Разработка и построение прогностических моделей на основе нейронной сети в аналитической платформе Deductor
Содержание
Введение
Практическая и математическая постановка задачи
Анализ существующих алгоритмов и методов решения задачи
. «Наивная» модель прогнозирования.
. Экстраполяция.
. Прогнозирование методом среднего и скользящего
среднего.
. Регрессионные модели.
. Метод декомпозиции временного ряда.
. Метод «ближайшего соседа» (NN - “nearest neighbor”)
или системы рассуждений на основе аналогичных случаев
. Метод опорных векторов (SVM - Support Vector
Machine).
. Метод деревьев решений.
. Кластеризация
. Метод ассоциативных правил
Описание разрабатываемого алгоритма, его укрупненная схема
Решение контрольного примера
Оценка точности решения
Заключение и выводы
Список литературы
Введение
Прогнозирование
- одна из самых востребованных, но при этом и самых сложных, задач анализа.
Проблемы при ее решении обусловлены многими причинами - недостаточное качество
и количество исходных данных, изменения среды, в которой протекает процесс,
воздействие субъективных факторов. [1]
Качественный
прогноз является ключом к решению таких актуальных бизнес-задач, как
оптимизация складских запасов и финансовых потоков, бюджетирование, оценка
инвестиционной привлекательности и многих других. [1]
Нейронные
сети - это очень мощный и гибкий механизм прогнозирования. При определении того,
что нужно прогнозировать, необходимо указывать переменные, которые
анализируются и предсказываются. Второй важный этап при построении нейросетевой
прогнозирующей системы - это определение следующих трех параметров: периода
прогнозирования, горизонта прогнозирования и интервала прогнозирования. Период
прогнозирования - это основная единица времени, на которую делается прогноз.
Горизонт прогнозирования - это число периодов в будущем, которые покрывает
прогноз. То есть, может понадобиться прогноз на 10 дней вперед, с данными на
каждый день. В этом случае период - сутки, а горизонт - 10 суток. Наконец,
интервал прогнозирования - частота, с которой делается новый прогноз. Часто
интервал прогнозирования совпадает с периодом прогнозирования. Выбор периода и горизонта
прогнозирования обычно диктуется условиями принятия решений в области, для
которой производится прогноз. Выбор этих двух параметров - едва не самое
трудное в нейросетевом прогнозировании. Для того чтобы прогнозирование имело
смысл, горизонт прогнозирования должен быть не меньше, чем время, необходимое
для реализации решения, принятого на основе прогноза. [2]
В
некоторых случаях не так важно предсказание конкретных значений прогнозируемой
переменной, как предсказание значительных изменений в ее поведении. Такая
задача возникает, например, при предсказании момента, когда текущее направление
движения рынка (тренд) изменит свое направление на противоположное. [2]
Точность
прогноза, требуемая для конкретной проблемы, оказывает огромное влияние на
прогнозирующую систему. Также огромное влияние на прогноз оказывает обучающая
выборка. [2]
Практическая
и математическая постановка задачи
Структура
прогностической модели похожа на структуры моделей, используемых для решения
других задач анализа, например распознавания, идентификации и т.п. Модель
прогноза отличается только характером используемых данных и алгоритмами их
обработки. Обобщенная структура прогностической модели представлена на Ошибка!
Источник ссылки не найден.. [3 стр. 533]
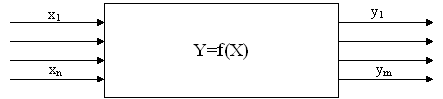
Рисунок
1. - Обобщенная модель прогноза
Здесь
набор входных переменных xi (i=1..n), образующих вектор X, -
исходные данные для прогноза. Набор выходных переменных yi (j=1..m),
образующих вектор результата Y, есть набор прогнозируемых величин. [3 стр. 533]
Когда
решается задача прогнозирования значений временного ряда, описывающего динамику
изменения некоторого бизнес-процесса, входные значения - наблюдения за
развитием процесса в прошлом, в выходные - прогнозные значения процесса в
будущем. При этом временные интервалы прошлых наблюдений и временные интервалы,
по которым требуется получить прогноз, должны соответствовать друг другу.
Например, если требуется получить прогноз по продажам за будущую неделю,
наблюдения, на основе которых будет строиться прогноз, также должны быть за
неделю. Обучающая выборка стоится путем преобразования временного рядас помощью
скользящего окна. [3 стр. 533]
Кроме
того, количество прогнозируемых наблюдений за историей развития процесса в
прошлом, на основе которого строится прогноз, должно быть больше, чем число
прогнозируемых интервалов, то есть n<m. Иначе говоря, если мы хотим получить
прогноз на неделю, то для этого должны взять наблюдения за несколько прошедших
недель. [3 стр. 533]
Анализ
существующих алгоритмов и методов решения задачи
1. «Наивная»
модель прогнозирования
модель прогнозирование кластеризация вектор
«Наивная»
модель прогнозирования предполагает, что последний период прогнозируемого
временного ряда лучше всего описывает будущее этого ряда. В таких моделях
прогноз, как правило, является довольно простой функцией от наблюдений
прогнозируемой величины в недалеком прошлом. [3 стр. 533]
Простейшая
модель описывается выражением:
(t+1)=y(t),
где
y(t) - последнее наблюдаемое значение, y(t+1) - прогноз. [3 стр. 533]
Данная
модель не только не учитывает закономерности прогнозируемого процесса (что в
той или мной степени свойственно многим статистическим методам
прогнозирования), но и не защищена от случайных изменений в данных, а также не
отражает сезонные колебания частоты и тренды. [3 стр. 533-534]
2. Экстраполяция
Экстраполяция
представляет собой попытку распространить закономерность поведения некоторой
функции из интервала, в котором известны ее значения, за его пределы. Иными
словами, если значение функции f(x) известны в некотором интервале [x0,xn],
то целью экстраполяции является определение наиболее вероятного значения в
точке xn+1. [3 стр. 534]
Экстраполяция
применима только в тех случаях, когда функция f(x) (а соответственно, и
описываемый с ее помощью временной ряд) достаточно стабильна и не подвержена
резким изменениям. Если это требование не выполняется, скорее всего, поведением
функции в различных интервалах будет подчиняться разным закономерностям. [3
стр. 534]
Наиболее
популярным методом в экстраполяции в настоящее время является экспоненциальное
сглаживание. Основной его принцип заключается в том, чтобы учесть в прогнозе
все наблюдения, но с экспоненциально убывающими весами. Метод позволяет принять
во внимание сезонные колебания ряда и предсказать поведение трендовой
составляющей. [3 стр. 535]
3. Прогнозирование
методом среднего и скользящего среднего
Наиболее
простая модель этой группы - обычное усреднение набора наблюдений
прогнозируемого ряда. Преимущество такого подхода по сравнению с «наивной»
моделью очевидно: при усреднении сглаживаются резкие изменения и выбросы
данных, что делает результаты прогноза более устойчивыми к изменчивости ряда.
[3 стр. 535]
В
формуле прогноза на основе среднего предполагается, что ряд усредняется по достаточно
длительному интервалу времени (в пределе - по всем наблюдениям). С точки зрения
прогноза это не вполне корректно, так как старые значения временного ряда могли
сформироваться на основе иных закономерностей и утратить актуальность. Поэтому
свежие наблюдения из недалекого прошлого лучше описывают прогноз, чем более
старые значения того же ряда. Чтобы повысить точность прогноза, можно
использовать скользящее среднее:
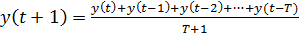 . [3 стр.
535]
. [3 стр.
535]
Смысл
данного метода заключается в том, что модель «видит» только ближайшее прошлое
на T отсчетов по времени и прогноз строится только на этих наблюдениях. Чем
меньшее количество наблюдений используется для вычисления скользящего среднего,
тем точнее будут отражены изменения показателей, на основе которых строится
прогноз. Однако, если для прогнозируемого скользящего среднего используется
только одно или два наблюдения, такой прогноз может быть слишком упрощенным.
Чтобы определить, сколько наблюдений желательно включить в скользящее среднее,
нужно исходить из предыдущего опыта и имеющейся информации о наборе данных.
Необходимо соблюдать равновесие между повышенным откликом скользящего среднего
на несколько самых поздних наблюдений и большой изменчивостью скользящего
среднего. [3 стр. 535-356]
Более
хороших результатов удается добиться при использовании метода экспоненциальных
средних. Соответствующая модель описывается с помощью формулы:
(t+1)=α∙y(t)-(1-α)∙y’(t),
где
y(t+1) - прогнозируемое значение, y(t) - текущее наблюдаемое значение, y’(t) -
прошлый прогноз текущего значения, α - параметр сглаживания (0≤α≤1). Параметр α позволяет определять степень участия прошлых значений ряда в
формировании прогноза. В пределе, когда α=1, мы получим обычный «наивный» прогноз, а при α=0 прогнозируемая величина всегда будет равна
предыдущему прогнозу. [3 стр. 536-537]
Метод
экспоненциальных средних можно пояснить с помощью диаграммы, представленной на
Рис. 2. [3 стр. 537]
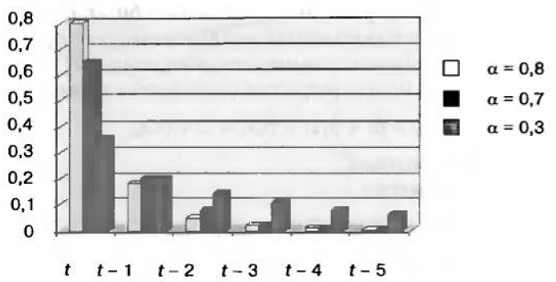
Рис.
2. - Прогнозирование методом экспоненциальных средних
Как
видно на рисунке, при больших α
увеличивается вклад самых свежих значений ряда, а с удалением в прошлое вклад
значений резко уменьшается. При малых значениях α вклад значений ряда в результат прогнозирования
распределяется более равномерно. [3 стр. 357]
Обычно
при прогнозировании модели экспоненциального сглаживания строятся прогнозы на
некотором тестовой наборе при α={0,01;0,02…0,98;0,99}.
Затем определяется, при каком α
обеспечивается наиболее высокая точность прогнозирования, и это значение
применяется в дальнейшем. [3 стр. 537]
4. Регрессионные
модели
К
числу наиболее мощных, развитых и универсальных моделей прогнозирования
относятся регрессионные модели. Регрессия - это технология статистического
анализа, целью которой является определение лучшей модели, устанавливающей
взаимосвязь между выходной (зависимой) переменной и набором входных
(независимых) переменных. [3 стр. 537]
Применение
регрессионных моделей оказывается особенно полезным в следующих случаях:
· входные переменные задачи известны или легко поддаются
изменению, а выходные - нет;
· значения входных переменных известны изначально, и на их
основе требуется предсказать значения выходных переменных;
· требуется
установить причинно-следственные связи между входными и выходными переменными
также в силу этих связей. [3 стр. 537-538]
В
технологиях прогнозирования наиболее широко используется такой вид
регрессионной модели, как обобщенная линейная модель. Ее популярность вызвана
тем, что многие процессы в управлении, экономике и бизнесе линейны по своей
природе. Кроме того, существуют методы, которые позволяют привести нелинейную
модель с минимальными потерями точности. [3 стр. 358]
Обобщенная
линейная модель регрессии описывается следующим уравнением:
=β0+β1x1+β2x2+…+βnxn,
где
xi - значение i-го наблюдения, βi -
коэффициент регрессии. [3 стр. 538]
Логистическая
регрессия - это разновидность множественной регрессии, общее назначение которой
состоит в анализе связи между несколькими независимыми переменными (называемыми
также регрессорами или предикторами) и зависимой переменной. Бинарная
логистическая регрессия, как следует из названия, применяется в случае, когда
зависимая переменная является бинарной (т.е. может принимать только два
значения). [4]
5. Метод
декомпозиции временного ряда
Одним
из методов прогнозирования временных рядов является определение факторов,
которые влияют на каждое значение временного ряда. Для этого выделяется каждая
компонента временного ряда, вычисляется ее вклад в общую составляющую, а затем
на его основе прогнозируются будущие значения временного ряда. Данный метод
получил название декомпозиции временного ряда. [3 стр. 538]
Фактически
декомпозиция - это выделение компонент временного ряда и их проекция на будущее
с последующей комбинацией для получения прогноза. Проблема заключается в том,
чтобы обеспечить достаточно высокую точность для отдельных компонент очень
затруднительно. [3 стр. 538]
При
декомпозиции при помощи линейного тренда, что типично для многих реальных
временных рядов, он представляет собой прямую линию, описываемую уравнением:
=a+b∙x,
где
y - значение ряда, a, b -коэффициенты, определяющие расположение и наклон линии
тренда, t - время. [3 стр. 538]
Если
уравнение линии тренда известно, с его помощью можно рассчитать значение тренда
в любой, в том числе будущий, момент времени. Достаточно воспользоваться
уравнением:
i+k=a+b∙(t’+k),
где
t’ - начало прогноза, k -горизонт прогноза. [3 стр. 538]
При
использовании сезонности для прогнозирования методом декомпозиции сначала из
временного ряда убирается тренд и сглаживается возможная циклическая
компонента. Тогда можно считать, что оставшиеся данные будут обусловлены в
основном сезонными колебаниями. На основе этих данных вычисляются так
называемые сезонные индексы, которые характеризуют изменения временного ряда во
времени. [3 стр. 538]
Прецедент
- это описание ситуации в сочетании с подробным указанием действий,
предпринимаемых в данной ситуации. Таким образом, вывод, основанный на
прецедентах, представляет собой такой метод анализа данных, который делает
заключения относительно данной ситуации по результатам поиска аналогий,
хранящихся в базе прецедентов. Данный метод по своей сути относится к категории
"обучение без учителя", т.е. является "самообучающейся"
технологией, благодаря чему рабочие характеристики каждой базы прецедентов с
течением времени и накоплением примеров улучшаются. [5]
Преимущества
метода:
· простота использования полученных результатов.
· решения не уникальны для конкретной ситуации, возможно их
использование для других случаев.
· целью поиска
является не гарантированно верное решение, а лучшее из возможных. [5]
Недостатки метода "ближайшего соседа":
· данный метод не создает каких-либо моделей или правил,
обобщающих предыдущий опыт, - в выборе решения они основываются на всем массиве
доступных исторических данных, поэтому невозможно сказать, на каком основании
строятся ответы.
· существует сложность выбора меры "близости"
(метрики). От этой меры главным образом зависит объем множества записей,
которые нужно хранить в памяти для достижения удовлетворительной классификации
или прогноза. Также существует высокая зависимость результатов классификации от
выбранной метрики.
· при использовании метода возникает необходимость полного
перебора обучающей выборки при распознавании, следствие этого - вычислительная
трудоемкость.
· типичные
задачи данного метода - это задачи небольшой размерности по количеству классов
и переменных. [5]
7. Метод опорных
векторов (SVM - Support Vector
Machine)
SVM
отображает векторы входных данных на более многомерное пространство, где
строится «оптимальная гиперплоскость», разделяющая данные. С каждой стороны от
этой гиперплоскости строятся две параллельных гиперплоскости. На Рис. 3
приведен пример, в котором оптимальная гиперплоскость разделяет две категории
данных (треугольники и квадраты). Оптимально разделяющая гиперплоскость
определяет максимальное расстояние между двумя параллельными гиперплоскостями.
Чем больше расстояние между двумя гиперплоскостями, тем точнее модель. Точки
данных, лежащие на одной из двух параллельных гиперплоскостей, которые
определяют наибольшее расстояние, называются опорными векторами. [6]
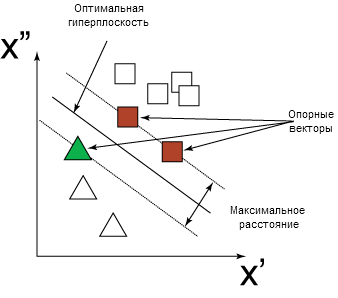
Рис.
3. - Двухмерное представление оптимальной гиперплоскости, разделяющей данные и
опорные вектора
SVM,
а также NN и модели логистической регрессии представляют собой мощные
универсальные методы, которые хотя и различаются математически, дают в какой-то
мере сопоставимые результаты. [6]
8. Метод
деревьев решений
Метод
деревьев решений (decision trees) является одним из наиболее популярных методов
решения задач классификации и прогнозирования. [5]
Если
зависимая переменная принимает непрерывные значения, то дерево решений
устанавливает зависимость этой переменной от независимых переменных, т.е.
решает задачу численного прогнозирования. [5]
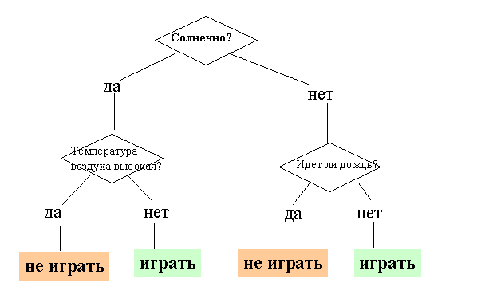
Рис.
4. - Дерево решений "Играть ли в гольф?"
Чтобы
решить задачу, представленную на Рис. 4, т.е. принять решение, играть ли в
гольф, следует отнести текущую ситуацию к одному из известных классов (в данном
случае - «играть» или «не играть»). Для данной задачи (как и для любой другой)
может быть построено множество деревьев решений различного качества, с
различной прогнозирующей точностью. [5]
9. Кластеризация
модель прогнозирование кластеризация вектор
С
другой стороны, в тех случаях, когда целевая переменная, или отклик, не имеет
значения или отсутствует, очень популярна технология кластеризации. [6]
Применение кластеризации, т.е. разбиение временного ряда на гомогенные отрезки,
в задачах прогнозирования было предложено давно. Еще в 1974 году Russel Fogler
опубликовал статью «A pattern recognition model for forecasting». В этой статье
автор впервые предложил прогнозирование временных рядов разбить на два этапа:
· кластеризация
· прогнозирование
внутри кластера. [7]
По
сути дела такой подход является комбинацией двух различных моделей временных
рядов - первая модель определяет кластер, вторая прогнозирует внутри кластера.
[7]
На
Рис. 5 показан пример, в котором входные данные разделены на две группы. Данные
первой группы обозначены зелеными треугольниками, а данные второй группы ― красными квадратами. [6]
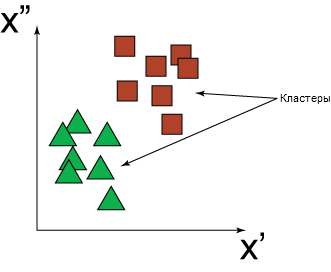
Рис.
5. - Двухмерное представление результата кластеризации набора входных данных на
группы зеленых треугольников и красных квадратов
Вся
цель подобного нагромождения моделей состоит в повышении точности
прогнозирования временных рядов. Однако нужно четко понимать, что создание
комбинированных моделей весьма трудоемко, потому как нужно создать не только
модель для кластеризации, но множество моделей прогнозирования внутри каждого
кластера. [7]
10. Метод
ассоциативных правил
Когда
целевая переменная или степень сходства не имеет значения, но важны связи между
входными элементами, для их поиска может использоваться так называемый метод
ассоциативных правил. [6]
Впервые
задача поиска ассоциативных правил (association rule mining) была предложена
для нахождения типичных шаблонов покупок, совершаемых в супермаркетах, поэтому
иногда ее еще называют анализом рыночной корзины (market basket analysis). [5]
Хотя
все прогностические методы имеют свои сильные и слабые стороны, точность модели
в значительной мере зависит от исходных данных и функций, используемых для
обучения прогностической модели. Как упоминалось выше, построение модели в
значительной мере состоит из анализа данных и манипулирования ими. Обычно из
сотен полей доступных исходных данных выбирается некоторое подмножество, и до
передачи в метод прогностического моделирования эти поля предварительно
обрабатываются. Таким образом, секрет качественной прогностической модели часто
кроется в хорошей подготовительной работе, которая даже важнее, чем метод,
используемый для обучения модели. Это не означает, что от прогностического
метода ничего не зависит. Если используется неподходящий метод или выбран
неподходящий набор входных параметров, хорошие данные не помогут. [6]
Описание
разрабатываемого алгоритма, его укрупненная схема
Алгоритм состоит из следующих пунктов:
· получение временного ряда с интервалом в выбранную временную
итерацию;
· заполнение «пробелов» в истории;
· сглаживание ряда методом скользящих средних (или другим);
· получение ряда относительного изменения прогнозируемой
величины;
· формирование таблицы «окон» с глубиной погружения временных
интервалов;
· добавление к таблице дополнительных данных (например,
изменение величины за предыдущие годы);
· шкалирование;
· определение обучающей и валидационной выборок;
· подбор параметров нейросети;
· обучение нейросети;
· проверка
работоспособности нейросети в реальных условиях. [2]
Метод
окон (метод windowing) позволяет выявить закономерности во временном ряде на
основе сведения анализа временного ряда к задаче распознавания образов и
последующего ее решения на нейросети. Основная идея метода: вводится два окна,
одно из которых входное (input), второе - выходное (output). Эти окна
фиксированного размера для наблюдения данных. Окна способны перемещаться с
некоторым шагом S. В результате получаем некоторую последовательность
наблюдений, которая составляет обучающее множество. Входному окну соответствует
вход нейросети, а выходному окну - желаемый образ. [5]
Возьмем
глубину погружения равной 4, т.е. прогнозирование величины на следующую
итерацию будет осуществляться по результатам четырех предыдущих итераций. Далее
следует преобразовать величину к следующему виду:
Таблица
1. Первый вариант «окна» данных
|
Hist1
|
Hist2
|
Hist3
|
Hist4
|
Hist0
|
|
D-1
|
D-2
|
D-3
|
D-4
|
D
|
|
D-2
|
D-3
|
D-4
|
D-5
|
D-1
|
|
D-3
|
D-4
|
D-5
|
D-6
|
D-2
|
|
…
|
…
|
…
|
…
|
Первые
четыре колонки являются входами нейросети, последняя - выход, т. е. на основе
предыдущих значений изменения величины прогнозируется следующее значение ряда.
Таким образом, мы получаем так называемое «скользящее окно», в котором
представлены данные за пять недель. Окно можно двигать по временной оси и
изменять его ширину. Чтобы учесть предыдущие годы и учесть возможные сезонные
зависимости добавим еще один столбец в выборку, который показывает изменение
величины в прошлый год за тот же период (см. Таблица 2). [2]
Таблица
2.Второй вариант «окна» данных
|
LastY
|
Hist1
|
Hist2
|
Hist3
|
Hist4
|
Hist0
|
|
L
|
D-1
|
D-2
|
D-3
|
D-4
|
D
|
|
L-1
|
D-2
|
D-3
|
D-4
|
D-5
|
D-1
|
|
L-2
|
D-3
|
D-4
|
D-5
|
D-6
|
D-2
|
|
…
|
…
|
…
|
…
|
…
|
…
|
Таким
образом готовится обучающая выборка и именно в таком виде предоставляются
данные для последующего анализа. Можно не ограничиваться только прошлым годом,
а подавать данные за несколько предыдущих лет, но следует учитывать, что сеть в
таком случае разрастается, что иногда приводит к плохим результатам. [2]
Решение
контрольного примера
В
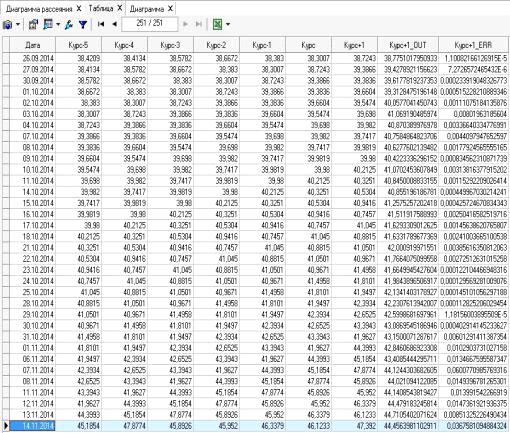
качестве исходных данных используем файл «kurs_dollar_01.11.2013_15.11.2014», в
котором хранятся данные по курсам доллар/рубль на выбранный промежуток времени.
Формат данных представлен в табл.1. Данные получены с официального сайта ЦБ РФ
(www.cbr.ru <#"784044.files/image007.jpg">
4. На 2-ом шаге мастера настроим поля следующим образом: поле «Курс»
назначим используемым, глубину погружения зададим равной 5 (т.к. одна сессия -
это неделя, т.е. 5 рабочих дней), а горизонт прогнозирования - 1 (будем
прогнозировать на 17.11.2014).
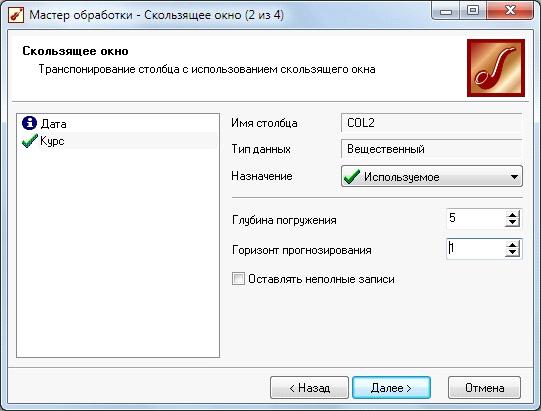
5. Подтвердив следующие шаги мастера, получим таблицу «окна» данных.
6. Для прогнозирования нужно построить модель. Запустим «Мастер
обработки» еще раз, и в секции «Data Mining» выберем пункт «Нейросеть».
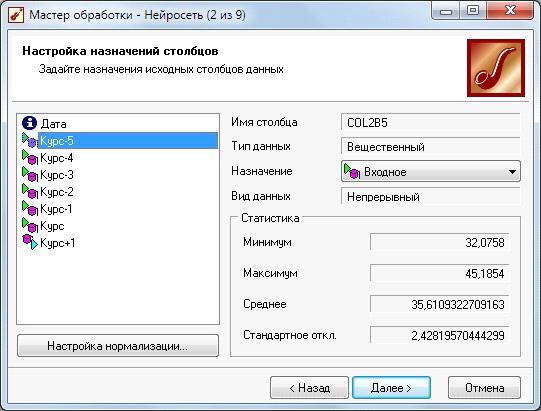
7. На 2-ом шаге мастера настроим поля исходных данных. Для модели
необходимо выбрать в качестве входных полей «Курс - 5» … «Курс», а выходным
будет поле «Курс + 1». Поле «Дата» - информационное.
8. Оставив настройки 3-его шага мастера неизменными (95% - обучающее
множество, 5% - тестовое).
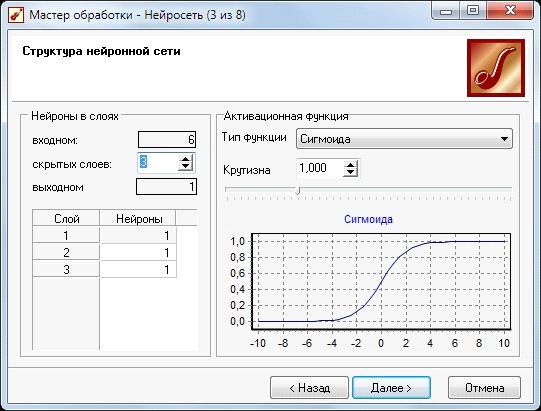
. На 4-ом изменим структуру нейросети - зададим число скрытых
слоев равным 3.
10. Оставим настройки процесса обучения нейронной сети на 5-ом шаге
мастера без изменений.
11. На 6-ом шаге укажем параметры остановки обучения: ошибка должна
быть меньше 0,005; в обучающем и тестовом множестве должно быть распознано 95%.
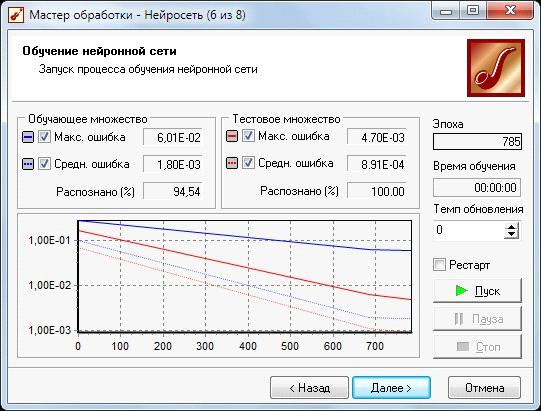
12. Произведем обучение нейронной сети с указанными параметрами.
.
Для анализа полученной модели на 8-ом шаге мастера выберем следующие способы
отображения: в секции «Data Mining» укажем «Диаграмма рассеяния», «Табличные
данные» - «Таблица», «Графики» - «Диаграмма».
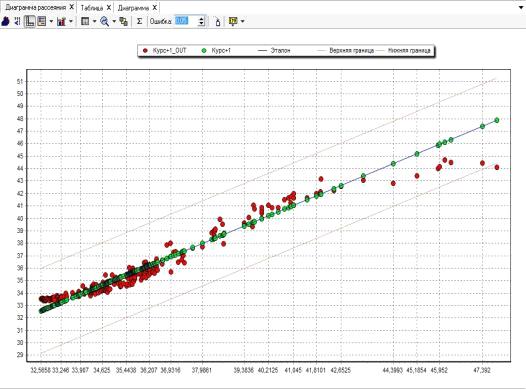
Рисунок
6 - Диаграмма рассеяния построенной нейросети
Рисунок
7 - Таблица значений построенной нейросети
Рисунок
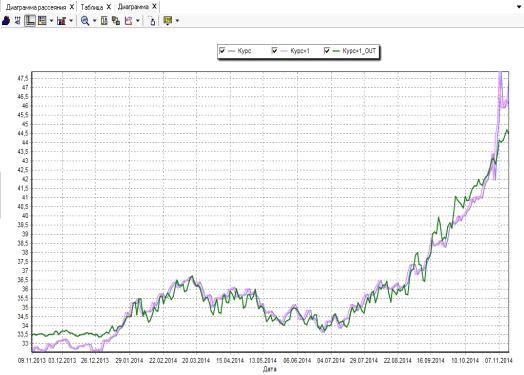
8 - График изменения значений построенной нейросети
Оценка
точности решения
Для
проверки прогностических качеств модели используют процедуру кросс-проверки.
Модель строится по выборке с обрезанным «хвостом», а затем сравниваются «хвост»
и прогноз. [8] В нашем случае прогноз последней сессии, построенный
нейросетью, оказался неинформативным - значения на 15.11.2014 не совпадают на
2,938 (-6,2%).
Судя
по диаграмме, разброс между эталонными значениями выходного поля и значениями,
рассчитанными моделью, достаточно велик. Это говорит о необходимости увеличения
обучающей выборки либо предобработки данных. К примеру, стоит удалить аномалии,
убрать шумы, изменить набор входных параметров и т.п.
Заключение и
выводы
К
недостаткам прогнозирования с помощью нейронных сетей можно отнести следующее:
длительное время обучения, проблема переобучения, трудность определения
положения обучающей выборки и значащих входов. [8]
Как
видно из Рисунок 8 график значений нейросети (Курс+1_OUT) значительно
отличается от графика известных значений на следующий день (Курс) в начальном
(незначительные отличия) и конечном (значительные) периоде исследования.
Значительно ближе к целевому значению график, полученный с помощью аппроксимации
скользящим окном (Курс+1), что говорит о неспособности нейронной модели
предсказывать краткосрочное будущее достаточно подробно, как это может
потребоваться трейдеру валютного рынка.
Список литературы
1. Deductor 4
- прогнозирование. BIGroup Labs. [В Интернете] [Цитировано: 20 10 2014 r.]
http://www.bi-grouplabs.ru/ResourceAnalitic/Forcast2/DedForcast.html.
.
Прогнозирование с помощью нейронных сетей. [В Интернете] [Цитировано: 20 10
2014 r.] http://apsheronsk.bozo.ru/Neural/Lec9.htm.
. Паклин, Н.
и Орешков, В. Бизнес-аналитика: от данных к знаниям. СПб. : Питер, 2013.
. Паклин, Н.
Логистическая регрессия и ROC-анализ - математический аппарат. BaseGroup Labs.
[В Интернете] [Цитировано: 03 11 2014 r.]
http://www.basegroup.ru/library/analysis/regression/logistic/.
5.
Чубукова, И. А. Data Mining. Интуит
- национальный открытый университет. [В Интернете] [Цитировано: 03 11 2014 r.]
http://lnfm1.sai.msu.ru/~rastor/Books/Chubukova-Data_Mining.pdf.
. Гуаццелли,
Алекс. Прогнозирование будущего: Часть 2. Методы прогностического
моделирования. developerWorks Россия. [В Интернете] IBM, 01 10 2012 r.
[Цитировано: 03 11 2014 r.]
http://www.ibm.com/developerworks/ru/library/ba-predictive-analytics2/.
. Пешнина, М.
А. Материалы Международного молодежного научного форума «ЛОМОНОСОВ-2014». [1
электрон. опт. диск (DVD-ROM)] М. : МАКС Пресс, 2014 r.
. Пауков, Д.
ПРОГНОЗИРОВАНИЕ С ПОМОЩЬЮ ИСКУССТВЕННЫХ НЕЙРОННЫХ СЕТЕЙ. ДНТУ. [В Интернете]
[Цитировано: 20 10 2014 r.]
http://masters.donntu.edu.ua/2006/kita/kiryan/library/art06.htm.
. Чубукова,
И. А. Лекция 9: Методы классификации и прогнозирования. Деревья решений. Интуит
- национальный открытый университет. [В Интернете] [Цитировано: 03 11 2014 r.]
http://www.intuit.ru/studies/courses/6/6/lecture/174.