Семантические сети
Оглавление
Введение
Представление знаний семантическими сетями
Классификация семантических сетей
Концептуальные графы
Практическое применение семантических сетей
Достоинства и недостатки семантических сетей
Заключение
Список литературы
Введение
В основе исследований в области искусственного интеллекта лежит подход,
связанный со знаниями. Опора на знания - базовая парадигма искусственного
интеллекта. Как и многие фундаментальные научные категории (например, алгоритм,
интеллект, деятельность и т. д.), понятие «знание» относится к интуитивно
определяемым. В БСЭ дается следующее его толкование: «Знание - проверенный
практикой результат познания действительности, верное ее отражение в сознании
человека. Знания бывают житейскими, донаучными, художественными, научными
(теоретическими и эмпирическими)». Знания о некоторой предметной области
представляют собой совокупность сведений об объектах этой предметной области,
их существенных свойствах и связывающих их отношениях, процессах, протекающих в
данной предметной области, а также методах анализа, возникающих в ней ситуаций
и способах разрешения, ассоциируемых с ними проблем.
В «Словаре русского языка» Ожегова знание определяется как «постижение
действительности сознанием» и «совокупность сведений, познаний в какой-нибудь
области». Интерпретация знаний как «совокупности сведений, образующих целостное
описание, соответствующее некоторому уровню осведомленности об описываемом
вопросе, предмете, проблеме и т. д.» дана в толковом словаре искусственного
интеллекта. Семантические сети же являются моделью представления знаний.
Представление
знаний семантическими сетями
Семантика - раздел языкознания, изучающий
значение единиц языка, прежде всего его слов и словосочетаний. В более общем
смысле, семантика определяет смысл знаков (образов, обозначений) и их
сочетаний.
Семантическая сеть (смысловая сеть) - модель предметной
области, представленная в виде графа, вершинами которого являются понятия, а
дуги (ребра) - отношения между ними.
В качестве понятий обычно выступают абстрактные
или конкретные объекты (огурец, машина, любовь, Маша). В качестве отношений
наиболее часто используются следующие (смысловая классификация):
. таксономические («класс - подкласс -
экземпляр», «множество - подмножество - элемент» и т.п.). Данный тип отношения
называют также отношением AKO (англ. A Kind Of - является разновидностью), IS A
(является, это есть) или гипонимии (гипероним - общая сущность; гипоним -
частная сущность);
. структурные («часть - целое»). Данный тип
отношения называют также отношением Part of (является частью), Has part
(состоит из, включает в себя), агрегации (лат. aggregatio - присоединение),
композиции (лат. compositio - составление, связывание, сложение, соединение)
или меронимии (холоним - сущность, включающая в себя другие; мероним -
сущность, являющаяся частью другой);
. родовые («предок» - «потомок»);
. производственные («начальник» -
«подчиненный»);
. функциональные (определяемые обычно глаголами
«производит», «влияет» и т.п.);
. количественные (больше, меньше, равно и
т.п.);
. пространственные (далеко от, близко от, за,
под, над и т.п.);
. временные (раньше, позже, в течение и т.п.);
. атрибутивные (иметь свойство, иметь
значение);
. логические (И, ИЛИ, НЕ);
. казуальные (причинно-следственные).
Отношения можно также классифицировать по степени
участия (арности) понятий в отношениях:
. унарное (рекурсивное) - отношение связывает
понятие само с собой;
. бинарное - отношение связывает два понятия;
. N-арное - отношение, связывающее более двух
понятий.
Приведем пример двух простых семантических сетей
(рисунок 1). Один из них (слева) описывает понятие «помидор», а другой (справа)
описывает факт «Маша укрепила стул клеем».
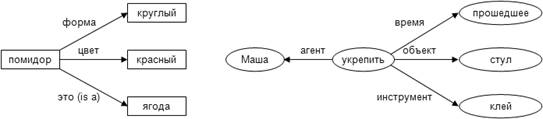
Рисунок
1- Примеры семантических сетей
В разных вариациях семантических сетей для отображения
понятий используются различные геометрические примитивы: прямоугольники, овалы,
прямоугольники со скругленными углами и т.п.
Проблема поиска решения в семантической сети сводится
к задаче поиска фрагмента сети, соответствующего поставленному запросу.
Например, вопрос «Какого цвета помидор?» можно графически представить в виде
подсети (рисунок 2).

Рисунок
2 - Представление вопроса в виде подсети
Наложение подсети вопроса на сеть, описывающую
предметную область, дает ответ - «красный».
Семантические сети широко используются в экспертных
системах в качестве языка представления знаний (например, в экспертной системе
PROSPECTOR), в системах распознавания речи и понимания естественного языка. Непосредственное
отношение к сетевым моделям имеют исследования по реляционным, сетевым и
иерархическим БД.
Начиная с конца 50-ых годов были создано и применены
на практике десятки вариантов семантических сетей. Несмотря на то, что
терминология и их структура различаются, существуют сходства, присущие
практически всем семантическим сетям:
1. узлы семантических сетей представляют собой концепты
предметов, событий, состояний;
2. различные узлы одного концепта относятся к различным
значениям, если они не помечено, что они относятся к одному концепту;
3. дуги семантических сетей создают отношения между
узлами-концептами (пометки над дугами указывают на тип отношения);
4. некоторые отношения между концептами представляют
собой лингвистические падежи, такие как агент, объект, реципиент и инструмент
(другие означают временные, пространственные, логические отношения и отношения
между отдельными предложениями;
5. концепты организованы по уровням в соответствии со
степенью обобщенности так как, например, сущность, живое существо, животное,
плотоядное.
Однако существуют и различия: понятие значения с точки зрения философии;
методы представления кванторов общности и существования и логических
операторов; способы манипулирования сетями и правила вывода, терминология. Все
это варьируется от автора к автору. Несмотря не некоторые различия, сети удобны
для чтения и обработки компьютером, а также достаточно мощны, чтобы представить
семантику естественного языка.
Классификация
семантических сетей
Для всех семантических сетей справедливо разделение по арности и
количеству типов отношений.
По количеству типов отношений, сети могут быть однородными и
неоднородными. Однородные сети обладают только одним типом отношений (стрелок),
например, таковой является классификация биологических видов. В неоднородных
сетях количество типов отношений больше двух. Классические иллюстрации данной
модели представления знаний представляют именно такие сети. Неоднородные сети
представляют больший интерес для практических целей, но и большую сложность для
исследования.
По арности, типичными являются сети с бинарными отношениями (связывающими
ровно два понятия). Бинарные отношения очень просты и удобно изображаются на
графе в виде стрелки между двух концептов. Кроме того, они играют
исключительную роль в математике. На практике, однако, могут понадобиться
отношения, связывающие более двух объектов - N-арные. При этом возникает
сложность - как изобразить подобную связь на графе, чтобы не запутаться.
Концептуальные графы снимают это затруднение, представляя каждое отношение в
виде отдельного узла. Помимо концептуальных графов существуют и другие
модификации семантических сетей, это является ещё одной основой для
классификации (по реализации) [1].
Концептуальные
графы
Дальнейшим развитием графовых структур, моделирующих
семантику естественного языка, являются концептуальные графы, предложенные
Джоном Сова (1984г.).
Концептуальный граф - это двудольный ориентированный
граф, состоящий из вершин двух типов: понятий (англ. concept) и концептуальных
отношений (англ. conceptual relation). Двудольный граф - это граф,
множество вершин которого можно разбить на две части таким образом, что каждое
ребро графа соединяет какую-то вершину из одной части с какой-то вершиной
другой части, то есть не существует ребра, соединяющего две вершины из одной и
той же части (рисунок 3).

Рисунок
3 - Двудольный граф
Понятия в концептуальных графах отображаются
прямоугольниками, отношения между ними - эллипсами [2]. В отличие от
семантических сетей отношение между понятиями отображаются не именованной дугой
графа, а вершиной соответствующего типа, которая связывает два понятия дугами
без метки. Рассмотренный выше пример «Маша укрепила стул клеем» представлен на
рисунке 4.

Рисунок
4 - Пример концептуального графа
Авторы первых семантических сетей не уделяли должного
внимания к четкому семантическому разделению отношений вида «класс - подкласс»
(«множество» - «подможество») и «класс» - «экземпляр» («множество» - «элемент»).
Например, отношения, характеризующие свойства и поведение класса
(«млекопитающие»), могут отличаться от отношений подкласса («собака»), также
как отношения подкласса («собака») от отношений конкретного экземпляра
(«Тузик»). Графического или символьного выделения таксономии (иерархии) понятий
в семантических графах не предусмотрено. В концептуальных графах внутри
вершины, обозначающей понятие, можно указывать имена его типа и экземпляра
(разновидности типа). Например, «персона: Маша», «млекопитающее: собака» или
«собака: Тузик».
При описании конкретных, но неименованных (анонимных)
экземпляров, используется маркер «#». Например, «персона: #1234» или «собака:
#4321».
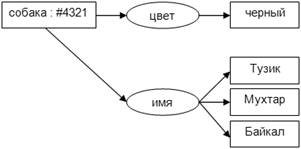
Использование анонимных экземпляров позволяет
упростить описание и представление предметной области (базы знаний), как набора
концептуальных графов. В частности, факт, что три собаки «Тузик», «Мухтар» и
«Байкал» черного цвета можно описать вместо одного графа двумя (рисунок 5).
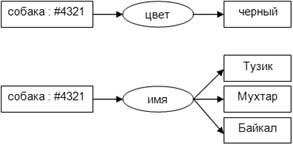
Рисунок
5 - Пример использования анонимных экземпляров
Вместо обращения к экземпляру по имени можно
использовать маркер «*», обозначающий любой экземпляр типа. Имена понятий
«собака» и «собака: *» являются эквивалентными.
Дополнительно к обобщающему маркеру «*» допускается
использование переменных для более упрощенного и наглядного отображения графов.
В частности, для минимизации пересечений и поворотов стрелок. Например, факт
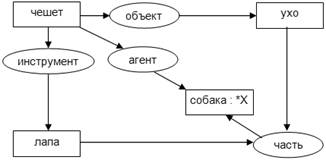
«Собака чешет лапой ухо» представлен на рисунке 6.
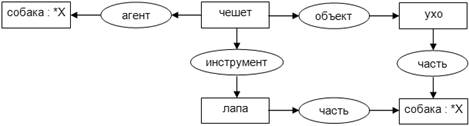
Рисунок
6 - Пример использования переменной
Как отмечено ранее, база знаний представляет собой
набор концептуальных графов. Каждый отдельный граф представляет собой один факт
(высказывание, правило) из предметной области, описываемый через ассоциативные
отношения между понятиями. Для представления второго базового механизма
структурирования знаний - обобщения понятий - в теории концептуальных графов
используются иерархии типов. Отдельная иерархия представляется в виде решетки,
описывающей таксономические отношения (отношения наследования) между понятиями,
включая множественное наследование. Для представления иерархии типов в виде
решетки в нее включается два специальных типа:
. универсальный тип (англ. universal type),
являющийся супертипом для всех типов. Обозначается символом «┬»;
. абсурдный тип (англ. absurd type), являющийся
подтипом для всех типов. Обозначается символом «┴».
На рисунке 7 приведен пример иерархии типов.

Рисунок
7 - Пример иерархии типов геометрической фигуры
Теория концептуальных графов предусматривает четыре
вида операций, позволяющие создавать новые графы на основе существующих. К ним
относятся:
– копирование - создание точной копии какого -
либо графа;
– объединение
двух графов в один, если они имеют семантически общие вершины-понятия. Для
графов, отображенных на рис <https://sites.google.com/site/anisimovkhv/learning/knowledge/lecture/tema5>унке
8, результат объединения выглядит следующим образом:
Рисунок
8 - Пример объединения двух графов
– ограничение
- замена вершины-понятия графа другой вершиной-понятием, представляющими его
специализацию, или замена имени типа на имя подтипа (экземпляра). Пример
применения операции для графов, отображенных на рис
<https://sites.google.com/site/anisimovkhv/learning/knowledge/lecture/tema5>унке
9:

Рисунок
9 - Пример применения операции «ограничение»
– упрощение - исключение дублирующих понятий или
отношений. Дублирование часто возникает в результате операции объединения.
Пример применения операции для графа, отображенного на рисунке 10:
Рисунок
10 - Пример применения операции «упрощение»
В дополнение к возможности определения отношений между
понятиями предметной области, выраженными в одном высказывании, с помощью
концептуальных графов можно выражать отношения между высказываниями. Например,
предложение: «Вася предполагает, что Маша любит мороженное». Здесь
«предполагает» является отношением между субъектом «Вася» и высказыванием «Маша
любит мороженное». Все предложение целиком является высказыванием о высказывании
(метавысказыванием).
В формализме концептуальных графов выделяется особый
класс понятий - утверждение (англ. proposition). Понятие «утверждение» включает
в себя один или несколько концептуальных графов, что и позволяет определять
метавысказывания. Визуально «утверждение» выражается в виде прямоугольника,
внутри которого располагаются другие концептуальные графы (рисунок 11).
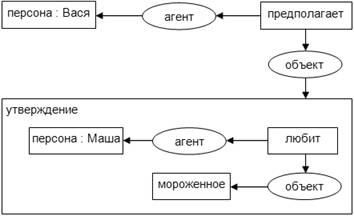
Рисунок
11 - Пример метавысказывания
Помимо отображения высказываний в виде графов,
наиболее наглядной и доступной для понимания форме, они могут быть выражены в
т.н. линейной форме. При этом понятия заключаются в квадратные скобки, а
отношения - в круглые. Например, граф, отображенный на рисунке 11, в линейной
форме выглядит следующим образом:
[персона: Вася] <- (агент) <- [предполагает]
-> (объект) ->
[[персона: Маша] <- (агент) <- [любит] ->
(объект) -> [мороженное]].
При наличии более, чем двух дуг, соединяющих понятие
или отношение с другими, они перечисляются через «-». Например, для графа на
рисунке 4 линейная форма:
[Маша] <- (агент) <- [укрепить] -
> (время) -> [прошедшее]
> (объект) -> [стул]
> (инструмент) -> [клей].
Аналогичный
подход используется, если в графе имеются контуры. Например, для графа на рис
<https://sites.google.com/site/anisimovkhv/learning/knowledge/lecture/tema5>унке
6 линейная форма:
[собака:
*X] -
<-
(агент) <- [чешет] -
>
(объект) -> [ухо]
>
(инструмент) -> [лапа]
<-
(часть) -
<-
[ухо]
<-
[лапа].
Существуют
и другие способы текстово-символьного описания концептуальных графов. В
частности, в международном стандарте «ISO/IEC IS 24707:2007. Information
technology - Common Logic (CL): a framework for a family of logicbased
languages» («Информационная технология - Общие положения: Основы семейства
логически-ориентированных языков») дается описание языка CGIF (Conceptual Graph
Interchange Format, формат обмена концептуальными графами).
Практическое
применение семантических сетей
семантический сеть концептуальный граф
Существующая сеть WWW представляет собой гигантское количество информации
в формате, приспособленном для человеческого восприятия. Пользователь может
перескакивать с одной ссылки на другую, давать запросы различным поисковым
системам или же находить сайты, просто вводя их адреса. И хотя веб-страницы
весьма привлекательны для человека, для компьютерной программы же,
обрабатывающей их содержимое, они не более чем строчки из случайных символов.
Компьютерная программа не способна, загрузив произвольный документ, будь
то веб-страница или какой-то файл, понять его содержание. Она может сделать
некие догадки, основываясь на HTML- или XML-тэгах, но всё равно требуется
человек-программист, который должен разобраться в них и понять смысл, или
семантику, каждого из тэгов. С точки зрения компьютера, существующая Сеть WWW -
это полная неразбериха. К счастью, выход есть: это семантическая сеть.
Как представлял себе Тим Бернерс-Ли, семантическая сеть должна стать
неким дополнением сети WWW, состоящим из понятной машинам информации.
Реализация этой новой Сети станет возможна благодаря ряду новых стандартов,
разрабатываемых WWW-Консорциумом (W3C). Когда семантическая сеть наберёт
обороты, значительное число информационных ресурсов будут пригодными для
использования как человеком, так и программными агентами. Другими словами, программные
агенты наконец-то научаться читать Интернет.
Подобно тому, как семантическая сеть является расширением обычной сети
WWW, семантические веб-сервисы (SW-сервисы или SWS) расширяют понятие обычных
веб-сервисов.
В настоящее время создаются программы, способные искать нужные им порты и
регистры, такие как UDDI-сервер, который является перечнем доступных
веб-сервисов. И хотя программа может найти некий веб-сервис без помощи
человека, она не в состоянии понять, как именно им пользоваться и даже просто
для чего он предназначен. Язык описания веб-сервисов (WSDL) даёт нам инструмент
для описания того, каким образом взаимодействовать с тем или иным веб-сервисом,
тогда как семантическая разметка снабжает нас информацией о том, что и как
делает данный сервис.
Чтобы SW-сервисы стали реальностью, язык разметки должен быть достаточно
информативным с тем, чтобы компьютер был способен самостоятельно понимать смысл
записанных на нём выражений. Ниже приводятся требования, которым должен
отвечать такой язык:
– необходимость поиска сервисов (обнаружение - discovery);
– программы должны иметь возможность самостоятельно находить (или
обнаруживать) требуемые им веб-сервисы. Ни WSDL, ни UDDI не позволяют программе
понять, для чего именно с точки зрения клиента служит тот или иной веб-сервис.
Семантический же веб-сервис сможет предъявить описание своих свойств и
возможностей с тем, чтобы программы могли сами распознавать его предназначение;
– необходимость запускать сервисы (запуск - invocation);
– программы должны уметь самостоятельно узнавать, каким образом
запускать и исполнять данный сервис. Например, если выполнение сервиса
представляет собой многошаговую процедуру, то программе требуется знать, как ей
следует взаимодействовать с сервисом, чтобы требуемая последовательность шагов
осуществилась. SW-сервис предъявляет исчерпывающий перечень того, что должен
уметь агент для запуска и выполнения данного сервиса. Сюда же следует отнести
описание входных и выходных данных этого сервиса;
– необходимость использования вместе нескольких сервисов
(композиция);
– программы должны уметь отбирать нужные им веб-сервисы и
комбинировать их для достижения своих целей. Сервисам необходимо будет тесно
взаимодействовать друг с другом, так чтобы получающийся в результате их
комбинирования результат был приемлемым решением поставленной задачи. Таким
образом, программные агенты смогут строить совершенно новые сервисы, комбинируя
сервисы, уже имеющиеся в Сети.
– необходимость узнавать, что происходит после запуска сервиса
(мониторинг);
– программный агент должен уметь определять свойства данного
сервиса и следить за его выполнением. Некоторым сервисам может требоваться
определённое время для исполнения работы, и агенты должны быть в состоянии
следить за ходом выполнения сервиса.
Снабдив агентов возможностями самостоятельно обнаруживать, запускать,
комбинировать и следить за исполнением сервисов без участия человека, можно
будет создать новые достаточно функциональные приложения. Представим себе некую
Интегрированную Среду Разработки (IDE - Integrated Developer Environment),
которая не только содержит перечень доступных сервисов, но также предлагает
подходящие их комбинации, удовлетворяющие требованиям, сформулированным нами на
языке высокого уровня. Вместо того, чтобы пролистывать длинные списки сервисов в
поисках того, входные параметры которого соответствуют нашему приложению, можно
просто обращаеться к среде IDE, которая предложит сервисы, в точности,
подходящие для наших целей.
Можно будет также создать неких персональных агентов, чтобы употребить
всю мощь Сети на пользу конечному пользователю. Например, такой персональный
агент вполне мог бы провести подготовку к празднованию дня рождения, получив
лишь минимальные входные данные от пользователя. Подобный агент мог бы
скомбинировать сервисы по заказу товаров, их покупке и доставке самостоятельно,
преследуя поставленную перед ним пользователем на языке высокого уровня цель -
подготовку праздника. Когда такие вещи будут делаться автоматически,
пользователь сможет экономить как время, так и деньги [3].
Превращению Интернета в семантическую сеть способствует и Военное научное
агентство DARPA. Оно разрабатывает новый язык программирования DAML (DARPA
Agent Markup Language), основанный на XML. Он предназначен для детального
описания смысла хранимой на Web-странице информации. Рабочая версия DAML
появится летом, и DARPA надеется, что консорциум утвердит W3C в качестве
стандарта. Предполагается, что DAML послужит существенным стимулом для
превращения Интернета из "свалки" информации в семантическую Сеть.позволит
Web-агентам и поисковым системам комбинировать смысловое содержание нескольких
страниц (например, учитывать в рубрикаторе все иерархические разделы,
относящиеся к конкретному сайту), что позволит выполнять поиск предельно точно.
Другое преимущество DAML - возможность унификации жаргонных выражений,
применяемых в разных областях промышленности и относящихся к одному и тому же
технологическому элементу.
Еще одним важным проектом в сфере семантического веба является
DBpedia.org. Авторы этого проекта формализовали (привели к одной форме) данные
Википедии, а доступ к базе данных открыли. Данные эти связаны, в результате
можно делать запросы и получать очень интересные результаты. Так, в конце
сентября был запущен фасетный поиск на данных, которые DBPedia извлекла из
Википедии. Проект делался совместно с немецкой поисковой компанией Neofine и
находится здесь: http://dbpedia.neofonie.de/browse/.
Таким образом, теперь для ответа на вопросы типа «Какие ученые родились в
России в период с 1900 по 1910 год» достаточно использовать соответствующие
фильтры в интерфейсе поисковика от DBPedia и Neofine:
http://dbpedia.neofonie.de/browse/rdf-type:Scientist/personBirthDate-year~:1900~1910/personBirthPlace:Russian%20Empire/.опубликовал
свою версию топ Semantic Web продуктов за 2008 год [4]:
. Yahoo! SearchMonkey
Продукт от Яху позволяет получать структурированный контент прямо на SERP
(Search Engine Result Page). Работает это следующим образом:
– Cоздатель сайта добавляет RDF разметку в XHTML или использует
микроформаты, задавая таким образом семантику на странице. Также можно
выгружать семантическую информацию роботу Яху в виде xml feed.
– Любой разработчик, в том числе и создатель сайта, может написать
небольшое приложение на PHP с помощью SearchMonkey developer tool, которое имеет
доступ ко всем полям из индекса Яху (можно добавлять свои провайдеры данных) и
на выходе получить сниппет (аннотацию к поисковому результату) в нужном виде.
После этого этот сниппет будет показываться на результатах поиска персонально
для него
– Любое разработанное приложение можно расшарить другим
пользователям, а также добавить в Yahoo! Search Gallery, после чего модераторы
могут включить его по умолчанию для всех пользователей.
В общем, персонализация (которой, правда, мало кто будет пользоваться,
наверное) и семантизация в одном продукте, причем от одного из гигантов
интернет-поиска. Однозначно можно согласиться с ReadWriteWeb, поставившем его
на первое место среди Semantic Web продуктов в этом году.
. Powerset
Один из двух самых известных семантических поисковиков (2-й - Hakia -
тоже попал в наш топ, речь о нем пойдет чуть ниже). В этом году в июле
состоялась сделка, в результате которой Powerset был куплен Майкрософтом.
Следов сильной интеграции поисковика и продуктов от Майкрософт пока не видно,
разве что на странице результатов поиска появилась кнопка «Try this search on
Live Search».позиционирует себя как поисковую систему, умеющую извлекать факты.
Существенным ограничением является то, что пока он умеет работать только с
двумя источниками, причем очень качественными: википедией и социальной базой
знаний freebase.
В результатах иногда случаются накладки, например, по запросу «Vladimir
Putin» (http://www.powerset.com/explore/go/vladimir-putin) мы видим, что
Людмилу Путину на freebase называют «Lyudmila Putin», хотя на wikipedia все
корректно («Lyudmila Putinа»).
. Open Calaisв конце 2007 года купила ClearForest, которая занималась
разработкой Open Calais. В этом году они выпустили Open Calais API, позволяющее
через web-сервис извлекать из переданного текста людей, компании, события и
места. Поддерживается только английский язык:( Пример использования API есть в
книге Practical Artificial Intelligence Programming With Java.
В настоящий момент на сервисе уже зарегистрировано более 6000
разработчиков и выполняется больше 1 миллиона транзакций в день.
. Dapper MashupAds
Сервис для создания семантической рекламы от Dapper реализует подход
сверху вниз, при котором сам пользователь указывает какие поля что означают на
его сайте и создает рекламу, в отличие от традиционных алгоритмов контекстной
рекламы, которые автоматически по содержимому страницу принимают решение о том,
какие объявления размещать на этой ней.
Благодаря технологии можно создать такую рекламу, которая, например, по
рецепту блюда предложит купить все его ингредиенты в одном месте.
Реализовано все на базе потрясающего воображение сервиса для создания
mashup’ов dapper.net. Вы просто указываете шаблоны страниц с интересующим вас
содержимым, отмечаете интересующие вас поля и создаете из этого компонент в
одном из многочисленных поддерживаемых форматов (flash widget, rss, xml, html).
За 5 минут можно создать сервис, который отдает текущее содержимое тизера на
морде Яндекса: http://www.dapper.net/services/YandexTeaser.
Достоинства
и недостатки семантических сетей
Достоинства семантических сетей:
– универсальность, достигаемая за счет выбора
соответствующего набора отношений. В принципе с помощью семантической сети
можно описать сколь угодно сложную ситуацию, факт или предметную область;
– близость структуры сети, представляющей
систему знаний, семантической структуре фраз на естественном языке;
– соответствие современным представлениям об
организации долговременной памяти человека.
Недостатки семантических сетей:
– сетевая модель не дает (точнее, не содержит)
ясного представления о структуре предметной области, поэтому формирование и
модификация такой модели затруднительны;
– сетевые модели представляют собой пассивные
структуры, для обработки которых необходим специальный аппарат формального
вывода;
– проблема поиска решения в семантической сети
сводится к задаче поиска фрагмента сети, соответствующего подсети, отражающей
поставленный запрос. Это, в свою очередь, обуславливает сложность поиска
решения в семантических сетях;
– представление, использование и модификация
знаний при описании систем реального уровня сложности оказывается трудоемкой
процедурой, особенно при наличии множественных отношений между ее понятиями
[4].
Заключение
Семантические сети могут быть записаны практически на любом языке
программирования на любой машине. Самые популярные в этом отношении языки LISP
и PROLOG. Однако многие версии были созданы и на FORTRANе, PASCALе, C и других
языках программирования. Для хранения всех узлов и дуг необходима большая
память, хотя первые системы были выполнены в 60-х годах на машинах, которые
были гораздо меньше и медленнее современных компьютеров.
Один из самых распространенных языков, разработанных для записи
естественного языка в виде сетей, - это PLNLP (Programming Language for Natural
Language Processing). PLNLP работает с двумя видами правил:
. с помощью правил декодирования производится синтаксический
анализ линейной языковой цепочки и строится сеть;
. с помощью правил кодирования сканируется сеть порождается
языковая цепочка или другая трансформированная сеть.
Помимо специальных языков для семантических сетей было также разработано
специальное аппаратное обеспечение. На обычных компьютерах могут быть успешно
выполнены операции с языками синтаксического анализа и операции сканирования
сетей. Однако для больших баз знаний нахождение нужных правил или доступ к
предзнаниям может потребоваться очень много времени. Чтобы позволить различным
процессам поисках проходить одновременно Фальман разработал систему NETL,
которая представляет собой семантическую сеть, которая может использоваться с
параллельным аппаратным обеспечением. Таким образом он хотел создать модель
человеческого мозга, в котором сигналы могут двигаться по различным каналам
одновременно. Другие ученые разработали параллельное программное обеспечение
для поиска наиболее вероятной интерпретации двусмысленных фраз естественного
языка.
Список
литературы
1. Башмаков А.И., Башмаков И.А. Интеллектуальные
информационные технологии: Учеб. пособие. - М.: Изд-во МГТУ им. Н.Э. Баумана,
2005. - 304 с : ил. - (Информатика в техническом университете).
2. Википедия - [Электронный ресурс]. - Режим доступа:
https://ru.wikipedia.org/wiki/%D0%A1%D0%B5%D0%BC%D0%B0%D0%BD%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%B5%D1%82%D1%8C,
свободный (дата обращения 01.12.2014). - Загл. с экрана.