Применение нейронных сетей для прогнозирования в экономике
Курсовая работа
Применение нейронных
сетей для прогнозирования в экономике
Введение
нейронный прогнозирование
экономический потребительский
На сегодняшний день прогнозирование применяется во многих
областях человеческой деятельности, а именно в науке, управлении, экономике,
производстве и в других сферах. Прогнозирование не имеет четких границ, поэтому
смежно с задачами анализа данных. Прогнозирование является важным моментом при
принятии решений, направленных на определение тенденции динамики поведения
конкретного объекта или события на основе анализа его состояния в прошлом и
настоящем.
Необходимость и важность прогноза обуславливается стремлением
предугадать значения показателей в будущем и оценить показатели некоторого
объекта, взяв за основу известные данные о нем.
Точность прогноза обуславливается:
- объемом истинных исходных данных;
- периодом сбора данных;
- объемом не верифицированных данных и
периодом их сбора;
- свойствами системы и объекта, которые
подвергаются прогнозированию;
- методиками подхода к прогнозированию.
В наше время существует множество вариантов применения
прогнозов, а именно на фондовых рынках, для предсказания спортивных игр, для
оценки недвижимости, для прогнозирования экономических показателей и др.
Актуальность темы заключается в том, что в настоящее время
множество организаций, в том числе и коммерческих, нуждаются в эффективном и
качественном прогнозе для принятия решений, которые смогут позволить повысить
эффективность своей деятельности.
Программные продукты, которые используются для
прогнозирования:
- эконометрический пакет EViews Enterprise Edition 5 для построения АР модели;
- Multiple
Back-Propagation для работы с сетью Back
Propagation;
- программа для работы с радио-базисной
сетью.
Рядом научных исследований было доказано, что применение
нейронных сетей для прогнозирования дает большие преимущества относительно
статистических методов, так как нейронные сети более «чувствительны» ко многим
параметрам. [3,4,5].
Способность нейронной сети к прогнозированию зависит, в
первую очередь, от ее способности к обобщению и выделению скрытых зависимостей
между входными и выходными данными. После того, как сеть обучится, она способна
прогнозировать будущее значение некоторой последовательности на основе
нескольких значений, которые имеются и факторов, которые могут повлиять на
результат. [6].
Проблема, на решение которой будет направлена работа,
заключается в необходимости прогнозирования ВВП, ВНД и ИПЦ.
1. Постановка
задачи
Имеется ежемесячный индекс - ИПЦ и ежегодные значения ВВП и
ВНД, необходимо, используя нейронные сети, спрогнозировать значение показателей
ВВП, ВНД и ИПЦ на определенный период.
Прогнозирование экономических данных с помощью сети Back Propagation. Метод
обратного распространения ошибки (англ. backpropagation) - метод обучения
многослойного персептрона. Основная идея этого метода состоит в распространении
сигналов ошибки от выходов сети к её входам, в направлении, обратном прямому
распространению сигналов в обычном режиме работы [1].
Наиболее часто в качестве функций активации используются
следующие виды сигмоид:
Функция Ферми (экспоненциальная сигмоида):
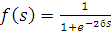 (1.1)
(1.1)
Рациональная сигмоида (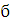 >0):
>0):
 (1.2)
(1.2)
Гиперболический тангенс:
 (1.3)
(1.3)
где s - выход сумматора нейрона, - произвольная
константа.
Прогнозирование в экономике с помощи RBF сетей. В качестве
радиально базисной функции использовать функцию Гаусса:
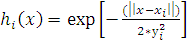 , (1.4)
, (1.4)
где х - входной вектор
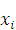 - i-я опорная точка или i-ый образ обучающей
последовательности,
- i-я опорная точка или i-ый образ обучающей
последовательности,
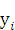 - параметр рассеяния одномерной функции
- параметр рассеяния одномерной функции  .
.
В качестве  обычно используют эвклидово расстояние:
обычно используют эвклидово расстояние:
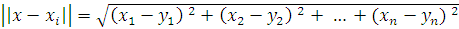 (1.5)
(1.5)
Центры определяются на основе обучающей
последовательности и имеют ту же размерность n, что и входной вектор
Сравнить результаты, полученные при помощи нейронной сети, с
классической регрессионной моделью АР.
2. Описание нейронных сетей, используемых
для прогнозирования
.1 Нейронная сеть с обратным распространением
Back Propagation. Архитектура, функции, свойства
Наиболее широко используемыми и общепризнанными нейронными
сетями являются так называемые сети с обратным распространением («back
propagation»). Эти сети предсказывают состояние фондовой биржи, распознают
почерка, синтезируют речь из текста, управляют автомашиной. Мы видим, что
обратное распространение скорее относится к алгоритмам обучения, а не к сетевой
архитектуре. Такую сеть более правильно назвать сетью с прямой передачей
сигналов [1].
На рис. 2.1 приведена классическая трехуровневая архитектура
нейронной сети.
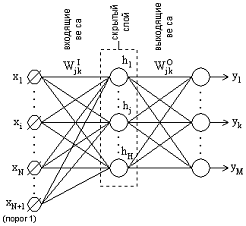
Рис. 2.1 - Архитектура нейронной сети BP
Обозначим: 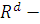 мерное пространство.
мерное пространство.
Входной вектор 
Выходной вектор 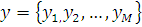 .
.
Нейронная сеть выполняет функциональное преобразование,
которое может быть представлено как
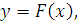 (2.1)
(2.1)
где 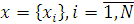
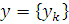 ,
, 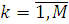
Скрытый слой на самом деле может состоять из нескольких
слоев, однако можно полагать, что достаточно рассматривать лишь три слоя для
описания этого типа поведения. Для нейронной сети с N входными вершинами, Н
вершинами скрытого слоя и М выходными вершинами величины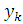 задаются так:
задаются так:
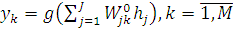 , (1.7)
, (1.7)
 - выходной вес связи от вершины j скрытого слоя
к вершине k выходного слоя;- функция (которая будет определена позже),
выполняющая отображение
- выходной вес связи от вершины j скрытого слоя
к вершине k выходного слоя;- функция (которая будет определена позже),
выполняющая отображение 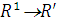 .
.
Выходные сигналы вершин скрытого слоя  , j=1,2, …, H задаются
так:
, j=1,2, …, H задаются
так:
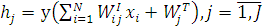 (2.2)
(2.2)
здесь 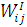 - входной вес связи (i, j);
- входной вес связи (i, j);
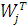 - величина порога (вес от узла, который имеет
постоянный сигнал, равный 1 к узлу j);
- величина порога (вес от узла, который имеет
постоянный сигнал, равный 1 к узлу j);
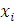 - сигнал на выходе i-го входного узла;
- сигнал на выходе i-го входного узла;
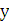 - так называемая функция «сигмоид», которая
задается так:
- так называемая функция «сигмоид», которая
задается так:
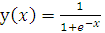 (2.3)
(2.3)
Функция  в (2) называется функцией активации (нейронной
сети), иногда ее называют «функцией зажигания» нейронной сети.
в (2) называется функцией активации (нейронной
сети), иногда ее называют «функцией зажигания» нейронной сети.
Функция g в уравнении (1) может быть такой же самой, что и 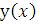 или другой. В нашем изложении мы будем
принимать g или функцией вида
или другой. В нашем изложении мы будем
принимать g или функцией вида  , или единичной функцией, т.е. линейной.
Необходимо, чтобы функция активации была нелинейной, и имела ограниченный
выход, т.е. была ограниченной. График функций приведен на рис. 2.2.
, или единичной функцией, т.е. линейной.
Необходимо, чтобы функция активации была нелинейной, и имела ограниченный
выход, т.е. была ограниченной. График функций приведен на рис. 2.2.
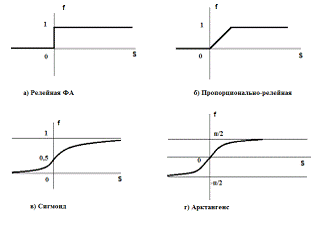
Рис. 2.2 - Функции активации
.2 Нейронные сети с радиально-базисными функциями
(РБФ-сети)
Сети радиальных базисных функций (Radial Basis Functions,
RBF-Netze, RBF-сети) представляют собой специальный тип нейронных сетей с
прямыми связями. Основное их назначение - аппроксимация и интерполяция
многомерных функций для решения, в частности, задач прогнозирования. Их
математическую основу составляет теория аппроксимации и интерполяции
многомерных функций [2].сети обладают рядом характерных свойств:
. Архитектура сетей с прямыми связями первого порядка
(FF-сети): связи от нейронов одного слоя к нейронам следующего слоя;
. Быстрое обучение;
. Отсутствие «патологий» сходимости. В них в отличие
от backpropagation-сетей не возникает проблемы локальных минимумов;
. Более длительное время их подготовки и настройки
из-за необходимости выполнения более сложных расчетов;
. RBF-сети - хорошие аппроксиматоры функций.
Рассмотрим структуру RBF-сетей (рис. 1.3). RBF-сети,
в отличие от сети BP, имеют только один слой скрытых нейронов. На рис. 1.3
единственный выходной нейрон выдает значение функции.
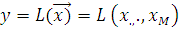 (2.4)
(2.4)
Сами нейроны используют гауссовскую функцию внутри себя:
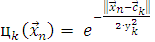 (2.5)
(2.5)
где в качестве метрики используется
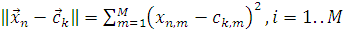 (2.6)
(2.6)
Таким образом, по своему построению RBF-сети - это
двухслойные сети первого порядка, причем оба слоя соединены весовой матрицей W. Входной вектор x передается на нейроны
скрытого слоя. При этом каждый нейрон скрытого слоя получает полную информацию
о входном векторе x.
Следовательно образом имеем следующие обозначения и данные: N реализаций 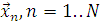 , K нейронов скрытого слоя
, K нейронов скрытого слоя 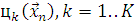 и M - размерность входящего
вектора, а в месте с тем и размерность центров
и M - размерность входящего
вектора, а в месте с тем и размерность центров 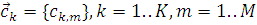
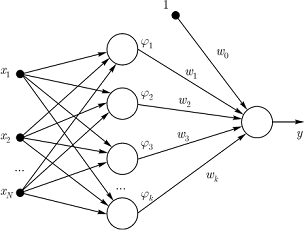
Рисунок 2.3 - Строение RBF-сети
Выходной нейрон является простым сумматором:
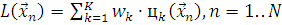 (2.7)
(2.7)
То есть нейроны выходного слоя образуют линейную комбинацию
выходов нейронов скрытого слоя (hidden layer). В RBF-сетях в качестве опорных
точек в простейшем случае могут быть использованы образы обучающей
последовательности.
Работа RBF-сетей. Необходимо
формировать входной вектор. Для решения этой задачи ЛПР формирует зависимости
между выходными переменными и входными с учетом лаг.
Рассмотрим задачу, когда имеется N реализаций, и необходимо
построить хорошую интерполяционную функцию. В таком случае необходимо взять
количество нейронов скрытого слоя K равным количеству реализаций N (здесь и далее
используются индексы k и n для номеров нейронов и
номеров элементов выборки соответственно, но предполагается, что k = n).
В качестве центров нейронов можно использовать
непосредственно значения реализаций или же большие значения, то есть 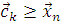 , где k = n, а в качестве параметра
рассеивания использовать
, где k = n, а в качестве параметра
рассеивания использовать 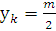 , m - размерность входящего вектора.
, m - размерность входящего вектора.
Такие соображения необходимы, чтобы исполнялось условие:
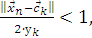 (2.8)
(2.8)
Далее для каждой точки из множества выборки находим значения
нейронов и строим следующую матрицу
 (2.9)
(2.9)
Также имеется вектор 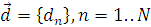 - набор действительных
значений выходов для соответствующих элементов выборки. В итоге необходимо
решить систему
- набор действительных
значений выходов для соответствующих элементов выборки. В итоге необходимо
решить систему
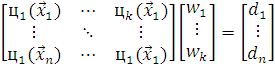 , (2.10)
, (2.10)
где 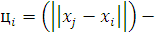 определяет радиальную функцию с центром в точке
определяет радиальную функцию с центром в точке  с вынужденным вектором
с вынужденным вектором  .
.
Относительно вектора  и на этом процесс
настройки параметров сети заканчивается. Полученная сеть довольно хорошо
интерполирует входящую выборку, но как аппроксиматор она плохая, и использовать
ее в качестве прогнозирующей функции нежелательно.
и на этом процесс
настройки параметров сети заканчивается. Полученная сеть довольно хорошо
интерполирует входящую выборку, но как аппроксиматор она плохая, и использовать
ее в качестве прогнозирующей функции нежелательно.
Данный метод можно обобщить для случая, когда количество
нейронов скрытого слоя не равно количеству элементов входящей выборки, то есть 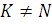 .
.
Что касается настройки весов, то в качестве метода настройки
будем использовать метод градиентного спуска. Для этого зададим функцию,
которую будем минимизировать:
 (2.11)
(2.11)
 (2.12)
(2.12)
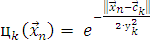 (2.13)
(2.13)
(2.14)
Сделав все подстановки получаем
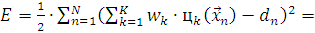 (2.15)
(2.15)
 (2.16)
(2.16)
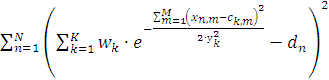 (2.17)
(2.17)
Необходим найти градиенты 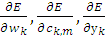 . Ниже представлены уже
выведенные формулы:
. Ниже представлены уже
выведенные формулы:
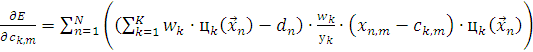 (2.18)
(2.18)
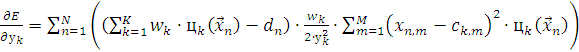 (2.19)
(2.19)
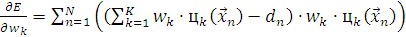 (2.20)
(2.20)
где 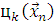 не подставляется в силу громоздкости формулы.
не подставляется в силу громоздкости формулы.
Далее каждый параметр настраивается следующим путем:
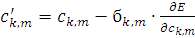 (2.21)
(2.21)
 (2.22)
(2.22)
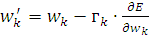 (2.23)
(2.23)
где 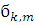 ,
, 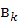 и
и 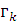 - размеры шага спуска, а
знак минус указывает, что используется антиградиент, так как стоит задача
минимизации [2].
- размеры шага спуска, а
знак минус указывает, что используется антиградиент, так как стоит задача
минимизации [2].
При использовании постоянного шага, или шага очень маленького
размера возникает проблема медленной сходимости, или остановки в небольшом
локальном минимуме. Чтобы избежать следующей проблемы необходимо использовать
следующий механизм регулировки размера шага
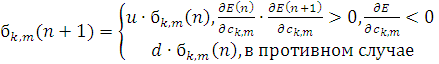 (2.24)
(2.24)
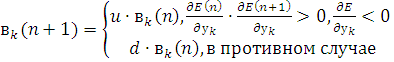 (2.25)
(2.25)
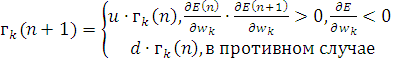 (2.26)
(2.26)
где 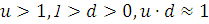 . Предпочтительно брать
. Предпочтительно брать 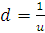 . Таким образом, если
идем в направлении спуска, то шаг увеличивается и мы ускоряемся, а если мы
проскочили минимум, то размер шага уменьшаем.
. Таким образом, если
идем в направлении спуска, то шаг увеличивается и мы ускоряемся, а если мы
проскочили минимум, то размер шага уменьшаем.
3. Обзор программных продукты для реализации
поставленной задачи
3.1 Программный продукт для построения АР модели - Eviews
Эконометрический пакет Eviews обеспечивает особо сложный и
тонкий инструментарий обработки данных, позволяет выполнять регрессионный
анализ. С помощью этого программного средства можно очень быстро выявить
наличие статистической зависимости в анализируемых данных и затем, используя
полученные взаимосвязи, сделать прогноз изучаемых показателей.
Целесообразно выделить следующие сферы применения Eviews:
. анализ научной информации и оценивание;
. финансовый анализ;
. макроэкономическое прогнозирование;
. моделирование;
. прогнозирование состояния рынков.
Особо широкие возможности открывает Eviews при анализе
данных, представленных в виде временных рядов.
ЕViews позволяет работать с различными типами переменных,
однако лучше всего его возможности раскрываются при решении задачи
прогнозирования количественных показателей, представляющих собой временной ряд.
Высокие функциональные возможности при обработке количественных переменных,
позволяют говорить о Eviews как о надежном инструменте для прогнозирования
продаж, динамики ресурсов, финансовых показателей. EViews позволяет строить
прогноз сразу же после построения модели. Для проверки прогностических
способностей модели допускается использование механизма кросс проверки.
3.2 Реализация сети Back-Propagation
Back-Propagation Algorithm - приложение программного
обеспечения для обучения нейронных сетей с обратным распространением ошибки и
несколько алгоритмов обратного распространения.
Основные свойства:
. Простота в использовании;
. Легко настраиваемый;
. Быстрая подготовка;
. Обеспечивает RMS графику в процессе обучения;
. Формирует код обученных сетей;
. Проводит входной анализ чувствительности;
. Поддерживает NVIDIA CUDA.
По сравнению с алгоритмом обратного распространения Multiple
обратного распространения предлагает лучшие возможности обобщения и более
быстрое время на обучение.
3.3 Программа для РБФ сетей
Программа для реализации РБ сетей написана на языке
программирования C#. Были реализованы функции для обработки входных данных и
получения необходимых характеристик модели и критериев прогноза. Рассмотри
каждый из них [3].
Показатели модели:
. RSquare. Коэффициент детерминации (R2 - R-квадрат) -
это доля дисперсии зависимой переменной, объясняемая рассматриваемой моделью
зависимости, то есть объясняющими переменными. Более точно - это единица минус
доля необъяснённой дисперсии (дисперсии случайной ошибки модели, или условной
по факторам дисперсии зависимой переменной) в дисперсии зависимой переменной. В
частном случае линейной зависимости R2 является квадратом так называемого
множественного коэффициента корреляции между зависимой переменной и
объясняющими переменными (рис. 3.3). В частности, для модели парной линейной
регрессии коэффициент детерминации равен квадрату обычного коэффициента
корреляции между y и x.
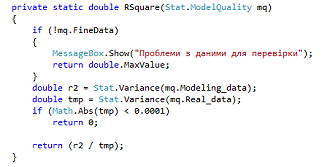
Рисунок 3.1 - Реализация коэффициент детерминации
. SSR - Sum Squared Residual - сумма квадратов отклонений - показатель
«полной» вариации количественной переменной относительно одной или нескольких
фиксированных величин. Значение С.К. зависит не только от степени разброса
данных, но также от объема выборки (рис. 3.4).
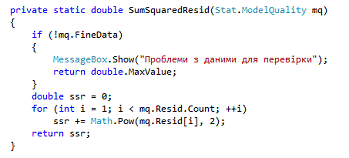
Рисунок 3.2 - Реализация Sum Squared Residual
3. DW - DurbinWatson - статистический критерий,
используемый для тестирования автокорреляции первого порядка элементов
исследуемой последовательности. Наиболее часто применяется при анализе
временных рядов и остатков регрессионных моделей (рис. 3.3).
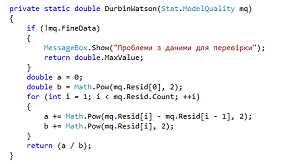
Рисунок 3.3 - Реализация статистического критерия Дарбина -
Уотсона
Показатели прогноза:
1. RMSE - Root Mean Square Error - Среднеквадратичная
ошибка - расстояние между двумя точками (рис. 3.6). В случае если речь идет о
привязке данных, в качестве точек, между которыми измеряется расстояние могут
выступать исходная точка и конечная точки (например, результат трансформации),
в этом случае RMSE будет показателем насколько исходная точка близка к конечной
- текущая ошибка. Желаемое положение выходной точки (точка, поставленная
пользователем) и результатом ее трансформации (точка, поставленная моделью).
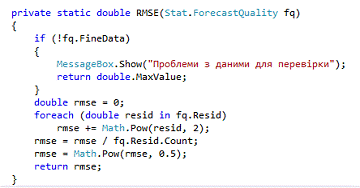
Рисунок 3.4 - Реализация Root Mean Square Error
2. MAPE - средняя абсолютная ошибка в процентах - погрешность
измерения - оценка отклонения измеренного значения величины от её истинного
значения. Погрешность измерения является характеристикой (мерой) точности измерения
(рис. 3.5).

Рисунок 3.5 - Реализация MAPE
. Коэффициент неравенства Тейла реализован на рисунке
3.6.

Рисунок 3.6 - Коэффициент неравенства Тейла
Процесс функционирование сети RBF имеет очень много
особенностей. Такая сеть лучше всего решает задачи интерполяции
(прогнозирования внутри пространства исследования).
4. Построение прогноза на основе
авторегрессионной модели
Авторегрессионная (AR-) модель (Autoregressive model) -
модель временных рядов, в которой значения временного ряда в данный момент
линейно зависят от предыдущих значений этого же ряда [3].
Рассмотрим стохастический процесс АР(1)
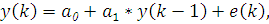
где 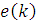 - последовательность белого шума с нулевым
средним. = 0.
- последовательность белого шума с нулевым
средним. = 0.
4.1 Построение АР моделей для ВВП в пакете Eviews 5
Построим авторегрессионные модели первого порядка - АР(1) и
модель третьего порядка - АР(3). Сравним результаты показателей моделей и
прогноза и выберем лучшую модель для дальнейшей работы и сравнительного
анализа.
Для построения модели мы берем выборку из 24 данных,
предварительно разбив ее на обучающую выборку и проверочную в соотношении
примерно 80% к 20%. На обучающей выборке мы получим необходимые для прогноза
коэффициенты модели и показатели качества модели, а на проверочной выборке
проверим их на адекватность. Будем работать с обучающей выборкой данных с 1990
г. по 2009 г., а период с 2010 года по 2013 год оставим для прогнозирования и
анализа качества прогноза (проверочная выборка).
Построим АР (1) для ВВП. Необходимо вычислить
частичную автокорреляционную функцию с помощью команды системы (рис. 4.1) для
данных ВВП (рис. 4.2).
smpl 1990 2013.correl

Рисунок 4.1 - ЧАКФ для ВВП
Из результатов видно, что для того, чтобы модель была
наиболее корректной, мы должны учесть полученные лаги. В формуле 4.4 представлена запись
лагов для данных ВВП.
=VVP(-1)+VVP(-2)+VVP(-6)
После построения АР(1) модели для ВВП получим значения
коэффициентов и необходимых критериев для оценки качества модели (рис. 4.3).
Вычисление прогноза на один шаг для ВВП представлено в формуле 4.5.
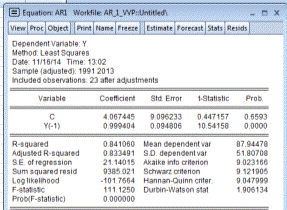
Рисунок 4.2 - Статистические данные для ВВП
= c1+c2*VVP(-1),
где с1 и с2 - коэффициенты модели;(-1) - значение показателя VVP на
предыдущем шаге.
Для анализа качества будущих показателей прогноза модели мы
берем такие показатели, как R-squared = 0,84106, Sum squared resid = 9385,021, Durbin-Watson stat = 1,9061.
После указания периода прогнозирования модели, мы получили
характеристики для прогноза. Для оценки качества модели нам необходимо взять
такие показатели, как Root Mean Squared Error = 39,85, Mean Absolute Error = 22,07, Theil Inequality Coefficient = 0,136.
Построим АР (3) для ВВП. Также, как и для модели
первого порядка вычисляем частичную автокорреляционную функцию с помощью
команды системы (рис. 4.4) для данных ВВП (рис. 4.5).
smpl 1990 2013.correl
Рисунок 4.3. - ЧАКФ для ВВП
Из подученного результата видно, что лаги для учета
построения прогноза не изменились, поэтому оставляем их как для модели АР(1)
(формула 4.6).
=VVP(-1)+VVP(-2)+VVP(-6)
После построения АР(3) модели для ВВП получим значения
коэффициентов и необходимых критериев качества модели (рис. 4.6). Вычисление
прогноза на один шаг для ВВП представлено в формуле 4.7.
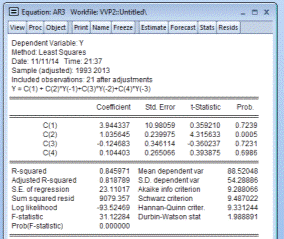
Рисунок 4.4. - Статистические данные для ВВП
(k)=c1+c2*y(-1)+c3*y(-2)+c4*y(-4)
где с1, с2, с3, с4 - коэффициенты модели;(-1), y(-2), y(-3),
y(-4) - значение показателя VVP на (n-1), (n-2), (n-3), (n-4) шагах.
Из результатов видно, что значение таких показателей, как R-squared = 0,8459, Sum Squared resid = 9079,357, Durbin-Watson = 1,988.
лучше, чем у модели АР(1), следовательно, для дальнейшей
работы и прогноза результатов будем использовать модель АР(3).
Лучшие показатели модели дали нам хорошие показатели прогноза
в сравнении с моделью АР(1). На рисунке 4.7 представлены показатели модели
АР(3).
Рисунок 4.5. - Показатели модели
Необходимые значения Root Mean Squared Error = 34.578, Mean Absolute
Present Error = 19,87, Theil Inequality Coefficient = 0,116.
Анализ показателей модели и прогноза для всех данных
представлен в п. 4.4.
4.2 Построение АР моделей для ВНД в пакете Eviews 5
Построим авторегрессионные модели первого порядка - АР(1) и
модель третьего порядка - АР(3). Сравним результаты показателей моделей и
прогноза и выберем лучшую модель для дальнейшей работы и сравнительного
анализа.
Для построения модели мы берем выборку из 24 данных,
предварительно разбив ее на обучающую выборку и проверочную в соотношении
примерно 80% к 20%, как и для данных ВВП. На обучающей выборке мы получим
необходимые для прогноза коэффициенты модели и показатели качества модели, а на
проверочной выборке проверим их на адекватность. Будем работать с обучающей
выборкой данных с 1990 г. по 2009 г., а период с 2010 года по 2013 год оставим
для прогнозирования и анализа качества прогноза (проверочная выборка).
Построим АР (1) для ВНД. Необходимо вычислить
частичную автокорреляционную функцию с помощью команды системы (рис. 4.8) для
данных ВНД (рис. 4.9).
smpl 1990 2013.correl
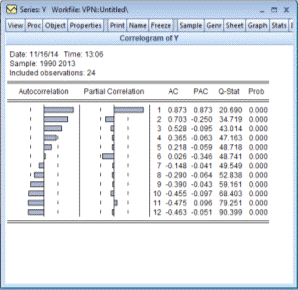
Рисунок 4.6. - ЧАКФ для ВНД
Из результатов видно, что для того, чтобы модель была
наиболее корректной, мы должны учесть полученные лаги. В формуле 4.8
представлена запись лагов для данных ВНД.
=VND(-1)+ VND(-2)+VND(-6)
Аналогичным образом с ВВП получим значения коэффициентов и
необходимых критериев качества модели для ВНД данных по АР (1) модели (рис.
4.10). Вычисления прогноза на один шаг для ВНД представлено в формуле 4.9.
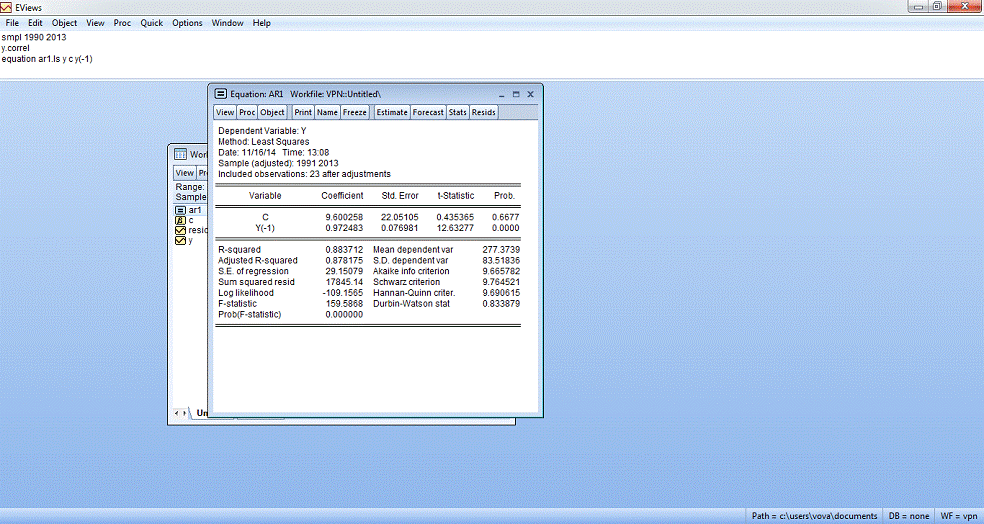
Рисунок 4.7. - Статистические данные для ВНД
VND = c1+c2* VND (-1),
где с1 и с2 - коэффициенты модели;
VND (-1) - значение показателя VND на предыдущем шаге.
Для анализа качества будущих показателей прогноза модели мы
берем такие показатели, как R-squared = 0,8837, Sum squared resid = 17845,14, Durbin-Watson stat = 0,8338.
После указания периода прогнозирования модели, мы получили
характеристики для прогноза. Для оценки качества модели нам необходимо взять
такие показатели, как Root Mean Squared Error = 56,141, Mean Absolute Error = 13,24, Theil Inequality Coefficient = 0.0789.
Построим АР (3) для ВНД. Также, как и для модели
АР(1), для данных ВНД вычисляем частичную автокорреляционную функцию с помощью
команды системы (рис. 4.11) для данных ВНД (рис. 4.12).
smpl 1990 2013.correl

Рисунок 4.8. - ЧАКФ для ВНД
Из полученного результата видно, что лаги для учета
построения прогноза не изменились, поэтому оставляем их как для модели АР(1)
(формула 4.10).
=VND(-1)+ VND(-6)+VND(-7)
После построения АР(3) модели для ВНД получим значения
коэффициентов и необходимых критериев качества модели (рис. 4.13). Вычисление
прогноза на один шаг для ВНД представлено в формуле 4.11.

Рисунок 4.9. - Статистические данные для ВНД
(k)=c1+c2*y(-1)+c3*y(-2)+c4*y(-4)
где с1, с2, с3, с4 - коэффициенты модели;(-1), y(-2), y(-3),
y(-4) - значение показателя ВНД на (n-1), (n-2), (n-3), (n-4) шагах.
Из результатов видно, как и в случае ВВП, что значение таких
показателей, как R-squared = 0,9284, Sum Squared resid = 10585,12, Durbin-Watson = 2,10054, лучше, чем
у модели АР(1), следовательно, для дальнейшей работы и прогноза результатов
будем использовать модель АР(3).
После построения прогноза на один шаг можно заметить (рис.
4.12), что показатели прогноза АР(3) хуже, чем показатели прогноза АР(1),
поэтому для дальнейшей работы и сравнительного анализа мы будем использовать
показатели модели АР(1).
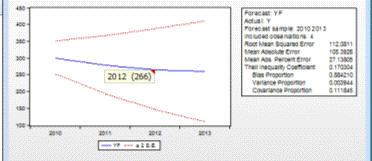
Рисунок 4.10 - Показатели прогноза
Root Mean Squared Error = 112,0811, Mean Absolute
Present Error = 27,13, Theil Inequality Coefficient = 0,1703.
Анализ показателей модели и прогноза для всех данных
представлен в п. 4.4
.3 Построение АР моделей для Индекса
потребительских цен в пакете Eviews 5
Построим авторегрессионные модели первого порядка - АР(1) и
модель третьего порядка - АР(3). Сравним результаты показателей моделей и
прогноза и выберем лучшую модель для дальнейшей работы и сравнительного
анализа.
Для построения модели мы берем выборку из 168 данных,
предварительно разбив ее на обучающую выборку и проверочную в соотношении 80% к
20%. На обучающей выборке мы получим коэффициенты модели, а на проверочной
выборке проверим их на адекватность. Будем работать с обучающей выборкой данных
с 2000.01 г. по 2012.12 г., а для периода с 2013.01 года по 2013.12 год оставим
для прогнозирования и анализа качества прогноза (проверочная выборка).
Построим АР (1) для ИПЦ. Необходимо вычислить
частичную автокорреляционную функцию с помощью команды системы (рис. 4.13) для
данных ИПЦ (рис. 4.14).
smpl 2000:1 2013:12.correl
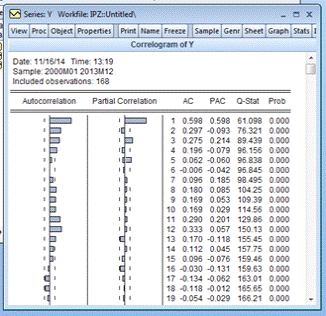
Рисунок 4.11. - ЧАКФ для ИПЦ
Из результатов видно, что для того, чтобы модель была
наиболее правильной, мы должны учесть полученные лаги. В формуле 4.12
представлена запись корреляции ИПЗ с учетом лагов.=IPZ(-1)+IPZ(-3)+IPZ(-5) (4.12)
После построения АР(1) модели для ИПЦ получим значения
коэффициентов и некоторых критериев качества модели (рис. 4.15). Вычисление
прогноза на один шаг для ИПЦ представлено в формуле 4.13.
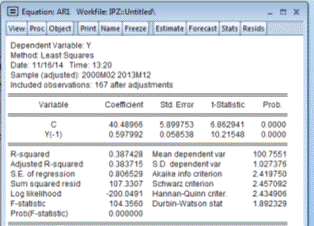
Рисунок 4.12. - Статистические показатели модели
IPZ = c1+c2* IPZ (-1),
где с1 и с2 - коэффициенты модели;
IPZ (-1) - значение показателя IPZ на предыдущем шаге.
Для анализа качества будущих показателей прогноза модели мы
берем такие показатели, как:
R-squared = 0,3874, Sum squared resid = 107,3307,
Durbin-Watson stat = 1,8923. После указания периода прогнозирования модели, мы получили
характеристики для прогноза. Для оценки качества модели нам необходимо взять
такие показатели, как Root Mean Squared Error = 0.684, Mean Absolute Error = 0.6133, Theil Inequality Coefficient = 0.0034.
Построим АР (3) для ИПЦ. Также, как и для модели
первого порядка вычисляем частичную автокорреляционную функцию с помощью
команды системы (рис. 4.16) для данных ИПЦ (рис. 4.17).
smpl 2000:1 2013:12.correl
Рисунок 4.13. - ЧАКФ для ИПЦ
Из подученного результата видно, что лаги для учета
построения прогноза не изменили, поэтому оставляем их как для модели АР(1)
(формула 4.12).
=IPZ(-1)+IPZ(-3)+IPZ(-5)
После построения АР(3) модели для ИПЦ получим значения
коэффициентов и необходимых критериев качества модели (рис. 4.18). Вычисление
прогноза на один шаг для ИПЦ представлено в формуле 4.15.

Рисунок 4.14. - Статистические данные для ИПЦ
(k)=c1+c2*y(-1)+c3*y(-2)+c4*y(-4)
где с1, с2, с3, с4 - коэффициенты модели;(-1), y(-2), y(-3),
y(-4) - значение показателя ИПЦ на (n-1), (n-2), (n-3), (n-4) шагах.
Из результатов видно, что значение таких показателей, как R-squared = 0,3872, Sum squared resid = 100,4924, Durbin-Watson = 1,9576.
немного лучше, чем у модели АР(1), следовательно, для
дальнейшей работы и прогноза результатов будем использовать модель АР(3).
Лучшие показатели модели дали нам хорошие показатели прогноза
в сравнении с моделью АР(1). На рисунке 4.19 представлены показатели прогноза
модели АР(3).
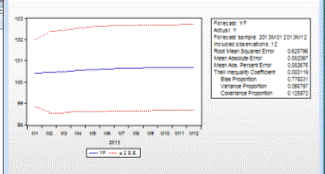
Рисунок 4.15 - Показатели прогноза модели АР(3)
Как мы видим, значения Root Mean
Squared Error = 0,6257, Mean Absolute Present Error = 0,5526, Theil Inequality
Coefficient = 0,0031.
Анализ показателей модели и прогноза для всех данных
представлен в п. 4.4.
4.4 Анализ результатов АР моделей для ВВП, ВНД и ИПЦ
После проведённых вычислений были получены АР модели первого
АР(1) и третьего АР(3) порядков. Выберем лучшие модели для получение
качественного и достоверного результата [4].
Для этого построим сравнительные таблицы и выберем лучший
результат.
Таблица 4.1. - Сравнение результатов для данных ВВП
|
Модель
|
Прогноз
|
|
R-squared
|
SSR
|
DW
|
RMSE
|
MAPE
|
Theil
|
|
АР(1)
|
0,84106
|
9385,021
|
1,9061
|
39,85
|
22,07
|
0,136
|
|
АР(3)
|
0,8459
|
9079,357
|
1,988
|
34.578
|
19,87
|
0,116
|
Из таблицы мы видим, что модель АР(3) лучше подходит для
прогнозирования, так как показатели модели и самого прогноза лучше, чем у
модели АР(1).
Аналогичным образом составим таблицу 4.2 для ВНД.
Таблица 4.2 - Сравнение результатов для данных ВНД
|
Модель
|
Прогноз
|
|
R-squared
|
SSR
|
DW
|
RMSE
|
MAPE
|
Theil
|
|
АР(1)
|
0,8837
|
17845,14
|
0,8338
|
56,141
|
13,24
|
0.0789
|
|
АР(3)
|
0,9284
|
10585,12
|
2,10054
|
112,0811
|
27,13
|
0,1703
|
Показатели модели в данном случае лучше у модели АР(3), но
так как нас интересует прогноз, то необходимо взять модель АР(1), так как
показатели прогноза, исходя из полученных данных, точнее.
И составим таблицу 4.3 для ИПЦ.
Таблица 4.3 - Сравнение результатов для данных ИПЦ
|
Модель
|
Прогноз
|
|
R-squared
|
SSR
|
DW
|
RMSE
|
MAPE
|
Theil
|
|
АР(1)
|
0,3872
|
107,3307
|
1,8923
|
0.684
|
0.6133
|
0.0034
|
|
АР(3)
|
0,3874
|
100,4924
|
0,6257
|
0,5526
|
0,0031
|
Для ИПЦ лучшей является модель АР(3).
После анализа всех результатов, лучшей, в большинстве
случаем, оказалась модель АР(3), так как при ее составлении учитываются
показатели не только предыдущего шага (y-1), но и (y-2), (y-3) и (y-4). Результаты прогноза
представлены в приложении Г.
5. Построение прогноза с помощью РБ сетей
5.1 Построение прогноза с данными ВВП и ВНД.
Будем работать с выборкой данных с 1990 г. по 2009 г., а для
периода с 2010 года по 2013 год оставим для прогнозирования и анализа качества
прогноза (рис. 5.1) [5], [6].
Рисунок 5.1. - Выбор переменной и периода
Укажем лаги, полученные из АР модели для более точного
результата (рис. 5.2).
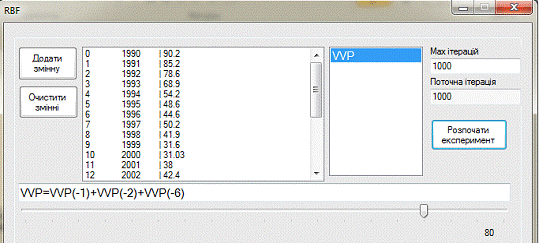
Рисунок 5.2. - Лаги для модели ВВП
После указания лагов мы вводим количество итераций. Точность
напрямую зависит от количества результатов. Чем больше итераций, тем точнее
результат. Укажем количество итераций, равное 1000. После выберем «Начало
эксперимента» и получим график зависимости реальных значений и прогноза (рис.
5.3).
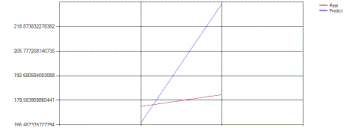
Рисунок 5.3. - Результат прогноза для ВВП
Для ВНД.
Будем работать с выборкой данных с 1990 г. по 2009 г., а для
периода с 2010 года по 2013 год оставим для прогнозирования и анализа качества
прогноза (рис. 5.4).
Рисунок 5.4. - Выбор переменной и периода
Укажем лаги, полученные из АР модели для более точного
результата (рис. 5.5).
Рисунок 5.5. - Лаги для модели ВНД
После указания лагов мы вводим количество итераций. Точность
напрямую зависит от количества результатов. Чем больше итераций, тем точнее
результат. Укажем количество итераций, равное 1000. После выберем «Начало
эксперимента» и получим график зависимости реальных значений и прогноза (рис.
5.6).
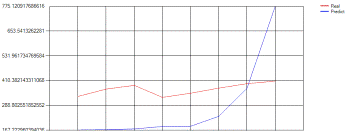
Рисунок 5.6. - Результат прогноза для ВНД
Аналогичным образом проведем такие же операции и для Индекса
потребительских цен.
5.2 Прогнозирование с данными индекса потребительских цен
Будем работать с обучающей выборкой данных с 2000.01 г. по
2012.12 г., а для периода с 2013.01 года по 2013.12 год оставим для
прогнозирования и анализа качества прогноза (проверочная выборка) (рис. 5.7).
Рисунок 5.7. - Выбор переменной и периода
Укажем лаги, полученные из АР модели для более точного
результата (рис. 5.8).

Рисунок 5.8. - Лаги для модели ИПЦ
После указания лагов мы вводим количество итераций. Точность
напрямую зависит от количества результатов. Чем больше итераций, тем точнее
результат. Укажем количество итераций, равное 1000. После выберем «Начало
эксперимента» и получим график зависимости реальных значений и прогноза (рис.
5.9).
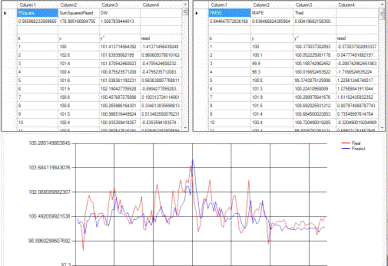
Рисунок 5.9. - Результат прогноза для ИПЦ
5.3 Анализ результатов прогнозирования РБ сети
В таблице приведены результаты работы программы на указанных
выборках для РБФ сетей:
|
Индекс
|
Модель
|
Прогноз
|
|
R-squared
|
SSR
|
DW
|
RMSE
|
MAPE
|
Theil
|
|
VVP
|
0.085161
|
345.911
|
0.98
|
39.2686
|
18.49319
|
0.11481
|
|
VND
|
0.8402446
|
169.0521879
|
1.298697661
|
43.2015
|
10.762
|
0.05983
|
|
IPZ
|
0.362128
|
60.82697
|
1.874823
|
0.727345
|
0.510006
|
0.003614
|
В п. 7 приведено сравнение результатов прогнозирования РБ
сетей с другими методами (АР - модель и сети BP).
6. Построение прогноза с помощью сети Back Propagation
6.1 Построение прогноза на основе данных ВВП и ВНД
Для данных ВВП были просчитаны результаты с учетом лагов,
полученные из АР модели (рис. 6.1) [7], [8].
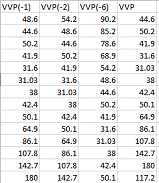
Рисунок 6.1. - Лаги данных ВВП
После выбора данных ВВП с лагами была запущена тренировка
нейронной сети (рис. 6.2) и на рисунке 6.3. показана динамика обучения сети.

Рисунок 6.2. - Загрузка данных ВВП

Рисунок 6.3. - Обучение нейронной сети на предоставленных
данных
После завершения обучения строится график выходов реальных и
прогноза (желаемых) на тренировочных и тестовых данных (рис. 6.4).

Рисунок 6.4. - Реальные и желаемые результаты
Аналогичным образом сделаем просчет для данных ВНД с учетом
лагов, полученные из АР модели (рис. 6.5)
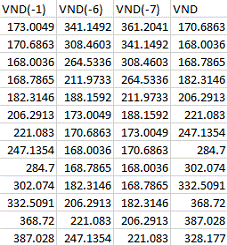
Рисунок 6.5. - Лаги данных ВНД
После выбора данных ВНД с лагами была запущена тренировка
нейронной сети (рис. 6.6) и на рисунке 6.7. показана динамика обучения сети.

Рисунок 6.6. - Загрузка данных ВНД

Рисунок 6.7. - Обучение нейронной сети на предоставленных
данных
После завершения обучения строится график выходов реальных и
прогноза (желаемых) на тренировочных и тестовых данных (рис. 6.8).
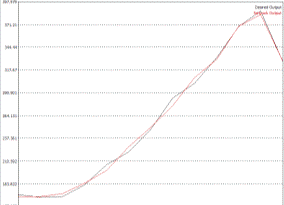
Рисунок 6.8. - Реальные и желаемые результаты
6.2 Построение прогноза на основе данных ИПЦ
Исходя из анализа показателей ВВП и ВПН построим прогноз для
данных Индекса потребительских цен с учетом лагов, полученные из АР модели
(рис. 6.9).

Рисунок 6.9. - Лаги данных ВНД
После выбора данных ИПЦ с лагами была запущена тренировка
нейронной сети (рис. 6.10) и на рисунке 6.11. показана динамика обучения сети.

Рисунок 6.10. - Загрузка данных ИПЦ
После завершения обучения строится график выходов реальных и
прогноза (желаемых) на тренировочных и тестовых данных (рис. 6.8).

Рисунок 6.11. - Реальные и желаемые результаты
После прогона в программе, мы получим отдельные файлы с
результатами. Все характеристики модели и прогноза представлены в таблице 6.4.
Таблица 6.4. Результаты работы нейронной сети BP
|
Индекс
|
Модель
|
Прогноз
|
|
R-squared
|
SSR
|
DW
|
RMSE
|
MAPE
|
Theil
|
|
VVP
|
0.976
|
131.777
|
2.55105
|
36.2479
|
6.938119
|
0.028026
|
|
VND
|
0.97332
|
249.4204
|
2.869335
|
60.18347
|
5.137732
|
0.013376
|
|
IPZ
|
0.628414
|
55.43077
|
1.783512
|
0.177768
|
0.058082
|
0.002873
|
Анализ результатов прогноза с помощью сети BP дает хорошие
показатели модели и прогноза. Сравнение результатов BP с АР - моделью и РБ
сетями описано в п. 7. Результаты прогноза представлены в приложении Г.
7. Общий анализ результатов
7.1 Анализ результатов АР, РБ - сетей и сетей BP [9]
Таблица 7.1. - Общая таблица результатов
|
Индекс
|
Тип
|
Модель
|
Прогноз
|
|
|
R-squared
|
SSR
|
DW
|
RMSE
|
MAPE
|
Theil
|
|
VVP
|
AR
|
0,8459
|
9079,357
|
1,988
|
34.578
|
19,87
|
0,116
|
|
RBF
|
0.677606
|
8830.086
|
1.8052184
|
21.7099
|
26.192
|
0.478925
|
|
MBP
|
0.976139
|
8131.7775
|
2.55105
|
36.24791
|
6.938119
|
0.028026
|
|
VND
|
AR
|
0,8837
|
17845,14
|
0,8338
|
56,141
|
13,24
|
0.0789
|
|
RBF
|
0.621948999
|
1639.37703
|
0.82727594
|
22.67
|
56.3990
|
0.393145
|
|
MBP
|
0.973327
|
249.4204
|
2.869335
|
60.18347
|
5.137732
|
0.013376
|
|
IPZ
|
AR
|
0,3872
|
100,4924
|
1,9576
|
0,6257
|
0,5526
|
0,0031
|
|
RBF
|
0.5659662
|
178.98516
|
1.5087839
|
0.844647
|
0.6364
|
0.00419
|
|
MBP
|
0.628414
|
55.43077
|
1.783512
|
0.177768
|
0.058082
|
0.002873
|
Посмотрев на таблицу, можно сказать, что практически всегда
лучший результат дает сеть MBP. АР(3) всегда дает хорошее значение DW, кроме
значения показателя ВНД, так как для ВНД используется АР(1). В двух случаях MBP дает
лучший показатель RMSE, но этого недостаточно для того, что бы использовать
данный метод для прогноза.
7.2 Комбинирование оценок прогнозов, полученных
разными методами
Для двух методов прогнозирования среднее значение
определяется:
 , (7.1)
, (7.1)
где  комбинированный прогноз,
комбинированный прогноз,
 прогнозы, полученные различными методами [3].
прогнозы, полученные различными методами [3].
Погрешность комбинированного метода:
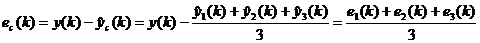 , (7.2)
, (7.2)
где 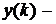 фактическое значение прогнозируемой
переменной.
фактическое значение прогнозируемой
переменной.
Взвешенное усреднение прогнозов. Если информация относительно
характеристик индивидуальных прогнозов отсутствует, то можно присвоить
различные весовые коэффициенты отдельным прогнозам на основе субъективных или
экспертных утверждений:
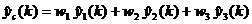 , (7.3)
, (7.3)
где 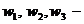 весовые коэффициенты.
весовые коэффициенты.
Очевидно, что большие значения весовых коэффициентов необходимо
присваивать тем индивидуальным прогнозам, которые имеют меньшую дисперсию
ошибок. При этом для корректности вычислений необходимо, чтобы выполнялось
условие:
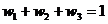 (7.4)
(7.4)
Выбор весовых коэффициентов с помощью погрешности прогнозов. Как правило, погрешности прогнозов для
конкретных моделей и процессов известны или их можно определить. Это дает
возможность объективно подойти к решению задачи выбора весовых коэффициентов.
Т.к. модели, которые дают меньшие суммы квадратов ошибок прогнозов, генерируют
прогнозы качественнее. Исходя из этого, логично принять эту меру за основу для
определения весовых коэффициентов.
Запишем сумму квадратов ошибок прогнозирования (для исторического
прогноза):
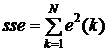 (7.5)
(7.5)
Теперь можно записать выражения для весовых коэффициентов
отдельных прогнозов:
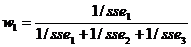 , (7.6)
, (7.6)
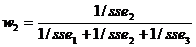 , (7.7)
, (7.7)
 (7.7)
(7.7)
где  суммы квадратов погрешностей для каждого
из методов, которые используются в данном случае.
суммы квадратов погрешностей для каждого
из методов, которые используются в данном случае.
Рассчитаем комбинированный прогноз для ВВП. Для каждого, ранее полученного прогноза,
посчитаем ошибку и квадрат ошибки. После необходимо посчитать сумму квадрата (SUM) отклонений и такой показатель, как
1/сумму квадратов отклонений (1/SUM).
Затем необходимо посчитать сумму 1/SUM и вычислить
значение w1, w2, w3. Из примера видно, что сумма показателей w1, w2, w3 равняется 1, что свидетельствует о правильности расчетов.
После чего, имея значения w1, w2, w3 и прогноза по каждому
методу, рассчитаем прогноз комбинированным методом по формуле 7.8.
Forecast 1 = w1*AP1+w2*RBF1+w3*BP1
--------------------------------------------------------------
(7.8)4
= w1*AP4+w2*RBF4+w3*BP4
Получив все значения прогноза комбинированным методом,
посчитаем ошибку и квадрат ошибки.
Сравнив все результаты можно сделать вывод, что прогноз
комбинированным методом намного лучше, чем каждым отдельным методом.
Для прогнозирования экономического показателя ВВП необходимо
использовать комбинированный прогноз, который включает в себя АР модель, РБ
сети и сети с обратным распространением.
Рассчитаем комбинированный прогноз для ВНД. Для каждого, ранее
полученного прогноза, посчитаем ошибку и квадрат ошибки. После необходимо
посчитать сумму квадрата (SUM) отклонений и такой показатель, как 1/сумму
квадратов отклонений (1/SUM).
Затем необходимо посчитать сумму 1/SUM и вычислить значение w1, w2, w3. Из примера видно, что
сумма показателей w1, w2, w3 равняется 1, что свидетельствует о правильности
расчетов.
После чего, имея значения w1, w2, w3 и прогноза по каждому
методу, рассчитаем прогноз комбинированным методом по формуле 7.9.
Forecast 1 = w1*AP1+w2*RBF1+w3*BP1
---------------------------------------------------------- (7.9)4 =
w1*AP4+w2*RBF4+w3*BP4
Получив все значения прогноза комбинированным методом,
посчитаем ошибку и квадрат ошибки.
Сравнив все результаты можно сделать вывод, что прогноз
комбинированным методом не является самым лучшим. В данном случае необходимо
использовать BP сеть.
Для прогнозирования экономического показателя ВНД необходимо
использовать прогноз РБ сетью, так как погрешность расчетов данным методом
будет наименьшей, а прогноз наилучшим.
Рассчитаем комбинированный прогноз для ИПЦ. Для каждого, ранее
полученного прогноза, посчитаем ошибку и квадрат ошибки. После необходимо
посчитать сумму квадрата (SUM) отклонений и такой показатель, как 1/сумму
квадратов отклонений (1/SUM).
Затем необходимо посчитать сумму 1/SUM и вычислить значение w1, w2, w3. Из примера видно, что
сумма показателей w1, w2, w3 равняется 1, что свидетельствует о правильности
расчетов.
После чего, имея значения w1, w2, w3 и прогноза по каждому
методу, рассчитаем прогноз комбинированным методом по формуле 7.10.
Forecast 1 = w1*AP1+w2*RBF1+w3*BP1
--------------------------------------------------------
(7.10)4 = w1*AP4+w2*RBF4+w3*BP4
Получив все значения прогноза комбинированным методом,
посчитаем ошибку и квадрат ошибки.
Сравнив все результаты можно сделать вывод, что прогноз
комбинированным методом намного лучше, чем каждым отдельным методом.
Для прогнозирования экономического показателя ИПЦ необходимо
использовать комбинированный прогноз, который включает в себя АР модель, РБ
сети и сети с обратным распространением.
В результате проведения комбинирования, можно отметить, что в
большинстве случаев данный метод дает более точный результат, подтверждая это
значением ошибки, которая ниже, чем у остальных методов.
Выводы
Использование нейронных сетей для анализа финансовой
информации является перспективной альтернативой (или дополнением) для традиционных
методов исследования. В силу своей адаптивности одни и те же нейронные сети
могут использоваться для анализа нескольких инструментов и рынков, в то время
как найденные игроком для конкретного инструмента закономерности с помощью
методов технического анализа могут работать хуже или не работать вообще для
других инструментов.
Специфика объекта исследования накладывает некоторые
особенности на использование нейронных сетей для анализа данных. Такой
особенностью является выбор функции ошибки нейронной сети, отличной от
традиционной среднеквадратичной. Следует отметить, что одной из важных
составляющих анализа данных с помощью нейронных сетей является предобработка
данных, направленная на сокращение размерности входов сети, повышение
совместной энтропии входных переменных и нормировку входных и выходных данных.
В ходе работы были проведены расчеты и анализ для нахождения
лучшего метода прогнозирования. Были рассмотрены авторегрессионные модели
первого и третьего порядка, проводилась работа с нейронными сетями типа Back Propagation и PБ. Также, для улучшения
результатов прогноза, был просчитан комбинированный прогноз, который включал в
себя все обработанные методики.
Список литературы
1. Ю.П. Зайченко Конспект лекций по курсу
«Основы проектирования интеллектуальных систем».
2. Ю.П. Зайченко «Основи проектування
інтелектуальних систем». - К: Слово, 2004.
. П.І. Бідюк Конспект лекцій по курсу
«Прогнозування в економіці і фінансах».
5. Г.К. Вороновский, К.В. Махотило, С.Н.
Петрашев, С.А. Сергеев «Генетические алгоритмы, искусственные нейронные сети и
проблемы виртуальной реальности», Харьков, Основа, 1997 г.
6. Тейл, Г. Прикладное экономическое
прогнозирование [Текст]: учебник/ Генри Тейл: Пер. под ред. Э.Б. Ершова. - М.:
Прогресс, 1970. - 509 с.
. Громова, Н.М. Основы экономического
прогнозирования [Текст]: учеб. пособие / Н.М. Громова, Н.И. Громова. -
М.:Академия Естествознания, 2007. - 112 с.
8. Brey, T. Artificial Neural network
versus multiple linear regression: predicting P/B ratios from empirical data [Текст] / T. Brey,
A. Jarre-Teichmann, O. Borlich // Marine ecology progress series. - 1996. -
Vol. 140. - P.251-256.
. Blonda P. RBF Networks Exploiting
Supervised Data in the Adaptation of Hidden Neuron Parameters: Advances in
Artificial Intelligence Lecture Notes in Computer Science [Текст] / P. Blonda,
A. Baraldi, A. D’Addabbo, C. Tarantino, R. De Blasi // AI*IA. - 2001. - Vol.
2175.¬ - P.51-56.
10. Н.Г. Загоруйко «Прикладные методы анализа
данных и знаний», Новосибирск, Издательство Института математики, 1999 г.
Приложение
Листинг программы для РБ сети
Статистические характеристики:
using System;
using System. Collections. Generic;System. Linq;System.
Text;System. Threading. Tasks;System. Windows. Forms;
RBF_RMG
{static class Stat
{class ForecastQuality
{bool fine_data;
bool FineData
{{return fine_data;}
}List<double> resid;
List<double> Resid
{{return resid;}
}List<double>
predict_data;
void Calc()
{(predict_data!= null &&
real_data!= null)(predict_data. Count == real_data. Count)
{_data = true;
= new List<double>();(int
i = 0; i < predict_data. Count; ++i). Add (real_data[i] - predict_data[i]);=
Stat.MAE(this);= Stat.MAPE(this);= Stat.ME(this);= Stat.MPE(this);= Stat.
Theil(this);= Stat.RMSE(this);;
}_data = false;
}List<double> Predict_data
{{return predict_data;}
{_data = value;();
}
}
List<double> real_data;
List<double> Real_data
{{return real_data;}
{_data = value;();
}
}
double mae;
double Mae
{{return mae;}
}double mape;
double Mape
{{return mape;}
}
double me;
public double Me
{{return me;}
}double mpe;
double Mpe
{{return mpe;}
}
double theil;
double Theil
{{return theil;}
}
double rmse;
double RMSE
{{return rmse;}
}void SaveForecastQualityResult
(string file_name)
{(! fine_data)
{. Show («Не можливо зберегти результати оцінки якості моделі\nПроблеми з даними»);;
}fn = DateTime. Now. ToString()
+ «_» + file_name +».csv»;= fn. Replace(»:»,».»);.IO. StreamWriter file = new
System.IO. StreamWriter(fn);line = «RMSE; MAPE; Theil;»;. WriteLine(line);=
this.rmse. ToString() +»;» + this.mape. ToString() +»;» + this.theil.
ToString() +»;»;. WriteLine(line);. WriteLine(»;»);= «k; y; y^; resid;»;.
WriteLine(line);(int i = 0; i < real_data. Count; ++i)
{= (i + 1).ToString() +»;» +
real_data[i].ToString() +»;» + predict_data[i].ToString() +»;» +
resid[i].ToString();. WriteLine(line);
}. Close();
}
}
class ModelQuality
{bool fine_data;
bool FineData
{{return fine_data;}
}
double rsquare;
double Rsquare
{{return rsquare;}
}
double ssr;
double SumSquaredResid
{{return ssr;}
}
double DW
{{return dw;}
}
List<double> resid;
List<double> Resid
{{return resid;}
}List<double>
modeling_data;
void Calc()
{(modeling_data!= null
&& real_data!= null)(modeling_data. Count == real_data. Count)
{_data = true;
= new List<double>();(int
i = 0; i < modeling_data. Count; ++i). Add (real_data[i] -
modeling_data[i]);
= Stat. SumSquaredResid(this);=
Stat. DurbinWatson(this);= Stat.RSquare(this);;
}_data = false;
}List<double>
Modeling_data
{{return modeling_data;}
{_data = value;();
}
}List<double> real_data;
List<double> Real_data
{{return real_data;}
{_data = value;();
}
}
void SaveModelQualityResult
(string file_name)
{(! fine_data)
{. Show («Не можливо зберегти результати оцінки якості прогнозу\nПроблеми з даними»);;
}fn = DateTime. Now. ToString()
+ «_» + file_name +».csv»;= fn. Replace(»:»,».»);.IO. StreamWriter file = new
System.IO. StreamWriter(fn);line = «RSquare; SumSquaredResid; DW;»;.
WriteLine(line);= this.rsquare. ToString() +»;» + this.ssr. ToString() +»;» +
this.dw. ToString() +»;»;. WriteLine(line);. WriteLine(»;»);= «k; y; y^;
resid;»;. WriteLine(line);(int i = 0; i < real_data. Count; ++i)
{= (i + 1).ToString() +»;» +
real_data[i].ToString() +»;» + modeling_data[i].ToString() +»;» +
resid[i].ToString();. WriteLine(line);
}. Close();
}
}private double CXY
(List<double> X, List<double> Y, int lag)
{cxy = 0;x_av = X.
Average();y_av = Y. Average();(int i = lag; i < X. Count; ++i)+= (Y[i] -
y_av) * (X [i - lag] - x_av);(cxy / X. Count);
}
public List<double>
CrossCorrelXY (List<double> X, List<double> Y, int MAX_LAG)
{
{(X. Count!= Y. Count)new
Exception («ПОМИЛКА!!! Розмірність рядів X та Y різна»);
<double> correl = new
List<double>();cxx_0 = Math. Pow (Stat.CXY (X, X, 0), 0.5);cyy_0 = Math.
Pow (Stat.CXY (Y, Y, 0), 0.5);cxy_i;(int i = 1; i <= MAX_LAG; ++i)
{_i = Stat.CXY (X, Y, i);. Add
(cxy_i / (cxx_0 * cyy_0));
}
correl;
}(Exception ex)
{. Show (ex. Message);.
Exit();null;
}
}
public List<double>
CorrelYY (List<double> Y, int MAX_LAG)
{<double> correl = Stat.
CrossCorrelXY (Y, Y, MAX_LAG);correl;
}
static double Expected
(List<double> series)
{series. Sum() / series.
Count();
}static double Variance
(List<double> series)
{<double> temp = new
List<double>();(double argX in series)
{. Add((argX - Expected(series))
* (argX - Expected(series)));
}temp. Sum() / (temp. Count() -
1);
}
static double ACF
(List<double> series, int poriadok)
{r = 0;(int i = poriadok + 1; i
< series. Count; i++)+= (series[i] - Expected(series)) * (series [i -
poriadok] - Expected(series));r / ((series. Count - 1) * Variance(series));
}
static List<double> PACF
(List<double> series, int poriadok)
{[,] phi = new double [poriadok,
poriadok];[0, 0] = ACF (series, 1);(int l = 2; l <= poriadok; l++)
{s = 0, s1 = 0;(int j = 1; j
<= l - 1; j++)
{+= phi [l - 2, j - 1] * ACF
(series, l - j);+= phi [l - 2, j - 1] * ACF (series, j);
}[l - 1, l - 1] = (ACF (series,
l) - s) / (1 - s1);(int j = 1; j <= l - 1; j++)[l - 1, j - 1] = phi [l - 2,
j - 1] - phi [l - 1, l - 1] * phi [l - 2, l - j - 1];
}<double> res = new
List<double>();(int i = 0; i < poriadok; i++). Add (phi[i, i]);res;
}
static double Cov
(List<double> X, List<double> Y)
{<double> temp = new
List<double>();(int i = 0; i < X. Count; i++). Add((X[i] -
Expected(X)) * (Y[i] - Expected(Y)));temp. Sum() / ((X. Count - 1) * Math. Sqrt
(Variance(X)) * Math. Sqrt (Variance(Y)));
}
static double MAE (Stat.
ForecastQuality re)
{(! re. FineData)
{
MessageBox. Show («Прoблеми з даними для
моделювання»);
return double. MaxValue;
}mae = re. Resid. Sum (item
=> Math. Abs(item));= mae / re. Resid. Count;mae;
}
static double MAPE (Stat.
ForecastQuality re)
{(! re. FineData)
{
MessageBox. Show («Прoблеми з даними для
моделювання»);
return double. MaxValue;
}mape = 0;(int i = 0; i < re.
Resid. Count; ++i)+= Math. Abs (re. Resid[i] / re. Real_data[i]);
= 100 * mape / re. Resid.
Count;mape;
}
static double ME (Stat.
ForecastQuality re)
{(! re. FineData)
{
MessageBox. Show («Прoблеми з даними для
моделювання»);
return double. MaxValue;
}me = re. Resid. Sum();= me /
re. Resid. Count;me;
}
static double MPE (Stat.
ForecastQuality re)
{(! re. FineData)
{
MessageBox. Show («Прoблеми з даними для
моделювання»);
return double. MaxValue;
}mpe = 0;(int i = 0; i < re.
Resid. Count; ++i)+= re. Resid[i] / re. Real_data[i];
= mpe / re. Resid. Count;Math.
Abs(mpe);
}
static double Theil (Stat.
ForecastQuality re)
{(! re. FineData)
{
MessageBox. Show («Прoблеми з даними для
моделювання»);
return double. MaxValue;
}
u = 0;a = 0;b1 = 0;b2 = 0;(int i
= 0; i < re. Resid. Count; ++i)+= Math. Pow (re. Resid[i], 2);
= a / re. Resid. Count;= Math.
Pow (a, 0.5);
(int i = 0; i < re.
Real_data. Count; ++i)+= Math. Pow (re. Real_data[i], 2);
= b1 / re. Real_data. Count;=
Math. Pow (b1, 0.5);
(int i = 0; i < re.
Predict_data. Count; ++i)+= Math. Pow (re. Predict_data[i], 2);
= b2 / re. Predict_data. Count;=
Math. Pow (b2, 0.5);
= a / (b1 + b2);u;
}
static double RMSE (Stat.
ForecastQuality fq)
{(! fq. FineData)
{
MessageBox. Show («Прoблеми з даними для перевірки»);
return double. MaxValue;
}rmse = 0;(double resid in fq.
Resid)+= Math. Pow (resid, 2);= rmse / fq. Resid. Count;= Math. Pow (rmse,
0.5);rmse;
}
static double RSquare (Stat.
ModelQuality mq)
{(! mq. FineData)
{
MessageBox. Show («Прoблеми з даними для
перевірки»);
return double. MaxValue;
}r2 = Stat. Variance (mq.
Modeling_data);tmp = Stat. Variance (mq. Real_data);(Math. Abs(tmp) <
0.0001)0;
(r2 / tmp);
}
static double DurbinWatson
(Stat. ModelQuality mq)
{(! mq. FineData)
{
MessageBox. Show («Прoблеми з даними для
перевірки»);
return double. MaxValue;
}a = 0;b = Math. Pow (mq.
Resid[0], 2);(int i = 1; i < mq. Resid. Count; ++i)
{+= Math. Pow (mq. Resid[i] -
mq. Resid [i - 1], 2);+= Math. Pow (mq. Resid[i], 2);
}(a / b);
}
static double MSE (Stat.
ForecastQuality re)
{(! re. FineData)
{
MessageBox. Show («Прoблеми з даними для
перевірки»);
return double. MaxValue;
}mse = 0;(double resid in re.
Resid)+= Math. Pow (resid, 2);= mse / re. Resid. Count;mse;
}
static double SumSquaredResid
(Stat. ModelQuality mq)
{(! mq. FineData)
{
MessageBox. Show («Прoблеми з даними для
перевірки»);
return double. MaxValue;
}ssr = 0;(int i = 1; i < mq.
Resid. Count; ++i)+= Math. Pow (mq. Resid[i], 2);ssr;
}
}
}