Разработка модуля контроля знаний именного склонения для интеллектуальной системы обучения русскому языку как иностранному
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
РОССИЙСКОЙ ФЕДЕРАЦИИ
Федеральное государственное бюджетное
образовательное учреждение высшего профессионального образования
НАЦИОНАЛЬНЫЙ ИССЛЕДОВАТЕЛЬСКИЙ
ТОМСКИЙ ПОЛИТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Институт кибернетики
Направление - Информатика и
вычислительная техника
Кафедра - Оптимизация систем
управления
РАЗРАБОТКА МОДУЛЯ КОНТРОЛЯ ЗНАНИЙ
ИМЕННОГО СКЛОНЕНИЯ ДЛЯ ИНТЕЛЛЕКТУАЛЬНОЙ СИСТЕМЫ ОБУЧЕНИЯ РУССКОМУ ЯЗЫКУ КАК
ИНОСТРАННОМУ
Выпускная квалификационная работа
(на соискание квалификации магистр)
Студент гр. 8ВМ15
Д.И. Фирстов
Томск 2013
Реферат
Основная задача выпускной квалификационной работы - разработка алгоритмов
контроля знаний именного склонения для системы обучения русскому языку как
иностранному.
В работе проводится анализ существующих на рынке автоматизированных
систем обучения, даётся описание требований к разрабатываемой системе в целом и
к модулю контроля знаний в частности, приводится описание используемых
лингвопроцессорных средств, делается обоснование их выбора. В последней главе
подробно рассматриваются разработанные алгоритмы, их достоинства и недостатки.
Оглавление
Реферат
Введение
1. Автоматизированные обучающие системы
1.1 Инструментальные оболочки
1.1.1 Moodle
1.1.2 Blackboard Learning System
1.1.3 СТ Курс
1.2 Интеллектуальные обучающие системы
2. Система КЛИОС
2.1 Общие требования к системе
2.2 Модуль проверки упражнений
3. Лингвистические процессоры
3.1 АОТ
3.2 Cognitive Dwarf
3.3 DictaScope
3.4 pymorphy2
3.5 ABBYY Compreno
4. Алгоритмы решения и проверки упражнений на
именную часть русского языка
4.1 Алгоритм проверки упражнений типа «Заданный
ответ»
4.2 Алгоритм проверки упражнений типа «Поставить
слово / словосочетание в заданную форму»
4.3 Алгоритм проверки упражнений типа «Склонение с
числами»
4.4 Алгоритм проверки упражнений типа «Ответить по
модели»
4.4.1 Выявление преобразований
4.4.2 Применение правил преобразования
4.5 Недостатки алгоритмов
Заключение
Список литературы
Введение
Томский политехнический университет уже более 10 лет занимается обучением
иностранных студентов. По данным сайта ТПУ на сегодняшний день международная
среда университета представлена 2100 студентами из 40 стран мира [1].
Иностранные студенты сильно различаются по уровню языковой подготовки. Русским
языком владеют лишь единицы. Так как обучение в ТПУ ведётся в основном на
русском языке, кафедра РКИ ИМОЯК проводит специальные курсы, на которых
студенты изучают основы русского языка.
Студенты приезжают из разных стран, у них разные национальные
особенности. Из-за этого при обучении требуется индивидуальный подход, что в
силу большого количества приезжих студентов обеспечить в полной мере
невозможно. По этой причине было принято решение создать в Томском
политехническом университете автоматизированную систему обучения русскому языку
как иностранному.
В настоящее время автоматизированные обучающие системы набирают всё бо́льшую популярность. Их достоинства
очевидны. Такие системы позволяют проводить дистанционные занятия, что
экономически выгодно [2]. Кроме того, они подталкивают студента к
самостоятельной учебной деятельности, что приводит к снижению нагрузки на
преподавателя. Также, обучающие компьютерные программы позволяют широко
использовать возможности мультимедиа, что способствует, по мнению психологов и
педагогов, лучшему усвоению материала [3].
Предполагается, что создание такой системы позволит повысить
эффективность преподавания русского языка как иностранного. Система планируется
как веб-ориентированая, поэтому студенты могут пользоваться ей из дома или из
любого другого места, где есть выход в сеть Интернет. Автоматизированный
интеллектуальный контроль знаний позволит им работать над своими языковыми
навыками самостоятельно, без непосредственного участия преподавателя. Также
система может использоваться и на очных занятиях в качестве дополнительного
учебного материала.
Важной частью этой системы является модуль проверки упражнений. Основная
задача этого модуля - контроль знаний студентов. Модуль должен анализировать
ответы студентов на естественном языке и оценивать их правильность.
Первым этапом в обучении студентов русскому языку является именная часть
русской грамматики. К этой части относится склонение существительных,
местоимений и прилагательных.
Исходя из сказанного выше, можно сформулировать цель данной работы.
Основной целью является разработка программного модуля, который должен в
автоматическом режиме проверять упражнения на именную часть русской грамматики
и оценивать качество их выполнения. Для этого требуется решить следующие
задачи:
. Рассмотреть существующие программные решения для обучения
студентов и контроля их знаний. Сделать выводы об их применимости в данной
ситуации.
. Проанализировать упражнения на именную часть грамматики русского
языка, предоставленные преподавателями кафедры РКИ ИМОЯК.
. Сделать обзор современных лингвистических программных средств и
выбрать наиболее подходящие для решения задачи проверки предоставленных
упражнений.
. Составить алгоритмы проверки упражнений, реализовать их и
протестировать. Проанализировать достоинства и недостатки такого решения.
1. Автоматизированные обучающие системы
Автоматизированные обучающие системы можно условно разделить на два типа [4]:
. Системы или курсы, разрабатываемые под определённую предметную
область специально привлечёнными для этой цели программистами под руководством
преподавателя данной дисциплины.
. Инструментальные оболочки, предназначенные для заполнения их
учебными материалами и тестовыми заданиями из любой предметной области. Такие
системы могут заполняться преподавателями и не требуют знаний языков
программирования. Иногда требуется лишь знание языка разметки HTML.
1.1 Инструментальные оболочки
На сегодняшний день наиболее известны на российском рынке три
инструментальные системы (оболочки): «Blackboard Learning», СДО «СТ Курс» и «Moodle» [4].
Типовая структурная схема, характерная для вышеуказанных инструментальных
оболочек, изображена на Рис. 1.
Возможности, предоставляемые данными комплексами разработчикам учебных
курсов, незначительно отличаются друг от друга, и поэтому создаваемая
преподавателями система дистанционного обучения обычно состоит из независимых
подсистем обучения и контрольного тестирования.
Подсистема обучения представляет собой программу, осуществляющую вывод на
дисплей в установленной последовательности порций учебного материала в
текстовой форме, написанного на языке HTML, который сопровождается
дополнительными средствами отображения информации (анимация, мультипликация,
звук, гипертекст, глоссарий и т. д.). Наполнение программ конкретным предметно-ориентированным
содержанием обеспечивает создание различных типов обучающих курсов в учебных
целях.
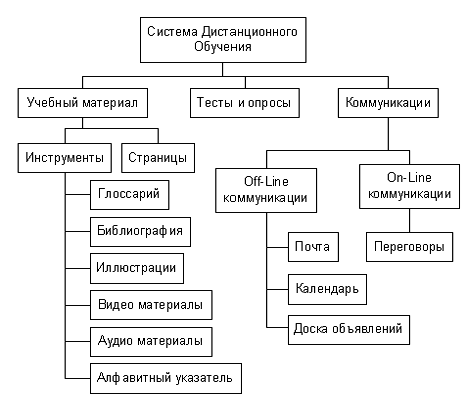
Рис.
1. Пример структурной схемы системы дистанционного обучения «СТ Курс»
Контрольное тестирование использует методы стандартизованного контроля
знаний. Суть их состоит в том, что обучаемому предлагается выборка специальных
заданий и по ответам на неё выносится суждение о его знаниях. Для этого
выделяются некоторые признаки, в соответствии с которыми ответ обучаемого относится
к категории правильных или неправильных. Чаще всего это происходит путём
указания эталона ответа и определения процедуры сравнения. На каждый вопрос
имеется простой ответ, который может быть формально проверен и оценён как
правильный, неправильный или частично правильный (например, неполный). Вопросы
обычно классифицируются по типам соответственно типу ожидаемого ответа.
Наиболее распространенная форма ответов - выборочная: вопрос сопровождается
несколькими готовыми вариантами ответов, из которых нужно выбрать один или
несколько правильных ответов.
Вторым по популярности идёт числовой ответ. Обычно это результат решения
предложенной задачи.
Кроме этого, иногда используется текстовый ответ, но без анализа, т. е.
правильным считается ответ, полностью совпадающий с эталоном.
Также применяются тесты, в которых предоставляется возможность в ответе
устанавливать соответствие между элементами двух списков:
Более продвинутые типы вопросов включают вопросы на правильную
последовательность, вопросы на указывание (ответ - одна или несколько областей
на рисунке), а также графические вопросы (ответ - простой граф).
Рассмотрим более подробно указанные системы.
1.1.1 Moodle
Moodle
(Modular Object-Oriented Dynamic
Learning Environment - Модульная объектно-ориентированная
динамическая среда обучения) - это свободная система с открытым исходным кодом.
Она предоставляет студентам и преподавателям следующие возможности [5]:
. Для преподавателей:
) Возможность добавления документов простым перетаскиванием файла.
) Простое встраивание средств мультимедиа.
) Виртуальные «награды» студентам за успехи в учёбе.
) Возможность гибко управлять курсом обучения конкретного
студента.
) Форумы, wiki,
глоссарии, комментарии и личные сообщения как инструменты дистанционного
общения преподавателя со студентами и с другими преподавателями.
) Возможность создания всех перечисленных выше видов тестов.
) Возможность оценивания работы учеников по разным критериям.
) Предоставление студентам критериев для оценки работ своих
сокурсников.
. Для студентов:
) Возможность хранения файлов.
) Отслеживание прогресса по курсам.
) Возможность создания персональной домашней страницы.
1.1.2 Blackboard Learning System
Blackboard Learning
System - это коммерческая оболочка для
создания электронных курсов. Она состоит из четырёх модулей [6]:
. Обучающая система, которая предоставляет возможность создания
онлайн курсов и управления ими.
. Портальная система, которая может быть использована для создания
онлайн сообществ.
. Система управления содержимым для централизованного контроля над
всеми ресурсами курса.
. Система ведения журнала успеваемости и анализа результатов
обучения.
Что касается автоматизированного контроля знаний, данная система
предоставляет все описанные выше методы тестирования.
1.1.3 СТ Курс
«СТ Курс» - это российская система дистанционного обучения, разработанная
компанией Cognitive Technologies. На данный момент её развитие
прекращено.
Система в первую очередь ориентирована на создание платных курсов на
договорной основе. В системе есть специальный модуль, отвечающий за оформление
договоров на обучение [7].
Все предоставляемые системой возможности изображены на Рис. 1.
1.2
Интеллектуальные обучающие системы
Анализ ответов, вводимых в свободной текстовой форме, является самой
естественной и наиболее сложной задачей при организации системы контроля знаний
обучаемых. К сожалению, рассмотренные выше инструментальные комплексы не
позволяют создавать преподавателям русского языка интеллектуальные системы
обучения РКИ.
Интеллектуальный анализ решений - это процедура проверки, при которой
обучающая система способна проанализировать ответы студента на тестовые
задания, указать, что именно неправильно или неполно освещено в ответе и, как
следствие, какие знания недостаточно усвоены студентом. В связи с этим
интеллектуальные обучающие системы могут предоставлять обучаемому подробную
информацию об ошибках и соответственно адаптировать учебный процесс к
индивидуальным особенностям студента.
Эта адаптация может включать, например, постоянный подбор и организацию
структуры следующей порции учебного материала - в зависимости от того, какие
компоненты знания и процедуры изучаемого предмета обучаемым и насколько хорошо.
Также могут учитываться его эмоциональное и когнитивное состояние,
мотивация к обучению, учебные цели (подготовка к итоговому экзамену по предмету
или изучение полного курса «с нуля», в индивидуальных формах и темпе).
Интеллектуализация компьютерного обучения предполагает использование
методов и моделей представления знаний на базе систем, основанных на знаниях.
В последние десять лет в мире появилось немало интеллектуальных обучающих
систем для формализованных предметных областей отличных от РКИ. Некоторые из
них являются коммерческими. Одним из лидеров, например, может быть названа
компания СarnegieLearning, продающая ИОС для изучения математики сотням школ в
США. Обзор и состояние работ по созданию интеллектуальных систем обучения за
рубежом дан в работе [8].
В России, к сожалению, такие работы ведутся пока в сравнительно небольших
масштабах и не вышли на коммерческий уровень. К числу интересных работ можно
отнести работы, по созданию ИОС «Волга», разрабатываемой ИПУ РАН в
сотрудничестве с КГТУ и другими вузами. Поскольку эту работу можно отнести к
числу пионерских в области создания интеллектуальных обучающих систем
нацеленных на изучение математики в вузах и в школах, рассмотрим её подробнее.
ИОС «Волга» позволяет осуществлять углубленную индивидуализацию обучения
на основе логико-оптимизационных методов автоматизации планирования действий
ИОС с веб-интерфейсом для удалённых пользователей. В рамках данного проекта
разрабатываются и внедряются оригинальные методы дедукции, абдукции, решения
логических уравнений и многокритериальной оптимизации.
Центральное место в ИОС занимает модуль управления процессом обучения,
который использует для планирования и выбора действий системы логические
«решатели» и методы теории принятия решений. Для генерации новой порции
учебного материала и помощи обучаемому этот модуль задействует знания о
предметной области и педагогическую модель. Также он использует сведения об
обучаемом, которые хранятся в модели обучаемого и извлекаются по запросу
анализатором действий.
Метазнания о компетенции обучаемого первоначально формируется путём
диагностирования обучаемого с помощью тестов, когда осуществляется испытание
обучаемого на знание определений, правил, исключений и т. п., а также на умение
выполнять простейшие или более сложные упражнения. При этом осуществляется
последующее итеративное уточнение компетентностной модели обучаемого по
результатам его ответов в ходе решения задач после изучения им очередной порции
материала, предложенной ему с учётом достигнутой компетенции.
Для отслеживания уровня умений и поддержки индивидуального подбора задач
используется оверлейная модель обучаемого (это модель, которая предполагает,
что знания (умения) обучаемого являются подмножеством знаний (умений) о
предметной области, имеют ту же структуру и отличаются лишь тем, что менее
полны). Умения обучаемого моделируются как набор продукционных правил вида
«если - то», имеющиеся в когнитивной модели обучения и помеченные маркерами
«выучено» или «не выучено».
Система содержит компьютерные программы («решатели») автоматического
решения следующих школьных и вузовских задач:
) Вычислительного типа «дано - требуется»;
) На доказательство предъявленного утверждения;
) На поиск условий разрешимости задачи того или иного типа и др.
Знания о предметной области, которые использует «решатель» в настоящий
момент, охватывает некоторые разделы геометрии и математической статистики.
«Решатель» участвует в проверке решения студента на завершенность и в генерации
подсказок.
В первом случае среди найденных автоматически вариантов решений ищутся
совпадающие с решением студента или наиболее близкие к нему.
Во втором случае повторяется такой же поиск; подсказывается первый
незавершённый шаг из найденного решения. Если это не помогает студенту, то в
дальнейшем выводится поочередно последовательность подсказок, постепенно,
приводящих решение задачи к конечному результату.
Эта система на данный момент непригодна для обучения студентов русскому
языку из-за её ориентированности на точные науки.
2. Система КЛИОС
.1 Общие требования к системе
Анализ процесса обучения РКИ показал, что компьютерная система для
обучения иностранных студентов русскому языку должна отвечать следующим
функциональным требованиям, выполнение которых обеспечивает достижение высокой
эффективности в изучении русского языка в вузе [4].
. Система должна обладать справочно-обучающими, тренажерными,
тестирующими и диагностирующими функциями, которые могут использоваться в
процессе работы системы, как в отдельности, так и в совокупности, в зависимости
от поставленной пользователем задачи.
Наличие в системе справочно-обучающих функций, позволит пользователям не
только подготовительного отделения, но и старших курсах университета найти
необходимую справочную информацию по грамматике русского языка, произношению и
объяснению смысла незнакомых слов, встречающихся по произвольному тексту. Кроме
того система в этом режиме работы даёт возможность пользователю самостоятельно
изучать русский язык, последовательно осваивая теоретический и практический
материалы, содержание которых соответствует выбранному пользователем стандарту
обучения: элементарному, базовому или первому уровню.
В тренажёрном режиме работы система должна предоставлять каждому студенту
для самостоятельного выполнения совокупность упражнений по фонетике или
грамматике изучаемого раздела языка. Система оценивает правильность их
исполнения и при наличии ошибок даёт дополнительный материал на данную тему
пока студент не добьётся результатов, близких к 100%.
Тестирующие функции системы должны позволять не только оценивать общий
уровень владения русским языком, но и диагностировать пробелы в знаниях РКИ,
контролировать усвоение изучаемого материала по конкретной тематике с
установлением количественной меры его измерения (в процентной или бальной
системе).
Система должна предоставлять преподавателям возможность создания
традиционных тестирующих упражнений: множественный выбор, соответствие,
установление правильной последовательности, подстановка пропущенные в слове
символов, краткий ответ. Кроме этого, система должна самостоятельно без
привлечения преподавателя проводить обработку текстового материала задания, и производить
оценку правильности его выполнения студентом путем сравнения его с
результатами, полученными самой системой.
. Система должна обеспечивать индивидуальность обучения студентов
обучения РКИ, которая обеспечивается:
) Применением клиент-серверной технологии e-learning, позволяющей
студентам организовать доступ в систему не только в классе, но и с любого
компьютера, подключенного к сети Интернет.
) Организацией перед началом учебного года тестирования каждого
иностранного студента, приезжающего в ИМОЯК, для выявления индивидуальных
психофизиологических особенностей личности.
) Разработкой для каждого студента адаптивного плана
индивидуального обучения на основе результатов психофизиологического
тестирования личности и результатов текущих контрольных точек по пройденным
разделам русского языка.
. Система должна быть рассчитана как на обучение иностранных
студентов на подготовительном отделении ИМОЯК в соответствии с установленным
ГОСТом для элементарного, базового и первого уровня обучения РКИ, так и на использование
её в Центрах, занимающихся дистанционной подготовкой иностранных граждан
русскому языку.
Кроме того она должна использоваться на старших курсах, как справочная
система, воспроизводящая произношение незнакомого слова и определяющая его
смысл, при условии, что тезаурус системы будет предварительно заполнен
преподавателями специальных предметов.
Наряду с обеспечением требований, предъявляемых к выполнению системой
функций и области её применения система должна удовлетворять и конкретным
требованиям, выполнение которых обеспечивает достижение высокой эффективности в
изучении русского языка в вузе.
. Система должна быть способна понимать и производить тексты на
естественном языке.
. Система должна имитировать общение на естественном языке.
. Система должна уметь оценивать ответы учащегося в текстовой
форме и предлагать ему индивидуальную траекторию освоения темы.
. Система оценивания должна быть адекватной и оценивать ошибки
только определённой тематики.
. Преподаватель должен иметь постоянный доступ к информации о
работе и достижениях студента.
. Система подбора упражнений со стороны преподавателя должна быть
автоматизирована.
. Каждый тематический (грамматический) блок должен содержать:
теоретическую информацию, систему упражнений (тренажер) и коммуникативные
текстовые упражнения, имитирующие общение на естественном языке.
. В каждом тематическом блоке должно присутствовать звуковое
сопровождение.
2.2 Модуль проверки упражнений
Неотъемлемой частью системы КЛИОС является интеллектуальный модуль проверки
упражнений. Под интеллектуальностью модуля мы понимаем возможность решать
задания в автоматическом режиме и сравнивать полученные результаты с ответами,
данными студентом.
На наш взгляд такое решение позволит значительно повысить качество
проверки. Дело в том, что в такой области как русский язык довольно сложно
составить формализованные тесты для проверки знаний. Приведём пример из
предоставленных преподавателями русского языка упражнений:
Упражнение
Ответьте на вопросы, используя слова из скобок.
) Где вы были вчера? (наш университет)
) Где Маша была на выходных? (кино)
) Где он был в субботу? (театр)
Рассмотрим первый вопрос из списка. Он может быть обращён как к группе
людей, так и к одному человеку, соответственно на него можно дать, например,
такие ответы:
Вчера мы были в нашем университете.
Вчера я был в нашем университете.
Вчера я была в нашем университете.
Однако слово «вчера» в данном случае не обязательно должно располагаться
в начале предложения. (Строго говоря, его положение зависит от семантического
ударения предложения, то есть от того, что хочет подчеркнуть автор. Например, в
данной ситуации семантическое ударение падает на слово «университет». Если же
автор хочет подчеркнуть, что он был в университете именно вчера, ему требуется
поставить обстоятельство времени в конец предложения. Однако пока такие
тонкости построения предложений учитывать не требуется.) Мы можем ответить ещё
и следующим образом:
Мы были в нашем университете вчера.
Мы были вчера в нашем университете.
Таким образом, комбинируя предложенные выше варианты, мы получаем всего
девять возможных ответов на первый вопрос упражнения. При использовании
традиционных систем контроля знаний, преподавателю бы пришлось во время
создания упражнения задать все девять вариантов, что привело бы к резкому
падению эффективности его труда. Если же система будет сама генерировать все
возможные ответы на вопрос, а потом сравнивать ответы студента со
сгенерированными ответами, такой проблемы удастся избежать.
Кроме того, система позиционируется не только как учебное пособие, но и
как тренажёр для самостоятельного обучения. Подобный подход может позволить
студентам без участия преподавателя проверять свои знания по интересующей их
части грамматики.
Чтобы добиться описанной выше интеллектуальности, требуется использовать
средства автоматического лингвистического анализа - лингвистические процессоры.
Фактически, нам требуется проводить преобразование вопроса в ответ. Для
этого нам нужно иметь возможность выполнять следующие изменения предложения:
. Удалять слова с заданной синтаксической функцией. В приведённом
выше примере можно заметить, что при ответе на вопрос удаляется слово «где» -
обстоятельство места, выраженное местоимением. Также удаляется и вопросительный
знак.
. Добавлять новые слова. В данном примере происходит добавление
предлога «в» после сказуемого. Кроме того, добавляется знак пунктуации: на
место удалённого вопросительного знака ставится точка.
. Заменять слова. Такое требуется, например, при ответе на вопрос.
Выше можно заметить, что слово «вы» меняется либо на «мы», либо на «я» (в
зависимости от того, как понимать поставленный вопрос).
. Изменять форму существующих слов. Мы можем видеть, что в примере
меняется форма слова «были» (в зависимости от замены слова «вы»), а также
происходит склонение слов из скобок. Тут следует обратить внимание, что в
скобках стоит не одно слово, а словосочетание, то есть при склонении должна
учитываться связь слов.
. Перемещать слова. Мы видим, что слова из скобок ставятся после
добавленного ранее предлога «в»: «были в нашем университете».
Таким образом, от лингвистических процессоров требуется следующее:
· возвращать синтаксическую функцию слов, что может быть
использовано при удалении слов с заданной функцией, вставке и перемещении;
· возвращать синтаксические связи между словами для возможности
их склонения;
· возвращать морфологические характеристики слов, входящих в
предложение, со снятой омонимией (то есть, в результатах анализа не должно быть
неоднозначных интерпретаций).
Правильное снятие омонимии очень важно для правильного склонения слов. О
том, какие лингвистические процессоры были рассмотрены и как они удовлетворяют
заданным требованиям, рассказывается в следующей главе.
3. Лингвистические процессоры
Лингвистический процессор - это компьютерная программа, которая
каким-либо образом преобразует входной текст на естественном языке. В
литературе также используется термин «анализатор». Это понятие несколько уже.
Под анализатором в данной работе понимается программа, преобразующая входное
предложение в некоторое машинное представление. Условно лингвистические
анализаторы можно разделить на четыре вида:
. Графематические анализаторы.
. Морфологические анализаторы.
. Синтаксические анализаторы.
. Семантические анализаторы.
Графематический анализ представляет собой начальный этап обработки
текста, в ходе которого определяются элементы грамматической структуры (слова,
знаки пунктуации, числа, сокращения и т. д.). Можно выделить следующие основные
функции графематического анализа [9]:
· разбиение текста на графемы;
· определение границ предложений;
· различение слов и служебных графем (например, знаков
пунктуации);
· определение регистра слов;
· распознавание собственных имен;
· распознавание сокращений.
Морфологические анализаторы служат для получения начальной формы слов,
выделенных на этапе графематического анализа, части речи и их морфологических
характеристик, а также для склонения слов. В данной работе мы рассматриваем два
морфологических анализатора: морфологический анализатор из пакета АОТ и
библиотека pymorphy2.
На этапе синтаксического анализа определяются синтаксические связи между
словами, устанавливается, какую синтаксическую функцию выполняет каждое слово.
На выходе обычно строится синтаксическое дерево, где узлы - это слова, а связи
- отношения между ними. В данной работе рассматривается четыре синтаксических
анализатора: синтаксический анализатор из пакета АОТ, DictaScope Syntax,
Cognitive Dwarf и Abbyy Compreno.
Семантический анализатор возвращает семантический граф, где узлы - это
понятия языка, а связи - отношения между ними. В данной работе семантические
анализаторы не используются.
.1 АОТ
Программный пакет АОТ - это набор лингвистических процессоров,
осуществляющих последовательную обработку текста [10]. Общая схема представлена
на Рис. 2.
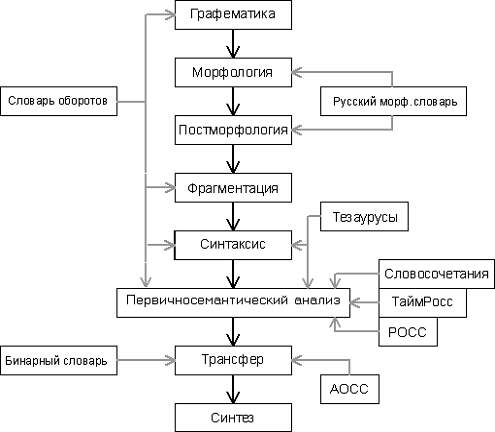
Рис.
2. Структурная схема пакета АОТ
Кроме
анализа, система предоставляет возможность синтеза текста на другом языке. За
это отвечают процессоры «Трансфер» и «Синтез». Однако как было сказано выше,
нас интересует только морфологический и синтаксический анализ.
Русский
морфологический словарь АОТ базируется на грамматическом словаре А.А. Зализняка
и включает на данный момент около 161 тысячи лемм. Также, модуль
морфологического анализа позволяет получать все формы заданного слова, что
можно использовать для решения обозначенной ранее задачи склонения.
Большим
недостатком морфологического анализатора является отсутствие поддержки буквы
«ё», тогда как, согласно Официальному порталу Комиссии «Русский язык в СМИ»
Совета по русскому языку при Правительстве Российской Федерации, употребление
буквы «ё» обязательно в учебных пособиях для иностранцев [11].
Что
касается синтаксического анализатора, даже на простых предложениях он выдавал
неверные результаты (см. Таблицу 1). Здесь и далее работа анализаторов
показывается на примере предложений из упражнений, предоставленных
преподавателями русского языка кафедры РКИ ИМОЯК.
Таблица
1. Результаты работы синтаксического анализатора АОТ
|
Исходное предложение
|
Результат разбора
|
|
Папа мыл пол.
|
пол - сказуемое (ПОЛЫЙ, кр. прил.) ├ Папа -
подлежащее (ПАПА, сущ.) └ мыл (МЫЛО, сущ.)
|
|
Какие это часы? Это часы с будильником.
|
часы (ЧАСЫ, сущ.) └ Какие (КАКОЙ, мест. прил.) это
(ЭТОТ, мест. прил.)
|
|
Чья машина стоит у подъезда?
|
стоит - сказуемое (СТОЯТЬ, глаг.) ├ машина -
подлежащее (МАШИНА, сущ.) │ └ Чья (ЧЕЙ, мест. прил.) └ у
подъезда - предложная группа
|
Как мы видим из результатов тестирования, не все предложения разобраны
правильно. На первое предложение дана хоть и грамматически верная, но маловероятная
интерпретация. Для второго предложения не было построено связного дерева. Для
третьего предложения дан верный разбор.
.2 Cognitive Dwarf
Cognitive Dwarf - это
программный пакет, включающий в себя синтаксический анализатор для русского и
английского языков и систему автоматического перевода (русско-английское и
англо-русское направления) [12].
В настоящее время существует только консольное приложение,
предоставляющее доступ к функциям пакета. На вход этому приложению поступает
файл с текстом на русском или английском языке. Результат работы консольного
приложения сохраняется в выходном файле, который в зависимости от параметров
запуска может содержать следующее:
· список слов с текстами нормальных форм и морфологическими
атрибутами;
· список синтаксических связей;
· дерево синтаксического разбора;
· перевод на другой язык.
Как видно из описания, программа не позволяет склонять отдельные слова и
делать какие-то иные преобразования над входными данными, кроме перевода.
Программа распространяется бесплатно, однако исходные коды её закрыты, и
лицензия разрешает использование данного пакета только в целях исследования или
обучения.
Протестируем программу на тех же примерах, что и предыдущий пакет.
Результаты приведены в Таблице 2.
Таблица
2. Результаты тестирования программного пакета Cognitive Dwarf
|
Исходное предложение
|
Результат разбора
|
|
Папа мыл пол.
|
мыл - сказуемое (мыть, глаг.) ├ Папа - подлежащее
(папа, сущ.) └ пол - прямое дополнение (пол, сущ.)
|
|
Какие это часы? Это часы с будильником.
|
Какие (какой, мест. прил.) это (этот, мест. прил.) часы
(час, сущ.)
|
|
Чья машина стоит у подъезда?
|
стоит - сказуемое (стоять, глаг.) ├ машина -
подлежащее (машина, сущ.) │ └ Чья - определение (чей, мест.
прил.) └ у - предложная группа (у, предл.) └ подъезда (подъезд,
сущ.)
|
Как мы видим из данной таблицы, для первого и для третьего предложения
был получен верный разбор. Однако результаты разбора второго предложения даже
хуже, чем в АОТ: здесь вообще нет связей в дереве, а также слово «часы»
нормализовано неверно.
.3 DictaScope
Синтаксический анализатор DictaScope Syntax, строит
дерево зависимостей для входного предложения на естественном языке (русском) [13].
При построении дерева снимается морфологическая омонимия, словам (лексемам)
присваиваются грамматические значения, для каждой подчинительной связи
определяется её тип. Производится сегментация предложения: выделение простых
предложений в составе сложного, выделение оборотов, в том числе вложенных -
причастных, деепричастных, адъективных и так далее, определение рядов
однородных членов. Снимается функциональная омонимия знаков препинания,
определяются их роли. Учёт пунктуации позволяет добиться правильного анализа
длинных предложений со сложной структурой.
Выделяются некоторые составные текстовые объекты (организации, даты и так
далее). Каждый составной объект представлен в дереве одной вершиной, имеющей
синтаксические связи.
Кроме того программа выполняет следующие функции:
· может быть произведено разбиение входного текста на отдельные
предложения;
· могут быть исправлены некоторые орфографические ошибки;
· производится поверхностно-семантический анализ: определение
действия, субъекта и объекта для каждого предложения, в том числе для простых в
составе сложного.
Как мы видим, данный программный продукт не предоставляет возможности
склонения слов и словосочетаний, а также любого другого изменения входного
предложения.
Ядро анализатора DictaScope Syntax реализует универсальные языковые
зависимости, что позволяет применять его для разработки анализаторов различных
языков на единой платформе. Созданы экспериментальные версии для английского и
немецкого языков. Русская версия является в настоящее время наиболее
проработанной.
Компания Диктум предоставляет бесплатный доступ к веб-сервису DictaScope
Syntax для образовательных учреждений.
В Таблице 3 приведены результаты тестирования программы DictaScope
Syntax.
Таблица
3. Результаты тестирования синтаксического анализатора DictaScope Syntax.
|
Исходное предложение
|
Результат разбора
|
|
Папа мыл пол.
|
мыл (мыть, глаг.) ├ Папа (папа, сущ.) └ пол
(пола, сущ.)
|
|
Какие это часы? Это часы с будильником.
|
часы (часы, сущ.) ├ Какие (какой, мест. прил.) └
это (этот, мест. прил.)
|
|
Чья машина стоит у подъезда?
|
стоит (стоять, глаг.) ├ машина (машина, сущ.) │
└ Чья (чей, мест. прил.) └ у (у, предл.) └ подъезда
(подъезд, сущ.)
|
Сразу следует отметить, что в отличие от других программных пакетов,
DictaScope Syntax не возвращает синтаксические функции слов.
Что касается результатов разбора, то можно заметить, что в первом
предложении неверно нормализовано слово «пол». В то же время, второе
предложение было проанализировано правильно. Для третьего предложения результат
получился практически идентичным первым двум анализаторам.
.4 Pymorphy2
Pymorphy2 - это библиотека для морфологического анализа и склонения слов. Она
распространяется по лицензии MIT,
что позволяет использовать её в любых целях.
Возможности библиотеки [14]:
· приводить слово к нормальной форме;
· ставить слово в нужную форму;
· возвращать грамматическую информацию о слове.
При работе используется словарь OpenCorpora - проекта по созданию открытого и свободного корпуса
русского языка. Кроме того, библиотека может обрабатывать слова, не
содержащиеся в словаре.
Большим плюсом является поддержка буквы «ё», которая, как было показано
выше, необходима при обучении иностранцев русскому языку. Этот фактор послужил
решающим при выборе данной библиотеки в качестве инструмента для склонения слов
в модуле контроля знаний.
3.5 ABBYY Compreno
ABBYY Compreno - это
разрабатываемая в данный момент технология синтаксического и семантического
анализа текстов на естественном языке [15]. Центральным ядром создаваемой
технологии служит универсальная иерархия понятий и модель отношений между этими
понятиями. В литературе это дерево понятий называется Universal Semantic Hierarchy (USH).
Второй, но не менее важной частью технологии является полный
синтаксический разбор текста. Семантические отношения универсальны, а способы
их реализации в каждом языке - свои. Для каждого языка синтаксическое описание
делается заново, но сами средства, которые разные языки используют для
кодирования смысла, перечислимы. При описывании нового языка используется
разные элементы конструктора (тот же линейный порядок, различные типы
синтаксических преобразований, грамматические значения, предлоги, специальные
конструкции).
Технология Compreno также позволяет определять и более сложные
синтаксические связи, такие как анафора: «Хоть мальчик и хотел поиграть, но он
понимал, что у него мало времени», эллипсис: «он любит красное вино, а она -
белое». Выделяемые системой связи между понятиями также выражаются в древесной
структуре. Таким образом, система стремится к определению смысла текста,
написанного на обычном языке, позволяя машине «понять» этот текст и
трансформировать его в универсальное представление, не зависящее от языка.
При анализе используется USH, синтаксическое описание языка, а также
статистика взаимоотношений между словами.
Среди результатов разбора можно заметить две ошибки. Во втором примере
неверно определён контекст, и как следствие, неверно нормализовано слово
«часы». В третьем предложении для слова «машина» не определена синтаксическая
функция (в этом случае слову присваивается функция «иная функция»).
Таблица
4. Результаты работы синтаксического анализатора ABBYY
Compreno
|
Исходное предложение
|
Результат разбора
|
|
Папа мыл пол.
|
мыл - сказуемое (мыть, глаг.) ├ Папа - подлежащее
(папа, сущ.) └ пол - прямое дополнение (пол, сущ.)
|
|
Какие это часы? Это часы с будильником.
|
часы - подлежащее (час, сущ.) └ Какие - определение
(какой, мест. прил.) └ это - частица (этот, мест. прил.)
|
|
Чья машина стоит у подъезда?
|
стоит - сказуемое (стоять, глаг.) ├ машина - иная
функция (машина, сущ.) │ └ Чья - определение (чей, мест. прил.) └
подъезда - обстоятельство (подъезд, сущ.) └ у - предлог (у, предл.)
|
После тестирования мы можем сделать вывод о том, что на данный момент
самый качественный синтаксический анализ проводит ABBYY Compreno. Ошибка с неверной нормализацией
слова «часы» связана с невозможностью на данный момент обеспечить полное
понимание системой контекста предложения. Это следует учитывать при дальнейшей
разработке, однако мы не считаем подобные ошибки критичными.
Как уже было сказано, для склонения слов будет использоваться библиотека pymorphy2. Так как сам модуль контроля знаний
пишется на языке C#, библиотека pymorphy2 была оформлена в виде сервиса Windows, к которому можно обращаться через
определённый порт машины.
4. Алгоритмы решения и проверки упражнений на именную часть русского
языка
Именные части речи в русском языке - это имя существительное, имя
прилагательное, имя числительное, местоимение. Именные части речи - это
самостоятельные (имеющие значение), изменяемые (склоняемые) части речи,
являющиеся членами предложения [16].
Имя существительное занимает одно из главных мест в нашей речи. Все, что
существует в мире, названо словом - именем существительным.
Имена существительные делятся на одушевлённые и неодушевлённые. Деление
на одушевлённые и неодушевлённые имена существительные не всегда совпадает с
делением всего существующего в природе на живое и неживое. Например, названия
растений, слова «народ», «детвора», «стая», «молодёжь» относятся к
неодушевленным. А такие слова как «кукла», «мертвец», «покойник», «туз»,
«валет», «козырь» (карточные термины) - к одушевлённым.
Имена существительные относятся к мужскому, женскому, среднему роду.
Обычно определить род имён существительных нетрудно, но есть группа слов, у
которых правильно определить род можно, только обратившись к словарю: лебедь -
мужской род; шампунь - мужской род; шасси - средний род. На подобные слова
студентам следует обратить особое внимание и научиться правильно определять их
род.
Некоторые существительные мужского рода, обозначающие профессию, род
занятий, могут употребляться для обозначения лиц как мужского, так и женского
пола (адвокат, геолог, продавец). Это вызывает некоторую сложность при
генерации правильного ответа. Например, в следующем упражнении возможны по два
варианта решения каждого задания:
Упражнение
Поставьте прилагательные из скобок в правильную форму.
) (хороший) доктор
) (талантливый) профессор
) (известный) адвокат
Имена прилагательные обозначают признак предмета и отвечают на вопросы
какой? какая? какое? какие? С помощью имён прилагательных предмет можно
охарактеризовать с различных точек зрения.
Местоимения - это слова, которые используются вместо имени, обозначают
лица (я, ты, мы, вы, он, она, оно, они), указывают на предметы, признаки
предметов, количество предметов, не называя их конкретно (тот, этот, всякий,
столько). От всех других именных частей речи местоимения отличаются тем, что
они сами по себе не имеют самостоятельного значения, но в речи, в тексте это
значение становится конкретным, потому что соотносится с конкретным лицом,
предметом, признаком, количеством. Из-за этого возникают проблемы при решении
некоторых заданий: на вопросы с местоимениями можно дать по несколько разных
ответов. Подробно это было проиллюстрировано в пункте 2.2.
По значению и грамматическим особенностям выделяется девять разрядов
местоимений:
) личные (я, мы; ты, вы; он, она, оно; они);
) возвратное (себя);
) притяжательные (мой, твой, наш, ваш, свой);
) указательные (этот, тот, такой, таков, этакий, столько);
) определительные (сам, самый, весь, всякий, каждый, иной);
) относительные (кто, что, какой, каков, который, сколько, чей);
) вопросительные (кто? что? какой? чей? который? сколько? где?
когда? куда? откуда? зачем? почему? каков?);
) отрицательные (никто, ничто, ничей);
) неопределенные (некто, нечто, кто-то, кто-нибудь, кто-либо,
кое-кто).
На элементарном уровне студенты изучают личные, притяжательные и
вопросительные местоимения.
Местоимения имеют морфологические признаки той части речи, с которой
соотносятся.
Начальная форма для именных частей речи - именительный падеж,
единственное число, мужской род (кроме имени существительного). Непостоянные
признаки также общие. Именные части речи изменяются по падежам, числам, родам
(кроме имени существительного).
Упражнения на именную часть русской грамматики направлены на развитие у
студентов умения безошибочно склонять слова в правильную с точки зрения
грамматического контекста форму. Поэтому среди упражнений на именную часть
можно выделить два основных типа:
. Упражнения на постановку слов и словосочетаний в заданную форму.
. Употребление правил склонения слов в ситуации диалога (например,
при ответе на вопрос).
По своей форме упражнения можно разделить на четыре категории:
. Упражнения по модели. В этих упражнениях студенту даётся модель
- пример того, как нужно выполнять задания данного упражнения. Приведём примеры
таких упражнений:
Упражнение 1.
Раскройте скобки по модели.
Модель: Я люблю гулять (город) - Я люблю гулять по городу.
) Максим едет (дорога).
) Елена после учёбы ходила (магазины).
) Девушка идёт (улица).
Упражнение 2.
Отвечайте на вопросы по модели.
Модель: Чьи тетради лежат на столе? (наш студент Борис) - Тетради нашего
студента Бориса лежат на столе.
) Чья машина стоит у подъезда? (наш профессор)
) Чьи журналы лежат на полке? (наш преподаватель и наши студенты)
) Чьи стихи ты читаешь? (один молодой испанский поэт)
. Упражнения на простое склонение. В этих упражнениях студенту в
задании прямо указывается, в какую форму требуется поставить слова из вопроса.
Технически упражнения этого типа отличаются от предыдущих лишь тем, что здесь
не происходит изменения самого предложения из задания, а меняется лишь форма
слов. Однако с точки зрения преподавателей такие упражнения легче для
студентов, поэтому должны быть вынесены в отдельный тип. Примеры упражнений
данного типа:
Упражнение 3.
Поставьте слова в форму творительного падежа.
) известная актриса
) талантливый ученик
) любознательный студент
Упражнение 4.
Поставьте слова из скобок в форму предложного падежа.
) Кумар скучает о (семья).
) Иван думает о (учёба).
) В песне поётся о (дружба).
. Упражнения на склонение с числами. Упражнения этого типа учат
студентов правильно ставить слова во множественное число. Они выделяются в
отдельный тип потому, что в русском языке разным количественным числительным
соответствуют разные формы главных слов. Проиллюстрируем это утверждение
примером: 1 иностранный студент, 2 иностранных студента, 5 иностранных
студентов. В первом случае и существительное, и прилагательное стоят в форме
именительного падежа единственного числа. Во втором случае происходит нарушение
согласования существительного с зависимым от него прилагательным: здесь
существительное стоит в единственном числе и родительном падеже, а
прилагательное стоит во множественном числе и также в родительном падеже. В
третьем случае оба слова стоят во множественном числе и родительном падеже.
Примеры упражнений этого типа:
Упражнение 5.
Поставьте слова в правильную форму.
) 1 (мясная котлета)
) 2 (порция супа)
) 10 (ломтик хлеба)
. Упражнения с заданным ответом. В эту группу выделяются
упражнения, в которых по тем или иным причинам не нужна интеллектуальная
проверка, либо она на данный момент не может быть обеспечена.
К упражнениям, которые не требуют интеллектуальной проверки, относятся
упражнения на изучение слов:
Упражнение 6.
Напишите названия месяцев в заданном порядке.
) Первый месяц весны.
) Второй месяц лета.
) Первый зимний месяц.
) Последний месяц осени.
На каждый из этих вопросов можно дать однозначный ответ, поэтому для их
проверки не требуется привлечение искусственного интеллекта.
Также к данному типу относятся упражнения, которые система не может
решить на данный момент. Например, это задания, где нужно вставить подходящий
по смыслу предлог:
Упражнение 7.
Вставьте подходящий по смыслу предлог.
) Алёна гуляет __ улице.
) Вадим спешит __ своему другу.
) Паван готовится __ экзамену.
Для решения подобных заданий требуется понимание контекста, что пока
невозможно.
Кроме того, в этом типе могут быть реализованы и различные мультимедийные
задания: упражнения с видео, аудио и игровыми компонентами.
.1 Алгоритм проверки упражнений типа «Заданный ответ»
В данном типе упражнений можно выделить три основных подтипа:
. Выбор единственного правильного варианта. Студенту предлагается
несколько различных ответов, среди которых только один может быть правильным.
. Выбор нескольких правильных вариантов. Студенту также
предлагается несколько различных ответов, среди которых может быть несколько
правильных вариантов, либо ни одного.
. Открытый ответ. Студенту предлагается дать ответ в виде одного
или нескольких предложений. При этом преподаватель заранее даёт правильный
ответ на свой вопрос, а ответ студента сравнивается с ответом преподавателя.
Алгоритмы проверки первого и второго подтипов не представляют интереса.
Проверка же третьего подтипа отличается от традиционных систем контроля знаний
тем, что и ответ, данный студентом, и ответ, заданный преподавателем проходят
через синтаксический анализатор, после чего происходит сравнение полученных
синтаксических деревьев. При этом сравниваются не только сами слова, но и их синтаксическая
функция. Это позволяет зачесть ответ студента как правильный даже в том случае,
когда он несколько отличается от ответа преподавателя. Проиллюстрируем это
примером.
Преподаватель создаёт упражнения, в которых студенту требуется составить
предложение со словом, которым обозначается предмет, изображённый на рисунке.
Студенту показывается модель ответа. Например, на картинке изображено яблоко, а
студенту требуется составить просьбу - обращение к продавцу: «Дайте мне,
пожалуйста, это яблоко».
Предположим, что студент даст на первый вопрос следующий ответ:
Дайте мне этот учебник, пожалуйста.
Очевидно, что из-за перестановки вводного слова «пожалуйста» правильность
ответа не пострадала, но если здесь применить подход, применяемый в
традиционных системах контроля знаний (а именно, посимвольное сравнение), ответ
будет помечен как неверный. Это может привести к неправильному пониманию
студентом данной темы.
Теперь посмотрим, как будут выглядеть синтаксические деревья ответа
студента и ответа преподавателя. Как было сказано выше, для получения
синтаксического дерева используется анализатор ABBYY Compreno.
Дайте мне, пожалуйста, этот учебник.
Дайте - сказуемое
├ мне - косвенное дополнение
├ пожалуйста - частица
└ учебник - прямое дополнение
└ этот - согласованное определение
Дайте мне, пожалуйста, этот учебник.
Дайте - сказуемое
├ мне - косвенное дополнение
├ учебник - прямое дополнение
│ └ этот - согласованное
определение
└ пожалуйста - частица
Как мы видим, данные синтаксические деревья отличаются лишь расположением
веток, что не влияет на работу алгоритма сравнения.
Теперь предположим, что студент ввёл ответ с верными словами, но с
некорректным для русского языка порядком слов:
Дайте учебник мне, пожалуйста, этот.
Дерево для этого ответа уже будет другим:
#субстантиватор - подлежащее
├ Дайте - сказуемое
│ ├ учебник - прямое
дополнение
│ └ мне - косвенное
дополнение
├ пожалуйста - частица
└ этот - согласованное
определение
Сравнение этих деревьев вернёт отрицательный результат. Однако студент
правильно написал все слова, поэтому ему может быть присвоена половина от
максимального балла за ответ. В будущем, когда будет создана подсистема
корректировки курса, в таких случаях туда будет отправляться информация о том,
что студент выучил предложенные слова, однако не может правильно составить
предложение (ошибка - неверный порядок слов). И подсистема должна будет
скорректировать курс так, чтобы увеличить количество упражнений на правильный
порядок слов и уменьшить количество упражнений на изучение новых слов.
программный лингвопроцессорный язык обучение
4.2 Алгоритм проверки упражнений типа «Поставить слово / словосочетание в
заданную форму»
В упражнениях этого типа преподавателю не требуется вводить верный ответ.
Он может быть сгенерирован машиной. Преподавателю нужно лишь указать форму, в
которую будут склоняться слова. Формой может быть число или падеж. Для
прилагательных может быть ещё и род. Алгоритм генерации правильного ответа на
задания данного типа таков:
. Найти в тексте задания слова в скобках. Если таковые имеются,
значит эти слова должны быть поставлены в форму, указанную преподавателем. Если
скобок в тексте нет, то преподаватель хочет, чтобы студент склонял все слова из
задания. То же самое должна сделать и машина.
. Далее требуется определить главные слова в скобках. Эти слова
можно сразу поставить в нужную форму. Как было сказано выше, склонение слов
осуществляется сервисом на основе библиотеки pymorphy2. Так как pymorphy2 не может снять омонимию, на вход
сервису, кроме самого слова и формы, в которую нужно поставить это слово,
передаётся текущая форма слова. В общем случае pymorphy2 выдаёт несколько вариантов разбора
для каждого слова, среди которых выбирается тот, который наиболее близок к
переданной текущей форме. Для этого варианта слова и осуществляется склонение.
. После склонения главных слов, им нужно присвоить новую
синтаксическую функцию. Синтаксическая функция определяется с помощью ABBYY Compreno. Если во входном тексте некоторые
слова заменить знаком «\», их синтаксическая роль в предложении будет
определена автоматически. Таким образом, для определения правильной синтаксической
функции достаточно заменить скобки данным знаком.
. После склонения главных слов требуется склонять зависимые слова.
Однако по правилам русского языка склоняются лишь те слова, которые находятся с
главным в связи типа согласование. В согласование вступают прилагательные (и
местоимённые прилагательные), притяжательные местоимения, числительные, а также
существительные, выполняющие роль приложения. То есть, среди слов, зависимых от
данного, нужно найти все прилагательные, притяжательные местоимения, числительные
и существительные с синтаксической функцией приложение и поставить в требуемую
форму.
. После того как зависимые слова поставлены в нужную форму,
остаётся лишь удалить скобки (если они были).
. Правильный ответ готов.
После генерации правильного ответа нужно провести синтаксический анализ
ответа студента. После этого происходит сравнение синтаксических деревьев по
алгоритму, описанному в пункте 4.1.
Также, студенту нужно вернуть текстовое представление правильного ответа.
Оно получается по следующему алгоритму:
. В результат записываются последовательно все слова, не
являющиеся подставленными автоматически при анализе. Знаки препинания также
считаются словами.
. Если слово оказалось в начале предложения, то оно пишется с
прописной буквы.
. Если слово является именем собственным, оно также пишется с
прописной буквы.
. Если слово в оригинале было написано с большой буквы и, при
этом, не находилось в начале предложения, оно должно быть написано с прописной
буквы.
. После этого удаляются лишние пробелы перед (или после) знаками
препинания, дублирующие пробелы заменяются одинарными.
. Результат возвращается студенту.
4.3 Алгоритм проверки упражнений типа «Склонение с числами»
При реализации данного алгоритма проверки пришлось немного изменить
алгоритм склонения из предыдущего типа. Причина этого кроется в том, что при
постановке слова во множественное число не всегда соблюдается согласование
слов. Об этом подробнее говорилось при описании данного типа. Чтобы обойти
данную проблему, было введено такое понятие как форма для зависимых слов.
Теперь при склонении словосочетаний зависимым словам может присваиваться форма,
отличная от той, которая присваивается главному слову.
Алгоритм генерации правильного ответа
выглядит следующим образом:
1. Выделение из текста слова, содержащего одни цифры.
. Если число кончается на единицу, и при этом предпоследняя цифра
- не 1, форма для главного слова и для зависимых слов - именительный падеж,
единственное число.
. Если число кончается на 2, 3 или 4 и предпоследняя цифра - не
единица, форма для главного слова - родительный падеж, единственное число, а
для зависимых слов - родительный падеж, множественное число.
. В ином случае форма и для главного слова, и для зависимых -
родительный падеж, множественное число.
. Далее происходит склонение слов в указанные формы.
. После этого получается текстовое представление ответа машины.
. Это текстовое представление сравнивается с текстовым
представлением ответа студента.
4.4 Алгоритм проверки упражнений типа «Ответить по модели»
В упражнениях этого типа преподаватель вводит модель, которая
анализируется системой. Модель, фактически, показывает, как преобразовать
вопрос в ответ. Мы выделяем следующие виды преобразований:
. Склонение слов в скобках.
. Удаление слов.
. Вставка новых слов.
. Замена слов.
. Перестроение дерева.
Смысл этих преобразований был рассказан в пункте 2.2. Здесь мы подробнее
остановимся на алгоритмах данных преобразований. Данные алгоритмы должны
последовательно применяться к исходному предложению. В результате их работы
должен получаться верный ответ.
.4.1 Выявление преобразований
Для выявления необходимых преобразований используются два синтаксических
дерева: дерево модели вопроса (ДМВ) и дерево модели ответа (ДМО). В результате
работы каждого из приведённых ниже алгоритмов получается список преобразований
данного типа. После создания списка преобразований очередного типа, происходит
преобразование ДМВ в соответствии с выявленным списком.
Склонение слов в скобках
Для того чтобы просклонять слова в скобках, требуется сначала определить
форму, в которую их нужно ставить. Так как мы работаем над именной частью
русского языка, формой этой будет число и падеж. Для определения нужной формы
сначала выделяется главное слово в скобках (это слово, которое не имеет
родителя). Если таких слов несколько, то берётся первое из них. Далее в ДМО
ищется слово с такой же нормальной формой, как у главного слова из скобок. При
нахождении такого слова создать правило склонения слов в скобках, в котором
будет содержаться падеж и число этого слова. Также, после этого нужно
просклонять слова в скобках в запомненную форму. Пример:
Вы смотрите фильм? (программа «Новости»)
Нет, я смотрю программу «Новости».
Главным словом в скобках является слово «программа». В ДМО оно стоит в
винительном падеже единственного числа. Следовательно, слова из скобок нужно
ставить в эту форму. После работы алгоритма исходное предложение будет
выглядеть так:
Вы смотрите фильм? (программу «Новости»)
А в списке правил преобразования будет одно правило, предписывающее склонять
слова из скобок в форму единственного числа винительного падежа.
Удаление
Для того чтобы определить, слова с какими синтаксическими функциями
требуется удалить из предложения, нужно сравнить каждую ветку ДМВ с каждой
веткой ДМО. При отсутствии какой-либо ветки формируется правило удаления этой
ветки. В правиле содержится лишь синтаксическая функция удаляемого слова. При
этом следует учитывать, что при ответе на вопросы меняется форма местоимений.
Также удаляются все знаки препинания, отсутствующие в ДМО.
Проиллюстрируем это на примере:
Вы смотрите фильм? (программу
«Новости»)
Нет, я смотрю программу «Новости».
Модель вопроса состоит из двух предложений, соответственно в ней два
корня. Проверяем наличие первого корня («смотреть») в ДМО. Затем проверяем
наличие слова «вы» в ДМО. Его там нет, но есть замена для него - слово «я».
Значит слово «вы» не должно удаляться. Теперь проверяем наличие слова «фильм».
Оказывается, что его нет в ДМО, поэтому формируется правило, что из вопроса
требуется удалять прямое дополнение (коим и является слово «фильм»). Вся ветка,
начинающаяся со слова «программа» присутствует в ДМО. Кроме прямого дополнения
нужно удалять ещё знак вопроса и скобки, которые также отсутствуют в ДМО.
В результате получается следующее:
Вы смотрите программу «Новости»
Вставка новых слов
Эта операция аналогична удалению, только здесь алгоритму предстоит
добавлять в ДМВ слова из ДМО, которые пока отсутствуют в ДМВ. Покажем это на
примере. Сейчас в ДМВ отсутствуют слово «Нет» и знаки препинания: запятая и
точка. Слово «Нет» присоединяется к слову «смотрите». Ему назначается
синтаксическая роль частица. Запятая вставляется после слова с синтаксической
ролью частица. Точка вставляется в конец предложения. В результате исходное
предложение будет выглядеть так:
Нет, Вы смотрите программу «Новости».
Замена слов
Этот этап выполняется, если в данном упражнении происходит смена вопроса
на ответ, либо утвердительного предложения на вопросительное. В этом случае
происходит замена местоимений первого лица на второе и наоборот. Следует
отметить, что в результате работы этого правила может получиться несколько
вариантов ответа. Рассмотрим наш пример.
В данном случае нужно заменять слово «Вы» на местоимение первого лица:
местоимение «мы» или местоимение «я». При этом также требуется склонять главный
для местоимения глагол в нужную форму. В результате проведённой замены мы
получим два ответа:
Нет, я смотрю программу «Новости».
Нет, мы смотрим программу «Новости».
Эти ответы выглядят как правильные, однако если взглянуть на получившееся
дерево, мы заметим, что оно некорректно:
смотрю
├ нет
└ я
программу
└ Новости
смотрим
├ нет
└ мы
программу
└ Новости
Перестроение дерева
Под перестроением дерева понимается восстановление правильного вида
дерева. Здесь происходит сравнение текущего дерева с ДМО. В случае каких-либо
несоответствий формируется правило, устраняющее их.
Для данного примера таким несоответствием является то, что прямое
дополнение сейчас не присоединено к сказуемому. Создаётся правило, исправляющее
данную ситуацию:
смотрим
├ нет
├ мы
└ программу
└ Новости
В результате мы получаем полностью идентичное ответу дерево. После всех
преобразований у нас формируется список правил, применяя которые мы можем
преобразовывать и другие вопросы из упражнения.
.4.2 Применение правил преобразования
Рассмотрим, как будет преобразован следующий вопрос:
Они строят магазин? (больница)
Первое правило заставляет алгоритм склонять слово «больница» в
винительный падеж:
Они строят магазин? (больницу)
Следующее правило говорит о том, что должны быть удалены прямое
дополнение («магазин»), а также вопросительный знак и скобки:
Они строят больницу
Далее вставляются слово «Нет» и знаки препинания: точка и запятая:
Нет, они строят больницу.
Далее должна происходить замена слов, однако в данном случае она не
требуется, так как в нашем примере нет местоимений первого или второго лица.
Поэтому следующим шагом формируется окончательное дерево решения:
строят
├ Нет
├ они
└ больницу
.5 Недостатки алгоритмов
Большим недостатком разработанных алгоритмов является возникновение
ошибок при отклонении от модели задачи. Например, если с той же моделью
попробовать преобразовать предложение «Они играют в футбол? (баскетбол)», то
получится ответ: «Нет, они играют баскетбол», так как предлог «в» не предусматривается
моделью. Он будет удалён вместе с дополнением «футбол».
Также, в заданиях «Ответить по модели» не могут употребляться разные
предлоги. То есть, к примеру, в Упражнение 1 мы не можем вставить выделенный
вопрос:
Упражнение 1.
Раскройте скобки по модели.
Модель: Я люблю гулять (город) - Я люблю гулять по городу.
) Максим едет (дорога).
) Елена после учёбы ходила (магазины).
) Девушка идёт (улица).
) Луиза зашла (друг).
Четвёртый вопрос будет обработан неверно. Система вернёт ответ: «Луиза
зашла по другу», что, конечно, неверно.
По тем же причинам нельзя в одном задании типа «Ответить по модели»
использовать разные вопросительные слова.
Чтобы устранить проблемы, вызванные отклонениями от модели, нужно
накапливать в системе модели предложений и их возможных изменений. Также
требуется разработать механизм, который будет определять принадлежность того
или иного предложения определённой модели. Это позволит постепенно уйти от
необходимости задавать модель в некоторых упражнениях (например, в упражнениях,
в которых требуется ответить на вопрос, используя слова из скобок). Также это
позволит сделать общение с системой более естественным.
Что касается проблем связанных с разными предлогами, то здесь пока сложно
что-то исправить. Ведь выбор правильного предлога требует понимания контекста,
а как было показано в главе 3, современные лингвистические процессоры пока не
могут этого позволить. Данная проблема будет одним из направлений моего
исследования в аспирантуре.
Заключение
Итак, исходя из целей работы, сделаем выводы. Имеющиеся на рынке системы
автоматизированного обучения не упрощают преподавателям задачу обучения
студента, а скорее усложняют её за счёт несовершенства применяемых в них
средств контроля знаний. С целью снять имеющиеся в таких системах ограничения
была начата разработка системы КЛИОС, составной частью которой является
интеллектуальный модуль проверки упражнений, который является предметом данной
работы.
В ходе проведённой работы были проанализированы имеющееся на рынке
лингвистическое программное обеспечение. Исходя из результатов тестирования
лингвистических процессоров, были выбраны два наиболее подходящих для решения
поставленной задачи.
На их основе были разработаны алгоритмы проверки упражнений на именную
часть русского языка. Кроме проверки, система может сама генерировать
правильный ответ на упражнения большинства рассмотренных типов. Это позволяет
повысить эффективность труда преподавателя и даёт возможность использовать
систему в качестве тренажёра для самостоятельного обучения. Также, как было
показано в четвёртой главе, результаты проверки упражнений могут быть
использованы для корректировки личного плана обучения студента.
Результаты работы применены в системе КЛИОС и используются
преподавателями русского языка кафедры РКИ на подготовительных курсах. В
дальнейшем работа будет развиваться, добавятся упражнения по системе глагола.
Список литературы
1. Лелюхина О.А. Обучение иностранных студентов //
Национальный исследовательский Томский политехнический университет: [сайт].
[2013].
2. Колтунов И.И., Николаенко А.В., Фатеев И.В.
Методологическое обоснование дистанционного обучения на основе современных
информационных технологий // Материалы международной научно-технической
конференции ААИ «Автомобиле- и тракторостроение в России: приоритеты развития и
подготовка кадров». Москва. 2010. Книга 12.
. Епифанова М.А., Железовский А.Б., Шнейдер М.Е.
Влияние мультимедийных средств на реализацию основных принципов обучения //
Высшее профессиональное образование: современные тенденции, проблемы, перспективы:
Сб. научных трудов Седьмой Международной заочной научно-методической
конференции. Саратов. 2010. сс. 146-151.
. Савинов А.П., "Интеллектуальные
лингвопроцессорные тренажеры для интенсивного усвоения русского языка как
иностранного. Концепции их построения и проблемы," Известия ТПУ, [в
печати].
. Features tour // MoodleDocs: [сайт]. [2013].
. Blackboard, Inc // Wikipedia, the free encyclopedia:
[сайт]. [2013].
. Система дистанционного обучения «СТ Курс».
Челябинск: 2004. Презентация.
. Смирнова Н.В. Следящие интеллектуальные обучающие
системы: состояние и перспективы // In: Интеллектуальные системы управления.
Коллективная монография под редакцией акад. РАН Васильева С. Н. Москва:
Машиностроение, 2010.
. Седунов А.А. Модель графематического анализа в
системе обработки естественного языка // Вестник Воронежского государственного
университета. 2007. No. 2.
. Технологии // АОТ: [сайт]. [2003].
. Азбучные истины | 7. Буква ё // ГРАМОТА.РУ -
справочно-информационный интернет-портал «Русский язык»: [сайт].
. Описание программного пакета синтаксического разбора
и машинного перевода Cognitive Dwarf. Москва: 2006. Документ.
. Синтаксический анализатор // ООО Диктум: [сайт].
[2013].
. Коробов М. Морфологический анализатор pymorphy2 //
Морфологический анализатор pymorphy2: [сайт]. [2013].
. Андреев С. Синтаксический и семантический анализ
текстов // ABBYY: [сайт]. [2011].
. Именные части речи, их общие и отличительные
признаки // Naexamen.ru: [сайт]. [2011].