Алгоритм обратного распространения ошибки
Содержание
Введение
Глава 1. Обучение нейронных сетей
1.1 Общие подходы нейронных сетей
Глава 2. Алгоритм обратного распространения ошибки
2.1 Описание алгоритма обратного распространения ошибки
2.2 Реализация алгоритма обратного распространения ошибки на
примере аппроксимации функции
2.3 Анализ алгоритма обратного распространения ошибки
Список использованной литературы
Введение
В последние несколько лет <#"721503.files/image001.gif">
Рис 1 - График полинома
Нейронная сеть сталкивается с точно такой же трудностью. Сети с
большим числом весов моделируют более сложные функции и, следовательно, склонны
к переобучению. Сеть же с небольшим числом весов может оказаться недостаточно
гибкой, чтобы смоделировать имеющуюся зависимость. Например, сеть без
промежуточных слоев на самом деле моделирует обычную линейную функцию.
Как же выбрать "правильную" степень сложности для сети?
Почти всегда более сложная сеть дает меньшую ошибку, но это может
свидетельствовать не о хорошем качестве модели, а о переобучении.
Ответ состоит в том, чтобы использовать механизм контрольной
кросс-проверки
<#"721503.files/image002.gif">
Нелинейность такого вида удобна простотой расчета
производной:
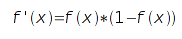
Для обучения сети используется P пар векторов сигналов:
входной вектор I и вектор, который должен быть получен на выходе сети D. Сеть,
в простом случае, состоит из N слоев, причем каждый нейрон последующего слоя
связан со всеми нейронами предыдущего слоя связями, с весами w [n].
При прямом распространении, для каждого слоя рассчитывается
(и запоминается) суммарный сигнал на выходе слоя (S [n]) и сигнал на
выходе нейрона. Так, сигнал на входе i-го нейрона n-го слоя:
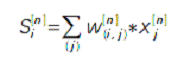
Здесь w (i,j) - веса связей n-го слоя. Сигнал на
выходе нейрона рассчитывается применением к суммарному сигналу нелинейности
нейрона.
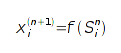
Сигнал выходного слоя x [N] считается выходным
сигналом сети O.
По выходному сигналу сети O и сигналу D, который должен
получится на выходе сети для данного входа, рассчитываться ошибка сети. Обычно
используется средний квадрат отклонения по всем векторам обучающей выборки:
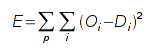
Для обучения сети используется градиент функции ошибки по
весам сети. Алгоритм обратного распространения предполагает расчет градиента
функции ошибки "обратным распространением сигнала" ошибки. Тогда
частная производная ошибки по весам связей рассчитывается по формуле:
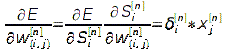
Здесь δ - невязка сети, которая
для выходного слоя рассчитывается по функции ошибки:
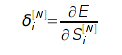
А для скрытых слоев - по невязке предыдущего слоя:
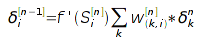
Для случая сигмоидной нелинейности и среднего квадрата
отклонения как функции ошибки:
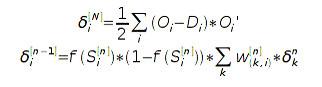
Собственно обучение сети состоит в нахождении таких значений
весов, которые минимизируют ошибку на выходах сети. Существует множество методов,
основанных или использующих градиент, позволяющих решить эту задачу. В
простейшем случае, обучение сети проводится <#"721503.files/image011.gif">
Такой метод обучения называется "оптимизация методом
градиентного спуска" и, в случае нейросетей, часто считается частью метода
обратного распространения ошибки.
2.2
Реализация алгоритма обратного распространения ошибки на примере аппроксимации
функции
Задание: Пусть имеется таблица значений аргумента (xi)
и соответствующих значений функции (f (xi)) (эта таблица
могла возникнуть при вычислениях некоторой аналитически заданной функции при
проведении эксперимента по выявлению зависимости силы тока от сопротивления в
электрической сети, при выявлении связи между солнечной активностью и
количеством обращений в кардиологический центр, между размером дотаций фермерам
и объемом производства сельхозпродукции и т.п.).
В среде Matlab необходимо построить и обучить нейронную сеть
для аппроксимации таблично заданной функции 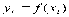 , i=1, 20. Разработать
программу, которая реализует нейросетевой алгоритм аппроксимации и выводит
результаты аппроксимации в виде графиков.
, i=1, 20. Разработать
программу, которая реализует нейросетевой алгоритм аппроксимации и выводит
результаты аппроксимации в виде графиков.
Аппроксимация заключается в том, что, используя имеющуюся
информацию по f (x), можно рассмотреть аппроксимирующую функцию z (x) близкую в
некотором смысле к f (x), позволяющую выполнить над ней соответствующие
операции и получить оценку погрешности такой замены.
Под аппроксимацией обычно подразумевается описание некоторой,
порой не заданной явно, зависимости или совокупности представляющих ее данных с
помощью другой, обычно более простой или более единообразной зависимости. Часто
данные находятся в виде отдельных узловых точек, координаты которых задаются
таблицей данных. Результат аппроксимации может не проходить через узловые
точки. Напротив, задача интерполяции - найти данные в окрестности узловых
точек. Для этого используются подходящие функции, значения которых в узловых
точках совпадают с координатами этих точек [8].
Задача. В среде Matlab необходимо построить и обучить
нейронную сеть для аппроксимации таблично заданной функции (см. рисунок 5).
|
xi
|
0,1
|
0,2
|
0,3
|
0,4
|
0,5
|
0,6
|
0,7
|
0,8
|
0,9
|
1
|
|
f (xi)
|
2,09
|
2,05
|
2, 19
|
2,18
|
2,17
|
2,27
|
2,58
|
2,73
|
2,82
|
3,04
|
|
xi
|
1,1
|
1,2
|
1,3
|
1,4
|
1,5
|
1,6
|
1,8
|
1,9
|
2
|
|
f (xi)
|
3,03
|
3,45
|
3,62
|
3,85
|
4, 19
|
4,45
|
4,89
|
5,06
|
5,63
|
5,91
|
Рисунок 5. Таблица значений функции В математической среде
Matlab в командном окне записываем код программы создания и обучения нейронной
сети.
Для решения воспользуемся функцией newff (.) - создание
"классической" многослойной НС с обучением по методу обратного
распространения ошибки, т.е. изменение весов синапсов происходит с учетом
функции ошибки, разница между реальными и правильными ответами нейронной сети,
определяемыми на выходном слое, распространяется в обратном направлении -
навстречу потоку сигналов. Сеть будет иметь два скрытых слоя. В первом слое 5 нейронов,
во втором - 1. Функция активации первого слоя - 'tansig' (сигмоидная функция,
возвращает выходные векторы со значениями в диапазоне от - 1 до 1), второго -
'purelin' (линейная функция активации, возвращает выходные векторы без
изменений). Будет проведено 100 эпох обучения. Обучающая функция 'trainlm' -
функция, тренирующая сеть (используется по умолчанию, поскольку она
обеспечивает наиболее быстрое обучение, но требует много памяти) [9].
Код программы:
= zeros (1, 20);i = 1: 20 %создание массива P (i) = i*0.1;
%входные данные (аргумент) end T= [2.09 2.05 2.19 2.18 2.17 2.27 2.58 2.73
2.82 3.04 3.03 3.45 3.62 3.85 4.19 4.45 4.89 5.06 5.63 5.91]; %входные данные
(значение функции) net = newff ([-1 2.09], [5 1],{'tansig' 'purelin'});
%создание нейронной сети net. trainParam. epochs = 100; %задание числа эпох
обучения net=train (net,P,T); %обучение сети y = sim (net,P); %опрос обученной
сети figure (1);
hold on;('P');('T');
plot (P,T,P,y,'o'),grid; %прорисовка графика исходных данных
и функции, сформированной нейронной сетью.
Результат работы нейронной сети.
Результат обучения (см. рис.2): график показывает время
обучения нейронной сети и ошибку обучения. В этом примере нейронная сеть прошла
все 100 эпох постепенно обучаясь и уменьшая ошибки, дошла до 10-2,35
(0,00455531).

Рисунок 2. Результат обучения нейронной сети
График исходных данных и функции, сформированной нейронной
сетью (см. рис.3): кружками обозначены исходные данные, а линия - функция,
сформированная нейронной сетью. Далее по полученным точкам можно построить
регрессию и получить уравнение аппроксимации (см. рисунок 8). Мы использовали
кубическую регрессию, так как ее график наиболее точно проходит через
полученные точки. Полученное уравнение имеет вид:
=0.049x3+0.88x2-0.006x+2.1.
Таким образом, видим, что используя нейронную сеть, можно
довольно быстро найти функцию, зная лишь координаты точек, через которые она
проходит.

Рисунок 3. График исходных данных и функции, сформированной
нейронной сетью
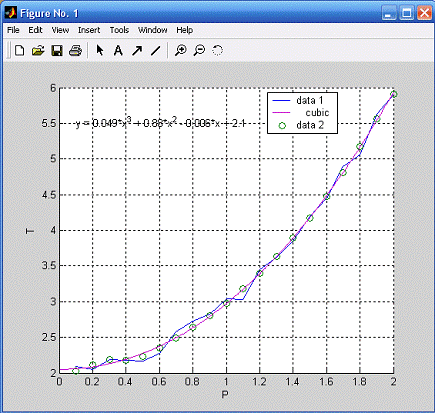
Рисунок 4. График функции аппроксимации
2.3 Анализ
алгоритма обратного распространения ошибки
Алгоритм обратного распространения ошибки осуществляет так
называемый градиентный спуск по поверхности ошибок. Не углубляясь, это означает
следующее: в данной точке поверхности находится направление скорейшего спуска,
затем делается прыжок вниз на расстояние, пропорциональное коэффициенту
скорости обучения и крутизне склона, при этом учитывается инерция, то есть
стремление сохранить прежнее направление движения. Можно сказать, что метод
ведет себя как слепой кенгуру - каждый раз прыгает в направлении, которое
кажется ему наилучшим. На самом деле шаг спуска вычисляется отдельно для всех
обучающих наблюдений, взятых в случайном порядке, но в результате получается
достаточно хорошая аппроксимация спуска по совокупной поверхности ошибок.
Несмотря на достаточную простоту и применимость в решении
большого круга задач, алгоритм обратного распространения ошибки имеет ряд
серьезных недостатков. Отдельно стоит отметить неопределенно долгий процесс
обучения. В сложных задачах для обучения сети могут потребоваться дни или даже
недели, а иногда она может и вообще не обучиться. Это может произойти из-за следующих
нижеописанных факторов.
1. Паралич сети
В процессе обучения сети, значения весов могут в результате
коррекции стать очень большими величинами. Это может привести к тому, что все
или большинство нейронов будут выдавать на выходе сети большие значения, где
производная функции активации от них будет очень мала. Так как посылаемая
обратно в процессе обучения ошибка пропорциональна этой производной, то процесс
обучения может практически замереть. В теоретическом отношении эта проблема
плохо изучена. Обычно этого избегают уменьшением размера шага (скорости
обучения), но это увеличивает время обучения. Различные эвристики
использовались для предохранения от паралича или для восстановления после него,
но пока что они могут рассматриваться лишь как экспериментальные.
2. Локальные минимумы
Как говорилось вначале, алгоритм обратного распространения
ошибки использует разновидность градиентного спуска, т.е. осуществляет спуск
вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к
минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов,
долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть
в локальный минимум (неглубокую долину), когда рядом имеется более глубокий
минимум. В точке локального минимума все направления ведут вверх, и сеть
неспособна из него выбраться. Статистические методы обучения могут помочь
избежать этой ловушки, но они медленны.
3. Размер шага
Алгоритм обратного распространения ошибки имеет
доказательство своей сходимости. Это доказательство основывается на том, что
коррекция весов предполагается бесконечно малой. Ясно, что это неосуществимо на
практике, так как ведет к бесконечному времени обучения. Размер шага должен
браться конечным, и в этом вопросе приходится опираться только на опыт. Если
размер шага очень мал, то сходимость слишком медленная, если же очень велик, то
может возникнуть паралич или постоянная неустойчивость.
4. Временная неустойчивость
Если сеть учится распознавать буквы, то нет смысла учить
"Б", если при этом забывается "А". Процесс обучения должен
быть таким, чтобы сеть обучалась на всем обучающем множестве без пропусков
того, что уже выучено. В доказательстве сходимости это условие выполнено, но
требуется также, чтобы сети предъявлялись все векторы обучающего множества
прежде, чем выполняется коррекция весов. Необходимые изменения весов должны
вычисляться на всем множестве, а это требует дополнительной памяти; после ряда
таких обучающих циклов веса сойдутся к минимальной ошибке. Этот метод может
оказаться бесполезным, если сеть находится в постоянно меняющейся внешней
среде, так что второй раз один и тот же вектор может уже не повториться. В этом
случае процесс обучения может никогда не сойтись, бесцельно блуждая или сильно
осциллируя. В этом смысле алгоритм обратного распространения ошибки не похож на
биологические системы.
Заключение Нейронные сети хорошо осуществляют сглаживание или
подбор значений функций по точкам. Нейронные сети могут подобрать большинство
функций. Причем, это могут быт как функции одной переменной, так и нескольких.
В данной курсовой работе было представлено, каким образом
нейронные сети способны помочь людям в генерации знаний, которые основывались
бы на всех первоначальных данных. Исследования в области нейронных сетей в
основном достаточно наглядны. По сравнению с другими вычислительными методами в
статистике и науке они имеют значительные преимущества. Так, у моделей на
основе нейронных сетей очень гибкие теоретические требования; кроме того, им
необходимы совсем небольшие объемы предварительных знаний относительно
формирования задачи.
В соответствии с задачами в курсовой работе было выполнено
следующее.
. Проведен обзор алгоритмов обучения нейронных сетей.
. Рассмотрены методы ускорения обучения нейронной сети.
. Изучены области применения нейронных сетей.
. Рассмотрен алгоритм обратного распространения ошибки.
. Реализован алгоритм обратного распространения ошибки на
примере аппроксимации функции.
В ходе выполнения данной курсовой работы была построена и
обучена нейронная сеть для аппроксимации таблично заданной функции , i=1,20 в среде Matlab.
Разработана программа, которая реализует нейросетевой алгоритм аппроксимации и
выводит результаты аппроксимации в виде графиков.
Для решения использована функция newff (.) - создание
"классической" многослойной НС с обучением по методу обратного
распространения ошибки.
Как мощный механизм обучения нейронные сети могут широко
применяться в различных областях. Существует, однако, возможность недоразумений
в оценке методик машинного обучения. Они никогда не смогут полностью заменить
людей в процессе решения задачи. Нейронные сети должны использоваться для
обобщения данных, а не для определения, атрибуты и критерии которого весьма
важны при сборе данных. Нейронные сети адаптивны по своей природе, они могут
подражать решению проблемы человеком, но они не сообщат нам, какой из критериев
решения задачи должен быть принят во внимание перед сбором данных. Кроме того,
обучающиеся машины часто используются при формализации знаний из данных
реального мира, но сами обучающиеся машины не могут генерировать принципы
формализации.
Список
использованной литературы
1. Бестенс Д.,
Ван ден Берг, Вуд Д. Нейронные сети и финансовые рынки. - М.: Диалектика
<http://ru.wikipedia.org/w/index.php?title=%D0%94%D0%B8%D0%B0%D0%BB%D0%B5%D0%BA%D1%82%D0%B8%D0%BA%D0%B0_(%D0%B8%D0%B7%D0%B4%D0%B0%D1%82%D0%B5%D0%BB%D1%8C%D1%81%D1%82%D0%B2%D0%BE)&action=edit&redlink=1>,
2009. - 224 с.
. Вороновский
Г.К. Махотило К.В. Петрашев С.Н. Сергеев С.А. - Генетические алгоритмы,
искусственные нейронные сети и проблемы виртуальной реальности - СПб.:
БХВ-Петербург
<http://ru.wikipedia.org/wiki/%D0%91%D0%A5%D0%92-%D0%9F%D0%B5%D1%82%D0%B5%D1%80%D0%B1%D1%83%D1%80%D0%B3>,
2007. - 544 с.
. Горбань А. Н,
Хлебопрос Р.Г. Демон Дарвина. Идея оптимальности и естественный отбор -
Вильямс, 2011. - 83 с.
. Горбань А. Н,
Дунин-Барковский, Кирдин А.Н. Нейроинформатика. МЦНМО, 2010. - 143 с.
5. Заенцев И. В Нейронные
сети. Основные модели. - ВГУ. 2011. - 321c.
6.
Федотов В.Х. Нейронные сети в экономике Чебоксары, 2006. - 171с.
.
http://ru. wikipedia.org/wiki/Нейронная_сеть
.
http://www.statsoft.ru/HOME/TEXTBOOK/modules/stneunet.html
9. http://mechanoid. narod.ru/nns/base/index.html#golovko
. http://www.scorcher.ru/neuro/science/neurocomp/mem52. htm
. http://www.neuroproject.ru/neuro. php