Организация и алгоритмы работы поисковых систем
Санкт-Петербургский государственный
политехнический университет
Институт информационных технологий и
управления
Кафедра «Компьютерные
интеллектуальные технологии»
КУРСОВАЯ РАБОТА
по дисциплине «Информатика»
Организация и алгоритмы работы
поисковых систем
Санкт-Петербург 2013
СОДЕРЖАНИЕ
СПИСОК ОСНОВНЫХ ТЕРМИНОВ
ВВЕДЕНИЕ
. ОБЩИЕ ПОЛОЖЕНИЯ О ПОИСКОВЫХ СИСТЕМАХ
.1 Определение поисковых систем
.2 Классификации поисковых систем
.3 История развития поисковых систем
. УСТРОЙСТВО И ПРИНЦИПЫ РАБОТЫ ПОИСКОВЫХ СИСТЕМ
.1 Структура поисковой системы
.1.1 Веб-сервер поисковой системы
.1.2 Поисковые роботы
.1.3 Индексатор
.1.4 База данных
.2 Модели поиска поисковых систем
.2.1 Теоретико-множественные модели
.2.2 Вероятностные модели
.2.3 Алгебраические модели
.2.4 Модели поиска в существующих поисковых системах
.3 Оценка качества поиска
.3.1 Критерии оценки качества работы поисковой системы
.3.2 Машинное обучение
.3.3 Асессоры поисковых систем
. ПОИСК В СЕТИ
.1 Обработка запроса поисковой системой
.1.1 Метапоиск
.1.2 Базовый поиск
.2 Подготовка базы данных
.3 Ранжирование
.4 Пользовательские запросы
.4.1 Общие положения
.4.2 Классификация по виду
.4.3 Обработка запросов
.4.4 Персонализация запроса
.5 Выдача результатов
.6 Сайт и поисковая система
ЗАКЛЮЧЕНИЕ
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
СПИСОК ОСНОВНЫХ ТЕРМИНОВ
Поисковая выдача - результаты, выдаваемые поисковой системой в ответ на
запрос пользователя.
Релевантность - степень соответствия ресурса поисковому запросу.
Ранжирование - сортировка сайтов в поисковой выдаче на основании
определённого критерия. Чаще всего критерием служит соответствие ресурса
запросу пользователя.
Метаданные - это информация о веб-странице содержащаяся в её коде в
специальных метатегах. Например: имя автора документа, тип контента, ключевые
слова и т.д.
ВВЕДЕНИЕ
Со времён, когда в 1990 году появился первый веб-сайт, созданный «Отцом»
веба Тимом Бернерсом-Ли, интернет разросся до небывалых размеров. По оценке
компании Pingdom в 2012 году количество веб-сайтов в
интернете было на уровне 612 миллионов и, естественно, эта цифра продолжает
расти. Так как же нам найти интересующую нас информацию среди миллионов
веб-страниц? На помощь приходят так называемые поисковые системы. Они призваны
облегчить человеку поиск и сэкономить самый дорогой из имеющихся в нашем
распоряжении ресурсов - время.
За качественными и количественными изменениями интернета качественно
начали изменяться и поисковые системы. Сегодня поиск в сети Интернет - задача
не из разряда простых. Современные поисковые системы - это огромные сети
серверов, а также множество людей, потративших свои силы на оптимизацию
поисковых алгоритмов, улучшение программного обеспечения серверов, общей
архитектуры поисковых машин и прочие меры, направленные, главным образом, на улучшение
качества выдаваемых пользователю результатов и повышение скорости выдачи этих
результатов. Благодаря этому процессу непрерывного развития, найти необходимую
информацию в сети Интернет становится проще, даже не смотря на всё
увеличивающиеся объёмы WEBа.
Сейчас поисковики учатся понимать пользователя и определять, что же он
хочет найти на самом деле. В результате этого процесса поиск в сети со стороны
поисковой системы представляет собой далеко не тривиальную задачу. В
соответствии с этим её работа сейчас представляет собой очень сложный с
технической и алгоритмической точки зрения, процесс.
В связи с вышесказанным у некоторых людей может возникнуть желание
поближе познакомиться с тем, как устроены поисковые системы. Именно для
удовлетворения этойпотребности и создавалась данная курсовая работа, т.е. с
целью дать непросвещённому в этом деле человеку общее представление о том, как
устроены поисковые системы, а также как они решают свою главную проблему -
показ пользователю тех интернет-ресурсов, которые смогут максимально
исчерпывающе ответить на его запрос.
Задачами курсовой работы в связи с обозначенной целью являются:
. Уточнить, что такое поисковые системы, в общем.
. Выделить основные типы поисковых систем.
. Исследовать их внутреннее техническое и логическое устройство.
. Исследовать какие существуют алгоритмы поиска, как
осуществляется формирование выдачи результатов поиска пользователю.
. Проанализировать, как владельцы сайтов могут повлиять на выдачу
результатов поисковыми системами.
Методы исследования, использованные при написании курсовой работы:
. Анализ литературы и веб-ресурсов.
. Обобщение.
. Синтез.
1. ОБЩИЕ ПОЛОЖЕНИЯ О ПОИСКОВЫХ СИСТЕМАХ
1.1
Определение поисковых систем
Поисковая система - это программно-аппаратный комплекс, который
осуществляет поиск в сети Интернет необходимой информации.
Поисковые системы обычно разделяют на две части: front-end и back-end. Под front-end’ом подразумевают веб-интерфейс,
через который осуществляется взаимодействие пользователя с back-end’ом.Back-end - это поисковая машина,
осуществляющая поиск в сети Интернет и\или подготавливающая результаты для
возврата их пользователю в front-end составляющую.
1.2
Классификации поисковых систем
Разделяют несколько вариантов классификации поисковых систем. Чаще всего
используют классификацию по классу, следующую ниже, но иногда применяют
классификацию, основанную на назначении поисковой системы.
1.
Классификация поисковых систем по классу
Выделяют два основных класса поисковых систем:
— Каталоги - это структурированный набор ссылок на веб-сайты с
их кратким описанием. Они имели широкое распространение на заре интернета,
когда количество ресурсов в сети было сравнительно небольшое.
2.
Классификация поисковых систем по назначению
Иногда разделяют поисковые системы по назначению:
. Тематические - этот вид поисковых систем работает с ограниченным
контентом и выполняет поиск информации в интернете только среди определенных
ресурсов, например в соответствии с религиозными или профессиональными
предпочтениями. Так, поисковик Google ориентирован на ортодоксальных иудеев, он
работает исключительно с разрешенным, для этой религии, контентом.
. Специализированные - это поисковые системы для работы с
определенной информацией, например поиск по онлайн-магазинам, FTP-серверам и
прочие.
. Универсальные - поиск в таких системах организован вне
зависимости от вида контента.Пользователь может запрашивать текстовую
информацию, графический, видео- или аудио-контент. Непосредственно поиск
охватывает все ресурсы интернета без ограничений. Все ведущие поисковые системы
(Google, Яндекс, Yahoo!,Bing и
т.д.) являются универсальными.
1.3
История развития поисковых систем
Первой поисковой системой был «Wandex», созданный в 1993 году, который осуществлял поиск по сайтам сети с
помощью поискового бота, выдавая в результате список соответствующих запросу
ресурсов. Ранжирование не производилось. Следует отметить, что всего в
интернете того времени присутствовало около 620 веб-ресурсов, а сам поиск
осуществлялся только по определённым словам.
Следующей примечательной полнотекстовой поисковой системой стал WebCrawler, запущенный в 1994 году, который, в
отличие от своих предшественников, позволял пользователям искать по любым
ключевым словам на любой веб-странице - с тех пор это стало стандартом во всех
основных поисковых системах.
Первой революционной поисковой системой стал BackRub.Он впервые начала учитывать внешние ссылки на сайт и
ранжировать в соответствии с этим. Её создателями были Лари Пейдж и Сергей
Брин, которые двумя годами позднее основали Google.Предшественники BackRub ранжировали сайты по количеству посещений, что не
всегда являлось верным критерием полезности ресурса.
В 1996 году русскоязычным пользователям интернета стало доступно
морфологическое расширение к поисковой машине Altavista и оригинальные
российские поисковые машины «Рамблер» и «Апорт», а в 1997 была открыта
поисковая машина Яндекс.
В 1998 году запустилась поисковая система MSN, которая, правда, работала на чужой поисковой выдаче.
Постепенно из общей массы похожих поисковых систем начинают выделятся
самые успешные, начинается череда слияний и поглощений, из которой выделяются Googleи Yahoo!. Поисковые гиганты старательно обрастают
дополнительными сервисами, чтобы завязать пользователя на себе.
Спохватившись, в борьбу вступает Microsoftсо своим LiveSearch, который выходит в 2006 году, с
этого момента Microsoftсам формирует свою выдачу.
В том же году Yahoo!
отказываются от использования поисковой выдачи Google и начинают самостоятельно формировать поисковую
выдачу.
В 2009 году Microsoft
анонсирует новую поисковую систему Bing, пришедшую на замену устаревшему LiveSearch. В том же, 2010-ом году компания Microsoft подписала контракт с Yahoo! на то, что последняя будет
использовать поисковую выдачу системы Bing в следующие 10 лет.
По состоянию на 2011 год, доля поисковых систем на мировой арене была
следующая:
1. Google - 83,87%
2. Yahoo! - 6,20%
3. Baidu - 4,22% - Китайская национальная поисковая система
4. Bing - 3,69%
. Яндекс - 1,7%
и т.д. …
2. УСТРОЙСТВО И ПРИНЦИПЫ РАБОТЫ ПОИСКОВЫХ СИСТЕМ
.1
Структура поисковой системы
.1.1
Веб-сервер поисковой системы
Веб-сервер поисковой системы - этовеб-сервер, который осуществляет
взаимодействие между пользователем и остальными компонентами поисковой системы.
Как правило, он обеспечивает работу веб-интерфейса поисковой системы (сайта).
Веб-сервер также держит на себе страницу выдачи результатов пользователю в виде
html-страницы.


Рис. 2.1 Веб-интерфейс Google
2.1.2
Поисковые роботы
Поисковой робот - это программа, являющаяся составной частью поисковой
системы и предназначенная для перебора страниц Интернета с целью занесения
информации о них в базу данных поисковика. По принципу действия паук напоминает
обычный браузер. Он анализирует содержимое страницы, сохраняет его в некотором
специальном виде на сервере поисковой машины и отправляется по следующим ссылкам,
содержащимся на этой странице.
Поисковой робот обычно подразделяется на «Планировщика» и «Паука».
Планировщик (Crawler или
«Червяк») - это программа, основная цель которой вытаскивать из ресурса все
ссылки на прочие страницы/ресурсы и сохранять их в своей базе, одновременно
составляя путь для «Паука». После того как все ссылки будут найдены,
«Планировщик» начинает планомерный переход по этим ссылкам и весь процесс
начинается сначала.
Паук (Spider) - это главная часть поискового
робота. Он переходит по спланированному «Планировщиком» маршруту и сохраняет
веськод страницы в базу данных.
У разных поисковых систем поисковые роботы могут различаться, но принцип
действия у всех схожий - найти контент и скачать его.
Существует несколько подкатегорий поисковых роботов. Одни занимаются
поиском картинок, другие просматривают быстро обновляющиеся сайты, третьи
проверяют сайты на работоспособность и т.д.
2.1.3
Индексатор
Индексатор - это программа, осуществляющая обработку скаченных поисковыми
роботами страниц и их анализ. Как правило, индексатор разбивает страницу на
несколько частей и анализирует каждую из них. Индексатор предназначен для
добавления информации о сайтах в регулярно обновляемую базу данных (индекс)
поисковой системы.
В результате индексации создается группа индекс-файлов страницы, в
котором каждому предложению соответствует свой номер, а каждому слову - номер в
предложении. Также в этих файлах содержатся специальные теги, помогающие
правильно соотносить элементы на странице. При этом создается так называемая
«область индексирования» - это уникальный префикс, назначаемый каждому
проиндексированному сайту. Как можно догадаться, индекс-файл - очень хороший
приём, помогающий экономить много дискового пространства. Ещё большей экономии
можно достичь, используя специальные алгоритмы сжатия файлов.
Индексаторы также выстраивают обратный индекс - это когда слову
соответствуют веб-ресурсы. Индексатор, в связи с этим, производит ранжирование
в зависимости от релевантности ресурса.
2.1.4 База
данных
База данных - это хранилище всех данных, которые поисковая система
скачивает и анализирует. Иногда базу данных называют индексом поисковой
системы, поскольку именно в ней хранятся индекс-файлы каждого ресурса
обработанного системой. Она постоянно обновляется и пополняется служебными
программами - поисковыми ботами и индексаторами.
2.2 Модели
поиска поисковых систем
Модель поиска -это некоторое упрощение реальности, на основании которого
получается формула, позволяющая программе принять решение: какой документ
считать найденным и как его ранжировать. Ниже приведены только актуальные и
использующиеся до сих пор модели поиска.
Основные модели поиска разделяют на три типа:
— Теоретико-множественные.
— Вероятностные.
— Алгебраические.
2.2.1
Теоретико-множественные модели
В основе теоретико-множественных моделей лежит идея о том, что смысл
документов может быть выражен множеством ключевых слов, представляющих собой
слова или словосочетания естественного языка из текстов документов.
1. Булевская
модель поиска и её расширение
В Булевской модели поиска запрос формируется в виде логического
выражения, используя, для этого, операторы булевой логики: И, ИЛИ, НЕ. Модель
ориентирована на поиск по тексту, где критерием релевантности будет
соответствие результата поисковому запросу, т.е. документ, имеющий совпадающие
метаданные со значениями, заданными в запросе, будет считаться релевантным.
В расширенной Булевской модели используются не чёткие бинарные величины,
а относительные, называемые весовыми коэффициентами, значения которых лежат в
диапазоне [0;1]. Это придает большую гибкость данной модели и позволяет
производить ранжирование отобранных документов.
Плюсами Булевской модели поиска является её простота реализации, а также
сложность для обычного пользователя, поскольку далеко не каждый сможет грамотно
управляться с операторами Булевой логики при формировании своего запроса.
2.2.2
Вероятностные модели
Основная идея таких моделей: наивысшая эффективность поиска достигается
тогда, когда подходящие, по критерию присутствия ключевых слов, документы
ранжируются по убыванию вероятности их релевантности запросу. Для вычисления
вероятности используется обучающая выборка, созданная человеком, или исходя из
списка ключевых слов документа на основании того предположения, что
определённые ключевые слова имеют меньшую вероятность релевантности для
конкретной тематики.
Сети вывода
Сети вывода основаны на так называемой Байесовской сети, которая
построена на четырёх ключевых узлах. Первый узел - это документы, изученные
пользователем в процессе предыдущих поисков. Второй узел - это список ключевых
слов, содержащихся на странице. Третий узел - это запросы, состоящие из этих
ключевых слов. Четвёртый узел - это неизвестные заранее поисковой системе
потребности пользователя. Все узлы первого и второго типов формируются заранее
для заданной коллекции. Узлы третьего типа и их связь с узлами первого и
четвёртого типа формируются каждый раз при отправке запроса пользователем.
При получении запроса происходит вычисление примерной информационной
потребности пользователя, затем для каждого документа из коллекции подходящих
ресурсов осуществляется вероятностная оценка релевантности запросу относительно
пользовательских потребностей. На основании этой оценки происходит ранжирование
ресурсов.
К плюсам данной модели можно отнести:
— Хорошее теоретическое обоснование.
— При имеющейся информации дают лучшее ранжирование ответов.
К минусам можно отнести:
— Требуется информация о релевантности или ее приближенные
оценки.
— Структура документа описывается только ключевыми словами.
— Оптимальные результаты получаются только в случае постоянно
машинного обучения на основе информации о релевантности.
2.2.3
Алгебраические модели
1.
Векторно-пространственные модели
Векторные модели сейчас являются самыми распространёнными и применяемыми
на практике моделями. Векторные модели, в отличие от Булевских, с лёгкостью
позволяют ранжировать релевантные запросы. Суть таких моделей сводится к тому,
что документ в векторной модели рассматривается как неупорядоченное множество
обозначений документа, где обозначения - это все слова, даты, названия и т.д.
формирующие документ.
Вес каждого определения, чаще всего, определяется подсчётом количества
его повторений в тексте.
Все определения коллекции релевантных документов упорядочиваются. Теперь
для каждого документа составляется вектор, состоящий из всех определений
коллекции, который и будет представлением данного документа в векторном
пространстве. Очевидно, что размерность вектора и векторного пространства
одинакова для всей коллекции.
Более формально

где 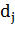 - векторное представление -го документа,
- векторное представление -го документа, 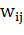 - вес
- вес 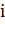 -го терма в
-го терма в  -м документе,
-м документе,  - общее количество различных термов
во всех документах коллекции.
- общее количество различных термов
во всех документах коллекции.
Запрос также раскладывается на обозначения, затем составляется вектор,
после чего в выдаче осуществляется ранжирование коллекции релевантных ресурсов
согласно их удалённости от вектора запроса в порядке убывания.
Достоинства:
— Учет весов повышает эффективность поиска.
— Позволяет оценить степень соответствия документа запросу.
— Косинусная метрика удобна при ранжировании.
Недостатки:
— Нет достаточного теоретического обоснования для построения
пространства терминов.
— Поскольку обозначения не являются независимыми друг от друга,
то они не могут быть полностью ортогональными.
Имеет преимущество перед другими моделями ввиду простоты и изящества.
2.3 Оценка
качества поиска
Корректная оценка качества поиска является одним из ключевых факторов
успешности поисковой системы. Оценку качества поисковой выдачи производят на
основании множества критериев, а также с помощью оценки качества поиска людьми
специальной должности, именуемой, асессор.
2.3.1
Критерии оценки качества работы поисковой системы
— Точность выдачи - отношение числа выданных релевантных
документов к сумме числа выданных релевантных и числа выданных нерелевантных
документов.
— Полнота выдачи - отношение числа выданных релевантных
документов к сумме числа выданных релевантных и числа не выданных релевантных
документов.
— Потери информации - отношение числа не выданных релевантных
документов к сумме числа выданных релевантных и числа не выданных релевантных
документов.
— Информационный шум - отношение числа выданных нерелевантных
документов к сумме числа выданных релевантных и числа выданных нерелевантных
документов.
— Чувствительность - отношение числа выданных релевантных
документов к сумме числа выданных релевантных и числа не выданных релевантных
документов.
— Специфичность - отношение числа невыданных нерелевантных
документов к сумме числа выданных нерелевантных и числа невыданных
нерелевантныхдокументов.
На практике для сравнения поисковых систем используются усредненные
графики зависимости полноты от точности. Чтобы избежать сравнения пар полнота -
точность используются однозначные оценки. Одной из таких оценок является
E-мера, позволяющая избежать сравнения пар полнота - точность за счет введения
отношения их значимости.
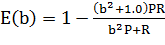 ,
,
где P - точность, R - полнота, b - отношение значимости полноты и
точности.
2.3.2
Машинное обучение
Машинное обучение сейчас активно используется в Яндексе. Такая система у
них называется Матрикснет. С помощью неё поисковая машина стала учитывать
намного больше критериев релевантности, а качество поиска заметно улучшилось,
что только упрочило позиции поисковика в российском сегменте интернета.
Машинное обучение практикуется и в Google. Программа называется Seti. По словам разработчиков, пока что они не готовы
полностью доверить ранжирование программе, т.к. машинное обучение не способно
на 100% адекватно действовать в нестандартной ситуации. Так же надо учитывать
охват поисковой системы Google,
который несравнимо больше охвата Яндекса.
Следует отметить, что Googleсовместно
с NASAв мае 2013 года запустил проект
Quantum Artificial Intelligence Lab (QAIL), основной задачей которого является исследование возможности
использования квантового компьютера в машинном обучении. Это исследование
способно совершить революцию в машинном обучении, используя машину с
нереальной, для сегодняшних суперкомпьютеров, скоростью произведения сложных
вычислений.
2.3.3
Асессоры поисковых систем
Асессоры поисковых систем - это специальные люди, работающие в штате
компании-поисковика. Они берут на себя роль по составлению обучающей выборки
для программ машинного обучения, а также для оценки качества поиска. Они
первые, кто тестирует новые изменения в алгоритме поиска и только после
успешного прохождения тестирования асессорами, алгоритм проходит следующие
стадии тестирования.
3. ПОИСК В СЕТИ
3.1
Обработка запроса поисковой системой
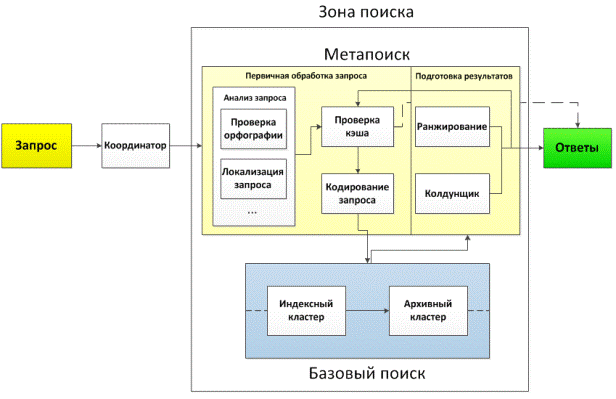
Рис. 3.1 Путь от запроса до поисковой выдачи
Выше представлена немного упрощённая схема осуществления поиска, на
которой схематично изображены следующие основные этапы обработки запроса:
. Координатор - направляет запрос на ближайший и менее загруженный
сервер.
. Метапоиск -анализирует запрос, пытается понять его суть,
проверяет, не был ли этот запрос уже обработан ранее, ранжирует найденные на
этапе базового поиска результаты.
. Базовый поиск - осуществляет поиск релевантных результатов по
базе данных.
Координатор не представляет особого интереса с точки зрения логической
структуры, т.к. он не имеет составных локальных частей, а его функционал
однообразен. Поэтому детально рассматривать будем только метапоиск и базовый
поиск.
3.1.1
Метапоиск
Метапоиск можно условно разделить на два логических отдела, в которых
происходит:
— Первичная обработка запроса.
— Подготовка результатов.
В отделе первичной обработки происходит анализ запроса и его
интерпретация. Также проверяется, не был ли этот запрос ранее обработан
системой. В случае если такой запрос уже обрабатывался недавно, то выводятся
его результаты, иначе запрос считается новым. Такой запрос специально кодируют
и передают в базовый поиск.
Во время анализа запроса происходит:
— Определение языка.
— Анализ запроса на опечатки.
— Запрос разбирается по словам и анализируется смысл каждого
слова и его совокупный смысл, перебираются возможные трактовки и отбирается
самый вероятный вариант.
— Запрос классифицируется.
— Определяются синонимичные варианты этого же запроса.
— Определяется его географическая принадлежность.
Выше перечислены только основные процессы, происходящие во время анализа.
Результаты, пришедшие в результате базового поиска, отправляются в
условный отдел подготовки результатов. В нём происходит два действия:
— Документы ранжируются по степени релевантности запросу по
специальному алгоритму.
— Специальная программа, именуемая «колдунщик», «подмешивает» в
поисковую выдачу результаты поиска из прочих сервисов, соответствующих запросу.
Например, по запросу «Зима», будет возвращены изображения, подобранные по этому
же запросу и т.д. Что будет добавлять колдунщик - зависит от наличия
результатов по этому поиску, а также от особенностей самой поисковой системы.
3.1.2
Базовый поиск
Базовый поиск осуществляется в том случае, когда пришедший в систему
запрос считается новым. Во время базового поиска осуществляется поиск по
запросу, пришедшему в специальной форме.
Базовый поиск делится на два этапа:
. Поиск по индексной базе данных.
. Поиск по архивной базе данных.
Из индексной базы данных, с помощью поискового алгоритма системы,
«вытаскивают» идентификаторы документов, а затем, по этим идентификаторам,
«вытаскивают» данные из архивной базы, которые составляют краткое превью ресурса
в поисковой выдаче. В архивной базе данных также находится последняя копия
страницы, которую обрабатывал поисковик.
3.2
Подготовка базы данных
Индексация
Индексация веб-ресурса поисковой системой происходит после скачивания
контента ресурса поисковыми роботами. Производит индексацию соответствующая
программа - индексатор. Определяют два вида индекса: прямой и инвертированный.
Процесс составления инвертированного индекса (или обратного) происходит
примерно следующим образом:
. Скачанная страница очищается от языка разметок,, т.е. от тегов
html, вставок кода JavaScript и прочих служебных инструкций.
. Далее составляется прямой индекс. Реализации могут быть разные,
но принцип остается неизменным. Обычно все слова, знаки препинания и т.д.,
упаковывают в массив.
. Текст страницы, преобразованный согласно правилам машинной
морфологии, т.е. приведённый к начальной форме c отбрасыванием «не слов»,
выстраивается в алфавитном порядке. Слова, которые не удалось привести к
первозданному виду, например, слова с опечатками или новые слова и т.д.;
оставляются «как есть».
. Далее составляется инвертированный индекс страницы. Составляется
он следующим образом: для каждого слова сопоставлены все его вхождения в
оригинальном тексте (или прямом индексе).
. Затем обратный (или инвертированный) индекс каждого
обработанного ресурса используется системой для составления глобального
обратного индекса, в котором каждому слову соответствуют сайты и места
вхождения этого слова в тексте на сайтах. Наличие в обратном индексе позиции вхождения
слова помогает лучше ранжировать ресурсы в выдаче, т.к. так можно определять
порядок слов на странице, что позволяет корректно обрабатывать многословные
запросы.
. Прямой индекс существует для того, что бы восстанавливать цитаты
из текста, в которые входят слова из запроса, на странице выдачи результатов.
3.3
Ранжирование
1. Алгоритмы
ранжирования сайтов
Алгоритмы ранжирования сайтов - это система формул, с помощью которых
поисковая поисковик осуществляет ранжирование сайтов в поисковой выдаче. Они
используют специальные критерии, благодаря которым, формулы начинают обретать
смысл и выполнять свои функции.
Алгоритмы ранжированияпоисковых систем, как и критерии, которые они
учитывают, находятся в строжайшем секрете, для того, чтобы никто не смог подстроится
под требования поисковой системы для улучшения позиции в выдаче.
2. Критерии
релевантности
Критерии, которые учитывает поисковая система для расчёта релевантности
страницы, находятся, как уже было сказано, в строжайшем секрете. Однако чисто
эмпирическим путём владельцам сайтов удалось выявить некоторые закономерности,
которые оказывают влияние на позиции веб-ресурсов в поисковой выдаче.
Вот немногие, которые считаются самыми основными:
— Индекс цитирования - количество внешних ссылок на страницу.
Чем авторитетнее сайт, с которого ссылаются, тем более высокий коэффициент
релевантности страницы.
— Уникальность контента.
— Количество посетителей.
— Процент отказа (слишком скорый уход пользователя со
страницы).
— Частота вхождения ключевого слова на странице.
— Частота обновления ресурса.
— Как часто переходят на сайт со страницы поисковой выдачи.
— Наличие слов одной тематики с ключевым словом на странице и
их количество. Т.е. определяется, не является ли ресурс мусорным спам-сайтом с
простым набором ключевых слов.
— География посетителей.
— Возраст сайта и релевантных страниц.
— Внутренний код страницы. Чем он яснее и правильнее, тем выше
ранг.
— Покупка или продажа ссылок. Фактор, понижающий ранг в выдаче.
Факторов ранжирования у поисковых систем может быть очень много.
Например, разработчики Google
пишут, что их алгоритмы учитывают более 200 критериев, а разработчики Яндекса,
рапортуют о более чем 500 критериев, которые учитывает их система, построенная
на машинном обучении и вероятностной модели поиска.
3.4
Пользовательские запросы
.4.1 Общие
положения
Поисковый запрос - обычно это слово, фраза, выражение, вводимое
пользователем в поисковую строку поисковой системы с целью получения списка
сайтов, в которых данное слово, фраза, выражение повторяется.
Запросы определяют по частотности, т.е. по популярности:
— Низкочастотные (НЧ) запросы - наименее часто вводимые
пользователями в поисковую строку запросы, соответствующие определенной
тематике.
— Высокочастотные (ВЧ) - наиболее часто создаваемые запросы.
Запросы также определяют по конкурентности, т.е. по количеству сайтов,
которые отвечают на данный запрос:
— Низкоконкурентные - характеризует малое количество сайтов,
отвечающих на запрос.
— Высококонкурентные - наиболее сложные для продвижения ввиду
множества ресурсов, которые по ним продвигаются, т.е. стремятся оказаться в
«топе» поисковой выдачи.
3.4.2
Классификация по виду
Пользовательские запросы подразделяются на следующие три вида:
— Транзакционные
— Навигационные
— Информационные
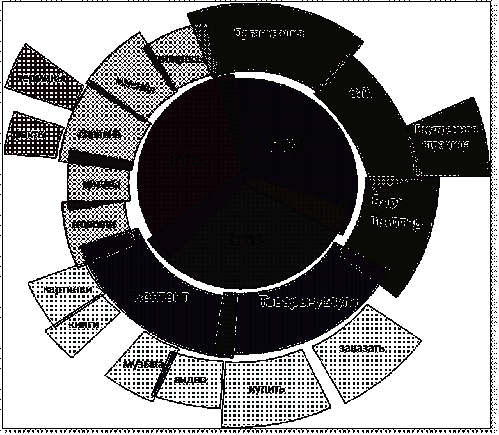
Рис. 3.2 Классификация запросов
поисковый запрос база данные
Транзакционные запросы(trns)
- это запросы, которые формируют пользователи с целью совершить какое-либо
дальнейшее действие, т.е.что-либо купить, продать, скачать и т.д.
Например: «купить кондиционер спб», «скачать фильм Куда приводят мечты» и
т.д.
Навигационные запросы (nvgt)-
формируются с целью найти конкретное место в мировой сети Интернет - сайт
интересующей их компании, тематический форум или доску объявлений.
Например: «сайт правительства спб», «официальный сайт компании Крупской»
и т.д.
Информационные запросы(info)-самый
широкий в смысловом плане класс запросов, к нему относится все остальное: это
новости, справочные запросы по фактам и терминам, поиск мнений и отзывов,
ответы на вопросы и многое другое.
Например: «самая высокая гора в мире», «рейтинг фильмов 2013» и т.д.
3.4.3
Обработка запросов
1. Парсер
Чтобы приступить к поиску, первым делом надо пользовательский запрос
обработать и понять о чём он. Делает это специальная программа - парсер
запросов.
Парсер представляет собой очередь агентов, каждый из которых производит
какое-либо более или менее атомарное действие над запросом, начиная от
разбиения его на слова и другие регулярные сущности типа URL-ов и телефонных
номеров, и заканчивая сложными классификаторами типа детектора цитат.
Агенты выстроены в очередь. Каждый запрос прогоняется через эту очередь,
причём результаты работы каждого агента влияют на дальнейший логический путь
запроса - например, запрос, классифицированный как навигационный, не попадёт на
обработку детектора цитат. Сам запрос здесь представляется как некая доска
объявлений, на которой каждый агент может оставить свое сообщение, прочитать
сообщения других агентов и при необходимости изменить или отменить их. По
завершении запрос передается дополнительным программам и, в конечном счете,
отправляется на дальнейшую стадию обработки, где все записанные агентами
дополнительные параметры используются как факторы ранжирования.
2. Словари
Помогают обрабатывать запросы парсерам (понять смысл) специальные файлы,
содержащие сгруппированные массивы строк, каждый из которых имеет определенный
смысл. Каждой из этих групп слов может быть сопоставлен маркер. Он обозначает,
что в случае нахождения в запросе такого фрагмента всему запросу будет
поставлен флаг, сигнализирующий, что предметом этого запроса является кино.
В этих же словарях задаются синонимы слов, из данной тематики. Благодаря
им, если, к примеру, в запросе есть слово “саундтрек”, то запрос будет расширен
словосочетаниями “звуковая дорожка”, “саунд трек” и аббревиатурой “OST”.
Словари делятся на два больших класса:
— Частотные выражения-маркеры - характеризующие определенную
тематику или намерение пользователя. Такие словари составляются вручную.
— Объекты - фильмы, рецепты, блюда, знаменитые личности,
географические названия и т.д.
Таких словарей существует несколько десятков. Размер некоторых из них -
сотни тысяч, даже миллионы подобных строк. На их основе происходит первичная
обработка запроса, его раскрашивание, т.е. определение к какому словарю
относятся слова из запроса, после чего работает более сложная логика.
3. Маркеры
Маркеры помогают поисковой системе понять смысл запроса. Запрос
разбирается на слова и словосочетания. Эти слова, словосочетания, а также весь
запрос целиком пропускается через словари. В результате получаем ряд
соответствий, которые говорят нам, к какой тематике относятся части запроса или
запрос целиком.
В случае вхождения одного маркера в другой, верхний маркер «поедает»
внутренний.

Рис. 3.3 Маркеры
Например, запрос «пираты Карибского моря» будет иметь три маркера:
«пираты» - как название, «Карибского моря» - как ещё одно название, и «пираты
Карибского моря» - как фильм. В результате запрос будет определён, в
большинстве случаев, как фильм «Пираты Карибского моря».
3.4.4
Персонализация запроса
Персонализация - это один из способов предоставлять пользователям именно
те результаты, которые они искали.
Например, ответ на запрос “Северное сияние” для разных людей будет
отличаться. Путешественнику покажут ответ о природном явлении, москвичке,
интересующейся покупками, - торговый центр, любителю кино - ссылки на
информацию о фильме.
Осуществляют персонализацию на основании истории поиска, местоположению
пользователя. Некоторые поисковые системы добавляют категории, влияющие на
персонализацию.
Методы сбора поисковой истории у поисковых систем схожи:
— Использования специальных расширений для браузеров (или
встраивание подобных в свой, продвигаемый поисковиком, браузер).
— Привязка истории к аккаунтам пользователям в прочих ресурсах
поисковика, таких как: почта, социальная сеть и т.д.
Определение местоположение пользователя помогает правильно ранжировать
результаты выдачи. Например, жителю Москвы, по запросу «вызвать электрика»,
будут показаны сайты, релевантные запросу «вызвать электрика Москва» (или «… в
Москве», или «Москва, вызвать электрика», и т.п.)
3.5 Выдача
результатов
Когда поиск уже произведён и результаты были отсортированы по релевантности,
следующим этапом результаты будут возвращаться в веб-интерфейс поисковой
системы.
Поисковая выдача состоит из ссылок на релевантные ресурсы и сниппетов, а
её результаты также дополняются специальными роботами, которые называются
колдунщики.
1. Сниппеты
Сниппеты -это небольшой отрезок текстовой информации, который выводится
рядом со ссылкой в поисковой выдаче. Другими словами, это краткое описание
страницы сайта, релевантное поисковому запросу.
В качестве сниппета используются обычно куски текста из этого документа.
Идеальный вариант призван предоставить пользователю возможность составить
мнение о содержимом страницы, не переходя на нее (но это, если он получился
удачным, а это не всегда так).

Рис. 3.4 Структура одного результата на странице выдачи
На изображении кусок текста, выделенный жёлтым цветом - «Превью страницы»
является сниппетом.
Сниппет формируется автоматически, а вот какие именно фрагменты текста
будут использоваться в нем - решает алгоритм, и, что важно, для разных запросов
у одной и той же веб-страницы будут разные сниппеты.
Сниппет берётся из прямого индекса поисковой системы.
В дополнительные опции, в выдаче, ещё иногда добавляют просмотр
сохранённой копии интернет-страницы, которую обработал поисковик.
3.6 Сайт и
поисковая система
. Ключевые
слова
Ключевое слово - это слово в тексте, способное в совокупности с другими
ключевыми словами представлять текст. В вебе используется главным образом для
поиска.
Набор ключевых слов документа называют поисковым образом документа. Набор
ключевых слов близок к аннотации, плану и конспекту, которые тоже представляют
документ с меньшей детализацией, но набор, при этом, лишён синтаксической
структуры.
2.
Семантическое ядро
Семантическое ядро - это набор ключевых слов всего ресурса, которые
наиболее точно характеризуют тематику, товар или услугу, предлагаемые сайтом.
Семантическое ядро состоит из тех слов, которые смогла обнаружить, при
сканировании документа, поисковая система. От того, как оно грамотно составляется
разработчиками сайта, зависит релевантность сайта по отношению к запросам, по
которым хотят продвинуть ресурс.
ЗАКЛЮЧЕНИЕ
В данной курсовой работе было выяснено, что такое поисковая система по
своей сути; из чего она состоит. Был проанализирован процесс поиска и выделены
его составные части; дана классификация алгоритмам поиска; а также выявлено,
каким образом могут влиять разработчики сайта на поисковую выдачу. В результате
проведённой работы были достигнуты все поставленные цели.
В дальнейшем мною планируется расширение своих знаний по этому вопросу и
использование их на практике.
СПИСОК Использованных ИСТОЧНИКОВ
1. Сегалович
И. Как работают поисковые системы// Yandex.ru: поисковая система и IT-компания
- URL - http://download.yandex.ru/company/iworld-3.pdf. - (дата обращения:
13.11.2013).
. [frony].
Эксклюзив: Как алгоритм Google управляет интернетом// Habrahabr.ru -
IT-интернет портал - URL - http://habrahabr.ru/post/95833/ - (дата обращения:
15.11.2013)
3. Долинин
М. Обработка и классификация запросов. Часть первая: парсер запросов//
Habrahabr.ru - IT-интернет портал - URL -
http://habrahabr.ru/company/mailru/blog/174321/ - (дата обращения: 14.11.2013)
. Долинин
М. Обработка и классификация запросов. Часть вторая: навигационные запросы// Habrahabr.ru - IT-интернет
портал - URL - http://habrahabr.ru/company/mailru/blog/176363/ - (дата обращения:
14.11.2013)
. Яндекс.
Алгоритм работы индексатора// Yandex.ru - Поисковая система - URL - http://api.yandex.ru/server/doc/concepts/y-ds-indexer-alg.xml -
(дата обращения: 13.12.2013)
. Азаров
А. Архитектура Google//I2R.ru - Библиотека
Интернет Индустрии - URL - http://www.i2r.ru/static/334/out_22655.shtml - (дата обращения: 13.12.2013)
. [cast]. Построение индекса для поисковой
машины// Habrahabr.ru - IT-интернет
портал - URL - http://habrahabr.ru/post/124728/ - (дата обращения:14.12.2013)
. Елисеева
М.Заглянем за ширму? Обратная сторона сниппетов или устройство поисковых
систем// Rodinalinkov.ru - простая биржа статей с вечными ссылками - URL - http://www.rodinalinkov.ru/blog/ 2013/11/03/zaglyanem-za-shirmu-obratnaya-st/#.Uq5AXSiviVF- (дата обращения: 12.12.2013)
. Шарапов
Р. Модели информационного поиска// Муромский институт Владимирского
государственного университета. - 2011. - 16 апреля - С. 4.
10. Кузнецов
М. Математическиемодели информационного поиска web-ресурсов// Прикаспийский журнал: управление и высокие
технологии - Системный анализ и математическое моделирование - №2 (22) 2013 -
С.6.
11. Бойцов
Л.Обзорная статья, посвященная методам индексации текстов, в основном
словарным, и алгоритмам поиска по сходству. // ITMan - IT-блог
- URL - http://www.itman.narod.ru/ir/review/review.html- (дата обращения: 11.11.2013)
. Лифшиц
Ю. Модели информационного поиска.PageRank. «Алгоритмы для интернета». Лекция №3// ITMan - IT-блог
- URL - http://www.itman.narod.ru/ir/lectures/3.html - (дата обращения: 18.11.2013)
. Гулин
А. Оптимизация алгоритмов ранжирования методами машинного обучения. Яндекс на
РОМИП// Yandex.ru - Поисковая система - URL - romip.ru/romip2009/15_yandex.pdfý - (дата обращения: 15.12.2013)