Анализ интервального вариационного ряда 'Численность экономически активного населения по субъектам Российской Федерации в 2012 году'
Содержание
Введение
1. Табличное
и графическое представление вариационного ряда
1.1
Ранжирование исходных данных, определение наличия выбросов
1.2
Определение числа групп
1.3
Определение величины интервала
1.4
Графическое изображение вариационного ряда
1.5
Графическое изображение рядов распределения
2.
Характеристика центральной тенденции распределения
3.
Оценка вариации изучаемого признака
4.
Характеристика структуры распределения
5.
Характеристика формы распределения
6.
Сглаживание эмпирического распределения
Заключение
Список
использованной литературы
Введение
Статистическое
наблюдение
Статистическим
наблюдением является:
Массовое
(оно охватывает большое число случаев) проявление исследуемого явления для
получения правдивых статистических данных;
Планомерное
(проводится по разработанному плану), включающее вопросы методологии,
организации сбора и контроля достоверности информации;
Систематическое
(проводится систематически, либо непрерывно, либо регулярно);
Научно
организованное (для повышения достоверности данных), которое зависит от
программы наблюдения, содержания анкет, качества подготовки инструкций
наблюдения за явлениями и процессами социально-экономической жизни, которое
заключается в сборе и регистрации отдельных признаков у каждой единицы совокупности.
[1]
Для
успешной подготовки и проведения статистического наблюдения необходимо решить
программно-методологические, организационные вопросы, для реализации которых
нужно составить организационный план статистического наблюдения.
Организационный
план - это документ, в котором должны быть отражены важнейшие вопросы по
организации и проведению предстоящих мероприятий. Он составляется для того,
чтобы успешно проводить статистические наблюдения. В нем указываются: органы,
проводящие наблюдение, время и сроки наблюдения, подготовительные работы,
которые были проведены для дальнейшего наблюдения, порядок комплектования и
обучения кадров, необходимых для проведения статистического наблюдения, порядок
его проведения, порядок приема и сдачи материалов, получение и предоставление
предварительных и окончательных итогов. Вопрос о времени проведения
статистического наблюдения должен быть обязательно решен, включая выбор сезона,
срока и критического момента наблюдения.
Для
того чтобы выбрать сезон, нужно проследить, чтобы изучаемый объект пребывал в
обычном для него состоянии.
Время
начала и окончания сбора статистических данных называют периодом, или сроком.
Срок
наблюдения определяется рядом факторов: он зависит от специфики и особенностей
объекта наблюдения.
Критическим
моментом статистического наблюдения называют момент времени, по состоянию на
который фиксируются собранные данные, которые получены в процессе
статистического наблюдения, например, выбирают момент окончания одних суток и
начала других.
Организация,
осуществляющая подготовку, проведение статистического наблюдения и несущая
ответственность за свою работу, - это орган наблюдения. У органа наблюдения
должны быть четко определены сферы деятельности, функции, права, круг
обязанностей, за которые он несет ответственность.
Место,
где происходит регистрация наблюдаемых фактов и заполнение статистических
формуляров, называют местом статистического наблюдения.
В
ходе проведения статистического наблюдения важной задачей является получение
достоверных и объективных данных о состоянии обследуемых объектов. Существенное
значение для проведения хорошего статистического наблюдения имеет определение
кадрового состава.
Успешное
проведение статистического наблюдения обеспечивается четкой структурой и
разработанностью его организационного плана.
Ошибки
статистического наблюдения
Важнейшей
задачей статистического наблюдения является достоверность и точность собираемой
статистической информации.
Любое
статистическое наблюдение предполагает получение данных, которые будут полно и
точно отражать действительность.
В
процессе проведения статистического наблюдения могут возникать погрешности,
которые приводят к снижению достоверности статистического наблюдения.
Основное
требование, которое предъявляется к статистическому наблюдению - это точность
статистических данных.
Точность
- это уровень соответствия значения какого-либо признака или показателя,
который был получен вследствие статистического наблюдения, действительному его
значению. В процессе подготовки и проведения статистического исследования,
чтобы предупредить возможность появления отклонений или разности между
исчисленными показателями, нужно предусмотреть и осуществить ряд мероприятий.
Если же такие отклонения возникли, их называют ошибками статистического
наблюдения.
Материалы,
собранные в результате наблюдения, подвергаются всесторонней проверке и
контролю. Они проверяются с точки зрения полноты охвата всех единиц
совокупности наблюдения и правильности заполнения документов контроля.
Ошибки
статистического наблюдения - это ошибки репрезентативности и ошибки
регистрации.
Ошибки
репрезентативности показывают, в какой степени выборочная совокупность
представляет генеральную совокупность. Эти ошибки возникают потому, что
наблюдению подвергается только часть единиц изучаемой совокупности, и сведения
эти не могут абсолютно точно отобразить свойства всей массы явлений
совокупности.
Возникающие
в результате неправильного установления фактов ошибки регистрации можно
подразделить на:
случайные
- это ошибки, которые могут дать искажения как в одну, так и в другую сторону;
систематические
ошибки, возникающие вследствие нарушения принципов непреднамеренного отбора
единиц изучаемой совокупности. Систематические ошибки опасны, потому что они
влияют на полученные итоговые показатели;
преднамеренные
ошибки возникают вследствие умышленного искажения фактов.
Для
обеспечения достоверности данных статистического наблюдения предусматривают
проверку их качества с точки зрения полноты охвата изучаемого объекта
статистическим наблюдением, качества и др.
Проверка
данных статистического наблюдения на достоверность - это проведение
логического, арифметического и синтаксического контроля.
Содержание
и значение статистической сводки
Сведения
о каждой единице анализируемой совокупности, полученные в результате первой
стадии статистического исследования, характеризуют статистическое наблюдение с
различных его сторон, так как они обладают многочисленными признаками и
свойствами, которые изменяются во времени и пространстве. Для получения сводной
характеристики всего объекта при помощи обобщающих показателей нужно
систематизировать и обобщить результаты, которые были получены в ходе
статистического наблюдения. Это даст нам возможность выявить особенности и
черты статистической совокупности в целом и отдельных ее составляющих,
обнаружить закономерности изучаемых социально-экономических явлений и
процессов. Данную систематизацию называют сводкой первичного статистического
материала.
Второй
этап статистической работы - статистическая сводка - это обработка первичных
данных в целях получения обобщенных характеристик изучаемого явления или
процесса по ряду существенных для него признаков для выявления типичных черт и
закономерностей, присущих явлению или процессу в целом.
Статистическая
сводка - это переход от единичных данных к сведениям о группах единиц и
совокупности в целом.
Проведение
сводки включает три этапа:
предварительный
контроль - это проверка данных;
группировка
данных по заданным признакам - это определение производных показателей;
оформление
результатов сводки в виде статистических таблиц, они являются удобной формой
для восприятия полученной информации.
Смысловая
согласованность статистических сведений - это предварительный контроль.
В
соответствии с программой статистической сводки для того, чтобы в дальнейшем
предоставить полученную информацию в доступном для восприятия виде,
используется статистическая группировка данных.
Полученные
результаты группировки оформляются в виде группировочных таблиц, содержащих
сводную характеристику исследуемой совокупности по одному или нескольким
признакам, которые взаимосвязаны логикой анализа.
Различают
сводку простую и сложную.
Виды
сводок
Простая
статистическая сводка - это операция по подсчету общих итоговых и групповых
данных по совокупности единиц наблюдения и оформление этого материала в
таблицах.
Простая
статистическая сводка дает возможность определить число единиц изучаемой
совокупности и объем изучаемых признаков, но тем самым простая сводка не дает
представления о целостности состава изучаемой совокупности.
Если
единицы совокупности разбивают на однородные группы, после этого подсчитывают
итоги по каждой группе, а затем по всей совокупности в целом, такую
статистическую сводку называют сложной.
Сложная
сводка позволяет нам изучить состав совокупности и выявить влияние одних
признаков на другие, т. е. раскрыть свойственные данной совокупности
закономерности.
Сложная
статистическая сводка - это комплекс операций, включающих распределение единиц
наблюдения изучаемого социально-экономического явления или процесса на группы,
составление системы показателей для характеристики типичных групп и подгрупп
изучаемой совокупности явлений, подсчет числа единиц и итогов в каждой группе и
подгруппах и оформление результатов этой работы в виде статистических таблиц.
На
основе всестороннего теоретического анализа сущности и содержания изучаемых
явлений и процессов проводится статистическая сводка.
Программой
и планом проведения статистической сводки обеспечивается достоверность и
обоснованность ее результатов.
Программа
статистической сводки содержит перечень групп, на которые может быть разбита
или разбивается совокупность единиц статистического наблюдения, а также систему
показателей, характеризующих изучаемую совокупность явлений и процессов как в
целом, так и отдельных ее частей.
От
целей и задач исследования зависит программа статистической сводки.
Вместе
с программой статистической сводки составляют план ее проведения. План должен
содержать информацию о последовательности, сроках и технике проведения сводки,
ее исполнителях, о порядке и правилах оформления ее результатов в виде таблиц.
Сущность
и классификация группировок
Статистическая
группировка - это один из основных этапов проведения статистического
исследования.
Процесс
образования однородных групп на основе разделения статистической совокупности
на части или объединение изучаемых статистических единиц в совокупности по
определенным для них признакам называют статистической группировкой. Важнейшим
статистическим методом обобщения данных являются статистические группировки.
В
литературе [2] выделяют следующие виды статистических группировок:
типологические;
структурные;
аналитические
Качественно
однородные группы совокупностей, называют типологической группировкой.
Для
построения типологической группировки необходимо воспользоваться
количественными и качественными (атрибутивными) признаками.
Разделение
однородной совокупности на определенные группы, которые в дальнейшем будут
характеризовать структуру по определенному группировочному признаку, называют
структурной группировкой.
Здесь
также рассматриваются количественные и атрибутивные группировки.
Статистические
ряды распределения
Статистические
ряды распределения представляют собой упорядоченное расположение единиц
изучаемой совокупности на группы по группировочному признаку.
Различают
атрибутивные и вариационные ряды распределения.
Атрибутивный
- это ряд распределения, построенный по качественным признакам.
По
количественному признаку строится вариационный ряд распределения. Он состоит из
частоты (численности) отдельных вариантов или каждой группы вариационного ряда.
Данные числа показывают, насколько часто встречаются различные варианты
(значения признака) в ряду распределения. Сумма всех частот определяет
численность всей совокупности.
В
зависимости от характера вариации признака различают дискретные и интервальные
вариационные ряды распределения. В дискретном вариационном ряде распределения
группы составлены по признаку, изменяющемуся дискретно и принимающему только
целые значения.
В
интервальном вариационном ряде распределения группировочный признак,
составляющий основание группировки, может принимать в определенном интервале
любые значения.
Вариационные
ряды состоят из двух элементов: частоты и варианты.
Вариантой
называют отдельное значение варьируемого признака, которое он принимает в ряду
распределения.
Частота
- это численность отдельных вариант или каждой группы вариационного ряда. Если
частоты выражены в долях единицы или в процентах к итогу, то их называют
частостями.
Плотность
распределения - это отношение числа единиц совокупности к ширине интервала.
Анализ
рядов распределения можно проводить на основе их графического изображения.
Линейчатые и круговые диаграммы строятся для отображения структуры
совокупности.
Применяются
вместе с диаграммами и такие линии, как полигон, кумулята, огива, гистограмма.
Полигон
- ломаная кривая, строится на основе прямоугольной системы координат, когда по
оси Х откладываются значения признака, а по оси У - частоты.
Гладкая
кривая, соединяющая точки - это эмпирическая плотность распределения.
Кумулята
- ломаная кривая, строящаяся на основе прямоугольной системы координат, когда
по оси Х откладываются значения признака, а по оси У - накопленные частоты.
Для
дискретных рядов на оси откладываются сами значения признака, а для
интервальных - середины интервала.
На
основе гистограмм можно строить диаграммы накопленных частот с последующим
построением интегральной эмпирической функции распределения.
1.
Табличное и графическое представление вариационного ряда
.1 Ранжирование исходных данных, определение
наличия выбросов
Первым этапом статистического изучения вариации
являются построение вариационного ряда - упорядоченного распределения единиц
совокупности по возрастающим (чаще) или по убывающим (реже) значениям признака
и подсчет числа единиц с тем или иным значением признака.
Существуют три формы вариационного ряда:
ранжированный ряд;
дискретный ряд;
интервальный ряд.
Вариационный ряд часто называют рядом
распределения.
Этот термин используется при изучении вариации
как количественных, так и неколичественных признаков.
Ряд распределения представляет собой структурную
группировку.
Ранжированный ряд - это перечень отдельных
единиц совокупности в порядке возрастания (убывания) изучаемого признака.
Если численность единиц совокупности достаточно
велика, ранжированный ряд становится громоздким, а его построение, даже с
помощью ЭВМ, занимает длительное время. В таких случаях вариационный ряд
строится с помощью группировки единиц совокупности по значениям изучаемого
признака.
Если признак принимает небольшое число значений,
строится дискретный вариационный ряд.
Дискретный вариационный ряд - это
таблица, состоящая из двух строк или граф: конкретных значений варьирующего
признака Хi и числа единиц совокупности с данным значением признака F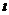 частот (F - начальная
буква англ. Слова frequency)
частот (F - начальная
буква англ. Слова frequency)
1.2 Определение числа групп
Число групп в дискретном вариационном ряду
определяется числом реально существующих значений варьирующего признака.
Если же признак может принимать дискретные
значения, то их число очень велико (например, поголовье скота на 1 января года
в разных сельхозпредприятиях может составлять от нуля до десятков тысяч голов),
тогда строится интервальный вариационный ряд.
Интервальный вариационный ряд строится и для
изучения признаков, которые могут принимать любые, как целые, так и дробные,
значения в области своего существования. Таковы, например, рентабельность
реализованной продукции, себестоимость единицы продукции, доход на 1 жителя
города, доля лиц с высшим образованием среди населения разных территорий и
вообще все вторичные признаки, значения которых рассчитываются путем деления
величины одного первичного признака на величину другого
Интервальный вариационный ряд представляет собой
таблицу, (состоящую из двух граф (или строк) - интервалов признака, вариация
которого изучается, и числа единиц совокупности, попадающих в данный интервал
(частот), или долей этого числа от общей численности совокупности (частостей).
При построении интервального вариационного ряда
необходимо выбрать оптимальное число групп (интервалов признака) и установить
длину интервала.
Поскольку при анализе вариационного ряда
сравнивают частоты в разных интервалах, необходимо, чтобы величина интервала
была постоянной. Оптимальное число групп выбирается так, чтобы в достаточной
мере отразилось разнообразие значений признака в совокупности и в то же время
закономерность распределения, его форма не искажалась случайными колебаниями
частот. Если групп будет слишком мало, не проявится йные скачки частот исказят
форму распределения.
Чаще всего число групп в вариационном ряду
устанавливают, придерживаясь формулы (1.1), рекомендованной американским
статистиком Стерджессом (Sturgess):
 (1.1)
(1.1)
где k - число групп; n - численность
совокупности.
Эта формула показывает, что число
групп - функция объема данных.
Предположим, необходимо построить
вариационный ряд распределения предприятий области по урожайности зерновых
культур за какой-то год. Число сельхозпредприятий, имевших посевы зерновых
культур, составило 143; наименьшее значение урожайности равно 10,7 ц/га,
наибольшее - 53,1 ц/га.
Имеем:
k=1+3.32*lq*143=8,16
Так как число групп целое,
следовательно, рекомендуется построить 8 или 9 групп.
1.3 Определение величины интервала
Зная число групп, рассчитывают величину
интервала:
 (1.2)
(1.2)
В нашем примере величина интервала
составляет:
а) при 8 группах= (53,1-10,7)/8 =5,3
ц/га
б) при 9 группах= (53,1-10,7)/9
=4,7 ц/га
Для построения ряда и анализа
вариации значительно лучше иметь по возможности округленные значения величины
интервала и его границ. Поэтому наилучшим решением будет построение
вариационного ряда с 9 группами с интервалом, равным 5 ц/га.
Границы интервалов могут указываться
разным образом: верхняя граница предыдущего интервала повторяет нижнюю границу
следующего или не повторяет.
В последнем случае второй интервал
будет обозначен как 15,1-20, третий как 20,1-25 и т.д., т.е. предполагается,
что все значения урожайности обязательно округлены до одной десятой. Кроме
того, возникает нежелательное осложнение с серединой интервала 15,1-20,
которая, строго говоря, уже будет равна не 17,5, а 17,55; соответственно при
замене округленного интервала 40-60 на 40,1-6,0 вместо округленного значения
его середины 50 получим 50,5, Поэтому предпочтительнее оставить интервалы с
повторяющейся округленной границей и договориться, что единицы совокупности,
имеющие значение признака, равное границе интервала, включаются в тот интервал,
где это точное значение впервые указывается. Так, хозяйство, имеющее
урожайность, равную 15 ц/га, включается в первую группу, значение 20 ц/га -во
вторую и т. д.
.4 Графическое изображение
вариационного ряда
Существенную помощь в анализе вариационного ряда
и его свойств оказывает графическое изображение.
Интервальный ряд изображается столбиковой
диаграммой, в которой основания столбиков, расположенные на оси абсцисс, - это
интервалы значений варьирующего признака, а высоты столбиков - частоты,
-соответствующие масштабу по оси ординат.
Данные таблиц показывают характерную для многих
признаков форму распределения: чаще встречаются значения средних интервалов
признака, реже - крайние; малые и большие значения признака. Форма этого
распределения близка к рассматриваемому в курсе математической статистики
закону нормального распределения.
Великий русский математик А.М. Ляпунов (1857 -
1918) доказал, что нормальное распределение образуется, если на варьирующую
переменную влияет большое число факторов, ни один из которых не имеет
преобладающего влияния.
Случайное сочетание множества примерно равных
факторов, влияющих на вариацию урожайности зерновых культур, как природных, так
и агротехнических, экономических, создает близкое к нормальному закону
распределения распределение хозяйств области по урожайности.
Если имеется дискретный вариационный ряд или
используются середины интервалов, то графическое изображение такого
вариационного ряда называется полигоном (от греч. Слова - многоугольник).
Отношение высоты полигона или диаграммы к их
основанию рекомендуется в пропорции примерно 5:8.
.5 Графическое изображение рядов распределения
Наглядно ряды распределения представляются при
помощи графических изображений.
Ряды распределения изображаются в виде:
полигона
гистограммы
кумуляты
огивы
Полигон - при построении полигона на
горизонтальной оси (ось абсцисс) откладывают значения варьирующего признака, а
на вертикальной оси (ось ординат) - частоты или частости.
Полигон используется для дискретных вариационных
рядов.
Если значения признака выражены в виде
интервалов, то такой ряд называется интервальным.
Интервальные ряды распределения изображают
графически в виде гистограммы, кумуляты или огивы.
При такой записи непрерывного признака, когда
одна и та же величина встречается дважды (как верхняя граница одного интервала
и нижняя граница другого интервала), то эта величина относится к той группе,
где эта величина выступает в роли верхней границы.
Гистограмма - Для построения гистограммы по оси
абсцисс указывают значения границ интервалов и на их основании строят
прямоугольники, высота которых пропорциональна частотам (или частостям).
Кумулята - для построения кумуляты необходимо
рассчитать накопленные частоты (частости). Они определяются путем
последовательного суммирования частот (частостей) предшествующих интервалов и
обозначаются S. Накопленные частоты показывают, сколько единиц совокупности
имеют значение признака не больше, чем рассматриваемое.
Распределение признака в вариационном ряду по
накопленным частотам (частостям) изображается с помощью кумуляты.
Кумулята или кумулятивная кривая в отличие от
полигона строится по накопленным частотам или частостям. При этом на оси
абсцисс помещают значения признака, а на оси ординат - накопленные частоты или
частности.
Огива строится аналогично кумуляте с той лишь
разницей, что накопленные частоты помещают на оси абсцисс, а значения признака
- на оси ординат.
Разновидностью кумуляты является кривая
концентрации или график Лоренца. Для построения
кривой концентрации на обе оси прямоугольной системы координат наносится
масштабная шкала в процентах от 0 до 100. При этом на оси абсцисс указывают
накопленные частости, а на оси ординат - накопленные значения доли (в
процентах) по объему признака.
Равномерному распределению признака соответствует
на графике диагональ квадрата. При неравномерном распределении график
представляет собой вогнутую кривую в зависимости от уровня концентрации
признака.
Для практической работы со статистическими
данными выбрана таблица «Численность экономически активного населения» в 2012
году из справочника «Регионы России» (таблица 1.1)
Таблица 1.1 Численность экономически активного
населения Российской Федерации в 2012 году (тыс. человек)
|
№
региона
|
Кол-во
человек
|
№
региона
|
Кол-во
человек
|
№региона
|
Кол-во
человек
|
№
региона
|
Кол-во
человек
|
№
региона
|
Кол-во
человек
|
№
региона
|
Кол-во
человек
|
|
1
|
752
|
16
|
815
|
31
|
1206
|
46
|
1895
|
61
|
314
|
76
|
530
|
|
2
|
660
|
17
|
717
|
32
|
133
|
47
|
843
|
62
|
1827
|
77
|
488
|
|
3
|
792
|
18
|
5893
|
33
|
443
|
48
|
681
|
63
|
95
|
78
|
35
|
|
4
|
1148
|
19
|
382
|
34
|
143
|
49
|
1438
|
64
|
451
|
79
|
496
|
|
5
|
560
|
20
|
547
|
35
|
198
|
50
|
793
|
65
|
128
|
80
|
1054
|
|
6
|
538
|
21
|
680
|
36
|
311
|
51
|
1793
|
66
|
262
|
81
|
774
|
|
7
|
371
|
22
|
24
|
37
|
460
|
52
|
1101
|
67
|
1314
|
82
|
441
|
|
8
|
592
|
23
|
667
|
38
|
2470
|
53
|
711
|
68
|
1529
|
83
|
192
|
|
9
|
597
|
24
|
513
|
39
|
1300
|
54
|
1754
|
69
|
22
|
84
|
13
|
|
10
|
3603
|
25
|
897
|
40
|
537
|
55
|
1323
|
70
|
10
|
85
|
101
|
|
11
|
439
|
26
|
515
|
41
|
1356
|
56
|
682
|
71
|
1227
|
86
|
304
|
|
12
|
576
|
27
|
339
|
42
|
2132
|
57
|
478
|
72
|
59
|
87
|
87
|
|
13
|
529
|
28
|
373
|
43
|
1984
|
58
|
2417
|
73
|
1476
|
88
|
33
|
|
14
|
556
|
29
|
2645
|
44
|
362
|
59
|
968
|
74
|
1366
|
|
|
|
15
|
720
|
30
|
202
|
45
|
439
|
848
|
75
|
1022
|
|
|
Используя программу STATISTIKA
проведем ранжирование статистических данных.
Выбросами, очевидно, будут Москва и Московская
область, так как разность между экономически активным населением Москвы (5893
тыс. чел) и Москвовской области (3603 тыс. чел) гораздо больше, чем разность
между экономически активным населением Санкт-Петербурга (2645 тыс. чел.) и
Краснодарского края (2470 тыс. чел.)
Таким образом, ранжированный ряд будет выглядеть
так, как представлено в таблице 1.2.
Таблица 1.2 Исходные данные, ранжированные по
возрастанию значений признака (тыс. человек)
|
Номер
региона
|
Количество
человек
|
Номер
региона
|
Количество
человек
|
Номер
региона
|
Количество
человек
|
Номер
региона
|
Количество
человек
|
Номер
региона
|
Количество
человек
|
Номер
региона
|
Количество
человек
|
|
1
|
10
|
16
|
202
|
31
|
460
|
46
|
597
|
61
|
848
|
76
|
1476
|
|
2
|
13
|
17
|
262
|
32
|
478
|
47
|
660
|
62
|
897
|
77
|
1529
|
|
3
|
22
|
18
|
304
|
33
|
488
|
48
|
667
|
63
|
968
|
78
|
1754
|
|
4
|
24
|
19
|
311
|
34
|
496
|
49
|
680
|
64
|
1022
|
79
|
1793
|
|
5
|
33
|
20
|
314
|
35
|
513
|
50
|
681
|
65
|
1054
|
80
|
1827
|
|
6
|
35
|
21
|
339
|
36
|
515
|
51
|
682
|
66
|
1101
|
81
|
1895
|
|
7
|
59
|
22
|
362
|
37
|
529
|
52
|
711
|
67
|
1148
|
82
|
1984
|
|
8
|
87
|
23
|
371
|
38
|
530
|
53
|
717
|
68
|
1206
|
83
|
2132
|
|
9
|
95
|
24
|
373
|
39
|
537
|
54
|
720
|
69
|
1227
|
84
|
2417
|
|
10
|
101
|
25
|
382
|
40
|
538
|
55
|
752
|
70
|
1300
|
85
|
2470
|
|
11
|
128
|
26
|
439
|
41
|
547
|
56
|
774
|
71
|
1314
|
86
|
2645
|
|
12
|
133
|
27
|
439
|
42
|
556
|
57
|
792
|
72
|
1323
|
87
|
3603
|
|
13
|
143
|
28
|
441
|
43
|
560
|
58
|
793
|
73
|
1356
|
88
|
5893
|
|
14
|
192
|
29
|
443
|
44
|
576
|
59
|
815
|
74
|
1366
|
|
|
|
15
|
198
|
30
|
451
|
45
|
592
|
60
|
843
|
75
|
1438
|
|
|
Переходя к построению табличного представления
вариационного ряда используем ППП, что упрощает задачу наблюдения и поэтапно
применяя подборку шага составим три таблицы с шагом k=15, 10 и 7,
руководствуясь, прежде всего тем, чтобы в конечном варианте таблицы
отсутствовали малонаполненные и нулевые группы и получена была мономодальная
таблица.
Главный недостаток таблицы с шагом k=15
(представленной на рисунке 1.1) наличие нулевых строк и нечётко определенная
мономодальность. При этом встречаются малонаполненные и нулевые ячейки.
|
10
|
10
|
11,62791
|
11,6279
|
|
7
|
17
|
8,13953
|
19,7674
|
|
15
|
32
|
17,44186
|
37,2093
|
|
16
|
48
|
18,60465
|
55,8140
|
|
13
|
61
|
15,11628
|
70,9302
|
|
3
|
64
|
3,48837
|
74,4186
|
|
5
|
69
|
5,81395
|
80,2326
|
|
5
|
74
|
5,81395
|
86,0465
|
|
3
|
77
|
3,48837
|
89,5349
|
|
2
|
79
|
2,32558
|
91,8605
|
|
3
|
82
|
3,48837
|
95,3488
|
|
1
|
83
|
1,16279
|
96,5116
|
|
0
|
83
|
0,00000
|
96,5116
|
|
2
|
85
|
2,32558
|
98,8372
|
|
1
|
86
|
1,16279
|
100,0000
|
|
0
|
86
|
0,00000
|
100,0000
|
Рис. 1.1 Таблица распределения с числом интервалов
k=15
В таблице с числом интервалов k=10
(представленной на рис. 1.2) уже отсутствуют нулевые строки, а так же
увеличивается мономодальность:
|
13
|
13
|
15,11628
|
15,1163
|
|
16
|
29
|
18,60465
|
33,7209
|
|
25
|
54
|
29,06977
|
62,7907
|
|
10
|
64
|
11,62791
|
74,4186
|
|
8
|
72
|
9,30233
|
83,7209
|
|
5
|
77
|
5,81395
|
89,5349
|
|
4
|
81
|
4,65116
|
94,1860
|
|
2
|
83
|
2,32558
|
96,5116
|
|
2
|
85
|
2,32558
|
98,8372
|
|
1
|
86
|
1,16279
|
100,0000
|
|
0
|
86
|
0,00000
|
100,0000
|
Рис. 1.2 Таблица
распределения с числом интевалов k=10
В таблице с числом интервалов k=8,
(представленной на рис.1.3) по мнению автора наиболее подходит для
статистического анализа:
|
15
|
15
|
17,44186
|
17,4419
|
|
28
|
43
|
32,55814
|
50,0000
|
|
19
|
62
|
22,09302
|
72,0930
|
|
10
|
72
|
11,62791
|
83,7209
|
|
5
|
77
|
5,81395
|
89,5349
|
|
5
|
82
|
5,81395
|
95,3488
|
|
2
|
84
|
2,32558
|
97,6744
|
|
2
|
86
|
2,32558
|
100,0000
|
|
0
|
86
|
0,00000
|
100,0000
|
Рис. 1.3 Таблица распределения с числом
интервалов k=8
Таким образом, данные статистического наблюдения
«Численность экономически активного населения Российской Федерации в 2012 году»
(тыс. чел.) предварительно могут быть сведены так как это представлено в
таблице 1.3:
Таблица 1.3 Численность экономически активного
населения по субъектам Российской Федерации в 2012 году (тыс. человек)
|
Численность
населения
|
Частоты
|
В
%
|
В
%, итого
|
|
До
198
|
15
|
15
|
17,44
|
17,44
|
|
От
198 до 575
|
28
|
43
|
32,56
|
50,00
|
|
От
575
до
951
|
19
|
62
|
22,09
|
72,09
|
|
От
951
до
1328
|
10
|
72
|
11,63
|
83,72
|
|
От
1328 до 1704
|
5
|
77
|
5,81
|
89,53
|
|
От
1704 до 2080
|
5
|
82
|
5,81
|
95,35
|
|
От
2080
до
2456
|
2
|
84
|
2,32
|
97,67
|
|
Свыше
2456
|
2
|
86
|
2,32
|
100,00
|
|
ИТОГО
|
86
|
86
|
100,0
|
100,00
|
При этом в данной таблице слабо выдержан её шаг
(за счет того, что ППП применяет расчет с округлением до четвертого знака после
запятой), при этом граница верхнего ряда начинается в области отрицательных
значений.
Рассчитав по формуле (1.2) и округлив до целых
значений, выясним его длину:
 тыс.чел.
тыс.чел.
Задав указанное значение в программе, уточним
таблицу.
В результате окончательная таблица будет
выглядеть в соответствии с рис.1.4:
|
21
|
21
|
24,41860
|
24,4186
|
|
27
|
48
|
31,39535
|
55,8140
|
|
15
|
63
|
17,44186
|
73,2558
|
|
9
|
72
|
10,46512
|
83,7209
|
|
5
|
77
|
5,81395
|
89,5349
|
|
5
|
82
|
5,81395
|
95,3488
|
|
1
|
83
|
1,16279
|
96,5116
|
|
3
|
86
|
3,48837
|
100,0000
|
|
0
|
86
|
0,00000
|
100,0000
|
|
0
|
86
|
0,00000
|
100,0000
|
Рис.1.4 Таблица распределения с числом
интервалов k=10 и шагом 330
В окончательном виде таблица «Численность
экономически активного населения Российской Федерации в 2012 году» (тыс. чел.)
примет вид (табл. 1.4):
Таблица 1.4 Численность экономически активного
населения в Российской Федерации в 2012 году (тыс. человек)
|
Численность
населения в субъектах РФ
|
Частоты
|
Коммулятивные
частоты S
|
В
%
|
В
%, итого
|
|
От
10
до
340
|
21
|
21
|
24,42
|
24,42
|
|
От
340
до
670
|
27
|
48
|
31,40
|
55,81
|
|
От
670
до
1000
|
15
|
63
|
17,44
|
73,26
|
|
От
1000
до
1330
|
9
|
72
|
10,47
|
83,72
|
|
От
1330
до
1660
|
5
|
77
|
5,81
|
89,53
|
|
От
1660 до 1990
|
5
|
82
|
5,81
|
95,35
|
|
От
1990
до
2320
|
1
|
83
|
1,16
|
96,51
|
|
От
2320
до
2650
|
3
|
86
|
3,49
|
100,00
|
|
ИТОГО
|
86
|
86
|
100,0
|
100,00
|
После окончательного представления
статистической таблицы, она подлежит анализу.
Традиционно для изображения вариационных рядов
распределения в отечественной практике используются графики: гистограмма,
огива, кумулята.

Рис. 1.5 Гистограмма распределения регионов
России по значению показателя «Численность экономически активного населения в
Российской Федерации в 2012 году» (тыс. человек) с наложенной кривой
нормального распределения с числом интервалов k=8.
Из данной гистограммы усматривается, что
наибольшее часть населения России проживает в регионах с численностью населения
от 330 до 660 тыс. человек.
Таким образом, можно сказать, что основная часть
экономически активного населения проживает в регионах с численностью до
проумиллиона человек.
При этом за счёт крупных агломераций -
Санкт-Петербурга и Центральной части России в конце гистограммы виден незначительное
увеличение количества жителей в крупных мегаполисах.
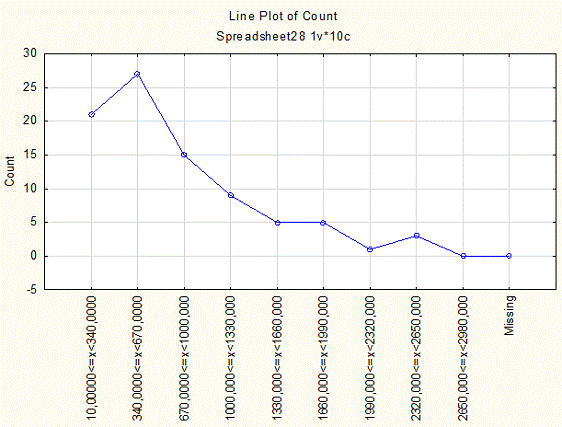
Рис. 1.6 Полигон распределения регионов России
по значению показателя «Численность экономически активного населения в
Российской Федерации в 2012 году» (тыс. человек) с числом интервалов k=8.
Аналогично гистограмме, представленной на
Рис.1.5 видно, что максимальное число субъектов Российской Федерации имеет
численность до полумиллиона человек.
При этом за счёт Санкт-Петербурга и Центральной
части Российской Федерации в конце полигона имеется небольшой всплеск
увеличения количества субъектов Российской Федерации.
Следует отметить, что в случае рассмотрения
полного состава первоначальных статистических данных (с учётом Москвы и
Московской области) этот пик был бы более заострён.

Рис. 1.7. Кумулята распределения регионов России
по значению показателя «Численность экономически активного населения в
Российской Федерации в 2012 году» (тыс. человек) с числом интервалов k=8
(абсолютные частоты).
Рассматривая кумуляты, представленные на Рис.1.7
и Рис.1.8 видно, что значительный прирост накопленных процентных частот (с
24,42% до 55,81%) обеспечивается выше признанным фактором, то есть за чёт
значительного числа субъектов Федерации с численностью экономически активного
населения от 340 до 670 тыс. чел. В других областях значений кумулята имеет
более плавное распределение.

Рис. 1.8. Кумулята распределения регионов России
по значению показателя «Численность экономически активного населения в
Российской Федерации в 2012 году» (тыс. человек) с числом интервалов k=8
(относительные частоты).
При этом, если бы кумулята строилась бы с учётом
100%-й выборки (с учетом выбросов) её конец был бы более заострен.
вариационный ряд асимметрия пирсон
2. Характеристика центральной тенденции
распределения
Для определения средних и наиболее типичных
значений совокупности С.Е. Казаринова [3] рекомендует показатели центра
распределения.
Основные из них - математическое ожидание,
среднее арифметическое, среднее геометрическое, среднее гармоническое,
степенные средние, взвешенные средние, центр сгиба, медиана, мода.
Расчет средних величин производится разными
способами, и, соответственно, применение их тоже зависит от исследуемой
совокупности.
У симметричного среднего одномерного
унимодального распределения математическое ожидание, медиана и мода одинаковы.
В математике и статистике среднее арифметическое
(или просто среднее) набора чисел - это сумма всех чисел в этом наборе,
делённая на их количество. Среднее арифметическое является наиболее общим и
самым распространенным понятием средней величины.
Термин среднее арифметическое предпочитают,
чтобы отличить его от других средних величин, таких как медиана и мода.
Частными случаями среднего арифметического
являются генеральное среднее (генеральной совокупности) и выборочное среднее
(выборки).
Среднее арифметическое рассчитывается по
формуле:
 (2.1)
(2.1)
Хотя среднее арифметическое часто
используется в качестве центральных тенденций, это понятие не относится к
робастной статистике, что означает, что среднее арифметическое подвержено
сильному влиянию «больших отклонений». Примечательно, что для распределений с
большим коэффициентом ассиметрии среднее арифметическое может не
соответствовать понятию «среднего», а значение среднего из робастной статистики
(например, медиана) может лучше описывать центральную тенденцию.
Классическим примером является
подсчёт среднего дохода. Например, отчет о «среднем» чистом доходе в Медине,
штат Вашингтон, подсчитанное как среднее арифметическое всех ежегодных чистых
доходов жителей, даст на удивление большое число из-за Билла Гейтса.
Если, например, рассмотреть выборку
(1,2,2,2,3,9). Среднее арифметическое равно 3,17, но пять значений из шести
ниже этого значения.
Другими характеристиками центральной
тенденции являются мода и медиана.
Мода - это значение во множестве
наблюдений, которое встречается наиболее часто. Иногда в совокупности
встречается более, чем одна мода (например: 2,5,5,5,8,9,9,9,10; мода = 5 и 9).
В этом случае говорят, что совокупность мультимодальна. Из структурных средних
величин только мода обладает таким уникальным свойством. Как правило
мультимодальность указывает на то, что набор данных не подчиняется нормальному
распределению.
Мода, как средняя величина,
употребляется чаще для данных, имеющих нечисловую природу. При экспертной
оценке с её помощью определяют наиболее типы продукта, что учитывается при
прогнозе продаж или планировании их производства.
Медиана - 50-й процентиль, квинтель
0,5 возможное значение признака, который делит ранжированную совокупность
(вариационный ряд выборки) на две равные части: 50 «нижних» единиц ряда будут
иметь значение признака не больше, чем медиана, а «верхние» 50% - не меньше,
чем медиана. Медиана является важной характеристикой распределения случайной
величины и так же как математическое ожидание, может быть использовано для
центрирования распределения. Однако медиана более робастна и поэтому может быть
более предпочтительна для распределений с т.н. тяжёлыми хвостами.
Медиана определяется для широкого
класса распределений (например, для всех непрерывных), а в случае
неопределенности, естественным образом доопределяется, в то время, как
математическое ожидание может быть не определено (например, у распределения
Коши).
Если предположить, что в одной
комнате оказалось 20 человек - 19 бедняков и 1 миллиардер, которые положили на
стол деньги: бедняки по 5 долларов, а богач 1 млрд., то в сумме получится
1000000095 долларов.
Среднее арифметическое в данном
случае будет 50000004,75 долл.
Медиана же составит 5
долл.(полусумма десятого и одиннадцатого значений ранжированного вариационного
ряда)
Таким образом, можно утверждать, что
каждый положил на стол не более 5 долларов.
В данном случае расчет средней
арифметической неподходящая характеристика, так как оно значительно превышает
сумму наличных, имеющихся у среднего человека.
К недостаткам данной характеристики
является то, что при наличии чётного количества случаев и два средних значения
различаются, то медианой может служить любое число между ними (например, в
выборке {1,2,3,4} медианой, по определению, может служить любое число из
интервала (2,3)). На практике в случае чаше всего используют среднее
арифметическое двух средних значений и применяют формулы:
 если n - чётное (2.1а)
если n - чётное (2.1а)
 если n - нечётное
(2.1б)
если n - нечётное
(2.1б)
Воспользовавшись программой
STATISTICA, рассчитываем среднее арифметическое, моду и медиану статистической
таблицы «Численность экономически активного населения в 2012 году» (тыс. чел.):
Таблица 2.1
|
Наименование
показателя
|
Средняя
арифметическая
|
Мода
|
Медиана
|
|
Значение
показателя
|
755,7558
|
439,0
|
568,000
|
Таким образом, среднеарифметическая в отдельно взятом
субъекте Российской Федерации составляет 755 тыс. человек, при этом при расчете
совокупности учитывались как малозаселенных районов в местностях крайнего
Севера и Дальнего Востока так и крупные агломерации. Данное обстоятельство
превышает значение, полученное в ходе графического анализа вариационного ряда.
В связи с тем, что в исходном статистическом
наблюдении встречаются два субъекта Федерации с численностью 439 тыс. чел., то
модой и является данная величина (в противном случае выборка была бы полимодальной).
Медианой является величина 568 тыс. чел.
Указанные значения лежат в плоскости ранее
рассмотренного графического изображения вариационного ряда.
3. Оценка вариации изучаемого признака
Вариация - различие значений какого-либо
признака у разных единиц совокупности за один и тот же промежуток времени.
Причиной возникновения вариации являются различные условия существования разных
единиц совокупности. Вариация - необходимое условие существования и развития
массовых явлений. Определение вариации необходимо при организации выборочного
наблюдения, статистическом моделировании и планировании экспертных опросов. По
степени вариации можно судить об однородности совокупности, устойчивости
значений признака, типичности средней, о взаимосвязи между какими-либо
признаками.
Различают абсолютные и относительные показатели
вариации. К абсолютным относят: размах вариации, среднее линейное отклонение,
среднеквадратическое отклонение, дисперсию, среднее квартальное расстояние.
Относительные показатели: относительный размах
вариации (коэффициент осцилляции), относительное отклонение по модулю (линейный
коэффициент вариации), коэффициент вариации, относительное квартальное
расстояние.
Размах вариации - это разность между
максимальным и минимальным значениями признака.
Он показывает пределы, в которых изменяется
величина признака в изучаемой совокупности.
Пример
Опыт работы у пяти претендентов на
предшествующей работе составляет: 2, 3, 4, 7 и 9 лет.
В данном случае размах вариации = 9 - 2 = 7 лет.
Для обобщенной характеристики различий в
значениях признака вычисляют средние показатели вариации, основанные на учете
отклонений от средней арифметической. За отклонение от средней принимается
разность:
(Xi - X) (3.1)
При этом во избежание превращения в нуль суммы
отклонений вариантов признака от средней (нулевое свойство средней) приходится
либо не учитывать знаки отклонения, то есть брать эту сумму по модулю, либо
возводить значения отклонений в квадрат.
Дисперсия (дисперсия случайной величины) - мера
разброса данной случайной величины, то есть её отклонение от математического
ожидания. В статистике часто употребляется квадратный корень из дисперсии,
называемый среднеквадратичным отклонением, стандартным отклонением или
стандартным разбросом. Стандартное отклонение измеряется в тех же единицах, что
и сама случайная величина, а дисперсия измеряется в квадратах этой единицы
измерения.
Из неравенства Чебышева следует, что случайная
величина удаляется от её математического ожидания не более, чем k стандартных
отклонений с вероятностью 1/k2/
Так, например, как минимум в 75% случаев
случайная величина удаляется от её среднего не более, чем на два стандартных
отклонения, а примерно в 89%- не более, чем на три.
Величина дисперсии по сгруппированным данным
определяется:
 (3.1)
(3.1)
где, xi
- середина i-го интервала; x
-средняя арифметическая величина признака в изучаемой совокупности; Fi
- абсолютные частоты i-го
интервала.
Коэффициент вариации - мера относительного
разброса случайной величины; показывает, какую долю среднего значения этой
величины составляет её средний разброс. В отличии от среднего квадратического
или стандартного отклонения измеряет не абсолютную , а относительную меру
разброса признака в статистической совокупности. Исчисляется в процентах.
Вычисляется только для количественных данных.
 (3.2)
(3.2)
Используя программу STATISTICA,
рассчитываем размах вариации, дисперсию, среднее квадратическое отклонение.
Коэффициент вариации программа STATISTICA не рассчитывает, что отражено в
таблице 3.1.
Таблица 3.1
|
Наименование
показателя
|
Размах
вариации
|
Дисперсия
|
Среднее
квадратическое отклонение
|
|
Значение
показателя
|
2635,000
|
369995,4
|
608,2725
|
Размах вариации получен путем определения
разницы между наибольшим значением статистической выборки (2645) и его
наименьшим значением.
Разброс случайной величины (её дисперсия)
говорит о значительном разбросе показателей вариации и необходимости исключения
самых больших и самых маленьких значений.
Это же подтверждает и показатель
среднеквадратического отклонения.
Данные полученные в ППП STATISTICA полностью
соответствуют расчетным данным (в соответствии с методическими указаниями ниже
будет приведена сравнительная таблица расчётов по ППП и ручных расчётов). При
этом даже уже на этом этапе наглядно видно, что размах вариации рассчитан
правильно.
4. Характеристика структуры распределения
При изучении вариации применяются такие
характеристики вариационного ряда, которые описывают количественно его
структуру, строение. Такова, например, медиана- величина варьирующего признака,
делящая совокупность на две равные части - со значениями признака меньше
медианы и со значениями признака больше медианы
Медиана не зависит от значений признака на краях
ранжированного ряда. Поэтому часто медиану используют как более надежный
показатель типичного значения признака, нежели арифметическая средняя, если ряд
значений неоднороден, включает резкие отклонения от средней. Вряд ли среднюю
можно считать типичной величиной.
При четном числе единиц совокупности за медийную
принимают арифметическую среднюю величину из двух центральных вариант, например
при десяти значениях признака - среднюю из пятого и шестого значений в
ранжированном ряду.
В интервальном вариационном ряду для нахождения
медианы применяется формула:
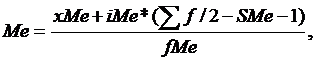 (4.1)
(4.1)
где Хме - начальное значение медианного
интервала;Ме - величина медианного интервала;
∑f - сумма частот ряда (численность
ряда);ме-1 - сумма накопленных частот в интервалах, предшествующих медианному;Ме
- частота медианного интервала.
В дискретном вариационном ряду медианой следует
считать значение признака в той группе, в которой накопленная частота;
превышает половину численности совокупности.
Квартили распределения
Аналогично медиане вычисляются значения
признака, делящие совокупность на четыре равные по числу единиц части. Эти
величины называются квартилями и обозначаются заглавной латинской' буквой Q с
подписным значком номера квартиля. Ясно, что Q2 совпадает с Me. Для первого и
третьего квартилей приведём формулы:
 для первого квартиля (4.2)
для первого квартиля (4.2)
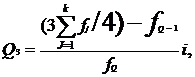 для третьего квартиля (4.3)
для третьего квартиля (4.3)
Значения признака, делящие ряд на
пять равных частей, называют квинтилями, на десять частей - децилями, на сто
частей - перцентилями. Поскольку эти характеристики применяются лишь при
необходимости подробного изучения структуры вариационного ряда, они обычно не
приводятся.
Особенности применения моды в
интервальном вариационном ряду:
) если все значения вариационного
ряда имеют одинаковую частоту, то говорят, что этот вариационный ряд не имеет
моды;
) если две соседних варианты имеют
одинаковую доминирующую частоту, то мода вычисляется как среднее арифметическое
этих вариант;
) если две несоседние варианты имеют
одинаковую доминирующую частоту, то такой вариационный ряд называется
бимодальным;
) если таких вариант более двух, то
ряд полимодальный.
Определение модального интервала в
случае интервального вариационного ряда:
) с равными интервалами модальный интервал
определяется по наибольшей частоте;
) при неравных интервалах - по
наибольшей плотности.
Формула определения моды при равных
интервалах внутри модального интервала:
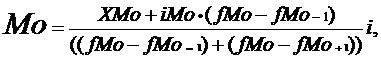 (4.4)
(4.4)
где Хмо - минимальная граница
модального интервала;Мо - величина модального интервала;Мо - частота модального
интервала;Мо-1 - частота интервала, предшествующего модальному;Мо+1 - частота
интервала, следующего за модальным.
Покажем расчет моды на примере,
приведенном в таблице 2.
Используя программу STATISTICA
рассчитаем (Lower quartile) - нижний (первый) квартиль - Q1, который равен
362,0000 и(Upper quartile) - верхний (третий) квартиль -Q3, который равен
1054,0000
В самом деле, из статистической
таблицы (1.4) «Численность экономически активного населения в 2012 году» (тыс.
чел.) видно, что эти значения находятся в первой и четвертой четвертях значений
статистических данных.
Одновременно рассчитываем медиану и
моду интервальном вариационном ряду, руководствуясь формулами (4.1 и 4.4):
Для этого определяем сначала
интервал, в котором она находится (медианный интервал). Таким интервалом будет
такой, комулятивная частота которого равна или превышает половину суммы частот.
Начальное значение медиального
интервала в соответствии с таблицей 1.4) «Численность экономически активного
населения в 2012 году» (тыс. чел.) составляет интервал от 340 до 670 тыс. чел.;
сумма частот данного ряда составляет - 27; величина медиального интервала 330;
сумма частот ряда - 86 (половина сумма частот - 43); сумма частот ряда,
предшествующих медиальному - 21.
При определении значения медианы
предполагают, что значение единиц в границах интервала распределяется
равномерно. Следовательно, если 27 единиц, находящихся в этом интервале,
распределяются равномерно в интервале, равном 330, то 3 единицам (43-40) будет
соответствовать следующая его величина:
* 3/27 = 36,7
Прибавив полученную величину к
минимальной границе медианного интервала, получим искомое значение медианы:
Ме = 340 +36,7 = 376,7 тыс. чел.
Поскольку в данном случае, значение
полученное из статистических формул, решено эмпирически, а программа STATISTICA
использует конкретные данные, то можно считать, что задача решена правильно.
Подставляя в формулу необходимые
данные, решаем:
Ме = 340 + 330* (86/2 - 40)/27=
376,7 тыс. чел.,
что полностью соответствует
полученному ранее значению.
Аналогично рассчитывается мода
интервального вариационного ряда.
Чтобы найти моду, первоначально
определим модальный интервал. Из таблицы (1.4)«Численность экономически
активного населения в 2012 году» (тыс. чел.) видно, что наибольшая частота
соответствует интервалу, где варианта лежит в пределах от 340 до 670 тыс. чел.
(нижняя граница модального интервала 340 тыс. чел.)
Величина модального интервала равна
330; частота модального интервала равна 27; частота интервала, предшествующего
модальному - 21; частота интервала, следующего за модальным - 15.
Подставляя в формулу, расчета моды в
интервальном вариационном ряду получим:
Мо = 340 + 330 *(27 - 21)/((27 - 21) + (27 -
15))=
+330*6/6+6=340+2040/12= 510 тыс.чел.
В связи с много вариантностью таблицы
«Численность экономически активного населения в 2012 году» (тыс. чел.) и
большим наличием данных в этой строке мода несколько различается от данных,
полученных с помощью ППП STATISTICA .
Это дополнительно свидетельствует о том, что
статистическую обработку показателей лучше выполнять с помощью прикладных
средств с первоначальным объёмом данных, чем сведенных в таблицу.
5. Характеристика формы распределения
Асимметрия - или коэффициент асимметрии (термин
был впервые введен Пирсоном, 1895) является мерой несимметричности
распределения, то есть числовым значением, характеризующим степени
несимметричности распределения данной случайной величины.
Например, если асимметрия (показывающая
отклонение распределения от симметричного) существенно отличается от 0, то
распределение несимметрично, в то время как нормальное распределение абсолютно
симметрично.
Итак, у симметричного распределения асимметрия
равна 0.
Асимметрия распределения с длинным правым хвостом
положительна. Если распределение имеет длинный левый хвост, то его асимметрия
отрицательна. Коэффициент асимметрии рассчитывается по формуле:
 (5.1)
(5.1)
где 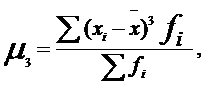 (5.1а)
(5.1а)
где, 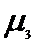 -центральный момент третьего
порядка;
-центральный момент третьего
порядка;
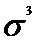 -средний квадрат отклонений в кубе.
-средний квадрат отклонений в кубе.
Если 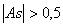 , то асимметрия значительная.
, то асимметрия значительная.
Если 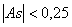 , то As незначительная.
, то As незначительная.
Если As<0, то As - левосторонняя.
При этом 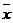 >Ме>Мо.
>Ме>Мо.
Если As>0, то As -
правосторонняя.
Коэффициент асимметрии изменяется от -3 до +3.
Для однородных совокупностей характерны
одновершинные кривые, много вершинная кривая говорит о неоднородности
совокупности и необходимости перегруппировки.
Выяснение общего характера распределения
предполагает оценку его однородности.
Преобразовав (Таб.1.4) рассчитаем асимметрию
данной выборки (Таб.5.1):
Таблица 5.1
|
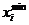 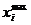 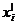  
|
|
|
|
|
|
10
|
340
|
175
|
21
|
-4113390702,50
|
|
340
|
670
|
505
|
27
|
-425712816,64
|
|
670
|
1000
|
835
|
15
|
7464379,57
|
|
1000
|
1300
|
1165
|
9
|
616864970,21
|
|
1300
|
1660
|
1495
|
5
|
2019918197,33
|
|
1660
|
1990
|
1825
|
5
|
6112244434,84
|
|
1990
|
2320
|
2155
|
1
|
2739558294,75
|
|
2320
|
2650
|
2485
|
3
|
15512801588,43
|
|
k
|
|
|
86
|
22469748345,99
|
При этом  равен
755,7558.
равен
755,7558.
Из таблицы находим центральный
момент третьего порядка (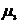 ) равный
261276143,56
) равный
261276143,56
Возведя среднее квадратическое
отклонение (СКО = 608,2725) в куб (СКО =  ) и применив формулу (5.1) получаем
значение асимметрии равное 1,161.
) и применив формулу (5.1) получаем
значение асимметрии равное 1,161.
Эксцесс - (термин был впервые введен
Пирсоном, 1905) или точнее, коэффициент эксцесса измеряет «пикообразность»
распределения. Если эксцесс (показывающий «остроту пика» распределения)
существенно отличен от 0, то распределение имеет или более закругленный пик,
чем нормальное, или, напротив, имеет более острый пик (возможно, имеется
несколько пиков). Обычно, если эксцесс положителен, то пик заострен, если
отрицательный, то пик закруглен. Эксцесс нормального распределения равен 0.
Используя формулу:
 5.2)
5.2)
И преобразовав (Таб.6.1) рассчитаем
эксцесс.
Таблица 5.2
|

|
|
|
|
|
|
10
|
340
|
175
|
21
|
2388875508145,11
|
|
340
|
670
|
505
|
27
|
106749957906,35
|
|
670
|
1000
|
835
|
15
|
591508787,13
|
|
1000
|
1300
|
1165
|
9
|
252448411241,92
|
|
1300
|
1660
|
1495
|
5
|
1493212811854,14
|
|
1660
|
1990
|
1825
|
5
|
6535481910936,26
|
|
1990
|
2320
|
2155
|
1
|
3833311054490,20
|
|
2320
|
2650
|
2485
|
3
|
26825422172547,80
|
|
k
|
|
|
86
|
41436093335908,90
|
При этом равен
755,7558
СКО = 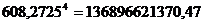
Рассчитав в Microsoft Excel эксцесс,
получим:
Ех1 = 0,520 для Таб. 1.4
Ех2 = - 0,050 для Таб. 6.1
Таким образом, можно говорить, что
правосторонняя асимметрия с длинным правым хвостом, поскольку значение
показателей лнжит в пределах значений от -3 до +3 можно говорить, что она
подчиняется нормальному распределению.
Одной из часто встречающихся
статистических проблем является проверка гипотез относительно математического
ожидания исследуемых выборок. Существует целый ряд статистических тестов,
называемых t-тестами Стьюдента, проверяющих различные гипотезы относительно
математического ожидания. тест для одной выборки
Этот тест используется для проверки
гипотезы о том, что математическое ожидание случайной величины X,
представленной выборкой xS , имеет заданное значение μ. Тест
требует, чтобы переданная в него выборка являлась выборкой нормальной случайной
величины.
В процессе своей работы тест
вычисляет t-статистику
Если величина X распределена
нормально, то статистика t будет иметь распределение Стьюдента с N-1 степенями
свободы. Это позволяет нам использовать распределение Стьюдента для определения
уровня значимости, соответствующего полученному значению t-статистики.
Замечание.
В случае если X не является
нормальной случайной величиной, то величина t будет иметь другое, неизвестное
распределение, и, строго говоря, t-тест Стьюдента нельзя применять. Однако в
соответствии с центральной предельной теоремой при росте размера выборки
распределение t будет стремиться к распределению Стьюдента. Таким образом, если
размер выборки достаточно велик, то мы можем использовать t-тест, даже если
требование нормальности распределения не выполняется. Однако не существует
простого способа определить, какое N достаточно велико. В каждом конкретном
случае есть своя граница, зависящая от того, насколько исследуемое
распределение отклоняется от нормального. Некоторые источники приводят в
качестве «достаточно большого N» 30, но даже этот размер выборки может
оказаться недостаточен. Альтернативой в этом случае может являться
непараметрический тест - критерий знаков <C:\Documents and
Settings\Admin\Local Settings\Temp\Rar$DI15.218\signtest.php> или W-критерий
Уилкоксона <C:\Documents and Settings\Admin\Local
Settings\Temp\Rar$DI15.218\wilcoxonsignedrank.php>.
При необходимости сравнения только
двух групп можно использовать частный случай дисперсионного анализа - критерий
Стьюдента. Если при проведении t-анализа имеются только средние
значения, величина стандартного отклонения и численностью групп можно пойти по
пути изучения возможности R.
Ниже приведем сравнение статистических
показателей рассчитанных различными способами (табл.5.3)
Таблица 5.3
|
№
|
Название
показателя
|
Значение
в ППП STATISTIKA
|
Значения
ручного расчета по сгруппированным данным
|
|
1
|
Средняя
арифметическая
|
755,7558
|
779,6
|
|
2
|
Медиана
|
568,0000
|
578,8
|
|
3
|
Мода
|
439,0000
|
448,0
|
|
4
|
Дисперсия
|
369995,4
|
389243,3
|
|
5
|
Верхний
квартиль
|
362,0000
|
387,0
|
|
6
|
Нижний
квартиль
|
1054,0000
|
1069,0
|
|
7
|
Размах
вариации
|
2635,0000
|
2635,0
|
|
8
|
Среднее
квадратическое отклонение
|
608,2725
|
612,275
|
6. Сглаживание эмпирического распределения
Проверка гипотезы о законе распределения
Сравнивая полученные величины теоретических
частот f' c эмпирическими (фактическими) частотами f, убеждаемся, что их
расхождения могут быть весьма невелики.
В данное распределение близко к нормальному.
Объективная характеристика соответствия
теоретических и эмпирических частот может быть получена при помощи специальных
статистических показателей, которые называют критериями согласия.
Для оценки близости эмпирических и теоретических
частот применяются критерий согласия Пирсона, критерий согласия Романовского,
критерий согласия Колмогорова.
Наиболее распространенным является
критерий согласия Пирсона, , который
можно представить как сумму отношений квадратов расхождений между f' и f к
теоретическим частотам по формуле 6.1:
, который
можно представить как сумму отношений квадратов расхождений между f' и f к
теоретическим частотам по формуле 6.1:
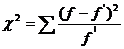 (6.1)
(6.1)
Вычисленное значение критерия 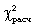 необходимо
сравнить с табличным (критическим) значением
необходимо
сравнить с табличным (критическим) значением 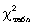 .
Табличное значение определяется по специальной таблице, оно зависит от принятой
вероятности Р и числа степеней свободы k (при этом k = m - 3, где m - число
групп в ряду распределения для нормального распределения). При расчете критерия
согласия Пирсона должно соблюдаться следующее условие: достаточно большим
должно быть число наблюдений (n
.
Табличное значение определяется по специальной таблице, оно зависит от принятой
вероятности Р и числа степеней свободы k (при этом k = m - 3, где m - число
групп в ряду распределения для нормального распределения). При расчете критерия
согласия Пирсона должно соблюдаться следующее условие: достаточно большим
должно быть число наблюдений (n  50), при этом если в
некоторых интервалах теоретические частоты < 5, то интервалы объединяют для
условия > 5.
50), при этом если в
некоторых интервалах теоретические частоты < 5, то интервалы объединяют для
условия > 5.
Если 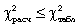 ,
то расхождения между эмпирическими и теоретическими частотами распределения
могут быть случайными и предположение о близости эмпирического распределения к
нормальному не может быть отвергнуто.
,
то расхождения между эмпирическими и теоретическими частотами распределения
могут быть случайными и предположение о близости эмпирического распределения к
нормальному не может быть отвергнуто.
Используя статистическую таблицу 1.4 (стр.19) и
методические указания произведем расчет и анализ значений критерия согласия
Пирсона, объединив некоторые интервалы с частотами < 5 предыдущих
интервальных рядов:
Таблица 6.1 Таблица для расчёта сглаживания
эмпирического распределения.
|
№
|
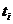  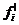 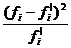
|
|
|
|
|
|
|
|
|
1
|
10
|
340
|
175
|
21
|
-0,95476
|
-20,05
|
-59,5298
|
-108,938
|
|
2
|
340
|
670
|
505
|
27
|
-0,41224
|
-11,1305
|
-42,4894
|
-113,647
|
|
3
|
670
|
1000
|
835
|
15
|
0,130277
|
1,954162
|
4,144309
|
28,43563
|
|
4
|
1000
|
1300
|
1150
|
9
|
0,648137
|
5,833237
|
7,422538
|
0,335247
|
|
5
|
1300
|
1660
|
1480
|
5
|
1,190657
|
5,953287
|
4,208498
|
0,14886
|
|
6
|
1660
|
1990
|
1825
|
5
|
1,757837
|
8,789187
|
6,213252
|
0,23691
|
|
7
|
1990
|
2650
|
2320
|
4
|
2,571617
|
10,28647
|
5,817369
|
0,567753
|
|
k
|
|
|
|
86
|
|
|
-74,2132
|
-192,86
|
рассчитаем в Microsoft Excel по
формуле (6.2)
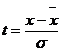 (6.2)
(6.2)
Где x - значение изучаемого
признака;
- среднее арифметическое (в нашем
случае 755,7558);
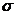 - среднее квадратическое (в нашем
случае 608,2725)
- среднее квадратическое (в нашем
случае 608,2725)
Аналогично рассчитываем по
формуле(6.3):
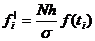 6.3)
6.3)
где N - объем совокупности; h -
величина интервала
Если все эмпирические частоты равны
соответствующим теоретическим частотам, то χ2 равно нулю. Очевидно, что чем
больше отличаются эмпирические и теоретические частоты, тем χ2 больше; если
расхождение несущественно, то χ2 должно быть малым. Имеются специальные
таблицы критических значений χ2 при 5%-ном и 1%-ном уровнях
значимости. Критические значения зависят от числа степеней свободы (d.f. -
degrees of freedom) и уровня значимости.
Число степеней свободы
рассчитывается так: если эмпирический ряд распределения имеет k категорий, то k
эмпирических частот f1, f2, …, fk должны быть связаны следующим соотношением:

Если параметры теоретического
распределения известны, то только k - 1 частот могут принимать произвольные значения,
т. Е. свободно варьировать, а последняя частота может быть найдена из
указанного соотношения. Поэтому говорят, что система из k частот благодаря
наличию одной связи теряет одну «степень свободы» и имеет только k - 1 степеней
свободы. Кроме того, если при нахождении теоретических частот р параметров
теоретического распределения неизвестны, то они должны быть найдены по данным
эмпирического ряда. Это накладывает на эмпирические частоты еще р связей,
благодаря чему система теряет еще р степеней свободы. Таким образом, число
свободно варьируемых частот (а значит, и число степеней свободы) становится
равным:
d.f. = (k - 1) - р = k - (р + 1).
Полученное значение критерия χ2 сравнивается
с табличным при числе степеней свободы, равном числу групп (с условием Ф.
Йейтса), за минусом трех - по числу фиксированных параметров в формуле
нормального закона распределения и с учетом равенства сумм теоретических и
фактических частот.
Сумма теоретических частот
нормального распределения меньше суммы фактических частот, так как нормальный
закон не ограничен рамками фактических минимума и максимума.
Ясно, что гипотеза о соответствии
распределения хозяйств по урожайности нормальному закону не может быть
отклонена.
Какое практическое значение может
иметь произведенная проверка гипотезы? Во-первых, соответствие нормальному
закону позволяет прогнозировать, какое число хозяйств (или доля совокупности)
попадает в тот или иной интервал значений признака. Во-вторых, нормальное
распределение возникает при действии на вариацию изучаемого показателя
множества независимых факторов. Из этого следует, что нельзя существенно
снизить вариацию урожайности, воздействуя только на один-два управляемых
фактора, скажем удобрения или энергозатраты.
С помощью критерия χ2 можно
проверять не только гипотезу о согласии эмпирического распределения с
нормальным законом, но и с любым другим известным законом распределения -
равномерным распределением, распределением Пуассона и т. Д. Например, суд
рассматривает жалобу посетителей казино на то, что, по их мнению, игральная
кость, которой там пользуются, фальшива, некоторые числа очков, якобы, выпадают
чаще, чем другие, и этим пользуются крупье, обирающие игроков.
Суд назначает экспертизу игральной
кости: эксперт делает 600 бросков и записывает число выпавших единиц, двоек,
троек и т. Д.
Полученное эмпирическое
распределение сравнивается с теоретическим, т. Е. равномерным: в правильной
кости вероятность выпадения каждого числа очков должна быть равна 1/6, при 600
бросках это даст по 100 выпадений каждого числа очков. С помощью критерия χ2 проверяется
нулевая гипотеза о том, что различия эмпирического и теоретического
распределений случайны, т. Е. не являются систематическим результатом
фальсификации формы кости или положения центра тяжести в ней; H0 : fфакт =
fтеор
Используя методические указания и
программу STATISTICA, произведем сглаживание эмпирического распределения путём
последовательного построения нормального, логнормального и прямоугольного типов
распределения.
В результате получим следующие
таблицы (Таб.6.2 - Таб.6.4)
Проверка гипотезы о нормальном распределении
переменной Var1.
Проверка гипотезы о прямоугольном распределении
переменной Var1
Проверка гипотезы о логарифмически нормальном
распределении переменной Var1.
Проиллюстрируем полученные данные, сгладив
эмпирическое распределение переменной Var1 нормальным распределением а
соответствии с рисунками (Рис.6.1. - Рис.6.3.)
Таблица 6.2
|
Upper Boundare
|
Variable: Var1, Distribution:
Normal (Spreadsheet41) Chi-Square = 12,19147, df = 3 (adjusted) , p = 0,00676
|
|
Observed Frequency
|
Cumulative Observed
|
Percent Observed
|
Cumul.% Observed
|
Expected Frequency
|
Cumulative Expected
|
Percent Expected
|
Cumul. % Expected
|
Observed Expected
|
|
<=339.375
|
21
|
21
|
24.41860
|
24.4186
|
21.22654
|
21.22654
|
24.68202
|
24.6820
|
-0.22654
|
|
668.750
|
27
|
48
|
31.39535
|
55.8140
|
16.88266
|
38.10920
|
19.63100
|
44.3130
|
10.11734
|
|
998.125
|
15
|
63
|
17.44186
|
73.2558
|
18.20812
|
56.31732
|
21.17223
|
82.6373
|
-3.20812
|
|
1327.50
|
9
|
72
|
10.46512
|
83.7209
|
14.75117
|
71.06849
|
17.15252
|
82.6378
|
-5.75117
|
|
1656.875
|
5
|
77
|
5.81395
|
89.5349
|
8.97647
|
80.04496
|
10.43776
|
93.0755
|
-3.97647
|
|
1986.25
|
5
|
82
|
5.81395
|
95.3488
|
4.10260
|
84.14756
|
4.77046
|
97.8460
|
0.89740
|
|
2315.625
|
1
|
83
|
1.16279
|
96.5116
|
1.40805
|
85.55561
|
1.63727
|
99.4833
|
-0.40805
|
|
< infinity
|
3
|
86
|
3.48837
|
100.000
|
0.44439
|
86.00000
|
0.51673
|
100.000
|
2.55561
|
Таблица 6.3
|
Upper Boundare
|
Variable: Var1, Distribution:
Rectangular (Spreadsheet44) Chi-Square = 56,88372, df = 5, p = 0,00000
|
|
Observed Frequency
|
Cumulative Observed
|
Percent Observed
|
Cumul.% Observed
|
Expected Frequency
|
Cumulative Expected
|
Percent Expected
|
Cumul. % Expected
|
Observed Expected
|
|
<=339.375
|
21
|
21
|
24.41860
|
24.4186
|
10,77040
|
10,77040
|
12,52372
|
12,5237
|
10,22960
|
|
668.7500
|
27
|
48
|
31.39535
|
55.8140
|
10,77040
|
21,54080
|
12,52372
|
25,0474
|
16,22960
|
|
998.1250
|
15
|
63
|
17.44186
|
73.2558
|
10,77040
|
32,31120
|
12,52372
|
37,5712
|
4,22960
|
|
1327.500
|
9
|
72
|
10.46512
|
83.7209
|
10,77040
|
43,08159
|
12,52372
|
50,0949
|
|
1656.875
|
5
|
77
|
5.81395
|
89.5349
|
10,77040
|
53,85199
|
12,52372
|
62,6186
|
-5,77040
|
|
1986.250
|
5
|
82
|
5.81395
|
95.3488
|
10,77040
|
64,62239
|
12,52372
|
75,1423
|
-5,77040
|
|
2315.625
|
1
|
83
|
1.16279
|
96.5116
|
10,77040
|
75,39279
|
12,52372
|
87,6660
|
-9,77040
|
|
< infinity
|
3
|
86
|
3.48837
|
100.0000
|
10.60721
|
86.00000
|
12,33397
|
100,000
|
-7,60721
|
Таблица 6.4.
|
Upper Boundare
|
Variable: Var1, Distribution:
Rectangular (Spreadsheet44) Chi-Square = 56,88372, df = 5, p = 0,00000
|
|
Observed Frequency
|
Cumulative Observed
|
Percent Observed
|
Cumul.% Observed
|
Expected Frequency
|
Cumulative Expected
|
Percent Expected
|
Cumul. % Expected
|
Observed Expected
|
|
<=339.3750
|
21
|
21
|
24.41860
|
24.4186
|
33,00682
|
33,00682
|
38,38002
|
38,3800
|
-12,0068
|
|
668.75000
|
27
|
48
|
31.39535
|
55.8140
|
19,44743
|
52,45425
|
22,61329
|
60,9933
|
7,5526
|
|
998.12500
|
15
|
63
|
17.44186
|
73.2558
|
10,48496
|
62,93920
|
12,19181
|
73,1851
|
4,5150
|
|
1327.50000
|
9
|
72
|
10.46512
|
83.7209
|
6,30037
|
69,23957
|
7,32601
|
80,5111
|
2,6996
|
|
1656.87500
|
5
|
77
|
5.81395
|
89.5349
|
4,08683
|
73,32640
|
4,75213
|
85,2633
|
0,9132
|
|
1986.25000
|
5
|
82
|
5.81395
|
95.3488
|
2,80099
|
76,12739
|
3,25697
|
88,5202
|
2,1990
|
|
2315.62500
|
1
|
83
|
1.16279
|
96.5116
|
2,00097
|
78,12836
|
2,32671
|
90,8469
|
-1,0010
|
|
< infinity
|
3
|
86
|
3.48837
|
100.0000
|
7,87164
|
86.00000
|
9,15307
|
100,0000
|
-4,8716
|

Рис. 6.1
Рис. 6.2
Рис. 6.3
Заключение
В рассмотренной таблице интервального
вариационного ряда «Численность экономически активного населения по субъектам
Российской Федерации в 2012 году» определена среднестатистическая численность
населения в субъектах России, при этом выбросами оказались Москва и Московская
область.
Наибольшая часть населения России проживает в
субъектах Федерации с численностью от 275 до 540 тыс. чел.
Мода таблицы составляет 439 тыс. чел., медиана
568 тыс. чел., при этом мода в таблице возникла по причине наличия в составе
России 2 регионов с одинаковым количеством жителей (в противно случае таблица
была бы полимодальной).
Среднее арифметическое составляет 755,7558 тыс.
чел., что дополнительно свидетельствует о факте проживания основного населения
России в относительно небольших по численности субъектах Федерации.
Проведенная характеристика форм распределения с
расчетом коэффициентов асимметрии и эксцесса показал, что имеет место
нормальное распределение с правосторонней асимметрией.
Это же было проверено критериями согласия
Пирсона.
Список использованной литературы
1. Боровиков В.П., STATISTICA.
Искусство анализа данных на компьютере: для профессионалов / В.П. Боровиков. -
2-е изд. - СПб. : - 2011. - 688 с.
. Венецкий И.Г., Основные
математико-статистические понятия и формулы в экономическом анализе. Справочник
/ И.Г. Венецкий, В.И. Венецкая. - 2-е изд., перераб. и доп. - М.: Статистика,
1979 - 477 с.
. Ефимова М.Р., Общая теория
статистики: учеб. / М.Р. Ефимова, Е.В. Петрова, В.Н. Румянцев. - М.: ИНФРА-М,
2002. - 416 с.