Автоматизация процесса поиска плагиата
Содержание
Введение
1. Техническое задание на разработку системы
1.1 Назначение и цели создания системы
1.2 Характеристика объекта компьютеризации
1.2.1 Описание структуры и процесса функционирования объекта
1.2.2 Существующая информационная система
1.2.3 Обоснование необходимости в разработке системы
1.3 Требования к системе в целом
1.4 Требования к функциям системы
1.4 Требования к видам обеспечения
1.5.1 Требования к техническому обеспечению
1.5.2 Требования к программному обеспечению
2. Функциональная структура подсистемы
1.2 Учет работ
1.2 Обнаружение плагиата
1.3 Формирование отчетности
2. Информационное обеспечение системы
2.1 Выбор устройства управления данными
2.2 Разработка моделей данных
2.3 Организация сбора и обработки информации
3. Математический аппарат подсистемы
3.1 Учет работ
3.2 Обнаружение плагиата
3.2.1 Основные понятия
3.2.2 Алгоритмы для обнаружения плагиата
3.4 Формирование отчетности
4. Программное обеспечение системы
4.1 Структура и функции частей программного обеспечения системы
4.2 Разработка специального программного обеспечения
5. Техническое обеспечение системы
5.1 Выбор конфигурации параметров сервера
5.2 Выбор конфигурации параметров рабочей станции
5.3 Выбор периферийных устройств
6. Организация компьютерной сети
6.1 Выбор и обоснование технологии передачи данных
6.2 Выбор сетевого оборудования
Заключение
Приложение А - Функциональная структура системы
Приложение Б. Схема данных БД университета
Введение
Внедрение IT технологий и автоматизации в сферу образования,
в частности, в ВУЗы несет в себе много пользы, но так же появляются очевидные
минусы, такие как плагиат. Проблема плагиата заключает в себе вопрос об
интеллектуальной собственности, следственно, для разделения собственности
необходим инструмент, позволяющий определить плагиат. Плагиатом является
присвоение чужой собственности себе, в данном случае - программный код.
Маленькое количество учебных заведений может похвастаться
большим и богатым инструментарием для повышения уровня оценивания работы
студентов. Иными словами, без необходимых инструментов преподаватель не в
состоянии поставить объективную оценку студенту. Так же основной идеей обучения
в университет является получение навыков, понимание принципа обучения в данной
области, а касательно области IT технологий главной идеей является развитие
логического мышления в ходе выполнения работы. Работы, касающиеся разработки
программного обеспечения вырабатывают математическое мышление. В случае
плагиата программного кода, человек теряет возможность к обучению, не учит
ничего нового.
К сожалению, преподаватель не в состоянии разработать задания
к лабораторным работам в размере 100 штук, чтобы каждая работа была уникальной,
но в тоже время была четко направлена на изучение данного алгоритма,
синтаксического приёма языка программирования. С увеличением количества заданий
теряется качество задания и зачастую выходит так, что преподаватель принимает
большее участие в решении лабораторной нежели студент (объяснение идеи
лабораторной работы). Для достижения максимальной целенаправленности и
целостности задачи - количество задач уменьшается до минимально допустимого
уровня, а варианты разбрасываются на несколько студентов. Чтобы оценить работу
студентов сначала необходимо сравнить работы по одинаковому заданию - найти в
них схожести и только после этого проверять саму работу. Для увеличения
производительно и скорости поиска плагиата разрабатывают специальные системе по
поиску плагиата, чтобы максимально автоматизировать процесс и выиграть больше
времени на живое общение со студентом.
1. Техническое задание на разработку системы
.1 Назначение
и цели создания системы
Главным оценочным фактором работы студентов является
преподаватель. Он играет немаловажную роль при оценивании работы студента и
проверке в усвоении материала. Приложение усилий для решения поставленной
задачи, она же проблема, является неотъемлемой частью, т.к. выполнение задание
направлено на поиск и обработку информации, что развивает логическую
деятельность и самостоятельность к обучению. Преподаватель тоже человек и
физически не способен обработать 100 заданий с одинаковой структурой в
реализации. В данном случае возникает необходимость автоматизировать
целостность работы и программного кода, чтобы увеличить качество оценивания.
Назначение такой системы заключается в определении авторства
работы студента, которая обеспечивает поиск плагиата кода среди имеющихся работ
студентов и накоплении работ. Поиск основывает на алгоритмах-детекторах кода в
заданном языке программирования.
Целями создание компьютеризированной системы являются:
Получение оценочной информации о работе и коэффициенте
плагиата
Повышение эффективности оценивания работы студента;
.2
Характеристика объекта компьютеризации
1.2.1
Описание структуры и процесса функционирования объекта
Основным объектом компьютеризации является
процесс принятия работы. Процесс принятия представляет собой 3 этапный механизм
в сочетании с человеческим фактором (Рис 1.1). Где 1-ый этап это добавление
работы в систему (регистрация), в качестве второго этапа выступает анализ
работы и выявления плагиата. 3-ий этап является обязательным, даже при 100%
-ном прохождении работы через систему.

Рисунок 1.1 - Процесс принятия работы.
1.2.2
Существующая информационная система
Конкретной существующей системы, которая выполняла
поставленную задачу не было обнаружено, поскольку в рамках учебного заведения
системы создаются студентами/аспирантами и не попадают в публичный доступ. Но
существуют подсистемы, которые выполняют конкретную отточенную функцию - поиск
плагиата. Список существующих подсистем представлен ниже:
) SIM (Software Similarity Tester) - детектор с открытым
кодом, разработанный Диком Грюном (Dick Grune). Работа детектора SIM основывается на
алгоритме поиска по матрице совпадений подстрок; используется представление
программного кода в виде токенов. SIM поддерживает такие языки программирования как
Си, Ява, Паскаль, Модула-2, Миранда. Недостатком данного детектора является
невозможность выявления плагиата, полученного путем перемещения блоков кода.
плагиат оценочная информация поиск
2) Plan-X - детектор с открытым кодом; разработан Кристой Фотель (Christa Fotel) и Ларсом Лэнжером (Lars Langer). Для поиска плагиата в
детекторе используется утилита для работы с XML файлами - XML Store. Plan-X поддерживает только язык
SML, что и является
недостатком этого детектора.
) JPlag - детектор, доступный в режиме он-лайн. Разработчиком является Guido Malpohl. В основе работы
детектора лежит алгоритм жадного строкового замощения, что требует предварительной
токенизации исходного программного кода. Jplag поддерживает следующие
языки программирования: Си, Си++, Ским (Scheeme), Ява.
) MOSS (Measure of Software Similarity) - детектор, доступный в сети Интернет в
режиме он-лайн. Разработан в 1994 году Алексом Айкеном (Alex Aiken). Для поиска плагиата
используется алгоритм просеивания для построения идентификационных меток.
Поддерживает большое количество языков, в частности: Си, СИ++, Лисп, Хаскель,
Паскаль, Пижон, Ассемблер и др.
) SID (Software Integrity System) - доступный в режиме
он-лайн детектор, разработан коллективом авторов: X. Chen, B. Francia и др. Основан на
использовании Колмогоровской сложности, требует предварительной токенизации
текста программы. Поддерживает языки Ява и Си++.
1.2.3
Обоснование необходимости в разработке системы
Зачастую, проблема таких подсистем заключается в их
недоступности, несовместимости для интеграции или же недопустимых требованиях.
Таким образом в рамках разработки системы появляется необходимость создания
собственной подсистемы обнаружения или же частичной интеграции существующих
частей кода и пользовательской реализации остальных частей системы для
реализации.
1.3
Требования к системе в целом
Система по поиску плагиата в программном коде должна
автоматизировать обнаружение плагиата в программном коде, его модулях и
бинарных файлах. Также система должна обеспечивать конфиденциальность данных и
имеющихся в ней модулей и централизованную сохранность данных системы.
Система должна состоять из 2 блоков:
· Блок коммуникации с пользователем (клиент)
· Блок интеграции (серверная часть)
1.4
Требования к функциям системы
Система должна выполнять следующие функции:
. Учет работ (бинарных файлов) - обеспечивает учет
работ студентов; предварительная загрузка данных и частичная обработка
(сохранение в состав непроверенных работ).
2. Обнаружение плагиата - функция, которая
реализовывает обнаружение плагиата программного кода.
. Формирование отчетности по поиску - функция должна
предоставлять возможность генерирования отчет (статистических данных о схожести
работ студентов между собой).
.4 Требования
к видам обеспечения
1.5.1
Требования к техническому обеспечению
Техническое обеспечение системы должно максимально и наиболее
эффективным образом использовать существующие технические средства.
В состав комплекса должны следующие технические средства:
¾ Сервер;
Требования к техническим характеристикам сервера:
¾ Процессор не менее 3Гц.
¾ Оперативная память не
менее 1024 Мб.
¾ Жесткий диск объемом 320
Gb и выше.
¾ Сетевой адаптер Fast Ethernet
100BASE-FX.
Минимальные требования к рабочей станции:
¾ Частота процессора должна
быть не менее 2.8 Ггц.
¾ Оперативная память не
менее - 512 и более мегабайта.
¾ Сетевая карта с
интерфейсом Fast Ethernet 100Base-FX.
¾ Процессор с частотой
работы не менее 300 MГц, количество ядер 2 и выше.
1.5.2
Требования к программному обеспечению
Требования к ОС:
¾ Система должна обладать
высокой надежностью, эффективностью и гибкостью
¾ Система должна быть
многозадачной, т.е. должна управлять разделением совместно используемых
ресурсов, таких как процессор, оперативная память, файлы и внешние устройства.
¾ Система должна обеспечить
поддержку многопользовательского режима, т.е. обладать средствами защиты
информации каждого пользователя от несанкционированного доступа других
пользователей.
¾ Система должна позволять
распараллеливание вычислений в рамках одной задачи.
Требования к средствам разработки:
¾ Средства разработки (СР)
должны предоставлять инструменты для правильной и удобной реализации нашей
системы.
¾ СР должны предоставлять
возможность тестировать систему в процессе разработки.
¾ СР должны выполнять
сложные алгоритмы за минимальный промежуток времени.
Требования к разрабатываемой системе:
¾ Должна обеспечить
многопользовательский доступ.
¾ Должна выполнять
прогнозирование ценовых индексов с высокой точностью.
¾ Должна быть совместима с
системным программным обеспечением.
2.
Функциональная структура подсистемы
Функциональная структура системы представлена в ПРИЛОЖЕНИИ А.
.2 Учет работ
Данная функция обеспечивает добавление работы и бинарных
файлов в СУБД.
Входные данные: работа студента.
Выходные данные: успешно добавленная работа студента (ID в СУБД и файлы на
соответствующей файловой системе)
Порядок выполнения функции:
. Студент входит в личный кабинет.
2. Добавляет свою работу на проверку (заливает на
сервер).
.2
Обнаружение плагиата
Данная функция обеспечивает проверку бинарных файлов на
плагиат и обнаружение участков кода, которые походы с уже имеющимися работами в
системе.
Входные данные: список непроверенных работ.
Выходные данные: список работ не прошедших проверку
(процентное соотношение плагиата в работе).
Порядок выполнения функции:
. Подсистема обнаружения плагиата выполняет запрос к
СУБД и получает список непроверенных работ.
2. Подсистема выполняет обработку работ согласно
разработанному алгоритму.
. Подсистема обнаружения выполняет обращения к СУБД с
целью записи результатов.
1.3
Формирование отчетности
Данная функция обеспечивает отчет об обнаружениях и поиске
плагиата.
Входные данные: список студентов, номера работ.
Выходные данные: отчет по работам.
Порядок выполнения функции:
. Преподаватель авторизуется в системе и входит в
класс, в котором он хочет произвести просмотр.
2. Преподаватель выбирает работы, которые он хочет
посмотреть на наличие плагиата.
. Система производит запрос к СУБД для получения
результатов и генерирует табличный отчет о плагиате.
2.
Информационное обеспечение системы
2.1 Выбор
устройства управления данными
В настоящее время существует большое
количество СУБД такие как:
¾ Microsoft Access;
¾ PostgreSql;
¾ MySQL;
¾ Oracle
database;
¾ MS SQL Server.
Однако у каждой из них есть свои
достоинства и недостатки.
Для хранения данных была выбрана СУБД MySQL. Так как данная СУБД
хорошо совместима и интегрируется, является клиент-серверной СУБД и может
продолжать расширяться по мере наполнения информацией, без заметного уменьшения
быстродействия. Также СУБД данного типа является самой быстрой СУБД по
производительности и обработке выборке по заданному условию. По сравнению с
Microsoft Access обладает большой надежностью хранения данных, гарантирует не
разрушение таблиц и не ограничивает размер базы данных.
Обеспечивает безопасность доступа к данным
(закрытие несанкционированного доступа к данным и возможное встроенное
шифрование данных).
СУБД компании Oracle является дорогим и
платным обеспечением. Postgre также подходит по критериям, но дополнительный
функционал СУБД (наследование таблиц и т.д.) не является необходимым.
.2 Разработка
моделей данных
Для работы с СУБД необходимо
спроектировать логическую модель, которая будет представлять основу для СУБД и
работы серверной части.
В ходе анализа системы были выявлены
следующие сущности: Студент, Работа, Результаты (Таблица 3.2.1).
Таблица 3.2.1 - ЛМД
|
Сущность
|
Описание
|
|
Студент
|
Студент группы,
который будет наполнять контентом СУБД
|
|
Работа
|
Работа студента
(бинарные файлы)
|
|
Результаты
|
Результаты
после поиска плагиата
|
Данная логическая модель данных рассчитана на интеграцию в
существующею СУБД университета, где можно получить детальную информацию о
студенте, списке предметов для группы. Схема СУБД университета представлена в
ПРИЛОЖЕНИИ Б.
С помощью средств giffy.com была разработана
логическая схема данных (Рис 3.2.1)

Рисунок 3.2.1 - Логическая схема данных на
уровне ключевых сущностей
Далее в сущности были добавлены атрибуты
(Рис 3.2.2)
Рисунок 3.2.2 - Логическая модель данных с
атрибутами
После разработки логической модели данных
атрибуты приобрели типы для составления физической модели данных (Рис 3.3.3)
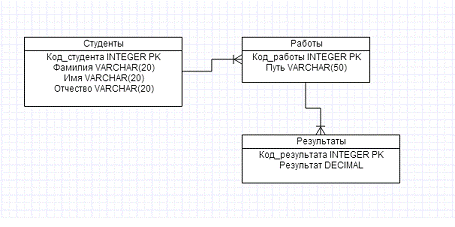
Рисунок 3.3.3 - Физическая модель данных
2.3
Организация сбора и обработки информации
Сбор информации осуществляется по мере наполнения СУБД студентами
загрузившими свои бинарные файлы в систему. Обработка файлов и выполнение
основной функции выполняется при вызове операции преподавателем.
3.
Математический аппарат подсистемы
.1 Учет работ
Учет работ производится за счет выполнения POST запроса с клиентского
компьютера (компьютера студента), при условиях удачной авторизации пользователя
в сети. Файлы прикрепленные в POST запросе проверяются на валидность (файлы должны
имеет соответствующие расширения согласно языку программирования). В ходе успешной
валидации в БД заносится запись в таблицу "Работы" по
соответствующему id студента и файлы сохраняются на файловую систему.
.2
Обнаружение плагиата
.2.1 Основные
понятия
Обнаружение плагиата производится за счет определенного
спектра алгоритмов по поиску схожестей, зависимостей и т.д. Большая часть
программного кода, которая была заимствована, имеет маскирующие изменения кода
с целью сокрытия плагиата (переименование переменных, перестановка команд,
переписывание фрагмента кода без изменения сути программного кода).
Следовательно алгоритмы для поиска обязаны основываться на анализе
"представления" программы. Обобщенная структура системы представлена
на рис 1.

Детекторы могут разрабатываться с нуля или же базироваться на
существующих библиотеках, open-source проектах.
Главная роль системы - поиск плагиата. Поиск плагиата в
программном коде имеет некоторые проблемы. В число таких проблем входит:
. Программы, написанные разными студентами, могут быть
похожими не только функционально, но и стилистически. Данная ситуация возможна,
когда студенты решают типовые задачи при изучении конкретных языков
программирования
. Разные по стилю написания программы могут быть очень
похожи по логике управления и исполнения. Это возможно в том случае, если,
согласно, студентами реализован одинаковый метод решения поставленной задачи.
Следовательно, конечный результат работы принимает преподаватель, система
выполняет только поиск плагиата. Обобщенная схема работы системы изображена на
рис 2.

3.2.2
Алгоритмы для обнаружения плагиата
Системы обнаружения плагиата рассматривают исходный код “как
есть”, так же, как и с обычными текстовыми системами. Но они крайне
неэффективны для решения задачи плагиата исходного кода, т.к. переименование
функций и переменных или несущественные изменения в коде являются серьезными
препятствиями для их правильной работы. Иногда используется параметризованное
представление кода. Один из его вариантов таков: имена функций и переменных
заменяются при первой встрече в коде на ноль, а при последующих на расстояние
до предыдущей позиции. Обычно детекторы основанные на этих двух представлениях
лучше находят плагиат, чем системы “подсчитывающие отличительные черты”, а
также способны находить плагиат в случаях, когда скопирована только часть
программы.
Токенизация
Пусть у нас есть две строки кода for (int i = 0; i <= n; i
+ +) и for (int j = 0; (j − 1) < n; j + +). Очевидно, что у них
одинаковая функциональность, и плагиатор мог из одной получить другую без
особых усилий, а для ранее описанных представлений они совершенно различны. Для
борьбы с такого рода изменениями придуман метод токенизированного представления
кода. Основная идея этого представления это сохранение существенных и
игнорирование всех поверхностных (то есть легко модифицируемых) деталей кода
программы. Процедура токенизации выглядит примерно так:
Каждый оператору языка заменяется на уникальный ключ.
Строим строку из полученных кодов, сохраняя порядок
следования их в исходном коде программы. Один символ строки (токен) код одного
оператора. Таким образом мы автоматически игнорируем названия функций и
переменных (классов, объектов и так далее), разделительные символы,
предотвращаем влияние мелких изменений кода программы (см. пример выше).
Алгоритм Хескела
Пусть у нас есть две программы, представим их в виде строк
токенов a и b соответственно. Одним из критериев сходства строк считается длина
их наибольшей общей подпоследовательности. Мы всегда можем найти такой элемент
строки ai, что НОП строк a0 = a|a|a|a|−1. aia1. ai−1 и b будет
значительно меньше (максимум в два раза), чем НОП (a, b) (если НОП (a, b) >
1). Чтобы избежать этого явления можно воспользоваться алгоритмом сравнения
строк Хескела, он требует нескольких проходов, но работает за линейное время.
Разобьем строки a и b на k-граммы (подстроки длины k). Найдем те k-граммы,
которые встречаются в a и b только по одному разу. Для каждой такой пары
проверим совпадают ли элементы строк, непосредственно лежащие над ними; если
это так, то проведем ту же проверку и для них и так далее, пока несовпадение не
будет найдено. Аналогично для строк, лежащих ниже соответствующих k-граммов.
Получаем набор общих непересекающиеся подстрок a и b. Их общая длина может
служить мерой схожести программ соответвующих a и b. Достоинства.
Линейная трудоемкость алгоритма
Недостатки.
Возможность совпадения токенизированного представления
программ, но отсутствия совпадения в исходных кодах программ.
Небольшое количество уникальных k-граммов в больших
программах, соответственно многие совпадения, не содержащие в себе таких
k-граммов будут проигнорированы.
Вставка в найденный блок или изменение на семантически
эквивалентный оператора во многих случаях будет приводить к игнорированию той
части блока, в которой не содержится уникальный k-грамм.
Нельзя организовать базу данных, ускоряющую проверку
"один против всех".
Жадное строковое замощение
Рассмотрим эвристический алгоритм получения жадного
строкового замощения (The Greedy String Tiling). Он получает на вход две строки
символов над определенным алфавитом (у нас это множество допустимых токенов), а
на выходе дает набор их общих непересекающихся подстрок близкий к оптимальному.
Подстроку, входящую в этот набор, мы будем называть тайлом (tile). Пусть P и T
токенизированные представления сравниваемых программ.- минимальная длина
наибольшего общего префикса строк Pp и Tt, при которой он учитывается
алгоритмом.
Длина самого большого из пока найденных на текущей итерации
алгоритма общих префиксов строк Pp и Tt обозначается maxmatch.
Набор тайлов мы будем обозначать как tiles.
Множество, содержащие кандидатов на попадание в набор тайлов,
обозначется mathes.
Алгоритм можно разделить на две фазы:
. Ищутся наибольшие общие подстроки P и T, состоящие только
из непомеченных элементов (вначале алгоритма все элементы непомечены). Для
этого используются три вложенных цикла: первые пробегает по всем возможным Pp,
второй по всем Tt, а третий находит наибольший общий префикс Pp и Tt. Далее
существует три варианта в зависимости от соотношения величин maxmatch и
найденного префикса: a) если maxmatch меньше, то мы удаляем из списка общих
подстрок matches все до этого добавленные и помещаем туда найденный префикс. b)
если maxmatch больше, то ничего не меняем. c) если они равны, то добавляем
наибольший общий префикс Pp и Tt к списку matches.2. Проходим по списку, если
текущий элемент списка подстрока, не содержащая помеченных элементов, то
помещаем ее в выходной набор tiles (теперь эту подстроку называют tile отсюда и
название алгоритма), помечаем все элементы рассматриваемой строки, входящие в P
и T. Если длины строк в списке (maxmatch) больше чем MinimumMatchLength, то
переходим к первой фазе. Приведем псевдокод этого алгоритма:
Greedy-String-Tiling (String P,
String T)
{= {};{=
MinimumMatchLength;unmarked tokens Pp in P
{unmarked tokens Tt in T
{= 0;(Pp+j == Tt+j) &&
unmarked (Pp+j) && unmarked (Tt+j)++;(j == maxmatch)
{= matches ∪ match (p, t, j);
} else if (j > maxmatch)
{= {match (p, t, j) }; maxmatch
= j;
}
}
}match (p, t, maxmatch) ∈ matches
{(not occluded)
{j = 0. (maxmatch − 1)
{(Pp+j); mark (Tt+j);
}= tiles ∪ matches (a, b,
maxmatch);
}
}
} while (maxmatch >
MinimumMatchLength); return tiles;
}
}
. Вначале мы находим наибольшие общие подстроки, состоящие из
непомеченных символов, потому что считаем, что длинные совпадения для нашей
задачи наиболее содержательны. Понятно, что вследствие этой эвристики мы иногда
можем не найти более оптимальное (в плане количества покрывающих подстрок)
общее частичное покрытие, но это было бы нам абсолютно безразлично без
следующей эвристики.
. Если в алгоритме мы будем позволять учитывать слишком
маленькие наибольшие общие префиксы, то случайные совпадения небольшого
количества токенов будут влиять на определение схожести программ, чтобы избежать
этого вводится константа MinimumMatchLength.
Заметим, что “not occluded” (не пересекающиеся) означает, что
ни один токен с Pp по Pp+maxmatch−1 и с Tt по Tt+maxmatch−1 не был
помечен на предыдущих итерациях. Как бы то ни было, меньшие тайлы не могут быть
созданы до больших. Этого достаточно, чтобы утверждать, что нужно про-верять
только метки на концах предполагаемого тайла, чтобы узнать содер-жит ли он
помеченные символы. Очевидно, это можно проделать за O (1), тогда
асимптотическая сложность времени работы всего алгоритма в худ-шем случае O
(n3). h (Tj−1Tj. Tj+|P |−2. Tj+|P |−1
Достоинства.
Преимущества токенизированного представления.
Общие подстроки меньшей длины, чем MinimumMatchLength
игнорируются, поэтому алгоритм не принимает в расчет небольшие случайно
совпавшие участки кода.
При разбиении совпавшего участка кода на две и более части
вставкой одного-нескольких блоков или одиночных операторов, а также
перестановкой небольшого количества независимых операторов, функция схожести
слабо изменяется. (Длина совпадения должна быть значительно больше
MinimumMatchLength, количество вставленных операторов мало по сравнению с
длиной совпадения.)
Алгоритм нечувствителен к перестановкам больших фрагментов
кода.
Недостатки.
Возможность совпадения токенизированного представления
программ, но отсутствия совпадения в исходных кодах программ.
Разбиение совпадения на блоки, вставкой или заменой оператора
на похожий (например, for на while), каждый длиной меньше MinimumMatchLength,
ведет к полному игнорированию совпадения.
Из-за эвристик, используемых в алгоритме, совпадения, длиной
мень-шей чем MinimumMatchLength, будут проигнорированы.
Нельзя организовать базу данных, ускоряющую проверку
один-против-всех.
Метод отпечатков
В этом алгоритме мы представляем токенизированную программу в
виде набора отпечатков (меток, fingerprints), так чтобы эти наборы для похожих
программ пересекались. Этот метод позволяет организовать эффективную проверку
по базе данных. Метод отпечатков можно представить в виде четырех нижеследующих
шагов:
. Последовательно хэшируем 2 подстроки токенизированной
программы P длины k (фиксированный параметр). Обычно используют хэш-функцию из
алгоритма Карпа-Рабина поиска подстроки в строке.
. Выделяем некоторое подмножество их хэш-значений, хорошо
характеризующее P. Проделываем те же шаги для токенизированных программ T1, T2.
Tn и помещаем их выбранные хэш-значения в хэш-таблицу.
. С помощью хэш-таблицы (базы) получаем набор участков строки
P, подозрительных на плагиат.
Если в двух программах есть общая подстрока длиной, например,
два символа, то необязательно, что мы нашли плагиат - скорее всего это
совпадение просто случайность и обусловлено малой мощностью нашего алфавита. То
есть значение k может способствовать игнорированию “шума”, но при больших
значениях k, мы можем проигнорировать настоящий случай плагиата, поэтому это
число нужно выбирать с осторожностью. Пусть наша хэш-функция - это h, а h1, h2.
h|P |−k+1 - последовательность значений хэш-функций, полученных на шаге
1. Рассмотрим некоторые возможные реализации шага 2:
Наивный подход заключается в выборе каждого i-ого из n
хэш-значений, но он неустойчив к модификациям кода. (Если мы добавим в начало
файла один лишний символ, то получим совершенно другое подмножество
хэш-значений после выполнения алгоритма.)
.4
Формирование отчетности
Формирование отчетности осуществляется за счет сравнительного
запроса к СУБД и представлении данных в табличном виде.
4.
Программное обеспечение системы
4.1 Структура
и функции частей программного обеспечения системы
В качестве ОС для сервера и клиента была выбрана Windows - одна из самых
распространенных систем и быстронастраиваемых с развернутой СУБД MySQL. В качестве среды
разработки была выбрана MS Visual Studio 2012, т.к. языком разработки является C#. VS 2012 в сочетании с ReSharper 8.01 ускоряет процесс
разработки и рефакторинга кода. Язык программирования С# интегрировал в себя
много положительных черт своих предшественников - Delphi, C++, Java и т.д. Язык
C# является объектно
ориентированным языком программирования, легко поддается рефакторингу и имеет
массу преимуществ, например, как garbage collector и удобный interface builder для разработки
пользовательского интерфейса.
Схема программного обеспечения представлена на рисунке 5.1.1

Рисунок 5.1.1 - Схема программного обеспечения
4.2
Разработка специального программного обеспечения
В качестве специального программного обеспечения будет
представлен модуль, который занимается поиском плагиата в программного коде -
непосредственная реализация алгоритмов для получения результата о плагиате.
5.
Техническое обеспечение системы
5.1 Выбор
конфигурации параметров сервера
Сервер будет оснащен:
. Процессором четырёхъядерный Intel Core i5-3470 (3.2
ГГц) потому что такой процессор обладает хорошей производительностью,
температурным режимом, который позволяет долго работать, высокой скоростью
работы.
2. Оперативная память DDR3-1333 4 Г, так как обработка
выборки больших размеров и нагрузка многозадачности выше чем у клиентской
машины.
. Жесткий диск класса IDE HDD 1Tb. Диски этого класса
обеспечивают высокую надежность и производительность работы, обладают низким
уровнем шума, высокой скоростью и низкой ценой.
5.2 Выбор
конфигурации параметров рабочей станции
Рабочая станция будет оснащена:
. Процессором Двухъядерный Intel Pentium G645 (2.9
ГГц), поскольку рабочая станция задействуется для загрузки работы и не требует
большых вычислительныз способностей.
2. Оперативная память DDR3-1333 2 ГБ, размер
оперативной памяти выбран стандартного "среднего" размера для более
высокой скорости манипулирования многооконности и большего количество
одновременно запущенных процессов.
. Жесткий диск класса IDE HDD 320Gb, поскольку жествкий диск
данного типа является оптимальным в отношении цена/размер.
5.3 Выбор
периферийных устройств
Разрабатываемая подсистема во время своей работы нуждается в
следующих периферийных устройствах:
монитор Монитор 23" Dell UltraSharp U2312HM Black (для администрирования
сервера) обладает оптимальным размером, отличными, сочными красками и углами
обзора;
мышь HP 329G. Отличный дизайн, вес,
точность работы на любых поверхностях (для администрирования сервера);
клавиатура Logitech 640DC удобная и обладает не
высокой ценой (для администрирования сервера).
6.
Организация компьютерной сети
6.1 Выбор и
обоснование технологии передачи данных
Для работы системы необходимо обеспечить интернет-соединение
по стандарту 802.3u с пропускной способностью в 100Мб (можно и ниже, но
рекомендовано). Стандарт 802.3u следующими типами:
BASE-FX - вариант Fast Ethernet с использованием
волоконно-оптического кабеля
BASE-SX - удешевленная альтернатива 100BASE-FX с
использованием многомодового волокна, так как использует недорогую
коротковолновую оптику.100BASE-SX может работать на расстояниях до 300 метров
(980 футов)
100BASE-BX - вариант Fast Ethernet по
одножильному волокну. Используется одномодовое волокно, наряду со специальным
мультиплексором, который разбивает сигнал на передающие и принимающие волны.
100BASE-LX - 100 Мбит/с
Ethernet с помощью оптического кабеля. Максимальная длина сегмента 15
километров в полнодуплексном режиме по паре одномодовых оптических волокон.
BASE-LX WDM - 100 Мбит/с
Ethernet с помощью волоконно-оптического кабеля.
Пропускная способность в
100Mb является оптимальной,
поскольку скорость передачи является достаточно быстрой по сравнению с 10Mb.
6.2 Выбор
сетевого оборудования
Топология будет иметь древовидную структуру (Рис 6.2.1)

Рисунок 6.2.1 - Структура сети
На рисунке 6.2.2 представлена структура одной из комнат,
которая позволяет производить сетевую передачу данных.

Рисунок 6.2.2 - Схема сети
В качестве элемента маршрутизации был выбран маршрутизатор
Asus RT-N10P, поскольку он имеет wan порт, 4 порта для RJ-45, относительно
дешевый.
Заключение
Разработанная система позволяет эффективно обнаруживать
плагиат в программном коде и эффективно повысить качество оценивания работы.
Система работает дистанционно, что позволяет добавлять работы
независимо от присутствия преподавателя.
Приложение А
- Функциональная структура системы

Рисунок А.1 - Обобщенная структура системы.

Рисунок А.2 - Нотация бизнес-процесса IDEF0.

Рисунок А.3 - Описание процесса функционирования "Учета
работ"

Рисунок А.4 - Описание процесса функционирования "Поиск
плагиата"
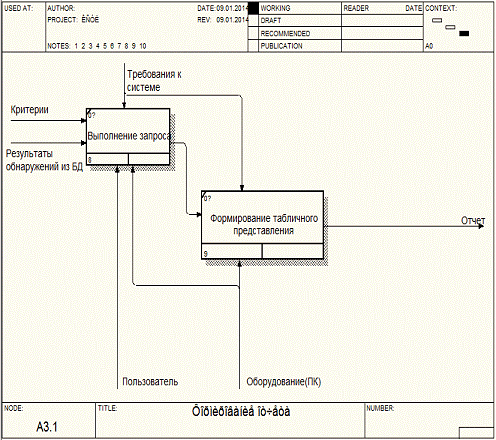
Рисунок А.5 - Описание процесса функционирования
"Формирование отчетности"
Приложение Б.
Схема данных БД университета
