|
Демон понимания
|
Наличие усов
|
Наличие шерсти
|
Наличие хвоста
|
Вес более 50 кг
|
|
Кошка
|
W11 = 10
|
W12
= 10
|
W14
= 0
|
|
Собака
|
W21
= 0
|
W22
= 10
|
W23
= 8
|
W24
= 0
|
|
Человек
|
W31
= 2
|
W32
= 0
|
W33
= 0
|
W34
= 10
|
Допустим, что на считывающем устройстве пандемониума
появляется образ в виде кошки. Вычислительные демоны сформируют следующие
признаки: d1 = 1 (что означает - есть усы), d2= 1 (есть шерсть), d3=1 (имеется хвост), d4= 0 (вес более 50 кг).
Демоны понимания произведут обработку признаков:
демон кошки - D1 = 10*1 + 10*1 + 10*1 + 0*0 = 30;
демон собаки - D2 = 0*1 + 10*1 + 8*1 + 0*0 = 18;
демон человека - D3 = 2*1 + 0*1 + 0*1 + 10*0 = 2.
Таким образом, наибольшее число баллов набрала кошка.
Теперь предположим, что на входе появился человек.
Вычислительные демоны дадут признаки: d1 = 0 (что означает - нет усов), d2 = 0 (нет шерсти), d3 = 0 (нет хвоста), d4 = 1 (вес более 50 кг).
Демоны понимания произведут обработку поступивших признаков:
демон кошки - D1 = 10*0 + 10*0 + 10*0 + 0*1 = 0;
демон собаки - D2 =0*0 + 10*0 + 8*0 + 0*1 = 0;
демон человека - D3 = 2*0 + 0*0 + 0*0 + 10*1 = 10.
Вывод очевиден - на входе человек.
Пандемониум представляет собой обучающееся устройство, и
каждый демон понимания осуществляет настройку своего способа комбинации
выходных сигналов вычислительных демонов. Эта подстройка выполняется путем
подбора весов wij и определяется обратной связью с окружающей средой,
указывающей на правильность или полезность принимаемого решения, т.е. здесь
подразумевается присутствие учителя, который сообщает системе правильную
классификацию. Конкретные алгоритмы настройки системы могут быть самыми
разнообразными и включать в себя математические методы оптимизации.
Когда весовые коэффициенты более-менее подобраны и
принимаемое решение близко к оптимальному, то для любого вычислительного демона
становится возможным вычислить его ценность для всей системы в целом. Ценность
вычислительного демона определяется тем, насколько используется его выход.
Мерой такой ценности может быть величина
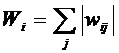 (2.2)
(2.2)
Определение ценности позволяет производить изменения в
используемом множестве вычислительных демонов. Например, можно автоматически
исключать малоценные демоны и заменять их другими. Таким образом система приобретает
самоорганизующийся характер и ее настройка не сводится просто к самооптимизации
параметров.
Автором системы были предложены два способа получения новых
вычислительных демонов. Оба они основаны на том соображении, что целесообразно
создавать демоны, имеющие что-то общее с уже существующими, которые доказали
свою ценность. Эти методы называются слиянием и делением с мутацией.
Слияние заключается в том, что выходные сигналы двух демонов
высокой ценности комбинируются между собой, например по принципу «все или
ничего». На рисунке 2.1 на вход одного из вычислительных демонов поступают
сигналы от двух других демонов. Этот результирующий демон возник в результате
слияния.
Персептрон
Розенблатта
Способ распознавания, заложенный в пандемониуме О. Селфрижда,
плохо согласуется с нашими представлениями о процессах, происходящих в мозге.
Поэтому этот способ характерен для кибернетики «черного ящика». Альтернативным
подходом является попытка копирования процессов коры головного мозга,
реализованная в другом устройстве распознавания образа - персептроне.
Термин «персептрон» был введен в 1950-х гг. Фрэнком
Розенблаттом для некоторого класса интеллектуальных систем распознавания
образов, способных обучаться на опыте. Первоначально персептрон Розенблатта
(рисунок 2.2) содержал узлы трех типов. Сенсорные, или с-узлы, имитировали
светочувствительные клетки сетчатки глаза. Они соответствовали демонам
изображения, или демонам данных, пандемониума Селфриджа. Обычно предполагается,
что с-узлы являются элементами типа «все или ничего», но это не обязательно.
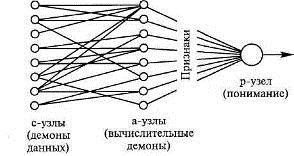
Рисунок 2.2 - Персептрон Розенблатта
Следующий слой состоял из ассоциативных, или а-узлов, которые
в общих чертах соответствуют вычислительным демонам пандемониума. В
первоначальных вариантах исполнения персептрона соединения, идущие от с-узлов,
формировались случайным образом еще в процессе конструирования системы, поэтому
они определяли некоторые случайные свойства изображения. Как и в пандемониуме,
при обучении персептрона вычислялись данные о ценности каждого а-узла. Входные
соединения а-узла, ценность которых в процессе работы оказывалась малой,
аннулировались, после чего случайным или псевдослучайным образом устанавливался
новый набор соединений.
Выходы а-узлов были соединены с узлами реакции, или р-узлами,
соответствующими демонам понимания пандемониума. В отличие от пандемониума
р-узел дает только ответ «да» или «нет».
Как а-узлы, так и р-узлы персептрона представляли собой
математические нейроны. Некоторые из соединений между узлами являлись
возбуждающими, а некоторые - тормозящими. Веса синапсов, идущих к р-узлам,
изменялись в процессе обучения персептрона.
Алгоритм обучения персептрона состоял в следующем. Если
реакция р-узла являлась правильной (т.е. он срабатывал, когда образ принадлежал
к распознаваемому классу, или не срабатывал, когда образ не принадлежал
указанному классу), то веса не изменялись.
Если р-узел не срабатывал, когда распознаваемый образ на
самом деле относился к рассматриваемому классу, то веса синапсов, бывших активными,
увеличиваются на некоторую величину с. С другой стороны, если р-узел срабатывал
на образ, который не принадлежал распознаваемому классу, то веса активных
синапсов уменьшались на величину с.
С помощью этих весов вычислялись ценности каждого а-узла, и
если ценность была мала, то его синапсы (связи с с-узлами) разрушались и
строились новые.
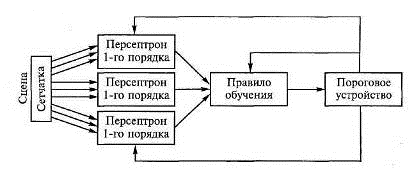
Рисунок 2.3 - Многослойный персептрон Гамбы
На рисунке 2.3 приведена схема популярного в свое время
многослойного персептрона Гамбы, являющегося развитием изложенного выше
однослойного персептрона.
В заключение отметим, что, несмотря на отмеченное сходство
идей, персептрон в большей степени, чем пандемониум, соответствует нашим
представлениям о структуре и процессах функционирования мозга. Возможно поэтому
он оказался более эффективен и получил в наши дни дальнейшее развитие и
применение в нейросетевых и нейрокомпьютерных технологиях.
2.2.4 Предварительная обработка изображений
На первом этапе обработки изображений, поступающих со
считывающего устройства, решается задача фильтрации, т.е. понижения разного
рода шумов (помех), вносимых измерительными системами и каналами связи.
Допустим, что в компьютер поступает некоторое двумерное
изображение, которое можно описать функцией f (х, у), представляющей
собой распределение, например, яркости, светимости, плотности. В дальнейшем эту
функцию будем называть зачерненностъю.
Для последующей обработки необходимо выполнить квантование
(дискретизацию) этой функции как по пространству, так и по значению
зачерненности.
Сегментация
Обычно изображение состоит из двух частей: компонентов
образа, подлежащего распознаванию, и фона. Под сегментацией понимается
отнесение элементов изображения либо к компонентам образа, либо к фону.
Существуют два метода сегментации - разделение по порогу и обнаружение края.
Разделение по порогу. Сегментация осуществляется исключительно на
основе значения функции зачерненности каждого элемента изображения. Если
функция f (х, у) >  , где - значение некоторой пороговой величины, то соответствующий
элемент изображения классифицируется как компонента распознаваемого образа, в
противном случае он относится к фону.
, где - значение некоторой пороговой величины, то соответствующий
элемент изображения классифицируется как компонента распознаваемого образа, в
противном случае он относится к фону.
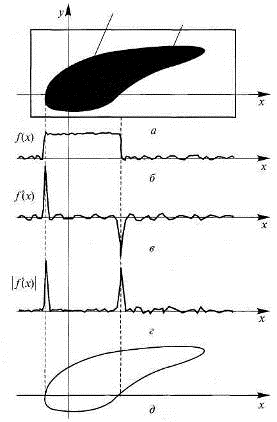
Рисунок 2.4 - Распределение функции зачерненности у = f (х, у) в плоскости х - у (а), в сечении у = 0 (б),
распределение ее производной по х (в), модуля производной (г) и особенностей
поля производной (д)
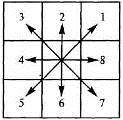
Рисунок 2.5 - Правило формирования цепного
кода
На сегментированном таким образом изображении легко выделить
контуры распознаваемого образа. Обозначим через S некоторое интересующее
нас подмножество элементов изображения, относящееся к компонентам образа, а
через S'
- дополнение подмножества (фон). Тогда контур будет состоять из элементов
подмножества S,
которые имеют в качестве соседних элементы подмножества S'. Пользуясь этим
правилом, несложно создать алгоритм, выявляющий контурные пикселы.
Обнаружение края. Обычно граница между компонентами образа и
фоном характеризуется резким изменением функции зачерненности. Поэтому
обнаружить эту границу можно путем дифференцирования функции f (х, y) по координатам, как
схематично показано на рис. x.x. Ложные края можно удалить, а утраченные - восстановить,
используя априорную информацию об образе.
Обработка
сегментированных изображений
Топологические особенности контура можно выявить, пользуясь
цепным кодом. Правило формирования цепного кода иллюстрирует рисунок 2.6 Для
кодирования очередного пиксела контура используются числа от 1 до 8 в
зависимости от его расположения относительно начального пиксела.
По записи контура в цепном коде можно вычислить ряд признаков
распознаваемого образа, в частности, площадь, ограниченную контуром (если он
замкнут), кривизну в определенном пикселе контура, а также определить, замкнут
ли контур. Можно установить, обладает ли контур локальной вогнутостью или
выпуклостью.
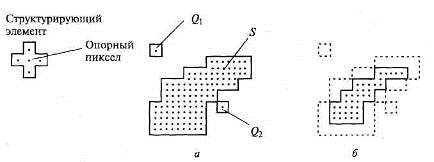
Рисунок 2.6 - Распознаваемый образ S и случайные частицы Q1 и Q2 до (а) и после (б)
применения операции поверхностного разрушения
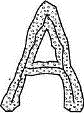
Рисунок 2.7 - Изображение буквы и ее остова
С выявленным компонентом образа можно производить операции
поверхностного разрушения (сжатия, прореживания) и наращивания (расширения).
Эти операции применяют для улучшения качества изображения. Для реализации
указанных операций необходимо перемещать некоторый структурирующий элемент по
изображению образа. Если структурирующий элемент полностью укладывается в
подмножество S,
перемещение структурирующего элемента продолжается дальше без модификации
изображения. Если же структурирующий элемент не входит в S полностью, то элемент
изображения, соответствующий положению опорного пиксела структурирующего
элемента, удаляется. На рисунке 2.6 приведен пример этой операции.
Структурирующий элемент (см. рисунок 2.6, а) состоит из центрального пиксела,
являющегося опорным, и четырех соседних с ним пикселов. На рисунке 2.6, б
удаленные после операции поверхностного разрушения пикселы изображены
штриховыми линиями.
Операция, обратная поверхностному разрушению, называется
наращиванием. Эту операцию можно также трактовать как поверхностное разрушение
подмножества S'.
В случае применения операции наращивания к подмножеству S компоненты изображения
расширяются - к ним добавляются пикселы фона, соседние с S.
Операции разрушения и наращивания можно применять
многократно. Таким способом можно добиться очищения изображений - удаления
малых случайных частиц (таких как Q1 и Q2 на рисунке 2.6, а) и заполнения случайных
промежутков.
Многократное поверхностное разрушение контура в конечном
итоге приводит к полному устранению подмножества S. Однако с помощью этой
же операции можно составить алгоритм, выделяющий остов изображения - линии
толщиной в один пиксел, которые проходят посередине подмножества S, сохраняя его топологию.
Пример выделения остова приведен на рисунке 2.7.
Остовы выявляют структуру изображения, и их можно
использовать при формулировке признаков.
Распознавание
по методу Паркса
Джоном Парксом была предложена оригинальная система выделения
признаков, полезных для распознавания символов, главным образом, букв и цифр.
Система Паркса работает с остовами, оставшимися после применения процедур
сегментации и поверхностного разрушения. Входное изображение просматривается с
целью обнаружения отрезков прямых, которые могут быть ориентированы различным
образом. Просмотр осуществляется средствами электроники, но точно так же, как
если бы на каждый участок исходного массива, содержащий 7x7 пикселов,
накладывалась решетка, состоящая из 7 х 7 фотоэлементов. Эта решетка движется
по изображению слева направо, перемещаясь каждый раз на один пиксел. Пройдя
таким образом строку, решетка опускается на один пиксел вниз и снова перемещается
слева направо. В каждом положении регистрируется выходной сигнал каждого
фотоэлемента и производятся определенные сравнения между группами
фотоэлементов.
На рисунке 2.8 показано, какие сравнения могут осуществляться
между подмножествами фотоэлементов. Среднее из значений фотоэлементов,
помеченных знаком «+», сопоставляется со средним из значений, помеченных знаком
«-». Если оказывается, что изображение более темное под ячейками «+», то мы
получаем данные относительно возможности присутствия в этой области
горизонтального отрезка. Строки фотоэлементов взяты длиной всего в пять
пикселов, что позволяет не слишком строго отбирать линии по направлению.
Аналогичное сопоставление данных, полученных от
фотоэлементов, составляющих вертикаль, выделяет отрезки линий, расположенных
примерно вертикально. По такому же принципу выделяются и наклонные линии.

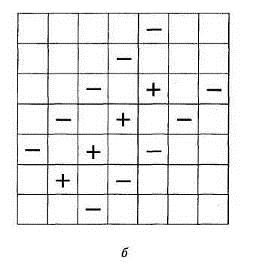

Рисунок 2.8 - Расположение пикселов при поиске горизонтальных
(а) и наклонных (б) отрезков изображения
Новый массив опять рассматривается с помощью ячейки 7x7
(рисунок 2.9), которая при определенных условиях указывает на наличие
некоторого морфологического признака символа. Таким признаком может быть
изменение направления линии; острые, прямые или тупые углы; слияние или
пересечение линий. Всего получается 54 различных морфологических признака.
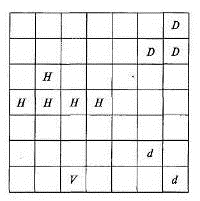
Рисунок 2.9 - Пример заполнения решетки на втором этапе
сканирования: Н - наличие горизонтального участка; V - наличие вертикального
участка; D
и d - наличие наклонных
участков
Представление символа сводится к перечислению его
морфологических признаков с указанием их примерного расположения. Простая
программа, составленная на основе статистических данных, собранных на свободно
написанных цифрах, позволяет осуществлять довольно надежное распознавание.
Система выделения признаков, предложенная Парксом
(первоначальный просмотр изображения с помощью решетки и обнаружение отрезков
прямых) очень хорошо соответствует процессу, который происходит в зрительной
коре мозга животных на начальных этапах обработки изображений. Поэтому метод
Паркса можно классифицировать как нейрокибернетический подход.
2.3 Обзор существующих программных средств для
распознавания символов
В настоящее время получили распространение две конкурирующие
между собой системы распознавания текстовой информации - FineReader (компания «Бит») и CuneiForm (компания «Cognitive Technologies»). Разработчики этих
систем тщательно оберегают свои ноу-хау, однако некоторые принципы,
используемые этими программами, становятся известными.
2.3.1
Основные принципы работы системы FineReader
Компанией «Бит» была разработана специальная технология
распознавания символов, которая получила название фонтанного преобразования (от
англ. font - шрифт), а на ее основе - коммерческий продукт - система
оптического распознавания FineReader.
В основе фонтанного преобразования лежит так называемый
принцип целостности. В соответствии с ним любой воспринимаемый объект
рассматривается как целое, состоящее из частей, связанных между собой
определенными отношениями.
Для выделения целого требуется определить его части. Части
же, в свою очередь, можно рассматривать только в составе целого. Поэтому
целостный процесс восприятия может происходить только в рамках гипотезы о
воспринимаемом объекте - целом.
При распознавании текста человеком любое решение принимается
путем последовательного выдвижения и проверки гипотез с привлечением знаний как
о самом исследуемом объекте, так и о содержании всего текста.
Первый шаг восприятия - это формирование гипотезы о
воспринимаемом объекте. Гипотеза может формироваться как на основе априорной
модели объекта, контекста и результатов проверки предыдущих гипотез (процесс
«сверху вниз»), так и на основе предварительного анализа объекта («снизу
вверх»). Второй шаг - уточнение восприятия (проверка гипотезы), при котором
производится дополнительный анализ объекта в рамках выдвинутой гипотезы и в
полную силу привлекается контекст.
Каждая гипотеза должна быть объектом, который можно было бы
оценить или сравнить с другими. Гипотезы выдвигаются последовательно, а затем
объединяются в список и сортируются на основе предварительной оценки. Для
окончательного выбора гипотезы активно используются контекст и другие
дополнительные источники знания.
Как уже отмечалось выше, сегодня известны три подхода к
распознаванию символов - шаблонный, структурный и признаковый. Принципу
целостности отвечают лишь первые два. Поэтому компания «Бит» принципиально не
использует признаковый подход. Вместе с тем разработчики FineReader обращают внимание на
недостатки шаблонного и структурного подходов. Шаблонные системы довольно
устойчивы к дефектам изображения и имеют высокую скорость обработки входных
данных, но надежно распознают только те шрифты, шаблоны которых им известны.
Если распознаваемый шрифт хоть немного отличается от эталонного, шаблонные
системы могут делать ошибки даже при обработке очень качественных изображений.
К недостаткам структурных систем относится их высокая
чувствительность к дефектам изображения, нарушающим составляющие элементы.
Кроме того, векторизация изображений сама по себе может добавлять
дополнительные дефекты.
Фонтанное преобразование, предлагаемое разработчиками системы
FineReader, по их мнению, совмещает
в себе достоинств шаблонной и структурной систем и позволяет избежать
недостатков, присущих каждой из них по отдельности. В основе этой технологии
лежит использование структурж пятенного эталона (термин введен разработчиками
системы). Изображение представляется в виде набора пятен, связанных меж собой n-арными отношениями,
задающими структуру символа.
Эти отношения, т.е. расположение пятен друг относительно
друга, образуют структурные элементы, составляющие символ. Так, отрезок - это
один тип n-арных
отношений между пятнами, эллипс - другой, дуга - третий.
Другие отношения задают пространственное расположение образующих
символ элементов. Используются связи между структурными элементами, которые
определяются либо метрическими характеристиками этих элементов (например,
«длина больше»), либо их взаимным расположением на изображении (например,
«правее», «соприкасается»).
При задании структурных элементов и отношений применяются
конкретизирующие параметры, позволяющие доопределить структурный элемент или
отношение при использовании этого элемента в эталоне конкретного класса.
Конкретизирующими могут являться, например, параметры, задающие диапазон
допустимой ориентации отрезка или предельное допустимое расстояние между
характерными точками структурных элементов. Пример задания конкретизирующих
параметров для буквы «А», приведен на рисунке 2.10.
Конкретизирующие параметры используются также для определения
качества распознавания. Так, если вычисленный конкретизирующий параметр
находится где-то посередине допустимого интервала, то качество распознавания
считается высоким, в противном случае - низким. Таким образом, система сама
себе ставит оценку.

Рисунок 2.10 - Пример задания конкретизирующих параметров
Построение и тестирование структурно-пятенных эталонов для
классов распознаваемых объектов - процесс сложный и трудоемкий. База изображений,
которая используется для отладки описаний, должна содержать примеры хороших и
плохих (предельно допустимых) изображений для каждой графемы, а изображения
базы разделяются на обучающее и контрольное множества.
Построение и тестирование структурно-пятенных эталонов для
классов распознаваемых объектов - процесс сложный и трудоемкий. База
изображений, которая используется для отладки описаний, должна содержать
примеры хороших и плохих (предельно допустимых) изображений для каждой графемы,
а изображения базы разделяются на обучающее и контрольное множества.
Разработчик описания предварительно задает набор структурных
элементов (разбиение на пятна) и отношения между ними.
Система обучения по базе изображений автоматически вычисляет
параметры элементов и отношений. Полученный эталон проверяется и корректируется
по контрольной выборке изображений данной графемы. По этой же выборке
проверяется результат распознавания, т.е. оценивается качество подтверждения
гипотез.
Распознавание с использованием структурно-пятенного эталона
происходит следующим образом. Эталон накладывается на изображение, и отношения
между выделенными на изображении пятнами сравниваются с отношениями пятен на
эталоне. Если выделенные. на изображении пятна и отношения между ними
удовлетворяют эталону некоторого символа, то данный символ добавляется в список
гипотез о результате распознавания входного изображения. Гипотезы сортируются
согласно оценкам их качества, и преимущество отдается той, которая имеет
максимальный балл.
2.3.2
Основные принципы работы системы CuneiForm
По мнению разработчиков CuneiForm, их система является
более интеллектуальной, поскольку задача распознавания текста в ней решается на
основе взаимодействия структурного, признакового, растрового, дифференциального
и лингвистического уровней.
Работает система по принципу «одной кнопки». Это означает,
что при нажатии кнопки «Сканируй и распознавай» запускается весь процесс
обработки документа: сканирование, фрагментация страницы на текстовые и
графические блоки, сегментация, сжатие-расширение, выделение остовов,
распознавание текста, проверка орфографии и формирование выходного файла.
Интеллектуальный алгоритм позволяет автоматически подобрать
оптимальный уровень яркости сканера (адаптивное сканирование) в зависимости от
фона документа, сохранить иллюстрации или, в зависимости от решаемой задачи,
удалить ненужные графические элементы для максимального сокращения последующего
редактирования.
За распознавание текста отвечает целый ряд модулей
(сканирования, выбора яркости, предобработки документа, фрагментации и др.),
каждый из которых решает свою задачу. На вход модуля распознавания поступает
полученное после сканирования изображение.
В CuneiForm используется несколько методов распознавания. Образ каждого
символа раскладывается на отдельные элементы - события. К примеру, событием
является фрагмент от одной линии пересечения до другой. Совокупность событий
представляет собой компактное описание символа.
Другие методы основаны на использовании соотношения «масс»
отдельных элементов символов и описании их характерных признаков (закругления,
прямые углы и т.д.). По каждому из этих описаний существуют базы данных, в
которых находятся соответствующие эталоны. Поступающий на обработку элемент
изображения сравнивается с эталоном, а затем на основании этого сравнения
решающая функция выносит вердикт о соответствии изображения конкретному
символу.
Таким образом, в отличие от FineReader, здесь в полной мере
используется признаковый подход, в частности, рассмотренный выше метод Паркса.
Поскольку в системе CuneiForm используется не один, а сразу несколько
методов распознавания, распознаваемый образ сравнивается не с одним, а с
несколькими типами эталонов, представленными различными способами.
Кроме того, существуют алгоритмы, которые позволяют работать
с текстами низкого качества. Так, для разрезания «склеенных» символов
существует метод оценки оптимальных разбиений (ноу-хау не раскрываются). И,
напротив, для «рассыпанных» элементов разработан алгоритм их соединения.
В версии CuneiForm 96 впервые применен алгоритм самообучения.
Принцип его состоит в следующем. В каждом тексте присутствуют четко и нечетко
пропечатанные символы. Если после того, как система распознала текст (как это
делает обычная система, например предыдущая версия CuneiForm 2.95), выясняется, что
точность оказалась ниже пороговой, то производится дораспозна-вание текста на
основе шрифта, который генерируется системой по хорошо пропечатанным символам.
Как утверждают разработчики, результаты применения CuneiForm 96 показали, что
использование самообучающихся алгоритмов позволяет повысить точность
распознавания низкокачественных текстов в 4 - 5 раз. Но главное преимущество
заключается в том, что самообучающиеся системы обладают гораздо большим
потенциалом повышения точности распознавания, открывая новое направление в
теории распознавания символьной информации.
Не ограничиваясь геометрическими методами распознавания,
разработчики системы CuneiForm дополнили ее орфографическим, синтаксическим и
семантическим дораспознаваниями и контролем. При этом разработчикам пришлось
решить две важные задачи. Во-первых, было необходимо реализовать быстрый доступ
к большому (порядка 100 000 слов) словарю. В результате удалось построить
систему хранения слов, где на каждое слово уходило не более одного байта, а
доступ осуществлялся за минимальное время (ноу-хау не раскрывается). Во-вторых,
потребовалось построить систему коррекции результатов распознавания,
ориентированную на альтернативность событий (подобно системе проверки
орфографии).
Сама по себе альтернативность результатов распознавания
очевидна и обусловлена хранением коллекций букв вместе с оценками соответствия.
Словарный контроль с использованием словарной базы приводил к изменению этих
оценок. В итоге применение словаря позволило реализовать схему дораспознавания
символов.
Таким образом, рассматриваемая система обладает» свойством
самообучения. Она самосовершенствуется в процессе работы, настраиваясь на
конкретный текст. Критерий качества распознавания, необходимый при построении
алгоритма самообучения, формируется с помощью конкретизирующих параметров,
словаря, контекста.
Последняя версия CuneiForm 2000 отличается, главным образом,
тем, что в ней используется несколько алгоритмов распознавания на основе
нейронных сетей. Их применение, по утверждению разработчиков, повысило качество
распознавания текстов на 60%.
Заметим, что на вход нейросети могут подаваться признаки
образов, выделенные, например, по методу Паркса, или результаты
непосредственного сканирования. Эти две схемы использования нейросети схематично
изображены на рисунке 2.11.
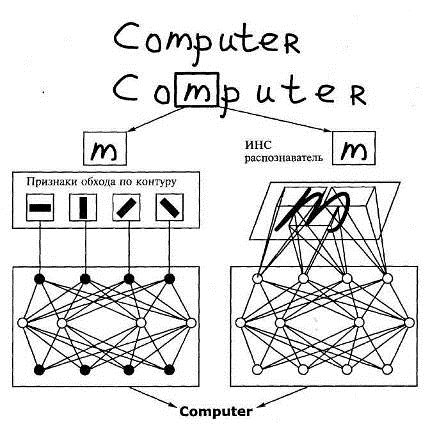
Рисунок 2.11 - Схема распознавания текста с помощью
персептрона с предварительным выделением признаков по методу Паркса (слева) и
путем непосредственного сканирования изображения (справа)
3.
Выбор метода решения
3.1
Выбор общей модели функционирования программного средства
В то время как потребность в системах, способных точно
идентифицировать образы, в том числе и зрительные, растет, в настоящее время
нет применимой альтернативы к системам распознавания на основе комбинации
методов, которые нейтрализуют существующие недостатки.
Один из важных подходов к задаче предполагает использование
разделяющих функций. В условиях, когда мы обладаем лишь немногочисленными
априорными сведениями о распознаваемых образах, при построении распознающей
системы лучше всего использовать обучающую процедуру. Большая сложность задачи,
большое количество входных данных требуют гибкой защитной системы, которая
способна анализировать грандиозное количество информации не традиционным
способом. Система распознавания на основе нейросетей могла бы в перспективе
решить многие из проблем.
3.1.1
Преимущества систем распознавания образов на основе нейросетей
Первым преимуществом в использовании нейросетей при обнаружении
вторжений является гибкость, которую эти сети предоставляют. Нейросеть способна
анализировать данные, даже если эти данные являются неполными или искаженными,
обладает возможностью проводить анализ данных в нелинейном режиме. Более того,
способность обрабатывать данные от большого количества источников в нелинейном
режиме является особенно важной, поскольку некоторые образы достаточно сложны
по своей структуре. И в перспективе существует возможность обработки по
нескольким значимым параметрам. Поскольку задача распознавания требует
достаточной производительности компьютеров, скорость обработки в нейросети
может быть достаточной для решения в реальном времени, что может использоваться
в динамических системах, в которых необходимо распознавание и классификация
каких-либо образов.
Характерно, что выходные данные нейросети выражаются в форме
вероятности, нейросеть предоставляет возможность прогнозирования
(предсказания). Система обнаружения вторжений на основе нейронной сети
идентифицирует вероятность того, что отдельное событие, либо серия событий
указывают на параметры образа, который можно отнести к какому-либо классу не
смотря на различия между подаваемым образом и образом, хранимым в базе. По мере
того, как нейросеть «набирается опыта», она будет улучшать свою способность
определять класс образа. Однако наиболее важное преимущество нейросетей
заключается в способности нейросетей «изучать» новые характеристики и параметры
образов и идентифицировать элементы, которые не похожи на те, что наблюдались прежде.
Нейросеть может быть обучена распознавать известные классы
образов с высокой степенью точности. В то время как это представляет собой
очень ценную способность, поскольку некоторые классы имеют ряд постоянных
признаков, по которому можно точно определить принадлежность к данному классу,
сеть также имеет способность использовать эти знания для идентификации классов,
которые неточно соответствуют характеристикам предыдущих образов.
3.1.2
Недостатки систем распознавания образов на основе нейросетей
Поскольку способность искусственной нейросети
идентифицировать класс принадлежности того или иного образа полностью зависит
от точности обучения системы, обучающие данные и используемые методы обучения
являются наиболее важными. Порядок обучения требует большого количества данных
с тем, чтобы убедиться, что результаты являются статистически значимыми.
Однако, основное неудобство применения нейросетей для детектирование вторжения
- это природа «черного ящика» нейросети. В отличие от экспертных систем,
которые имеют жестко закодированные правила анализа событий, нейросети
адаптированы на анализ данных по результатам ее обучения. Веса и активационные
функции узлов обычно замораживаются после того, как сеть достигла допустимого
уровня успеха в идентификация событий. Хотя анализ изображений достигает
достаточно хорошего значения, базовый уровень его зачастую не известен.
Проблема «черного ящика» весьма характерна для нейросетевых приложений [2].
3.1.3
Выбор критериев анализа и типа используемой нейросети
Термины «нехарактерный», «неизвестный», «не соответствует»
следует рассматривать как нечто, отсутствующее в предыдущем опыте. Иными
словами разрабатываемая система должна накапливать определенные знания о
поведении тех или иных процессов и сигнализировать об отклонениях в случае их
появления.
Чаще всего в задачах подобного рода используются нейронные
сети того или иного вида в зависимости от решаемой задачи и точности получаемых
результатов.
Таким образом, необходимо выбрать тип используемой нейронной
сети или комплекса нейронных сетей.
Выделим основные типы нейронных сетей [3]:
Однонаправленные многослойные сети сигмоидального типа.
Обучение данного вида сетей проводится, как правило, с
учителем. Иными словами сеть настраивается таким образом, чтобы при данных
входах получать на выходе ожидаемые значения. С точки зрения математики
выполняют аппроксимацию стохастической функции нескольких переменных путем
преобразования множества входных переменных xÎRN во множество выходных
переменных yÎRM. Могут применяться для
прогнозирования и диагностики неисправностей.
Радиальные нейронные сети.
Относятся к категории сетей, обучаемых с учителем. Отличаются
некоторыми специфическими свойствами, обеспечивающими более простое отображение
характеристик моделируемого процесса.
Рекуррентные сети как ассоциативные запоминающие устройства.
Сети с обратной связью между различными слоями нейронов. Их
общая черта состоит в передаче сигналов с выходного либо скрытого слоя во
входной слой. Главный принцип работы сводится к запоминанию входных (обучающих)
выборок таким образом, чтобы при представлении новой выборки система смогла
сгенерировать ответ - какая из запомненных ранее выборок наиболее близка к
вновь поступившему образу. Частая область применения - распознавание заученных
образов.
Рекуррентные сети на базе персептрона.
Представляют собой развитие однонаправленных сетей
персептронного типа за счет добавления в них соответствующих обратных связей.
Используются для моделирования динамических процессов, обработки и
распознавания сигналов.
Сети с самоорганизацией на основе конкуренции.
При обучении используется метод обучения без учителя, то есть
результат обучения зависит только от структуры входных данных. Нейронные сети
данного типа часто применяются для решения самых различных задач, от восстановления
пропусков в данных до анализа данных и поиска закономерностей, например, в
финансовой задаче. В частности могут использоваться прогнозирования.
Сети с самоорганизацией корреляционного типа.
Нечеткие нейронные сети.
Характерной особенностью этих сетей является возможность
использования нечетких правил вывода для расчета выходного сигнала. По
сравнению с традиционными решениями нечеткие нейронные сети демонстрируют
качества, связанные с их способностью гладкой аппроксимации пороговых функций.
3.1.4
Общее описание исследуемых нейронных сетей
Однослойные
сети. Персептрон
В соответствии с [4] персептрон представляет собой модель
обучаемой распознающей системы. Он содержит матрицу светочувствительных
элементов (S-элементы),
ассоциативные элементы (А-элементы) и реагирующие элементы (R-элементы). По сути
персептрон состоит из одного слоя искусственных нейронов, соединенных с помощью
весовых коэффициентов с множеством входов.
В 60е годы персептроны вызвали большой интерес.
Розенблатт [4] доказал теорему об обучении персептрона и тем самым показал, что
персептрон способен научиться всему, что он способен представлять. Уидроу [5-7]
дал ряд убедительных демонстраций систем персептронного типа. Исследования
возможности этих систем показали, что персептроны не способны обучиться ряду
простых задач. Минский [8] строго проанализировал эту проблему и показал, что
имеются жесткие ограничения на то, что могут выполнять однослойные персептроны,
и, следовательно, на то, чему они могут обучаться.
Один из самых пессимистических результатов Минского
показывает, что однослойный персептрон не может воспроизвести такую простую функцию
как ИСКЛЮЧАЮЩЕЕ ИЛИ. Это - функция от двух аргументов, каждый из которых
может быть нулем или единицей. Она принимает значение единицы, когда один из
аргументов равен единице (но не оба). Если проблему представить с помощью
однослойной однонейронной системы, то легко видеть, что при любых значениях
весов и порогов невозможно расположить прямую линию, разделяющую плоскость
(пространство образов) так, чтобы реализовывалась функция ИСКЛЮЧАЮЩЕЕ ИЛИ.
Имеется обширный класс функций (наряду с функцией ИСКЛЮЧАЮЩЕЕ ИЛИ), не
реализуемых однослойной сетью. Об этих функциях говорят, что они являются
линейно неразделимыми, и они накладывают определенные ограничения на
возможности однослойных сетей. Линейная разделимость ограничивает однослойные
сети задачами классификации, в которых множества точек (соответствующих входным
значениям) могут быть разделены геометрически. В случае двух входов разделитель
является прямой линией. В случае трех входов разделение осуществляется
плоскостью, рассекающей трехмерное пространство. Для четырех или
более входов визуализация невозможна и необходимо мысленно представить n-мерное пространство,
рассекаемое ‘ ‘гиперплоскостью’’ - геометрическим объектом, который рассекает
пространство четырех или большего числа измерений. Как показано в [9],
вероятность того, что случайно выбранная функция окажется линейно разделимой,
весьма мала. Так как линейная разделимость ограничивает возможности
персептронного представления, то однослойные персептроны на практике ограничены
простыми задачами.
Чтобы сеть представляла практическую ценность, нужен
систематический метод (алгоритм) для вычисления значений весов и порогов.
Процедуру подстройки весов обычно называют обучением. Цель обучения состоит в
том, чтобы для некоторого множества входов давать желаемое множество выходов.
Алгоритм обучения персептрона был предложен в [4] и имеет множество
модификаций.
Многослойные
сети
Серьезное ограничение представляемости однослойными сетями
можно преодолеть, добавив дополнительные слои. Многослойные сети можно получить
каскадным соединением однослойных сетей, где выход одного слоя является входом
для последующего слоя, причем такая сеть может привести к увеличению
вычислительной мощности лишь в том случае, если активационная функция между
слоями будет нелинейной.
Многослойные сети способны выполнять общие классификации,
отделяя те точки, которые содержаться в выпуклых ограниченных или
неограниченных областях. Если рассмотреть простую двухслойную сеть с двумя
нейронами в первом слое, соединенными с единственным нейроном во втором слое,
то каждый нейрон первого слоя разбивает плоскость на две полуплоскости,
образуя в пространстве образов V-образную область, а нейрон второго слоя реализует различные
функции при подходящем выборе весов и порога. Аналогично во втором слое может
быть использовано три нейрона с дальнейшим разбиением плоскости и созданием
области треугольной формы. Включением достаточного числа нейронов во входной
слой может быть образован выпуклый многоугольник любой желаемой формы. Точки,
не составляющие выпуклой области, не могут быть отделены о других точек
плоскости двухслойной сетью.
Трехслойная сеть является более общей. Ее классифицирующие
возможности ограничены лишь числом искусственных нейронов и весов. Ограничения
на выпуклость отсутствуют. Теперь нейрон третьего слоя принимает в качестве
входа набор выпуклых многоугольников, и их логическая комбинация может быть
невыпуклой. При добавлении нейронов и весов число сторон многоугольника может
неограниченно возрастать. Это позволяет аппроксимировать область любой формы с
любой точностью. В добавок не все выходные области второго слоя должны
пересекаться. Возможно, следовательно, объединять различные области, выпуклые и
невыпуклые, выдавая на выходе единицу всякий раз, когда входной вектор
принадлежит одной из них.
Для обучения искусственных нейронных сетей широко применяется
процедура обратного распространения
Сети
Хопфилда
Сети, рассмотренные выше, не имели обратных связей, т.е.
связей, идущих от выходов сети к их входам. Отсутствие обратных связей гарантирует
безусловную устойчивость сетей. Так как сети с обратными связями имеют пути от
выходов к входам, то отклик таких сетей является динамическим, т.е. после
приложения нового входа вычисляется выход и, передаваясь по сети обратной
связи, модифицирует вход. Затем выход повторно вычисляется и процесс
повторяется снова и снова. Для устойчивой сети последовательные итерации
приводят к все меньшим изменениям выхода, пока в конце концов выход не
становится постоянным. Для многих сетей процесс никогда не заканчивается, такие
сети называются неустойчивыми. Проблема устойчивости ставила в тупик первых
исследователей. Никто не был в состоянии предсказать, какие из сетей будут
устойчивыми, а какие будут находится в постоянном изменении. К счастью, в
работе [10] была получена теорема, описавшая подмножество сетей с обратными
связями, выходы которых в конце концов достигают устойчивого состояния. Это
замечательное достижение открыло дорогу дальнейшим исследованиям.
Дж. Хопфилд сделал важный вклад как в теорию, так и в применение
систем с обратными связями. В его работе [11] при имитации поведения ансамбля
нейронов использовались переменные, описывающие состояния нейронов (вектор
состояния s), и переменные, описывающие связи между нейронами (оператор
памяти W),
а также два уравнения, определяющие изменение s со временем. Одно из
этих уравнений представляет изменение s под действием оператора W (выработка реакции на
стимул), а второе - изменение матрицы W, квадратичное по s (запоминание). При этом
вектор состояния ансамбля нейронов представляет собой вектор в фазовом
пространстве динамической системы, а ‘ ‘память’’ реализована как система
аттракторов. Запоминание новой информации осуществляется путем усложнения по
определенному алгоритму структуры аттракторов. Такой подход допускает простую
механическую аналогию, если представить себе вектор состояния как положение
частицы, движущейся под действием силы тяжести и трения по некоторому рельефу.
При скатывании с ‘ ‘горы’’ в одну из ‘‘низин’’ потенциальная энергия системы
уменьшается, и в конце концов материальная точка останавливается из-за трения.
Положение частицы в конечном состоянии (т.е. та из низин, в которой она
останавливается) зависит как от формы рельефа, так и от начального состояния, с
которого началось скатывание. Функционирование сети легко визуализируется
геометрически. В случае двух бинарных нейронов в выходном слое каждой вершине
квадрата соответствует одно из четырех состояний системы (00,01,10,11). В
случае трехнейронной системы пространство образов представлено кубом (в
трехмерном пространстве), имеющим 8 вершин, каждая из которых помечена
трехбитовым бинарным числом. В общем случае система с n нейронами имеет 2n различных сосояний и
представляется n - мерным гиперкубом. Когда подается новый входной вектор, сеть переходит
из вершины в вершину, пока не стабилизируется. Устойчивая вершина определяется
сетевыми весами, текущими входами и величиной порога. Если входной вектор
частично неправилен или неполон, то сеть стабилизируется к вершине, ближайшей к
желаемой.
Дополнительно в ходе анализа поставленной задачи были найдены
следующие обобщенные решения на базе нейронных сетей с точки зрения их
реализации:
Процесс обучения нейросети:
· задание параметров обучения нейросети;
· процесс обучения нейросети;
· сохранение весовых коэффициентов
нейросети;
Каждый из критериев анализа может являться входной
информацией для многослойной сети на базе персептрона с алгоритмом обратного
распространения ошибки (англ.: error back propagation). Дополнительным
преимуществом рассматриваемого сигмоида является автоматический контроль
усиления. То есть для слабых сигналов, когда сумма для нейрона с номером j,
часто называемая сигналом внутреннего возбуждения, близка к нулю, кривая
вход-выход имеет сильный наклон, дающий большое усиление. Когда величина
сигнала внутреннего возбуждения становится больше по модулю, усиление
снижается. Таким образом, большие по величине сигналы воспринимаются сетью без
насыщения, а слабые сигналы проходят по сети без чрезмерного ослабления. Что
является важным для данной НИР.
Основная проблема практической реализации в том, что
оптимальные выходные значения нейронов всех слоев, кроме последнего, как
правило, не известны, и двух или более слойный персептрон уже невозможно
обучить, руководствуясь только величинами ошибок на выходах НС. Один из
вариантов решения этой проблемы - разработка наборов выходных сигналов,
соответствующих входным, для каждого слоя НС, что, конечно, является очень
трудоемкой операцией и не всегда осуществимо. Второй вариант - динамическая подстройка
весовых коэффициентов синапсов, в ходе которой выбираются, как правило,
наиболее слабые связи и изменяются на малую величину в ту или иную сторону, а
сохраняются только те изменения, которые повлекли уменьшение ошибки на выходе
всей сети. Очевидно, что данный метод «наугад», несмотря на свою кажущуюся
простоту, требует громоздких рутинных вычислений. И, наконец, третий, более
приемлемый вариант - распространение сигналов ошибки от выходов НС к ее входам,
в направлении, обратном прямому распространению сигналов в обычном режиме
работы. Этот алгоритм обучения НС получил название процедуры обратного
распространения. Именно он будет использоваться в дальнейшем.
3.2
Детализация модели функционирования программного средства
Было выяснено, что при проектирования данной системы
однослойная нейросеть, структура которой описана ниже, будет являться
недостаточной для выполнения задачи.
В ходе практической реализации было обнаружено, что модель
многослойной нейронной сети сигмоидального типа, использующая стратегию подбора
весовых коэффициентов при помощи алгоритма обратного распространения ошибки,
является достаточной для осуществления поставленной задачи.
При подборе архитектуры нейросети воспользуемся теоремой
Колмогорова, из которой следует, что разрабатываемая нейросеть должна иметь не
менее чем один скрытый слой с количеством нейронов = 2*(число входов)+1. Более
точное количество скрытых слоёв нейросети и количество нейронов на них будет
зависеть от обучаемой выборки.
3.2.1
Детализация функционирования многослойной ИНС сигмоидального типа использующей
для обучения алгоритм обратного распространения ошибки
Среди различных структур нейронных сетей (НС) одной из
наиболее известных является многослойная структура, в которой каждый нейрон
произвольного слоя связан со всеми аксонами нейронов предыдущего слоя или, в
случае первого слоя, со всеми входами НС. Такие НС называются полносвязными.
Когда в сети только один слой, алгоритм ее обучения с учителем довольно
очевиден, так как правильные выходные состояния нейронов единственного слоя
заведомо известны, и подстройка синаптических связей идет в направлении,
минимизирующем ошибку на выходе сети. По этому принципу строится, например,
алгоритм обучения однослойного персептрона. В многослойных же сетях оптимальные
выходные значения нейронов всех слоев, кроме последнего, как правило, не
известны, и двух или более слойный перцептрон уже невозможно обучить,
руководствуясь только величинами ошибок на выходах НС. Один из вариантов
решения этой проблемы - разработка наборов выходных сигналов, соответствующих
входным, для каждого слоя НС, что, конечно, является очень трудоемкой операцией
и не всегда осуществимо. Второй вариант - динамическая подстройка весовых
коэффициентов синапсов, в ходе которой выбираются, как правило, наиболее слабые
связи и изменяются на малую величину в ту или иную сторону, а сохраняются
только те изменения, которые повлекли уменьшение ошибки на выходе всей сети.
Очевидно, что данный метод «тыка», несмотря на свою кажущуюся простоту, требует
громоздких рутинных вычислений. И, наконец, третий, более приемлемый вариант -
распространение сигналов ошибки от выходов НС к ее входам, в направлении,
обратном прямому распространению сигналов в обычном режиме работы. Этот
алгоритм обучения НС получил название процедуры обратного распространения.
Именно он будет рассмотрен в дальнейшем.
Согласно методу наименьших квадратов, минимизируемой целевой
функцией ошибки НС является величина:
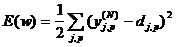 (3.2.1.1)
(3.2.1.1)
где 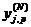 - реальное выходное состояние нейрона j
выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp
- идеальное (желаемое) выходное состояние этого нейрона.
- реальное выходное состояние нейрона j
выходного слоя N нейронной сети при подаче на ее входы p-го образа; djp
- идеальное (желаемое) выходное состояние этого нейрона.
Суммирование ведется по всем нейронам выходного слоя и по всем
обрабатываемым сетью образам. Минимизация ведется методом градиентного спуска,
что означает подстройку весовых коэффициентов следующим образом:
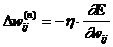 (3.2.1.2)
(3.2.1.2)
Здесь wij - весовой коэффициент синаптической связи,
соединяющей i-ый нейрон слоя n-1 с j-ым нейроном слоя n, h - коэффициент скорости обучения, 0<h<1.
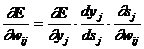 (3.2.1.3)
(3.2.1.3)
Здесь под yj, как и раньше, подразумевается выход
нейрона j, а под sj - взвешенная сумма его входных сигналов, то есть
аргумент активационной функции. Так как множитель dyj/dsj
является производной этой функции по ее аргументу, из этого следует, что
производная активационной функция должна быть определена на всей оси абсцисс. В
связи с этим функция единичного скачка и прочие активационные функции с
неоднородностями не подходят для рассматриваемых НС. В них применяются такие
гладкие функции, как гиперболический тангенс или классический сигмоид с
экспонентой. В случае гиперболического тангенса
 (3.2.1.4)
(3.2.1.4)
Третий множитель ¶sj/¶wij, очевидно, равен выходу
нейрона предыдущего слоя yi(n-1). Что касается первого
множителя в (3.2.1.3), он легко раскладывается следующим образом:
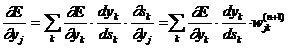 (3.2.1.5)
(3.2.1.5)
Здесь суммирование по k выполняется среди нейронов слоя n+1.
Введя новую переменную
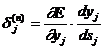 (3.2.1.6)
(3.2.1.6)
мы получим рекурсивную формулу для расчетов величин dj(n)
слоя n из величин dk(n+1) более старшего слоя n+1.
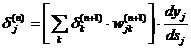 (3.2.1.7)
(3.2.1.7)
Для выходного же слоя
 (3.2.1.8)
(3.2.1.8)
Теперь мы можем записать (3.2.1.2) в раскрытом виде:
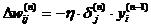 (3.2.1.9)
(3.2.1.9)
Иногда для придания процессу коррекции весов некоторой
инерционности, сглаживающей резкие скачки при перемещении по поверхности
целевой функции, (3.2.1.9) дополняется значением изменения веса на предыдущей
итерации
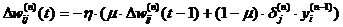 (3.2.1.10)
(3.2.1.10)
где m - коэффициент
инерционности, t - номер текущей итерации.
Таким образом, полный алгоритм обучения НС с помощью процедуры
обратного распространения строится так:
. Подать на входы сети один из возможных образов и в режиме
обычного функционирования НС, когда сигналы распространяются от входов к
выходам, рассчитать значения последних. Напомним, что
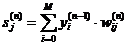 (3.2.1.11)
(3.2.1.11)
где M - число нейронов в слое n-1 с учетом нейрона с постоянным
выходным состоянием +1, задающего смещение; yi(n-1)=xij(n)
- i-ый вход нейрона j слоя n.
j(n) = f(sj(n)),
где f() - сигмоид (3.2.1.12)q(0)=Iq, (3.2.1.13)
где Iq - q-ая компонента вектора входного образа.
. Рассчитать d(N)
для выходного слоя по формуле (3.2.1.8).
Рассчитать по формуле (3.2.1.9) или (3.2.1.10) изменения весов Dw(N) слоя N.
. Рассчитать по формулам (3.2.1.7) и (3.2.1.9) (или (3.2.1.7) и
(3.2.1.10)) соответственно d(n) и Dw(n) для всех остальных слоев, n=N-1,… 1.
. Скорректировать все веса в НС
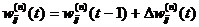 (3.2.1.14)
(3.2.1.14)
. Если ошибка сети существенна, перейти на шаг 1. В противном
случае - конец.
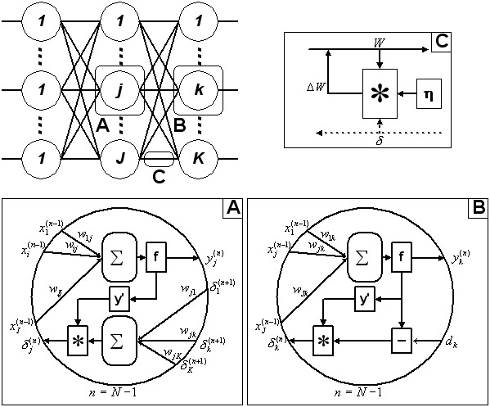
Рисунок 3.1 - Диаграмма сигналов в сети при обучении по алгоритму
обратного распространения
Сети на шаге 1 попеременно в случайном порядке предъявляются все
тренировочные образы, чтобы сеть, образно говоря, не забывала одни по мере
запоминания других. Алгоритм иллюстрируется рисунком 3.1.
Из выражения (3.2.1.9) следует, что когда выходное значение yi(n-1)
стремится к нулю, эффективность обучения заметно снижается. При двоичных
входных векторах в среднем половина весовых коэффициентов не будет
корректироваться, поэтому область возможных значений выходов нейронов [0,1]
желательно сдвинуть в пределы [-0.5,+0.5], что достигается простыми
модификациями логистических функций. Например, сигмоид с экспонентой
преобразуется к виду
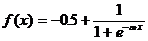 (3.2.1.15)
(3.2.1.15)
Теперь коснемся вопроса емкости НС, то есть числа образов,
предъявляемых на ее входы, которые она способна научиться распознавать. Для
сетей с числом слоев больше двух, он остается открытым. Как показано в [4], для
НС с двумя слоями, то есть выходным и одним скрытым слоем, детерминистская
емкость сети Cd оценивается так:
Nw/Ny<Cd<Nw/Ny×log(Nw/Ny)
(3.2.1.16)
где Nw - число подстраиваемых весов, Ny -
число нейронов в выходном слое.
Следует отметить, что данное выражение получено с учетом некоторых
ограничений. Во-первых, число входов Nx и нейронов в скрытом слое Nh
должно удовлетворять неравенству Nx+Nh>Ny.
Во-вторых, Nw/Ny>1000. Однако вышеприведенная оценка
выполнялась для сетей с активационными функциями нейронов в виде порога, а
емкость сетей с гладкими активационными функциями, например - (3.2.1.15),
обычно больше. Кроме того, фигурирующее в названии емкости прилагательное
«детерминистский» означает, что полученная оценка емкости подходит абсолютно
для всех возможных входных образов, которые могут быть представлены Nx
входами. В действительности распределение входных образов, как правило,
обладает некоторой регулярностью, что позволяет НС проводить обобщение и, таким
образом, увеличивать реальную емкость. Так как распределение образов, в общем
случае, заранее не известно, мы можем говорить о такой емкости только
предположительно, но обычно она раза в два превышает емкость детерминистскую.
В продолжение разговора о емкости НС логично затронуть вопрос о
требуемой мощности выходного слоя сети, выполняющего окончательную
классификацию образов. Дело в том, что для разделения множества входных
образов, например, по двум классам достаточно всего одного выхода. При этом
каждый логический уровень - «1» и «0» - будет обозначать отдельный класс. На
двух выходах можно закодировать уже 4 класса и так далее. Однако результаты
работы сети, организованной таким образом, можно сказать - «под завязку», - не
очень надежны. Для повышения достоверности классификации желательно ввести
избыточность путем выделения каждому классу одного нейрона в выходном слое или,
что еще лучше, нескольких, каждый из которых обучается определять
принадлежность образа к классу со своей степенью достоверности, например:
высокой, средней и низкой. Такие НС позволяют проводить классификацию входных
образов, объединенных в нечеткие (размытые или пересекающиеся) множества. Это
свойство приближает подобные НС к условиям реальной жизни.
Рассматриваемая НС имеет несколько «узких мест». Во-первых, в
процессе обучения может возникнуть ситуация, когда большие положительные или
отрицательные значения весовых коэффициентов сместят рабочую точку на сигмоидах
многих нейронов в область насыщения. Малые величины производной от
логистической функции приведут в соответствие с (3.2.1.7) и (3.2.1.8) к
остановке обучения, что парализует НС. Во-вторых, применение метода
градиентного спуска не гарантирует, что будет найден глобальный, а не локальный
минимум целевой функции. Эта проблема связана еще с одной, а именно - с выбором
величины скорости обучения. Доказательство сходимости обучения в процессе
обратного распространения основано на производных, то есть приращения весов и,
следовательно, скорость обучения должны быть бесконечно малыми, однако в этом
случае обучение будет происходить неприемлемо медленно. С другой стороны,
слишком большие коррекции весов могут привести к постоянной неустойчивости
процесса обучения. Поэтому в качестве h обычно выбирается число меньше 1, но не очень маленькое,
например, 0.1, и оно, вообще говоря, может постепенно уменьшаться в процессе
обучения. Кроме того, для исключения случайных попаданий в локальные минимумы
иногда, после того как значения весовых коэффициентов застабилизируются, h кратковременно сильно увеличивают, чтобы
начать градиентный спуск из новой точки. Если повторение этой процедуры
несколько раз приведет алгоритм в одно и то же состояние НС, можно более или
менее уверенно сказать, что найден глобальный максимум, а не какой-то другой.
3.3
Окончательный вариант решения
Таким образом, описав общую модель функционирования
программного средства и детализировав ее основные особенности, можно
представить следующую функциональную схему разрабатываемого программного
средства с учетом добавления некоторых функционально необходимых элементов,
отображующую взаимосвязь различных блоков:
Рисунок 3.2 - Функциональная схема окончательного варианта
решения
Заключение
В ходе данной работы был создан прототип программного
средства, осуществляющего автоматизированное обнаружение вторжений через анализ
файлов системных журналов.
Были разработаны и обоснованы базовые принципы построения
данного типа программных средств и определены основные направления дальнейшего
совершенствования. В процессе разработки было применено значительное количество
оригинальных методик и качественно новых решений, часть которых основана на
базовых концепциях современных интеллектуальных систем.
Также был сделан тщательный анализ современной ситуации в
разработке средств обнаружения атак и существующих подходов к обнаружению атак
в целом.
Список
источников
распознавание зрительный образ нейронный
1. Selfridge O. Pandemonium. A paradigm for learning.
Proceedings of Symposium on Mechanization of Though Processes. - London, 1959.
2. Ryan, J., Lin, M., and Miikkulainen, R. Intrusion Detection
with Neural Networks. AI Approaches to Fraud Detection and Risk Management:
Papers from the 1997 AAAIWorkshop (Providence, Rhode Island), Menlo Park, CA:
AAAI, 1997
3. Ф.
Уоссермен, Нейрокомпьютерная техника, М., Мир, 1992
. Розенблатт
Ф. Принципы нейродинамики. М.: Мир.1965
5. Windrow B. The speed of adaptetion in adaptive control
system. 1961
6. Windrow B. A statistical theory of adaptetion. Adaptive
control systems. 1963
7. Windrow B., Angell J.B. Reliable, trainable networks for
computing and control. 1962
. Минский
М.Л., Пайперт С..Персепроны.М.: Мир.1971
9. Wider R.O. Single-stage logic, Paper presented at the
AIEE Fall General Meeting. 1960
10. Cohen M.A., Grossberg S.G. Absoiute stability of global
pattern formation and parallel memory storage by compatitive neural
networks.1983
. Hopfield J.J. Neural networks and physical systems with
emergent collective computational abilities. Proseedings of the National
Academy of Science 79.1982
12. Итоги
науки и техники: физические и математические модели нейронных сетей, том 1 -
М.: ВИНИТИ, 1990
13. Нейронные
сети. STATISTICA Neural Networks: Пер. с англ. - М.: Горячая
линия-Телеком, 2001
. Сергей
А. Терехов. Лекции по теории и приложениям искусственных нейронных сетей -
Снежинск, Лаборатория Искусственных Нейронных Сетей НТО-2, ВНИИТФ
(alife.narod.ru)
. Осовский
C. Нейронные сети для
обработки информации.: Пер. с польского И.Д. Рудинского. - М.: Финансы и
статистика, 2002
. Ясницкий
Л.Н. Введение в искусственный интеллект: Учеб. Пособие для студ. высш. учеб. заведений
- М.: Издательский центр «Академия», 2005
. Рутковская
Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и
нечеткие системы: Пер. с польск. - М.: Горячая линия-Телеком, 2006
. Безопасность
жизнедеятельности.: Учебное пособие /Под общ. ред. Ю.В. Зайцева. - Рязань,
РГРТА, 2000