Статистический анализ многомерных неоднородных данных в программной среде R
Оглавление
Введение
Глава 1. Обзор литературы
1.1 EM алгоритмы для FMM
1.2 Использование R для анализа FMM
Глава 2. Методика исследования
2.1 Описание EM алгоритма
2.2 Примеры ассиметричных
распределений
Глава 3. Результаты численных
экспериментов
3.1 Модельные данные
3.2 Реальные данные
Заключение
Библиографический список
Приложения
Введение
При статистическом анализе
многомерных данных из различных областей человеческой деятельности часто
возникает проблема неоднородности данных, которая может быть переформулирована
как задача классификации. С точки зрения теории вероятности, при решении данной
задачи наиболее адекватным является параметрический подход, при котором для
описания данных используется модель смеси вероятностных распределений (Finite
Mixture Model - FMM). В качестве базовой модели используется модель смеси
нормальных распределений, поскольку она наиболее полно изучена теоретически.
Однако на практике, например, в задачах генетики, обработки сигналов, медицины
и экономики, данные чаще всего демонстрируют асимметричное распределение с ярко
выраженными тяжелыми хвостами. Поскольку нормальное распределение является
симметричным, требуется использование модели асимметричных распределений, в
частности скошенного нормального распределения. В условиях указанной модели для
одновременной оценки параметров и классификации наблюдений традиционно
используется итерационный алгоритм расщепления смесей распределений, который в
англоязычной литературе имеет название Expectation-Maximization (EM).
Существует множество реализаций EM
алгоритма для некоторых из перечисленных выше задач, но для научных
исследований представляется наиболее удобным использование реализаций данного
алгоритма из специализированных библиотек среды статистического
программирования R. В данных
библиотеках реализованы различные версии EM
алгоритма для классификации как симметричных, так и асимметричных одномерных и
многомерных наблюдений. Более того, язык программирования R
позволяет относительно быстро разрабатывать и тестировать новые алгоритмы.
Основной целью данной работы является изучение
возможностей среды статистических вычислений R
для классификации многомерных неоднородных ассиметричных данных с помощью EM
алгоритмов, в частности, классификации многомерных данных по финансовой отчетности
предприятий из ранее проведенного исследования.
Таким образом, объектом данного исследования
является модель смеси многомерных распределений, а предметом исследования -
классификация неоднородных данных с помощью EM
алгоритмов расщепления смесей распределений. Основными задачами являются:
подготовка обзора по соответствующим реализациям EM
алгоритмов в R, проверка
работоспособности данных алгоритмов на модельных данных, а также адаптация
указанных алгоритмов для задачи оценивания кредитных рейтингов предприятий.
алгоритм статистический
вычисление
Глава 1.
Обзор литературы
1.1 EM алгоритмы для FMM
EM алгоритм является общим методом
для нахождения оценок максимального правдоподобия параметров моделей по данным
с пропусками. В случае FMM пропусками являются все значения категориальной
переменной, обозначающей принадлежность наблюдения к одной из компонент смеси
распределений. Данная переменная называется переменной классификации. Примером
такой переменной может служить переменная, классифицирующая пациентов согласно
категориям заболевания, при наличии клинических данных о состоянии пациентов.
При этом предполагается, что значения данной переменной являются СВ или, в
общем случае, реализациями случайного процесса, примером которого может быть
цепь Маркова.
Существует множество подходов к
оцениванию параметров модели FMM, включая метод максимального правдоподобия
(Maximum Likelihood-based Inference - ML), байесовский метод на основе метода
Монте-Карло c использованием цепи Маркова (Bayesian approach based on Markov
chain Monte Carlo), онлайн EM алгоритм (Online EM). Как правило, последние
методы являются более эффективными в вычислительном плане, позволяя оценивать
параметры смесей в более жестких условиях, таких как большая размерность
модели, большой объем данных и т.п. Поскольку в задаче оценивания кредитных
рейтингов
названные проблемы не являются столь существенными, для данной работы выбраны
EM алгоритмы на основе метода максимального правдоподобия, поскольку алгоритмы
данного типа имеют более простую реализацию и хорошо представлены в программных
библиотеках R, о которых пойдет речь в следующем разделе.
Алгоритм EM на базе ML предоставляет
общий подход, который может быть применен для FMM с различными распределениями
вероятностей. Так, для классификации симметричных данных может быть применен EM
алгоритм для расщепления смеси гауссовских (нормальных) распределений, а для
асимметричных данных - алгоритмы EM расщепления смеси скошенных нормальных и
t-распределений Стьюдента. Все указанные алгоритмы в общем случае применимы для
случая многомерных данных. Для данных, у которых пропущенные номера классов
подчиняются марковской зависимости, также может быть использована специальная
версия EM алгоритма с учетом марковской зависимости.
1.2 Использование R для анализа FMM
Свободная среда
статистического программирования R предоставляет исчерпывающий набор встроенных
функций и библиотек расширений для анализа данных с использованием широко круга
статистических методов и моделей. Полный список библиотек может быть найден на
сайте CRAN в разделе Contributed extension packages, где по ссылке CRAN Task
Views <#"786307.files/image001.gif">,
где 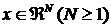 - вектор числовых характеристик,
- вектор числовых характеристик,
 - априорные вероятности классов,
такие что
- априорные вероятности классов,
такие что 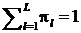 ,
,
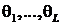 - параметры распределений,
- параметры распределений, 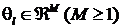 ,
,
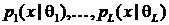 - функции плотности распределения
(компоненты смеси).
- функции плотности распределения
(компоненты смеси).
Обозначим через 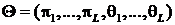 составной
вектор всех параметров смеси,
составной
вектор всех параметров смеси, 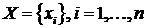 - выборку наблюдений,
- выборку наблюдений, 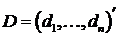 - вектор
классификации, где
- вектор
классификации, где 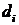 принимает
значение номера класса, которому соответствует наблюдение
принимает
значение номера класса, которому соответствует наблюдение 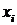 , тогда логарифмическая
функция правдоподобия параметров
, тогда логарифмическая
функция правдоподобия параметров
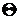 по выборке
по выборке 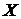 представляется
в виде функционала который можем оптимизировать с помощью
различных алгоритмов.
представляется
в виде функционала который можем оптимизировать с помощью
различных алгоритмов.
Во многих задачах классификация 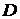 неизвестна,
поэтому возникает задача совместного оценивания параметров и классификации.
Такие задачи относится к задачам анализа данных с пропусками, которые успешно
решаются с помощью EM алгоритмов. Данные алгоритмы
являются итерационными, и для их применения требуется предварительно задать
начальные
значения
параметров
модели,
а также определить механизм их обновления на каждой итерации. Обозначим через
неизвестна,
поэтому возникает задача совместного оценивания параметров и классификации.
Такие задачи относится к задачам анализа данных с пропусками, которые успешно
решаются с помощью EM алгоритмов. Данные алгоритмы
являются итерационными, и для их применения требуется предварительно задать
начальные
значения
параметров
модели,
а также определить механизм их обновления на каждой итерации. Обозначим через 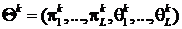 значения соответствующих параметров
на k-ой итерации. С помощью
формулы Байеса получим апостериорные вероятности для возможных реализаций
пропущенных значений классификационной переменной:
значения соответствующих параметров
на k-ой итерации. С помощью
формулы Байеса получим апостериорные вероятности для возможных реализаций
пропущенных значений классификационной переменной:

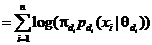 ,
,
 ,
,
причем 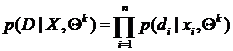 -
апостериорная вероятность для реализации вектора классификации .
-
апостериорная вероятность для реализации вектора классификации .
В частном случае, если является
смесью из многомерных нормальных распределений с параметрами 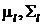 и
плотностью
и
плотностью
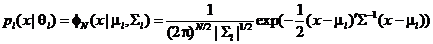 ,
,
где через 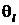 обозначен
составной вектор всех данных параметров независимых параметров из , то в
результате максимизации функционала по выборке данных с учетом значений
параметров
обозначен
составной вектор всех данных параметров независимых параметров из , то в
результате максимизации функционала по выборке данных с учетом значений
параметров 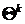 и
апостериорных вероятностей на текущей итерации, формулы для обновления оценок
параметров принимают вид
и
апостериорных вероятностей на текущей итерации, формулы для обновления оценок
параметров принимают вид
 ,
,
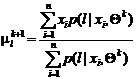 ,
,
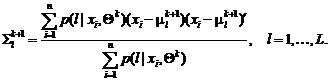
Определим общую схему EM
алгоритма. При заданной
выборке, заданных
законах распределения , начальных
значениях параметров 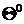 , можно
использовать итерационный алгоритм последовательного уточнения оценок вектора
параметров смеси и вектора классификации выборки. Данный алгоритм относится к
классу ЕМ-алгоритмов, широко применяемых в задачах статистического оценивания
параметров в условиях априорной неопределенности. При этом k итерация
(
, можно
использовать итерационный алгоритм последовательного уточнения оценок вектора
параметров смеси и вектора классификации выборки. Данный алгоритм относится к
классу ЕМ-алгоритмов, широко применяемых в задачах статистического оценивания
параметров в условиях априорной неопределенности. При этом k итерация
(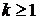 ) предлагаемого
ЕМ-алгоритма включает два последовательно выполняемых этапа:
) предлагаемого
ЕМ-алгоритма включает два последовательно выполняемых этапа:
этап Е (Expectation):
оценивание при текущих
значениях параметров модели апостериорных
вероятностей классов, знание которых позволяет оценить вектор классификации
выборки;
этап М (Maximization): обновление
оценок параметров смеси  из условия
максимума логарифмической функции правдоподобия на
основании полученных ранее апостериорных вероятностей классов.
из условия
максимума логарифмической функции правдоподобия на
основании полученных ранее апостериорных вероятностей классов.
Работа алгоритма продолжается
до достижения заданного условия остановки.
2.2 Примеры ассиметричных
распределений
В данном разделе дадим обзор распределений
вероятностей, которые могут быть использованы как компоненты смеси. Перечислим
только те распределения, которое представлены в программной библиотеке mixsmsn
в соответствии с описанием. Все данные распределения относятся к специальному
классу на основе скошенных нормальных распределений SMSN(Scale
Mixtures
of Skew-Normal
distribution), а модели смесей
на основе данных распределений формируют класс моделей FMSMSN
(Finite Mixures
of Scale
Mixtures
of Skew-Normal
distributions), для которых в
указанной библиотеки реализованы алгоритмы моделирования данных и анализа с
помощью EM алгоритма.
Приведем полный список распределений
реализованных в библиотеке с принятыми сокращениями, которые в качестве
параметров при вызове функций: нормальное распределение (Normal),
асимметричное нормальное распределение (Skew.normal),
асимметричное слеш-распределение
(Skew.slash) и асимметричное
нормальное
распределение з засорениями (asymmetric
contaminated-normal - Skew.cn), а также t-распределение
Стьюдента (t)
и его асимметричная версия (Skew.t).
Все данные распределения представлены как для одномерного, так и для
многомерного случая.
Скошенное N-мерное
нормальное
распределение (skew-normal)
имеет плотность
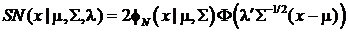 ,
,
где 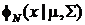 - функция плотности N-мерного нормального
распределения
с вектором средних
- функция плотности N-мерного нормального
распределения
с вектором средних  и
ковариационной матрицей
и
ковариационной матрицей 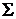 ,
,
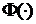 - функция распределения
стандартного нормального закона,
- функция распределения
стандартного нормального закона,
 - вектор параметров смещения
(асимметричности).
- вектор параметров смещения
(асимметричности).
Определим остальные распределения из
класса SMSN.
Определение. Случайный вектор 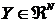 имеет
распределение из класса SMSN, если
имеет
распределение из класса SMSN, если
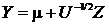 ,
,
где - вектор параметров центрального
положения,
 - случайный вектор с распределением
- случайный вектор с распределением
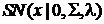 ,
,
U -
неотрицательная случайная величина, независимая относительно Z, с функцией
распределения 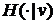 ,
, 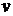 - параметр
(вектор параметров).
- параметр
(вектор параметров).
Согласно определению, маргинальная функция
плотности случайной величины Y
имеет представление
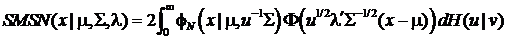 ,
,
где выбор функции определяет
конкретное распределение из класса SMSN.
Перечислим частные случаи
распределения из класса SMSN, которые реализованы в
библиотеке mixsmsn и
определим, при каких условиях они относятся к классу:
) нормальное распределение, если 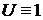 и
и 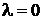 ;
;
) скошенное нормальное
распределение, если ;
) скошенное t-распределение,
если 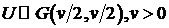 - Гамма-распределение;
- Гамма-распределение;
) скошенное слеш-распределение, если
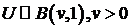 -
Бета-распределение;
-
Бета-распределение;
) скошенное нормальное распределение
с засорениями (skew-contaminated normal), если U является
дискретной случайной величиной, принимающей с вероятностью  значение
значение  и с
вероятностью
и с
вероятностью 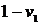 и значение
1, где
и значение
1, где  .
.
Для моделей смесей с распределениями
из класса SMSN, которые
представлены выше, примем соответствующие обозначения (относительно
распределения вероятностей для компонент смеси) нормальное - FMNOR, скошенное
нормальное - FMSN, скошенное
t-распределение - FMST, скошенное слеш-распределение - FMSSL и скошенное
нормальное распределение с засорениями - FMSCN.
Глава 3. Результаты численных экспериментов
В данной главе приводятся численные эксперименты
с использованием моделей типа FMSMSN
с распределениями, описанными в разделе 2.2. В разделе 3.1 продемонстрируем
использование функций из библиотеки mixsmsn
в R: вначале
смоделируем выборку асимметричных данных и применим к их анализу EM
алгоритм в предположениях симметричности и асимметричности распределений.
Последнее необходимо для того, чтобы кроме работоспособности реализованных
процедур показать, насколько нарушение предположения о симметричности данных
влияет на адекватность результатов. В разделе 3.2 применим EM
алгоритм для классификации ненормированных квартальных данных по финансовому
состоянию предприятий промышленности в предположении описанных моделей
распределений из класса SMSN
для сравнения с методикой классификации, использующей обычный кластерный анализ
в пространстве нормированных коэффициентов.
.1 Модельные данные
Согласно, смоделируем выборку  из модели FMSN с
из модели FMSN с 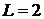 компонентами,
имеющими скошенное многомерное нормальное распределение размерности
компонентами,
имеющими скошенное многомерное нормальное распределение размерности 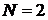 . Выберем
следующие параметры:
. Выберем
следующие параметры:
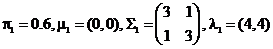 ;
;
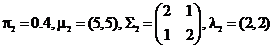 ,
,
Оценим параметры и классификацию полученной
выборки в условиях двух режимов применения EM
алгоритма: в предположении модели FMNOR
или модели FMSN. Для
сравнения результатов будет использовать статистики информационных критериев AIC,
BIC, EDC
и ICL. Полученные
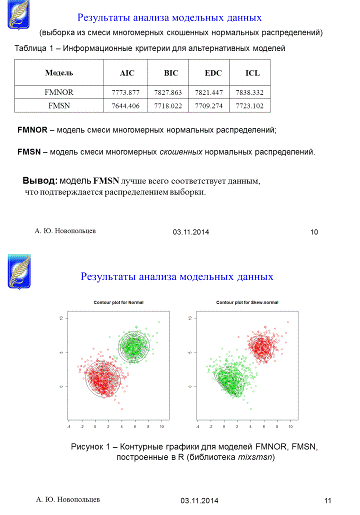
результаты приведены в таблице 1. Согласно данным результатам, все статистики
принимают наименьшие значения для модели FMSN,
которая является образующей для выборки данных, что и следовало доказать.
Таблица 1. - Информационные критерии для
альтернативных моделей
|
Модель
|
AIC
|
BIC
|
EDC
|
ICL
|
|
FMNOR
|
7773.877
|
7827.863
|
7821.447
|
7838.332
|
|
FMSN
|
7644.406
|
7718.022
|
7709.274
|
7723.102
|
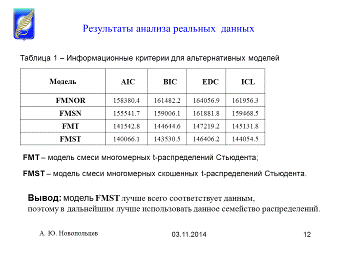
Также, на рисунке 1 визуализирована используемая
выборка данных с нанесением контурных линий, где слева нанесены контурные линии
для случая оценивания модели FMNOR,
а справа - FMSN. Согласно
данному рисунку, графическая визуализация в данном случае менее информативна.
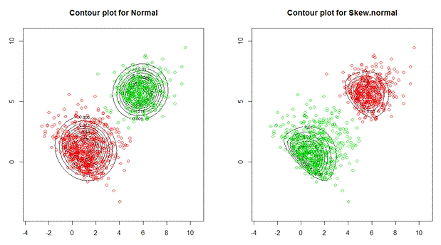
Рисунок 1.
-
Контурные графики для моделей FMNOR,
FMSN
Большой интерес вызывает сравнение оцененных
классификаций (в предположении различных моделей) с истинной классификацией,
обозначающей принадлежность каждого наблюдения к заданной компоненте смеси, для
чего, как правило, используются оценки ошибок классификации. Однако последнее
оказалось невозможным, поскольку функция генерации выборки данных,
реализованная в библиотеке mixsmsn,
не предоставляет вектор классификации при генерации данных.
.2 Реальные данные
Применим EM
алгоритм к квартальным данным по финансовому состоянию предприятий (16
кварталов, 300 предприятий, 4800 наблюдений). Оценим все имеющиеся в библиотеки
модели: FMNOR, FMSN,
FMSSL, FMSCN,
и FMT и FMST.
Для оценивания будем использовать ненормированные коэффициенты. Также будем
классифицировать выборку на 4 класса, т.е. рассмотрим случай 4 компонент в
смеси распределений.
При вычислении некоторых коэффициентов для 4
наблюдений были получены пропущенные значения. Исключив данные наблюдения из
анализа, получим выборку из 4796 наблюдений. Применим EM
алгоритм для оценивания каждой из перечисленных моделей. В ходе экспериментов
при оценивании моделей FMSSL,
FMSCN не была достигнута
сходимость EM алгоритма,
поэтому были получены результаты только для остальных четырех моделей, которые
представлены в таблице 2.
Таблица 2. - Информационные критерии для
альтернативных моделей
|
Модель
|
AIC
|
BIC
|
EDC
|
ICL
|
|
FMNOR
|
158380.4
|
161482.2
|
164056.9
|
161956.3
|
|
FMSN
|
155541.7
|
159006.1
|
161881.8
|
159468.5
|
|
FMT
|
141542.8
|
144644.6
|
147219.2
|
145131.8
|
|
FMST
|
140066.1
|
143530.5
|
146406.2
|
144054.5
|
Согласно таблице 2, наилучшее соответствие
данным достигнуто при использовании модели FMST
(смесь скошенных многомерных t-распределений),
поскольку значениями статистик всех информационных критериев для данной модели
принимают наименьшее значение.
Также были предприняты попытки оценить все
вышеуказанные модели по соответствующим нормированным данным, однако во всех случаях
в вычислениях возникли ошибки, что не позволило оценить ни одну из моделей.
Последнее может свидетельствовать о неприменимости моделей и алгоритмов из
библиотеки mixsmsn
к нормированным данным. Это вызывает трудности при сравнении классификации, полученной
с помощью кластерного анализа в пространстве нормированных коэффициентов, с
классификациями, полученными с помощью указанных алгоритмов по ненормированным
данным, поэтому здесь данное сравнение не приводится. В целом, оценивание такой
выборки данных для данных алгоритмов оказалось довольно трудной задачей
(потребовалось довольно много времени для вычислений), поэтому в дальнейших
исследованиях предлагается разбить всю выборку данных по кварталам и оценивать
получаемые подвыборки отдельно.
Заключение
В данной работе получены следующие результаты:
) подготовлен обзор по методам и алгоритмам
параметрической классификации многомерных неоднородных наблюдений с помощью
алгоритмов типа EM,
предназначенных для анализа преимущественно асимметричных данных;
) подготовлен обзор основных программных
библиотек для среды статистического программирования R,
которые могут быть полезны для решения указанные методы и алгоритмы;
) проведены эксперименты на модельных и реальных
данных, иллюстрирующие особенности применения процедур, реализующих указанные
алгоритмы;
) выявлены недостатки указанного программного
обеспечения, как отсутствие вектора истинной классификации при моделировании
данных, а также их неприменимость к нормированным данным при анализе данных по
финансовому состоянию предприятий.
Приведенные обзор литературы свидетельствует о
широкой востребованности данной темы, как в научных исследованиях, так и на
практике. Обилие программных реализаций соответствующих методов и алгоритмов, в
частности в R, дает большие
возможности по анализу данных без необходимости самостоятельно писать данные
алгоритмы. Однако, ввиду специфичности конкретной задачи, требуется доработка
отдельных алгоритмов, что относительно быстро может быть достигнуто при
использовании языка статистического программирования R.
Библиографический список
1. Айвазян,
С.А.
Прикладная статистика. Классификация и снижение размерности / С.А. Айвазян [и
др.]. -
М.: Финансы и статистика, 1989. - 607с.
2. Mengersen,
K. Mixtures: Estimation and Applications / K. Mengersen, C.P. Robert, D.M. Titterington.
- Hoboken, N.J.: Wiley,
2011. - 311 p.
. Fraley,
C. Model-based Clustering, Discriminant Analysis and Density Estimation / C.
Fraley, A.E. Raftery // J. of the American Statistical Association. - 2002.
-Vol. 97, № 458. - P. 611-631.
5. Dempster,
A.P. Maximum likelihood from incomplete data via the EM algorithm / A.P.
Dempster, N.M. Laird, D.B. Rubin // Journal of the Royal Statistics Society.
Ser. B. - 1977. - Vol. 39, № 1. - P. 1-38.
6. Малюгин, В.И. Система
статистических кредитных рейтингов предприятий: методика построения,
верификации и применения / В.И. Малюгин [и др.] // Банковский Вестник.
Исследования банка. - №5. - 2013. - 73 с.
7. Bilmes,
J.A. A Gentle Tutorial of the EM Algorithm and its Application to Parameter
Estimation for Gaussian Mixture and Hidden Markov Models: Technical Report /
J.A. Bilmes; Int. Computer Science Institute, Berkeley CA. - Berkeley,
1998. - 13 p.
8. Comprehensive
R Archive Network: [Electronic resource] / R Foundation. - Mode of access:
#"786307.files/image060.gif">