Вопросно-ответная система
Содержание
Введение
.
Проблемы
.
Обзор предметной области
.1
Задача анализа вопроса
.
Методы анализа вопросов
.1
Символьные шаблоны вопросов
.2
Синтаксические шаблоны вопросов
.3
Статистика употребления слов в вопросах
.
Оценка методов анализа вопросов
.1
Создание тестовой коллекции вопросов
.2
Метрики
.3
Результаты простого эксперимента
Вывод
Список
литературы
Введение
В связи с бурным развитием информационных технологий и непрерывным
увеличением объемов информации, доступной в глобальной сети Интернет, всё
большую актуальность приобретают вопросы эффективного поиска и доступа к
данным. Зачастую стандартный поиск с использованием ключевых слов не даёт
желаемого результата, в связи с тем, что такой подход не учитывает языковые и
смысловые взаимосвязи между словами запроса. Поэтому сейчас активно развиваются
технологии обработки естественных языков (Natural Language Processing, NLP) и основанные на них вопросно-ответные системы (Question-Answering Systems, QAS).
Вопросно-ответная система - это информационная система, являющаяся
гибридом поисковых, справочных и интеллектуальных систем, которая использует
естественно-языковой интерфейс. На вход такой системе подаётся запрос,
сформулированный на естественном языке, после чего он обрабатывается с
использованием методов NLP, и
генерируется естественно-языковой ответ. В качестве базового подхода к задаче
поиска ответа на вопрос обычно применяется следующая схема: сначала система тем
или иным образом (например, поиском по ключевым словам) отбирает документы,
содержащие информацию, связанные с поставленным вопросом, затем фильтрует их,
выделяя отдельные текстовые фрагменты, потенциально содержащие ответ, после
чего из отобранных фрагментов генерирующий модуль синтезирует ответ на вопрос.
В качестве источника информации QA-система использует либо локальное хранилище, либо глобальную сеть, либо
и то и другое одновременно. Несмотря на явные преимущества использования
Интернета, такие как доступ к огромным, постоянно растущим информационным
ресурсам, с этим подходом связана существенная проблема - информация в
Интернете неструктурированна и для её корректного извлечения необходимо
создание так называемых "оберток" (wrapper), то есть подпрограмм, которые обеспечивают
унифицированный доступ к различным информационным ресурсам.
Современные QA-системы
разделяют на общие (open-domain) и специализированные (closed-domain). Общие системы, то есть системы, ориентированные на
обработку произвольных вопросов, имеют достаточно сложную архитектуру, но тем
не менее на практике дают достаточно слабые результаты и невысокую точность
ответов. Но, как правило, для таких систем более важным оказывается степень
покрытия знаний, нежели точность ответов. В специализированных системах,
отвечающих на вопросы, связанные с конкретной предметной областью, напротив,
точность ответов зачастую оказывается критическим показателем (лучше вообще не
дать ответа на вопрос, чем дать неправильный ответ).
1.
Проблемы
Однако сегодня вопросно-ответные системы показывают далеко не
впечатляющие результаты. Так, лучшая система на дорожке GikiCLEF 2009
продемонстрировала точность 47% (отметим, что это результат работы систем на
многоязыковой коллекции). Отдельно отметим тот факт, что сегодня очень мало
русскоязычных вопросно-ответных систем участвует в открытой независимой оценке
качества. В публикациях встречается только один случай, дающий возможность
сравнить хотя бы две системы - это участие системы Стокона (сегодня AskNet.ru)
и Exacatus.ru на семинаре РОМИП 2006 (2., 23). Обе системы используют метод
семантического индексирования, который является сегодня только одним из
множества методов, используемых исследователями в мире (3,4). По мнению
авторов, требуется провести исследование других популярных методов на
русскоязычном корпусе.
Анализ существующих работ показал, что для проведения независимой оценки
на корпусах русского языка всего спектра методов, применяемых в
вопросно-ответных системах, требуется создание исследовательской программной
платформы в согласии с т.н. типовой архитектурой вопросно-ответной системы
(Common architecture for Question Answering (3)). В качестве основы
предлагается использовать систему с открытым исходным кодом OpenEphyra, которая
уже была использована другими исследователями для работы с английским, немецким
и голландским языками (5). Архитектура системы OpehEphyra повторяет типовую
архитектуру.
Основными задачами для работы являются реализация практически всех
модулей конвейера системы для русского языка. Авторы предполагают задействовать
следующие существующие программные библиотеки для обработки русского языка:
библиотеки лексического, морфологического и синтаксического разбора от aot.ru
(6), модуль морфологического разбора предложений mystem (7), классификацию
вопросов системы AskNet.ru для русского языка (8., 34), тезаурус русского языка
RussNet (9). Ряд недостающих модулей необходимо разработать самостоятельно:
синтаксические шаблоны вопросов и ответов, модуль категоризации вопросов,
модуль распознавания именованных сущностей.

Рис.1. Архитектура системы OpenEphyra (10., 1)
Целью работы является подготовка базовой исследовательской системы для
выступления на семинарах РОМИП, CLEF, TREC. Без подобной системы авторы считают
невозможным проведение экспериментальных исследований методов автоматического
ответа на вопросы на русском языке. Учитывая результаты аналогичного проекта на
голландском языке - в работе (5) была достигнута точность 3.5% - авторы
ожидают, что базовая реализация системы продемонстрирует точность того же
порядка на дорожке РОМИП прошлых лет. Отдельной проблемой является
невозможность повторно использовать вопросно-ответные дорожки РОМИП в
автоматическом режиме (2). Для решения этой проблемы авторы планируют создать
повторно используемую тестовую коллекцию на основе подмножества заданий РОМИП,
с использованием регулярных выражений для сравнения ответов, как предложено
организаторами TREC в работе (11).
Далее в статье обсуждается только первый этап работы вопросно-ответной
системы - модуль анализа вопросов. Рассмотрены: постановка задачи анализа
вопроса, методы анализа вопросов и доступный аппарат экспериментального
исследования методов на тестовой коллекции вопросов.
2. Обзор
предметной области
Системы вопросно-ответного поиска в сравнении с традиционными поисковыми
системами получают вопросительно предложение на естественном языке (на
английском, на русском и т.д.), а не набор ключевых слов, и возвращают краткий
ответ, а не список документов и ссылок. Современные системы информационного
поиска позволяют нам получить список целых документов, которые могут содержать
интересующую информацию, при этом оставляют пользователю работу по получению
нужных данных из документов, упорядоченных по уровню релевантности запросу.
Например, пользователь вводит следующий вопрос: "Кто является президентом
России?" и в качестве ответа получает имя человека, а не список
релевантных ссылок на документы. Таким образом, нахождение ответа на вопрос
извлечением небольшого отрывка текста из документа, в котором непосредственно
содержится сам ответ, в отличие от информационного поиска совсем другая задача.
Большая часть существующих проектов в области вопросно-ответного поиска
предназначены для английского языка. Если сравнить несколько работ в данной
сфере исследований, то можно прийти к стандартной схеме устройства
вопросно-ответных систем. Как правило, работа типовой вопросно-ответной системы
состоит из нескольких этапов:
.этап анализа вопроса, введенного пользователем;
.этап информационного поиска;
.этап извлечения ответа.
На первом этапе производится ввод вопроса на естественном языке и
первичная обработки и формализация предложения различными анализаторами
(синтаксическим, морфологическим, семантическим), определяются соответствующие
его атрибуты для дальнейшего их использования. Далее на втором этапе происходит
поиск и анализ документов - отбираются документы и их фрагменты, в которых
может содержаться ответ на исходный вопрос. На третьем этапе происходит
извлечение ответа: система, получая текстовые документы или их фрагменты,
извлекает из них слова, предложения или отрывки текста, которые могут стать
ответом.
Следует отметить, что важную роль в результатах и разработке играет
использование различных словарей-тезаурусов. Применение данных словарей решают
задачу определения типов сущностей для выявления ответов, нахождение начальной
формы слов для использования их в поисковых запросах. Также данные словари
используются для нахождения синонимов слов.
.1 Задача анализа вопроса
Первым этапом работы является создание модуля анализа вопросов (Question
Analysis на Рис.1). Для модуля ставится следующая задача: для вопроса на
естественном языке выделить фокус вопроса, опору вопроса и
определить семантический тэг ответа (Рис.2).

Рис. 2. Недетализированная диаграмма IDEF0 для процесса анализа вопроса.
Фокус вопроса (англ.: question focus) - это такие сведения, содержащиеся
в вопросе, которые несут в себе информацию об ожиданиях пользователя от
информации в ответе (4).
Опора вопроса (англ.: question support) - это остальная часть
вопроса (после "вычета" фокуса), которая несёт в себе
информацию, поддерживающую выбор конкретного ответа.
Семантический тэг ответа (англ.: answer tag, answer type) - класс запрашиваемой
пользователем информации согласно некоторой ранее заданной таксономии.
Ниже приведены примеры анализа вопросов из заданий РОМИП 2009,
выполненного вручную (Таб.2.1., сохранена орфография реальных запросов).
Таблица 2.1.
Примеры анализа вопросов из заданий РОМИП 2009. (3., 12)
|
№
|
Вопрос, жирным шрифтом
выделен фокус
|
Семантический тэг
|
|
nqa2009_6368
|
как отключить перехват
клавиатуры?
|
Recipe
|
|
nqa2009_7185
|
сколько стоит поченить
гнездо у телефона сони эрикссон?
|
Money
|
|
nqa2009_6425
|
в каких религиях как
рассматривается карма?
|
Definition
|
|
nqa2009_3123
|
отечественная война кто с
кем ?
|
Country
|
|
nqa2009_8557
|
являются ли чердаки
пожароопасными помещениями?
|
Yes/No
|
|
nqa2009_7801
|
какое колличество циклов
чтения/записи предусмотренно
|
Cardinal
|
|
компанией fujifilm для
картриджей стандарта lto 4?
|
|
|
nqa2009_8763
|
когда начнется распродажа в
меге ?
|
Date
|
|
nqa2009_9150
|
Time
|
|
nqa2009_8754
|
когда можно сводить кошек?
|
Age
|
|
nqa2009_6797
|
какие в тамбове есть студии
звукозаписи??
|
Organization
|
Таксономия семантических тэгов обычно выбирается разработчиками системы
так, чтобы покрыть большую часть вопросов к системе. Следующая таксономия была заимствована из (3) и дополнена авторами несколькими тэгами, чтобы лучше покрывать тестовую коллекцию вопросов РОМИП 2009: Age, Disease,
Ordinal, Recipe, Animal, Duration, Organ, Salutation, Areas, Event,
Organization, Substance, Attraction, Geological objects, People, Term (Reverse
definition), Cardinal, Law, Percent, Time, Company-roles, Location, Person,
Title-of-work, Country, Manner, Phrase (NNP), URL, Date, Measure, Plant,
Weather, Date-Reference, Money, Product, Yes/No, Definition, Occupation, Reason.
3. Методы
анализа вопросов
В этом разделе дан краткий обзор существующих методов анализа вопросов.
.1
Символьные шаблоны вопросов
Простейшим способом определить тэг или фокус в вопросе является
подготовка шаблонов (регулярных выражений) для распознавания распространённого
вопросительного оборота. Ниже приведёны некоторые правила, используемые в
системе OpenEphyra для английского языка (Таб.3.1.).
Таблица 3.1.
Символьные шаблоны вопросов из системы OpenEphyra (10)
|
Семантический
|
Регулярное выражение
вопроса
|
|
Тэг
|
|
|
NEaward
|
(what|which|name|give|tell)
(.* )?(accolade|award|certification|decoration|honoring|
|
|
honouring|medal|prize|reward)
|
|
NEbird
|
(what|which|name|give|tell)
(.* )?bird
|
|
NEbirthstone
|
(what|which|name|give|tell)
(.* )?birthstone
|
|
NEcolor
|
(what|which|name|give|tell)
(.* )?(color|colour)
|
|
NEconflict
|
(what|which|name|give|tell)
(.* )?(battle|conflict|conquest|crisis|crusade|liberation|
|
|
massacre|rebellion|revolt|revolution|uprising|war)
|
|
NEdate
|
(when|what|which|name|give|tell)
(.* )?(birthday|date|day)
|
|
NEdate-century
|
(when|what|which|name|give|tell)
(.* )?century
|
Для выделения фокуса в работе (3) использовались следующие шаблоны,
использующие в т.ч. и морфологическую информацию (Таб.3.2., на английском
языке):
Таблица 3.2.
Примеры шаблонов для выделения фокуса вопроса на английском языке (3)
|
Вопросительное слово
|
Шаблон
|
|
What, which , name , list,
|
question word +
headword of first noun cluster
|
|
identify
|
|
|
Who, why, whom, when
|
question word
|
|
Where
|
question word + main verb
|
|
How
|
question word
plus next word if it seeks an count attribute + headword of first
|
|
noun cluster
|
|
question word
plus the next word if it seeks an attribute
|
|
if question
seeks a methodology, then just question word
|
Очевидными недостатками такого подхода являются:
1. Практическая невозможность покрыть значимую часть реальных вопросов
пользователей. Набор вопросов подбирается так, чтобы обработать конкретный
набор тестовых заданий. Выйти за пределы этого покрытия "неудобным
вопросом" достаточно легко.
2. После ряда экспериментов становится очевидно, что связь между
вопросительными словами и семантическими тэгами не так прямолинейна. Так слово
"кто" может сигнализировать и о персоне, и об организации, и о
стране, и о народе (например, в вопросе "Кто выиграл войну?").
. Выделение фокуса на основе шаблонов также работает в очень ограниченных
случаях.
Метод шаблонов успешно использовался в системах, учувствовавших в TREC-8
(1999), в котором организаторы подготовили вопросы для дорожки QA вручную.
Однако, уже в TREC-9 (2000) были предложены задания на основе реальных запросов
пользователей и те системы, которые не применили иные методы анализа вопроса,
заметно отстали от адаптировавшихся лидеров.
3.2 Синтаксические шаблоны вопросов
Для выделения фокуса вопроса следующим шагом после символьных
шаблонов стал метод синтаксических шаблонов. В основе метода лежит
предположение, что фокус вопроса часто находится в определённом синтаксическом
отношении с вопросительным словом, м.б. не в одном, но набор вариантов этих
отношений ограничен. Если выполнить синтаксический разбор предложения, то получится
синтаксическое дерево (Рис.3.). Этот пример наглядно демонстрирует, что для
работы на коллекции реальных вопросов пользователей система в т.ч. должна
справляться с опечатками и орфографическими ошибками.
Вот пример синтаксического шаблона для распознавания фокуса,
используемого в системе OpenEphyra:
(ROOT (SBARQ (WHNP (WP What)) (SQ (VP (VBZ is) (NP (NP (DT
the) (NN name)) (PP (IN of) (*NP xx)))))))
Здесь в скобочной нотации задано синтаксическое дерево со словами или их
синтаксическими/морфологическими метками в узлах. Такой шаблон дерева
сравнивается с реальным деревом вопроса и, в случае совпадения, фокусом
считаются члены предложения, соответствующие позиции xx в шаблоне.
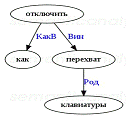
Рис.3. Синтаксическое дерево, построенное системой SemanticAnalyzer (12.,
1) для вопроса nqa2009_6368 "как отключить перехват клавиатуры?"
3.3
Статистика употребления слов в вопросах
В работе (3) предложен метод автоматического
обучения статистической модели для простановки семантического тэга. Для каждого
вопроса из обучающей выборки выделяют три "потока" признаков
(features stream):
1. все слова как есть и дополнительные метки к некоторым из них
(например, метка bqw означает, что вопросительное слово стоит в начале
предложения);
2. метки частей речи слов и порядковые номера слов в предложении;
3. Фокусные слова с гиперонимами, согласно лексическому тезаурусу.
Ниже приведены признаки для одного вопроса на английском языке
(Таб.3.3.).
Таблица
3.3.
Признаки для вопроса
" Which European city hosted the 1992 Olympics?" (3)
|
Слова как есть
|
Which which_bqw
which_JJ European city host 1992 olympics
|
|
Части речи
|
|
hosted_VBD DT_3
CD_4 1992_CD NNS_5 olympics_NNS
|
|
|
Гиперонимы
|
European city
metropolis urban_center municipality urban_area
|
|
geographical_area
|
geographic_area
|
geographical_region
|
|
geographic_region region
|
|
location entity metropolis
|
urban_center
|
|
city_center
|
central_city
|
financial_center
|
Hub
|
civic_center
|
|
municipal_center
down_town inner_city
|
|
|
Разметив вручную коллекцию из более 4 тыс. вопросов авторы (3) посчитали,
какие свойства чаще означают каждый семантический тэг. Для этого использовался
математический аппарат максимизации энтропии. Всего на коллекции из 4 тыс.
вопросов было порождено 36 тыс. признаков. Ниже приведены веса для принятия
решения о простановке того или иного тэга на основании выявленных признаков
(Таб.3.4.).
Недостатком статистического метода является необходимость создания
большой обучающей коллекции вопросов вручную. Так, авторы работы (3) не
удовлетворены размером своей коллекции из 4 тыс. вопросов TREC-9.
Таблица 3.4.
Признаки для простановки семантического тэга (3)
|
Признаки
|
Семантический тэг
|
Вес
|
|
many | COUNT0
|
CARDINAL
|
6,87
|
|
why_WRB
|
REASON
|
33,04
|
|
Region
|
LOCATION
|
5,75
|
|
who_V
|
PERSON
|
4,09
|
|
when_V | DEFN0
|
DATE
|
17,31
|
|
Period
|
DURATION
|
7,66
|
|
Government
|
LOCATION
|
9,56
|
4. Оценка методов анализа вопросов
Рассмотрим процедуру экспериментального исследования методов анализа
вопросов.
.1 Создание
тестовой коллекции вопросов
Как и в других задачах информационного поиска предлагается создать
текстовую коллекцию вопросов и выполнить анализ вручную с помощью инструмента
асессора. В качестве тестовой коллекции авторы используют задания к вопросно-ответной
дорожке семинара РОМИП 2009. Это 9617 русскоязычных вопросов, сформулированных
пользователями в интернете.
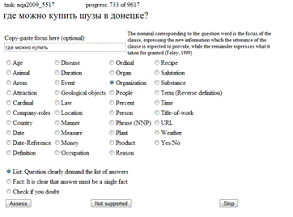
Рис.4. Интерфейс асессора
Авторами был разработана программа - интерфейс асессора - позволяющая выделять
фокус и проставлять семантический тэг у вопроса (Рис.4.). Было обработано 733
вопроса.
.2 Метрики
В качестве основной метрики предлагается использовать ошибку
простановки семантического тэга: Et = (M-N)/M, где
N - число вопросов, обработанных асессором, M - число вопросов, для
которых модулем анализа вопроса был проставлен тот же семантический тэг, что и
асессором (3).
Вторая метрика должна оценивать правильность выделения фокуса в вопросе.
Авторы не нашли существующей метрики в литературе, поэтому предлагают свои
метрики: точность P и полноту R выделения фокуса
у заданного вопроса:

В обоих множествах игнорируются незначимые слова: вопросные слова,
предлоги, союзы. Элементами обоих множеств являются не слова как лексические
единицы, а позиции слов в предложении, т.е. множество может содержать несколько
экземпляров одного слова, если оно повторялось в предложении-вопросе. В
качестве метрик по всей коллекции вопросов следует брать средние точность и
полноту.
.3 Результаты
простого эксперимента
На коллекции русскоязычных вопросов был поставлен эксперимент по
исследованию тривиальной реализации модуля простановки семантического тэга.
Модуль использовал таблицу поиска слов в вопросе для выбора того или иного
семантического тэга. Ниже перечислены все правила работы модуля (Таб.4.1.).
Таблица 4.1.
Правила работы тривиального модуля анализа вопросов на русском языке.
|
Слово
|
Тэг
|
Слово
|
Тэг
|
|
Скачать
|
URL
|
подарить | подарок
|
Product
|
|
Кто
|
Person
|
Ли
|
Yes/No
|
|
Как
|
Recipe
|
Definition
|
|
Где
|
Location
|
цена | стоимость | сколько
стоит
|
Money
|
|
когда | в каком году
|
Date
|
возраст | сколько лет
|
Age
|
Эксперимент показал, что такая реализация модуля анализа вопроса даёт
ошибку 67%. На момент написания статьи авторы не проводили экспериментов с
выделением фокуса.
Вывод
В задаче автоматического ответа на вопрос на естественном языке первым
этапом работы системы является анализ вопроса. Качество работы модуля анализа
вопроса существенно влияет на качество работы системы в целом (3). Зарубежными
исследователями были поставлены эксперименты по анализу вопросов на английском
языке, причём разные исследовательские группы, использовали разные методы
решения этой первой задачи.
В настоящей работе выполнен обзор существующих методов для английского
языка, разработана процедура оценки методов, обработана вручную тестовая
коллекция русскоязычных вопросов и поставлен эксперимент для исследования
некоторой тривиальной реализации модуля. Авторы планируют собрать полный
конвейер типовой вопросно-ответной системы из тривиально реализованных модулей,
который станет экспериментальной площадкой для исследования более эффективных
методов.
семантический
тэг вопрос шаблон
Список литературы
1. Carol
Peters. What happened in CLEF 2009 Introduction to the Working Notes. //
Proceedings of CLEF’2009. URL:
http://www.clef-campaign.org/2009/working_notes/CLEF2009WN-%20intro2.pdf
2. Российский
семинар по Оценке Методов Информационного Поиска. Труды четвертого российского
семинара РОМИП'2006. СПб.: НУ ЦСИ, 2006, 274 с.
3. Abraham
Ittycheriah. A Statistical Approach For Open Domain Question Answering //
Advances in Open Domain Question Answering. Springer Netherlands, 2006. Part 1. Vol.32.
4. Burger,
J. и др. Issues, tasks and program structures to roadmap research in question
& answering (Q&A). NIST DUC Vision and Roadmap Documents, 2001. URL:
http://www.nlpir.nist.gov/projects/duc/roadmapping.html
6. Segalovich
I. A fast morphological algorithm with unknown word guessing induced by a
dictionary for a web search engine. MLMTA, 2003.
7. Поисковая
система AskNet.ru [Электронный ресурс]: Перечень вопросов, поддерживаемых
системой AskNet для проведения семантического поиска. URL:
http://www.asknet.ru/Technology/ListOfQueryru.htm (дата обращения: 27.11.2009).
. Азарова
И. В. и др. Разработка компьютерного тезауруса русского языка типа WordNet //
Доклады научной конференции "Корпусная лингвистика и лингвистические базы
данных" / Под ред. А.С. Герда. СПб., 2002. С. 6-18.
9. Semantic
Analyzer group blog [Электронный ресурс]. URL: http://semanticanalyzer.info/