Признаки символов, используемые для автоматического распознавания
Оглавление
Введение
1.
Типовые проблемы, связанные с распознаванием символов
2.
Структура систем оптического распознавания текстов
3.
Методы предобработки изображений текстовых символов
4.
Признаки символов, используемые для автоматического распознавания
4.1
Корреляция и сопоставление шаблонов
4.2
Статистические распределения точек
4.3
Интегральные преобразования
4.4
Структурный анализ
5.
Классификация символов
5.1
Сравнение с эталоном
5.2
Нейросетевые структуры
6.
Постобработка результатов распознавания
7.
Реализация алгоритма распознавания букв
8.
Тестирование программы
9.
Анализ алгоритмов оптического распознавания символов
10.
Обзор существующих систем оптического распознавания символов
Заключение
Список
литературы
Приложения
Введение
символ автоматическое распознавание
текстовый
Задача распознавания текстовой информации при
переводе печатного и рукописного текста в машинные коды является одной из
важнейших составляющих проектов, имеющих целью автоматизацию документооборота.
Вместе с тем эта задача является одной из наиболее сложных и наукоемких в
области автоматического анализа изображений. Даже человек, читающий рукописный
текст, в отрыве от контекста делает в среднем 4% ошибок. Что касается систем
считывания печатных документов, то здесь сложность заключается в том, что в
ответственных приложениях, таких как, например, автоматизация ввода
паспортно-визовой информации, необходимо обеспечить высокую надежность
распознавания (более 98-99%) даже при плохом качестве печати и оцифровки
исходного текста.
В последние десятилетия, благодаря использованию
современных достижений компьютерных технологий, были развиты новые методы
обработки изображений и распознавания образов, благодаря чему стало возможным
создание таких систем распознавания печатного текста, которые удовлетворяли бы
основным требованиям систем автоматизации документооборота. Тем не менее,
создание каждого нового приложения в данной области по-прежнему остается
творческой задачей и требует дополнительных исследований в связи со
специфическими требованиями по разрешению, быстродействию, надежности
распознавания и объему памяти, которыми характеризуется каждая конкретная
задача разработки проблемно-ориентированной системы автоматического ввода в
компьютер бумажной документации.
Различные технологии, объединенные под общим
термином "распознавание символов", подразделяются на распознавание в
реальном режиме времени и распознавание в пакетном режиме, каждый из которых
характеризуется собственной аппаратной частью и собственными алгоритмами распознавания.
В типичной системе оптического распознавания
текстов (OCR) вводимые символы читаются и оцифровываются оптическим сканером.
После этого каждый символ подвергается локализации и выделению, и получившаяся
матрица подвергается предобработке, т. е. сглаживанию, фильтрации и
нормализации. В результате предобработки выделяются характерные признаки, после
чего производится классификация. В работе описываются базовые идеи и методы,
позволяющие решить указанные подзадачи, а также их модификации, используемые в
современных системах распознавания.
Теория машинного зрения существует не первый
день, по этому в литературе можно найти достаточно подходов и решений. Для
начала перечислим некоторые из них:
. Алгоритм скелетизации.
Это метод распознавания одинарных бинарных образов,
основанный на построение скелетов этих образов и выделения из скелетов ребер и
узлов. Далее по соотношению ребер, их числу и числу узлов строится таблица
соответствия образам. Так, например, скелетом круга будет один узел, скелетом
буквы П - три ребра и два узла, причем ребра относятся как 2:2:1. В
программировании данный метод имеет несколько возможных реализаций, подробнее
информацию по методу скелетезации можно найти ниже в разделе ссылки.
. Нейросетевые структуры.
Направление было очень популярным в 60е-70е
годы, в последствии интерес к ним немного поубавился, т.к солидное число
нейронов требует солидные вычислительные мощности, которые обычно отсутствуют
на простеньких мобильных платформах. Однако надо иметь ввиду, что нейросети
иногда дают весьма интересные результаты, за счет своей нелинейной структуры,
более того некоторые нейросети способны распознавать образы инвариантные
относительно поворота без какой либо внешней предобработки. Так, например, сети
на основе неокогнейтронов способны выделять некоторые характерные черты
образов, и распознавать их как бы образы не были повернуты.
. Инвариантные числа.
Из геометрии образов можно выделить некоторые
числа, инвариантные относительно размера и поворота образов, далее можно
составить таблицу соответствия этих чисел конкретному образу (почти как в
алгоритме скелетезации). Примеры инвариантных чисел - число Эйлера,
эксцентриситет, ориентация (в смысле расположения главной оси инерции
относительно чего-нибудь тоже инвариантного).
. Поточечное процентное сравнение с эталоном.
Здесь должна быть некоторая предобработка, для
получения инвариантности относительно размера и положения, затем осуществляется
сравнение с заготовленной базой эталонов изображений - если совпадение больше
чем какая-то отметка, то считаем образ распознанным.
1. Типовые проблемы, связанные с распознаванием
символов
Существует ряд существенных проблем, связанных с
распознаванием рукописных и печатных символов. Наиболее важные из них
следующие:
разнообразие форм начертания символов;
искажения изображений;
вариации размеров и масштаба символов.
Каждый отдельный символ может быть написан
различными стандартными шрифтами, например (Gothic, Elite, Courier, Orator),
специальными шрифтами, использующимися в системах OCR, а также множеством
нестандартных шрифтов. Кроме того, различные символы могут обладать сходными
очертаниями. Например, 'U и 'V, 'S' и '5', 'Z' и '2', 'G' и '6 '.
Искажения цифровых изображений символов могут
быть следующих видов:
Искажения формы: разорванность строк, непропечатанность
символов, изолированность отдельных точек, неплоский характер информационного
носителя (например, эффект коробления), смещения символов или их частей
относительно местоположения в строке;вращения с изменением наклона
символов;грубым дискретом оцифровке изображений;
Кроме того, необходимо выделить радиометрические
искажения: дефекты освещения, тени, блики, неравномерный фон, ошибки при
сканировании или при съемке видеокамерой.
Существенным является и влияние исходного
масштаба печати. В принятой терминологии масштаб 10, 12 или 17 означает, что в
дюйме строки помещаются 10, 12 или 17 символов. При этом, например, символы
масштаба 10 обычно крупнее и шире символа масштаба 12.
Помимо указанных проблем, система оптического
распознавания текста (OCR), должна выделять на изображении текстовые области, в
них выделять отдельные символы, распознавать эти символы и быть
нечувствительной к способу печати (верстки) и расстоянию между строками.
. Структура систем оптического распознавания
текстов
Как правило, системы OCR состоят из нескольких
блоков, предполагающих аппаратную или программную реализацию:
оптический сканер;
блок локализации и выделения элементов текста;
блок предобработки изображений;
блок выделения признаков;
блок распознавания;
блок постобработки результатов распознавания.
В результате работы оптического сканера исходный
текст вводится в компьютер в виде полутонового или бинарного изображения.
В целях экономии памяти и уменьшения затрат
времени на обработку информации, в системах OCR, как правило, применяется
преобразование полутонового изображения в черно-белое. Такую операцию называют
бинаризацией. Однако необходимо иметь в виду, что операция бинаризации может
привести к ухудшению эффективности распознавания.
Программное обеспечение в системах OCR отвечает
за представление данных в цифровом виде и разбиение связного текста на
отдельные символы.
После разбиения символы, представленные в виде
бинарных матриц, подвергаются сглаживанию, фильтрации с целью устранения шумов,
нормализации размера, а также другим преобразованиям с целью выделения
признаков, используемых впоследствии для распознавания.
Распознавание символов происходит в процессе
сравнения выделенных характерных признаков с эталонными признаками, отбираемыми
в ходе статистического анализа результатов, полученных в процессе обучения
системы.
Таким образом, смысловая или контекстная
информация может быть использована как для разрешения неопределенностей,
возникающих при распознавании символов, обладающих идентичными размерами, так и
для корректировки слов и фраз в целом.
3. Методы предобработки изображений текстовых
символов
Предобработка является важным этапом в процессе
распознавания образов и позволяет производить сглаживание, нормализацию,
сегментацию и аппроксимацию отрезков линий.
Сглаживание состоит из операций заполнения и
утоньшения. Заполнение устраняет небольшие разрывы и пробелы.
Утоньшение представляет собой процесс уменьшения
толщины линии, в которой сразу несколько пикселов ставятся в соответствие
только одному пикселу. Известны последовательные, параллельные и гибридные
алгоритмы утоньшения. Наиболее общие методы утоньшения основаны на итеративном
размывании контуров, при котором окно (3х3) движется по изображению, и внутри
окна выполняются соответствующие операции. После завершения каждого этапа все
выделенные точки удаляются.
Скелетизация представляет собой восстановление
траектории пишущего инструмента в качестве входной информации которого
используют либо скелет изображения, либо контур изображения. Несмотря на
большую эффективность использования «скелетизации» восстановление траектории по
скелету изображения имеет существенный недостаток: критически важной
информацией при восстановлении траектории является форма граничного конура в
окрестности областей пересечения штрихов. Из скелета изображения эта информация
недоступна (см. рис. 1). К недостаткам «скелетизации» можно отнести также
большую чувствительность к шуму на границе изображения и, как следствие,
возникновение случайных «отростков» в скелете изображения. Поэтому методы
восстановления траектории, основанные на получении скелета, приводят к ошибкам
при обработке изображений с достаточно сложной траекторией.
Альтернативой «скелетизации» является метод
предобработки, который состоит в следующем: изображение символа разбивается на
полосы черных точек, соответствующие непересекающимся отрезкам штрихов
(регулярные области) и области пересечения штрихов (узловые области).

Рисунок 1 - Изображение символа и его скелет
Существующие алгоритмы выделения регулярных
областей основываются на точечной обработке изображений. В данной работе
предлагается алгоритм, построенный только на использовании ломаной,
аппроксимирующей контур изображения.
Основными особенностями предлагаемого метода
являются:
высокая скорость обработки изображений, которая
достигается за счет отсутствия точечной обработки;
отсеивание изображений, для которых метод
выделения траекторий неприемлем (изображения с пятнами и заплывами) уже на
этапе предобработки.
Нормализация состоит из алгоритмов, устраняющих
перекосы отдельных символов и слов, а также включает в себя процедуры,
осуществляющие нормализацию символов по высоте и ширине после соответствующей
их обработки.
Сегментация осуществляет разбиение изображения
на отдельные области. Как правило, прежде всего необходимо очистить текст от
графики и рукописных пометок, поскольку перечисленные методы позволяют
обрабатывать лишь незашумленный текст. Очищенный от различных пометок текст уже
может быть сегментирован.
Большинство алгоритмов оптического распознавания
разделяют текст на символы и распознают их по отдельности.
Это простое решение действительно эффективно,
если только символы текста не перекрывают друг друга. Слияние символов может
быть вызвано типом шрифта, которым был набран текст, плохим разрешением
печатающего устройства или высоким уровнем яркости, выбранным для
восстановления разорванных символов.
Разбиение текста на слова возможно в том случае,
если слово является состоятельным признаком, в соответствии с которым выполняется
сегментация. Подобный подход сложно реализовать из-за большого числа элементов,
подлежащих распознаванию, но он может быть полезен, если набор слов в кодовом
словаре ограничен по условию задачи.
Под аппроксимацией отрезков линий понимают
составление графа описания символа в виде набора вершин и прямых ребер, которые
непосредственно аппроксимируют цепочки пикселей исходного изображения. Данная
аппроксимация осуществляется в целях уменьшения объема данных и может
использоваться при распознавании, основанном на выделении признаков,
описывающих геометрию и топологию изображения.
4. Признаки символов, используемые для
автоматического распознавания
Считается, что выделение признаков является
одной из наиболее трудных и важных задач в распознавании образов. Для
распознавания символов может быть введено большое количество различных систем
признаков. Проблема заключается в том, чтобы выделить именно те признаки,
которые позволят эффективно отличать один класс символов от всех остальных.
В данном разделе описан ряд основных методик
распознавания символов.
.1 Корреляция и сопоставление шаблонов
Введенная матрица символов сравнивается с
набором эталонов. Вычисляется степень сходства между образом и каждым из
эталонов. Классификация тестируемого изображения символа происходит по методу
ближайшего соседа.
С практической точки зрения этот метод легко
реализовать, и многие коммерческие системы его используют. Однако даже
небольшое темное пятно, попавшее на внешний контур символа, может существенно
повлиять на результат распознавания. Поэтому для достижения хорошего качества
распознавания в системах, использующих сопоставление шаблонов, применяются
другие способы сравнения изображений.
Одна из основных модификаций алгоритма сравнения
шаблонов использует представление шаблонов в виде набора логических правил.
4.2 Статистические распределения точек
В данной группе методов выделение признаков
осуществляется на основе анализа различных статистических распределений точек.
Наиболее известные методики этой группы используют вычисление моментов и
подсчет пересечений.
Моменты различных порядков с успехом
используются в таких задачах обработки изображений как зрение роботов,
обнаружение и распознавание летательных аппаратов и судов по снимкам, анализ
сцен и распознавание символов. В последнем случае в качестве признаков
используют значения статистических моментов совокупности "черных"
точек относительно некоторого выбранного центра.
Наиболее общеупотребительными в приложениях
такого рода являются построчные, центральные и нормированные моменты.
Для цифрового изображения, хранящегося в
двумерном массиве, построчные моменты являются функциями координат каждой точки
изображения следующего вида:
|
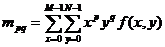 , ,
|
|
где p,q=0,l,...,; M и N являются
размерами изображения по горизонтали и вертикали и f(x,y) является яркостью
пикселя в точке (х,у) на изображении.
Центральные моменты являются функцией расстояния
точки от центра тяжести символа:
|
 , ,
|
|
где х и у с чертой - координаты центра тяжести.
Наконец, нормированные центральные моменты
получаются в результате деления центральных моментов на моменты нулевого
порядка.
Следует отметить, что строковые моменты, как
правило, обеспечивают низкий уровень распознавания. Центральные и нормированные
моменты предпочтительнее из-за их большей инвариантности к преобразованиям
изображений.
В методе пересечений признаки формируются путем
подсчета того, сколько раз произошло пересечение изображения символа с
выбранными прямыми, проводимыми под определенными углами, например, 0, 45, 90,
135 градусов. Этот метод часто используется в коммерческих системах благодаря
тому, что он инвариантен к дисторсии и небольшим стилистическим вариациям
символов, а также обладает достаточно высокой скоростью и не требует
значительных вычислительных затрат. Так, например, представлена на рынке
OCR-систем автоматическое устройство, которое читает любые заглавные
буквенно-цифровые символы. В качестве алгоритма распознавания используется
метод пересечений.
Существует множество других методов
распознавания, основанных на выделении признаков из статистического
распределения точек. Например, метод зон предполагает разделение площади рамки,
объемлющей символ, на области, и последующее использование плотностей точек в
различных областях в качестве набора характерных признаков.
В методе матриц смежности в качестве признаков
рассматриваются частоты совместной встречаемости "черных" и
"белых" элементов в различных геометрических комбинациях.
.3 Интегральные преобразования
Среди современных технологий распознавания,
основанных на преобразованиях, выделяются методы, использующие
Фурье-дескрипторы символов, а также дескрипторы границ.
Преимущества методов, использующих
преобразования Фурье-Меллина, связаны с тем, что они обладают инвариантностью к
масштабированию, вращению и сдвигу символа. Основной недостаток этих методов
заключается в нечувствительности к резким скачкам яркости на границах. В то же
время, при фильтрации шума на границах это свойство может оказаться полезным.
.4 Структурный анализ
Структурные признаки обычно используются для
выделения общей структуры образа. Они описывают геометрические и топологические
свойства символа.
Одними из наиболее используемых признаков
являются штрихи и пробелы, применяемые для определения следующих характерных
особенностей изображения: концевых точек, пересечения отрезков, замкнутых
циклов, а также их положения относительно рамки, объемлющей символ.
Пусть матрица, содержащая утоньшенный символ,
разделена на ряд областей, каждой из которых присвоены буквы А, B, С и т.д.
Символ рассматривается как набор штрихов. При этом штрих является прямой линией
(λ)
или кривой (c), и соединяет некоторые две точки в начертании символа. Штрих
является кривой, если его точки удовлетворяют следующему выражению:
в противном случае - это прямая. В данной
формуле (xi,yi) является точкой, принадлежащей штриху; ax+by+c=0 - уравнение
прямой, проходящей через концы штриха, коэффициент 0.69 получен опытным путем.
При введенных обозначениях признаки символа
могут быть записаны, например, в виде 'AλC'
и 'AcD', что означает наличие прямой, проходящей из области 'А' в область 'С',
и кривой, проходящей из области 'А' в область 'D' соответственно. Достоинство
структурных признаков по сравнению с другими методами определятся устойчивостью
к сдвигу, масштабированию и повороту символа на небольшой угол, а также - к
возможным дисторсиям и различным стилевым вариациям шрифтов.
К сожалению, задача выделения признаков данного
типа находится пока в процессе исследования и не имеет еще общепризнанного
решения.
5. Классификация символов
В существующих системах OCR используются
разнообразные алгоритмы классификации, то есть отнесения признаков к различным
классам. Они существенно различаются в зависимости от выбранных признаков и от
правил классификации.
.1 Сравнение с эталоном
Для классификации символов необходимо в первую
очередь создать библиотеку эталонных векторов признаков. Для этого на стадии
обучения оператор или разработчик вводит в систему OCR большое количество
образцов начертания символов. Для каждого образца система выделяет признаки и
сохраняет их в виде соответствующего вектора признаков. Набор векторов
признаков, описывающих символ, называется классом или кластером.
В процессе эксплуатации системы OCR может
появиться необходимость расширить базу знаний. Для осуществления данной цели
некоторые системы обладают возможностью дообучения в реальном режиме времени.
Однако процесс обучения требует участия оператора и существенных затрат
времени, хотя и проводятся исследования, направленные на автоматизацию процесса
обучения, что в будущем позволит свести к минимуму участие в нем
человека-оператора.
Задачей классификации является определение
класса, которому принадлежит вектор признаков, полученный для данного символа.
Алгоритмы классификации основаны на определении
степени близости набора признаков рассматриваемого символа каждому из классов.
Правдоподобие получаемого результата зависит от выбранной метрики пространства
признаков. К наиболее известным метрикам относится Евклидово расстояние:
|
 , ,
|
|
где  - i-й признак из j-го эталонного
вектора;
- i-й признак из j-го эталонного
вектора; 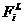 - i-й
признак тестируемого изображения символа.
- i-й
признак тестируемого изображения символа.
При классификации по методу
ближайшего соседа символ будет отнесен к классу, вектор признаков которого
наиболее близок к вектору признаков символа. Следует учитывать, что затраты на
вычисления возрастут с увеличением количества используемых признаков и классов.
Одна из методик, позволяющих
улучшить метрику сходства, основана на статистическом анализе эталонного набора
признаков. При этом в процессе классификации более надежным признакам отдается
больший приоритет:
|
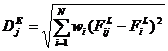 , ,
|
|
где wi, - вес i-го признака.
Другая методика классификации, требующая знания
априорной информации, основана на использовании формулы Байеса. Из правила
Байеса следует, что рассматриваемый вектор признаков принадлежит классу
"j", если отношение правдоподобия К больше чем отношение априорной
вероятности класса j к априорной вероятности класса L.
.2 Нейросетевые структуры
Искусственные нейронные сети достаточно широко
используются при распознавании символов. Алгоритмы, использующие нейронные сети
для распознавания символов, часто строятся следующим образом. Поступающее на
распознавание изображение символа (растр) приводится к некоторому стандартному
размеру. Как правило, используется растр размером 16х16 пикселей. Примеры таких
нормализованных растров показаны на Рис. 2.
Рисунок 2 - Растровое изображение
Значения яркости в узлах нормализованного растра
используются в качестве входных параметров нейронной сети. Число выходных
параметров нейронной сети равняется числу распознаваемых символов. Результатом
распознавания является символ, которому соответствует наибольшее из значений
выходного вектора нейронной сети (см. Рис 3, показана только часть связей и
узлов растра). Повышение надежности таких алгоритмов связано, как правило, либо
с поиском более информативных входных признаков, либо с усложнением структуры
нейронной сети.
Надежность распознавания и потребность программы
в вычислительных ресурсах во многом зависят от выбора структуры и параметров
нейронной сети. Изображения цифр приводятся к единому размеру (16х16 пикселей).
Полученное изображение подается на вход нейронной сети.
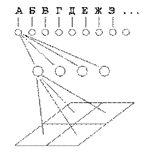
Рисунок 3 - Часть нейронной сети
В качестве входных параметров нейронной сети
вместо значений яркости в узлах нормализованного растра могут использоваться
значения, характеризующие перепад яркости. Такие входные параметры позволяют
лучше выделять края буквы. Система распознавания рукопечатных цифр,
использующие такие входные параметры. Поступающие на распознавание изображения
приводятся к размеру 16х16 пикселей. После этого они подвергаются
дополнительной обработке с целью выделения участков с наибольшими перепадами в
яркости.
Одним из широко используемых методов повышения
точности распознавания является одновременное использование нескольких
различных распознающих модулей и последующее объединение полученных результатов
(например, путем голосования). При этом очень важно, чтобы алгоритмы,
используемые этими модулями, были как можно более независимы. Это может
достигаться как за счет использования распознающих модулей, использующих
принципиально различные алгоритмы распознавания, так и специальным подбором
обучающих данных.
Один из таких методов был предложен несколько
лет назад и основан на использовании трех распознающих модулей (машин). Первая
машина обучается обычным образом. Вторая машина обучается на символах, которые
были отфильтрованы первой машиной таким образом, что вторая машина видит смесь
символов, 50% из которых были распознаны первой машиной верно и 50% неверно.
Наконец, третья машина обучается на символах, на которых результаты
распознавания 1-ой и 2-ой машин различны. При тестировании распознаваемые
символы подаются на вход всем трем машинам. Оценки, получаемые на выходе всех
трех машин складываются. Символ, получивший наибольшую суммарную оценку
выдается в качестве результата распознавания.
Более детальная информация по данному методу
распознавания образов представлена в приложении «Б».
6. Постобработка результатов распознавания
В высокоточных системах OCR, таких как,
например, системы считывания и обработки машиночитаемых паспортно-визовых
документов, качество распознавания, получаемое при распознавании отдельных
символов, не считается достаточным. В таких системах необходимо использовать
также контекстную информацию. Использование контекстной информации позволяет не
только находить ошибки, но и исправлять их.
Существует большое количество приложений OCR, использующих
глобальные и локальные позиционные диаграммы, триграммы, п-граммы, словари и
различные сочетания этих методов. Рассмотрим два подхода к решению такой
задачи: словарь и набор бинарных матриц, аппроксимирующих структуру словаря.
Доказано, что словарные методы являются одними
из наиболее эффективных при определении и исправлении ошибок классификации
отдельных символов. При этом после распознавания всех символов некоторого слова
словарь просматривается в поисках этого слова, с учетом того, что оно, возможно,
содержит ошибку. Если слово найдено в словаре, это не говорит об отсутствии
ошибок. Ошибка может превратить одно слово, находящееся в словаре, в другое,
также входящее в словарь. Такая ошибка не может быть обнаружена без
использования смысловой контекстной информации, только она может подтвердить
правильность написания. Если слово в словаре отсутствует, считается, что в
слове допущена ошибка. Для исправления ошибки прибегают к замене такого слова
на похожее слово из словаря. исправление не производится, если в словаре
найдено несколько подходящих вариантов замены. В этом случае интерфейс
некоторых систем позволяет предложить пользователю различные варианты решения,
например, исправить ошибку, игнорировать ее и продолжать работу или внести это
слово в словарь.
Главный недостаток в использовании словаря
заключается в том, что операции поиска и сравнения, применяющиеся для
исправления ошибок, требуют значительных вычислительных затрат, возрастающих с
увеличением объема словаря.
Некоторые разработчики с целью преодоления
трудностей, связанных с использованием словаря, пытаются выделять информацию о
структуре слова из самого слова. Такая информация говорит о степени
правдоподобия п-граммов (например, пары и тройки букв) в тексте. N-граммы также
могут быть глобально позиционированными, локально позиционированными или вообще
непозиционированными.
Например, степень достоверности
непозиционированной пары букв может быть представлена в виде бинарной матрицы,
элемент которой равен 1, тогда и только тогда, когда соответствующая пара букв
имеется в некотором слове, входящем в словарь. Позиционная бинарная диаграмма
Dy является бинарной матрицей, определяющей, какая из пар букв имеет ненулевую
вероятность возникновения в конкретной позиции (i,j). Набор всех позиционных
диаграмм включает бинарные матрицы для каждой пары положений.
7. Реализация алгоритма распознавания букв
В рамках курсовой работы была написана программа
частично реализующая основные блоки автоматического распознавания букв.
На рисунке 4 представлена блок схема реализуемой
программы.
Рисунок 4 - Блок схема программы
Процесс распознавания:
Загрузка изображения. Для начала нам необходимо
изображение, с которым потом можно работать. Загружаем его стандартными
методами ОС Windows.
В данной программе распознаются только бинарные
образы, поэтому вторым этапом после получения картинки, она бинаризуется. При
работе с цветным изображением преобразование из цветного в черно-белое
изображение идет по стандартной формуле
:=0.3*R+0.59*G+0.11*B
Далее алгоритм довольно прост: есть некоторая
планка, если цвет оттенка серого выше - он считается белым, если ниже -
считается черным. Как видно бинаризация очень проста, однако для серьезного
улучшения качества работы распознавания, и уменьшения времени работы
последующих модулей, на этом месте лучше ввести некий фильтр, пускай даже самый
простенький. В данной программе не используется никакой фильтр, однако место
где он может быть включен обозначено.
Зачастую полученное изображение изобилует
помехами, не имеющими никакого отношения к символам и только мешающие процессу
распознавания. Используя простейший метод, считающий плотность точек в заданной
области, удается избавиться от большего количества помех.
Разбиение изображения на части, каждая из
которых содержит свой уникальных объект называется сегментацией.
В данной программе реализовано попиксельное
сравнение с эталонными символами заданного шрифта. Если процент совпадения
эталона и выделенного символа не ниже заданной границы, то символ считается
распознанным.
Исходный текст программы находится в приложении
А.
8. Тестирование программы
Открываем изображение (Рис. 5). Подходит любое
изображение в формате BMP.
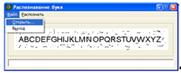
Рисунок 5 - Открытое изображение
Для распознавания необходимо выбрать пункт меню
«Распознать». После этого происходит бинаризация, очистка от шума (Рис. 6) и
начинается сам процесс распознавания символов (Рис. 7).
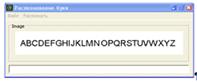
Рисунок 6 - Бинаризация и удаление шума
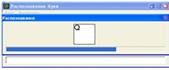
Рисунок 7 - Распознавание символов
Распознанные символы после окончания работы
программы выводятся в строке под рисунком (Рис 8).

Рисунок 8 - Распознанные символы
9. Анализ Алгоритмов оптического распознавания
символов
В случае, когда речь идет о распознавании
печатных символов следует упомянуть, что почти бесконечное разнообразие
печатной продукции изготавливается при помощью ограниченного набора оригиналов
символов, которые группируются по стилю (набору художественных решений),
который отличает данную группу от других. Одна группа, включающая все
алфавитные знаки, цифры и стандартный набор служебных символов, называется
гарнитурой. Однако широко распространился другой термин - шрифт, этот термин и
будет использоваться в дальнейшем.
Любой печатный текст имеет первичное свойство -
шрифты, которыми он напечатан. С этой точки зрения существуют два класса
алгоритмов распознавания печатных символов: шрифтовой и безшрифтовый
(omnifont). Шрифтовые или шрифтозависимые алгоритмы используют априорную
информацию о шрифте, которым напечатаны буквы. Это означает, что программе ОРС
должна быть предъявлена полноценная выборка текста, напечатанного данным
шрифтом. Программа измеряет и анализирует различные характеристики шрифта и
заносит их в свою базу эталонных характеристик. По окончании этого процесса
шрифтовая программа оптического распознавания символов (ОРС) готова к
распознаванию данного конкретного шрифта. Этот процесс условно можно назвать
обучением программы. Далее обучение повторяется для некоторого множества
шрифтов, которое зависит от области применения программы.
К недостаткам данного подхода следует отнести
следующие факторы:
Алгоритм должен заранее знать шрифт, который ему
представляют для распознавания, т.е. он должен хранить в базе различные
характеристики этого шрифта. Качество распознавания текста, напечатанного
произвольным шрифтом, будет прямо пропорционально корреляции характеристик
этого шрифта со шрифтами, имеющимися в базе программы. При существующем
богатстве печатной продукции в процессе обучения невозможно охватить все шрифты
и их модификации. К примеру, Полиграфбуммаш СССР в свое время стандартизировал
около 15-20 различных шрифтов, в современных компьютерных системах верстки
документов используется более 100 шрифтов. Другими словами, этот фактор
ограничивает универсальность таких алгоритмов.
Для работы программы распознавания необходим блок
настройки на конкретный шрифт. Очевидно, что этот блок будет вносить свою долю
ошибок в интегральную оценку качества распознавания, либо функцию установки
шрифта придется возложить на пользователя.
Программа, основанная на шрифтовом алгоритме
распознавания символов, требует от пользователя специальных знаний о шрифтах
вообще, об их группах и отличиях друг от друга, шрифтах, которыми напечатан
документ, пользователя. Отметим, что в случае, если бумажный документ не создан
самим пользователем, а пришел к нему извне, не существует регулярного способа
узнать с использованием каких шрифтов этот документ был напечатан. Фактор
необходимости специальных знаний сужает круг потенциальных пользователей и
сдвигает его в сторону организаций, имеющих в штате соответствующих
специалистов.
С другой стороны, у шрифтового подхода имеется
преимущество, благодаря которому его активно используют и, по-видимому, будут
использовать в будущем. А именно, имея детальную априорную информацию о
символах, можно построить весьма точные и надежные алгоритмы распознавания.
Вообще, при построении шрифтового алгоритма распознавания надежность
распознавания символа является интуитивно ясной и математически точно выразимой
величиной. Эта величина определяется как расстояние в каком-либо метрическом
пространстве от эталонного символа, предъявленного программе в процессе
обучения, до символа, который программа пытается распознать.
Второй класс алгоритмов - безшрифтовые или
шрифтонезависимые, т.е. алгоритмы, не имеющие априорных знаний о символах,
поступающих к ним на вход. Эти алгоритмы измеряют и анализируют различные
характеристики (признаки), присущие буквам как таковым безотносительно шрифта и
абсолютного размера (кегля), которым они напечатаны. В предельном случае для
шрифтонезависимого алгоритма процесс обучения может отсутствовать. В этом
случае характеристики символов измеряет, кодирует и помещает в базу программы
сам человек. Однако на практике, случаи, когда такой путь исчерпывающе решает
поставленную задачу, встречаются редко. Более общий путь создания базы
характеристик заключается в обучении программы на выборке реальных символов.
К недостаткам данного подхода можно отнести
следующие факторы:
Реально достижимое качество распознавания ниже,
чем у шрифтовых алгоритмов. Это связано с тем, что уровень обобщения при
измерениях характеристик символов гораздо более высокий, чем в случае
шрифтозависимых алгоритмов. Фактически это означает, что различные допуски и
огрубления при измерениях характеристик символов для работы безшрифтовых алгоритмов
могут быть в 2-20 раз больше по сравнению с шрифтовыми.
Следует считать большой удачей, если
безшрифтовый алгоритм обладает адекватным и физически обоснованным, т.е.
естественно проистекающим из основной процедуры алгоритма, коэффициентом
надежности распознавания. Часто приходится мириться с тем, что оценка точности
либо отсутствует, либо является искусственной. Под искусственной оценкой
подразумевается то, что она существенно не совпадает с вероятностью правильного
распознавания, которую обеспечивает данный алгоритм.
Достоинства этого подхода тесно связаны с его
недостатками. Основными достоинствами являются следующие:
Универсальность. Это означает с одной стороны
применимость этого подхода в случаях, когда потенциальное разнообразие
символов, которые могут поступить на вход системы, велико. С другой стороны, за
счет заложенной в них способности обобщать, такие алгоритмы могут
экстраполировать накопленные знания за пределы обучающей выборки, т.е.
устойчиво распознавать символы, по виду далекие от тех, которые присутствовали
в обучающей выборке.
Технологичность. Процесс обучения
шрифтонезависимых алгоритмов обычно является более простым и интегрированным в
том смысле, что обучающая выборка не фрагментирована на различные классы (по
шрифтам, кеглям и т.д.). При этом отсутствует необходимость поддерживать в базе
характеристик различные условия совместного существования этих классов
(некоррелированность, не смешиваемость, систему уникального именования и т.п.).
Проявлением технологичности является также тот факт, что часто удается создать
почти полностью автоматизированные процедуры обучения.
Удобство в процессе использования программы. В
случае, если программа построена на шрифтонезависимых алгоритмах, пользователь
не обязан знать что-либо о странице, которую он хочет ввести в компьютерную
память и уведомлять об этих знаниях программу. Также упрощается
пользовательский интерфейс программы за счет отсутствия набора опций и
диалогов, обслуживающих обучение и управление базой характеристик. В этом
случае процесс распознавания можно представлять пользователю как “черный ящик”
(при этом пользователь полностью лишен возможности управлять или каким-либо
образом модифицировать ход процесса распознавания). В итоге это приводит к
расширению круга потенциальных пользователей за счет включения в него людей
обладающих минимальной компьютерной грамотностью.
10. Обзор существующих систем оптического
распознавания символов
Большинство программ оптического распознавания
символов (OCR Optical Character Recognition) работают с растровым изображением,
которое получено через факс-модем, сканер, цифровую фотокамеру или другое
устройство.
Основное назначение OCR-систем состоит в анализе
растровой информации (отсканированного символа) и присвоении фрагменту
изображения соответствующего символа. После завершения процесса распознавания
OCR-системы должны уметь сохранять форматирование исходных документов,
присваивать в нужном месте атрибут абзаца, сохранять таблицы, графику ит.д.
Современные программы распознавания поддерживают все известные текстовые и
графические форматы и форматы электронных таблиц, а некоторые поддерживают
такие форматы, как HTML и PDF.
Работа с OCR-системами, как правило, не должна
вызывать особых затруднений. Большинство таких систем имеют простейший
автоматический режим сканируй и распознавай. Кроме того, они поддерживают и
режим распознавания изображений из файлов. Однако для того, чтобы достигнуть
лучших из возможных для данной системы результатов, желательно (а нередко и
обязательно) предварительно вручную настроить ее на конкретный вид текста,
макет бланка и качество бумаги.
Очень важным при работе с OCR-системой является
удобство выбора языка распознавания и типа распознаваемого материала (пишущая
машинка, факс, матричный принтер, газета ит.д.), а также интуитивная понятность
пользовательского интерфейса. При распознавании текстов, в которых использовано
несколько языков, эффективность распознавания зависит от умения OCR-системы
формировать группы языков. В то же время в некоторых системах уже имеются
комбинации для наиболее часто используемых языков, например: русский и
английский.
На данный момент существует огромное количество
программ, поддерживающих распознавание текста.
Начнем обзор с лидера в этой области FineReader.
Это программный продукт фирмы ABBYY Software, раньше разрабатывался фирмой Bit
Software. Восьмая версия программы (8.0) знает огромное количество форматов для
сохранения, включая PDF и имеет возможность прямого распознавания из
PDF-файлов. Новая технология Intelligent Background Filtering (интеллектуальной
фильтрации фона) позволяет отсеять информацию о текстуре документа и фоновом
шуме изображения: иногда для выделения текста в документе используется серый
или цветной фон. Человеку это не мешает читать, но обычные алгоритмы
распознавания текста испытывают серьезные затруднения при работе с буквами,
расположенными поверх такого фона. Теперь программа FineReader умеет определять
зоны, содержащие подобный текст, отделяя текст от фона документа, находя точки,
размер которых меньше определенной величины, и удаляя их. При этом контуры букв
сохраняются, так что точки фона, близко расположенные к этим контурам, не
вносят помех, способных ухудшить качество распознавания текста.

Рисунок 9 - Распознавание в FineReader
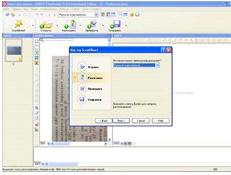
Рисунок 10 - Распознавание в FineReader через
мастера
Новая версия ABBYY FineReader 8.0 Professional
Edition сочетает в себе непревзойдённую точность распознавания, простоту
использования и широкий диапазон настроек. Повышено качество распознавания
факсов и документов, отсканированных с низким разрешением, на новый уровень
выведено распознавание изображений, полученных с помощью цифровой камеры. Новый
быстрый режим распознавания позволяет в несколько раз ускорить обработку
качественно отпечатаных документов. Реализовано автоматизированное выполнение
типовых задач распознавания, в том числе и по собственным сценариям. Быстрее и
точнее стало преобразование PDF-файлов, добавлена функция защиты PDF-файлов
паролем. Теперь в комплект поставки системы входит утилита для распознавания
скриншотов.
Преимущества FineReader 8.0 перед другими
системами оптического распознавания символов:
Повышение точности распознавания трудночитаемых
документов. Изображения документов, которые были отсканированы с низким
разрешением, ABBYY FineReader 8.0 распознаёт на 15%* лучше, чем системы
CuneiForm, Readiris Pro 7. Также повышено качество распознавания факсов - на
30%* результаты достигнуты благодаря усовершенствованию уникальной
OCR-технологии ABBYY.
Повышение точности распознавания
специализированных текстов. Добавлена возможность подключать при распознавании
пользовательский словарь Microsoft Word. Это дополнительный способ повышения
точности распознавания специализированных текстов.
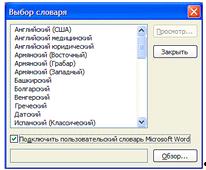
Рисунок 11 - Выбор словаря
Повышение точности распознавания цифровых
фотографий. Теперь для распознавания необязательно оснащать компьютер сканером.
ABBYY FineReader 8.0 позволяет распознавать фотографии документов, сделанные
цифровой камерой. С точки зрения OCR-системы, цифровые фотографии значительно
отличаются от отсканированных изображений. На снимках нередко встречаются
искажения: неравномерное освещение, плохая фокусировка, «изогнутые» строки на
краях документа, и т.д. Кроме того, в файлах цифровых фотографий зачастую
отсутствует информация о разрешении. ABBYY FineReader 8.0 отличает
сфотографированные документы от отсканированных и применяет для обработки
снимков новую адаптивную технологию распознавания. Поэтому FineReader 8.0
справляется с наиболее частыми дефектами фотографий и распознаёт
сфотографированные документы на 40% точнее, чем системы CuneiForm, Readiris Pro
7.
Интеллектуальное распознавание. В ABBYY
FineReader 8.0 усовершенствована технология обработки PDF-файлов. Как известно,
некоторые PDF-файлы содержат так называемый текстовый слой, причём его
содержимое может не полностью соответствовать видимому на экране документу.
FineReader 8.0 предварительно анализирует содержимое файла и для каждого
текстового блока принимает решение: распознать его или извлечь соответствующий
текст из текстового слоя. Таким образом удаётся увеличить качество
распознавания и в 2 раза сократить время обработки.
Создание PDF-файлов, защищённых паролем. В
восьмой версии ABBYY FineReader появилась возможность защиты PDF-файлов
паролем. Пароль может быть установлен как на открытие файла, так и на прочие
действия с документом (печать, извлечение содержимого, возможность
редактирования, внесение комментариев, добавление/удаление страниц и др.).
Предусмотрена возможность выбрать один из трёх уровней шифрования: 40-битный,
128-битный на основе стандарта RC4, 128-битный уровень, основанный на стандарте
AES (Advanced Encryption Standard).
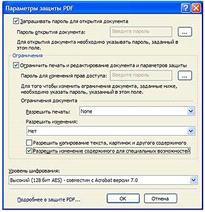
Рисунок 12 - Параметры защиты PDF
Создание PDF-файлов, отформатированных под
желаемый размер экрана. PDF-документы с тегами автоматически переформатируются
под нужный размер экрана. Теперь ABBYY FineReader 8.0 способен создавать такие
PDF-файлы, которые удобно просматривать на экранах любого размера, в частности,
на экранах карманных компьютеров.
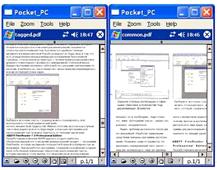
Рисунок 13 - Создание PDF-файлов желаемого
размера
Автоматическая обработка документов. Процесс
распознавания документов очень часто состоит из одного и того же набора
операций. Например, сканирование, распознавание, сохранение распознанного
текста в определённом формате. Для экономии времени пользователя в ABBYY
FineReader 8.0 предусмотрена возможность автоматизации однотипных действий. Для
этого описано несколько наиболее распространённых сценариев обработки
документов. Для запуска сценария достаточно просто нажать одну кнопку - вся
остальная работа будет выполнена системой автоматически, в соответствии с
настройками сценария.
Рисунок 14 - Менеджер сценариев
Кроме того, в ABBYY FineReader 8.0 можно
создавать собственные, пользовательские сценарии. Мастер сценариев поможет
быстро и просто настроить FineReader на решение тех или иных задач. Например,
распознать документ, сохранить результаты в PDF и отправить по указанному
адресу электронной почты - и всё это нажатием одной кнопки!
Рисунок 15 - Мастер сценариев
Экономия времени при распознавании. В ABBYY
FineReader 8.0 добавлен новый режим распознавания - «Быстрый». Он позволяет в
2-2,5 раза ускорить обработку документов с простым оформлением. Этот режим
предназначен для оптимизации временных затрат при распознавании большого
количества хорошо отсканированных изображений (например, при создании
электронного архива офисной документации).
Распознавание и восстановление гиперссылок.
Восьмая версия системы автоматически находит в тексте гиперссылки на веб-сайты,
адреса электронной почты, файлы, ftp-серверы и воспроизводит их как ссылки в
выходных документах. Такие документы могут быть сохранены в форматах Microsoft
Word, PDF и HTML. Кроме того, в распознанный текст можно добавлять собственные
гиперссылки.Screenshot Reader. Это простое и удобное приложение предназначено
для распознавания текста с любой области экрана компьютера. Screenshot Reader
позволит переводить в редактируемый формат такие тексты, которые нельзя
скопировать обычным способом (например, тексты с интернет-страниц, созданных
при помощи технологии Flash). Как распознанный текст, так и снимок экрана могут
быть сохранены в виде файла или переданы в буфер обмена. Таким образом, при
помощи ABBYY Screenshot Reader можно: быстро собрать в один файл цитаты из
нескольких открытых документов, получить в виде текста содержание папки с
файлами, название файлов и атрибуты, сохранить в виде текста историю писем в
Outlook, извлечь текст из сообщений об ошибках, сообщений в строке статуса, и
т.д., сохранить данные только из выбранного столбца таблицы (в
интернет-браузере, базе данных и т.д.).
Исправление разрешения. Эта функция помогает в
тех случаях, когда изображение не содержит информации о разрешении. Если
обрабатывать такие изображения без предварительной коррекции, качество окажется
невысоким. Поэтому ABBYY FineReader 8.0 при добавлении изображений в пакет
проверяет каждое из них. В случаях, когда разрешение изображений не указано или
имеет нетипичное значение, производится его коррекция. Пользователь может
устанавливать разрешение изображений вручную.
Рисунок 16 - Исправление разрешения
Обрезание изображений. В ABBYY FineReader 8.0
есть функция обрезания изображения; предусмотрены автоматический и ручной
режимы. Функция предназначена для удаления чёрных полей (они иногда возникают
при сканировании книг), для приведения страниц пакета к одинаковому размеру,
для удаления с фотографий документов областей, не содержащих текста.
«Выпрямление» строк. Зачастую при сканировании
толстых книг и журналов строки текста вблизи сгиба оказываются искривлены.
Аналогичная проблема встречается при фотографировании: строки искривляются
вблизи краёв документа. В ABBYY FineReader 8.0 появилась функция, позволяющая
устранить подобные искажения и увеличить таким образом качество распознавания.
Указание дополнительных свойств. ABBYY
FineReader 8.0 позволяет указать для распознанного документа дополнительные
свойства, такие как описание, автор, тема, ключевые слова. Сохранить подобный
документ можно в формате PDF, DOC/RTF, XLS, HTML, Word XML или LIT. Указанные
свойства могут в дальнейшем использоваться для индексирования и поиска по
документам.
Удобная работа с многостраничными документами.
При открытии многостраничных TIFF- и PDF-файлов ABBYY FineReader 8.0 позволяет
указать диапазон страниц, которые необходимо открыть. Это удобно, например,
когда требуется распознать не всю книгу в формате PDF, а только некоторые её
главы.
Новые входные и выходные форматы. ABBYY
FineReader 8.0 способен открывать графические файлы формата TIFF, сжатые по
алгоритму LZW. Существует возможность сохранять результаты распознавания в
формат Microsoft Reader eBook (LIT), один из самых популярных форматов для
создания электронных книг.
Настройки сохранения RTF/ DOC. Существует режим
сохранения - «Колонки, таблицы, абзацы, шрифты». Он позволяет, с одной стороны,
сохранить близкое к оригиналу оформление документа, а с другой стороны - легко
редактировать распознанный текст.
Рисунок 17 - Выбор настроек сохранения
FineReader 8.0 поддерживает 179 языков распознавания,
включая 36 языков со словарной поддержкой. Также добавлены словари для
венгерского, датского, польского, итальянского, голландского (Нидерланды),
норвежского (букмол и нюнорск), португальского (Португалия), финского языков
распознавания. Это позволило увеличить качество распознавания на всех
перечисленных языках. Огромное количество языков распознавания со словарной
поддержкой. Словари для словенского и башкирского языков.
Используя все возможности современных программ
верстки, дизайнеры часто создают объекты сложной формы, такие, как обтекание
непрямоугольной картинки многоколоночным текстом. В FineReader 8.0 реализована
поддержка распознавания таких объектов и их сохранение в файлах формата MS
Word. Теперь документы сложной верстки будут точно воспроизведены в этом
текстовом редакторе. Даже таблицы распознаются с максимальной точностью,
сохраняя при этом все возможности для редактирования.FormReader еще одна
программа для распознавания текста от ABBYY, основанная на ABBYY FineReader
Engine. Эта программа предназначена для распознавания и обработки форм, которые
могут быть заполнены вручную. Производители утверждают, что программа ABBYY
FormReader может обрабатывать формы с фиксированной схемой так же хорошо, как и
формы, чья структура может меняться. Для распознавания была применена новая
технология ABBYY FlexiForm technology.CuneiForm один из главных конкурентов
FineReader как на российском, так и на мировом рынке. Производителем является
российский разработчик программного обеспечения Cognitive Technologies. По
словам производителей, OCR CuneiForm выгодно отличается уровнем распознавания,
особенно текстов низкого качества; удобным интерфейсом с наличием встроенных
мастеров помощников в работе; встроенным текстовым редактором, не уступающим по
своей функциональности популярным текстовым процессорам, и многими другими
возможностями.CuneiForm способна распознавать любые полиграфические и
машинописные гарнитуры всех начертаний и шрифтов, получаемые с принтеров, за
исключением декоративных и рукописных. Также программа способна распознавать
таблицы различной структуры, в том числе и без линий и границ; редактировать и
сохранять результаты в распространенных табличных форматах. Существенно
облегчает работу и возможность прямого экспорта результатов в MS Word и MS
Excel (для этого теперь не нужно сохранять результат в файл RTF, а затем
открывать его с помощью MS Word).
Также программа снабжена возможностями массового
ввода возможностью пакетного сканирования, включая круглосуточное, сканирования
с удаленных компьютеров локальной сети и организации распределенного
параллельного сканирования в локальной сети.
В системе используется целый ряд уникальных
технологий, среди которых адаптивное распознавание, нейронные сети, когнитивный
анализ альтернатив распознавания и другие.
О высокой конкурентоспособности этой системы
говорит тот факт, что ведущие мировые производители вычислительной техники
поставляют свою продукцию с этой программой. Наиболее популярные в России
сканеры и многофункциональные устройства Canon, Hewlett-Packard, OKI, Seiko
Epson, Olivetti поставляются в комплекте с OCR CuneiForm.
Ведущие производители программного обеспечения
также лицензировали российскую информационную технологию для применения со
своими продуктами. В популярные программные пакеты Corel Draw (Corel
Corporation), FaxLine/OCR&Business Card Wizard (Inzer Corporation) и многие
другие встроена OCR-библиотека CuneiForm. Хочется отметить, что эта программа
стала первой в России OCR-системой, получившей MS Windows Compatible Logo.
Основные преимущества CuneiForm перед другими
системами оптического распознавания символов:отличается от других программ
этого класса высоким уровнем распознавания, особенно текстов низкого качества и
наличием встроенных мастеров - помощников в работе; мощным встроенным текстовым
редактором.сочетает в себе распознавания текстов передовые технологии и
результаты многолетних исследований и разработок отечественных ученых и
программистов.
Интерфейс программы содержит выпадающие
контекстные меню, панели быстрого доступа, контекстную помощь.

Рисунок 16 - Основное окно CuneiForm
Автоматический подбор оптимальных параметров
сканирования. Возможность импортирования отсканированных или полученных через
факс-модем графических файлов во многих форматах. Обработка изображений: печать
образа, инвертирование, поворот.распознает любые полиграфические, машинописные
гарнитуры всех начертаний и шрифты, получаемые с принтеров за исключением
декоративных и рукописных. В систему встроены специальные алгоритмы для
распознавания текста с матричного принтера, печатной машинки, плохих ксерокопий
и факсов.Самообучающиеся адаптивные алгоритмы распознавания повышают
вероятность распознавания низкокачественных документов.

Рисунок 17 - Распознавание текста в CuneiForm
Автоматический и полуавтоматический режимы
поиска блоков текста, таблиц и графики, который обеспечивает большую гибкость
при работе с многоколоночными текстами и текстами сложной структуры и с
графическими элементами. Режим ручной фрагментации для работы с текстами особо
сложной структуры.
Система распознает русский, английский,
смешанный русско-английский, украинский, немецкий, французский, испанский,
португальский, итальянский, голландский, датский, шведский, финский, сербский,
хорватский, польский, казахский, узбекский и другие языки.
Словарь общеупотребительной лексики каждого
поддерживаемого языка для контекстной проверки и повышения качества результатов
распознавания. Возможность создания и пополнения пользовательского словаря, а
также возможность экспорта/импорта словаря в/из текстовых файлов.позволяет
получить полную копию вводимого документа, включая: шрифтовое оформление и
форматирование; расположение текста, иллюстраций и таблиц; колонки, абзацы, отступы,
стили и размеры шрифтов; черно-белые, 256-градационные серые и цветные
24-битные иллюстрации в выходном RTF-файле.
Распознавание таблиц различной структуры, в том
числе и без линий разграфки. Редактирование таблиц (уменьшение/увеличение,
удаление/создание колонок и т.д.) Сохранение результатов в распространенных
табличных форматах.
В программу встроен многофункциональный
редактор, не уступающий по своим возможностям популярным текстовым процессорам.
Одновременная подсветка распознанного текста и исходного изображения,
снабженная функцией "следующий/предыдущий сомнительно распознанный".
Поддержка иллюстраций, таблиц, колонок, колонтитулов, сложного форматирования и
различных шрифтов. Возможность редактирования текстовых документов популярных
форматов.
Опции командной строки и поддержка Drag&Drop
для вызова из внешних приложений, сканирования, распознавания и сохранения
результатов в автоматическом режиме.Pro 7 профессиональная программа
распознавания текста. По словам производителей (I.R.I.S.), данная OCR
отличается от аналогов высочайшей точностью преобразования обычных
(каждодневных) печатных документов, таких как письма, факсы, журнальные статьи,
газетные вырезки, в объекты, доступные для редактирования (включая файлы PDF).
Основными достоинствами программы являются: возможность более или менее точного
распознавания картинок, сжатых по максимуму (с максимальной потерей качества)
методом JPEG, поддержка цифровых камер и автоопределения ориентации страницы.
Поддержка до 92 языков (включая русский).11 продукт компании ScanSoft.
Ограниченная версия этой программы (OmniPage11 Limited Edition, OmniPage Lite)
обычно поставляется в комплекте с новыми сканерами (на территории Европы и
США). Разработчики утверждают, что их программа практически со 100% точностью распознает
печатные документы, восстанавливая их форматирование, включая столбцы, таблицы,
переносы (в том числе переносы частей слов), заголовки, названия глав, подписи,
номера страниц, сноски, параграфы, нумерованные списки, красные строки, графики
и картинки. Есть возможность сохранения в форматы Microsoft Office, PDF и в 20
других форматов, распознавания из файлов PDF, редактирование прямо в формате
PDF. Система искусственного интеллекта позволяет автоматически обнаруживать и
исправлять ошибки после первого исправления вручную. Новый специально
разработанный модуль Despeckle позволяет распознавать документы с ухудшенным
качеством (факсы, копии, копии копий ит.д.). Преимуществами программы являются
возможность распознавания цветного текста и возможность корректировки голосом.
Заключение
Исследование методов и программно-аппаратных
систем оптического распознавания символов позволяет сформулировать следующие
выводы:
. Современное состояние технологии
автоматического распознавания печатных текстов (OCR) позволяет решать задачу
автоматизации ввода информации при необходимом уровне надежности.
. При построении системы OCR, включающей
оптическое устройство оцифровки изображений, блок локализации и выделения
элементов текста, блок предобработки изображения; блок выделения признаков,
блок распознавания символов и блок постобработки результатов распознавания,
необходимо использовать методы и алгоритмы, обладающие высокой робастностью к
яркостно-геометрическим искажениям и сложным текстурным фонам.
. В качестве таких методов и алгоритмов, могут
быть использованы: процедуры определения строк, знакомест на основе модификаций
преобразования Hough; методы, основанные на исследовании устойчивых
статистических распределений точек; методы, использующие интегральные преобразования,
а также структурный анализ символов.
. При разработке современных систем OCR для
повышения качества распознавания символов и слов необходимо учитывать
контекстную информацию. Использование контекстной информации позволяет не
только находить ошибки, но и исправлять их.
Переходя к программе разработанной в ходе
выполнения курсовой работы необходимо отметить, что хотя в ней и не применяются
системы искусственного интеллекта (перцептроны и нейросети), а используется
довольно простой метод сравнения с эталонными символами, алгоритм дает
приемлемый результат на заранее известном наборе эталонов.
Применение этого метода уместно в тех случаях,
когда необходимо распознавать большие объемы текстов напечатанных одним шрифтом
в едином размере. При таких условиях результаты распознавания могут
конкурировать с методами основанными на использовании нейросетей и не уступать
им по скорости распознавания.
При всём этом метод сравнения с эталоном гораздо
проще других алгоритмов, использует простой математический аппарат. Однако
небольшие отклонения входных данных от эталонных значений приводят к резкому
падению качества распознавания.
Список литературы
Бутаков
А., Островский В. И., Фадеев И.Л. "Обработка изображений на ЭВМ", -
М.: Радио и связь, 1987.
Дуда
Р., Харт П. Распознавание образов и анализ сцен. - М.: Мир, 1986.
Котович
Н.В., Славин О.А. Распознавание скелетных образов // Методы и средства работы с
документами - сборник трудов Института системного анализа РАН - 2000.
Приложение А Исходный текст программы
{Бинаризация - делает картинку чернобелой}
function Binarise(Bmp:
TBitmap):TBitmap;= record,G,R:Byte;;= ^TRGB;x,y: word;: TBitmap;: pRGB;:=
TBitmap.Create;.Width := Bmp.Width;.Height := Bmp.Height;.PixelFormat :=
pf8bit;y := 0 to Bmp.Height - 1 do:=Bmp.ScanLine[y];x := 0 to Bmp.Width - 1
do(0.3*Dest^.R + 0.59*Dest^.G + 0.11*Dest^.B) < 200 then.Canvas.Pixels[x,y]
:= clBlack;(Dest);;;:= TmpBmp;;
{Фукнция
максимума}Max(x,y:Integer):Integer;x>y
then Result:=x else Result:=y;
end;
{Разница между двумя изображениями}
function
GetDifferents(Bmp1,Bmp2:TBitmap):Integer;,c2:PByte;,y,x1,y1,i,Diff:Integer;.PixelFormat:=pf24bit;.PixelFormat:=pf24bit;:=0;:=Max(Bmp1.Width,Bmp2.Width);:=Max(Bmp1.Height,Bmp2.Height);y:=0
to y1-1 doBmp1.Height>y then c1:=Bmp1.Scanline[y];Bmp2.Height>y then
c2:=Bmp2.Scanline[y];x:=0 to x1-1 doi:=0 to 2
do(Diff,Integer(c1^<>c2^));(c1);(c2);;;:=Round(10000*(Diff/(x1*y1)));;RemoveBreak(Bmp:TBitmap);,y:Integer;:array
of Boolean;,Max,TempStart,Start:Integer;(Arr,Bmp.Height);y:=0 to Bmp.Height-1
do[y]:=False;x:=0 to Bmp.Width-1 do if Bmp.Canvas.Pixels[x,y]<>$FFFFFF
then[y]:=True;;;;:=0;:=0;y:=0 to Length(Arr)-1 doArr[y] thenTemp=0 then
TempStart:=y;(Temp);elseTemp>Max then:=Temp;:=TempStart;;:=0;;;Temp>Max
then:=Temp;:=TempStart;;.Canvas.Draw(0,-Start,Bmp);.Height:=Max;(Arr,Bmp.Width);x:=0
to Length(Arr)-1 do[x]:=False;y:=0 to Bmp.Height-1 do if
Bmp.Canvas.Pixels[x,y]<>$FFFFFF then[x]:=True;;;;:=0;:=0;x:=0 to
Length(Arr)-1 doArr[x] thenTemp=0 then TempStart:=x;(Temp);elseTemp>Max then:=Temp;:=TempStart;;:=0;;;Temp>Max
then:=Temp;:=TempStart;;.Canvas.Draw(-Start,0,Bmp);
Bmp.Width:=Max;;
{Сравнение с эталоном}
function
GetChar(Bmp:TBitmap):Char;='ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';,SizeEnd:Integer;:TBitmap;:Integer;:Byte;:Integer;:Integer;:=#0;:=Round(Bmp.Height*0.90);:=Round(bmp.Height*1.10);:=10000;:=TBitmap.Create;.PixelFormat:=pf24Bit;i:=SizeBegin
to SizeEnd doc:=1 to Length(CharList)
do.Width:=i*2;.Height:=i*2;.Canvas.FillRect(Rect(0,0,CharBmp.Width,CharBmp.Height));.Canvas.Font.Name:='Arial';.Canvas.Font.Size:=i;.Canvas.TextOut(0,0,CharList[c]);(CharBmp);:=GetDifferents(Bmp,CharBmp);Temp<Min
then:=Temp;:=CharList[c];;;.Free;;Prepare(Bmp:TBitmap):TBitmap;:array of array
of Byte;,j,k:Integer;,Max:Integer;:array of array[0..2] of
Integer;:TBitmap;f(x1,y1:Integer);(Size);[x1][y1]:=2;BmpArr[x1+1][y1]=1 then
f(x1+1,y1);BmpArr[x1-1][y1]=1 then f(x1-1,y1);BmpArr[x1][y1+1]=1 then
f(x1,y1+1);BmpArr[x1][y1-1]=1 then
f(x1,y1-1);;d(x1,y1:Integer);[x1][y1]:=0;BmpArr[x1+1][y1]=2 then
d(x1+1,y1);BmpArr[x1-1][y1]=2 then d(x1-1,y1);BmpArr[x1][y1+1]=2 then
d(x1,y1+1);BmpArr[x1][y1-1]=2 then d(x1,y1-1);;(BmpArr,Bmp.Width);i:=0 to
Length(BmpArr)-1 do(BmpArr[i],Bmp.Height);j:=0 to Bmp.Height-1 do
Bmp.Canvas.Pixels[i,j]=$FFFFFF then
BmpArr[i][j]:=0 [i][j]:=1;;i:=0 to
Bmp.Width-1 doj:=0 to Bmp.Height-1 doBmpArr[i][j]=1
then:=0;(i,j);(ArrSize,Length(ArrSize)+1);[Length(ArrSize)-1][0]:=Size;[Length(ArrSize)-1][1]:=i;[Length(ArrSize)-1][2]:=j;;;:=ArrSize[0][0];k
:= 0 to Length(ArrSize)-1 do ArrSize[k][0]>Max then
:=ArrSize[k][0];:=Round(Max/10);k:=0 to Length(ArrSize)-1 do
ArrSize[k][0]<Max then (ArrSize[k][1],ArrSize[k][2]);:=
TBitmap.Create;.Width := Bmp.Width;.Height := Bmp.Height;i:=0 to Bmp.Width-1
doj:=0 to Bmp.Height-1 do BmpArr[i][j]=0 then .Canvas.Pixels[i,j]:=$FFFFFF
.Canvas.Pixels[i,j]:=$000000;:= TmpBmp;;
{Сегментация}GetImageChars(Bmp:TBitmap):String;,j:Integer;:array
of Boolean;:Boolean;:array[0..1] of array of
Integer;:TBitmap;:Char;:='';.PixelFormat:=pf24Bit;(BmpArrX,Bmp.Width);i:=0 to
Bmp.Width-1 do[i]:=False;j:=0 to Bmp.Height-1 doBmp.Canvas.Pixels[i,j]=0
then[i]:=True;;;;:=False;i:=0 to Bmp.Width-1 doBmpArrX[i] thennot ok
then:=True;(CharPos[0],Length(CharPos[0])+1);[0][Length(CharPos[0])-1]:=i;;else
if ok then:=False;(CharPos[1],Length(CharPos[1])+1);[1][Length(CharPos[1])-1]:=i;;.ProgressMax(Length(CharPos[0]));.ProgressReset;.Left
:= Form1.Left;.Top := Form1.Top + (Form1.Height - Form2.Height) div
2;.Show;:=TBitmap.Create;i:=0 to Length(CharPos[0])-1 do.Height:=Bmp.Height;.Width:=CharPos[1][i]-CharPos[0][i];.Canvas.CopyRect(Rect(0,
,[1][i]-CharPos[0][i],.Height1),.Canvas,(CharPos[0][i],0,CharPos[1][i],Bmp.Height-1));(TmpBmp);:=
Result + GetChar(TmpBmp);
//
Прогресс распознавания.VPic(TmpBmp);
Form2.ProgressAdd;.ProcessMessages;;.Hide;.Free;;TForm1.nOpenClick(Sender:
TObject);dlgOpen.Execute
then.Picture.Bitmap.LoadFromFile(dlgOpen.FileName);;TForm1.nExitClick(Sender:
TObject);;;TForm1.nRaspoznClick(Sender: TObject);.Enabled :=
false;.Picture.Bitmap := Binarise(Image1.Picture.Bitmap);.Picture.Bitmap :=
Prepare(Image1.Picture.Bitmap);.Text:=GetImageChars(Image1.Picture.Bitmap);.Enabled
:= true;;
Приложение Б Нейронные сети
1.
Введение в нейронные сети
Теория
нейронных сетей включают широкий круг вопросов из разных областей науки:
биофизики, математики, информатики, схемотехники и технологии. Поэтому понятие
"нейронные сети" детально определить сложно.
Искусственные
нейронные сети (НС) - совокупность моделей биологических нейронных сетей.
Представляют собой сеть элементов - искусственных нейронов - связанных между
собой синоптическими соединениями. Сеть обрабатывает входную информацию и в
процессе изменения своего состояния во времени формирует совокупность выходных
сигналов.
Работа
сети состоит в преобразовании входных сигналов во времени, в результате чего
меняется внутреннее состояние сети и формируются выходные воздействия. Обычно
НС оперирует цифровыми, а не символьными величинами.
Большинство
моделей НС требуют обучения. В общем случае, обучение - такой выбор параметров
сети, при котором сеть лучше всего справляется с поставленной проблемой.
Обучение - это задача многомерной оптимизации, и для ее решения существует
множество алгоритмов.
Искусственные
нейронные сети - набор математических и алгоритмических методов для решения широкого
круга задач. Выделим характерные черты искусственных нейросетей как
универсального инструмента для решения задач:
НС
дают возможность лучше понять организацию нервной системы человека и животных
на средних уровнях: память, обработка сенсорной информации, моторика.
НС
- средство обработки информации:
гибкая
модель для нелинейной аппроксимации многомерных функций;
средство
прогнозирования во времени для процессов, зависящих от многих переменных;
классификатор
по многим признакам, дающий разбиение входного пространства на области;
средство
распознавания образов;
инструмент
для поиска по ассоциациям;
модель
для поиска закономерностей в массивах данных.
НС
свободны от ограничений обычных компьютеров благодаря параллельной обработке и
сильной связанности нейронов.
В
перспективе НС должны помочь понять принципы, на которых построены высшие
функции нервной системы: сознание, эмоции, мышление.
Современные
искусственные НС по сложности и "интеллекту" приближаются к нервной
системе таракана, но уже сейчас демонстрируют ценные свойства:
Обучаемость.
Выбрав одну из моделей НС, создав сеть и выполнив алгоритм обучения, мы можем
обучить сеть решению задачи, которая ей по силам. Нет никаких гарантий, что это
удастся сделать при выбранных сети, алгоритме и задаче, но если все сделано
правильно, то обучение бывает успешным.
Способность
к обобщению. После обучения сеть становится нечувствительной к малым изменениям
входных сигналов (шуму или вариациям входных образов) и дает правильный
результат на выходе.
Способность
к абстрагированию. Если предъявить сети несколько искаженных вариантов входного
образа, то сеть сама может создать на выходе идеальный образ, с которым она
никогда не встречалась.
.
Искусственные нейронные сети
.1
Формальный нейрон
Биологический
нейрон - сложная система, математическая модель которого до сих пор полностью
не построена. Введено множество моделей, различающихся вычислительной
сложностью и сходством с реальным нейроном. Одна из важнейших - формальный
нейрон (Рисунок 2.1.1). Несмотря на простоту ФН, сети, построенные из таких
нейронов, могут сформировать произвольную многомерную функцию на выходе.
Рисунок
2.1.1 - Формальный нейрон
Нейрон
состоит из взвешенного сумматора и нелинейного элемента. Функционирование
нейрона определяется формулами:
|
 (1) (1)
|
|
|
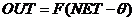 (2) (2)
|
|
где хi - входные сигналы, совокупность всех
входных сигналов нейрона образует вектор x;- весовые коэффициенты, совокупность
весовых коэффициентов образует вектор весов w;- взвешенная сумма входных
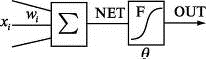
сигналов, значение NET передается на нелинейный элемент;
Ө - пороговый уровень данного нейрона;-
нелинейная функция, называемая функцией активации.
Нейрон имеет несколько входных сигналов x и один
выходной сигнал OUT Параметрами нейрона, определяющими его работу, являются:
вектор весов w, пороговый уровень Ө и вид функции активации F.
.2 Виды функций активации
Рассмотрим основные виды функций активации,
получившие распространение в искусственных НС.
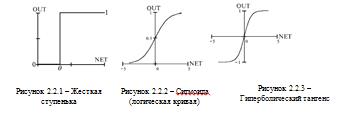
. Жесткая ступенька (рисунок 2.2.1):

Используется в классическом
формальном нейроне. Развита полная теория, позволяющая синтезировать
произвольные логические схемы на основе ФН с такой нелинейностью. Функция
вычисляется двумя-тремя машинными инструкциями, поэтому нейроны с такой
нелинейностью требуют малых вычислительных затрат.
Эта функция чрезмерно упрощена и не
позволяет моделировать схемы с непрерывными сигналами. Отсутствие первой
производной затрудняет применение градиентных методов для обучения таких
нейронов. Сети на классических ФН чаще всего формируются, синтезируются, т.е.
их параметры рассчитываются по формулам, в противоположность обучению, когда
параметры подстраиваются итеративно.
. Логистическая функция (сигмоида,
функция Ферми, рисунок 2.2.2):
Применяется очень часто для
многослойных перцептронов и других сетей с непрерывными сигналами. Гладкость,
непрерывность функции - важные положительные качества. Непрерывность первой
производной позволяет обучать сеть градиентными методами (например, метод
обратного распространения ошибки).
Функция симметрична относительно
точки (NET=0, OUT=1/2), это делает равноправными значения OUT=0 и OUT=1, что
существенно в работе сети. Тем не менее, диапазон выходных значений от 0 до 1
несимметричен, из-за этого обучение значительно замедляется.
Данная функция - сжимающая, т.е. для
малых значений NET коэффициент передачи K=OUT/ NET велик, для больших значений
он снижается. Поэтому диапазон сигналов, с которыми нейрон работает без
насыщения, оказывается широким.
Значение производной легко выражается
через саму функцию. Быстрый расчет производной ускоряет обучение.
. Гиперболический тангенс (рисунок
2.2.3):
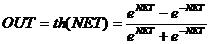
Тоже применяется часто для сетей с
непрерывными сигналами. Функция симметрична относительно точки (0,0), это
преимущество по сравнению с сигмоидой.
. Пологая ступенька (рисунок 2.2.4):
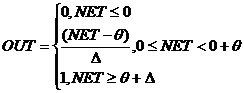
Рассчитывается легко, но имеет
разрывную первую производную в точках NET = Ө , NET = Ө + Δ что
усложняет алгоритм обучения.
. Экспонента: 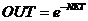 .
Применяется в специальных случаях.
.
Применяется в специальных случаях.
. SOFTMAX-функция:

Здесь суммирование производится по
всем нейронам данного слоя сети. Такой выбор функции обеспечивает сумму выходов
слоя, равную единице при любых значениях сигналов NETi данного слоя. Это
позволяет трактовать OUTi как вероятности событий, совокупность которых (все
выходы слоя) образует полную группу. Это полезное свойство позволяет применить
SOFTMAX-функцию в задачах классификации, проверки гипотез, распознавания
образов и во всех других, где требуются выходы-вероятности.
. Участки синусоиды:
 для
для  или
или 
. Гауссова кривая (рисунок 2.2.5):
для или
. Линейная функция, OUT = K NET,
K=const. Применяется для тех моделей сетей, где не требуется последовательное
соединение слоев нейронов друг за другом.

Выбор функции активации определяется:
Спецификой задачи.
Удобством реализации на ЭВМ, в виде
электрической схемы или другим способом.
Алгоритмом обучения: некоторые алгоритмы
накладывают ограничения на вид функции активации, их нужно учитывать.
Чаще всего вид нелинейности не оказывает
принципиального влияния на решение задачи. Однако удачный выбор может сократить
время обучения в несколько раз.
.3 Ограничения модели нейрона
Вычисления выхода нейрона предполагаются
мгновенными, не вносящими задержки. Непосредственно моделировать динамические
системы, имеющие "внутреннее состояние", с помощью таких нейронов
нельзя.
В модели отсутствуют нервные импульсы. Нет
модуляции уровня сигнала плотностью импульсов, как в нервной системе. Не
появляются эффекты синхронизации, когда скопления нейронов обрабатывают
информацию синхронно, под управлением периодических волн
возбуждения-торможения.
Нет четких алгоритмов для выбора функции
активации.
Нет механизмов, регулирующих работу сети в целом
(пример - гормональная регуляция активности в биологических нервных сетях).
Чрезмерная формализация понятий:
"порог", "весовые коэффициенты". В реальных нейронах нет
числового порога, он динамически меняется в зависимости от активности нейрона и
общего состояния сети. Весовые коэффициенты синапсов тоже не постоянны.
"Живые" синапсы обладают пластичностью и стабильностью: весовые
коэффициенты настраиваются в зависимости от сигналов, проходящих через синапс.
Существует большое разнообразие биологических
синапсов. Они встречаются в различных частях клетки и выполняют различные
функции. То' рмозные и возбуждающие синапсы реализуются в данной модели в виде
весовых коэффициентов противоположного знака, но разнообразие синапсов этим не
ограничивается. Дендро-дендритные, аксо-аксональные синапсы не реализуются в
модели ФН.
В модели не прослеживается различие между
градуальными потенциалами и нервными импульсами. Любой сигнал представляется в
виде одного числа.
. Многослойный перцептрон
Формальные нейроны могут объединяться в сети
различным образом. Самым распространенным видом сети стал многослойный
перцептрон (рисунок 2.1).
Сеть состоит из произвольного количества слоев
нейронов. Нейроны каждого слоя соединяются с нейронами предыдущего и
последующего слоев по принципу "каждый с каждым". Первый слой (слева)
называется сенсорным или входным, внутренние слои называются скрытыми или
ассоциативными, последний (самый правый, на рисунке состоит из одного нейрона)
- выходным или результативным. Количество нейронов в слоях может быть
произвольным. Обычно во всех скрытых слоях одинаковое количество нейронов.
Обозначим количество слоев и нейронов в слое.
Входной слой: NI нейронов; NH нейронов в каждом скрытом слое; NO выходных
нейронов. х - вектор входных сигналы сети, у - вектор выходных сигналов.
Существует путаница с подсчетом количества слоев
в сети. Входной слой не выполняет никаких вычислений, а лишь распределяет
входные сигналы, поэтому иногда его считают, иногда - нет. Обозначим через NL
полное количество слоев в сети, считая входной.
Работа многослойного перцептрона (МСП)
описывается формулами:
где индексом i всегда будем обозначать номер
входа, j - номер нейрона в слое, l - номер слоя.- й входной сигнал j-го нейрона
в слоеl;- весовой коэффициент i-го входа нейрона номер j в слое l;- сигнал NET
j-го нейрона в слое l; - выходной сигнал нейрона;
Өjl - пороговый уровень нейрона j в слое
l;
Введем обозначения: Wjl - вектор-столбец весов
для всех входов нейрона j в слое l; Wl - матрица весов всех нейронов в слое l.
В столбцах матрицы расположены вектора Wjl. Аналогично Xjl - входной
вектор-столбец слоя l.
Каждый слой рассчитывает нелинейное
преобразование от линейной комбинации сигналов предыдущего слоя. Отсюда видно,
что линейная функция активации может применяется только для тех моделей сетей,
где не требуется последовательное соединение слоев нейронов друг за другом. Для
многослойных сетей функция активации должна быть нелинейной, иначе можно
построить эквивалентную однослойную сеть, и многослойность оказывается
ненужной. Если применена линейная функция активации, то каждый слой будет
давать на выходе линейную комбинацию входов. Следующий слой даст линейную
комбинацию выходов предыдущего, а это эквивалентно одной линейной комбианции с
другими коэффициентами, и может быть реализовано в виде одного слоя нейронов.
Многослойная сеть может формировать на выходе
произвольную многомерную функцию при соответствующем выборе количества слоев,
диапазона изменения сигналов и параметров нейронов. Как и ряды, многослойные
сети оказываются универсальным инструментом аппроксимации функций. Видно
отличие работы нейронной сети от разложения функции в ряд:
Ряд: 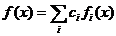
Нейронная сеть:
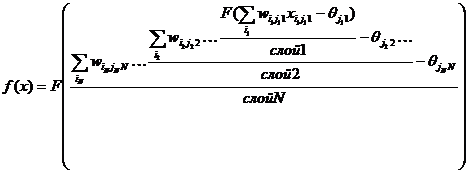
За счет поочередного расчета
линейных комбинаций и нелинейных преобразований достигается аппроксимация
произвольной многомерной функции при соответствующем выборе параметров сети.
В многослойном перцептроне нет
обратных связей. Такие модели называются сетями прямого распространения. Они не
обладают внутренним состоянием и не позволяют без дополнительных приемов
моделировать развитие динамических систем.
.1 Алгоритм решения задач с помощью
МСП
Чтобы построить МСП, необходимо
выбрать его параметры. Чаще всего выбор значений весов и порогов требует
обучения, т.е. пошаговых изменений весовых коэффициентов и пороговых уровней.
Общий алгоритм решения:
Определить, какой смысл вкладывается
в компоненты входного вектора x. Входной вектор должен содержать формализованное
условие задачи, т.е. всю информацию, необходимую для получения ответа.
Выбрать выходной вектор y таким
образом, чтобы его компоненты содержали полный ответ поставленной задачи.
Выбрать вид нелинейности в нейронах
(функцию активации). При этом желательно учесть специфику задачи, т.к. удачный
выбор сократит время обучения.
Выбрать число слоев и нейронов в
слое.
Задать диапазон изменения входов,
выходов, весов и пороговых уровней, учитывая множество значений выбранной
функции активации.
Присвоить начальные значения весовым
коэффициентам и пороговым уровням и дополнительным параметрам (например,
крутизне функции активации, если она будет настраиваться при обучении).
Начальные значения не должны быть большими, чтобы нейроны не оказались в
насыщении (на горизонтальном участке функции активации), иначе обучение будет
очень медленным. Начальные значения не должны быть и слишком малыми, чтобы
выходы большей части нейронов не были равны нулю, иначе обучение также
замедлится.
Провести обучение, т.е. подобрать
параметры сети так, чтобы задача решалась наилучшим образом. По окончании
обучения сеть готова решить задачи того типа, которым она обучена.
Подать на вход сети условия задачи в
виде вектора x. Рассчитать выходной вектор y, который и даст формализованное
решение задачи.
.2 Формализация задачи распознавания
букв алфавита
Будем представлять буквы в виде
точечных изображений (рисунок 2.2.1).

Темной клетке-пикселу на изображении
соответствует Iij = 1, светлому - Iij = 0. Задача состоит в том, чтобы
определить по изображению букву, которая была предъявлена.
Построим МСП с Ni * Nj входами,
каждому входу соответствует один пиксел: хk =Iij, = 1..Ni* Nj. Яркости пикселов
будут компонентами входного вектора.
В качестве выходных сигналов выберем
вероятности того, что предъявленное изображение соответствует данной букве: y =
(c1...cM)T . Сеть рассчитывает выход:

где выход с1 = 0,9 означает, к
примеру, что предъявлено изображение буквы "А", и сеть уверена в этом
на 90%, выход с2 = 0,1 - что изображение соответствовало букве "Б" с
вероятностью 10% и т.д.
Другой способ: входы сети выбираются
так же, а выход - только один, номер m предъявленной буквы. Сеть учится давать
значение m по предъявленному изображению I:
В данном методе существует
недостаток: буквы, имеющие близкие номера m, но непохожие изображения, могут
быть перепутаны сетью при распознавании.
.3 Выбор количества нейронов и слоев
Нет строго определенной процедуры
для выбора количества нейронов и количества слоев в сети. Чем больше количество
нейронов и слоев, тем шире возможности сети, тем медленнее она обучается и
работает и тем более нелинейной может быть зависимость вход-выход.
Количество нейронов и слоев связано:
со сложностью задачи;
с количеством данных для обучения;
с требуемым количеством входов и
выходов сети;
с имеющимися ресурсами: памятью и
быстродействием машины, на которой моделируется сеть;
Были попытки записать эмпирические
формулы для числа слоев и нейронов, но применимость формул оказалась очень
ограниченной.
Если в сети слишком мало нейронов
или слоев:
сеть не обучится и ошибка при работе
сети останется большой;
на выходе сети не будут передаваться
резкие колебания аппроксимируемой функции y(x).
Превышение требуемого количества
нейронов тоже мешает работе сети.
Если нейронов или слоев слишком
много:
быстродействие будет низким, а
памяти потребуется много - на фон-неймановских ЭВМ;
сеть переобучится: выходной вектор
будет передавать незначительные и несущественные детали в изучаемой зависимости
y(x), например, шум или ошибочные данные;
зависимость выхода от входа окажется
резко нелинейной: выходной вектор будет существенно и непредсказуемо меняться
при малом изменении входного вектора x;
сеть будет неспособна к обобщению: в
области, где нет или мало известных точек функции y(x) выходной вектор будет
случаен и непредсказуем, не будет адекватен решамой задаче.
. Алгоритмы обучения
Алгоритмы обучения бывают с учителем
и без. Алгоритм называется алгоритмом с учителем, если при обучении известны и
входные, и выходные вектора сети. Имеются пары вход + выход - известные условия
задачи и решение. В процессе обучения сеть меняет свои параметры и учится
давать нужное отображение X -> Y . Сеть учится давать результаты, которые
нам уже известны. За счет способности к обобщению сетью могут быть получены
новые результаты, если подать на вход вектор, который не встречался при
обучении.
Алгоритм относится к обучению без
учителя, если известны только входные вектора, и на их основе сеть учится
давать наилучшие значения выходов. Что понимается под “наилучшими” -
определяется алгоритмом обучения.
.1 Алгоритм обратного распространения
Среди различных структур нейронных
сетей (НС) одной из наиболее известных является многослойная структура, в
которой каждый нейрон произвольного слоя связан со всеми нейронов предыдущего
слоя или, в случае первого слоя, со всеми входами НС. Такие НС называются
полносвязными. Когда в сети только один слой, алгоритм ее обучения с учителем
довольно очевиден, так как правильные выходные состояния нейронов единственного
слоя заведомо известны, и подстройка синаптических связей идет в направлении,
минимизирующем ошибку на выходе сети. По этому принципу строится, например,
алгоритм обучения однослойного перцептрона. В многослойных же сетях оптимальные
выходные значения нейронов всех слоев, кроме последнего, как правило, не
известны, и двух или более слойный перцептрон уже невозможно обучить,
руководствуясь только величинами ошибок на выходах НС. Один из вариантов
решения этой проблемы - разработка наборов выходных сигналов, соответствующих
входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией
и не всегда осуществимо. Второй вариант - динамическая подстройка весовых
коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые
связи и изменяются на малую величину в ту или иную сторону, а сохраняются
только те изменения, которые повлекли уменьшение ошибки на выходе всей сети.
Очевидно, что данный метод, несмотря на свою кажущуюся простоту, требует
громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант -
распространение сигналов ошибки от выходов НС к ее входам, в направлении,
обратном прямому распространению сигналов в обычном режиме работы. Этот
алгоритм обучения НС получил название процедуры обратного распространения.
Согласно методу наименьших
квадратов, минимизируемой целевой функцией ошибки НС является величина:
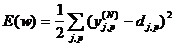 (1)
(1)
где  - реальное выходное состояние
нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа;
djp - идеальное (желаемое) выходное состояние этого нейрона.
- реальное выходное состояние
нейрона j выходного слоя N нейронной сети при подаче на ее входы p-го образа;
djp - идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем
нейронам выходного слоя и по всем обрабатываемым сетью образам. Минимизация
ведется методом градиентного спуска, что означает подстройку весовых
коэффициентов следующим образом:
 (2)
(2)
Здесь wij - весовой коэффициент
синаптической связи, соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, h - коэффициент скорости
обучения, 0<h<1.
Как показано в [2],
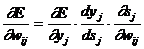 (3)
(3)
Здесь под yj, , подразумевается выход
нейрона j, а под sj - взвешенная сумма его входных сигналов, то есть аргумент
активационной функции. Так как множитель dyj/dsj является производной этой
функции по ее аргументу, из этого следует, что производная активационной
функция должна быть определена на всей оси абсцисс. В связи с этим функция
единичного скачка и прочие активационные функции с неоднородностями не подходят
для рассматриваемых НС. В них применяются такие гладкие функции, как
гиперболический тангенс или классический сигмоид с экспонентой. В случае
гиперболического тангенса
 (4)
(4)
Третий множитель ¶sj/¶wij, очевидно, равен выходу
нейрона предыдущего слоя yi(n-1).
Что касается первого множителя в
(3), он легко раскладывается следующим образом[2]:
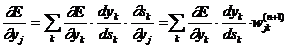 (5)
(5)
Здесь суммирование по k выполняется
среди нейронов слоя n+1.
Введя новую переменную
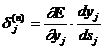 (6)
(6)
мы получим рекурсивную формулу для
расчетов величин dj(n) слоя n
из величин dk(n+1) более
старшего слоя n+1.
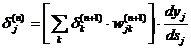 (7)
(7)
Для выходного же слоя
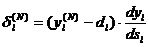 (8)
(8)
Теперь мы можем записать (2) в
раскрытом виде:
 (9)
(9)
Иногда для придания процессу
коррекции весов некоторой инерционности, сглаживающей резкие скачки при
перемещении по поверхности целевой функции, (9) дополняется значением изменения
веса на предыдущей итерации
 (10)
(10)
где m - коэффициент инерционности, t - номер текущей
итерации.
Таким образом, полный алгоритм
обучения НС с помощью процедуры обратного распространения строится так:
. Подать на входы сети один из
возможных образов и в режиме обычного функционирования НС, когда сигналы
распространяются от входов к выходам, рассчитать значения последних.
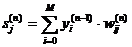 (11)
(11)
где M - число нейронов в слое n-1 с
учетом нейрона с постоянным выходным состоянием +1, задающего смещение;
yi(n-1)=xij(n) - i-ый вход нейрона j слоя n.(n) = f(sj(n)), где f() - сигмоид (12)(0)=Iq, (13)
где Iq - q-ая компонента вектора
входного образа.
. Рассчитать d(N) для выходного слоя по
формуле (8).
Рассчитать по формуле (9) или (10)
изменения весов Dw(N) слоя N.
. Рассчитать по формулам (7) и (9)
(или (7) и (10)) соответственно d(n)
и Dw(n) для
всех остальных слоев, n=N-1,...1.
. Скорректировать все веса в НС
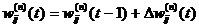 (14)
(14)
. Если ошибка сети существенна,
перейти на шаг 1. В противном случае - конец.
Рассматриваемая НС имеет несколько
нюансов. Во-первых, в процессе обучения может возникнуть ситуация, когда
большие положительные или отрицательные значения весовых коэффициентов сместят
рабочую точку на сигмоидах многих нейронов в область насыщения. Малые величины
производной от логистической функции приведут в соответствие с (7) и (8) к
остановке обучения, что парализует НС. Во-вторых, применение метода
градиентного спуска не гарантирует, что будет найден глобальный, а не локальный
минимум целевой функции. Эта проблема связана еще с одной, а именно - с выбором
величины скорости обучения. Доказательство сходимости обучения в процессе
обратного распространения основано на производных, то есть приращения весов и,
следовательно, скорость обучения должны быть бесконечно малыми, однако в этом
случае обучение будет происходить неприемлемо медленно. С другой стороны,
слишком большие коррекции весов могут привести к постоянной неустойчивости
процесса обучения. Поэтому в качестве h
обычно выбирается число меньше 1, но не очень маленькое, например, 0.1, и оно,
вообще говоря, может постепенно уменьшаться в процессе обучения. Кроме того,
для исключения случайных попаданий в локальные минимумы иногда, после того как
значения весовых коэффициентов застабилизируются, h кратковременно сильно
увеличивают, чтобы начать градиентный спуск из новой точки. Если повторение
этой процедуры несколько раз приведет алгоритм в одно и то же состояние НС,
можно более или менее уверенно сказать, что найден глобальный максимум, а не
какой-то другой.
.2 Алгоритмы обучения без учителя
Рассмотренный алгоритм обучения
нейронной сети с помощью процедуры обратного распространения подразумевает
наличие некоего внешнего звена, предоставляющего сети кроме входных так же и
целевые выходные образы. Алгоритмы, пользующиеся подобной концепцией,
называются алгоритмами обучения с учителем. Для их успешного функционирования
необходимо наличие экспертов, создающих на предварительном этапе для каждого
входного образа эталонный выходной.
Главная черта, делающая обучение без
учителя привлекательным, - это его "самостоятельность". Процесс
обучения, как и в случае обучения с учителем, заключается в подстраивании весов
синапсов. Некоторые алгоритмы, правда, изменяют и структуру сети, то есть
количество нейронов и их взаимосвязи, но такие преобразования правильнее
назвать более широким термином - самоорганизацией, и в рамках данной статьи они
рассматриваться не будут. Очевидно, что подстройка синапсов может проводиться
только на основании информации, доступной в нейроне, то есть его состояния и
уже имеющихся весовых коэффициентов. Исходя из этого соображения и, что более
важно, по аналогии с известными принципами самоорганизации нервных клеток,
построены алгоритмы обучения Хебба.
.2.1 Алгоритм обучения Хебба
Сигнальный метод обучения Хебба
заключается в изменении весов по следующему правилу:
 (1)
(1)
где yi(n-1) - выходное значение
нейрона i слоя (n-1), yj(n) - выходное значение нейрона j слоя n; wij(t) и
wij(t-1) - весовой коэффициент синапса, соединяющего эти нейроны, на итерациях
t и t-1 соответственно; a -
коэффициент скорости обучения. Здесь и далее, для общности, под n
подразумевается произвольный слой сети. При обучении по данному методу
усиливаются связи между возбужденными нейронами.
Существует также и дифференциальный
метод обучения Хебба.
 (2)
(2)
Здесь yi(n-1)(t) и yi(n-1)(t-1) -
выходное значение нейрона i слоя n-1 соответственно на итерациях t и t-1;
yj(n)(t) и yj(n)(t-1) - то же самое для нейрона j слоя n. Как видно из формулы
(2), сильнее всего обучаются синапсы, соединяющие те нейроны, выходы которых
наиболее динамично изменились в сторону увеличения.
Полный алгоритм обучения с
применением вышеприведенных формул будет выглядеть так:
. На стадии инициализации всем
весовым коэффициентам присваиваются небольшие случайные значения.
. На входы сети подается входной
образ, и сигналы возбуждения распространяются по всем слоям согласно принципам
классических прямопоточных (feedforward) сетей, то есть для каждого нейрона
рассчитывается взвешенная сумма его входов, к которой затем применяется
активационная (передаточная) функция нейрона, в результате чего получается его
выходное значение yi(n), i=0...Mi-1, где Mi - число нейронов в слое i;
n=0...N-1, а N - число слоев в сети.
. На основании полученных выходных
значений нейронов по формуле (1) или (2) производится изменение весовых
коэффициентов.
. Цикл с шага 2, пока выходные
значения сети не застабилизируются с заданной точностью. Применение этого
нового способа определения завершения обучения, отличного от использовавшегося
для сети обратного распространения, обусловлено тем, что подстраиваемые
значения синапсов фактически не ограничены.
На втором шаге цикла попеременно
предъявляются все образы из входного набора.
Следует отметить, что вид откликов
на каждый класс входных образов не известен заранее и будет представлять собой
произвольное сочетание состояний нейронов выходного слоя, обусловленное
случайным распределением весов на стадии инициализации. Вместе с тем, сеть
способна обобщать схожие образы, относя их к одному классу. Тестирование
обученной сети позволяет определить топологию классов в выходном слое. Для
приведения откликов обученной сети к удобному представлению можно дополнить
сеть одним слоем, который, например, по алгоритму обучения однослойного
перцептрона необходимо заставить отображать выходные реакции сети в требуемые
образы.
.2.2 Алгоритм обучения Кохонена
Другой алгоритм обучения без учителя
- алгоритм Кохонена - предусматривает подстройку синапсов на основании их
значений от предыдущей итерации.
 (3)
(3)
Из вышеприведенной формулы видно,
что обучение сводится к минимизации разницы между входными сигналами нейрона,
поступающими с выходов нейронов предыдущего слоя yi(n-1), и весовыми коэффициентами
его синапсов.
Полный алгоритм обучения имеет
примерно такую же структуру, как в методах Хебба, но на шаге 3 из всего слоя
выбирается нейрон, значения синапсов которого максимально походят на входной
образ, и подстройка весов по формуле (3) проводится только для него. Эта, так
называемая, аккредитация может сопровождаться затормаживанием всех остальных
нейронов слоя и введением выбранного нейрона в насыщение. Выбор такого нейрона
может осуществляться, например, расчетом скалярного произведения вектора
весовых коэффициентов с вектором входных значений. Максимальное произведение
дает выигравший нейрон.
Другой вариант - расчет расстояния
между этими векторами в p-мерном пространстве, где p - размер векторов.
 , (4)
, (4)
где j - индекс нейрона в слое n, i -
индекс суммирования по нейронам слоя (n-1), wij - вес синапса, соединяющего
нейроны; выходы нейронов слоя (n-1) являются входными значениями для слоя n.
Корень в формуле (4) брать не обязательно, так как важна лишь относительная
оценка различных Dj.
В данном случае,
"побеждает" нейрон с наименьшим расстоянием. Иногда слишком часто
получающие аккредитацию нейроны принудительно исключаются из рассмотрения,
чтобы "уравнять права" всех нейронов слоя. Простейший вариант такого
алгоритма заключается в торможении только что выигравшего нейрона.
При использовании обучения по
алгоритму Кохонена существует практика нормализации входных образов, а так же -
на стадии инициализации - и нормализации начальных значений весовых
коэффициентов.
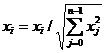 , (5)
, (5)
где xi - i-ая компонента вектора
входного образа или вектора весовых коэффициентов, а n - его размерность. Это
позволяет сократить длительность процесса обучения.
Инициализация весовых коэффициентов
случайными значениями может привести к тому, что различные классы, которым
соответствуют плотно распределенные входные образы, сольются или, наоборот,
раздробятся на дополнительные подклассы в случае близких образов одного и того
же класса. Для исключения такой ситуации используется метод выпуклой
комбинации. Суть его сводится к тому, что входные нормализованные образы
подвергаются преобразованию:
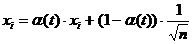 , (6)
, (6)
где xi - i-ая компонента входного
образа, n - общее число его компонент, a(t)
- коэффициент, изменяющийся в процессе обучения от нуля до единицы, в
результате чего вначале на входы сети подаются практически одинаковые образы, а
с течением времени они все больше сходятся к исходным. Весовые коэффициенты
устанавливаются на шаге инициализации равными величине
 , (7)
, (7)
где n - размерность вектора весов
для нейронов инициализируемого слоя.
На основе рассмотренного выше метода
строятся нейронные сети особого типа - так называемые самоорганизующиеся структуры
- self-organizing feature maps. Для них после выбора из слоя n нейрона j с
минимальным расстоянием Dj (4) обучается по формуле (3) не только этот нейрон,
но и его соседи, расположенные в окрестности R. Величина R на первых итерациях
очень большая, так что обучаются все нейроны, но с течением времени она
уменьшается до нуля. Таким образом, чем ближе конец обучения, тем точнее
определяется группа нейронов, отвечающих каждому классу образов. В приведенной
ниже программе используется именно этот метод обучения.
. Нейронные сети Хопфилда и Хэмминга
Среди различных конфигураций
искуственных нейронных сетей (НС) встречаются такие, при классификации которых
по принципу обучения, строго говоря, не подходят ни обучение с учителем, ни
обучение без учителя. В таких сетях весовые коэффициенты синапсов
рассчитываются только однажды перед началом функционирования сети на основе
информации об обрабатываемых данных, и все обучение сети сводится именно к
этому расчету. С одной стороны, предъявление априорной информации можно
расценивать, как помощь учителя, но с другой - сеть фактически просто
запоминает образцы до того, как на ее вход поступают реальные данные, и не
может изменять свое поведение, поэтому говорить о звене обратной связи с
"миром" (учителем) не приходится. Из сетей с подобной логикой работы
наиболее известны сеть Хопфилда и сеть Хэмминга, которые обычно используются
для организации ассоциативной памяти.
Структурная схема сети Хопфилда
приведена на рисунке 4.1. Она состоит из единственного слоя нейронов, число
которых является одновременно числом входов и выходов сети. Каждый нейрон
связан синапсами со всеми остальными нейронами, а также имеет один входной
синапс, через который осуществляется ввод сигнала. Выходные сигналы, как
обычно, образуются на аксонах.

Рисунок 4.1 - Структурная схема сети
Хопфилда
Задача, решаемая данной сетью в
качестве ассоциативной памяти, как правило, формулируется следующим образом.
Известен некоторый набор двоичных сигналов (изображений, звуковых оцифровок,
прочих данных, описывающих некие объекты или характеристики процессов), которые
считаются образцовыми. Сеть должна уметь из произвольного неидеального сигнала,
поданного на ее вход, выделить ("вспомнить" по частичной информации)
соответствующий образец (если такой есть) или "дать заключение" о
том, что входные данные не соответствуют ни одному из образцов. В общем случае,
любой сигнал может быть описан вектором X = { xi: i=0...n-1}, n - число
нейронов в сети и размерность входных и выходных векторов. Каждый элемент xi
равен либо +1, либо -1. Обозначим вектор, описывающий k-ый образец, через Xk, а
его компоненты, соответственно, - xik, k=0...m-1, m - число образцов. Когда
сеть распознaет (или "вспомнит") какой-либо образец на основе
предъявленных ей данных, ее выходы будут содержать именно его, то есть Y = Xk,
где Y - вектор выходных значений сети: Y = { yi: i=0,...n-1}. В противном
случае, выходной вектор не совпадет ни с одним образцовым.
Если, например, сигналы представляют
собой некие изображения, то, отобразив в графическом виде данные с выхода сети,
можно будет увидеть картинку, полностью совпадающую с одной из образцовых (в
случае успеха) или же "вольную импровизацию" сети (в случае неудачи).
На стадии инициализации сети весовые
коэффициенты синапсов устанавливаются следующим образом [3][4]:
 (1)
(1)
Здесь i и j - индексы,
соответственно, предсинаптического и постсинаптического нейронов; xik, xjk -
i-ый и j-ый элементы вектора k-ого образца.
Алгоритм функционирования сети
следующий (p - номер итерации):
. На входы сети подается неизвестный
сигнал. Фактически его ввод осуществляется непосредственной установкой значений
аксонов:
(0) = xi , i = 0...n-1, (2)
поэтому обозначение на схеме сети
входных синапсов в явном виде носит чисто условный характер. Ноль в скобке
справа от yi означает нулевую итерацию в цикле работы сети.
. Рассчитывается новое состояние
нейронов
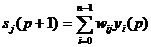 , j=0...n-1 (3)
, j=0...n-1 (3)
и новые значения аксонов
 (4)
(4)
где f - активационная функция в виде
скачка.
. Проверка, изменились ли выходные
значения аксонов за последнюю итерацию. Если да - переход к пункту 2, иначе
(если выходы застабилизировались) - конец. При этом выходной вектор
представляет собой образец, наилучшим образом сочетающийся с входными данными.
Иногда сеть не может провести
распознавание и выдает на выходе несуществующий образ. Это связано с проблемой
ограниченности возможностей сети. Для сети Хопфилда число запоминаемых образов
m не должно превышать величины, примерно равной 0.15•n. Кроме того, если два
образа А и Б сильно похожи, они, возможно, будут вызывать у сети перекрестные ассоциации,
то есть предъявление на входы сети вектора А приведет к появлению на ее выходах
вектора Б и наоборот.
Когда нет необходимости, чтобы сеть
в явном виде выдавала образец, то есть достаточно, скажем, получать номер
образца, ассоциативную память успешно реализует сеть Хэмминга. Данная сеть
характеризуется, по сравнению с сетью Хопфилда, меньшими затратами на память и
объемом вычислений, что становится очевидным из ее структуры (рисунок 4.2).
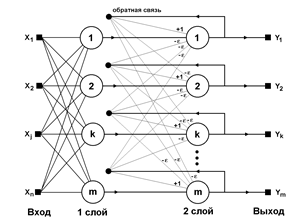
Рисунок 4.2 - Структурная схема сети
Хэмминга
Сеть состоит из двух слоев. Первый и
второй слои имеют по m нейронов, где m - число образцов. Нейроны первого слоя
имеют по n синапсов, соединенных со входами сети (образующими фиктивный нулевой
слой). Нейроны второго слоя связаны между собой ингибиторными (отрицательными
обратными) синаптическими связями. Единственный синапс с положительной обратной
связью для каждого нейрона соединен с его же аксоном.
Идея работы сети состоит в
нахождении расстояния Хэмминга от тестируемого образа до всех образцов.
Расстоянием Хэмминга называется число отличающихся битов в двух бинарных
векторах. Сеть должна выбрать образец с минимальным расстоянием Хэмминга до
неизвестного входного сигнала, в результате чего будет активизирован только
один выход сети, соответствующий этому образцу.
На стадии инициализации весовым
коэффициентам первого слоя и порогу активационной функции присваиваются
следующие значения:
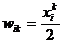 , i=0...n-1, k=0...m-1 (5)= n / 2,
k = 0...m-1 (6)
, i=0...n-1, k=0...m-1 (5)= n / 2,
k = 0...m-1 (6)
Здесь xik - i-ый элемент k-ого
образца.
Весовые коэффициенты тормозящих
синапсов во втором слое берут равными некоторой величине 0 < e < 1/m. Синапс нейрона,
связанный с его же аксоном имеет вес +1.
Алгоритм функционирования сети
Хэмминга следующий:
. На входы сети подается неизвестный
вектор X = {xi:i=0...n-1}, исходя из которого рассчитываются состояния нейронов
первого слоя (верхний индекс в скобках указывает номер слоя):
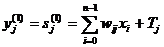 , j=0...m-1 (7)
, j=0...m-1 (7)
После этого полученными значениями
инициализируются значения аксонов второго слоя:
(2) = yj(1), j = 0...m-1 (8)
. Вычислить новые состояния нейронов
второго слоя:
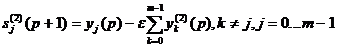 (9)
(9)
и значения их аксонов:
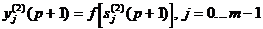 (10)
(10)
Активационная функция f имеет вид
порога (рис. 2б), причем величина F должна быть достаточно большой, чтобы любые
возможные значения аргумента не приводили к насыщению.
. Проверить, изменились ли выходы
нейронов второго слоя за последнюю итерацию. Если да - перейди к шагу 2. Иначе
- конец.
Из оценки алгоритма видно, что роль
первого слоя весьма условна: воспользовавшись один раз на шаге 1 значениями его
весовых коэффициентов, сеть больше не обращается к нему, поэтому первый слой
может быть вообще исключен из сети (заменен на матрицу весовых коэффициентов),
что и было сделано в ее конкретной реализации, описанной ниже.