Основы программирования на языке Паскаль
Фильтрация строк с использованием автоматов
Alexander Babaev
Необходимость фильтрации строк
Строки используются очень часто. А применимо к
Интернет-программированию можно сказать, что строки используются постоянно.
Любой ответ сервера – это строка, запрос клиента – тоже строка. Работа с
XML-файлами – это опять работа со строками, пускай и очень формализованная.
Поэтому необходимо уметь быстро и эффективно обрабатывать строковые данные.
Основная операция, которая используется – это конкатенация (слияние). Она
реализована для всего, чего угодно и обычно очень прозрачна. Вторая же операция
– это изменение строк. И тут мнения относительно того, что использовать,
расходятся.
Стандартные методы фильтрации строк
Для начала вспомним, как происходит работа со строками
в обычной программе. Используется несколько методов. Первый можно назвать
классическим. В этом случае для получения результата используются стандартные
операции поиска, замены, конкатенации и удаления частей строки. Такой метод
оправдан для быстрого решения самых простых задач, но как только требуется
реализовать что-нибудь более-менее сложное, мгновенно начинаются проблемы.
Кроме того, этот способ совершенно не масштабируется и очень сложно изменяется.
Второй метод – использование регулярных выражений
(регэкспов). Подробно рассматривать их не имеет смысла, есть отличная книга Дж.
Фридла [1], в которой все подробно описано, в том числе и применимо к Java.
Достоинства подхода заключаются в том, что регулярные выражения
стандартизованы, обладают огромнейшими возможностями и очень компактно
записываются. То есть если вы научились использовать регулярные выражения в
Perl или PHP, вам ничего не стоит использовать их в Java (хотя все равно
приходится каждый раз выяснять нюансы реализации). Самый главный недостаток –
сложность, которая произрастает из огромной мощности регулярных выражений.
Простые регэкспы может понять даже начинающий программист, но более-менее
сложные начинающему уже не по зубам. Регэкспы же, подобные представленному в
листинге 1, не поймет никто даже при очень большом желании (в листинге
представлена примерно восьмая часть регулярного выражения, предназначенного для
проверки корректности e-mail адреса и его соответствия RFC). Впрочем, есть
люди, которые «читают» регулярные выражения «с листа». Данный пример не совсем
показателен в том смысле, что и программа, выполняющая аналогичную функцию,
будет очень и очень сложна. Но есть и гораздо более простые задачи, (примеры
таких задач будут рассмотрены ниже), в которых регулярные выражения
использовать так же неудобно.
Листинг 1.Часть регулярного выражения,
предназначенного для проверки корректности e-mail адреса, соответствия его RFC.
|
^[\040\t]*(?:\([^\\\x80-\xff\n\015()]*(?:(?:\\[^\x80-
\xff]|\([^\\\x80-\xff\n\015()]*(?:\\[^\x80-\xff][^\\\x80-
\xff\n\015()]*)*\))[^\\\x80-
\xff\n\015()]*)*\)[\040\t]*)*(?:(?:[^(\040)<>@,;:".\\\[\]\000-
\037\x80-\xff]+(?![^(\040)<>@,;:".\\\[\]\000-\037\x80-
\xff])|"[^\\\x80-\xff\n\015"]*(?:\\[^\x80-\xff][^\\\x80-
\xff\n\015"]*)*")[\040\t]*(?:\([^\\\x80-
\xff\n\015()]*(?:(?:\\[^\x80-\xff]|\([^\\\x80-
\xff\n\015()]*(?:\\[^\x80-\xff][^\\\x80-
… … … … …
\xff])|\[(?:[^\\\x80-\xff\n\015\[\]]|\\[^\x80-
\xff])*\])[\040\t]*(?:\([^\\\x80-\xff\n\015()]*(?:(?:\\[^\x80-
\xff]|\([^\\\x80-\xff\n\015()]*(?:\\[^\x80-\xff][^\\\x80-
\xff\n\015()]*)*\))[^\\\x80-\xff\n\015()]*)*\)[\040\t]*)*)*>)$
|
Другой немаловажный недостаток регулярных выражений
состоит в том, что мало кто понимает, как они работают. «Я пишу это, он делает
то…» А как – это проблема тех, кто библиотеку разрабатывает. «Чукча не
читатель, чукча писатель». В результате – ляпы, непонятные «глюки», и
неправильно, некорректно работающий программный код. Зачастую регэкспы
ненастраиваемы. Чтобы изменить регулярное выражение, часто приходится изменять
код и перекомпилировать его. Нельзя просто поменять значение одной переменной
для того, чтобы немного изменить логику работы.
Фильтрация строк
После довольно длительного использования различного
рода методов обработки строк появилось желание совместить настраиваемость
обычного класса и мощность регулярных выражений, а в качестве базы для этого
использовать автоматы [2-4]. Рассмотрим такой подход на конкретном примере.
Пускай необходимо обрабатывать строки записей в интернет-форуме. При этом
требуется реализовать обработку следующих правил:
Все слова длиннее некоторого количества символов N
разбивать пробелами на отрезки, длина которых меньше, либо равна N.
Если длина сообщения больше M, то оставлять только
первые M символов.
Заменять три точки символом многоточия.
Заменять два подряд идущих символа «минус»,
обрамленных пробелами, символом «тире».
Заменять символы «"»правильными кавычками в
русском тексте – «елочками» и «лапками».
Заменять ссылки на интернет-ресурсы (#"7236.files/image001.jpg">
Рисунок 1. Граф состояний автомата, управляющего
работой фильтра.
Листинг 2 показывает, как эта логика реализована в
коде.
Листинг 2. Реализация автомата.
|
public String
process(String aString) throws FilterException
{
// что такое правила –
будет объяснено чуть позже, тут они
// инициализируются,
потому что фильтр может быть использован
// повторно
initRules();
// проверим, что на
вход получена корректная строка
if (aString == null || aString.length()
== 0)
{
return
"";
}
// инициализация
Source
source = new Source(aString);
Result result = new Result();
// основной цикл
длится, пока мы находимся «не в состоянии завершения»
while (!result.getLastRuleResult().
equals(RuleResult.FILTER_FINISHED_PROCESSING))
{
result.setLastRuleResult(RuleResult.CHAR_NOT_CHANGED);
// строка обработана полностью
if
(source.isStringFinished())
{
break;
}
// перед каждой
обработкой – происходит внутренняя инициализация
// так же
проверяется, что нет зацикливания
try
{
source.prepare();
}
catch
(FilterException e)
{
e.printStackTrace();
if
(e.getCanContinue().equals(FilterException.CONTINUABLE))
{
continue;
}
else if
(e.getCanContinue().equals(FilterException.FATAL))
{
throw e;
}
}
// прогоняем правила,
соответствующие текущему символу
processRules(source,
result);
// если ни одно правило
не было применено, то
// выполняем правило
по умолчанию
if
(result.getLastRuleResult().
equals(RuleResult.CHAR_NOT_CHANGED))
{
EMPTY_RULE.process(source, result, this);
}
else if
(result.getLastRuleResult().equals(
RuleResult.FILTER_FINISHED_PROCESSING))
{
break;
}
}
// В процессе работы
фильтра в строку включаются тэги (основное
// его предназначение –
форматирование для вывода в HTML)
// В результате ошибок
и неаккуратностей некоторые теги могут быть
// незакрыты. Следующий
метод дополняет строку закрывающими
// тегами в корректном порядке.
result.appendEndAppendersInReverseOrder();
return result.getResult();
}
|
Теперь, когда понятно, как работает основной цикл
программы, посмотрим на некоторые правила. Например, вот правило замены трех
точек специальным символом (в листинге 3 приведен только метод обработки
символа, но не весь класс).
 Листинг 3. Реализация правила замены трех точек
на «&hellip;»
Листинг 3. Реализация правила замены трех точек
на «&hellip;»
|
public class HellipRule
extends AbstractRule
{
private static final char
CHARACTER = '.';
private static final
Character INITIATOR = new Character(CHARACTER);
public Character
getInitiatorCharacter()
{
return INITIATOR;
}
public void process(Source
aSource, Result aResult, IFilter aFilter)
{
// проверяем, что за текущей точкой
будут еще две точки
if (StringUtils.isSymbol(aSource.getSource(),
aSource.getPosition() + 1, CHARACTER) &&
StringUtils.isSymbol(aSource.getSource(),
aSource.getPosition() + 2, CHARACTER))
{
// в результат выводим нужную
строку
aResult.append("…");
// выставляем состояние автомату,
чтобы он
// переходил к следующему символу
aResult.setLastRuleResult(RuleResult.CHAR_FINISHED_PROCESSING);
// перескакиваем обработку всех трех точек
aSource.addToPosition(3);
}
}
}
|
В листинге 4 представлено правило общей обработки
«двойных символов». Это правило, которое является базой для множества правил
форматирования, позволяющих выделять текст «жирным», «наклонным» и так далее,
не прибегая к тегам HTML, но обрамляя нужные куски текста в «звездочки»,
«наклонные черты» и другие легко запоминающиеся символы.
Листинг 4. Реализация правила обработки «двойных
символов».
|
public void process(Source aSource, Result aResult,
IFilter aFilter)
{
int nextPosition =
aSource.getPosition() + 1;
// проверяется, что следующий
символ – такой же, как и предыдущий
if (isSymbol(aSource.getSourceString(),
nextPosition, getSymbol()))
{
// смотрим на текущее состояние
правила, чтобы определить,
// создавать открывающий или
закрывающий тег
if
(getState().equals(DoubleCharacterState.STATE_OUT))
{
setState(DoubleCharacterState.STATE_IN);
aSource.addToPosition(2);
aResult.append(getPrefix());
// записываем в «строки
окончаний» закрывающий тег, который
// является парным к текущему –
чтобы автоматически
// закрыть тег в конце строки,
если не окажется
// парного к тому, который
сейчас вставляется (1)
aResult.addEndAppend(getPostfix());
// устанавливаем состояние
«окончания обработки символа»
aResult.setLastRuleResult(RuleResult.CHAR_FINISHED_PROCESSING);
}
else if
(getState().equals(DoubleCharacterState.STATE_IN))
{
if
(aResult.containsEndAppend(getPostfix()))
{
setState(DoubleCharacterState.STATE_OUT);
aSource.addToPosition(2);
aResult.append(getPostfix());
// удаляем закрывающий тег из «строк окончаний».
// Если бы мы его тут не
удалили, после окончания
// обработки строки, он бы
вставился автоматически.
aResult.removeEndAppend(getPostfix());
// устанавливаем состояние
«окончания обработки символа»
aResult.
setLastRuleResult(RuleResult.CHAR_FINISHED_PROCESSING);
}
}
}
}
|
Структура библиотеки JFilter
Классы
На рисунке 2 представлена диаграмма классов
библиотеки, при этом большая часть классов правил убрана, чтобы повысить
читаемость.
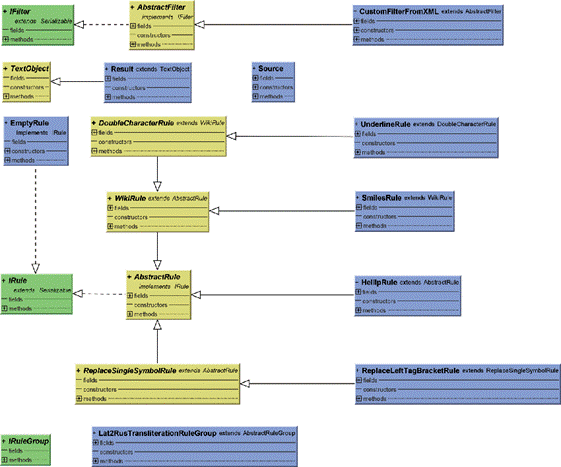
Рисунок 2. Диаграмма классов.
Описание
В библиотеке JFilter есть несколько интерфейсов:
IFilter (листинг 5), который описывает сам фильтр.
Листинг 5. Интерфейс фильтра
|
public interface IFilter
extends Serializable
{
/**
* Обрабатывает строку, возвращая в
качестве результата строку
* после фильтрации.
* @param aSourceString – исходная
строка
* @return - обработанная строка
* @throws FilterException - если
произошла фатальная ошибка
* (зацикливание)
*/
public String
process(String aSourceString) throws FilterException;
/**
* Выключает правило по его
rule.getClass().getName()
* @param aRuleClass – класс правила
(что-то вроде IRule.class)
*/
public void
disableRuleByClassName(Class aRuleClass);
/**
* Включает правило по его
rule.getClass().getName()
* @param aRuleClass – класс правила
(что-то вроде IRule.class)
*/
public void
enableRuleByClassName(Class aRuleClass);
/**
* Включает все правила.
*/
public void enableAllRules();
/**
* Выключает все правила.
*/
public void disableAllRules();
/**
* Добавляет правило в фильтр.
* @param aRule правило, которое
нужно добавить в фильтр.
void addRule(IRule aRule);
}
|
IRule (листинг 6), показывающий, какие методы должны
быть у правила.
Листинг 6. Интерфейс правила.
|
public interface IRule
extends Serializable
{
/**
* Метод, который вызывается перед
обработкой произвольной строки.
*/
public void initialize();
/**
* Инициализация параметров правила.
Этот метод используется в
* основном для установки параметров
правила при загрузке
* конфигурации фильтра из XML.
* @param aParameters - карта
параметров.
*/
void setParameters(Map
aParameters) throws FilterException;
/**
* Включает или выключает правило.
*/
public void
setEnabled(boolean aEnabled);
/**
* @return true, если правило
включено, false – иначе.
*/
public boolean isEnabled();
/**
* @return - символ, который является
инициатором данного правила.
*/
public Character
getInitiatorCharacter();
/**
* Обрабатывает текущую строку при
помощи правила.
* @param aSource - исходная строка,
текущая позиция
* @param aResult - текущий результат
обработки
* @param aFilter - текущий фильтр
*/
public void process(Source
aSource, Result aResult, IFilter aFilter);
}
|
IRuleGroup (листинг 7) – интерфейс работы с группой
однотипных правил, как, например, правила транслитерации.
Листинг 7. Интерфейс группы правил.
|
public interface IRuleGroup
{
/**
* Добавляет правила группы в указанный
фильтр.
* @param aFilter
*/
public void
addRules(IFilter aFilter);
/**
* Включает или выключает все
правила, входящие в группу.
*/
public void
setEnabled(boolean aEnabled);
/**
* Возвращает true, если все правила
группы включены в указанном фильтре.
* @param aFilter
*/
public boolean
isEnabled(IFilter aFilter);
/**
* Инициализация параметров группы.
Этот метод используется в
* основном для установки параметров
правила при загрузке
* конфигурации фильтра из XML.
* @param aParameters карта
параметров
*/
public void
setParameters(Map aParameters);
}
|
Для упрощения работы с системой написано несколько
классов, помогающих при создании новых фильтров и правил. Такими классами
являются AbstractFilter и AbstractRule. Первый описывает все методы,
необходимые для работы стандартного фильтра. Поэтому для того, чтобы создать
нужный фильтр, можно просто создать класс-наследник AbstractFilter и в
конструкторе вызвать метод addRule(), добавив все необходимое в нужной
последовательности (листинг 8).
Листинг 8. Составление фильтра из отдельных
правил.
|
public class WikiFilter
extends AbstractFilter
{
public WikiFilter(int
aMaxWordLength, int aMaxStringLength)
{
// замена
< на <
// замена
& на &
addRule(new
ReplaceAmpersandTagBracketRule());
// правило экранирования – для возможности вывода
спецсимволов
addRule(new EkranRule());
// правило замены #"7236.files/image004.gif">#"#">http://www.rsdn.ru/
Похожие работы на - Основы программирования на языке Паскаль
|