Паралельні і розподілені обчислення
ОДЕСЬКА ДЕРЖАВНА АКАДЕМІЯ ХОЛОДУ
ФАКУЛЬТЕТ ІНФОРМАЦІЙНИХ ТЕХНОЛОГІЙ
КАФЕДРА ІНФОРМАЦІЙНО-КОМУНІКАЦІЙНИХ
ТЕХНОЛОГІЙ
КУРСОВА РОБОТА
по дисципліні: "Паралельні і
розподілені обчислення"
Виконав студент 3 курсу групи 532
Михайлов Сергій
Науковий керівник Бондаренко В.Г.
ОДЕСА - 2012р.
Завдання
На курсову роботу студентові Михайлову Сергію.
. Теоретична частина.
Описати стандарти OpenMP i MPI, як основні засоби
програмування для багатопроцесорних систем.
. Практична частина.
Завдання 1. Розробити програму паралельного розрахунку
означеного інтеграла для функції  з кроком дискретизації 0,00002.
з кроком дискретизації 0,00002.
Завдання 2. Розробити паралельну програму множення
квадратної матриці на квадратну матрицю.
Оглавление
Введення
1. Теоретична частина. Варіант 3. Описати стандарти OpenMP i MPI,
як основні засоби програмування для многопроцесорних систем
1.1 OpenMР
1.1.1 Директиви OpenMP
1.1.2 Оператори OpenMP Оператори OpenMP використовуються спільно з
директивами
1.2 MPI
2. Практична частина
2.1 Завдання А. Варіант 7. Розробити програму паралельного
розрахунку означеного інтеграла для функції  з кроком дискретизації 0,00002
з кроком дискретизації 0,00002
2.1.1 Метод рішення
2.1.2 Алгоритм і блок-схема роботи програми
2.1.3 Текст програми
2.1.4 Таблиця і графік проведених експериментів
2.1.5 Висновок
2.2 Завдання Б. Варіант 3. Розробка паралельної програми множення
квадратної матриці на квадратну матрицю
2.2.1 Постановка завдання
2.2.2 Послідовний алгоритм множення двох квадратних матриць
2.2.3 Текст програми
2.2.4 Результати обчислювальних експериментів
2.2.5 Висновки
Перелік посилань
Введення
Минуло мало чим більше 50 років з моменту появи
перших електронних обчислювальних машин - комп'ютерів. За цей час сфера їх
вживання охопила практично всі області людської діяльності. Сьогодні неможливо
уявити собі ефективну організацію роботи без вживання комп'ютерів в таких
областях, як планерування і управління виробництвом, проектування і розробка складних
технічних пристроїв, видавнича діяльність, освіта - словом, у всіх областях, де
виникає необхідність в обробці великих об'ємів інформації. Проте найбільш
важливим як і раніше залишається використання їх в тому напрямі, для якого вони
власне і створювалися, а саме, для вирішення великих завдань, що вимагають
виконання величезних об'ємів обчислень. Такі завдання виникли в середині
минулого століття у зв'язку з розвитком атомної енергетики, авіабудування,
ракетно-космічних технологій і ряду інших галузей науки і техніки.
У наш час коло завдань, що вимагають для свого
рішення застосування потужних обчислювальних ресурсів, ще більш розширився. Це
пов'язано з тим, що сталися фундаментальні зміни в самій організації наукових
досліджень. Унаслідок широкого впровадження обчислювальної техніки значно
посилився напрям чисельного моделювання і чисельного експерименту. Чисельне
моделювання, заповнюючи проміжок між фізичними експериментами і аналітичними
підходами, дозволило вивчати явища, які є або дуже складними для дослідження
аналітичними методами, або дуже дорогими або небезпечними для
експериментального вивчення. При цьому чисельний експеримент дозволив значно
здешевити процес наукового і технологічного пошуку. Стало можливим моделювати в
реальному часі процеси інтенсивних фізико-хімічних і ядерних реакцій, глобальні
атмосферні процеси, процеси економічного і промислового розвитку регіонів і так
далі Вочевидь, що вирішення таких масштабних завдань вимагає значних
обчислювальних ресурсів.
Обчислювальний напрям вживання комп'ютерів завжди
залишався основним двигуном прогресу в комп'ютерних технологіях. Не дивно тому,
що як основна характеристика комп'ютерів використовується такий показник, як
продуктивність - величина, що показує, яку кількість арифметичних операцій він
може виконати за одиницю часу. Саме цей показник з найбільшою очевидністю
демонструє масштаби прогресу, досягнутого в комп'ютерних технологіях. Так,
наприклад, продуктивність одного з найперших комп'ютерів EDSAC складала всього
біля 100 операцій в секунду, тоді як пікова продуктивність найпотужнішого на
сьогоднішній день суперкомп'ютера Earth Simulator оцінюється в 40 трильйонів
операций/сек. Тобто сталося збільшення швидкодії в 400 мільярдів разів!
Неможливо назвати іншу сферу людської діяльності, де прогрес був би настільки
очевидний і так великий.
Природно, що у будь-якої людини відразу ж виникає
питання: за рахунок чого це виявилося можливим? Як не дивно, відповідь досить
проста: зразкове 1000-кратне збільшення швидкості роботи електронних схем і максимально
широке розпаралелювання обробки даних.
Ідея паралельної обробки даних як потужного
резерву збільшення продуктивності обчислювальних апаратів була висловлена
Чарльзом Беббіджем приблизно за сто років до появи першого електронного
комп'ютера. Проте рівень розвитку технологій середини 19-го століття не
дозволив йому реалізувати цю ідею. З появою перших електронних комп'ютерів ці
ідеї неодноразово ставали відправною крапкою при розробці самих передових і
продуктивних обчислювальних систем. Без перебільшення можна сказати, що вся
історія розвитку високопродуктивних обчислювальних систем - це історія
реалізації ідей паралельної обробки на тому або іншому етапі розвитку
комп'ютерних технологій, природно, у поєднанні із збільшенням частоти роботи
електронних схем.
Принципово важливими рішеннями в підвищенні
продуктивності обчислювальних систем були: введення конвеєрної організації
виконання команд; включення в систему команд векторних операцій, що дозволяють
однією командою обробляти цілі масиви даних; розподіл обчислень на безліч
процесорів. Поєднання цих 3-х механізмів в архітектурі суперкомп'ютера Earth
Simulator, що складається з 5120 векторно-конвеєрних процесорів, і дозволило
йому досягти рекордної продуктивності, яка в 20000 разів перевищує продуктивність
сучасних персональних комп'ютерів. Вочевидь, що такі системи надзвичайно дороги
і виготовляються в одиничних екземплярах. Ну, а що ж виробляється сьогодні в
промислових масштабах? Широка різноманітність вироблюваних в світі комп'ютерів
з великою мірою умовності можна розділити на чотири класи:
персональні комп’ютери (Personal
Computer - PC);
- робочі станції (WorkStation - WS);
- суперкомп’ютери (Supercomputer - SC);
- кластерні системи.
Ця умовність розподілення пов’язана в першу чергу
з швидким прогресом в розвитку мікроелектронних технологій.
Персональні комп’ютери. Це комп’ютер, призначений
для експлуатації одним користувачем, тобто для особистого використання. До ПК
умовно можна віднести також і будь-який інший комп’ютер, використовуваний
конкретною людиною в якості свого особистого комп’ютера. Персональним
комп’ютером називають однопроцесорну систему, що використовує процесори Intel
або AMD і що працює під управлінням операційних систем Microsoft
Windows та інших.
Робочі станції. Робоча станція, як місце фахівця,
є повноцінний комп’ютер або комп’ютерний термінал (пристрої вводу/виводу,
відокремлені і часто віддалені від керуючого комп’ютера), набір необхідного
програмного забезпечення, по необхідності доповнюється допоміжним обладнанням.
Це найчастіше комп’ютери, які містять від одного до чотирьох RISC процесорів
(RISC (Restrictes instruction set computer - комп’ютер із спрощеним
набором команд) - архітектура процесора, в якій швидкодія збільшується за
рахунок спрощення команд, щоб їх декодування було простіше, а час використання
- коротше) і розрахованими на багато користувачів ОС, що відносяться до
сімейства OC UNIX.
Суперкомп’ютери. Суперкомп’ютер - обчислювальна
машина, значно перевищує за своїми технічними параметрами більшість існуючих
комп’ютерів. Як правило, сучасні суперкомп’ютери представляють собою велику
кількість високопродуктивних серверних комп’ютерів, з’єднаних один з одним
локальною високошвидкісною магістраллю, для досягнення максимальної
продуктивності у рамках підходу розпаралелювання обчислювальної задачі.
Кластерні системи. З декількох процесорів і
загальної для них пам’яті формується обчислювальний вузол. Якщо отриманої
обчислювальної потужності не достатньо, то об’єднується декілька вузлів
високошвидкісними каналами. За таким принципом побудовані CRAY, SV1, HP
Exemplar, SUN, останні моделі IBM SP2. Кластерні технології стали
дешевою альтернативою суперкомпютерів. Сьогодні не складає великих труднощів
створити невелику кластерну систему, об’єднавши обчислювальні потужності
комп’ютерів окремої лабораторії або навчального класу.
Отже, багатопроцесорні системи, міцно
затвердилися у діапазоні виготовлених обчислювальних систем, починаючи з
персональних комп’ютерів і закінчуючи суперкомп’ютерами на базі
векторно-конвеєрних технологій, а, з іншою, підвищує актуальність їх освоєння,
оскільки для всіх типів багатопроцесорних систем потрібне використання
спеціальних технологій програмування для того, щоб програма могла повною мірою
використовувати ресурси високопродуктивної обчислювальної системи.
паралельне розподілене обчислення матриця
1.
Теоретична частина. Описати стандарти OpenMP i MPI, як основні засоби
програмування для многопроцесорних систем
1.1
OpenMР
OpenMP стандарт програмного інтерфейсу додатків
для паралельних систем з загальною пам'яттю. Підтримує мови C, C + +, Фортран.
Модель програми в OpenMP
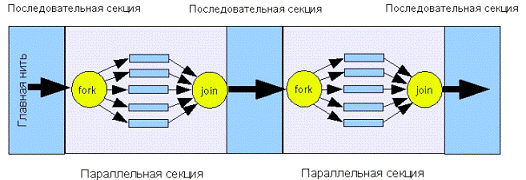
Рис. 1.1 Модель паралельної програми в OpenMP
Модель паралельної програми в OpenMP можна
сформулювати наступним чином:
Програма складається з послідовних і паралельних
секцій (рис. 1,1).
У початковий момент часу створюється головна
нитка, яка виконує послідовні секції програми.
При вході в паралельну секцію виконується
операція fork, що породжує сімейство ниток. Кожна нитка має свій унікальний числовий
ідентифікатор (Головної нитки відповідає 0). При розпаралелювання циклів всі
паралельні нитки виконують один код. У загальному випадку нитки можуть
виконувати різні фрагменти коду.
При виході з паралельної секції виконується
операція join. Завершується виконання всіх ниток, крім головної.
OpenMP складають наступні компоненти:
Директиви компілятора - використовуються для
створення потоків, розподілу роботи між потоками і їх синхронізації. Директиви
включаються у вихідний текст програми. Підпрограми бібліотеки -
використовуються для встановлення та визначення атрибутів потоків. Виклики цих
підпрограм включаються у вихідний текст програми.
Змінні оточення - використовуються для управління
поведінкою паралельної програми. Змінні оточення задаються для середовища
виконання паралельної програми відповідними командами (наприклад, командами
оболонки в операційних системах UNIX). Використання директив компілятора і
підпрограм бібліотеки підпорядковується правилам, які розрізняються для різних
мов програмування. Сукупність таких правил називається прив'язкою до мови.
Прив'язка до мови C
У програмах на мові С, імена функцій і змінних
оточення OMP починається з omp, omp_ або OMP_. Формат директиви: # pragma omp
директива [оператор_1 [, оператор_2, …]] В OpenMP-програмі використовується
заголовний файл omp. h
#include "omp. h"
#include <stdio. h>f (double x)
{4.0/ (1 + x * x);
}() {long N = 100000;i;h, sum, x;= 0; 21= 1.0/N;
#pragma omp parallel shared (h)
{
#pragma omp for private (x) reduction (+: sum)(i
= 0; i < N; i++) {= h * (i + 0.5);= sum + f (x);
}
}("PI = %f\n", sum / N);
}
1.1.1
Директиви OpenMP
Далі наводиться перелік директив OpenMP. Описи
директив OpenMP орієнтовані на специфікацію версії 2.5.
…
end parallel
private;;;;;;;_threads.
sections
…
end sections
Обрамляє паралельну секцію програми. Вкладені
секції програми, що задаються директивами section, розподіляються між нитками.
З даною директивоюможуть використовуватися наступні оператори:
private;;;;.
single
…
end single
Обрамляє блок програми, який повинен виконуватися
однією ниткою. З даною директивою можуть використовуватися наступні оператори:
;;;.
Визначає межі паралельної секції програми. З
даною директивою можуть використовуватися наступні оператори (їх опис дається
далі):
…workshare
Ділить блок на частини, виконання яких
розподіляється між нитками таким чином, що кожна частина виконується один раз.
Блок може містити тільки такі конструкції:
привласнення масивів;
скалярні присвоювання;;;;;.
parallel do
цикл doparallel do
Об'єднує директиви parallel і do.
parallel sections
.parallel sections
Об'єднує директиви parallel і sections.
parallel workshare .parallel workshare Об'єднує
директиви parallel і workshare.
master
.master
Обрамляє блок програми, який повинен виконуватися
тільки головною ниткою.
critical [ (блокування)]
.critical [ (блокування)]
Обрамляє блок програми, доступ до якого в
будь-який момент часу може отримати тільки одна нитка (критична секція).
Блокування - необов'язкове ім'я критичної секції.
Квадратні дужки вказують, що ім'я не є
обов'язковим і може бути опущено.
barrier Директива бар'єрної синхронізації ниток.
Кожна нитка, виконання якої досягло даної точки, призупиняє своє виконання до
тих пір, поки всі нитки не досягнуть даної точки.
atomic Оголошує операцію атомарної (при
виконанні атомарної операції одночасний доступ до пам'яті за записом різних
ниток заборонений). Застосовується тільки до оператора, безпосередньо
наступного після даної директиви. Він може мати наступний вигляд:
x = x {+ | - | * | / |. AND. |. OR. |. EQV. |.
NEQV. } скалярное_выражение_не_содержащее_x x =
скалярное_выражение_не_содержащее_x {+ | - | * | / |. AND. |. OR. |. EQV. |.
NEQV. } X x = {MAX | MIN | IAND | IOR | IEOR} (x, скалярное_выражение_не_содержащее_x)
x = {MAX | MIN | IAND | IOR | IEOR} (Скалярное_выражение_не_со держащее_x, x)
flush [ (список змінних)]
Дана директива задає точку синхронізації, в якій
значення змінних, зазначених у списку і видимих з даної нитки, записуються в
пам'ять. Цим забезпечується узгодження вмісту пам'яті, доступного різним
ниткам.
.ordered
Забезпечує збереження того порядку виконання
ітерацій циклу, який відповідає послідовному виконанню програми.
(список common-блоків)
Визначає common-блоки, перераховані в списку,
локальними.
1.1.2 Оператори
OpenMP Оператори OpenMP використовуються спільно з директивами
private (список змінних) Оголошує змінні
зі списку локальними.
firstprivate (список змінних)
Оголошує змінні зі списку локальними і ініціює їх
значеннями з блоку програми, що передує даній директиві.
lastprivate (список змінних)
Оголошує змінні зі списку локальними і призначає
їм значення з того блоку програми, який був виконаний останнім.
copyprivate (список змінних)
Після завершення виконання блоку, заданого
директивою single, значення локальних змінних зі списку розподіляються між
іншими нитками.
nowait
Скасовує бар'єрну синхронізацію при завершенні
виконання паралельної секції.
shared (список змінних)
Оголошує змінні зі списку загальними для всіх
ниток.
default (private | shared | none)
Даний оператор дозволяє змінити правила
визначення області видимості змінних, діють за умовчанням. Варіант private
використовується тільки в мові Fortran. reduction (операція | вбудована
функція: список змінних) Оператор приведення значень локальних змінних зі
списку за допомогою зазначеної операції або вбудованої функції мови. Операція
редукції застосовується до декільком значенням і повертає одне значення.
if (скалярний логічне вираз)
Умовний оператор.
num_threads (скалярний цілий вираз)
schedule (характер_распределения_итераций
([количество_итерацій_цикла])
Даний оператор задає спосіб розподілу ітерацій
циклу між нитками:
static - кількість ітерацій циклу, переданих для
виконання кожної нитки фіксоване і розподіляється між нитками за принципом
кругового планування.
Якщо кількість ітерацій не зазначено, воно
вважається рівним 1;
dynamic - кількість ітерацій циклу, переданих для
виконання кожної нитки фіксовано. Чергова "порція" ітерацій
передається звільнилася нитки;
guided - кількість ітерацій циклу, переданих для
виконання кожної нитки поступово зменшується. Чергова "порція"
ітерацій передається звільнилася нитки;
runtime - тип розподілу роботи визначається під
час виконання програми, наприклад, за допомогою змінної оточення
OMP_SCHEDULE.(список імен common-блоків). При виконанні цього оператора дані з
головної нитки копіюються в локальні екземпляри common-блоку на початку кожної
паралельної секції. Імена задаються міжсимволами "/".
Підпрограми OpenMP
Підпрограми, що формують середовище виконання
паралельної програми Тут і далі спочатку наводиться інтерфейс підпрограм OpenMP
для мови C, потім для мови Fortran.
void omp_set_num_threads (int
threads);omp_set_num_threads (threads) integer threads
Задає кількість потоків (threads) при виконанні
паралельних секцій програми.
int omp_get_num_threads (void);function
omp_get_num_threads ()
Повертає кількість потоків, використовуваних для
виконання паралельної секції.
int omp_get_max_threads (void);function
omp_get_max_threads ()
Повертає максимальну кількість потоків, які можна
використовувати для виконання паралельних секцій програми.
int omp_get_thread_num (void);function
omp_get_thread_num ()
Повертає ідентифікатор нитки, з якої викликається
дана функція.
int omp_get_num_procs (void);function
omp_get_num_procs ()
Повертає кількість процесорів, доступних в даний
момент програмі.
int omp_in_parallel (void);function omp_in_parallel
()
Повертає значення true при виклику з активної
паралельної секції програми.
void omp_set_dynamic (int
threads);omp_set_dynamic (threads) logical threads
Включає або відключає можливість динамічного
призначення кількості потоків при виконанні паралельної секції. За
замовчуванням ця можливість відключена.
int omp_get_dynamic (void);function
omp_get_dynamic ()
Повертає значення true, якщо динамічне
призначення кількості потоків дозволено.
void omp_set_nested (int nested);omp_set_nested
(nested) integer nested
Дозволяє або забороняє вкладений паралелізм. За
замовчуванням вкладений паралелізм заборонений.
int omp_get_nested (void);function omp_get_nested
()
Визначає, чи дозволений вкладений паралелізм.
Підпрограми для роботи з блокуваннями
Блокування використовуються для запобігання
ефектів, що призводять до непередбачуваного (Недетермінірованного) поведінки
програми. Серед таких ефектів, наприклад, гонки за даними, коли більш ніж один
потік має доступ до однієї і тієї ж змінної.
void omp_init_lock (omp_lock_t *
lock);omp_init_lock (lock) integer (kind = omp_lock_kind):: lock
Ініціалізує блокування, пов'язану з
ідентифікатором lock, для використання в наступних викликах підпрограм.
void omp_destroy_lock (omp_lock_t *
lock);omp_destroy_lock (lock) integer (kind = omp_lock_kind):: lock
Перекладає блокування, пов'язану з
ідентифікатором lock, в стан невизначеності.
void omp_set_lock (omp_lock_t *
lock);omp_set_lock (lock) integer (kind = omp_lock_kind):: lock
Перекладає потоки зі стану виконання в стан очікування
до тих пір, поки блокування, пов'язана з ідентифікатором lock, не виявиться
оступною. Потік стаєвласником доступною блокування.
void omp_unset_lock (omp_lock_t *
lock);omp_unset_lock (lock) integer (kind = omp_lock_kind):: lock
Після виконання даного виклику потік перестає
бути власником блокування, пов'язаної з ідентифікатором lock. Якщо потік не був
власником блокування, результат виклику не визначений.
int omp_test_lock (omp_lock_t * lock);function
omp_test_lock (lock) integer (kind = omp_lock_kind):: lock
Повертає значення "істина", якщо
блокування пов'язана з ідентифікатором lock.
void omp_init_nest_lock (omp_nest_lock_t *
lock);omp_init_nest_lock (lock) integer (kind = omp_nest_lock_kind):: lock
Ініціалізує вкладену блокування, пов'язану з
ідентифікатором lock.
void omp_destroy_nest_lock (omp_nest_lock_t *
lock);omp_destroy_nest_lock (lock) integer (kind = omp_nest_lock_kind):: lock
Перекладає вкладену блокування, пов'язану з
ідентифікатором lock, в стан невизначеності.
void omp_set_nest_lock (omp_nest_lock_t *
lock);omp_set_nest_lock (lock) integer (kind = omp_nest_lock_kind):: lock
Перекладає виконуються потоки в стан очікування
до тих пір, поки вкладена блокування, пов'язана з ідентифікатором lock, не
стане доступною. Потік стає власником блокування.
void omp_unset_nest_lock (omp_nest_lock_t *
lock);omp_unset_nest_lock (lock) integer (kind = omp_nest_lock_kind):: lock
Звільняє виконується потік від володіння
вкладеної блокуванням, пов'язаної ідентифікатором lock. Якщо потік не був
власником блокування, результат не визначений.
int omp_test_nest_lock (omp_nest_lock_t *
lock);function omp_test_nest_lock (lock) integer (kind = omp_nest_lock_kind)::
lock
Функція, що дозволяє визначити, чи пов'язана
вкладена блокування з ідентифікатором lock. Якщо пов'язана, повертається
значення лічильника, в іншому випадку повертається значення 0.
Таймери
Для профілювання OpenMP програми можна
використовувати таймери.
double omp_get_wtime (void);precision function
omp_get_wtime ()
Повертає час у секундах, що минув з довільного
моменту в минулому. Точка відліку залишається незмінною протягом усього часу
виконання програми.
double omp_get_wtick (void);precision function
omp_get_wtick ()
Повертає час у секундах, що минув між
послідовними "тиками". Цей час є мірою точності таймера.
Змінні оточення OpenMP
Змінні оточення задаються наступним чином:
export ЗМІННА = значення (в середовищі
UNIX)ЗМІННА = значення (в середовищі Microsoft Windows)_NUM_THREADS
Задає кількість ниток при виконанні паралельних
секцій програми.
OMP_SCHEDULE
Задає спосіб розподілу ітерацій циклів між
нитками. Можливі значення:
static;;.
Кількість ітерацій (необов'язковий параметр)
вказується після одного з цих ключових слів, відділяючись від нього комою,
наприклад:
Export OMP_ SCHEDULE = "static,
10"OMP_DYNAMIC
Якщо цієї змінної присвоєно значення false,
динамічний розподіл ітерацій циклів між нитками заборонено, якщо true -
дозволено.
OMP_NESTED
Якщо цієї змінної присвоєно значення false,
вкладений паралелізм заборонений, якщо true - дозволено
1.2
MPI
MPI-програма являє собою набір незалежних
процесів, кожен з яких виконує свою власну програму (неnобов'язково одну і ту
ж), написану на мові C або FORTRAN. З'явилися реалізації MPI для C + +, проте
розробники стандарту MPI за них відповідальності не несуть. Процеси M P
I-програми взаємодіють один з одним за допомогою виклику комунікаційних
процедур. Як правило, кожен процес виконується у своєму власному адресному
просторі, однак допускається і режим поділу пам'яті.не специфікує модель
виконання процесу - це може бути як послідовний процес, так і багатопотокових.
MPI ненадає ніяких засобів для розподілу процесів по обчислювальним вузлам і
для запуску їх на виконання. Ці функції покладаються або на операційну систему,
або на програміста. Зокрема, на n CUBE 2 використовується стандартна команда
xnc, а на кластерах - спеціальний командний файл (зкріпт) mpirun, який
припускає, що виконані модулі вже якимось чином розподілені по комп'ютерах
кластера. MPI не накладає жодних обмежень на те, що процеси будуть розподілені
по процесорах, зокрема, можливий запуск MPI-програми з декількома процесами на
звичайній однопроцесорній системі.
функції ініціалізації та закриття MPI-процесів;
функції, що реалізують комунікаційні операції
типу точка- точка;
функції, що реалізують колективні операції;
функції для роботи з групами процесів і
комунікаторами;
функції для роботи зі структурами даних;
функції формування топології процесів.
Набір функцій бібліотеки MPI далеко виходить за
рамки набору функцій, мінімально необхідного для підтримки механізму передачі
повідомлень, описаного в першій частині. Однак складність цієї бібліотеки не
повинна лякати користувачів, оскільки, в кінцевому підсумку, все це безліч
функцій призначено для полегшення розробки ефективних паралельних програм.
Зрештою, користувачеві належить право самому вирішувати, які кошти з наданого
арсеналу використовувати, а які ні. В принципі, будь-яка паралельна програма
може бути написана з використанням всього 6 MPI-функцій, а достатньо повну і
зручне середовище програмування становить набір з 24 функцій. Кожна з MPI
функцій характеризується способом виконання:
. Локальна функція - виконується всередині
викликає процесу.
Її завершення не вимагає комунікацій.
. Нелокальна функція - для її завершення потрібне
виконання MPI-процедури іншим процесом.
. Глобальна функція - процедуру повинні
виконувати всі процеси групи. Недотримання цієї умови може призводити до
зависання завдання.
. Блокувальна функція - повернення управління з
процедури гарантує можливість повторного використання параметрів, беруть участь
у виклику. Ніяких змін в стані процесу, викликав блокуючий запит, до виходу з
процедури не може відбуватися.
. Не блокувальна функція - повернення з процедури
відбувається негайно, без очікування закінчення операції і до того, як буде
дозволено повторне використання параметрів, що беруть участь в запиті.
Завершення неблокирующих операцій здійснюється
спеціальними функціями. Використання бібліотеки MPI має деякі відмінності у
мовах C і FORTRAN. У мові C всі процедури є функціями, і більшість з них
повертає код помилки. При використанні імен підпрограм і іменованих констант
необхідно строго дотримувати регістр символів. Масиви індексуються з 0. Логічні
змінні представляються типом int (true відповідає 1, а false - 0). Визначення
всіх іменованих констант, прототипів функцій і визначення типів виконується
підключенням файлу mpi. h. Введення власних типів у MPI було продиктовано тим
обставиною, що стандартні типимов на різних платформах мають різне уявлення.
MPI допускає можливість запуску процесів паралельної програми на комп'ютерах
різних платформ, забезпечуючи при цьому автоматичне перетворення даних при
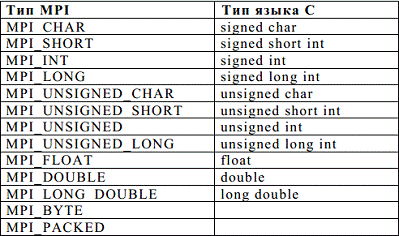
пересиланнях. У таблиці наведено відповідність зумовлених в MPI типів
стандартних типів мови С.
БАЗОВІ ФУНКЦІЇ MPI
Будь яка прикладна MPI-програма (додаток) повинна
починатися з виклику функції ініціалізації MPI-функції MPI_Init. В результаті
виконання цієї функції створюється група процесів, в яку поміщаються всі
процеси додатки, створюється область зв’язку, об’єднує всі процеси-додатки.
Процеси у групі впорядковані пронумеровані від 0 до groupsize 1, де groupsize
одне число процесів у групі. Крім цього створюється зумовлений комунікатор
MPI_COMM_SELF, що описує свою область зв’язку для кожного окремого процесу.
int MPI _ Init (int*argc, char* * * argv)
У програмах на C кожному процесу при
ініціалізації передаються аргументи функції main, отримані з командного рядка.
Функція завершення MPI-програм MPI _ Finalize:
int MPI_ Finalize (void)
Функція закриває все MPI-процеси і ліквідує всі
галузі зв'язку.
Функція визначення числа процесів в галузі
зв'язку
MPI _ Comm _ size int MPI _ Comm _ size (MPI _
Commcomm, int * size)
Функція повертає кількість процесів у галузі
зв'язку комунікатора comm. До створення явно груп і пов'язаних з ними
комуністичної катори єдино можливими значеннями параметра COMM є MPI _COMM _W
ORLD і MPI _COMM _SELF, які створюються автоматично при ініціалізації MPI.
Підпрограма є локальною.
Функція визначення номера процесу MPI _ C omm _
rank
int MPI _ Comm _ rank (MPI _ Commcomm, int *
rank)
Функція повертає номер процесу, що викликав цю
функцію. Номери процесів лежать в діапазоні 0. size - 1 (значення size може
бути визначено за допомогою попередньої функції). Підпрограма є локальної. У
мінімальний набір слід включити також дві функції передачі і прийому
повідомлень.
Функція передачі повідомлення MPI _ S end
int MPI _ Send (void * buf, intcount, MPI _
Datatypedatatype, intdest, inttag, MPI _ Commcomm)
Функція виконує посилку count елементів типу
datatype повідомлення з ідентифікатором tag процесу dest в галузі зв'язку
комунікатора comm. Мінлива buf - це, як правило, масив або скалярна змінна. В
останньому випадку значення count = 1.
Функція прийому повідомлення MPI _ Recv
int MPI _ Recv (void * buf, intcount, MPI _
Datatypedatatype, intsource, inttag, MPI _Cmmcomm, MPI _ Status * status)
2.
Практична частина
2.1 Завдання 1. Розробити програму паралельного розрахунку
означеного інтеграла для функції з кроком дискретизації 0,00002
2.1.1
Метод рішення
Рішення багатьох технічних завдань зводиться до обчислення
певних інтегралів, точний вираз яких складно, вимагає тривалих обчислень і
незавжди виправдане практично. Тут буває цілком достатньо їх наближеного
значення. Найпростішим наближеним методом є метод прямокутників. Нехай на
відрізку [a,b], a<b, задана безперервна функція f (x). Потрібно обчислити
інтеграл чисельно рівний прощу відповідної криволінійної 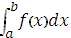 трапеції. Розіб’ємо підставу цієї трапеції, тобто відрізок [a;
b], на n рівних частин (відрізків) довжини
трапеції. Розіб’ємо підставу цієї трапеції, тобто відрізок [a;
b], на n рівних частин (відрізків) довжини 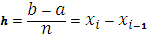 (крок розбиття) за допомогою точок х0=а, х1, х2,…хn=b. Можна
записати, що хі=х0+h*i, де і=1,2,…, n. У середині
(крок розбиття) за допомогою точок х0=а, х1, х2,…хn=b. Можна
записати, що хі=х0+h*i, де і=1,2,…, n. У середині  кожного такого відрізка побудуємо ординату уі=f (сі) графіка
функції у= f (х). Прийнявши цю ординату за висоту, будуємо прямокутник з
площиною h* уі.
кожного такого відрізка побудуємо ординату уі=f (сі) графіка
функції у= f (х). Прийнявши цю ординату за висоту, будуємо прямокутник з
площиною h* уі.
Тоді сума площ всіх n прямокутників дає площа ступінчатої
фігури, яка була наближена до наближеного значення шуканого визначеного
інтегралу:

Рис. 2.1 Метод прямокутників
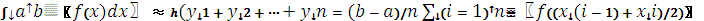

Формула середніх прямокутників
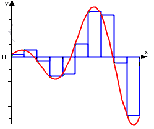
Рис. 2.2 Метод лівих прямокутників

Формула метода лівих прямокутників
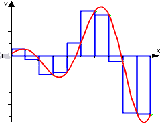
Рис. 2.3 Метод правих прямокутників

Формула метода правих прямокутників
При використанні бібліотеки MPI площа фігури, описуваною
функцією, можна розділити між процесами, потім зібрати обчислені окремими
процесами суми і отримати шукану площу.
2.1.2
Алгоритм і блок-схема роботи програми

Рис. 2.4 Блок-схема алгоритму розрахунку
означеного інтегралу
Алгоритм роботи програми:
1. Початок роботи програми.
. Оголошення змінних, присвоєння інтегралу кордон
інтеграції із кроком дискретизації, завдання констант.
. Ініціалізація MPI.
. Визначення кількості процесів.
. Визначення номера процесу.
. Якщо номер процесу дорівнює 0, то починає
працювати таймер, в іншому випадку, починається пункт 7.
. циклом від першого до останнього інтервалу,
який визначений номером процесу, з кроком, рівним числу процесорів і
підсумуванням висоти відрізань, визначуваних заданою функцією.
. Обчислення всіх локальних сум площі інтегралу.
. Якщо номер процесу дорівнює 0, то зупиняємо
таймер, виконуємо обчислення площі інтегралу у нульовому процесі,і передача
локальної суми від поточного процесу до нульового.
. Фіналізація MPI.
. Кінець роботи програми.
2.1.3
Текст програми
#include "stdafx. h"
#include "math. h"
#include "mpi. h"
{PI=3.1415926535897932;
// крок дискретизаціїIntervalWidth = 0.00002;
// інтервал відa = PI;
// вивід на екран значення а("a =
%.16f\n", a);
// інтервал доb = (PI) /2;
// вивід на екран значення b("b =
%.16f\n", b);
// кількість інтервалівnumbIntervals = (int) (
(b-a) /IntervalWidth);
// висота інтервалуIntervalHeight = 0.0;
// координата поточної точки на осі хx = 0.0;
// поточний інтервалInterval = 0;
// локальна сума на одному комп’ютеріsummaLocal =
0.0;
// локальна сума на всіх комп’ютерахsummaGlobal;
// номер процесуProcNumb;
// ранг процесуProcRank;
// ім’я процесуprocessor_name
[MPI_MAX_PROCESSOR_NAME];
// довжина імені процесуnamelen;
// час початку і кінця розрахунку процесуt1, t2;
// ініціалізація MPI_Init (&argc,&argv);
// кількість комп’ютерів у кластері_Comm_size
(MPI_COMM_WORLD,&ProcNumb);
// номер процесу_Comm_rank
(MPI_COMM_WORLD,&ProcRank);
// ім’я процесу у кластері_Get_processor_name
(processor_name,&namelen);("Process %d of %d running on %s\n",
ProcRank,);(ProcRank == 0)
{("numbIntervals = %i\n",
numbIntervals);= MPI_Wtime ();
}
// цикл від першого до останнього інтервалу з
кроком рівним числу процесорів(Interval=1+ProcRank; Interval <=
numbIntervals; Interval
+=ProcNumb)
{= a + (IntervalWidth * ( (double)
Interval-0.5));+= (sin (x) +cos (x));
}= IntervalWidth *
IntervalHeight;("summaLocal is approximately %.16f\n",
summaLocal);_Reduce (&summaLocal, &summaGlobal, 1,
MPI_DOUBLE,_SUM,0,MPI_COMM_WORLD);(ProcRank == 0)
{= MPI_Wtime ();("Integral is approximately
%.16f\n", summaGlobal);("Time is %f seconds \n", t2-t1);
}
// фіналізація MPI_Finalize ();0;
}
Значення інтегралу  дорівнює 1.8749238809545756
дорівнює 1.8749238809545756
2.1.4
Таблиця і графік проведених експериментів
Проведемо два експерименти розрахунку визначеного
інтегралу з різним кроком дискретизації і різною кількістю процесорів у
кластері. Заповнимо таблицю результатами:
Таблиця 2.1 Розрахунок визначеного інтегралу
|
Крок
дискретизації / кількість процесів
|
1
процес
|
2
процеси
|
4
процеси
|
8
процесів
|
|
0,0002
|
0,004235
|
0,002028
|
0,002264
|
0,002635
|
|
0,00002
|
0,0857
|
0,023864
|
0,011583
|
0,013237
|
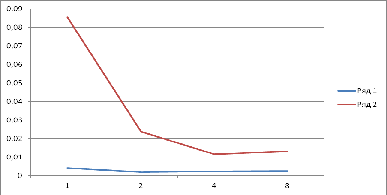
Рисунок 2.5 Графік залежності швидкості і часу розрахунку
певного інтегралу
2.1.5
Висновок
З таблиці розрахунку визначеного інтегралу і
графіку залежності швидкості від часу, ми бачимо, що при використанні
паралельних обчислень, час на обробку визначеного інтегралу зменшується
(відбувається прискорення обчислення за рахунок того, що кожний комп’ютер
виконує менше циклів розрахунку).
Також із таблиці ми можемо побачити, що чим
більше процесів ми використовуємо, тим менше часу іде на розрахунок інтегралу.
Але, чим більше процесів бере участь у розрахунку інтегралу, тим менше
прискорення часу відбувається (якщо ми використовуємо два процеси замість
одного, ми отримуємо прискорення у 1.046 разів, а при використанні 8 процесів
замість чотирьох, отримаємо прискорення у 1.004 раз). Це відбувається тому,що
при збільшенні числа процесів, збільшується і час на передачу повідомлень між
процесами.
2.2
Завдання 2. Розробка паралельної програми множення квадратної матриці на
квадратну матрицю
2.2.1
Постановка завдання
Множення матриці A розміру m×n і матриці B розміру n×l наводить до
здобуття матриці C розміру m×l, кожен елемент
якої визначається відповідно до вираження:

Кожен елемент результуючої матриці C є скалярний
твір відповідних рядки матриці A і стовпця матриці B:
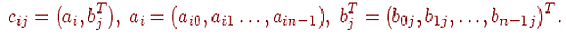
Цей алгоритм передбачає виконання m*n*l операцій
множення і стільки ж операцій складання елементів вихідних матриць. При
множенні квадратних матриць розміру n×n кількість
виконаних операцій має порядок O (n3).
Відомі послідовні алгоритми множення матриць, що
володіють меншою обчислювальною складністю (наприклад, алгоритм Страссена
(Strassen’s algorithm)).
Послідовний алгоритм множення матриць
представляється трьома вкладеними циклами.
2.2.2
Послідовний алгоритм множення двох квадратних матриць
double MatrixA [Size] [Size];MatrixB [Size]
[Size];MatrixC [Size] [Size];i,j,k;
.(i=0; i<Size; i++) {(j=0; j<Size; j++)
{[i] [j] = 0;(k=0; k<Size; k++) {[i] [j] =MatrixC [i] [j] + MatrixA [i] [k]
*MatrixB [k] [j];
}
}
}
Цей алгоритм є ітеративним і орієнтований на
послідовне обчислення рядків матриці С. Дійсно, при виконанні однієї ітерації
зовнішнього циклу (циклу по змінній i) обчислюється один рядок результуючої
матриці (см. рис.2.6).

З визначення операції матричного множення
виходить, що обчислення всіх елементів матриці C може бути виконано незалежно
один від одного. Як результат, можливий підхід для організації паралельних
обчислень полягає у використанні як базова підзадача процедури визначення
одного елементу результуючої матриці С. Для проведення всіх необхідних
обчислень кожна підзадача повинна містити по одному рядку матриці А і одному стовпцю
матриці В. Загальна кількість отримуваних при такому підході підзадач
виявляється рівним n2 (по числу елементів матриці C).
Розглянувши запропонований підхід, можна
відзначити, що досягнутий рівень паралелізму є в більшості випадків
надлишковим. Зазвичай при проведенні практичних розрахунків така кількість
сформованих підзадач перевищує число наявних процесорів і робить неминучим етап
укрупнення базових завдань.
У цьому плані може виявитися корисною агрегація
обчислень вже на кроці виділення базових підзадач. Можливе рішення може
полягати в об'єднанні в рамках однієї підзадачі всіх обчислень, пов'язаних не з
одним, а з декількома елементами результуючої матриці С. Для подальшого
розгляду визначимо базове завдання як процедуру обчислення всіх елементів одного
з рядків матриці С. Такий підхід призводить до зниження загальної кількості
підзадач до величини n. Для виконання всіх необхідних обчислень базовій
підзадачі мають бути доступні один з рядків матриці A і всі стовпці матриці B.
Просте вирішення цієї проблеми:
Алгоритм є ітераційною процедурою, кількість
ітерацій якої збігається з числом підзадач. На кожній ітерації алгоритму кожна
підзадача містить по одному рядку матриці А і одному стовпцю матриці В. Прі
виконанні ітерації проводиться скалярне множення рядків, що містяться в
підзадачах, і стовпців, що наводить до здобуття відповідних елементів
результуючої матриці С. По завершенні обчислень в кінці кожної ітерації стовпці
матриці В мають бути передані між підзадачами з тим, аби в кожній підзадачі
виявилися нові стовпці матриці В і могли бути обчислені нові елементи матриці
C. При цьому дана передача стовпців між підзадачами має бути організована так,
щоб після завершення ітерацій алгоритму в кожній підзадачі послідовно виявилися
всі стовпці матриці С.
Можлива проста схема організації необхідної
послідовності передач стовпців матриці В між підзадачами полягає в
представленні топології інформаційних зв'язків підзадач у вигляді кільцевої
структури. В цьому випадку на кожній ітерації підзадача i, 0<i<n,
передаватиме свій стовпець матриці В підзадачі з номером i+1 (відповідно до
кільцевої структури підзадача n-1 передає свої дані підзадачі з номером 0) -
див. рис.2.5 Після виконання всіх ітерацій алгоритму необхідна умова буде
забезпечена - в кожній підзадачі по черзі виявляться всі стовпці матриці С.
На рис. 2.5 представлені ітерації алгоритму
матричного множення для випадку, коли матриці складаються з чотирьох рядків і
чотирьох стовпців (n=4). На початку обчислень в кожній підзадачі i,
0<i<n, розташовуються i-я рядок матриці A і i-й стовпець матриці B. В
результаті їх перемножування підзадача отримує елемент cii результуючої матриці
С.
Далі підзадачі здійснюють обмін стовпцями, в ході
якого кожна підзадача передає свій стовпець матриці B наступній підзадачі
відповідно до кільцевої структури інформаційних взаємодій. Далі виконання
описаних дій повторюється до завершення всіх ітерацій паралельного алгоритму.

Рис. 2.7 Загальна схема передачі даних для
першого паралельного алгоритму матричного множення при стрічковій схемі
розділення даних
2.2.3
Текст програми
#include "stdafx. h"
#include <stdio. h>
#include <stdlib. h>
#include <conio. h>
#include <time. h>
#include "mpi. h"
// Функція випадкового ініціалізації елементів
матриціRandomDataInitialization (double* pAMatrix, double* pBMatrix, int Size)
{i, j; // Loop variables(unsigned (clock ()));(i=0; i<Size; i++)(j=0;
j<Size; j++) {[i*Size+j] = rand () /double (1000);[i*Size+j] = rand ()
/double (1000);
}
}
// Функція для виділення пам'яті і ініціалізації
елементів матриціProcessInitialization (double* &pAMatrix, double*
&pBMatrix,* &pCMatrix, double* &pCMatrixSum, int &Size) {
// Установка розміру матриці{("\nEnter size
of matricies: ");(stdout);_s ("%d", &Size);("\nChosen
matricies' size = %d\n", Size);(Size <= 0)("\nSize of objects must
be greater than 0! \n");
}(Size <= 0);
// Виділення пам'яті= new double [Size*Size];=
new double [Size*Size];= new double [Size*Size];= new double [Size*Size];
// Ініціалізація елементів матриці(pAMatrix,
pBMatrix, Size);(int i=0; i<Size*Size; i++) {[i] = 0;[i] = 0;
}
}
// Функція форматованого виведення матриціPrintMatrix
(double* pMatrix, int RowCount, int ColCount) {i, j; // Loop variables(i=0;
i<RowCount; i++) {(j=0; j<ColCount; j++)("%7.4f", pMatrix
[i*RowCount+j]);("\n");
}
}
// Функція для множення
матрицьSerialResultCalculation (double* pAMatrix, double* pBMatrix,* pCMatrix,
int Size, int nCommRank, int nCommSize) {i, j, k; // Loop variables(i=0;
i<Size; i++) {(j=0+nCommRank; j<Size; j+=nCommSize) {(k=0; k<Size;
k++) {[i*Size+j] +=[i*Size+k] *pBMatrix [k*Size+j];
}
}
}
}
// Функція для обчислювальних завершення процесуProcessTermination
(double* pAMatrix, double* pBMatrix,* pCMatrix, double* pCMatrixSum) {[]
pAMatrix;[] pBMatrix;[] pCMatrix;[] pCMatrixSum;
}main (int argc, char* argv []) {* pAMatrix; //
Перший аргумент матричного множення* pBMatrix; // Другий аргумент матричного
множення* pCMatrix; // Результат матриці* pCMatrixSum; // Результат
матриціSize; // Розмір матриціnCommRank, nCommSize, namelen,
nCounter;nIntervals;processor_name [MPI_MAX_PROCESSOR_NAME];t1, t2;_Status
status;_Init (&argc, &argv);_Comm_rank (MPI_COMM_WORLD,
&nCommRank);_Comm_size (MPI_COMM_WORLD, &nCommSize);_Get_processor_name
(processor_name,&namelen);(nCommRank == 0) {("Parallel matrix
multiplication program\n");
// Розподіл пам'яті і ініціалізацію елементів
матриці(pAMatrix, pBMatrix, pCMatrix, pCMatrixSum, Size);
// Вихідна матриця("Initial A Matrix
\n");(pAMatrix, Size, Size);("Initial B Matrix \n");(pBMatrix,
Size, Size);= MPI_Wtime ();(nCounter = 1; nCounter < nCommSize; nCounter++)
{_Send (&Size, 1, MPI_INT, nCounter, 0, MPI_COMM_WORLD);_Send (pAMatrix,
Size*Size, MPI_DOUBLE, nCounter, 1,MPI_COMM_WORLD);_Send (pBMatrix, Size*Size,
MPI_DOUBLE, nCounter, 2,MPI_COMM_WORLD);_Send (pCMatrix, Size*Size, MPI_DOUBLE,
nCounter, 3,MPI_COMM_WORLD);
}
} else {_Recv (&Size, 1, MPI_INT, 0, 0,
MPI_COMM_WORLD,_STATUS_IGNORE);= new double [Size*Size];= new double
[Size*Size];= new double [Size*Size];_Recv (pAMatrix, Size*Size, MPI_DOUBLE, 0,
1, MPI_COMM_WORLD,_STATUS_IGNORE);_Recv (pBMatrix, Size*Size, MPI_DOUBLE, 0, 2,
MPI_COMM_WORLD,_STATUS_IGNORE);_Recv (pCMatrix, Size*Size, MPI_DOUBLE, 0, 3,
MPI_COMM_WORLD,_STATUS_IGNORE);
}
// множення матриць(pAMatrix, pBMatrix, pCMatrix,
Size, nCommRank, nCommSize);_Reduce
(pCMatrix,pCMatrixSum,Size*Size,MPI_DOUBLE,MPI_SUM,0,MPI_COMM_W);("Process
%d of %d running on %s\n", nCommRank, nCommSize,_name);(nCommRank == 0) {
// Виведення результатів матриці("\n Result
Matrix Sum: \n");(pCMatrixSum, Size, Size);
// Завершення обчислювального процесу(pAMatrix,
pBMatrix, pCMatrix, pCMatrixSum);= MPI_Wtime ();("Time is %f seconds
\n", t2-t1);
}_Finalize ();
}
2.2.4
Результати обчислювальних експериментів
Експерименти виконувалися з використанням двох,
чотири і восьми процесорів.
Таблиця 2.2 Результати обчислювальних
експериментів по дослідженню паралельного алгоритму матричного множення при
стрічковій схемі розподілу даних
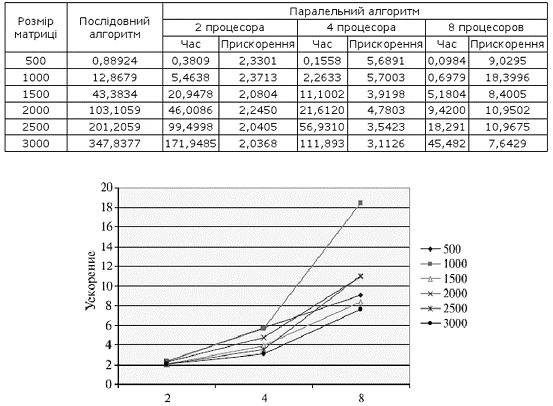
Рис. 2.6 Графік залежності швидкості множення
матриці на матрицю від кількості використовуваних процесів і від розмірності
матриці
2.2.5
Висновки
Як можна відмітити з приведених результатів
обчислювальних експериментів, використання паралельних обчислень прискорює
процес множення матриць. Із збільшенням розмірності матриці, за інших рівних
умов, зменшується ефективність використання паралельних обчислень. Це
відбувається тому, що в цьому випадку багато часу витрачається на пересилку
даних між процесами.
Перелік
посилань
1. Корнєєв В.Д. "Паралельне програмування в МРІ". Друге
видання, випр. Новосибірськ, 2002.
2.
Інтернет - сайт: <http://iproc.ru/programming/mpich-windows/>
.
Інтернет - сайт: http://bigor. bmstu.ru/? cnt/? doc=Parallel/base. cou
<http://bigor.bmstu.ru/?cnt/?doc=Parallel/base.cou>
.
Хорошевский
<http://studdi.ru/lection/avs/books/horoshevskii-v-arhitektura-vychislitelnyh-sistem-v-g-horoshevskii-moskva-mgtu-im-baumana-2008-520-s.html>
В.Г. "Архітектура обчислювальних систем". М: Навчальний посібник для
вузів, 2005.
.
Інтернет - сайт:
<http://www.intuit.ru/department/calculate/paralltp/9/2.html>
. Бувайло
Д.П., Толок В.А. "Розподілені обчислення". Навчальний посібник для
студентів математичних спеціальностей, 2002.
. С.А.
Немнюгин "Средства программирования для многопроцессорных вычислительных
систем".
. А.А.
Букатов, В.Н. Дацюк, А.И. Жегуло "Программирование многопроцессорных
вычислительных систем".