Распределение системами управления базами данных
Министерство
образования науки и молодежной политики РД
ГПОБУ
"Республиканский
аграрно - экономический колледж"
Курсовой
проект
По
дисциплине: "Технология
разработки и защиты баз данных"
На
тему:
"Распределение
системами управления базами данных"
Выполнила студентка
гр.:П-31
Алпаутова А.Х
Руководитель:
Магомедбегов Р.Р
Хасавюрт
2014 г.
Содержание
Введение
. Распределение
базы данных
.1 Основные
понятие базы данных
.2 Система
клиент сервер
.3 Преимущества
и недостатки СУБД
. Отражение
структуры организации
.1 Повышение
доступности данных
.2 Повышение
надежности
.3 Повышение
производительности
. Экономические
выгоды
.1 Модульность
системы
.2 Повышение
сложности
.3 Увеличение
сложности
. Усложнение контроля за условность
данных
.1 Отсутствие
стандартов
.2 Недостатки
опыта
Заключение
Список использованной литературы
Введение
Основной предпосылкой разработки систем,
использующих базы данных, является стремление объединить все обрабатываемые в
организации данные в единое целое и обеспечить к ним контролируемый доступ.
Хотя интеграция и предоставление контролируемого доступа могут способствовать
централизации, последняя не является самоцелью. На практике создание
компьютерных сетей приводит к децентрализации обработки данных. Децентрализованный
подход, по сути, отражает организационную структуру многих компаний, логически
состоящих из отдельных подразделений, отделов, проектных групп и т.п., которые
физически распределены по разным офисам, отделениям, предприятиям или филиалам,
причем каждая отдельная производственная единица имеет дело с собственным
набором обрабатываемых данных. Разработка распределенных баз данных, отражающих
организационные структуры предприятий, позволяет сделать общедоступными данные,
поддерживаемые каждым из существующих подразделений, обеспечив при этом их
хранение именно в тех местах, где они чаще всего используются. Подобный подход
расширяет возможности совместного использования информации, одновременно
повышая эффективность доступа к ней. Цель:
Исследование возможностей распределенных СУБД.
Распределенные
системы призваны решить проблему информационных островов. Если на предприятии
имеется несколько баз данных, их иногда рассматривают как некие разрозненные
территории, представляющие собой отдельные и труднодоступные для многих места,
подобные удаленным друг от друга островам. Данное положение может являться
следствием географической разобщенности, несовместимости используемой
компьютерной архитектуры, несовместимости используемых протоколов связи и т.д.
Подобное положение дел способна изменить интеграция отдельных баз данных в одно
логическое целое.
1. Распределенные базы данных
Появление вычислительных систем с базами данных
привело к смене прежних способов обработки данных, в которых для каждого
приложения определялись и поддерживались собственные наборы данных, новыми, в
которых все данные определялись и поддерживались централизованно. А в последнее
время происходит быстрое развитие технологий сетевой связи и обмена данными,
вызванное созданием Шете1, появлением мобильных и беспроводных вычислительных
средств, а также "интеллектуальных" устройств. Теперь под влиянием
этих двух противоположных тенденций технология распределенных баз данных
способствует обратному переходу от централизованной обработки данных к децентрализованной.
Создание технологии систем управления распределенными базами данных является
одним из самых больших достижений в области баз данных.
В основном мы рассматривали централизованные
системы баз данных, т.е. системы, в которых единственная логическая база данных
размещалась в пределах одного узла и находилась под управлением одной СУБД
(данные из источников передавались в центральный вычислительный центр с супер
ЭВМ и там обрабатывались).
Теперь обсудим принципы и проблемы, связанные с
распределенными СУБД, позволяющими конечным пользователям иметь доступ не
только к данным, сохраняемым на их собственном узле, но и к данным, размещенным
на различных удаленных узлах. В прессе уже неоднократно делались заявления о
том, что в связи с нарастающим процессом перехода организаций к технологии
распределенных баз данных централизованные базы данных буквально через
несколько лет превратятся в антикварную редкость.
1.1 Основные понятия
Чтобы начать обсуждение проблем, связанных с
распределенными СУБД, прежде всего необходимо уяснить, что же такое
распределенная база данных.
Распределенная база данных - набор логически
связанных между собой совокупностей разделяемых данных (и их описаний), которые
физически распределены в некоторой компьютерной сети.
Из этого вытекает следующее определение
распределенной СУБД:
Распределенная СУБД - программный комплекс,
предназначенный для управления распределенными базами данных и обеспечивающий
прозрачный доступ пользователей к распределенной информации.
Распределенная система управления базой данных
(распределенная СУБД) состоит из единой логической базы данных, разделенной на
некоторое количество фрагментов. Каждый фрагмент базы данных сохраняется на
одном или нескольких компьютерах, работающих под управлением отдельных СУБД и
соединенных между собой сетью связи. Любой узел способен независимо
обрабатывать запросы пользователей, требующие доступа к локально сохраняемым
данным (т.е. каждый узел обладает определенной степенью автономности), а также
способен обрабатывать данные, сохраняемые на других компьютерах сети.
Пользователи взаимодействуют с распределенной
базой данных через приложения. Приложения могут подразделяться на не требующие
доступа к данным на других узлах (локальные приложения) и требующие подобного
доступа (глобальные приложения). В распределенной СУБД должно существовать хотя
бы одно глобальное приложение, поэтому любая такая СУБД должна иметь следующие
характеристики:
• имеется набор логически связанных разделяемых
данных;
• сохраняемые данные разбиты на некоторое
количество фрагментов;
• может быть предусмотрена репликация фрагментов
данных;
• фрагменты и их копии распределяются по разным
узлам;
• узлы связаны между собой сетевыми
соединениями;
• доступ к данным на каждом узле происходит под
управлением СУБД;
• СУБД на каждом узле способна поддерживать
автономную работу локальных приложений;
• СУБД каждого узла поддерживает хотя бы одно
глобальное приложение;
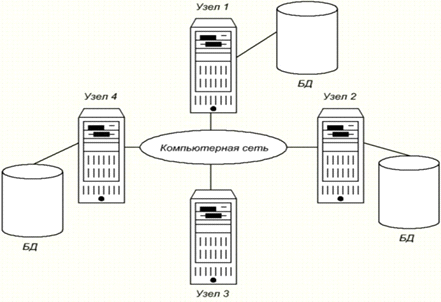
Но нет необходимости в том, чтобы на каждом из
узлов системы существовала своя собственная локальная база данных, что и
показано на примере топологии распределенной СУБД, представленной на рисунке
1:Рис. 1. Топологии распределенной СУБД, с локальной базой данных на каждом из
узлов системы.

В общем случае режимы использования БД имеют вид
(рис. 2):
Рассмотри основные понятия, применяемые в
системах управления распределенными базами данных.
Архитектура клиент-сервер - структура локальной
сети, в которой применено распределенное управление сервером и рабочими
станциями (клиентами) для максимально эффективного использования вычислительной
мощности.
Атрибут - характеристика элемента данных в
объекте.
Вызов процедуры - передача управления
подпрограмме или процедуре с последующим возвратом к основной программе по
окончании выполнения подпрограммы или процедуры.
Вызов удаленной процедуры (RemoteProcedureCall)
- вызов процедуры с другого компьютера.
Запрос - процесс обращения пользователя к БД с
целью ввода, получения или изменения информации в БД.
Инкапсуляция - объединение данных и программы
(кода) в "кап¬суле", модуле.
Класс - объединяющая концепция набора объектов,
имеющих общие характеристики (атрибуты).
Компонент - аналог класса в приложении Delphi.
Клиент - компьютер, обращающийся к совместно
используемым ресурсам, которые предоставляются другим компьютером (сервером).
Логическая структура БД - определение БД на
физически независимом уровне; ближе всего соответствует концептуальной модели
БД.
Локализация (размещение) - распределение данных
по узлам (участкам) сети с учетом дублирования (наличия копий).
Локальная автономность означает, что информация
локальной БД и связанные с ней определения данных принадлежит локальному
владельцу и им управляются.
Локальная вычислительная сеть (ЛВС) - коммуникационная
система, поддерживающая в пределах здания или некоторой другой территории один
или несколько скоростных каналов передачи цифровой информации, предоставленных
подключенным устройствам для кратковременного монопольного использования.
Метод - набор подпрограмм, оперирующих с
данными.
Наследование - передача определенных свойств от
класса к его производному.
Объект - комбинация элементов данных,
характеризующихся атрибутами, и методов их обработки, упакованных вместе в
одном модуле.
Пользователь БД - программа или человек,
обращающийся к базе данных
Полиморфизм - возможность переопределения
процедуры в производном классе.
Прозрачность - устройство или часть программы,
которая работает настолько четко и просто, что ее действия незаметны
пользователю.
Распределенный запрос - запрос, при обработке
которого используются данные из БД, расположенные в разных узлах сети.
Свойство - аналог атрибута в приложении Delphi.
Сервер - узловая станция компьютерной сети,
предназначенная в основном для хранения данных коллективного пользования и для
обработки в ней запросов, поступающих от пользователей других узлов.
Событие - сигнал запуска метода.
Среда (ComputerAidedSoftwareEngineering - CASE)
- среда создания программного обеспечения, ориентированная на разработку
программы от планирования и моделирования до кодирования и документирования.
Топология БД, или структура распределенной БД, -
схема распределения физической организации базы данных в сети.
Транзакция - последовательность операций
модификации данных в БД, переводящая БД из одного непротиворечивого состояния в
другое непротиворечивое состояние.
Удаленный запрос - запрос, который выполняется с
использованием модемной связи.
Фрагмент логический - блок данных, однородных
для транзакций с точки зрения доступа.
Фрагментация (расчленение) - процесс разбиения
целостного объекта глобального типа на несколько частей (фрагментов).
Фрагмент хранимый - физическая реализация
логического фрагмента.
Шлюз - устройство для соединения разнотипных
сетей, работающих по разным протоколам.
Возможность реализации удаленной транзакции -
обработка одной транзакции, состоящей из множества SQL-запросов, на одном
удаленном узле.
Поддержка распределенной транзакции допускает
обработку транзакции, состоящей из нескольких запросов SQL, которые выполняются
на нескольких узлах сети (удаленных или локальных), но каждый запрос в этом
случае обрабатывается только на одном узле.
Большинство требований, предъявляемых к
распределенным БД, аналогично требованиям к централизованным БД, но их
реализация имеет свою, рассматриваемую ниже специфику. В частности, в
распределенной БД иногда полезна избыточность.
Дополнительными специфическими требованиями
являются:
• язык описания данных (ЯОД) в рамках схемы
должен быть один для всех локальных БД;
• доступ должен быть коллективным к любой
области РБД с соответствующей защитой информации;
• подсхемы должны быть определены в месте
сосредоточения алгоритмов (приложений, процессов) пользователя;
• степень централизации должна быть разумной;
• необходим сбор и обработка информации об
эффективности функционирования РБД.
В дальнейшем К. Дейт сформулировал 12 правил для
РБД.. Локальная автономность.
. Отсутствие опоры на центральный узел.
.Непрерывное функционирование (развитие) РБД.
.Независимость РБД от расположения локальных БД.
.Независимость от фрагментации данных.
.Независимость от репликации (дублирования)
данных.
. Обработка распределенных запросов.
. Обработка распределенных транзакций.
. Независимость от типа оборудования.
. Независимость от операционной системы..
Независимость от сетевой архитектуры.
. Независимость от типа СУБД.
Схема распределенной БД может быть представлена
в виде, показанном на рис. З.

Рис. 3. Схема распределенной БД
В ней выделяют пользовательский, глобальный
(концептуальный), фрагментарный (логический) и распределенный (локальный)
уровни представления данных (рис. 4), определяющие сетевую СУБД.

Рис. 4. Уровни представления данных в
распределенной БД
Пользовательский уровень состоит из фрагментов
глобального уровня, которые составляют фрагментарный, логический уровень.
Выделяют горизонтальную и вертикальную
фрагментации (расчленение). Горизонтальная фрагментация связана с делением
данных но узлам. Горизонтальные фрагменты не перекрываются. Вертикальная
фрагментация связана с группированием данных по задачам.
Фрагментация чаще всего не предполагает
дублирования информации в узлах. В то же время при размещении фрагментов по
узлам (локализации) распределенного уровня в узлах разрешается иметь копии той
или иной части РБД.
После размещения данных каждый узел имеет
локальное, узловое представление (локальная логическая модель). Физическую
реализацию (логического) фрагмента называют хранимым фрагментом.
Сеть в распределенной БД образуют сетевые
операционные системы (например, Windows NT, NovellNetWare). В качестве СУБД,
изначально предназначавшихся для использования в сети, следует назвать BTrieve,
Oracle, InterBase, Sybase, Informix.
В силу распределённой данных особую значимость
приобретает словарь данных (справочник) распределенной БД, который в отличие от
словаря централизованной БД имеет распределенную, многоуровневую структуру.
В общем случае могут быть выделены сетевой,
общий внешний, общий концептуальный, локальные внешние, локальные
концептуальные и внутренние составляющие словаря распределенной БД.
Естественно, что для работы в распределенной БД
необходимы администраторы распределенных БД и локальных БД, рабочими
инструментами которых являются перечисленные словари.
Схема работы распределенной БД показана на рис.
5.

Рис. 5. Схема работы распределенной базы данных
Пользовательский запрос, определяемый
приложением, поступает в систему управления распределенной базы данных (СУРБД),
через сетевую и локальную операционные системы попадает в локальную СУБД. Если
запрос связан с локальными данными, СУБД осуществляет вызов данных из локальной
БД, которые поступают пользователю. Если часть данных для выполнения приложения
находится в другой локальной БД, локальная СУБД дополнительно через локальные и
сетевую операционные системы осуществляет удаленный вызов процедуры
(RemoteProcedureCall - PRC), после выполнения которой данные передаются
пользователю.
Возможны четыре стратегии хранения данных:
централизованная (часто обеспечиваемый архитектурой клиент-сервер), расчленение
(фрагментации), дублирование, смешанная.
Сравнительные характеристики стратегий хранения
приведены в табл.
Таблица 1
|
Название
|
Суть Стратегии
|
Достоинство
|
Недостатки
|
|
Централизация (в том числе
технология клиент- сервер)
|
Единственная копия в одном узле
|
Простота структуры
|
Скорость обработки ограничена
одним узлом Ограниченный доступ Малая надежность Долговременная память
определяет объем БД
|
|
Локализация (расчленение)
|
Единственная копия, расчленение по
узлам (полная копия БД не допускается)
|
Объем БД определяется памятью сети
Снижение стоимости РБД Время отклика при параллельной обработке уменьшается
Малая чувствительность к узким местам Повышенная надежность при высокой
локализации данных
|
Запрос может быть по всем узлам
Доступ хуже, чем при централизации Рекомендации применения: долговременная
память ограничена по сравнению с объемом БД; должна быть повышена
эффективность функционирования при высокой степени локализации
|
В каждой локальной БД полная копия
|
Выше надежность, доступ и
эффективность
|
Объем БД ограничен долговременной
памятью
|
управление база данные хранение
Отметим, что в обычной сети имеет место
равноправие компьютеров, что может вызвать дополнительные осложнения в части
доступа к данным в процедурах обновления и запросов
В связи с этим часто используют архитектуру
клиент-сервер (рис. 6) - структуру локальной сети, в которой применено
распределенное управление сервером и рабочими станциями (клиентами) для
максимально эффективного использования вычислительной мощности.

Рис. 6. Архитектура клиент-сервер
В этой структуре один из компьютеров, имеющий
самый большой объем памяти и наиболее высокое быстродействие, становится
приоритетным, называемым сервером. На сервере чаще всего хранятся только
данные, запрашиваемые клиентами.
К клиентам не предъявляются столь жесткие
требования по памяти и быстродействию. На них располагаются словари и
приложения, служащие своеобразными фильтрами для данных сервера. В связи с этим
обмен информацией в архитектуре (рис. 6) фактически минимизируется.
Работа в архитектуре клиент-сервер может
поддерживаться и с помощью схемы OpenDataBaseConnectivity (ODBC), как показано
на рис. 7.

Рис. 7. ODBC в архитектуре клиент-сервер
В этом случае сеть образуется путем соединения
серверов. Такое соединение обеспечивается или средствами СУБД (SQL Server) или
мониторами транзакций (TUXEDO).
.2 Система клиент-сервер
Совместно с термином "клиент-сервер"
используются три понятия.
.Архитектура:речьидет о концепции построения
варианта
распределенной
БД.
.Технология:говорят о последовательности
действий в распределенной БД.
. Система: рассматриваются совокупность элементов
и их взаимодействие.
Технология клиент-сервер позволяет повысить
производительность труда:
• сокращается общее время выполнения запросов за
счет мощного сервера;
• уменьшается доля и увеличивается эффективность
использования клиентом (для вычислений) центрального процессора;
• уменьшается объем использования клиентом
памяти "своего" компьютера;
• сокращается сетевой трафик.
К таким крупномасштабным системам предъявляются
следующие требования:
) гибкость структуры;
) надежность;
) доступность данных;
) легкость обслуживания системы;
) масштабируемость приложений;
) переносимость приложений (на разные
платформы);
) многозадачность (возможность выполнения многих
приложений).
Отметим, что архитектуре клиент-сервер
предшествовала архитектура файл-сервер,
в которой возможны следующие варианты.
. На компьютерах-клиентах имеется копия БД.
Работа по такому варианту имеет следующие сложности: синхронизация данных
различных копий в конце работы БД; высокий трафик (потоки данных между сервером
и клиентами, поскольку передается в любом случае содержимое всей БД).
. В СУБД Access, которая изначально создана как
локальная, предусмотрен режим деления базы данных. Таблицы остаются на сервере
(back-end), а остальные объекты (запросы, отчеты) передаются клиентам (front-end).
В этом случае по-прежнему большой трафик, в силу чего при использовании
файл-серверов количество подключаемых клиентов - при их надежной работе - до
четырех.
В то же время требовалось подключение десятков и
даже сотен клиентов [1-3]. Этого удалось достичь в архитектуре (режиме,
технологии) клиент-сервер. В этом режиме трафик резко уменьшается, поскольку по
сети передаются только те данные, которые соответствуют запросам клиентов [2].
Для этого пришлось построить СУБД, изначально
предназначенные для работы в сети. Фирма Microsoft вынуждена была - в
дополнение к СУБД Access, которая использовалась с помощью приложения ODBC
только для клиентских целей - предложить в качестве сервера Microsoft SQL
Server. Такая структура оказалась тяжеловесной и неудобной, так как
разработчику требовалось знать уже две СУБД.
Из других предложений очень удачным оказался
программный продукт Delphi, в рамках которого могут использоваться СУБД dBase,
Paradox, и, при отдельной инсталляции, InterBase (режим клиент-сервер). При этом
СУБД InterBase поддерживается, наряду с языком программирования SQL, мощным,
понятным, простым и широко распространенным языком программирования (Object)
Pascal, построенным с применением объектно¬ориентированного подхода.
Последнее обстоятельство позволяет легко строить
объектно-ре¬ляционные базы данных. Высокая степень автоматизации
программирования дает возможность резко упростить и снизить трудоемкость
процедур создания интерфейса пользователя, и особенно алгоритма приложения.
В системе клиент-сервер возможно выделить
следующие составляющие: сервер, клиент, интерфейс между клиентом и сервером,
администратор.
Сервер осуществляет управление общим для
множества клиентов ресурсом. Он выполняет следующие задачи:
• управляет общей БД;
• осуществляет доступ и защиту данных, их
восстановление;
• обеспечивает целостность данных.
К БД на сервере предъявляются те же требования,
как и к цент¬рализованной многопользовательской БД.
Следует отметить, что результаты запросов
клиента помещаются в рабочую область памяти сервера, которая в ряде СУБД
(например, Oracle) называют "табличная область". Поскольку она не
занимает много места, для каждого клиента-пользователя целесообразно создавать
свою табличную область. В этом случае исходные таблицы становятся для пользователя
недоступными, а архивация (копирование) БД приложения клиента упрощается.
Клиент хранит в компьютере свои приложения, с
помощью которых осуществляется запрос данных на сервере. Клиент решает
следующие задачи:
• предоставляет интерфейс пользователю;
• управляет логикой работы приложений;
• проверяет допустимость данных;
• осуществляет запрос и получение данных с
сервера.
Средством передачи данных между клиентом и
сервером является сеть (коаксиальный кабель, витая пара) с сетевым (сетевая
операционная система - СОС) и коммуникационным программным обеспечением.
В качестве СОС могут использоваться Windows NT,
NovellNetWare. Коммуникационное программное обеспечение позволяет компьютерам
взаимодействовать на языке специальных программ - коммуникационных протоколов.
В общем случае такое взаимодействие
осуществляется с помощью семиуровневой схемы ISO с соответствующими
протоколами. Длялокальныхсетейсхемаупрощается.
Протоколамидля
Windows NT служит
Transmission Control Program/Internet Program (TCP/IP), для
NetWare - Sequenced Packed eXchange/Internet Packed eXchaned (SPX/IPX).
Разнообразие сетевых средств делает необходимым
создание стан¬дартного промежуточного программного обеспечения клиент-сервер,
находящегося на сервере и клиентах. Говорят о прикладном программном интерфейсе
(ApplicationProgrammingInterface - API). Сюда относятся
OpenDataBaseConnectivity (ODBC) и
IntegratedDatabaseApplicationProgrammingInterface (IDAPI), используемый в
приложении Delphi и СУБД InterBase.
Взаимодействие клиентов и сервера можно представить
себе следующим образом.
При обращении пользователя к приложению
компьютер-клиент запрашивает у пользователя имя и пароль. После этого - при
правильном ответе - приложение может быть запущено клиентом. Приложение дает
возможность подключиться к серверу, которому сообщается имя и пароль
пользователя.
Если подключение осуществлено, начинает работать
сервер, вы¬полняющий два вида процессов: переднего раздела и фоновые.
Процессы переднего раздела непосредственно
обрабатывают запросы, фоновая составляющая связана с управлением процессом
обработки.
Работа сервера может иметь такой порядок.
. После поступления запроса диспетчер ставит его
в очередь по схеме "первым пришел - первым обслужен".
. Процесс переднего раздела выбирает "самый
старый" запрос и начинает его обработку. После завершения результаты
помещаются в очередь для передачи клиенту.
. Диспетчер посылает результаты из очереди
соответствующему клиенту.
При обработке запроса фоновые процессы выполняют
другие важные операции, основными из которых являются следующие:
• запись данных из БД в промежуточную (буферную)
память ра¬бочей области (при чтении) и обратно (при обновлении);
• запись в журнал транзакций;
• архивация (копирование) групп транзакций;
• аварийное завершение транзакций;
• периодическая запись на диск контрольных точек
для обеспе¬чения восстановления данных в РБД после аппаратного сбоя.
Администратор распределенной БД (АРБД) должен
решать следующие задачи:
. Настройка конфигурации сети.
. Создание распределенной БД.
. Работа с разработчиками приложений.
. Создание новых пользователей и управление
полномочиями.
. Регулярная архивация БД и выполнение операций
по ее вос¬становлению.
. Управление доступом к БД с помощью ОС и СОС,
средств защиты и доступа.
В больших системах АРБД может состоять из ряда
лиц, отвечающих, например, за ОС, сеть, архивацию, защиту.
Таким образом, система клиент-сервер
своеобразна: с одной стороны, ее можно считать разновидностью централизованной
многопользовательской БД, с другой стороны, она является частным случаем РБД.
В связи с этим имеется специфика и в процессе
проектирования. Оно по-прежнему начинается с создания приложения, затем -
интерфейса и БД. Однако в силу специфики системы этапы фрагментации и размещения
отсутствуют и есть свои особенности.
Основное ограничение для работы такой системы -
минимальный трафик. Поэтому при разработке приложения, помимо обычных задач
(уяснения цели приложения, логики обработки, вида интерфейса) особое внимание
следует обратить на разработку DLL-сценария и распределение функций между
клиентами и сервером.
Использование для составления сценария
CASE-средств значительно сокращает трудоемкость работ по проектированию. Иначе
эта процедура выполняется вручную с помощью команд языка SQL.
Важнейшей является задача распределения функций.
По самой сути технологии на сервере расположена БД, а на компьютерах-клиентах -
приложения. Однако при прямолинейных процедурах обеспечения целостности и
запросах в сети может возникнуть объемный сетевой трафик.
Чтобы его снизить, возможно использовать
следующие рекомендации.
. Обеспечение целостности для всех приложений
лучше централизовать и осуществлять на сервере. Это позволит не только
сократить трафик, но и рационально использовать СУРБД, улучшив управление
целостностью (ссылочной, ограничений, триггеров) данных.
. Целесообразно использовать на сервере хранимые
процедуры, совокупность которых можно инкапсулировать в виде пакета (модуля). В
результате трафик уменьшится:клиент будет передавать только вызов процедуры и
ее параметры, а сервер - результаты выполнения процедуры.
.В ряде случаев клиентам следует получать
уведомления базы данных (например, заведующему складом - о нижнем уровне
запасов, при котором следует выполнять новый заказ). Если уведомление
производится по запросу клиента, трафик увеличивается. Проще эту (хранимую)
процедуру разместить на сервере, который будет автоматически уведомлять клиента
о возникновении события. В то же время клиент при необходимости может получать
информацию с помощью простых вызовов процедур.
В режиме клиент-сервер выделяют две
разновидности структуры: одноуровневую, о которой шла речь до сих пор, и
многоуровневую (рис. 8).

Рис. 8. Одноуровневая - "толстый"
клиент (а) и многоуровневая - "тонкий" клиент
(б) структуры клиент-сервер
При использовании режима "толстого"
клиента (одноуровневая структура) клиентские приложения находятся
непосредственно на машинах пользователей, либо частично на сервере в виде
системы хранимых процедур. Сложность клиентской части порой требует ее
администрирования. Использование системы хранимых процедур в значительной мере
снижает нагрузку на сеть.
При использовании "тонкого" клиента
(многоуровневая структура) приложения пользователей лежат и выполняются на
отдельном мощном сервере (сервере приложений, который может быть и на одном
компьютере с сервером БД), что в значительной мере снижает требования к
пользо¬вательским машинам.
Так, в СУБД InterBase в одноуровневой структуре
в каждом клиенте имеется утилита BorlandDatabaseEngine (BDE - ядро Delphi)
объемом 8 Мбайт. В многоуровневой структуре BDE-утилита имеется только в
сервере приложений, а объем памяти, занимаемой клиентом, снижается до 212
кбайт.
Достигается этот результат за счет усложнения структуры.
.3 Преимущества и недостатки распределенных СУБД
Распределенные системы баз данных имеют
дополнительные преимущества перед традиционными централизованными системами баз
данных, К сожалению, эта технология не лишена и некоторых недостатков. В этом
разделе описаны как преимущества, так и недостатки, свойственные
Распределенным СУБД.
Обзорная таблица
|
Преимущества
|
Недостатки
|
|
Отображение структуры организации
|
Повышение сложности
|
|
Разделяемость и локальная
автономность
|
Увеличение стоимости
|
|
Повышение доступности данных
|
Проблемы защиты
|
|
Повышение надежности
|
Усложнение контроля за
целостностью данных
|
|
Повышение производительности
|
Отсутствие стандартов
|
|
Экономические выгоды
|
Недостаток опыта
|
|
Модульность системы
|
Усложнение процедуры разработки
базы данных
|
2. Отражение структуры организации
Крупные организации, как правило, имеют
множество отделений, которые могут находиться в разных концах страны и даже за
ее пределами. Например, компания DreamHome имеет многочисленные отделения в
различных городах Великобритании. Вполне логично будет предположить, что
используемая этой компанией база данных должна быть распределена между ее
отдельными офисами. В каждом отделении компании DreamHome может поддерживаться
база данных, содержащая сведения о его персонале, сдаваемых в аренду объектах
недвижимости, которыми занимаются сотрудники данного отделения, а также о
клиентах, которые владеют или желают получить в аренду эти объекты. В подобной
базе данных персонал отделения сможет выполнять необходимые ему локальные запросы.
А руководству компании может потребоваться выполнять глобальные запросы,
предусматривающие получение доступа к данным, которые хранятся во всех или в
некоторых существующих отделениях компании.
Высокая степень разделяемости и локальной
автономности Г еографическаяраспределенность организации может быть отражена в
распределении ее данных, причем пользователи одного узла смогут получать доступ
к данным, хранящимся на других узлах. Данные могут быть помещены на тот узел,
где зарегистрированы пользователи, чаще всего работающие с этими данными. В
результате заинтересованные пользователи получают локальный контроль над
требуемыми им данными и могут устанавливать или регулировать локальные
ограничения на их использование. Администратор глобальной базы данных (АБД)
отвечает за систему в целом. Как правило, часть этой ответственности
делегируется на локальный уровень, благодаря чему АБД локального уровня
получает возможность управлять локальной СУБД.
2.1 Повышение
доступности данных
В централизованных СУБД отказ центрального
компьютера вызывает прекращение функционирования всей СУБД. Однако отказ одного
из узлов распределенной СУБД или линии связи между узлами приводит к тому, что
становятся недоступными лишь некоторые узлы, тогда как вся система в целом сохраняет
свою работоспособность. Распределенные СУБД проектируются таким образом, чтобы
обеспечивалось их функционирование, несмотря на подобные отказы. Если выходит
из строя один из узлов, система сможет перенаправить запросы, адресованные
отказавшему узлу, на другой узел.
2.2 Повышение
надежности
Если организована репликация данных, в
результате чего данные и их копии будут размещены на нескольких узлах, отказ
отдельного узла или линии связи между узлами не приведет к прекращению доступа
к данным в системе.
2.3 Повышение производительности
Если данные размещены на самом нагруженном узле,
который унаследовал от систем-предшественников высокий уровень
распараллеливания обработки, то развертывание распределенной СУБД может
способствовать повышению скорости доступа к базе данных (по сравнению с
доступом к удаленной централизованной СУБД). Более того, поскольку каждый узел
работает только с частью базы данных, степень использования центрального
процессора и служб вводавывода может оказаться ниже, чем в случае
централизованной СУБД.
3. Экономические выгоды
В 1960-е годы мощность вычислительных средств
возрастала пропорционально квадрату стоимости ее оборудования, поэтому система,
стоимость которой была втрое выше стоимости данной, превосходила ее по мощности
в девять раз. Эта зависимость получила название закона Гроша. Однако в
настоящее время считается общепринятым положение, согласно которому намного
дешевле собрать из небольших компьютеров систему, мощность которой будет
эквивалентна мощности одного большого компьютера. Оказывается, что намного
выгоднее устанавливать в подразделениях организации собственные маломощные
компьютеры, кроме того, гораздо дешевле добавить в сеть новые рабочие станции,
чем модернизировать систему с мэйнфреймом.
Второй потенциальный источник экономии имеет
место в том случае, если базы данных географически удалены друг от друга и
приложения требуют осуществления доступа к распределенным данным. В этом случае
из-за относительно высокой стоимости передачи данных по сети (по сравнению со
стоимостью их локальной обработки) может оказаться экономически выгодным
разделить приложение на соответствующие части и выполнять необходимую обработку
на каждом из узлов локально.
3.1 Модульность
системы
В распределенной среде расширение существующей
системы осуществляется намного проще. Добавление в сеть нового узла не
оказывает влияния на функционирование уже существующих. Подобная гибкость
позволяет организации легко расширяться. Перегрузки из-за увеличения размера
базы данных обычно устраняются путем добавления в сеть новых вычислительных
мощностей и устройств внешней памяти. В централизованных СУБД расширение базы
данных может потребовать замены оборудования (более мощной системой) и
используемого программного обеспечения (более мощной или более гибкой СУБД).
3.2 Повышение
сложности
Распределенные СУБД, способные скрыть от
конечных пользователей распределенную природу используемых ими данных и
обеспечить необходимый уровень производительности, надежности и доступности,
безусловно, являются более сложными программными комплексами, чем
централизованные СУБД. Тот факт, что данные могут подвергаться копированию,
также создает дополнительную предпосылку усложнения программного обеспечения
распределенной СУБД.Если репликация данных не поддерживается на требуемом
уровне, система будет иметь более низкий уровень доступности данных, надежности
и производительности, чем централизованные системы, а все изложенные выше
преимущества превратятся в недостатки.
3.3 Увеличение
стоимости
Увеличение сложности означает и увеличение
затрат на приобретение и сопровождение распределенной СУБД (по сравнению с
обычными централизованными СУБД). К тому же развертывание распределенной СУБД
требует дополнительного оборудования, необходимого для установки сетевых
соединений между узлами. Следует ожидать и увеличения расходов на оплату
каналов связи, вызванных ростом сетевого трафика. Кроме того, возрастут затраты
на оплату труда персонала, который потребуется для обслуживания локальных СУБД
и сетевых соединений.
4. Усложнение контроля за целостностью данных
Целостность базы данных означает правильность и
согласованность хранящихся в ней данных. Требования обеспечения целостности
обычно формулируются в виде некоторых ограничений, выполнение которых будет
гарантировать защиту информации в базе данных от разрушения. Реализация
ограничений поддержки целостности обычно требует доступа к большому количеству
данных, используемых при выполнении проверок, но не требует выполнения операций
обновления. В распределенных СУБД повышенная стоимость передачи и обработки
данных может препятствовать организации эффективной защиты от нарушений
целостности данных.
4.1 Отсутствие стандартов
Хотя вполне очевидно, что функционирование
распределенных СУБД зависит от эффективности используемых каналов связи, только
в последнее время стали вырисовываться контуры стандартов на каналы связи и
протоколы доступа к данным. Отсутствие стандартов существенно ограничивает
потенциальные возможности распределенных СУБД. Кроме того, не существует
инструментальных средств и методологий, способных помочь пользователям в
преобразовании централизованных систем в распределенные.
4.2 Недостаток опыта
В настоящее время в эксплуатации находится уже
несколько систем- прототипов и распределенных СУБД общего назначения, что
позволило уточнить требования к используемым протоколам и установить круг
основных проблем. Однако на текущий момент распределенные системы общего
назначения еще не получили широкого распространения. Соответственно, еще не
накоплен необходимый опыт промышленной эксплуатации распределенных систем,
сравнимый с опытом эксплуатации централизованных систем. Такое положение дел
является серьезным сдерживающим фактором для многих потенциальных сторонников
данной технологии.
Заключение
Подводя итоги нашей работы, выделим следующие
моменты.
Системы управления базами данных - одна из
фундаментальных составляющих компьютерного обеспечения информационных
процессов, являющаяся основой для построения большинства современных
информационных систем. Главной функцией СУБД является эффективное хранение и
предоставление данных в интересах конкретных прикладных задач.
Сам рынок СУБД за последнее время значительно
фрагментировался. В свою очередь, быстро меняющиеся потребности современного
бизнеса постоянно повышают требования к приложениям и инфраструктуре. Появились
целые секторы, в которых использование универсальных СУБД либо слишком дорого,
либо неэффективно. Для решения конкретного спектра задач в определенных
отраслях становится более подходящим использование специализированные СУБД.
Список использованной литературы
.Ф94 базы данных :учебное пособие
для студе.учреждений сред. Проф,оброзования/ Э.В.Фуфаев, Д.Э.Фуфаев. -6-е
изд,сред-М,:издательский центр "АКАДЕМИЯ",2011-320c.
.Бураков П.В., Петров В.Ю. Введение
в системы баз данных: Учебное пособ. - Изд-во: СПбГУ ИТМО, 2010. - 129 с.
.Гришков В.И. Исследование
возможностей объектного представления данных в прикладных системах // Труды
СПИИРАН. Вып.1, т.3. - СПб: СПИИРАН, 2003.
.Роб П., Коронел К. Системы баз
данных: проектирование, реализация и управление. - 5-е изд., перераб. и доп. -
СПб.: БХВ-Петербург, 2004. - 1040 с.
.www.atomas.ru/tp/8/8_5.html
.www.mirosoft.com-сайт
компании Microsoft.