|
Количество грузчиков
|
Склад
|
|
№1
|
№2
|
№3
|
№4
|
№5
|
|
2
|
10
|
12
|
14
|
8
|
18
|
|
4
|
6
|
8
|
9
|
5
|
12
|
|
5
|
5
|
6
|
6
|
3
|
10
|
|
6
|
3
|
4
|
4
|
2
|
8
|
|
8
|
2
|
3
|
2
|
1
|
4
|
1.2
Концептуальная модель операции
Задача оптимизации формирования
численности бригад сводится к минимаксной задаче оптимального распределения
программных модулей между процессорами, которая формулируется следующим
образом:
алгоритм программная реализация сценарий
В результате проектирования информационной
системы выделено множество программных модулей R={R1,.,Ri,.,Rm}. Эти модули являются
информационно-независимыми друг от друга и могут параллельно выполняться на
многопроцессорной вычислительной системе, которая содержит Do процессоров. Для каждого
из программных модулей определены варианты их реализации, которые формально
задаются переменной dij, определяющей количество процессоров, которые
могут использоваться для выполнения Ri-го программного модуля в
j-м варианте. Необходимо
распределить имеющиеся процессоры по программным модулям, чтобы их выполнение
было закончено в кратчайшее время, т.е. следует уменьшить отрезок времени,
начинающийся с момента начала выполнения работ и заканчивающийся в момент
выполнения последнего модуля.
- Количество грузчиков n, занятых на j-м складе при i-м варианте распределения
грузчиков соответствует количеству процессоров dij, которые могут использоваться
для выполнения программного модуля в j-м варианте;
- Процессор Di (по условию задачи N) ставится в соответствие
складу Мj;
Наличие этих соответствий и позволяет свести на
концептуальном уровне решаемую задачу к минимаксной задаче оптимального
распределения программных модулей между процессорами и применить для её решения
алгоритмы, разработанные для данной задачи.
1.3
Математическая постановка задачи
Рассмотрим математическую постановку
минимаксной задачи оптимального распределения программных модулей между
процессорами. Для этого введем переменные:
В поставленной задаче необходимо
произвести разрузочно-погрузочные работы на N-складах, время выполнения
всех работ - tij (N), где N - количество работников.
В ходе решения задача сводится к формированию
численности бригад, которые произведут все работы за минимальное количество
времени. Решение производится в соответствии с алгоритмом прямой прогонки.
Уравнение Беллмана будет выглядеть следующим образом:

Решение уравнения Беллмана даст нам
оптимальное распределение численности работников по бригадам и минимальным
затратам на выполнение требуемых работ.
2.
Алгоритмизация решения задачи
2.1 Анализ
методов решения задачи
Данный метод решения задачи решается в m этапов, где m - количество программных
модулей. Затем задача решается в соответствии с алгоритмом обратной прогонки.
Идея динамического программирования, основанная на алгоритме
обратной прогонки, состоит в том, что в качестве этапа, для которого на первом
шаге находится локальное оптимальное управление, рассматривается последний этап
принятия решений. Решения, принятые на этом этапе не оказывают влияния на
последующий этап, так как этот этап является последним. Однако при таком
подходе является неизвестным состояние, в котором будет находиться система
перед началом выполнения последнего этапа. Поэтому локальное оптимальное
управление необходимо найти для всех возможных состояний, в которых может
находиться система, перед выполнением последнего этапа. После этого
осуществляется переход к оптимизации управления на предпоследнем этапе.
Оптимальное управление на этом этапе находится с учётом того, что уже известно
оптимальное управление на последнем этапе. Таким образом, для каждого состояния
предпоследнего этапа находится локальное оптимальное управление. Такая
процедура повторяется для всех последующих этапов: n-2, n-3, …, i, …, 2, вплоть
до первого этапа, то есть, оптимальное решение для первого этапа определяется с
учётом ранее найденных оптимальных решений для последующих этапов.
2.2 Выбор и
описание метода
Современная трактовка метода динамического программирования
позволяет находить оптимальное решение не только для аддитивных критериев, но и
для минимаксных.
В данном случае для проектирования
информационной системы выделено множество программных модулей R={R1,., Ri,.,Rm}. Эти модули являются
информационно-независимыми друг от друга и могут параллельно выполняться на
многопроцессорной вычислительной системе, которая содержит Do процессоров.
Для каждого из программных модулей
определены варианты их реализации, которые формально задаются переменной dij, определяющей количество
процессоров, которые могут использоваться для выполнения Ri-го программного модуля в
j-м варианте. Необходимо
распределить имеющиеся процессоры по программным модулям, чтобы их выполнение
было закончено в кратчайшее время, т.е. следует уменьшить отрезок времени,
начинающийся с момента начала выполнения работ и заканчивающийся в момент
выполнения последнего модуля.
Учитывая, что нам является известным
значение времени t (dij (z)) выполнения Ri-го модуля в j (z) варианте распределения,
то пусть Ti (z) - время выполнения i-го модуля в z-м варианте -
определяется следующим образом: Ti (z) = t (dij (z)).
Очевидно, что время окончания реализации всех программных модулей
для z-го варианта составит Т (z) =  Ti (z).
Ti (z).
Тогда из всего множества вариантов необходимо выбрать такой
вариант, для которого T (l) = T (z) =
T (z) =  Ti (z) = t (dij (z)).
Ti (z) = t (dij (z)).
Уравнение Беллмана для минимаксной задачи
при реализации алгоритма прямой прогонки имеет следующий вид:
Wi (S) = max{wi (S,Ui),
Wi-1 ( -1 (S,Ui)) },
-1 (S,Ui)) },
где -1 (S,Ui) - оператор, задающий номер состояния, в
котором находилась система на предыдущем (i-1) этапе. Для рассматриваемой задачи уравнение Беллмана
представляется как
Ti (D) = max{ (t (dij),
Ti-1 (D-dij)) }.
Интерпретация основных компонент уравнения Беллмана:
- этапы - i=m, где m - количество программных
модулей. Текущее значение i соответствует ситуации распределения имеющихся процессоров
между первым, вторым,., i-м программными модулями.
В частности:
i=1 - соответствует ситуации
распределения всех процессоров для реализации только первого программного
модуля;
i=2 - предполагает
распределение процессоров между R1-м и R2-м программными модулями;
i=3 - предполагает
распределение процессоров между R1-м, R2-м и R3-м программными модулями;
i=m - соответствует
распределению процессоров между всеми программными модулями;
- состояние - в качестве состояния выбирается текущее
количество процессоров D,
распределяемых между программными модулями min{dij} DD0;
DD0;
- управление - задает количество процессоров, которое
выделяется на i-м этапе для реализации Ri-го программного модуля. Таким образом,
минимум берется по dij, а максимум выбирается из значений t (dij)
и Ti-1 (D-dij);
- оператор перехода - представляется в виде выражения D-dij.
Этот параметр задает количество процессоров, которое должно распределяться
между первым, вторым,., i-1-м
программными модулями при условии, что текущее количество распределяемых
процессоров равно D и принято управление, соответствующее
выделению dij процессоров для реализации Ri-го программного модуля;
- локальный доход на i-м этапе - этой компоненте соответствует время выполнения i-го программного модуля при условии выделения его для
реализации dij процессоров. Очевидно, что это время равно
t (dij);
- условный оптимальный
доход Ti (D) определяет время
окончания реализации первого, второго,., i-го программных модулей
при условии, что распределяется D процессоров.
2.3
Конструирование алгоритма решения задачи
В основе метода динамического программирования лежит принцип
оптимальности Беллмана т. е оптимальное управление строится постепенно. На
каждом шаге оптимизируется управление только этого шага. Вместе с тем на каждом
шаге управление выбирается с учётом последствий, так как управление,
оптимизирующее целевую функцию только для данного шага, может привести к
неоптимальному эффекту всего процесса. Управление на каждом шаге должно быть
оптимальным с точки зрения процесса в целом. Это основное правило динамического
программирования, сформулированное Беллманом, называется принципом
оптимальности. Из этого следует, что для того чтобы найти оптимальное решение
на последнем шаге надо сначала найти оптимальное решения для первого, затем для
второго и так далее пока не пройдем все этапы до последнего.
На предприятии необходимо выполнить разгрузочно-погрузочные работы
на M складах предприятия. Время выполнения
работы на каждом складе зависит от количества грузчиков  - где n количество грузчиков, занятых на j-м складе при i-м варианте
распределения грузчиков. На предприятии имеются грузчики в количестве N человек. Требуется сформировать бригады на каждый склад
таким образом, чтобы выполнить все работы за минимальное время.
- где n количество грузчиков, занятых на j-м складе при i-м варианте
распределения грузчиков. На предприятии имеются грузчики в количестве N человек. Требуется сформировать бригады на каждый склад
таким образом, чтобы выполнить все работы за минимальное время.
Этап 1. Текущее количество процессоров D распределяется только для выполнения первого программного модуля R1:
T1 (D) = max
(t (d1,j), T0 (D-d1,j)) = t (d1,j),
так как выражение T0 (D-d1,j) неопределенно.
Результаты выполнения первого шага представляются в таблице 1.
Результаты выполнения первого шага
|
Состояние D
|
Управление U1
|
Оптимальный доход T1 (D)
|
|
D1,1=d1,1
D1,2=d1,2 ... D1,j=d1,j D1,N
(1) =d1,N (1)
|
U1=d1,1
U1=d1,2 ... U1=d1, j U1=d1,N
(1)
|
Т1 (D) =t (d1,1)
Т1 (D) =t (d1,2)
..... Т1 (D) =t (d1,j)
Т1 (D) =t (d1,N
(1))
|
Остальные таблицы формируются по такому же
алгоритму, но с учетом вычисленных данных.
Этап 2. Текущее количество процессоров D распределяется между
двумя программными модулями R1 и R2. Тогда i=2 и уравнение Беллмана имеет следующий вид:
T2 (D) = max
(t (d2,j), T1 (D-d2,j)).
Результаты выполнения второго шага
представлены в таблице:
Результаты выполнения второго шага
|
Управление U2
|
Состояние второго этапа
|
|
D1,1
|
D1,2
|
…
|
D1,j
|
D1,N (1)
|
|
U2 = d 2,1
|
  … …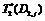 
|
|
|
|
|
|
D 2,1 = d
2,1+D 1,1
|
D2,2 = d2,1+D1,2
|
…
|
D 2,j = d
2,1+D1,j
|
D2,N
(1) = d2,1+D1,N
(1)
|
|
U2 = d 2,
i
|
 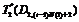 … … 
|
|
|
|
|
|
D2, (i-1) N
(1) +1 = = d2, i+D1,1
|
D2, (i-1) N
(1) +2 = = d2, i+D1,2
|
…
|
D2, (i-1) N
(1) +j = = d2, i+D1,j
|
D2, i×N (1) =d2,
i+D1,N (1)
|
|
U2 = d
2, N (2)
|
  …… ……
|
|
|
|
|
|
D2, (N
(2) - 1) N (1) +1 = = d2,N (2) +D1,1
|
D2, (N
(2) - 1) N (1) +2 = = d2,N (2) +D1,2
|
…
|
…
|
D2, (N
(2) ×N (1)) = = d2,N
(2) +D1,N (1)
|
При составлении таблицы используются
следующие правила и выполняются определенные процедуры:
количество строк равно количеству
различных значений управлений U2. В каждой строке указывается соответствующее
значение: d2,1,., d2,j,., d2,N (1);
количество столбцов соответствует
количеству состояний на предыдущем i=1 шаге, т.е. в заголовке столбцов указываются
значения
D1,1, D1,2,., D1,j,.,D1,N (1);
каждая клетка таблицы разбивается на 2
части. В нижней части записывается сумма значений, указанных в заголовках соответствующих
столбцов и строк. Эта сумма определяет состояние для второго этапа - количество
процессоров, распределяемых на этапе. Недопустимые значения вычеркиваются, и
для них не определяются значения верхней части клетки;
производится заполнение верхней части
каждой клетки, в которой указывается максимальное из следующих двух значений:
первое значение - время выполнения второго модуля при реализации управления U2; второе значение - время
выполнения первого модуля на оставшихся процессорах;
составляется окончательная таблица для второго этапа принятия
решения. Эта таблица содержит три столбца: в первом столбце указываются
уникальные значения состояний для второго этапа (табл). В промежуточной таблице
имеются повторяющиеся значения состояний. таком случае необходимо для состояния
D2,1 найти клетки, имеющие такие же значения состояний, и среди
них выбрать клетку с минимальным значением T2* (D2,1), т.е.
T2 (D2,1) = min{ T2* (D2,1) }. Оптимальное значение управления U2 для состояния D2,1 указывается во втором столбце
окончательной таблицы, а в третьем столбце записывается условное оптимальное
время выполнения первых двух программных модулей R1 и R2 при наличии D2,1 процессоров - T2 (D2,1). Аналогичные действия выполняются для всех остальных
состояний D2,s, s= , и критерия.
, и критерия.
Окончательная таблица для второго этапа
|
Состояние D2, i
|
Управление U2
|
Условное оптимальное время T2 (D2, i)
|
|
D2,1
|
U2,1
|
T2 (D2,1)
|
|
D2,2
|
U2,2
|
T2 (D2,2)
|
|
.
|
.
|
.
|
|
D2,s
|
U2,s
|
T2 (D2,s)
|
|
.
|
.
|
.
|
|
D2,z
(2)
|
U2,z
(2)
|
T2 (D2,z
(2))
|
Этап 3. Совершаем
распределение между R1-м, R2-м, R3-м программными модулями текущего количества процессоров D. Функциональное
уравнение Беллмана для i=3 имеет следующий вид:
T3 (D) = max
(t (d3,j), T2 (D-d3,j)).
Формируются элементы 3-го этапа, при их
формировании используем следующее соотношение:
T2*
(D3, (i-1) z (2) +j) = max (t (d3, i), T2 (D3,
(i-1) z (2) +j - d2, i)).
Значения T2 (D3, (i-1) z (2) +j - d2, i) выбираются из третьего
столбца окончательной таблицы для второго этапа. Аналогично шагу 2
конструируется окончательная таблица для третьего этапа, содержащая в первом
столбце перечень уникальных состояний для третьего этапа, во втором столбце
оптимальные управления для каждого состояния и в третьем столбце значения
условного оптимального времени выполнения трех программных модулей: R1, R2, R3. Выполнение алгоритма
прямой прогонки прекращается при i=m. После этого в окончательной таблице m-го этапа для состояния,
соответствующего предельному количеству процессоров D0, находится оптимальное
время Tm (Dm,N (m),z (m)) выполнения всех
программных модулей R1., Rm, а также оптимальное количество процессоров, выделенных для
реализации Rm-го модуля. На основании этого значения вычисляется оптимальное
количество процессоров, которое назначено для реализации оставшихся модулей: R1,R2,. Rm-1. Это число процессоров
является входом в окончательную таблицу (m-1) - го этапа, что
позволяет установить оптимальное количество процессоров для Rm-1-го модуля. Процесс
последовательного обратного просмотра окончательных таблиц позволяет определить
оптимальное число процессоров для Rm-го, Rm-1-го, Rm-2-го,., R1-го программных модулей.
Выполнение третьего шага
|
Управление U3
|
Состояние предыдущего второго этапа
|
|
D2,1
|
D2,2
|
…
|
D2,j
|
D2,z (2)
|
|
U3 = d3,1
|
  … … 
|
|
|
|
|
|
  … … 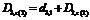
|
|
|
|
|
|
U3 = d3, i
|
  … … 
|
|
|
|
|
|
  … …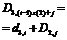 
|
|
|
|
|
|
U3 = d3,N
(3)
|
 ……… ………
|
|
|
|
|
|
 ……… ………
|
|
|
|
|
3.4
Проектирование сценария диалога
При создании сценария диалога необходимо учитывать следующие
возможности:
- Ввод данных, их
корректировку;
- Задание условий
- Просмотр исходных данных;
- Вывод результата и ход
решения задачи.
В ходе реализации программы был создан сценарий диалога с
пользователем, примеры которых будут представлены на следующих рисунках.
При первом запуске приложения перед пользователем появится
стартовое окно программы "Оптимизация формирования численности
бригад", на которой представлена вся информация, касающаяся этой темы. На
рисунке 2.1 представлено это действие.

Рисунок 2.1 - Стартовое окно программы
Перед пользователем появляется выбор. Он может задать таблицу
времени выполнения работы по умолчанию, при выборе пункта "Пример
задачи", в следствии чего таблица заполнился автоматически Либо задать
таблицу самостоятельно. Для этого ему необходимо выбрать из контекстного меню
количество необходимого ему элементов задачи: количество складов, грузчиков,
вариантов распределения грузчиков. После необходимо сохранить изменения таблицы
и приступить к заполнению таблицы. Примеры этих действий представлены на
рисунке 2.2.
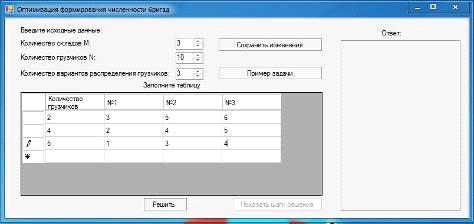
Рисунок 2.2 - Реализация самостоятельного заполнения таблицы
Значения в таблице представлены количеством грузчиков и
временем, затраченным на выполнение работ соответственно. Для получение ответа
пользователю необходимо нажать кнопку "Решить" и в правой части
программы будет представлен результат решения. Все это представлено на рисунке
2.3
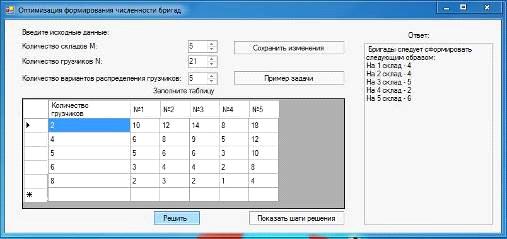
Рисунок 2.3 - Результат решения программы
Также пользователь имеет возможность просмотреть пошаговое
решение задачи, в этом случае ему необходимо выбрать из контекстного меню пункт
"Показать шаги решения". Результат пошаговых решений программа
записывает в блокнот, который и демонстрирует пользователю итог решений.
3.5 Описание
структур данных
В таблице 1 представлены функции, процедуры используемые в
программе.
Таблица 2.1
|
numM
|
Задает количество складов
|
|
numN
|
Задает количество грузчиков
|
|
numStr
|
Задает количество вариантов распределения
грузчиков
|
|
buttonRazmer
|
Сохраняет введенные изменения таблицы времени
выполнения работ
|
|
buttonDemo
|
Задает таблицу по умолчанию
|
|
buttonResh
|
Производит решение
|
|
buttonSteps
|
Демонстрирует пошаговое решение задачи
|
В таблице 2 представлены структуры и классы, используемые в
программе
Таблица 2.2
|
Form
|
class
|
Создает окно
|
|
M
|
int
|
Столбцы
|
|
Str
|
Int
|
Строки
|
|
N
|
Int
|
Количество рабочих
|
|
Text
|
string
|
Решение
|
|
Answ
|
String
|
Ответ
|
|
Int [,] a
|
Int
|
Исходная матрица
|
|
Int [,] T
|
Int
|
Матрица времени выполнения
|
|
Int [] rabs
|
Int
|
Массив с количество работников
|
|
Int [] U
|
Int
|
Массив управления
|
|
Int [] sost2,
sost3,sost4, sost5, sost6
|
Int
|
Состояния
|
|
Step
|
Int
|
Шаги
|
|
Int [] difMas1,
difMas1, difMas3
|
Int
|
Временные массивы для хранения уникальных
состояний
|
|
Int [,] temp21 temp22, temp31, temp32, temp41, temp42, temp51,
temp52, temp61, temp62
|
Int
|
Временные матрицы для определенных шагов
1,2,3,4,5,6
|
|
Int [,] tab2, tab3,
tab4, tab5,, tab6;
|
int
|
Итоговые таблицы
|
|
i=0, j=0, s=0, p=N, t=0;
|
int
|
Переменные, счетчики
|
|
Print (int [,] mas)
|
Public string
|
Функция вывода двумерного массива
|
|
niz (ref int [,] temp1,
int [,] a, int [,] tab)
|
Public string
|
Функция заполнения матрицы, соответствующая
значениям нижней части
|
|
verh (int [,] temp1,
ref int [,] temp2, int [,] a, int [] difMas, int step)
|
Public string
|
Функция заполнения матрицы, соответствующая
значениям верхней части
|
|
max (int a, int b)
|
public int
|
Функция нахождения максимального элемента из
двух
|
|
min (int a, int b)
|
public int
|
Функция нахождения минимального элемента из
двух
|
|
countDifEl (int [,]
mas, int [,] mas2, int [] U, int [,] tab, ref int [] difMas1, ref int []
difMas2, ref int [] difMas3, ref int [] sost)
|
public void
|
Функция нахождения различных значений
(количеств работников) в нижней части клетки и минимальных в верхней
|
|
search (int [,] mas,
int [,] mas2, int a, int b, ref int f)
|
public void
|
Функция поиска состояния (количества
работников) для обратного просмотра
|
|
minTime (int step, int
[,] tab, ref int [] answer, ref int t)
|
public string
|
Функция нахождения минимального времени
выполнения работ
|
|
printAnswer (int [] answer)
|
public string
|
Функция вывода ответа
|
3.6
Структурная схема алгоритма сценария диалога и описание его программной
реализации
Структурная схема алгоритма сценария диалога была разработана
с помощью Microsoft Visio Studio 2007 и представлена на рисунке 2.7, описание ее
в таблице 2.3

Рисунок 2.7 - Структурная схема алгоритма сценария
Алгоритм сценария диалога основан на проверки сообщений,
приходящих в головную подпрограмму о нажатии того или иного пункта меню
действий и в зависимости от этого действия могут идти по разным ветвям
Таблица 2.3 Описание блоков структурной схемы алгоритма сценария
|
Номер блока
|
Тип
|
Назначение
|
|
1
|
Пуск
|
Запуск программы
|
|
2
|
Решение
|
Выбор метода решения 3-самостоятельно заполнить
данные 4 - по умолчанию
|
|
3
|
Действие
|
Заполнение таблицы, выбор параметров
|
|
4
|
Действие
|
Автоматическое заполнение всех данных
|
|
5
|
Действие
|
Решение задачи
|
|
6
|
Решение
|
Вывод ответа на экран
|
|
7
|
Решение
|
Вывод решения задачи
|
3.7
Структурная схема функционального алгоритма решения задачи
На рисунке 2.8 представлена структурная схема алгоритма
решения задачи. Описание блоков структурной схемы алгоритма решения задачи
приведено в таблице 2.4
Таблица 2.4
|
Номер блока
|
Тип
|
Назначение
|
|
1
|
Пуск
|
Запуск программы
|
|
2
|
Ввод данных
|
Заполнение матрицы времени выполнения работ
|
|
3
|
Формирование окончательной таблицы для первого
этапа
|
|
4
|
Действие
|
Нахождение промежуточной таблицы i этапа
|
|
5
|
Решение
|
Формирование окончательной таблицы i этапа
|
|
6
|
Действие
|
Проверка достигли ли мы последнего этапа, если i=m, то идем к следующему
этапу, иначе возвращаемся на 4 этап.
|
|
7
|
Действие
|
Решение задачи в соответствии с алгоритмом
обратной прогонки.
|
|
8
|
Окончание
|
Выход из программы
|

Рисунок 2.8 - Структурная схема алгоритма решения задачи
4. Численные
эксперименты
4.1 Ручная
реализация алгоритма решения задачи
Шаг 1:
Производится распределение грузчиков для выполнения
разгрузочно-погрузочных работ на 1 складе:
T1 (2) =10 // время
выполнения работы 2-мя рабочими на складе
T1 (4) =6 // время выполнения
работы 4-мя рабочими на складе
T1 (5) =5 // время выполнения
работы 5-мя рабочими на складе
T1 (6) =3 // время выполнения
работы 6-мя рабочими на складе
T1 (8) =2 // время выполнения
работы 48-мя рабочими на складе
Шаг 2:
|
t (mij)
|
t1 (M - mij)
|
|
10 (2)
|
6 (4)
|
5 (5)
|
3 (6)
|
2 (8)
|
|
12 (2)
|
12 4
|
12 6
|
12 7
|
12 8
|
12 10
|
|
8 (4)
|
10 6
|
8 8
|
8 9
|
8 10
|
8 12
|
|
6 (5)
|
10 7
|
6 9
|
6 10
|
6 11
|
18 13
|
|
4 (6)
|
10 8
|
6 10
|
5 11
|
4 12
|
18 14
|
|
3 (8)
|
10 10
|
6 12
|
5 13
|
3 14
|
18 16
|
Из 12 выделенных - 11 уникальных значений. На следующем шаге
11 столбцов.
Шаг 3:
|
t (mij)
|
t2 (M - mij)
|
|
12 (4)
|
10 (6)
|
10 (7)
|
8 (8)
|
6 (9)
|
6 (10)
|
5 (11)
|
4 (12)
|
5 (13)
|
3 (14)
|
3 (16)
|
|
14 (2)
|
14 6
|
14 8
|
14 9
|
14 10
|
14 11
|
14 12
|
14 13
|
14 14
|
14 15
|
14 16
|
14 18
|
|
9 (4)
|
12 8
|
10 10
|
10 11
|
9 12
|
9 13
|
9 14
|
9 15
|
9 16
|
9 17
|
9 15
|
9 20
|
|
6 (5)
|
12 9
|
10 11
|
10 12
|
8 13
|
6 14
|
6 15
|
6 16
|
6 17
|
6 18
|
6 17
|
6 21
|
|
4 (6)
|
12 10
|
10 12
|
10 13
|
8 14
|
6 15
|
6 16
|
5 17
|
4 18
|
5 19
|
4 18
|
_______
|
|
2 (8)
|
12 12
|
10 14
|
10 15
|
8 16
|
6 17
|
6 18
|
5 19
|
4 20
|
5 21
|
_______
|
_______
|
Сумма в нижней части не больше 21, 15 - уникальных значений.
На следующем шаге 15 столбцов.
Шаг 4:
|
t (mij)
|
|
|
14 (6)
|
12 (8)
|
10 (9)
|
10 (10)
|
10 (11)
|
9 (12)
|
8 (13)
|
6 (14)
|
6 (15)
|
6 (16)
|
5 (17)
|
4 (18)
|
5 (19)
|
5 (21)
|
4 (20)
|
|
18 (2)
|
14 8
|
12 10
|
12 11
|
10 12
|
10 13
|
9 14
|
8 15
|
8 16
|
8 17
|
8 18
|
8 19
|
8 20
|
8 21
|
-
|
-
|
|
12 (4)
|
14 10
|
12 12
|
12 13
|
10 14
|
10 15
|
9 16
|
8 17
|
6 18
|
6 19
|
6 20
|
5 21
|
-
|
-
|
-
|
-
|
|
10 (5)
|
14 11
|
12 13
|
12 14
|
10 15
|
10 16
|
9 17
|
8 18
|
6 19
|
6 20
|
6 21
|
-
|
-
|
-
|
-
|
-
|
|
8 (6)
|
14 12
|
12 14
|
12 15
|
10 16
|
10 17
|
9 18
|
8 19
|
6 20
|
6 21
|
-
|
-
|
-
|
-
|
-
|
-
|
|
4 (8)
|
14 14
|
12 16
|
12 17
|
10 18
|
10 19
|
9 20
|
8 20
|
-
|
-
|
-
|
-
|
-
|
-
|
-
|
-
|
На следующем шаге 11 уникальных столбцов
Шаг 5:
|
t (mij)
|
|
|
14 (8)
|
12 (10)
|
12 (11)
|
10 (12)
|
10 (13)
|
9 (14)
|
8 (15)
|
8 (16)
|
8 (17)
|
6 (18)
|
6 (19)
|
|
18 (2)
|
18 10
|
18 12
|
18 13
|
18 14
|
18 16
|
18 16
|
18 18
|
18 18
|
18 19
|
18 20
|
18 21
|
|
12 (4)
|
14 12
|
12 14
|
12 15
|
12 16
|
12 18
|
12 18
|
12 20
|
18 20
|
12 21
|
-
|
-
|
|
10 (5)
|
14 13
|
12 15
|
12 16
|
10 17
|
10 19
|
10 19
|
10 21
|
10 21
|
-
|
-
|
-
|
|
8 (6)
|
14 14
|
12 16
|
12 17
|
10 18
|
10 20
|
9 20
|
8 21
|
-
|
-
|
-
|
-
|
|
4 (8)
|
14 16
|
12 18
|
12 19
|
10 20
|
10 21
|
-
|
-
|
-
|
-
|
-
|
-
|
Время выполнения всех разгрузочно-погруззочных работ составит
Т=8. Для этого потребуется:
- на 5 склад отправить 6
грузчиков,
- на 4 склад отправить 2
грузчика,
- на 3 склад отправить 5
грузчиков,
- на 2 склад отправить 4
грузчика,
- на 1 склад отправить 21-
(6+2+5+4) =4 грузчика.
3.8 Машинные
эксперименты с разработанными данными
При расчете исходных данных, программой были получены
следующие результаты представленные на рисунках 3.1-3.

Рисунок 3.1 - Задание таблицы времени
Рисунок 3.2 - Вывод ответа

Рисунок 3.3 - Распределение бригад на 1 и 2 шагах

Рисунок 3.4 - Распределение бригад на 3 и 4 шагах

Рисунок 3.4 - Распределение бригад на 5 шаге
3.9 Сравнение
результатов ручного и машинного расчетов
При ручном расчете время выполнения всех
разгрузочно-погрузочных работ составит Т=8. Для этого потребуется:
- на 5 склад отправить 6
грузчиков,
- на 4 склад отправить 2
грузчика,
- на 3 склад отправить 5
грузчиков,
- на 2 склад отправить 4
грузчика,
- на 1 склад отправить 21-
(6+2+5+4) =4 грузчика.
Машинные расчеты дали аналогичные результаты, как на
отдельном шаге, так и в конечном итоге.
Заключение
Результатом выполнения настоящей курсовой работы является
программный продукт, реализующий решение задачи распределения программных
модулей между процессорами. Сравнение ручного расчёта и машинных экспериментов
говорит о том, что разработанная программа соответствует требованиям
технического задания.
Использование программного продукта помогает принять
оптимальное решение при минимаксной задаче оптимального распределения
программных модулей между процессорами.
Список
используемой литературы
1. Черноморов
Г.А. Теория принятия решений: Учебное пособие / Юж. - Рос. гос. техн. ун-т.
Новочеркасск: Ред. журн. "Изв. вузов. Электромеханика" 2002, 276 с.
2. Черноморов
Г.А. Методические указания к выполнению курсовой работы по дисциплине
"Системный анализ и исследование операций”/ Новочерк. гос. техн. ун-т.
Новочеркасск: НГТУ, 1998. С.76.
Приложение а
- листинг программы
using System;System. Collections.
Generic;System.componentModel;System. Data;System. Drawing;System. Linq;System.
Text;System. Threading. Tasks;System. Windows. Forms;System. IO;System.
Diagnostics;Kursovaya
{partial class Form1: Form
{N, M, str;Form1 ()
{();= 21; M = 5; str = 5; // N - количество грузчиков, М -
складов, str - строк в исходной таблице
// матрица по умолчанию[,] T = new int [5, 6] { { 2, 10, 12,
14, 8, 18 }, { 4, 6, 8, 9, 5, 12 }, { 5, 5, 6, 6, 3, 10 }, { 6, 3, 4, 4, 2, 8
}, { 8, 2, 3, 2, 1, 4 } };. Columns. Add ("","Количество
грузчиков");
for (int i = 1; i < M+1; i++) dataGridView1.
Columns. Add ("", "№" + i);(int j = 0; j < str; j++)
{. Rows. Add ();
}(int j = 0; j < M+1; j++)(int i = 0; i <
str; i++)[j, i]. Value = T [i, j];. AutoResizeColumns ();
}void button1_Click (object sender, EventArgs e)
{. Clear ();
// размер исходной матрицыM = dataGridView1. ColumnCount-1; // столбцыstr =
dataGridView1. RowCount - 1; // строки N = 21; // количество рабочихi = 0, j = 0, s = 0,
p = N, t = 0;text = " "; // сюда будет помещаться решениеansw =
" "; // сюда будет помещен ответ
int [,] a = new int [str, M+1]; // исходная матрица
int [] U = new int [str]; // массив управления[] sost2,
sost3, sost4, sost5, sost6;
int step = 0; // шаги[] difMas1 = new int [] { 0 }; //
временные массивы для хранения уникальных состояний (количеств работников)
int [] difMas2 = new int [] { 0 };[] difMas3 =
new int [] { 0 };
int n=0;[,] temp21, temp22; // временные матрицы для 2
шага[,] tab2; // итоговая т-ца для 2 шага
int [,] temp31, temp32, tab3, temp41, temp42,
tab4, temp51, temp52, tab5, temp61, temp62, tab6;[] answer= new int [M];ans = false;+=
"\r\nРазмерность: M =" +
(M+1) + " str =" + str + "\r\nИсходная матрица: \r\n";(j = 0; j < str; j++)
{(i = 0; i < M+1; i++)
{[j, i] = Convert. ToInt32 (dataGridView1 [i, j].
Value);+= a [j, i]. ToString () + " ";
}+= " \r\n";
}+= "\r\nМатрица времени выполнения: \r\n";
for (j = 0; j < str; j++)
{(i = 1; i < M+1; i++)
{[j, i-1] = Convert. ToInt32 (dataGridView1 [i,
j]. Value);+= T [j, i-1]. ToString () + " ";
}+= " \r\n";
}
// Заполенение матрицы работников
for (i = 0; i <= N; i++)[i] = i;
// Заполенение матрицы управления(i = 0; i < str; i++)
U [i] = a [i,0];
// ШАГ 1
step = 1;+= "\r\n\tШаг1: Распределение
работников для выполнения работ на первом складе\r\n";
int [,] tab1 = new int [str, 3];(i = 0; i <
str; i++)
{[i, 0] = a [i, 0];[i, 1] = a [i, 0];[i, 2] = T
[i, 0];
}+= "\r\nИтоговая таблица после "+step+"
шага";
text +=print (tab1);
// ШАГ 2(step + 1 <= M)
{
step = 2;+= "\r\n\tШаг2: Распределение работников между
первым и вторым складами\r\n";= tab1. GetLength (0); // кол-во строк
предыдущей т-цы= new int [str, n]; // количество столбцов равно кол-ву строк
предыдущей т-цы
temp22 = new int [str, n];
sost2 = new int [1];
// заполнение матрицы, соответствующей значениям в нижней
части клетки+= "\r\nМатрица, соответствующая значениям в нижней части клетки\r\n";
for (i = 0; i < str; i++)(j = 0; j < n;
j++)
{[i, j] = a [i, 0] + tab1 [j, 0];(temp21 [i, j]
> N) temp21 [i, j] = - 1;
}+= print (temp21);
// заполнение матрицы, соответствующей значениям в верхней
части клетки+= "\r\nМатрица, соответствующая значениям в верхней части
клетки\r\n";
for (i = 0; i < str; i++)(j = 0; j < n;
j++)(temp21 [i, j]! = - 1)[i, j] = max (a [i, 2], a [j, 1]);temp22 [i, j] = -
1;+= print (temp22);
// Вызов функции для нахождения уникальных значений
количества работников и минимального времени
countDifEl (temp21, temp22, U, tab1, ref difMas1,
ref difMas2, ref difMas3, ref sost2);= new int [difMas1. Length, 3];(i = 0; i
< difMas1. Length; i++)
{[i, 0] = difMas1 [i]; tab2 [i, 1] = difMas3 [i];
tab2 [i, 2] = difMas2 [i];
}+= "\r\nИтоговая таблица после " + step + "
шага";
text += print (tab2);(step + 1 <= M)
{
// ШАГ 3= 3;+= "\r\n\tШаг3: Распределение работников
между первым, вторым и третьим складами\r\n";= tab2. GetLength (0); //
кол-во строк предыдущей т-цы= new int [str, n]; // количество столбцов равно
кол-ву строк предыдущей т-цы
temp32 = new int [str, n];
sost3 = new int [1];
// заполнение матрицы, соответствующей значениям в нижней
части клетки
text += niz (ref temp31, a, tab2);
// заполнение матрицы, соответствующей значениям в верхней
части клетки
text += verh (temp31, ref temp32, a, difMas2,
step);. Resize (ref difMas1, 1); Array. Resize (ref difMas2, 1); Array. Resize
(ref difMas3, 1);
// Вызов функции для нахождения уникальных значений
количества работников и минимального времени
countDifEl (temp31, temp32, U, tab2, ref difMas1,
ref difMas2, ref difMas3, ref sost3);= new int [difMas1. Length, 3];(i = 0; i
< difMas1. Length; i++)
{[i, 0] = difMas1 [i]; tab3 [i, 1] = difMas3 [i];
tab3 [i, 2] = difMas2 [i];
}+= "\r\nИтоговая таблица после " + step + "
шага";
text += print (tab3);(step + 1 <= M)
{
// ШАГ 4= 4;+= "\r\n\tШаг4: Распределение работников
между первым, вторым, третьим и 4 складами\r\n";= tab3. GetLength (0); //
кол-во строк предыдущей т-цы= new int [str, n]; // количество столбцов равно
кол-ву строк предыдущей т-цы
temp42 = new int [str, n];
sost4 = new int [1];
// заполнение матрицы, соответствующей значениям в нижней
части клетки
text += niz (ref temp41, a, tab3);
// заполнение матрицы, соответствующей значениям в верхней
части клетки
text += verh (temp41, ref temp42, a, difMas2,
step);. Resize (ref difMas1, 1); Array. Resize (ref difMas2, 1); Array. Resize
(ref difMas3, 1);
// Вызов функции для нахождения уникальных значений
количества работников и минимального времени
countDifEl (temp41, temp42, U, tab3, ref difMas1,
ref difMas2, ref difMas3, ref sost3);= new int [difMas1. Length, 3];(i = 0; i
< difMas1. Length; i++)
{[i, 0] = difMas1 [i]; tab4 [i, 1] = difMas3 [i];
tab4 [i, 2] = difMas2 [i];
}+= "\r\nИтоговая таблица после " + step + "
шага";
text += print (tab4);(step + 1 <= M)
{
// ШАГ 5= 5;+= "\r\n\tШаг5: Распределение работников
между 1,2,3,4 и 5 складами\r\n";= tab4. GetLength (0); // кол-во строк
предыдущей т-цы= new int [str, n]; // количество столбцов равно кол-ву строк
предыдущей т-цы
temp52 = new int [str, n];
sost5 = new int [1];
// заполнение матрицы, соответствующей значениям в нижней
части клетки
text += niz (ref temp51, a, tab4);
// заполнение матрицы, соответствующей значениям в верхней
части клетки
text += verh (temp51, ref temp52, a, difMas2,
step);. Resize (ref difMas1, 1); Array. Resize (ref difMas2, 1); Array. Resize
(ref difMas3, 1);
// Вызов функции для нахождения уникальных значений
количества работников и минимального времени
countDifEl (temp51, temp52, U, tab4, ref difMas1,
ref difMas2, ref difMas3, ref sost5);= new int [difMas1. Length, 3];(i = 0; i
< difMas1. Length; i++)
{[i, 0] = difMas1 [i];[i, 1] = difMas3 [i];[i, 2]
= difMas2 [i];
} += "\r\nИтоговая таблица после " + step + " шага";
text += print (tab5);(step + 1 <= M)
{
// ШАГ 6= 6;+= "\r\n\tШаг6: Распределение работников
между 1,2,3,4,5 и 6 складами\r\n";= tab5. GetLength (0); // кол-во строк
предыдущей т-цы= new int [str, n]; // количество столбцов равно кол-ву строк
предыдущей т-цы
temp62 = new int [str, n];
sost6 = new int [1];
// заполнение матрицы, соответствующей значениям в нижней
части клетки
text += niz (ref temp61, a, tab5);
// заполнение матрицы, соответствующей значениям в верхней
части клетки
text += verh (temp61, ref temp62, a, difMas2,
step);. Resize (ref difMas1, 1); Array. Resize (ref difMas2, 1); Array. Resize
(ref difMas3, 1);
// Вызов функции для нахождения уникальных значений
количества работников и минимального времени
countDifEl (temp61, temp62, U, tab5, ref difMas1,
ref difMas2, ref difMas3, ref sost6);= new int [difMas1. Length, 3];(i = 0; i
< difMas1. Length; i++)
{[i, 0] = difMas1 [i];[i, 1] = difMas3 [i];[i, 2]
= difMas2 [i];
} += "\r\nИтоговая таблица после " + step + " шага";
text += print (tab6);
text += "\r\nОбратный просмотр таблиц\r\n";
// Обратный просмотр на 6 шаге-;
text += minTime (step, tab6, ref answer, ref t);
step--;(temp61, temp62, p, t, ref s);[step] = tab5 [s, 1];-;= tab5 [s, 0];=
tab5 [s, 2];(temp51, temp52, p, t, ref s);[step] = tab4 [s, 1];-;= tab4 [s,
0];= tab4 [s, 2];(temp41, temp42, p, t, ref s);[step] = tab3 [s, 1];-;= tab3
[s, 0];= tab3 [s, 2];(temp31, temp32, p, t, ref s);[step] = tab2 [s, 1];-;=
tab2 [s, 0];= tab2 [s, 2];(temp21, temp22, p, t, ref s);[step] = tab1 [s, 1];+=
printAnswer (answer);= printAnswer (answer);= true;
}(! ans)
{ += "\r\nОбратный просмотр таблиц\r\n";
// Обратный просмотр на 5 шаге-;
text += minTime (step, tab5, ref answer, ref t);
step--;(temp51, temp52, p, t, ref s);[step] = tab4 [s, 1];-;= tab4 [s, 0];=
tab4 [s, 2];(temp41, temp42, p, t, ref s);[step] = tab3 [s, 1];-;= tab3 [s,
0];= tab3 [s, 2];(temp31, temp32, p, t, ref s);[step] = tab2 [s, 1];-;= tab2
[s, 0];= tab2 [s, 2];(temp21, temp22, p, t, ref s);[step] = tab1 [s, 1];+=
printAnswer (answer);= printAnswer (answer);= true;
}
}(! ans)
{ += "\r\nОбратный просмотр таблиц\r\n";
// Обратный просмотр на 4 шаге-;
text += minTime (step, tab4, ref answer, ref t);
step--;(temp41, temp42, p, t, ref s);[step] = tab3 [s, 1];-;= tab3 [s, 0];=
tab3 [s, 2];(temp31, temp32, p, t, ref s);[step] = tab2 [s, 1];-;= tab2 [s,
0];= tab2 [s, 2];(temp21, temp22, p, t, ref s);[step] = tab1 [s, 1];+=
printAnswer (answer);= printAnswer (answer);= true;
}
}(! ans)
{ += "\r\nОбратный просмотр таблиц\r\n";
// Обратный просмотр на 3 шаге-;
text += minTime (step, tab3, ref answer, ref t);
step--;(temp31, temp32, p, t, ref s);[step] = tab2 [s, 1];-;= tab2 [s, 0];=
tab2 [s, 2];(temp21, temp22, p, t, ref s);[step] = tab1 [s, 1];+= printAnswer
(answer);= printAnswer (answer);= true;
}
}(! ans)
{ += "\r\nОбратный просмотр таблиц\r\n";
// Обратный просмотр на 2 шаге-;
text += minTime (step, tab2, ref answer, ref t);
step--;(temp21, temp22, p, t, ref s);[step] = tab2 [s, 1];+= printAnswer
(answer);= printAnswer (answer);= true;
}
}sw = new StreamWriter ("new. txt");.
WriteLine (text);. Close ();. Text += answ;. Enabled = true;
}
// Функция для вывода двумерного массиваstring print (int [,]
mas)
{i = 0, j = 0;sol="";x = mas. GetLength
(0), y = mas. GetLength (1);+= "\r\n";(i = 0; i < x; i++)
{(j = 0; j < y; j++)
{+= mas [i, j] + " ";
}+= "\r\n";
}sol;
}
// функция для заполнения матрицы, соответствующей значениям
в нижней части клетки
public string niz (ref int [,] temp1, int [,] a,
int [,] tab)
{text = "\r\nМатрица, соответствующая значениям в нижней
части клетки\r\n";
for (int i = 0; i < temp1. GetLength (0);
i++)(int j = 0; j < temp1. GetLength (1); j++)
{[i, j] = a [i, 0] + tab [j, 0];(temp1 [i, j]
> N) temp1 [i, j] = - 1;
}+= print (temp1);text;
}
// функция для заполнения матрицы, соответствующей значениям
в верхней части клетки
public string verh (int [,] temp1, ref int [,]
temp2, int [,] a, int [] difMas, int step)
{text = "\r\nМатрица, соответствующая значениям в
верхней части клетки\r\n";
for (int i = 0; i < temp1. GetLength (0); i++)(int
j = 0; j < temp1. GetLength (1); j++)
{(temp1 [i, j]! = - 1)[i, j] = max (a [i, step],
difMas [j]);temp2 [i, j] = - 1;
}+= print (temp2);text;
}
// Функция нахождения максимального элемента из двух
public int max (int a, int b)
{(b > a) return b;
else return a;
}
// Функция нахождения минимального элемента из двух (0 не
учитывается)
public int min (int a, int b)
{( (a > 0) & (b < a)) return b;
else return a;
}
// Функция нахождения различных значений (количеств
работников) в нижней части клетки и минимальных в верхней
public void countDifEl (int [,] mas, int [,]
mas2, int [] U, int [,] tab, ref int [] difMas1, ref int [] difMas2, ref int []
difMas3, ref int [] sost)
{a = 0;count=0;[0] = mas [0, 0];[0] = mas2 [0,
0];[0] = U [0];[0] = tab [0, 0];(int i = 0; i < mas. GetLength (0); i++)(int
j = 0; j < mas. GetLength (1); j++)
{(mas [i, j]! = - 1)
{= 0;(int k = 0; k < difMas1. Length; k++)
if (mas [i, j] == difMas1 [k]) // проверяется, нет ли такого
элемента в массиве с различными элементами
{ // если есть, то выбрать минимальное значение для верхней
части клетки
a = difMas2 [k];[k] = min (difMas2 [k], mas2 [i,
j]);(a > difMas2 [k])
{[k] = U [i];[k] = tab [j, 0];
};
}count++;(count == difMas1. Length)
{. Resize (ref difMas1, difMas1. Length + 1); // увеличение размера массива на 1
Array. Resize (ref difMas2, difMas2. Length +
1);. Resize (ref difMas3, difMas3. Length + 1);. Resize (ref sost, sost. Length
+ 1);[difMas1. Length - 1] = mas [i, j];[difMas2. Length - 1] = mas2 [i,
j];[difMas3. Length - 1] = U [i];[sost. Length-1] =tab [j,0];
}
}
}
}
// Функция поиска состояния (количества работников) для
обратного просмотра
public void search (int [,] mas, int [,] mas2,
int a, int b, ref int f)
{(int i = 0; i < mas. GetLength (0); i++)(int
j = 0; j < mas. GetLength (1); j++)( (mas [i, j]! = - 1) & (mas [i, j]
== a) & (mas2 [i, j] == b))
{ f = j; break; }
}
public string minTime (int step, int [,] tab, ref
int [] answer, ref int t)
{text=" ";(int i = 0; i < tab.
GetLength (0); i++)
if (tab [i, 0] == N)
{+= "Минимальное время, за которое будут выполнены
работы, составляет T = " + tab [i, 2];[step] = tab [i, 1];
t = tab [i, 2];text;
}text;
}string printAnswer (int [] answer)
{text = " ";+= "Бригады следует сформировать
следующим образом: \r\n";
for (int i = 0; i < answer. Length; i++) text
+= "На " + (i +
1) + " склад - " +
answer [i] + "\r\n";
return text;
}
// Кнопка задания размеров таблицы
private void button2_Click (object sender,
EventArgs e)
{
textBox1. Clear ();. Columns. Clear ();= int.
Parse (numM. Text);= int. Parse (numN. Text);= int. Parse (numStr. Text);.
Columns. Add ("","Количество грузчиков");(int i = 1; i < M+1; i++)
dataGridView1. Columns. Add ("", "№" + i);(int j = 0; j
< str; j++)
{. Rows. Add ();
}. Text = "Заполните таблицу";. Enabled = true;. Enabled = false;
}
// матрица по умолчаниюvoid
buttonDemo_Click (object sender, EventArgs e)
{. Clear ();. Columns. Clear ();
N = 21; M = 5; str = 5; // N - количество грузчиков, М -
складов, str - строк в исходной таблице[,] T = new int [5, 6] { { 2, 10, 12,
14, 8, 18 }, { 4, 6, 8, 9, 5, 12 }, { 5, 5, 6, 6, 3, 10 }, { 6, 3, 4, 4, 2, 8
}, { 8, 2, 3, 2, 1, 4 } };. Columns. Add ("", "Количество
грузчиков");
for (int i = 1; i < M + 1; i++) dataGridView1.
Columns. Add ("", "№" + i);(int j = 0; j < str; j++)
{. Rows. Add ();
}(int j = 0; j < M + 1; j++)(int i = 0; i <
str; i++)[j, i]. Value = T [i, j];. AutoResizeColumns ();. Enabled = true;.
Enabled = false;
}void buttonSteps_Click (object sender, EventArgs
e)
{. Start ("C: \\Windows\\System32\\notepad.
exe", "new. txt");
}
}
}