Анализ Финляндии
Курсовой
проект
по
дисциплине «Статистика»
«Анализ
Финляндии»
ОГЛАВЛЕНИЕ
1. ВВЕДЕНИЕ
. РАСЧЕТНАЯ ЧАСТЬ
.1 Исходные данные для проведения
анализа
.2 Базовый анализ данных
.3 Анализ временных рядов
.4 Корреляционный анализ
.5 Регрессионный анализ
.6 Дисперсионный анализ
.7 Факторный анализ
.8 Кластерный анализ
. ЗАКЛЮЧЕНИЕ
СПИСОК
ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. ВВЕДЕНИЕ
В качестве объекта исследования была выбрана
одна из стран Европы - Финляндия.
Финляндия расположена на севере Европы, значительная
часть её территории находится за Северным полярным кругом (25 %). На суше
граничит со Швецией (граница составляет 586 км), Норвегией (граница составляет
716 км) и Россией (граница составляет 1265 км), морская граница с Эстонией
проходит по Финскому заливу, со Швецией - по некоторым местам Ботнического
залива Балтийского моря. Длина внешней береговой линии (без учёта извилистости)
равна 1 100 км. Длина береговой линии (без островов) составляет 46 000 км. В
прибрежной зоне располагается почти 81 000 островов (размером более 100 м²).
Финляндия относится к числу малых высокоразвитых
индустриальных стран. Её доля в мировом производстве невелика - 0,4 %, в
мировой торговле - 0,8 %.
Финляндия входит в передовую группу стран мира
по показателю ВВП на душу населения - 34 585 долларов США (по паритету
покупательной способности) или 44 488 долларов США (по номинальному значению)
по данным 2010 года.
Преимущества: промышленность, ориентированная на
экспорт и качество. Развитый сектор хай-тек (мобильные телефоны Nokia,
интернет-услуги). Первое место в мире по производству бумаги. Быстрое
восстановление объёмов экспорта после рецессии. Низкая инфляция, временами ниже
2 % в год. Растущая инвестиционная привлекательность. Ворота к российской и
прибалтийской экономике. Часть зоны евро. Усиленный рост экономики. В 2003 и
2006 г. Финляндия была названа самой конкурентоспособной из малых стран.
Слабые стороны: сильная рецессия в 1991-1993
гг., реальный ВВП снизился на 15 %. Быстро стареющее население, ранний выход на
пенсию. Большие госдолги и внешний долг; высокая безработица (10 %). Неразвитый
внутренний рынок; периферийное расположение в Европе.
Финляндия относится к одним из самых северных
аграрных стран. Сельскохозяйственные угодья занимают 8 % от всей территории
страны. Площадь пахотных земель составляет 2,4 млн гектар. Большая часть ферм -
это небольшие хозяйства с площадью пахотных земель меньше 10 гектар, но
прослеживается тенденция в сторону увеличения размера ферм. Земледелие, также
как и скотоводство, высоко механизировано.
Транспортная система Финляндии считается хорошо
продуманной.
% населения Финляндии принадлежит к семьям, в
которых есть дети. В численном отношении, на конец 2009 года, 1 015 000 человек
- люди, проживающие одни. Две трети всех семей - официально зарегистрированные.
21 % семей - так называемые гражданские браки. 12 % семей - семьи, где один
родитель (мать-одиночка, отец одиночка).
Финляндия первая в мире страна, где было введено
понятие прав пациента в 60-х годах ХХ века. Эти права на самом деле применяются
в жизни, значительно усложняя работу врача и облегчая участие в лечении
пациента. Например, скрыть диагноз от пациента в Финляндии невозможно и даже
преступно; в то же время у пациента есть и право не знать о своём диагнозе, о
чём он должен уведомить врача.
Медицина в Финляндии является доказательной, то
есть применяются только те методы лечения (и диагностики), эффективность
которых научно доказана.
В данный момент (2010 г.) медицина практически
бесплатна для жителей страны. Почти все затраты на лечение компенсируются из
государственного бюджета. Инсулин и другие лекарства, необходимые при
хронических заболеваниях, бесплатны для граждан Финляндии.
Магнитный и рентгеновский томографы имеются в
каждой районной больнице (примерно один томограф на каждые 20 тысяч жителей).
2. РАСЧЕТНАЯ ЧАСТЬ
.1 Исходные данные для проведения анализа
Данная таблица содержит числовые данные с 1991
по 2010 гг. по следующим группам.
Таблица 1
Экономические показатели Финляндии
|
Годы
|
Показатели
|
|
Экономика
|
Население
|
|
ВНП,
млрд. долларов
|
ВНД,
млрд. долларов
|
ВНД
на душу населения, долларов
|
Прирост
ВНП, %
|
ЧН,
тыс. чел.
|
Число
родившихся, чел.
|
Число
умерших, чел.
|
Внешняя
миграция, прибыло, чел.
|
|
1991
|
125,2
|
120,6
|
24069,76
|
-6
|
5009,16
|
65395
|
49294
|
19001
|
|
1992
|
110,1
|
104,8
|
20814,20
|
-3,5
|
5034,766
|
66731
|
49884
|
14554
|
|
1993
|
87,3
|
82,5
|
16306,04
|
-0,8
|
5061,394
|
64826
|
50988
|
14795
|
|
1994
|
100,6
|
96,2
|
18919,84
|
3,6
|
5086,368
|
65231
|
48000
|
11611
|
|
1995
|
130,7
|
126,4
|
24736,92
|
4
|
5107,802
|
63067
|
49280
|
12222
|
|
1996
|
128,2
|
124,9
|
24360,75
|
3,6
|
5125,177
|
60723
|
49167
|
13294
|
|
1997
|
122,9
|
120,7
|
23484,86
|
6,2
|
5139,257
|
59329
|
49108
|
13564
|
|
1998
|
129,7
|
126,7
|
24592,97
|
5
|
5151,024
|
57108
|
49262
|
14192
|
|
1999
|
130,2
|
128,5
|
24897,69
|
3,9
|
5161,995
|
57574
|
49345
|
14744
|
|
2000
|
121,7
|
120,8
|
23347,43
|
5,3
|
5173,37
|
56742
|
49339
|
16895
|
|
2001
|
124,6
|
124,4
|
23989,17
|
2,3
|
5185,18
|
56189
|
48550
|
18955
|
|
2002
|
135,1
|
135,3
|
26035,76
|
1,8
|
5197,305
|
55555
|
49418
|
18113
|
|
2003
|
164,1
|
162,9
|
31258,47
|
2
|
5210,595
|
56630
|
48996
|
17838
|
|
2004
|
188,9
|
190,4
|
36422,42
|
4,1
|
5226,067
|
57758
|
47600
|
20333
|
|
2005
|
195,6
|
196,5
|
37474,27
|
2,9
|
5244,342
|
57745
|
47928
|
21355
|
|
2006
|
207,8
|
209,8
|
39834,98
|
4,4
|
5265,936
|
58840
|
48065
|
22451
|
|
2007
|
246,1
|
246,2
|
46543,07
|
5,4
|
5290,431
|
58729
|
49077
|
26029
|
|
2008
|
272
|
273,4
|
51417,25
|
1
|
5316,334
|
59530
|
49094
|
29114
|
|
2009
|
240,7
|
244,9
|
45840,70
|
-8,2
|
5341,546
|
60430
|
49883
|
26699
|
|
2010
|
238,7
|
242,9
|
45275,94
|
3,6
|
5364,546
|
60980
|
50887
|
25636
|
|
Годы
|
Показатели
|
|
Промышленное
производство и СХ
|
Иностранная
торговля и Правительственные расходы
|
|
Объем
промышленного производства, млрд. долл.
|
Валовая
добавленная стоимость СХ, млрд. долл.
|
Индекс
производства пищевых продуктов, 2006=100
|
Ввод
жилых зданий, тыс. кв. метров общей площади
|
Экспорт
товаров и услуг, млрд. долл.
|
Импорт
товаров и услуг, млрд. долл.
|
Расходы
на здравоохранение, млрд. долл
|
Расходы
на оборону, млрд. долл.
|
|
1991
|
24,4
|
7,51
|
98
|
1348,059
|
27,54
|
28,80
|
9,64
|
2,25
|
|
1992
|
23,8
|
5,51
|
92
|
1141,576
|
28,63
|
27,53
|
8,48
|
2,09
|
|
1993
|
23,8
|
4,37
|
95
|
1124,843
|
27,94
|
23,57
|
6,81
|
1,57
|
|
1994
|
25,2
|
5,03
|
97
|
872,983
|
35,21
|
29,17
|
8,05
|
1,71
|
|
1995
|
25,7
|
5,23
|
94
|
617,937
|
47,05
|
37,90
|
10,33
|
1,96
|
|
1996
|
27,0
|
5,13
|
95
|
891,608
|
47,43
|
38,46
|
10,38
|
2,05
|
|
1997
|
29,5
|
4,92
|
99
|
1158,318
|
47,93
|
38,10
|
9,46
|
1,97
|
|
1998
|
31,8
|
3,89
|
88
|
1139,01
|
50,58
|
38,91
|
9,60
|
1,95
|
|
1999
|
33,4
|
3,91
|
92
|
1326,684
|
50,78
|
39,06
|
9,63
|
1,69
|
|
2000
|
36,7
|
3,65
|
98
|
1301,799
|
53,55
|
41,38
|
8,76
|
1,58
|
|
2001
|
37,6
|
3,74
|
97
|
1065,724
|
52,33
|
39,87
|
9,22
|
1,50
|
|
2002
|
38,9
|
4,05
|
100
|
1024,989
|
55,39
|
41,88
|
10,54
|
1,62
|
|
2003
|
40,2
|
4,92
|
1111,518
|
64,00
|
52,51
|
13,46
|
2,30
|
|
2004
|
42,2
|
5,67
|
97
|
1054,636
|
75,56
|
62,34
|
15,49
|
2,64
|
|
2005
|
43,7
|
5,87
|
101
|
1097,045
|
82,15
|
74,33
|
16,43
|
2,74
|
|
2006
|
48,0
|
4,16
|
100
|
1119,912
|
93,51
|
85,20
|
17,25
|
2,91
|
|
2007
|
52,3
|
7,38
|
101
|
1088,823
|
113,21
|
100,90
|
19,69
|
2,95
|
|
2008
|
52,2
|
8,16
|
99
|
938,579
|
127,84
|
116,96
|
22,58
|
3,54
|
|
2009
|
43,7
|
7,22
|
101
|
1039,023
|
89,06
|
86,65
|
21,66
|
3,61
|
|
2010
|
45,5
|
7,16
|
101
|
1309,667
|
95,48
|
93,09
|
21,48
|
3,58
|
|
Годы
|
Труд
и образование
|
|
Трудовые
ресурсы, тыс. чел.
|
ЧБ,
тыс. чел.
|
Расходы
на образование, млрд. долл.
|
|
1991
|
2573,5
|
167,3
|
7,76
|
|
1992
|
2532
|
293,7
|
6,72
|
|
1993
|
2509,1
|
406,5
|
5,24
|
|
1994
|
2489,4
|
408,3
|
6,44
|
|
1995
|
2514,6
|
384,7
|
8,23
|
|
1996
|
2523
|
363,3
|
7,95
|
|
1997
|
2510,7
|
316,3
|
7,50
|
|
1998
|
2535,7
|
289,1
|
7,78
|
|
1999
|
2585,5
|
261,1
|
7,94
|
|
2000
|
2613,6
|
253,5
|
7,18
|
|
2001
|
2633,3
|
239,6
|
7,60
|
|
2002
|
2636
|
237,2
|
8,38
|
|
2003
|
2625,5
|
236,3
|
10,50
|
|
2004
|
2620,8
|
230,6
|
12,09
|
|
2005
|
2639,5
|
221,7
|
12,32
|
|
2006
|
2681,8
|
203,8
|
12,88
|
|
2007
|
2708,4
|
184,2
|
14,52
|
|
2008
|
2736
|
172,4
|
16,59
|
|
2009
|
2692,1
|
220,8
|
14,92
|
|
2010
|
2694,7
|
226,4
|
15,28
|
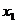 - валовой национальный продукт
(ВНП), млрд. долл.
- валовой национальный продукт
(ВНП), млрд. долл.
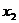 - валовой национальный доход, млрд.
долл.
- валовой национальный доход, млрд.
долл.
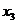 - валовой национальный доход на
душу населения, долл.
- валовой национальный доход на
душу населения, долл.
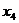 - прирост ВНП, %
- прирост ВНП, %
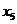 - численность населения, тыс. чел.
- численность населения, тыс. чел.
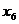 - число родившихся, чел.
- число родившихся, чел.
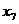 - число умерших, чел.
- число умерших, чел.
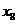 - внешняя миграция, прибыло, чел.
- внешняя миграция, прибыло, чел.
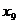 - объем промышленного производства,
млрд. долл.
- объем промышленного производства,
млрд. долл.
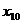 - валовая добавленная стоимость
сельского хозяйства, млрд. долл.
- валовая добавленная стоимость
сельского хозяйства, млрд. долл.
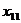 - индекс производства пищевых продуктов
- индекс производства пищевых продуктов
 - ввод жилых зданий, тыс. кв.
метров общей площади.
- ввод жилых зданий, тыс. кв.
метров общей площади.
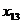 - экспорт товаров и услуг, млрд.
долл.
- экспорт товаров и услуг, млрд.
долл.
 - импорт товаров и услуг, млрд.
долл.
- импорт товаров и услуг, млрд.
долл.
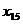 - расходы на здравоохранение, млрд.
долл.
- расходы на здравоохранение, млрд.
долл.
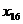 - расходы на оборону, млрд. долл.
- расходы на оборону, млрд. долл.
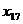 - численность занятых в экономике,
тыс. чел.
- численность занятых в экономике,
тыс. чел.
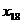 - численность безработных, тыс.
чел.
- численность безработных, тыс.
чел.
 - расходы на образование, млрд.
долл.
- расходы на образование, млрд.
долл.
2.2 Базовый анализ данных
Цель анализа - установить степень однородности
рядов данных. Проводится в среде MS
Excel с помощью
инструмента «Описательная статистика» Пакета анализа.
Этот инструмент дает возможность построить
таблицу параметров описательной статистики для одного или более наборов входных
данных. Для каждого набора входных данных в выходном интервале строится таблица
со следующей информацией: Среднее, Стандартная ошибка, Медиана, Мода,
Стандартное отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал,
Минимум, Максимум, Сумма, Счет и Уровень надежности(доверительный интервал).
Статистической обработке подвергается один или несколько наборов данных,
располагаемых в интервале, ссылка на который задается в поле Входной интервал.
Переключатель Группирование дает возможность уточнить, как размещаются данные:
по столбцам или по строкам. Если столбцы или строки данных имеют метки, то при
установленном флажке Метки в первой строке / Метки в первом столбце они
используются в качестве заголовков столбцов статистических параметров выходной
таблицы. Адрес верхней левой ячейки для этой таблицы задается в поле Выходной
интервал. При установленном флажке Итоговая статистика создается подробная
выходная таблица, установив соответствующие флажки, можно поместить в нее
дополнительные данные.
Для нормальных и близких к нормальному
распределений показатель интенсивности вариации служит индикатором однородности
совокупности. Он вычисляется по формуле:
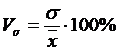
Принято считать, что при
выполнимости неравенства 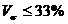 совокупность
является количественно однородной по данному признаку.
совокупность
является количественно однородной по данному признаку.
|
x17
|
x18
|
x19
|
|
Среднее
|
2602,76
|
265,84103
|
9,891305
|
|
Стандартная
ошибка
|
17,078129
|
16,691033
|
0,7682955
|
|
Медиана
|
2617,2
|
238,43515
|
8,09125
|
|
Стандартное
отклонение
|
76,375715
|
74,64457
|
3,4359219
|
|
Дисперсия
выборки
|
5833,2499
|
5571,8119
|
11,805559
|
|
Эксцесс
|
-1,2482698
|
-0,4121172
|
-0,945076
|
|
Асимметричность
|
0,0951452
|
0,777611
|
0,6837207
|
|
Интервал
|
246,6
|
240,9841
|
11,354
|
|
Минимум
|
2489,4
|
167,2775
|
5,238
|
|
Максимум
|
2736
|
408,2616
|
16,592
|
|
Сумма
|
52055,2
|
5316,8205
|
197,8261
|
|
Счет
|
20
|
20
|
20
|
|
Интенсивность
вариации:
|
2,9344125
|
28,07865
|
34,73679
|
Выводы: Все показатели из групп «Экономика» имеют
неоднородные ряды данных. В группе «Население» у всех показателей ряды
однородные, то же самое можно сказать и про группу «Промышленность и сельское
хозяйство». В группе «Труд и образование» только показатель «Расходы на
образование» имеет неоднородный ряд, а остальные показатели имеют однородные
ряды. В группе «Иностранная торговля и правительственные расходы» три
показателя имеют неоднородные ряды и только показатель «Расходы на оборону»
имеет однородный ряд.
2.3 Анализ временных рядов
Цель анализа - выявить закономерности
распределения данных, построение тренда и осуществление прогноза на его основе.
Проводится в среде MS
Excel с помощью
инструментов «Скользящее среднее» и «Экспоненциальное сглаживание» Пакета
анализа.
Среднее скользящее значение относится к
категории аналитических инструментов, которые, как принято говорить,
"следуют за тенденцией". Его назначение состоит в том, чтобы
позволить определить время начала новой тенденции, а также предупредить о ее
завершении или повороте. Методы скользящего среднего предназначены для
отслеживания тенденций непосредственно в процессе их развития, их можно
рассматривать как искривленные линии тренда.
Простая и логически ясная модель временного ряда
имеет следующий вид:
Yt = b
+ εt
где b - константа, ε
- случайная ошибка. Константа b относительно стабильна на каждом временном
интервале, но может также медленно изменяться со временем. Один из интуитивно
ясных способов выделения значения b из данных состоит в том, чтобы использовать
сглаживание скользящим средним, в котором последним наблюдениям приписываются
большие веса, чем предпоследним, предпоследним большие веса, чем пред-
предпоследним, и т.д.
Точная формула простого экспоненциального
сглаживания имеет вид:
St = α
yt + (1 - α)
St-1
Когда эта формула применяется рекурсивно, каждое
новое сглаженное значение (которое является также прогнозом) вычисляется как
взвешенное среднее текущего наблюдения и сглаженного ряда. Очевидно, результат
сглаживания зависит от параметра α.
Если α равен 1, то
предыдущие наблюдения полностью игнорируются. Если α
равен 0, то игнорируются текущие наблюдения. Значения α
между 0 и 1 дают промежуточные результаты. Эмпирические исследования показали,
что простое экспоненциальное сглаживание весьма часто дает достаточно точный
прогноз.
Основным содержанием метода аналитического
выравнивания временных рядов является расчет общей тенденции развития (тренда)
как функции времени:
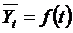
где 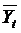 - теоретические значения временного
ряда, вычисленные по соответствующему аналитическому уравнению на момент
времени t.
- теоретические значения временного
ряда, вычисленные по соответствующему аналитическому уравнению на момент
времени t.
С помощью Microsoft Excel строить
трендовые модели достаточно просто. Сначала эмпирический временной ряд следует
представить в виде диаграммы одного из следующих типов: гистограмма, линейчатая
диаграмма, график, точечная диаграмма, диаграмма с областями, а затем щелкнуть
на диаграмме правой кнопкой мыши на одном из маркеров данных. В результате на
диаграмме будет выделен сам временной ряд, а на экране раскроется контекстное
меню. В этом меню следует выбрать команду (Добавить линию тренда). На экран
будет выведено диалоговое окно. На вкладке Туре (Тип) этого диалогового окна
выбирается требуемый тип тренда:
1. линейный (Linear);
2. логарифмический (Logarithmic);
3. полиномиальный, от 2-й до 6-й степени
включительно (Polinomial);
. степенной (Power);
5. экспоненциальный (Exponential);
6. скользящее среднее, с указанием периода
сглаживания от 2 до 15 (Moving
Average).
Проведем данный анализ для наиболее значимого
показателя каждой группы.
В группе «Экономика» таким
показателем является показатель - валовой национальный продукт.
|
Годы
|
x1
|
Скользящее
среднее
|
Экспоненциальное
сглаживание
|
|
1991
|
125,2
|
-
|
-
|
|
1992
|
110,1
|
-
|
125,20
|
|
1993
|
87,3
|
107,53
|
114,63
|
|
1994
|
100,6
|
99,33
|
95,50
|
|
1995
|
130,7
|
106,20
|
99,07
|
|
1996
|
128,2
|
119,83
|
121,21
|
|
1997
|
122,9
|
127,27
|
126,10
|
|
1998
|
129,7
|
126,93
|
123,86
|
|
1999
|
130,2
|
127,60
|
127,95
|
|
2000
|
121,7
|
127,20
|
129,52
|
|
2001
|
124,6
|
125,50
|
124,05
|
|
2002
|
135,1
|
127,13
|
124,43
|
|
2003
|
164,1
|
141,27
|
131,90
|
|
2004
|
188,9
|
162,70
|
154,44
|
|
2005
|
195,6
|
182,87
|
178,56
|
|
2006
|
207,8
|
197,43
|
190,49
|
|
2007
|
246,1
|
216,50
|
202,61
|
|
2008
|
272
|
241,97
|
233,05
|
|
2009
|
240,7
|
252,93
|
260,32
|
|
2010
|
238,7
|
250,47
|
246,58
|
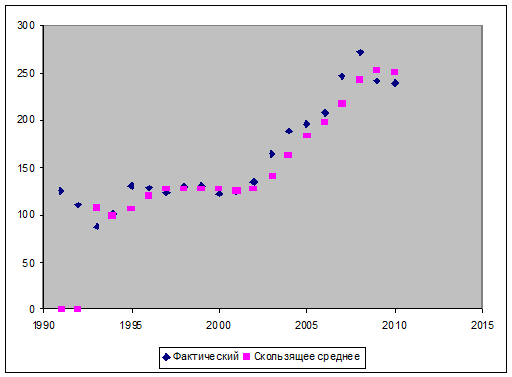
Рис. 1. График скользящего среднего для
показателя валовой национальный продукт

Рис. 2. График экспоненциального сглаживания для
показателя валовой национальный продукт
Для того, чтобы выявить наилучшее
уравнение тренда для показателя - валовой внутренний продукт
построим график фактических значений данного показателя и добавим на него линии
линейного, степенного и экспоненциального трендов с указанием уравнения и
величины достоверности аппроксимации R2.
Как видно, из рисунка 3, наиболее
лучшей модель тренда является экспоненциальная модель с уравнением 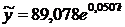 , так как
имеет самую наибольшую величину достоверности аппроксимации R2=0,83.
, так как
имеет самую наибольшую величину достоверности аппроксимации R2=0,83.
По полученному уравнению рассчитаем
прогнозные значения валового внутреннего продукта для 2011 и 2012 годов,
которым имеют значения t=21 и t=20
соответственно.
г.: 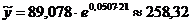 млрд. долл.
млрд. долл.
г.:  млрд. долл.
млрд. долл.
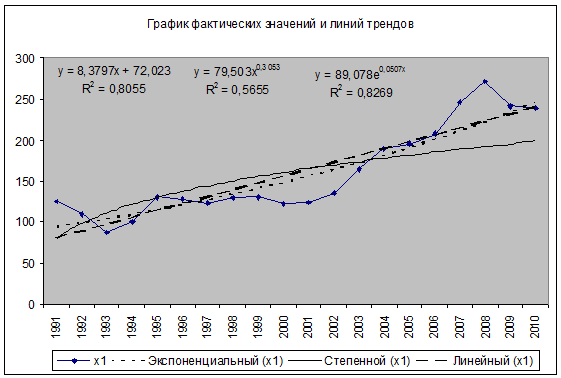
Рис. 3. Линии трендов для показателя
валовой национальный продукт
|
Годы
|
x5
|
Скользящее
среднее
|
Экспоненциальное
сглаживание
|
|
1991
|
5009,16
|
|
|
|
1992
|
5034,766
|
|
5009,16
|
|
1993
|
5061,394
|
5035,11
|
5027,08
|
|
1994
|
5086,368
|
5060,84
|
5051,10
|
|
1995
|
5107,802
|
5085,19
|
5075,79
|
|
1996
|
5125,177
|
5106,45
|
5098,20
|
|
1997
|
5139,257
|
5124,08
|
5117,08
|
|
1998
|
5151,024
|
5138,49
|
5132,60
|
|
1999
|
5161,995
|
5150,76
|
5145,50
|
|
2000
|
5173,37
|
5162,13
|
5157,05
|
|
2001
|
5185,18
|
5173,52
|
5168,47
|
|
2002
|
5197,305
|
5185,29
|
5180,17
|
|
2003
|
5210,595
|
5197,69
|
5192,16
|
|
2004
|
5226,067
|
5211,32
|
5205,07
|
|
2005
|
5244,342
|
5227,00
|
5219,77
|
|
2006
|
5265,936
|
5245,45
|
5236,97
|
|
2007
|
5290,431
|
5266,90
|
5257,25
|
|
2008
|
5316,334
|
5290,90
|
5280,48
|
|
2009
|
5341,546
|
5316,10
|
5305,58
|
|
2010
|
5364,546
|
5340,81
|
5330,76
|
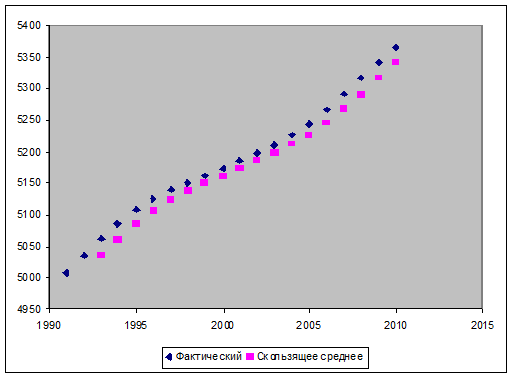
Рис. 4. График скользящего среднего для
показателя численность населения
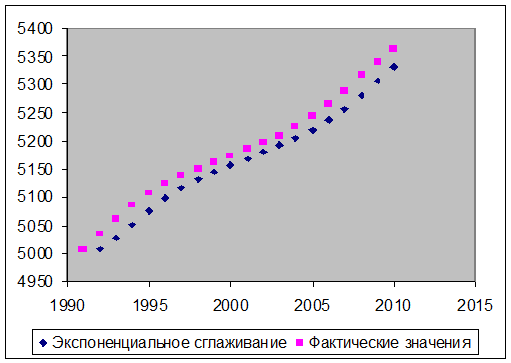
Рис. 5. График экспоненциального сглаживания для
показателя численность населения
Для того, чтобы выявить наилучшее
уравнение тренда для показателя - численность населения, построим
график фактических значений данного показателя. Добавим на него линии
линейного, степенного и экспоненциального трендов с указанием уравнения и величины
достоверности аппроксимации R2.
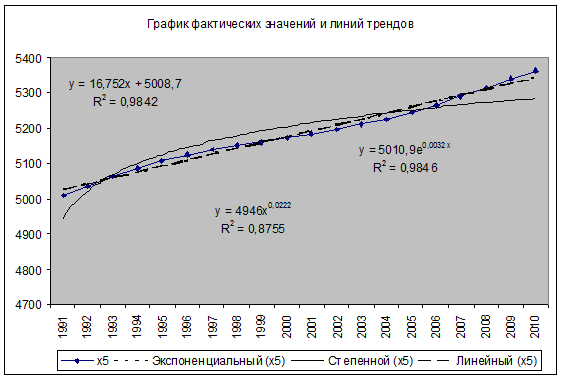
Рис. 6. Линии трендов для показателя
численность населения.
Как видно, из рисунка 6, наиболее
лучшей моделью тренда является экспоненциальная модель с уравнением 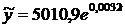 , так как
имеет самую наибольшую величину достоверности аппроксимации R2=0,9846.
, так как
имеет самую наибольшую величину достоверности аппроксимации R2=0,9846.
По полученному уравнению рассчитаем
прогнозные значения валового внутреннего продукта для 2011 и 2012 годов,
которым имеют значения t=21 и t=22
соответственно.
г.:  тыс. чел.
тыс. чел.
г.: 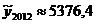 тыс. чел.
тыс. чел.
2.4 Корреляционный анализ
Коэффициент корреляции, как и ковариационный
анализ, характеризует степень, в которой два измерения «изменяются вместе». В отличие
от ковариационного анализа коэффициент корреляции масштабируется таким образом,
что его значение не зависит от единиц, в которых выражены переменные двух
измерений (например, если вес и высота являются двумя измерениями, значение
коэффициента корреляции не изменится после перевода веса из фунтов в
килограммы). Любое значение коэффициента корреляции должно находиться в
диапазоне от -1 до +1 включительно.
Корреляционный анализ дает возможность
установить, ассоциированы ли наборы данных по величине, т. е. большие значения
из одного набора данных связаны с большими значениями другого набора
(положительная корреляция) или наоборот, малые значения одного набора связаны с
большими значениями другого (отрицательная корреляция), или данные двух
диапазонов никак не связаны (нулевая корреляция).
В строке меню Сервис выбирается пункт Анализ
данных. В открывшемся окне необходимо выбрать инструмент анализа Корреляция.
Далее следуя логике анализа:
указывается диапазон значений всех переменных
для анализа;- указывается свободная ячейка, в которой будут размещены
результаты или дается название новому рабочему листу и выполняется расчёт.В
качестве зависимых показателей возьмем показатели группы, характеризующей
экономику страны (в частности ВВП). Выясним, какие показатели (показатели какой
группы) вносят наибольший вклад в формирование ВВП страны?
Получили следующую корреляционную матрицу:
|
|
y
|
x5
|
x6
|
x7
|
x8
|
x9
|
x10
|
x11
|
x12
|
x13
|
x14
|
x15
|
x16
|
x17
|
x18
|
|
y
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x5
|
0,8965
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x6
|
-0,2819
|
-0,5
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x7
|
-0,0755
|
-0
|
0,33
|
1
|
|
|
|
|
|
|
|
|
|
|
|
|
x8
|
0,9283
|
0,8
|
-0,3
|
0,03
|
1
|
|
|
|
|
|
|
|
|
|
|
|
x9
|
0,8982
|
0,9
|
-0,6
|
-0,2
|
0,88
|
1
|
|
|
|
|
|
|
|
|
|
|
x10
|
0,691
|
0,4
|
0,34
|
0,14
|
0,68
|
0,37
|
1
|
|
|
|
|
|
|
|
|
|
x11
|
0,6002
|
0,6
|
-0,2
|
-0,1
|
0,67
|
0,62
|
0,47
|
1
|
|
|
|
|
|
|
|
|
x12
|
-0,005
|
0
|
-0,1
|
0,27
|
0,18
|
0,1
|
-0
|
0,07
|
1
|
|
|
|
|
|
|
|
x13
|
0,966
|
0,9
|
-0,4
|
-0,2
|
0,88
|
0,95
|
0,54
|
0,58
|
-0
|
1
|
|
|
|
|
|
|
x14
|
0,9862
|
0,9
|
-0,3
|
-0,1
|
0,92
|
0,92
|
0,63
|
0,61
|
-0
|
0,99
|
1
|
|
|
|
|
|
x15
|
0,9926
|
0,9
|
-0,2
|
-0
|
0,92
|
0,86
|
0,71
|
0,62
|
-0
|
0,94
|
1
|
1
|
|
|
|
|
x16
|
0,9356
|
0,8
|
-0
|
0,04
|
0,86
|
0,71
|
0,79
|
0,55
|
0,02
|
0,83
|
0,9
|
0,96
|
1
|
|
|
|
x17
|
0,8859
|
0,9
|
-0,5
|
-0,1
|
0,95
|
0,94
|
0,48
|
0,65
|
0,2
|
0,89
|
0,9
|
0,86
|
0,74
|
1
|
|
|
x18
|
-0,6826
|
-0,6
|
0,44
|
0,17
|
-0,8
|
-0,7
|
-0,5
|
-0,5
|
-0,5
|
-0,6
|
-0,6
|
-0,6
|
-0,8
|
1
|
|
x19
|
0,9967
|
0,9
|
-0,3
|
-0,1
|
0,92
|
0,89
|
0,69
|
0,61
|
-0
|
0,95
|
1
|
1
|
0,95
|
0,88
|
-0,7
|
статистика
ряд корреляция еxcel
Анализируя эту корреляционную матрицу, видим,
что наиболее существенный вклад в ВВП страны вносят показатели всех групп, в
той или иной степени. К наиболее существенным показателям имеющим r
> 0,7 относятся:
- численность населения, тыс. чел.
(r = 0,897)
- внешняя миграция, прибыло, чел. (r = 0,928)
- объем промышленного производства
(r = 0,898)
- экспорт товаров и услуг, млрд.
долл. (r = 0,966)
- импорт товаров и услуг, млрд.
долл. (r = 0,986)
- расходы на здравоохранение, млрд.
долл. (r = 0,993)
- расходы на оборону, млрд. долл. (r = 0,936)
- численность занятых в экономике,
тыс. чел. (r = 0,886)
- расходы на образование, млрд.
долл. (r = 0,997)
2.5 Регрессионный анализ
Режим работы "Регрессия" служит для
расчета параметров уравнения линейной регрессии и проверки его адекватности
исследуемому процессу.
Для решения задачи регрессионного анализа в MS
Excel выбираем в меню Сервис команду Анализ данных и инструмент анализа
"Регрессия".
В появившемся диалоговом окне задаем следующие
параметры:
· Входной интервал Y - это диапазон
данных по результативному признаку. Он должен состоять из одного столбца.
· Входной интервал X - это диапазон
ячеек, содержащих значения факторов (независимых переменных). Число входных
диапазонов (столбцов) должно быть не больше 16.
· Флажок Метки, устанавливается втом
случае, если в первой строке диапазона стоит заголовок.
· Флажок Уровень надежности
активизируется, если в поле, находящееся рядом с ним необходимо ввести уровень
надежности, отличный от установленного по умолчанию. Используется для проверки
значимости коэффициента детерминации R2 и коэффициентов регрессии.
· Константа ноль. Данный флажок
необходимо установить, если линия регрессии должна пройти через начало
координат (а0=0).
· Выходной интервал/ Новый рабочий
лист/ Новая рабочая книга - указать адрес верхней левой ячейки выходного
диапазона.
· Флажки в группе Остатки
устанавливаются, если необходимо включить в выходной диапазон соответствующие
столбцы или графики.
После нажатия кнопки ОК в выходном диапазоне
получаем отчет.
Построим уравнение зависимости ВВП от
показателей, имеющих r
> 0,7, полученных в предыдущем анализе. Результаты выполнения инструмента
Регрессия представлены ниже:
|
Регрессионная
статистика
|
|
Множественный
R
|
0,999175
|
|
R-квадрат
|
0,998351
|
|
Нормированный
R-квадрат
|
0,996867
|
|
Стандартная
ошибка
|
3,091748
|
|
Наблюдения
|
20
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
df
|
SS
|
MS
|
F
|
Значимость
F
|
|
Регрессия
|
9
|
57879,05
|
6431,005
|
672,7762
|
1,04E-12
|
|
Остаток
|
10
|
95,58908
|
9,558908
|
|
|
|
Итого
|
19
|
57974,64
|
|
|
|
|
|
Коэффициенты
|
Стандартная
ошибка
|
t-статистика
|
P-Значение
|
Нижние
95%
|
Верхние
95%
|
|
Y-пересечение
|
165,9428
|
211,6086
|
0,7842
|
0,4511
|
-305,5506
|
637,4362
|
|
x5
|
-0,0649
|
0,0381
|
-1,7027
|
0,1195
|
-0,1498
|
0,0200
|
|
x8
|
0,0003
|
0,0008
|
0,3936
|
0,7021
|
-0,0015
|
0,0022
|
|
x9
|
-0,2459
|
0,5524
|
-0,4451
|
0,6657
|
-1,4767
|
0,9849
|
|
x13
|
1,2764
|
0,5491
|
2,3247
|
0,0424
|
0,0530
|
2,4997
|
|
x14
|
-0,8366
|
0,5861
|
-1,4275
|
0,1839
|
-2,1424
|
0,4692
|
|
x15
|
5,5956
|
3,7738
|
1,4828
|
0,1690
|
-2,8128
|
14,0041
|
|
x16
|
10,2395
|
9,9726
|
1,0268
|
0,3287
|
-11,9809
|
32,4598
|
|
x17
|
0,0674
|
0,0649
|
1,0384
|
0,3236
|
-0,0772
|
0,2121
|
|
x19
|
2,7203
|
5,1439
|
0,5288
|
0,6085
|
-8,7412
|
14,1817
|
Выборочная модель множественной линейной
регрессии может быть записана в виде:

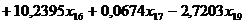 .
.
EXCEL
автоматически рассчитал коэффициенты множественной корреляции (множественный R) и
детерминации (R-квадрат), а
также скорректированный коэффициент детерминации (нормированный R-квадрат)
Мы получили следующие показатели
тесноты связи: R2=0,998 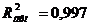 , R=0,99.
, R=0,99.
Между коэффициентом детерминации и
скорректированным коэффициентом существуют незначительные различия, значит
можно использовать R2 и R для оценки
тесноты связи. Множественный коэффициент корреляции (R = 0,99)
свидетельствует о прямой связи между факторами и результатом, множественный
коэффициент детерминации показывает, что 99,8% вариации ВВП связано с
включенными в модель факторами.
Дадим оценку значимости уравнения в
целом, условного начала и коэффициентов чистой регрессии.
Оценка значимости уравнения в целом
проводится на основе дисперсионного анализа.
Предположим, что уравнение не
значимо для генеральной совокупности (Н0) в качестве альтернативной гипотезы
выдвинем предположение о значимости уравнения (НА). Проверим эти гипотезы на 5%
уровне значимости. В качестве критерия выберем критерий F-Фишера, его
фактическое значение равно 672,77. Сравним его с критическим значением  , которое
можно найти, используя встроенную функцию FРАСПОБР(
, которое
можно найти, используя встроенную функцию FРАСПОБР(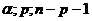 ).
).
В нашем случае: 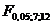 =FРАСПОБР(0,05;9;10)=3,02.
=FРАСПОБР(0,05;9;10)=3,02.
Поскольку фактическое значение
превышает критическое, принимаем гипотезу о значимости уравнения в целом,
следовательно, уравнение в целом значимо,
2.6 Дисперсионный анализ
Дисперсионным анализом называют совокупность
статистических методов, предназначенных для обработки данных экспериментов,
целью которых являлось не установление каких-то свойств и параметров, а
сравнение эффектов различных воздействий на каком-либо экспериментальном
материале. Методы дисперсионного анализа используются для проверки гипотез о
наличии связи между результативным признаком и исследуемыми факторами, а также
для установления силы влияния факторов и их взаимодействий.
Однофакторный дисперсионный анализ используется
в тех случаях, когда есть в распоряжении три или более независимые выборки,
полученные из одной генеральной совокупности путем изменения какого-либо
независимого фактора, для которого по каким-либо причинам нет количественных
измерений.
Проводится в среде MS
Excel с помощью
инструмента «Однофакторный дисперсионный анализ» Пакета анализа.
Результаты выполнения анализа
|
Однофакторный
дисперсионный анализ
|
|
ИТОГИ
|
|
|
|
|
|
|
|
Группы
|
Счет
|
Сумма
|
Среднее
|
Дисперсия
|
|
|
|
x1
|
20
|
3200,2
|
160,01
|
3051,297
|
|
|
|
x2
|
20
|
3178,8
|
158,94
|
3325,768
|
|
|
|
x3
|
20
|
609622,5
|
30481,12
|
1,1E+08
|
|
|
|
x4
|
20
|
40,6
|
2,03
|
14,87379
|
|
|
|
x5
|
20
|
103692,6
|
5184,63
|
9979,812
|
|
|
|
x6
|
20
|
1199112
|
59955,6
|
11597223
|
|
|
|
x7
|
20
|
983165
|
49158,25
|
760820,5
|
|
|
|
x8
|
20
|
371395
|
18569,75
|
27286184
|
|
|
|
x9
|
20
|
725,6142
|
36,28071
|
92,12897
|
|
|
|
x10
|
20
|
107,462
|
5,3731
|
2,009487
|
|
|
|
x11
|
20
|
1942
|
97,1
|
12,62105
|
|
|
|
x12
|
20
|
21772,73
|
1088,637
|
29943,88
|
|
|
|
x13
|
20
|
1265,171
|
63,25855
|
823,3025
|
|
|
|
x14
|
20
|
1096,61
|
54,8305
|
778,4797
|
|
|
|
x15
|
20
|
258,9353
|
12,94677
|
26,41525
|
|
|
|
x16
|
20
|
46,2116
|
2,31058
|
0,490652
|
|
|
|
x17
|
20
|
52055,2
|
2602,76
|
5833,25
|
|
|
|
x18
|
20
|
5316,821
|
265,841
|
5571,812
|
|
|
|
x19
|
20
|
197,8261
|
9,891305
|
11,80556
|
|
|
|
Дисперсионный
анализ
|
|
|
|
|
|
|
|
Источник
вариации
|
SS
|
df
|
MS
|
F
|
P-Значение
|
F
критическое
|
|
Между
группами
|
1,17E+11
|
18
|
6,48E+09
|
822,8476
|
2,5054E-280
|
1,632496479
|
|
Внутри
групп
|
2,84E+09
|
361
|
7880826
|
|
|
|
|
Итого
|
1,2E+11
|
379
|
|
|
|
|
Внутригрупповая изменчивость (SS) обычно
называется остаточной компонентой или дисперсией ошибки. Это значит, что обычно
при проведении эксперимента она может быть предсказана или объяснена. С другой
стороны, SS между группами можно объяснить различиями между средними значениями
в группах. Иными словами, принадлежность к некоторой группе объясняет
межгрупповую изменчивость, т.к. нам известно, что эти группы обладают разными
средними значениями.
Проверка значимости в дисперсионном анализе
основана на сравнении компоненты дисперсии, обусловленной межгрупповым
разбросом и компоненты дисперсии, обусловленной внутригрупповым разбросом. Если
верна нулевая гипотеза (равенство средних в двух выборках), то можно ожидать
сравнительно небольшое различие выборочных средних из-за чисто случайной
изменчивости. Поэтому, при нулевой гипотезе, внутригрупповая дисперсия будет
практически совпадать с общей дисперсией, подсчитанной без учета групповой
принадлежности. Полученные внутригрупповые дисперсии можно сравнить с помощью
F-критерия, проверяющего, действительно ли отношение дисперсией значимо больше
1. В нашем случае, критерий показывает, что различие между средними
статистически значимо.
2.7 Факторный анализ
Методами факторного анализа решаются три
основных вида задач:
отыскание скрытых, но предполагаемых
закономерностей, которые определяются воздействием внутренних или внешних причин
(факторов) на изучаемый процесс;
·выявление и изучение статистической связи
признаков с факторами или главными компонентами;
·сжатие информации путем описания процесса при
помощи общих факторов или главных компонент, число которых меньше количества
первоначально взятых признаков (параметров), однако с той или иной степенью
точности обеспечивающих воспроизводимость корреляционной матрицы.
Следует пояснить, что в факторном анализе
понимается под сжатием информации. Дело в том, что корреляционная матрица получается
путем обработки исходного массива данных. Корреляционная матрица образована из
попарных коэффициентов корреляции компонент случайного вектора. Предполагается,
что та же самая корреляционная матрица может быть получена с использованием тех
же объектов, но описанных меньшим числом параметров. Таким образом, якобы
происходит уменьшение размерности задачи, хотя на самом деле это не так. Это не
сжатие информации в общепринятом смысле - восстановить исходные данные по
корреляционной матрице нельзя.
Проведем факторный анализ для показателей,
участвовавших в регрессионном анализе, с помощью программы AtteStat,
которая является приложением для Excel.
Были получены следующие результаты:
|
Корреляционная
матрица
|
|
1,000
|
0,896
|
0,928
|
0,898
|
0,966
|
0,986
|
0,993
|
0,936
|
0,886
|
0,997
|
|
0,896
|
1,000
|
0,828
|
0,925
|
0,916
|
0,902
|
0,898
|
0,771
|
0,871
|
0,899
|
|
0,928
|
0,828
|
1,000
|
0,877
|
0,884
|
0,917
|
0,919
|
0,859
|
0,948
|
0,918
|
|
0,898
|
0,925
|
0,877
|
1,000
|
0,950
|
0,919
|
0,864
|
0,714
|
0,945
|
0,887
|
|
0,966
|
0,884
|
0,950
|
1,000
|
0,988
|
0,940
|
0,831
|
0,887
|
0,954
|
|
0,986
|
0,902
|
0,917
|
0,919
|
0,988
|
1,000
|
0,972
|
0,897
|
0,886
|
0,977
|
|
0,993
|
0,898
|
0,919
|
0,864
|
0,940
|
0,972
|
1,000
|
0,960
|
0,862
|
0,996
|
|
0,936
|
0,771
|
0,859
|
0,714
|
0,831
|
0,897
|
0,960
|
1,000
|
0,738
|
0,945
|
|
0,886
|
0,871
|
0,948
|
0,945
|
0,887
|
0,886
|
0,862
|
0,738
|
1,000
|
0,876
|
|
0,997
|
0,899
|
0,918
|
0,887
|
0,954
|
0,977
|
0,996
|
0,945
|
0,876
|
1,000
|
|
Метод
главных факторов
|
|
|
|
|
|
|
|
|
Число
положительных собственных значений
|
|
10
|
|
|
|
|
|
|
|
|
|
|
Число
факторов
|
|
|
|
|
|
|
|
|
|
10
|
|
|
|
|
|
|
|
|
|
|
Матрица
факторного отображения
|
|
|
|
|
|
|
|
0,991
|
-0,108
|
-0,021
|
-0,044
|
-0,026
|
-0,026
|
-0,030
|
0,023
|
-0,020
|
-0,006
|
|
0,930
|
0,177
|
-0,220
|
0,228
|
0,050
|
-0,003
|
0,002
|
0,005
|
0,001
|
-0,002
|
|
0,948
|
0,022
|
0,300
|
0,018
|
0,090
|
0,030
|
-0,034
|
0,001
|
0,003
|
0,000
|
|
0,938
|
0,322
|
-0,052
|
-0,055
|
-0,063
|
0,081
|
-0,006
|
-0,005
|
-0,004
|
0,000
|
|
0,974
|
0,078
|
-0,138
|
-0,157
|
0,039
|
-0,018
|
0,002
|
0,015
|
0,011
|
0,011
|
|
0,987
|
-0,036
|
-0,064
|
-0,120
|
0,059
|
-0,010
|
0,043
|
-0,018
|
-0,005
|
-0,010
|
|
0,983
|
-0,173
|
-0,028
|
0,041
|
-0,013
|
-0,020
|
-0,021
|
-0,026
|
-0,012
|
0,011
|
|
0,904
|
-0,415
|
0,040
|
0,062
|
-0,025
|
0,046
|
0,046
|
0,011
|
0,004
|
0,002
|
|
0,929
|
0,276
|
0,227
|
0,046
|
-0,053
|
-0,054
|
0,040
|
0,002
|
0,001
|
0,002
|
|
0,988
|
-0,133
|
-0,034
|
-0,002
|
-0,060
|
-0,021
|
-0,036
|
-0,008
|
0,022
|
-0,007
|
|
Выделенные
и накопленные дисперсии (в %)
|
|
91,70
|
91,70
|
|
|
|
|
|
|
|
|
|
4,51
|
96,21
|
|
|
|
|
|
|
|
|
|
2,20
|
98,41
|
|
|
|
|
|
|
|
|
|
1,04
|
99,45
|
|
|
|
|
|
|
|
|
|
0,27
|
99,72
|
|
|
|
|
|
|
|
|
|
0,14
|
99,87
|
|
|
|
|
|
|
|
|
|
0,09
|
99,96
|
|
|
|
|
|
|
|
|
|
0,02
|
99,98
|
|
|
|
|
|
|
|
|
|
0,01
|
100,00
|
|
|
|
|
|
|
|
|
|
0,00
|
100,00
|
|
|
|
|
|
|
|
|
|
Повернутая
матрица факторного отображения
|
|
0,713
|
0,442
|
0,451
|
-0,297
|
-0,002
|
-0,007
|
-0,045
|
0,014
|
-0,0000001
|
0,0000004
|
|
0,466
|
0,774
|
0,407
|
-0,130
|
0,033
|
0,021
|
-0,005
|
-0,024
|
-0,0000004
|
0,0000004
|
|
0,594
|
0,304
|
0,715
|
-0,165
|
0,024
|
0,122
|
0,004
|
-0,023
|
-0,0000002
|
0,0000001
|
|
0,353
|
0,617
|
0,599
|
-0,347
|
-0,126
|
-0,019
|
-0,004
|
0,017
|
0,0000001
|
-0,0000001
|
|
0,545
|
0,545
|
0,443
|
-0,458
|
0,021
|
0,011
|
-0,007
|
0,037
|
0,0000000
|
0,0000008
|
|
0,646
|
0,472
|
0,450
|
-0,389
|
0,012
|
0,013
|
0,004
|
-0,146
|
0,0000000
|
0,0000001
|
|
0,762
|
0,449
|
0,412
|
-0,210
|
0,004
|
0,003
|
-0,046
|
-0,028
|
0,0000000
|
0,0000036
|
|
0,903
|
0,273
|
0,307
|
-0,120
|
-0,015
|
0,001
|
0,038
|
0,000
|
-0,0000011
|
-0,0000001
|
|
0,394
|
0,452
|
0,777
|
-0,179
|
0,009
|
-0,071
|
-0,019
|
-0,008
|
-0,0000011
|
0,0000008
|
|
0,733
|
0,454
|
0,429
|
-0,255
|
-0,020
|
-0,024
|
-0,077
|
0,027
|
0,0000000
|
-0,0000004
|
Анализируя полученные результаты, приходим к
выводу, что на ВНП самое сильное и значимое влияние оказывает только один
фактор (дисперсия 91,70%).
.8 Кластерный анализ
Методами кластерного анализа решается задача
разбиения (классификации, кластеризации) множества объектов таким образом,
чтобы все объекты, принадлежащие одному кластеру (классу, группе) были более
похожи друг на друга, чем на объекты других кластеров.
Метод средней связи Кинга является одним из
важнейших иерархических агломеративных методов кластерного анализа. Процесс
классификации состоит из элементарных шагов:
.Поиск и объединение двух наиболее похожих
объектов в матрице сходства.
.Основанием для помещения объекта в кластер
является близость двух объектов, в зависимости от меры сходства.
.На каком-либо этапе ранее объединенные в один
кластер объекты считаются одним объектом с усредненными по кластеру
параметрами.
.На следующем этапе находятся два очередных
наиболее похожих объекта, и процедура повторяется с шага 2 до полного
исчерпания матрицы сходства.
Универсальность метода
При использовании представленного здесь не
возникает проблемы возможного несоответствия применяемой меры и шкалы
измерения, т.к. метод оперирует не исходными объектами, а построенной матрицей
сходства, по определению являющейся количественной. Координаты центра тяжести
кластера вычисляются не по исходным данным - они являются продуктом манипуляций
с матрицей сходства.
В качестве меры различия для метода средней
связи используется любая из представленных в программе мер, чем и определяется
универсальность метода для любых типов данных, в том числе для смешанных
данных.
Результаты анализа
|
Число
объектов
|
|
|
|
|
|
20
|
|
|
|
|
|
|
Число
параметров
|
|
|
|
|
|
19
|
|
|
|
|
|
|
Заданное
число кластеров
|
|
|
|
|
5
|
|
|
|
|
|
|
Процедура:
Метод средней связи Кинга
|
|
|
|
Тип
связи: Евклидово расстояние**
|
|
|
|
Объединенные
объекты, уровень связи
|
|
|
|
8
|
9
|
812,5429
|
|
|
|
|
13
|
14
|
1503,822
|
|
|
|
|
17
|
18
|
1683,296
|
|
|
|
|
6
|
7
|
1691,319
|
|
|
|
|
8
|
9
|
2374,921
|
|
|
|
|
13
|
15
|
2572,566
|
|
|
|
|
8
|
9
|
2592,207
|
|
|
|
|
6
|
7
|
3007,138
|
|
|
|
|
9
|
10
|
3492,513
|
|
|
|
|
2
|
4
|
4259,03
|
|
|
|
|
2
|
3
|
4599,02
|
|
|
|
|
3
|
4
|
4757,176
|
|
|
|
|
7
|
8
|
6194,969
|
|
|
|
|
4
|
5
|
6441,806
|
|
|
|
|
1
|
7477,76
|
|
|
|
|
1
|
2
|
6979,573
|
|
|
|
|
1
|
2
|
10918,18
|
|
|
|
|
2
|
3
|
12103,6
|
|
|
|
|
1
|
2
|
20680,26
|
|
|
|
|
Номер
кластера, численность, объекты
|
|
|
|
1
|
2
|
1
|
5
|
|
|
|
2
|
3
|
2
|
4
|
3
|
|
|
3
|
4
|
10
|
11
|
12
|
13
|
|
4
|
3
|
14
|
15
|
16
|
|
|
5
|
3
|
17
|
19
|
18
|
|
3. ЗАКЛЮЧЕНИЕ
Инструмент дает возможность построить таблицу
параметров описательной статистики для одного или более наборов входных данных.
Для каждого набора входных данных в выходном интервале строится таблица со
следующей информацией: Среднее, Стандартная ошибка, Медиана, Мода, Стандартное
отклонение, Дисперсия выборки, Эксцесс, Асимметричность, Интервал, Минимум,
Максимум, Сумма, Счет и Уровень надежности(доверительный интервал).
Статистической обработке подвергается один или несколько наборов данных,
располагаемых в интервале, ссылка на который задается в поле Входной интервал.
Переключатель Группирование дает возможность уточнить, как размещаются данные:
по столбцам или по строкам. Если столбцы или строки данных имеют метки, то при
установленном флажке Метки в первой строке / Метки в первом столбце они
используются в качестве заголовков столбцов статистических параметров выходной
таблицы. Адрес верхней левой ячейки для этой таблицы задается в поле Выходной
интервал. При установленном флажке Итоговая статистика создается подробная
выходная таблица, установив соответствующие флажки, можно поместить в нее
дополнительные данные.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Диденко
Н.И. «Мировая экономика: методы анализа экономических процессов»
2. Эконометрика:
Учебник / Под ред. Н.И. Елисеевой. - М.: Финансы и статистика, 2009.
. Ефимова
М.Р., Петрова Е.В., Румянцев В.Н. и др. Общая теория статистики: Учебник. - М.:
Инфра-М, 2010
. Анализ
статистической совокупности в программе MS
Excel: методические
указания и задание к лабораторной работе №1. - Пенза:
Информационно-издательский центр ПГУ, 2011. - 52 с.
. http://www.stat.fi/index_en.html
. http://www.nationmaster.com
. http://unstats.un.org/unsd/snaama/introduction.asp
. http://data.worldbank.org/indicator