Множественный регрессионный анализ качества учебно-познавательной деятельности
УКРАИНСКАЯ
ИНЖЕНЕРНО-ПЕДАГОГИЧЕСКАЯ АКАДЕМИЯ
МИНИСТЕРСТВО
ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ
Кафедра
информатики и компьютерных технологий
Модульное
задание № 2.5
по
дисциплине: Основы научных исследований
на
тему: «Множественный регрессионный анализ качества учебно-познавательной
деятельности»
Харьков
2007 г
Задание 1. На основании данных табл. 1 требуется
построить модель зависимости семестровой успеваемости одного студента y от его
посещения лекционных занятий x1 (%), внимательности x2 (%) и стремления к
приобретению знаний x3 (%) в виде полинома
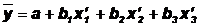
Вариант №.2: Значение из таблицы
уменьшается на (2/50), т.е. на 0,04.
Таблица 1.
Данные по 15 студентам ВУЗа
|
№
студента
|
Значение
 Значение Значение 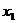 Значение Значение 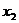 Значение Значение 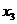
|
|
|
|
|
1
|
3,36
|
49,96
|
49,96
|
2,96
|
|
2
|
4,56
|
91,96
|
82,96
|
5,96
|
|
3
|
3,36
|
49,96
|
49,96
|
2,96
|
|
4
|
3,76
|
66,96
|
66,96
|
3,96
|
|
5
|
3,76
|
66,96
|
66,96
|
3,96
|
|
6
|
2,76
|
32,96
|
16,96
|
1,96
|
|
7
|
4,76
|
99,96
|
99,96
|
5,96
|
|
8
|
2,96
|
41,96
|
32,96
|
1,96
|
|
9
|
3,76
|
66,96
|
66,96
|
3,96
|
|
10
|
2,86
|
41,96
|
32,96
|
1,96
|
|
11
|
3,96
|
74,96
|
82,96
|
4,96
|
|
12
|
32,96
|
16,96
|
0,96
|
|
13
|
4,16
|
74,96
|
82,96
|
4,96
|
|
14
|
4,36
|
82,96
|
82,96
|
4,96
|
|
15
|
4,36
|
82,96
|
82,96
|
4,96
|
Ход работы:
Задача решается в два этапа:
1. Построение корреляционного поля
(диаграмм рассеяния пар переменных (,), (,) и (,)).
. Вывод результатов множественного
регрессионного анализа и их интерпретация.
Построение корреляционного поля
средствами пакета Statistica включает, в свою очередь, два основных этапа:
Создание таблицы исходных данных;
Построение двумерных диаграмм рассеяния.

Для построения таблицы исходных данных
необходимо:
. Выбрать в меню File команду New. Откроется
окно
Create new document
(Рис.1).
С
помощью счетчика выбрать нужное количество столбцов (Number of variables) и
строк (Number of cases), в нашем случае соответственно 4 и 15. Нажать OK.
. На экране появится окно для ввода исходных
данных (Рис. 2).

. Для обозначения столбцов, необходимо два раза
щелкнуть левой кнопкой мыши в поле названия столбца. Появится окно (Рис. 3).

В этом окне в строке Name вводится имя первого
столбца Успеваемость. В списке Display format выбрается формат данных General.
Нажать ОК. Аналогично даются имена второму, третьему и четвертому столбцам,
соответственно Посещение, Внимательность и Стремление.
. Ввод числовых данных в столбцы полученной
таблицы (Рис 4).

. Для построения диаграмм рассеяния выбрать в
меню Graphs команду Scatter plots. Откроется окно (Рис. 5).
Нажать кнопку  . Откроется
окно, в котором нужно выбрать необходимые
. Откроется
окно, в котором нужно выбрать необходимые  и
и  . В качестве выбирается
Посещение, в качестве -
Успеваемость. Получаем раскрытое окно (Рис. 6).
. В качестве выбирается
Посещение, в качестве -
Успеваемость. Получаем раскрытое окно (Рис. 6).
Нажать ОК. Окно Рис. 6 закроется. В окне Рис. 5
выбрать вкладку Advanced. В открывшемся окне (Рис. 7) из списка Fit выбрать
режим Off.
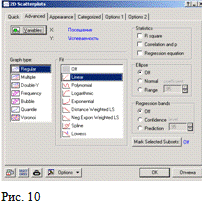
Нажать ОК. Получим первую диаграмму рассеяния
(Рис. 8).
Закрыть окно Рис. 8 без сохранения.
Затем необходимо построить диаграмму с линией
регрессии. Для этого в меню Graphs выбираем команду Scatterplots. Откроется
окно (Рис. 9).

Нажать кнопку  . Откроется
окно (Рис. 5). Нажать кнопку . В качестве нужно
выбрать Посещение, в качестве - Успеваемость. Получим раскрытое
окно (Рис. 6). Нажать ОК. Окно Рис. 6 закроется. В окне Рис. 5 выбрать вкладку
Advanced. В открывшемся окне (Рис. 10) из списка Fit выбрать режим Linear.
. Откроется
окно (Рис. 5). Нажать кнопку . В качестве нужно
выбрать Посещение, в качестве - Успеваемость. Получим раскрытое
окно (Рис. 6). Нажать ОК. Окно Рис. 6 закроется. В окне Рис. 5 выбрать вкладку
Advanced. В открывшемся окне (Рис. 10) из списка Fit выбрать режим Linear.
Нажать ОК. Получим вторую диаграмму рассеяния с
линией регрессии (Рис. 11).

Убедившись в присутствии линии регрессии,
закрыть окно Рис. 11 без сохранения.
Аналогично строятся остальные
диаграммы рассеяния. Для них в качестве нужно выбрать Успеваемость, в
качестве для третьей
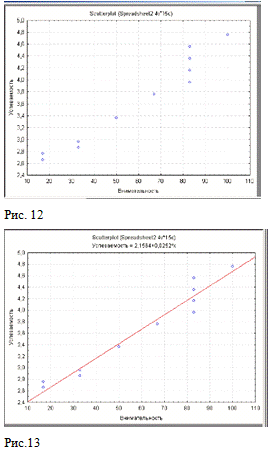
и четвертой - Внимательность (для пятой и шестой - Стремление). Третья
диаграмма рассеяния представлена на Рис. 12, четвертая - на Рис. 13, пятая - на
Рис. 14, шестая - на Рис. 15.


- Вывод результатов множественного
регрессионного анализа и их интерпретация
Выбрать в
меню
Statistics команду Multiple
Regression. Откроется окно множественного регрессионного
анализа (Рис. 16). Нажать кнопку .
В открывшемся окне выбрать показатель и факторы соответственно из первого и
второго списков (Рис. 17).

Нажать ОК в окнах Рис. 17 и Рис. 16. Окно примет
такой вид (Рис. 18).
Объяснения полученных результатов:- имя
показателя. В нашем случае - Успеваемость.
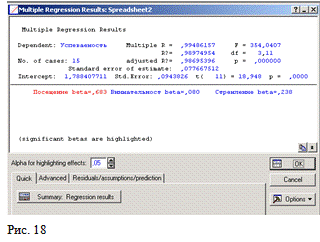
No. of cases - число случаев, по которым
построена регрессия. В примере число равно 15.R - коэффициент множественной
корреляции (эта статистика полезна в множественной регрессии, когда нужно
описать зависимости между переменными).? - квадрат коэффициента множественной
корреляции, обычно называемый коэффициентом детерминации. Он показывает долю
общего разброса (относительно выборочного среднего зависимых переменных),
которая объясняется построенной регрессией.R? - скорректированный коэффициент
детерминации.
Standard error of estimate - стандартная
ошибка
оценки.
Является
мерой рассеяния наблюдаемых значений относительно регрессионной прямой.- оценка
свободного члена регрессии. Значение коэффициента b0 в уравнении регрессии..
Error - стандартная ошибка оценки свободного члена. Стандартная ошибка
коэффициента b0 в уравнении регрессии.(df) and p-value - значение t-критерия и
уровня p. t-критерий используется для проверки гипотезы о равенстве нулю
свободного члена регрессии.- значение F-критерия (критерия Фишера).- число
степеней свободы F-критерия.- уровень значимости.
В информационной части прежде всего смотрим на
значение коэффициента детерминации. В нашем задании R? = 0,9897. Это значит,
что построенная регрессия объясняет 98,97 % разброса значений Успеваемости
относительно среднего. Это хороший результат.
Далее смотрим на значение F-критерия и уровень
его значимости p.критерий используется для проверки значимости регрессии. В
данном задании большое значение F-критерия = 354,0407 и даваемый в окне уровень
значимости p=0,000000 показывают, что построенная регрессия высоко значима.
Нажимаем на кнопку  -
краткие результаты регрессии. Появляется следующая электронная таблица с
результатами анализа (Рис. 19).
-
краткие результаты регрессии. Появляется следующая электронная таблица с
результатами анализа (Рис. 19).

В третьем столбце таблицы видно оценки
неизвестных параметров модели:
Итак, искомая модель зависимости показателя от
факторов имеет вид:
Успеваемость = 1, 788408 + 0,021789 * Посещение
+
+ 0,002052* Внимательность + 0,103059 *
Стремление
Эта модель интерпретируется
следующим образом: если при прочих равных условиях (= ‘ceteris paribus’)
переменная (посещение)
увеличивается (уменьшается) на единицу, то согласно этой оценке переменная (успеваемость)
увеличивается (уменьшается) на 0,021789 единиц. В нашем случае это значит, что
увеличение (уменьшение) посещения на 1 % приведет, при прочих равных условиях,
к увеличению (уменьшению) успеваемости на 0,021789 балла.
Задание 2. На основании данных табл.
2 требуется построить модель зависимости выполнения домашних работ студентом 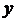 (%) от
проведенного в библиотеке количества часов (часы), качества дидактических
материалов (0 - 50
баллов) и стремления достичь высоких результатов в учебе (%) в виде
полинома
(%) от
проведенного в библиотеке количества часов (часы), качества дидактических
материалов (0 - 50
баллов) и стремления достичь высоких результатов в учебе (%) в виде
полинома
Таблица 2.
Данные по 15 студентам ВУЗа
|
№
студента
|
Значение
Значение Значение Значение
|
|
|
|
|
1
|
75
|
12
|
15
|
80
|
|
2
|
80
|
19
|
23
|
56
|
|
3
|
79
|
17
|
40
|
85
|
|
4
|
73
|
14
|
29
|
69
|
|
5
|
87
|
18
|
34
|
78
|
|
6
|
86
|
18
|
35
|
72
|
|
7
|
90
|
12
|
12
|
89
|
|
8
|
97
|
16
|
49
|
85
|
|
9
|
61
|
11
|
35
|
61
|
|
10
|
97
|
17
|
18
|
89
|
|
11
|
59
|
15
|
21
|
50
|
|
12
|
96
|
17
|
50
|
89
|
80
|
12
|
43
|
85
|
|
14
|
55
|
11
|
27
|
40
|
|
15
|
86
|
13
|
33
|
74
|
множественный
регрессионный диаграмма рассеяние
Ход работы:
Строим корреляционное поле средствами пакета
Statistica.
Аналогично заданию 1 выполняем последовательно
те же действия, что и на Рис. 1-3.
Заполняем заголовки столбцов и числовые данные в
соответствии с заданием (Рис. 20).
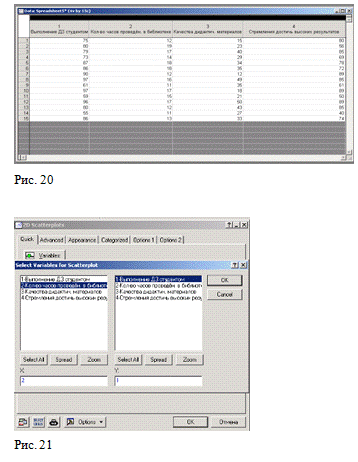
- После строим диаграмму рассеяния.
В качестве выбирается
Кол-во часов, проведённое в библиотеке, в качестве - Выполнение
ДЗ студентом. Получаем раскрытое окно (Рис. 21).
В окне 2D Scatterplots выбираем вкладку
Advanced. В открывшемся окне (Рис. 7) из списка Fit выбрать режим Off. Нажать
ОК. Получим первую диаграмму рассеяния (Рис. 22).

Закрываем окно Рис. 22 без сохранения и затем
переходим к построению диаграммы с линией регрессии (Рис. 23).

Аналогично строятся остальные
диаграммы рассеяния. Для них в качестве нужно выбрать Выполнение ДЗ
студентом, в качестве для третьей
и четвертой - Качество дидактических материалов (для пятой и шестой -
Стремление достичь высоких результатов). Третья диаграмма рассеяния
представлена на Рис. 24, четвертая - на Рис. 25, пятая - на Рис. 26, шестая -
на Рис. 27.

Вывод результатов множественного
регрессионного анализа и их интерпретация
Выбрать в меню
Statistics команду
Multiple Regression. Откроется
окно множественного регрессионного анализа (Рис. 28). Нажать кнопку . В
открывшемся окне выбрать показатель и факторы соответственно из первого и
второго списков (Рис. 29).

Нажать ОК в окнах Рис. 29 и Рис. 28.
Окно примет такой вид (Рис. 30).
Объяснения полученных результатов:
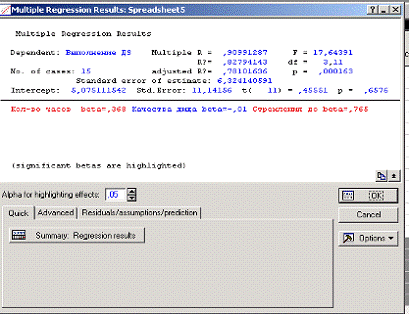
Рис. 30
Dependent - имя показателя. В нашем
случае - Выполнение ДЗ ст.. of cases - число случаев, по которым построена
регрессия. В примере число равно 15.R - коэффициент множественной корреляции
(эта статистика полезна в множественной регрессии, когда нужно описать
зависимости между переменными).? - квадрат коэффициента множественной корреляции,
обычно называемый коэффициентом детерминации. Он показывает долю общего
разброса (относительно выборочного среднего зависимых переменных), которая
объясняется построенной регрессией.R? - скорректированный коэффициент
детерминации.
Standard
error of estimate - стандартная ошибка оценки.
Является
мерой рассеяния наблюдаемых значений относительно регрессионной прямой.- оценка
свободного члена регрессии. Значение коэффициента b0 в уравнении регрессии..
Error - стандартная ошибка оценки свободного члена. Стандартная ошибка
коэффициента b0 в уравнении регрессии.(df) and p-value - значение t-критерия и
уровня p. t-критерий используется для проверки гипотезы о равенстве нулю
свободного члена регрессии.- значение F-критерия (критерия Фишера).- число
степеней свободы F-критерия.- уровень значимости.
В информационной части, прежде
всего, смотрим на значение коэффициента детерминации. В нашем задании R? =
0,8279. Это значит, что построенная регрессия объясняет 82,79 % разброса
значений Выполнения ДЗ студентом относительно среднего. Это хороший результат.
Далее смотрим на значение F-критерия
и уровень его значимости p.критерий используется для проверки значимости
регрессии. В данном задании небольшое значение F-критерия = 17,6439 и даваемый
в окне уровень значимости p=0,000163 показывают, что построенная регрессия
средне значима.
Нажимаем на кнопку - краткие
результаты регрессии. Появляется следующая электронная таблица с результатами
анализа (Рис. 31).
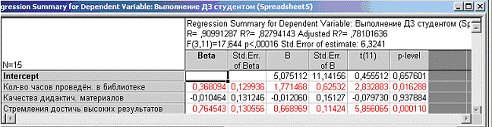
(Рис. 31).
В третьем столбце таблицы видно
оценки неизвестных параметров модели:= 5,075112;= 1,771468;= - 0,012060;=
0,668969.
Итак, искомая модель зависимости
показателя от факторов имеет вид:
Выполнение ДЗ студентом = 5,075112 +
1,771468 * Количество часов проведённых в библиотеке - 0,012060 * Качество
дидактических материалов + 0,668969 * Стремление достичь высоких результатов
Эта модель интерпретируется
следующим образом: если при прочих равных условиях (= ‘ceteris paribus’)
переменная (количество
часов проведённых в библиотеке) увеличивается (уменьшается) на единицу, то
согласно этой оценке переменная (выполнение ДЗ студентом)
увеличивается (уменьшается) на 1,771468 единиц. В нашем случае это значит, что
увеличение (уменьшение) количество часов проведённых в библиотеке на 1 %
приведет, при прочих равных условиях, к увеличению (уменьшению) выполнению ДЗ
студентом на 1,771468 балла.