CHAR:
(CHAR "CHAR" 2)
#\A
(CHAR "STRING" 5)
#\G
Изменить элемент с помощью функции SETF:
(setq k "DESTRUCTION")
"DESTRUCTION"
(setf (char k 0) #\L)
#\L
"LESTRUCTION"
Строки можно соединять с помощью CONCATENATE:
(setq k "DESTRUCTION")
"DESTRUCTION"
(setq k1 (concatenate 'string "FATAL " k))
"FATAL DESTRUCTION"
Сравнить строки с помощью предиката STRING= OBJ_1 OBJ_2, надо заметить, что вместо
предиката STRING= можно использовать предикат EQUAL.
(STRING= "LISP" "LISP")
(STRING= "C-LISP" "H-LISP")
NIL
(EQUAL "!" "!")
После того как интерпретатор LISP встречает атом, происходит его сравнение с ранее известными атомами. При
этом если атом новый, то происходит резервирование памяти под структуру атома.
При чтении строкового типа такого не происходит, поэтому к нему прибегают,
когда к данным, представленными последовательностью знаков алфавита не нужно
присваивать значения.
Комплексные
числа
На языке математики комплексным числом называется выражение вида a + ib,
где a и b - любые действительные числа, i - специальное число, которое
называется мнимой единицей. Я Common Lisp возможно
использование комплексных чисел, они представляются парой вещественных числе в
форме: #C(REAL IMAGINARY).
В соответствии с правилами комплексного анализа, Lisp выполняет все арифметические операции с комплексными
числами, вычисляет корни, тригонометрические и логарифмические значения,
возводит в степень и т.п.
В приведенном примере результатами алгебраических выражений являются
комплексные числа, это одна из важных особенностей языка LISP.
(* 2 (+ #c(10 5) 4))
#C(28 10)
(log -10)
#C(2.302585d0 3.141593d0)
(* 2 (+ (log -10) 5))
#C(14.60517d0 6.283185d0)
(sin(log (expt #c(10 5) 2)))
#C(-1.451832 0.123302)
Классы и
объекты
Иерархия классов состоит из двух основных семейств классов: встроенных и
определенных пользователем. Классы, которые представляют типы данных, такие как
INTEGER, STRING и LIST, являются встроенными. Они находятся в отдельном разделе
иерархии классов, организованные соответствующими связями дочерних и
родительских классов, и для работы с ними используются функции, о которых
говорилось ранее. Нельзя унаследовать от этих классов, однако можно определить
специализированные методы для них, эффективно расширяя поведения этих классов. Lisp дает возможность создать сложный
объект - классы и задает поведение для своих экземпляров.
Класс, как тип данных, состоит из трех частей: имени, отношения к другим
классам и имен слотов. Базовая форма DEFCLASS выглядит достаточно просто:
(DEFCLASS (КЛАСС-ПРЕДОК) (СЛОТЫ)...)
В поле наследуемого класса можно ничего не вписывать, если этого не
требуется. Большая часть DEFCLASS состоит из списка спецификаторов слотов.
Каждый спецификатор определяет слот, который будет частью экземпляра класса.
Каждый слот в экземпляре является местом, которое может хранить значение, к
которому можно получить доступ через функцию SLOT-VALUE. SLOT-VALUE в качестве
аргументов принимает объект и имя слота и возвращает значение нужного слота в
данном объекте. Эта функция может использоваться вместе с SETF для установки
значений слота в объекте.
Класс также наследует спецификаторы слотов от своих
суперклассов, так что набор слотов, присутствующих в любом объекте, является
объединением всех слотов, указанных в форме DEFCLASS для класса, а также
указанных для всех его суперклассов.
Создаются новые объекты типа класс с помощью функции MAKE-INSTANCE, возвращаемым значением её является
новый объект.
Используя данное определение нового класса, новые объекты будут
создаваться со слотами, которые не связаны со значениями. Любая попытка
получить значение для несвязанного значения приведет к выдаче ошибки, так что
нужно задать значение до того, как его считывать.
(defclass MAI ()
(Faculty))
#<Standard-Class MAI #x367FCB8>
(defclass student (MAI)
(progress))
#<Standard-Class STUDENT #x38ED2E0>
(defparameter *Isaev (make-instance 'student))
*ISAEV
(setf (slot-value *ISAEV 'PROGRESS) "GOOD")
"GOOD"
"GOOD"
(SETF (SLOT-VALUE *ISAEV 'FACULTY) '7)
7
(SLOT-VALUE *ISAEV 'FACULTY)
Lisp предоставляет три способа управления начальными значениями слотов.
Первые два требуют добавления опций в спецификаторы слотов в DEFCLASS: с
помощью опции :initarg указывается имя, которое потом будет использоваться как
именованный параметр при вызове MAKE-INSTANCE и переданное значение будет
сохранено в слоте. Вторая опция - :initform, указывает выражение на Lisp,
которое будет использоваться для вычисления значения, если при вызове
MAKE-INSTANCE не был передан аргумент :initarg . В заключение, для полного
контроля за инициализацией объекта, можно определить метод для обобщенной
функции INITIALIZE-INSTANCE, которую вызывает MAKE-INSTANCE.
(defclass boxer ()
((name
:initarg :name)
(weight
:initarg :weight
:initform 0)
(height
:initarg :height
:initform 0)))
#<Standard-Class BOXER #x36D2450>
(defparameter *Ali
(make-instance 'boxer :name "Mohammed Ali"
:weight 91 :height 191))
*ALI
(slot-value *Ali 'weight)
91
В большинстве случаев, комбинации опций :initarg и
:initform будет достаточно для нормальной инициализации объекта. Однако, хотя
начальное выражение может быть любым выражением Lisp, оно не имеет доступа к
инициализируемому объекту, так что оно не может инициализировать один слот,
основываясь на значении другого. Для выполнения такой задачи необходимо
определить метод для обобщенной функции INITIALIZE-INSTANCE.
Основной метод INITIALIZE-INSTANCE, специализированный
для STANDARD-OBJECT берет на себя заботу об инициализации слотов, основываясь
на данных, заданных опциями :initarg и :initform.
Методы представляют собой входящие в состав класс
фрагменты кода, которые выполняются с набором аргументов, который удовлетворяет
определенному шаблону. Методы не являются, как это можно было бы ожидать,
функциями, они не могут вызываться непосредственно с набором аргументов, а лишь
встраиваются в обобщенные функции.
В примере, приведенном ниже, с помощью определенного метода
INITIALIZE-INSTANCE слот account-type устанавливается в значение :gold, :silver или :bronze
в зависимости от установленного значения в слоте balance.
(defclass bank-account ()
((customer-name
:initarg :customer-name
:initform (error "Must supply a customer
name."))
(balance
:initarg :balance
:initform 0)
(account-number
:initform (incf *account-numbers*))
account-type))
#<Standard-Class BANK-ACCOUNT #x36AF0F8>
(defvar *account-numbers* 0)
*ACCOUNT-NUMBERS*
(defmethod initialize-instance :after ((account bank-account)
&key)
(let ((balance (slot-value account 'balance)))
(setf (slot-value account 'account-type)
(cond
((>= balance 100000) :gold)
((>= balance 50000) :silver)
(t :bronze)))))
#<Standard-Method INITIALIZE-INSTANCE :AFTER
(BANK-ACCOUNT) #x3879138>
(defparameter *acc* (make-instance 'bank-account
:customer-name "FS14"
:balance 1000))
*ACC*
(slot-value *acc* 'account-type)
:BRONZE
всегда присваивает начальное значение названной переменной[4].
DEFVAR
присваивает начальное значение переменной, которая еще не определена [4].
Заключение
В курсовой работе были рассмотрены основные типы данных и особенности
языка программирования LISP.
Мы увидели, что LISP
представляет собой объекты, которые принадлежат к одному, или к нескольким
типам одновременно. В этом отношении Лисп также опередил свое время на многие
десятилетия и в нем объектно-ориентированный подход, как мы убедились,
реализован исключительно ярко и удобно.
Конечно, за 50 лет эволюции языка LISP в нем появилось немало производных типов данных,
которые предназначены для решения тех или иных специфичных задач. Сегодня
Common Lisp поддерживает работу с разнообразными типами объектов. Это важная
оговорка - в LISP тип имеют не переменные, а именно
объекты, в которых размещены те или иные данные. При этом любая переменная
может иметь в качестве значения объект произвольного типа.
Список
использованных источников
1. Большакова
Е.И., Груздева Н.В. «Основы программирования на языке ЛИСП» - М.: МГУ, 2010
. Семенов
М. «Язык Лисп для персональных ЭВМ» - М.: МГУ, 1989.
. Хювянен
Э., Сеппянен Й. «Мир Лиспа» - М.: Наука, т. 1, 2, 1984.
. Интернет-источник:
http://www.lisper.ru/ (06.11.2015).