Моделирование процесса функционирования вычислительной системы
КУРСОВАЯ РАБОТА
по дисциплине: «Моделирование»
На тему:
Моделирование процесса
функционирования вычислительной системы
Реферат
Имитационное моделирование, математическое ожидание, критерий согласия
хи-квадрат, гистограмма, закон распределения, дисперсия, критерий Фишера,
диаграмма рассеяния, закон распределения, корреляционная матрица.
В рамках курсовой работы необходимо разработать программу, имитирующую
работу заданной системы массового обслуживания, а затем, на основе имитационных
результатов, оценить её работу и определить пути усовершенствования системы. В
ходе курсовой работы выполнен обзор теоретического материала, использованного
для решения поставленной задачи; сформулировано техническое задание на
разработку программы; смоделирована работа системы; определены основные
достоинства и недостатки данной системы; предложены и реализованы варианты
оптимизации работы системы.
Содержание
Введение
. Обзор
методов и средств решения задачи
.1 Общие
сведения об имитационном моделировании систем
.2 Метод
наименьших квадратов
.3 Критерий
Фишера
.4 Алгоритм
проверки значимости выборочных коэффициентов регрессии
.5 Критерий
согласия хи-квадрат
.6
Определение методов решения
. Разработка
концептуальной модели системы
. Разработка
структурной схемы модели системы
. Разработка
программы имитации работы системы
. Анализ и
оценка результатов моделирования
.1 Значения
требуемых характеристик
.2
Исследование характеристик системы
.3 Анализ
эффективности работы системы
. Анализ и
оценка результатов моделирования
7. Результат
работы программы в оптимальных условиях
Выводы
Введение
В цех на участок обработки поступают партии деталей по три в каждой.
Интервалы между приходами деталей равномерно распределены в интервале 40±10
минут. Первичная обработка деталей происходит на одном из станков двух типов.
Деталь поступает на обработку на станок с меньшей очередью. Станок первого типа
обрабатывает деталь в среднем за 30 минут (закон распределения
экспоненциальный) и допускает 8% брака, второго типа соответственно в среднем
20 минут и 10% брака. Количество станков первого типа - 2, второго типа - 2.
Все бракованные детали возвращаются на повторную обработку на свой станок.
Детали, которые были забракованы дважды, считаются отходами и отправляются на
утилизацию.
После первичной обработки детали поступают в накопитель, а из него во
вторичную обработку, которую проводят два параллельно работающих станка
третьего типа за время, распределенное по нормальному закону со средним 25
минут и среднеквадратическим отклонением 2 минуты. Причем второй станок
третьего типа подключается к работе, только если в накопителе находится более
трех деталей. Затраты на содержание станков первого, второго и третьего типов
составляют соответственно 4, 3, 1.5 единиц стоимости в час, независимо от того,
используется станок или нет. Цена реализации готовой детали составляет 200
единиц стоимости, а стоимость покупки необработанной детали - 45 единиц
стоимости.
Есть возможность повысить качество первичной обработки деталей.
Уменьшение уровня брака в работе станков на r процентов требует дополнительных затрат r*4 единиц стоимости на каждую деталь.
Действия по повышению эффективности качества первичной обработки могут
проводиться для обоих типов станков независимо друг от друга.
Смоделировать процесс обработки 1000 партий деталей. Определить
характеристики очереди деталей, количество забракованных деталей, коэффициенты
использования станков, прибыль цеха.
2. Обзор
методов и средств решения задачи
2.1 Общие
сведения об имитационном моделировании систем
С развитием вычислительной техники широкое применение получили
имитационные методы моделирования для анализа систем, преобладающими в которых
являются стохастические воздействия. Суть ИМ заключается в имитации процесса
функционирования системы во времени, соблюдением таких же соотношений
длительности операций как в системе оригинале. При этом имитируются
элементарные явления, составляющие процесс; сохраняется их логическая
структура, последовательность протекания во времени. Результатом ИМ является
получение оценок характеристик системы.
Имитационное моделирование - это процесс конструирования модели реальной
системы и постановки экспериментов на этой модели с целью либо понять поведение
системы, либо оценить (в рамках ограничений, накладываемых некоторым критерием
или совокупностью критериев) различные стратегии, обеспечивающие
функционирование данной системы [2]. Все имитационные модели используют принцип
черного ящика. Это означает, что они выдают выходной сигнал системы при
поступлении в нее некоторого входного сигнала. Поэтому в отличие от
аналитических моделей для получения необходимой информации или результатов
необходимо осуществлять "прогон" имитационных моделей, т. е. подачу
некоторой последовательности сигналов, объектов или данных на вход модели и
фиксацию выходной информации, а не "решать" их. Происходит своего
рода "выборка" состояний объекта моделирования (состояния - свойства
системы в конкретные моменты времени) из пространства (множества) состояний
(совокупность всех возможных значений состояний). Насколько репрезентативной
окажется эта выборка, настолько результаты моделирования будут соответствовать
действительности. Этот вывод показывает важность статистических методов оценки
результатов имитации. Таким образом, имитационные модели не формируют свое
собственное решение в том виде, в каком это имеет место в аналитических
моделях, а могут лишь служить в качестве средства для анализа поведения системы
в условиях, которые определяются экспериментатором.
2.2 Метод
наименьших квадратов
Предположим, что между экспериментальными данными предполагается линейная
зависимость:
 (2.2.1)
(2.2.1)
Зависимость (2.2.1) носит название линейной регрессии. Исходные данные
для получения оценок параметров модели (2.3.1) обычно записывают в виде матриц:
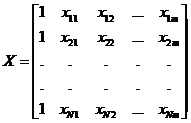
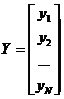 ,
,
где
i - номер эксперимента, N - их
количество.
Для
того чтобы функция регрессии (2.2.1) достаточно хорошо описывала эмпирическую
зависимость, ее параметры  подбирают таким образом, что отклонения
подбирают таким образом, что отклонения 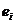 между измеренными
между измеренными 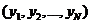 и
теоретическими значениями
и
теоретическими значениями 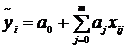 принимали бы минимальные значения. В качестве такого
критерия выбирают сумму квадратов отклонений:
принимали бы минимальные значения. В качестве такого
критерия выбирают сумму квадратов отклонений:
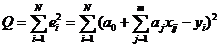 (2.2.2)
(2.2.2)
Выбор
критерия в таком виде объясняется тем, что при этом формулы расчета значений достаточно просты, хорошо зарекомендовали себя в
практике, а сами эти значения обладают определенными свойствами. Критерий
(2.2.2) является обобщенным показателем рассеивания вокруг искомой линейной
зависимости.
Параметры
подбирают из условий минимизации (2.2.2). Необходимым
условием существования минимума критерия (2.2.2) является равенство нулю
частных производных по неизвестным параметрам Минимизируя
функцию Q положим
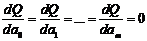 (2.2.3)
(2.2.3)
система
линейных уравнений (2.3.3), как это легко найти, в матричной форме записывается
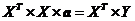 (2.2.4)
(2.2.4)
Из
(2.3.4) следует, что
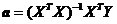 (2.2.5)
(2.2.5)
Оценку
 , найденную по формуле (2.3.5) называют оценкой
наименьших квадратов, или оценкой МНК.
, найденную по формуле (2.3.5) называют оценкой
наименьших квадратов, или оценкой МНК.
2.3
Критерий Фишера
Оценкой качества всей модели в целом может служить критерий Фишера [2]:
если
 (2.3.1)
(2.3.1)
то
уравнение в целом не значимо. Здесь 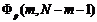 -
критическая граница распределения Фишера с
-
критическая граница распределения Фишера с 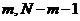 степенями
свободы соответствующая уровню значимости р;
степенями
свободы соответствующая уровню значимости р;  -
среднее значение
-
среднее значение 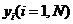 .
.
Вычисление
отношения (2.4.1) позволяет выявить, насколько существенно различие этих двух
показателей, т.е. в какой мере замена на  улучшает наши представления о характере зависимости.
улучшает наши представления о характере зависимости.
Применение
Ф-критерия дает возможность конкретно оценить действительную связь между
переменными. Если условию Фишера удовлетворяют несколько моделей, то
предпочтение отдают наиболее простым аналитическим выражениям.
2.4
Алгоритм проверки значимости выборочных коэффициентов регрессии
Известна
формула, позволяющая вычислить 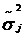 - оценку
дисперсии оценок
- оценку
дисперсии оценок 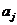 :
:
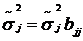 (2.4.1)
(2.4.1)
где
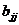 - диагональный элемент матрицы:
- диагональный элемент матрицы: 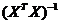 [3].
[3].
Соотношения
(2.4.1) позволяют проверять гипотезы о значимости выборочных коэффициентов
регрессии. Если расчетная значимость j - ого коэффициента
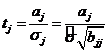
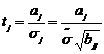 (2.4.2)
(2.4.2)
меньше
по модулю теоретической значимости 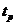 , то
теоретический коэффициент регрессии принимается равным нулю
, то
теоретический коэффициент регрессии принимается равным нулю  , с вероятностью ошибки
, с вероятностью ошибки 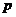 . Здесь - значение
. Здесь - значение 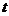 -
статистики Стьюдента с
-
статистики Стьюдента с 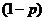 доверительной вероятностью и
доверительной вероятностью и 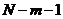 степенями свободы.
степенями свободы.
Известен
алгоритм последовательного исключения факторов из модели. На каждом этапе
рассчитываются эмпирические значимости всех коэффициентов регрессии  . Затем они ранжируются по назначению их модулей, и
если минимальное значение оказывается меньше теоретической значимости, то
соответствующий коэффициент выводится из модели и все расчеты повторяются.
Расчеты заканчиваются тогда, когда все коэффициенты регрессии оказываются
значимыми.
. Затем они ранжируются по назначению их модулей, и
если минимальное значение оказывается меньше теоретической значимости, то
соответствующий коэффициент выводится из модели и все расчеты повторяются.
Расчеты заканчиваются тогда, когда все коэффициенты регрессии оказываются
значимыми.
2.5
Критерий согласия хи-квадрат
При обработке результатов машинного эксперимента с моделью системы часто
возникает задача определения эмпирического закона распределения случайной
величины. Общая схема решения этой задачи сводится к тому, что:
·
строят по
результатам имитационного эксперимента гистограмму (оценку функции плотности
распределения вероятностей);
·
выдвигают
гипотезу о согласии эмпирического закона с каким-либо теоретическим
распределением;
·
проверяют
гипотезу с помощью одного из статистических критериев согласия (Пирсона,
Колмогорова, Смирнова и т.д.
В качестве критерия проверки гипотезы по критерию Пирсона выбирают
величину, которая характеризует степень расхождения эмпирического и
теоретического закона следующим образом:
 (2.5.1)
(2.5.1)
где:
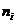 - количество значений случайной величины
- количество значений случайной величины 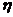 , попавших в i-ый подынтервал;
, попавших в i-ый подынтервал;
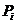 -
вероятность попадания случайно величины в i -
ый подынтервал;
-
вероятность попадания случайно величины в i -
ый подынтервал;
d- количество
подынтервалов, на которые разбивается интервал измерения в имитационном
эксперименте, 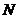 - объем наблюдений.
- объем наблюдений.
Проверка гипотезы о согласованности эмпирического и теоретического
законов распределения с помощью критерия согласия Пирсона осуществляется в
последовательности:
Результаты
наблюдений  группируют в интервальный вариационный ряд. Объем
наблюдений должен быть достаточно большим
группируют в интервальный вариационный ряд. Объем
наблюдений должен быть достаточно большим 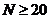 . Если
частота, соответствующая какому-либо интервалу, окажется меньше 5, то интервал
объединяют с соседним, так, чтобы частота попадания значения случайной величины
в подынтервал была бы больше или равна 5.
. Если
частота, соответствующая какому-либо интервалу, окажется меньше 5, то интервал
объединяют с соседним, так, чтобы частота попадания значения случайной величины
в подынтервал была бы больше или равна 5.
1. Выдвигают гипотезу о виде
распределения по виду гистограммы.
Задают
уровень значимости  .
.
Определяют
теоретическую вероятность попадания случайно величины в каждый из подинтервалов.
попадания случайно величины в каждый из подинтервалов.
Вычисляют
величину расхождения законов .
.
Определяют
число степеней свободы  .
.
По
вычисленным значениям и по
таблицам находят вероятность . Если
она превышает уровень значимости , то
считают, что гипотеза о виде распределения отвергается.
. Если
она превышает уровень значимости , то
считают, что гипотеза о виде распределения отвергается.
2.6
Определение методов решения
Для решения поставленной задачи используется метод имитационного
моделирования, так как он является наиболее приемлемым для такого типа задач.
Хотя универсальным инструментальным средством создания моделей являются языки
программирования общего пользования (Pascal, C/C++ и др.) и средства визуального проектирования программ (Delphi, Visual C++), облегчающие выполнение некоторых трудоемких операций,
например, создание интерфейса программы, в данной работе использован язык GPSS. Язык GPSS позволяет быстрее и с меньшими затратами (по
сравнению с универсальными языками программирования) создавать и исследовать
модели.
Анализ и оценка результатов моделирования производилась средствами пакета
Statistica 6.0, включающего широкий спектр
методов для расчета основных статистических характеристик параметров системы,
построения гистограмм, реализации параметрической идентификации модели и прочих
целей.
3.
Разработка концептуальной модели системы
Концептуальная модель системы разрабатывается для облегчения дальнейшего
создания программы имитации её работы, а также для определения целей
моделирования.
Входные
переменные:
T1 -
Время выполнения задачи станком первого типа(30 мин.; экспоненциальное
распределение)
T2 -
Время выполнения задачи станком второго типа(20 мин.; экспоненциальное
распределение)
T3 -
Время выполнения задачи станком третьего типа (25мин.; нормальное
распределение)
Выходные
переменные:
N-
кол-во забракованных деталей
K1, K2, K3, K4, K5 - коэффициенты использования
станков
P -
прибыль цеха
M
(назв. очереди) - максимальная длина очереди
A
(назв. очереди) - среднее время пребывания в очереди
4.
Разработка структурной схемы модели системы

Рисунок 1 - Q-схема системы
Система включает в себя 4 станка 2-х типов, которые обрабатывают
поступающие детали. После первичной обработки деталей, они поступают сначала на
накопитель, а затем уже на вторичную обработку 2-мя дополнительными станками.
концептуальный модель массовый обслуживание

Рисунок 2. Блок-схема алгоритма работы системы
5. Разработка программы имитации работы системы
Программа написана с помощью языка GPSS.
generate 40,10
split 2,tt
tt assign 1,2
queue sum_obr
; ищем самую маленькую очередь
t0 test le q$ss11,q$ss12,t1
test le q$ss21,q$ss22,t2
test le q$ss11,q$ss21,next21 ; ss11-минимальная
очередь
t4 transfer ,next11
t1 test le q$ss21,q$ss22,t3
test le q$ss12,q$ss21,next21 ; ss12 -
минимальная очередь
transfer ,next12
t2 test le q$ss22,q$ss11,t4
t5 transfer ,next22 ; ss22 -
минимальная очередь
t3 test le q$ss12,q$ss22,t5
transfer ,next12 ; ss12 - минимальная очередь
;обработка первым станком первого типа
next11 queue ss11
seize stan11
depart ss11
advance(exponential(1,0,30))
release stan11
queue count11
transfer .08,to_nakop,reobr11
;обработка вторым станком первого типа
next12 queue ss12
seize stan12
depart ss12
advance(exponential(2,0,30))
release stan12
queue count12
transfer .08,to_nakop,reobr12
;обработка первым станком второго типа
next21 queue ss21
seize stan21
depart ss21
advance(exponential(1,0,20))
release stan21
queue count21
transfer .1,to_nakop,reobr21
;обработка вторым станком второго типа
next22 queue ss22
seize stan22
advance(exponential(2,0,20))
release stan22
queue count22
transfer .1,to_nakop,reobr22
; цикл для повторной обработки детали
reobr11
loop 1,next11
queue brak
terminate 1
reobr12 loop 1,next12
queue brak
terminate 1
reobr21 loop 1,next21
queue brak
terminate 1
reobr22 loop 1,next22
queue brak
terminate 1
;накопитель
to_nakop queue nakop
;если очередь на выполнение больше 3, обработка выполняется вторым
станком
test le q$nakop,3,met1
;обработка 1м станком
next31
seize stan31
depart nakop
advance(normal(1,25,2))
release stan31
queue count31
transfer ,end1
met1 transfer both next31,next32
;обработка 2м станком
next32 seize stan32
depart nakop
advance(normal(1,25,2))
release stan32
queue count32
transfer ,end1
end1 depart sum_obr
queue obr
terminate 1
start 3000
6. Анализ
и оценка результатов моделирования
6.1
Значения требуемых характеристик
Результаты, полученные в процессе моделирования приведены в табл. 1.
Таблица 1
Значения характеристик системы
|
Характеристика
|
Значение
|
|
Коэффициенты использования
станков
|
0,124;0,353;0,65;0,749;0,996;0,847
|
|
Количество забракованных
деталей
|
17
|
|
Среднее время пребывания в
очереди ss11, максимальная длина
|
14,181 2
|
|
Среднее время пребывания в
очереди ss12, максимальная длина
|
10,869 2
|
|
Среднее время пребывания в
очереди ss21, максимальная длина
|
9,190 2
|
|
Среднее время пребывания в
очереди ss22, максимальная длина
|
12,622 2
|
|
Прибыль цеха
|
594311
|
6.2
Исследование характеристик системы
Характеристика
«Среднее время нахождения заявки в системе»
Таблица 2

Таблица 3


Рисунок 3.
Гистограмма распределения среднего времени нахождения заявки в системе
Выдвинутая
гипотеза о том, что закон распределения времени обработки заявок первым станком
является нормальным, отвергается при уровне значимости  , так как p=0,00001<a=0.05.
, так как p=0,00001<a=0.05.
Характеристика
«Среднее время обработки запроса станком третьего типа»
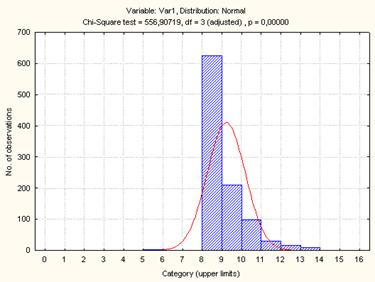
Рисунок 4.
Гистограмма распределения среднего времени обработки запроса станком 3-го типа
Выдвинутая
гипотеза о том, что закон распределения времени обработки заявок третьим
станком является нормальным, отвергается при уровне значимости , так как p=0,00001<a=0.05
6.3 Анализ
эффективности работы системы
Построив имитационную модель системы и проанализировав её работу, можно
прийти к следующим выводам.
Система работает не так эффективно, как хотелось бы. Время нахождения
заданий в очереди довольно велико. Но сама система для обработки поступающих
задач имеет большой потенциал и можно увеличить их интенсивность и частоту в
несколько раз, и в целом система может работать и при большей нагрузке.
Оптимизируем существующую систему. В качестве параметра для оптимизации
выберем - среднее время пребывания деталей в накопителе
Уровни факторов будут изменяться согласно данным, приведенным в таблице
4.
В табл. 5 приведена матрица планирования для проведения полного
факторного эксперимента. Полный факторий эксперимент дает возможность
определить коэффициенты регрессии, соответствующие не только линейным эффектам,
но и всем эффектам взаимодействий. При проведении эксперимента используют либо
исходные значения факторов, либо стандартизованные значения (для удобства). Для
перехода к стандартизованным значениям применяют преобразование:
Таблица 4
|
Факторы (обозначение)
|
Содержательная
интерпретация факторов
|
Уровни факторов
|
Интервал варьирования,
единицы измерения
|
|
|
-1
|
0
|
+1
|
|
|
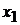 Среднее время выполнения заданий станком первого
типа Среднее время выполнения заданий станком первого
типа
|
20
|
30
|
40
|
10
|
|
|
 Среднее время выполнения заданий станком второго
типа Среднее время выполнения заданий станком второго
типа
|
20
|
25
|
30
|
5
|
|
|
 Среднее время выполнения заданий станком третьего
типа Среднее время выполнения заданий станком третьего
типа
|
25
|
30
|
35
|
5
|
|
Таблица 5
|
№
|
x1
|
x2
|
x3
|
x1*x2
|
x1*x3
|
x2*x3
|
x1*x2*х3
|
y
|
|
1
|
20
|
20
|
25
|
400
|
500
|
500
|
10000
|
39,702
|
|
2
|
20
|
20
|
35
|
400
|
700
|
700
|
1400
|
6025.022
|
|
3
|
20
|
30
|
25
|
600
|
500
|
750
|
15000
|
45.040
|
|
4
|
20
|
30
|
35
|
600
|
700
|
1050
|
21000
|
|
5
|
40
|
20
|
25
|
800
|
1000
|
500
|
20000
|
47.877
|
|
6
|
40
|
20
|
35
|
800
|
1400
|
700
|
28000
|
5963.850
|
|
7
|
40
|
30
|
25
|
1200
|
1000
|
750
|
30000
|
52.075
|
|
8
|
40
|
30
|
35
|
1200
|
1400
|
1050
|
42000
|
6193.367
|

Рисунок 5. Диаграмма рассеяния для линейной модели (Y(X1)

Рисунок 6. Диаграмма рассеяния для линейной модели (Y(X2)
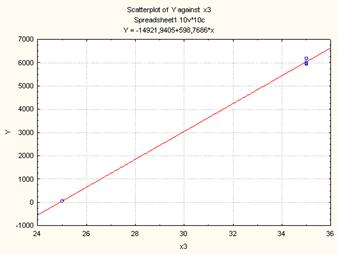
Рисунок 7. Диаграмма рассеяния для линейной модели (Y(X3)
Рисунок 8. Диаграмма рассеяния для линейной модели (Y(X12)
Рисунок 9. Диаграмма рассеяния для линейной модели (Y(X13)
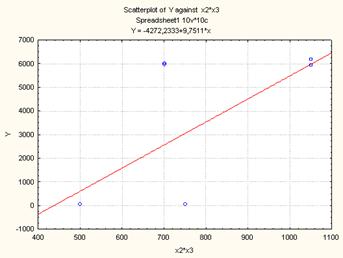
Рисунок 10. Диаграмма рассеяния для линейной модели (Y(X23)

Рисунок 11. Диаграмма рассеяния для линейной модели (Y(Х123)

Рисунок 12 . Выборочная корреляционная матрица
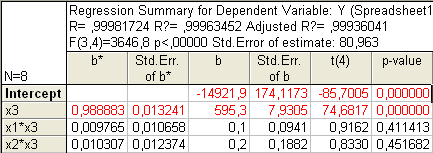
Рисунок 13. Множественная регрессия от х3,x1*x3, x2*x3
Параметрическая идентификация структурной модели зависимости на основе
метода наименьших квадратов (МНК) средствами Statistica.
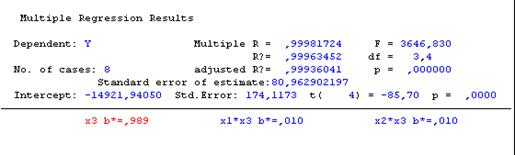
Так как p-значения свободного члена и х3
меньше уровня значимости α=0,05, следовательно, коэффициенты при этих
факторах не равны нулю и учитываются при расчете окончательного варианта
функционирования. Так как р- значения х13 и х23 больше уровня значимости α=0,05,
то коэффициент при этом
факторе равен нулю и статистически не учитывается.
Уравнение корреляции:
L=-14921,9+595,3Х3
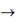 min
min
25≤Х3≤35
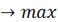
Оптимальное
решение Lmin=39,4
Оптимальные характеристики, рассчитанные аналитически, совпадают с
оптимальными характеристиками, полученными имитационным методом.
1.
Результат
работы программы в оптимальных условиях
) Характеристика
«Среднее время нахождения заявки в системе»

Рисунок 14. Гистограмма распределения времени нахождения заявки в системе
Построив гистограмму по результатам имитационного эксперимента с
использованием программных средств Statistica, выдвигаем гипотезу о том, что
время нахождения заявки в системе распределяется по нормальному закону.
Предполагаем, что эмпирический закон согласуется с теоретическим
распределением. Проверим эту гипотезу с помощью статистического критерия
согласия Пирсона при заданном уровне значимости α=0,05.
p=0,304 > α=0.05 =>гипотеза о согласии теоретического и экспериментального распределения не
опровергается при уровне значимости 0,05.
2)
Характеристика «Среднее время обработки запроса станком третьего типа»
Рисунок 15. Гистограмма распределения времени обработки заявки станком
3го типа
Выдвигается гипотеза экспоненциальном законе распределения. Проверим эту
гипотезу с помощью статистического критерия согласия Пирсона при заданном уровне
значимости α=0,05.=0,14577 > α=0.05 =>гипотеза о согласии
теоретического и экспериментального распределения не опровергается при уровне
значимости 0,05.
Выводы
В результате проделанной работы было исследовано поведение система
массового обслуживания, работающей в реальном времени. Проведя анализ выходных
данных, были обнаружены её узкие места, а также была проведена работа по
устранению некоторых недостатков. Для этого была проведена процедура по
оптимизации модели работы системы, исследованы ее статистические
характеристики.
Можно сказать, что данная модель в достаточной мере справляется с
выполнением. Но она могла бы функционировать лучше, если станки третьего типа
будут обслуживать заявки одновременно, начиная с первых двух поступивших.
2. Верещагин В.В. Учебное пособие по
использованию языка программирования GPSS/PC, 2009.
Приложение
А
Листинг программы имитации работы системы на языке моделирования GPSS с исходно заданными
входными переменными и параметрами системы.
generate 40,102,ttassign 1,2sum_obrtest l q$ss11,q$ss12,t1l
q$ss21,q$ss22,t2!l q$ss11,q$ss21,next21transfer ,next11test l q$ss21,q$ss22,t3l
q$ss12,q$ss21,next21,next12test l q$ss22,q$ss11,t4transfer ,next22test l
q$ss12,q$ss22,t5,next12queue
ss11stan11ss11(exponential(1,0,30))Pp1,FR$stan11stan11count11.08,to_nakop,reobr11queue
ss12stan12ss12(exponential(2,0,30))Pp2,FR$stan12stan12count12.08,to_nakop,reobr12queue
ss21stan21ss21(exponential(1,0,20))Pp3,FR$stan21stan21count21.1,to_nakop,reobr21queue
ss22stan22ss22(exponential(2,0,20))Pp4,FR$stan22stan22count22.1,to_nakop,reobr22loop
1,next11brak1loop 1,next12brak1loop 1,next21brak1loop 1,next22brak1_nakop queue
nakople q$nakop,3,met1seize
stan31nakop(normal(1,25,2))Pp5,FR$stan31stan31count31,end1transfer both
next31,next32seize
stan32nakop(normal(1,25,2))Pp6,FR$stan32stan32count32,end1depart
sum_obrobr13000
Приложение Б
Результаты работы программы имитации, соответствующей исходному варианту системы






