Работа в среде Statistika
Введение
Теория вероятности и математическая статистика -
это наука, занимающаяся изучением закономерностей массовых случайных явлений,
то есть статистических закономерностей. Такие же закономерности, только в более
узкой предметной области социально-экономических явлений, изучает статистика.
Между этими науками имеется общность методологии и высокая степень взаимосвязи.
Практически любые выводы сделанные статистикой рассматриваются как
вероятностные.
Особенно наглядно вероятностный характер
статистических исследований проявляется в выборочном методе, поскольку любой
вывод сделанный по результатам выборки оценивается с заданной вероятностью.
С развитием рынка постепенно сращивается
вероятность и статистика, особенно наглядно это проявляется в управлении рисками,
товарными запасами, портфелем ценных бумаг и т.п. За рубежом теория вероятности
и математическая статистика применятся очень широко. В нашей стране пока широко
применяется в управлении качеством продукции, поэтому распространение и
внедрение в практику методов теории вероятности актуальная задача.
Предмет и метод математической
статистики. Статистическое описание совокупности объектов занимает
промежуточное положение между индивидуальным описанием каждого из объектов
совокупности, с одной стороны, и описанием совокупности по её общим свойствам,
совсем не требующим её расчленения на отдельные объекты, - с другой. По
сравнению с первым способом статистические данные всегда в большей или меньшей
степени обезличены и имеют лишь ограниченную ценность в случаях, когда
существенны именно индивидуальные данные (например, учитель, знакомясь с
классом, получит лишь весьма предварительную ориентировку о положении дела из
одной статистики числа выставленных его предшественником отличных, хороших,
удовлетворительных и неудовлетворительных оценок). С другой стороны, по
сравнению с данными о наблюдаемых извне суммарных свойствах совокупности
статистические данные позволяют глубже проникнуть в существо дела. Например,
данные гранулометрического анализа породы (то есть данные о распределении
образующих породу частиц по размерам) дают ценную дополнительную информацию по
сравнению с испытанием нерасчленённых образцов породы, позволяя в некоторой
мере объяснить свойства породы, условия её образования и прочее.
Метод исследования, опирающийся
на рассмотрение статистических данных о тех или иных совокупностях объектов,
называется статистическим. Статистический метод применяется в самых различных
областях знания. Однако черты статистического метода в применении к объектам
различной природы столь своеобразны, что было бы бессмысленно объединять,
например, социально-экономическую статистику, физическую статистику, звёздную
статистику и тому подобное в одну науку.
Общие черты статистического
метода в различных областях знания сводятся к подсчёту числа объектов, входящих
в те или иные группы, рассмотрению распределения количеств, признаков,
применению выборочного метода (в случаях, когда детальное исследование всех
объектов обширной совокупности затруднительно), использованию теории вероятностей
при оценке достаточности числа наблюдений для тех или иных выводов и т. п. Эта
формальная математическая сторона статистических методов исследования,
безразличная к специфической природе изучаемых объектов, и составляет предмет
М. с.
1. Теория
Cлучайная величина
(переменная) - величина, которая в результате испытания примет одно и только
одно возможное значение, наперед неизвестное и зависящее от случайных причин,
которые заранее не могут быть учтены.
Дискретная (прерывная) случайная величина -
величина, которая принимает отдельные, изолированные возможные значения с
определенными вероятностями. Число возможных значений дискретной случайной
величины может быть конечным или бесконечным.
Непрерывная случайная величина - величина,
которая может принимать все значения из некоторого конечного или бесконечного
промежутка. Очевидно, число возможных значений непрерывной случайной величины
бесконечно.
Выборочная совокупность (выборка) - совокупность
случайно отобранных объектов.
Генеральная совокупность - совокупность
объектов, из которых производится выборка.
Объем совокупности (выборочной или генеральной)
- число объектов этой совокупности.
Пусть из генеральной совокупности извлечена
выборка, причем х1 наблюдалась ровно n1
раз, х2 - n2
раз, xk
- nk раз,… и ∑ ni
=
n - объем выборки.
Наблюдаемые значения хi
называют вариантами, а последовательность вариант, записанных в возрастающем
порядке, - вариационным рядом. Числа наблюдений называют частотами, а их
отношения к объему выборки ni/n
= Wi - относительными
частотами.
Статистическое распределение выборки - перечень
вариант и соответствующих им частот или относительных частот.
Полигон частот - ломаная, отрезки которой
соединяют точки (x1;
n1),
(x2;
n2),
…, (xk;
nk). Для построения
полигона частот на оси абсцисс откладывают варианты хi,
а на оси ординат - соответствующие им частоты ni.
Точки с координатами (xi;
ni) соединяют
отрезками прямых и получают полигон частот.
Полигон относительных частот - ломаная, отрезки
которой соединяют точки плоскости {XOW} с координатами: (х1; W1),
(x2;
W2),
… .
Гистограмма частот - ступенчатая фигура,
состоящая из прямоугольников, основаниями которых служат частичные интервалы
длиною h, а высоты равны
отношению ni/h
(плотность частоты).
Для построения гистограммы частот на оси абсцисс
откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси
абсцисс на расстоянии ni/h.
Площадь i-го
частичного прямоугольника равна h·ni/h
= ni - сумме частот
вариант i-го интервала;
следовательно, площадь гистограммы частот равна сумме всех частот, т. е. объему
выборки.
Гистограмма относительных частот - ступенчатая
фигура, состоящая из прямоугольников, основаниями которых служат частичные
интервалы длиною h, а высоты
равны отношению Wi/h
(плотность относительной частоты).
Для построения гистограммы относительных частот
на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки,
параллельные оси абсцисс на расстоянии Wi/h.
Площадь гистограммы относительных частот равна единице.
Простейшие описательные статистики.
Для описания случайных величин используются
описательные статистики: минимум, максимум, среднее, дисперсия, стандартное
отклонение, медиана, мода и т. д. Статистики дают общее представление о
значениях, которые принимают случайные величины.
Минимум и максимум (min,
max) - это минимальное
и максимальное значения переменной.
Среднее (xs)
- сумма значений переменной, делённая на n
(число значений переменной)
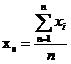
Дисперсия (s2,
variance, термин ввёл Фишер
в 1918 году) - меняется от 0 до µ. Это
наиболее часто используемая мера изменчивости случайной величины. Вычисляется
по формуле:
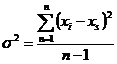
Значение 0 означает отсутствие изменчивости,
т.е. переменная постоянна.
Стандартное отклонение (s,
standart deviation) - корень квадратный из дисперсии. Более удобная
характеристика, так как измерена в тех же единицах, что и исходная величина.
Чем выше дисперсия и стандартное отклонение, тем
сильнее разбросаны значения случайной величины относительно среднего.
Медиана (термин ввёл Гальтон, 1882) - значение,
которое разбивает выборку на две равные части. Половина наблюдений лежит выше
медианы, и половина - ниже. В некоторых
случаях, например, при описании доходов населения
медиана более удобна, чем среднее (xs).
Медиана дает общее представление о том, где
сосредоточены значения переменной, иными словами, где находится ее центр. Сумма
абсолютных расстояний между точками выборки и медианой минимальна. Медиана
вычисляется следующим образом. Выборка упорядочивается в порядке возрастания.
Как уже указывалось, получаемая последовательность 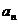 ,
где n = 1, 2,…., 2m+1
называется вариационным рядом или порядковыми статистиками. Если число
наблюдений нечетно, то медиана выборки оценивается как Me
=
,
где n = 1, 2,…., 2m+1
называется вариационным рядом или порядковыми статистиками. Если число
наблюдений нечетно, то медиана выборки оценивается как Me
=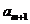 .
Если число наблюдений четно, то медиана оценивается как Me
=
.
Если число наблюдений четно, то медиана оценивается как Me
=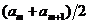 .
.
Квантиль-p
(Кендалл, 1940) - число xp,
ниже которого находится p-я
часть (доля) выборки. Например, квантиль 0.20 - это такое значение xp,
ниже которого находится 20% значений переменной.
Процентиль-p
- значение квантили в процентах. Например, 25-я процентиль переменной - это
значение, ниже которого располагается 25% значений переменной.
Нижняя и верхняя квартиль (лат. quarta
- четверть, Гальтон, 1882) равны, соответственно, 25-й и 75-й процентилям.
точки - нижняя квартиль, медиана и верхняя
квартиль - делят выборку на 4 равные части.
Квартильный размах (Гальтон, 1882) - разность
значений 75-й и 25-й процентили. То есть это интервал, содержащий медиану, в
который попадает 50% наблюдений.
Мода (Пирсон, 1894) - наиболее часто
встречающееся (самое модное) значение переменной. Например, модный цвет платья
или песня на радио, т.е. это варианта, имеющая наибольшую частоту.
Если распределение имеет несколько мод, то оно
называется мультимодальным. Например, в социологических опросах это означает,
что существует несколько определённо различных мнений. Также это может служить
индикатором того, что выборка не является однородной и наблюдения, возможно,
порождены двумя или более наложенными распределениями.
Асимметрия,
или коэффициент асимметрии (Пирсон, 1895) - это мера несимметричности
распределения. Если коэффициент значительно отличается от 0, распределение
является асимметричным.
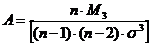
где 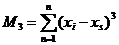 ;
s3 - стандартное
отклонение (сигма) в третьей степени; xs
-
среднее значение; n - число
наблюдений.
;
s3 - стандартное
отклонение (сигма) в третьей степени; xs
-
среднее значение; n - число
наблюдений.
Эксцесс, или коэффициент эксцесса (Пирсон, 1905)
- острота пика распределения.
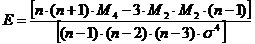 ,
,
где 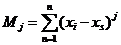 ;
s4 - стандартное
отклонение, возведённое в 4-ю степень.
;
s4 - стандартное
отклонение, возведённое в 4-ю степень.
Функция распределения - функция F(x),
определяющая вероятность того, что случайная величина Х в результате испытания
примет значение, меньшее х, т.е.
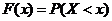 .
.
Геометрически это равенство можно истолковать
так: F (x) есть вероятность того, что случайная величина примет значение,
которое изображается на числовой оси точкой, лежащей левее точки х.
Плотностью распределения вероятностей
непрерывной случайной величины Х называют функцию f(x) - первую производную от
функции распределения F(x):
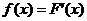 .
.
Зная плотность распределения, можно вычислить
вероятность того, что непрерывная случайная величина Х примет значение,
принадлежащее заданному интервалу. Вычисление основано на следующей теореме.
Теорема. Вероятность того, что непрерывная
случайная величина Х примет значение, принадлежащее интервалу (a, b), равна
определенному интегралу от плотности распределения, взятому в пределах от a до
b:
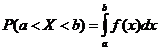
При решении задач, которые выдвигает практика,
приходится сталкиваться с различными распределениями непрерывных случайных
величин. Плотности распределения непрерывных случайных величин называют также
законами распределений. Часто встречаются, например, законы равномерного,
нормального и показательного распределений.
Эмпирическая функция распределения (функция
распределения выборки) - функция F*(x),
определяющая для каждого значения х относительную частоту события Х < x.
В отличии от эмпирической функции распределения
выборки функцию распределения F(x)
генеральной совокупности называют теоретической функцией распределения.
Различие между эмпирической и теоретической
функцией состоит в том, что теоретическая функция F(х) определяет вероятность
события Х < х, а эмпирическая функция F*(х) определяет
относительную частоту этого же события. Из теоремы Бернулли следует, что
относительная частота события Х < х, т. е. F*(х), стремится по
вероятности к вероятности F (х) этого события. Другими словами, при больших n
числа F*(х) и F(х) близки между собой. Отсюда следует
целесообразность использования эмпирической функции распределения выборки для
приближенного представления теоретической (интегральной) функции распределения
генеральной совокупности.
Функция F*(х) обладает всеми
свойствами F(х) :
- значения эмпирической функции принадлежат
отрезку [0;1];
- F*(х) - неубывающая функция;
если х1 - наименьшая
варианта, то F*(х) = 0 при 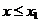 ;
если хk - наибольшая варианта, то F*(х) = 1 при
;
если хk - наибольшая варианта, то F*(х) = 1 при  .
.
Эмпирическая функция распределения выборки
служит для оценки теоретической функции распределения генеральной совокупности.
Вероятностные распределения и их свойства.
Нормальное распределение - это распределение
вероятностей непрерывной величины, которая описывается плотностью
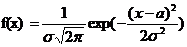
где a и s параметры закона,
интерпретируемые соответственно как среднее значение и дисперсия случайной
величины. Нормальный закон с параметрами a=0 и σ2=1
называют стандартным. Для нормального распределения среднее (xs),
мода (Mo) и медиана (Me)
равны: xs=Mo=
Me = a;
ассиметрия (A)
и
эксцесс (E) : A
= E = 0.
Нормальное распределение вероятностей наиболее
часто используется на практике. Это распределение дает хорошую модель для
реальных явлений, в которых :
- имеется сильная тенденция данных
группироваться вокруг центра;
- положительные и отрицательные
отклонения от центра равновероятны;
частота отклонений быстро падает, когда
отклонения от центра становятся большими.
Множество величин имеют нормальное
распределение, например, распределение приращений индексов развитых стран,
курсы акций, физические величины, ошибки измерений и т. д.
Полезно знать правила 2- и 3-сигм, или 2- и
3-стандартных отклонений, которые связаны с нормальным распределением и
используются в разнообразных приложениях. Если от точки среднего или, что то же
самое, от точки максимума плотности нормального распределения отложить вправо и
влево соответственно два и три стандартных отклонения (2- и 3-сигм), то площадь
под графиком нормальной плотности, подсчитанная по этому промежутку, будет
соответственно равна 95,45% и 99,73% всей площади под графиком. Другими
словами, это можно выразить следующим образом: 95,45% и 99,73% всех независимых
наблюдений из нормальной совокупности, например размеров детали или цены акций,
лежит в зоне 2- и 3-стандартных отклонений от среднего.
Равномерное распределение используется при
описании переменных, у которых каждое значение равновероятно. Это распределение
описывается плотностью:

Равномерному распределению подчинены ошибки
округления при измерениях, время ожидания пассажиром прибытия метро при точных
интервалах движения поездов и т. д. Для
равномерного распределения среднее и медиана равны xs=Me=(a+b)/2;
дисперсия 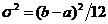 ; ассиметрия A
= 0, эксцесс E = -1,2.
Показательным
(экспоненциальным) называют распределение вероятностей непрерывной случайной
величины X, которое
описывается плотностью:
; ассиметрия A
= 0, эксцесс E = -1,2.
Показательным
(экспоненциальным) называют распределение вероятностей непрерывной случайной
величины X, которое
описывается плотностью:
 ,
,
где λ - постоянная
положительная величина.
Показательное распределение описывает события,
которые можно назвать редкими. Для этого распределения среднее xs
=
1/λ,
мода
Mo=0, медиана Me
= (1/λ)ln2;
дисперсия σ2=1/λ2,
асимметрия A=2, эксцесс E=6.
Показательное распределение является частным случаем распределения Вейбула:
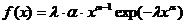
Данное распределение используется при описании
времен отказов в теории надежности, коэффициентов смертности в области
демографии, интервалов между заходами на непопулярные сайты и т. д.
Логнормальное распределение описывается
плотностью:
 ,
,
Это распределение используется, например, при
моделировании таких переменных как доходы, возраст новобрачных, допустимое
отклонение в продуктах питания вредных веществ от стандарта, выбросы
предприятиями вредных веществ и т.д. Основные характеристики логнормального
распределения: среднее xs=
a·exp(σ2/2)
= M(X),
мода Mo = a·exp(-σ2),
медиана Me = a;
дисперсия D(X)
= a2·exp(σ2)·(exp(σ2)-1).
В различных прикладных задачах статистики
используются и другие вероятностные распределения: гамма-распределение,
распределение Эрланга, Хи-квадрат-распределение, биноминальное распределение,
полиномиальное распределение, распределения Стьюдента, Релея и т.д.
Почему важно нормальное распределение.
Нормальное распределение (термин был введен
Гальтоном в 1889 г.) иногда называемое гауссовским, важно по многим причинам.
Распределение большого числа переменных, статистик, разностей является
нормальным или может быть получено из нормального распределения с помощью
некоторых преобразований. Рассуждая философски, можно сказать, что нормальное
распределение представляет собой одну из эмпирических проверенных истин
относительно общей природы действительности и его положение может
рассматриваться как один из фундаментальных законов природы.
На практике не все статистики, но многие из них,
либо имеют нормальное распределение, либо имеют распределение, связанное с
нормальным распределением и вычисляемое на основе нормального распределения,
такое как t, F или Хи - квадрат.
Если же объем выборки достаточно большой, то
переменные чаще всего "нормально распределены". Известно, что при
возрастании объема выборки форма распределения статистики критерия оценки
приближается к нормальной форме, даже если распределение исследуемых переменных
не является нормальным. Этот принцип называется центральной предельной
теоремой.
Поэтому часто изучение характера функций
распределения случайных величин начинают с проверки выборки (переменной) на
нормальность и, если оценка на нормальность дает отрицательный результат, то
тогда осуществляют сравнение данных с другими распределениями.
Кроме определения описательных статистик и
подгонки вероятностных распределений реальным данным при первичной обработке
существует еще несколько важных этапов работы с данными: визуализация, оценка
однородности распределения и проведение анализа резко выделяющихся наблюдений.
Визуализация
Визуализация - это важный этап работы с данными.
Многие закономерности, не видимые в таблицах в численном виде, отчетливо
проявляются на графиках.
В программе STATISTICA
6.0 кроме
гистограмм и простых диаграмм рассеивания используются также другие различные
графики. Среди них наиболее распространенные:
· различные виды диаграмм рассеивания;
· нормальные вероятностные графики;
· диаграммы размаха;
· линейные графики;
· диаграммы пропущенных значений и
интервалов.
Ограничимся рассмотрением только двумерных
графиков.
Двумерные диаграммы рассеивания - используются
для визуального исследования зависимости между двумя переменными X
и Y (например, двумя
курсами акций, курсом доллара и курсом гривны, рекламой и объемом продаж и
т.д.) Данные изображаются точками в двумерном пространстве. Эти графики позволяют:
· оценить графически взаимосвязь переменных. Если
переменные сильно связаны, то множество точек данных принимает определенную
форму, например, точки ложатся около прямой или криволинейной линии. Если
переменные не связаны, то точки образуют, так называемое, "облако
рассеяния" на значительной площади графика;
· оценить графически однородность
данных. Если данные на диаграмме рассеивания группируются около различных
средних (компактно укладываются группами на различных участках графика), то
данные не однородны;
· определить форму зависимостей,
вокруг которых группируются данные, чтобы потом можно было выбрать подходящий
тип преобразований данных для их "линеаризации" или выбора
подходящего нелинейного уравнения подгонки;
· оценить наличие выбросов (резко
выделяющихся наблюдений).
При оценке данных используются простые диаграммы
рассеивания, составные диаграммы, комбинированные диаграммы рассеивания с
гистограммами и т.д.
Нормальные вероятностные графики - позволяют
визуально исследовать насколько распределение данных близко к нормальному. Если
наблюдаемые значения распределены нормально, то все значения на таком графике
должны располагаться близко к прямой линии. Если значения не являются нормально
распределенными, то будет наблюдаться отклонение от прямой линии.
Диаграммы размаха - характеризуют диапазоны
значений выбранной переменной и строятся отдельно для групп наблюдений.
Центр (медиана или среднее) и статистики
диапазонов или вариации (например, квартили, стандартные ошибки или стандартные
отклонения) вычисляются для каждой группы наблюдений.
Диаграммы размаха позволяют оценить однородность
данных и наличие аномальных наблюдений с точки зрения отклонения от среднего
или моды.
Линейные графики - представляют собой двухмерные
линейные графики одной или многих переменных, на которых отдельные точки
соединены линиями. Линейные графики дают простой способ наглядного
представления последовательности большого числа значений (например, рыночных
цен на акции в зависимости от времени).
Если в последовательности данных очень много
наблюдений и они существенно различаются, то необходимо сглаживание такого
временного ряда для обнаружения общей структуры последовательности данных.
Линейные графики служат для визуализации данных и полезны при изучении
временных рядов, сравнении нескольких временных рядов между собой и т.д.
Диаграммы пропущенных значений и интервалов -
дают возможность исследовать шаблон распределения или распределения пропущенных
данных. Эти диаграммы применяются для определения количества пропущенных
значений данных, а также для выяснения является ли распределение данных более
или менее случайным или в их расположении можно обнаружить некоторую
закономерность. Часто эти диаграммы называют "картами" файла данных.
Все указанные графики, а также множество других
их видов можно построить, воспользовавшись пунктом меню Графики (Graphs)
программы STATISTICA
V.6.0.
Оценка однородности данных.
(Предварительно необходимо ознакомиться с [5] §8
- §12 стр. 288-307)
Гипотеза однородности состоит в том, что генеральные
совокупности, из которых извлечены выборки, одинаковы. Другими словами, если
выборки однородны, то они имеют одинаковые, причем неизвестные, непрерывные
функции распределения. Для нормальных совокупностей задача однородности часто
связана с оценкой средней в группах. Такие задачи часто возникают на практике.
Например, сравнение средних доходов в разных группах людей, сравнение средних
показателей для разных групп объектов и т.д. Возможны два варианта организации
данных: можно иметь дело с независимыми и зависимыми группами наблюдений. Если
выборка случайно разбита на группы, то, скорее всего, они независимы. Если есть
две группы, которые основываются на одной и той же выборке объектов наблюдений
(например, пациенты до и после лечения, посещения на сайт до и после рекламы),
то тогда выборки зависимые.
Обычно, проводя группировку данных, преследуют
цель выделить группы однородных объектов (реальные исходные данные, как
правило, неоднородны). Следует отметить, что на вопрос: как в общем случае
провести группировку данных? - нет однозначного ответа. В каждом конкретном
случае при изучении данных сравниваются различные способы группировки, и
интуитивно находится нужный вариант. Поэтому оценка на однородность необходимый
этап любого статистического исследования.
При оценке двух групп на однородность проводят
оценку равенства средних и дисперсий выборок.
Для оценки равенства средних обычно используется
t-критерий (критерий
Стьюдента). Для двух групп статистика t-критерия
равна
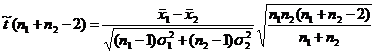
где  ,
, -
количество наблюдений в первой и второй выборках;
-
количество наблюдений в первой и второй выборках;  -
средние;
-
средние; 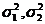 -
выборочные дисперсии.
-
выборочные дисперсии.
Известно, что статистика 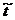 при
справедливости гипотезы: "средние в двух выборках равны" имеет
распределение Стьюдента
при
справедливости гипотезы: "средние в двух выборках равны" имеет
распределение Стьюдента  с
с 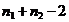 степенями
свободы. Поэтому большие по абсолютной величине значения свидетельствуют
против гипотезы о равенстве средних значений, т.е. если
степенями
свободы. Поэтому большие по абсолютной величине значения свидетельствуют
против гипотезы о равенстве средних значений, т.е. если
 ,(1)
,(1)
то гипотеза отвергается.
Статистический критерий равенства или
однородности дисперсий двух нормальных выборок основан на статистике
 ,
,
Известно, что статистика 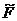 при
справедливости гипотезы: "дисперсии в двух выборках равны" имеет
распределение Фишера-Снедекора. При уровне значимости α
гипотеза верна, если
при
справедливости гипотезы: "дисперсии в двух выборках равны" имеет
распределение Фишера-Снедекора. При уровне значимости α
гипотеза верна, если
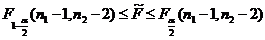 ,(2)
,(2)
иначе она отвергается.
Процедура оценки однородности двух выборок
реализована в модуле Основная статистика/Таблицы (Basic
Statistics/Tables).
Анализ резко выделяющихся наблюдений.
Удобнее всего анализ резко выделяющихся
наблюдений (выбросов) основывать на изучении информации представленной в
графическом виде. С этой целью следует использовать уже упоминавшиеся диаграммы
рассеяния и размаха.
Считают, что переменные зависимы, если их
значения каким-то образом согласованы друг с другом в имеющихся наблюдениях.
Например, рост человека однозначно связан с его весом, объем винчестера - с его
ценой, количество автомобилей в городе с количеством аварий и т.д. Реальные
процессы или объекты могут характеризоваться набором переменных, которые бывают
зависимые и независимые.
Независимые переменные (входные,
показатели-аргументы, предикторные) - переменные описывающие условия
формирования реального изучаемого процесса или функционирования объекта. Это
переменные, которые поддаются заданию, измерению или частичному управлению или
регулированию.
Зависимые переменные (выходные, отклики,
результирующие или объясняющие) - переменные, которые характеризуют процесс или
результат (эффективность) функционирования объекта. Обычно это переменные
позволяющие прогнозировать процесс или описывать объект.
Случайные переменные (латентные, остаточные) -
скрытые, которые не поддаются непосредственному измерению случайные остаточные
компоненты, отражающие влияние на зависимые переменные неучтенных факторов, а
также случайные ошибки в измерении или определении показателей. Часто эти
переменные именуют "остатками".
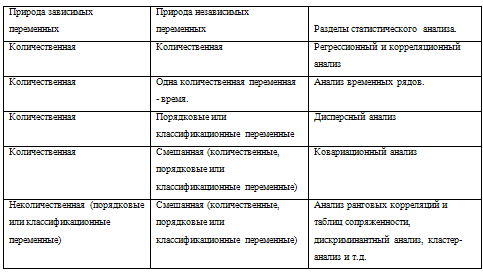
Зависимые и независимые переменные могут быть:
ü количественные, т.е. скалярно
измеряющие в определенной шкале некие свойства (денежный доход, численность
рабочих, физические величины и т.д.);
ü порядковые (ординарные), т.е.
позволяющие упорядочить некоторые свойства процесса или объекта по степени их
проявления (разряд рабочего, уровень образования и т.д.);
ü классификационные (номинальные),
т.е. разбивающие обследованную совокупность на однородные классы, которые не
поддаются упорядочиванию (по определенным свойствам). Например: профессия
рабочего, мотив эмиграции, отрасли промышленности и т.д.
В зависимости от видов переменных для
исследования взаимосвязей применяются различные разделы статистики (см.
таблицу). Основные разделы этой таблицы реализованы в виде модулей в программном
продукте STATISTICA.
Ключевым понятием, описывающим связи между
переменными, является корреляция (от английского слова correlation
- согласование, связь, взаимозависимость). Две переменные могут быть связаны либо
функциональной зависимостью, либо статистической, либо быть независимыми между
собой.
Статистическая зависимость - зависимость, при
которой изменение одной из величин влечет изменение распределения другой. Если
при изменении одной из величин изменяется среднее значение другой величины,
то такая статистическая зависимость называется корреляционной.
Коэффициент корреляции (парный коэффициент
корреляции, коэффициент корреляции Пирсона) - характеризует степень тесноты
связи между нормально распределенными случайными переменными X
и Y. Выборочное
значение r коэффициента корреляции подсчитывается по формуле:
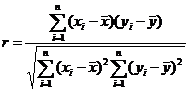 (1)
(1)
Значение r является измерителем степени тесноты
линейной статистической связи между переменными и изменяется в пределах 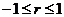 .
При
.
При 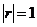 соотношение
(1) подтверждает чисто функциональную линейную зависимость между переменными X
и Y, при r=0
свидетельствует о полной независимости переменных. Положительные значения
коэффициента корреляции указывают на одинаковый характер тенденции
взаимосвязанного изменения величин X
и Y (например,
увеличивается X и увеличивается Y),
отрицательные значения указывают на противоположную тенденцию. В случае если
распределения величин X
и Y отличаются от
нормального или одна из величин не является случайной, коэффициент корреляции
можно использовать лишь в качестве одной из возможных характеристик степени
тесноты связи.
соотношение
(1) подтверждает чисто функциональную линейную зависимость между переменными X
и Y, при r=0
свидетельствует о полной независимости переменных. Положительные значения
коэффициента корреляции указывают на одинаковый характер тенденции
взаимосвязанного изменения величин X
и Y (например,
увеличивается X и увеличивается Y),
отрицательные значения указывают на противоположную тенденцию. В случае если
распределения величин X
и Y отличаются от
нормального или одна из величин не является случайной, коэффициент корреляции
можно использовать лишь в качестве одной из возможных характеристик степени
тесноты связи.
Оценка значимости коэффициента корреляции
основывается на проверке гипотезы об отсутствии корреляционной связи между
переменными (см. [5] §22 стр.
327). Известно, что
величина 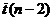 при
условии малых значений r распределена по закону Стьюдента с n-2
степенями свободы. Поэтому если окажется, что
при
условии малых значений r распределена по закону Стьюдента с n-2
степенями свободы. Поэтому если окажется, что
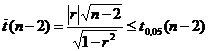 , (2)
, (2)
то гипотеза об отсутствии корреляционной связи
принимается. Если 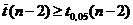 , то коэффициент
корреляции значимо отличается от нуля, а величены X
и Y коррелированы.
Здесь
, то коэффициент
корреляции значимо отличается от нуля, а величены X
и Y коррелированы.
Здесь 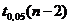 -
5%-ная точка распределения Стьюдента с n-2
степенями свободы. Следует иметь в виду, что значимость коэффициента корреляции
сильно зависит как от его величины, так и объема выборки по которой он
вычислен.
-
5%-ная точка распределения Стьюдента с n-2
степенями свободы. Следует иметь в виду, что значимость коэффициента корреляции
сильно зависит как от его величины, так и объема выборки по которой он
вычислен.
Корреляционное отношение - измеритель степени
тесноты корреляционной связи любой формы (в том числе и нелинейной). Для
определения корреляционного отношения область значений независимой переменной X
разбивают на интервалы группирования, определяют средние ординаты 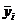 для
каждого интервала группирования и рассчитывают корреляционное отношение
для
каждого интервала группирования и рассчитывают корреляционное отношение 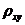
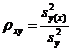 , (3)
, (3)
где 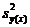 -
дисперсия средних около общего
среднего
-
дисперсия средних около общего
среднего 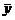 ,
,
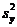 -
общая выборочная дисперсия величины y
(см. [5]
§11-13 стр. 270-274). Значения
корреляционного отношения лежат в пределах
-
общая выборочная дисперсия величины y
(см. [5]
§11-13 стр. 270-274). Значения
корреляционного отношения лежат в пределах 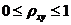 ,
причем
,
причем 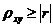 .
.
Частный коэффициент корреляции позволяет оценить
степень тесноты линейной связи между двумя переменными, очищенной от
опосредованного влияния других факторов (переменных) Его значение определяется
по формуле:
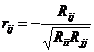 ,
,
где 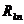 -
алгебраическое дополнение для парного коэффициента корреляции
-
алгебраическое дополнение для парного коэффициента корреляции  в
определителе корреляционной матрицы MR
анализируемых показателей. Программа STATISTICA
имеет специальную процедуру для вычисления корреляционной матрицы в случае
многомерных таблиц исходных данных.
в
определителе корреляционной матрицы MR
анализируемых показателей. Программа STATISTICA
имеет специальную процедуру для вычисления корреляционной матрицы в случае
многомерных таблиц исходных данных.
Если исследуется связь между несколькими
переменными (более двух), то корреляцию в этом случае называют множественной.
Степень тесноты множественной связи оценивается множественным коэффициентом
корреляции R. Квадрат величины R
называют коэффициентом детерминации. Множественный коэффициент корреляции
изменяется в пределах  . Он оценивает,
какая доля дисперсии исследуемой зависимой переменной определяется через
функцию регрессии совокупным влиянием независимых переменных. В статистике в
специальных вычислительных процедурах множественный коэффициент корреляции
определяют или по матрице парных коэффициентов корреляции или по вектору
частных коэффициентов корреляции. Коэффициенты множественной и частной
корреляции определяются в модуле Множественная регрессия программы STATISTICA.
. Он оценивает,
какая доля дисперсии исследуемой зависимой переменной определяется через
функцию регрессии совокупным влиянием независимых переменных. В статистике в
специальных вычислительных процедурах множественный коэффициент корреляции
определяют или по матрице парных коэффициентов корреляции или по вектору
частных коэффициентов корреляции. Коэффициенты множественной и частной
корреляции определяются в модуле Множественная регрессия программы STATISTICA.
Ложные корреляции. На практике существуют также
ложные корреляции. Это означает, что если найдены переменные с высоким
значением коэффициентов корреляции, то отсюда еще не следует, что между ними
действительно существует причинная связь или закономерность. Необходимо быть
уверенным, что на исследуемые переменные не влияют другие переменные. Курьезный
пример из статистики - найденная статистиками высокая корреляция между числом
родившихся младенцев и количеством прилетевших аистов в северных областях
Европы. Причина связи лежит в третьей неизвестной влияющей переменной. Второй
пример ложных корреляций - ущерб, понесенный от пожара, и количество пожарных,
тушивших пожар. Здесь есть третья влияющая переменная - величина пожара.
Использование частных корреляций позволяет исключать влияние подобных переменных.
Наряду с группировкой и визуализацией данных
вычисление корреляций - это стандартный начальный этап всякого исследования,
связанного с анализом данных.
Условное среднее  -
среднее арифметическое наблюдавшихся значений величины Y,
соответствующих X=x.
Функция изменения условного среднего
-
среднее арифметическое наблюдавшихся значений величины Y,
соответствующих X=x.
Функция изменения условного среднего 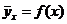 от
независимой переменной X
называется уравнением регрессии. Уравнения регрессии строятся для зависимых
переменных. Эти переменные входят в левую часть уравнения. Независимые
переменные входят в правую часть уравнения и позволяют предсказывать зависимую
переменную.
от
независимой переменной X
называется уравнением регрессии. Уравнения регрессии строятся для зависимых
переменных. Эти переменные входят в левую часть уравнения. Независимые
переменные входят в правую часть уравнения и позволяют предсказывать зависимую
переменную.
Предсказанные значения зависимой переменной -
значения 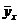 ,
вычисленные по уравнению регрессии с оцененными коэффициентами регрессии.
,
вычисленные по уравнению регрессии с оцененными коэффициентами регрессии.
Остатки - разности между наблюдаемыми и
предсказанными значениями зависимой переменной:
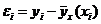
Сумма квадратов остатков - сумма вида:

Сумма квадратов зависимой переменной,
скорректированная на среднее
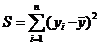
Сумма квадратов предсказанной зависимой
переменной, скорректированная на среднее
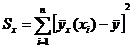
Известно, что для суммы квадратов указанных
величин, выполняется равенство:
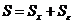 .
.
Коэффициент детерминации и скорректированный
коэффициент детерминации
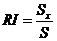 ,
,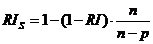 ,
,
где: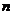 - число наблюдений,
- число наблюдений,  - число параметров
модели (число независимых переменных плюс 1, так как обычно в модель включается
свободный член).
- число параметров
модели (число независимых переменных плюс 1, так как обычно в модель включается
свободный член).
Наибольшее применение получили уравнения регрессии,
отражающие взаимосвязь одной зависимой переменной с одной (парная регрессия)
или несколькими (множественная регрессия) независимыми переменными.
Чаще всего используют следующие парные и
множественные зависимости:
) Парная и множественная линейная регрессия:
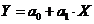 ,
,  (1)
(1)
2) Парная и множественная параболическая
регрессия:
 ,
, 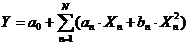 (2)
(2)
) Парная и множественная гиперболическая
регрессия:
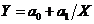 ,
, 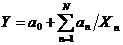 (3)
(3)
4) Парная и множественная степенная регрессия:
 ,
, 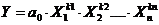 (4)
(4)
5) Парная и множественная показательная
регрессия:
 ,
, 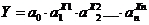 ,
,
 (5)
(5)
Обычно стараются использовать линейные
зависимости или зависимости, которые
приводят к линейным путям преобразования переменных. Параметры уравнения
регрессии подбираются методом наименьших квадратов. Он обеспечивает минимальную
сумму квадратов отклонений фактических величин Y
от вычисленных по уравнению регрессии для заданных значений независимых
переменных.
Для линейной регрессии парного типа коэффициенты
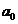 и
и
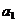 находятся
из решения системы уравнений:
находятся
из решения системы уравнений:
 ,(6)
,(6)
где: 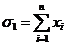 ,
,
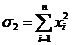 ,
,
 ,
,
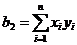 .
.
Данная система
получается путем минимизации функционала
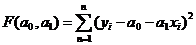 .
.
Из решения системы (6) получаем:
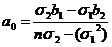 (7)
(7)
 (8)
(8)
Таким образом, функция
множественной регрессии имеет вид:
 ,(9)
,(9)
где: - функция остатков с нулевым средним и неизвестной дисперсией, определяющая
случайное отклонение зависимой переменной от уравнения регрессии.
Предполагается, что величины не коррелированы в
разных опытах. Часто считают, что остатки нормально распределены.
- функция остатков с нулевым средним и неизвестной дисперсией, определяющая
случайное отклонение зависимой переменной от уравнения регрессии.
Предполагается, что величины не коррелированы в
разных опытах. Часто считают, что остатки нормально распределены.
Регрессионный анализ данных предполагает, что
выбирается наиболее оптимальный вид функции регрессии 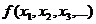 из
набора (1)-(5), оцениваются коэффициенты функции регрессии
из
набора (1)-(5), оцениваются коэффициенты функции регрессии 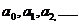 и
строятся для них доверительные интервалы, проверяется гипотеза о значимости
регрессии, оценивается степень адекватности модели и т.д.
и
строятся для них доверительные интервалы, проверяется гипотеза о значимости
регрессии, оценивается степень адекватности модели и т.д.
Обычно подбор уравнения регрессии осуществляют
по шагам. На первом этапе выбирают зависимую переменную и одну наиболее весомую
независимую переменную, полученную по результатам корреляционного анализа.
Далее строят парную зависимость, определяют коэффициент корреляции и его
значимость. На втором шаге добавляют следующую весомую переменную и строят
регрессионное уравнение зависимой переменной Y
от двух выбранных независимых переменных. Определяют коэффициент множественной
корреляции и оценивают регрессию. Далее при необходимости добавляют следующую
переменную и т.д. Возможен обратный путь, связанный с поэтапным исключением
малозначащих переменных. На каждом шаге проводят графический анализ данных,
исключают некоторые аномальные наблюдения и оценивают значимость регрессии.
Оценка степени адекватности модели осуществляется путем применения различных
процедур анализа распределения остатков.
Увеличение размерности уравнений регрессии
увеличивает значение коэффициента детерминации. Однако увеличивать размерность
(более 2-3-х переменных в модели) путем добавления новых независимых переменных
имеет смысл, когда наблюдается явное улучшение показателей регрессии:
увеличение коэффициента детерминации RI
и уменьшение суммы квадратов остатков  .
Следует придерживаться общего правила, что не следует гнаться за чрезмерной
сложностью модели.
.
Следует придерживаться общего правила, что не следует гнаться за чрезмерной
сложностью модели.
Для оценки значимости уравнения регрессии в
целом применяют F-критерий:
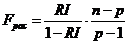
-критерий используется для проверки гипотезы о
значимости регрессии. Она утверждает, что между зависимой переменной и
независимыми переменными нет линейной связи, то есть что коэффициенты регрессии
равны нулю, против альтернативы, что они не равны нулю. Для проверки гипотезы
расчетное значение F-критерия
сравнивается с табличным значением F-критерия
при уровне значимости 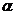 и
и 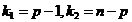 степенях
свободы. Если
степенях
свободы. Если 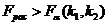 , то уравнение
регрессии можно признать статистически значимым, т.е. гипотеза о значимости
регрессии подтверждается. Табличные значения F-критерия (критерия Фишера)
приводятся в приложении 1.
, то уравнение
регрессии можно признать статистически значимым, т.е. гипотеза о значимости
регрессии подтверждается. Табличные значения F-критерия (критерия Фишера)
приводятся в приложении 1.
Оценка значимости независимых переменных
осуществляется на основе t-критерия
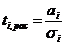 ,
,
где: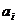 -
численное значение i-того
коэффициента уравнения множественной регрессии;
-
численное значение i-того
коэффициента уравнения множественной регрессии;
 -
среднеквадратичное отклонение параметра как
случайной величины относительно среднего уровня.
-
среднеквадратичное отклонение параметра как
случайной величины относительно среднего уровня.
Расчетное значение t-критерия
сравнивают по абсолютной величине с табличным значением t-критерия
при заданном уровне значимости и 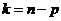 степенях
свободы. Если
степенях
свободы. Если 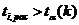 , то параметр считается
значимым и соответствующая независимая переменная отбирается в уравнение
множественной регрессии. Табличные значения t-критерия
(критерия Стъюдента) приводятся в приложении 2.
, то параметр считается
значимым и соответствующая независимая переменная отбирается в уравнение
множественной регрессии. Табличные значения t-критерия
(критерия Стъюдента) приводятся в приложении 2.
В случае если данные подчинены нелинейной связи,
то используют преобразованные переменные:  и
и
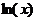 для
уравнений вида (4),
для
уравнений вида (4), 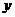 и
и 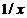 для
уравнений вида (3), и
для
уравнений вида (3), и  для
уравнений вида (5), и
для
уравнений вида (5), и 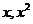 для
уравнений вида (2) и т.д. При таком преобразовании переменных задача сводится к
определению линейного уравнения регрессии вида (1). Исходные нелинейные связи
можно установить на основе визуализации данных при анализе парных связей.
для
уравнений вида (2) и т.д. При таком преобразовании переменных задача сводится к
определению линейного уравнения регрессии вида (1). Исходные нелинейные связи
можно установить на основе визуализации данных при анализе парных связей.
2. Постановка
задачи
Данные взяты из таблицы значений переменных для
варианта №6.
Переменные по варианту: 1,2,7,4,9,12,23,8,15,13.
|
10,3
|
0,5
|
18,3
|
9
|
11,5
|
24,5
|
25
|
7
|
6,4
|
0,4
|
|
16
|
0,5
|
17,5
|
9
|
11,7
|
20,4
|
25,5
|
7,8
|
7,8
|
0,3
|
|
10,3
|
0,5
|
6,3
|
7
|
7,3
|
20,3
|
25,5
|
7,9
|
6,3
|
0,3
|
|
10,3
|
0,5
|
1,8
|
7
|
6,2
|
15,7
|
26
|
7,7
|
5,9
|
0,3
|
|
16,3
|
0,5
|
20,9
|
9
|
12
|
19,5
|
25,5
|
7,8
|
7,9
|
0,3
|
|
12,5
|
0,5
|
10,3
|
7
|
11,1
|
11,7
|
24,5
|
7,4
|
6,2
|
0,4
|
|
10
|
0,5
|
0,8
|
7
|
4,7
|
16,6
|
26
|
7,7
|
6
|
0,3
|
|
9,5
|
0,5
|
8,9
|
8
|
9,7
|
18,5
|
27,5
|
7,7
|
6,2
|
0,3
|
|
14,6
|
0,5
|
16,4
|
4
|
12,3
|
83,9
|
26
|
7,8
|
16,5
|
0,5
|
|
14,2
|
0,5
|
10
|
4
|
7,8
|
75,9
|
26
|
8,4
|
15,8
|
0,5
|
|
14,4
|
0,5
|
29
|
4
|
9,1
|
81,4
|
26
|
8
|
14,4
|
0,5
|
|
15
|
0,5
|
29,3
|
4
|
5,8
|
94,4
|
27
|
8,2
|
15,8
|
0,4
|
|
13,1
|
0,5
|
15,6
|
4
|
10,4
|
77,3
|
27
|
8,5
|
16
|
0,5
|
|
12,2
|
0,5
|
20,4
|
4
|
10
|
27,3
|
8,3
|
15,9
|
0,4
|
|
13,3
|
0,5
|
28,5
|
4
|
7,8
|
105,9
|
25,5
|
8,3
|
17,8
|
0,4
|
|
15,6
|
0,5
|
7,8
|
4
|
12,6
|
79
|
23,2
|
8
|
15,4
|
0,1
|
|
14,4
|
0,5
|
14
|
4
|
7,4
|
75,9
|
26
|
8,3
|
13,9
|
0,2
|
|
15,3
|
0,5
|
19,8
|
4
|
9,1
|
65,7
|
28,3
|
8,4
|
14,2
|
0,1
|
|
14,1
|
0,5
|
7,2
|
4
|
10,3
|
82,3
|
24,5
|
7,9
|
21
|
0,2
|
|
14,2
|
0,5
|
18
|
4
|
12,6
|
78,7
|
27
|
7,8
|
16
|
0,6
|
|
13,4
|
0,5
|
15,6
|
4
|
8,1
|
69,6
|
27,5
|
8,4
|
12,1
|
0,1
|
|
13,6
|
0,5
|
14,4
|
4
|
8,7
|
58,7
|
27
|
7,8
|
13,9
|
0,3
|
|
9,6
|
0,5
|
16,4
|
4
|
12,6
|
118,9
|
26
|
7,7
|
22,4
|
0,4
|
|
9
|
0,5
|
5
|
4
|
7,4
|
115,2
|
27
|
8,4
|
20,3
|
0,4
|
|
8,5
|
0,5
|
29,8
|
4
|
8
|
155,6
|
27
|
8
|
25,2
|
0,3
|
|
9
|
0,5
|
29,2
|
4
|
4,9
|
147
|
27,3
|
8,1
|
24,3
|
0,3
|
|
9,4
|
0,5
|
20,2
|
4
|
6,4
|
104,1
|
27,3
|
8,5
|
20,3
|
0,4
|
|
9,3
|
0,5
|
5,2
|
4
|
5,5
|
108,7
|
26
|
8,4
|
20,4
|
0,4
|
|
9,4
|
0,5
|
22,2
|
4
|
7,1
|
109,1
|
23,2
|
8,2
|
20,7
|
0,3
|
|
11,5
|
0,5
|
10
|
4
|
11,2
|
102
|
22,4
|
8
|
21
|
0,2
|
|
10,5
|
0,5
|
9,2
|
4
|
9,7
|
92
|
28,3
|
8,2
|
20,4
|
0,3
|
|
11,2
|
0,5
|
32
|
4
|
9,7
|
73,6
|
25
|
8,3
|
18,7
|
0,2
|
|
10,5
|
0,5
|
14,8
|
4
|
9
|
61
|
27
|
7,7
|
36,4
|
0,2
|
|
11,1
|
0,5
|
19,2
|
4
|
12,6
|
48,6
|
27,3
|
7,6
|
30,6
|
0,6
|
|
10,3
|
0,5
|
40
|
4
|
9,4
|
77,1
|
27
|
8,2
|
43,2
|
0,1
|
|
10,1
|
0,5
|
29,2
|
4
|
10,7
|
65
|
27,3
|
7,5
|
43,5
|
0,3
|
|
9,2
|
0,9
|
8
|
3
|
10,4
|
40,4
|
27
|
7,8
|
10,7
|
0,4
|
|
8,4
|
0,9
|
5
|
3
|
9,6
|
42
|
27,3
|
7,8
|
11,2
|
0,4
|
|
10,2
|
0,9
|
9
|
3
|
6,3
|
38
|
27,3
|
8,1
|
10,6
|
0,3
|
|
10,3
|
0,9
|
5,5
|
3
|
6,5
|
40,3
|
26
|
8
|
10,8
|
0,3
|
|
10,5
|
0,9
|
10,5
|
3
|
8
|
38,9
|
26
|
8,1
|
12,1
|
0,4
|
|
10,6
|
0,5
|
6
|
3
|
9,5
|
43,4
|
27
|
8,2
|
10,9
|
0,4
|
|
11,4
|
0,5
|
8,5
|
3
|
7,4
|
42,9
|
24
|
8
|
11,8
|
0,3
|
|
11,4
|
0,5
|
9
|
3
|
6,9
|
43,3
|
27
|
8,1
|
12
|
0,2
|
|
11,4
|
0,5
|
9,5
|
3
|
8,2
|
40
|
25
|
8
|
12,4
|
0,3
|
|
11,3
|
0,5
|
5,5
|
3
|
8,6
|
37,6
|
25
|
8,1
|
11,7
|
0,2
|
|
14
|
0,5
|
5
|
3
|
10,1
|
40,8
|
26,5
|
7,9
|
10,9
|
3
|
|
14
|
0,5
|
5
|
3
|
9,3
|
42
|
25,5
|
7,9
|
11,3
|
0,6
|
|
13,4
|
0,5
|
7
|
3
|
6,6
|
44,3
|
8,3
|
12
|
0,4
|
|
13,2
|
0,5
|
8,5
|
3
|
5,9
|
41,6
|
23,5
|
8,2
|
11,1
|
0,3
|
|
13,1
|
0,5
|
7
|
3
|
8,3
|
39,9
|
25,3
|
8,1
|
12,1
|
0,3
|
|
13,2
|
0,5
|
8,5
|
3
|
7,6
|
40,8
|
24,5
|
8,1
|
12,1
|
0,3
|
|
12,4
|
0,5
|
19,7
|
3
|
8,1
|
22
|
26
|
28
|
6,4
|
0,3
|
|
13,1
|
0,5
|
20,8
|
3
|
8,2
|
13,4
|
24,5
|
16
|
7,8
|
0,3
|
|
12,3
|
0,5
|
23,5
|
3
|
8,2
|
10,1
|
26,6
|
15
|
6,3
|
0,3
|
|
11,5
|
0,5
|
23,8
|
3
|
8,1
|
12,7
|
25,5
|
17
|
5,9
|
0,4
|
|
12,5
|
0,5
|
16,9
|
3
|
8,1
|
8,7
|
24,2
|
18
|
7,9
|
0,4
|
|
12,3
|
0,5
|
17,4
|
3
|
8,1
|
10,1
|
23,2
|
21
|
6,2
|
0,3
|
|
12,5
|
0,5
|
10,6
|
3
|
7,9
|
9,5
|
25,5
|
13
|
6
|
0,4
|
|
12,2
|
0,5
|
8,6
|
3
|
8,1
|
10,6
|
24,2
|
17
|
6,2
|
0,5
|
|
12,5
|
0,5
|
4,3
|
3
|
8,2
|
14
|
23,5
|
18,5
|
16,5
|
0,3
|
|
11,4
|
0,3
|
4,5
|
3
|
8,2
|
13,8
|
25,5
|
19,5
|
15,8
|
0,5
|
|
9,2
|
0,5
|
13
|
3
|
8,1
|
9,2
|
25,5
|
9,5
|
14,4
|
0,3
|
|
9,3
|
0,5
|
19,1
|
9
|
7,3
|
9,2
|
23,5
|
21,8
|
15,8
|
0,2
|
|
10
|
0,5
|
22,3
|
12
|
8,1
|
13,4
|
24,2
|
11,5
|
16
|
0,2
|
|
9,4
|
0,5
|
23,8
|
7
|
8,1
|
14
|
25,5
|
10,4
|
15,9
|
0,3
|
|
13,4
|
0,5
|
20
|
9
|
8,6
|
13,8
|
22,4
|
2,8
|
17,8
|
0,5
|
|
10
|
0,5
|
12,6
|
8
|
8
|
13,4
|
24,2
|
14,9
|
15,4
|
0,1
|
|
10,3
|
0,5
|
3
|
3
|
8,1
|
9
|
23,5
|
8
|
13,9
|
0,4
|
|
9
|
0,5
|
8
|
3
|
8,1
|
7,9
|
23,2
|
12
|
14,2
|
0,4
|
|
10,2
|
0,5
|
20
|
3
|
8,1
|
7,4
|
27,3
|
13,5
|
21
|
0,4
|
|
10,4
|
0,5
|
13,5
|
3
|
8,1
|
13,4
|
24
|
13,5
|
16
|
0,3
|
|
6
|
0,5
|
3
|
3
|
8,2
|
11,4
|
19,4
|
10,5
|
12,1
|
0,4
|
|
7
|
0,5
|
8
|
3
|
8,1
|
11,4
|
20,2
|
14,5
|
13,9
|
0,4
|
|
13,4
|
0,5
|
19,8
|
3
|
7,9
|
24,6
|
25,6
|
19,5
|
22,4
|
0,3
|
|
13,4
|
0,5
|
5,2
|
9
|
8,4
|
11,4
|
23,5
|
7,9
|
20,3
|
0,3
|
|
11
|
0,5
|
1
|
8
|
8,6
|
9
|
23,5
|
21,7
|
25,2
|
0,3
|
|
12
|
0,5
|
14,5
|
3
|
7,9
|
7,9
|
25
|
16
|
24,3
|
0,3
|
|
6,5
|
0,5
|
3
|
3
|
8,2
|
8,4
|
22,4
|
9
|
20,3
|
0,3
|
|
12,1
|
0,5
|
13,6
|
3
|
8,1
|
10,6
|
25,5
|
16
|
20,4
|
0,2
|
|
11,4
|
0,3
|
4,5
|
3
|
8,2
|
13,8
|
25,5
|
19,5
|
15,8
|
0,5
|
|
11,4
|
0,5
|
3
|
3
|
8,1
|
8,6
|
22,4
|
67
|
15,2
|
0,4
|
|
9,3
|
0,5
|
19,1
|
9
|
7,3
|
9,2
|
23,5
|
21,8
|
15,8
|
0,2
|
|
10,3
|
0,5
|
19
|
3
|
8,1
|
19,8
|
24
|
17,1
|
0,2
|
|
9,4
|
0,5
|
23,8
|
7
|
8,1
|
14
|
25,5
|
10,4
|
15,9
|
0,3
|
|
9,3
|
0,5
|
20
|
3
|
8,1
|
6,7
|
26,3
|
13
|
14,2
|
0,2
|
|
10
|
0,5
|
12,6
|
8
|
8
|
13,4
|
24,2
|
14,9
|
15,4
|
0,1
|
|
10,2
|
0,5
|
10
|
3
|
7,9
|
14
|
25,5
|
10,5
|
15,4
|
0,1
|
|
9
|
0,5
|
8
|
3
|
8,1
|
7,9
|
23,2
|
12
|
14,2
|
0,4
|
|
10,1
|
0,5
|
13,1
|
3
|
8,1
|
9,5
|
24,5
|
10,5
|
15,6
|
0,4
|
Для заданных данных необходимо выполнить пять
лабораторных работ, с помощью программного приложения STATISTIKA
6.0 or 7.0.
Выполнение
) Выполнение работы в программе STATISTIC
V7.0.
Результат расчетов таблиц статистик, в виде
таблицы значений.
Определение моды, гармонического среднего и
других непараметрических статистик, в виде таблицы значений.
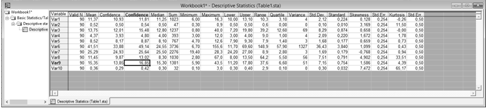
При подсчете разных значений для переменных
большое значение имеет разброс значений в переменной. Чем более они
приблизительны друг другу, тем менее разными будут значения в таблицах
рассеивания, а так же это будет существенно влиять на моду, гармоническое
среднее и другие непараметрические статистики.

Построение гистограммы рассеяния для переменной
1.

Построение гистограммы рассеяния для переменной
2.
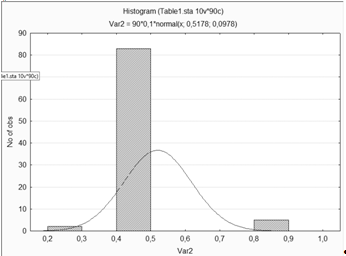
Построение гистограммы рассеяния для переменной
7.
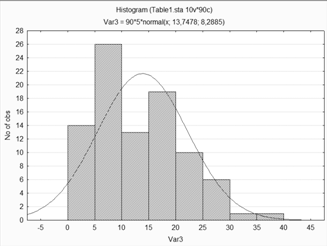
Построение гистограммы рассеяния для переменной
4.
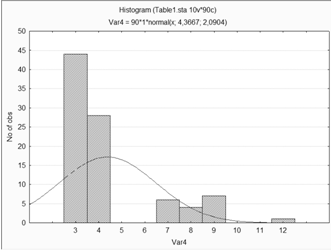
Построение диаграмм рассеяния для переменной 1.
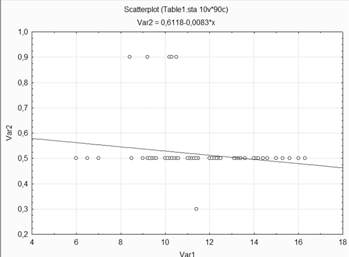
Построение диаграмм рассеяния для переменной 2.
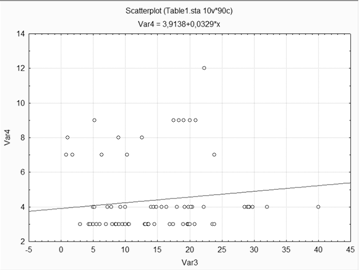
Построение диаграмм рассеяния для переменной 7.
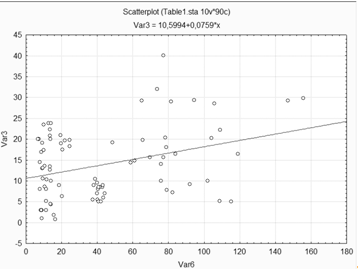
Построение диаграмм рассеяния для переменной 4.

Выводы: выполнение оценки основных
статистических характеристик при анализе данных с использованием прикладного
программного обеспечения - STATISTIC V7.0 позволило определить параметры для
таблицы статистик, в виде таблицы значений, для каждой из 10 переменных. Так же
определить моды, гармонического среднего и других непараметрических статистик
,и преобразовать их в вид таблицы значений. Удалось построить гистограмму
рассеивания, а так же диаграмму рассеивания для выбранных переменных из
варианта (1,2,7,4).
) Оценка
характера распределений данных
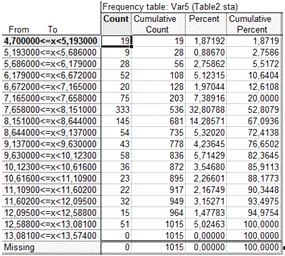
Таблица частот для переменной 1. (п. 6)

Гистограмма частот для переменной 1. (п.7)
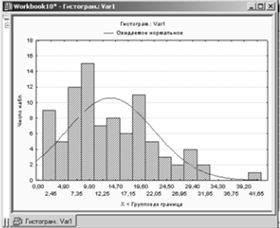
Файл данных для оценки нормальности по первому
методу (согласно п.8).

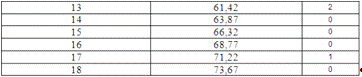
Таблица со значениями асимметрии и эксцесса для
переменной 1. (13)
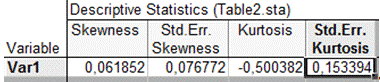
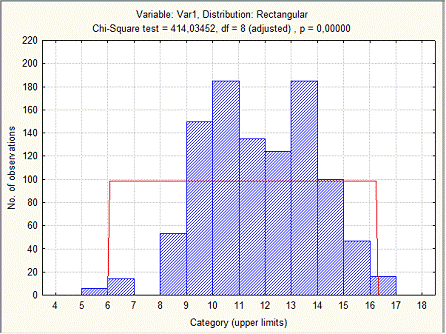
Таблица расчетных данных для нормального
распределения (согласно п.17).

Гистограмма расчетных данных для нормального
распределения (согласно п.19).

Чем ближе значение Хи-Квадрат к нулю, тем более
вероятней можно утверждать что распределение по данной переменной не является
нормальной.
Таблица и гистограмма расчетных данных, выводы о
равномерном распределении выборки (согласно п. 20).

Равномерное распределение по Хи-квадрату
позволяет определить распределение на данной переменной. В данном случае
"разброс значений" очень большой.
Таблица и гистограмма расчетных данных, выводы о
показательном распределении выборки (согласно п. 21).
Случай с переменной 9.
Таблица частот
Гистограмма
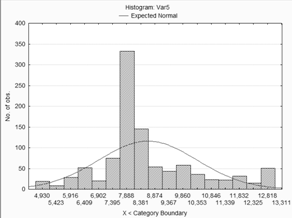
Файл данных для оценки нормальности по первому
методу
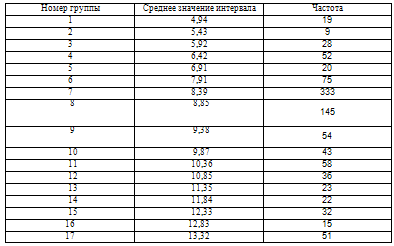
Таблица со значениями асимметрии и эксцесса для
переменной 9. (13)

Файл данных для оценки нормальности по первому
методу, для переменной 9.
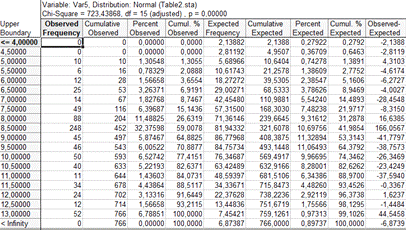
Делая вывод из таблицы приведенной выше, можно
сказать что распределение не нормальное.
Гистограмма для оценки по первому методу.
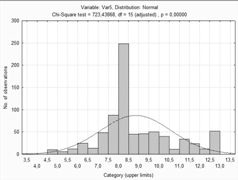
Таблица и гистограмма расчетных данных, выводы о
равномерном распределении выборки
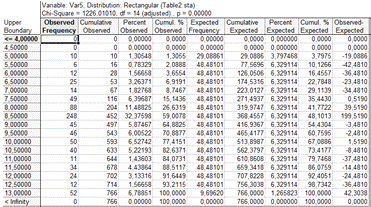
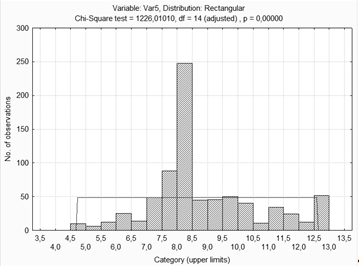
Делая вывод по таблицам, и прикрепленным к ним
гистограммам можно сказать что переменная не распределена нормально.
3) Элементы первичной обработки данных
Диаграмма рассеяния
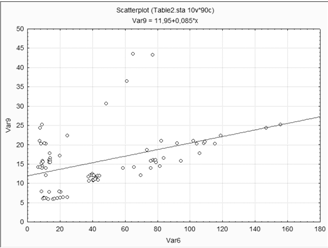
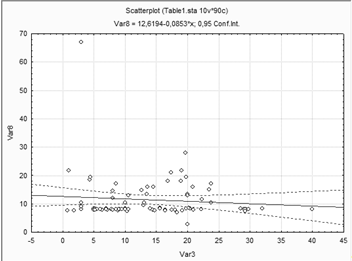
Выводы. Взаимосвязь переменных между собой
наблюдается в том, что практически отсутствуют аномальные точки в данной
диаграмме рассеивания. Так же можно сказать что переменные связаны между собой.
Наблюдается однородность данных. Отсутствие
отдельных облаков данных.
Наблюдается зависимость двух переменных.
Имеются несколько "выбросов" или
отделенных аномальных значений, которые не влияют на остальной массив.
Измененная диаграмма рассеивания при помощи
кисти.
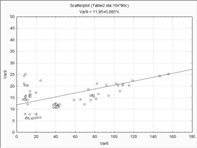
Графики зависимостей двух любых переменных от
времени
Для п.23

Для п.1

На некоторых промежутках времени наблюдается
разность поведения переменных, к примеру в Кэйс 15-22 переменная 23 возрастает
,а переменная 1 наоборот спадает.
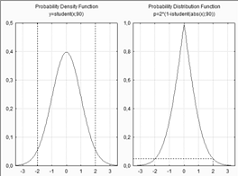
Графики распределения согласно критерию
Стьюдента:
Графики распределения согласно критерию Фишера:
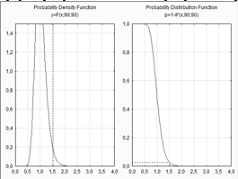
Таблица t-критериев
для независимых выборок:

Диаграмма размаха

4) Анализ взаимосвязей
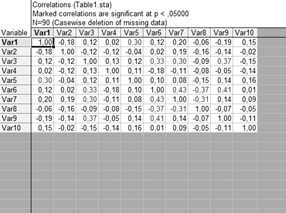
Матрица для значения: 0,02

Матрица для значения: -0,08
Матрица для значения: -0,08
Выводы
статистический выборочный
вероятностный statistik
Закрепили теоретические сведения по
статистическому оцениванию параметров распределений, и получить практические
навыки по определению основных выборочных характеристик при анализе данных с
использованием прикладного программного обеспечения.
Выполнили оценку основных статистических
характеристик при анализе данных с использованием STATISTIC V6.0 или STATISTIC
V7.0.
Получили практические навыки проверки
соответствия выбранной теоретической модели распределения исходным данным с
использованием прикладного программного обеспечения.
Изучили методы первичной обработки
статистической информации и приобретение практических навыков предварительного
анализа данных с использованием прикладного программного обеспечения. Методы
анализа структуры и тесноты статистической связи между показателями массива
исходных данных и приобретение практических навыков оценки взаимосвязей с
использованием прикладного программного обеспечения.
Установили конкретные виды зависимостей и их
параметров для количественного описания связей между показателями массива
данных и приобретение практических навыков определения функций регрессии с
применением прикладного программного обеспечения.
Список использованной литературы
1.
Боровиков
В. STATISTICA для профессионалов. СПб.: Питер. 2001. - 655с.
2.
Боровиков
В. Программа STATISTICA для студентов и инженеров. М.: Компьютер-пресс,
2001.-301 с.
3.
Айвазян
С.А., Енюков И.С., Мешалкин Л.Д. Прикладная статистика: Основы моделирования и
первичная обработка данных. М.: Финансы и статистика, 1983. - 472 с.
4.
Гмурман
В.Е. Руководство к решению задач по теории вероятностей и математической
статистике. М.: Выс. Школа, 1979. - 477 с.
5.
Гихман
И.И., Скороход А.В., Ядренко М.И. Теория вероятностей и математическая статистика.
- К.: Вища школа, 1988. - 438 с.
6.
Гмурман
В.Е. Теория вероятности и математическая статистика. / Учебное пособ. для
вузов. М.: Высшая школа, 1998. - 479 с.
7.
Методические
указания и задания к выполнению курсовой работы по дисциплине
"Вероятностные процессы и математическая статистика в
эколого-экономических системах" (для студентов специальности 7.080407
"Компьютерный эколого-экономический мониторинг")/ Составители: Г.В.
Аверин, Л.Г. Голубева, А.С. Хоруженко, А.М. Бачинский. - Донецк: ДонНТУ, 2002