Проектирование базы данных
Проектирование базы
данных для предметной области «Аптека»
Введение
База данных (БД) - некая именованная совокупность
данных, отражающая состояние объектов или явлений в некоторой выбранной
предметной области и связи между ними. Она создаётся для хранения данных и
доступа к ним.
Предметной областью называют любую область
деятельности человека или часть реального мира, подлежащую изучению для
организации управления ею и автоматизации.
Данные - любые сведения, которые в процессе их
структурирования становятся информацией. Структурирование заключается во вводе
определённых правил и способов представления данных.
Система БД - компьютеризированная система хранения
информации, основная цель которой - хранить структурированные данные и
предоставлять доступ к ним по требованию пользователя.
Каждая система БД состоит из четырёх элементов: данных,
аппаратного обеспечения (накопители для хранения данных, процессоры и
оперативная и долгосрочная память), программного обеспечения (СУБД - система
управления базами данных) и пользователей, которые делятся на три группы:
администраторы, прикладные программисты и конечные пользователи.
По сравнению с другими способами хранения информации БД
обладает следующими преимуществами:
сокращение избыточности в хранении данных;
обеспечение безопасности данных;
устранение возможных противоречий в данных;
поддержание целостности и корректности данных;
и обеспечение независимости приложений от физической
организации данных.
Всё это делает базы данных крайне интересным объектом для
разного рода исследований и удобным инструментом для выполнения многих работ,
связанных с хранением и систематизацией данных.
В данной работе будет рассмотрено построение базы данных на
основе реляционной модели данных. Она основана на принципах теории множеств:
объекты представляют собой элементы некоторых множеств и подмножеств, а сама БД
есть совокупность двумерных связанных между собой таблиц.
1.
Анализ предметной области и разработка логической модели БД
1.1
Описание предметной области
информационный запрос логический база
Создание любой базы данных начинается с изучения и анализа
предметной области. В нашем случае необходимо создать базу данных для нужд
аптеки:
Аптека продает медикаменты и изготавливает их по рецептам.
Лекарства могут быть разных типов:
. Готовые лекарства: таблетки, мази, настойки:
. Изготовляемые аптекой: микстуры, мази, растворы, настойки,
порошки.
Различие в типах лекарств отражается в различном наборе
атрибутов, их характеризующих. Микстуры и порошки изготавливаются только для
внутреннего применения, растворы для наружного, внутреннего применения и для
смешивания с другими лекарствами и мази только для наружного применения.
Лекарство различны также по способу приготовления и по времени приготовления.
Порошки и мази изготавливаются смешиванием различных компонент. При
изготовлении растворов и микстур ингредиенты не только смешивают, но и
отстаивают с последующей фильтрацией лекарства, что увеличивает время
изготовления.
В аптеке существует справочник технологий приготовления
различных лекарств. В нем указываются: идентификационный номер технологии,
название лекарства и сам способ приготовления. На складе на все медикаменты
устанавливается критическая норма, т.е. когда какого-либо вещества на складе
меньше критической нормы, то составляются заявки на данные вещества и их в
срочном порядке привозят с оптовых складов медикаментов.
Для изготовления аптекой лекарства, больной должен принести
рецепт от лечащего врача. В рецепте должно быть указано: Ф.И.О., подпись и
печать врача, Ф.И.О., возраст и диагноз пациента, также количество лекарства и
способ применения. Больной отдает рецепт регистратору, он принимает заказ и
смотрит, есть ли компоненты заказываемого лекарства. Если не все компоненты
имеются в наличии, то делает заявки на оптовые склады лекарств и фиксирует
Ф.И.О., телефон и адрес необслуженного покупателя, чтобы сообщить ему, когда
доставят нужные компоненты. Такой больной пополняет справочник заказов - это те
заказы, которые находятся в процессе приготовления, с пометкой, что не все
компоненты есть для заказа. Если все компоненты имеются, то они резервируются
для лекарства больного. Покупатель выплачивает цену лекарства, ему возвращается
рецепт с пометкой о времени изготовления. Больной также пополняет справочник
заказов в производстве. В назначенное время больной приходит и по тому же
рецепту получает готовое лекарство. Такой больной пополняет список отданных
заказов.
Ведется статистика по объемам используемых медикаментов.
Через определенный промежуток времени производится инвентаризация склада. Это
делается для того, чтобы определить, есть ли лекарства с критической нормой,
или вышел срок хранения или недостача.
Из этого относительно неформального описания информационной
структуры предметной области нам нужно получить чёткое формализованное описание
её объектов и связей между ними в терминах некоторой модели. Этот процесс будет
происходить в несколько этапов, первым из которых будет концептуальное
проектирование. Оно тоже проходит в несколько шагов:
v Анализ общих информационных требований.
v Выявление информационных объектов, сущностей, и
связей между ними. К этому шагу существует два подхода:
проблемно-ориентированный и объектно-ориентированный. Наиболее рациональным
является сочетание обоих подходов.
v Построение концептуальной модели предметной
области. На этом этапе создаётся ER-диаграмма, некоторый граф, в котором
вершины представляют собой сущности, а дуги - связи между ними.
После того, как мы получили концептуальную модель, начинается
логическое проектирование - разработка логической схемы предметной
области, ориентированной на выбранную СУБД, и проектирование интерфейса с
прикладными программами. Это тоже проходит в несколько фаз:
v Выбор СУБД. Осуществляется с учётом модели
данных, стоимости, технических характеристик и системных требований, языковых
средств и удобства использования.
v Отображение концептуальной модели на логическую
схему по следующим простым правилам: каждая простая сущность становится
таблицей, каждый атрибут становится столбцом таблицы, причём уникальные
атрибуты становятся первичным ключом, а связи между таблицами определяет
внешний ключ.
v Планирование использования БД для решения
прикладных задач.
И только после всего этого начинается физическое
проектирование, создаются физические структуры в соответствии с логической
моделью: выбирается тип и размер данных, проектирование доступа к ним,
поддержка целостности и безопасности, разработка средств автоматической
обработки данных, интерфейса и прикладных программ.
В приведённом выше описании предметной области были выделены
следующие сущности: заказ, рецепт, готовые лекарства, изготавливаемые
лекарства, вещества (медикаменты), технологии, клиенты (больные). К этим
сущностям также можно добавить производителя медикаментов и готовых
лекарств и кассовый чек, в который войдут и заказанные, и готовые
лекарства. Врач выписывает больному рецепт, тот приходит в
аптеку, приобретает готовые лекарства и делает заказ на изготавливаемые
лекарства. Для их изготовления по определённой технологии необходимы
медикаменты.
Все эти сущности имеют атрибуты:
· Заказ (номер, ID клиента, номер рецепта,
статус, дата приёма, дата исполнения, дата выдачи, стоимость);
· Чек (номер, дата, номер заказа,
готовые лекарства, общая стоимость)
· Рецепт (номер, врач, Ф.И.О.
пациента, лекарства);
· Клиент (ID, фамилия, имя,
отчество, телефон, адрес);
· Готовые лекарства (номер, торговое
название, действующее вещество (международное непатентованное название),
категория, номер производителя, тип, кол-во на складе, критическая норма, срок
годности, стоимость);
· Изготавливаемые лекарства (номер,
наименование, тип, компоненты, кол-во в наличии, номер технологии, срок
хранения, стоимость);
· Технологии (номер, название
лекарства, способ приготовления, длительность);
· Производители (номер, название)
· Медикаменты (номер, наименование,
кол-во на складе, номер производителя, критическая норма, срок годности,
стоимость);
· Доставка/списание (номер,
наименование, кол-во на складе, дата доставки, дата списания (срок годности)) -
вспомогательная таблица.
.2
Состав информационных запросов к БД
Сама по себе база данных может только хранить данные. Как
правило, этого недостаточно, пользователям нужно изменять, добавлять, удалять
данные, просматривать их и делать выборку данных по определённым условиям. Всё
это можно делать при помощи информационных запросов. Примеры таких запросов для
нашей БД:
. Получить сведения о готовых лекарствах и их
производителях.
. Получить перечень готовых лекарств, для которых
остаток на складе близок к критической норме или ниже её.
. Получить список изготавливаемых лекарств, их способ
и длительность приготовления.
. Отсортировать лекарства по стоимости.
. Вывести список всех клиентов, живущих в одном месте
(на одной улице, в одном доме).
. Показать список клиентов с их диагнозами и
назначениями.
. Получить список заказов со статусами и клиентов,
сделавших эти заказы.
. Получить перечень готовых лекарств, сгруппированных
по области применения (категории), среднюю, минимальную и максимальную цену в
категории.
.3
Разработка логической модели БД
Теперь, когда мы представляем себе, какие задачи должна
выполнять наша БД, нужно построить логическую модель базы данных, с учётом
связей между таблицами и появления новых вспомогательных таблиц. В реляционных
БД связи между таблицами бывают трёх видов:. Один-к-одному, 1:1 - когда
одной записи в родительской таблице соответствует одна запись в дочерней,. Один-ко-многим,
1:М - когда одной записи в родительской таблице соответствует несколько записей
в дочерней,. Многие-ко-многим, М:М - когда одной записи в родительской таблице
может соответствовать несколько записей в дочерней и наоборот. Этот вид связи
не поддерживается в большинстве СУБД, поскольку каждая связь М:М может быть
разбита на несколько связей 1:М, для чего заводится вспомогательная таблица.
Целостность сущности обеспечивается первичным ключом -
атрибутом или несколькими атрибутами, по которым можно однозначно
идентифицировать запись, а целостность связи - внешним ключом, создаваемым во
внешней таблице. Для связи 1:М внешний ключ должен совпадать по составу полей с
первичным. Первичный ключ обладает двумя свойствами: уникальностью значения и
минимальной достаточностью (то есть в первичном ключе не должно быть атрибутов,
удаление которых повлияет на его уникальность).
Во всех таблицах первичным ключом является число - номер
записи в таблице, потому что:
v Для хранения и передачи в качестве внешнего ключа
численная переменная потребляет меньше памяти,
v И номер записи однозначно уникален: лекарств с
одним названием много, даже у одного производителя может быть несколько форм
выпуска одного и того же препарата.
Итак, первая часть работы завершена: у нас есть модель базы
данных, список сущностей с атрибутами и первичными ключами, и определены виды
связей между этими сущностями. Следующий шаг - физическая реализация БД, но
прежде чем приступать к его выполнению, необходимо убедиться, что наша БД будет
удовлетворять некоторым требованиям.
.4
Нормализация БД
Цель нормализации - окончательное устранение избыточности в
хранении данных и обеспечение их согласованности и целостности. Процесс
нормализации основан на концепции нормальных форм. Отношение находится в
некоторой нормальной форме, если оно удовлетворяет всем её ограничениям.
Существует множество нормальных форм, но для наших целей достаточно рассмотреть
три из них: первую, вторую и третью.
Отношение входит в первую нормальную форму, если его атрибуты
содержат только скалярные значения (если оно представимо в виде плоской
двумерной таблицы). Любое отношение входит в первую нормальную форму по
умолчанию, поскольку реляционная модель данных требует, чтобы значения всех
атрибутов были только скалярными.
Отношение входит во вторую нормальную форму, если оно
находится в первой нормальной форме, и нет неключевых атрибутов, функционально
зависящих от части сложного первичного ключа. Если первичный ключ простой, то
отношение автоматически входит во вторую нормальную форму. В случае выявления
каких-либо аномалий все атрибуты, зависящие от части ключа, выносятся в
отдельное отношение. Этот процесс называется декомпозицией.
В построенной выше логической модели все отношения либо имеют
простой ключ, либо не имеют функционально зависимых от части ключа атрибутов.
Следовательно, наша БД удовлетворяет требованиям второй нормальной формы.
И, наконец, отношение входит в третью нормальную форму, если
оно находится во второй нормальной форме, и все его неключевые атрибуты взаимно
независимы, то есть, не связаны функциональной зависимостью. Если такая
зависимость между неключевыми атрибутами есть, то снова производится
декомпозиция: все зависимые атрибуты выносятся в отдельное отношение. В
отношениях рассматриваемой нами БД нет функциональных зависимостей между
неключевыми атрибутами, следовательно, она попадает в третью нормальную форму.
2.
Физическая реализация БД
2.1 Обзор СУБД MS SQL Server
Для реализации базы данных была выбрана СУБД от компании
Microsoft - MS SQL Server 2008 R2. Основной используемый язык запросов - Transact-SQL, реализующий стандарт ANSI/ISO по структурированному
языку запросов SQL с расширениями. MS SQL Server 2008 R2 является реляционной
централизованной клиент-серверной СУБД. Это значит, что она обладает следующими
преимуществами: низкой нагрузкой на локальную сеть, удобством централизованного
управления и, как следствие, высокими надёжностью, доступностью и
безопасностью.
.2
Разработка структуры БД. Создание таблиц и связей между ними
Разработанная база данных состоит из 13 таблиц: 8 основных и
5 вспомогательных. Ниже приведён состав этих таблиц:
Таблица 1. Готовые лекарства
|
№
|
Имя поля
|
Тип данных
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
Торговое название
|
nvarchar(50)
|
|
|
3
|
Международное непатентованное название
|
nvarchar(50)
|
|
|
4
|
Категория
|
nvarchar(50)
|
|
|
5
|
Тип
|
nvarchar(100)
|
|
|
6
|
Производитель
|
Int
|
FK
|
|
7
|
Количество на складе
|
Int
|
|
|
8
|
Критическая норма
|
Int
|
|
|
9
|
Срок годности
|
Date
|
|
|
10
|
Стоимость
|
Int
|
|
Таблица 2. Изготавливаемые лекарства
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
Наименование
|
nvarchar(50)
|
|
|
3
|
Тип
|
nvarchar(50)
|
|
|
4
|
Имеется в наличии
|
Int
|
|
|
5
|
Номер технологии
|
Int
|
FK
|
|
6
|
Срок хранения, дней
|
Int
|
|
|
7
|
Стоимость
|
Int
|
|
Таблица 3. Клиенты
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
ID
|
Int
|
PK
|
|
2
|
nvarchar(50)
|
|
|
3
|
Имя
|
nvarchar(50)
|
|
|
4
|
Отчество
|
nvarchar(50)
|
|
|
5
|
Телефон
|
Int
|
|
|
6
|
Адрес
|
nvarchar(50)
|
|
Таблица 4. Производители
|
№Имя поляТип данныхТип ключа
|
|
|
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
Название
|
nvarchar(50)
|
|
Таблица 5. Компоненты
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
Наименование
|
nvarchar(50)
|
|
|
3
|
Производитель
|
Int
|
FK
|
|
4
|
Количество на складе
|
Int
|
|
|
5
|
Критическая норма
|
Int
|
|
|
6
|
Срок хранения, дней
|
Int
|
|
|
7
|
Стоимость
|
Int
|
|
Таблица 6. Рецепты
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
Врач
|
nvarchar(50)
|
|
|
3
|
ID клиента
|
Int
|
FK
|
|
4
|
Диагноз
|
nvarchar(50)
|
|
|
5
|
nvarchar(MAX)
|
|
Таблица 7. Заказы
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
ID клиента
|
Int
|
FK
|
|
3
|
Номер рецепта
|
Int
|
FK
|
|
4
|
Статус
|
nvarchar(20)
|
|
|
5
|
Дата приёма
|
Date
|
|
|
6
|
Дата исполнения
|
Date
|
|
|
7
|
Дата выдачи
|
Date
|
|
|
8
|
Стоимость
|
Int
|
|
Таблица 8 (вспомогательная). Состав заказов
|
№Имя поляТип данныхТип ключа
|
|
|
|
|
1
|
Номер заказа
|
Int
|
PK
|
|
2
|
Номер лекарства
|
Int
|
PK
|
|
3
|
Количество
|
nvarchar(50)
|
|
Таблицы 9,10 (вспомогательные). Назначения (готовые и
изготавливаемые)
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер рецепта
|
Int
|
PK
|
|
2
|
Номер лекарства
|
Int
|
PK
|
|
3
|
Дозировка
|
nvarchar(50)
|
|
Таблица 11. Технологии
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер
|
Int
|
|
2
|
Способ приготовления
|
nvarchar(MAX)
|
|
|
3
|
Длительность, часов
|
Int
|
|
Таблица 12 (вспомогательная). Доставка / Списание
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер
|
Int
|
PK
|
|
2
|
Номер лекарства
|
Int
|
FK
|
|
3
|
Дата доставки
|
Date
|
|
|
4
|
Количество на складе
|
Int
|
|
|
5
|
Дата списания
|
Date
|
|
Таблица 13 (вспомогательная). Состав
|
№
|
Имя поля
|
Тип данных
|
Тип ключа
|
|
1
|
Номер лекарства
|
Int
|
PK
|
|
2
|
Номер ингредиента
|
Int
|
PK
|
|
3
|
Количество, грамм
|
Int
|
|
После создания всех этих таблиц необходимо установить между
ними связи. В MS SQL Server это делается предельно просто: создаётся новая
диаграмма, на неё добавляются все таблицы БД, после чего связь устанавливается
путём перетаскивания поля-источника данных из родительской таблицы на поле в
дочерней. Тип данных обоих полей должен совпадать, одно из полей
(поле-источник) должно быть ключевым. После установления всех связей в
соответствии с логической моделью БД, диаграмма связей выглядит вот так:

Диаграмма связей БД.
.3
Работа с таблицами
Теперь созданные таблицы необходимо заполнить, причём
начинать заполнение данными нужно с тех таблиц, которые являются источниками
данных для других. В нашем случае это таблицы «Клиенты» и «Производители», за ними
можно заполнять «Готовые лекарства», «Компоненты», «Рецепты» и так далее. В
последнюю очередь заполняются вспомогательные таблицы, созданные для
организации связи М:М.
После заполнения всех таблиц данными можно приступить к
последней части данной работы - реализации информационных запросов к БД.
3.
Реализация запросов к БД
3.1
Язык структурированных запросов SQL
Как уже было упомянуто в пункте 2.1, MS SQL Server реализует
язык запросов Transact-SQL, полностью соответствующий стандарту ISDL SQL, со следующими
дополнительными возможностями:
. Управляющие операторы;
. Разделение переменных на локальные и глобальные;
. Дополнительные функции обработки строк, дат и других
типов данных;
. Поддержка аутентификации Windows при помощи пары
«логин-пароль».
Основными операторами Transact-SQL являются:
v SELECT, UPDATE, DELETE, INSERT - операторы для
манипулирования данными;
v GRANT и REVOKE - операторы управления
правами доступа;
v CREATE, ALTER и DROP - операторы для создания
изменения и удаления БД и её составных частей: таблиц, индексов, представлений,
триггеров и хранимых процедур.
Transact-SQL поддерживает следующие типы данных:
v Числовые: целые int, фиксированного формата decimal, с плавающей точкой float и real;
v Символьные (строковые): char(n), nchar(n), varchar(n);
v Двоичные: binary, varbinary, bit;
v Денежные: money, smallmoney;
v Время и дата: date, time,
datetime;
v Объёмные: text, ntext, image.
Помимо этого, Transact SQL содержит множество операторов: арифметических,
логических, агрегатных, математических, строковых, статистических и системных
функций. Всё это даёт практически неограниченные возможности управления
данными.
.2
Синтаксис SQL-операторов выборки и модификации данных
Для выборки данных в MS SQL Server используется оператор SELECT. Его полный синтаксис
крайне громоздок и сложен, поэтому рассмотрим его основные предложения:
1. SELECT [ALL | DISTINCT] < select_list
>
. [INTO new_table]
. [FROM {<table_source>} [,… n]]
. [GROUP BY [ALL] group_by_expression [,…
n]]
. [HAVING < search_condition >]
. [ORDER BY < order_expression >]
Предложение SELECT определяет состав столбцов результирующего
набора данных. При выборе параметра DISTINCT повторяющиеся строки будут удалены
из выборки, при выборе параметра ALL (установлен по умолчанию) строки могут
повторяться.
Предложение INTO создаёт новую таблицу на основе
результирующих данных, предложение FROM указывает таблицу-источник данных. Если
INTO не используется, то результирующие данные сохраняются во временной таблице
(представлении).
Предложение WHERE определяет условия поиска строк,
возвращаемых запросом. Этим условием может быть любое логическое
выражение-предикат, принимающее значения TRUE, FALSE или UNKNOWN.
Предложение ORDER BY указывает порядок сортировки данных по
некоторому столбцу: ASC - по возрастанию, DESC - по убыванию. ПО умолчанию
данные будут отсортированы в порядке возрастания.
Предложение GROUP BY объединяет данные в выборке в группы по
значению какого-либо атрибута и при необходимости вычисляет некоторые сводные
значения. Вместе с GROUP BY используется предложение HAVING, накладывающее
ограничения на выбор групп аналогично с предложением WHERE, но с использованием
агрегатных функций.
Оператор SELECT обладает свойством мультивложенности: в
предложении WHERE для определения условия можно воспользоваться подзапросом, и
любой подзапрос может иметь свой подзапрос. Вложенные подзапросы, содержащие
параметры, передаваемые из внешнего, называются коррелируемыми.
Для добавления, изменения и удаления данных используются
соответственно операторы INSERT, UPDATE и DELETE. Их синтаксис намного проще чем у SELECT:
. INSERT
[INTO] {table_or_view_name} [(column,…)]
{VALUES ({DEFAULT | NULL | expression},…)
| SELECT…
| DEFAULT VALUES
2. UPDATE
{table_or_view_name}{column = {expression |
DEFAULT | NULL}},…
[WHERE {<search_condition> | CURRENT OF
{cursor}]
. DELETE
[FROM] {table_name | view_name}
[WHERE {<search_condition>] | [CURRENT OF]]
После рассмотрения синтаксиса основных SQL-запросов можно
приступить к их формированию и выполнению.
3.3
Результаты выполнения SQL-запросов
В пункте 1.2 были рассмотрены задачи, которые должна
выполнять наша база данных. Сформируем SQL-запрос для каждой из них:
. Получение сведений о готовых лекарствах и их
производителях:
SELECT A. Номер, A. [Торговое название], A. [Международное
непатентованное название], B. [Название производителя]
FROM dbo. [Готовые лекарства] AS A JOIN dbo. Производители AS B
ON A. [Номер производителя]=B. Номер

Результат выполнения запроса №1
2. Получение перечня готовых лекарств с остатком на
складе меньше критической нормы:
SELECT A. [Торговое название], A. Тип, A. [Количество на складе,
упаковок], A.
[Срок годности]
FROM dbo. [Готовые лекарства] AS A
WHERE A. [Количество на складе, упаковок]<A. [Критическая норма,
упаковок]

Результат выполнения запроса №2
. Список изготавливаемых лекарств со способом и
длительностью приготовления:
SELECT DISTINCT A. Наименование, B. [Способ приготовления],
B. [Длительность, часов]
FROM dbo. [Изготавливаемые лекарства] AS A JOIN dbo. Технологии AS B
ON A. [Номер технологии]=B. Номер
4. Сортировка готовых лекарств по стоимости
SELECT A. Номер, A. [Торговое название], A. [Срок годности], A. Стоимость
FROM dbo. [Готовые лекарства] AS A
ORDER BY A. Стоимость DESC

Результат выполнения запроса №4
5. Список всех клиентов, живущих в одном месте:
SELECT A.ID, A. [Имя], A. Фамилия, A. Адрес FROM dbo. Клиенты AS A A. Адрес LIKE ‘%Малфой’ // здесь могла
быть любая строка

Результат выполнения запроса №5
6. Список диагнозов и назначений:
SELECT A. Номер, A. Врач, A. Диагноз, A. Лекарства FROM dbo. Рецепты AS ABY A.
Врач
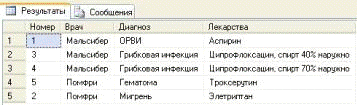
Результат выполнения запроса №6
. Список клиентов, их заказов и статусов:
SELECT A. Номер, A. [Номер рецепта], A. [Дата приёма], A. Статус, B. Имя, B. Фамилия, B. Адрес
FROM dbo. Заказы AS A JOIN dbo. Клиенты AS BA. [ID клиента]=B.ID

Результат выполнения запроса №7
8. Список лекарств, сгруппированных по фармакологической
группе (категории) с выводом максимальной, минимальной и средней цены по
категории:
SELECT A. Категория, MAX (A. Стоимость) AS [Максимальная цена], MIN (A. Стоимость) AS [Минимальная цена], AVG (A. Стоимость) AS [Средняя цена]
FROM dbo. [Готовые лекарства] AS A
GROUP BY A. Категория
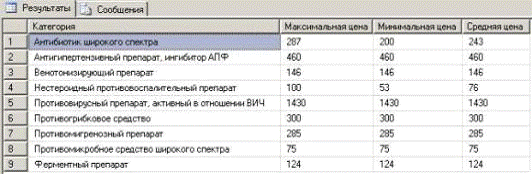
Результат выполнения запроса №8
Все вышеприведённые запросы можно оформить, как хранимые
процедуры, и тогда на вход можно будет подавать любые параметры выборки.
Заключение
В ходе выполнения данной работы была спроектирована база
данных для предметной области «Аптека», содержащая 13 таблиц. Все отношения в
данной БД удовлетворяют условиям третьей нормальной формы, для каждого
определены первичные и внешние ключи. Сформированы 8 запросов для выполнения
основных задач - учёта лекарств и медикаментов, сбора статистики используемых
технологий и ингредиентов, статистики выполнения заказов и их доставки.
Список
литературы и других источников
1. http://www.sql.ru/ - форум
SQL-программистов.
2. http://ru.wikipedia.org - свободная
энциклопедия.
. Роберт Виейра Программирование баз
данных Microsoft SQL Server 2005. Базовый курс = Beginning Microsoft SQL Server 2005
Programming. - М.: «Диалектика», 2007. - С. 832.
4. Аллен Дж. Тейлор. SQL для чайников = SQL
for Dummies. - 7-е изд. - М.: Диалектика, 2010. - 416 с.
. Алекс Кригель, Борис Трухнов. SQL.
Библия пользователя. Язык запросов SQL = SQL Bible. - 2-е изд. - М.:
Диалектика, 2009. - 752 с.
. К.Дж. Дейт. Введение в системы баз
данных / Пер. с англ. - 8-е изд. - М.: Вильямс, 2005. - 1328 с.
. Кузнецов С.Д. Основы баз данных. - 2-е
изд. - М.: Интернет-университет информационных технологий; БИНОМ. Лаборатория
знаний, 2007. - 484 с.
. Майк Гандерлой, Джозеф Джорден, Дейвид
Чанц Освоение Microsoft SQL Server 2005 = Mastering Microsoft SQL Server 2005.
- М.: «Диалектика», 2007. - С. 1104.
. Роберт Э. Уолтерс, Майкл Коулс SQL
Server 2008: ускоренный курс для профессионалов = Accelerated SQL Server 2008.
- М.: «Вильямс», 2008. - С. 768.