Хранение данных в системе сетевых технологий
Введение
Ключевым фактором рыночного успеха в сегодняшних условиях высокой
конкуренции становится оперативное принятие эффективных деловых решений. Однако
естественное стремление многих организаций усовершенствовать свои процессы
принятия решений может натолкнуться на труднопреодолимое препятствие - огромный
объем и высокая сложность данных, содержащихся в разнообразных оперативных и
производственных системах этих организаций. Сделать такую информацию доступной
более широкому кругу бизнес-пользователей - вот одна из наиболее серьезных
проблем, стоящих сегодня перед профессионалами в области информационных
технологий.
Многие организации для решения этой задачи избирают путь построения
хранилища (data warehouse), позволяющего «высвободить»
информацию из жестких рамок оперативных систем и лучше осознать проблемы
реального бизнеса. Несмотря на то, что хранилища данных бывают различных типов
и могут опираться на разные методологии, и даже философии, построения, все они
имеют некоторые общие признаки:
Информация в хранилище данных организовывается вокруг базовых понятий,
используемых в деятельности предприятия (это, например, клиенты, продукты,
продажи или поставщики), т.е. применяется методология проектирования,
управляемого данными.
«Сырые» данные собираются из неинтегрированных оперативных и
унаследованных приложений, очищаются от ошибок, затем агрегируются и
предоставляются в виде, понятом бизнес-пользователям.
На основании откликов пользователей, а также закономерностей,
обнаруженных с помощью хранилища данных, архитектура последнего со временем
претерпевает изменения - то есть процесс создания хранилища является
итеративным.
Построение хранилищ данных - процесс сложный по самой своей природе и
поэтому обычно дорогостоящий и длительный.
Поскольку процесс создания хранилищ данных является итеративным по своей
природе, он требует регулярного перепроектирования в течение всего жизненного
цикла приложения.
Объектом курсовой работы выступает хранилище данных.
Целью курсовой работы является теоретическое изучение понятия «хранилища
данных», а также анализ построения хранилища данных.
Исходя из целей курсовой работы, ее задачами являются:
обозначить сущность хранилища данных;
проанализировать процесс создания хранилища данных;
рассмотреть архитектуры хранилищ данных;
дать определение метаданным хранилища данных
В качестве источников литературы были использованы учебники и учебные
пособия по информатике, вычислительной технике, информационным технологиям
системам. Для более глубокой проработки темы использовались материалы сети
Интернет.
1. Сущность и построение хранилища
данных
Хранилище данных (data warehouse) по
сути, представляет собой центр, в который собирается вся необходимая информация
из различных подразделений предприятия. Прежде чем попасть в хранилище, данные
должны быть соответствующим образом обработаны. Базы данных, в которых
происходит накопление, обработка первичных данных, на основании которых
строится хранилище, будем далее называть транзакционными (Приложение А). Разные
отделы могут использовать неодинаковые системы обработки со своими
транзакционными БД. Соответственно, прежде чем использовать эти разрозненные
данные, их нужно проанализировать. Этот процесс занимает весьма длительный
период в процессе подготовки к созданию хранилища.
Поскольку хранилище - это объединение и интеграция данных, необходимо
выявить разницу в форматах хранения информации в различных источниках, провести
ревизию корректного заполнения полей таблиц, построить план взаимосвязи
информации, а также решить, какая информация из транзакционных баз будет
необходима для дальнейшего использования в хранилище.
Хранилище данных должно решать определенные задачи:
получение полной информации о клиенте,
предоставление конкретных данных для последующего анализа определенного
сегмента рынка и т.д.
Хранилище должно быть гибким. Практика показывает, что по мере развития
бизнеса задачи меняются. Соответственно, меняются требования к данным,
отчетности и, как следствие, к хранилищу.
Основанием для начала проектирования хранилища служит все возрастающая
потребность бизнеса компании в определенных категориях данных за различный
период времени. Объем информации, на основании которой необходимо принимать
решение, постоянно растет и становится головной болью аналитиков и менеджеров
компании. Это может привести к большим затратам времени на оценку реального
состояния дел, составление планов работ, а также получение недостоверных данных
- ведь разобраться в большом количестве отчетов, таблиц, операций и т.д.
становится весьма непросто (Приложение Б). При этом данные из различных
подразделений поступают зачастую в разных форматах, с разной степенью
детализации и качества. Другими словами, достигается некая «точка кипения»,
когда требуется вносить серьезные изменения в информационную систему компании.
Хранилище предоставляет возможность получения каждым подразделением
данных в разрезе интересующих его показателей, в удобном и привычном для
сотрудников этого подразделения виде. Можно сравнить хранилище с огромным
складом с большим ассортиментом продукции, а информацию по подразделениям,
получаемых из него, с небольшим специализированными отделами, где собрана
соответствующая категория товаров.
1.1
Типичная структура хранилища данных
Ральф Кимбалл (Ralph Kimball), один из авторов концепции хранилищ данных,
описывал хранилище данных как «место, где люди могут получить доступ к своим
данным». Он же сформулировал и основные требования к хранилищам данных:
поддержка высокой скорости получения данных из хранилища;
поддержка внутренней непротиворечивости данных;
возможность получения и сравнения так называемых срезов данных (slice and
dice);
наличие удобных утилит просмотра данных в хранилище;
полнота и достоверность хранимых данных;
поддержка качественного процесса пополнения данных
В отличие от оперативных баз данных, хранилища данных проектируются таким
образом, чтобы время выполнения запросов на выборку данных было минимальным.
Обычно данные копируются в хранилище из оперативных баз данных согласно
определенному расписанию (раз в день, раз в месяц, раз в квартал).
Типичная структура хранилища данных существенно отличается от структуры
обычной реляционной БД. Как правило, эта структура денормализована (это
позволяет повысить скорость выполнения запросов), поэтому может допускать
избыточность данных.
Логически структуру хранилища данных можно представить как многомерную
базу данных, которая представляет собой так называемый OLAP- куб. OLAP-куб
имеет несколько измерений, которые можно считать осями координат (если таких
измерений три, то тогда уместна геометрическая интерпретация в виде куба, на
практике обычно бывает более трех измерений, которые не отобразить никакой
геометрической фигурой). На пересечении осей располагаются показатели (один или
несколько - как получится), они и являются предметом многомерного анализа.
Основной операцией, применяемой к OLAP-кубам, является операция
агрегирования показателей (т.е. вычисления агрегатных функций, таких как сумма,
минимальное, максимальное, среднее значение показателя) применительно к
различным измерениям. Например, можно вычислить суммарные объемы продаж за
различные периоды времени, по отдельным группам товаров, по различным регионам
и т.д.
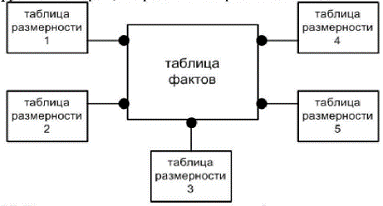
Рисунок 1. Типичная структура хранилища данных - схема «звезда»
Реализация OLАР-кубов может быть различной. В последнее время наиболее
распространенным вариантом является использование денормализованной реляционной
структуры. В этом случае основными составляющими структуры хранилищ данных
(рис.3.13) являются таблица фактов (fact table) и таблицы измерений (dimension
tables), соединенные по схеме «звезда» (star schema). Название «звезда»
используется в том случае, если каждое измерение содержится в одной таблице
размерности.
Таблица фактов является основной таблицей хранилища данных. Как правило,
она содержит сведения об объектах или событиях, совокупность которых будет в
дальнейшем анализироваться. Обычно говорят о четырех наиболее часто
встречающихся типах фактов. К ним относятся:
• факты, связанные с транзакциями (Transaction facts). Они
основаны на отдельных событиях (типичными примерами которых являются телефонный
звонок или снятие денег со счета с помощью банкомата);
• факты, связанные с «моментальными снимками» (Snapshot facts).
Основаны на состоянии объекта (например, банковского счета) в определенные
моменты времени, например на конец дня или месяца. Типичными примерами таких
фактов являются объем продаж за день или дневная выручка;
• факты, связанные с элементами документа (Line-item facts).
Основаны на том или ином документе (например, счете за товар или услуги) и
содержат подробную информацию об элементах этого документа (например,
количестве, цене, проценте скидки);
• факты, связанные с событиями или состоянием объекта (Event or
state facts). Представляют возникновение события без подробностей о нем
(например, просто факт продажи или факт отсутствия таковой без иных
подробностей).
Таблица фактов, как правило, содержит уникальный составной ключ,
объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные
значения либо значения типа «дата/время». Таблица фактов может содержать сотни
тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые
описания, как правило, невыгодно - лучше поместить их в меньшие по объему
таблицы измерений. При этом как ключевые, так и некоторые неключевые поля
должны соответствовать измерениям OL АР-куба. Помимо этого таблица фактов
содержит одно или несколько числовых полей для хранения показателей, на
основании которых в дальнейшем будут получены агрегатные данные.
Отметим, что для многомерного анализа пригодны таблицы фактов, содержащие
как можно более подробные данные (то есть данные, соответствующие самой
детальной таблице оперативной БД). Например, в банковской системе в качестве
факта можно принять одну транзакцию клиента (снять деньги со счета, положить,
перевести на другой счет и т.д.). В системе предприятия, работающего в сфере
торговли или услуг, фактом может быть каждая продажа или каждая услуга,
оказанная клиенту.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. Таблицы
измерений содержат как минимум одно описательное поле (обычно с именем члена
измерения) и. как правило, целочисленное ключевое поле (обычно это суррогатный
ключ) для однозначной идентификации члена измерения. Нередко таблицы измерений
содержат некоторые дополнительные атрибуты членов измерений, содержавшиеся в
исходной оперативной базе данных (например, адреса и телефоны клиентов).
Каждая таблица измерений должна находиться в отношении один ко многим с
таблицей фактов.
Очень многие измерения могут представлять собой иерархию. Например, если
вычислять агрегатные данные продаж по регионам, то можно выделить уровни
отдельных населенных пунктов, областей, округов, стран, которые представляют
собой иерархию. Для представления иерархии в реляционной БД может
использоваться несколько таблиц, связанных отношением один ко многим и
соответствующих различным уровням иерархии в измерении, или одна таблица с
внутренними иерархическими связями.
Если хотя бы одно из измерений содержится в нескольких связанных таблицах,
такая схема хранилища данных носит название «снежинка» (snowflake schema).
Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним
уровням иерархии измерения и находящиеся в соотношении «один ко многим» с
таблицей измерений, соответствующей нижнему уровню иерархии, иногда называют
консольными таблицами (outrigger table). Схема «снежинка» изображена на рисунке
2.
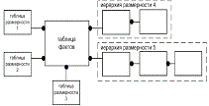
Рисунок 2. Структура хранилища данных - схема «снежинка»
Если измерение, содержащее иерархию, основано на одной таблице измерений,
то она должна содержать столбец, указывающий на «родителя» данного члена в этой
иерархии. Например, населенный пункт в качестве родителя имеет область, область
- округ, округ - страну, а у страны в качестве родителя обычно устанавливается
какое-либо значение по умолчанию, соответствующее отсутствию родителя. Отметим,
что скорость роста таблиц измерений должна быть незначительной по сравнению со
скоростью роста таблицы фактов; например, добавление новой записи в таблицу
измерений, характеризующую товары, производится только при появлении нового
товара, не продававшегося ранее.
Одно измерение куба может содержаться как в одной таблице (в том числе и
при наличии нескольких уровней иерархии), так и в нескольких связанных
таблицах.
Даже при наличии иерархических измерений с целью повышения скорости
выполнения запросов к хранилищу данных нередко предпочтение отдается схеме
«звезда».
1.2
Организация хранилищ данных
Все данные в ХД делятся на три основные категории (рисунок 3):
детальные данные;
агрегированные данные;
метаданные

Рисунок 3. Архитектура хранилища данных
Детальными являются данные, переносимые непосредственно из ОИД. Они
соответствуют элементарным событиям, фиксируемым OLTP-системами (например,
продажи, эксперименты и др.). Принято разделять все данные на измерения и
факты. Измерениями называются наборы данных, необходимые для описания событий
(например, города, товары, люди и т.п.). Фактами называются данные, отражающие
сущность события (например, количество проданного товара, результаты
экспериментов и т. п.). Фактические данные могут быть представлены в виде
числовых или категориальных значений.
В процессе эксплуатации ХД необходимость в ряде детальных данных может
снизиться. Ненужные детальные данные могут храниться в архивах в сжатом виде на
более емких накопителях с более медленным доступом (например, на магнитных
лентах). Данные в архиве остаются доступными для обработки и анализа. Регулярно
используемые для анализа данные должны храниться на накопителях с быстрым
доступом (например, на жестких дисках).
На основании детальных данных могут быть получены агрегированные
(обобщенные) данные. Агрегирование происходит путем суммирования числовых
фактических данных по определенным измерениям. В зависимости от возможности
агрегировать данные они подразделяются на следующие типы:
аддитивные - числовые фактические данные, которые могут быть
просуммированы по всем измерениям;
полуаддитивные - числовые фактические данные, которые могут быть
просуммированы только по определенным измерениям;
неаддитивные - фактические данные, которые не могут быть просуммированы
ни по одному измерению.
Проведенные исследования показали, что большинство пользователей СППР
работают не с детальными, а с агрегированными данными. Архитектура ХД должна
предоставлять быстрый и удобный способ получать интересующую пользователя
информацию. Для этого необходимо часть агрегированных данных хранить в ХД, а не
вычислять их при выполнении аналитических запросов. Очевидно, что это ведет к
избыточности информации и увеличению размеров ХД. Поэтому при проектировании
таких систем важно добиться оптимального соотношения между вычисляемыми и
хранящимися агрегированными данными. Те данные, к которым редко обращаются
пользователи, могут вычисляться в процессе выполнения аналитических запросов.
Данные, которые требуются более часто, должны храниться в ХД.
Для удобства работы с ХД необходима информация о содержащихся в нем
данных. Такая информация называется метаданными (данные о данных). Согласно
концепции Захмана метаданные должны отвечать на следующие вопросы - что, кто,
где, как, когда и почему:
что (описание объектов) - метаданные описывают объекты предметной
области, информация о которых хранится в ХД. Такое описание включает: атрибуты
объектов, их возможные значения, соответствующие поля в информационных
структурах ХД, источники информации об объектах и т. п.;
где (описание места хранения) - метаданные описывают местоположение
серверов, рабочих станций, ОИД, размещенные на них программные средства и
распределение между ними данных;
как (описание действий) - метаданные описывают действия, выполняемые над
данными. Описываемые действия могли выполняться как в процессе переноса из ОИД
(например, исправление ошибок, расщепление полей и т.п.), так и в процессе их
эксплуатации в ХД;
когда (описание времени) - метаданные описывают время выполнения разных
операций над данными (например, загрузка, агрегирование, архивирование,
извлечение и т. п.);
почему (описание причин)- метаданные описывают причины, повлекшие
выполнение над данными тех или иных операций. Такими причинами могут быть
требования пользователей, статистика обращений к данным и т.п.
Так как метаданные играют важную роль в процессе работы с ХД, то к ним
должен быть обеспечен удобный доступ. Для этого они сохраняются в репозитории
метаданных с удобным для пользователя интерфейсом.
Данные, поступающие из ОИД в ХД, перемещаемые внутри ХД и поступающие из
ХД к аналитикам, образуют следующие информационные потоки (рисунок 3):
входной поток (Inflow) - образуется данными, копируемыми из ОИД в ХД;
поток обобщения (Upflow) - образуется агрегированием детальных данных и
их сохранением в ХД;
архивный поток (Downflow)- образуется перемещением детальных данных,
количество обращений к которым снизилось;
поток метаданных (MetaFlow) - образуется потоком информации о данных в
репозиторий данных;
выходной поток (Outflow)- образуется данными, извлекаемыми
пользователями;
обратный поток (Feedback Flow) - образуется очищенными данными,
записываемыми обратно в ОИД.
Самый мощный из информационных потоков - входной - связан с переносом
данных из ОИД. Обычно информация не просто копируется в ХД, а подвергается
обработке: данные очищаются и обогащаются за счет добавления новых атрибутов.
Исходные данные из ОИД объединяются с информацией из внешних источников -
текстовых файлов, сообщений электронной почты, электронных таблиц и др. При
разработке ХД не менее 60 % всех затрат связано с переносом данных.
Процесс переноса, включающий в себя этапы извлечения, преобразования и
загрузки, называют ETL-процессом (Е - extraction, Т - transformation, L -
loading: извлечение, преобразование и загрузка, соответственно). Программные
средства, обеспечивающие его выполнение, называются ETL-системами. Традиционно
ETL-системы использовались для переноса информации из устаревших версий
информационных систем в новые. В настоящее время ETL-процесс находит все
большее применение для переноса данных из ОИД в ХД и ВД.
Более подробно этапы ETL-процесса отображены на рисунке 4.
Извлечение данных - чтобы начать ETL-процесс, необходимо извлечь данные
из одного или нескольких источников и подготовить их к этапу преобразования.
Можно выделить два способа извлечения данных:
. Извлечение данных вспомогательными программными средствами
непосредственно из структур хранения информации (файлов, электронных таблиц, БД
и т.п. Достоинствами такого способа извлечения данных являются:
отсутствие необходимости расширять OLTP-систему (это особенно важно, если
ее структура закрыта);
данные могут извлекаться с учетом потребностей процесса переноса.
. Выгрузка данных средствами OLTP-систем в промежуточные структуры.
Достоинствами такого подхода являются:
возможность использовать средства OLTP-систем, адаптированные к
структурам данных;
средства выгрузки изменяются вместе с изменениями OLTP-систем и ОИД;
возможность выполнения первого шага преобразования данных за счет
определенного формата промежуточной структуры хранения данных.
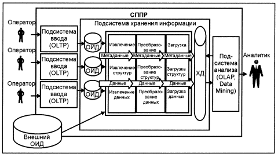
Рисунок 4. ETL-процесс.
Преобразование данных - после того как сбор данных завершен, необходимо
преобразовать их для размещения на новом месте. На этом этапе выполняются
следующие процедуры:
обобщение данных (aggregation) - перед загрузкой данные обобщаются.
Процедура обобщения заменяет многочисленные детальные данные относительно
небольшим числом агрегированных данных. Например, предположим, что данные о
продажах за год занимают в нормализованной базе данных несколько тысяч записей.
После обобщения данные преобразуются в меньшее число кратких записей, которые
будут перенесены в ХД;
перевод значений (value translation) - в ОИД данные часто хранятся в
закодированном виде для того, чтобы сократить избыточность данных и память для
их хранения. Например, названия товаров, городов, специальностей и т.п. могут
храниться в сокращенном виде. Поскольку ХД содержат обобщенную информацию и
рассчитаны на простое использование, закодированные данные обычно заменяют на
более понятные описания;
создание полей (field derivation) - при создании полей для конечных
пользователей создается и новая информация. Например, ОИД содержит одно поле
для указания количества проданных товаров, а второе - для указания цены одного
экземпляра. Для исключения операции вычисления стоимости всех товаров можно
создать специальное поле для ее хранения во время преобразования данных;
очистка данных (cleaning) - направлена на выявление и удаление ошибок и
несоответствий в данных с целью улучшения их качества. Проблемы с качеством
встречаются в отдельных ОИД, например, в файлах и БД могут быть ошибки при
вводе, отдельная информация может быть утрачена, могут присутствовать
«загрязнения» данный и др. Очистка также применяется для согласования атрибутов
полей таким образом, чтобы они соответствовали атрибутам базы данных
назначения.
Загрузка данных - после того как данные преобразованы для размещения в
ХД, осуществляется этап их загрузки. При загрузке выполняется запись
преобразованных детальных и агрегированных данных. Кроме того, при записи новых
детальных данных часть старых может переноситься в архив.
2. OLAP системы
2.1
Определение OLAP-систем
С концепцией многомерного анализа данных тесно связывают оперативный
анализ, который выполняется средствами OLAP-систем.(On-Line Analytical
Processing) - технология оперативной аналитической обработки данных,
использующая методы и средства для сбора, хранения и анализа многомерных данных
в целях поддержки процессов принятия решений.
Основное назначение OLAP-систем - поддержка аналитической деятельности,
произвольных (часто используется термин ad-hoc) запросов
пользователей-аналитиков. Цель OLAP-анализа - проверка возникающих гипотез.
У истоков технологии OLAP стоит основоположник реляционного подхода Э.
Кодд. В 1993 г. он опубликовал статью под названием «OLAP для
пользователей-аналитиков: каким он должен быть». В данной работе изложены
основные концепции оперативной аналитической обработки и определены следующие
12 требований, которым должны удовлетворять продукты, позволяющие выполнять
оперативную аналитическую обработку.
Ниже перечислены 12 правил, изложенных Коддом и определяющих OLAP.
. Многомерность - OLAP-система на концептуальном уровне должна
представлять данные в виде многомерной модели, что упрощает процессы анализа и
восприятия информации.
. Прозрачность - OLAP-система должна скрывать от пользователя реальную
реализацию многомерной модели, способ организации, источники, средства
обработки и хранения.
. Доступность - OLAP-система должна предоставлять пользователю единую,
согласованную и целостную модель данных, обеспечивая доступ к данным независимо
оттого, как и где они хранятся.
. Постоянная производительность при разработке отчетов -
производительность OLAP-систем не должна значительно уменьшаться при увеличении
количества измерений, по которым выполняется анализ.
. Клиент-серверная архитектура - OLAP-система должна быть способна
работать в среде «клиент-сервер», т.к. большинство данных, которые сегодня
требуется подвергать оперативной аналитической обработке, хранятся
распределенно. Главной идеей здесь является то, что серверный компонент
инструмента OLAP должен быть достаточно интеллектуальным и позволять строить
общую концептуальную схему на основе обобщения и консолидации различных
логических и физических схем корпоративных БД для обеспечения эффекта
прозрачности.
. Равноправие измерений - OLAP-система должна поддерживать многомерную
модель, в которой все измерения равноправны. При необходимости дополнительные
характеристики могут быть предоставлены отдельным измерениям, но такая
возможность должна быть предоставлена любому измерению.
. Динамическое управление разреженными матрицами - OLAP-система должна
обеспечивать оптимальную обработку разреженных матриц. Скорость доступа должна
сохраняться вне зависимости от расположения ячеек данных и быть постоянной
величиной для моделей, имеющих разное число измерений и различную степень
разреженности данных.
. Поддержка многопользовательского режима - OLAP-система должна
предоставлять возможность работать нескольким пользователям совместно с одной
аналитической моделью или создавать для них различные модели из единых данных.
При этом возможны как чтение, так и запись данных, поэтому система должна
обеспечивать их целостность и безопасность.
. Неограниченные перекрестные операции - OLAP-система должна обеспечивать
сохранение функциональных отношений, описанных с помощью определенного
формального языка между ячейками гиперкуба при выполнении любых операций среза,
вращения, консолидации или детализации. Система должна самостоятельно
(автоматически) выполнять преобразование установленных отношений, не требуя от
пользователя их переопределения.
. Интуитивная манипуляция данными - OLAP-система должна предоставлять
способ выполнения операций среза, вращения, консолидации и детализации над
гиперкубом без необходимости пользователю совершать множество действий с
интерфейсом. Измерения, определенные в аналитической модели, должны содержать
всю необходимую информацию для выполнения вышеуказанных операций.
. Гибкие возможности получения отчетов - OLAP-система должна поддерживать
различные способы визуализации данных, т.е. отчеты должны представляться в
любой возможной ориентации. Средства формирования отчетов должны представлять
синтезируемые данные или информацию, следующую из модели данных в ее любой
возможной ориентации. Это означает, что строки, столбцы или страницы должны
показывать одновременно от 0 до N измерений, где N- число измерений всей
аналитической модели. Кроме того, каждое измерение содержимого, показанное в
одной записи, колонке или странице, должно позволять показывать любое
подмножество элементов (значений), содержащихся в измерении, в любом порядке.
. Неограниченная размерность и число уровней агрегации - исследование о
возможном числе необходимых измерений, требующихся в аналитической модели,
показало, что одновременно может использоваться до 19 измерений. Отсюда
вытекает настоятельная рекомендация, чтобы аналитический инструмент мог
одновременно предоставить хотя бы 15, а предпочтительно - 20 измерений. Более
того, каждое из общих измерений не должно быть ограничено по числу определяемых
пользователем-аналитиком уровней агрегации и путей консолидации.
Дополнительные правила Кодда.
Набор этих требований, послуживших де-факто определением OLAP, достаточно
часто вызывает различные нарекания, например, правила 1, 2, 3, 6 являются
требованиями, а правила 10, 11 - неформализованными пожеланиями. Таким образом,
перечисленные 12 требований Кодда не позволяют точно определить OLAP. В 1995 г.
Кодд к приведенному перечню добавил следующие шесть правил:
. Пакетное извлечение против интерпретации - OLAP-система должна в равной
степени эффективно обеспечивать доступ как к собственным, так и к внешним
данным.
. Поддержка всех моделей OLAP-анализа - OLAP-система должна поддерживать
все четыре модели анализа данных, определенные Коддом: категориальную,
толковательную, умозрительную и стереотипную.
. Обработка ненормализованных данных - OLAP-система должна быть
интегрирована с ненормализованными источниками данных. Модификации данных,
выполненные в среде OLAP, не должны приводить к изменениям данных, хранимых в
исходных внешних системах.
. Сохранение результатов OLAP: хранение их отдельно от исходных данных -
OLAP-система, работающая в режиме чтения-записи, после модификации исходных
данных должна результаты сохранять отдельно. Иными словами, обеспечивается
безопасность исходных данных.
. Исключение отсутствующих значений- OLAP-система, представляя данные
пользователю, должна отбрасывать все отсутствующие значения. Другими словами,
отсутствующие значения должны отличаться от нулевых значений.
. Обработка отсутствующих значений - OLAP-система должна игнорировать все
отсутствующие значения без учета их источника. Эта особенность связана с 17-м
правилом.
Кроме того, Кодд разбил все 18 правил на следующие четыре группы, назвав
их особенностями. Эти группы получили названия В, S, R и D.
Основные особенности (В) включают следующие правила:
многомерное концептуальное представление данных (правило 1);
интуитивное манипулирование данными (правило 10);
доступность (правило 3);
пакетное извлечение против интерпретации (правило 13);
поддержка всех моделей OLAP-анализа (правило 14);
архитектура «клиент-сервер» (правило 5);
прозрачность (правило 2);
многопользовательская поддержка (правило 8)
Специальные особенности (S):
обработка ненормализованных данных (правило 15);
сохранение результатов OLAP: хранение их отдельно от исходных данных
(правило 16);
обработка отсутствующих значений (правило 18). Особенности представления
отчетов (R):
гибкость формирования отчетов (правило 11);
стандартная производительность отчетов (правило 4);
автоматическая настройка физического уровня (измененное оригинальное
правило 7).
Управление измерениями (D):
универсальность измерений (правило 6);
неограниченное число измерений и уровней агрегации (правило 12);
неограниченные операции между размерностями (правило 9).
2.2
Архитектура OLAP-систем
система включает в себя два основных компонента:
OLAP-сервер - обеспечивает хранение данных, выполнение над ними
необходимых операций и формирование многомерной модели на концептуальном
уровне. В настоящее время OLAP-серверы объединяют с ХД или ВД;
OLAP-клиент - представляет пользователю интерфейс к многомерной модели
данных, обеспечивая его возможностью удобно манипулировать данными для
выполнения задач анализа.серверы скрывают от конечного пользователя способ
реализации многомерной модели. Они формируют гиперкуб, с которым пользователи
посредством OLAP-клиента выполняют все необходимые манипуляции, анализируя
данные. Между тем способ реализации очень важен, т.к. от него зависят такие
характеристики, как производительность и занимаемые ресурсы. Выделяют три
основных способа реализации:
MOLAP- для реализации многомерной модели используют многомерные БД;
ROLAP- для реализации многомерной модели используют реляционные БД;
HOLAP - для реализации многомерной модели используют и многомерные и
реляционные БД.
Часто в литературе по OLAP-системам можно встретить аббревиатуры DOLAP и
JOLAP.- настольный (desktop) OLAP. Является недорогой и простой в использовании
OLAP-системой, предназначенной для локального анализа и представления данных,
которые загружаются из реляционной или многомерной БД на машину клиента.-
основанная на Java, коллективная OLAP-API-инициатива, предназначенная для
создания и управления данными и метаданными на серверах OLAP. Основной
разработчик - Hyperion Solutions. Другими членами группы, определяющей
предложенный API, являются компании IBM, Oracle и др.серверы используют для
хранения и управления данными многомерные БД. При этом данные хранятся в виде
упорядоченных многомерных массивов. Такие массивы подразделяются на гиперкубы и
поликубы.
В гиперкубе все хранимые в БД ячейки имеют одинаковую мерность, т.е.
находятся в максимально полном базисе измерений.
В поликубе каждая ячейка хранится с собственным набором измерений, и все
связанные с этим сложности обработки перекладываются на внутренние механизмы
системы.
Физически данные, представленные в многомерном виде, хранятся в «плоских»
файлах. При этом куб представляется в виде одной плоской таблицы, в которую
построчно вписываются все комбинации членов всех измерений с соответствующими
им значениями мер.
Можно выделить следующие преимущества использования многомерных БД в
OLAP-системах:
поиск и выборка данных осуществляются значительно быстрее, чем при
многомерном концептуальном взгляде на реляционную БД, т.к. многомерная база
данных денормализована и содержит заранее агрегированные показатели,
обеспечивая оптимизированный доступ к запрашиваемым ячейкам и не требуя
дополнительных преобразований при переходе от множества связанных таблиц к
многомерной модели;
многомерные БД легко справляются с задачами включения в информационную
модель разнообразных встроенных функций, тогда как объективно существующие
ограничения языка SQL делают выполнение этих задач на основе реляционных БД
достаточно сложным, а иногда и невозможным.
С другой стороны, имеются также существенные недостатки:
за счет денормализации и предварительно выполненной агрегации объем
данных в многомерной БД, как правило, соответствует (по оценке Кодда) в 2,5...
100 раз меньшему объему исходных детализированных данных;
в подавляющем большинстве случаев информационный гиперкуб является сильно
разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные
значения удается удалить только за счет выбора оптимального порядка сортировки,
позволяющего организовать данные в максимально большие непрерывные группы. Но
даже в этом случае проблема решается только частично. Кроме того, оптимальный с
точки зрения хранения разреженных данных порядок сортировки, скорее всего, не
будет совпадать с порядком, который чаще всего используется в запросах. Поэтому
в реальных системах приходится искать компромисс между быстродействием и
избыточностью дискового пространства, занятого базой данных;
многомерные БД чувствительны к изменениям в многомерной модели. Так при
добавлении нового измерения приходится изменять структуру всей БД, что влечет
за собой большие затраты времени.
На основании анализа достоинств и недостатков многомерных БД можно
выделить следующие условия, при которых их использование является эффективным:
объем исходных данных для анализа не слишком велик (не более нескольких
гигабайт), т.е. уровень агрегации данных достаточно высок;
набор информационных измерений стабилен;
время ответа системы на нерегламентированные запросы является наиболее
критичным параметром;
требуется широкое использование сложных встроенных функций для выполнения
кроссмерных вычислений над ячейками гиперкуба, в том числе возможность
написания пользовательских функций.серверы используют реляционные БД. По словам
Кодда, «реляционные БД были, есть и будут наиболее подходящей технологией для
хранения данных. Необходимость существует не в новой технологии БД, а скорее в
средствах анализа, дополняющих функции существующих СУБД, и достаточно гибких,
чтобы предусмотреть и автоматизировать разные виды интеллектуального анализа,
присущие OLAP».
В настоящее время распространены две основные схемы реализации
многомерного представления данных с помощью реляционных таблиц: схема «звезда»
(рисунок 5) и схема «снежинка» (рисунок 6).
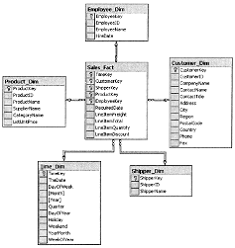
Рисунок 5. Пример схемы «звезда»

Рисунок 6. Пример схемы «снежинка»
Основными составляющими таких схем являются денормализованная таблица
фактов (Fact Table) и множество таблиц измерений (Dimension Tables).
Таблица фактов, как правило, содержит сведения об объектах или событиях,
совокупность которых будет в дальнейшем анализироваться. Обычно говорят о
четырех наиболее часто встречающихся типах фактов. К ним относятся:
факты, связанные с транзакциями (Transaction facts). Они основаны на
отдельных событиях (типичными примерами которых являются телефонный звонок или
снятие денег со счета с помощью банкомата);
факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на
состоянии объекта (например, банковского счета) в определенные моменты времени,
например на конец дня или месяца. Типичными примерами таких фактов являются
объем продаж за день или дневная выручка;
факты, связанные с элементами документа (Line-item facts). Основаны на
том или ином документе (например, счете за товар или услуги) и содержат
подробную информацию об элементах этого документа (например, количестве, цене,
проценте скидки);
факты, связанные с событиями или состоянием объекта (Event or state
facts). Представляют возникновение события без подробностей о нем (например,
просто факт продажи или факт отсутствия таковой без иных подробностей).
Таблица фактов, как правило, содержит уникальный составной ключ,
объединяющий первичные ключи таблиц измерений. При этом как ключевые, так и
некоторые не ключевые поля должны соответствовать измерениям гиперкуба. Помимо
этого таблица фактов содержит одно или несколько числовых полей, на основании
которых в дальнейшем будут получены агрегатные данные.
Для многомерного анализа пригодны таблицы фактов, содержащие как можно
более подробные данные, т.е. соответствующие членам нижних уровней иерархии
соответствующих измерений. В таблице фактов нет никаких сведений о том, как
группировать записи при вычислении агрегатных данных. Например, в ней есть
идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой
категории относится данный продукт или в каком городе находится данный клиент.
Эти сведения, в дальнейшем используемые для построения иерархий в измерениях
куба, содержатся в таблицах измерений.
Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В
подавляющем большинстве случаев эти данные представляют собой по одной записи
для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также
содержат как минимум одно описательное поле (обычно с именем члена измерения)
и, как правило, целочисленное ключевое поле (обычно это суррогатный ключ) для
однозначной идентификации члена измерения. Если измерение, соответствующее
таблице, содержит иерархию, то такая таблица также может содержать поля,
указывающие на «родителя» данного члена в этой иерархии. Каждая таблица
измерений должна находиться в отношении «один-ко-многим» с таблицей фактов.
В сложных задачах с иерархическими измерениями имеет смысл обратиться к
расширенной схеме «снежинка» (Snowflake Schema). В этих случаях отдельные
таблицы фактов создаются для возможных сочетаний уровней обобщения различных
измерений (рисунок 6). Это позволяет добиться лучшей производительности, но
часто приводит к избыточности данных и к значительным усложнениям в структуре
базы данных, в которой оказывается огромное количество таблиц фактов.
Увеличение числа таблиц фактов в базе данных определяется не только
множественностью уровней различных измерений, но и тем обстоятельством, что в
общем случае факты имеют разные множества измерений. При абстрагировании от
отдельных измерений пользователь должен получать проекцию максимально полного гиперкуба,
причем далеко не всегда значения показателей в ней должны являться результатом
элементарного суммирования. Таким образом, при большом числе независимых
измерений необходимо поддерживать множество таблиц фактов, соответствующих
каждому возможному сочетанию выбранных в запросе измерений, что также приводит
к неэкономному использованию внешней памяти, увеличению времени загрузки данных
в БД схемы «звезды» из внешних источников и сложностям администрирования.
Использование реляционных БД в OLAP-системах имеет следующие достоинства:
в большинстве случаев корпоративные хранилища данных реализуются
средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ
непосредственно над ними. При этом размер хранилища не является таким критичным
параметром, как в случае MOLAP;
в случае переменной размерности задачи, когда изменения в структуру
измерений приходится вносить достаточно часто, ROLAP-системы с динамическим
представлением размерности являются оптимальным решением, т.к. в них такие
модификации не требуют физической реорганизации БД;
реляционные СУБД обеспечивают значительно более высокий уровень защиты
данных и хорошие возможности разграничения прав доступа.
Главный недостаток ROLAP по сравнению с многомерными СУБД - меньшая
производительность. Для обеспечения производительности, сравнимой с MOLAP,
реляционные системы требуют тщательной проработки схемы базы данных и настройки
индексов, т.е. больших усилий со стороны администраторов БД. Только при
использовании схем типа «звезда» производительность хорошо настроенных
реляционных систем может быть приближена к производительности систем на основе
многомерных баз данных. информация хранение сеть
локальный
HOLAP-серверы используют гибридную архитектуру, которая объединяет
технологии ROLAP и MOLAP. В отличие от MOLAP, которая работает лучше, когда
данные более-менее плотные, серверы ROLAP показывают лучшие параметры в тех
случаях, когда данные довольно разрежены. Серверыприменяют подход ROLAP для
разреженных областей многомерного пространства и подход MOLAP - для плотных
областей. Серверы HOLAP разделяют запрос на несколько подзапросов, направляют
их к соответствующим фрагментам данных, комбинируют результаты, а затем
предоставляют результат пользователю.
Заключение
Таким образом, во-первых, хранилище данных должно решать определенные
задачи: получение полной информации о клиенте, предоставление конкретных данных
для последующего анализа определенного сегмента рынка и т.д. Во-вторых,
хранилище должно быть гибким. Практика показывает, что по мере развития бизнеса
задачи меняются. Соответственно, меняются требования к данным, отчетности и,
как следствие, к хранилищу. Появление новых систем, слияния и поглощения
компаний являются отправной точкой для наполнения хранилища новой информацией.
Отсюда следует, что используемые для загрузки данных в хранилища ETL-средства также должны обеспечивать
гибкость и быстроту внесения таких изменений. Бизнес требует срочной реакции на
любые изменения для правильного принятия решений. В-третьих, хранилище должно
быть актуальным. Данные, которые в дальнейшем будут использованы для отчетности
или анализа не должны быть устаревшими. Бизнес может оценить значение хранилища
при постоянном использовании только свежих, актуальных данных.
При построении хранилища данных, первый, и основной этап - это правильная
постановка задачи. Компания должна четко понимать, какую цель она преследует,
создавая хранилище. Неверное понимание задачи может привести потом к
несоответствию требованиям собственного бизнеса компании. Следующий этап - это
выбор технология, которые будут использованы для построения хранилища. Сюда
входит выбор средств построения моделей данных, ETL-, BI-средств
т.д. в зависимости от поставленной задачи. Дальнейшие этапы совпадают с
обычными IT-проектами: анализ структур и
качества данных, проектирование, разработка, тестирование и внедрение в
эксплуатацию. Практика показывает, что большую сложность вызывает именно этап
тестирования результатов, поскольку для этого требуется разработанная
технология сравнения получаемых данных с реальными.
Чаще всего хранилища данных на российском рынке используются для
получения управленческой отчетности или анализа данных по конкретному сегменту
бизнеса компании.
Кроме того, необходимо отметить, что существуют три основных проблемы, которым
уделяется недостаточное внимание при создании хранилищ данных: качество данных,
оптимальный выбор источников данных и производительность и масштабируемость. На
рынке имеется несколько средств очистки данных, которые начинают применяться
для очистки грязных данных разнообразных типов. Однако эти средства, конечно,
не затрагивают все типы грязных данных, и, конечно, лишь немногие предприятия
принимают на вооружение такие средства или процессы для предотвращения или
обнаружения и очистки грязных данных, а также для отслеживания и проведения
количественной оценки качества данных в хранилищах данных. Сегодня в хранилищах
данных содержится множество данных, которые никогда не используются
приложениями, выполняемыми над этими хранилищами данных, и эти ненужные данные
являются одной из причин снижения эффективности выполнения запросов. Нужно
обеспечить возможность регистрации полного набора запросов. Нужно обеспечить
возможность регистрации полного набора запросов, генерируемых всеми
приложениями, и использования таблиц и полей, фигурирующих в запросах, для
тонкой настройки содержимого хранилищ данных. В сегодняшних хранилищах данных
для хранения данных и управления ими в значительной степени используются
системы РБД. Однако возможности сегодняшних систем РБД не достаточны для
обработки запросов, ориентированных на сканирование, таких как группировка
записей и вычисление агрегатов, и операций перемещения файлов, которые
преобладают на этапе преобразования данных хранилищ данных и этапе подготовки
данных при добыче данных.
Список использованных источников
1 Гудсон Дж. Практическое руководство по доступу к данным
[Текст] / Дж.Гудсон, Р. Стюард Пер.: С. Таранушенко СПб.: БХВ-Петербург, 2013.
- 304 с. - ISBN 978-5-9775-0921-3
Дунаев В. Базы данных. Язык SQL для студента [Текст] :
СПб.: БХВ-Петербург, 2012. - 320 с. - ISBN 978-5-9775-0113-2
Кузин А. Базы данных [Текст] / А.Кузин, С. Левонисова
М.: Академия, 2012. - 320 с. - ISBN 978-5-7695-9308-6
Могилев А. Технологии поиска и хранения информации.
Технологии автоматизации управления [Текст] / А. Могилев, Л. Листрова. - СПб.:
БХВ-Петербург, 2012. - 320 с. - ISBN 978-5-9775-0469-0
Нестеров С.А. Базы данных [Текст] : М.: Политех, 2013.
- 150 с.
Ржеуцкая С.Ю. Базы данных. Язык SQL [Текст] : В.:
ВоГТУ, 2010. - 159 с.
7 Сарка Д. Microsoft SQL Server 2012. Реализация хранилищ данных. Учебный
курс Microsoft [Текст] / Д. Сарка, М. Лах, Г. Йеркич. - М.: Русская Редакция,
2014. - 816 с. - ISBN 978-5-7502-0431-1
8 Станек У.Р. Microsoft SQL Server 2012. Справочник администратора [Текст] : СПб.: БХВ-Петербург,
2013. - 576 с. - ISBN 978-5-9775-0917-6
Токмаков Г.П. Базы данных. Концепция баз данных,
реляционная модель данных, языки SQL [Текст] : УлГТ, 2010. - 193 с.
Фуфаев Э.В. Базы данных. Изд. 7-е [Текст] / Э.В.
Фуфаев, Д.Э. Фуфаев. - М.: Академия, 2012. - 320 с.
Цифровой. Открытые системы. СУБД 10/2013 Периодическое
издание [Текст] : М.: Открытые Системы, 2013.