Функции принадлежности. Нечеткие деревья решений
ЧАСТЬ 1
Дать описание основных положений нечеткой
логики: функций принадлежности, лингвистические переменные, база правил
нечетких высказываний, механизм (алгоритм) нечеткого логического вывода,
фазификация, дефазификация и др.
Функции принадлежности - Введенное определение
нечеткого множества не накладывает ограничений на выбор функции принадлежности.
Однако, на практике целесообразно использовать аналитическое представление
функции принадлежности μ A x нечеткого
множества A с элементами x, нечетко обладающими определяющим множество
свойством R. Типизация функций принадлежности в контексте решаемой технической
задачи существенно упрощает соответствующие аналитические и численные расчеты
при применении методов теории нечетких множеств. Выделяют следующие типовые
функции принадлежности.
|
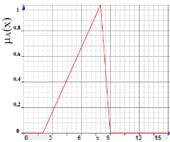
Треугольные
(трапецеидальные) функции принадлежности, использующиеся для задания
неопределенностей типа: «приблизительно равно», «среднее значение»,
«расположен в интервале», «подобен объекту», «похож на предмет»
|
|
|

|
Квадратичный
и гармонический Z-сплайны S-образные функции принадлежности, использующиеся
для задания неопределенностей типа: «большое количество», «большое значение»,
«значительная величина», «высокий уровень»
|
|
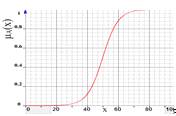
S-сигмоидальная
и S-линейная функции. П-образные функции принадлежности, использующиеся для
задания неопределенностей типа: «приблизительно в пределах от и до»,
«примерно равно», «около»
|
|
|

|
Колоколообразная
и гауссова функции. Существует множество других функций принадлежности
нечетких множеств, заданных как композиции вышеупомянутых базовых функций
(двойная гауссова, двойная сигмоидальная ), либо как комбинации по участкам
возрастания и убывания (сигмоидально-гауссова, сплайн-треугольная)
|
Существуют прямые и косвенные методы построения
функций принадлежности:
Прямые методы (наиболее известны методы
относительных частот, параметрический, интервальный) целесообразно использовать
для измеримых свойств, признаков и атрибутов, таких как скорость, время,
температура, давление и т.п. При использовании прямых методов зачастую не
требуется абсолютно точного поточечного задания μ A x . Как
правило, бывает достаточно зафиксировать вид функции принадлежности и
характерные точки, по которым дискретное представление функции принадлежности
аппроксимируется непрерывным аналогом - наиболее подходящей типовой функцией
принадлежности.
Косвенные методы (наиболее известен метод парных
сравнений) используются в тех случаях, когда отсутствуют измеримые свойства
объектов в рассматриваемой предметной области. В силу специфики рассматриваемых
задач при построении нечетких систем автоматического управления, как правило,
применяются прямые методы. В свою очередь, в зависимости от числа привлеченных
к опросу экспертов как прямые, так и косвенные методы делятся на одиночные и
групповые. Наиболее грубую оценку характеристических точек функции
принадлежности можно получить путем опроса одного эксперта, который просто
задает для каждого значения x ∈ X
соответствующее значение μ A x .
Пример. Рассмотрим нечеткое множество A ,
соответствующее понятию «расход теплоносителя небольшой». Объект x - расход
теплоносителя, X 0;x max - множество физически возможных значений скорости
изменения температуры. Эксперту предъявляются различные значения расхода
теплоносителя x и задается вопрос: с какой степенью уверенности 0 ≤
μ A x ≤ 1 эксперт считает, что данный расход
теплоносителя x небольшой. При μ A x= 0 - эксперт
абсолютно уверен, что расход теплоносителя x небольшой. Приμ
A x = 1 - эксперт абсолютно уверен, что расход
теплоносителя x нельзя классифицировать как небольшой.
Метод относительных частот. Пусть имеется m
экспертов, n 1 из которых на вопрос о принадлежности элемента x ∈
X нечеткому множеству A отвечают положительно. Другая часть экспертов n 2 = m -
n 1 отвечает на этот вопрос отрицательно. Тогда принимается μ
A x = n 1 n 1 + n 2 = n 1 m .
Пример. Рассмотрим нечеткое множество A ,
соответствующее понятию «скорость изменения температуры положительная средняя».
Объект x - скорость изменения температуры, X - x max ; x max - множество
физически возможных значений скорости изменения температуры. Экспертам
предъявляются различные значения скорости изменения температуры x и каждому из
них задается вопрос: считает ли эксперт, что данная скорость изменения
температуры x положительная средняя. Результаты

Лингвистические переменные - понятие нечеткой и
лингвистической переменных используется при описании объектов и явлений с
помощью нечетких множеств.
Определение 1. Нечеткая переменная
характеризуется тройкой (a, X, A),
где a - наименование переменной;
Х - универсальное множество (область определения
a);- нечеткое множество на X, описывающее ограничения (т.е. mA(x)) на значения
нечеткой переменной a.
Определение 2. Лингвистической переменной(ЛП)
называется набор (β, Т, Х, G,
М),
где β - наименование
лингвистической переменной;
Т - множество ее значений (терм-множество),
представляющее собой наименования нечетких переменных, областью определения
каждой из которых является множество X. Множество Т называется базовым термом -
множеством лингвистической переменной;- синтаксическая процедура, позволяющая
оперировать элементами терм-множества Т, в частности, генерировать новые термы
(значения). Множество ТÈ G(T), где
G{Т} - множество сгенерированных термов, называется расширенным термом -
множеством лингвистической переменной;- семантическая процедура, позволяющая
превратить каждое новое значение лингвистической переменной, образуемое
процедурой G, в нечеткую переменную, т.е. сформировать соответствующее нечеткое
множество.
Пример. Пусть эксперт определяет толщину изделия
с помощью понятий «Малая толщина», «Средняя толщина» и «Большая толщина», при
этом минимальная толщина равна 10 мм, а максимальная - 80 мм. Формализация
такого описания может быть проведена с помощью следующей ЛП
(β, Т, Х, G, М),
где β - толщина
изделия;
Т - {«Малая толщина», «Средняя толщина»,
«Большая толщина»};
Х - [10, 80];- процедура образования новых
термов с помощью связок «и» «или» и модификаторов типа «очень», «слегка», «не»
и т.п. Например: «Малая или средняя толщина». «Очень большая толщина»;-
процедура задания на X = [10, 80] нечетких подмножеств: A1 = «Малая толщина»,
A2 = «Средняя толщина» и A3 = «Большая толщина», а также нечетких множеств для
термов из G(T) в соответствии с правилами трансляции нечетких связок и
модификаторов «и» «или» «не» «очень» «слегка» и других операций над нечеткими
множествами вида: A Ç B, A ÈB.
База правил нечетких высказываний - Правила
преобразований нечетких высказываний. Правило преобразования конъюнктивной
формы. Справедливо выражение:
<α есть α'
и
β
есть
β'>⇒<(α,
β) есть
(α'∩β')>.
Здесь ⇒
- знак подстановки, α'∩β'
- значение
лингвистической переменной (α, β), соответствующее
исходному высказыванию <α есть
α'
и
β
есть
β'>,
которому
на X×Y
ставится
в соответствие нечеткое множество 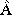 ∩
∩
 c
функцией принадлежности
c
функцией принадлежности
 (x,y) =
(x,y) = 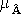 (x,y)Λ
(x,y)Λ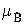 (x,y)
= μA(x)ΛμB(y).
(x,y)
= μA(x)ΛμB(y).
Механизм (алгоритм) нечеткого логического вывода
- это процесс получения нечетких заключений на основе нечетких условий или
предпосылок.
Применительно к нечеткой системе управления
объектом, нечеткий логический вывод- это процесс получения нечетких заключений
о требуемом управлении объектом на основе нечетких условий или предпосылок,
представляющих собой информацию о текущем состоянии объекта.
Логический вывод осуществляется поэтапно.
)Фаззификация(введение нечеткости) - это
установка соответствия между численным значением входной переменной системы
нечеткого вывода и значение функции принадлежности соответствующего ей терма
лингвистической переменной. На этапе фаззификации значениям всех входным
переменным системы нечеткого вывода, полученным внешним по отношению к системе
нечеткого вывода способом, например, при помощи статистических данных, ставятся
в соответствие конкретные значения функций принадлежности соответствующих
лингвистических термов, которые используются в условиях (антецедентах) ядер
нечетких продукционных правил, составляющих базу нечетких продукционных правил
системы нечеткого вывода. Фаззификация считается выполненной, если найдены
степени истинности  (a) всех
элементарных логических высказываний вида «
(a) всех
элементарных логических высказываний вида «  ЕСТЬ
ЕСТЬ
 »,
входящих в антецеденты нечетких продукционных правил, где -
некоторый терм с известной функцией принадлежности µ(x), -
четкое численное значение, принадлежащее универсуму лингвистической переменной
»,
входящих в антецеденты нечетких продукционных правил, где -
некоторый терм с известной функцией принадлежности µ(x), -
четкое численное значение, принадлежащее универсуму лингвистической переменной  .
.
)Агрегирование- это процедура определения
степени истинности условий по каждому из правил системы нечеткого вывода. При
этом используются полученные на этапе фаззификации значения функций
принадлежности термов лингвистических переменных, составляющих вышеупомянутые
условия (антецеденты) ядер нечетких продукционных правил.
Если условие нечеткого продукционного правила
является простым нечетким высказыванием, то степень его истинности
соответствует значению функции принадлежности соответствующего терма
лингвистической переменной.
Если условие представляет составное
высказывание, то степень истинности сложного высказывания определяется на
основе известных значений истинности составляющих его элементарных высказываний
при помощи введенных ранее нечетких логических операций в одном из оговоренных
заранее базисов.
)Активизация в системах нечеткого вывода - это
процедура формирования функций принадлежности m(y) консеквентов каждого их
продукционных правил, которые находятся при помощи одного из методов нечеткой
композиции:
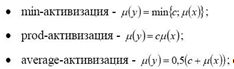
где µ(x) функция принадлежности термов
лингвистических переменных консеквента продукционного правила, c - степень
истинности нечетких высказываний, образующих антецедент нечеткого
продукционного правила.
)Аккумуляция (или аккумулирование)в системах
нечеткого вывода - это процесс нахождения функции принадлежности выходной
лингвистической переменной. Результат аккумуляции выходной лингвистической
переменной определяется как объединение нечетких множеств всех подзаключений
нечеткой базы правил относительно соответствующей лингвистической переменной.
(Объединение функций принадлежности всех
подзаключений проводится как правило классически 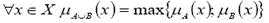 (max-объединение).
(max-объединение).
5)Дефаззификация в системах нечеткого вывода -
это процесс перехода от функции принадлежности выходной лингвистической
переменной к её четкому (числовому) значению. Цель дефаззификации состоит в
том, чтобы, используя результаты аккумуляции всех выходных лингвистических
переменных, получить количественные значения для выходной переменной, которое
используется внешними по отношению к системе нечеткого вывода объектам
менеджмента.
Переход от полученной в результате аккумуляции
функции принадлежности µ(y) выходной лингвистической переменной к численному
значению y выходной переменной производится одним из следующих методов:
· метод центра тяжести заключается в расчете
центроида площади:
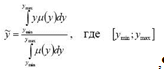 ,
,
где [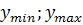 ]-
носитель нечеткого множества выходной лингвистической переменной;
]-
носитель нечеткого множества выходной лингвистической переменной;
метод центра площади заключается в расчете
абсциссы y, делящей площадь, ограниченную кривой функции принадлежности µ(x),
так называемой биссектрисы площади
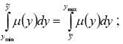
метод левого модального значения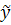 =
=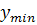 ;
;
метод правого модального значения= .
.
Рассмотренные этапы нечеткого вывода могут быть
реализованы неоднозначным образом: агрегирование может проводиться не только в
базисе нечеткой логики Заде, активизация может проводиться различными методами
нечеткой композиции, на этапе аккумуляции объединение можно провести отличным
от max-объединения способом, дефаззификация также может проводиться различными
методами. Таким образом, выбор конкретных способов реализации отдельных этапов
нечеткого вывода определяет тот или иной алгоритм нечеткого вывода. В настоящее
время остается открытым вопрос критериев и методов выбора алгоритма нечеткого
вывода в зависимости от конкретной задачи. На текущий момент в системах
нечеткого вывода наиболее часто применяются алгоритмы Мамдани, Цукамото,
Ларсена, Сугено.
ЧАСТЬ 2
Описать нечеткие деревья решений
Нечеткие деревья решений
. Деревья решений и типы решаемых задач
Стремительное развитие информационных
технологий, в частности, прогресс в методах сбора, хранения и обработки данных
позволил многим организациям собирать огромные массивы данных, которые
необходимо анализировать. Объемы этих данных настолько велики, что возможностей
экспертов уже не хватает, что породило спрос на методы автоматического
исследования (анализа) данных, который с каждым годом постоянно увеличивается.
Деревья решений - один из таких методов
автоматического анализа данных. Первые идеи создания деревьев решений восходят
к работам Ховленда (Hoveland) и Ханта(Hunt) конца 50-х годов XX века. Однако,
основополагающей работой, давшей импульс для развития этого направления,
явилась книга Ханта (Hunt, E.B.), Мэрина (Marin J.) и Стоуна (Stone, P.J)
"Experiments in Induction", увидевшая свет в 1966г.
Терминология
|
Название
|
Описание
|
|
Объект
|
Пример,
шаблон, наблюдение
|
|
Атрибут
|
Признак,
независимая переменная, свойство
|
|
Метка
класса
|
|
Узел
|
Внутренний
узел дерева, узел провверки
|
|
Лист
|
Конечный
узел дерева, узел решения
|
|
Проверка
(test)
|
Условие
в узле
|
Деревья решений - это способ представления
правил в иерархической, последовательной структуре, где каждому объекту
соответствует единственный узел, дающий решение.
Под правилом понимается логическая конструкция,
представленная в виде "если ...то ...".
Графическая иллюстрация дерева решений
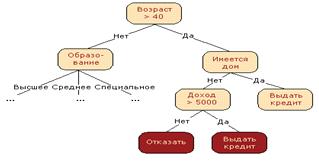
Область применения деревья решений в настоящее
время широка, но все задачи, решаемые этим аппаратом могут быть объединены в
следующие три класса:
Описание данных: Деревья решений позволяют
хранить информацию о данных в компактной форме, вместо них мы можем хранить
дерево решений, которое содержит точное описание объектов.
Классификация: Деревья решений отлично
справляются с задачами классификации, т.е. отнесения объектов к одному из
заранее известных классов.
Целевая переменная должна иметь дискретные
значения.
Регрессия: Если целевая переменная имеет
непрерывные значения, деревья решений позволяют установить зависимость целевой
переменной от независимых(входных) переменных. Например, к этому классу
относятся задачи численного прогнозирования(предсказания значений целевой
переменной).
. Алгоритм построения нечеткого дерева решений
Главной идеей в таком подходе является сочетание
возможностей деревьев решений и нечеткой логики,. Отличительной чертой деревьев
решений является то, что каждый пример определенно принадлежит конкретному
узлу. В нечетком случае это не так. Для каждого атрибута необходимо выделить
несколько его лингвистических значений и определить степени принадлежности
примеров к ним. Вместо количества примеров конкретного узла нечеткое дерево
решений группирует их степень принадлежности. Коэффициент - это соотношение
примеров узла N для целевого значения i, вычисляемый как:, где μN(Dj)
- степень
принадлежности примера Dj к узлу N, μi(Dj) - степень
принадлежности примера относительно целевого значения i, S N - множество всех
примеров узла N. Затем находим коэффициент, обозначающий общие характеристики
примеров узла N. В стандартном алгоритме дерева решений определяется отношение
числа примеров, принадлежащих конкретному атрибуту, к общему числу примеров.
Для нечетких деревьев используется отношение, для расчета которого учитывается
степень принадлежности.
Выражение даѐт оценку среднего количества
информации для определения класса объекта из множества P N. На следующем шаге
построения нечеткого дерева решений алгоритм вычисляет энтропию для разбиения
по атрибуту A со значениями aj: , где узел N|j - дочерний для узла N. Алгоритм
выбирает атрибут с максимальным приростом информации.
Узел N разбивается на несколько подузлов N|j.
Степень принадлежности примера Dk узла N|j вычисляется пошагово из узла N как,
где μi(Dk,aj)
показывает
степень принадлежности Dk к атрибуту aj. Подузел N|j удаляется, если все
примеры в нем имеют степень принадлежности, равную нулю. Алгоритм повторяется
до тех пор, пока все примеры узла не будут классифицированы либо пока не будут
использованы для разбиения все атрибуты.
Принадлежность к целевому классу для новой
записи находится по формуле, где - коэффициент соотношения примеров листа
дерева l для значения целевого класса k, μl(Dj) - степень
принадлежности примера к узлу l, χk - принадлежность
значения целевого класса k к положительному значению исхода классификации.
. Пример: построение дерева решений о выдаче
кредита
В таблице 1 представлены данные о семи клиентах
банка: проживание в регионе (в годах), доход (в денежных единицах) и рейтинг
выдачи ему кредита. Необходимо построить нечеткое дерево решений, с помощью
которого определить рейтинг выдачи кредита для клиента, который проживает в
регионе 25 лет, и доход его составляет 32 000 (будет решаться задача регрессии).
Таблица - Обучающие примеры для построения
нечеткого дерева решений
|
№
|
Проживание
в регионе
|
Доход
|
Рейтинг
|
|
D1
|
0
|
10
000
|
0.0
|
|
D2
|
10
|
15
000
|
0.0
|
|
D3
|
15
|
20
000
|
0.1
|
|
D4
|
20
|
30
000
|
0.3
|
|
D5
|
30
|
25
000
|
0.7
|
|
D6
|
40
|
35
000
|
0.9
|
|
D7
|
40
|
50
000
|
1.0
|
Предположим, что атрибут "проживание в
регионе" может принимать значения "временно",
"продолжительно", "постоянно", а атрибут "доход"
- "малый", "средний" и "высокий". Степень
принадлежности каждого примера к значениям атрибутов представлена в таблице
ниже. Общий вид функции для атрибутов показан на графики функций принадлежности

Степень принадлежности примеров к атрибутам
|
№
|
Проживание
в регионе
|
Доход
|
|
Временно
|
Продолжительно
|
Постоянно
|
Малый
|
Средний
|
Высокий
|
|
D1
|
1
|
0
|
1
|
0
|
0
|
|
D2
|
0,8
|
0,2
|
0
|
0,6
|
0,4
|
0
|
|
D3
|
0,5
|
0,5
|
0
|
0,1
|
0,9
|
0
|
|
D4
|
0,2
|
0,8
|
0
|
0
|
1
|
0
|
|
D5
|
0
|
0,5
|
0,5
|
0
|
1
|
0
|
|
D6
|
0
|
0
|
1
|
0
|
0,6
|
0,4
|
|
D7
|
0
|
0
|
1
|
0
|
0
|
1
|
В начале необходимо найти значение - общая
энтропия.да = 0 + 0 + 0,1 + 0,3 + 0,7 + 0,9 + 1,0 = 3, Pнет = 1 + 1 + 0,9 + 0,7
+ 0,3 + 0,1 + 0 = 4,
= Pда + Pнет = 3 + 4 = 7, бит.
Теперь рассчитаем E(SN, проживание в регионе). P
да временно = min(0;1) + min(0;0,8) + min(0,1;0,5) + min (0,3;0,2) + min(0,7;0)
+ min(0,9;0) + min(1;0) = 0 + 0 + 0,1 + 0,2 + 0 + 0 + 0 = 0,3P нет временно =
min(1;1) + min(1;0,8) + min(0,9;0,5) + min (0,7;0,2) + min(0,3;0) +min(0,1;0) +
min(0;0) = 1 + 0,8 + 0,5 + 0,2 + 0 + 0 + 0 = 2,5 P временно = 0,3 + 2,5 = 2,8
E(проживание в регионе, временно)= бит. Для продолжительного и постоянного
проживания в регионе проводятся аналогичные вычисления. Результат сведем в итог
расчетов для атрибута "проживание в регионе"
|
Временно
|
Продолжительно
|
Постоянно
|
|
Рда
|
0,3
|
0,9
|
2,4
|
|
Рнет
|
2,5
|
1,7
|
0,4
|
|
Е
в битах
|
0,491
|
0,931
|
0,592
|
Отсюда находим энтропию: E(SN, проживание в
регионе) =  бит. Рассчитаем
прирост информации для данного атрибута. G(SN, проживание в регионе) = 0,985 -
0,653 = 0,332 бит. Проводя подобные вычисления для атрибута "доход",
получаем E(SN, доход) = 0,691 бит, G(SN, доход) = 0,294 бит. Максимальный
прирост информации обеспечивает атрибут "проживание в регионе",
следовательно, разбиение начнется с него. На следующем шаге алгоритма
необходимо для каждой записи рассчитать степень принадлежности к каждому новому
узлу по формуле. Пример в таблице ниже.
бит. Рассчитаем
прирост информации для данного атрибута. G(SN, проживание в регионе) = 0,985 -
0,653 = 0,332 бит. Проводя подобные вычисления для атрибута "доход",
получаем E(SN, доход) = 0,691 бит, G(SN, доход) = 0,294 бит. Максимальный
прирост информации обеспечивает атрибут "проживание в регионе",
следовательно, разбиение начнется с него. На следующем шаге алгоритма
необходимо для каждой записи рассчитать степень принадлежности к каждому новому
узлу по формуле. Пример в таблице ниже.
К узлам [проживание в регионе = временно и доход
= высокий] и [проживание врегионе = продолжительно и доход = высокий] не
принадлежит ни одна запись, поэтому они удаляются из дерева. Для каждого узла
находятся коэффициенты PNi. Полученное дерево представленона рисунке ниже после
таблицы.
Принадлежность записей новым узлам дерева
|
Проживание
в регионе
|
Временно
|
продолжительно
|
Постоянно
|
Малый
|
Средний
|
Высокий
|
Малый
|
Средний
|
Высокий
|
Малый
|
Средний
|
Высокий
|
|
D1
|
1
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
|
D2
|
0.6
|
0.4
|
0
|
0.2
|
0.2
|
0
|
0
|
0
|
0
|
|
D3
|
0.1
|
0.5
|
0
|
0.1
|
0.5
|
0
|
0
|
0
|
0
|
|
D4
|
0
|
0.2
|
0
|
0
|
0.8
|
0
|
0
|
0
|
0
|
|
D5
|
0
|
0
|
0
|
0
|
0.5
|
0
|
0
|
0.5
|
0
|
|
D6
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
0.6
|
0.4
|
|
D7
|
0
|
0
|
0
|
0
|
0
|
0
|
0
|
1
|
Графическая иллюстрация полученного нечеткого
дерева решений
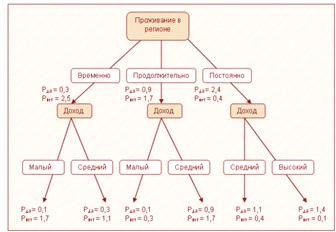
Теперь определим кредитный рейтинг для клиента,
проживающего в регионе 25 лет, и с доходом 30 000.За положительный исход в
данной задаче принято одобрение в выдаче кредита, поэтому χ
да
= 1,0, χнет
= 0,0. Новый клиент принадлежит к двум узлам: [проживание в регионе =
продолжительно и доход = средний] и [проживание в регионе = постоянно и доход =
средний], со степенями 0,8 и 0,2 соответственно. Подставляя полученные значения
в формулу, рассчитываем кредитный рейтинг
. 
В итоге мы получили кредитный рейтинг, равный
0,395. Он означает, что степень принадлежности записи к тому, что кредит
клиенту будет выдан, равна 0,395, а к невыдаче - 0,605. Следовательно, этому
клиенту банком будет отказано.
Решая задачу классификации, выбирается тот класс
i, для которого значение Pi максимально.
Применение и основные выводы.
Нечеткие деревья решений применяются в Data
Mining как для решения задач классификации, так и для решения задачи регрессии,
когда необходимо знать степени принадлежности к тому или иному исходу. Они
могут быть использованы в различных областях: в банковском деле для решения
задачи скоринга, в медицине для диагностики различных заболеваний, в
промышленности для контроля качества продукции и так далее.
Безусловным достоинством данного подхода
является высокая точность классификации, достигаемая за счет сочетания
достоинств нечеткой логики и деревьев решений. Процесс обучения происходит
быстро, а результат прост для интерпретации. Так как алгоритм способен выдавать
для нового объекта не только класс, но и степень принадлежности к нему, это
позволяет управлять порогом для классификации.
Однако для этого необходим репрезентативный
набор обучающих примеров, в противном случае сгенерированное алгоритмом дерево
решений будет слабо отражать действительность и, как следствие, выдавать
ошибочные результаты.
ЧАСТЬ 3
Описать cовременное практическое применение
механизмов анализа нечеткой информации
Различные типы интеллектуальных систем имеет
свои особенности, например, по возможностям обучения, обобщения и выработки
результатов, что делает их наиболее пригодными для решения одних классов задач
и менее пригодными - для других.
Различные нейропакеты помогают успешно решать
такие задачи, как оценка рейтинга ценных бумаг (нейропакет S&PCBRS);
контроль валютных операций в двадцати трех странах мира (Inspector); анализ
займов, кредитное планирование и прогноз экономической активности (Nexpert
Object); формирование портфеля ценных бумаг (Open Interface); оценка кредитных
займов, прогноз курсов валют, анализ биржевой и рыночной активности, прогноз
экономических и биржевых индексов (BrainMaker); биржевые прогнозы, проверка
подлинности кредитных карт (HNC). Помимо анализа финансовой деятельности нейросети
успешно справляются с идентификацией непривычных для людей образов,
распознаванием речи (Avalanche), синтезом речи и текста (Back propagation),
управлением роботом (Cerebellatron), идентификация написанных от руки символов
(Неокогнитрон, Япония) нечеткий решение функция
принадлежность
Нечеткие деревья решений применяются
в Data Mining
<http://www.basegroup.ru/glossary_ajax/definitions/data_mining> как для
решения задач классификации, так и для решения задачи регрессии, когда
необходимо знать степени принадлежности к тому или иному исходу. Они могут быть
использованы в различных областях: в банковском деле для решения задачи
скоринга <http://www.basegroup.ru/glossary_ajax/definitions/scoring>, в
медицине для диагностики различных заболеваний, в промышленности для контроля
качества продукции и так далее.
Безусловным достоинством данного
подхода является высокая точность
<http://www.basegroup.ru/glossary_ajax/definitions/precision>
классификации, достигаемая за счет сочетания достоинств нечеткой логики и деревьев
решений. Процесс обучения происходит быстро, а результат прост для
интерпретации. Так как алгоритм способен выдавать для нового объекта не только
класс, но и степень принадлежности к нему, это позволяет управлять порогом для
классификации.
Однако для этого необходим
репрезентативный набор обучающих примеров, в противном случае сгенерированное
алгоритмом дерево решений будет слабо отражать действительность и, как
следствие, выдавать ошибочные результаты.
СПИСОК ИСПОЛЬЗУЕМОЙ ЛИТЕРАТУРЫ
http://www.stgau.ru/company/personal/user/8068/files/lib.pdf://stu.scask.ru/book_ins.php?id=26://www.pcweek.ru/themes/detail.php?ID=43833
Обработка
нечеткой информации в системах принятия решений А.Н.Борисов, 1989
Лекции
по принятию решений в условиях нечеткой информации Губко М.В. 2004