Проверка гипотезы о независимости логарифмической доходности за различные интервалы времени при большом, среднем и малом объеме торгов
Федеральное
государственное образовательное бюджетное учреждение высшего профессионального
образования
«Финансовый
университет при Правительстве Российской Федерации»
Кафедра
«Теория вероятности и математическая статистика»
Курсовая
работа на тему:
«Проверка
гипотезы о независимости логарифмической доходности за различные интервалы
времени при большом, среднем и малом объеме торгов»
Вид
исследуемых данных:
Котировки
акций компаний, входящих в индекс
AMEX Major Market
Выполнила:
студентка группы ПМ2-1
Радостева М.В.
Научный руководитель:
проф. Браилов А.В.
Москва 2014
г.
Содержание
Введение
1. Предварительный анализ данных
1.1 Количество торговых дней
1.2 Скачки цен
2. Теоретическая справка по проверке гипотез
2.1 Статистическая гипотеза и ошибки первого и
второго рода
2.2 Схема проверки статистической гипотезы
2.3 Р-значение критерия
2.4 Критерий 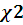 -Пирсона
-Пирсона
2.5 Критерий Колмогорова
3. Проверка гипотез для модельных данных
4. Выбор альтернативной гипотезы и оценка
мощности критерия
4.1 Альтернативные гипотезы
4.2 Мощность критерия
5. Проверка гипотез для реальных данных
Заключение
Литература
Приложения
Введение
Целью исследования является проверка гипотезы о независимости
логарифмической доходности за различные интервалы времени при большом, среднем
и малом объеме торгов (для каждого года и каждого тиккера будем искать
эмпирическое распределение логарифмических доходностей, а затем, делая выборку
меньше квантиля 1/3 уровня, от 1/3 до 2/3 и больше 2/3, получим соответственно
малый, средний и большой объем торгов для каждого года и каждого тиккера).
Альтернативные гипотезы будут такие: зависимость прямая и зависимость обратная.
В качестве объекта исследования выступают котировки акций компаний,
входящих в индекс AMEX Major Market в период с 1 января 2010 года по 31 декабря
2013 года. Используются данные 20 компаний входящие в индекс, тиккеры этих
компаний следующие:
AXP, BA, CVX, DD, DIS, DOW, GE, HPQ, IBM, JNJ, JPM, KO, MCD, MMM, MRK, MSFT, PG, WFC, WMT, XOM.
Проверка гипотезы будет осуществляться 20*4=80 раз.
Главный критерий: - критерий 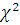 Пирсона.
Пирсона.
Планируемая новизна состоит в том, что я использую 2 альтернативные
гипотезы вместо одной.
1. Предварительный анализ данных
В качестве исследуемых данных я взяла индекс AMEX Major Market и входящие
в него 20 компаний. Источники списка компаний, входящих в индекс и
соответствующие им котировки акций взяла с сайта #"815987.files/image003.gif">
Рисунок 1.График с максимальным однодневным повышением цены (HPQ)
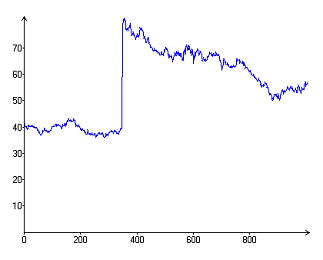
Рисунок 2.График с максимальным однодневным снижением цены (KO)
2. Теоретическая справка по проверке гипотез
.1 Статистическая гипотеза и ошибки первого и второго рода
Для начала следует отметить, что мы подразумеваем под статистической
гипотезой.
Статистическая гипотеза - это всякое высказывание о виде
неизвестного распределения или о параметрах известных распределений.[2, c.253]
Статистические гипотезы бывают параметрическими, то есть гипотезы о
параметрах распределения известного вида и непараметрические, которые
предполагают о виде неизвестного распределения.
Одну из гипотез выдвигают в качестве основной и называют  , а другую, являющуюся ее логическим
отрицанием, то есть противоположную - в качестве конкурирующей (или
альтернативной) гипотезы и обозначают
, а другую, являющуюся ее логическим
отрицанием, то есть противоположную - в качестве конкурирующей (или
альтернативной) гипотезы и обозначают 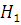 .[5,c.245]
.[5,c.245]
Статистическая гипотеза бывает простой или сложной. Статистическая
гипотеза называется простой, если параметр определен однозначно, соответственно
сложной называется такая гипотеза, параметр которой не определен однозначно.
Например, гипотеза :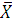 =5 - простая, а альтернативные ей :
=5 - простая, а альтернативные ей : , :
, : , :
, :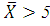 - сложные.
- сложные.
На основе выборки из генерального распределения 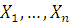 необходимо принять либо гипотезу , либо .Правило, по которому принимается
одна из гипотез и отвергается другая, называют статистическим критерием
проверки гипотезы .
необходимо принять либо гипотезу , либо .Правило, по которому принимается
одна из гипотез и отвергается другая, называют статистическим критерием
проверки гипотезы .
При проверке выдвинутой гипотезы могут возникать ошибки первого и второго
рода.
Если отклоняется нулевая гипотеза, которая на самом деле
верна, то это ошибка первого рода, а если принимается нулевая гипотеза, которая
на самом деле не верна, то это ошибка второго рода.
Вероятность ошибки первого рода обозначается через 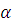 и называется уровнем значимости.
Вероятность ошибки второго рода обозначается
и называется уровнем значимости.
Вероятность ошибки второго рода обозначается 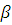 .
.
Желательно, чтобы и первая, и вторая ошибки были малы, однако более
важным является контроль уровня . Вероятность задается заранее, обычно малым числом, поскольку это -
вероятность ошибочного заключения.[4,c. 289]
Например, уровень значимости =0,05 будет означать, что при
проверке гипотезы в среднем в 5 из 100 случаев мы совершим ошибку первого
рода.
Таблица 5. Таблица принятия решения при ошибках 1-го и 2-го рода
|
Статистическое решение
|
Реальная ситуация
|
|
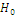 верна верна
|
ложна
|
|
 отвергается отвергается
|

|
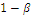
|
|
не отвергается
|
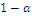
|
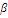
|
Множество значений критерия, при которых нулевая гипотеза отклоняется,
называется областью критических значений (обозначим 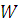 ). Для критериев проверки гипотез
выбираются надлежащие «уровни значимости»(0,01; 0,05; и др.), которые считаются
практически невозможными (с некоторым риском).
). Для критериев проверки гипотез
выбираются надлежащие «уровни значимости»(0,01; 0,05; и др.), которые считаются
практически невозможными (с некоторым риском).
Критическая область данного критерия - это такая область, вероятность попадания
в которую в случае, когда гипотеза 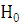 верна, в точности равна уровню
значимости.[4, c.293]
верна, в точности равна уровню
значимости.[4, c.293]
Под мощностью критерия (обозначим  ) понимается вероятность не совершить
ошибку второго рода.
) понимается вероятность не совершить
ошибку второго рода.
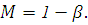
Чем больше мощность критерия, тем вероятность ошибки второго рода меньше.
Также стоит отметить, что одновременное уменьшение ошибок 1-го и 2-го рода
возможно только при увеличении объема выборок. Поэтому обычно при заданном
уровне значимости отыскивается критерий с наибольшей мощностью.
2.2 Схема проверки статистической гипотезы
1) Для основной гипотезы формируются альтернативные гипотезы 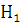 .
.
2) Задается значение уровня значимости .
3) Рассматриваются теоретические выборки значений случайных величин,
о которых сформулирована гипотеза , и формулируется случайная величина
T. Значения и распределение T определяется по выборкам при предположении о
верности гипотезы . Т - статистика критерия.
4) Задается область критических значений и область принятия гипотезы
(область принятия решения D - это область, вероятность попадания
в которую статистики T
определяется как 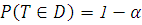 ).
).
5) Вычисляются наблюдаемые значения статистики критерия, и
проверяется попадание статистики критерия в одну из областей. Если статистика
попала в область принятия гипотезы , то принимается, в противном случае -
отвергается.
2.3 Р-значение критерия
В своей работе я буду использовать такое понятие как Р-значение, поэтому
стоит дать определение этому понятию.
Для фиксированной реализации 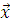 случайной выборки
случайной выборки 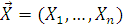 Р-значением статистического критерия
называется такое число
Р-значением статистического критерия
называется такое число  для любого уровня значимости , при котором гипотеза принимается, и
для любого уровня значимости , при котором гипотеза принимается, и 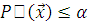 для любого уровня значимости , при котором гипотеза отвергается.
для любого уровня значимости , при котором гипотеза отвергается.
Пусть 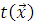 - наблюдаемое фиксированное значение статистики критерия, а
- наблюдаемое фиксированное значение статистики критерия, а  - наблюдаемые значения статистики
критерия для случайной выборки, тогда Р-значение удовлетворяет соотношению:
- наблюдаемые значения статистики
критерия для случайной выборки, тогда Р-значение удовлетворяет соотношению:
) Если критическая область представлена в виде  , где
, где 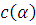 - непрерывно убывающая функция, то
- непрерывно убывающая функция, то 
2) Если критическая область представлена в виде  , где - непрерывно возрастающая функция, то
, где - непрерывно возрастающая функция, то 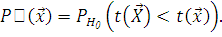
P-значение
с гораздо большей точностью, чем обычные способы проверки статистических
гипотез, позволяет установить, принимается ли гипотеза или отвергается.
2.4 Критерий 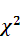 -Пирсона
-Пирсона
Для начала стоит отметить, что я применяю критерий Пирсона для проверки независимости
логарифмических доходностей, поэтому теоретическая справка будет касаться
непосредственно проверки независимости по данному критерию.
Пусть имеется случайная выборка  из генеральной совокупности
двумерной дискретной случайной величины
из генеральной совокупности
двумерной дискретной случайной величины 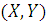 , где случайная величина
, где случайная величина 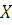 может принимать значения
может принимать значения 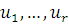 , а случайная величина
, а случайная величина 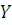 - значения
- значения  . Определим случайную величину
. Определим случайную величину 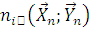 , реализация
, реализация  которой равна количеству элементов
выборки
которой равна количеству элементов
выборки 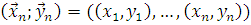 , совпадающих с элементом
, совпадающих с элементом 
Определим случайные величины

При этом  - количество элементов выборки
- количество элементов выборки 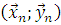 , в которых встретилось значение
, в которых встретилось значение  , а
, а 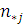 - количество элементов выборки , в которых встретилось значение
- количество элементов выборки , в которых встретилось значение 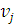 , кроме того, имеются очевидные
равенства
, кроме того, имеются очевидные
равенства

Результаты наблюдений удобно оформлять в виде таблицы, называемой
таблицей сопряженности признаков.
Таблица 6. Сопряженность признаков
|
X
|
Y
|
|

|

|
…
|

|
|
|
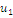
|
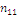
|
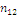
|
…
|
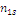
|
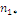
|
|
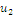
|

|
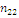
|
…
|
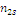
|
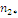
|
|
…
|
…
|
…
|
…
|
…
|
…
|
|
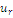
|

|
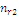
|
…
|
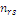
|

|
|
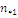
|

|
…
|
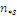
|
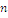
|
Пусть далее
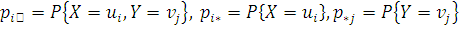 ,
, .
.
Дискретные случайные величины и независимы тогда и только тогда,
когда 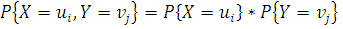 ,
,
Потому основная гипотеза о независимости дискретных случайных величин
записывается следующим образом:
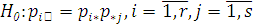
А соответствующая альтернативная гипотеза:
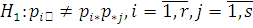
Для проверки основной гипотезы К. Пирсон предложил использовать
статистику  , называемую статистикой Фишера - Пирсона, реализация
, называемую статистикой Фишера - Пирсона, реализация 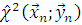 которой определяется формулой
которой определяется формулой
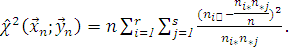
Из закона больших чисел следует, что при 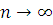
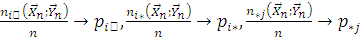
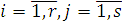 .
.
Поэтому при истинности гипотезы и больших объемах выборки должно выполняться приближенное
равенство
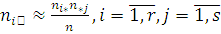
Значит значение статистики должны быть «не слишком большими».
Стоит отметить, что в данном случае - наблюдаемые частоты, а  - ожидаемые при выполнении гипотезы
частоты. В общем случае величина =
- ожидаемые при выполнении гипотезы
частоты. В общем случае величина =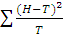 , где Н-наблюдаемые частоты, Т -
теоретические частоты.
, где Н-наблюдаемые частоты, Т -
теоретические частоты.
Теорема. Если истина гипотеза , то распределение статистики при слабо сходится к случайной величине,
имеющей -распределение с числом степеней свободы


В соответствии с теоремой критерий независимости отклоняет гипотезу на уровне значимости 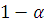 , если
, если
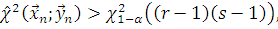
где 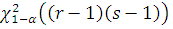 - квантиль уровня значимости
- квантиль уровня значимости 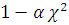 -распределения с числом степеней
свободы
-распределения с числом степеней
свободы 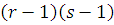 . При этом считается, что критерий можно использовать, если
. При этом считается, что критерий можно использовать, если 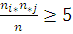 . [2,c. 229]
. [2,c. 229]
2.5 Критерий Колмогорова
Для проверки равномерности распределения P-значения основного критерия используется критерий
Колмогорова.
Пусть  - конкретная выборка из распределения с неизвестной
непрерывной функцией распределения
- конкретная выборка из распределения с неизвестной
непрерывной функцией распределения  и
и 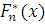 - эмпирическая функция распределения.
Выдвигается простая гипотеза :
- эмпирическая функция распределения.
Выдвигается простая гипотеза :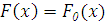 (альтернативная
(альтернативная 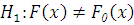 ).
).
Сущность критерия Колмогорова состоит в том, что вводят в рассмотрение
функцию

называемой статистикой Колмогорова, представляющей собой максимальное
отклонение эмпирической функции распределения  от гипотетической функции
распределения
от гипотетической функции
распределения 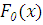 .[5,c.218]
.[5,c.218]
Колмогоров доказал, что при закон распределения случайной
величины 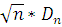 независимо от вида распределения
случайной величины X стремится к
закону распределения Колмогорова:
независимо от вида распределения
случайной величины X стремится к
закону распределения Колмогорова:
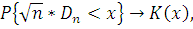 где
где 
Вследствие этой теоремы критерий согласия с критической областью
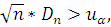
где  - корень уравнения
- корень уравнения 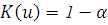 , имеет при уровень стремящийся к . Другими словами, - асимптотический уровень
значимости. Именно этот критерий и называется критерием Колмогорова.[1,c.110]
, имеет при уровень стремящийся к . Другими словами, - асимптотический уровень
значимости. Именно этот критерий и называется критерием Колмогорова.[1,c.110]
3. Проверка гипотез для модельных данных
При помощи программы Квантили распределения статистики критерия.mtc найду квантили распределения
статистики. В этой программе используется модель Геометрического броуновского
движения как закон распределения цены. Методом Монте-Карло из закона
формируется вектор лог доходностей, из которого извлекаются два независимых
вектора с лагом (для проверки независимости лог доходностей за различные
интервалы времени). По этим векторам составляется статистика Фишера - Пирсона, 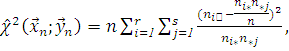 для нее формируется эмпирический
закон, по которому строятся 999 квантилей.
для нее формируется эмпирический
закон, по которому строятся 999 квантилей.
Таблица 7. Квантили распределения статистики основного критерия
|
Квантиль
|
Год
|
Полугодие
|
Квартал
|
|
Квантиль
|
Год
|
Полугодие
|
Квартал
|
|
0,01
|
0,212209
|
0,190866
|
0,270893
|
|
0,26
|
1,348938
|
1,366501
|
1,47774
|
|
0,02
|
0,29627
|
0,288334
|
0,274617
|
|
0,27
|
1,390744
|
1,412067
|
1,481946
|
|
0,03
|
0,364877
|
0,383766
|
0,277533
|
|
0,28
|
1,424658
|
1,449122
|
1,492978
|
|
0,04
|
0,421587
|
0,432326
|
0,353039
|
|
0,29
|
1,463484
|
1,490348
|
1,504944
|
|
0,05
|
0,474784
|
0,481633
|
0,533717
|
|
0,3
|
1,505292
|
1,52572
|
1,508504
|
|
0,06
|
0,522376
|
0,530711
|
0,565893
|
|
0,31
|
1,540634
|
1,568695
|
1,524439
|
|
0,07
|
0,569517
|
0,572774
|
0,592452
|
|
0,32
|
1,58461
|
1,604254
|
1,548935
|
|
0,08
|
0,621419
|
0,611021
|
0,676011
|
|
0,33
|
1,6301
|
1,647083
|
1,592983
|
|
0,09
|
0,666182
|
0,673119
|
0,682049
|
|
0,34
|
1,667164
|
1,689975
|
1,642586
|
|
0,1
|
0,710072
|
0,713267
|
0,69203
|
|
0,35
|
1,708413
|
1,721693
|
1,782258
|
|
0,11
|
0,758454
|
0,766168
|
0,834539
|
|
0,36
|
1,746473
|
1,759768
|
1,787561
|
|
0,12
|
0,796424
|
0,811475
|
0,866205
|
|
0,37
|
1,786811
|
1,802213
|
1,842816
|
|
0,13
|
0,841143
|
0,861614
|
0,881731
|
|
0,38
|
1,820294
|
1,85263
|
1,861932
|
|
0,14
|
0,881345
|
0,899595
|
0,888882
|
|
0,39
|
1,857478
|
1,89051
|
1,90949
|
|
0,15
|
0,923983
|
0,948974
|
0,905634
|
|
0,4
|
1,904023
|
1,931484
|
1,947937
|
|
0,16
|
0,958279
|
1,003884
|
0,98703
|
|
0,41
|
1,9395
|
1,980798
|
1,981577
|
|
0,17
|
0,996083
|
1,037002
|
1,105524
|
|
0,42
|
1,979172
|
2,025527
|
2,061731
|
|
0,18
|
1,040536
|
1,073771
|
1,15342
|
|
0,43
|
2,023613
|
2,067322
|
2,071946
|
|
0,19
|
1,082136
|
1,12282
|
1,177975
|
|
0,44
|
2,072715
|
2,118749
|
2,091278
|
|
0,2
|
1,119096
|
1,161194
|
1,186946
|
|
0,45
|
2,111856
|
2,165422
|
2,109638
|
|
0,21
|
1,160081
|
1,191907
|
1,192258
|
|
0,46
|
2,161316
|
2,216254
|
2,156932
|
|
0,22
|
1,197078
|
1,225916
|
1,263278
|
|
0,47
|
2,20531
|
2,269086
|
2,210036
|
|
0,23
|
1,239606
|
1,268261
|
1,291518
|
|
0,48
|
2,25519
|
2,312832
|
2,230974
|
|
0,24
|
1,297406
|
1,370875
|
|
0,49
|
2,296319
|
2,356298
|
2,309355
|
|
0,25
|
1,307549
|
1,32795
|
1,40098
|
|
0,5
|
2,353332
|
2,40329
|
2,379999
|
Следует отметить, что для модельных данных я проверяю независимость для
различных объемов выборки и различных интервалов времени, не беря во внимание
объемы торгов. Так как объемы торгов и цены могут, как зависеть друг от друга,
так и на отдельных интервалах времени идти в разрез, что проследить для меня не
представляется возможным, однако для реальных данных я буду рассматривать
нужные объемы торгов.
При помощи программы Гистограммы P-значений.mtc строится гистограмма Р-значения при
большом, среднем и малом объеме торгов.

Рисунок 3. Гистограмма P-значения при объеме выборки соответствующему году
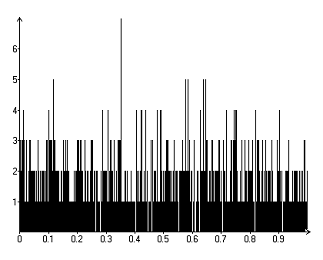
Рисунок 4. Гистограмма Р-значения при объеме выборки
соответствующему полугодию
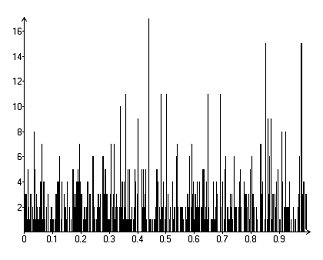
Рисунок 5.Гистограмма Р-значения при объеме выборки
соответствующему кварталу
Для проверки гипотезы о равномерном распределении статистики основного
критерия по критерию Колмогорову используется программа Проверка
равномерности распределения по Колмогорову.mtc, по результатам которой получено, что при объеме
выборки соответствующему году, полугодию и кварталу равномерность
подтверждается.
4. Выбор альтернативной гипотезы и оценка мощности критерия
.1 Альтернативные гипотезы
В качестве альтернативных гипотез были выбраны:
 зависимость прямая и
зависимость прямая и  зависимость обратная
зависимость обратная
Как известно, при прямой зависимости коэффициент корреляции положителен,
а при обратной зависимости - отрицателен. Исходя и этого, я буду использовать
коэффициент корреляции 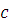 и -
и -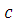 , где
, где 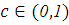 .
.
Таблица 8. Шкала Чеддока для оценки связи величин
|
Коэффициент корреляции
|
0,1-0,3
|
0,3-0,5
|
0,5-0,7
|
0,7-0,9
|
0,9-1
|
|
Характеристика связи
|
Слабая
|
Умеренная
|
Заметная
|
Высокая
|
Весьма высокая
|
Чтобы сгенерировать столбец лог доходностей с нужным коэффициентом
корреляции, можно использовать следующее наблюдение:
Если взять две случайные величины и такие, что 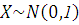 и
и 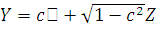 , где
, где 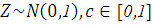 ( и
( и  независимы), то коэффициент
корреляции будет определен следующим образом:
независимы), то коэффициент
корреляции будет определен следующим образом:

Учитывая, что 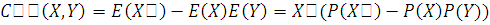 можем высчитать теоретические частоты для критерия Пирсона, чтобы были верны
альтернативные гипотезы, необходимо, чтобы выполнялось равенство:
можем высчитать теоретические частоты для критерия Пирсона, чтобы были верны
альтернативные гипотезы, необходимо, чтобы выполнялось равенство:
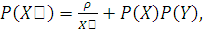
где 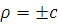 .
.
4.2 Мощность критерия
Используя программу Мощность критерия.mtc, найду мощность критерия. Эта программа генерирует
зависимые векторы лог доходностей, находит критическую точку из эмпирического
закона квантилей распределения статистики основного критерия при уровне
значимости 0,05 и подсчитывает количество значений статистики основного
критерия, когда гипотеза отвергается.
Таблица 9. Мощность критерия  Пирсона (при альтернативных гипотезах
Пирсона (при альтернативных гипотезах 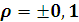 )
)
|
Год
|
Полугодие
|
Квартал
|
|
cor=0.1
|
0,189
|
0,143322
|
0,00963
|
|
cor=-0.1
|
0,20275
|
0,160641
|
0,056869
|
Таблица 10. Мощность критерия Пирсона (при альтернативных гипотезах 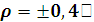 )
)
|
Год
|
Полугодие
|
Квартал
|
|
cor=0.45
|
0,8735
|
0,705066
|
0,062323
|
|
cor=-0.45
|
0,996875
|
0,835729
|
0,223866
|
Таблица 11. Мощность критерия Пирсона (при альтернативных гипотезах 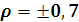 )
)
|
Год
|
Полугодие
|
Квартал
|
|
cor=0.7
|
1
|
0,992746
|
0,623306
|
|
cor=-0.7
|
1
|
1
|
0,750456
|
Из полученных таблиц можно сделать следующие выводы, используя шкалу
Чеддока:
) критерий Пирсона при объеме выборки, соответствующим году и полугодию
различает умеренную, заметную, высокую и весьма высокую связь, но «не видит»
слабую связь.
) критерий Пирсона при объеме выборки, соответствующему кварталу может
выявить только высокую и весьма высокую связи.
5. Проверка гипотез для реальных данных
Осуществлю проверку гипотезы для реальных данных. Используя программу Таблица
P-значений для реальных данных.mtc, построю таблицы P-значений для разных лет, увеличивая интервал с одного года до трех лет с
целью проверки гипотезы для разных интервалов времени, плюс ко всему возьму еще
временные лаги внутри интервала и среднее P-значение для интервала буду записывать в таблицу. Проверка
гипотезы осуществляется, как и для модельных данных.
Таблица 12. Р-значение для 2010 года
Таблица 13. Р-значение для 2010-2011 года
|
Тикер
|
LoVol
|
MidVol
|
HiVol
|
|
Тикер
|
LoVol
|
MidVol
|
HiVol
|
|
AXP
|
0,557914
|
*
|
0,400567
|
|
AXP
|
0,326861
|
0,397901
|
0,665877
|
|
BA
|
*
|
*
|
0,397486
|
|
BA
|
0,450909
|
0,541213
|
0,597816
|
|
CVX
|
*
|
0,36422
|
0,455713
|
|
CVX
|
0,480225
|
0,558233
|
0,440618
|
|
DD
|
*
|
*
|
0,628117
|
|
DD
|
0,474186
|
0,473104
|
0,48183
|
|
DIS
|
0,428474
|
*
|
0,46461
|
|
DIS
|
0,556177
|
0,537366
|
0,470059
|
|
DOW
|
0,402894
|
0,500714
|
0,445179
|
|
DOW
|
0,45598
|
0,543201
|
0,421619
|
|
GE
|
*
|
0,464988
|
0,414716
|
|
GE
|
0,408725
|
0,308426
|
0,465294
|
|
HPQ
|
0,511029
|
0,619891
|
0,447884
|
|
HPQ
|
0,528725
|
0,439844
|
0,635754
|
|
IBM
|
0,141832
|
0,540194
|
0,582706
|
|
IBM
|
0,447186
|
0,459201
|
0,419221
|
|
JNJ
|
0,540445
|
0,551198
|
0,40995
|
|
JNJ
|
0,453775
|
0,391611
|
0,568046
|
|
JPM
|
0,425264
|
0,572697
|
0,522786
|
|
JPM
|
0,436953
|
0,367436
|
0,488387
|
|
MCD
|
*
|
*
|
0,331444
|
|
MCD
|
0,603153
|
0,598473
|
0,475952
|
|
MMM
|
0,346181
|
0,449117
|
0,658432
|
|
MMM
|
0,418066
|
0,385329
|
0,490713
|
|
MRK
|
0,51303
|
0,313206
|
0,554154
|
|
MRK
|
0,433396
|
0,601723
|
0,434701
|
|
MSFT
|
0,434989
|
*
|
0,480137
|
|
MSFT
|
0,504703
|
0,49188
|
0,513336
|
|
PG
|
0,383791
|
0,39558
|
*
|
|
PG
|
0,377388
|
0,322722
|
0,515827
|
|
WFC
|
0,587041
|
0,314507
|
0,482952
|
|
WFC
|
0,607685
|
0,381943
|
0,387109
|
|
WMT
|
0,608907
|
*
|
0,364565
|
|
WMT
|
0,560696
|
0,593696
|
0,475119
|
|
XOM
|
0,633724
|
*
|
0,550189
|
|
XOM
|
0,303261
|
0,36408
|
0,485668
|
Таблица 14. Р-значение для 2010-2012 года
Таблица 15. Р-значение для 2010-2013 года
|
Тикер
|
LoVol
|
MidVol
|
HiVol
|
|
Тикер
|
LoVol
|
MidVol
|
HiVol
|
|
AXP
|
0,412745
|
0,515418
|
0,394794
|
|
AXP
|
0,521679
|
0,340627
|
0,438692
|
|
BA
|
0,396126
|
0,408306
|
0,515569
|
|
BA
|
0,32797
|
0,370844
|
0,412125
|
|
CVX
|
0,493677
|
0,67446
|
0,432729
|
|
CVX
|
0,563931
|
0,521064
|
0,448528
|
|
DD
|
0,407298
|
0,42981
|
0,538101
|
|
DD
|
0,604508
|
0,497683
|
0,295598
|
|
DIS
|
0,430522
|
0,547582
|
0,546618
|
|
DIS
|
0,460859
|
0,566999
|
0,558142
|
|
DOW
|
0,612919
|
0,539571
|
0,613542
|
|
DOW
|
0,399373
|
0,260319
|
0,377966
|
|
GE
|
0,514242
|
0,361082
|
0,500587
|
|
GE
|
0,401584
|
0,506217
|
0,496939
|
|
HPQ
|
0,508279
|
0,529314
|
0,452316
|
|
HPQ
|
0,494285
|
0,33891
|
0,629783
|
|
IBM
|
0,506052
|
0,531967
|
0,412422
|
|
IBM
|
0,396862
|
0,59184
|
0,485678
|
|
JNJ
|
0,353095
|
0,567353
|
0,47607
|
|
JNJ
|
0,633337
|
0,407489
|
0,490151
|
|
JPM
|
0,521271
|
0,358118
|
0,42221
|
|
JPM
|
0,446384
|
0,431656
|
0,411316
|
|
MCD
|
0,56318
|
0,446386
|
0,507871
|
0,339997
|
0,469438
|
0,507178
|
|
MMM
|
0,395935
|
0,636341
|
0,40173
|
|
MMM
|
0,342824
|
0,384554
|
0,472047
|
|
MRK
|
0,432286
|
0,461236
|
0,503718
|
|
MRK
|
0,362647
|
0,405695
|
0,355256
|
|
MSFT
|
0,55388
|
0,461645
|
0,550172
|
|
MSFT
|
0,501458
|
0,427457
|
0,415952
|
|
PG
|
0,57843
|
0,664752
|
0,60946
|
|
PG
|
0,431453
|
0,52199
|
0,556742
|
|
WFC
|
0,570051
|
0,546203
|
0,38627
|
|
WFC
|
0,453614
|
0,52142
|
0,401999
|
|
WMT
|
0,337808
|
0,482247
|
0,6452
|
|
WMT
|
0,616505
|
0,493713
|
0,592804
|
|
XOM
|
0,542863
|
0,348985
|
0,382743
|
|
XOM
|
0,484994
|
0,501198
|
0,42633
|
Далее по полученным данным построю гистограммы Р-значений при большом,
среднем и малом объеме торгов, используя программу Гистограммы Р-значений
для реальных данных.mtc

Рисунок 6. Гистограмма Р-значений при малом объеме торгов
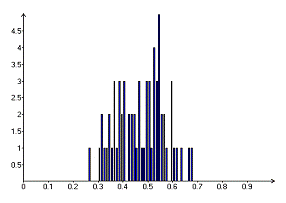
Рисунок 7. Гистограмма Р-значений при среднем объеме торгов
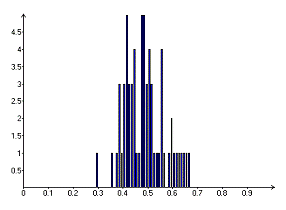
Рисунок 8. Гистограмма Р-значений при большом объеме торгов
Программа Доля проверок, в которых гипотеза принималась.mtc, ищет критическую точку для
распределения Пирсона, затем сравнивает полученное значение со статистикой
критерия по реальным данным, подсчитывая количество тех значений статистики
критерия, которые не попадают в критическую область. Полученное количество делится
на общее количество статистики критерия.
Таблица 16. Доля проверок, в которых гипотеза принималась при 1% и
5% уровнях значимости
|
Уровень значимости
|
LoVol
|
MidVol
|
HiVol
|
|
1%
|
0,993573
|
0,998695
|
0,991587
|
|
5%
|
0,96401
|
0,977807
|
0,959135
|
С помощью программы Медианы Р-значений.mtc найду медианы Р-значений. Эта программа ищет
Р-значение, которое лежит в середине ранжированного ряда.
Таблица 17. Медианы Р-значений по годам
|
Год
|
LoVol
|
MidVol
|
HiVol
|
|
2010
|
0,473009
|
0,464988
|
0,460161
|
|
2011
|
0,453775
|
0,459201
|
0,48183
|
|
2012
|
0,506052
|
0,515418
|
0,500587
|
|
2013
|
0,453614
|
0,469438
|
0,448528
|
Таблица 18. Медианы Р-значений по тикерам
|
Тикер
|
LoVol
|
MidVol
|
HiVol
|
|
AXP
|
0,467212
|
0,397901
|
0,41963
|
|
BA
|
0,396126
|
0,408306
|
0,463847
|
|
CVX
|
0,493677
|
0,539649
|
0,444573
|
|
DD
|
0,474186
|
0,473104
|
0,509966
|
|
DIS
|
0,44569
|
0,547582
|
0,508339
|
|
DOW
|
0,429437
|
0,520142
|
0,433399
|
|
GE
|
0,408725
|
0,413035
|
0,481117
|
|
HPQ
|
0,509654
|
0,484579
|
0,541049
|
|
IBM
|
0,422024
|
0,53608
|
0,45245
|
|
JNJ
|
0,49711
|
0,479344
|
0,483111
|
|
JPM
|
0,441669
|
0,399546
|
0,455299
|
|
MCD
|
0,56318
|
0,469438
|
0,491565
|
|
MMM
|
0,371058
|
0,417223
|
0,48138
|
|
MRK
|
0,432841
|
0,433466
|
0,46921
|
|
MSFT
|
0,503081
|
0,461645
|
0,496736
|
|
PG
|
0,407622
|
0,458785
|
0,556742
|
|
WFC
|
0,578546
|
0,451681
|
0,394554
|
|
WMT
|
0,584801
|
0,493713
|
0,533962
|
|
XOM
|
0,513928
|
0,36408
|
0,455999
|
Исходя из того, что медиана - это численное значение признака, которое
находится в середине ранжированного ряда, то это адекватное среднее значение
признака. Максимум Р-значений по компаниям приходится на компанию Wal-Mart
Stores Inc.( американская компания-ритейлер, управляющая крупнейшей в мире
розничной сетью), а минимум на 3M Company (американская диверсифицированная
инновационно-производственная компания). 3М Company ориентирована на повышение качества продукции, так
как связана с инновациями, а Wal-Mart Stores Inc. ориентирована на количество,
так как развивает розничную торговлю. По полученной таблице логарифмические
доходности более независимы у WMT, значит, их доход практически не зависит от
полученной прибыли накануне, а у МММ наблюдается зависимость, возможно это
происходит следующим образом: если инновационный продукт прижился, то они
получают прибыль, которую вкладывают в более крупный проект, если он окажется
успешен, то они получат еще больше прибыли, если нет, то им придется вкладывать
в мелкие проекты и от них ждать доходов, но уже не таких крупных. Все равно
прослеживается зависимость, а для розничной торговли все может быть спонтаннее,
но все равно зависимость тоже для отдельных лет может наблюдаться. Если
смотреть по годам, то здесь зависимость лог доходностей по тикерам
рассматривается, здесь максимальная зависимость может наблюдаться для компаний,
которые зависят друг от друга, в той или иной степени, производят
взаимодополняющие блага, а снижение зависимости может наблюдаться из- за того,
что одна из компаний перешла на производство других предметов быта.
Заключение
В результате проведенной работы получилось, что гипотеза о независимости
логарифмических доходностей для различных интервалов времени при большом,
среднем и малом объеме торгов принимается при 0,01 и 0,05 уровнях значимости
практически всегда, однако гистограмма Р-значений не равномерна на отрезке
[0,1] , что не дает мне с полной уверенностью сказать, что они независимы и
гипотеза принимается в отличие от результатов
прошлого года.
Новизна состоит в том, что в работе были использованы новые программы и
две альтернативные гипотезы
Литература
1) Браилов А.В. Лекции по математической статистике.-М.:
Финакадемия, 2007
2) Гмурман В.Е. - Руководство к решению задач по теории
вероятностей и математической статистике: Учеб. Пособие - 12-е
изд.,перераб.-М.:Высшее образование, 2006-476 с. (Основы наук)
) Горяинов Б.В., Павлов И.В., Цветкова Г.М. и др.
Математическая статистика: под ред. ЗарубинаВ.С., Крищенко А.П. - М.:Изд-во
МГТУ им. Н.Э.Баумана, 2001. - 424 с.(Сер. Математика в техническом
университете; Вып. XVII).
) Ниворожкина Л.И., Морозова З.А. Теория вероятностей
и математическая статистика - М.:Эксмо, 2008. - 432 с. - (Техническое
образование).
) Письменный Д. Конспект лекций по теории вероятностей
и математической статистике и случайным процессам. - М.: Айрис-пресс, 2008. -
256 с. - (Высшее образование).
) http://finance.yahoo.com.
) Аюпов Д. (2013). Проверка гипотезы о независимости
логарифмической доходности за различные интервалы времени при большом, среднем
и малом объеме торгов Москва: ФГОУ ВПО "Финансовый университет при
Правительстве РФ".
) Безделина Е. (2013). Проверка следствий гипотезы о
независимости логарифмической доходности за различные интервалы времени Москва:
ФГОУ ВПО "Финансовый университет при Правительстве РФ".
) Петухова С. (2013). Проверка гипотезы о нормальном
распределении дневной логарифмической доходности по модифицированному критерию
Пирсона. Москва: ФГОУ ВПО "Финансовый университет при Правительстве
РФ".
Приложение 1
Таблица 19. Характеристики компьютера
|
Тип процессора
|
Intel Core i5 2450M
|
|
Тактовая частота
|
2.50 GHz
|
|
Частота системной шины
|
99.76 MHz
|
|
Объем кэш-памяти второго уровня
|
512KB
|
Таблица 20. Список программ, работающих более 10 секунд
|
Гистограмма Р-значений.mtc
|
15 c.
|
|
Квантили распределения статистики критерия.mtc
|
2 м. 35 с.
|
|
Мощность критерия.mtc
|
29 с.
|
Приложение 2
.Число торговых дней
//источник [7]
//время работы 656 мс
Y=2010:2013;
T=loadtextcol("Tickers.txt","Tickers");
NT=0(#T,#Y);(y in Y)
{=date(y,1,1);=date(y,12,31);(t
in T)
{=loaddaily(d1,d2,t+".csv","CLOSE");(t.num,y.num)=sum(X>0);
}
}=["год/тикер","2010","2011","2012","2013"];=[F;T,NT];(tiker,"Число торговых дней.csv");
3,4.Скачки цен
//источник [7]
//Радостева 2014 г.
//717 мс=2010:2013;=loadtextcol("Tickers.txt","Tickers");=0(#T,#Y);
NT1=0(#T,#Y);
for (y in Y)
{=date(y,1,1);=date(y,12,31);(t
in T)
{=loaddaily(d1,d2,t+".csv","CLOSE");=select(X,X>0);=I(2:#I);=I(1:(#I-1));(t.num,y.num)=max(I1/I);
NT1(t.num,y.num)=min(I1/I);
}
}=["год/тикер","2010","2011","2012","2013"];=[F;T,NT-1];(U,"Скачки цен вверх.csv");
U=[F;T,NT1-1];(U,"Скачки цен вниз.csv");
1,2.Графики со скачками
//источник
[7]
//2.8 c
Tickers=loadtextcol("Tickers.txt","Tickers");
Max = 0; MaxTic =
super(1);= 1; MinTic = super(1);
d1 =
date(2010,1,1);= date(2013,12,31);
for(i in Tickers)
{= loaddaily
(d1,d2,i +
".csv","CLOSE");=select(Close,Close>0);=I(2:#I);=
I(1:(#I-1));(max(C1/C) > Max)
{= max(C1/C);
MaxTic = i;
}(min(C1/C) <
Min)
{= min(C1/C);
MinTic = i;
}
}
//Построение графиков цен
акций с мин. и макс. скачками
for(i in
[MaxTic;MinTic])
{= loadnumcol(i +
".csv","CLOSE");= select(Close,Close>0);= 1:#C;=
select(X,Close>0);(i);(XX,C,blue);();
show();();
}
7. Квантили распределения
статистики критерия
//Источник [7] и [8]
//Радостева 2014г.
//2м 35с(0);
//число дней для года,
полугодия, квартала,
//которые соответствуют
большому, среднему и малому объемам торгов
k=[240;120;60];
//временной лаг
lag=1:8;
m=10000;=0(m,#k);=0(m,#k);
//закон геометрического
броуновского движения
law
L()=exp(sum(nlaw(0,1)(1)));(j in 1:#k)
{(i in 1:m)
{
//содаем два независимых
вектора,показывающих лог доходность
Log=dif(ln(L(k(j))));(lg
in 1:8)
{=Log(1:#Log-lg);=Log(lg+1:#Log);=#Y;=max(X)+1;=max(Y)+1;=min(X)-1;=min(Y)-1;=elaw(Y).invpg(1/3);=elaw(X).invpg(1/3);
//интервалы для вычисления
частот торгов=[minX;-rX;rX;maxX];
DY=[minY;-rY;rY;maxY];
r1=#DX-1;//количество
интервалов для X=#DY-1;//то же самое для Y=0(r1,r2);
//создаем таблицу частот
for (c in 1:r1)(d
in 1:r2)(c,d)=sum(X>=DX(c)& X<DX(c+1) &>=DY(d) & Y<DY(d+1));=(r1-1)*(r2-1);//степень свободы
n1=sum(rows(n));=sum(cols(n));
//создаем таблицу
произведения частот
t=n1&*n2;
//проверка условия
использования критерия(min(t/k(j))>5)
x2=sum((n-t/p)^2/t)*p;//статистика критерия
St(i,j)=x2;
}
}
}
Lew=0.001:0.999:0.001;=[Lew];(i
in 1:#k)
{=elaw(St.c(i));=[qi,El.q(Lew)];
}
savetable(["Квантиль","Год","Полугодие","Квартал";qi],
"Квантили распределния
статистики.csv");
3,4,5. Гистограммы Р-значений
//источники [7] и [8]
//Радостева 2014г.
//15 c(0);
q=loadnumcol("Квантили
распределения
статистики.csv","Квантиль");=loadnumcol("Квантили
распределния статистики.csv","Год");=loadnumcol("Квантили
распределения статистики.csv","Полугодие");=loadnumcol("Квантили
распределения статистики.csv","Квартал");
//эмпирические законы
распределения
Qy=elaw(y);
Qhy=elaw(hy);=elaw(quarter);
m=1000;
//объем выборок для года,
полугодия, квартала
k=[240;120;60];
//временной лаг
lag=1:8;
PV=0(m,#k);
//закон геометрического
броуновского движенияL()=exp(sum(nlaw(0,1)(1)));
for(j in 1:#k)
{(i in 1:m)
{=dif(ln(L(k(j))));
for (lg in lag)
{
//создаём два независимых
вектора,
//показывающих лог доходность
X=Log(1:#Log-lg);
Y=Log(1+lg:#Log);=#Y;=max(X)+1;=max(Y)+1;=min(X)-1;=min(Y)-1;=elaw(Y).invpg(1/3);=elaw(X).invpg(1/3);
//интервалы для вычисления
частот
DX=[minX;-rX;rX;maxX];
DY=[minY;-rY;rY;maxY];
r1=#DX-1;//количество
интервалов для X=#DY-1;//то же самое для Y=0(r1,r2);
//создаем таблицу частот
for (c in 1:r1)(d
in 1:r2)(c,d)=sum(X>=DX(c)& X<DX(c+1) &>=DY(d) &
Y<DY(d+1));=sum(rows(n));
n2=sum(cols(n));
//создаем таблицу
произведения частот
t=n1&*n2;
if
(min(t/k(j))>5)
x2=sum((n-t/p)^2/t)*p;
s=x2;
//находим Р-значение для
года, полугодия, квартала
if (j==1)
PV(i,j)=Qy.pg(s);(j==2) PV(i,j)=Qhy.pg(s);(j==3) PV(i,j)=Qquarter.pg(s);
}
}
}=0.001;=0:1:h;=PV.c(1).intfrgel(Pt);=PV.c(2).intfrgel(Pt);=PV.c(3).intfrgel(Pt);
savetable(["PV","Год","Полугодие","Квартал";
[Pt(2:#Pt),PV.c(1),PV.c(2),PV.c(3)]],"Таблица
Р-значений.csv");(TOF1,blue);("При объеме выборки соответствующему
году");
axes();();();(TOF2,blue);
wintitle("При объеме
выборки соответствующему полугодию");
axes();();();(TOF3,blue);
wintitle("При объеме
выборки соответствующему кварталу");();
Проверка равномерности распределения
по Колмогорову
//Радостева 2014г
//32мс=loadnumcol("Таблица
Р-значений.csv","Год");=loadnumcol("Таблица
Р-значений.csv","Полугодие");=loadnumcol("Таблица
Р-значений.csv","Квартал");
Lteor=ulaw(0,1);=elaw(Yh);Lnab2=elaw(Ym);Lnab3=elaw(Yl);=0:1:0.1;
//Критерий Колмогорова=max(abs(Lnab1.pl(XX)-Lteor.pl(XX)))*(#Yh)^0.5;=max(abs(Lnab2.pl(XX)-Lteor.pl(XX)))*(#Ym)^0.5;=max(abs(Lnab3.pl(XX)-Lteor.pl(XX)))*(#Yl)^0.5;=pvKolm(DD1);=pvKolm(DD2);
Z3=pvKolm(DD3);="Не
принимается при объеме выборки соответствующему году";="Не
принимается при объеме выборки соответствующему полугодию";="Не
принимается при объеме выборки соответствующему
кварталу";(Z1>0.05)="При объеме выборки соответствующему году
принимается";(Z2>0.05)="При объеме выборки соответствующему полугодию
принимается";(Z3>0.05)="При объеме выборки соответствующему
кварталу принимается";
[k1;k2;k3];
9,10,11. Мощность критерия
//источник [7]
//Радостева 2014г.
//29c(0);
q=loadnumcol("Квантили
распределения
статистики.csv","Квантиль");=loadnumcol("Квантили
распределения статистики.csv","Год");=loadnumcol("Квантили
распределения
статистики.csv","Полугодие");=loadnumcol("Квантили
распределения статистики.csv","Квартал");=[240;120;60];
//временной лаг
lag=1:8;
g=0(2,3);
Tkr=[elaw(y).q(1-0.05/2);elaw(hy).q(1-0.05/2);elaw(quarter).q(1-0.05/2)];
Count=0(2,3);=1000;
//коэффициент корреляции
po=0.7;//0.1,0.45
K=0(2,3);
C=[po;-po];
law
L()=exp(sum(nlaw(0,1)(1)));(a in 1:#C)
{(j in 1:#S)
{(i in 1:m)
{=dif(ln(L(S(j))));
for(lg in lag)
{
//создаем зависимые лог
доходности
LnX=Log(1:#Log-lg);=LnX*C(a)+(1-C(a)^2)^0.5*Log(1+lg:#Log);
maxX=max(LnX)+1;
maxY=max(LnY)+1;=min(LnX)-1; minY=min(LnY)-1;=elaw(LnX).invpg(1/3);
rY=elaw(LnY).invpg(1/3);=[minX;-rX;rX;maxX];=[minY;-rY;rY;maxY];
//количество
интервалов=#D1-1;=#D2-1;=#LnX;
//создаем таблицу частот
частоты
n=0(r1,r2);(c in
1:r1)(d in
1:r2)(c,d)=sum(LnX>=D1(c)&LnX<D2(c+1)&>=D2(d)&LnY<D2(d+1));=sum(cols(n));=sum(rows(n));
//таблица произведения частот
t=n1&*n2;
if(min(t/k)>5)
{
//сколько раз проверялась
гипотеза
g(a,j)=g(a,j)+1;
z=sum((n-t/k)^2/t)*k;
//количество раз, когда
гипотеза не выполнялась
if
(Tkr(j)<abs(z)) Count(a,j)=Count(a,j)+1;
}
}
}
}
}=Count/g;(["
","Год","Полугодие","Квартал";["cor="+po;"cor="+(-po)],Count],
"Мощность
критерия.csv");
12,13,14,15.Таблица
Р-значений для реальных данных
//источник [7] и [8]
//Радостева 2014г.
//2.8с= date(2010,1,1);
d2 =
date(2010,12,31);= loadtextcol("Tickers2.txt","Tickers");=
["LoVol","MidVol","HiVol"];
//временной лаг
lag=[1:5;10:25:5;30:50:10];
//суперматрица, размер
которой определяется количеством элементов
//матрицы Tickers и
количеством элементов матрицы Vars,
//все элементы которой
являются "пустыми" строками символов
TabPV =
super(#Tickers,#Vars);=2010:2013;(y in Y)
{=
date(2010,1,1);= date(y,12,31);(ticker in Tickers)
{=
loaddaily(d1,d2,ticker + ".csv","Volume");
V =
select(V0,V0>0);//отбираются акции только по рабочим дням=
elaw(V);//эмпирическое распределение
//эмпирические
квантили(определяется объем торгов уровня квантили 1/3)= LV.invpl(1/3);
//эмпирические
квантили(определяется объем торгов уровня квантили 2/3)
v2 =
LV.invpl(2/3);= loaddaily(d1,d2,ticker + ".csv","Adj
Close");= select(P0,V0>0);(min(P)>0);(nv in 1:#Vars)
{(ticker.num,nv)
="*";//-1 для построения диаграммы(nv==1) C = (V<=v1)(1:#V-1);(nv==2) C =
(V>v1 & V<v2)(1:#V-1);
if(nv==3) C =
(V>=v2)(1:#V-1);
//определяется дневная
логдоходность для C
lnR =
select(dif(ln(P)), C);
m = #lnR;//число наблюдений
//если число наблюдений
меньше 50,
//то прерывается выполнение
тела оператора for
// и начинается переход к
следующему элементу матрицы
if(m<50)
continue;
minR =
min(lnR)-1;//нижняя граница= max(lnR)+1;//верхняя граница=
elaw(lnR).invpg(1/3);
Q = [-r;r];= [minR; Q; maxR];
//разбиваем на интервалы= [minR; Q; maxR]; //разбиваем на интервалы= #D1-1;
//количество интервалов, на которые разбили= #D2-1;//количество интервалов, на
которые разбили
pv=0(#lag);(lg in
1:#lag)
{
//случайные величины с учетом
временных лагов
lnR1 =
lnR(1:m-lag(lg));= lnR(1+lag(lg):m);
n = #lnR1;
//условие использования
критерия
if(n<50) continue;
p = 0(r1,r2);
// p - матрица вероятностей
попадания доходностей
//в получившиеся интервалы
for (i in 1:r1)
{(j in 1:r2)
{(i,j) =
sum(lnR1>=D1(i)&lnR1<D1(i+1) &>=D2(j)&lnR2<D2(j+1))/n;
}
}
//проверка того, что
логдоходность попадает вся
//в общий
интервал(abs(sum(p)-1) < 0.000001);= (r1-1)*(r2-1);// степень свободы
критерия= sum(cols(p));//сумма столбцов матрицы p= sum(rows(p));//сумма строк
матрицы р
t = p1&*p2;
if(min(t*n) >
5)
{
//если выполняется условие,
при котором можно
//использовать критерий
Пирсона:
//теоритические частоты
>=5=n*sum((p-t)^2/t);
//сколько раз считался
критерий для одного года //и тикера
Count=Count+1;(lg)
= x2law(k).pg(z); // P-значение
}
}
//среднее значение(Count)
TabPV(ticker.num,nv) =sum(pv)/Count;
}
}= ["Тикер",Vars];=
[H; [Tickers,TabPV]];(Out,"tab"+y+".csv");
}
6,7,8.Гистограмма
Р-значений для реальных данных
//Радостева 2014г.
//1.8с=2011:2013;
//загружаем данные по каждому
объему торгов
X1=loadnumcol("tab2010.csv","LoVol");=loadnumcol("tab2010.csv","MidVol");=loadnumcol("tab2010.csv","HiVol");
//убираем данные, где
статистика не посчиталась
LoVol=select(X1,X1>0&X2>0&X3>0);=select(X2,X1>0&X2>0&X3>0);=select(X3,X1>0&X2>0&X3>0);
//строим векторы Р-начений
для каждого объема торгов
for (y in Y)
{=[LoVol;loadnumcol("tab"+y+".csv","LoVol")];=[MidVol;loadnumcol("tab"+y+".csv","MidVol")];=[HiVol;loadnumcol("tab"+y+".csv","HiVol")];
}
//выбираем шаг=0.01;=0:1:h;
//разбиваем на
интервалы=LoVol.intfrgel(Pt);
TOF2=MidVol.intfrgel(Pt);=HiVol.intfrgel(Pt);
//рисуем(TOF1,blue);("При
малом объеме торгов");
axes();();();(TOF2,blue);
wintitle("При большом
среднем торгов");
axes();();();(TOF3,blue);
wintitle("При большом
объеме торгов");();
16.Доля проверок, в
которых гипотеза проверялась
//источник [7]
//Радостева 2014г.
//5.8c= date(2010,1,1);
d2 =
date(2010,12,31);= loadtextcol("Tickers2.txt","Tickers");=
["LoVol","MidVol","HiVol"];
//временной лаг=[1:5;10:25:5;30:50:10];=
super(#Tickers,#Vars);=2010:2013;=0(2,3);=0(2,3);(y in Y)
{=
date(2010,1,1);= date(y,12,31);(ticker in Tickers)
{=
loaddaily(d1,d2,ticker + ".csv","Volume");
V =
select(V0,V0>0);//отбирабтся акции только по рабочим дням=
elaw(V);//эмпирическое распределение
//эмпирические
квантили(определяется объем торгов
//уровня квантили 1/3)=
LV.invpl(1/3);
//эмпирические
квантили(определяется объем торгов
//уровня квантили 2/3)
v2 =
LV.invpl(2/3);= loaddaily(d1,d2,ticker + ".csv","Adj
Close");= select(P0,V0>0);(min(P)>0);(nv in 1:#Vars)
{(ticker.num,nv)
="*";//-1 для построения диаграммы(nv==1) C = (V<=v1)(1:#V-1);(nv==2) C =
(V>v1 & V<v2)(1:#V-1);
if(nv==3) C =
(V>=v2)(1:#V-1);
//определяется дневная
логдоходность для C
lnR =
select(dif(ln(P)), C);
m = #lnR;//число
наблюдений(m<50) continue;= min(lnR)-1;//нижняя граница=
max(lnR)+1;//верхняя граница
r =
elaw(lnR).invpg(1/3);= [-r;r];
D1 = [minR; Q; maxR];
//разбиваем на интервалы= [minR; Q; maxR]; //разбиваем на интервалы= #D1-1;
//количество интервалов, на которые разбили= #D2-1;//количество интервалов, на
которые разбили
pv=0(#lag);(lg in
1:#lag)
{
//случайные величины с учетом
временных лагов
lnR1 =
lnR(1:m-lag(lg));= lnR(1+lag(lg):m);= #lnR1;(n<50) continue; = 0(r1,r2);
//p - матрица вероятностей
попадания доходностей
//в получившиеся интервалы
for (i in 1:r1)
{(j in 1:r2)
{(i,j) =
sum(lnR1>=D1(i)&lnR1<D1(i+1) &>=D2(j)&lnR2<D2(j+1))/n;
}
}
//проверка того, что
логдоходность попадает вся
//в общий
интервал(abs(sum(p)-1) < 0.000001);= (r1-1)*(r2-1);// степень свободы
критерия= sum(cols(p));//сумма столбцов матрицы p= sum(rows(p));//сумма строк
матрицы р
t =
p1&*p2;=x2law(k);=[L.q(1-0.01/2);L.q(1-0.05/2)];
if(min(t*n) > 5)
{
//если выполняется условие,
при котором
//можно использовать критерий
Пирсона:
// теоритические частоты
>=5
z=n*sum((p-t)^2/t);(kr
in 1:#Tkr)
{(kr,nv)=Cou(kr,nv)+1;
//сколько раз гипотеза
выполнялась
if(Tkr(kr)>abs(z))
Res(kr,nv)=Res(kr,nv)+1;
}
}
}
}
}
}(["Уровень значимости","LoVol","MidVol","HiVol";
[["1%";"5%"],Res/Cou]],
"Доля проверок, в
которых гипотеза принималась.csv");
17,18.Медиана Р-значений
//Радостева 2014г
//16мс=2011:2013;
//загружаем таблицу
Р-значений при разных объемов торгов
LoVol=loadnumcol("tab2010.csv","LoVol");=loadnumcol("tab2010.csv","MidVol");=loadnumcol("tab2010.csv","HiVol");(y
in Y)
{=[LoVol,loadnumcol("tab"+y+".csv","LoVol")];=[MidVol,loadnumcol("tab"+y+".csv","MidVol")];=[HiVol,loadnumcol("tab"+y+".csv","HiVol")];
}=loadtextcol("Tickers2.txt","Tickers");=2010:2013;=0(#Y,3);=0(#Tickers,3);
//медианы по годам(y in 1:#Y)
{
X1=LoVol.c(y);X2=MidVol.c(y);X3=HiVol.c(y);
X1=select(X1,X1>0);X2=select(X2,X2>0);X3=select(X3,X3>0);(y,1)=median(X1);(y,2)=median(X2);
MedYear(y,3)=median(X3);
}
//медианы по тикерам
for (tic in
1:#Tickers)
{='LoVol.r(tic);X2='MidVol.r(tic);X3='HiVol.r(tic);=select(X1,X1>0);X2=select(X2,X2>0);X3=select(X3,X3>0);(tic,1)=median(X1);(tic,2)=median(X2);(tic,3)=median(X3);
}(["Год","LoVol","MidVol","HiVol";Y,MedYear],
"Медианы Р-значений по
годам.csv");
savetable(["Тикер","LoVol","MidVol","HiVol";Tickers,MedTic],
"Медианы Р-значений по
тикерам.csv");